助力智能化农田作物除草,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统
在我们前面的系列博文中,关于田间作物场景下的作物、杂草检测已经有过相关的开发实践了,结合智能化的设备可以实现只能除草等操作,玉米作物场景下的杂草检测我们则少有涉及,这里本文的主要目的就是想要基于YOLOv7系列的模型来开发构建玉米田间作物场景下的玉米苗和杂草检测识别系统。
春节前后我们已经基于YOLO系列最新的YOLOv8模型开发构建了相应的项目,感兴趣可以自行移步阅读:
《助力智能化农田作物除草,基于轻量级YOLOv8n开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
《助力智能化农田作物除草,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
随后我们基于首个端到端的目标检测模型DETR开发构建了相应的检测模型,如下:
《助力智能化农田作物除草,基于DETR(DEtection TRansformer)模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
完成上述开发之后,我们想尝试基于早期开山的YOLOv3模型来开发构建对应的检测模型,如下所示:
《助力智能化农田作物除草,基于YOLOv3全系列【yolov3tiny/yolov3/yolov3spp】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
之后我们基于同样的数据使用最为经典的YOLOv5系列的模型来开发构建对应的检测模型,如下:
《助力智能化农田作物除草,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
YOLOv5全系列的模型表现亮眼,激发了我们更进一步的想法,这里我们随后就基于美团视觉团队发布的最新YOLOv6分支模型同样的数据场景开发构建了对应的检测模型,如下:
《助力智能化农田作物除草,基于YOLOv6全系列【n/s/m/l】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
至此,整个YOLO家族只剩下YOLOv7尚未使用,所以本文的主要目的就是想要填补这一空挡,来开发对应的检测模型。
首先看下实例效果:
YOLOv7是 YOLO 系列最新推出的YOLO 结构,在 5 帧/秒到 160 帧/秒范围内,其速度和精度都超过了大部分已知的目标检测器,在 GPU V100 已知的 30 帧/秒以上的实时目标检测器中,YOLOv7 的准确率最高。根据代码运行环境的不同(边缘 GPU、普通 GPU 和云 GPU),YOLOv7 设置了三种基本模型,分别称为 YOLOv7-tiny、YOLOv7和 YOLOv7-W6。相比于 YOLO 系列其他网络 模 型 ,YOLOv7 的 检 测 思 路 与YOLOv4、YOLOv5相似,YOLOv7 网络主要包含了 Input(输入)、Backbone(骨干网络)、Neck(颈部)、Head(头部)这四个部分。首先,图片经过输入部分数据增强等一系列操作进行预处理后,被送入主干网,主干网部分对处理后的图片提取特征;随后,提取到的特征经过 Neck 模块特征融合处理得到大、中、小三种尺寸的特征;最终,融合后的特征被送入检测头,经过检测之后输出得到结果。
YOLOv7 网络模型的主干网部分主要由卷积、E-ELAN 模块、MPConv 模块以及SPPCSPC 模块构建而成 。在 Neck 模块,YOLOv7 与 YOLOv5 网络相同,也采用了传统的 PAFPN 结构。FPN是YoloV7的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV7里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。Head检测头部分,YOLOv7 选用了表示大、中、小三种目标尺寸的 IDetect 检测头,RepConv模块在训练和推理时结构具有一定的区别。
简单看下实例数据情况:


训练数据配置文件如下所示:
# txt path
train: ./dataset/images/train
val: ./dataset/images/test
test: ./dataset/images/test# number of classes
nc: 3# class names
names: ['maize', 'weedhe', 'weedkuo']这里主要是选择了yolov7-tiny、yolov7和yolov7x这三款不同参数量级的模型来进行开发训练,最终线上选取的是yolov7系列的模型作为推理模型,这里给出来yolov7的模型文件:
# parameters
nc: 3 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [12,16, 19,36, 40,28] # P3/8- [36,75, 76,55, 72,146] # P4/16- [142,110, 192,243, 459,401] # P5/32# yolov7 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 1]], # 0[-1, 1, Conv, [64, 3, 2]], # 1-P1/2 [-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [128, 3, 2]], # 3-P2/4 [-1, 1, Conv, [64, 1, 1]],[-2, 1, Conv, [64, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 11[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3], 1, Concat, [1]], # 16-P3/8 [-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]], # 24[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3], 1, Concat, [1]], # 29-P4/16 [-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], # 37[-1, 1, MP, []],[-1, 1, Conv, [512, 1, 1]],[-3, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [512, 3, 2]],[[-1, -3], 1, Concat, [1]], # 42-P5/32 [-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], # 50]# yolov7 head
head:[[-1, 1, SPPCSPC, [512]], # 51[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[37, 1, Conv, [256, 1, 1]], # route backbone P4[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 63[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[24, 1, Conv, [128, 1, 1]], # route backbone P3[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]], # 75[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3, 63], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 88[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3, 51], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]],[-2, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]], # 101[75, 1, RepConv, [256, 3, 1]],[88, 1, RepConv, [512, 3, 1]],[101, 1, RepConv, [1024, 3, 1]],[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]
在实验阶段保持完全相同的参数设置,等待全部训练完成之后来从多个指标的维度来进行综合的对比分析。
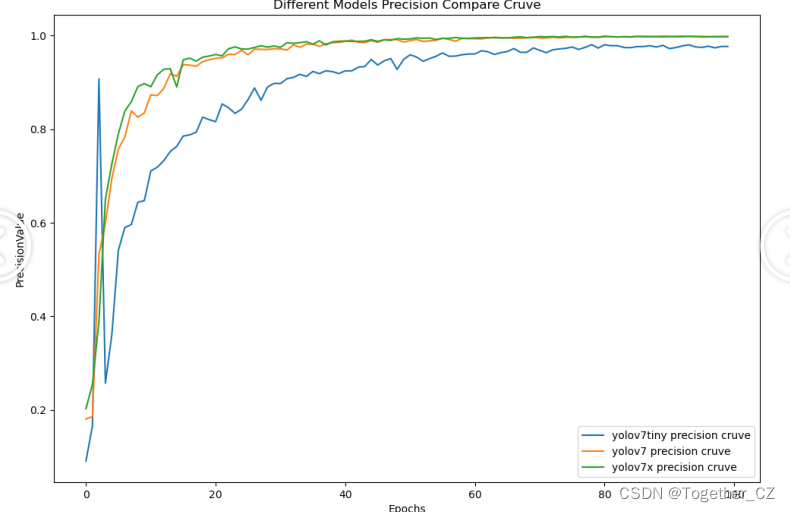
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能

