simple-pytest 框架使用指南
simple-pytest 框架使用指南
- 一、框架介绍
- 简介
- 框架理念:
- 框架地址
- 二、实现功能
- 三、目录结构
- 四、依赖库
- 五、启动方式
- 六、使用教程
- 1、快速开始
- 1.1、创建用例:
- 1.2、生成py文件
- 1.3、运行脚本
- 1.3.1 单个脚本运行
- 1.3.2 全部运行
- 1.4 报告查看
- 2、功能介绍
- 2.1、单个接口http请求与断言
- 2.2、长链路业务http请求与断言
- 2.3、数据库断言
- 2.4、变量设置
- 2.4.1、全局变量
- 2.4.2 系统配置变量
- 2.5 前后置处理
- 2.6 环境配置切换
- 2.7 文件读取
- 2.8 通知
一、框架介绍
简介
simple-pytest 框架主要参考了httprunner的yaml数据驱动部分设计思路,是基于 Pytest + Pytest-html+ Log + Yaml + Mysql 实现的简易版接口自动化框架。与httprunner不同的是,httprunner是个封装好的工具包,simple-pytest 是半封装的脚本,目的是让用户自己更容易学习Pytest工具,理解框架设计。
框架理念:
1、一个yaml就是一个接口,包含了接口的请求,断言等信息。
2、脚本执行使用pytest+python代码做逻辑处理,更加方便喜欢写代码的同学
3、让新手同学更加全面的理解pytest框架
4、为了
在学这个框架前,必备的一点常识是:
1、python基础语法
2、pytest基础包括用例执行,夹具使用等
框架地址
gitee: https://gitee.com/itestxs/simple-pytest
二、实现功能
- yaml数据驱动:实现数据驱动隔离
- 用例标签:在py脚本中可以通过case_tag做用例过滤
- 全局变量池:实现接口之间的关联取值
- 多断言:支持==,!=等多种断言,支持jsonpath的取值方式
- sql数据库断言: 直接在yaml测试用例中写入查询的sql即可断言,无需编写代码
- 自动生成用例代码: 在yaml文件中填写好测试用例, 可以转换为py脚本。
三、目录结构
- config ====>> 项目配置文件redis,mysql等
- data ====>> 测试数据文件管理
- logs ====>> 日志记录
- reports ====>> 结果报告,包括html
- test_cases ====>> 测试用例 ├── confset.py ====>> 测试夹具
- utils ====>> 各种工具类├── assertion ====>> 断言工具
- pytest.ini ====>> pytest配置文件
- conftest.py ====>> 全局夹具配置
- requirements.txt ====>> 相关依赖包文件
- run.py ====>> 执行用例入口文件
四、依赖库
requests==2.28.1
jsonpath==0.82
fastapi==0.88.0
pymysql==1.0.2
pyyaml==5.4.1
pytest==7.4.3
pytest-html==4.1.1
py==1.11.0
五、启动方式
1、先安装pip install requirements.txt
2、启用utils下的shopping_mock模块
3、运行run.py文件,然后,查看report的结果报告即可。
六、使用教程
1、快速开始
1.1、创建用例:
在data目录下创建yaml文件
主要的字段格式如下:
title:接口名字
base_url:域名地址,不填则默认取得setting的BASE_URL,如果填写了,则直接获取填写的
path:接口请求地址
method:请求方法
request_data:统一的请求参数,比如headers
cases:测试用例集合
case_name:测试用例名字,支持多个case_name年编写
case_tag:支持参数avl、dis、only 不填则为avl。其中avl就是可用的意思,dis不可用,only是代表只有当前用例生效。如果只传入only,则其他用例则不被执行,优先级是only>dis>avl。也可以自定义打tag
json:接口的请求体,可以直接输入字典格式(自动生成的用例不是字典格式)。请注意yaml的格式
params:接口的url请求参数。(待补充用例)
assert:断言,status_code是断言请求状态码。$.data是jsonpath的表达式,目前仅支持改表达式写法。目前支持的断言方式请在assert_type.py里查看包含,大于、不等于、等于一系列判断
sql:该case关联的sql,可以将该sql用来做前置还是以及后置
extract_sql:提起该sql的返回内容的某个字段存在变量池中,$.id 也是jsonpath表达式
assert_sql:sql的断言,用法同assert
yaml 模板用例如下:
title: "查询商品"
base_url: $config{BASE_URL}
path: /items
method: GET
request_data:headers:Content-Type: application/jsontoken: $global{token}cases:- case_name: "搜索-正常"# case_tag 支持参数avl、dis、only 不填则为avl,如果只传入only,则所有case 只会返回only的数据,也可以自定义打tagcase_tag: avlassert:- eq: [ status_code, 200 ]- ne: [ $.data, "" ]sql: select * from projectInfo where project="bm-scm"extract_sql:id: $.idassert_sql:- eq: [ $.id, 1 ]- case_name: "搜索-超出范围"case_tag: avlparams: "page=2&limit=10"assert:- eq: [ status_code, 200 ]- eq: [ $.data, [] ]
