Bert-as-service 实战
参考:bert-as-service 详细使用指南写给初学者-CSDN博客
GitHub - ymcui/Chinese-BERT-wwm: Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型)
下载:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
bert base chinese
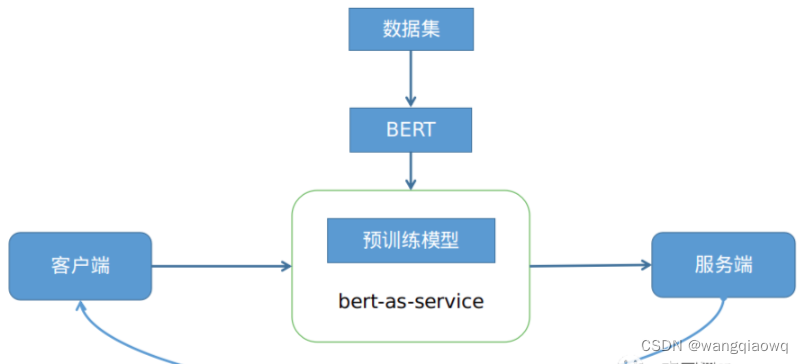
首先讲了下学习bert-as-service的起因,因为实际业务中需要使用bert做线上化文本推理服务,所以经过调研选择bert-as-service开源项目;然后从理论的角度详解了bert-as-service,很纯粹的输入一条文本数据,返回对应的embedding表示。
参考:https://zhuanlan.zhihu.com/p/156941424
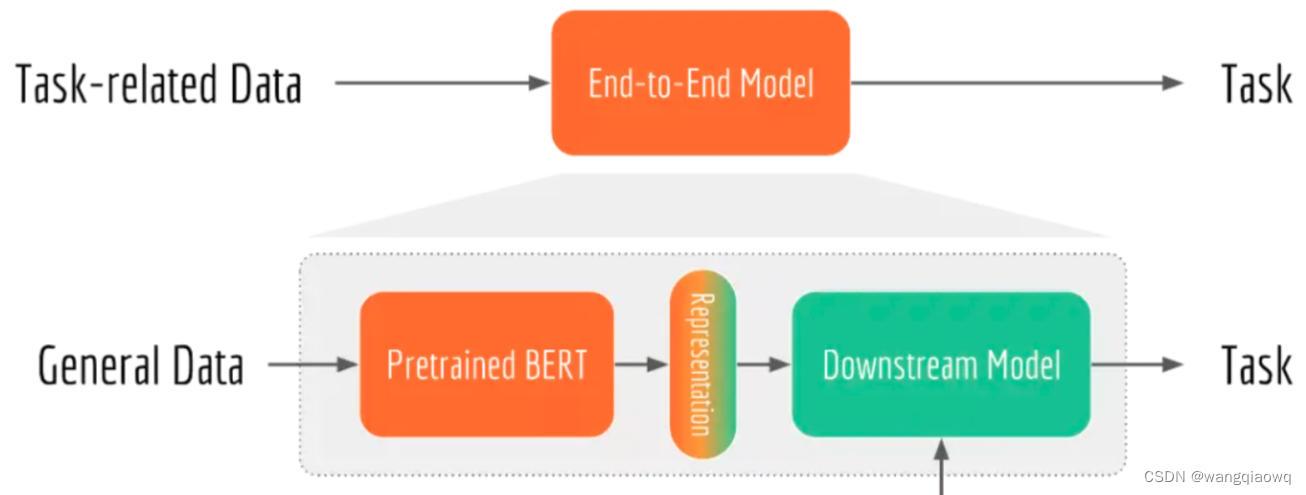
bert-as-service开源项目为我们提供线上的文本分类服务,所以一些基础的bert知识必不可少。
BERT这种预训练+微调两阶段模型和端到端模型的区别。
端到端模型就是使用任务相关的数据训练一个模型完成对应的任务。
而BERT这种两阶段模型属于迁移学习的范畴。
预训练阶段是通过无监督学习的方式学习海量的文本数据从而获得语言学知识;
而微调阶段则是利用预训练阶段学习到的语言学知识结合任务相关的数据去做不同的NLP任务。
预训练阶段因为要从海量的文本数据中学习语言学知识,所以需要大量的时间和计算资源。
虽然预训练阶段耗时耗资源,但是可以理解为一次性的。谷歌使用4-16个TPU花费4天才完成预训练模型。
计算机学习到了这些语言学知识后可以将这些“知识”以模型的方式存储起来,然后其他人可以直接使用这个模型结合各自的需求微调模型完成各自下游的任务。
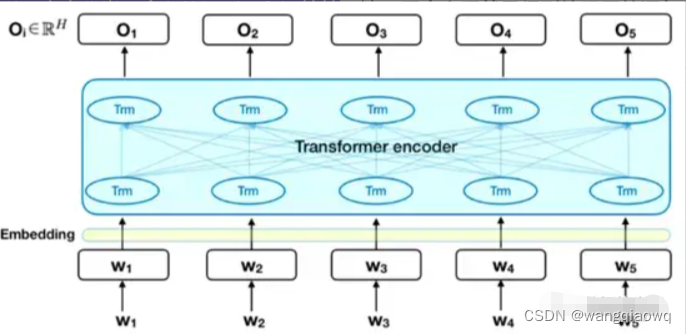
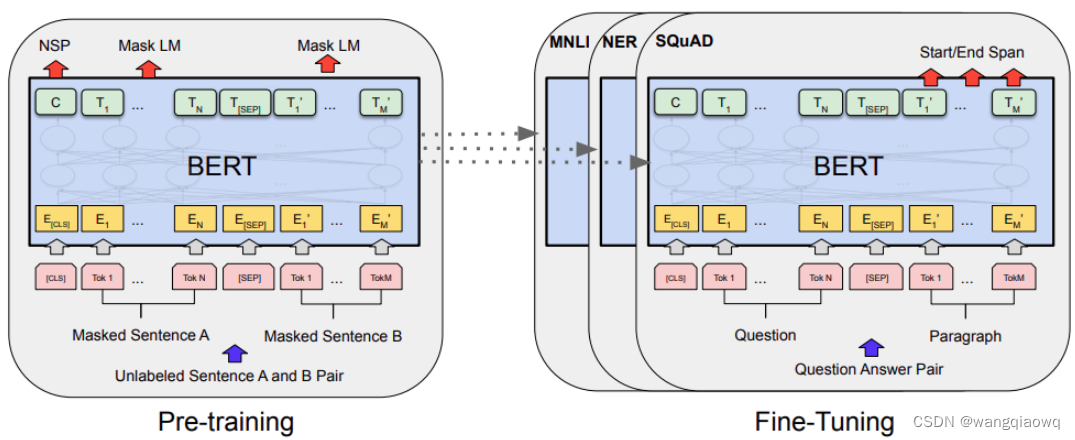
2. BERT模型
BERT模型由输入层embedding、编码层Transformer encoder和输出层三部分组成。
输入层将文本数据转化为词编码、句子对关系编码和位置编码三层embedding
编码层使用Transformer作为特征抽取器来获取文本语句的embedding表示
输出层则是根据下游的NLP任务来输出你想要的结果,可以是文本分类、命名体识别、翻译等等
主要是使用BERT模型来对用户搜索query和浏览资讯news等文本数据进行文本分类
离线文本分类服务
在线文本分类服务
bert-as-service简单来说就是通过Tensorflow和ZeroMQ来提供BERT线上化服务从而获取语句的embedding向量。
2. 获得有效的embedding向量表示
Max Pooling(最大池化)和Average Pooling(平均池化)是卷积神经网络(CNN)中两种常用的下采样(subsampling)方法,它们都属于池化操作,用于减少输入数据的空间维度(如图像的高度和宽度),同时保留关键的特征信息。
-
Max Pooling:
- 在一个池化窗口(例如2x2)内,Max Pooling会选择该窗口内所有元素的最大值作为输出。这样做的好处是可以突出重要的局部特征,比如在识别物体时可能特别关注对象边缘或最显著的特征点。
- Max Pooling对于输入中的噪声具有一定的鲁棒性,因为它只传递每个区域的最大响应,从而对微小变化不敏感。
- 由于它选择的是最大激活值,因此能够捕获到强烈、独特的特征信号,有助于提高模型的泛化能力。
-
Average Pooling:
- Average Pooling则是计算池化窗口内所有元素的平均值作为输出。
