面试笔记系列二之java基础+集合知识点整理及常见面试题
目录
Java面向对象有哪些特征,如何应用
Java基本数据类型及所占字节
Java中重写和重载有哪些区别
jdk1.8的新特性有哪些
内部类
1. 成员内部类(Member Inner Class):
2. 静态内部类(Static Nested Class):
静态内部类的特点:
静态内部类和非静态内部类的区别:
3. **局部内部类(Local Inner Class)**:
4. **匿名内部类(Anonymous Inner Class)**:
泛型
final和static的区别
接口和抽象类有哪些区别
怎样声明一个类不会被继承,什么场景下会用
深拷贝和浅拷贝
序列化
反射介绍
反射的步骤反射的步骤如下。
创建对象的几种方式
@Contended注解有什么用
Java中有四种引用类型
虚引用
Java中锁的分类
Java中==和equals有哪些区别
String、StringBuffer、StringBuilder区别及使用场景
String类和常量池
String对象的两种创建方式
3.2:String类型的常量池比较特殊。
Java代理的几种实现方式
静态代理
第二种:动态代理,包含JDK代理和CGLIB动态代理
JDK代理
CGLIB动态代理
JDK动态代理和CGLIB两种动态代理的比较
hashcode和equals如何使用
异常分类
Java异常处理方式
throw,throws的区别
自定义异常在生产中如何应用
过滤器与拦截器的区别
Integer常见面试题
值传递和引用传递有什么区别
集合
集合和数组的区别
集合框架底层数据结构
线程安全的集合
HashMap的put方法的具体流程?
HashMap原理是什么,在jdk1.7和1.8中有什么区别
HashMap和HashTable的区别及底层实现
HashMap和HashTable对比
HashMap扩容优化:
为什么hashmap扩容的时候是两倍?
hashmap线程安全的方式?
说一下 HashSet 的实现原理? - HashSet如何检查重复?HashSet是如何保证数据不可重复的?
ArrayList和LinkedList有什么区别
ArrayList扩容
Array和ArrayList的区别
List和数组之间的转换
数组类型和集合
高并发中的集合有哪些问题
ConcurrentHashMap底层原理是什么?
Java面向对象有哪些特征,如何应用
-
封装(Encapsulation):封装是指将数据和对数据的操作封装在对象内部,隐藏其具体实现细节,并通过公共接口进行访问。封装可以提高代码的安全性、可维护性和可复用性。
-
继承(Inheritance):继承是指允许一个类继承另一个类的属性和方法。通过继承,子类可以获得父类的属性和方法,并可以在此基础上进行扩展或修改。继承实现了代码的重用和层次化组织。
-
多态(Polymorphism):多态是指同一个类型的对象在不同的情况下表现出不同的行为。通过多态,可以在编译时不确定具体的对象类型,而在运行时确定调用的方法。多态使得代码具有灵活性和扩展性。
-
抽象(Abstraction):抽象是指从对象的共同特征中提取出抽象类或接口,用来描述一组相关的对象。抽象类和接口定义了对象的共同行为和规范,可以通过继承和实现来实现具体的功能。
如何应用Java面向对象的特征:
-
封装:将相关的数据和行为封装在对象内部,通过合适的访问修饰符(例如private、protected、public)限制访问权限。同时,提供合适的公共方法来操作对象的数据。
-
继承:通过使用extends关键字来实现继承关系,让子类继承父类的属性和方法。可以使用继承来实现代码的重用和层次化组织。
-
多态:通过使用多态,可以根据不同的实际对象类型来调用相应的方法,实现不同的行为。可以通过方法的重写(Override)和接口的实现(Implement)来实现多态。
-
抽象:当遇到一组有共同特征的对象时,可以使用抽象类或接口来定义这些对象的共同行为和规范。通过继承和实现来实现具体的功能。
以上是Java面向对象的特征和如何应用的简要介绍。在实际开发中,根据具体情况灵活应用这些特征,可以使代码更加有组织、可扩展和易维护。

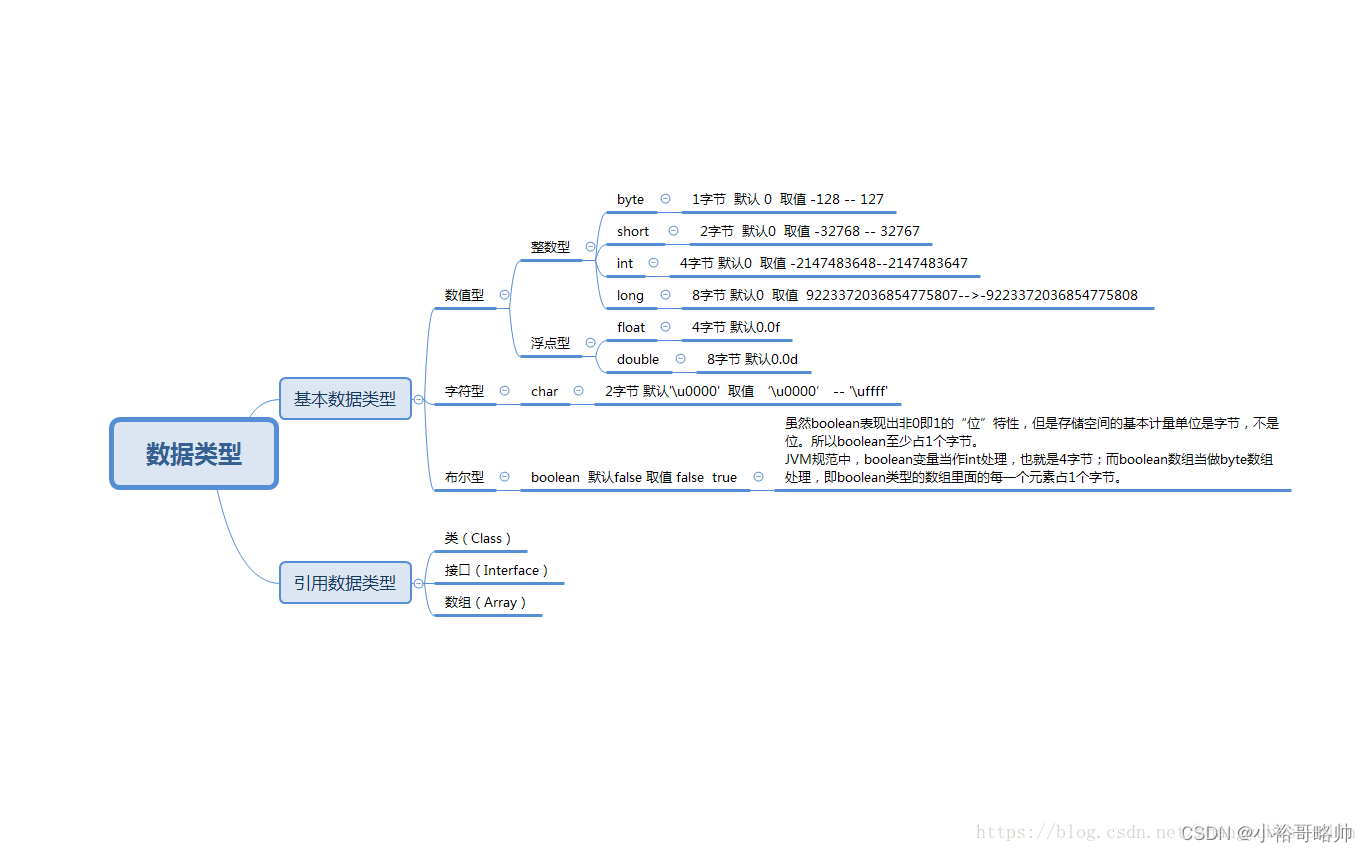
Java基本数据类型及所占字节
Java中重写和重载有哪些区别
在Java中,重写(Override)和重载(Overload)是两个常用的概念,用于实现多态性。它们之间的区别如下:
-
重写(Override):
-
重写指的是子类重新定义了父类中已有的方法,具有相同的方法名、参数列表和返回类型。
-
重写方法必须在继承关系中存在,即子类覆盖父类的方法。
-
重写方法的访问修饰符不能比父类更严格,可以更宽松或相同。
-
重写方法不能抛出比父类更宽泛的异常。
-
在运行时,根据对象的实际类型调用对应的重写方法,实现多态性。
-
-
重载(Overload):
-
重载指的是在同一个类中定义了多个具有相同名字但参数列表不同的方法。
-
重载方法的返回类型可以相同也可以不同,但不能仅仅通过返回类型来区分方法。
-
重载方法的访问修饰符可以相同也可以不同。
-
重载方法可以抛出任意的异常。
-
在编译时,根据方法调用时提供的参数类型和数量来确定调用哪个重载方法。
-
总结来说,重写用于子类重新定义父类方法的实现,而重载用于同一个类中根据参数的不同来定义多个方法。重写是实现多态性的关键,而重载则提供了更多的灵活性和便利性。

jdk1.8的新特性有哪些
Java 8 在发布时引入了许多新的语言特性和 API 改进。以下是 JDK 1.8 中一些主要的新特性:
1. **Lambda 表达式**:Lambda 表达式是 Java 8 中引入的一项重要特性,它简化了匿名内部类的使用,使代码更加简洁、易读。Lambda 表达式可以在函数式接口中使用,通过箭头符号 "->" 将参数和方法体分隔开。
2. **Stream API**:Stream 是 Java 8 中引入的用于处理集合数据的 API,提供了丰富的中间操作和结束操作,可以使代码更具表现力和可读性,并且支持并行操作。
3. **方法引用**:方法引用是一种简化 Lambda 表达式的语法,可以直接引用已有方法作为 Lambda 表达式的实现。
4. **接口的默认方法和静态方法**:在 Java 8 中,接口可以定义默认方法和静态方法,使接口可以包含具体实现而不仅仅是抽象方法,这样可以更好地支持接口的扩展和演进。
5. **Optional 类**:Optional 类是一个容器类,用于处理可能为空的值,避免空指针异常,并鼓励更好的代码实践。
6. **新的日期和时间 API**:Java 8 引入了新的日期时间 API(java.time 包),提供了更好的日期和时间处理方式,包括不可变性、线程安全性和清晰的设计。
7. **CompletableFuture 类**:CompletableFuture 是 Java 8 中引入的用于异步编程的类,通过它可以更容易地实现并发和异步操作。
8. **重复注解**:Java 8 允许在相同的地方多次使用同一个注解,这样可以避免代码中出现大量相同的注解。
9. **Java 类库的改进**:Java 8 中还做了许多类库的改进和增强,包括新的工具类、函数式接口、默认方法等。
Java 8 的这些新特性使得 Java 编程变得更加现代化、高效和简洁,提升了开发人员的编码体验和生产效率。
内部类
在 Java 中,有四种类型的内部类,它们分别是:成员内部类(Member Inner Class)、静态内部类(Static Nested Class)、局部内部类(Local Inner Class)和匿名内部类(Anonymous Inner Class)。下面我会分别介绍这四种内部类,并为每种内部类举一个简单的代码示例:
1. 成员内部类(Member Inner Class):
- 成员内部类是定义在另一个类中的普通类,可以访问外部类的实例成员和方法。
```java
public class Outer {
private int outerField;
public class Inner {
public void display() {
System.out.println("OuterField: " + outerField);
}
}
}
```
2. 静态内部类(Static Nested Class):
- 静态内部类是嵌套在外部类中并被声明为 static 的类,可以直接通过外部类访问静态内部类。
```java
public class Outer {
private static int outerStaticField;
public static class StaticInner {
public void display() {
System.out.println("OuterStaticField: " + outerStaticField);
}
}
}
```
静态内部类是嵌套在外部类中并被声明为 static 的类,它和非静态内部类有一些特点和区别:
静态内部类的特点:
1. 静态内部类可以直接通过外部类访问,无需实例化外部类。
2. 静态内部类不能访问外部类的非静态成员,但可以访问外部类的静态成员。
3. 静态内部类的实例可以独立存在,不依赖于外部类的实例。
4. 静态内部类通常用来作为外部类的帮助类,或者与外部类相关但又不依赖于外部类实例的逻辑。
静态内部类和非静态内部类的区别:
1. **访问外部类成员**:静态内部类不能直接访问外部类的非静态成员变量和方法,而非静态内部类可以直接访问外部类的所有成员。
2. **实例化**:静态内部类的实例不依赖于外部类的实例,可以直接使用outerClass.StaticInnerClass的方式实例化,而非静态内部类需要通过外部类的实例来创建。
3. **静态性**:静态内部类本身就是静态的,因此可以包含静态成员,而非静态内部类无法包含静态成员。
4. **使用场景**:静态内部类适合作为独立实体存在,或者与外部类无关但又需要在同一文件中定义的类;非静态内部类通常用于与外部类有关联的逻辑,需要访问外部类的实例成员。
总的来说,静态内部类和非静态内部类都有各自的优点和适用场景,选择哪种方式取决于需求和设计目的。静态内部类通常用于帮助类或独立实体,而非静态内部类通常用于与外部类相关联的逻辑。
3. **局部内部类(Local Inner Class)**:
- 局部内部类是定义在方法内部的类,只能在包含它的方法中使用,通常用于解决特定问题或局部逻辑。
```java
public class Outer {
public void display() {
class LocalInner {
public void show() {
System.out.println("Local Inner Class");
}
}
LocalInner localInner = new LocalInner();
localInner.show();
}
}
```
4. **匿名内部类(Anonymous Inner Class)**:
匿名内部类是一种没有显示定义类名的内部类,通常在创建对象的同时定义类并实例化对象,适用于只需要一次性使用的情况。以下是匿名内部类的特点:

