机器学习(II)--样本不平衡
现实中,样本(类别)样本不平衡(class-imbalance)是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单样本通常是占总交易数量的极少部分,而且对于有些任务而言少数样本更为重要。一般地,样本类别比例(Imbalance Ratio)(多数类vs少数类)严重不平衡时,分类算法将开始做出有利于多数类的预测。
一文解决样本不均衡(全)
数据抽样
随机抽样(random sampling)在机器学习领域,是很常见的做法。例如,将原始数据集随机分为训练集和测试集。常用的抽样方法有无放回抽样和有放回抽样。
针对非平衡的数据集,为了使得模型在这个数据集上学习的效果更加好,通过减少分类中多数类样本的数量(欠采样)或者增加分类中少数类样本的数量(过采样),来实现样本均衡。
过采样(over sampling)和欠采样(under sampling)也叫做上采样和下采样。
SMOTE是一种合成少数类过采样技术,主要策略为
- 首先,对每个少数类样本 x i \mathbf x_i xi,从它的最近邻中随机选 k k k 个样本;
- 然后,在 x i \mathbf x_i xi和近邻样本之间的连线上随机选一点作为新合成的少数类样本。
除了常用的smote之外,还有自适应合成采样,比如Borderline-SMOTE、Adaptive Synthetic Sampling(ADA-SYN)等,都包含在 imblearn Python 库中。
数据增强
数据增强(Data Augmentation)是指从原始数据中加工出更多的数据表示,提高原数据的数量和质量,从而提高模型的学习效果。
基于样本变换的数据增强
- 单样本增强:主要用于图像,比如几何操作、颜色变换、随机查出、剪切旋转等等,可参见imgaug开源库。
- 多样本增强:是指通过组合及转换多个样本的方式,比如刚刚提到的smote,还有SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值样本。
基于深度学习的数据增强
生成模型,如变分自编码网络(VAE)和生成生成对抗网络(GAN),其生成样本的方法也可以用于数据增强,这种基于网络合成的方法相比于传统的数据增强技术虽然过程复杂,但是生成的样本更加多样。
损失函数
损失函数层面的主流就是常用的代价敏感(cost-sensitive)学习,为不同的分类错误给予不同惩罚力度(权重),在调解类别平衡的同时,也不会增加计算复杂度。即对少数类样本给更大的权重系数,对多数类样本给更小的权重系数,通过这种方式可以在一定程度上解决样本不均衡的问题。
class weight 可以为不同类别的样本提供不同的权重,少数类的样本有更高的权重,从而模型可以平衡各类别的学习。如sklearn提供的class_weight参数,可以作为超参调试,避免决策边界偏重多数类的现象。
OHEM(Online Hard Example Mining)算法的核心是选择一些难样本(多样性和高损失的样本)作为训练的样本,针对性地改善模型学习效果。对于数据的类别不平衡问题,OHEM的针对性更强。
Focal loss的核心思想是在交叉熵损失函数(CE)的基础上增加了类别的不同权重以及困难(高损失)样本的权重(如下公式),以改善模型学习效果。
Focal Loss的核心思想是在交叉熵损失函数(CE)的基础上增加了类别的不同权重以及困难(高损失)样本的权重,以改善模型学习效果。
对于二元分类问题,交叉熵(cross entropy)损失函数定义为
CE ( p t ) = − log p t \text{CE}(p_t)=-\log p_t CE(pt)=−logpt
其中 P t P_t Pt 为正样本概率函数,用来简化公式:
p t = { p if y = 1 1 − p otherwise p_t=\begin{cases} p & \text{if } y=1 \\ 1-p & \text{otherwise} \end{cases} pt={p1−pif y=1otherwise
Focal Loss 函数定义如下:
FL ( p t ) = − a t ( 1 − p t ) γ log p t \text{FL}(p_t)=-a_t(1-p_t)^{\gamma}\log p_t FL(pt)=−at(1−pt)γlogpt
其中权重因子 a t a_t at 根据正负样本的分布设置,用来平衡损失函数分布
a t = { a if y = 1 1 − a otherwise a_t=\begin{cases} a & \text{if } y=1 \\ 1-a & \text{otherwise} \end{cases} at={a1−aif y=1otherwise
( 1 − p t ) γ (1-p_t)^{\gamma} (1−pt)γ 称为调制因子(modulating factor),
分解开来
FL ( p t ) = a t ( 1 − p t ) γ CE ( p t ) = { − a ( 1 − p ) γ log p if y = 1 − ( 1 − a ) p γ log ( 1 − p ) otherwise \text{FL}(p_t)=a_t(1-p_t)^{\gamma}\text{CE}(p_t) =\begin{cases} -a(1-p)^{\gamma}\log p & \text{if }y=1 \\ -(1-a)p^{\gamma}\log(1-p) & \text{otherwise} \end{cases} FL(pt)=at(1−pt)γCE(pt)={−a(1−p)γlogp−(1−a)pγlog(1−p)if y=1otherwise
调制因子减少了易于分类(概率高)的样本的贡献。
- 当 p t → 0 p_t\to 0 pt→0 的时候,调制因子趋于1,对于总的loss的贡献很大。当 p t → 1 p_t\to 1 pt→1的时候,调制因子趋于0,也就是对于总的loss的贡献很小。
- 当 γ = 0 \gamma=0 γ=0 的时候,focal loss就是传统的交叉熵损失,可以通过调整 γ \gamma γ 实现调制因子的改变。
引用作者的话:当 γ = 2 \gamma=2 γ=2 时,与 CE 相比,分类为 p t = 0.9 p_t = 0.9 pt=0.9 的示例的损失将降低 100 倍,而当 p t ≈ 0.968 p_t ≈ 0.968 pt≈0.968 时,其损失将降低 1000 倍。减少易于分类的示例的损失,可以让训练更多地关注难以分类的示例。