- 相比于Max Pooling,Average Pooling更侧重于保留整个区域的统计特性,而不是仅仅关注最大响应。这使得它能提供更加平滑的输出特征图,可能更有利于表达图像的全局信息或者背景信息。
- 在某些场景下,Average Pooling可以降低由于个别极端值造成的偏差,并且其运算相对于Max Pooling更为稳定。
使用场景:
-
Max Pooling通常用在需要强调局部最大特征或者对噪声有较强抵抗力的场合,特别是在图像分类、目标检测等任务中被广泛采用。
-
Average Pooling则更多地应用于那些希望保持整体特征强度均衡的任务,或者当模型设计者想要避免过度重视单个最大响应时。例如,在DenseNet架构中,模块间的连接常采用Average Pooling来保持信息的有效传递。
此外,近年来还有其他形式的池化层出现,如Global Average Pooling,它在ResNet、Inception等现代网络结构的末尾经常被用来将整个特征图的尺寸压缩为一维向量,直接与全连接层进行对接,从而减少参数数量并增强模型的稳健性。
2W条资讯数据主要分成四类。整体来看,不同的pooling方式得到的embedding表示结果有一定差异。同时,查看各自的pooling方式下相邻层之间的embedding表示类似;第一层和最后一层的embedding表示差距很大;最后一层embedding的表示最接近词编码,能最好的保留初始的词语信息。
3. 解耦bert模型和下游网络
Bert-as-service项目将bert预训练网络和下游网络解耦。将bert预训练网络放在配置GPU资源的服务端,同时服务多用户;下游网络一般是简单的轻量级模型,不需要复杂的深度学习库,放在CPU或者手机终端上使用。
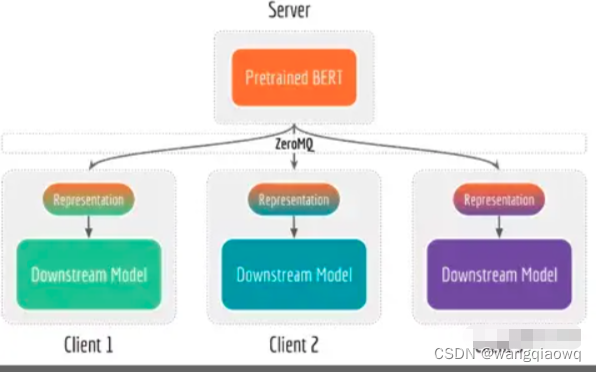
通过解耦bert模型和下游网络,当特征提取成为瓶颈时可以通过使用或者增加GPU资源来优化服务端,同理当下游网络成为瓶颈时可以添加CPU或者量化操作来优化客户端。当训练数据没有更新或者定义发生变化时只需在服务端重新训练BERT模型即可满足下游网络获取更新后的特征向量。这种请求汇集在一个地方的方法可以使服务端的GPU利用率大大提高。
5. 降低线上服务内存占用
Bert-as-service项目只需要在第一次收到新请求时生成一个新的BERT模型,后续只需要在事件循环中监听请求并提供服务即可。
6. 高可用的服务方式
当服务端收到多个客户端的请求后,主要通过ventilator组件来进行批处理调度和负载均衡。当收到多个客户端请求后,ventilator首先会将这些请求划分成多个小任务,然后将这些小任务分别发送给工人们。工人们收到这些小任务后开始工作,工作内容就是使用bert进行预测,预测完之后会将结果统一发送给sink组件。sink组件会将所有工人的预测结果统一装配,同时检查ventilator组件中各个客户端请求的完整性,如果某个客户端请求的数据已经全部预测完成了,那么就返回预测结果给对应的客户端完成本次请求。通过这种方式,可以轻松解决上面小任务调度体验问题。
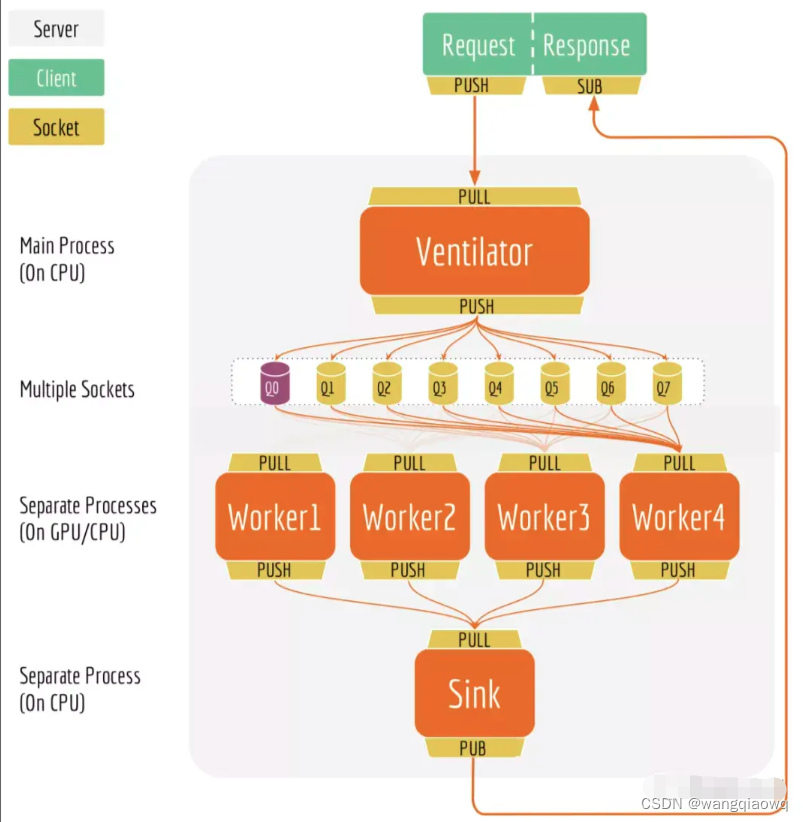
模型角度分析了不同的pooling策略对embedding向量的影响。通过解耦bert和下游网络、提供快速的预测服务、降低线上服务内存占用和高可用的服务方式,bert-as-service可以又快又好的提供线上推理服务。
实战bert-as-service
bert-serving-start -model_dir/tmp/english_L-12_H-768_A-12/ -num_worker=4
这里有两个参数需要说明下,一个是num_worker,这是分配的worker数目,一般分配的worker数目要少于GPU的颗数;另一个是model_dir,这是预训练模型的地址。
然后通过如下三行代码,我们就能轻松返回语句的embedding表示,简单到没朋友:

咱们就能使用BERT预训练模型得到文本的embedding表示向量。
3. 获取文本分类的结果
上面已经得到BERT模型最重要的encodding编码向量。实际业务中我们是文本分类任务,其实就是添加了一层全连接层的一个微调的模型。通过如下命令即可实现bert-as-service项目用于文本分类任务:
对于文本分类任务,一个句子中的N个字符对应了E_1,…,E_N,这N个embedding。文本分类实际上是将BERT得到的T_1这一层连接上一个全连接层进行多分类。
https://kexue.fm/archives/6736
Tokenizer(分词器/符化器)是自然语言处理(NLP)领域中用于文本预处理的核心组件。它的主要功能是对输入的自然语言文本进行切分,将连续的字符流转换成一系列离散的单元或标记(tokens)。这些标记可以是单词、子词、字符或其他有意义的语言单位,具体取决于tokenizer的设计和应用需求。
在不同的NLP任务中,tokenizer的选择和配置至关重要,因为它直接影响到模型对输入数据的理解程度。例如:
- 单词级分词:将文本分割成单个单词作为token,适用于英语等空格分隔语言。
- 字符级分词:将文本中的每个字符都视为一个独立的token,对于处理拼写错误、新词发现等问题特别有用。
- 子词级分词(如BPE, WordPiece):结合了单词和字符的优点,通过学习数据集中的高频子序列来生成tokens,常用于深度学习模型以应对OOV(Out-Of-Vocabulary)问题。
在现代NLP库中,如Hugging Face Transformers库提供的BertTokenizer等工具,不仅能够完成基本的分词工作,还能负责后续的转换步骤,如将tokens映射为唯一数字ID(词汇表索引)、添加特殊符号表示句子开始与结束等上下文信息,并支持对文本进行编码和解码操作,以便于神经网络模型的训练和推理。
在Keras中使用BERT进行文本分类是一个非常流行且效果通常较好的选择。BERT(Bidirectional Encoder Representations from Transformers)模型预训练了大规模的语料库,可以捕获文本中的深层次上下文信息,这使得它在多种NLP任务上,包括文本分类,都取得了非常好的性能。
Keras-BERT是基于Keras框架实现BERT模型的一个封装库,它可以简化在Keras环境中加载和微调BERT模型的过程。如果你的数据集不是特别大,并且有足够的计算资源(GPU),尤其是对于处理多类别文本分类问题时,Keras-BERT是一个不错的选择,因为它能够利用预训练好的语言模型来快速构建高质量的文本分类器。
然而,在实际应用中,选择哪个模型取决于多个因素:
- 数据量:小到中等规模数据集可能受益于BERT的预训练知识转移;但如果数据量极大,则可能需要考虑更轻量级或自定义的模型。
- 计算资源限制:BERT模型计算复杂度较高,对于硬件资源有限的情况,可能会考虑FastText、TextCNN、LSTM等较为轻量级的模型。
- 任务特定性:如果任务具有特定领域特性或者对速度有极高要求,可能需要针对特定场景定制模型或者寻找针对资源受限环境优化的预训练模型,如VAMPIRE或其他轻量级BERT变体(例如DistilBERT)。
- 模型复杂性与解释性需求:有时用户可能需要更容易解释的模型输出,而非最顶级的预测性能。
总之,Keras-BERT在许多情况下都是一个很好的起点,但务必根据具体项目需求权衡模型性能、计算成本以及可解释性等因素来做出最终决定。
当然,除了Keras-BERT之外,针对文本分类任务还有许多其他模型可以选择。以下是一些常见的深度学习模型:
-
卷积神经网络(CNN):例如TextCNN、Kim CNN等,利用卷积层提取局部特征,适用于捕捉文本中的n-gram特征。
-
循环神经网络(RNN)和长短时记忆网络(LSTM):通过处理序列数据来理解文本的上下文信息。可以尝试双向LSTM以获取前后文信息。
-
门控循环单元(GRU):作为RNN的一种变体,它在一定程度上简化了LSTM结构,但仍能较好地捕捉时间序列数据的长期依赖关系。
-
Transformer架构:
- BERT 的变种或优化版本:如DistilBERT、RoBERTa、ALBERT等,它们在保持一定性能的同时降低了计算复杂度。
- GPT系列:虽然GPT更多用于生成任务,但在某些情况下也可以进行微调以适应文本分类任务。
- XLNet 和 T5 等也属于Transformer家族,且在很多NLP任务中表现出色。
-
简单线性模型与集成方法:
- Logistic Regression配合TF-IDF或词嵌入表示可以实现基础但高效的文本分类器。
- 集成方法如随机森林(Random Forest)、梯度提升决策树(GBDT)结合文本特征也能获得不错的效果。
-
轻量级模型:
- FastText:Facebook提出的模型,其基于词袋模型和子词的信息构建,对计算资源需求相对较小。
每种模型都有其优势和适用场景,具体选择应根据项目的实际需求(如性能要求、资源限制、领域特性等)来进行权衡。
中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类
参考:keras BERT
https://github.com/CyberZHG/keras-bert/blob/master/README.zh-CN.md
------------------------------------------------------------------------------------------------------
LSTM做情感分类:

---------------------------------------------------------------------------------------------------------------------------------
双向编码器表示来自变换器(BERT,Bidirectional Encoder Representation from Transformers)
参考 【DSW Gallery】基于EasyNLP的BERT文本分类-阿里云开发者社区 (aliyun.com)
git clone https://github.com/alibaba/EasyNLP.git

python3 setup.py install
cd examples/appzoo_tutorials/sequence_classification/bert_classify wget http://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/classification/train.tsv wget http://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/classification/dev.tsv
训练和测试数据都是以\t隔开的.tsv文件,数据下载完成后,可以通过以下代码查看前5条数据。

在本教程中,我们使用最基础的BERT模型:bert-base-uncased。EasyNLP中集成了丰富的预训练模型库,如果想尝试其他预训练模型,如bert-large、albert等,也可以在user_defined_parameters中进行相应修改,具体的模型名称可见模型列表。
相关文章:
Bert-as-service 实战
参考:bert-as-service 详细使用指南写给初学者-CSDN博客 GitHub - ymcui/Chinese-BERT-wwm: Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型) 下载:https://storage.googleapis.com/bert_models/…...
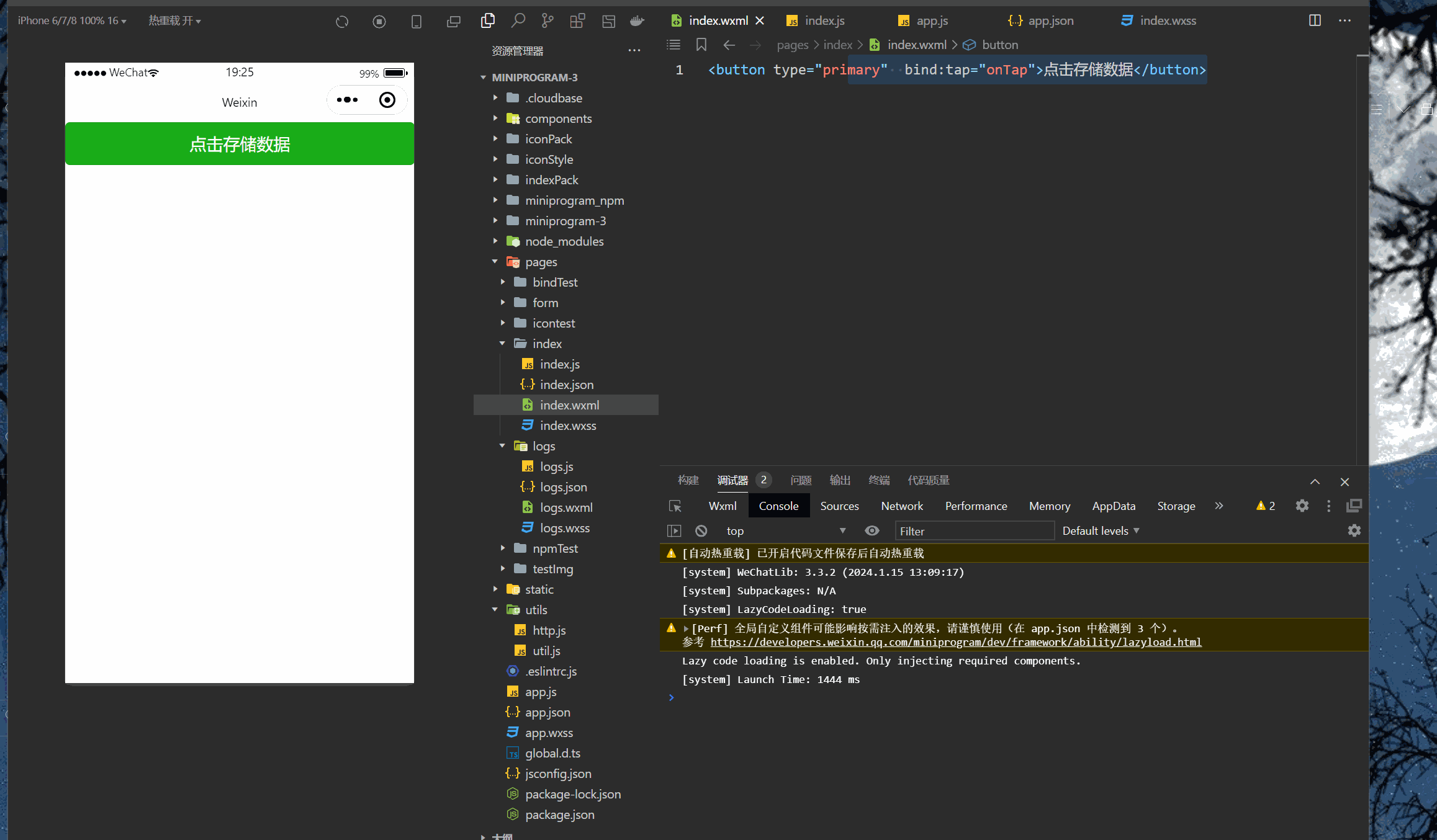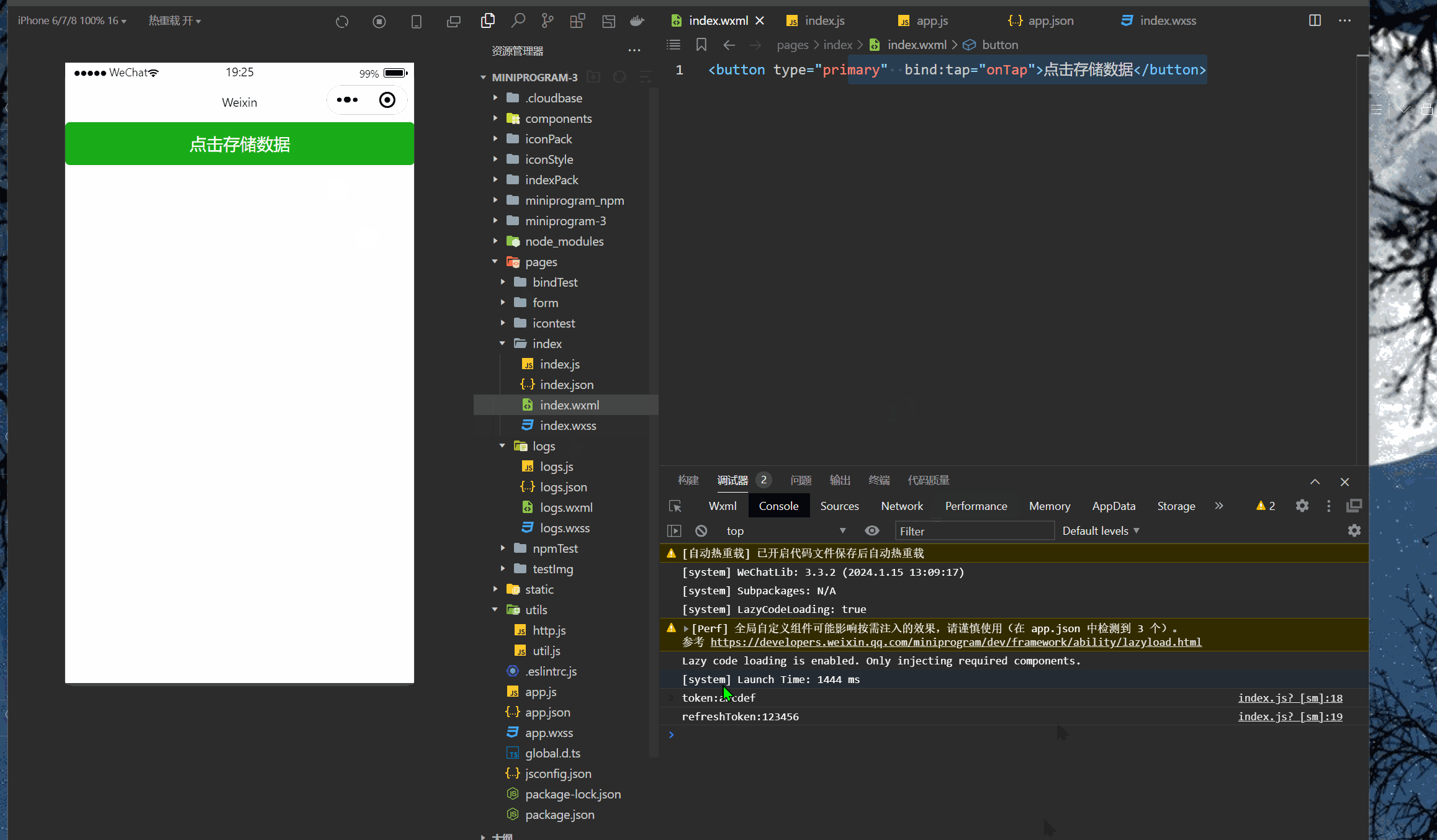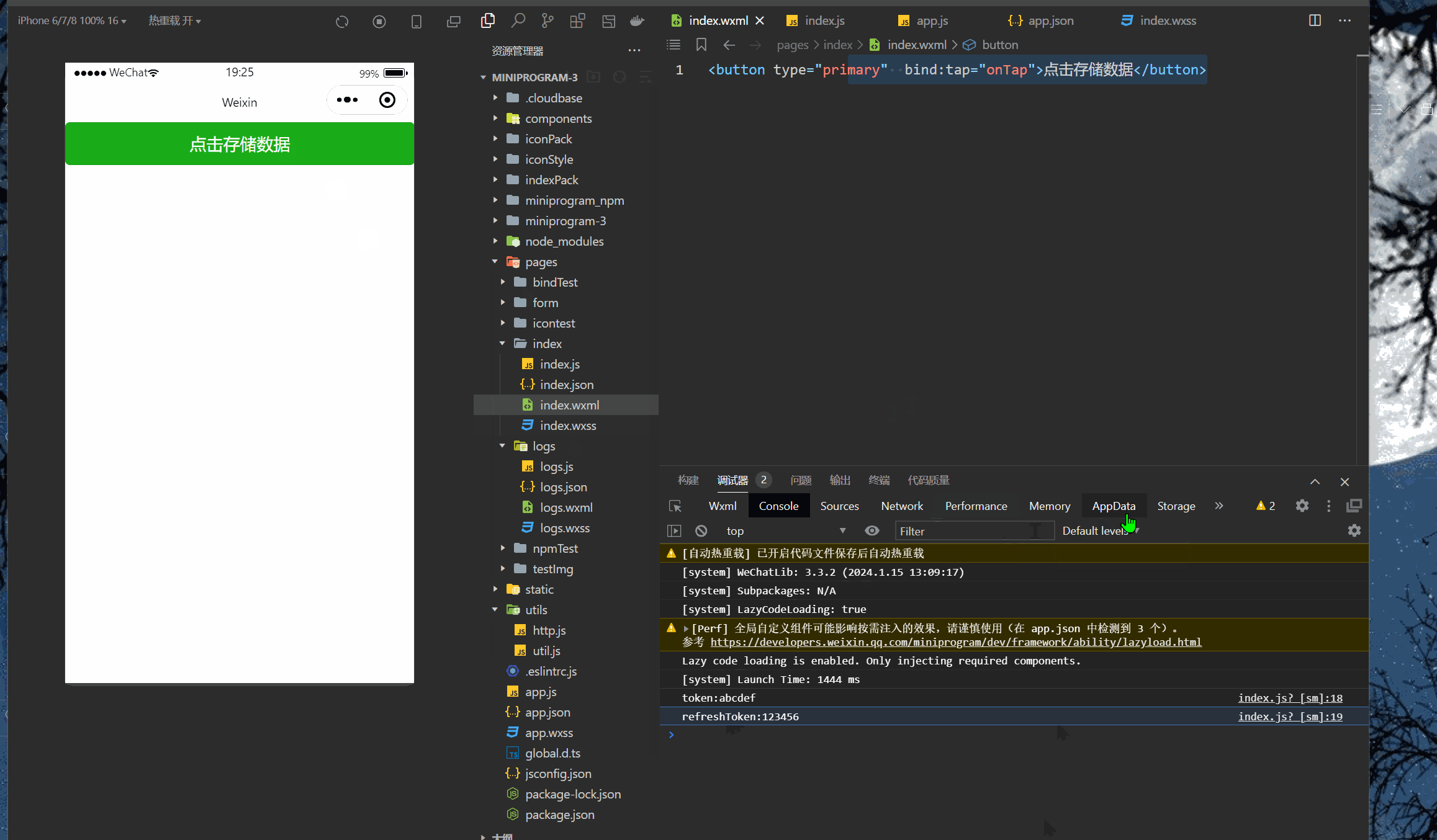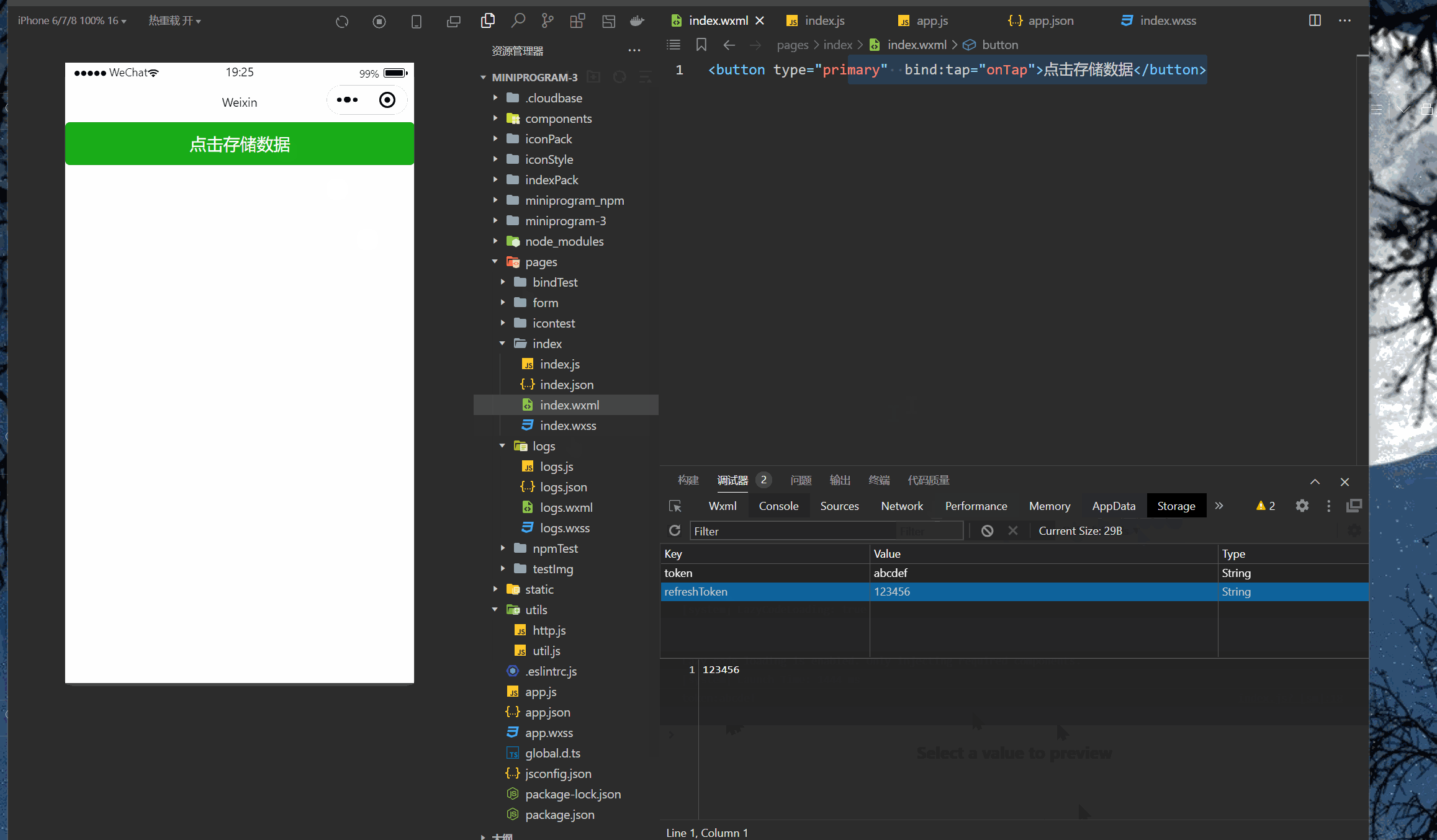
微信小程序(四十七)多个token存储
注释很详细,直接上代码 新增内容: 1.基础存储模板 2.中括号实现变量名匹配 源码: app.js App({//提前声明的变量名token:wx.getStorageSync(toke),refreshToken:wx.getSystemInfoAsync(refreshToken),setToken(key,token){//保存token到全局…...