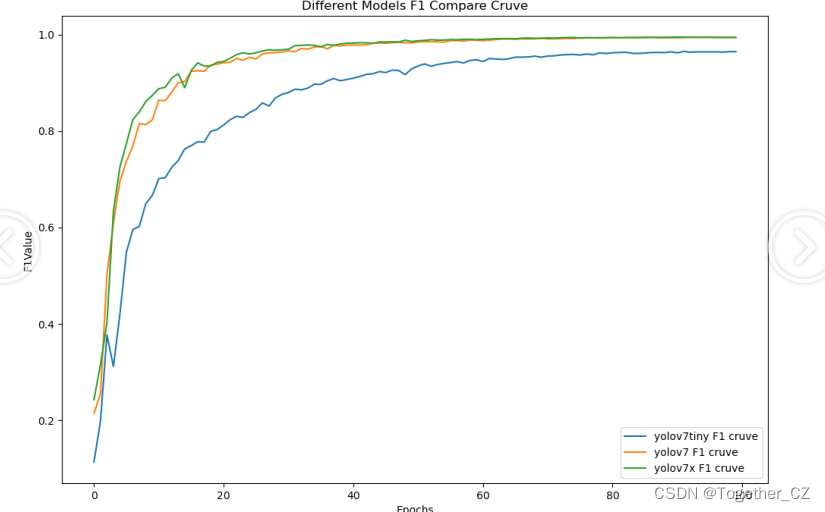
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
【loss曲线】
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
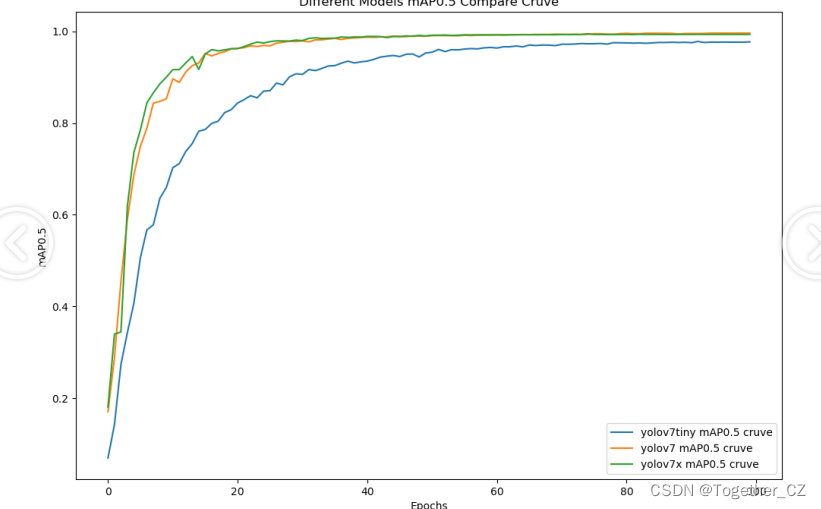
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
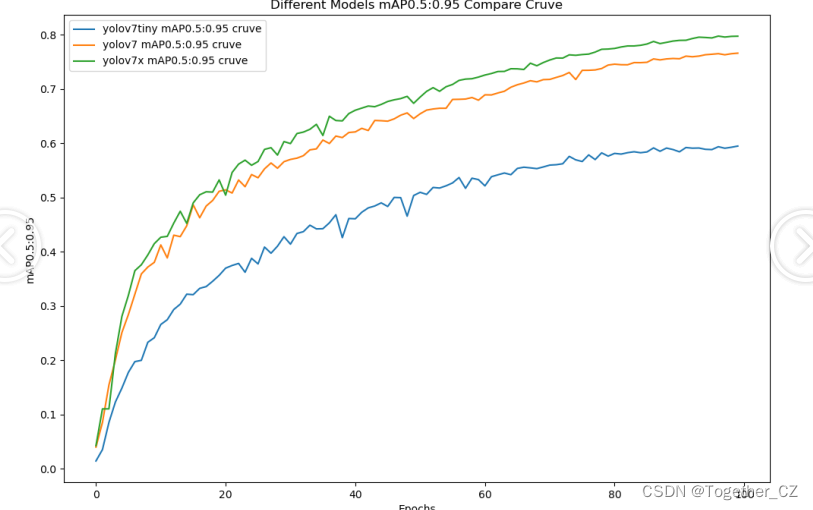
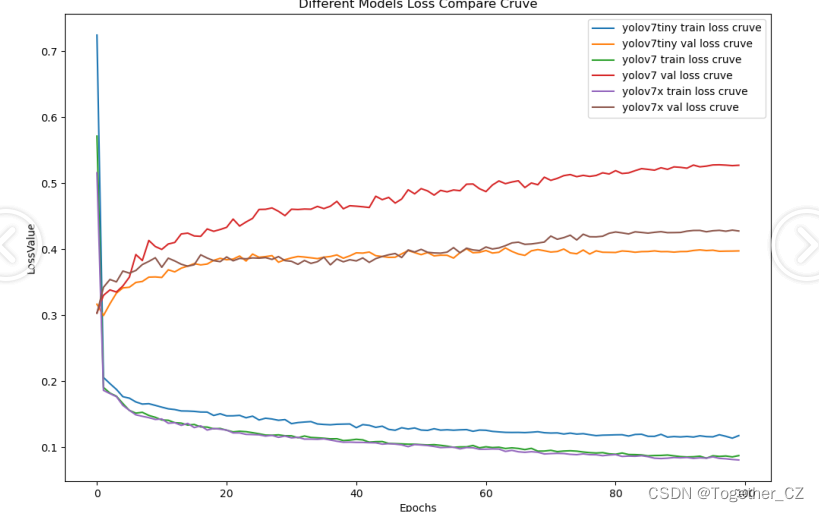
从整体实验对比结果来看:tiny系列模型的效果最次,被l和x系列的模型拉开了明显的差距,l和x系列的模型则达到了几近相同的水准,考虑到计算量的问题,这里最终选择使用yolov7来作为最终模型。
接下来我们详细看下yolov7模型的结果详情。
【Batch实例】


