JAVA设计模式——创建型模式
JAVA设计模式——创建型模式
- 一、创建型模式
- 1.单例模式(Singleton Pattern)
- 1.1 饿汉式
- 1.2 懒汉式
- 1.3 双重检验锁(double check lock)(DCL)
- 1.4 静态内部类
- 1.5 枚举
- 1.6 破坏单例的几种方式与解决方法
- 1.6.1 反序列化
- 1.6.2 反射
- 1.7 容器式单例
- 1.8 ThreadLocal单例
- 1.9 总结
- 2.工厂方法模式(Factory Method)
- 2.1 简单工厂模式
- 2.1.1 基础版
- 2.1.2 升级版
- 2.1.3 总结
- 2.2 工厂方法模式
- 2.2.1 代码实现
- 2.2.2 总结
- 3.抽象工厂模式(Abstract Factory)
- 3.1 代码实现
- 3.2 总结
- 4.原型模式(Prototype)
- 4.1 浅克隆
- 4.2 深克隆
- 4.3 克隆破坏单例与解决办法
- 4.4 总结
- 5.建造者模式(Builder)
- 5.1 常规写法
- 5.2 简化写法
- 5.3 链式写法
- 5.4 总结


一、创建型模式
1.单例模式(Singleton Pattern)
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
1.1 饿汉式
特点:类加载时就初始化,线程安全(在本类中创建本类对象)
// 构造方法私有化
private Singleton() {}// 饿汉式创建单例对象
private static Singleton singleton = new Singleton();public static Singleton getInstance() {return singleton;
}
1.2 懒汉式
特点:第一次调用才初始化,避免内存浪费。
/** 懒汉式创建单例模式 由于懒汉式是非线程安全, 所以加上线程锁保证线程安全*/
private static Singleton singleton;public static synchronized Singleton getInstance() {if (singleton == null) {singleton = new Singleton();}return singleton;
}
1.3 双重检验锁(double check lock)(DCL)
特点:安全且在多线程情况下能保持高性能
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getInstance() {if (singleton == null) {synchronized (Singleton.class) {if (singleton == null) {singleton = new Singleton();}}}return singleton;
}
但是在多线程的情况下,可能出现空指针的问题——volatile
1.4 静态内部类
特点:效果类似DCL,只适用于静态域
private static class SingletonHolder {private static final Singleton INSTANCE = new Singleton();}private Singleton (){}public static final Singleton getInstance() {return SingletonHolder.INSTANCE;}
1.5 枚举
特点:自动支持序列化机制,绝对防止多次实例化
枚举类实现单例模式是极力推荐的单例实现模式,因为枚举类型是线程安全的,并且只会装载一次,设计者充分的利用了枚举的这个特性来实现单例模式,枚举的写法非常简单,而且枚举类型是所用单例实现中唯一种不会被破坏的单例实现模式。
public enum Singleton {INSTANCE;
}
1.6 破坏单例的几种方式与解决方法
1.6.1 反序列化
Singleton singleton = Singleton.getInstance();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("D:/test.txt"));
oos.writeObject(singleton);
oos.flush();
oos.close();ObjectInputStream ois = new ObjectInputStream(new FileInputStream("D:/test.txt"));
Singleton singleton1 = (Singleton)ois.readObject();
ois.close();
System.out.println(singleton);//com.ruoyi.base.mapper.Singleton@50134894
System.out.println(singleton1);//com.ruoyi.base.mapper.Singleton@5ccd43c2
可以看到反序列化后,两个对象的地址不一样了,那么这就是违背了单例模式的原则了,解决方法只需要在单例类里加上一个readResolve()方法即可,原因就是在反序列化的过程中,会检测readResolve()方法是否存在,如果存在的话就会反射调用readResolve()这个方法。