1. **没有类名**:匿名内部类没有类名,通常直接在使用的地方通过 new 关键字创建对象并定义类。
2. **实现接口或继承父类**:匿名内部类通常用于实现接口或继承父类,并在创建对象时直接实现接口方法或重写父类方法。
3. **可以访问外部类的成员**:匿名内部类可以访问外部类的成员变量和方法,但是需要这些成员变量和方法是 final 或是 effectively final 的(Java 8 之后允许访问非 final 的局部变量)。
4. **一次性使用**:匿名内部类适用于只需要一次性使用、不需要长期保存引用的情况,可以简化代码结构。
5. **可以引用外部类的局部变量**:Java 8 之后,匿名内部类可以访问外部方法中的局部变量,前提是这些局部变量需要是 final 或 effectively final 的。
6. **简化代码**:匿名内部类可以减少编写类定义的代码量,并且可以更直观地展现代码逻辑。
虽然匿名内部类在某些情况下能够带来便利,但也应该注意避免滥用匿名内部类,特别是在逻辑复杂或需要复用的情况下,最好还是考虑使用具名的内部类或独立类来实现相应的功能。
```java
public class Outer {
public void display() {
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("Anonymous Inner Class");
}
};
new Thread(runnable).start();
}
}
```
以上是四种内部类的简单介绍和代码示例,通过使用不同类型的内部类,可以实现更灵活的代码设计和结构化。每种内部类都有不同的应用场景和特性,可以根据实际需求选择合适的内部类类型。
泛型
Java中的泛型是一种类型参数化的机制,允许在类、接口和方法中使用参数化类型。通过使用泛型,可以将类型的具体实例化延迟到使用时,提高代码的灵活性、可复用性和类型安全性。
Java的泛型主要包括以下几个方面:
-
泛型类(Generic Class): 使用泛型类可以在定义类时指定一个或多个类型参数,这些参数可以在类内部作为类型的占位符使用。使用泛型类可以创建具有不同类型参数的实例,从而提供了更灵活的数据类型支持。
例如,在定义一个
List时可以使用泛型参数来指定列表元素类型,如List<String>表示元素类型为字符串的列表。 -
泛型接口(Generic Interface): 泛型接口与泛型类类似,可以在接口定义中使用类型参数。通过泛型接口,可以创建实现指定类型参数的接口的实例。
例如,
Comparable<T>是一个泛型接口,用于实现可比较的对象。其中的类型参数T表示待比较的对象的类型。 -
泛型方法(Generic Method): 泛型方法可以在方法内部独立地使用泛型类型,可以有自己的类型参数。使用泛型方法可以在方法调用时指定不同的类型,并在方法内部进行参数和返回类型的类型推断。
例如,
Collections类中的sort方法就是一个泛型方法,可以对不同类型的数组进行排序。它根据方法调用时传入的参数类型进行类型推断。 -
通配符和上界(Wildcard and Upper Bound): 在使用泛型时,可以使用通配符
?来表示未知的类型,通常用于读取操作。通过使用上界,可以限制通配符所代表的类型的范围。例如,
List<?>表示一个未知类型的列表,可以获取列表中的元素,但无法添加任何元素。而List<? extends Number>表示一个类型为Number及其子类的列表,限制了可以添加的元素类型。
泛型的优势包括代码复用性高、提高代码的类型安全性、减少类型转换的错误以及提供更强大的编译时类型检查。通过在Java中使用泛型,可以编写更灵活和可维护的代码,并提高代码的可读性和可扩展性。
final和static的区别
final和static是Java中两个关键字,它们有不同的用途和含义:
-
final关键字:-
修饰变量:
final修饰的变量表示一个最终的常量,即不可再改变的值。一旦被赋初值后,该变量的值不能再被修改。final变量通常用大写字母命名,并在声明时或构造函数中进行初始化。 -
修饰方法:
final修饰的方法表示该方法是最终方法,子类无法对其进行重写。该方法在继承关系中起到稳定和约束的作用。 -
修饰类:
final修饰的类表示该类是最终类,不能被继承。该类一般是不希望被修改或继承的基础类。
-
-
static关键字:-
修饰变量:
static修饰的变量是静态变量(类变量),它属于类而不属于对象。静态变量在内存中只有一个副本,被所有对象共享。可以通过类名直接访问静态变量,无需创建实例。 -
修饰方法:
static修饰的方法是静态方法(类方法),它属于类而不属于对象。静态方法不依赖对象的实例,无法访问非静态成员变量,只能访问类的静态成员。可以直接使用类名调用静态方法。 -
修饰代码块:
static修饰的代码块是静态代码块,它在类初始化时执行,且只执行一次。
-
主要区别:
-
final关键字表示最终性,用于修饰不可变的变量、最终方法以及不可继承的类,强调不可修改或扩展的特性。 -
static关键字表示静态性,用于修饰类级别的变量、方法和代码块,强调共享和类级别的访问方式。
总之,final和static在Java中有不同的用途和含义,final修饰的是最终性和不可修改的特性,而static修饰的是静态性和共享性的特性。
虽然final和static在Java中的用途和含义不同,但它们也有一些相同点:
-
共享性:无论是
final还是static修饰的成员(变量、方法或代码块),它们都是类级别的,即在类的所有实例之间共享。 -
静态访问:
final修饰的成员以及static修饰的成员,都可以通过类名直接访问,不需要实例化对象。 -
声明周期:
final和static修饰的成员都在类初始化时创建,并且在整个程序的生命周期中保持不变。 -
常量:
final修饰的变量可以用来表示常量,而静态常量常常使用final和static一起修饰,用于表示类级别的常量。
虽然这些相同点存在,但要注意的是,final和static的主要作用是不同的。final主要用于表示最终性和不可修改性,而static主要用于表示静态性和共享性。它们的使用场景和语义上仍然有所区别。
接口和抽象类有哪些区别
接口(Interface)和抽象类(Abstract Class)是面向对象编程中的两个重要概念,它们之间有以下区别:
-
定义方式:
-
接口:接口只能定义抽象方法和常量,不能包含具体的方法实现。接口中的方法默认为
public abstract,常量默认为public static final,不需要显式声明。 -
抽象类:抽象类可以包含抽象方法和具体方法的声明,也可以包含成员变量。抽象类通过使用
abstract关键字来声明抽象方法,不需要显式标识成员变量和具体方法。
-
-
继承关系:
-
接口:一个类可以实现(implement)多个接口,通过关键字
implements来实现接口。接口之间可以实现多继承,一个接口可以继承多个其他接口。一个类实现接口时,必须实现接口中定义的所有方法。 -
抽象类:一个类可以继承(extends)一个抽象类,通过关键字
extends来继承抽象类。抽象类之间只能实现单继承,一个抽象类只能继承一个其他类或抽象类。子类继承抽象类时,必须实现抽象类中的抽象方法。
-
-
实例化对象:
-
接口:接口不能直接被实例化,即不能通过
new关键字来创建接口的对象。但可以通过实现接口的类来创建对象,并将其赋给接口类型的引用。 -
抽象类:抽象类不能直接被实例化,即不能通过
new关键字来创建抽象类的对象。但可以通过实现抽象类的子类来创建对象,并将其赋给抽象类类型的引用。
-
-
特殊功能:
-
接口:接口可以用于实现多态,通过接口类型的引用来调用实现类的方法。
-
抽象类:抽象类可以包含抽象方法和具体方法的实现,从而提供默认行为给子类使用。子类可以选择性地实现抽象方法,对于不需要修改的方法,可以继承抽象类中的具体实现。
-
总的来说,接口和抽象类都是用来实现多态和约束子类的机制,但在定义方式、继承关系、实例化对象和特殊功能等方面存在一些区别。根据具体的需求和设计场景,可以选择使用接口或抽象类来实现代码的灵活性和重用性。
相同:
1.不能够实例化
2.可以将抽象类和接口类型作为引用类型
3.一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍然需要
被声明为抽象类
怎样声明一个类不会被继承,什么场景下会用
如果一个类被final修饰,此类不可以有子类,不能被其它类继承,如果一个中的所有方法都没有重写的需要,当前类没有子类也罢,就可以使用final修饰类。
深拷贝和浅拷贝
Java中的拷贝操作分为深拷贝和浅拷贝两种方式,它们的区别在于拷贝过程中是否创建新的对象以及如何复制对象的成员。
浅拷贝(Shallow Copy): 浅拷贝是一种简单的拷贝方式,它创建一个新的对象,然后将原始对象的字段值复制到新对象中。但是,如果字段值是引用类型,浅拷贝只会复制引用,而不是创建一个新的引用对象。因此,新对象和原始对象会共享相同的引用对象,对其中一个对象所做的修改会影响另一个对象。
浅拷贝(Shallow Copy)是指在拷贝对象时,只复制对象本身和对象中的基本数据类型成员,而不复制对象中的引用类型成员。简单来说,浅拷贝只是拷贝了对象的引用,而不是创建一个新的独立对象。
以下是一个Java代码示例,展示了如何进行浅拷贝:
class Person implements Cloneable {private String name;private int age;private Address address; // 引用类型成员变量
public Person(String name, int age, Address address) {this.name = name;this.age = age;this.address = address;}
public void setAddress(Address address) {this.address = address;}
@Overridepublic Object clone() throws CloneNotSupportedException {return super.clone();}
@Overridepublic String toString() {return "Person [name=" + name + ", age=" + age + ", address=" + address + "]";}
}
class Address {private String city;
public Address(String city) {this.city = city;}
@Overridepublic String toString() {return "Address [city=" + city + "]";}
}
public class ShallowCopyExample {public static void main(String[] args) throws CloneNotSupportedException {Address address = new Address("New York");Person person1 = new Person("John", 25, address);
// 浅拷贝Person person2 = (Person) person1.clone();
// 修改person2的成员变量person2.setName("Mike");person2.setAddress(new Address("London"));
System.out.println("person1: " + person1);System.out.println("person2: " + person2);}
}
在上述示例中,Person类包含了一个引用类型的成员变量address,而Address类只有一个简单的city属性。通过调用clone()方法进行浅拷贝,将person1对象的内容复制到person2对象。当修改person2对象的成员变量时,person1对象的成员变量也会发生变化,因为它们共享同一个引用类型的成员变量。
输出结果如下:
person1: Person [name=John, age=25, address=Address [city=London]] person2: Person [name=Mike, age=25, address=Address [city=London]]
可以看到,person2对象修改了address引用的内容,导致person1对象的address也发生了变化。这就是浅拷贝的特点,只复制了引用,而没有创建新的独立对象。
深拷贝(Deep Copy): 深拷贝是一种更为复杂的拷贝方式,它不仅创建一个新的对象,还会递归复制对象的所有引用类型字段,包括它们所引用的对象,以保证复制后的对象与原始对象完全独立。因此,新对象和原始对象拥有各自独立的引用对象,互不影响。
在Java中,实现深拷贝的方式有多种,包括:
-
使用实现了Cloneable接口的clone方法来实现深拷贝。需要在被拷贝的类中重写clone方法,并在该方法中对引用类型字段进行深度拷贝。
-
使用序列化和反序列化来实现深拷贝。通过将对象序列化为字节流,然后再进行反序列化,可以创建一个新的独立对象。
-
使用第三方库,比如Apache Commons Lang中的SerializationUtils类或者Google Gson,它们提供了更便捷的深拷贝方式。
需要注意的是,并非所有的类都是可深拷贝的,如果类的字段包含不可变对象或者其他具有深度状态的对象,可能需要特殊处理来确保新对象的独立性。 同时,在进行对象拷贝时,还需要考虑性能和内存使用的问题,因为深拷贝可能需要递归地复制整个对象图,可能会导致性能和内存开销的增加。因此,在选择拷贝方式时,需要根据具体需求和场景来决定使用浅拷贝还是深拷贝。
序列化
Java序列化是指将对象转化为字节流的过程,可以将对象保存到文件、传输到网络或者在进程间进行通信。反序列化则是将字节流转化为对象的过程。Java的序列化机制主要通过ObjectOutputStream和ObjectInputStream来实现。
在以下情况下,我们通常需要实现Java序列化:
-
对象持久化:当我们需要将对象保存到磁盘或数据库中,以便之后重新读取和恢复时,可以使用Java序列化。通过将对象转为字节流,我们可以将其写入文件或数据库中。这对于需要长期保存对象状态的应用场景非常有用,比如缓存或数据存储。
-
进程间通信:当我们需要在不同的Java进程之间进行通信时,可以使用Java序列化来传递对象。通过将对象转为字节流,我们可以将其传输给其他进程,并在接收端进行反序列化恢复为对象。这在分布式系统、远程调用以及消息传递等场景下有广泛应用。
需要注意的是,为了使对象可以被序列化,相关的类需要实现Serializable接口,这是一个标记接口,仅起到标识该类可以被序列化的作用。同时,类中的所有域也必须是可序列化的,即要么是基本类型,要么是实现了Serializable接口的对象。
然而,并不是所有的场景都适合使用Java序列化。在一些需要高性能、传输大量数据或数据结构频繁改变的情况下,可能不适合使用序列化来传输对象,而选择其他的序列化方法或者数据交换格式。此外,需要特别注意序列化对版本升级的兼容性问题,因为序列化的对象需要保证版本一致,否则可能导致反序列化失败。
反射介绍
反射(Reflection)是指在程序运行时动态地获取、操作和修改类或对象的属性、方法和构造函数等信息的能力。通过反射,我们可以在运行时检查类、实例化对象、调用方法、获取和修改字段的值,以及操作构造函数等。
Java中的反射API位于java.lang.reflect包下,提供了一组类和接口,用于实现反射功能。常用的反射类和接口包括以下几个:
-
Class类:表示一个类或接口的运行时对象,可以获取类的构造函数、方法、字段等信息。 -
Constructor类:表示类的构造函数,用于创建类的实例对象。 -
Method类:表示类的方法,可以用于调用方法并获取方法的信息。 -
Field类:表示类的字段,可以用于获取和修改字段的值。
反射的主要应用场景包括:
-
动态加载类:在运行时通过类名字符串来动态加载并实例化对象。
-
运行时获取类的信息:获取类的构造函数、方法、字段等信息,包括注解、修饰符等。
-
动态调用方法:在运行时通过方法名和参数类型,动态调用类的方法。
-
对私有成员的访问:通过反射可以获取和修改类的私有字段和方法。
-
生成动态代理:使用反射可以在运行时生成代理对象,并在代理对象中增加额外的逻辑。
使用反射需要注意以下几点:
-
反射操作相对于直接调用代码的执行效率较低,因为涉及到查找、解析和执行步骤。
-
反射破坏了封装性,可以访问和修改原本无法访问的成员,因此需要谨慎使用。
-
由于反射在编译期无法进行类型检查,可能会在运行时抛出未检查的异常,需要进行异常处理和类型判断。
总结来说,反射是一种强大而灵活的机制,提供了在运行时动态操作类和对象的能力。它在某些情况下能够简化代码编写和提供更大的灵活性,但需要慎重使用,并考虑其可能带来的性能和安全性方面的影响。
反射的步骤反射的步骤如下。
使用反射的步骤主要包括以下几个:
-
获取类的
Class对象:首先需要获取目标类的Class对象,可以通过类名、对象实例或者Class类的forName()方法来获取。// 通过类名获取Class对象 Class<?> clazz = MyClass.class; // 通过对象实例获取Class对象 MyClass obj = new MyClass(); Class<?> clazz = obj.getClass(); // 通过类的全限定名获取Class对象 Class<?> clazz = Class.forName("com.example.MyClass"); -
获取构造函数对象(可选):如果需要通过构造函数创建对象,可以通过
Class对象的getConstructor()、getDeclaredConstructor()方法获取目标构造函数对象。// 获取指定参数类型的公共构造函数对象 Constructor<?> constructor = clazz.getConstructor(String.class, int.class); // 获取所有参数类型的构造函数对象(包括私有构造函数) Constructor<?> constructor = clazz.getDeclaredConstructor(String.class, int.class); // 禁用访问检查,允许访问私有构造函数 constructor.setAccessible(true);
-
创建对象(可选):如果获取了构造函数对象,可以使用
Constructor对象的newInstance()方法创建目标类的实例。// 使用构造函数对象创建对象实例 MyClass obj = (MyClass) constructor.newInstance("example", 123); -
获取方法对象:通过
Class对象的getMethod()、getDeclaredMethod()方法获取目标方法对象。// 获取指定名称和参数类型的公共方法对象 Method method = clazz.getMethod("methodName", int.class, String.class); // 获取所有名称和参数类型的方法对象(包括私有方法) Method method = clazz.getDeclaredMethod("methodName", int.class, String.class); // 禁用访问检查,允许访问私有方法 method.setAccessible(true); -
调用方法:通过方法对象的
invoke()方法调用目标方法。// 调用方法 Object result = method.invoke(obj, 123, "example");
-
获取和设置字段的值:通过
Class对象的getField()、getDeclaredField()方法获取目标字段对象。// 获取公共字段对象 Field field = clazz.getField("fieldName"); // 获取所有字段对象(包括私有字段) Field field = clazz.getDeclaredField("fieldName"); // 禁用访问检查,允许访问私有字段 field.setAccessible(true); // 获取字段的值 Object value = field.get(obj); // 设置字段的值 field.set(obj, newValue);
注意:在使用反射时,需要注意访问修饰符(public、private等),需禁用访问检查才能访问和修改私有成员。此外,还需要处理可能抛出的异常,如找不到构造函数、方法或字段等。
创建对象的几种方式
在Java中,我们可以使用以下几种方式来创建对象:
-
使用new关键字:
ClassName obj = new ClassName();
这是最常见的创建对象的方式。通过使用new关键字,我们可以在堆中分配内存,并创建一个新的对象。
-
使用Class的newInstance()方法:
ClassName obj = (ClassName) Class.forName("ClassName").newInstance();
Class.forName("ClassName")会返回一个代表ClassName类的Class对象,然后通过调用newInstance()方法来创建该类的对象。需要注意的是,这种方式要求ClassName类有一个无参的构造函数,否则会抛出InstantiationException异常。
-
使用Constructor类的newInstance()方法:
Constructor<ClassName> constructor = ClassName.class.getConstructor(); ClassName obj = constructor.newInstance();
这种方式使用反射的方式来创建对象。首先,我们获取到ClassName类的Constructor对象,然后使用newInstance()方法来创建对象。同样需要注意,这种方式要求ClassName类有一个无参的构造函数。
-
使用clone()方法:
ClassName obj = (ClassName) otherObj.clone();
这种方式是通过对象的clone()方法来创建一个对象的副本。需要注意的是,类必须实现Cloneable接口并重写clone()方法,否则会抛出CloneNotSupportedException异常。
-
使用反序列化:
ObjectInputStream in = new ObjectInputStream(new FileInputStream("filename"));
ClassName obj = (ClassName) in.readObject();
通过将对象序列化到文件中,然后再反序列化回来来创建对象。需要注意的是,类必须实现Serializable接口。
这些是创建对象的常见方式,在不同的场景下可以选择适合的方式来创建对象。每种方式都有其适用的情况和注意事项。
@Contended注解有什么用
这个注解是为了解决伪共享问题而存在的
Java缓存伪共享(Cache False Sharing)是指多个线程同时访问不同变量,但这些变量被存储在相邻的缓存行中,导致在多线程并发更新变量时,由于缓存一致性协议的原因,会频繁地使缓存行无效,降低了性能。
这个问题通常出现在多线程环境中,当多个线程同时修改一个共享的数据结构中的不同变量时,由于缓存行的对齐以及缓存一致性的机制,每个线程更新变量时,可能会同时使得其他线程缓存的行无效,导致额外的缓存同步开销。
(出现在缓存L1上)
这个注解会让当前类的属性,独占一个缓存行。在共享数据结构的变量之间增加一些无意义的填充变量,使得相邻的变量在不同的缓存行中,从而避免伪共享。
Java中有四种引用类型
-
强引用(Strong Reference):最常见的引用类型,也是默认的引用类型。使用强引用,一个对象不会被垃圾回收器回收,只有在没有任何强引用指向它时,才会被回收。
-
软引用(Soft Reference):通过软引用,可以让对象在内存不足时被回收。垃圾回收器在进行回收时,通常会保留软引用对象,只有当内存不足时,才会回收这些对象。
Object referent = new Object();
SoftReference<Object> softReference = new SoftReference<>(referent);
-
弱引用(Weak Reference):使用弱引用,可以让对象在下一次垃圾回收时被回收。垃圾回收器在回收时,不论内存是否充足,都会回收掉只有弱引用指向的对象。
-
虚引用(Phantom Reference):虚引用是最弱的一种引用类型,它的存在几乎没有实际的意义。可以用虚引用来跟踪对象被垃圾回收器回收的过程,无法通过虚引用访问对象,需要配合引用队列(ReferenceQueue)一起使用。
这四种引用类型的关系是:强引用 > 软引用 > 弱引用 > 虚引用。对象在没有任何引用指向时,会被回收。软引用和弱引用可以让对象在内存不足时被回收,虚引用可以让对象在被回收的同时收到通知。
使用不同的引用类型,可以更灵活地控制对象的生命周期和回收时机,适应不同的内存管理需求。需要注意的是,虚引用的使用相对较少,一般在某些高级的内存管理场景中才会涉及。
虚引用
虚引用(Phantom Reference)是Java中最弱的一种引用类型。与其他引用类型不同,虚引用的存在几乎没有实际的意义,它主要用于跟踪对象被垃圾回收器回收的过程。
以下是虚引用的一些特点和使用场景:
-
虚引用的创建:虚引用可以通过创建
PhantomReference对象来实现。虚引用对象需要传入一个引用队列(ReferenceQueue),用于在对象被回收时接收通知。Object referent = new Object(); ReferenceQueue<Object> queue = new ReferenceQueue<>(); PhantomReference<Object> phantomReference = new PhantomReference<>(referent, queue);
-
无法通过虚引用访问对象:与其他引用不同,虚引用无法通过
get()方法获得对应的对象。任何时候,使用虚引用的get()方法都会返回null。Object obj = phantomReference.get(); // 返回null
-
接收回收通知:当对象被垃圾回收器回收时,虚引用所关联的对象将被放入引用队列中。可以通过引用队列来获取被回收的对象信息,进行相关的处理操作。
ReferenceQueue<Object> queue = new ReferenceQueue<>(); // ... PhantomReference<Object> phantomReference = new PhantomReference<>(referent, queue); // ... Reference<?> reference = queue.poll(); if (reference != null) {// 执行相关处理操作 } -
虚引用的应用场景:虚引用的应用场景比较少见,一般在一些高级的内存管理场景中使用。例如,你可以使用虚引用来实现一些本地资源的释放,在对象被垃圾回收时进行清理操作,比如关闭文件句柄、释放网络连接等。
class ResourceCleaner {private ReferenceQueue<Object> queue = new ReferenceQueue<>(); // 注册虚引用,关联清理操作public void register(Object resource, Runnable cleanupAction) {PhantomReference<Object> phantomReference = new PhantomReference<>(resource, queue);// ...} // 在适当的时机执行清理操作public void cleanup() {Reference<?> reference = queue.poll();while (reference != null) {// 执行相关清理操作reference.clear();// ...reference = queue.poll();}} }
需要注意的是,因为虚引用的存在几乎没有实际的意义,开发中使用虚引用的场景较少,而且需要谨慎使用。错误使用虚引用可能会导致一些不可预测的问题,因此在使用虚引用时应仔细评估和规划。
Java中锁的分类
在Java中,锁可以按照以下几种分类标准来进行划分:
-
公平锁与非公平锁: 公平锁是指多个线程按照请求的顺序获取锁,而非公平锁则没有这样的保证。在公平锁中,线程们按照先来先服务的原则排队获取锁;而在非公平锁中,锁会倾向于允许当前已拿到锁的线程再次获取锁。
-
互斥锁与共享锁: 互斥锁(Exclusive Lock)是一种独占锁,它只允许一个线程在同一时间获取锁,并阻止其他线程访问被保护资源。而共享锁(Shared Lock)允许多个线程同时获取锁,并共享被保护资源的访问权限。互斥锁用于保护临界区,而共享锁用于并发读操作。
-
写锁与读写锁: 写锁与读写锁适用于对读写操作进行区分的场景。写锁(Write Lock)是独占锁,只允许一个线程进行写操作,并且阻塞其他线程的读写操作。读写锁(ReadWrite Lock)允许多个线程同时进行读操作,但只允许一个线程进行写操作。读操作之间不会互斥,读与写操作之间互斥。
-
悲观锁与乐观锁: 悲观锁(Pessimistic Locking)是一种保守策略,它假设会有其他线程对共享资源进行修改,因此在访问共享资源之前进行加锁。悲观锁的典型例子就是 synchronized 关键字和 ReentrantLock 类。相反,乐观锁(Optimistic Locking)假设并发冲突很少发生,不主动加锁,而是在更新操作时检查数据是否被其他线程修改过。
请注意,这些分类标准并不是严格独立的,而是相互关联的,同一个锁可能涵盖不同分类标准的特性。在实际应用中,根据具体需求,可以选择合适的锁类型来实现线程同步和资源访问控制。
Java中==和equals有哪些区别
equals 和== 最大的区别是一个是方法一个是运算符。
==:如果比较的对象是基本数据类型,则比较的是数值是否相等;如果比较的是引用数据类型,则比较的是对象
的地址值是否相等。
equals():用来比较方法两个对象的内容是否相等。
注意:equals 方法不能用于基本数据类型的变量,如果没有对 equals 方法进行重写,则比较的是引用类型的变量所指向的对象的地址。

