【大数据】Flink SQL 语法篇(七):Lookup Join、Array Expansion、Table Function
《Flink SQL 语法篇》系列,共包含以下 10 篇文章:
- Flink SQL 语法篇(一):CREATE
- Flink SQL 语法篇(二):WITH、SELECT & WHERE、SELECT DISTINCT
- Flink SQL 语法篇(三):窗口聚合(TUMBLE、HOP、SESSION、CUMULATE)
- Flink SQL 语法篇(四):Group 聚合、Over 聚合
- Flink SQL 语法篇(五):Regular Join、Interval Join
- Flink SQL 语法篇(六):Temporal Join
- Flink SQL 语法篇(七):Lookup Join、Array Expansion、Table Function
- Flink SQL 语法篇(八):集合、Order By、Limit、TopN
- Flink SQL 语法篇(九):Window TopN、Deduplication
- Flink SQL 语法篇(十):EXPLAIN、USE、LOAD、SET、SQL Hints
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
Flink SQL 语法篇(七):Lookup Join、Array Expansion、Table Function
- 1.Lookup Join(维表 Join)
- 2.Array Expansion(数组列转行)
- 3.Table Function(自定义列转行)
1.Lookup Join(维表 Join)
Lookup Join 定义(支持 Batch / Streaming):Lookup Join 其实就是维表 Join,比如拿离线数仓来说,常常会有用户画像,设备画像等数据,而对应到实时数仓场景中,这种实时获取外部缓存的 Join 就叫做维表 Join。
应用场景:小伙伴萌会问,我们既然已经有了上面介绍的 Regular Join,Interval Join 等,为啥还需要一种 Lookup Join?因为上面说的这几种 Join 都是 流与流之间的 Join,而 Lookup Join 是流与 Redis,MySQL,HBase 这种存储介质的 Join。Lookup 的意思就是实时查找,而实时的画像数据一般都是存储在 Redis,MySQL,HBase 中,这就是 Lookup Join 的由来。
实际案例:使用曝光用户日志流(show_log)关联用户画像维表(user_profile)关联到用户的维度之后,提供给下游计算分性别,年龄段的曝光用户数使用。
- 曝光用户日志流(
show_log)数据(数据存储在 Kafka 中)
log_id timestamp user_id
1 2021-11-01 00:01:03 a
2 2021-11-01 00:03:00 b
3 2021-11-01 00:05:00 c
4 2021-11-01 00:06:00 b
5 2021-11-01 00:07:00 c
- 用户画像维表(
user_profile)数据(数据存储在 Redis 中)
user_id(主键) age sex
a 12-18 男
b 18-24 女
c 18-24 男
注意:Redis 中的数据结构存储是按照 Key-Value 去存储的。其中 Key 为
user_id,Value 为age,sex的 JSON。
具体 SQL:
CREATE TABLE show_log (log_id BIGINT,`timestamp` as cast(CURRENT_TIMESTAMP as timestamp(3)),user_id STRING,proctime AS PROCTIME()
)
WITH ('connector' = 'datagen','rows-per-second' = '10','fields.user_id.length' = '1','fields.log_id.min' = '1','fields.log_id.max' = '10'
);CREATE TABLE user_profile (user_id STRING,age STRING,sex STRING) WITH ('connector' = 'redis','hostname' = '127.0.0.1','port' = '6379','format' = 'json','lookup.cache.max-rows' = '500','lookup.cache.ttl' = '3600','lookup.max-retries' = '1'
);CREATE TABLE sink_table (log_id BIGINT,`timestamp` TIMESTAMP(3),user_id STRING,proctime TIMESTAMP(3),age STRING,sex STRING
) WITH ('connector' = 'print'
);-- lookup join 的 query 逻辑
INSERT INTO sink_table
SELECT s.log_id as log_id, s.`timestamp` as `timestamp`, s.user_id as user_id, s.proctime as proctime, u.sex as sex, u.age as age
FROM show_log AS s
LEFT JOIN user_profile FOR SYSTEM_TIME AS OF s.proctime AS u
ON s.user_id = u.user_id
输出数据如下:
log_id timestamp user_id age sex
1 2021-11-01 00:01:03 a 12-18 男
2 2021-11-01 00:03:00 b 18-24 女
3 2021-11-01 00:05:00 c 18-24 男
4 2021-11-01 00:06:00 b 18-24 女
5 2021-11-01 00:07:00 c 18-24 男
注意:实时的 Lookup 维表关联能使用 处理时间 去做关联。
- 同一条数据关联到的维度数据可能不同:实时数仓中常用的实时维表都是在不断的变化中的,当前流表数据关联完维表数据后,如果同一个
