Pytorch 复习总结 4
Pytorch 复习总结,仅供笔者使用,参考教材:
- 《动手学深度学习》
- Stanford University: Practical Machine Learning
本文主要内容为:Pytorch 深度学习计算。
本文先介绍了深度学习中自定义层和块的方法,然后介绍了一些有关参数的方法。
Pytorch 语法汇总:
- Pytorch 张量的常见运算、线性代数、高等数学、概率论 部分 见 Pytorch 复习总结1;
- Pytorch 线性神经网络 部分 见 Pytorch 复习总结2;
- Pytorch 多层感知机 部分 见 Pytorch 复习总结3;
- Pytorch 深度学习计算 部分 见 Pytorch 复习总结4;
- Pytorch 卷积神经网络 部分 见 Pytorch 复习总结5;
- Pytorch 现代卷积神经网络 部分 见 Pytorch 复习总结6;
目录
- 一. 自定义块
- 1. 顺序块
- 2. 自定义前向传播
- 3. 嵌套块
- 二. 自定义层
- 1. 无参数层
- 2. 有参数层
- 三. 参数管理
- 1. 参数访问
- 2. 参数初始化
- 3. 延后初始化
- 四. 文件读写
- 1. 加载和保存张量
- 2. 加载和保存模型参数
层是神经网络的基本组成单元,如全连接层、卷积层、池化层等。块是由层组成的更大的功能单元,用于构建复杂的神经网络结构。块可以是一系列相互关联的层,形成一个功能完整的单元,也可以是一组层的重复模式,用于实现重复的结构。下图就是多个层组合成块形成的更大模型:

在实际应用中,经常会需要自定义层和块。
一. 自定义块
1. 顺序块
nn.Sequential 本质上就是一个顺序块,通过在块中实例化层来创建神经网络。 nn.Module 是 PyTorch 中用于构建神经网络模型的基类,nn.Sequential 和各种层都是继承自 Module,nn.Sequential 维护一个由多个层组成的有序列表,列表中的每个层连接在一起,将每个层的输出作为下一个层的输入。
如果想要自定义一个顺序块,必须要定义以下两个关键函数:
- 构造函数:将每个层按顺序逐个加入列表;
- 前向传播函数:将每一层按顺序传递给下一层;
import torch
from torch import nnclass MySequential(nn.Module):def __init__(self, *args):super().__init__()for idx, module in enumerate(args):self._modules[str(idx)] = moduledef forward(self, X):# self._modules的类型是OrderedDictfor block in self._modules.values():X = block(X)return Xnet = MySequential(nn.Linear(20, 256),nn.ReLU(),nn.Linear(256, 10)
)X = torch.rand(2, 20)
output = net(X)
上述示例代码中,定义 net 时会自动调用 __init__(self, *args) 函数,实例化 MySequential 对象;调用 net(X) 相当于 net.__call__(X),会自动调用模型类中定义的 forward() 函数,进行前向传播,每一层的传播本质上就是调用 block(X) 的过程。
2. 自定义前向传播
nn.Sequential 类将前向传播过程封装成函数,用户可以自由使用但没法修改传播细节。如果想要自定义前向传播过程中的细节,就需要自定义顺序块及 forward 函数,而不能仅仅依赖预定义的框架。
例如,需要一个计算函数 f ( x , w ) = c ⋅ w T x f(\bold x,\bold w)=c \cdot \bold w ^T \bold x f(x,w)=c⋅wTx 的层,并且在传播过程中引入控制流。其中 x \bold x x 是输入, w \bold w w 是参数, c c c 是优化过程中不需要更新的指定常量。为此,定义 FixedHiddenMLP 类如下:
import torch
from torch import nn
from torch.nn import functional as Fclass FixedHiddenMLP(nn.Module):def __init__(self):super().__init__()self.rand_weight = torch.rand((20, 20), requires_grad=False) # 优化过程中不需要更新的指定常量self.linear = nn.Linear(20, 20)def forward(self, X):X = self.linear(X)X = F.relu(torch.mm(X, self.rand_weight) + 1)X = self.linear(X) # 两个全连接层共享参数while X.abs().sum() > 1: # 控制流X /= 2return X
3. 嵌套块
多个层可以组合成块,多个块还可以嵌套形成更大的模型:
import torch
from torch import nn
from torch.nn import functional as Fclass FixedHiddenMLP(nn.Module):def __init__(self):super().__init__()self.rand_weight = torch.rand((20, 20), requires_grad=False) # 优化过程中不需要更新的指定常量self.linear = nn.Linear(20, 20)def forward(self, X):X = self.linear(X)X = F.relu(torch.mm(X, self.rand_weight) + 1)X = self.linear(X) # 两个全连接层共享参数while X.abs().sum() > 1: # 控制流X /= 2return X.sum()class NestMLP(nn.Module):def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),nn.Linear(64, 32), nn.ReLU())self.linear = nn.Linear(32, 16)def forward(self, X):return self.linear(self.net(X))net = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP()
)X = torch.rand(2, 20)
output = net(X)
二. 自定义层
和自定义块一样,自定义层也需要实现构造函数和前向传播函数。
1. 无参数层
import torch
from torch import nnclass CenteredLayer(nn.Module):def __init__(self):super().__init__()def forward(self, X):return X - X.mean()net = nn.Sequential(nn.Linear(8, 128), CenteredLayer())
X = torch.rand(4, 8)
output = net(X)
print(output.mean()) # tensor(0., grad_fn=<MeanBackward0>)
2. 有参数层
import torch
from torch import nn
import torch.nn.functional as Fclass MyLinear(nn.Module):def __init__(self, in_units, out_units):super().__init__()self.weight = nn.Parameter(torch.randn(in_units, out_units))self.bias = nn.Parameter(torch.randn(out_units,))def forward(self, X):linear = torch.matmul(X, self.weight.data) + self.bias.datareturn F.relu(linear)net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1)
)
X = torch.rand(2, 64)
output = net(X)
print(output) # tensor([[11.9497], [13.9729]])
三. 参数管理
在实验过程中,有时需要提取参数,以便检查或在其他环境中复用。本节将介绍参数的访问方法和参数的初始化。
1. 参数访问
net.state_dict()/net[i].state_dict():返回模型或某一层参数的状态字典;net[i].weight.data/net[i].bias.data:返回某一层的权重 / 偏置参数;net[i].weight.grad:返回某一层的权重参数的梯度属性。只有调用了backward()方法后才能访问到梯度值,否则为 None;
import torch
from torch import nnnet = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
output = net(X)print(net.state_dict())
'''
OrderedDict([('0.weight', tensor([[ 0.2178, -0.3286, 0.4875, -0.0347],[-0.0415, 0.0009, -0.2038, -0.1813],[-0.2766, -0.4759, -0.3134, -0.2782],[ 0.4854, 0.0606, 0.1070, 0.0650],[-0.3908, 0.2412, -0.1348, 0.3921],[-0.3044, -0.0331, -0.1213, -0.1690],[-0.3875, -0.0117, 0.3195, -0.1748],[ 0.1840, -0.3502, 0.4253, 0.2789]])), ('0.bias', tensor([-0.2327, -0.0745, 0.4923, -0.1018, 0.0685, 0.4423, -0.2979, 0.1109])), ('2.weight', tensor([[ 0.1006, 0.2959, -0.1316, -0.2015, 0.2446, -0.0158, 0.2217, -0.2780]])), ('2.bias', tensor([0.2362]))])
'''
print(net[2].state_dict())
'''
OrderedDict([('weight', tensor([[ 0.1006, 0.2959, -0.1316, -0.2015, 0.2446, -0.0158, 0.2217, -0.2780]])), ('bias', tensor([0.2362]))])
'''
print(net[2].bias)
'''
Parameter containing:
tensor([0.2362], requires_grad=True)
'''
print(net[2].bias.data)
'''
tensor([0.2362])
'''
如果想一次性访问所有参数,可以使用 for 循环递归遍历:
import torch
from torch import nnnet = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
output = net(X)print(*[(name, param.shape) for name, param in net[0].named_parameters()])
'''
('weight', torch.Size([8, 4])) ('bias', torch.Size([8]))
'''
print(*[(name, param.shape) for name, param in net.named_parameters()])
'''
('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([1, 8])) ('2.bias', torch.Size([1]))
'''
如果网络是由多个块相互嵌套的,可以按块索引后再访问参数:
import torch
from torch import nndef block1():return nn.Sequential(nn.Linear(4, 8), nn.ReLU(),nn.Linear(8, 4), nn.ReLU())def block2():net = nn.Sequential()for i in range(4):net.add_module(f'block {i}', block1())return netnet = nn.Sequential(block2(), nn.Linear(4, 1))
X = torch.rand(size=(2, 4))
output = net(X)print(net)
'''
Sequential((0): Sequential((block 0): Sequential((0): Linear(in_features=4, out_features=8, bias=True)(1): ReLU()(2): Linear(in_features=8, out_features=4, bias=True)(3): ReLU())(block 1): Sequential((0): Linear(in_features=4, out_features=8, bias=True)(1): ReLU()(2): Linear(in_features=8, out_features=4, bias=True)(3): ReLU())(block 2): Sequential((0): Linear(in_features=4, out_features=8, bias=True)(1): ReLU()(2): Linear(in_features=8, out_features=4, bias=True)(3): ReLU())(block 3): Sequential((0): Linear(in_features=4, out_features=8, bias=True)(1): ReLU()(2): Linear(in_features=8, out_features=4, bias=True)(3): ReLU()))(1): Linear(in_features=4, out_features=1, bias=True)
)
'''
print(net[0][1][0].bias.data)
'''
tensor([-0.0083, 0.2490, 0.1794, 0.1927, 0.1797, 0.1156, 0.4409, 0.1320])
'''
2. 参数初始化
PyTorch 的 nn.init 模块提供了多种初始化方法:
nn.init.constant_(layer.weight, c):将权重参数初始化为指定的常量值;nn.init.zeros_(layer.weight):将权重参数初始化为 0;nn.init.ones_(layer.weight):将权重参数初始化为 1;nn.init.uniform_(layer.weight, a, b):将权重参数按均匀分布初始化;nn.init.xavier_uniform_(layer.weight):nn.init.normal_(layer.weight, mean, std):将权重参数按正态分布初始化;nn.init.orthogonal_(layer.weight):将权重参数初始化为正交矩阵;nn.init.sparse_(layer.weight, sparsity, std):将权重参数初始化为稀疏矩阵;
初始化时,可以直接 net.apply(init_method) 初始化整个网络,也可以 net[i].apply(init_method) 初始化某一层:
import torch
from torch import nndef init_normal(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, mean=0, std=0.01)nn.init.zeros_(m.bias)def init_constant(m):if type(m) == nn.Linear:nn.init.constant_(m.weight, 1)nn.init.zeros_(m.bias)net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
output = net(X)# net.apply(init_normal)
net[0].apply(init_normal)
net[2].apply(init_constant)
3. 延后初始化
有些情况下,无法提前判断网络的输入维度。为了代码能够继续运行,需要使用延后初始化,即直到数据第一次通过模型传递时,框架才会动态地推断出每个层的大小。由于 PyTorch 的延后初始化功能还处于开发阶段,API 和功能随时可能变化,下面只给出简单示例:
import torch
from torch import nnnet = nn.Sequential(nn.LazyLinear(256), nn.ReLU(), nn.LazyLinear(10))print(net)
'''
Sequential((0): LazyLinear(in_features=0, out_features=256, bias=True)(1): ReLU()(2): LazyLinear(in_features=0, out_features=10, bias=True)
)
'''X = torch.rand(2, 20)
net(X)
print(net)
'''
Sequential((0): Linear(in_features=20, out_features=256, bias=True)(1): ReLU()(2): Linear(in_features=256, out_features=10, bias=True)
)
'''
四. 文件读写
可以使用 load 和 save 函数读写张量和模型参数。
1. 加载和保存张量
2. 加载和保存模型参数
相关文章:
Pytorch 复习总结 4
Pytorch 复习总结,仅供笔者使用,参考教材: 《动手学深度学习》Stanford University: Practical Machine Learning 本文主要内容为:Pytorch 深度学习计算。 本文先介绍了深度学习中自定义层和块的方法,然后介绍了一些…...