String、StringBuffer、StringBuilder区别及使用场景
String、StringBuffer和StringBuilder都是Java中用于处理字符串的类,它们在性能、线程安全性和可变性方面有所不同。
-
String(不可变字符串):
-
String对象是不可变的,一旦创建就不能被修改。每次对字符串进行操作(连接、替换等),都会创建一个新的String对象。
-
因为字符串是不可变的,所以String对象是线程安全的。
-
适合于字符串不经常变化的场景,例如作为方法参数、类属性等。
-
-
StringBuffer(可变字符串,线程安全):
-
StringBuffer对象是可变的,可以进行字符串的修改、追加、插入和删除等操作。它是线程安全的,因此适用于多线程环境。
-
每次对StringBuffer的操作都是在原有对象的基础上进行的,不会创建新的对象。
-
适合于字符串经常需要变化、需要线程安全的场景,例如在多线程环境下进行字符串处理的情况。
-
-
StringBuilder(可变字符串,非线程安全):
-
StringBuilder对象也是可变的,可以进行字符串的修改、追加、插入和删除等操作。与StringBuffer不同的是,StringBuilder是非线程安全的。
-
每次对StringBuilder的操作都是在原有对象的基础上进行的,不会创建新的对象。
-
适合于字符串经常需要变化,且在单线程环境下进行字符串处理的场景,例如在循环中进行大量字符串拼接的情况。
-
-
String类是不可变的,一旦创建就不能修改,每次修改都会创建一个新的对象;
-
StringBuffer和StringBuilder类是可变的,可以随意修改其中的内容,不会创建新的对象。
-
StringBuffer类是线程安全的,而StringBuilder类是非线程安全的。
String类和常量池
String对象的两种创建方式
String str1 = "abcd";
String str2 = new String("abcd");
System.out.println(str1==str2);//false这两种不同的创建方法是有区别的,第一种方式是在常量池中拿对象,第二种直接在堆内存中创建一个新对象(如果常量池中没有的话会在常量池里创建一个)。
记住:只要使用new方法,便需要创建新的对象。
3.2:String类型的常量池比较特殊。
它的主要使用方法有两种:
1、直接使用双引号声明出来的对象会直接存储到常量池中。
2、如果不是双引号声明的String对象,可以使用String提供的intern方法。String.intern()是一个Native方法,它的作用是:如果运行时常量池中已经包含一个等于此String对象内容的字符串,则返回常量池中该字符串的引用;如果没有则在常量池中创建与此String内容相同的字符串,并返回常量池中创建字符串的引用。
JDK6和JDK7的区别:
JDK6:
1、如果常量池中有,则不会放入。返回已有的常量池中的对象地址
2、如果没有,则将对象复制一份,并将放入到常量池中,并放回对象地址
JDK7之后:
1、如果常量池中有,则不会放入。返回已有的常量池中的对象地址
2、如果没有,则将对象的引用地址复制一份,放入到常量池中,并返回常量池中的引用地址
public class StringTest2 {public static void main(String[] args) {String s = new String("a")+new String("b");String s2 =s.intern();System.out.println(s2 =="ab");System.out.println(s =="ab");}
}DK6下输出:true false