key的维表的数据发生了变化,已关联到的维表的结果数据不会再同步更新。举个例子,维表中user_id为 1 1 1 的数据在 08 : 00 08:00 08:00 时age由12-18变为了18-24,那么当我们的任务在 08 : 01 08:01 08:01failover之后从 07 : 59 07:59 07:59 开始回溯数据时,原本应该关联到12-18的数据会关联到18-24的age数据。这是有可能会影响数据质量的。所以小伙伴萌在评估你们的实时任务时要考虑到这一点。 - 会发生实时的新建及更新的维表博主建议小伙伴萌应该建立起数据延迟的监控机制,防止出现流表数据先于维表数据到达,导致关联不到维表数据。
再说说维表常见的性能问题及优化思路。
所有的维表性能问题都可以总结为:高 QPS 下访问维表存储引擎产生的任务背压,数据产出延迟问题。
举个例子:
- 在没有使用维表的情况下:一条数据从输入 Flink 任务到输出 Flink 任务的时延假如为 0.1 m s 0.1\ ms 0.1 ms,那么并行度为 1 1 1 的任务的吞吐可以达到 1 q u e r y / 0.1 m s = 10000 q p s 1\ query\ /\ 0.1\ ms = 10000\ qps 1 query / 0.1 ms=10000 qps。
- 在使用维表之后:每条数据访问维表的外部存储的时长为 2 m s 2\ ms 2 ms,那么一条数据从输入 Flink 任务到输出 Flink 任务的时延就会变成 2.1 m s 2.1\ ms 2.1 ms,那么同样并行度为 1 的任务的吞吐只能达到 1 q u e r y / 2.1 m s = 476 q p s 1\ query\ /\ 2.1\ ms = 476\ qps 1 query / 2.1 ms=476 qps。两者的吞吐量相差 21 21 21 倍。
这就是为什么维表 Join 的算子会产生背压,任务产出会延迟。
那么当然,解决方案也是有很多的。抛开 Flink SQL 想一下,如果我们使用 DataStream API,甚至是在做一个后端应用,需要访问外部存储时,常用的优化方案有哪些?这里列举一下:
- 1️⃣ 按照 Redis 维表的 key 分桶 + local cache:通过按照
key分桶的方式,让大多数据的维表关联的数据访问走之前访问过的local cache即可。这样就可以把访问外部存储 2.1 m s 2.1\ ms 2.1 ms 处理一个 Query 变为访问内存的 0.1 m s 0.1\ ms 0.1 ms 处理一个 Query 的时长。 - 2️⃣ 异步访问外存:DataStream API 有异步算子,可以利用线程池去同时多次请求维表外部存储。这样就可以把 2.1 m s 2.1\ ms 2.1 ms 处理 1 1 1 个 Query 变为 2.1 m s 2.1\ ms 2.1 ms 处理 10 10 10 个 Query。吞吐可变优化到 10 q u e r y / 2.1 m s = 4761 q p s 10\ query\ /\ 2.1\ ms = 4761\ qps 10 query / 2.1 ms=4761 qps。
- 3️⃣ 批量访问外存:除了异步访问之外,我们还可以批量访问外部存储。举一个例子:在访问 Redis 维表的 1 1 1 Query 占用 2.1 m s 2.1\ ms 2.1 ms 时长中,其中可能有 2 m s 2\ ms 2 ms 都是在网络请求上面的耗时 ,其中只有 0.1 m s 0.1\ ms 0.1 ms 是 Redis Server 处理请求的时长。那么我们就可以使用 Redis 提供的
pipeline能力,在客户端(也就是 Flink 任务lookup join算子中),攒一批数据,使用pipeline去同时访问 Redis Sever。这样就可以把 2.1 m s 2.1\ ms 2.1 ms 处理 1 1 1 个 Query 变为 7 m s = 2 m s + 50 ∗ 0.1 m s 7\ ms=2\ ms + 50 * 0.1\ ms 7 ms=2 ms+50∗0.1 ms 处理 50 50 50 个 Query。吞吐可变为 50 q u e r y / 7 m s = 7143 q p s 50\ query\ /\ 7\ ms = 7143\ qps 50 query / 7 ms=7143 qps。
博主认为上述优化效果中,最好用的是 1️⃣ + 3️⃣,2️⃣ 相比 3️⃣ 还是一条一条发请求,性能会差一些。
既然 DataStream 可以这样做,Flink SQL 必须必的也可以借鉴上面的这些优化方案。具体怎么操作呢?看下文骚操作
- 1️⃣ 按照 Redis 维表的 key 分桶 + local cache:SQL 中如果要做分桶,得先做
group by,但是如果做了group by的聚合,就只能在udaf(user defined aggregation function)中做访问 Redis 处理,并且udaf产出的结果只能是一条,所以这种实现起来非常复杂。我们选择不做keyby分桶。但是我们可以直接使用local cache去做本地缓存,虽然【直接缓存】的效果比【先按照key分桶再做缓存】的效果差,但是也能一定程度上减少访问 Redis 压力。在博主实现的 Redis Connector 中,内置了local cache的实现。 - 2️⃣ 异步访问外存:目前博主实现的 Redis Connector 不支持异步访问,但是官方实现的 HBase Connector 支持这个功能,参考下面链接文章的,点开之后搜索
lookup.async。https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/hbase/ - 3️⃣ 批量访问外存:这玩意官方必然没有实现啊,但是,但是,但是,经过博主周末两天的疯狂 debug,改了改源码,搞定了基于 Redis 的批量访问外存优化的功能。
2.Array Expansion(数组列转行)
应用场景(支持 Batch / Streaming):将表中 ARRAY 类型字段(列)拍平,转为多行。
实际案例:比如某些场景下,日志是合并、攒批上报的,就可以使用这种方式将一个 Array 转为多行。
CREATE TABLE show_log_table (log_id BIGINT,show_params ARRAY<STRING>
) WITH ('connector' = 'datagen','rows-per-second' = '1','fields.log_id.min' = '1','fields.log_id.max' = '10'
);CREATE TABLE sink_table (log_id BIGINT,show_param STRING
) WITH ('connector' = 'print'
);INSERT INTO sink_table
SELECTlog_id,t.show_param as show_param