模型层面
解决不均衡问题,更为优秀的是基于采样+集成树模型等方法,可以在类别不均衡数据上表现良好。采样+集成学习这类方法简单来说,通过重复组合少数类样本与抽样的同样数量的多数类样本,训练若干的分类器进行集成学习。
EasyEnsemble 是利用模型集成(Ensemble)的方法多次欠采样。核心思路就是将多数类样本集随机分成 N 个子集,且每一个子集样本与少数类样本相同,然后分别将各个多数类样本子集与少数类样本进行组合,产生多个不同的训练集,进而训练多个不同的基分类器,最后bagging集成各基分类器,得到最终模型。
BalanceCascade 是利用增量训练的思想(Boosting)。核心思路就是在每一轮训练时都使用多数类与少数类数量上相等的训练集,然后使用该分类器对全体多数类进行预测,对于那些分类正确的多数类样本不放回,然后对这个更小的多数类样本欠采样产生训练集,然后进入下一轮迭代继续降低多数类数量。
通常,在数据集噪声较小的情况下,可以用BalanceCascade,可以用较少的基分类器数量得到较好的表现(基于串行的集成学习方法,对噪声敏感容易过拟合)。噪声大的情况下,可以用EasyEnsemble,基于串行+并行的集成学习方法,bagging多个Adaboost过程可以抵消一些噪声影响。
评估指标
分类常用的指标precision、recall、F1、混淆矩阵,对于样本不均衡的不同程度,都会明显改变这些指标的表现。可以采用AUC、AUPRC(更优)评估模型表现,AUC对样本的正负样本比例情况是不敏感。
相关文章:
机器学习(II)--样本不平衡
现实中,样本(类别)样本不平衡(class-imbalance)是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单样本通常是占总交易数量的极少部分,而且对于有些任务而言少数样本更…...

