在OceanBase使用中,如何优化因Join估算不准导致执行计划选错的问题
作者:胡呈清,爱可生公司旗下的DBA团队成员,擅长故障分析和性能优化。爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。本文约 1600 字,预计阅读需要 15 分钟。
数据库版本:OceanBase3.2.3.3
案例问题的描述
在关联字段包含组合主键的第1、2、4个字段的一个join查询中。如果执行Nested-Loop Join ,由于被驱动表仅匹配主键的第一、二个字段,虽然成本 cost1 较低,但实际效率不高。此外,驱动表的扇出 n(即输出行数)的估算值远小于实际值。在计算总成本时:
Join 总成本 ≈(驱动表成本 + n*cost1)
在本文所举的例子中,驱动表的成本是不变的,执行计划中 n 的估算值为 5000,但实际值为 60 万,cost1=154。n*cost1 在计算成本时远小于实际值。因此,优化器基于低估的n值选择了 Nested-Loop Join,由于被驱动表只能匹配主键的前两个字段,效率较低,导致整个查询时间耗费较多,但如果被驱动表能匹配主键的全部字段,效率会很高。
分析过程
1. 分析执行计划
问题 SQL 如下(执行耗时 500s+):
selectcount(*) from (SELECTJGBM AS QYDJID,SEGMENT3 AS FNUMBER,PERIOD_NAME AS SSQJ,...FROM(SELECT...FROMDC_ACCOUNTBALANCE_TEMP A,DEF_ACCOUNTCONFIG B,DC_ACCOUNT C,NVAT_ACCANDTAXIDMAPFORP07 D,BI_CHOICEOFUNIT EWHEREA.SEGMENT1 = D.ZTJGBMAND D.SBDWID = E.SBDWIDAND B.JGBM = E.DEPTCODEAND B.YXQSNY <= (substr(A.PERIOD_NAME, 4, 6) || substr(A.PERIOD_NAME, 1, 2))AND (substr(A.PERIOD_NAME, 4, 6) || substr(A.PERIOD_NAME, 1, 2)) <= B.YXJZNYAND C.QYDJID = B.SYZTAND C.FNUMBER = A.SEGMENT3AND C.ACCOUNTYEAR = substr(A.PERIOD_NAME, 4, 6)AND a.period_name = '10-2023') SUBGROUP BYJGBM,SEGMENT3,PERIOD_NAME ) X left join DC_ACCOUNTBALANCE A ON (A.SSQJ = X.SSQJAND A.QYDJID = X.QYDJIDAND A.FNUMBER = X.FNUMBER );执行计划如下(多余信息已删除),结合 SQL 内容进行解读:
- X 表是 A、B、C、D、E 等 5 张表关联的结果,然后与 A 表进行关联查询。从执行计划看,主要成本在 X 表,因此先执行 X 部分确认是否慢在这部分,执行耗时只要 5 秒,结果有 61 万行,但执行计划中估行只有 5123。
- X 部分很快,慢在 A 部分,因为是 Nested-Loop Join,A 作为被驱动表会循环查询 61万次(batch_join=false),每次查询走主键,执行计划13号算子中 range_key([A.SSQJ(0x7eb5a42ec400)], [A.QYDJID(0x7eb5a42ed840)], [A.DATAUSE(0x7ec8f84434e0)], [A.FNUMBER(0x7eb5a42eec80)]), range(MIN ; MAX) 部分信息说明索引里有 4个字段,但是range_cond([A.SSQJ(0x7eb5a42ec400) = ?(0x7ec8f8451e20)], [A.QYDJID(0x7eb5a42ed840) = ?(0x7ec8f8452950)])这部分表示只能用到索引的前两个字段,这会是慢的原因吗?有个信息可以提供佐证:A:table_rows:32310843, physical_range_rows:391, logical_range_rows:391 优化器估算A表每次查询需要扫描 391 行,这个效率确实是不高的。
- 在估算 Nested-Loop Join 的总成本时,计算逻辑是驱动表的成本+驱动表的扇出*\被驱动表查询一次的成本,这个 SQL 中驱动表的扇出(5123)比实际值(61 万)小很多,估算出的总成本比实际小很多。
