yolov8涨点技巧,添加SwinTransformer注意力机制,提升目标检测效果
目录
摘要
SwinTransformer原理
代码实现
YOLOv8详细添加步骤
ymal文件内容
one_swinTrans
three_swinTrans
启动命令
完整代码分享
摘要
Swin Transformer通过引入创新的分层注意力机制展现了其架构的独特性,该机制通过将注意力区域划分为块并在这些块内执行操作,从而有效降低了计算复杂性。其主要结构呈现分层形式,每个阶段包括一组基础块,负责捕捉不同层次的特征表示,形成了分层的特征提取过程。采用多尺度的注意力机制使得模型能够同时关注不同大小的特征,从而提高对图像中不同尺度信息的感知。在多个图像分类基准数据集上,Swin Transformer表现出与其他先进模型相媲美甚至更优的性能,且在相对较少的参数和计算成本下取得出色的结果。其模块化设计使得它在目标检测和语义分割等其他计算机视觉任务上也具备良好的通用性。
SwinTransformer原理
Swin Transformer 的一个关键设计元素是连续自注意力层之间窗口分区的移动,如图所示。移动的窗口桥接了前一层的窗口,提供了它们之间的连接,从而显着增强了建模能力。这种策略在现实世界的延迟方面也很有效:窗口内的所有查询补丁共享相同的密钥,这有利于硬件中的内存访问。相比之下,早期基于滑动窗口的自注意力方法 由于不同查询像素的键集不同,因此在通用硬件上延迟较低。
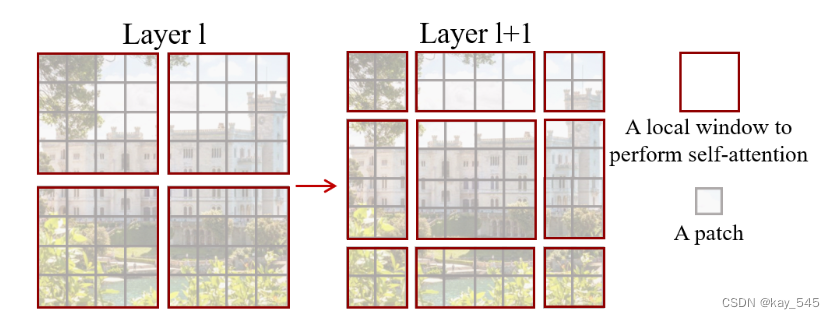
下图概述了 Swin Transformer 架构,其中展示了微型版本 。它首先通过补丁分割模块(如 ViT)将输入 RGB 图像分割成不重叠的补丁。每个补丁都被视为一个“token”,其特征被设置为原始像素 RGB 值的串联。在我们的实现中,我们使用 4 × 4 的 patch 大小,因此每个 patch 的特征维度为 4 × 4 × 3 = 48。线性嵌入层应用于此原始值特征,将其投影到任意维度(记为C)
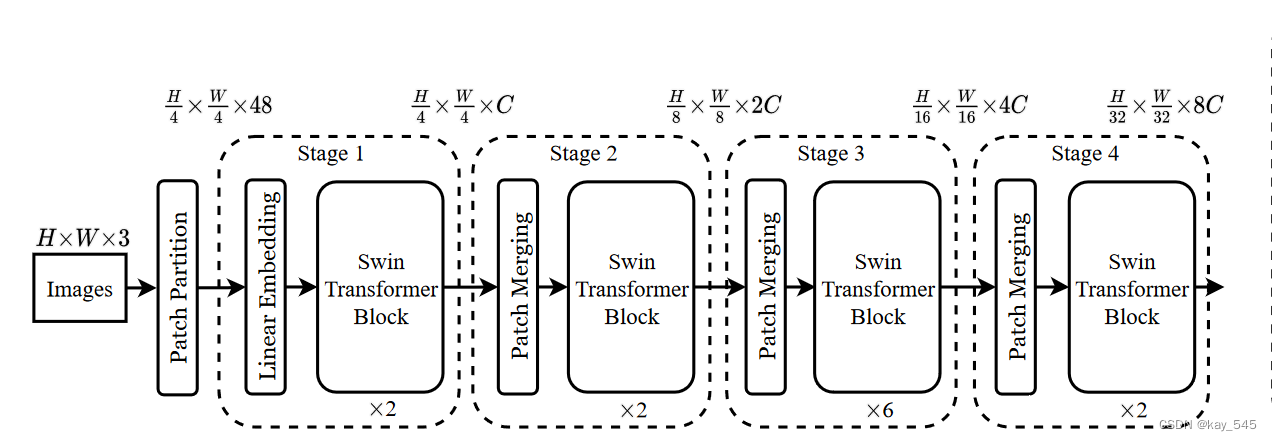
在这些补丁token上应用了几个经过修改的自注意力计算的 Transformer 块(Swin Transformer 块)。 Transformer 块维护tokens数量 ( H/4 ×W/4 ),与线性嵌入一起被称为“阶段 1”
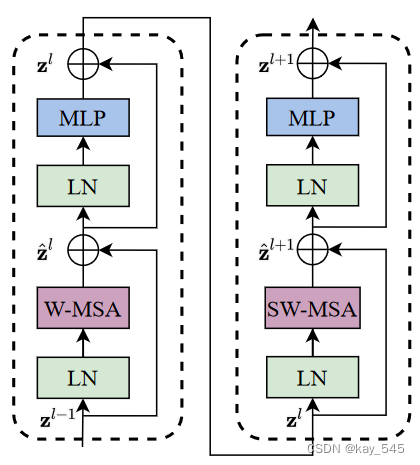
Swin Transformer 是通过将 Transformer 块中的标准多头自注意力(MSA)模块替换为基于移位窗口的模块而构建的,其他层保持不变。如上图所示,Swin Transformer 模块由基于移位窗口的 MSA 模块组成,后跟中间带有 GELU 非线性的 2 层 MLP。在每个 MSA 模块和每个 MLP 之前应用 LayerNorm (LN) 层,并在每个模块之后应用残差连接。
代码实现
class WindowAttention(nn.Module):def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # Wh, Wwself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5# define a parameter table of relative position biasself.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Wwcoords_flatten = torch.flatten(coords, 1) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Wwself.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)nn.init.normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)def forward(self, x, mask=None):B_, N, C = x.shapeqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)q = q * self.scaleattn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)# print(attn.dtype, v.dtype)try:x = (attn @ v).transpose(1, 2).reshape(B_, N, C)except:# print(attn.dtype, v.dtype)x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass SwinTransformer(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(SwinTransformer, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1, 1)num_heads = c_ // 32self.m = SwinTransformerBlock(c_, c_, num_heads, n)# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):y1 = self.m(self.cv1(x))y2 = self.cv2(x)return self.cv3(torch.cat((y1, y2), dim=1))class SwinTransformerB(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(Swin_Transformer_B, self).__init__()c_ = int(c2) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1, 1)num_heads = c_ // 32self.m = SwinTransformerBlock(c_, c_, num_heads, n)# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):x1 = self.cv1(x)y1 = self.m(x1)y2 = self.cv2(x1)return self.cv3(torch.cat((y1, y2), dim=1))class SwinTransformerC(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(Swin_Transformer_C, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(c_, c_, 1, 1)self.cv4 = Conv(2 * c_, c2, 1, 1)num_heads = c_ // 32self.m = SwinTransformerBlock(c_, c_, num_heads, n)# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):y1 = self.cv3(self.m(self.cv1(x)))y2 = self.cv2(x)return self.cv4(torch.cat((y1, y2), dim=1))class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xdef window_partition(x, window_size):B, H, W, C = x.shapeassert H % window_size == 0, 'feature map h and w can not divide by window size'x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size, H, W):B = int(windows.shape[0] / (H * W / window_size / window_size))x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return xclass SwinTransformerLayer(nn.Module):def __init__(self, dim, num_heads, window_size=8, shift_size=0,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,act_layer=nn.SiLU, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_sizeself.mlp_ratio = mlp_ratio# if min(self.input_resolution) <= self.window_size:# # if window size is larger than input resolution, we don't partition windows# self.shift_size = 0# self.window_size = min(self.input_resolution)assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"self.norm1 = norm_layer(dim)self.attn = WindowAttention(dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)def create_mask(self, H, W):# calculate attention mask for SW-MSAimg_mask = torch.zeros((1, H, W, 1)) # 1 H W 1h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1mask_windows = mask_windows.view(-1, self.window_size * self.window_size)attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))return attn_maskdef forward(self, x):# reshape x[b c h w] to x[b l c]_, _, H_, W_ = x.shapePadding = Falseif min(H_, W_) < self.window_size or H_ % self.window_size != 0 or W_ % self.window_size != 0:Padding = True# print(f'img_size {min(H_, W_)} is less than (or not divided by) window_size {self.window_size}, Padding.')pad_r = (self.window_size - W_ % self.window_size) % self.window_sizepad_b = (self.window_size - H_ % self.window_size) % self.window_sizex = F.pad(x, (0, pad_r, 0, pad_b))# print('2', x.shape)B, C, H, W = x.shapeL = H * Wx = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # b, L, c# create mask from init to forwardif self.shift_size > 0:attn_mask = self.create_mask(H, W).to(x.device)else:attn_mask = Noneshortcut = xx = self.norm1(x)x = x.view(B, H, W, C)# cyclic shiftif self.shift_size > 0:shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))else:shifted_x = x# partition windowsx_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, Cx_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C# W-MSA/SW-MSAattn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C# merge windowsattn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C# reverse cyclic shiftif self.shift_size > 0:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))else:x = shifted_xx = x.view(B, H * W, C)# FFNx = shortcut + self.drop_path(x)x = x + self.drop_path(self.mlp(self.norm2(x)))x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W) # b c h wif Padding:x = x[:, :, :H_, :W_] # reverse paddingreturn xclass SwinTransformerBlock(nn.Module):def __init__(self, c1, c2, num_heads, num_layers, window_size=8):super().__init__()self.conv = Noneif c1 != c2:self.conv = Conv(c1, c2)# remove input_resolutionself.blocks = nn.Sequential(*[SwinTransformerLayer(dim=c2, num_heads=num_heads, window_size=window_size,shift_size=0 if (i % 2 == 0) else window_size // 2) for i inrange(num_layers)])def forward(self, x):if self.conv is not None:x = self.conv(x)x = self.blocks(x)return xYOLOv8详细添加步骤
1. 复制以上代码在 ultralytics/nn/modules/conv.py 添加
2. 在ultralytics/nn/modules/init.py 注册SwinTransformer
3. 在ultralytics/nn/task.py 注册SwinTransformer(两处注册)
4. 成功添加SwinTransformer
ymal文件内容
one_swinTrans
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 6 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, SwinTransformer, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)three_swinTrans
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 6 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, SwinTransformer, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, SwinTransformer, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, SwinTransformer, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
启动命令
from ultralytics import YOLO# Load a model
# model = YOLO('yolov8s.yaml') # build a new model from YAML
model = YOLO('/ultralytics/cfg/models/v8/yolov8_swinTrans.yaml') # load a pretrained model (recommended for training)
# model = YOLO('yolov8s.yaml').load('yolov8s.pt') # build from YAML and transfer weights# Train the model
if __name__ == '__main__':model.train( )
完整代码分享
https://download.csdn.net/download/m0_67647321/88890624