YOLOv9中加入SCConv模块!
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、本文介绍 本文将一步步演示如何在YOLOv9中添加 / 替换新模块,寻找模型上的创新! 适用检测目标: YOLOv9模块…...

代码随想录算法训练营第四十七天丨198. 打家劫舍、 213. 打家劫舍 II、337. 打家劫舍 III
198. 打家劫舍 自己的思路: 初始化两个dp数组,dp[i][0]表示不偷第i户,在0-i户可以偷到的最大金额,dp[i][1]表示偷i户在0-i户可以偷到的最大金额。 class Solution:def rob(self, nums: List[int]) -> int:n len(nums)dp […...

龙蜥Anolis 8.4 anck 安装mysql5.7
el8没有用mysql5.7了,镜像里是mysql8。 禁用 sudo dnf remove mysql sudo dnf module reset mysql sudo dnf module disable mysql 修改Yum源 sudo vi /etc/yum.repos.d/mysql-community.repo [mysql57-community] nameMySQL 5.7 Community Server baseurlhttp:…...

【踩坑】修复xrdp无法关闭Authentication Required验证窗口
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 问题如下,时不时出现,有时还怎么都关不掉,很烦: 解决方法一:命令行输入 dbus-send --typemethod_call --destorg.gnome.Shell /org/gnome/Shell org.gn…...

python学习笔记 - 标准库常量
Python 中有一些内置的常量,它们是一些特殊的值,通常不会改变。以下是其中一些常见的内置常量及其详细解释以及使用示例: True: 表示布尔值真。给 True 赋值是非法的并会引发 SyntaxError。 x True print(x) # 输出:…...
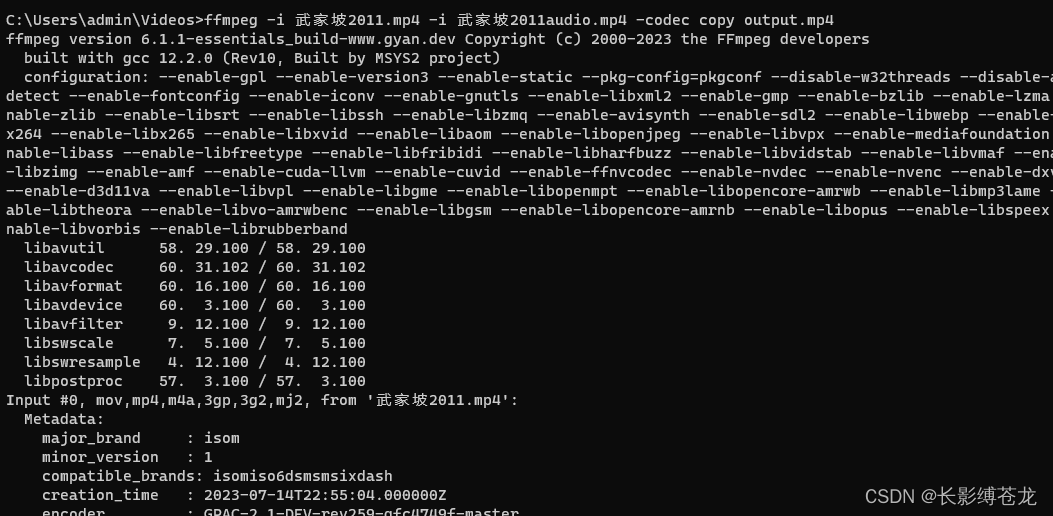
视频和音频使用ffmpeg进行合并和分离(MP4)
1.下载ffmpeg 官网地址:https://ffmpeg.org/download.html 2.配置环境变量 此电脑右键点击 属性 - 高级系统配置 -高级 -环境变量 - 系统变量 path 新增 文件的bin路径 3.验证配置成功 ffmpeg -version 返回版本信息说明配置成功4.执行合并 ffmpeg -i 武家坡20…...
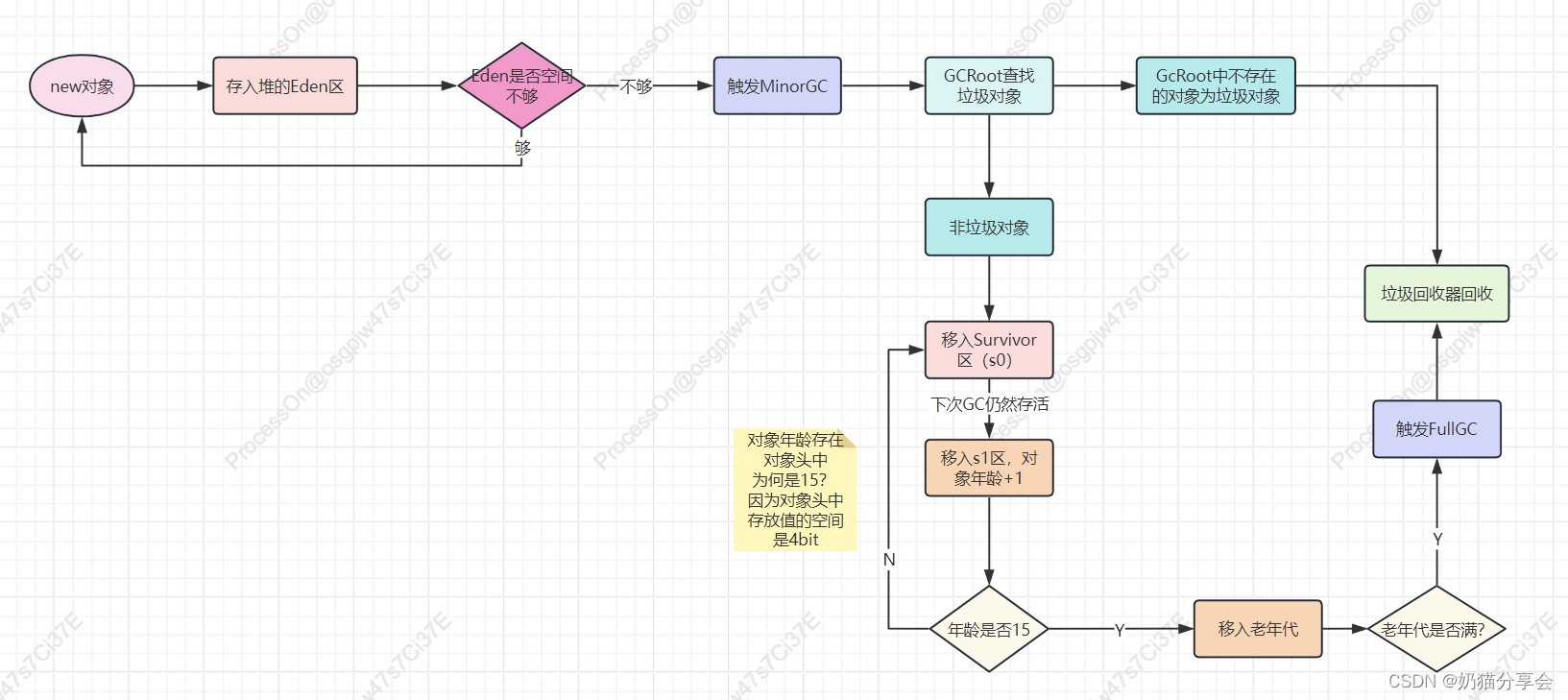
02| JVM堆中垃圾回收的大致过程
如果一直在创建对象,堆中年轻代中Eden区会逐渐放满,如果Eden放满,会触发minor GC回收,创建对象的时GC Roots,如果存在于里面的对象,则被视为非垃圾对象,不会被此次gc回收,就会被移入…...