# login.yaml
title: "登录"
path: /login
method: POST
request_data:headers:Content-Type: application/jsoncases:- case_name: "登录-正常"# case_tag 支持参数avl、dis、only 不填则为avl,如果只传入only,则所有case 只会返回only的数据,也可以自定义打tagcase_tag: avljson: {"username": "user1", "password": "password1"}extract:token: $.tokenassert:- eq: [status_code, 200]- ne: [$.token, ""]- case_name: "登录-用户名为空"case_tag: avljson: { "username": "", "password": "password1" }assert:- eq: [status_code, 401]- eq: [$.detail, "Invalid username or password"]
1.2、生成py文件
在utils目录下的yaml_to_py文件main修改,yaml_to_pys批量转换整个data文件夹下的yaml文件,yaml_to_py转换指定的yaml文件,参数,cover代表是否覆盖,传入true,则会覆盖你现有的。
if __name__ == '__main__':yaml_to_pys()# yaml_to_py("login.yaml")
case_datas 为自动获取测试用例集,可以通过get_case_data(case_tag=“tag”)中的case_tag去过滤特定标签用例。
1.3、运行脚本
1.3.1 单个脚本运行
每个执行py脚本都可直接右击执行
1.3.2 全部运行
点击运行run文件,可以通过testenv 参数指定获取哪个环境的配置。
1.4 报告查看
如果是单个配置,则直接在当前test_cases目录下就可以看到,如果是run脚本执行,则报告统一放在reports
目前的报告格式是pytest-html。如果要用allure,则可以自己修改使用。
2、功能介绍
2.1、单个接口http请求与断言
response = HttpRequest.simple_request(case_data)Assert(response, case_data.get("assert")).assert_util
#!/usr/bin/env python
# -*- coding: utf-8 -*-import pytestfrom utils.assertion.assert_util import Assert
from utils.http_request import HttpRequest
from utils.read_file_data import ReadFileDataclass TestLogin():case_datas = ReadFileData("login.yaml").get_case_data() # get_case_data("tag") 自定义tag输入@pytest.mark.parametrize('case_data', case_datas, ids=generate_ids(case_datas))def test_login(self, case_data):response = HttpRequest.simple_request(case_data)Assert(response, case_data.get("assert")).assert_utilif __name__ == '__main__':pytest.main(["test_login.py"])
2.2、长链路业务http请求与断言
该功能是添加购车然后付款的流程。 彼此之间有接口依赖问题,通常解决依赖问题有两种
- 第一种:使用框架自带的merge_cases_data函数
test_data = merge_cases_data(add_carts_data, order_pays_data) # 将多个用例合并。merge_cases_data 是依赖接口合并,有两个默认规则,如果两个接口用例数一样多的,如[x,y],[A,B]那用例合并后结果就是[x,A] ,[y,B],如果两个接口用例数不一样,如[x] [A,B]那结果就是[x,A],[x,B],如[x,y] [A]那结果就是[x,A],[y,A]。 - 第二种:自己编写代码逻辑。
每个yaml就是一个接口。获取每个yaml的接口数据,然后获取用例后if else逻辑。如果接口之前有变量依赖,请借助全局变量去取。
import pytestfrom utils.assertion.assert_util import Assert
from utils.http_request import HttpRequest
from utils.merge_cases import merge_cases_data, generate_ids
