mysql服务治理
一、性能监控指标和解决方案
1.QPS
一台 MySQL 数据库,大致处理能力的极限是,每秒一万条左右的简单 SQL,这里的“简单 SQL”,指的是类似于主键查询这种不需要遍历很多条记录的 SQL。
根据服务器的配置高低,可能低端的服务器只能达到每秒几千条,高端的服务器可以达到每秒钟几万条,所以这里给出的一万 TPS 是中位数的经验值。考虑到正常的系统不可能只有简单 SQL,所以实际的 TPS 还要打很多折扣。
我的经验数据,一般一台 MySQL 服务器,平均每秒钟执行的 SQL 数量在几百左右,就已经是非常繁忙了,即使看起来 CPU 利用率和磁盘繁忙程度没那么高,你也需要考虑给数据库“减负”了。
1.QPS 突增问题
有时候由于业务突然出现高峰,或者应用程序 bug,导致某个语句的 QPS 突然暴涨,也可能导致 MySQL 压力过大,影响服务。
我之前碰到过一类情况,是由一个新功能的 bug 导致的。当然,最理想的情况是让业务把这个功能下掉,服务自然就会恢复。
而下掉一个功能,如果从数据库端处理的话,对应于不同的背景,有不同的方法可用。我这里再和你展开说明一下。
-
一种是由全新业务的 bug 导致的。假设你的 DB 运维是比较规范的,也就是说白名单是一个个加的。这种情况下,如果你能够确定业务方会下掉这个功能,只是时间上没那么快,那么就可以从数据库端直接把白名单去掉。
-
如果这个新功能使用的是单独的数据库用户,可以用管理员账号把这个用户删掉,然后断开现有连接。这样,这个新功能的连接不成功,由它引发的 QPS 就会变成 0。
-
如果这个新增的功能跟主体功能是部署在一起的,那么我们只能通过处理语句来限制。这时,我们可以使用上面提到的查询重写功能,把压力最大的 SQL 语句直接重写成"select 1"返回。
当然,这个操作的风险很高,需要你特别细致。它可能存在两个副作用:
-
如果别的功能里面也用到了这个 SQL 语句模板,会有误伤;
-
很多业务并不是靠这一个语句就能完成逻辑的,所以如果单独把这一个语句以 select 1 的结果返回的话,可能会导致后面的业务逻辑一起失败。
所以,方案 3 是用于止血的,跟前面提到的去掉权限验证一样,应该是你所有选项里优先级最低的一个方案。
同时你会发现,其实方案 1 和 2 都要依赖于规范的运维体系:虚拟化、白名单机制、业务账号分离。由此可见,更多的准备,往往意味着更稳定的系统。
2.IOPS
1.定义
在数据库性能优化的过程中,了解IOPS(Input/Output Operations Per Second,即每秒输入/输出操作数)是至关重要的。
IOPS是衡量数据库磁盘性能的重要指标之一,可以帮助我们了解数据库在处理输入输出操作时的效率和吞吐量。
IOPS的计算公式如下所示:
IOPS = 请求的IO总数 / 测试时间IOPS的数值受多个因素的影响,主要包括以下几个方面:
1.硬件设备
数据库的硬件设备对IOPS有着直接的影响。例如,硬盘类型(机械硬盘还是固态硬盘)、硬盘容量、硬盘转速等都会影响IOPS的数值。一般来说,固态硬盘的IOPS要远高于机械硬盘。
2.数据库参数配置
数据库的参数配置也会对IOPS产生一定的影响。例如,innodb_io_capacity参数可以用来控制MySQL的IOPS性能,适当调整该参数的值可以提升数据库的IOPS表现。
那么如果当数据库的io负载过高,会带来哪些影响?
1.响应时间延长
因为没有io资源读写磁盘了,自然响应时间会延长
2.系统崩溃
极端情况超过系统io能力会导致系统崩溃重启等。
2.IOPS监控
可以使用一些专门的监控工具来监控数据库的IOPS。例如,MySQL自带的Performance Schema可以提供详细的性能统计信息,包括IOPS的数值。另外,还有一些第三方监控工具如pt-diskstats、mpstat等也可以提供有关IOPS的监控信息。
3.提升IOPS
思考一个问题:如果你的 MySQL 现在出现了性能瓶颈,而且瓶颈在 IO 上,可以通过哪些方法来提升性能呢?
针对这个问题,基于将io压力转移到内存的思路,可以考虑以下三种方法:
-
设置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 参数,减少 binlog 的写盘次数。这个方法是基于“额外的故意等待”来实现的,因此可能会增加语句的响应时间,但没有丢失数据的风险。
-
将 sync_binlog 设置为大于 1 的值(比较常见是 100~1000)。这样做的风险是,主机掉电时会丢 binlog 日志,但也总比io负载过高好
-
将 innodb_flush_log_at_trx_commit 设置为 2。这样做的风险是,主机掉电的时候会丢数据。
我不建议你把 innodb_flush_log_at_trx_commit 设置成 0。因为把这个参数设置成 0,表示 redo log 只保存在内存中,这样的话 MySQL 本身异常重启也会丢数据,风险太大。
而 redo log 写到文件系统的 page cache 的速度也是很快的,所以将这个参数设置成 2 跟设置成 0 其实性能差不多,但这样做 MySQL 异常重启时就不会丢数据了,相比之下风险会更小,因为page cache是操作系统层面的概念,它被所有进程共享,只有当操作系统物理内存不足等原因才会进行刷盘操作,但如果主机掉电或者关机后page cache会丢失。
3.连接池资源
1.短连接风暴
正常的短连接模式就是连接到数据库后,执行很少的 SQL 语句就断开,下次需要的时候再重连。如果使用的是短连接,在业务高峰期的时候,就可能出现连接数突然暴涨的情况。
MySQL 建立连接的过程,成本是很高的。除了正常的网络连接三次握手外,还需要做登录权限判断和获得这个连接的数据读写权限。
在数据库压力比较小的时候,这些额外的成本并不明显。
但是,短连接模型存在一个风险,就是一旦数据库处理得慢一些,连接数就会暴涨。max_connections 参数,用来控制一个 MySQL 实例同时存在的连接数的上限,超过这个值,系统就会拒绝接下来的连接请求,并报错提示“Too many connections”。对于被拒绝连接的请求来说,从业务角度看就是数据库不可用。
在机器负载比较高的时候,处理现有请求的时间变长,每个连接保持的时间也更长。这时,再有新建连接的话,就可能会超过 max_connections 的限制。
碰到这种情况时,一个比较自然的想法,就是调高 max_connections 的值。但这样做是有风险的。因为设计 max_connections 这个参数的目的是想保护 MySQL,如果我们把它改得太大,让更多的连接都可以进来,那么系统的负载可能会进一步加大,大量的资源耗费在权限验证等逻辑上,结果可能是适得其反,已经连接的线程拿不到 CPU 资源去执行业务的 SQL 请求。
那么这种情况下,你还有没有别的建议呢?我这里还有两种方法,但要注意,这些方法都是有损的。
第一种方法:先处理掉那些占着连接但是不工作的线程。
max_connections 的计算,不是看谁在 running,是只要连着就占用一个计数位置。对于那些不需要保持的连接,我们可以通过 kill connection 主动踢掉。这个行为跟事先设置 wait_timeout 的效果是一样的。设置 wait_timeout 参数表示的是,一个线程空闲 wait_timeout 这么多秒之后,就会被 MySQL 直接断开连接。
但是需要注意,在 show processlist 的结果里,踢掉显示为 sleep 的线程,可能是有损的。我们来看下面这个例子。