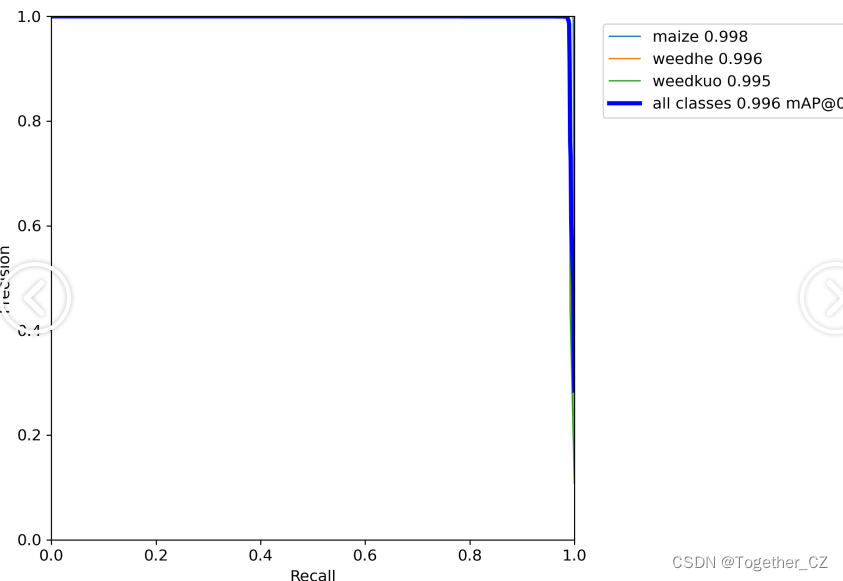
【PR曲线】
【训练可视化】

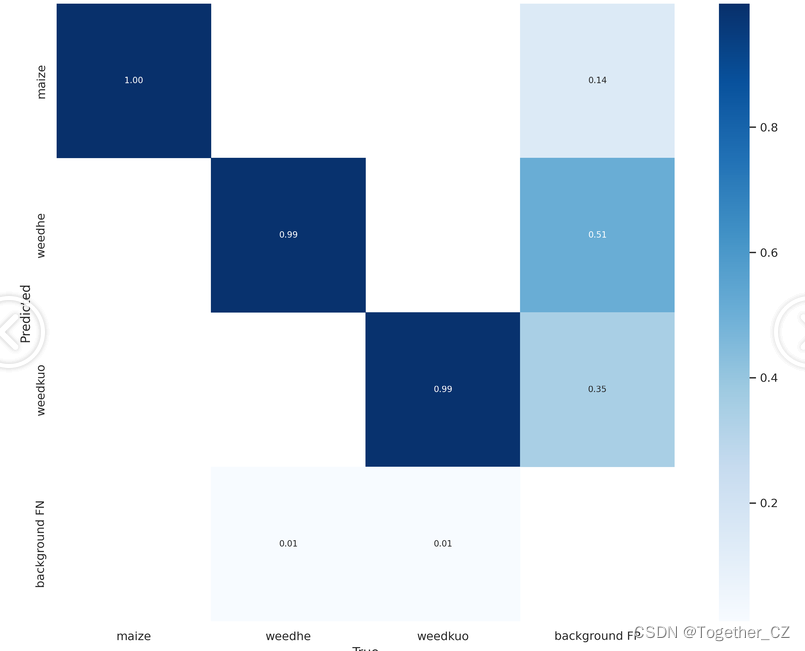
【混淆矩阵】
【离线推理实例】
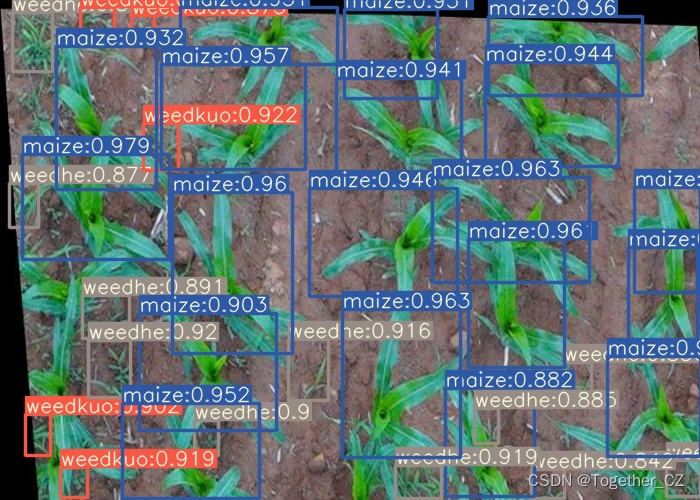
感兴趣的话都可以自行动手尝试下!
如果自己不具备开发训练的资源条件或者是没有时间自己去训练的话这里我提供出来对应的训练结果可供自行按需索取。
单个模型的训练结果默认YOLOv7-tiny
全系列三个模型的训练结果总集
相关文章:
助力智能化农田作物除草,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统
在我们前面的系列博文中,关于田间作物场景下的作物、杂草检测已经有过相关的开发实践了,结合智能化的设备可以实现只能除草等操作,玉米作物场景下的杂草检测我们则少有涉及,这里本文的主要目的就是想要基于YOLOv7系列的模型来开发…...