JDK7之后输出:true true

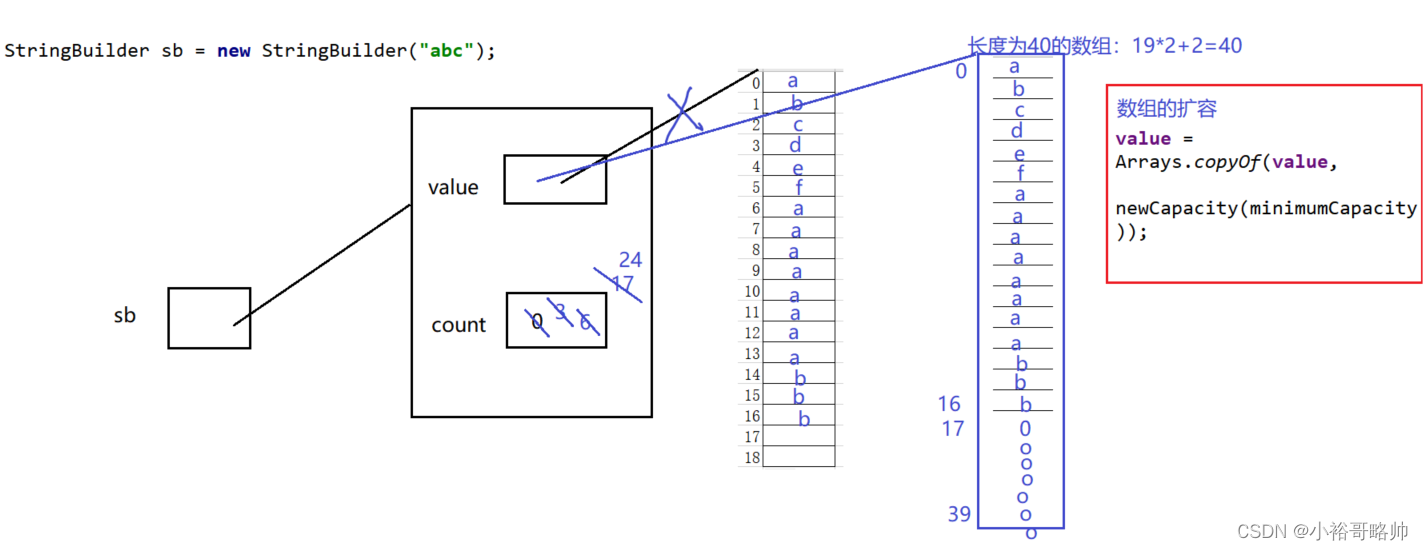
看到上面的结果可能还存在疑虑,我们接着分析一下1、String s = "ab";创建了一个对象,在编译已经确定要放入常量池 2、String s = “a”+ “b”;常量字符串拼接,底层优化为“ab”,和上面一样也生成一个对象。 3、String s = new String("ab");创建了两个对象,通过查看字节码文件:
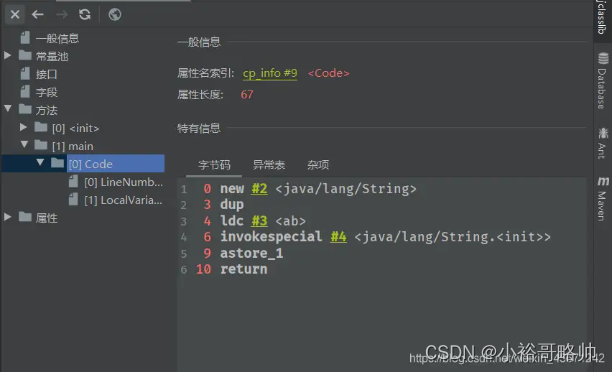
一个对象时new出来的另外一个对象是字符串常量池中的对象“ab”,字节码指令:ldc 4、String s = new String("a") + new String("b");字节码显示创建了6个对象
,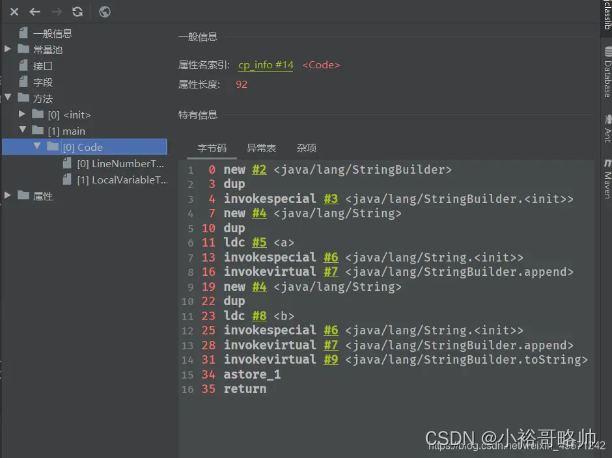
1、new StringBuilder对象
2、new String("a")
3、常量池中的a4、new String("b")
5、常量池中的b深入刨析StringBuilder的toString,调用的是new String(char[])
6、new String("ab"),此时常量池中并没有ab这个字符串强调一下toString()的调用,
先从常量池中找,没有在常量池中生成“ab” 再看看相关字符串的内容代码
String s1 = new String("计算机");
String s2 = s1.intern();
String s3 = "计算机";
System.out.println(s2);//计算机
System.out.println(s1 == s2);//false,因为一个是堆内存中的String对象一个是常量池中的String对象,
System.out.println(s3 == s2);//true,因为两个都是常量池中的String对象String str1 = "str";
String str2 = "ing";String str3 = "str" + "ing";//常量池中的对象
String str4 = str1 + str2; //在堆上创建的新的对象
String str5 = "string";//常量池中的对象
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
System.out.println(str4 == str5);//false尽量避免多个字符串拼接,因为这样会生成新对象。如果需要改变字符串的话可以使用StringBuffer和StringBuilder
Java代理的几种实现方式
静态代理
,只能静态的代理某些类或者某些方法,不推荐使用,功能比较弱,但是编码简单
// 定义一个共同的接口
interface Calculator {int add(int a, int b);
}
// 实现真正的计算类
class CalculatorImpl implements Calculator {@Overridepublic int add(int a, int b) {return a + b;}
}
// 创建代理类,并实现共同的接口
class CalculatorProxy implements Calculator {private Calculator calculator;
// 在构造函数中传入真正的计算类对象public CalculatorProxy(Calculator calculator) {this.calculator = calculator;}
@Overridepublic int add(int a, int b) {// 在调用真正对象的方法之前执行额外的逻辑System.out.println("Before calculation...");
// 调用真正对象的方法int result = calculator.add(a, b);
// 在调用真正对象的方法之后执行额外的逻辑System.out.println("After calculation...");
return result;}
}
public class Main {public static void main(String[] args) {// 创建真正的计算类对象Calculator calculator = new CalculatorImpl();
// 创建代理类对象,将真正的计算类对象传入Calculator proxy = new CalculatorProxy(calculator);
// 调用代理对象的方法int result = proxy.add(5, 3);System.out.println("Result: " + result);}
}
第二种:动态代理,包含JDK代理和CGLIB动态代理
JDK代理
JDK动态代理是Java提供的一种动态创建代理对象的机制。它基于Java反射机制,在运行时动态生成代理类和代理实例。JDK动态代理只能针对接口进行代理,它通过Proxy类和InvocationHandler接口来实现。
以下是JDK动态代理的基本步骤:
-
定义一个接口:首先需要定义一个共同的接口,该接口包含被代理对象的方法。
-
创建一个InvocationHandler对象:InvocationHandler接口是JDK动态代理的核心,它包含一个invoke方法,用于处理代理对象方法的调用。自定义一个类来实现InvocationHandler接口,并在invoke方法中编写处理逻辑。
-
使用Proxy类创建代理对象:使用Proxy类的
newProxyInstance方法动态创建代理对象。该方法需要传入三个参数:ClassLoader,代理接口数组和InvocationHandler对象。 -
通过代理对象调用方法:通过代理对象调用接口中的方法,实际上会触发InvocationHandler的invoke方法,并在该方法中执行具体的代理逻辑。
下面是一个简单的示例代码:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
// 定义接口
interface Calculator {int add(int a, int b);
}
// 实现InvocationHandler接口
class CalculatorInvocationHandler implements InvocationHandler {private Calculator target;
public CalculatorInvocationHandler(Calculator target) {this.target = target;}
@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {// 在方法调用之前添加额外逻辑System.out.println("Before calculation...");
// 调用真正对象的方法Object result = method.invoke(target, args);
// 在方法调用之后添加额外逻辑System.out.println("After calculation...");
return result;}
}
public class Main {public static void main(String[] args) {// 创建真正的计算类对象Calculator target = new CalculatorImpl();
// 创建InvocationHandler对象,将真正的计算类对象传入InvocationHandler handler = new CalculatorInvocationHandler(target);
// 使用Proxy类创建代理对象Calculator proxy = (Calculator) Proxy.newProxyInstance(target.getClass().getClassLoader(),new Class<?>[]{Calculator.class},handler);
// 调用代理对象的方法int result = proxy.add(5, 3);System.out.println("Result: " + result);}
}
在上述代码中,我们定义了一个接口Calculator,并实现了InvocationHandler接口的CalculatorInvocationHandler类。在invoke方法中,我们可以在方法调用前后添加额外的逻辑。在Main类中,我们创建了真正的计算类对象,并使用Proxy类的newProxyInstance方法创建代理对象。通过代理对象调用方法时,实际上会调用invoke方法,并在其中执行代理逻辑。
运行以上代码,你将看到额外的逻辑在方法调用前后被执行,并获得正确的计算结果。这就是JDK动态代理的基本原理。与静态代理相比,JDK动态代理更加灵活,可以适用于各种接口的代理场景。
CGLIB动态代理
CGLIB(Code Generation Library)是一个强大的第三方类库,用于在运行时扩展Java类的功能。它通过生成继承被代理类的子类,并重写父类的方法来实现动态代理。相比JDK动态代理,CGLIB动态代理不需要接口的支持,可以代理类而不仅仅是接口。
以下是使用CGLIB动态代理的基本步骤:
-
引入相关依赖:在项目中加入CGLIB的依赖,例如Maven项目可以添加以下依赖:
<dependency><groupId>cglib</groupId><artifactId>cglib</artifactId><version>3.3.0</version> </dependency>
-
定义一个被代理的类:不需要实现接口的普通类。
-
创建MethodInterceptor对象:MethodInterceptor是CGLIB提供的核心接口,包含一个intercept方法,在该方法中编写处理逻辑。
-
使用Enhancer创建代理对象:Enhancer是CGLIB提供的用于创建代理对象的类。通过设置父类、接口、拦截器等参数,调用create方法动态生成代理对象。
-
通过代理对象调用方法:通过代理对象调用方法,实际上会触发MethodInterceptor的intercept方法,并在该方法中执行具体的代理逻辑。
下面是一个简单的示例代码:
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
// 定义被代理的类
class Calculator {public int add(int a, int b) {return a + b;}
}
// 实现MethodInterceptor接口
class CalculatorMethodInterceptor implements MethodInterceptor {@Overridepublic Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {// 在方法调用之前添加额外逻辑System.out.println("Before calculation...");
// 调用真正对象的方法Object result = proxy.invokeSuper(obj, args);
// 在方法调用之后添加额外逻辑System.out.println("After calculation...");
return result;}
}
public class Main {public static void main(String[] args) {// 创建Enhancer对象Enhancer enhancer = new Enhancer();
// 设置父类(被代理类)enhancer.setSuperclass(Calculator.class);
// 设置拦截器enhancer.setCallback(new CalculatorMethodInterceptor());
// 创建代理对象Calculator proxy = (Calculator) enhancer.create();
// 调用代理对象的方法int result = proxy.add(5, 3);System.out.println("Result: " + result);}
}
在上述代码中,我们定义了一个被代理的类Calculator,并实现了CGLIB的MethodInterceptor接口来编写代理逻辑。通过设置父类和拦截器,使用Enhancer类创建代理对象。通过代理对象调用方法时,实际上会触发MethodInterceptor的intercept方法,并在其中执行代理逻辑。
运行以上代码,你将看到额外的逻辑在方法调用前后被执行,并获得正确的计算结果。这就是CGLIB动态代理的基本原理。与JDK动态代理不同,CGLIB动态代理不需要接口的支持,可以代理普通类。然而,由于使用了继承机制,CGLIB不能代理被标记为final的类和方法。
JDK动态代理和CGLIB两种动态代理的比较
JDK动态代理和CGLIB动态代理是两种常用的代理实现方式,它们具有不同的特点和适用场景。下面是它们的区别以及各自的优缺点:
JDK动态代理:
-
基于接口:JDK动态代理只能代理接口,需要目标类实现一个或多个接口。
-
使用Java反射机制:JDK动态代理是通过Proxy类和InvocationHandler接口实现的,利用Java反射机制生成代理类和代理实例。
-
平台独立性:JDK动态代理是Java标准库的一部分,因此具有很好的平台独立性,不依赖第三方库。
-
性能较低:相比CGLIB动态代理,JDK动态代理在生成代理类和调用方法时的性能较差。这是由于JDK动态代理在生成代理类时需要使用反射,以及在代理时涉及到方法调用的转发。
-
无法代理final类和方法:JDK动态代理由于基于接口,因此无法代理被标记为final的类和方法。
CGLIB动态代理:
-
基于继承:CGLIB动态代理可以直接代理普通类,不需要实现接口。它通过继承目标类的方式实现代理。
-
使用ASM字节码操作库:CGLIB动态代理使用ASM库操作字节码,在运行时动态生成代理类。
-
性能较高:相对于JDK动态代理,CGLIB动态代理在生成代理类和调用方法时的性能更高。这是因为CGLIB动态代理直接继承目标类,省去了方法调用的转发。
-
无法代理final方法:由于CGLIB动态代理是通过继承实现的,因此无法代理被标记为final的方法。但是,可以代理被final修饰的类。
综合来说,JDK动态代理和CGLIB动态代理各有优缺点:
-
JDK动态代理适用于代理接口的场景,具有很好的平台独立性,但性能较差。
-
CGLIB动态代理适用于代理普通类的场景,性能较高,但对final方法和类的代理受限。
因此,在选择动态代理方式时,需根据具体的需求和场景来选择适合的代理方式。
hashcode和equals如何使用
hashCode()和equals()是Java中的两个重要方法,都源自于java.lang.Object,用于对象的比较和哈希映射。下面是它们的使用方法:
-
hashCode()方法:
-
hashCode()方法用于计算对象的哈希码(hash code),返回一个int类型的值。
-
hashCode()方法的常规约定是,对于相等的对象,调用hashCode()方法应该返回相同的值。然而,对于不相等的对象,hashCode()方法返回相同的值并不是必需的。
-
在重写equals()方法时,通常也需要同时重写hashCode()方法,以保证在存储对象的哈希集合(如HashMap、HashSet)中能正常工作。
-
重写hashCode()方法时,应遵循以下原则:
-
如果两个对象通过equals()方法比较是相等的,则它们的hashCode()方法的返回值必须相等。
-
如果两个对象通过equals()方法比较不相等(即对象不相等),它们的hashCode()方法的返回值可以相等,也可以不相等。
-
-
-
equals()方法:
-
equals()方法用于比较两个对象是否相等,返回一个boolean类型的值。
-
默认情况下,equals()方法比较的是对象的引用,即判断两个对象是否指向同一个内存地址。但是,可以根据需要重写equals()方法,以便自定义对象的相等条件。
-
重写equals()方法时,应遵循以下原则:
-
对称性:如果a.equals(b)返回true,则b.equals(a)也应返回true。
-
自反性:对于任何非null的引用值x,x.equals(x)都应返回true。
-
传递性:如果a.equals(b)返回true,且b.equals(c)返回true,则a.equals(c)也应返回true。
-
一致性:对于任何非null的引用值x和y,多次调用x.equals(y)应始终返回相同的结果,前提是对象上没有修改导致equals()比较的结果发生变化。
-
对于任何非null的引用值x,x.equals(null)都应返回false。
-
-
异常分类
在Java中,异常分为三种不同的类型:
-
受检异常(Checked Exception): 受检异常是指在代码中明确需要进行处理的异常,在方法声明中通过throws关键字声明,或者在方法内部通过try-catch语句进行捕获和处理。受检异常通常表示程序可能面临的外部环境异常,需要程序员在代码中显式处理,否则编译时会报错。例如,IOException、SQLException等。
-
运行时异常(Runtime Exception): 运行时异常是指在程序执行过程中可能出现的异常,通常是由程序错误或异常情况引起的。与受检异常不同的是,运行时异常不要求在代码中显式处理,并且也不需要在方法声明中声明throws关键字。当发生运行时异常时,如果没有进行显式处理,则会沿着方法调用栈向上抛出,直到被捕获或导致程序终止。例如,NullPointerException、ArrayIndexOutOfBoundsException等。
-
错误(Error): 错误是指无法通过代码来处理的严重问题,通常是由虚拟机或系统错误引起的。错误表示JVM或系统发生了严重的问题,无法恢复和处理,一般不需要程序员进行处理。例如,OutOfMemoryError、StackOverflowError等。
Java异常类继承自Throwable类,其中受检异常继承自Exception,运行时异常继承自RuntimeException,错误继承自Error。通过了解和正确处理异常,可以增加程序的可靠性,并提供适当的错误处理和容错机制。
Java异常处理方式