相关文章:
yolov8涨点技巧,添加SwinTransformer注意力机制,提升目标检测效果
目录 摘要 SwinTransformer原理 代码实现 YOLOv8详细添加步骤 ymal文件内容 one_swinTrans three_swinTrans 启动命令 完整代码分享 摘要 Swin Transformer通过引入创新的分层注意力机制展现了其架构的独特性,该机制通过将注意力区域划分为块并在这些块内执…...
k8s初始化错误
报错详情: you can check the kubelet logs for further clues by running: ‘journalctl -u kubelet’ Alternatively, there might be issues with your Kubernetes configuration files or maybe the necessary ports are not opened. Check the status of …...

adb命名大全
1. 获取内部版本号: adb shell getprop ro.build.display.innerver 2. 获取按键值: adb shell getevent 3. 获取apk信息: adb shell dumpsys package 包名 ->info.txt 4. 获取应用包名:adb shell dumpsys window windows | gre…...
携手共赴难)
计算机发展史 (5)携手共赴难
就在痛苦艰难的时刻,孤独苦闷的巴贝奇意外地收到一封来信,写信人不仅 对他表示理解而且还希望与他共同工作。娟秀字体的签名,表明了她不凡的身份 ──伯爵夫人。 接到信函后不久,巴贝奇实验室门口走进来一位年轻的女士。她身披素雅…...
一键搞定简历设计!电子版简历制作指南3步走!
如今,随着无纸化办公趋势的流行,电子简历逐渐取代了纸质简历,成为我们最常用的简历设计格式。 然而,从纸质简历到电子简历后,对于非平面设计领域的学生来说,简历设计的难度可能再次超出了我们的能力范围。…...
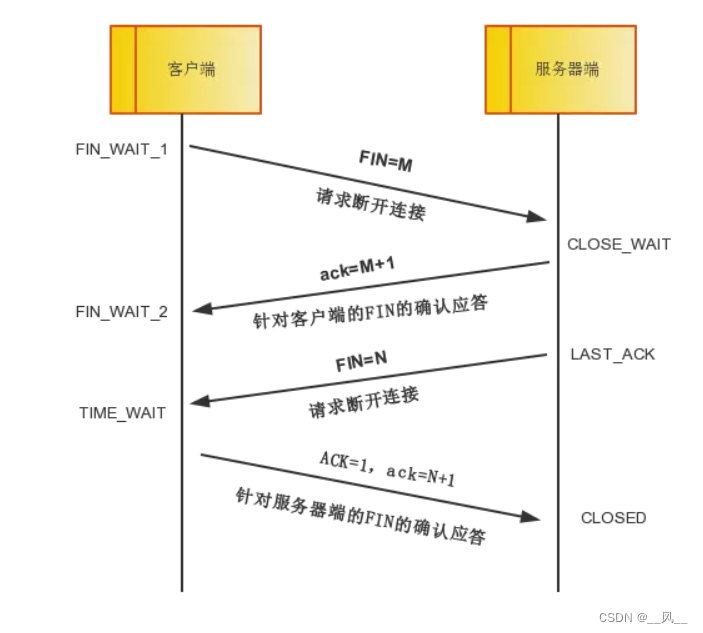
tcpdump 常用用法
简要记录下tcpdump用法 监控某个ip上的某个端口的流量 tcpdump -i enp0s25 tcp port 5432 -nn -S 各个参数作用 -i enp0s25 指定抓包的网卡是enp0s25 -nn 显示ip地址和数字端口 ,如果只 -n 则显示ip,但是端口为services文件中的服务名 如果一个…...
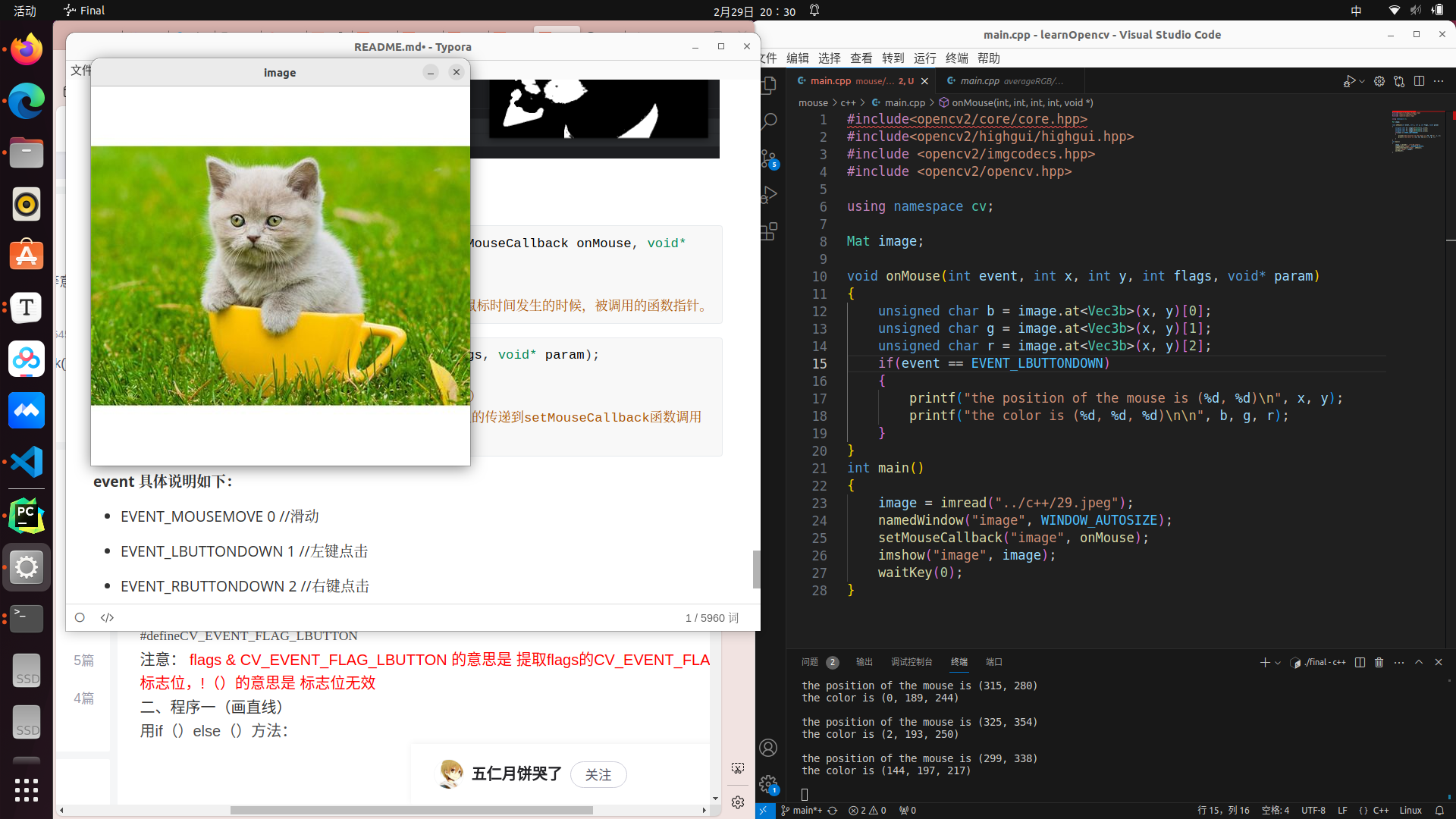
Opencv实战(5)平滑处理与常见函数
平滑处理 Opencv实战: Opencv(1)读取与图像操作 Opencv(2)绘图与图像操作 Opencv(3)详解霍夫变换 Opencv(4)详解轮廓 文章目录 平滑处理1.均值滤波2.方框滤波3.高斯滤波4.中值滤波5.双边滤波 常见函数(1).createTrackbar()(2).SetMouseCallback() 图像的平滑处理是…...