R语言数据可视化之美专业图表绘制指南(增强版):第1章 R语言编程与绘图基础
第1章 R语言编程与绘图基础 目录 第1章 R语言编程与绘图基础前言1.1 学术图表的基本概念1.1.1 学术图表的基本作用1.1.2基本类别1.1.3 学术图表的绘制原则 1.2 你为什么要选择R1.3 安装 前言 这是我第一次在博客里展示学习中国作者的教材的笔记。我选择这本书的依据是作者同时…...
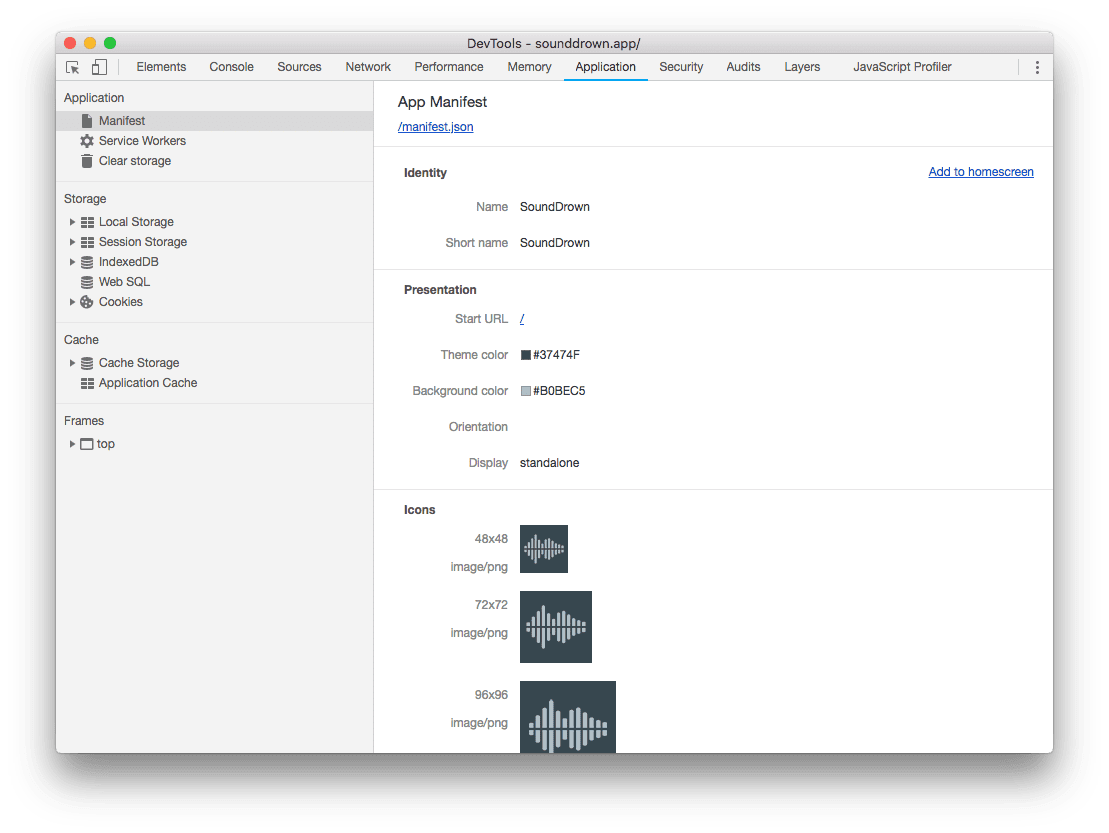
网站添加pwa操作和配置manifest.json后,没有效果排查问题
pwa技术官网:https://web.dev/learn/pwa 应用清单manifest.json文件字段说明:https://web.dev/articles/add-manifest?hlzh-cn Web App Manifest:Web App Manifest | MDN 当网站添加了manifest.json文件后,也引入到html中了&a…...