在Java中,有三种主要的异常处理方式:
-
try-catch块: 使用try-catch块可以捕获和处理异常。try块用于包含可能抛出异常的代码,catch块用于捕获并处理try块中抛出的异常。语法如下:
try {// 可能抛出异常的代码 } catch (ExceptionType1 e1) {// 处理异常类型 1 } catch (ExceptionType2 e2) {// 处理异常类型 2 } finally {// 可选的finally块,用于无论是否发生异常都会执行的代码 }在try块中,如果发生异常,则会跳转到与异常类型匹配的catch块,执行相应的处理代码。如果没有匹配的catch块,异常会传播到调用栈的上一层。无论是否发生异常,finally块中的代码都会被执行。
-
throws声明: 使用throws关键字可以在方法的声明中指定该方法可能抛出的异常。将异常以throws声明的方式抛出,可以将异常的处理责任交给调用该方法的地方。示例代码如下:
public void methodName() throws ExceptionType1, ExceptionType2 {// 可能抛出异常的代码 }当方法中的代码抛出了异常,调用该方法的地方可以选择捕获异常并处理,或者继续将异常上抛到更高层调用栈中进行处理。
-
使用finally块: finally块用于在try-catch块中的代码执行完毕后,无论是否发生异常,都会执行的代码块。finally块通常用于释放资源或进行必要的清理操作,例如关闭文件、释放资源等。语法如下:
try {// 可能抛出异常的代码 } catch (ExceptionType e) {// 处理异常 } finally {// 无论是否发生异常,都会执行的代码 }注意,finally块可以省略,try块和catch块可以单独存在。在没有catch块的情况下,try块中抛出的异常会被上层调用栈处理或继续上抛。
通过合理地使用这些异常处理方式,可以增加代码的健壮性和容错性,更好地处理异常情况,提高程序的稳定性。
throw,throws的区别
throw和throws是Java中异常处理的两个关键字,它们有以下区别:
-
throw关键字:
throw关键字用于手动抛出一个异常对象。它通常用于方法内部,用来抛出指定的异常,使得异常在方法内部被捕获或在调用栈中传播。例如:public void method() {if (condition) {throw new ExceptionType("Error occurred");} }在上述代码中,如果满足某个条件,
throw语句会抛出一个指定的异常对象,使得异常在方法内部被捕获或在调用栈中传播。 -
throws关键字:
throws关键字用于方法的声明中,用于指定该方法可能抛出的异常类型。它提供了一种声明异常的机制,使得调用该方法的代码可以采取相应的异常处理措施。例如:public void method() throws ExceptionType1, ExceptionType2 {// 可能抛出这两种异常类型的代码 }在上述代码中,
throws关键字后面列出了方法可能抛出的异常类型。当调用该方法时,调用者可以选择捕获这些异常并处理,或者将异常进一步上抛。
总结:
-
throw关键字用于手动抛出异常,表示在代码的某个条件成立时,主动地抛出异常对象。 -
throws关键字用于方法的声明中,指定该方法可能抛出的异常类型,并将异常处理的责任转移给调用该方法的代码。 -
throw抛出的异常是通过关键字new创建的对象,而throws声明的异常是指定的异常类型。 -
throw用于方法内部,throws用于方法的声明中。
需要注意的是,throw和throws关键字并不直接处理异常,它们只是在异常处理时的一种机制,实际的异常处理通过try-catch块或者上层调用栈来完成。
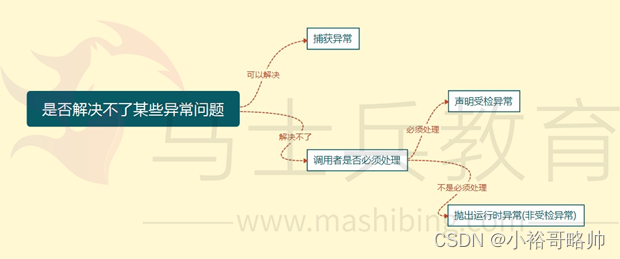
自定义异常在生产中如何应用
Java虽然提供了丰富的异常处理类,但是在项目中还会经常使用自定义异常,其主要原因是Java提供的异常类在某些情况下还是不能满足实际需球。例如以下情况: 1、系统中有些错误是符合Java语法,但不符合业务逻辑。
2、在分层的软件结构中,通常是在表现层统一对系统其他层次的异常进行捕获处理。
过滤器与拦截器的区别
过滤器(Filter)和拦截器(Interceptor)都是用于在Web应用中对请求进行处理和拦截的组件,但它们之间有一些区别:
-
含义:
-
过滤器(Filter):过滤器是在Servlet容器中执行的功能组件,对请求和响应进行预处理和后处理。它可以修改请求和响应的内容,或者对请求进行验证、安全性检查、日志记录等操作。
-
拦截器(Interceptor):拦截器也是用于对请求进行预处理和后处理的组件,但是拦截器是在Spring MVC框架内部执行的。它可以在请求被调度到处理器之前和之后进行一些公共的任务,如身份验证、权限检查、日志记录等。
-
-
使用场景:
-
过滤器(Filter):过滤器主要用于对HTTP请求和响应进行处理,可以对请求的URL、参数、头部等进行过滤和处理。
-
拦截器(Interceptor):拦截器主要用于对Controller的请求进行预处理和后处理,在请求到达Controller之前和离开Controller之后执行一些公共的任务、处理业务逻辑。
-
-
执行顺序:
-
过滤器(Filter):过滤器在Servlet容器中配置,并以链式结构执行。对于一个请求,过滤器按照配置的顺序依次执行,可以有多个过滤器配置,并且可以跨越多个Web应用。
-
拦截器(Interceptor):拦截器是在Spring MVC的上下文中配置的,并且只对DispatcherServlet的请求进行拦截。在一个请求中,拦截器的执行顺序由配置的顺序决定,同一个拦截器链上的多个拦截器按照配置的顺序依次执行。
-
总之,过滤器适合处理通用的URL级别的请求处理,例如编码转换、安全性验证等。拦截器更加适合对Controller级别的请求进行处理,例如权限检查、日志记录等。通过合理配置过滤器和拦截器,可以实现对请求的不同层面的处理和拦截,以满足不同业务需求。
过滤器(Filter)和拦截器(Interceptor)是在Web应用程序中用于处理和拦截请求的组件,它们之间有以下详细区别:
-
执行时机:
-
过滤器:过滤器是在Servlet容器中执行的,对请求和响应进行预处理和后处理。它们在请求进入Servlet容器之前被调用,并在请求离开容器后执行。过滤器可以在请求到达Servlet之前修改请求和响应内容,以及在响应返回给客户端之前对其进行处理。
-
拦截器:拦截器是在Spring MVC框架内部执行的,主要用于对Controller的请求进行预处理和后处理。拦截器在请求到达Controller之前和离开Controller之后执行,可以在请求处理之前做一些通用的准备工作,以及在请求处理完成后进行一些公共的收尾工作。
-
-
作用范围:
-
过滤器:过滤器是在Servlet容器中配置的,对请求进行过滤处理。过滤器可以作用于多个Servlet和多个Web应用程序,可以配置在web.xml中,并通过URL模式指定对哪些请求生效。
-
拦截器:拦截器是在Spring MVC的上下文中配置的,主要对DispatcherServlet的请求进行拦截处理。拦截器只作用于Spring MVC中的请求,并且只对DispatcherServlet的请求生效。
-
-
触发条件:
-
过滤器:过滤器可以对所有的请求进行过滤处理,包括静态资源请求。它们是基于URL模式进行匹配,可以以链式结构依次执行多个过滤器。
-
拦截器:拦截器只在DispatcherServlet中执行,并且只对具体的Controller请求进行拦截。拦截器是基于HandlerMapping进行匹配,只有当请求与某个Controller匹配成功时,相关的拦截器才会触发执行。
-
-
依赖框架:
-
过滤器:过滤器是Servlet容器的一部分,独立于其他框架。它们可以用于任何基于Servlet规范的Web应用程序,如JavaEE等。
-
拦截器:拦截器是Spring MVC框架的一部分,依赖于Spring MVC框架。它们可以利用Spring MVC框架提供的功能,如依赖注入、AOP等。
-
总的来说,过滤器和拦截器都是用于对请求进行处理和拦截的组件,但它们所处的执行时机、作用范围、触发条件和依赖框架等方面存在一些差异。根据具体的需求和场景,可以选择合适的过滤器或拦截器来实现请求的处理和拦截逻辑。
5,。配置文件不同
-
过滤器(Filter)配置:过滤器的配置是在web.xml文件中进行的,属于Servlet容器的配置。在web.xml中,可以通过
<filter>和<filter-mapping>元素来配置过滤器。其中,<filter>用于声明过滤器的类和名称,<filter-mapping>用于指定过滤器的名称和要过滤的URL模式或Servlet名称。 -
拦截器(Interceptor)配置:拦截器的配置是在Spring MVC的配置文件中进行的,属于Spring MVC框架的配置。要配置拦截器,需要在配置文件中声明拦截器,并将其添加到拦截器链中。可以使用
<mvc:interceptor>元素或在Java配置中使用addInterceptor()方法来配置拦截器。在配置拦截器时,需要指定拦截器类、要拦截的URL模式、排除的URL模式等。
Integer常见面试题
1.介绍一下自动装箱和自动拆箱
java的八种基本类型都对应着相应的包装类型
总的来说:装箱就是自动将基本数据类型转换为包装器类型;拆箱就是自动将包装器类型转换为基本数据类型。所以在运算赋值过程中,会自动进行拆箱和装箱。
拆箱装箱的过程 :
1)拆箱:Integer total = 99
实际上是调用了Integer total = Integer.valueOf(99) 这句代码
2)装箱:nt totalprim = total;
实际上行是调用了 int totalprim = total.intValue();这句代码
但是实际上拆箱装箱需要考虑常量池的存在!(下面会讲到)
2. Integer创建对象的几种方式和区别
在JVM虚拟机中有一块内存为常量池,常量池中除了包含代码中所定义的各种基本类型(如int、long等等)和对象型(如String及数组)的常量值还,还包含一些以文本形式出现的符号引用
对于基本数据,常量池对每种基本数据都有一个区间,在此区间中的数,都从常量池中存取共享!但是除了new创建对象的方式除外。
以Integer为例:
(-128——127为一个区间)
Integer total = 99
这句赋值的确是会是自动装箱,但是返回的地址却不是在堆中,而是在常量池中,因为99属于【-128,,127】区间。也就是说以这种方式创建的对象,都是取的一个地址!
Integer t1 = 99;//常量池
Integer t2 = 99;//常量池
System.out.println(t1 == t2);//true
Integer total = 128;
这句赋值也会进行自动装箱,但是由于不在区间内,所以取到的对象地址是在堆中。不会进行对象共享!每次都会创建新的对象
Integer t3 = 128;//堆
Integer t4 = 128;//堆
System.out.println(t3 == t4);//false
Integer total = Integer.valueOf(99) ,Integer total= Integer.valueOf(128)
这两种创建方式和上面的赋值是一样的,因为上面的自动装箱源码调用的就是这个方法!
Integer tt1 = Integer.valueOf(99);//常量池
Integer tt2 = Integer.valueOf(99);//常量池
System.out.println(tt1 == tt2);//true
Integer tt3 = Integer.valueOf(128);//堆
Integer tt4 = Integer.valueOf(128);//堆
System.out.println(tt3 == tt4);//fasle
Integer total = new Integer(99)
使用new关键字创建对象的时候,就不需要考虑常量池的问题,无论数值大小,都从堆中创建!
Integer n1 = new Integer(99);//堆
Integer n2 = new Integer(99);//堆
System.out.println(n1 == n2);//fasle
总结:
1)一共三种创建方式:
前两种是看似不同,其实内部机制完全相同,因为会自动装箱!但是一定要注意到常量池的问题。
Integer t1 = 99;//常量池
Integer t4 = 128;//堆
Integer tt2 = Integer.valueOf(99);//常量池
Integer tt4 = Integer.valueOf(128);//堆
Integer n1 = new Integer(99);//堆
Integer n2 = new Integer(99);//堆
2)在面试过程中如果遇到考查Integer的情况,基本都会给一段代码,判断输出是true还是fasle,这时候只要仔细分析对象的创建方式,以及返回的地址来源即可!
3.常见考查代码
总结:
两个数都是用==或者Integer.valueOf()方法赋值的话,只要比较数的大小,在【-128,127】之间就相同,不在就不同
两个数都是用new关键字创建的话,无论数值大小,一定不同
一个数用new,一个数用==或者Integer.valueOf(),也一定不同!
Integer in= new Integer(127);
Integer in2 = new Integer(127);
System.out.println(in==in2);//false
System.out.println(in.equals(in2));//true
Integer in3= new Integer(128);
Integer in4 = new Integer(128);
System.out.println(in3==in4);//false
System.out.println(in3.equals(in4));//true
Integer in5= 128;
Integer in6 = 128;
System.out.println(in5==in6);//false
System.out.println(in5.equals(in6));//true
Integer in7= 127;
Integer in8 = 127;
System.out.println(in7==in8);//true
System.out.println(in7.equals(in8));//true
值传递和引用传递有什么区别
值传递和引用传递是传递参数时的两种不同方式,它们之间的区别主要在于传递的是什么。
1. **值传递**:
- 值传递是指将变量的值复制一份传递给函数或方法。
- 在值传递中,传递的是变量的实际值,而不是变量本身。
- 当函数或方法使用传递的参数时,会操作参数值的副本,原始变量不受影响。
- 在 Java 中,传递基本数据类型时是值传递的方式。
2. **引用传递**:
- 引用传递是指将变量的引用(内存地址)传递给函数或方法。
- 在引用传递中,传递的是变量的实际引用,函数或方法可以通过该引用访问和修改原始变量。
- 当函数或方法使用传递的引用时,操作的是原始变量的值,可以改变原始变量的状态。
- 在某些语言中支持引用传递,比如 C++,但在 Java 中并不存在“引用传递”的概念。
在 Java 中,虽然对象引用作为参数传递给方法时传递的是引用的副本(即地址的副本),但实际上 Java 是使用值传递的方式。因为传递的是引用的值(地址的副本),而不是引用本身。这意味着在方法内虽然可以改变对象状态,却无法改变引用指向的对象。
总的来说,Java 中只有值传递这一种传递参数的方式,但对于对象引用的处理方式与传统的值传递有一些微妙的区别。希望这个解答对你有所帮助。如有任何问题,请继续提问。
集合
集合和数组的区别
集合(Collection)和数组(Array)是在编程中常用的数据结构,它们有以下几点区别:
1. **数据类型**:
- 数组是一种固定大小的、存储相同数据类型元素的连续内存区域。
- 集合是一种动态大小的、可以存储不同数据类型对象的数据结构。
2. **长度/大小**:
- 数组的长度是固定的,一旦创建就无法改变。
- 集合是动态的,可以根据需要动态添加或删除元素,大小是可变的。
3. **类型**:
- 数组可以包含基本数据类型和对象类型。
- 集合一般是针对对象类型的,可以存储任意类型的对象。
4. **语法**:
- 数组的声明和初始化方式比较简单,如 `int[] arr = new int[5]`。
- 集合的声明和初始化需要使用相关的集合类,如 `List<String> list = new ArrayList<>()`。
5. **功能**:
- 集合提供了丰富的方法和功能,如增删改查、排序、遍历等。
- 数组的功能相对简单,主要是通过索引访问元素,没有内置的方法来进行常见操作。
6. **扩展性**:
- 集合比数组更具扩展性和灵活性,可以更方便地进行元素的增删改查操作。
- 数组在大小固定和数据类型一致的情况下使用更加高效。
总的来说,集合更加灵活和功能丰富,适用于动态数据结构的场景,而数组更适合于静态、大小固定的数据集合。在实际编程中,根据需要选择合适的数据结构来存储和操作数据,常常会根据特定的场景来选择使用数组或集合。希望以上区别对你有所帮助,如有任何问题或需要进一步了解,请随时提出。
集合框架底层数据结构
Java 集合框架中的不同集合类底层使用不同的数据结构来实现,下面是一些常见的集合类及其底层数据结构:
1. **ArrayList**:
- ArrayList 使用数组作为底层数据结构来存储元素。
- 当数组空间不足时,会进行扩容操作(通常是当前容量的 1.5 倍),以保证能够继续添加元素。
2. **LinkedList**:
- LinkedList 使用双向链表来存储元素。
- 链表的每个节点都保存了元素值以及指向前一个节点和后一个节点的引用。
3. **HashMap**:
- HashMap 使用哈希表(数组 + 链表/红黑树)来存储键值对。
- 哈希表通过键的哈希值来计算存储位置,解决哈希冲突的方法有拉链法和开放定址法。
4. **HashSet**:
- HashSet 内部使用 HashMap 来存储元素。
- HashSet 中的元素存储在 HashMap 的 key 中,value 则使用一个静态常量。
5. **TreeMap**:
- TreeMap 使用红黑树(Red-Black Tree)作为底层数据结构。
- 红黑树是一种自平衡二叉搜索树,可以保证元素按照 key 的自然顺序(或自定义比较器)排列。
6. **LinkedHashMap**:
- LinkedHashMap 继承自 HashMap,使用哈希表和双向链表来维护元素的顺序。
- 可以保持元素插入顺序或访问顺序不变。
这些是 Java 集合框架中一些常见集合类的底层数据结构,不同的数据结构在不同场景下有着各自的优劣势。了解集合类底层数据结构有助于更好地理解集合类的特性和性能表现,从而更好地选择适合的集合类来满足需求。希望以上信息能够帮助你理解集合框架中常见集合类的底层数据结构。如有任何问题或需要进一步了解,请随时提出。
线程安全的集合
在 Java 中,部分集合类是线程安全的,也就是说它们在多线程环境下可以安全地进行并发操作而无需额外的同步措施。以下是一些常见的线程安全集合类:
1. **Vector**:Vector 是一个线程安全的动态数组,与 ArrayList 类似,但所有的方法都是同步的。
2. **Stack**:Stack 是一个基于 Vector 实现的栈,也是线程安全的。
3. **Hashtable**:Hashtable 是一个线程安全的哈希表,与 HashMap 类似,但所有的方法都是同步的。
4. **Collections.synchronizedList(List<T> list)**:通过 Collections 工具类的 synchronizedList 方法可以创建一个线程安全的 List。
5. **ConcurrentHashMap**:ConcurrentHashMap 是 Java 并发包中提供的线程安全的哈希表实现,使用分段锁技术来提高并发性能。
6. **CopyOnWriteArrayList**:CopyOnWriteArrayList 是一个线程安全的动态数组,采用写时复制(Copy-On-Write)策略,在写操作时会复制一份新的数组,因此读操作不会阻塞写操作,适合读多写少的场景。
7. **CopyOnWriteArraySet**:CopyOnWriteArraySet 是 CopyOnWriteArrayList 的 Set 实现,也是线程安全的。
这些线程安全的集合类提供了在多线程环境下安全地操作集合的方法,避免了线程竞态条件和并发修改异常。在选择集合类时,根据具体的需求和场景来考虑是否需要线程安全的集合类。需要注意的是,虽然线程安全集合类可以提供基本的线程安全性,但在特定复杂场景下可能仍需要额外的同步控制。希望以上信息对你有所帮助,如有任何问题或需要进一步了解,请随时提出。
HashMap的put方法的具体流程?
HashMap 的 put 方法是向 HashMap 中添加键值对的方法,在 Java 中实现了哈希表的功能,其具体流程如下:
1. **计算键的哈希值**:首先,HashMap 会根据键的 hashCode 方法计算键的哈希值。如果键为 null,则哈希值为 0。
2. **计算存储位置**:接着,HashMap 根据哈希值以及 HashMap 的容量进行计算,确定键值对在数组中的存储位置(也称为桶(Bucket))。
3. **查找是否存在相同键**:在确定的存储位置上,HashMap 需要检查是否已经存在相同哈希值的键,如果存在相同哈希值的键,则需要继续比较键的 equals 方法来确定是否是同一个键。
4. **插入/替换键值对**:如果没有找到相同的键,则直接插入键值对;如果找到了相同的键,则会替换相同键的值。
5. **检查是否需要进行扩容**:在插入后,HashMap 会检查当前已存储的键值对数量是否超过了负载因子乘以容量(负载因子用于控制 HashMap 扩容的时机),如果超过,则会触发扩容操作。
6. **进行扩容**:扩容操作会创建一个新的数组,将现有的键值对重新计算存储位置后插入到新数组中,同时更新 HashMap 的容量和阈值等属性。
总的来说,HashMap 的 put 方法首先根据键的哈希值确定存储位置,然后根据键的 equals 方法比较键是否相同,最后进行插入或替换操作。在插入过程中会根据负载因子是否超过阈值来触发扩容操作。这样可以保证 HashMap 的高效性和动态扩容能力。
希望以上信息对你有所帮助,如有任何问题或需要进一步了解,请随时提出。
HashMap原理是什么,在jdk1.7和1.8中有什么区别
HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为 null。HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使 HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。我们用下面这张图来介绍
HashMap 的结构。
JAVA7 实现
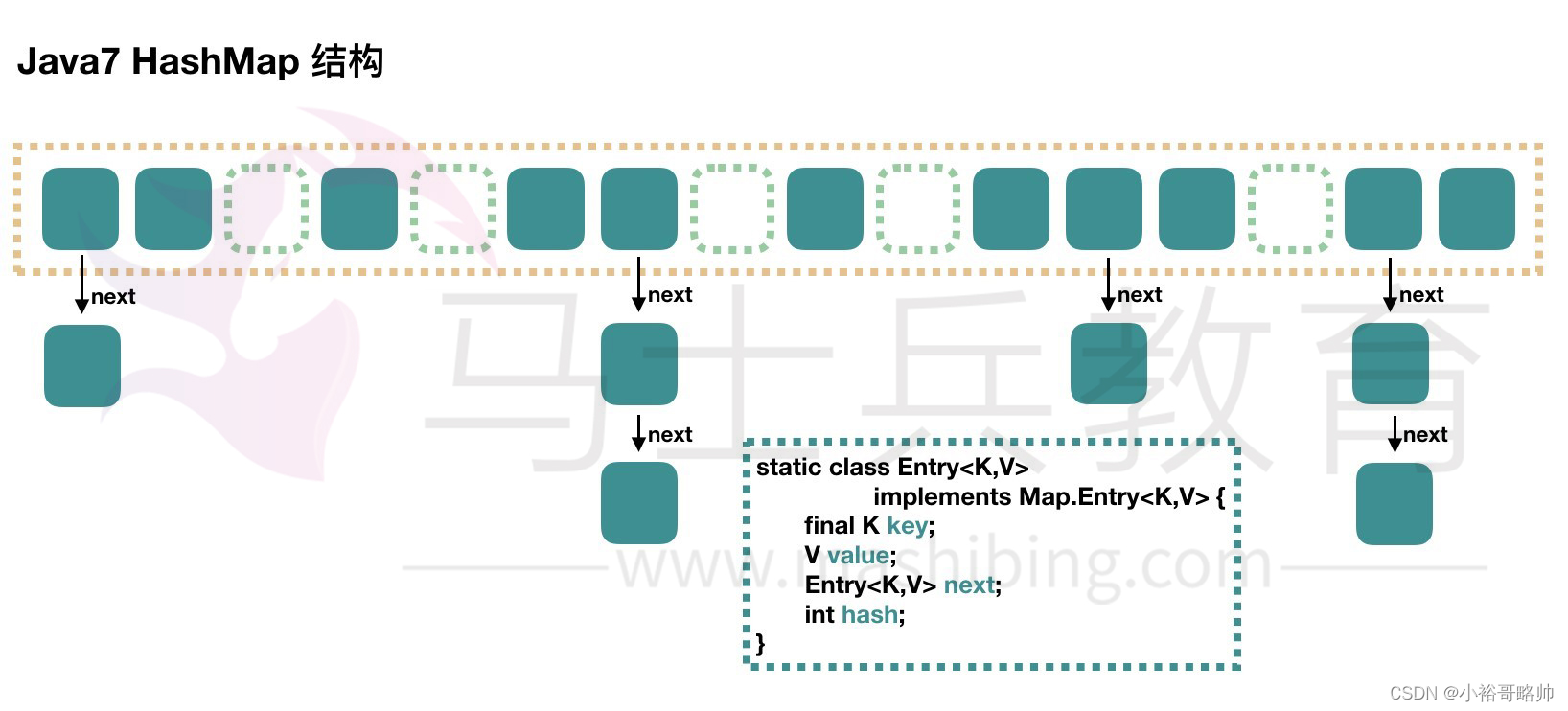
大方向上,HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色
的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
-
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
-
loadFactor:负载因子,默认为 0.75。
-
threshold:扩容的阈值,等于 capacity * loadFactor
JAVA8实现
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决
于链表的长度,为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。红黑树的插入和查找性能更好。
-
JDK 1.8中,对于哈希碰撞的处理采用了尾插法,新的键值对会添加到链表末尾而不是头部,以减少链表的倒置。