图 1 sleep 线程的两种状态
在上面这个例子里,如果断开 session A 的连接,因为这时候 session A 还没有提交,所以 MySQL 只能按照回滚事务来处理;而断开 session B 的连接,就没什么大影响。所以,如果按照优先级来说,你应该优先断开像 session B 这样的事务外空闲的连接。
但是,怎么判断哪些是事务外空闲的呢?session C 在 T 时刻之后的 30 秒执行 show processlist,看到的结果是这样的。

图 2 sleep 线程的两种状态,show processlist 结果
图中 id=4 和 id=5 的两个会话都是 Sleep 状态。而要看事务具体状态的话,你可以查 information_schema 库的 innodb_trx 表。

图 3 从 information_schema.innodb_trx 查询事务状态
这个结果里,trx_mysql_thread_id=4,表示 id=4 的线程还处在事务中。
因此,如果是连接数过多,你可以优先断开事务外空闲太久的连接;如果这样还不够,再考虑断开事务内空闲太久的连接。
从服务端断开连接使用的是 kill connection + id 的命令, 一个客户端处于 sleep 状态时,它的连接被服务端主动断开后,这个客户端并不会马上知道。直到客户端在发起下一个请求的时候,才会收到这样的报错“ERROR 2013 (HY000): Lost connection to MySQL server during query”。
从数据库端主动断开连接可能是有损的,尤其是有的应用端收到这个错误后,不重新连接,而是直接用这个已经不能用的句柄重试查询。这会导致从应用端看上去,“MySQL 一直没恢复”。
你可能觉得这是一个冷笑话,但实际上我碰到过不下 10 次。
所以,如果你是一个支持业务的 DBA,不要假设所有的应用代码都会被正确地处理。即使只是一个断开连接的操作,也要确保通知到业务开发团队。
第二种方法:减少连接过程的消耗。
有的业务代码会在短时间内先大量申请数据库连接做备用,如果现在数据库确认是被连接行为打挂了,那么一种可能的做法,是让数据库跳过权限验证阶段。
跳过权限验证的方法是:重启数据库,并使用–skip-grant-tables 参数启动。这样,整个 MySQL 会跳过所有的权限验证阶段,包括连接过程和语句执行过程在内。
但是,这种方法特别符合我们标题里说的“饮鸩止渴”,风险极高,是我特别不建议使用的方案。尤其你的库外网可访问的话,就更不能这么做了。
在 MySQL 8.0 版本里,如果你启用–skip-grant-tables 参数,MySQL 会默认把 --skip-networking 参数打开,表示这时候数据库只能被本地的客户端连接。可见,MySQL 官方对 skip-grant-tables 这个参数的安全问题也很重视。
除了短连接数暴增可能会带来性能问题外,实际上,我们在线上碰到更多的是查询或者更新语句导致的性能问题。其中,查询问题比较典型的有两类,一类是由新出现的慢查询导致的,一类是由 QPS(每秒查询数)突增导致的。
4.表大小阀值
你在编写一条查询语句的时候,可以依据你要查询数据表的数据总量,估算一下这条查询大致需要遍历多少行数据。