MongoDB聚合运算符:$cosh
文章目录 语法使用举例双曲余弦值角度双曲余弦值弧度 $cosh聚合运算符用来计算双曲余弦值,返回指定表达式的双曲余弦值。 语法 { $cosh: <expression> }<expression>为可被解析为数值的表达式$cosh返回弧度,使用$radiansToDegrees运算符可…...

Jenkins配置在远程服务器上执行shell脚本(两种方式)
Jenkins配置在远程服务器上执行shell脚本 方式一:通过SSH免密方式执行 说明:Jenkins部署在ServerA:10.1.1.74上,要运行的程序在ServerB:10.1.1.196 分两步 第一步:Linux Centos7配置SSH免密登录 Linux…...

Java+SpringBoot,打造社区疫情信息新生态
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 |…...

js ES6判断字符串是否以某个字符串开头或者结尾startsWith、endsWith
1.前言 startsWith:startsWith方法用于检查字符串是否以指定的字符串开头。 endsWith:endsWith方法用于检查字符串是否以指定的字符串结尾。 2.用法示例 const str Hello, world!;console.log(str.startsWith(Hello)); // true console.log(str.starts…...

Bert-as-service 实战
参考:bert-as-service 详细使用指南写给初学者-CSDN博客 GitHub - ymcui/Chinese-BERT-wwm: Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型) 下载:https://storage.googleapis.com/bert_models/…...