FROM show_log_table
-- array 炸开语法
CROSS JOIN UNNEST(show_params) AS t (show_param)
show_log_table 原始数据:
+I[7, [a, b, c]]
+I[5, [d, e, f]]
输出结果如下所示:
-- +I[7, [a, b, c]] 一行转为 3 行
+I[7, a]
+I[7, b]
+I[7, b]
-- +I[5, [d, e, f]] 一行转为 3 行
+I[5, d]
+I[5, e]
+I[5, f]
3.Table Function(自定义列转行)
应用场景(支持 Batch / Streaming):这个其实和 Array Expansion 功能类似,但是 Table Function 本质上是个 UDTF 函数,和离线 Hive SQL 一样,我们可以自定义 UDTF 去决定列转行的逻辑。
Table Function 使用分类:
Inner Join Table Function:如果 UDTF 返回结果为空,则相当于 1 1 1 行转为 0 0 0 行,这行数据直接被丢弃。Left Join Table Function:如果 UDTF 返回结果为空,折行数据不会被丢弃,只会在结果中填充null值。
public class TableFunctionInnerJoin_Test {public static void main(String[] args) throws Exception {FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);String sql = "CREATE FUNCTION user_profile_table_func AS 'flink.examples.sql._07.query._06_joins._06_table_function"+ "._01_inner_join.TableFunctionInnerJoin_Test$UserProfileTableFunction';\n"+ "\n"+ "CREATE TABLE source_table (\n"+ " user_id BIGINT NOT NULL,\n"+ " name STRING,\n"+ " row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),\n"+ " WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND\n"+ ") WITH (\n"+ " 'connector' = 'datagen',\n"+ " 'rows-per-second' = '10',\n"+ " 'fields.name.length' = '1',\n"+ " 'fields.user_id.min' = '1',\n"+ " 'fields.user_id.max' = '10'\n"+ ");\n"+ "\n"+ "CREATE TABLE sink_table (\n"+ " user_id BIGINT,\n"+ " name STRING,\n"+ " age INT,\n"+ " row_time TIMESTAMP(3)\n"+ ") WITH (\n"+ " 'connector' = 'print'\n"+ ");\n"+ "\n"+ "INSERT INTO sink_table\n"+ "SELECT user_id,\n"+ " name,\n"+ " age,\n"+ " row_time\n"+ "FROM source_table,\n"// Table Function Join 语法对应 LATERAL TABLE+ "LATERAL TABLE(user_profile_table_func(user_id)) t(age)";Arrays.stream(sql.split(";")).forEach(flinkEnv.streamTEnv()::executeSql);}public static class UserProfileTableFunction extends TableFunction<Integer> {public void eval(long userId) {// 自定义输出逻辑if (userId <= 5) {// 一行转 1 行collect(1);} else {// 一行转 3 行collect(1);collect(2);collect(3);}}}
}
执行结果如下:
-- userId <= 5,则只有 1 行结果
+I[3, 7, 1, 2021-05-01T18:23:42.560]
-- userId > 5,则有行 3 结果
+I[8, e, 1, 2021-05-01T18:23:42.560]
+I[8, e, 2, 2021-05-01T18:23:42.560]
+I[8, e, 3, 2021-05-01T18:23:42.560]
-- userId <= 5,则只有 1 行结果
+I[4, 9, 1, 2021-05-01T18:23:42.561]
-- userId > 5,则有行 3 结果
+I[8, c, 1, 2021-05-01T18:23:42.561]
+I[8, c, 2, 2021-05-01T18:23:42.561]
+I[8, c, 3, 2021-05-01T18:23:42.561]
相关文章:
:Lookup Join、Array Expansion、Table Function)
【大数据】Flink SQL 语法篇(七):Lookup Join、Array Expansion、Table Function
《Flink SQL 语法篇》系列,共包含以下 10 篇文章: Flink SQL 语法篇(一):CREATEFlink SQL 语法篇(二):WITH、SELECT & WHERE、SELECT DISTINCTFlink SQL 语法篇(三&…...
【云原生】Spring Cloud Gateway的底层原理与实践方法探究
🎉🎉欢迎光临🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟特别推荐给大家我的最新专栏《Spring 狂野之旅:从入门到入魔》 🚀 本…...
springboot 实现本地文件存储
springboot 实现本地文件存储 实现过程 上传文件保存文件(本地磁盘)返回文件HTTP访问服务器路径给前端,进行效果展示 存储 服务端接收上传的目的是提供文件的访问服务,对于SpringBoot而言,其对静态资源访问提供了很…...