================================================================================= |ID|OPERATOR |NAME |EST. ROWS|COST | --------------------------------------------------------------------------------- |0 |SCALAR GROUP BY | |1 |3947739| |1 | NESTED-LOOP OUTER JOIN| |5123 |3947543| |2 | SUBPLAN SCAN |X |5123 |3154937| |3 | HASH GROUP BY | |5123 |3154861| |4 | HASH JOIN | |5123 |3149203| |5 | TABLE SCAN |C |81314 |31453 | |6 | HASH JOIN | |63573 |2940900| |7 | HASH JOIN | |1898 |35447 | |8 | TABLE SCAN |D(IDX_ACCANDTAXIDMAPFORP07_CMB1) |2011 |778 | |9 | HASH JOIN | |1736 |32462 | |10| TABLE SCAN |E(IDX_BI_CHOICEOFUNIT_CMB1) |1704 |660 | |11| TABLE SCAN |B |29154 |11277 | |12| TABLE SCAN |A(IDX_DC_ACCOUNTBALANCE_TEMP_TEST)|639387 |2468263| |13| TABLE SCAN |A |1 |154 | =================================================================================Outputs & filters: -------------------------------------...13 - output([remove_const(1)(0x7ec8f846ba40)]), filter([A.FNUMBER(0x7eb5a42eec80) = ?(0x7ec8f8453480)]), access([A.FNUMBER(0x7eb5a42eec80)]), partitions(p0), is_index_back=false, filter_before_indexback[false], range_key([A.SSQJ(0x7eb5a42ec400)], [A.QYDJID(0x7eb5a42ed840)], [A.DATAUSE(0x7ec8f84434e0)], [A.FNUMBER(0x7eb5a42eec80)]), range(MIN ; MAX), range_cond([A.SSQJ(0x7eb5a42ec400) = ?(0x7ec8f8451e20)], [A.QYDJID(0x7eb5a42ed840) = ?(0x7ec8f8452950)])Used Hint: ...Optimization Info: ------------------------------------- ... A:table_rows:32310843, physical_range_rows:391, logical_range_rows:391, index_back_rows:0, output_rows:0, est_method:local_storage, optimization_method=cost_based, avaiable_index_name[DC_ACCOUNTBALANCE],...2. 分析表的统计信息
上一步我们分析得出:X 部分查询很快,慢在 A 表查询,要查询 61 万次。A 表查询时使用了主键的前两个字段,因此需要分析一下 A 表的统计信息,主键的 4 个字段的 NDV 分别是多少,结果如下:
- SSQJ、QYDJID 两个字段的 NDV 并不高,每组值的重复次数可以通过统计信息估算:32310843/(85*972)=391,这个就是执行计划中的 physical_range_rows:391,意思就是每次查询大概要扫 391 行数据,这个效率如果只执行一次是没啥问题的,但这个 SQL 里需要执行 61 万次,总耗时就大了。
- 另外 SQL 中关联字段包含了主键的 3 个字段,不在条件里的第 3 个字段 DATAUSE 实际值都为 1,从逻辑上来看,SQL 中加上 AND A.DATAUSE = 1 条件的结果不会变,这样的好处是 A 表查询时可以使用主键的所有字段,每次只需要扫 1 行数据,效率会高很多。另一种更好的方式是主键中去掉 DATAUSE 字段,不过 OB 不支持修改主键。
--查询 select column_name,num_distinct from all_tab_col_statistics where table_name='DC_ACCOUNTBALANCE'; --结果 column_name num_distinct SSQJ 85 QYDJID 972 DATAUSE 1 FNUMBER 26163. 改写