from utils.read_file_data import ReadFileDataclass TestAddPay():add_carts_data = ReadFileData("add_carts.yaml").get_case_data() # get_case_data("tag") 自定义tag输入order_pays_data = ReadFileData("order_pays.yaml").get_case_data()test_data = merge_cases_data(add_carts_data, order_pays_data) # 将多个用例合并print("testdata",test_data)@pytest.mark.parametrize('add_carts_data,order_pays_data', test_data, ids=generate_ids(test_data,"merge"))def test_add_pay(self, add_carts_data, order_pays_data):add_carts_response = HttpRequest.simple_request(add_carts_data)# print(add_carts_response.json())Assert(add_carts_response, add_carts_data.get("assert")).assert_utilorder_pays_response = HttpRequest.simple_request(order_pays_data)# print(order_pays_response.json())Assert(order_pays_response, order_pays_data.get("assert")).assert_utilif __name__ == '__main__':pytest.main(["test_add_pay.py"])
2.3、数据库断言
需要提前在config配置settings的MYSQL_CONFIG参数
data = SqlRequest.sql_request(case_data)
Assert(data, case_data.get("assert_sql")).sql_assert_util
如果要讲数据库字段提取出来,则写在
GlobalVars.update_global_vars(key=“data”, value=data) # 将参数手动添加到公共变量中
import jsonimport pytestfrom utils.assertion.assert_util import Assert
from utils.global_vars import GlobalVars
from utils.http_request import HttpRequest
from utils.read_file_data import ReadFileData
from utils.sql_reqeust import SqlRequestclass TestSearch():case_datas = ReadFileData("search_items.yaml").get_case_data() # get_case_data("tag") 自定义tag输入print(case_datas)@pytest.mark.parametrize('case_data', case_datas, ids=generate_ids(case_datas))def test_search_items(self, case_data):response = HttpRequest.simple_request(case_data)print(response.json())Assert(response, case_data.get("assert")).assert_util# demo1-数据库断言写法# from utils.mysql_manager import db # 注意一定要在测试用例中引用,要不然会连接不上数据库# data = db.select_db('select * from projectInfo where project="bm-scm"')# print("data",data)# GlobalVars.update_global_vars(key="data", value=data) # 将参数手动添加到公共变量中# assert data["id"] == 1# demo2-数据库断言写法data = SqlRequest.sql_request(case_data)print("data", data)GlobalVars.update_global_vars(key="data", value=data) # 将参数手动添加到公共变量中Assert(data, case_data.get("assert_sql")).sql_assert_utilif __name__ == '__main__':pytest.main(["test_search_items.py"])
2.4、变量设置
主要的变量有两种,一个是全局变量,主要是接口数据库字段等值的传参使用。一个是配置变量,拿去配置里的信息。
2.4.1、全局变量
使用用法:使用$global{}关键字获取
$global{token}
以上例子是获取全局变量中token的变量
注意:全局变量如果命名重复会导致值被替换,请使用不同的变量名。
2.4.2 系统配置变量
配置变量获取的是config里的setting值,启动的时候,会自动获取当前环境的配置
$config{BASE_URL}
2.5 前后置处理
目前前后置处理由用户自己处理,较为常用的用法是,使用pytest的夹具功能
2.6 环境配置切换
使用testenv参数即可切换生产以及测试环境的配置。默认不填的情况下,使用的是测试环境的配置。配置读取的是settings里的信息
2.7 文件读取
read_file_data提供函数,支持读取json、yaml、csv、txt等文件
2.8 通知
在config settings下配置project、feishu_key信息,运行run脚本,即可发送飞书通知,注意只有运行run脚本才可以发送飞书通知
![[图片]](https://img-blog.csdnimg.cn/direct/affdff9fa74240979f9a171f2dcc083b.png)
相关文章:
simple-pytest 框架使用指南
simple-pytest 框架使用指南 一、框架介绍简介框架理念:框架地址 二、实现功能三、目录结构四、依赖库五、启动方式六、使用教程1、快速开始1.1、创建用例:1.2、生成py文件1.3、运行脚本1.3.1 单个脚本运行1.3.2 全部运行 1.4 报告查看 2、功能介绍2.1、…...