Python进阶学习:Pandas--查看DataFrame中每一列的数据类型
Python进阶学习:Pandas–查看DataFrame中每一列的数据类型 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希…...
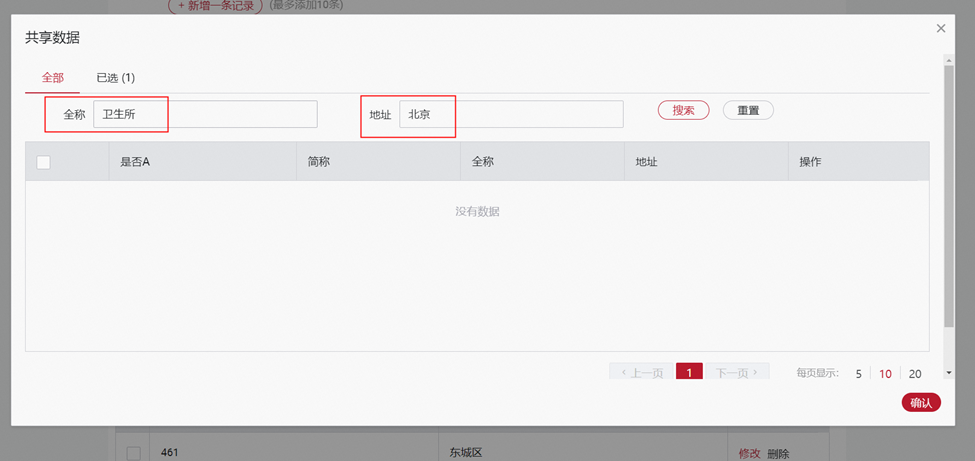
Groovy - 大数据共享搜索配置
数据共享搜索列中配置了搜索列,相应的数据共享接口中也需要支持根据配置的字段搜索,配置实体时,支持搜索的入参code必须是searchKeys,且接口应该是需要支持分页(入参必须是 current、pageSize)的。current …...