如果遍历行数在百万以内的,只要不是每秒钟都要执行几十上百次的频繁查询,可以认为是安全的。
遍历数据行数在几百万的,查询时间最少也要几秒钟,你就要仔细考虑有没有优化的办法。
遍历行数达到千万量级和以上的,我只能告诉你,这种查询就不应该出现在你的系统中。当然我们这里说的都是在线交易系统,离线分析类系统另说。遍历行数在千万左右,是 MySQL 查询的一个坎儿。MySQL 中单个表数据量,也要尽量控制在一千万条以下,最多不要超过二三千万这个量级。原因也很好理解,对一个千万级别的表执行查询,加上几个 WHERE 条件过滤一下,符合条件的数据最多可能在几十万或者百万量级,这还可以接受。但如果再和其他的表做一个联合查询,遍历的数据量很可能就超过千万级别了。
所以,每个表的数据量最好小于千万级别。
三、慢sql治理解决方案
1、什么是慢 SQL
什么是慢SQL?顾名思义,运行时间较长的 SQL 语句即为慢 SQL!
那问题来了,多久才算慢呢?
这个慢其实是一个相对值,不同的业务场景下,标准要求是不一样的。
我们都知道,我们每执行一次 SQL,数据库除了会返回执行结果以外,还会返回 SQL 执行耗时,以 MySQL 数据库为例,当我们开启了慢 SQL 监控开关后,默认配置下,当 SQL 的执行时长大于 10 秒,会被记录到慢 SQL 的日志文件中
2、慢 SQL 危害
这里要从慢 SQL 的危害谈起,以 MySQL 数据库为例,总结起来有以下几点:
1.当出现慢查询,DDL 操作都会被阻塞,也就是说创建表、修改表、删除表、执行数据备份等操作都需要等待,这对实时备份重要数据的系统来说是不可容忍的。
2.慢查可能会占用 mysql 的大量内存,严重的时候会导致服务器直接挂掉,整个系统直接瘫痪
3.慢 SQL 的执行时间过长,可能会导致应用的进程因超时被 kill,无法返回结果给到客户端
4.造成数据库幻读、不可重复读的概率更大,假设该慢 SQL 是一个更新操作但因执行时间过长未提交,而另一条 SQL 也在更新数据并且已提交,用户再次查询的时候,看到的数据可能与实际结果不符
5.严重影响用户体验,SQL 的执行时间越长,页面加载数据耗时也就越长
6.直接造成大量的数据库连接超时,服务无法正常响应。
如常见的连接池被耗尽的情况: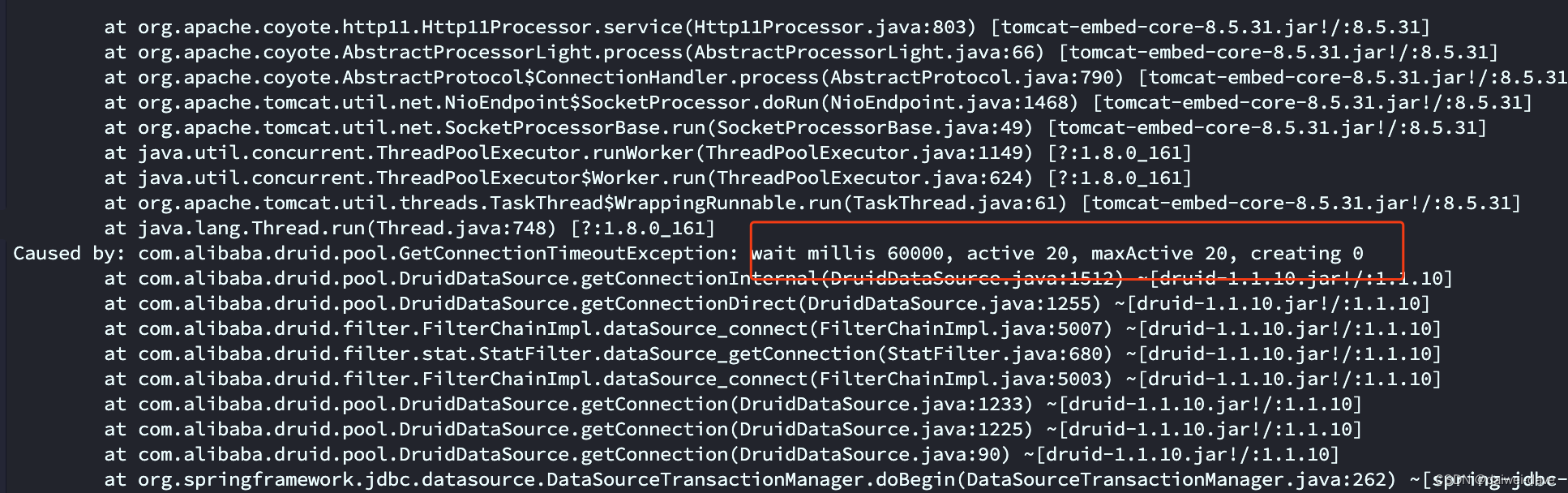
遇到这种问题快速的解决方案有
1.kill掉慢sql的进程
2.重启应用服务器
根本上解决方案则是定位慢sql并优化解决。
3.如何定位慢 SQL
1.开启慢sql监控
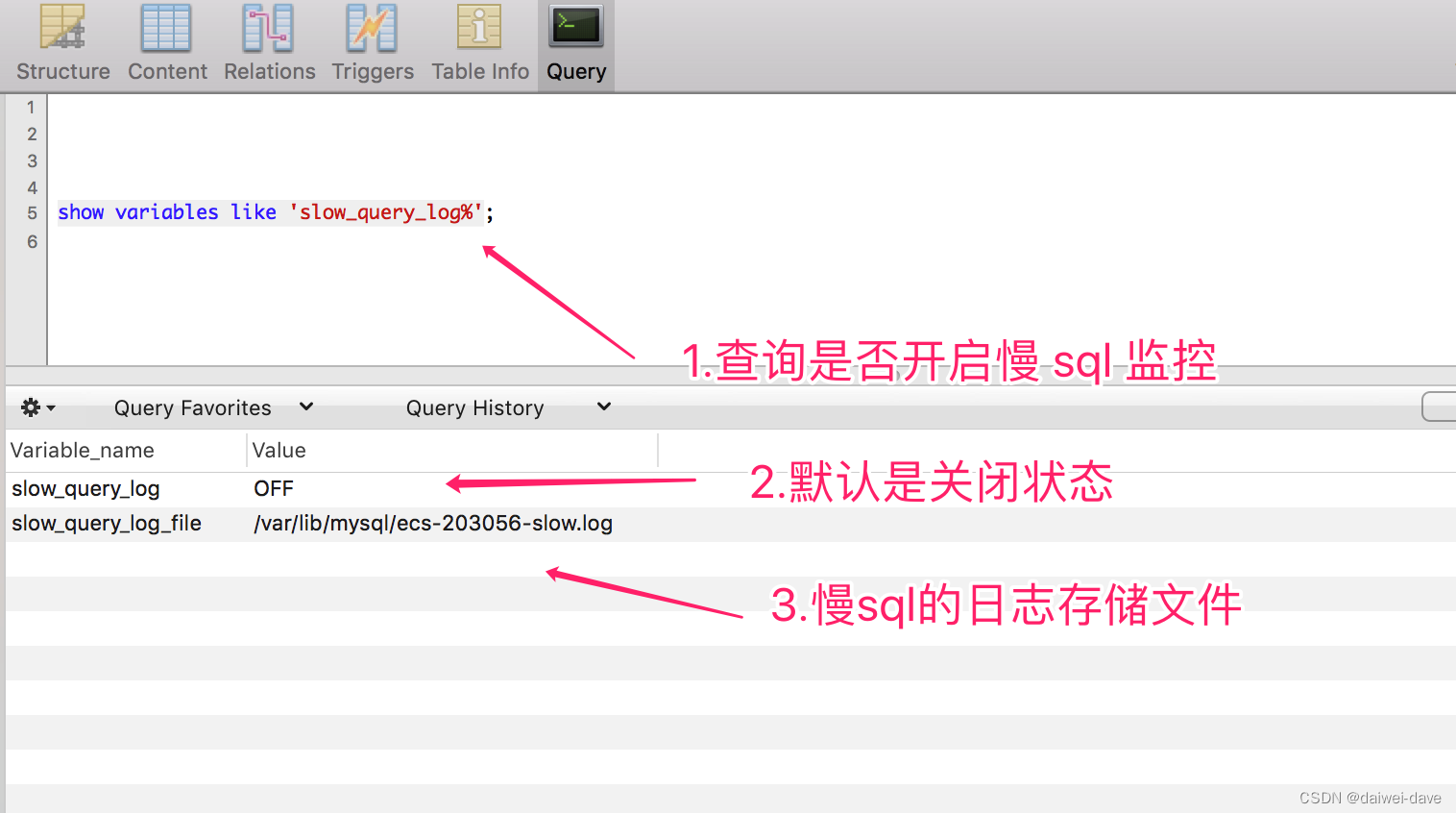
以 MySQL 为例,我们可以通过如下方式,查询是否开启慢 SQL 的监控。
show variables like 'slow_query_log%';
通过如下命令,开启慢 SQL 监控,执行成功之后,客户端需要重新连接才能生效。
-- 开启慢 SQL 监控
set global slow_query_log = 1;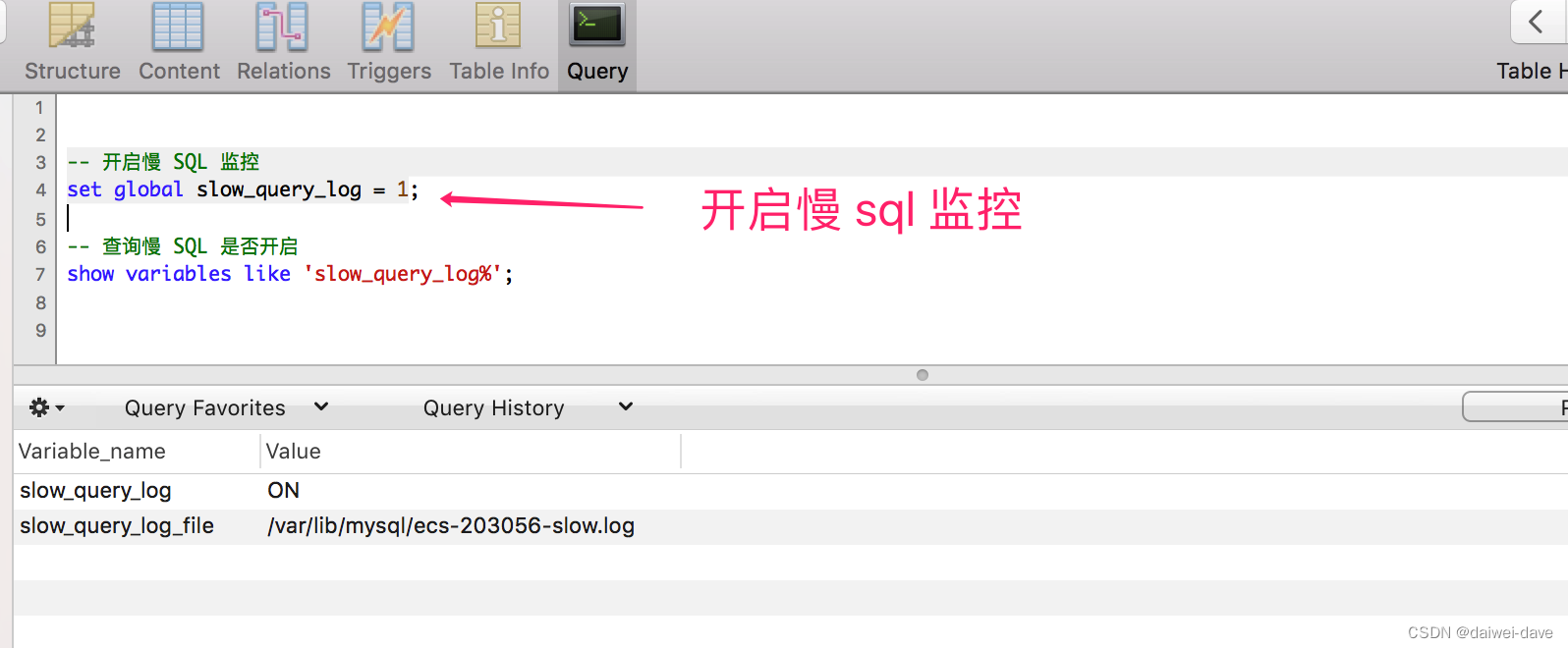
以上的操作,当服务器不重启会一直有效,但是当服务器一单重启之后,配置就会失效,如果想永久生效,可以通过修改全局配置文件my.cnf使之永久生效。