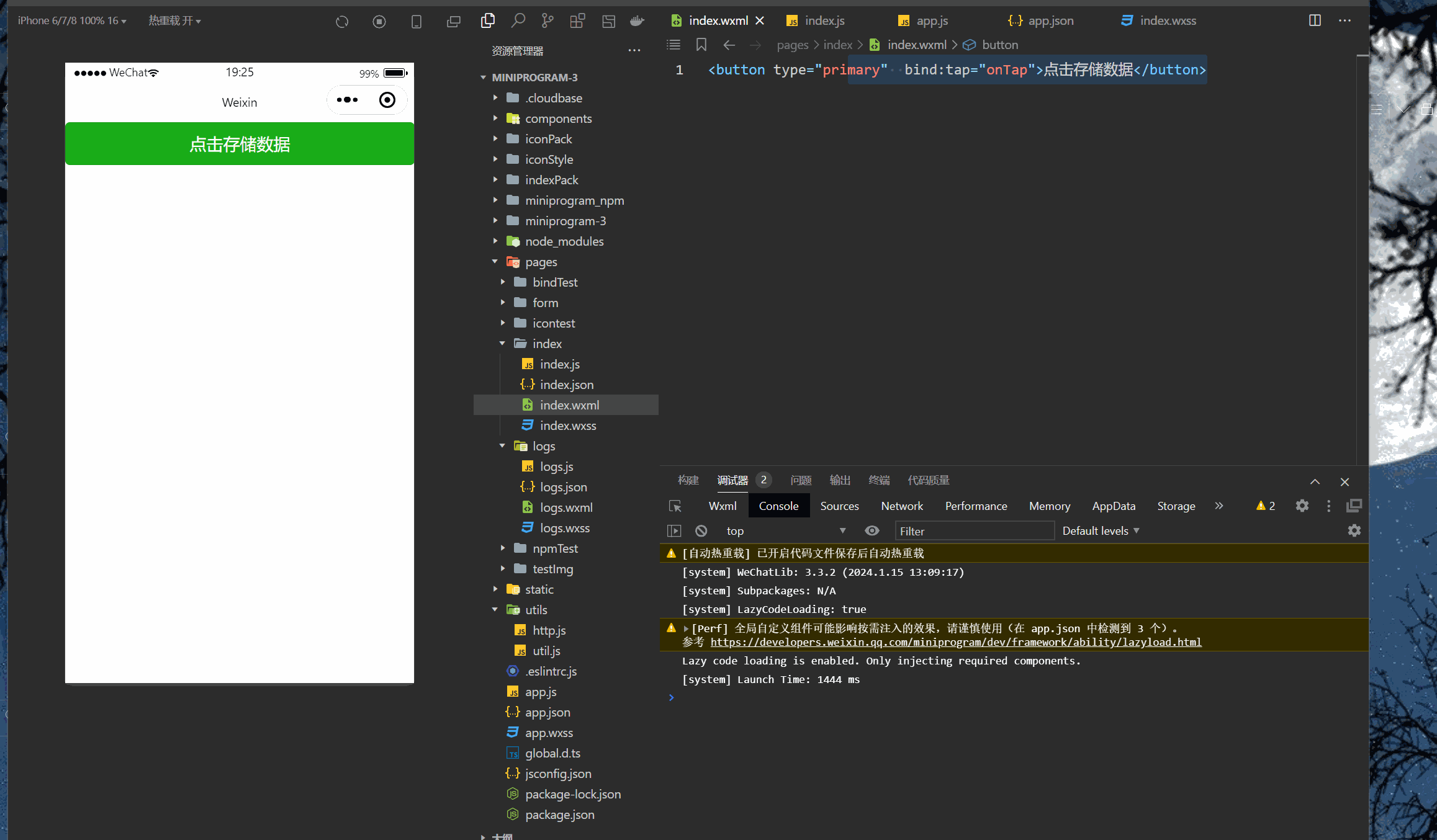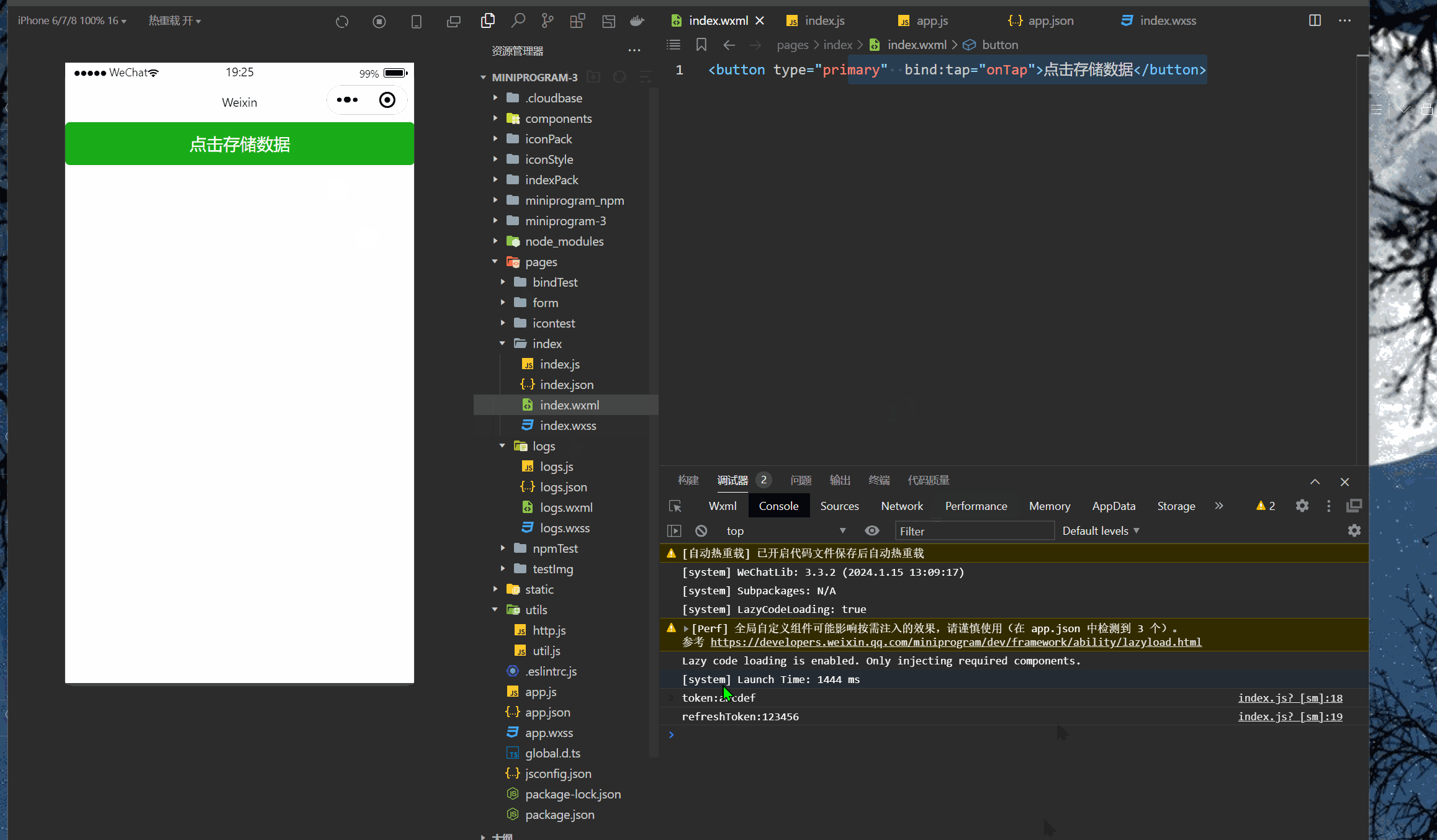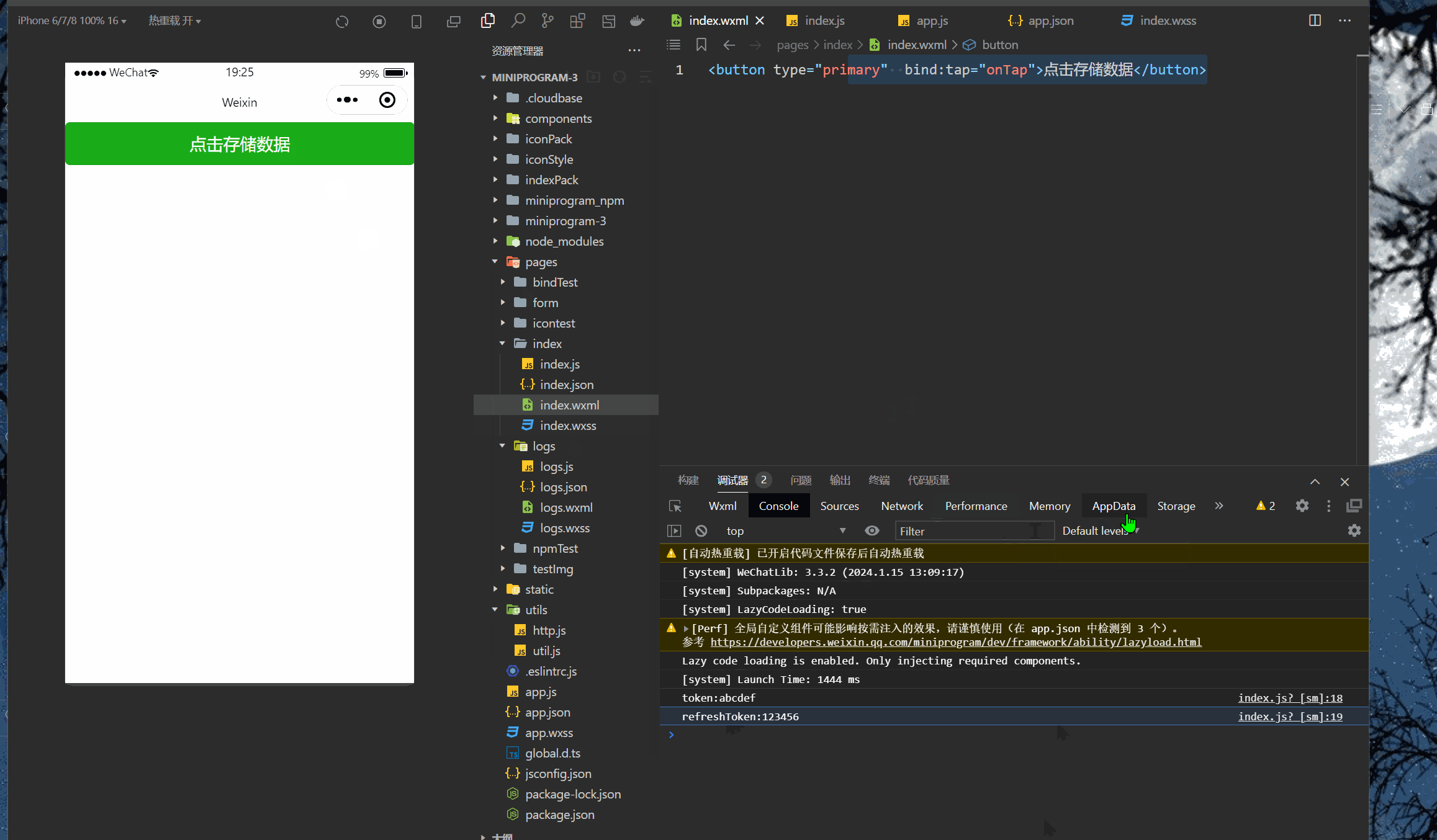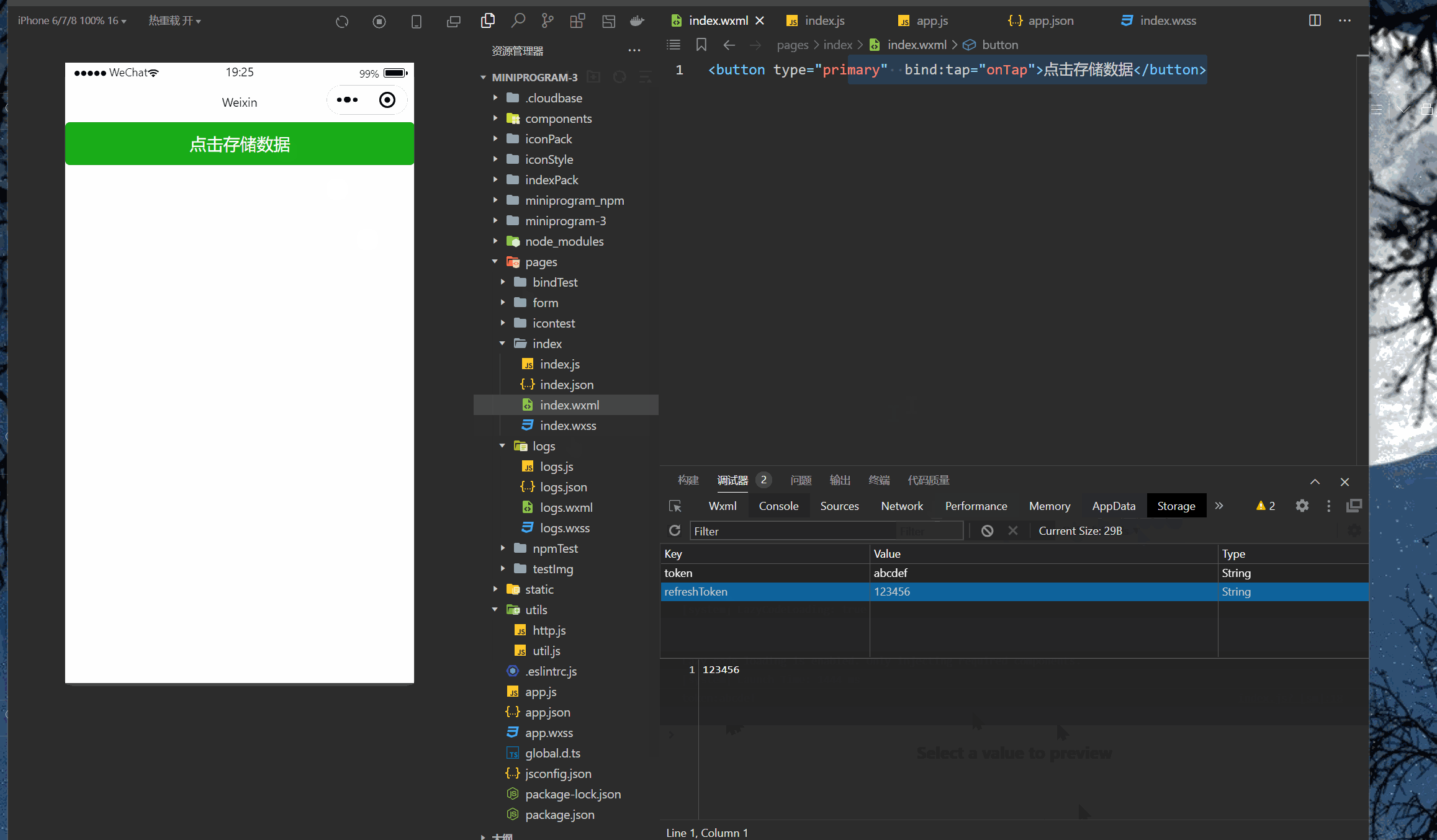
微信小程序(四十七)多个token存储
注释很详细,直接上代码 新增内容: 1.基础存储模板 2.中括号实现变量名匹配 源码: app.js App({//提前声明的变量名token:wx.getStorageSync(toke),refreshToken:wx.getSystemInfoAsync(refreshToken),setToken(key,token){//保存token到全局…...