private Object readResolve() {return singleton;}
//com.ruoyi.base.mapper.Singleton@50134894
//com.ruoyi.base.mapper.Singleton@50134894
1.6.2 反射
Singleton singleton = Singleton.getInstance();
Class<Singleton> singletonClass = Singleton.class;
Constructor<Singleton> constructor = singletonClass.getDeclaredConstructor();
constructor.setAccessible(true);
Singleton singleton1 = constructor.newInstance();
System.out.println(singleton);//com.ruoyi.base.mapper.Singleton@32a1bec0
System.out.println(singleton1);//com.ruoyi.base.mapper.Singleton@22927a81
同样可以看到,两个对象的地址不一样,这同样是违背了单例模式的原则,解决办法为使用一个布尔类型的标记变量标记一下即可,代码如下:
private static boolean singletonFlag = false;private Singleton() {if (singleton != null || singletonFlag) {throw new RuntimeException("试图用反射破坏异常");}singletonFlag = true;}
但是这种方法假如使用了反编译,获得了这个标记变量,同样可以破坏单例,代码如下:
Class<Singleton> singletonClass = Singleton.class;
Constructor<Singleton> constructor = singletonClass.getDeclaredConstructor();
constructor.setAccessible(true);
Singleton singleton = constructor.newInstance();
System.out.println(singleton); // com.ruoyi.base.mapper.Singleton@32a1bec0Field singletonFlag = singletonClass.getDeclaredField("singletonFlag");
singletonFlag.setAccessible(true);
singletonFlag.setBoolean(singleton, false);
Singleton singleton1 = constructor.newInstance();
System.out.println(singleton1); // com.ruoyi.base.mapper.Singleton@5e8c92f4
如果想使单例不被破坏,那么应该使用枚举的方式去实现单例模式,枚举是不可以被反射破坏单例的。
1.7 容器式单例
当程序中的单例对象非常多的时候,则可以使用容器对所有单例对象进行管理,如下:
public class ContainerSingleton {private ContainerSingleton() {}private static Map<String, Object> singletonMap = new ConcurrentHashMap<>();public static Object getInstance(Class clazz) throws Exception {String className = clazz.getName();// 当容器中不存在目标对象时则先生成对象再返回该对象if (!singletonMap.containsKey(className)) {Object instance = Class.forName(className).newInstance();singletonMap.put(className, instance);return instance;}// 否则就直接返回容器里的对象return singletonMap.get(className);}public static void main(String[] args) throws Exception {SafetyDangerLibrary instance1 = (SafetyDangerLibrary)ContainerSingleton.getInstance(SafetyDangerLibrary.class);SafetyDangerLibrary instance2 = (SafetyDangerLibrary)ContainerSingleton.getInstance(SafetyDangerLibrary.class);System.out.println(instance1 == instance2); // true}
}
1.8 ThreadLocal单例
不保证整个应用全局唯一,但保证线程内部全局唯一,以空间换时间,且线程安全。