以 CentOS 为例,打开my.cnf配置文件,添加如下配置变量。
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/ecs-203056-slow.log
long_query_time = 1最后,重启 mysql 服务器
2.配置慢 SQL 阀值
默认的慢 SQL 阀值是10秒,可以通过如下语句查询慢 SQL 的阀值。
-- 查询慢 SQL 的阀值
show variables like "long_query_time";
-- 修改慢 SQL 的阀值
set global long_query_time = 3;
3.查看慢sql
假如慢sql的阀值是3s,慢sql日志文件是在/mnt/cp/mysql/log/下面。
则执行下面命令即可抓起到对应的慢sql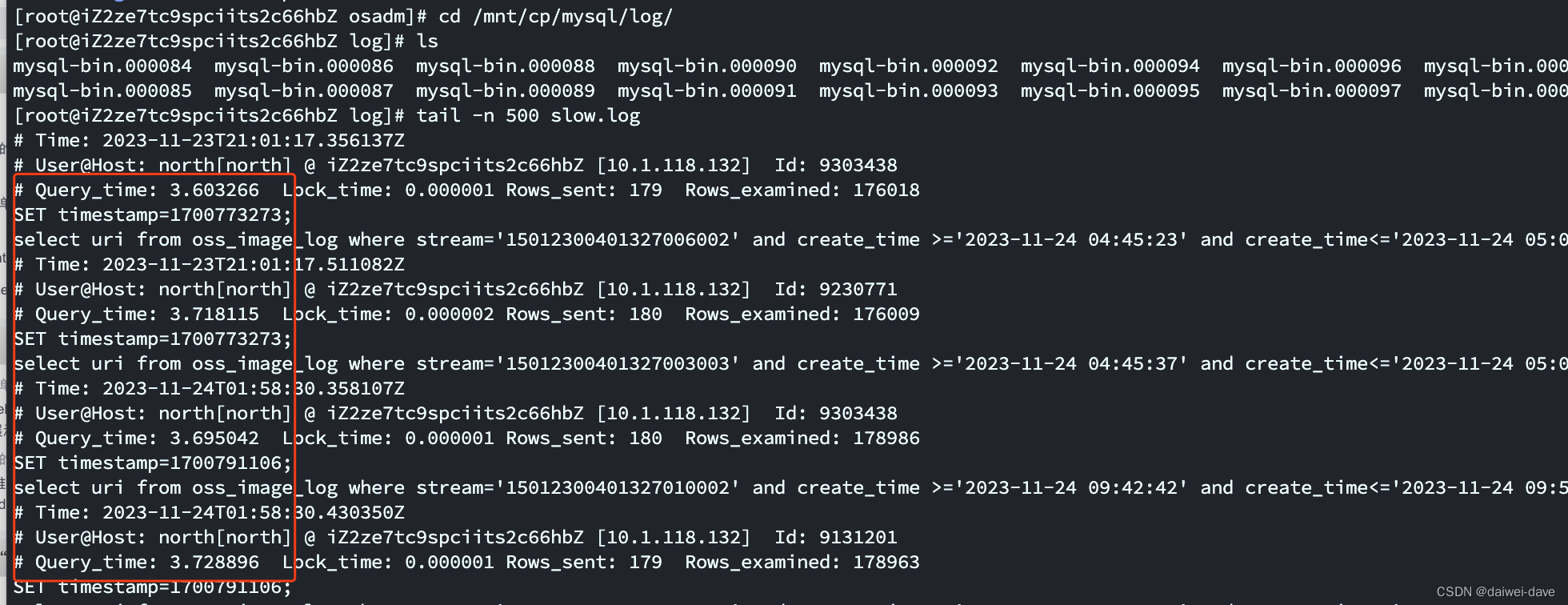
日志内容详解:
Time:表示客户端查询时间
root[root]:表示客户端查询用户和IP
Query_time:表示查询耗时
Lock_time:表示等待 table lock 的时间,注意InnoDB的行锁等待是不会反应在这里的
Rows_sent:表示返回了多少行记录(结果集)。
Rows_examined:表示检查了多少条记录。
4.分析慢 SQL的产生原因
其中影响成本开销值的计算,主要是I/O成本和CPU成本这两个指标。
从I/O成本视角看:
当表的数据量越大,需要的 I/O 次数也就越多
从磁盘读取数据比从缓存读取数据,I/O 消耗的时间更多
全表扫描比通过索引快速查找,I/O 消耗的时间和次数更多
从CPU成本视角看:
当 SQL 中有排序、子查询等复杂的操作时,CPU 需要先把数据存到临时表中,再对数据进行加工,需要的 CPU 资源更多
全表扫描相比于通过索引快速查找,需要的 CPU 资源也更多
因此我们不难发现,在没有开启缓存的情况下,当表的数据量越大,如果 SQL 又没有走索引,很容易发生查询慢的问题。
从引发性能问题的角度看,大体有以下三种可能:
-
索引没有设计好;
-
SQL 语句没写好;
-
MySQL 选错了索引。
接下来,我们就具体分析一下这三种可能,以及对应的解决方案。
导致慢查询的第一种可能是,索引没有设计好。
这种场景一般就是通过紧急创建索引来解决。MySQL 5.6 版本以后,创建索引都支持 Online DDL 了,对于那种高峰期数据库已经被这个语句打挂了的情况,最高效的做法就是直接执行 alter table 语句。
导致慢查询的第二种可能是,语句没写好。
比如,我们犯了导致语句没有使用上索引。
这时,我们可以通过改写 SQL 语句来处理。MySQL 5.7 提供了 query_rewrite 功能,可以把输入的一种语句改写成另外一种模式。
比如,语句被错误地写成了 select * from t where id + 1 = 10000,你可以通过下面的方式,增加一个语句改写规则。
|
| |
|
|
这里,call query_rewrite.flush_rewrite_rules() 这个存储过程,是让插入的新规则生效,也就是我们说的“查询重写”。你可以用图 4 中的方法来确认改写规则是否生效。