React中使用useActive
1.引入 import { useActivate } from "react-activation";2.React Activation 在React中使用react-activation,其实就是类似于Vue中的keep-alive,实现数据的缓存; 源码: import { ReactNode, ReactNodeArray, Context, Component…...

ElasticSearch安装和kibana控制台安装
文章目录 简介ElasticSearch安装环境下载参数密码配置启动 kibana安装修改config/kibana.yml配置 简介 Elasticsearch 是一个分布式文档存储。Elasticsearch 是存储已序列化为 JSON 文档的复杂数据结构。当集群中有多个 Elasticsearch 节点时,存储的文档分布在整个…...

VSCode安装与使用详细教程
一、引言 简要介绍VSCode(Visual Studio Code)是什么,它的主要特点和用途,以及为什么选择VSCode作为代码编辑器。 二、下载与安装 访问VSCode官方网站下载页面。选择适合操作系统的版本(Windows、macOS、Linux&…...

土壤墒情监测站的工作原理
TH-TS600】土壤湿度监测系统是一种用于实时监测土壤湿度的设备系统,通过多个传感器和数据采集设备组合而成。该系统能够安装在农田、果园、草地等不同类型的土壤中,实时监测土壤的水分含量,并将数据传输到数据采集设备中进行记录和分析。 土…...

Flutter 多标签页显示 有关TabController需要知道的知识
背景 很多应用都需要导航栏加多个标签页的方式来构建一个多页显示逻辑,比如购物软件常有:已完成,已发货,待付款三个顶部导航按钮,点击则下面的页面显示不同属性的订单 正文 在flutter中,实现这样的功能需…...

【Elasticsearch专栏 16】深入探索:Elasticsearch的Master选举机制及其影响因素分析
Elasticsearch,作为当今最流行的开源搜索和分析引擎,以其分布式、可扩展和高可用的特性赢得了广大开发者的青睐。在Elasticsearch的分布式架构中,集群的稳健性和高可用性很大程度上依赖于其Master节点的选举机制。本文将深入剖析Elasticsearc…...

Leetcode : 215. 数组中的第 K 个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。 请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。 思路:最开始排序算法&…...