public class ThreadLocalSingleton {private ThreadLocalSingleton(){}private static final ThreadLocal<ThreadLocalSingleton> threadLocalInstance = ThreadLocal.withInitial(() -> new ThreadLocalSingleton());public static ThreadLocalSingleton getInstance(){return threadLocalInstance.get();}public static void main(String[] args) {new Thread(() -> {System.out.println(Thread.currentThread().getName() + "-----" + ThreadLocalSingleton.getInstance());System.out.println(Thread.currentThread().getName() + "-----" + ThreadLocalSingleton.getInstance());}).start();new Thread(() -> {System.out.println(Thread.currentThread().getName() + "-----" + ThreadLocalSingleton.getInstance());System.out.println(Thread.currentThread().getName() + "-----" + ThreadLocalSingleton.getInstance());}).start();
// Thread-0-----com.ruoyi.library.domain.vo.ThreadLocalSingleton@53ac93b3
// Thread-1-----com.ruoyi.library.domain.vo.ThreadLocalSingleton@7fe11afc
// Thread-0-----com.ruoyi.library.domain.vo.ThreadLocalSingleton@53ac93b3
// Thread-1-----com.ruoyi.library.domain.vo.ThreadLocalSingleton@7fe11afc}
}
可以看到上面线程0和1他们的对象是不一样的,但是线程内部,他们的对象是一样的,这就是线程内部保证唯一。
1.9 总结
适用场景:
- 需要确保在任何情况下绝对只需要一个实例。如:
ServletContext,ServletConfig,ApplicationContext,DBPool,ThreadPool等。
优点:
- 在内存中只有一个实例,减少了内存开销。
- 可以避免对资源的多重占用。
- 设置全局访问点,严格控制访问。
缺点:
- 没有接口,扩展困难。
- 如果要扩展单例对象,只有修改代码,没有其它途径。
2.工厂方法模式(Factory Method)
2.1 简单工厂模式
简单工厂模式不是23种设计模式之一,他可以理解为工厂模式的一种简单的特殊实现。
2.1.1 基础版

// 工厂类
public class CoffeeFactory {public Coffee create(String type) {if ("americano".equals(type)) {return new Americano();}if ("mocha".equals(type)) {return new Mocha();}if ("cappuccino".equals(type)) {return new Cappuccino();}return null;}
}
// 产品基类
public interface Coffee {}// 产品具体类,实现产品基类接口
public class Cappuccino implements Coffee {}
基础版是最基本的简单工厂的写法,传一个参数过来,判断是什么类型的产品,就返回对应的产品类型。但是这里有一个问题,就是参数是字符串的形式,这就很容易会写错,比如少写一个字母,或者小写写成了大写,就会无法得到自己想要的产品类了,同时如果新加了产品,还得在工厂类的创建方法中继续加if,于是就有了升级版的写法。
2.1.2 升级版
// 使用反射创建对象
// 加一个static变为静态工厂
public static Coffee create(Class<? extends Coffee> clazz) throws Exception {if (clazz != null) {return clazz.newInstance();}return null;
}
升级版就很好的解决基础版的问题,在创建的时候在传参的时候不仅会有代码提示,保证不会写错,同时在新增产品的时候只需要新增产品类即可,也不需要再在工厂类的方法里面新增代码了。
2.1.3 总结
适用场景:
- 工厂类负责创建的对象较少。
- 客户端只需要传入工厂类的参数,对于如何创建的对象的逻辑不需要关心。
优点:
- 只需要传入一个正确的参数,就可以获取你所需要的对象,无须知道创建的细节。
缺点:
- 工厂类的职责相对过重,增加新的产品类型的时需要修改工厂类的判断逻辑,违背了开闭原则。
- 不易于扩展过于复杂的产品结构。
2.2 工厂方法模式
工厂方法模式是指定义一个创建对象的接口,让实现这个接口的类来决定实例化哪个类,工厂方法让类的实例化推迟到子类中进行。