第三节:Vben Admin登录对接后端login接口
系列文章目录 第一节:Vben Admin介绍和初次运行 第二节:Vben Admin 登录逻辑梳理和对接后端准备 第三节:Vben Admin登录对接后端login接口 第四节:Vben Admin登录对接后端getUserInfo接口 第五节:Vben Admin权限-前端控制方式 文章目录 系列文章目录前言一、Flask项目介绍…...

关于CSS 优先级布局应用的教程
在前端开发中,CSS 的优先级布局是非常重要的一部分。通过合理地应用 CSS 优先级,我们可以更加灵活地控制页面的布局和样式。本教程将向您介绍如何利用 CSS 优先级进行布局,并通过实例展示其应用。 1. 了解 CSS 优先级 在 CSS 样式表中&…...

vue2+elementui上传照片(el-upload 超简单)
文章目录 element上传附件(el-upload 超详细)代码展示html代码data中methods中接口写法 总结 element上传附件(el-upload 超详细) 这个功能其实比较常见的功能,后台管理系统基本上都有,这就离不开element的…...
)
目标检测新SOTA:YOLOv9问世,新架构让传统卷积重焕生机(附代码)
在目标检测领域,YOLOv9 实现了一代更比一代强,利用新架构和方法让传统卷积在参数利用率方面胜过了深度卷积。 继 2023 年 1 月 YOLOv8 正式发布一年多以后,YOLOv9 终于来了! 我们知道,YOLO 是一种基于图像全局信息进行预测的目标检测系统。自 2015 年 Joseph Redmon、Al…...
Javascript:输入输出
目录 一.前言 二.正文 1.输出 2.输入 3.字面量 概念: 三.结语 一.前言 Javascript作为运行浏览器的语言,对于学习前端的同学来说十分重要,那么从现在开始我们将开始介绍有关 Javascript。 二.正文 1.输出 document.write() : 向body内…...
Windows系统安装TortoiseSVN并结合内网穿透实现远程访问本地服务器——“cpolar内网穿透”
文章目录 前言1. TortoiseSVN 客户端下载安装2. 创建检出文件夹3. 创建与提交文件4. 公网访问测试 前言 TortoiseSVN是一个开源的版本控制系统,它与Apache Subversion(SVN)集成在一起,提供了一个用户友好的界面,方便用…...

HarmonyOS 开发之———应用程序入口—UIAbility的使用
谢谢关注!! 前言:上一篇文章主要介绍ArkJS 基础—〉自定义组件使用。如需了解谢谢查阅:http://t.csdnimg.cn/01PQ2 一、UIAbility概述 UIAbility是一种包含用户界面的应用组件,主要用于和用户进行交互。UIAbility也是系统调度的单元,为应用提供窗口在其中绘制界面。 …...
推荐几款优秀免费开源的导航网站
🦩van-nav 项目地址:van-nav项目介绍:一个轻量导航站,汇总你的所有服务。项目亮点:全平台支持,单文件部署,有配套浏览器插件。效果预览 🦩发现导航 项目地址:nav项目…...

input输入框过滤非金额内容保留一个小数点和2位小数
这篇是输入框过滤非金额内容保留一个小数点和2位小数,金额的其他格式化可以看这篇文章常用的金额数字的格式化方法 js方法直接使用 该方式可以直接使用过滤内容,也可以到onInput或onblur等地方过滤,自行使用 /*** 非金额字符格式化处理* p…...
推荐系统经典模型YouTubeDNN代码
文章目录 前言数据预处理部分模型训练预测部分总结与问答 前言 上一篇讲到过YouTubeDNN论文部分内容,但是没有代码部分。最近网上教学视频里看到一段关于YouTubeDNN召回算法的代码,现在我分享一下给大家参考看一下,并附上一些我对代码的理解…...
spring boot 使用RSA非对称加密,前后端传递参数加解密)
学习加密(三)spring boot 使用RSA非对称加密,前后端传递参数加解密
1.前面一篇是AES对称加密写了一个demo,为了后面的两者结合使用,今天去了解学习了下RSA非对称加密. 2.这是百度百科对(对称加密丶非对称加密)的解释: (1)对称加密算法在加密和解密时使用的是同一个秘钥。 (2)非对称加密算法需要两个密钥来进行加密和解密,这两个秘钥…...

面向对象编程入门:掌握C++类的基础(2/3):深入理解C++中的类成员函数
在C编程中,类是构建程序的基石,而理解类的默认成员函数对于高效使用C至关重要。本文将深入探讨这六个默认成员函数及其他相关概念,提供给读者一个全面的视角。 类的6个默认成员函数: 如果一个类中什么成员都没有,简称为…...

javaWeb学习04
AOP核心概念: 连接点: JoinPoint, 可以被AOP控制的方法 通知: Advice 指哪些重复的逻辑,也就是共性功能(最终体现为一个方法) 切入点: PointCut, 匹配连接点的条件,通知仅会在切入点方法执行时被应用 目标对象: Target, 通知所应用的对象 通知类…...
Day07:基础入门-抓包技术全局协议封包监听网卡模式APP小程序PC应用
目录 非HTTP/HTTPS协议抓包工具 WireShark 科来网络分析系统 WPE封包 思维导图 章节知识点: 应用架构:Web/APP/云应用/三方服务/负载均衡等 安全产品:CDN/WAF/IDS/IPS/蜜罐/防火墙/杀毒等 渗透命令:文件上传下载/端口服务/Sh…...