node express实现Excel文档转json文件
有些场景我们需要将Excel文档中的内容抽取出来生成别的文件,作为一个前端,服务框架最应该熟悉的就是node了,以下是基于多语言转换实现代码,看明白原理自己改一改就能用了 1.安装node环境 2.创建一个文件夹,文件夹中创建…...
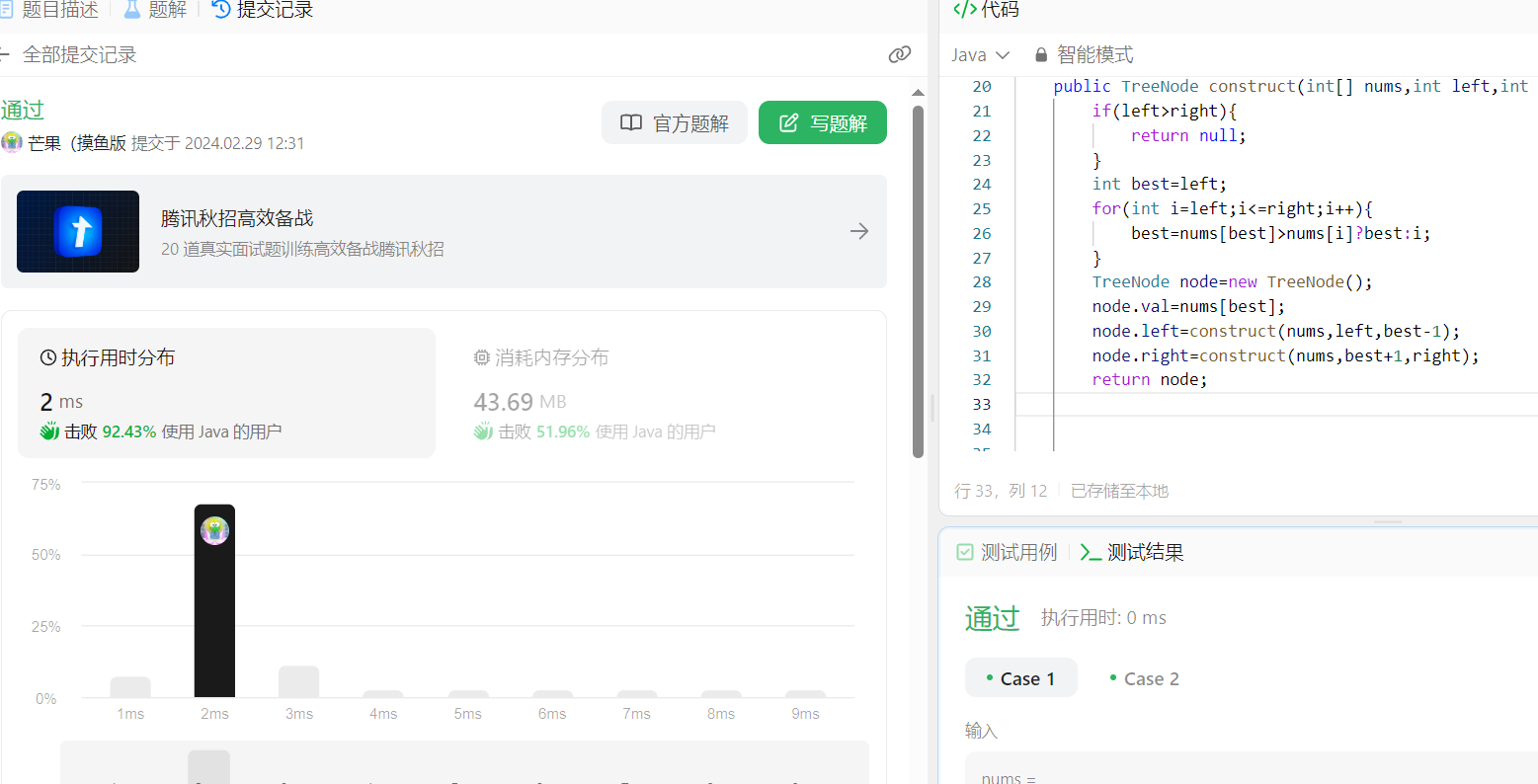
【算法分析与设计】最大二叉树
📝个人主页:五敷有你 🔥系列专栏:算法分析与设计 ⛺️稳中求进,晒太阳 题目 给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最…...
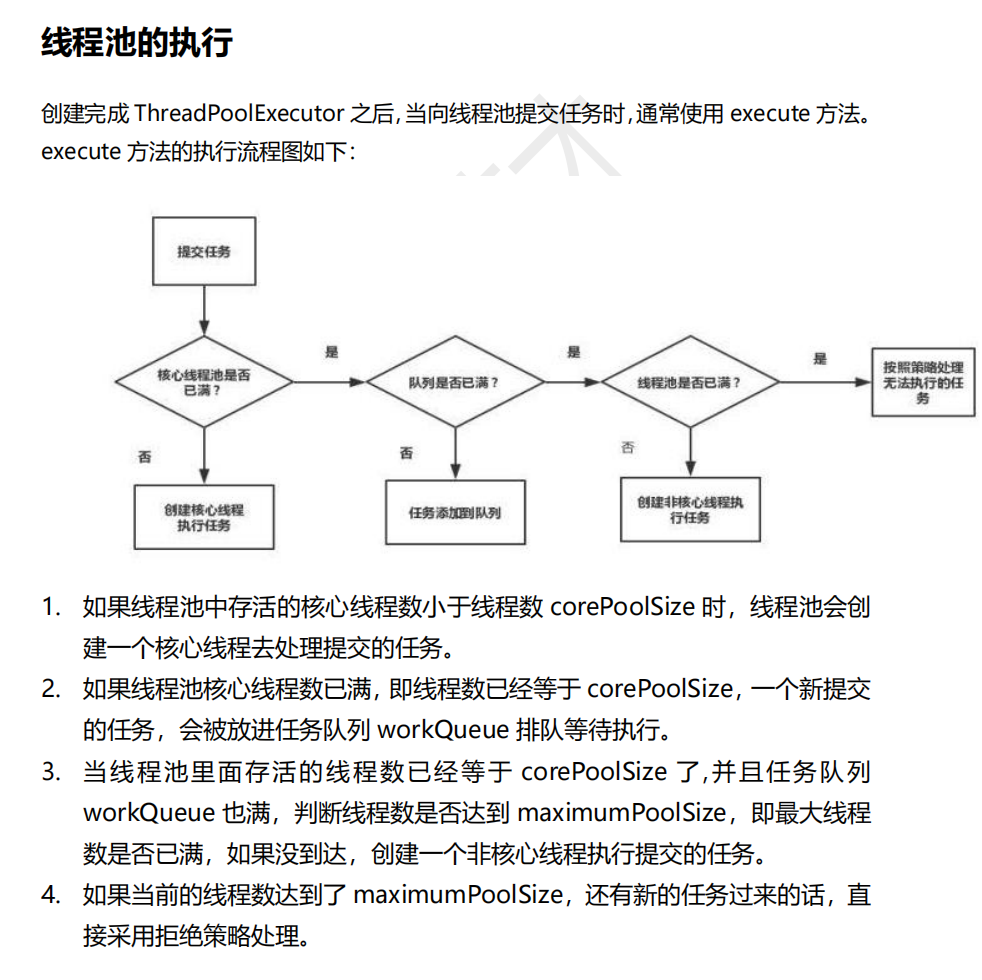
面试问答总结之并发编程
文章目录 🐒个人主页🏅JavaEE系列专栏📖前言:🎀多线程的优点、缺点🐕并发编程的核心问题 :不可见性、乱序性、非原子性🪀不可见性🪀乱序性🪀非原子性…...