linux nasm汇编中调用printf不报错,但调用scanf报错。抛出了分段错误(核心转储)
当我写了如下汇编时 ; nasm -f elf64 -g -F dwarf charsin.asm ; gcc charsin.o -no-pie -o charsin ; ld -o eatclib eatclib.o ; gdb eatclib[SECTION .data]SPrompt db Enter string data, followed by Enter: ,0IPrompt db Enter an integer value, followed by Enter: ,1…...
Linux系统——Nginx负载均衡模式
目录 一、Nginx优点 二、Nginx配置项——Conf Upstream 模块 三、Nginx负载均衡 1.负载均衡策略 1.1轮询 1.2IP_hash 1.3URL_hash 1.4Least_conn 1.5Weight 1.6Fair 2.Nginx负载均衡配置状态参数 3.什么是会话保持 3.1会话保持有什么作用呢 3.2Nginx会话保持 3…...

【自然语言处理之语言模型】讲解
自然语言处理之语言模型 1. 前言2. 传统语言模型3. 神经语言模型4. 训练语言模型5. 评估语言模型6. 总结 1. 前言 自然语言处理(Natural Language Processing,NLP)是计算机科学、人工智能和语言学交叉的一个领域,它研究计算机和人…...

输入一个整数n,输出这个整数的二进制的0和1的个数
输入一个整数n,输出这个整数的二进制的0和1的个数:除二取余法 代码: #include <cstdio> int main() {int n;scanf_s("%d", &n);int arr[2] { 0 };while (n) {int yu n % 2;arr[yu];n n / 2;}printf("0的个数是:…...

初阶数据结构:链表相关题目练习(补充)
目录 1. 单链表相关练习题1.1 移除链表元素1.2 反转链表1.3 链表的中间结点1.4 链表的倒数第k个结点1.5 合并两个有序链表1.6 链表分割1.7 链表的回文结构1.8 相交链表1.9 判断一个链表中是否有环1.10 寻找环状链表相遇点1.11 链表的深度拷贝 1. 单链表相关练习题 注࿱…...
java: 错误: 不支持发行版本 5
目录 一、问题描述 二、解决办法 方法一:修改idea设置中的jdk版本 方法二:配置pom.xml文件 方法三:配置maven的xml文件(推荐) 三、结果 一、问题描述 问题描述:今天创建了一个maven项目,…...

springSecruity--->和springboot结合的跨域问题
🤦♂️这个是我在springboot中使用springSecruity写一个小demo时遇到的问题,记录下来🤦♂️ 文章目录 跨域请求springboot项目中使用springSecruity导致跨域请求CrossOrigin请求失效解决方法springboot 中的跨域方法 跨域请求 什么是跨…...
网关kong记录接口处理请求和响应插件 tcp-log-with-body的安装
tcp-log-with-body 介绍 Kong的tcp-log-with-body插件是一个高效的工具,它能够转发Kong处理的请求和响应。这个插件非常适用于需要详细记录API请求和响应信息的情景,尤其是在调试和排查问题时。 软件环境说明 kong version 2.1.4 - 2.8.3 [可用亲测]C…...

ElasticSearch之Completion Suggester
写在前面 通过completion suggester可以实现如下的效果: 其实就是做的like xxx%这种。通过FST这种数据结构来存储,实现快速的前缀匹配,并且可以将es所有的数据加载到内存中所以速度completion的查询速度非常快。 需要注意,如果…...

ant 布局组件 组件等高设置
背景: 想实现一个和content等高的侧边栏,并增加侧边栏导航。 ant组件概述 Layout:布局容器,其下可嵌套 Header Sider Content Footer 或 Layout 本身,可以放在任何父容器中。Header:顶部布局,…...
不可多得的干货,网易的朋友给我这份339页的Android面经
这里先放上目录 一 性能优化 1.如何对 Android 应用进行性能分析 android 性能主要之响应速度 和UI刷新速度。 首先从函数的耗时来说,有一个工具TraceView 这是androidsdk自带的工作,用于测量函数耗时的。 UI布局的分析,可以有2块&#x…...