几个好用的 VUE Table
Vue easytable - 功能恰到好处 无学习成本 上手就用Vue good table - UI 清新 功能直给 适合小项目Vxe table - 宝藏级 table 组件 高级功能低调好用 维护频率高tabulator - 元老级 table 组件 高级功能平民化AG Grid - 媲美 Excel 的 Table 组件 能想到的复杂功能它都能做到...
)
Vue源码系列讲解——实例方法篇【三】(生命周期相关方法)
目录 0. 前言 1. vm.$mount 1.1 用法回顾 1.2 内部原理 2. vm.$forceUpdate 2.1 用法回顾 2.2 内部原理 3. vm.$nextTick 3.1 用法回顾 3.2 JS的运行机制 3.3 内部原理 能力检测 执行回调队列 4. vm.$destory 4.1 用法回顾 4.2 内部原理 0. 前言 与生命周期相关…...

百度SEO工具,自动更新网站的工具
在网站SEO的过程中,不断更新网站内容是提升排名和吸引流量的关键之一。而对于大多数网站管理员来说,频繁手动更新文章并进行SEO优化可能会是一项繁琐且耗时的任务。针对这一问题,百度自动更新文章SEO工具应运而生,它能够帮助网站管…...
供应链|NUS覃含章MS论文解读:数据驱动下联合定价和库存控制的近似方法 (二)
编者按 本次解读的文章发表于 Management Science,原文信息:Hanzhang Qin, David Simchi-Levi, Li Wang (2022) Data-Driven Approximation Schemes for Joint Pricing and Inventory Control Models. https://doi.org/10.1287/mnsc.2021.4212 文章在数…...

删除有序数组中的重复项Ⅱ
问题 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。 说明…...

Java底层自学大纲_数据结构和算法篇
数据结构和算法专题_自学大纲所属类别学习主题建议课时(h) A 数据结构和算法001 数据结构和算法基础,时间复杂度Ot和空间复杂度Os2.5 A 数据结构和算法002 数学知识回顾-指数、对数、级数、模运算、复杂度2.5 A 数据结构和算法003 高数知识…...
群晖NAS配置WebDav结合内网穿透实现公网访问本地影视资源
文章目录 本教程解决的问题是:按照本教程方法操作后,达到的效果是:1 使用环境要求:2 配置webdav3 测试局域网使用potplayer访问webdav3 内网穿透,映射至公网4 使用固定地址在potplayer访问webdav 国内流媒体平台的内…...

Vue3报错Promise executor functions should not be async.
解决方法 加注释。。。// eslint-disable-next-line no-async-promise-executor // eslint-disable-next-line no-async-promise-executor new Promise<boolean>(async (resolve, reject) > {... }),...
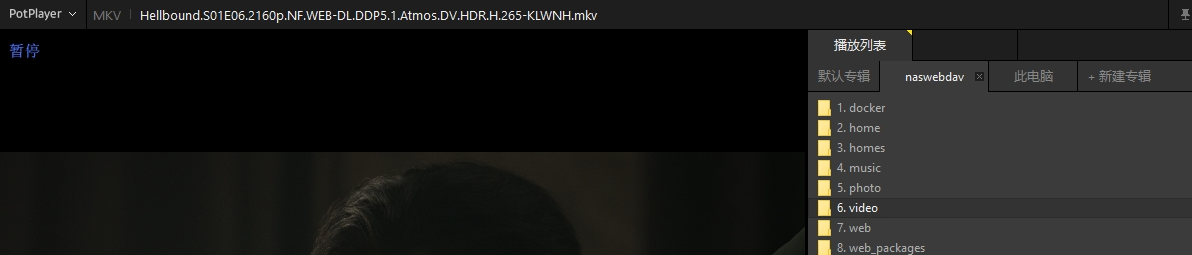
(正规api接口代发布权限)短视频账号矩阵系统实现开发--技术全自动化saas营销链路生态
短视频账号矩阵系统实现开发--技术全自动化saas营销链路生态源头开发(本篇禁止抄袭复刻) 一、短视频矩阵系统开发者架构 云罗短视频矩阵系统saas化系统,开发层将在CAP原则基础上使用分布式架构,对此网站的整体架构采用了基于B/S三层架构模式…...