#
HashMap和HashTable的区别及底层实现
HashMap和HashTable对比
HashMap和HashTable是Java中两个常用的键值对存储的类,它们之间有几个主要的区别和底层实现方式:
-
线程安全性:
-
HashMap是非线程安全的,不保证在多线程环境下的并发操作的正确性。
-
HashTable是线程安全的,通过在关键方法上添加synchronized关键字来保证线程安全性。但这也导致了在多线程环境下的性能相对较低。
-
-
键值对的null值:
-
HashMap允许键和值都为null。即可以插入null键,也可以插入null值。
-
HashTable不允许键或者值为null,如果插入null键或者值会抛出NullPointerException。
-
-
初始容量和扩容:
-
HashMap的初始容量默认为16,加载因子默认为0.75。当HashMap的元素个数超过容量和加载因子的乘积时,会进行扩容,扩容为原来容量的两倍。
-
HashTable的初始容量默认为11,加载因子默认为0.75。当元素个数超过容量和加载因子的乘积时,会进行扩容,扩容为原来容量的两倍再加1。
-
-
底层实现:
-
HashMap底层使用数组和链表/红黑树的数据结构实现。当链表长度超过阈值(8)时,链表会转换为红黑树,以提高查找效率。
-
HashTable底层使用数组和单向链表的数据结构实现。
-
总的来说,HashMap相对于HashTable来说更常用,它在性能上表现更好,允许null键和null值,但不是线程安全的。HashTable适用于旧版本的Java或者需要在多线程环境下进行操作时,但需要注意它的性能相对较低。
6.HashMap链表插入节点的方式 在Java1.7中,插入链表节点使用头插法。Java1.8中变成了尾插法
7.Java1.8的hash()中,将hash值高位(前16位)参与到取模的运算中,使得计算结果的不确定性增强,降低发生哈希碰撞的概率
image-20211018214936478
HashMap扩容优化:
扩容以后,1.7对元素进行rehash算法,计算原来每个元素在扩容之后的哈希表中的位置,1.8借助2倍扩容机制,元素不需要进行重新计算位置
JDK 1.8 在扩容时并没有像 JDK 1.7 那样,重新计算每个元素的哈希值,而是通过高位运算(e.hash & oldCap)来确定元素是否需要移动,比如 key1 的信息如下:

使用 e.hash & oldCap 得到的结果,高一位为 0,当结果为 0 时表示元素在扩容时位置不会发生任何变化,而 key 2 信息如下

高一位为 1,当结果为 1 时,表示元素在扩容时位置发生了变化,新的下标位置等于原下标位置 + 原数组长度hashmap,**不必像1.7一样全部重新计算位置**
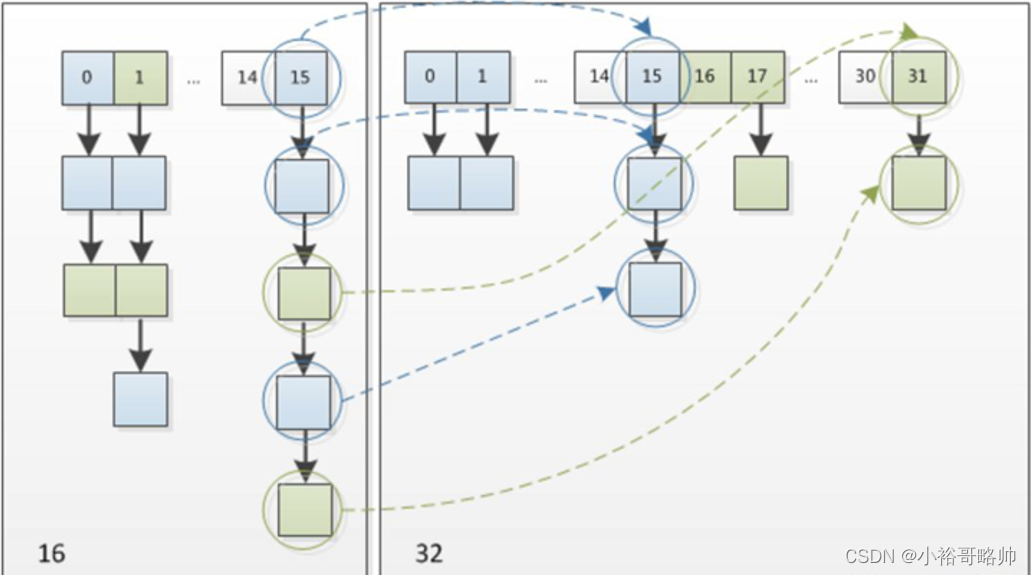
为什么hashmap扩容的时候是两倍?
查看源代码
在存入元素时,放入元素位置有一个 (n-1)&hash 的一个算法,和hash&(newCap-1),这里用到了一个&位运算符

