【深度学习】人脸识别工程化落地
文章目录
- 前言
- 1、facenet
- 2、使用
- 2.1.其它blog
- 2.2 实践
- 总结
前言
老早以前就希望能写一篇关于人脸识别的工程化落地的案例,一年前做疲劳驾驶时使用的dlib插件,它封装好了,人脸检测、对齐、相似度计算三个部分,就是插件比较难装,但同时也少了很多细节.
今天我们来做一些高级一点的, facenet网络
1、facenet
谷歌人脸识别算法,发表于 CVPR 2015,利用相同人脸在不同角度等姿态的照片下有高内聚性,不同人脸有低耦合性,提出使用 cnn + triplet mining 方法,在 LFW 数据集上准确度达到 99.63%。
测试时只需要计算人脸特征EMBEDDING,然后计算距离使用阈值即可判定两张人脸照片是否属于相同的个体。
在这里插入图片描述
简单来讲,在使用阶段,facenet即是:
1、输入一张人脸图片
2、通过深度卷积网络提取特征
3、L2标准化
4、得到一个长度为128特征向量。
2、使用
2.1.其它blog
其它人在使用中一般是这样的
#---------------------------------------------------## 检测图片#---------------------------------------------------#def detect_image(self, image_1, image_2):#---------------------------------------------------## 图片预处理,归一化#---------------------------------------------------#with torch.no_grad():image_1 = resize_image(image_1, [self.input_shape[1], self.input_shape[0]], letterbox_image=self.letterbox_image)image_2 = resize_image(image_2, [self.input_shape[1], self.input_shape[0]], letterbox_image=self.letterbox_image)photo_1 = torch.from_numpy(np.expand_dims(np.transpose(preprocess_input(np.array(image_1, np.float32)), (2, 0, 1)), 0))photo_2 = torch.from_numpy(np.expand_dims(np.transpose(preprocess_input(np.array(image_2, np.float32)), (2, 0, 1)), 0))if self.cuda:photo_1 = photo_1.cuda()photo_2 = photo_2.cuda()#---------------------------------------------------## 图片传入网络进行预测#---------------------------------------------------#output1 = self.net(photo_1).cpu().numpy()output2 = self.net(photo_2).cpu().numpy()#---------------------------------------------------## 计算二者之间的距离#---------------------------------------------------#l1 = np.linalg.norm(output1 - output2, axis=1)# plt.subplot(1, 2, 1)# plt.imshow(np.array(image_1))# plt.subplot(1, 2, 2)# plt.imshow(np.array(image_2))# plt.text(-12, -12, 'Distance:%.3f' % l1, ha='center', va= 'bottom',fontsize=11)# plt.show()return l1
核心思想是:传入两张图片,计算距离,设置阈值判断是否是同一个人.
可是,这种放在工程上,比如人脸开门是不行的,所谓人脸识别,必须有一个人脸库,送入一张图片和人脸库的所有图片进行遍历比对,挑出相似度最高的一张图片,和阈值比对,决定是否开门,并留存记录.
那肯定不能次次遍历人脸库啊,所以人脸库的图片要先转出特征向量的collection,存起来, 送入一张图片后,用模型抽取向量特征,和collections里面的向量比较.
如果人脸库太大,比如几万张特征,我们可以分batch存,每个batch找出最合适的,有点像桶排序,并且并行起来计算,是不是比较有意思.
2.2 实践
#---------------------------------------------------## 保存人脸库特征#---------------------------------------------------#def save_to_tensor(self):#---------------------------------------------------## 图片预处理,归一化#---------------------------------------------------#path_dir = "./img"file_name_list = os.listdir(path_dir)img_feature = {}with torch.no_grad():for file_name in file_name_list:image_1 = Image.open(os.path.join(path_dir,file_name))image_1 = resize_image(image_1, [self.input_shape[1], self.input_shape[0]], letterbox_image=self.letterbox_image)photo_1 = torch.from_numpy(np.expand_dims(np.transpose(preprocess_input(np.array(image_1, np.float32)), (2, 0, 1)), 0))if self.cuda:photo_1 = photo_1.cuda() #---------------------------------------------------## 图片传入网络进行预测#---------------------------------------------------#output1 = self.net(photo_1).cpu().numpy()img_feature[file_name] = output1print(img_feature)with open("img_feature.txt", "wb") as file:pickle.dump(img_feature, file)return None
经过这些代码,把./img/ 下的人脸库向量都以二进制的方式存入了文件中.
送入一张图片,只需要,将图片送入模型,获取当前人的人脸信息,然后和人脸库的向量比较,
def get_from_face_collection(self):input_file = "img/1_001.jpg"image_1 = Image.open(input_file)image_1 = resize_image(image_1, [self.input_shape[1], self.input_shape[0]], letterbox_image=self.letterbox_image)with torch.no_grad():photo_1 = torch.from_numpy(np.expand_dims(np.transpose(preprocess_input(np.array(image_1, np.float32)), (2, 0, 1)), 0))if self.cuda:photo_1 = photo_1.cuda() #---------------------------------------------------## 图片传入网络进行预测#---------------------------------------------------#output1 = self.net(photo_1).cpu().numpy()f = open('img_feature.txt','rb')img_feature_json = pickle.load(f)distance_map = {}for img_name, featrue_map in img_feature_json.items():l1 = np.linalg.norm(output1 - featrue_map, axis=1)distance_map[img_name] = l1print(distance_map)
distance_map 就是你说要的结果集,然后做个排序,找到top1 和阈值比对即可
git:https://github.com/justinge/facenet_pytorch.git
总结
还有用milivus向量库的,先挖个坑,最终工程化一个到位的.
相关文章:

【深度学习】人脸识别工程化落地
文章目录前言1、facenet2、使用2.1.其它blog2.2 实践总结前言 老早以前就希望能写一篇关于人脸识别的工程化落地的案例,一年前做疲劳驾驶时使用的dlib插件,它封装好了,人脸检测、对齐、相似度计算三个部分,就是插件比较难装,但同时也少了很多…...
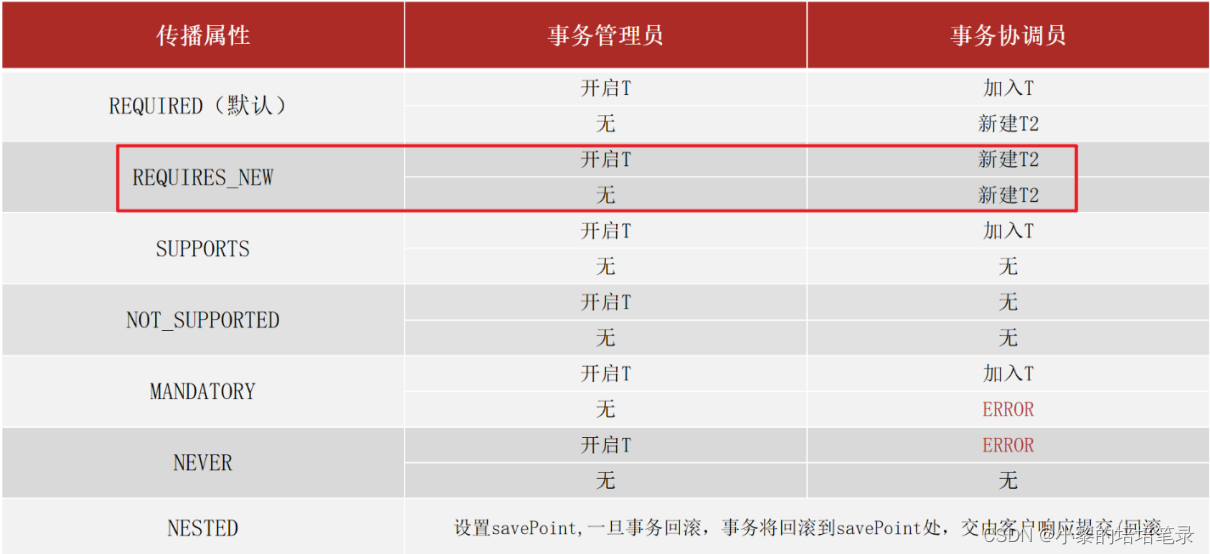
AOP面向切面编程思想。
目录 一、AOP工作流程 1、基本概念 2、AOP工作流程 二、AOP核心配置 1、AOP切入点表达式 2、AOP通知类型 三、AOP通知获取数据 1、获取参数 2、获取返回值 3、获取异常 四、AOP事务管理 1、Spring事务简介 2、Spring事务角色 3、事务属性 一、AOP工作流程 1、…...