通过elementUI学习vue
<template><el-radio v-model"radio" label"1">备选项</el-radio><el-radio v-model"radio" label"2">备选项</el-radio> </template><script>export default {data () {return {radio: 1}…...

如何打造优雅的浮动标签文本字段:SkyFloatingLabelTextField核心实现原理详解
如何打造优雅的浮动标签文本字段:SkyFloatingLabelTextField核心实现原理详解 【免费下载链接】SkyFloatingLabelTextField A beautiful and flexible text field control implementation of "Float Label Pattern". Written in Swift. 项目地址: https…...

Python百度搜索API开源项目:无限制免费搜索引擎集成的终极解决方案
Python百度搜索API开源项目:无限制免费搜索引擎集成的终极解决方案 【免费下载链接】python-baidusearch 自己手写的百度搜索接口的封装,pip安装,支持命令行执行。Baidu Search unofficial API for Python with no external dependencies 项…...
独占设备 → 虚拟共享设备)
SPOOLing 技术(假脱机技术)独占设备 → 虚拟共享设备
一、基础定义与核心定位 SPOOLing 全称:Simultaneous Peripheral Operations On-Line 中文:假脱机技术 一句话核心: 在联机状态下,用软件模拟实现脱机I/O的效果,将低速独占设备虚拟成高速共享设备,让 CPU 与…...
:从零构建领域知识图谱——基于Protege的本体建模与知识表示)
实战篇(一):从零构建领域知识图谱——基于Protege的本体建模与知识表示
1. 知识图谱与本体建模入门指南 第一次接触知识图谱时,我被那些复杂的术语吓得不轻。直到自己动手做了几个项目才发现,这东西就像搭积木一样有趣。知识图谱本质上就是用计算机能理解的方式,把现实世界中的事物和关系组织起来。比如在游戏领域…...

别再死记硬背了!用Python实战案例带你搞懂决策树、随机森林到XGBoost的进化史
从决策树到XGBoost:用Python实战演绎机器学习模型的进化之路 在机器学习领域,树模型家族以其直观的解释性和出色的预测能力,始终占据着重要地位。但很多学习者在接触决策树、随机森林、XGBoost等一系列算法时,常常陷入孤立记忆公式…...

C语言的发展及其版本
如果您是一名入门学者,或者您还不理解什么是编程语言,请查看:什么是编程语言。 如果您之前未接触任何编程语言,或者您不理解为什么学习C语言,请查看:为什么C语言是首选。 C语言于1972年11月问世,…...

MinerU 系列教程 第八课:Office 后端 - DOCX/PPTX 原生解析
MinerU 系列教程 第八篇 本篇教程将深入 Office 后端的原生文档解析机制。前三课分别剖析了 Pipeline、VLM、Hybrid 三种针对 PDF 的解析后端,而 Office 后端走了一条完全不同的路线 —— 直接从 DOCX/PPTX 的 XML 源码中提取结构化内容,无需 OCR、无需版面检测、无需任何 AI…...

Context Engineering:比Prompt Engineering更重要的AI任务构建秘籍!
Context Engineering是一门设计和构建动态系统的学科,旨在为LLM提供适时、适格、适切的信息和工具,以高效完成任务。它与Prompt Engineering的区别在于,后者关注提示词编写,前者则侧重完整的信息供给系统构建。Context Engineerin…...

内容资产化治理:轻量化中台驱动企业矩阵运营提质增效
摘要在企业全域矩阵运营规模化推进过程中,内容资产无序、运营流程碎片化、数据无法贯通已成为制约运营效率的核心问题。相较于重型中台高昂的部署与运维成本,基于云原生、低代码设计的轻量化内容中台,更适配中小微企业的数字化需求。本文从内…...

探究python-docx的段落缩进——从字体磅值到精准首行缩进
1. 为什么你的首行缩进总是不准确? 很多开发者第一次用python-docx处理段落缩进时,都会遇到这样的困惑:明明设置了固定缩进值(比如0.74厘米),为什么在不同文档里效果天差地别?这个问题我当年也踩…...