【Redis】redis通用命令
redis连接命令(客户端) 要在 redis 服务上执行命令需要一个 redis 客户端。Redis 客户端在我们之前安装redis 的src目录下,具体为/usr/local/redis/src。注意此redis实例没有设置密码,如果设置了密码需要先使用命令AUTH执行验证或…...
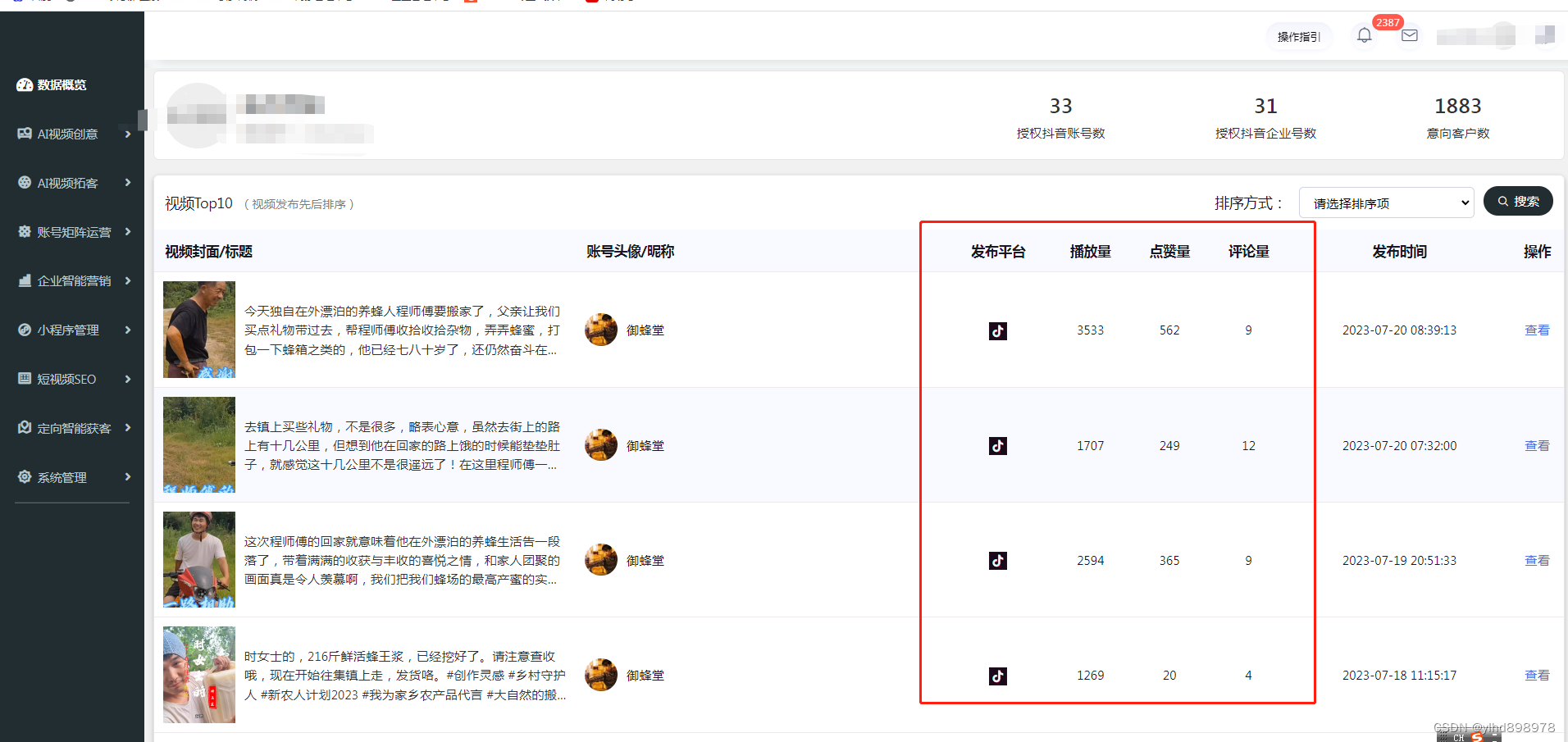
mysql服务治理
一、性能监控指标和解决方案 1.QPS 一台 MySQL 数据库,大致处理能力的极限是,每秒一万条左右的简单 