红外测温仪芯片方案开发设计
红外测温仪由光学系统、光电探测器、信号放大器及信号处理、显示输出等部分组成。光学系统汇集其视场内的目标红外辐射能量,视场的大小由测温仪的光学零件以及位置决定。被测物体辐射的红外首先进入测温仪的光学系统,再由光学系统汇聚射入的红外线&#…...
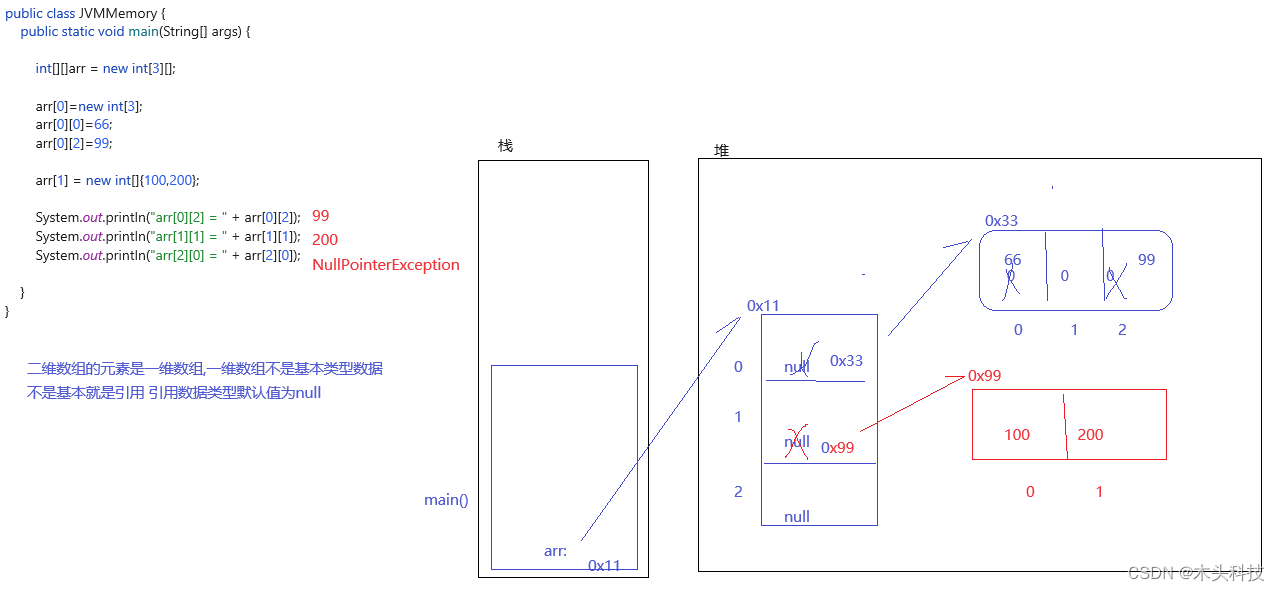
五、数组——Java基础篇
五、数组 1、数组元素的遍历 1.1数组的遍历:将数组内的元素展现出来 1、普通for遍历:根据下表获取数组内的元素 2、增强for遍历: for(数据元素类型 变量名:数组名){ 变量名:数组内的每一个值…...