实验7-变治技术及动态规划初步
目录 1.统计个数 2.数塔dp -A 3.Horspool算法 4.计数排序 5.找零问题1-最少硬币 1.统计个数 【问题描述】有n个数、每个元素取值在1到9之间,试统计每个数的个数 【输入形式】第一行,n的值;第二行...
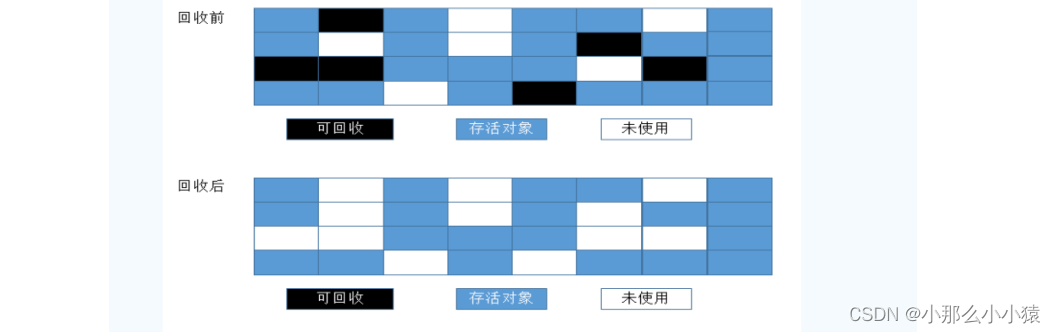
JVM垃圾回收机制GC理解
目录JVM垃圾回收分代收集如何识别垃圾引用计数法可达性分析法引用关系四种类型: 强、软、弱、虚强引用软引用 SoftReference弱引用 WeakReferenceWeakHashMap软引用与虚引用的使用场景虚引用与引用队列引用队列虚引用 PhantomReference垃圾回收算法引用计数复制 Cop…...

C++中的容器
1.1 线性容器1)std::array看到这个容器的时候肯定会出现这样的问题:为什么要引入 std::array 而不是直接使用 std::vector?已经有了传统数组,为什么要用 std::array?先回答第一个问题,与 std::vector 不同,…...
2023备战金三银四,Python自动化软件测试面试宝典合集(五)
接上篇八、抓包与网络协议8.1 抓包工具怎么用 我原来的公司对于抓包这块,在 App 的测试用得比较多。我们会使用 fiddler 抓取数据检查结果,定位问题,测试安全,制造弱网环境;如:抓取数据通过查看请求数据,请…...

SpringDI自动装配BeanSpring注解配置和Java配置类
依赖注入 上篇博客已经提到了DI注入方式的构造器注入,下面采用set方式进行注入 基于set方法注入 public class User {private String name;private Address address;private String[] books;private List<String> hobbys;private Map<String,String>…...
2月面经:真可惜...拿了小米的offer,字节却惨挂在三面
我是2月份参加字节跳动和华为的面试的,虽然我只拿下了小米的offer,但是我自己也满足了,想把经验分享出来,进而帮助更多跟我一样想进大厂的同行朋友们,希望大家可以拿到理想offer。 自我介绍 我是16年从南京工业大学毕…...

磐云PY-B8 网页注入
文章目录1.使用渗透机场景windows7中火狐浏览器访问服务器场景中的get.php,根据页面回显获取Flag并提交;2.使用渗透机场景windows7中火狐浏览器访问服务器场景中的post.php,根据页面回显获取Flag并提交;3.使用渗透机场景windows7中…...