SQL,这里的“简单 SQL”,指的是类似于主键查询这种不需要遍历很多条记录的 SQL。 根据服务器的配置高低,可能低端…...
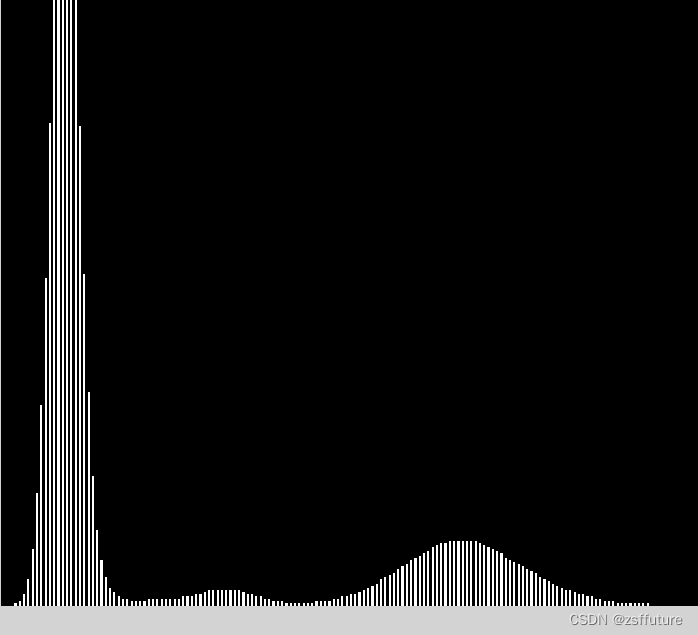
opencv--使用直方图找谷底进行确定分割阈值
直方图原理就不说了,大家自行百度 直方图可以帮助分析图像中的灰度变化,进而帮助确定最优二值化的灰度阈值(threshold level)。如果物体与背景的灰度值对比明显,此时灰度直方图就会包含双峰(bimodal histo…...