机器学习(II)--样本不平衡
现实中,样本(类别)样本不平衡(class-imbalance)是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单样本通常是占总交易数量的极少部分,而且对于有些任务而言少数样本更…...

几个好用的 VUE Table
Vue easytable - 功能恰到好处 无学习成本 上手就用Vue good table - UI 清新 功能直给 适合小项目Vxe table - 宝藏级 table 组件 高级功能低调好用 维护频率高tabulator - 元老级 table 组件 高级功能平民化AG Grid - 媲美 Excel 的 Table 组件 能想到的复杂功能它都能做到...
)
Vue源码系列讲解——实例方法篇【三】(生命周期相关方法)
目录 0. 前言 1. vm.$mount 1.1 用法回顾 1.2 内部原理 2. vm.$forceUpdate 2.1 用法回顾 2.2 内部原理 3. vm.$nextTick 3.1 用法回顾 3.2 JS的运行机制 3.3 内部原理 能力检测 执行回调队列 4. vm.$destory 4.1 用法回顾 4.2 内部原理 0. 前言 与生命周期相关…...

逆向网易云音乐加密接口:从搜索到播放的完整爬虫实践
1. 逆向网易云音乐加密接口的核心思路 第一次接触网易云音乐接口逆向时,我也被它复杂的加密机制搞得一头雾水。但经过多次实践后发现,整个过程其实可以拆解为两个关键环节:搜索关键词加密和歌曲ID加密。这两个环节就像接力赛的两棒࿰…...

深度学习模型解释:SHAP与LIME
深度学习模型解释:SHAP与LIME 引言 深度学习模型在各个领域取得了显著的成功,但它们往往被视为"黑盒",难以理解其决策过程。模型解释性已成为深度学习应用中的关键挑战,尤其是在医疗、金融等对决策可解释性要求较高的领…...

点云全局配准实战——Go-ICP从零实现与PCL集成优化
1. Go-ICP算法与点云配准基础 刚接触三维点云处理时,第一次听说"配准"这个词还以为是什么高深莫测的黑科技。其实简单来说,点云配准就是把不同视角扫描得到的点云数据对齐到同一个坐标系的过程。想象你拿着手机绕着物体拍了一圈照片ÿ…...

如何永久保存微信聊天记录:留痕工具的终极解决方案
如何永久保存微信聊天记录:留痕工具的终极解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMs…...

SEONIB 如何重新定义电商卖家的全球增长路径
一个普遍存在的认知误区及其现实后果 在当前的数字商业环境中,存在一个广泛流传但极具误导性的观点,即搜索引擎优化是一项仅适用于大型企业或拥有专门技术团队的复杂工程。这种认知导致无数电商卖家——无论是独立站运营者、平台卖家,还是新…...

船舶自动化中的数字化: 为什么可靠的边缘系统在海上至关重要?
前言海事行业正经历着深刻的技术变革。船舶不再是独立航行于海洋的孤立机械系统,而是日益成为互联互通、数据驱动的环境,导航、推进、安全和运营系统在其中持续交互。这场数字化转型,正重新定义船舶的设计、运营与维护方式。从驾控台系统、发…...
)
实战分享怎样实现IntelliJ IDEA 打包 Web 项目 WAR 包(含 Tomcat 部署 + 常见问题解决)
在 Java Web 开发中,“本地能跑”只是第一步,真正让很多人头疼的是后续这条链路: 项目打包 → 生成 WAR → 部署 Tomcat → 启动验证 → 排查报错。尤其是刚从 Spring Boot 内嵌容器模式转向传统 WAR 部署、或者接手老项目时,常常…...

开箱即用的AI神器!HG-ha/MTools快速部署,轻松处理图片、音视频编辑
开箱即用的AI神器!HG-ha/MTools快速部署,轻松处理图片、音视频编辑 1. 为什么选择HG-ha/MTools 在数字内容创作日益普及的今天,我们经常需要处理各种媒体文件。无论是社交媒体运营、电商产品展示,还是个人创作,都离不…...

[Android][避坑指南]Android Studio集成framework.jar的版本适配与实战解析
1. 为什么需要集成framework.jar 在Android系统开发中,framework.jar是个特殊的存在。它包含了Android框架层的核心类和方法,很多系统级API(比如SystemProperties、UserHandle等)都定义在这里。但如果你打开Android Studio的SDK M…...

LeetCode 插入排序 题解
LeetCode 插入排序 题解 题目描述 实现插入排序算法,对一个整数数组进行排序。 示例 1: 输入:nums [5,2,3,1] 输出:[1,2,3,5]示例 2: 输入:nums [5,1,1,2,0,0] 输出:[0,0,1,1,2,5]解题思路 方…...