多传感器融合定位十-基于滤波的融合方法Ⅰ其二
多传感器融合定位十-基于滤波的融合方法Ⅰ其二3. 滤波器基本原理3.1 状态估计模型3.2 贝叶斯滤波3.3 卡尔曼滤波(KF)推导3.4 扩展卡尔曼滤波(EKF)推导3.5 迭代扩展卡尔曼滤波(IEKF)推导4. 基于滤波器的融合4.1 状态方程4.2 观测方程4.3 构建滤波器4.4 Kalman 滤波实际使用流程4…...
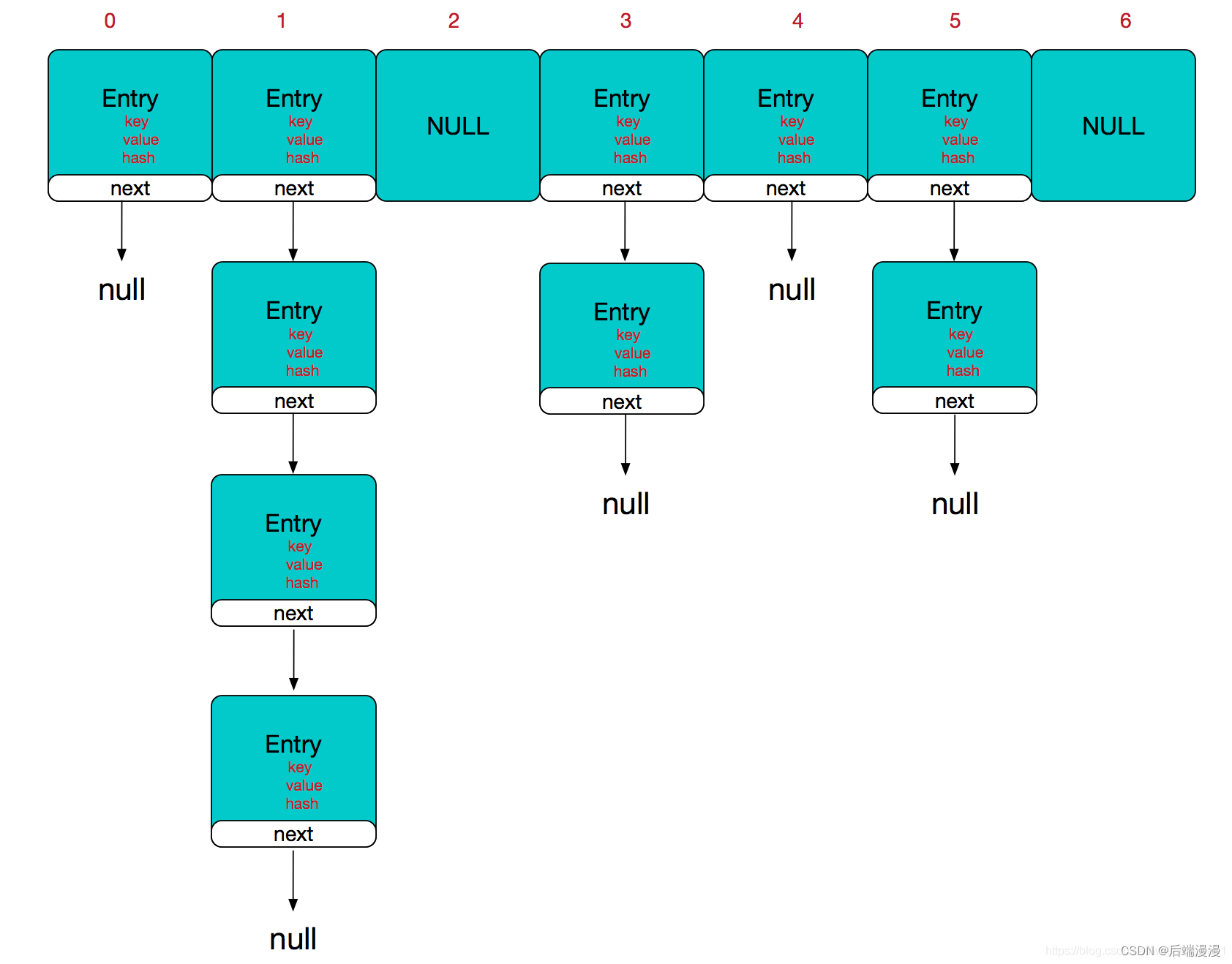
Java集合面试题:HashMap源码分析
文章目录一、HashMap源码二、HashMap数据结构模型图三、HashMap中如何确定元素位置四、关于equals与hashCode函数的重写五、阅读源码基本属性参考文章:史上最详细的 JDK 1.8 HashMap 源码解析参考文章:Hash详解参考文章:hashCode源码分析参考…...
,真题含思路)
华为OD机试 - 数组合并(Python),真题含思路
数组合并 题目 现在有多组整数数组, 需要将他们合并成一个新的数组。 合并规则, 从每个数组里按顺序取出固定长度的内容合并到新的数组中, 取完的内容会删除掉, 如果该行不足固定长度或者已经为空, 则直接取出剩余部分的内容放到新的数组中, 继续下一行。 如样例 1, 获得长度…...
Vue2创建移动端项目
一、Vscode Vscode 下载安装以及常用的插件 1、Vscode 下载 下载地址:Vscode 中文语言插件 搜索 chinese 主题 Atom 主题 文件图标主题 搜索 icon 源代码管理插件GitLens 搜索 GitLens Live Server _本地服务器 搜索 Live Server Prettier - Code formatt…...
PorterDuffXfermode与圆角图片
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 圆角图片 在项目开发中,我们常用到这样的功能:显示圆角图片。 这个是咋做的呢?我们来瞅瞅其中一种实现方式 /*** param bitmap 原图* p…...