如何用golang写一个自己的后端框架
如果你想要不使用任何现有的后端框架,完全从头开始创建一个后端框架,你需要实现Web服务器的基本组件,比如路由器、请求处理、中间件支持等。以下是一个简单的指南,用于创建一个基本的、不使用任何外部框架的Go后端框架。 步骤 1: 设置工作环境 确保你已经安装了Go语言环境…...

linux 如何给服务器批量做免密,如何批量挂在磁盘
前提条件 所有机器网络互通,且已做了免密登录 linux服务器批量做免密脚本如下 #!/bin/bash # 定义服务器列表文件 SERVERS_FILE"host" # 定义生成的密钥的存储目录 KEY_DIR"/root/.ssh" # 检查是否输入了文件路径 if [ $# -ne 1 ]; then …...

Android Activity的生命周期详解
在Android开发中,了解Activity的生命周期是非常重要的,它决定了Activity在不同状态下的行为和处理逻辑。Android中的Activity生命周期包括多个方法,每个方法都代表了Activity在特定状态下的行为。下面我们来逐一介绍这些方法及其对应的生命周…...

python学习笔记-内置类型
Python内置类型是Python编程语言中自带的基本数据类型,它们用于存储和处理数据。其中包括数字、序列、映射、类、实例和异常等主要类型。 在这些内置类型中,有一些是可变的,它们具有修改自身内容的能力,比如添加、移除或重排成员…...
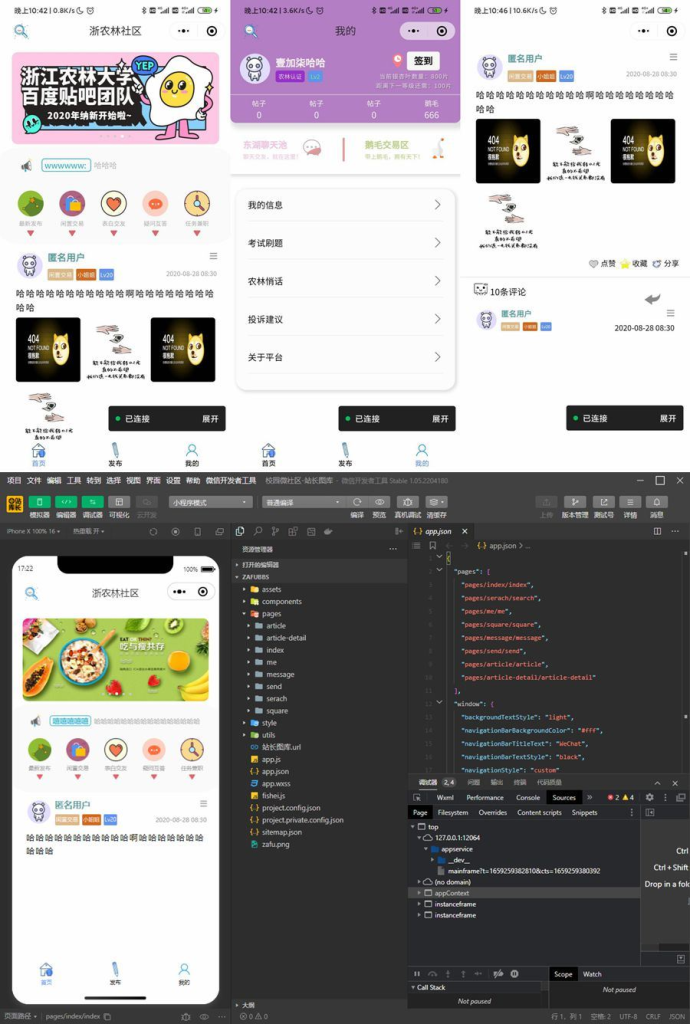
校园微社区微信小程序源码/二手交易/兼职交友微信小程序源码
云开发校园微社区微信小程序开源源码,这是一款云开发校园微社区-二手交易_兼职_交友_项目微信小程序开源源码,可以给你提供快捷方便的校园生活,有很多有趣实用的板块和功能,如:闲置交易、表白交友、疑问互答、任务兼职…...