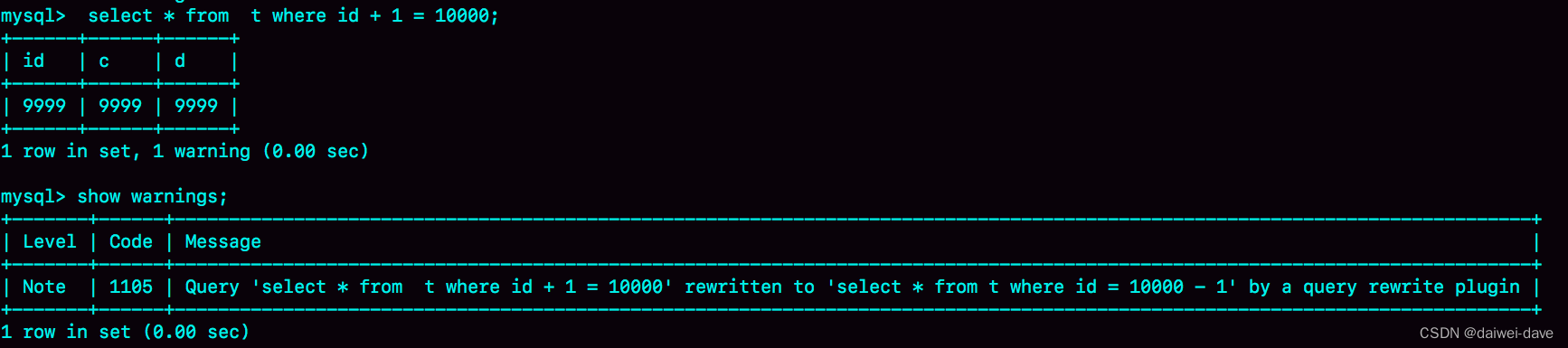
图 4 查询重写效果
导致慢查询的第三种可能,MySQL 选错了索引。
这时候,应急方案就是给这个语句加上 force index。
同样地,使用查询重写功能,给原来的语句加上 force index,也可以解决这个问题。
上面我和你讨论的由慢查询导致性能问题的三种可能情况,实际上出现最多的是前两种,即:索引没设计好和语句没写好。而这两种情况,恰恰是完全可以避免的。
比如,通过下面这个过程,我们就可以预先发现问题。
-
上线前,在测试环境,把慢查询日志(slow log)打开,并且把 long_query_time 设置成 0,确保每个语句都会被记录入慢查询日志;
-
在测试表里插入模拟线上的数据,做一遍回归测试;
-
观察慢查询日志里每类语句的输出,特别留意 Rows_examined 字段是否与预期一致。
不要吝啬这段花在上线前的“额外”时间,因为这会帮你省下很多故障复盘的时间。
如果新增的 SQL 语句不多,手动跑一下就可以。而如果是新项目的话,或者是修改了原有项目的 表结构设计,全量回归测试都是必要的。这时候,你需要工具帮你检查所有的 SQL 语句的返回结果。比如,你可以使用开源工具 pt-query-digest(pt-query-digest — Percona Toolkit Documentation)。
5.慢查询优化思路
在业务系统中,除了使用主键进行的查询,其他的都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。
慢查询的优化首先要搞明白慢的原因是什么?是查询条件没有命中索引?是load了不需要的数据列?还是数据量太大?
所以优化也是针对这三个方向来的。
1.首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
2.分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
3.如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
参考资料
慢SQL,压垮团队的最后一根稻草!https://blog.csdn.net/dxflqm_pz/article/details/126360562
参考资料
1.极客时间《MySQL实战45讲》
相关文章:
mysql服务治理
一、性能监控指标和解决方案 1.QPS 一台 MySQL 数据库,大致处理能力的极限是,每秒一万条左右的简单 SQL,这里的“简单 SQL”,指的是类似于主键查询这种不需要遍历很多条记录的 SQL。 根据服务器的配置高低,可能低端…...
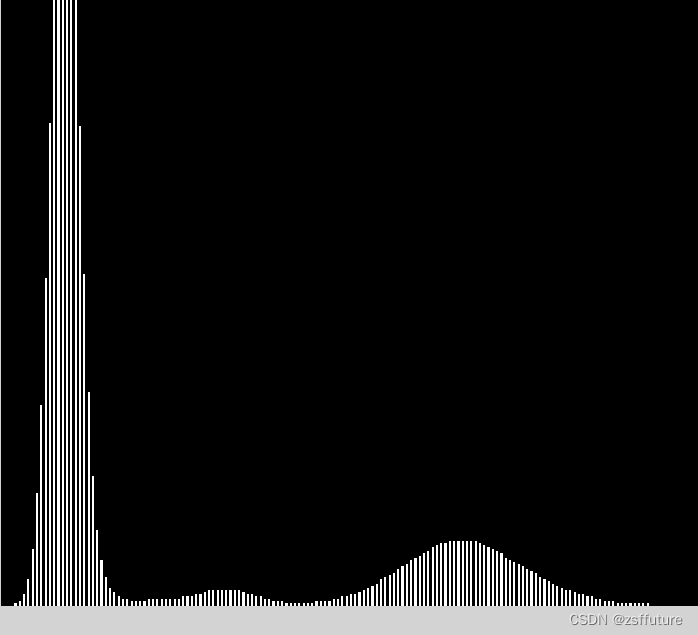
opencv--使用直方图找谷底进行确定分割阈值
直方图原理就不说了,大家自行百度 直方图可以帮助分析图像中的灰度变化,进而帮助确定最优二值化的灰度阈值(threshold level)。如果物体与背景的灰度值对比明显,此时灰度直方图就会包含双峰(bimodal histo…...