机器学习(II)--样本不平衡
现实中,样本(类别)样本不平衡(class-imbalance)是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单样本通常是占总交易数量的极少部分,而且对于有些任务而言少数样本更…...

几个好用的 VUE Table
Vue easytable - 功能恰到好处 无学习成本 上手就用Vue good table - UI 清新 功能直给 适合小项目Vxe table - 宝藏级 table 组件 高级功能低调好用 维护频率高tabulator - 元老级 table 组件 高级功能平民化AG Grid - 媲美 Excel 的 Table 组件 能想到的复杂功能它都能做到...
)
Vue源码系列讲解——实例方法篇【三】(生命周期相关方法)
目录 0. 前言 1. vm.$mount 1.1 用法回顾 1.2 内部原理 2. vm.$forceUpdate 2.1 用法回顾 2.2 内部原理 3. vm.$nextTick 3.1 用法回顾 3.2 JS的运行机制 3.3 内部原理 能力检测 执行回调队列 4. vm.$destory 4.1 用法回顾 4.2 内部原理 0. 前言 与生命周期相关…...

百度SEO工具,自动更新网站的工具
在网站SEO的过程中,不断更新网站内容是提升排名和吸引流量的关键之一。而对于大多数网站管理员来说,频繁手动更新文章并进行SEO优化可能会是一项繁琐且耗时的任务。针对这一问题,百度自动更新文章SEO工具应运而生,它能够帮助网站管…...
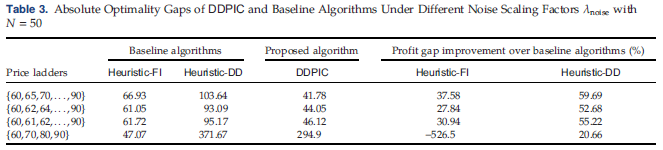
供应链|NUS覃含章MS论文解读:数据驱动下联合定价和库存控制的近似方法 (二)
编者按 本次解读的文章发表于 Management Science,原文信息:Hanzhang Qin, David Simchi-Levi, Li Wang (2022) Data-Driven Approximation Schemes for Joint Pricing and Inventory Control Models. https://doi.org/10.1287/mnsc.2021.4212 文章在数…...

删除有序数组中的重复项Ⅱ
问题 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。 说明…...

Java底层自学大纲_数据结构和算法篇
数据结构和算法专题_自学大纲所属类别学习主题建议课时(h) A 数据结构和算法001 数据结构和算法基础,时间复杂度Ot和空间复杂度Os2.5 A 数据结构和算法002 数学知识回顾-指数、对数、级数、模运算、复杂度2.5 A 数据结构和算法003 高数知识…...
群晖NAS配置WebDav结合内网穿透实现公网访问本地影视资源
文章目录 本教程解决的问题是:按照本教程方法操作后,达到的效果是:1 使用环境要求:2 配置webdav3 测试局域网使用potplayer访问webdav3 内网穿透,映射至公网4 使用固定地址在potplayer访问webdav 国内流媒体平台的内…...

Vue3报错Promise executor functions should not be async.
解决方法 加注释。。。// eslint-disable-next-line no-async-promise-executor // eslint-disable-next-line no-async-promise-executor new Promise<boolean>(async (resolve, reject) > {... }),...
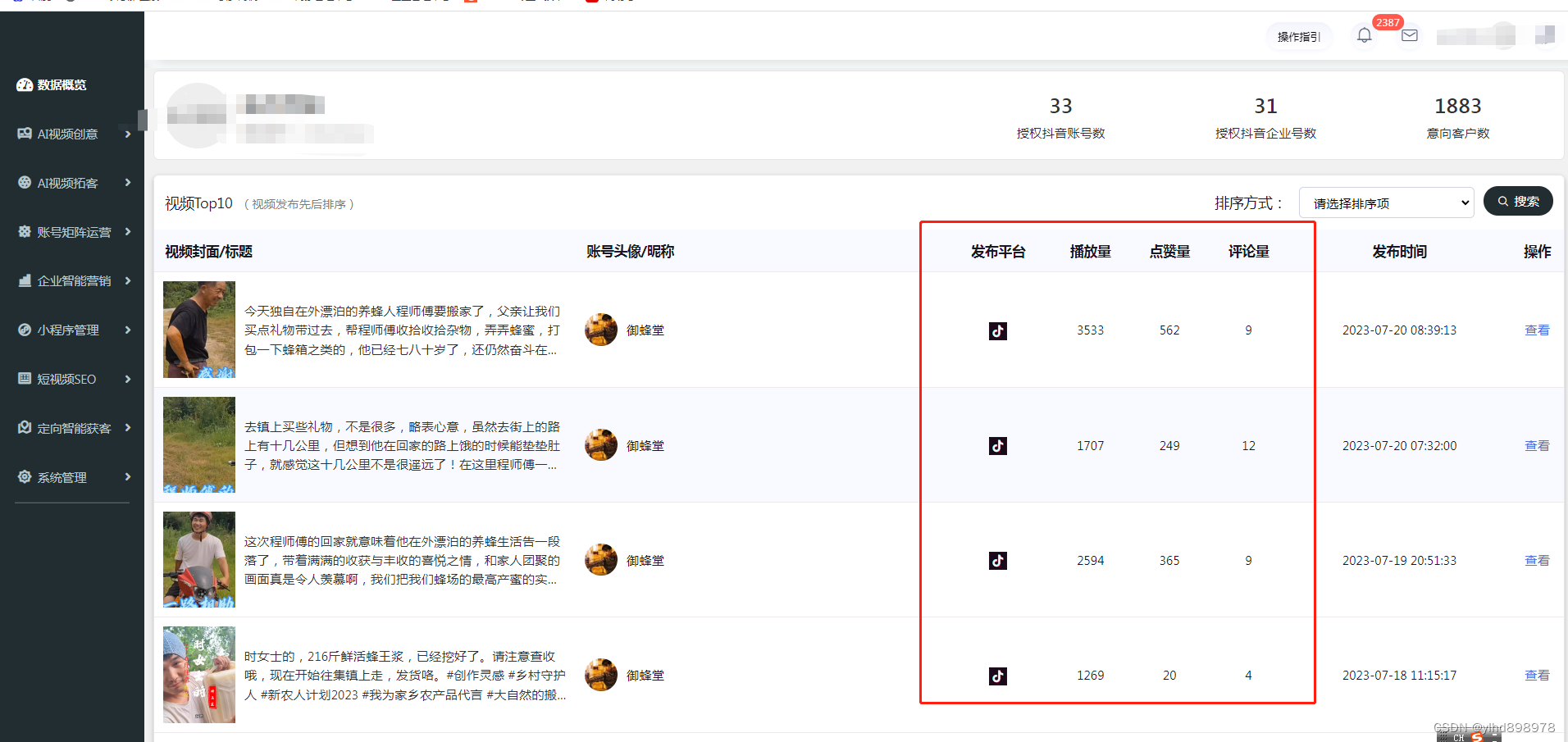
(正规api接口代发布权限)短视频账号矩阵系统实现开发--技术全自动化saas营销链路生态
短视频账号矩阵系统实现开发--技术全自动化saas营销链路生态源头开发(本篇禁止抄袭复刻) 一、短视频矩阵系统开发者架构 云罗短视频矩阵系统saas化系统,开发层将在CAP原则基础上使用分布式架构,对此网站的整体架构采用了基于B/S三层架构模式…...