Qt项目:网络1
文章目录 项目:网路项目1:主机信息查询1.1 QHostInfo类和QNetworkInterface类1.2 主机信息查询项目实现 项目2:基于HTTP的网络应用程序2.1 项目中用到的函数详解2.2 主要源码 项目:网路 项目1:主机信息查询 使用QHostI…...
软件测试有哪些常用的测试方法?
软件测试是软件开发过程中重要组成部分,是用来确认一个程序的质量或者性能是否符合开发之前提出的一些要求。软件测试的目的有两方面,一方面是确认软件的质量,另一方面是提供信息,例如,给开发人员或者程序经理反馈意见…...
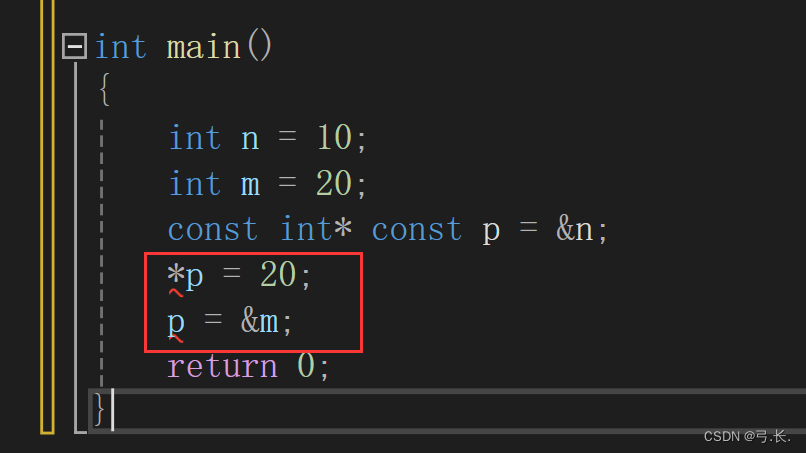
【C语言基础】:深入理解指针(一)
文章目录 一、内存和地址1. 内存2. 如何理解编址 二、指针变量和地址2.1 取地址操作符(&)2.2 指针变量和解引用操作符(*)2.2.1 指针变量2.2.2 如何拆解指针变量2.2.3 解引用操作符 2.3 指针变量的大小 三、指针变量类型的意义3.1 指针的解引用3.2 指针 - 整数3.3 void*指针…...
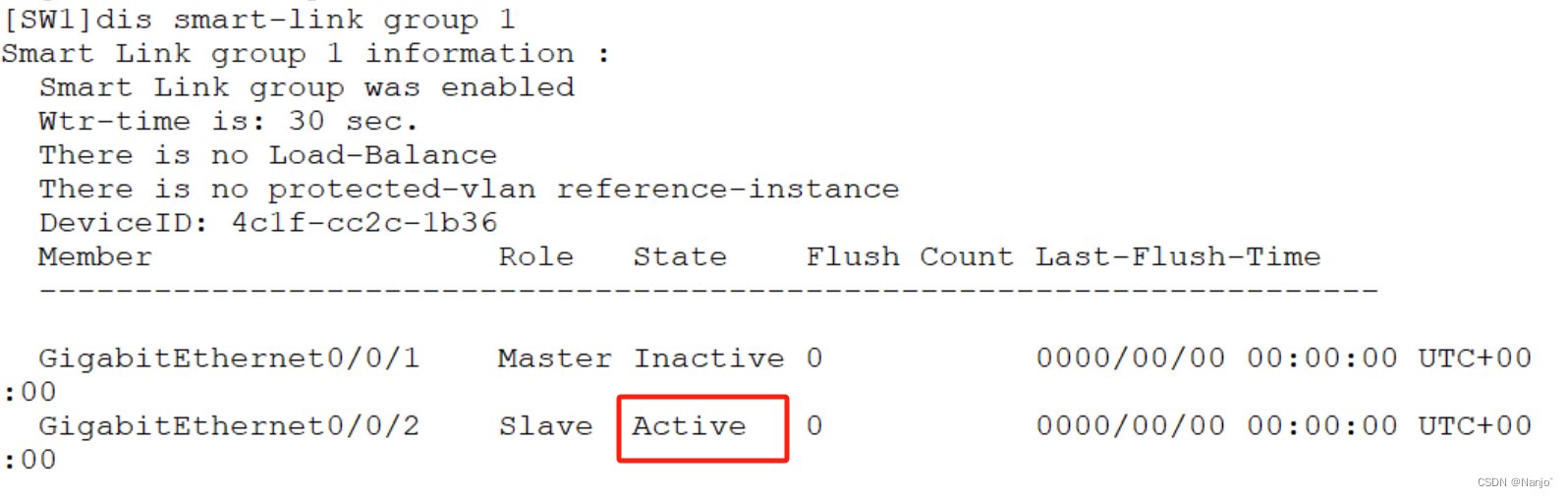
单点故障解决方案之Smart Link与Monitor Link
-SmartLink技术,创建Smart Link 组。在该组中,加入两个端口。其中1个端口是主端口,也称之为Master端口。另外1个端口是备份端口:也称之为 Slave 端口。 -Monitor Link 组也称之为“监控链路组,由上行端口和下行端口共同组成。下行…...