dolphinscheduler海豚调度(四)钉钉告警
在之前的博文中,我们已经介绍了DolphinScheduler海豚调度的基本概念和工作流程,以及Shell任务和SQL任务的实践。今天,让我们来学习DolphinScheduler中的另一个重要功能:钉钉告警。 钉钉群添加机器人 在钉钉群添加机器人…...
)
Java-Safe Point(安全点)
虽然安全点的概念和垃圾回收相关,但是概念还是比较独立的,所以本文是从这篇文章Java-虚拟机-垃圾收集器/垃圾收集算法/GCROOT根中抽出来的 安全点safe point 当执行垃圾回收(GC)的时候,不是立马就执行的,…...
大数据旅游数据分析:基于Python旅游数据采集可视化分析推荐系统
文章目录 基于Python旅游数据采集可视化分析推荐系统一、项目概述二、项目说明三、开发环境四、功能实现五、系统页面实现用户登录注册系统首页数据操作管理价格与销量分析旅游城市和景点等级分析旅游数据评分情况分析旅游数据评论情况分析旅游景点推荐Django系统后台管理 六、…...
打造智能汽车微服务系统平台:架构的设计与实现
随着智能汽车技术的飞速发展,微服务架构在汽车行业中的应用越来越广泛。采用微服务架构可以使汽车系统更加灵活、可扩展,并且有利于快速推出新功能和服务。本文将从设计原则、关键技术、数据安全等方面,介绍如何搭建智能汽车微服务系统平台架…...