如何准备大学生电子设计竞赛
大学生电子设计竞赛难度中上,一般有好几个类型题目可以选择,参赛者可以根据自己团队的能力、优势去选择合适自己的题目,灵活自主空间较大。参赛的同学们可以在暑假好好学习相关内容,把往年的题目拿来练练手。这个比赛含金量还是有…...

【Java容器(jdk17)】ArrayList深入源码,就是这么简单
ArrayList深入源码一、ArrayList源码解析1. MIXIN 的混入2. 属性说明3. 构造方法4. 其他方法(核心)iterator 和 listIterator 方法add方法remove 方法sort方法其他二、ArrayList 为什么是线程不安全的?体现哪些方面呢?三、ArrayLi…...
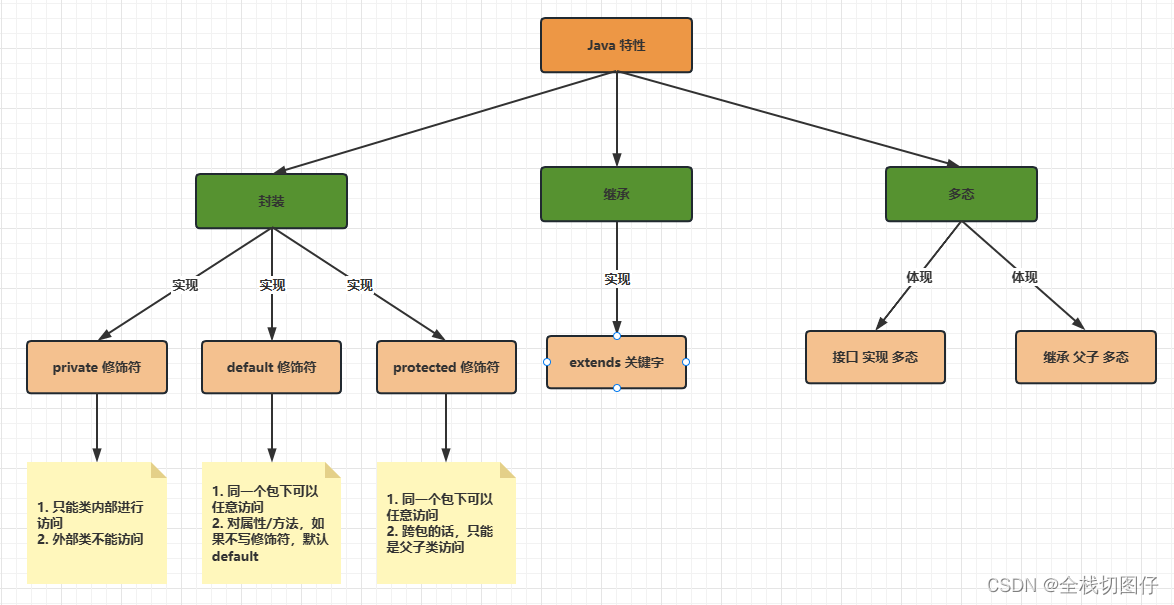
【Java 面试合集】简述下Java的三个特性 以及项目中的应用
简述下Java的特征 以及项目中的应用 1. 概述 上述截图中就是Java的三大特性,以及特性的实现方案。接下来就每个点展开来说说 2. 封装 满足:隐藏实现细节,公开使用方法 的都可以理解为是封装 而实现封装的有利手段就是权限修饰符了。可以根据…...
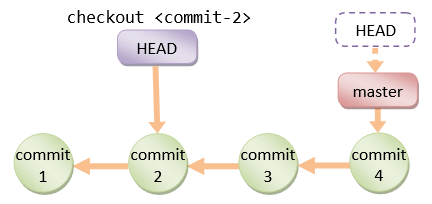
git基本概念图示【学习】
基本概念工作区(Working Directory)就是你在电脑里能看到的目录,比如名字为 gafish.github.com 的文件夹就是一个工作区本地版本库(Local Repository)工作区有一个隐藏目录 .git,这个不算工作区,…...