音频PCM介绍与运用
音频PCM介绍与运用 什么是PCM PCM (Pulse Code Modulation) 是一种数字音频编码方式,将模拟声音信号转换为数字信号的过程。在 PCM 中,声音信号被采样并量化为离散的数值,以便于数字化处理和传输。 以下是 PCM 的主要特点: 采样…...

计算机专业大学四年应该如何规划(Java方向)
计算机专业的学生,如何在大学四年内提高自己的竞争力,毕业之后直接进大厂工作? 以下将从大学四年计算机专业的学习规划、课程设置、能力提升、参考书籍等方面,为同学们提供一些建议和指导。 大一: 主攻技能学习并且达…...

算法D27|回溯算法4| 93.复原IP地址 78.子集 90.子集II
93.复原IP地址 本期本来是很有难度的,不过 大家做完 分割回文串 之后,本题就容易很多了 题目链接/文章讲解:代码随想录 视频讲解:回溯算法如何分割字符串并判断是合法IP?| LeetCode:93.复原IP地址_哔哩哔…...

C++实现XOR加解器
#include <Windows.h> #include <iostream> #include <fstream> #include <string>// 加解密函数,使用XOR运算 void XORCrypt(char* data, int size, const std::string& key) {int keyLength key.length();for (int i 0; i < siz…...