【Redis】redis通用命令
redis连接命令(客户端) 要在 redis 服务上执行命令需要一个 redis 客户端。Redis 客户端在我们之前安装redis 的src目录下,具体为/usr/local/redis/src。注意此redis实例没有设置密码,如果设置了密码需要先使用命令AUTH执行验证或…...
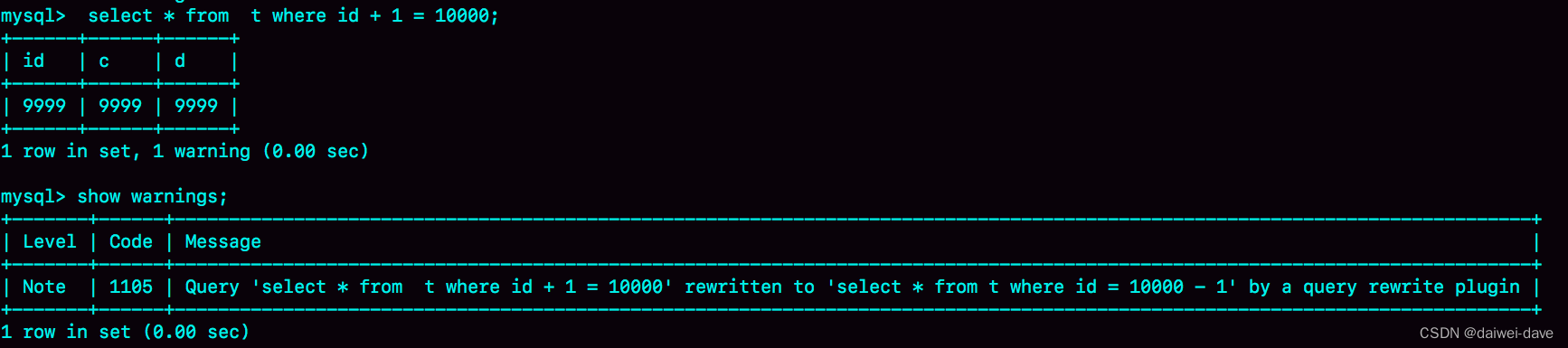
mysql服务治理
一、性能监控指标和解决方案 1.QPS 一台 MySQL 数据库,大致处理能力的极限是,每秒一万条左右的简单 SQL,这里的“简单 SQL”,指的是类似于主键查询这种不需要遍历很多条记录的 SQL。 根据服务器的配置高低,可能低端…...
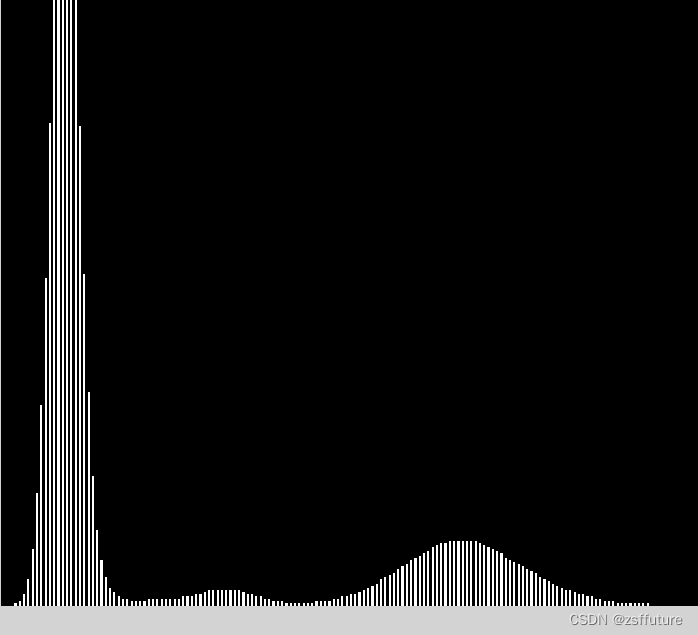
opencv--使用直方图找谷底进行确定分割阈值
直方图原理就不说了,大家自行百度 直方图可以帮助分析图像中的灰度变化,进而帮助确定最优二值化的灰度阈值(threshold level)。如果物体与背景的灰度值对比明显,此时灰度直方图就会包含双峰(bimodal histo…...

dolphinscheduler海豚调度(四)钉钉告警
在之前的博文中,我们已经介绍了DolphinScheduler海豚调度的基本概念和工作流程,以及Shell任务和SQL任务的实践。今天,让我们来学习DolphinScheduler中的另一个重要功能:钉钉告警。 钉钉群添加机器人 在钉钉群添加机器人…...
)
Java-Safe Point(安全点)
虽然安全点的概念和垃圾回收相关,但是概念还是比较独立的,所以本文是从这篇文章Java-虚拟机-垃圾收集器/垃圾收集算法/GCROOT根中抽出来的 安全点safe point 当执行垃圾回收(GC)的时候,不是立马就执行的,…...
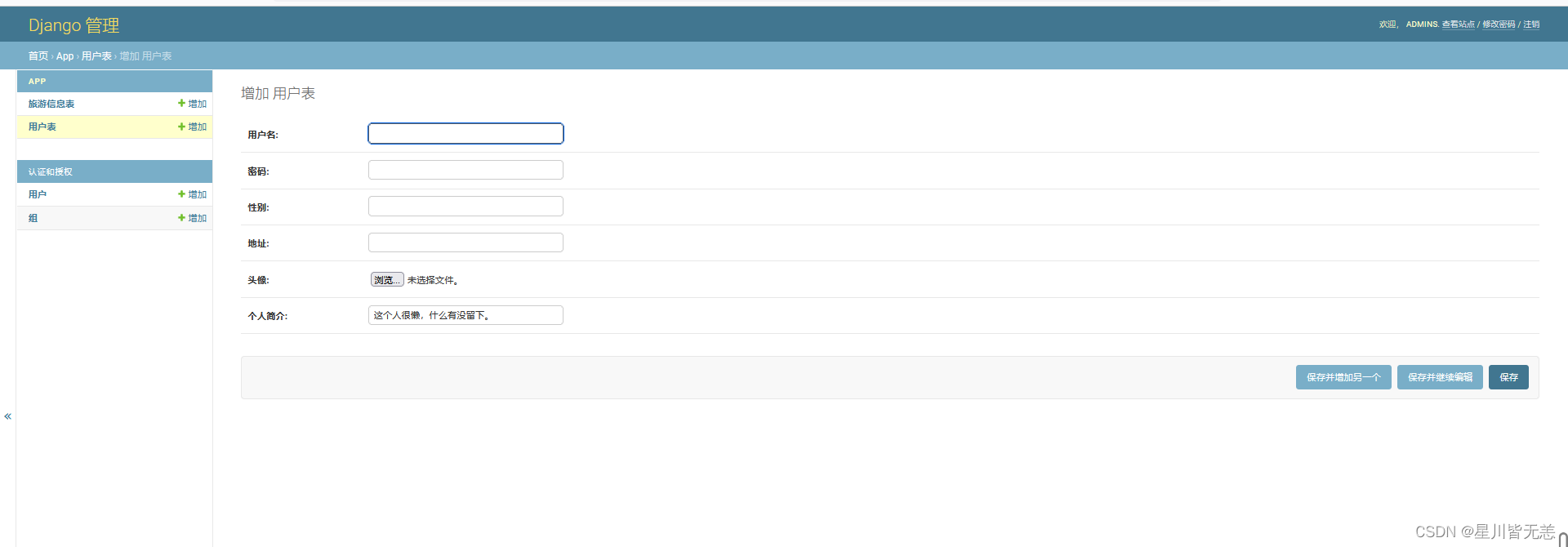
大数据旅游数据分析:基于Python旅游数据采集可视化分析推荐系统
文章目录 基于Python旅游数据采集可视化分析推荐系统一、项目概述二、项目说明三、开发环境四、功能实现五、系统页面实现用户登录注册系统首页数据操作管理价格与销量分析旅游城市和景点等级分析旅游数据评分情况分析旅游数据评论情况分析旅游景点推荐Django系统后台管理 六、…...
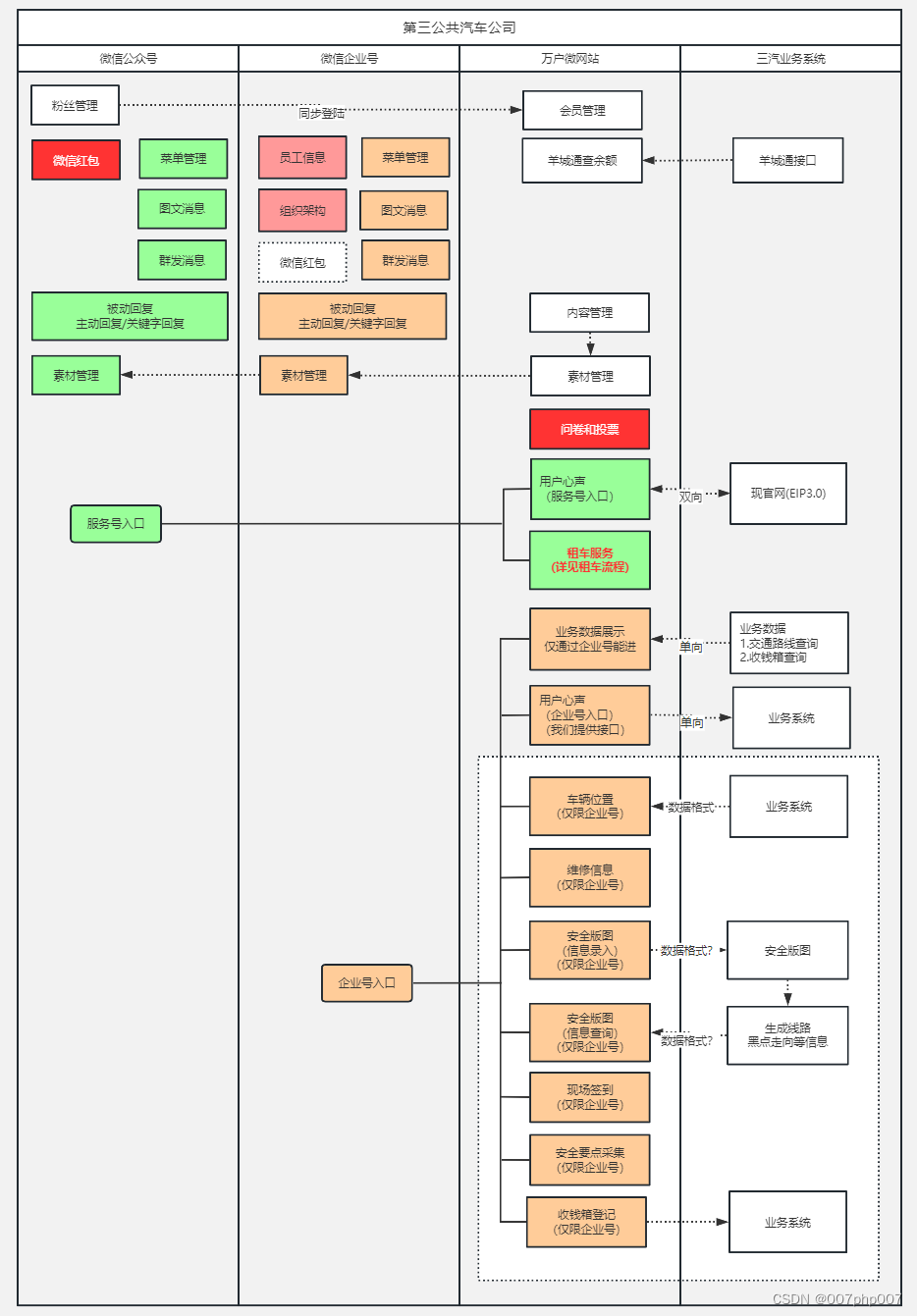
打造智能汽车微服务系统平台:架构的设计与实现
随着智能汽车技术的飞速发展,微服务架构在汽车行业中的应用越来越广泛。采用微服务架构可以使汽车系统更加灵活、可扩展,并且有利于快速推出新功能和服务。本文将从设计原则、关键技术、数据安全等方面,介绍如何搭建智能汽车微服务系统平台架…...