如何在 Angular 中使用 NgTemplateOutlet 创建可重用组件
简介 单一职责原则是指应用程序的各个部分应该只有一个目的。遵循这个原则可以使您的 Angular 应用程序更容易测试和开发。 在 Angular 中,使用 NgTemplateOutlet 而不是创建特定组件,可以使组件在不修改组件本身的情况下轻松修改为各种用例。 在本文…...

改进的yolo交通标志tt100k数据集目标检测(代码+原理+毕设可用)
YOLO TT100K: 基于YOLO训练的交通标志检测模型 在原始代码基础上: 修改数据加载类,支持CoCo格式(使用cocoapi);修改数据增强;validation增加mAP计算;修改anchor; 注: 实验开启weig…...

Obsidian Dataview数据索引与查询引擎:构建智能知识库的完整技术方案
Obsidian Dataview数据索引与查询引擎:构建智能知识库的完整技术方案 【免费下载链接】obsidian-dataview A data index and query language over Markdown files, for https://obsidian.md/. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-dataview …...

DELMIA焊枪批量导入实战:宏命令脚本优化与CATIA协同操作指南
1. DELMIA焊枪批量导入的核心逻辑 在焊装仿真项目中,批量导入焊枪姿态是个让人头疼的活儿。我做过十几个汽车焊装项目,发现传统手动操作不仅效率低下,还容易出错。后来摸索出这套宏命令脚本CATIA协同的工作流,效率直接提升5倍不止…...
:密钥体系与文件加密流程)
OP-TEE安全存储深度解析(一):密钥体系与文件加密流程
1. OP-TEE安全存储的核心价值 第一次接触OP-TEE的安全存储功能时,我完全被它的精妙设计震撼到了。想象一下,你的手机里存着指纹、人脸识别模板这些极度敏感的数据,如果这些信息被普通应用程序随意读取,后果简直不堪设想。而OP-TEE…...
)
手把手教你如何在企业网络中部署SyncE(含芯片选型指南)
手把手教你如何在企业网络中部署SyncE(含芯片选型指南) 在数字化转型浪潮中,企业网络对时钟同步精度的要求正从毫秒级向微秒级跃迁。SyncE(同步以太网)技术凭借其媲美传统SDH的同步性能,正在5G前传、金融交…...

利用TIGRAMITE进行时间序列因果分析:从数据准备到可视化全流程
1. TIGRAMITE入门:时间序列因果分析利器 第一次接触TIGRAMITE是在分析气象数据时,当时需要找出温度、湿度、风速之间的因果关系链。这个Python包让我眼前一亮——它不仅能自动识别变量间的因果方向,还能精确捕捉时间滞后效应。TIGRAMITE基于…...

终极指南:如何参与End-To-End开源加密项目开发
终极指南:如何参与End-To-End开源加密项目开发 【免费下载链接】end-to-end End-To-End is a crypto library to encrypt, decrypt, digital sign, and verify signed messages (implementing OpenPGP) 项目地址: https://gitcode.com/gh_mirrors/en/end-to-end …...

2026最权威的六大AI写作方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 伴随着人工智能生成内容也就是AIGC的普遍运用,各种各样的AI检测系统也跟着普及开…...

Visual C++ Redistributable AIO:一站式解决Windows运行时依赖问题的终极方案
Visual C Redistributable AIO:一站式解决Windows运行时依赖问题的终极方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为"VCRUNTIME14…...

Vue H5移动端应用集成NFC读取功能的实战解析
1. 为什么要在Vue H5应用中集成NFC功能? 最近两年,越来越多的线下场景开始使用NFC技术。比如商场里的智能货架、博物馆的电子讲解牌、会议签到系统等等。作为一个Vue开发者,我发现很多客户都希望在他们的H5应用中加入NFC读取功能,…...

[Android][避坑指南]Android Studio集成framework.jar的版本适配与实战解析
1. 为什么需要集成framework.jar 在Android系统开发中,framework.jar是个特殊的存在。它包含了Android框架层的核心类和方法,很多系统级API(比如SystemProperties、UserHandle等)都定义在这里。但如果你打开Android Studio的SDK M…...