QT之QSharedMemory共享内存
QSharedMemory是qt提供对共享内存操作的类,主要用来对内存卡写数据和读数据。 常用api: 1、void QSharedMemory::setKey(const QString &key) 为共享内存设置键值。如何当前的内存共享对象已经链接到底层的共享内存段(isAttached)&…...
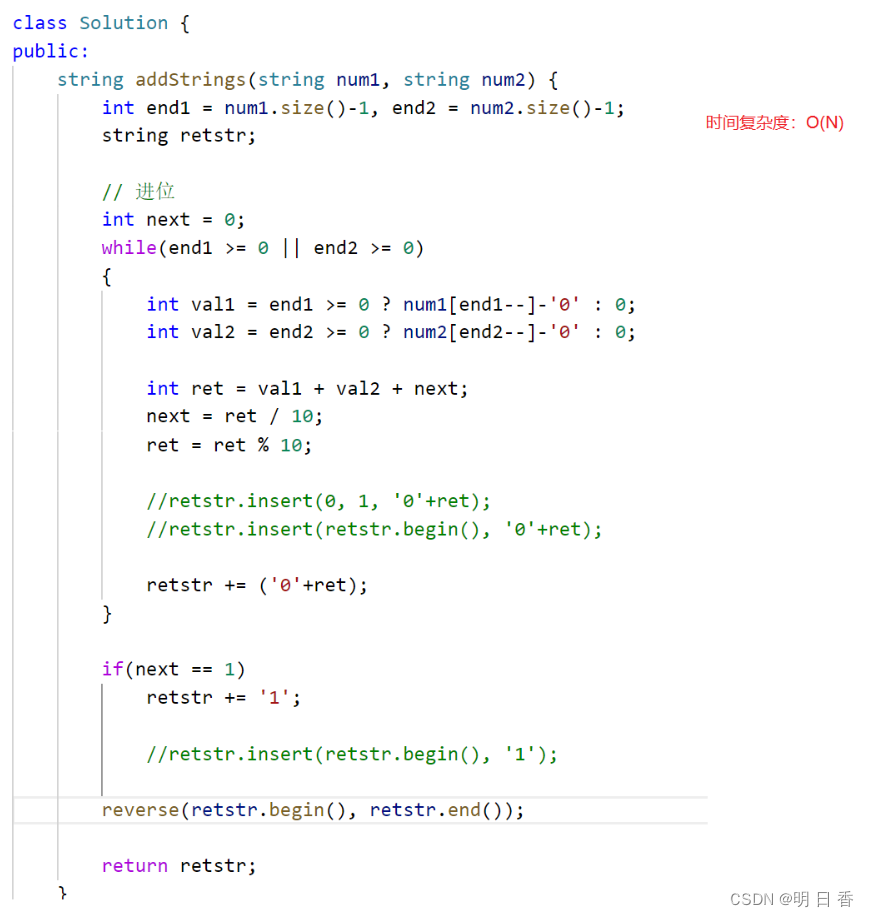
string 类 经典习题之数字字符相加
题目: 给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。 你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。 题目来源࿱…...