dolphinscheduler海豚调度(四)钉钉告警
在之前的博文中,我们已经介绍了DolphinScheduler海豚调度的基本概念和工作流程,以及Shell任务和SQL任务的实践。今天,让我们来学习DolphinScheduler中的另一个重要功能:钉钉告警。 钉钉群添加机器人 在钉钉群添加机器人…...
)
Java-Safe Point(安全点)
虽然安全点的概念和垃圾回收相关,但是概念还是比较独立的,所以本文是从这篇文章Java-虚拟机-垃圾收集器/垃圾收集算法/GCROOT根中抽出来的 安全点safe point 当执行垃圾回收(GC)的时候,不是立马就执行的,…...
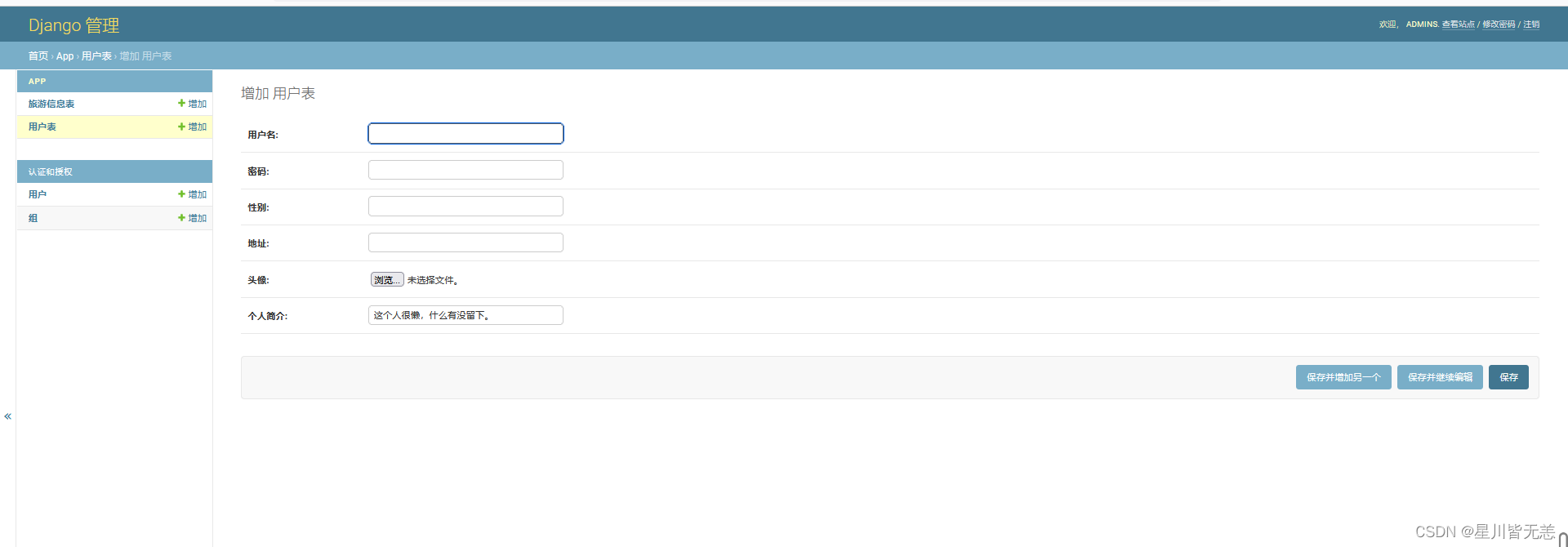