方法 1:加 AND A.DATAUSE = 1
加条件后,SQL 耗时从 500 秒降到 8 秒,执行计划如下,A 表每次只要扫描 1 行:
================================================================================= |ID|OPERATOR |NAME |EST. ROWS|COST | --------------------------------------------------------------------------------- |0 |SCALAR GROUP BY | |1 |3214924| |1 | NESTED-LOOP OUTER JOIN| |5123 |3214729| |2 | SUBPLAN SCAN |X |5123 |3154937| |3 | HASH GROUP BY | |5123 |3154861| |4 | HASH JOIN | |5123 |3149203| |5 | TABLE SCAN |C |81314 |31453 | |6 | HASH JOIN | |63573 |2940900| |7 | HASH JOIN | |1898 |35447 | |8 | TABLE SCAN |D(IDX_ACCANDTAXIDMAPFORP07_CMB1) |2011 |778 | |9 | HASH JOIN | |1736 |32462 | |10| TABLE SCAN |E(IDX_BI_CHOICEOFUNIT_CMB1) |1704 |660 | |11| TABLE SCAN |B |29154 |11277 | |12| TABLE SCAN |A(IDX_DC_ACCOUNTBALANCE_TEMP_TEST)|639387 |2468263| |13| TABLE GET |A |1 |11 | ================================================================================= Outputs & filters: ... 13 - output([remove_const(1)(0x7eb91646c790)]), filter(nil), access([A.SSQJ(0x7eb91646b730)]), partitions(p0), is_index_back=false, range_key([A.SSQJ(0x7eae68cec980)], [A.QYDJID(0x7eae68ceddc0)], [A.DATAUSE(0x7eae68cf05d0)], [A.FNUMBER(0x7eae68cef200)]), range(MIN ; MAX), range_cond([A.DATAUSE(0x7eae68cf05d0) = 1(0x7eae68cefeb0)], [A.SSQJ(0x7eae68cec980) = ?(0x7eb916451ce0)], [A.QYDJID(0x7eae68ceddc0) = ?(0x7eb916452810)], [A.FNUMBER(0x7eae68cef200) = ?(0x7eb916453340)]) ... Optimization Info: ------------------------------------- A:table_rows:32310843, physical_range_rows:1, logical_range_rows:1, index_back_rows:0, output_rows:1, est_method:local_storage, optimization_method=rule_based, heuristic_rule=unique_index_without_indexback改写 2:加 Hint 走 Hash Join
前面我们分析 A 表查询只能使用主键索引的前 2 个字段,效率不高,这种情况下可以看下 Hash Join 的执行效率,加 hint /*+ leading(X A) use_hash(A) */ 耗时只要 40 秒。执行计划如下,结合前面的分析进行解读:
被驱动表 A 除了关联条件没有其他条件,要做全表扫描,成本很高,所以总成本也很高,并且显然比 Nested-Loop Join 的成本高,在没有 Hint 干预的情况下,优化器会选 Nested-Loop Join。
总结
这是一个很经典的问题:如果Join 时关联表太多,执行计划容易选错。
原因是估算驱动表的扇出很容易产生误差,尤其 Join 的结果作为驱动表时,相当于要估算 Join 的结果有多少行,这个误差会更大。而优化器在估算 Nested-Loop Join 算法的成本逻辑中,驱动表的扇出对计算结果影响很大,也就是说 Nested-Loop Join 的成本估算结果很容易产生误差,所以执行计划容易选错。
相关文章:

在OceanBase使用中,如何优化因Join估算不准导致执行计划选错的问题
作者:胡呈清,爱可生公司旗下的DBA团队成员,擅长故障分析和性能优化。爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。本文约 1600 字,预计阅读需要 15 分钟。 数据库版本&…...
potplayer安装
官网 解压运行即可...

PostgreSQL 与MySQL 对比使用
一、前言 博主的系统既有 用到MySQL 也有用到PostgreSQL ,之所以用到这两种数据库,主要是现在都是国产替代,虽然说这两款数据库也不是国产的,但是相对开源,oracle是不让用了。所以现在使用比较多的就是这两个关系型数据…...

配置nginx代理访问openai接口
环境: 阿里云硅谷地区服务器,ubuntu22 操作步骤 1.安装nginx apt install nginx2.编辑文件/etc/nginx/sites-enabled/default,内容替换如下 server {listen 80;location / {proxy_pass https://api.openai.com;proxy_set_header Host api.…...
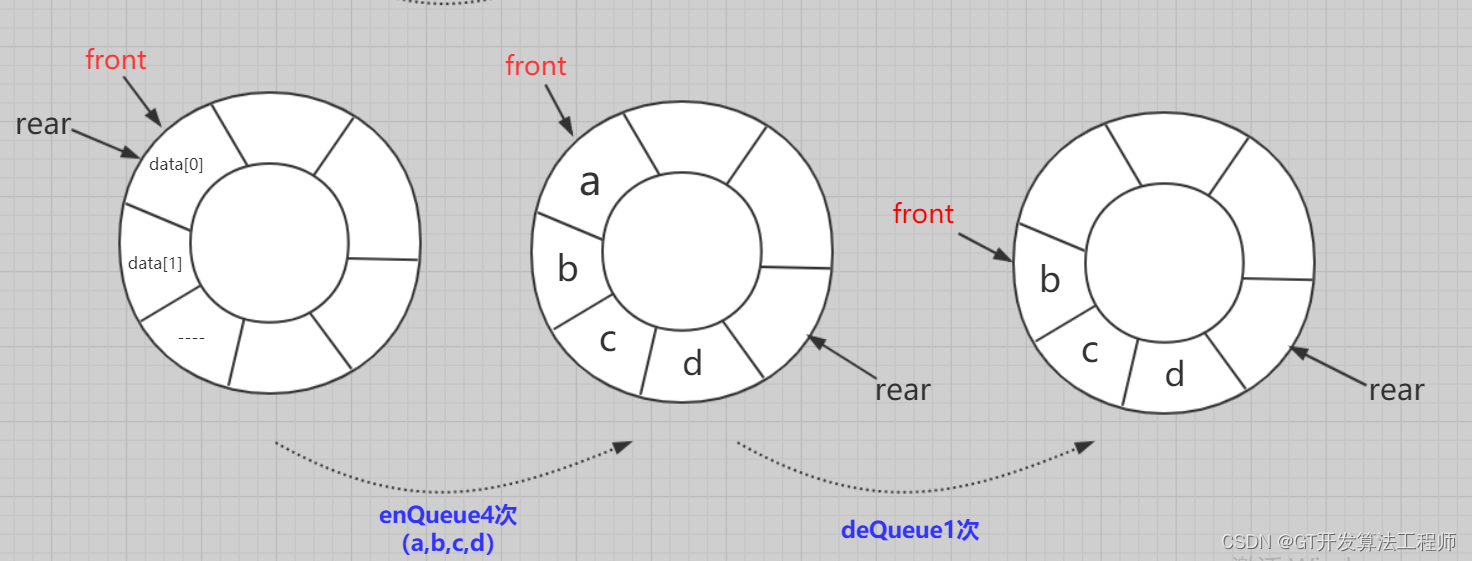
使用Python语言实现一个基于动态数组的序列队列
一、动态数组的实现 首先,我们需要创建一个DynamicArray类,该类将管理我们的动态数组。 动态数组能够动态地调整其大小,以容纳更多的元素。 目录 一、动态数组的实现 代码示例: 二、序列队列的实现 接下来,我…...
面试数据库篇(mysql)- 07索引创建原则与失效及优化
索引创建原则 1). 针对于数据量较大,且查询比较频繁的表建立索引。 2). 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。 3). 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。 4). 如果是字符…...

《互联网的世界》第三讲-tcp
dns 找到了地址,spf 确定了路径,如何运输数据呢?今天讲 tcp。 计算机网络领域的特定技术是最后当你干这个事时才要用的,我对孩子们这样说,实际上你可以随便看一个快递单子来理解端到端传输协议。 源地址,…...