机试指南:Ch5:线性数据结构 Ch6:递归与分治
文章目录 第5章 线性数据结构1.向量 vector2.队列 queue(1)队列的特点、应用(2)基本操作(3)例题例题1:约瑟夫问题2 (难度:中等) (4)习题习题1:排队打饭 (难度:中等) 3.栈 stack(1)栈…...

展厅设计的理念是什么
1、立足当地文化 升华本地精神 ,因地制宜,深入挖掘本土文化特色,撷取其精华,灵活运用、巧妙融入,做到掌控宏观全局。 重点突出,努力打造本土拳头品牌,挖掘其内涵,拓展延伸、着重展示…...

springboot 定时任务备份mysql数据库
记录在Linux 系统上定时备份MySQL数据库 1、在代码中添加备份 package org.jeecg.modules.xczxhhr.job;import lombok.extern.slf4j.Slf4j; import org.quartz.Job; import org.quartz.JobExecutionContext;import java.io.BufferedReader; import java.io.File; import java…...

PMP考试之20240301
1、在回顾项目团队最新的绩效报告时,项目经理注意到他们的产出出现了重大下降。项目经理决定: A.增加每个团队成员在截止日期前完成任务的压力 B.增加状态报告和团队评审会议的频率 C.为表现最好的团队成员提供特别奖励 D.改善和促进团队成员之间的信任和凝聚力…...
什么是MAC地址? win10电脑查看MAC地址的多种方法
您是否知道连接到家庭网络的每件硬件都有自己的身份?正如每个设备都分配有自己的 IP 地址一样,每个硬件都有一个唯一的网络标识符。 该标识符称为MAC 地址。MAC 代表媒体访问控制。您可能需要 MAC 地址来解决网络问题或配置新设备。在 Windows 中查找您…...
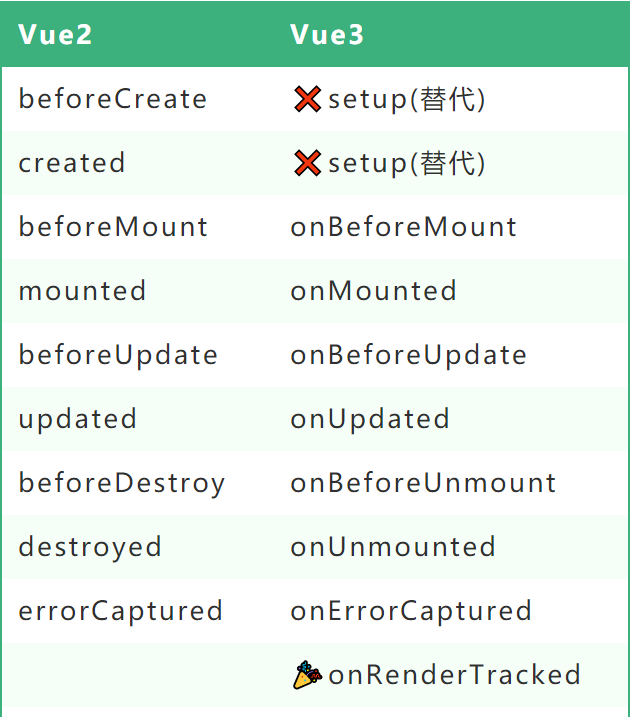
vue3中的基本语法
目录 基础素材 vue3的优化 使用CompositionAPI理由 1. reactive() 函数 2. ref() 函数 2.1. ref的使用 2.2. 在 reactive 对象中访问 ref 创建的响应式数据 3. isRef() 函数 4. toRefs() 函数 5. computed() 5.1. 通过 set()、get()方法创建一个可读可写的计算属性 …...

Timeplus-proton流处理器调研
概念 Timeplus是一个流处理器。它提供强大的端到端功能,利用开源流引擎Proton来帮助数据团队快速直观地处理流数据和历史数据,可供各种规模和行业的组织使用。它使数据工程师和平台工程师能够使用 SQL 释放流数据价值。 Timeplus 控制台可以轻松连接到不…...
H3C防火墙安全授权导入
一、防火墙授权概述 前面我们已经了解了一些防火墙的基本概念,有讲过防火墙除了一些基本功能,还有一些高级安全防护,但是这些功能需要另外独立授权,不影响基本使用。这里以H3C防火墙为例进行大概了解下。 正常情况下,防…...