机试指南:Ch5:线性数据结构 Ch6:递归与分治
文章目录 第5章 线性数据结构1.向量 vector2.队列 queue(1)队列的特点、应用(2)基本操作(3)例题例题1:约瑟夫问题2 (难度:中等) (4)习题习题1:排队打饭 (难度:中等) 3.栈 stack(1)栈…...

碳交易机制下需求响应的综合能源系统优化运行策略探索:实现双碳目标的路径与策略分析
碳交易机制下考虑需求响应的综合能源系统优化运行 综合能源系统是实现“双碳”目标的有效途径,为进一步挖掘其需求侧可调节潜力对碳减排的作用,提出了一种碳交易机制下考虑需求响应的综合能源系统优化运行模型。 首先,根据负荷响应特性将需求…...
_kaic)
springboot私家车位共享系统小程序(文档+源码)_kaic
第5章 系统实现 5.1管理员功能模块 管理员登录,管理员通过输入用户名,密码,验证码等信息进入私家车位共享系统,如图5-1所示。 图5-1管理员登录界面图 管理员登录进入私家车位共享系统可以查看首页、轮播图、公告、资源管理&#…...

游戏攻略新闻资讯主题模板源码 YK一点资讯模版 Zblog主题模版
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示一、详细介绍 游戏攻略新闻资讯主题模板源码 YK一点资讯模版 zblog主题模版 YK一点资讯(三栏昼夜自定义布局) 建议直接进入演示站观看效果。非常适合做游戏攻略、新闻资讯、CMS内容管理系统或者图片站等等 自定义布…...

别让Simulink生成的代码拖慢你的嵌入式系统:手把手教你配置这7个关键优化选项
Simulink代码生成优化实战:7个关键配置提升嵌入式系统性能 在资源受限的嵌入式系统中,每一字节的内存和每一个时钟周期都弥足珍贵。作为汽车电子和工业控制领域的工程师,我们常常面临这样的困境:Simulink模型在仿真阶段运行流畅&a…...

为什么选择Apache Camel:企业级集成框架的10大优势解析
为什么选择Apache Camel:企业级集成框架的10大优势解析 【免费下载链接】camel Apache Camel is an open source integration framework that empowers you to quickly and easily integrate various systems consuming or producing data. 项目地址: https://git…...

Kindle电子书封面修复终极指南:一键解决Kindle封面损坏问题
Kindle电子书封面修复终极指南:一键解决Kindle封面损坏问题 【免费下载链接】Fix-Kindle-Ebook-Cover A tool to fix damaged cover of Kindle ebook. 项目地址: https://gitcode.com/gh_mirrors/fi/Fix-Kindle-Ebook-Cover Fix-Kindle-Ebook-Cover是一款专门…...
的完整流程与命令)
STATA实证分析:手把手教你搞定工具变量回归(IV估计)的完整流程与命令
STATA实证分析:工具变量回归(IV估计)的保姆级实战指南 经济学研究中,内生性问题就像房间里的大象——人人都知道它存在,却常常选择视而不见。记得我第一篇投稿被拒时,审稿人那句"请考虑内生性问题的潜…...

北斗导航 | 常见GNSS数据处理工具
文章目录 1.ANUBIS 2.RTKLIB 3.BKG NTRIP Client (BNC) 4.TEQC 5.GFZRNX 6.RINGO 7.FAST 8.Inertial Explorer 涵盖功能、适用场景及优缺点: 1.ANUBIS 功能:支持多系统(GPS/BDS/Glonass/Galileo)数据质量分析,涵盖数据完整率、多路径误差、信噪比、周跳检测等,兼容RINE…...

你的微信聊天记录值得永久珍藏吗?WeChatMsg开源工具实现数据自主管理
你的微信聊天记录值得永久珍藏吗?WeChatMsg开源工具实现数据自主管理 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Tre…...

保姆级教程:用VSCode快速定位并修改openai库的代理配置,解决GPT-3.5/4 API连接超时
VSCode高效调试:解决OpenAI API连接超时的工程化实践 当你在VSCode中运行OpenAI API调用代码时,控制台突然抛出"Request timed out"错误——这种场景对现代开发者来说再熟悉不过。不同于简单粗暴地修改系统代理设置,本文将带你用工…...