大数据旅游数据分析:基于Python旅游数据采集可视化分析推荐系统
文章目录 基于Python旅游数据采集可视化分析推荐系统一、项目概述二、项目说明三、开发环境四、功能实现五、系统页面实现用户登录注册系统首页数据操作管理价格与销量分析旅游城市和景点等级分析旅游数据评分情况分析旅游数据评论情况分析旅游景点推荐Django系统后台管理 六、…...
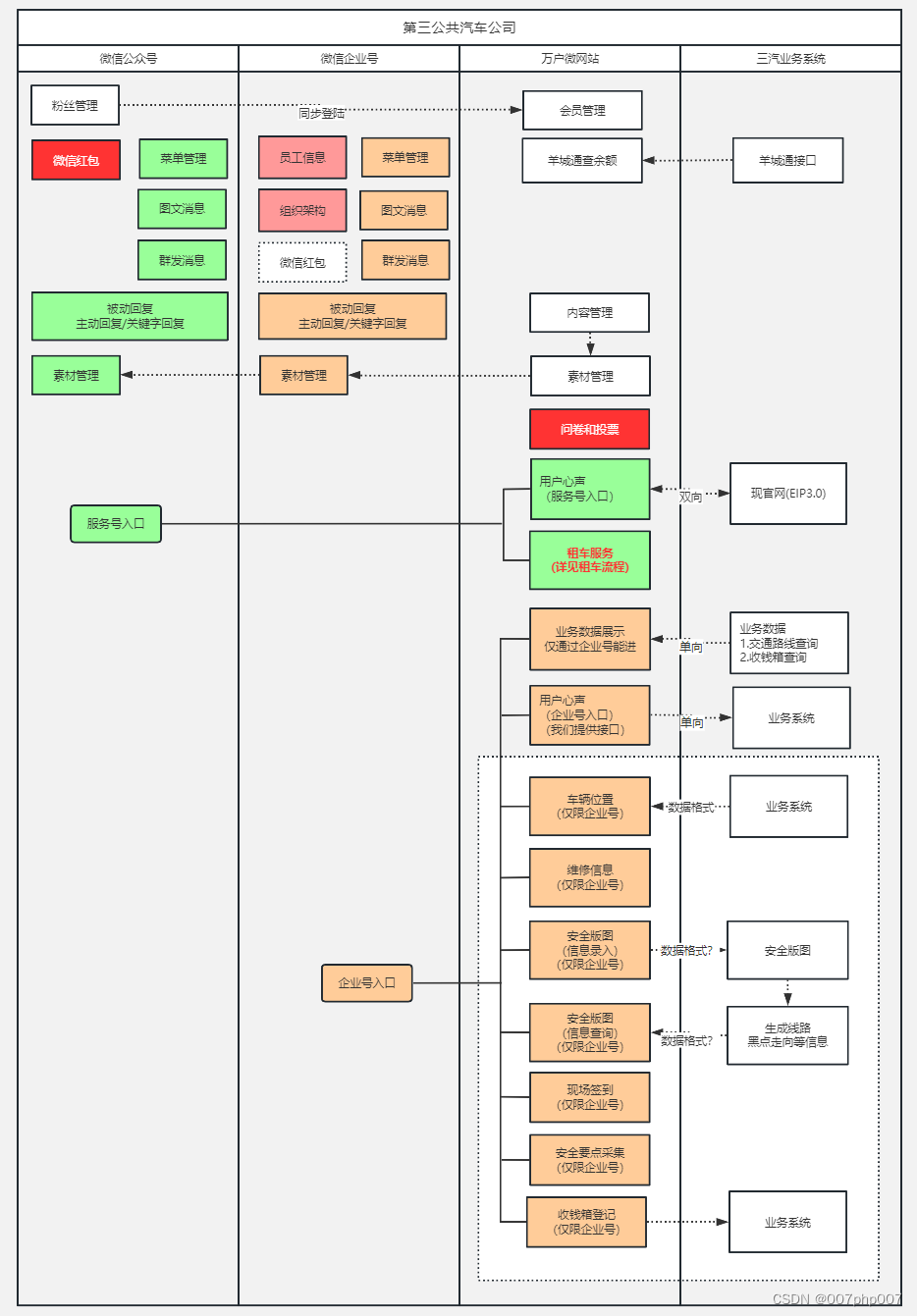
打造智能汽车微服务系统平台:架构的设计与实现
随着智能汽车技术的飞速发展,微服务架构在汽车行业中的应用越来越广泛。采用微服务架构可以使汽车系统更加灵活、可扩展,并且有利于快速推出新功能和服务。本文将从设计原则、关键技术、数据安全等方面,介绍如何搭建智能汽车微服务系统平台架…...