使用 OpenCV 通过 SIFT 算法进行对象跟踪
本文介绍如何使用 SIFT 算法跟踪对象 在当今世界,当涉及到对象检测和跟踪时,深度学习模型是最常用的,但有时传统的计算机视觉技术也可能有效。在本文中,我将尝试使用 SIFT 算法创建一个对象跟踪器。 为什么人们会选择使用传统的计…...

SHELL 脚本: 导出NEO4j DUMP并上传SFTP
前提 开通sftp账号 安装expect 示例 NEO4J_HOME/path/to/neo4j # neo4j 安装目录 DUMP_PATH/data/dump # DUMP本地保存目录 DUMP_FILEneo4j_$(date %F).dump #导出文件名称 UPLOAD_DIR/path/to/stfp/dump/ #上传目录 $NEO4J_HOME/bin/neo4j-admin dump --databaseneo4j --t…...

Vue 封装一个函数,小球原始高度不固定,弹起比例不固定、计算谈几次后,高度低于1米
## 简介 本文将介绍如何使用Vue封装一个函数,计算小球弹跳的次数,直到高度低于1米。函数的参数包括小球的原始高度和弹起比例。通过代码案例演示了如何使用Vue进行封装和调用。 ## 函数封装 vue <template> <div> <label for&qu…...

外地人能申请天津公租房吗?2024天津积分落户租房积分怎么加?
相关推荐:在天津工作的外地人可以申请天津公共租赁住房吗? 外地人可以申请天津公共租赁住房吗? 2024年定居天津租房如何加分? 根据《天津居住证积分指标及积分表》的规定,在天津租房也可以参加积分结算,每…...
)
毕业设计——基于springboot的聊天系统设计与实现(服务端 + 客户端 + web端)
整个工程包含三个部分: 1、聊天服务器 聊天服务器的职责一句话解释:负责接收所有用户发送的消息,并将消息转发给目标用户。 聊天服务器没有任何界面,但是却是IM中最重要的角色,为表达敬意,必须要给它放个…...

公告栏功能:自动弹出提醒,重要通知不再错过
发布查询时,您是否遇到这样的困扰: 1、查询发布时间未到,学生进入查询主页后发现未发布任何查询,不断进行咨询。 2、有些重要事项需要进入查询主页就进行强提醒,确保人人可见,用户需要反馈“我知道了”才能…...

阅读量优化的五个关键动作
别把阅读量当成玄学你可能每天盯着后台数据,看着那点可怜的阅读数发愁。其实,阅读量优化不是靠运气,也不是靠堆关键词,而是有迹可循的系统动作。很多人误以为只要内容“好”,自然有人看——但现实是,再好的…...

别再死记公式了!用Python+Matplotlib亲手画串联谐振曲线,理解幅频与相频特性
用Python动态绘制串联谐振曲线:从理论到可视化的工程实践 在电子工程和通信领域,串联谐振回路是一个既基础又关键的概念。传统教材往往通过复杂的公式推导来讲解谐振特性,但对于初学者而言,这些抽象数学表达式很难形成直观理解。今…...

告别‘哑巴’老车机:实测大众宝来/迈腾RCD300加装蓝牙音乐模块最全避坑指南
大众宝来/迈腾RCD300蓝牙音乐改装实战手册 老款大众车主的福音来了——无需更换原车主机,只需加装蓝牙模块,就能让RCD300这类"古董"车机秒变智能音乐终端。作为一位经历过三次改装失败才摸清门路的车主,我将用最直白的语言拆解整个…...

从加权平均到多项式拟合:局部加权回归的进阶之路
1. 从加权平均到局部回归:理解核平滑的本质 我第一次接触核平滑方法时,被它优雅的数学形式深深吸引。想象你是一位气象学家,手头有一堆散乱的气温观测数据,想要绘制一条平滑的气温变化曲线。传统方法可能会对所有数据点一视同仁&a…...

MacType深度解析:Windows字体渲染优化技术实现
MacType深度解析:Windows字体渲染优化技术实现 【免费下载链接】mactype Better font rendering for Windows. 项目地址: https://gitcode.com/gh_mirrors/ma/mactype Windows系统字体渲染模糊、边缘锯齿问题长期困扰着技术用户和设计师群体,MacT…...

LLM系列:1.python入门:10.函数
函数 一.函数基础 1. def - 定义与封装函数 作用:定义一个自定义函数,封装特定的处理逻辑。函数体内最终返回(return)的不是局部变量本身,而是局部变量指代的对象。 def function_name(param1, param2):""&q…...

前端 PDF 导出:从文件流下载到自动分页
🧑💻 写在开头 点赞 收藏 学会🤣🤣🤣 在工作中,我们经常会遇到需要生成 PDF 的业务,比如合同、报告等。 前后端合作 对于前端来说,最省事的就是后端生成 PDF 文件,前…...
选型与验收避坑指南)
从图纸到台架:一份给电机工程师的旋变(旋转变压器)选型与验收避坑指南
从图纸到台架:电机工程师的旋变选型与验收全流程实战指南 旋转变压器作为永磁同步电机的"神经末梢",其性能直接决定了整个电驱系统的控制精度与可靠性。在电动汽车三合一电驱系统开发中,我们常遇到这样的困境:实验室表现…...

Android13 Launcher3自定义Workspace网格布局与图标间距实战
1. 理解Launcher3的Workspace布局机制 在Android系统中,Launcher3是负责管理桌面、应用抽屉和快捷栏的核心组件。Workspace作为Launcher3的关键部分,决定了应用图标、文件夹和小工具的排列方式。Android13对Launcher3的架构做了进一步优化,使…...
)
TI盘古开发板+蓝牙模块:手把手教你实现无人机与消防小车的空地协同通信(附完整代码)
TI盘古开发板与蓝牙模块实战:空地协同通信系统开发全解析 1. 空地协同系统架构设计 在智能消防、农业巡检和工业监测等领域,无人机与地面设备的协同作业正成为技术热点。这套系统的核心在于建立稳定可靠的通信链路,实现实时数据交换与任务协…...