通讯录——C语言实现
头文件Contact.h #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<string.h> #include<stdlib.h> #pragma once #define MAX 100 #define MAX_NAME 20 #define MAX_SEX 5 #define MAX_TELE 12 #define MAX_ADDR 30//表示一个人的信息 //struct…...
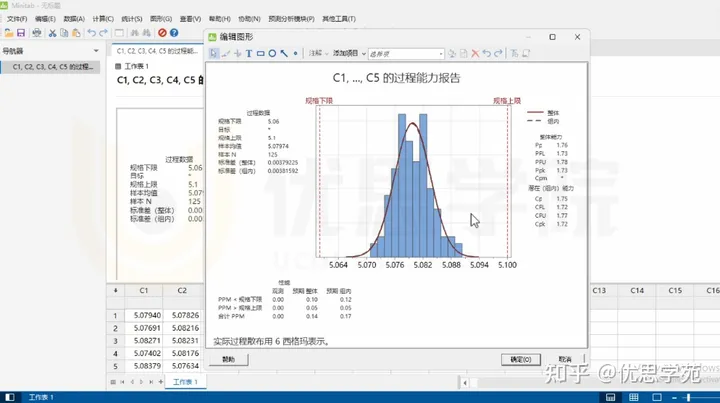
优思学院|3步骤计算出Cpk|学习Minitab
在生产和质量管理中,准确了解和控制产品特性至关重要。一个关键的工具是Cpk值,它是衡量生产过程能力的重要指标。假设我们有一个产品特性的规格是5.080.02,通过收集和分析过程数据,我们可以计算出Cpk值,进而了解生产过…...

基于Qwen-Image-Edit-F2P的Java开发者AI图像应用实战
基于Qwen-Image-Edit-F2P的Java开发者AI图像应用实战 最近在做一个电商后台项目,产品经理提了个需求,希望用户上传商品主图后,系统能自动生成不同风格的营销海报。团队里没有专门的前端设计师,后端又都是Java老手,大家…...

网盘直链解析工具终极指南:八大平台高速下载完整解决方案
网盘直链解析工具终极指南:八大平台高速下载完整解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

WandEnhancer:本地化增强WeMod游戏助手的开源解决方案
WandEnhancer:本地化增强WeMod游戏助手的开源解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer WandEnhancer是一款专注于WeMod游戏助…...

5步掌握NSC_BUILDER:Switch游戏文件管理的完整路径
5步掌握NSC_BUILDER:Switch游戏文件管理的完整路径 【免费下载链接】NSC_BUILDER Nintendo Switch Cleaner and Builder. A batchfile, python and html script based in hacbuild and Nuts python libraries. Designed initially to erase titlerights encryption …...

MySQL 事务日志写入机制
MySQL事务日志写入机制探秘 在数据库系统中,事务的持久性和一致性是核心特性,而MySQL通过事务日志(如InnoDB的redo log和binlog)确保数据安全。事务日志的写入机制直接影响数据库的性能与可靠性,理解其原理对优化和故…...

Git-RSCLIP实战:无需标注数据,用英文描述精准识别遥感图像
Git-RSCLIP实战:无需标注数据,用英文描述精准识别遥感图像 1. 模型核心能力解析 1.1 专为遥感优化的图文检索架构 Git-RSCLIP基于SigLIP架构深度改造,专门针对遥感图像特性进行了三项关键改进: 多尺度特征融合:遥感…...

ANIMATEDIFF PRO保姆级教程:手把手教你用文字生成电影感视频
ANIMATEDIFF PRO保姆级教程:手把手教你用文字生成电影感视频 1. 前言:开启你的AI电影创作之旅 想象一下,你只需要输入一段文字描述,就能获得一段具有电影质感的动态视频。这不是科幻电影的情节,而是ANIMATEDIFF PRO带…...

3DGS项目复现:从COLMAP稀疏重建到高斯模型训练全流程拆解
1. 3DGS项目复现概述 3D Gaussian Splatting(3DGS)是近年来计算机视觉领域的一项突破性技术,它通过将3D场景表示为大量可学习的高斯分布来实现高质量的视图合成。与传统的NeRF方法相比,3DGS在渲染速度、内存效率和场景细节保留方面…...

3个关键步骤快速上手Fiji:科研图像分析的完整解决方案
3个关键步骤快速上手Fiji:科研图像分析的完整解决方案 【免费下载链接】fiji A "batteries-included" distribution of ImageJ :battery: 项目地址: https://gitcode.com/gh_mirrors/fi/fiji Fiji科学图像处理平台是ImageJ的增强版本,专…...
)
用Quartus和Modelsim手把手教你:一个FPGA自动售货机的完整状态机设计(附Verilog代码)
从零构建FPGA自动售货机:状态机设计与Verilog实战指南 1. 项目概述与设计思路 想象一下,你正站在一台自动售货机前,准备购买一瓶饮料。这个看似简单的交互过程背后,隐藏着一套精密的状态控制系统。今天,我们将用FPGA和…...