当HashMap的容量是16时,它的二进制是10000,(n-1)的二进制是01111,与hash值得计算结果如下
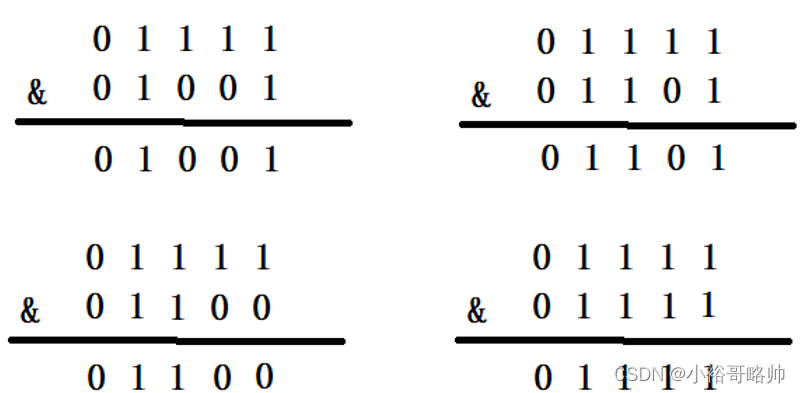
下面就来看一下HashMap的容量不是2的n次幂的情况,当容量为10时,二进制为01010,(n-1)的二进制是01001,向里面添加同样的元素,结果为
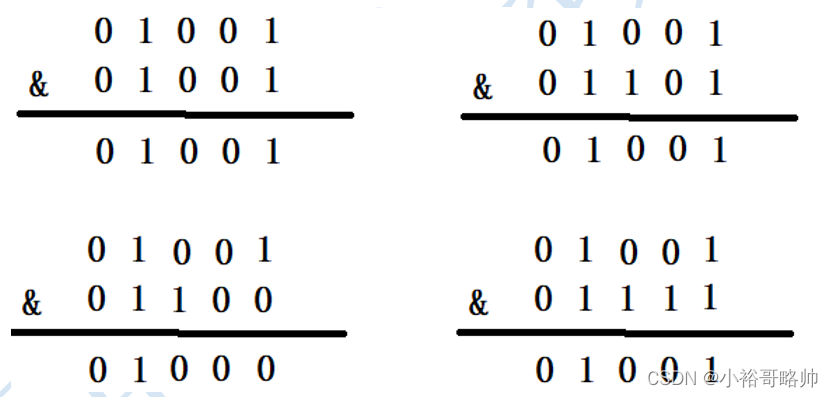
可以看出,有三个不同的元素进过&运算得出了同样的结果,严重的hash碰撞了
只有当n的值是2的N次幂的时候,进行&位运算的时候,才可以只看后几位,而不需要全部进行计算
在翻倍扩容的情况下,原来的N个元素将被分布到新数组的2N个位置上,这种分布方式可以有效地减少哈希冲突发生的可能性,提高了HashMap的查询和插入性能。
hashmap线程安全的方式?
HashMap本身是非线程安全的,也就是说在并发环境中同时读写HashMap可能会导致数据不一致的问题。如果在多线程环境中需要使用HashMap,可以使用以下几种方式来确保线程安全性:
-
使用Collections工具类的synchronizedMap方法,将HashMap包装成一个线程安全的Map。示例代码如下:
Map<Object, Object> synchronizedMap = Collections.synchronizedMap(new HashMap<>());
这种方式会对整个Map进行同步,保证每个操作的原子性和互斥性,但是会降低并发性能。
-
使用ConcurrentHashMap类,它是Java提供的线程安全的哈希表实现。ConcurrentHashMap采用了锁分段技术,在不同的段上实现了独立的锁,并发性能比使用Collections.synchronizedMap要好。示例代码如下:
Map<Object, Object> concurrentHashMap = new ConcurrentHashMap<>();
ConcurrentHashMap允许多个线程同时读取,且读操作不需要加锁。只有写操作需要加锁,并且写操作只锁定当前操作的段,不会导致整个Map被锁定。
-
使用并发工具类来控制对HashMap的访问,例如使用读写锁(ReentrantReadWriteLock)来保证读写操作的安全性。在读多写少的场景下,读取操作可以同时进行,而写入操作会独占锁。示例代码如下:
ReentrantReadWriteLock lock = new ReentrantReadWriteLock(); Map<Object, Object> map = new HashMap<>(); // 写操作 lock.writeLock().lock(); try {// 更新或者添加操作map.put(key, value); } finally {lock.writeLock().unlock(); } // 读操作 lock.readLock().lock(); try {// 读取操作Object value = map.get(key); } finally {lock.readLock().unlock(); }使用读写锁可以提高并发性能,因为读操作可以同时进行,读线程之间不会互斥。
请注意,在多线程环境中使用HashMap时,仅仅通过加锁来保证线程安全性可能不足以满足高并发的需求,还需要根据具体的业务场景来选择合适的方式。
说一下 HashSet 的实现原理? - HashSet如何检查重复?HashSet是如何保证数据不可重复的?
HashSet 是 Java 中的一种集合类,它基于哈希表实现。下面是 HashSet 的实现原理和它如何保证数据不可重复的方式:
1. **HashSet 的实现原理**:
- HashSet 内部是通过 HashMap 来实现的,实际上 HashSet 只是对 HashMap 中 key 集合的一种包装。
- 在 HashSet 内部使用 HashMap 存储元素,以元素作为 key,value 则为一个固定的对象(比如 `Object`)。
- 当向 HashSet 中添加元素时,实际上是将元素作为 key 放入 HashMap 中,value 则为一个固定的对象。
- HashSet 利用 HashMap 的 key 值不能重复的特性,保证元素不可重复。
2. **HashSet 如何检查重复**:
- 当向 HashSet 中添加元素时,首先会调用元素的 `hashCode()` 方法得到哈希码,然后根据哈希码计算出在数组中的位置。
- 如果该位置上已经存储了元素(存在哈希冲突),则会调用元素的 `equals()` 方法来比较新元素和已有元素是否相等。
- 如果新元素和已有元素相等(`equals()` 返回 true),则将新元素覆盖原有元素;否则将新元素插入到数组中。
- HashSet 通过哈希码和 equals 方法来检查重复元素,并确保数据不可重复。
通过利用哈希表的特性,HashSet 能够实现高效地检查重复元素,并保证集合中不包含重复数据。在使用 HashSet 时,需要保证集合中元素正确实现了 `hashCode()` 和 `equals()` 方法,以确保 HashSet 能够正确地工作。
ArrayList和LinkedList有什么区别
ArrayList和LinkedList是Java中常用的两种集合类,它们在实现上有以下区别:
-
数据结构:ArrayList是基于数组实现的动态数组,而LinkedList是基于双向链表实现的。
-
随机访问:ArrayList支持高效的随机访问,可以通过索引直接访问元素,时间复杂度为O(1)。而LinkedList需要从头节点或尾节点开始遍历,时间复杂度为O(n)。
-
插入和删除:LinkedList在插入和删除元素时,其时间复杂度是O(1),因为只需要修改节点的指针即可。而ArrayList在插入和删除元素时,需要移动其他元素,时间复杂度为O(n)。
-
内存占用:由于ArrayList是基于数组实现的,它需要分配一块连续的内存空间来存储元素。而LinkedList需要额外的空间来存储节点之间的指针关系。因此,如果需要存储大量的元素,ArrayList的内存占用通常比LinkedList更小。
根据上述区别,可以得出一些适用场景:
-
当需要高效的随机访问和修改元素时,使用ArrayList更合适。
-
当需要频繁执行插入和删除操作,而对随机访问性能要求较低时,使用LinkedList更合适。
-
LinkedList可以作为栈和队列使用
需要根据具体的场景和需求来选择使用ArrayList还是LinkedList。在实际开发中,可以根据数据访问和操作的特点选择最适合的集合类。
ArrayList扩容
每个ArrayList实例都有一个容量,该容量是指来存储列表元素的数组的大小,该容量至少等于列表数组的大小,随着ArrayList的不断添加元素,其容量也在自动增长,自动增长会将原来数组的元素向新的数组进行copy。如果提前预判数据量的大小,可在构造ArrayList时指定其容量。
-
创建新数组:根据当前数组的容量和扩容策略(一般是当前容量的1.5倍或2倍),创建一个新的数组。
-
复制元素:将当前数组中的元素逐个复制到新数组中。
-
更新引用:将ArrayList内部的引用指向新数组,以便后续的操作使用新数组。
没有指定初始容量时,初始数组容量为10
4.垃圾回收:旧的数组因为没有被引用,会由垃圾回收器进行回收。
Array和ArrayList的区别
Array(数组)和ArrayList(数组列表)在以下几个方面有区别:
-
大小固定 vs 可变大小:
-
数组的大小是固定的,在创建时需要指定长度,并且不能动态地改变数组的大小。
-
ArrayList的大小是可变的,可以动态地添加、删除和修改元素,它会根据需要自动增加或减少内部存储空间。
-
-
数据类型:
-
数组可以存储任意类型的元素,包括基本数据类型(如int、char等)和引用数据类型(如对象、字符串等)。
-
ArrayList只能存储引用数据类型的元素,不能直接存储基本数据类型,需要使用对应的包装类(如Integer、Character等)进行包装。
-
-
内存分配和访问:
-
数组在内存中是连续分配的,可以通过索引直接访问元素,访问速度更快。
-
ArrayList内部使用数组作为存储结构,但是它还包含了额外的逻辑来支持动态调整大小和其他操作。访问ArrayList中的元素需要通过方法调用。
-
-
功能和操作:
-
数组提供了一组基本操作,如读取和修改元素,通过索引查找元素等。但数组没有提供高级的集合操作,需要手动编写代码来实现例如过滤、映射等功能。
-
ArrayList实现了Java的List接口,提供了一组丰富的方法来操作其中的元素,如添加、删除、查找、排序等,同时还支持集合操作(如集合交并补、过滤、映射等)。
-
总结起来,数组适合在大小固定且需要高效访问的情况下使用,而ArrayList适用于需要动态大小和更多操作的场景。如果频繁进行插入、删除等操作,并且不需要直接访问元素的具体索引位置,使用ArrayList更加方便。
List和数组之间的转换
在Java中,可以使用以下方法进行List和数组之间的转换:
-
List转换为数组:
-
使用List的
toArray()方法将List转换为数组。示例代码如下:List<String> list = new ArrayList<>(); // 添加元素到List list.add("Hello"); list.add("World"); // 转换为数组 String[] array = list.toArray(new String[0]);注意:在将List转换为数组时,需要提供一个指定类型和大小的数组作为参数。如果指定的数组大小小于List的大小,则方法内部会创建一个新的数组,并将List中的元素复制到新数组中。
-
-
数组转换为List:
-
使用Arrays类的
asList()方法将数组转换为List。注意,这种方式返回的是一个固定大小的List,不能进行添加、删除操作。示例代码如下:String[] array = { "Hello", "World" }; // 转换为List List<String> list = Arrays.asList(array);通过
asList()得到的List是一个固定大小的List,对其进行添加或删除操作会抛出UnsupportedOperationException异常。 -
另一种方式是使用ArrayList的构造方法,将数组中的元素逐个添加到ArrayList中。示例代码如下:
String[] array = { "Hello", "World" }; // 转换为List List<String> list = new ArrayList<>(Arrays.asList(array));这种方式得到的是一个可操作的ArrayList,可以对其进行添加、删除等操作。
-
需要注意的是,在进行List和数组之间的转换时,数组中的数据类型必须与List中的元素类型一致。
数组类型和集合


##
高并发中的集合有哪些问题
第一代线程安全集合类
Vector、Hashtable
是怎么保证线程安排的: 使用synchronized修饰方法*
缺点:效率低下
第二代线程非安全集合类
ArrayList、HashMap
线程不安全,但是性能好,用来替代Vector、Hashtable
使用ArrayList、HashMap,需要线程安全怎么办呢?
使用 Collections.synchronizedList(list); Collections.synchronizedMap(m);
底层使用synchronized代码块锁 虽然也是锁住了所有的代码,但是锁在方法里边,并所在方法外边性能可以理解为稍有提高吧。毕竟进方法本身就要分配资源的
第三代线程安全集合类
在大量并发情况下如何提高集合的效率和安全呢?
java.util.concurrent.*
ConcurrentHashMap:
CopyOnWriteArrayList :
CopyOnWriteArraySet: 注意 不是CopyOnWriteHashSet*
底层大都采用Lock锁(1.8的ConcurrentHashMap不使用Lock锁),保证安全的同时,性能也很高。
ConcurrentHashMap底层原理是什么?
1.7 数据结构: 内部主要是一个Segment数组,而数组的每一项又是一个HashEntry数组,元素都存在HashEntry数组里。因为每次锁定的是Segment对象,也就是整个HashEntry数组,所以又叫分段锁。
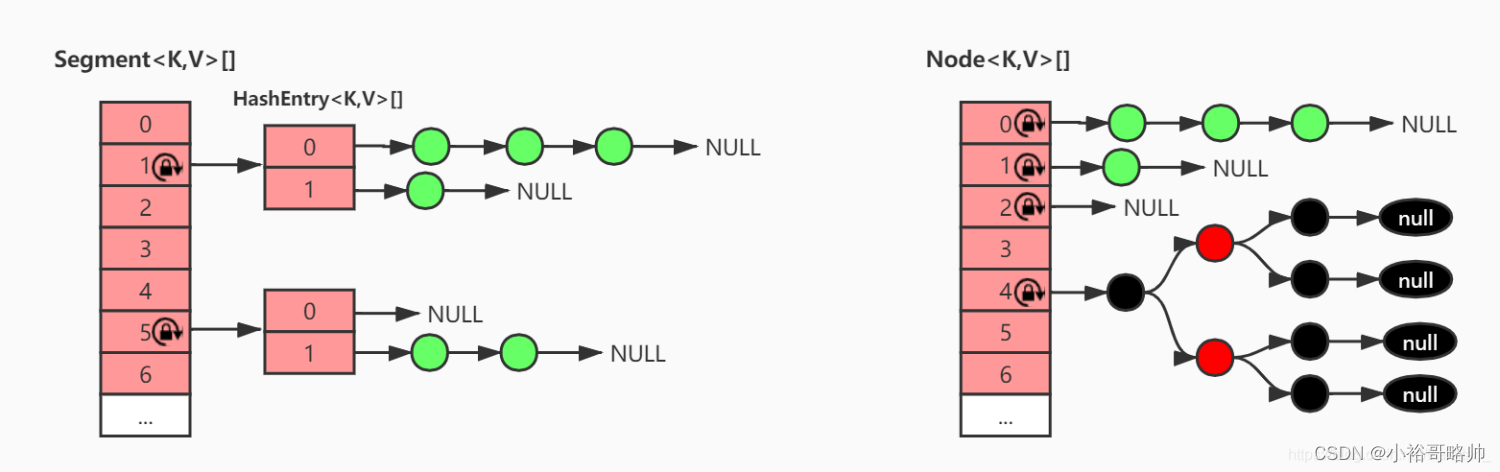
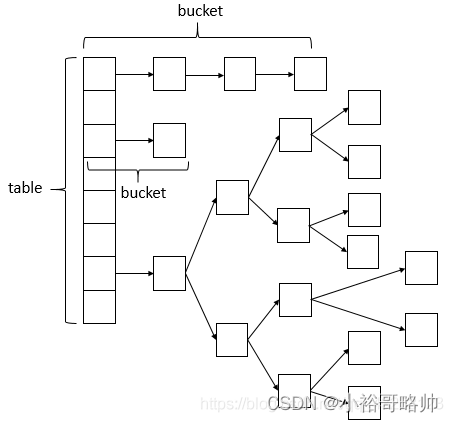
1.8 数据结构: 与HashMap一样采用:数组+链表+红黑树
底层原理则是采用锁链表或者红黑树头结点,相比于HashTable的方法锁,力度更细,是对数组(table)中的桶(链表或者红黑树)的头结点进行锁定,这样锁定,只会影响数组(table)当前下标的数据,不会影响其他下标节点的操作,可以提高读写效率。 putVal执行流程:
-
判断存储的key、value是否为空,若为空,则抛出异常
-
计算key的hash值,随后死循环(该循环可以确保成功插入,当满足适当条件时,会主动终止),判断table表为空或者长度为0,则初始化table表
-
根据hash值获取table中该下标对应的节点,如果该节点为空,则根据参数生成新的节点,并以CAS的方式进行更新,并终止死循环。
-
如果该节点的hash值是MOVED(-1),表示正在扩容,则辅助对该节点进行转移。
-
对数组(table)中的节点,即桶的头结点进行锁定,如果该节点的hash大于等于0,表示此桶是链表,然后对该桶进行遍历(死循环),寻找链表中与put的key的hash值相等,并且key相等的元素,然后进行值的替换,如果到链表尾部都没有符合条件的,就新建一个node,然后插入到该桶的尾部,并终止该循环遍历。
-
如果该节点的hash小于0,并且节点类型是TreeBin,则走红黑树的插入方式。
-
判断是否达到转化红黑树的阈值,如果达到阈值,则链表转化为红黑树。
相关文章:
面试笔记系列二之java基础+集合知识点整理及常见面试题
目录 Java面向对象有哪些特征,如何应用 Java基本数据类型及所占字节 Java中重写和重载有哪些区别 jdk1.8的新特性有哪些 内部类 1. 成员内部类(Member Inner Class): 2. 静态内部类(Static Nested Class&#…...
搭建LNMP环境并搭建论坛和博客
目录 一、LNMP架构原理 二、编译安装Nginx 三、编译安装MySQL 四、编译安装PHP 五、配置Nginx支持PHP解析 六、安装论坛 七、安装博客 一、LNMP架构原理 LNMP架构,是指在Linux平台下,由运行Nginx的web服务器,运行PHP的动态页面解析程序…...

蓝桥杯刷题2
1. 修建灌木 import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scan new Scanner(System.in);int n scan.nextInt();for (int i 1;i < n1;i){int distance Math.max(i-1,n-i);System.out.println(distance*2);}scan.close…...