JOSEF约瑟 JZS-7G-42 AC220V静态可调延时中间继电器 端子式导轨安装15ms-10s
系列型号:JZS-7G-57端子排延时中间继电器;JZS-7G-42X端子排延时中间继电器;JZS-7G-22X端子排延时中间继电器;JZS-7G-21端子排延时中间继电器;JZS-7G-41端子排延时中间继电器;JZS-7G-51端子排延时中间继电器…...

Hudi配置参数优化
1)Commits:表示一批记录原子性的写入到一张表中。 2)Cleans:清除表中不再需要的旧版本文件。 3)Delta_commit:增量提交指的是将一批记录原子地写入MergeOnRead类型表,其中一些/所有数据都可以写入增量日志。 4&…...

适用Java SpringBoot项目的分布式锁
在分布式系统中,常用到分布式锁,它有多中实现方式,如:基于redis,database,zookeeper等。Spring integration组件有这三种服务的分布式锁实现,今天来看看用的比较多的redis和database实现方式。 …...
面试笔记系列二之java基础+集合知识点整理及常见面试题
目录 Java面向对象有哪些特征,如何应用 Java基本数据类型及所占字节 Java中重写和重载有哪些区别 jdk1.8的新特性有哪些 内部类 1. 成员内部类(Member Inner Class): 2. 静态内部类(Static Nested Class&#…...
搭建LNMP环境并搭建论坛和博客
目录 一、LNMP架构原理 二、编译安装Nginx 三、编译安装MySQL 四、编译安装PHP 五、配置Nginx支持PHP解析 六、安装论坛 七、安装博客 一、LNMP架构原理 LNMP架构,是指在Linux平台下,由运行Nginx的web服务器,运行PHP的动态页面解析程序…...

蓝桥杯刷题2
1. 修建灌木 import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scan new Scanner(System.in);int n scan.nextInt();for (int i 1;i < n1;i){int distance Math.max(i-1,n-i);System.out.println(distance*2);}scan.close…...