微前端qiankun架构 (基于vue2实现)使用教程
工具使用版本 node --> 16vue/cli --> 5 创建文件 创建文件夹qiankun-test。 使用vue脚手架创建主应用main和子应用dev 主应用 安装 qiankun: yarn add qiankun 或者 npm i qiankun -S 使用qiankun: 在 utils 内创建 微应用文件夹 microApp,在该文件夹…...

记录robosense RS-LIDAR-16使用过程3
一、wireshark抓包保存pcap文件并解析ubuntu18安装wireshark,参考下面csdn教程,官网教程我看的一脸蒙(可能英语太差)https://blog.csdn.net/weixin_46048542/article/details/121730448?spm1001.2101.3001.6650.2&utm_medium…...

AI辅助构建复古像素风Hacker News聚合器:全栈开发实战
1. 项目概述:一个AI驱动的复古风Hacker News聚合器最近在逛Hacker News的时候,我总感觉“Show HN”板块里那些有趣的个人项目像流星一样,刷一下就过去了,想回头再找特别费劲。作为一个喜欢折腾的开发者,我就在想&#…...

Fulling框架:构建完整AI智能体的工程化实践指南
1. 项目概述:从“FullAgent”到“Fulling”的智能体进化之路最近在开源社区里,一个名为“Fulling”的项目引起了我的注意。它隶属于“FullAgent”这个组织,名字本身就很有意思。“Fulling”这个词,在英语里有“使…丰满、充实”的…...

初创公司如何构建高效董事会:从法律合规到战略增长引擎
1. 创业公司的董事会:从法律义务到增长引擎对于很多初次创业的创始人来说,“董事会”这个词听起来可能既遥远又麻烦。它像是公司法条里一个冷冰冰的规定,或者是在融资时不得不向投资人妥协、让渡控制权的象征。尤其是在公司刚起步、团队只有三…...

Deep Lake:统一多模态AI数据存储与向量检索的实践指南
1. 项目概述:Deep Lake,一个为AI而生的数据湖 如果你正在构建一个需要处理图像、文本、音频、PDF,甚至医学影像DICOM文件的大模型应用,或者你在训练一个需要高效加载海量数据的深度学习模型,那么你很可能正被数据管理…...

【Google全家桶AI功能2026终极前瞻】:20位谷歌AI Lab核心工程师闭门透露的7大颠覆性升级路径
更多请点击: https://intelliparadigm.com 第一章:Google全家桶AI功能2026升级全景图谱 2026年,Google正式将Gemini 3.5 Ultra深度集成至全系生产力产品中,实现跨端、实时、上下文感知的AI协同。核心升级聚焦于“意图理解前置化”…...

基础模型全生命周期管理的混合架构实践与优化
1. 基础模型全生命周期管理的架构挑战基础模型(Foundation Models)正在重塑AI技术栈的每个环节,从预训练到推理部署的全生命周期管理面临前所未有的系统架构挑战。传统HPC(高性能计算)集群和云原生平台各自为政的局面&…...

【数字孪生实战案例】怎样设置数据筛选条件,精准控制电子地图飞线的呈现效果?~山海鲸可视化
在数据可视化大屏应用里,电子地图飞线是展示跨地域关联数据的重要载体。当飞线数据量大、维度繁杂时,通过配置数据条件对地图飞线做精准筛选,能够过滤冗余信息、聚焦核心数据,让地图呈现更简洁直观,有效提升整体可视化…...

从零开始使用 Node js 调用 Taotoken 多模型 API 的实践感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始使用 Node.js 调用 Taotoken 多模型 API 的实践感受 作为一名 Node.js 后端开发者,我最近在项目中接入了 Taot…...

基于MCP协议构建监控数据连接器:统一多源数据赋能AI运维
1. 项目概述:一个面向开发者的监控数据连接器如果你是一名开发者,尤其是后端或运维工程师,那么“监控”这个词对你来说一定不陌生。从服务器CPU、内存使用率,到应用接口的响应时间、错误率,再到业务层面的关键指标&…...

基础设施可观测性:监控和诊断基础设施状态
基础设施可观测性:监控和诊断基础设施状态 一、基础设施可观测性概述 1.1 基础设施可观测性的定义 基础设施可观测性是指通过收集、分析和可视化基础设施的运行数据,来理解和监控基础设施状态的能力。它包括监控服务器、网络、存储等基础设施组件的性能和…...