机试指南:Ch5:线性数据结构 Ch6:递归与分治
文章目录 第5章 线性数据结构1.向量 vector2.队列 queue(1)队列的特点、应用(2)基本操作(3)例题例题1:约瑟夫问题2 (难度:中等) (4)习题习题1:排队打饭 (难度:中等) 3.栈 stack(1)栈…...

展厅设计的理念是什么
1、立足当地文化 升华本地精神 ,因地制宜,深入挖掘本土文化特色,撷取其精华,灵活运用、巧妙融入,做到掌控宏观全局。 重点突出,努力打造本土拳头品牌,挖掘其内涵,拓展延伸、着重展示…...

springboot 定时任务备份mysql数据库
记录在Linux 系统上定时备份MySQL数据库 1、在代码中添加备份 package org.jeecg.modules.xczxhhr.job;import lombok.extern.slf4j.Slf4j; import org.quartz.Job; import org.quartz.JobExecutionContext;import java.io.BufferedReader; import java.io.File; import java…...

开发者面试内卷:突出重围的差异化战术
当面试成为一场无声的战争对于广大软件测试从业者而言,当下的求职环境正经历着一场深刻而静默的变革。面试不再是简单的技术问答,而演变为一场综合能力的全面较量。技术基础、项目深度、思维逻辑乃至对行业趋势的洞察,都成为面试官衡量候选人…...

跨境合同怎么签?Docusign国际文件签署的5个隐藏技巧
跨境合同签署的5个Docusign高阶技巧:时区、多语言与合规实战 跨国业务合作中,电子签约已成为企业提升效率的关键工具。作为全球领先的电子签名平台,Docusign不仅提供基础的签署功能,更隐藏着一系列专为跨境场景设计的高级特性。本…...
”冠军)
国泰君安国际荣获2025年度离岸中资基金大奖“货币市场基金 - 港币(1年)”冠军
近日,香港中资基金业协会(HKCAMA)与彭博联合宣布2025年度“离岸中资基金大奖”获奖名单。国泰海通集团下属公司国泰君安国际控股有限公司(“国泰君安国际”或“公司”,股份代号:1788.HK)旗下国泰…...

别再抄作业了!2026奇点大会首次公开AI学习助手的“动态知识图谱构建协议”——支持实时跨域推理的底层逻辑
第一章:2026奇点智能技术大会:AI学习助手 2026奇点智能技术大会(https://ml-summit.org) 核心定位与能力演进 AI学习助手是本届大会首次发布的开源智能体框架,聚焦教育场景中的个性化知识建模与实时认知反馈。它不再仅依赖预训练语言模型的…...

如何高效使用LRCGET:离线歌词同步完整指南
如何高效使用LRCGET:离线歌词同步完整指南 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否曾面对数千首离线音乐,却因缺少…...

Python29_并发编程
Python29_并发编程 文章目录Python29_并发编程[toc]基本概念1 并发 vs 并行2 Python 的并发模型多线程编程1 基本使用2 线程同步3 线程间通信多进程编程1 基本使用2 进程池3 进程间通信异步IO(asyncio)1 基本概念2 基本使用3 高级特性并发编程选择指南实际应用示例1 并发下载器…...

终极显卡驱动清理指南:如何彻底卸载NVIDIA/AMD/Intel显卡驱动
终极显卡驱动清理指南:如何彻底卸载NVIDIA/AMD/Intel显卡驱动 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-unins…...

树莓派4B 无盘化部署实战:从零构建网络启动环境
1. 为什么需要无盘化部署? 第一次接触树莓派无盘启动这个概念时,我也觉得挺神奇的。毕竟树莓派一直以来都是依赖SD卡启动的,突然说可以完全不用存储介质,直接从网络启动系统,这听起来就像变魔术一样。但当我真正在实验…...

OV5640摄像头模组选型与二次开发避坑指南:DVP vs MIPI接口到底怎么选?
OV5640摄像头模组选型与二次开发避坑指南:DVP vs MIPI接口到底怎么选? 在智能硬件和嵌入式视觉项目中,摄像头模组的选择往往决定了整个系统的性能和开发难度。OV5640作为一款经典的500万像素CMOS图像传感器,凭借其出色的性价比和丰…...

告别繁琐切换:zoxide如何让你的终端导航效率提升10倍?
告别繁琐切换:zoxide如何让你的终端导航效率提升10倍? 【免费下载链接】zoxide A smarter cd command. Supports all major shells. 项目地址: https://gitcode.com/GitHub_Trending/zo/zoxide zoxide是一款智能cd命令工具,灵感源自z和…...