低代码与国产化部署:软件开发的未来趋势与应用实践
在数字化时代,软件开发已经成为企业创新和竞争力提升的关键。随着我国科技实力的不断提升,国产化部署逐渐成为软件开发领域的重要趋势。与此同时,低代码技术的发展也为国产化部署提供了新的机遇。本文将探讨如何在软件开发过程中充分发挥两者…...
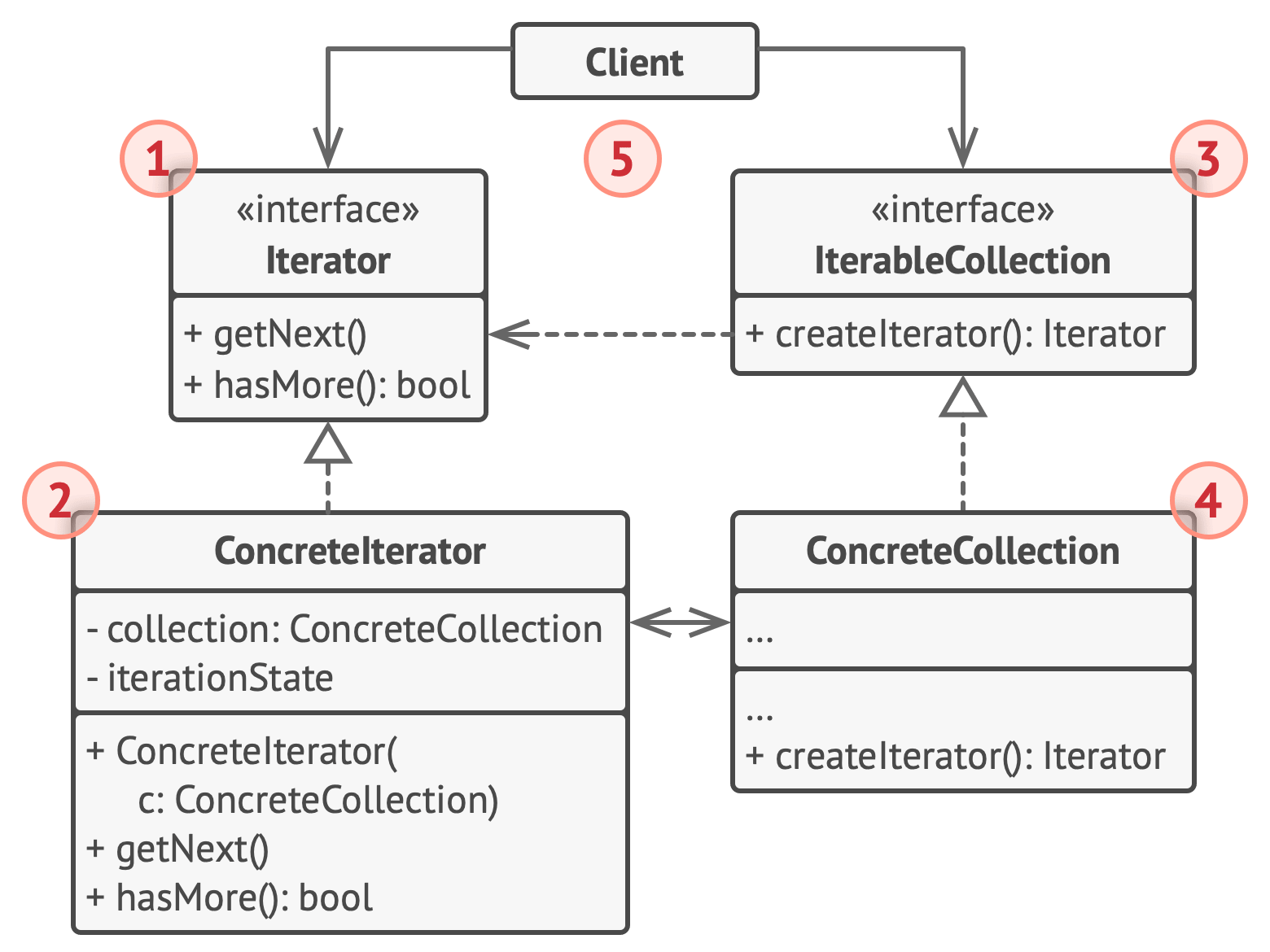
【Python笔记-设计模式】迭代器模式
一、说明 迭代器模式是一种行为设计模式,让你能在不暴露集合底层表现形式(列表、栈和树等)的情况下遍历集合中所有的元素。 (一) 解决问题 遍历聚合对象中的元素,而不需要暴露该对象的内部表示 (二) 使用场景 需要对聚合对象…...
Linux基本指令(上)
在Linux中,将文件夹称为目录,后面的内容都与目录相关。 1. ls指令 语法: ls [选项][目录或文件] 功能:对于目录,该命令列出该目录下的所有子目录与文件。对于文件,将列出文件名以及其他信息。 常用选项 …...
浅谈XSS简单漏洞xss-labs-master(初级)
一、环境以及xss漏洞简介 网上很多gethub自己下就行 XSS简介: 当用户访问被XSS注入的网页,XSS代码就会被提取出来。用户浏览器就会解析这段XSS代码,也就是说用户被攻击了。 用户最简单的动作就是使用浏览器上网,并且浏览器中有J…...
WordPress分类目录ID怎么看?如何查找WordPress标签ID?
在WordPress网站中,我们需要判断某篇文章是否属于某个分类目录,或者是否拥有某个标签,那么就需要用到分类目录ID和标签ID,那么WordPress分类目录ID怎么看?如何查找WordPress标签ID?下面boke112百科就跟大家…...
:用户操作)
达梦数据库基础操作(一):用户操作
达梦数据库基础操作(一):用户操作 1 达梦运行状态 SELECT banner as 版本信息 FROM v$version;1.2 达梦版本号 SELECT banner as 版本信息 FROM v$version;1.3 用户相关操作 默认用户名密码:SYSDBA/SYSDBA 注意:在哪个数据库下创建的用户…...
Java进阶(锁)——锁的升级,synchronized与lock锁区别
目录 引出Java中锁升级synchronized与lock锁区别 缓存三兄弟:缓存击穿、穿透、雪崩缓存击穿缓存穿透缓存雪崩 总结 引出 Java进阶(锁)——锁的升级,synchronized与lock锁区别 Java中锁升级 看一段代码: public class…...