Kubernetes的Sevice管理
服务原理: 所有服务都是根据这个服务衍生或者变化出来,根服务---- 服务感知后端靠标签 slelector 标签选择器 kubectl label pods web1 appweb kubectl cluter-info dump | grep -i service-cluster-ip-range 服务ip取值范围 Service 管理: 创建服务: --- kind: Serv…...
C# 高阶语法 —— Winfrom链接SQL数据库的存储过程
存储过程在应用程序端的使用的优点 1 如果sql语句直接写在客户端,以一个字符串的形式体现的,提示不友好,会导致效率降低 2 sql语句写在客户端,可以利用sql注入进行攻击,为了安全性,可以把sql封装在…...
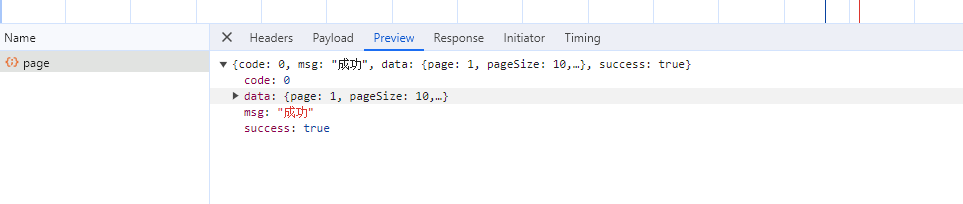
vue3+vite+ts配置多个代理并解决报404问题
之前配置接口代理总是报404,明明接口地址是对的但还是报是因数写法不对;用了vue2中的写法 pathRewrite改为rewrite 根路径下创建env文件根据自己需要名命 .env.development文件内容 # just a flag ENVdevelopment# static前缀 VITE_APP_PUBLIC_PREFIX"" # 基础模块…...

开创未来:探索OpenAI首个AI视频模型Sora的前沿技术与影响
Sora - 探索AI视频模型的无限可能 随着人工智能技术的飞速发展,AI视频模型已成为科技领域的新热点。而在这个浪潮中,OpenAI推出的首个AI视频模型Sora,以其卓越的性能和前瞻性的技术,引领着AI视频领域的创新发展。让我们将一起探讨…...
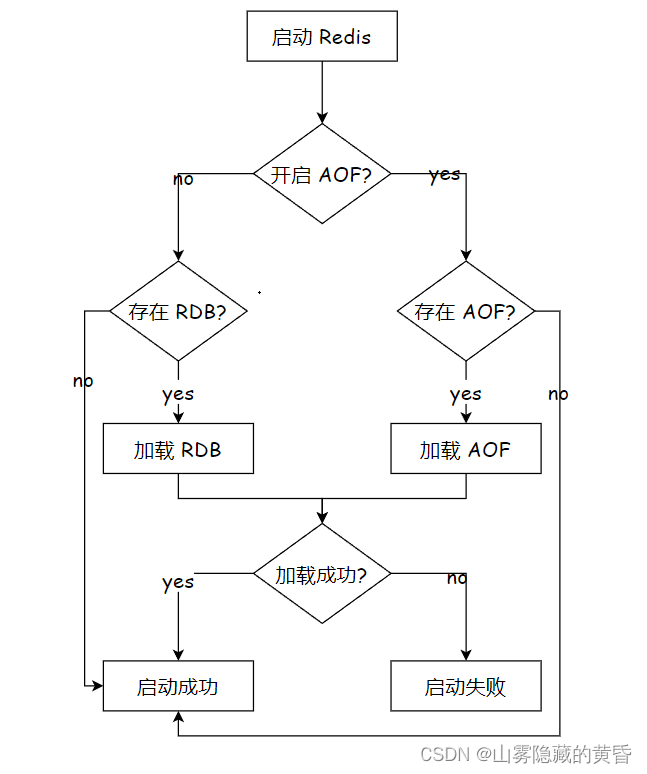
Redis---持久化
Redis是内存数据库,是把数据存储在内存中的,但是内存中的数据不是持久的,如果想要做到持久,那么就需要让redis将数据存储到硬盘上。 Redis持久化有两种策略: RDB > Redis DataBase RDB机制采取的是定期备份AOF …...
从 Flask 切到 FastAPI 后,起飞了!
我这几天上手体验 FastAPI,感受到这个框架易用和方便。之前也使用过 Python 中的 Django 和 Flask 作为项目的框架。Django 说实话上手也方便,但是学习起来有点重量级框架的感觉,FastAPI 带给我的直观体验还是很轻便的,本文就会着…...