低代码与国产化部署:软件开发的未来趋势与应用实践
在数字化时代,软件开发已经成为企业创新和竞争力提升的关键。随着我国科技实力的不断提升,国产化部署逐渐成为软件开发领域的重要趋势。与此同时,低代码技术的发展也为国产化部署提供了新的机遇。本文将探讨如何在软件开发过程中充分发挥两者…...
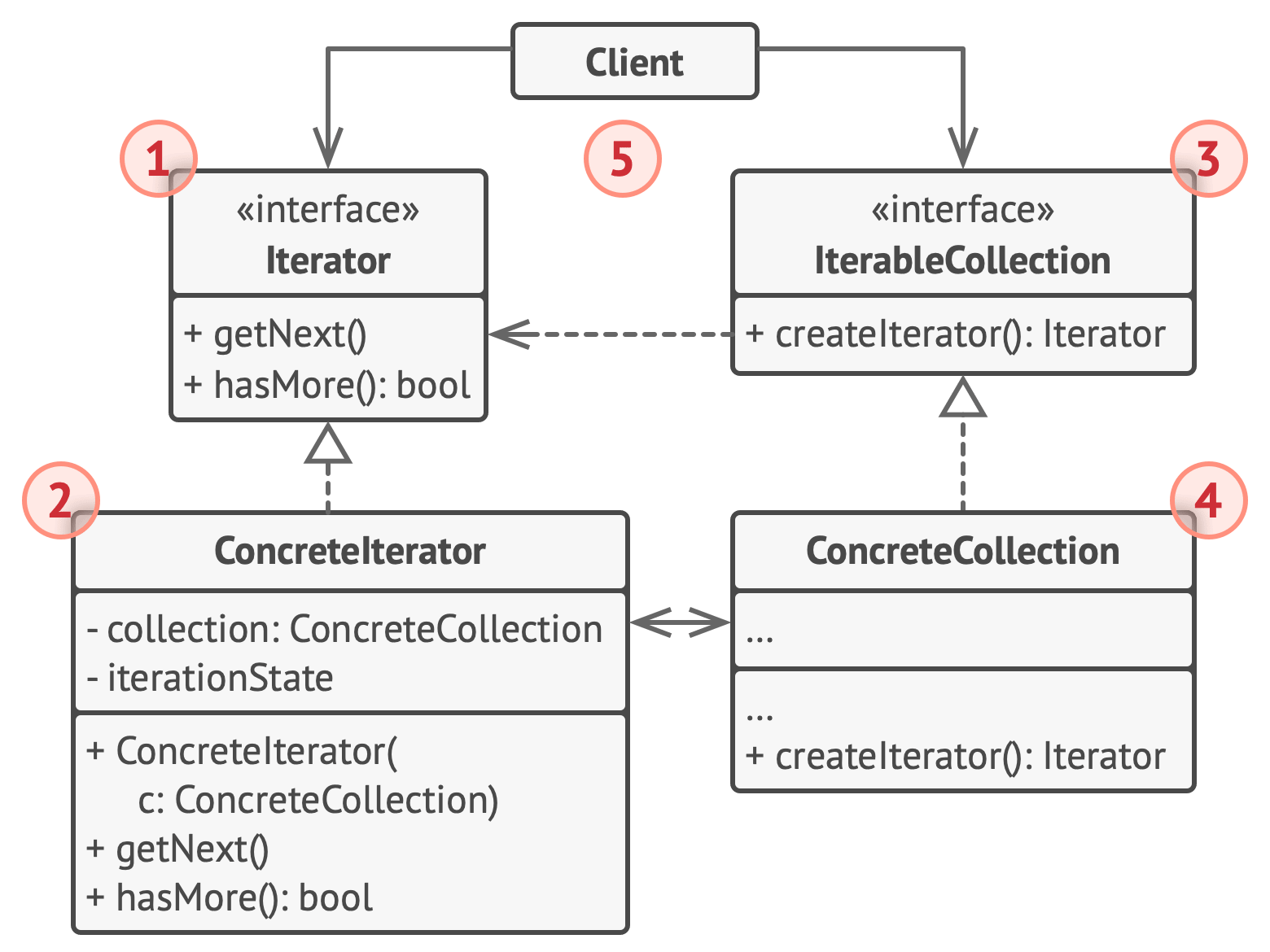
【Python笔记-设计模式】迭代器模式
一、说明 迭代器模式是一种行为设计模式,让你能在不暴露集合底层表现形式(列表、栈和树等)的情况下遍历集合中所有的元素。 (一) 解决问题 遍历聚合对象中的元素,而不需要暴露该对象的内部表示 (二) 使用场景 需要对聚合对象…...
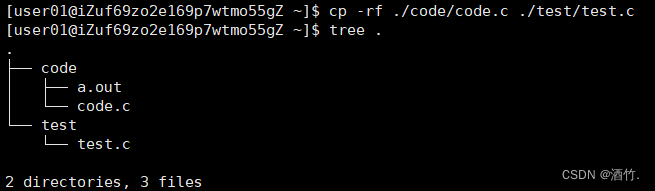
Linux基本指令(上)
在Linux中,将文件夹称为目录,后面的内容都与目录相关。 1. ls指令 语法: ls [选项][目录或文件] 功能:对于目录,该命令列出该目录下的所有子目录与文件。对于文件,将列出文件名以及其他信息。 常用选项 …...
浅谈XSS简单漏洞xss-labs-master(初级)
一、环境以及xss漏洞简介 网上很多gethub自己下就行 XSS简介: 当用户访问被XSS注入的网页,XSS代码就会被提取出来。用户浏览器就会解析这段XSS代码,也就是说用户被攻击了。 用户最简单的动作就是使用浏览器上网,并且浏览器中有J…...
WordPress分类目录ID怎么看?如何查找WordPress标签ID?
在WordPress网站中,我们需要判断某篇文章是否属于某个分类目录,或者是否拥有某个标签,那么就需要用到分类目录ID和标签ID,那么WordPress分类目录ID怎么看?如何查找WordPress标签ID?下面boke112百科就跟大家…...
:用户操作)
达梦数据库基础操作(一):用户操作
达梦数据库基础操作(一):用户操作 1 达梦运行状态 SELECT banner as 版本信息 FROM v$version;1.2 达梦版本号 SELECT banner as 版本信息 FROM v$version;1.3 用户相关操作 默认用户名密码:SYSDBA/SYSDBA 注意:在哪个数据库下创建的用户…...
Java进阶(锁)——锁的升级,synchronized与lock锁区别
目录 引出Java中锁升级synchronized与lock锁区别 缓存三兄弟:缓存击穿、穿透、雪崩缓存击穿缓存穿透缓存雪崩 总结 引出 Java进阶(锁)——锁的升级,synchronized与lock锁区别 Java中锁升级 看一段代码: public class…...

Flask+Gunicorn中文乱码解决方案
在使用FlaskGunicorn部署应用时,发现中文的输出存在乱码的现象。这是因为Python的默认编码是ASCII,而ASCII并不支持中文字符。 解决Python中文乱码问题的首要任务是确保使用合适的编码方式。当你处理中文字符时,应该使用UTF-8编码。UTF-8是一…...

vue3的开发小技巧
「总之岁月漫长,然而值得等待。」 目录 父组件调用子组件函数 父组件调用子组件函数 ref, defineExpose //父组件 代码 <child ref"ch">this.$refs.ch.fn();//子组件 函数抛出 const fn () > { }; defineExpose({ fn });...
十三、Qt多线程与线程安全
一、多线程程序 QThread类提供了管理线程的方法:一个对象管理一个线程一般从QThread继承一个自定义类,重载run函数 1、实现程序 (1)创建项目,基于QDialog (2)添加类,修改基于QThr…...

今日话题:---自卑
自卑是一种普遍存在的心理现象,它可能源于个人对自身能力、外貌、社会地位等方面的不满意或不自信。自卑感可能会导致消极的情绪和行为,如焦虑、抑郁、逃避现实等。然而,适度的自卑感也可能激发个人努力提升自己,从而实现自我成长…...
Unity 预制体与变体
预制体作用: 更改预制体,则更改全部的以预制体复制出的模型。 生成预制体: 当你建立好了一个模型,从层级拖动到项目中即可生成预制体。 预制体复制模型: 将项目中的预制体拖动到层级中即可复制。或者选择物体复制粘贴。…...
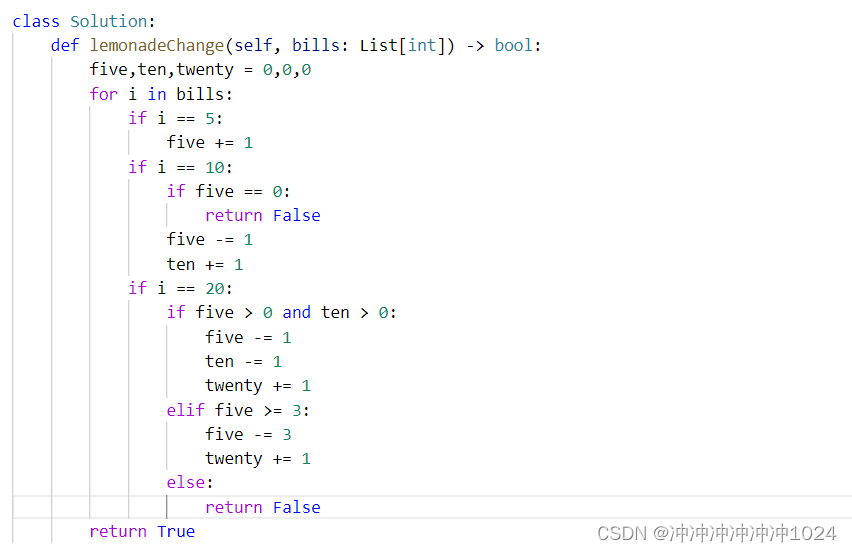
leetcode:860.柠檬水找零
题意:按照支付顺序,进行支付,能够正确找零。 解题思路:贪心策略:针对支付20的客人,优先选择消耗10而不是消耗5,因为5可以用来找零10或20. 代码实现:有三种情况(代表三种…...

Python程序的流程
归纳编程学习的感悟, 记录奋斗路上的点滴, 希望能帮到一样刻苦的你! 如有不足欢迎指正! 共同学习交流! 🌎欢迎各位→点赞 👍 收藏⭐ 留言📝 年轻是我们唯一拥有权利去编制梦想的时…...
C语言可以干些什么?C语言主要涉及哪些IT领域?
C语言可以干些什么?C语言主要涉及哪些IT领域? 在开始前我有一些资料,是我根据网友给的问题精心整理了一份「C语言的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家…...
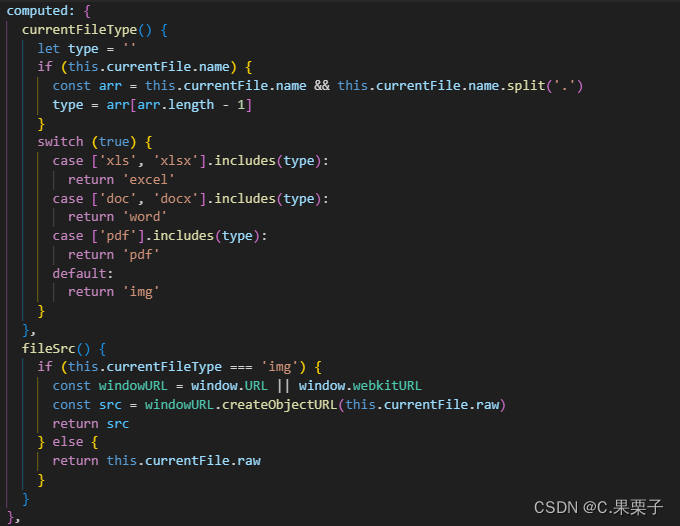
element-ui附件上传及在线查看详细总结,后续赋源码
一、附件上传 1、在element-ui上面复制相应代码 a、accept"image/*,.pdf,.docx,.xlsx,.doc,.xls" 是规定上传文件的类型,若是不限制,可以直接将accept‘all即可; b、:action"action" 这个属性就是你的上传附件的地址&am…...

投标中excel表格常用功能梳理
投标中excel表格常用功能梳理: 1.投标报价调整报价的办法: 目的调整报价,把“红框”的报价增加30%,50% 增加30%的步骤: 步骤1:选择1.3 复制(ctrlc) 步骤2:选择性黏贴 …...

Qt文件操作避坑指南:QFile与QTextStream/QDataStream的最佳搭配方案
Qt文件操作避坑指南:QFile与QTextStream/QDataStream的最佳搭配方案 在Qt开发中,文件操作是每个开发者都会遇到的基础需求。无论是配置文件读写、数据持久化还是日志记录,都离不开对文件系统的操作。Qt提供了QFile、QTextStream和QDataStream…...

WinUtil:5分钟掌握Windows系统管理工具的一键优化与软件批量安装
WinUtil:5分钟掌握Windows系统管理工具的一键优化与软件批量安装 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 还在为Windows系…...

WebLaTeX:免费在线LaTeX编辑器的终极解决方案,告别复杂安装的学术写作新体验
WebLaTeX:免费在线LaTeX编辑器的终极解决方案,告别复杂安装的学术写作新体验 【免费下载链接】WebLaTex A complete alternative for Overleaf with VSCode Web Git Integration Copilot Grammar & Spell Checker Live Collaboration Support. …...

USB-Disk-Ejector:重新定义Windows设备管理的终极革命
USB-Disk-Ejector:重新定义Windows设备管理的终极革命 【免费下载链接】USB-Disk-Ejector A program that allows you to quickly remove drives in Windows. It can eject USB disks, Firewire disks and memory cards. It is a quick, flexible, portable alterna…...
)
告别‘黑盒’:用改进的U-Net+数据增强,实战搞定皮肤镜图像分割(附ISIC 2017数据集代码)
医学图像分割实战:改进U-Net在皮肤镜分析中的应用详解 当第一次看到皮肤镜图像时,大多数人都会被那些看似随机分布的色素沉着和复杂纹理所困惑。作为一名长期从事医学影像分析的研究者,我清楚地记得刚开始接触ISIC数据集时的挫败感——那些模…...

5分钟掌握Open-Lyrics:AI音频转字幕终极指南
5分钟掌握Open-Lyrics:AI音频转字幕终极指南 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。 项目地址: htt…...

3分钟掌握PPTist模板系统:打造专业演示文稿的终极秘籍
3分钟掌握PPTist模板系统:打造专业演示文稿的终极秘籍 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing fo…...

Qwen2.5-7B-Instruct效果展示:复杂嵌套JSON Schema生成+字段类型校验
Qwen2.5-7B-Instruct效果展示:复杂嵌套JSON Schema生成字段类型校验 1. 模型能力概览 Qwen2.5-7B-Instruct是通义千问最新发布的7B参数规模指令调优模型,在结构化数据生成方面展现出卓越能力。本次展示聚焦其两大核心能力: 复杂嵌套JSON S…...

**发散创新:基于Python与ROS的机器人运动控制实战解析**在现代机器人系统开发
发散创新:基于Python与ROS的机器人运动控制实战解析 在现代机器人系统开发中,运动控制是实现精准操作的核心环节。本文将以 Python ROS(Robot Operating System) 为技术栈,深入剖析如何通过编程语言完成对差速驱动机器…...

WebLaTeX:革命性免费在线LaTeX编辑器,3分钟开启高效学术写作
WebLaTeX:革命性免费在线LaTeX编辑器,3分钟开启高效学术写作 【免费下载链接】WebLaTex A complete alternative for Overleaf with VSCode Web Git Integration Copilot Grammar & Spell Checker Live Collaboration Support. Based on GitHub…...