胡桃工具箱终极指南:免费开源的原神全能助手快速上手教程
胡桃工具箱终极指南:免费开源的原神全能助手快速上手教程 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.…...

PyCharm 怎么卸载插件
PyCharm卸载插件有两种方法:菜单栏操作:通过File/PyCharm > Settings/Preferences > Plugins,在Installed列表选择插件并点击Uninstall,重启生效。快捷键操作:使用CtrlAltS(Win/Linux)或C…...

阿里通义VimRAG:让AI同时“读文档、看图片、看视频“
传统AI知识库只能查文字,VimRAG让AI学会了"图文视频一起看"。先讲一个真实场景假设你是一家制造企业的工程师,公司知识库里有:10万份含图表的PDF技术文档5万张CAD设计图纸和产线照片上千条时长30到60分钟的操作培训视频现在你问AI一…...

MoeKoeMusic终极指南:如何用二次元风格免费畅听酷狗VIP音乐
MoeKoeMusic终极指南:如何用二次元风格免费畅听酷狗VIP音乐 【免费下载链接】MoeKoeMusic 一款开源简洁高颜值的酷狗第三方客户端 An open-source, concise, and aesthetically pleasing third-party client for KuGou that supports Windows / macOS / Linux / Web…...

华为交换机端口安全实战:从基础配置到高级防护
1. 华为交换机端口安全基础概念 第一次接触华为交换机的端口安全功能时,我也被各种MAC地址类型搞晕了。简单来说,端口安全就像给交换机接口装了个智能门禁系统,只允许登记过的设备接入网络。想象一下你家的智能门锁,只有录入指纹的…...
)
Windows 10下Veins+SUMO+OMNeT++环境搭建全攻略(避坑指南)
1. 环境准备:三大工具简介与版本选择 第一次接触车联网仿真时,我被VeinsSUMOOMNeT这个组合搞得晕头转向。后来才发现,这三个工具就像汽车工厂的三大部门:SUMO是道路规划师,负责构建交通场景;OMNeT是通信工…...

Win11Debloat终极指南:免费快速优化Windows 11系统的完整方案
Win11Debloat终极指南:免费快速优化Windows 11系统的完整方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter…...

迭代器管理化技术内部迭代器与外部迭代器
迭代器管理化技术:内部与外部迭代器的深度解析 在软件开发中,迭代器是遍历数据集合的重要工具,而迭代器管理化技术进一步优化了其使用方式。内部迭代器和外部迭代器是两种核心实现模式,前者由集合自身控制遍历逻辑,后…...

省预算方案:用STM32F103C8T6开发迷你无人机的全套硬件选型指南
省预算方案:用STM32F103C8T6开发迷你无人机的全套硬件选型指南 当创客精神遇上有限的预算,如何用不到300元打造一台可编程的迷你无人机?STM32F103C8T6(俗称"蓝色药丸")这颗售价仅12元的ARM Cortex-M3芯片&am…...

RMBG-1.4 开源部署实践:AI 净界降低技术门槛的三大设计
RMBG-1.4 开源部署实践:AI 净界降低技术门槛的三大设计 想给照片换个背景,或者把产品图抠出来做海报,你是不是还在用那些复杂的软件,一点点地描边、擦除?费时费力不说,遇到头发丝、毛绒玩具这种边缘模糊的…...