状态码转文字!!!(表格数字转文字)
1、应用场景:在我们的数据库表中经常会有status这个字段,这个字段经常表示此类商品的状态,例如:0->删除,1->上架,0->下架,等等。 2、我们返回给前端数据时,如果在页面显示0…...

Pytorch 复习总结 4
Pytorch 复习总结,仅供笔者使用,参考教材: 《动手学深度学习》Stanford University: Practical Machine Learning 本文主要内容为:Pytorch 深度学习计算。 本文先介绍了深度学习中自定义层和块的方法,然后介绍了一些…...

YOLOv9中加入SCConv模块!
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、本文介绍 本文将一步步演示如何在YOLOv9中添加 / 替换新模块,寻找模型上的创新! 适用检测目标: YOLOv9模块…...

软件报告管理化的信息汇总与呈现
在数字化浪潮席卷全球的今天,企业每天产生的数据量呈指数级增长。如何高效汇总、分析并呈现这些数据,成为提升决策效率的关键。软件报告管理化应运而生,它通过系统化的信息整合与可视化呈现,将海量数据转化为清晰、直观的决策依据…...

【深度学习】Mixup: 突破传统数据增强的邻域风险最小化实践
1. 从数据增强到Mixup:为什么我们需要突破传统方法 记得我第一次训练图像分类模型时,把所有经典数据增强方法都用上了——随机裁剪、水平翻转、颜色抖动。效果确实比不用增强要好,但在测试集上的准确率总是差强人意。直到接触了Mixup…...

Cortex-M7中断系统架构与优化实践
1. Cortex-M7中断系统架构解析在嵌入式实时系统中,中断机制是实现快速响应外部事件的关键。Cortex-M7的中断系统由嵌套向量中断控制器(NVIC)和系统控制块(SCB)两大模块构成,它们共同管理着处理器的异常和中断行为。NVIC作为中断系统的核心控制器…...

利用x-anylabeling与Labelme格式互转,提升数据标注效率
1. 为什么需要x-anylabeling与Labelme格式互转 在计算机视觉项目中,数据标注是绕不开的重要环节。我见过太多团队在标注工具之间来回切换时浪费大量时间,特别是当需要结合自动标注和手动标注时。x-anylabeling作为新兴的自动标注工具,而Label…...

大模型 kimi / deepseek /豆包/元宝 网页版登录
Kimi: https://kimi.moonshot.cn/ deepseek: https://www.deepseek.com 豆包: https://www.doubao.com 腾讯元宝: 官网网址:https://yuanbao.tencent.com网页对话入口:https://yuanbao.tenc…...

基于ESP32宾馆房间内自动售货机
第1章 系统的总体架构本系统采用客户端-服务器-设备端三层架构,各层之间通过WebSocket协议进行实时双向通信,确保指令的低延迟传输。采用B/S(Browser/Server)架构与物联网技术相结合的设计方案。软件系统主要由四部分组成&#x…...

SCI论文署名指南:通讯作者与共同通讯作者的权责与排序策略
1. 通讯作者的角色定位与核心职责 通讯作者在SCI论文中扮演着项目总指挥的角色,相当于建筑工地的项目经理。我见过不少年轻学者对这个身份存在误解,以为挂名通讯作者只是形式上的荣誉。实际上,通讯作者需要承担三大硬核责任:首先是…...

5分钟轻松搞定!Axure RP全系列中文汉化终极指南
5分钟轻松搞定!Axure RP全系列中文汉化终极指南 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axure RP的英文…...

DeepBSA实战指南:从安装到基因组分析的全流程解析
1. DeepBSA简介与核心功能 DeepBSA是一款专门为批量分离分析(BSA)设计的基因组分析工具,它最大的特点就是把复杂的生物信息学分析流程简化成了"一键式"操作。我第一次接触这个软件是在分析水稻抗病性状的实验中,当时就被…...

智能游戏自动化:深度解析BetterGI的5大核心技术实现原理
智能游戏自动化:深度解析BetterGI的5大核心技术实现原理 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连音游 |…...