工厂方法模式主要有以下几种角色:
- 抽象工厂(Abstract Factory):提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法来创建产品。
- 具体工厂(ConcreteFactory):主要是实现抽象工厂中的抽象方法,完成具体产品的创建。
- 抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能。
- 具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它和具体工厂之间一一对应。
2.2.1 代码实现

// 抽象工厂
public interface CoffeeFactory {Coffee create();
}
// 具体工厂
public class CappuccinoFactory implements CoffeeFactory {@Overridepublic Coffee create() {return new Cappuccino();}
}
// 抽象产品
public interface Coffee {
}
// 具体产品
public class Cappuccino implements Coffee {
}
2.2.2 总结
适用场景:
- 创建对象需要大量的重复代码。
- 客户端(应用层)不依赖于产品类实例如何被创建和实现等细节。
- 一个类通过其子类来指定创建哪个对象。
优点:
- 用户只需要关系所需产品对应的工厂,无须关心创建细节。
- 加入新产品符合开闭原则,提高了系统的可扩展性。
缺点:
- 类的数量容易过多,增加了代码结构的复杂度。
- 增加了系统的抽象性和理解难度。
3.抽象工厂模式(Abstract Factory)
抽象工厂模式是指提供一个创建一系列相关或相互依赖对象的接口,无须指定他们具体的类。


工厂方法模式中考虑的是一类产品的生产,如电脑厂只生产电脑,电话厂只生产电话,这种工厂只生产同种类的产品,同种类产品称为同等级产品,也就是说,工厂方法模式只考虑生产同等级的产品,但是现实生活中许多工厂都是综合型工厂,能生产多等级(种类)的产品,如上面说的电脑和电话,本质上他们都属于电器,那么他们就能在电器厂里生产出来,而抽象工厂模式就将考虑多等级产品的生产,将同一个具体工厂所生产的位于不同等级的一组产品称为一个产品族,如上图所示纵轴是产品等级,也就是同一类产品;横轴是产品族,也就是同一品牌的产品,同一品牌的产品产自同一个工厂。
抽象工厂模式的主要角色如下:
- 抽象工厂(Abstract Factory):提供了创建产品的接口,它包含多个创建产品的方法,可以创建多个不同等级的产品。
- 具体工厂(Concrete Factory):主要是实现抽象工厂中的多个抽象方法,完成具体产品的创建。
- 抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能,抽象工厂模式有多个抽象产品。
- 具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间是多对一的关系。
3.1 代码实现
// 咖啡店 抽象工厂
public interface CoffeeShopFactory {// 咖啡类Coffee createCoffee();// 甜点类Dessert createDessert();
}
// 美式风格工厂
public class AmericanFactory implements CoffeeShopFactory {@Overridepublic Coffee createCoffee() {return new Americano();}@Overridepublic Dessert createDessert() {return new Cheesecake();}
}
// 意式风格工厂
public class ItalyFactory implements CoffeeShopFactory {@Overridepublic Coffee createCoffee() {return new Cappuccino();}@Overridepublic Dessert createDessert() {return new Tiramisu();}
}

类图
3.2 总结
产品族:一系列相关的产品,整合到一起有关联性
产品等级:同一个继承体系
适用场景:
- 客户端(应用层)不依赖于产品类实例如何被创建和实现等细节。
- 强调一系列相关的产品对象(属于同一产品族)一起使用创建对象需要大量重复的代码。
- 提供一个产品类的库,所有的产品以同样的接口出现,从而使客户端不依赖于具体实现。
优点:
- 当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
缺点:
- 当产品族中需要增加一个新的产品时,所有的工厂类都需要进行修改。
4.原型模式(Prototype)
原型模式是指原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。调用者不需要知道任何创建细节,不调用构造函数。
原型模式包含如下角色:
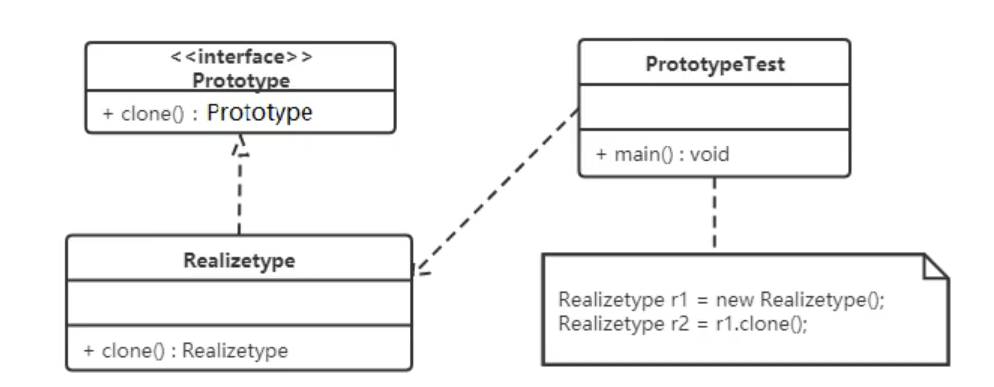
- 抽象原型类:规定了具体原型对象必须实现的的 clone() 方法。
- 具体原型类:实现抽象原型类的 clone() 方法,它是可被复制的对象。
- 访问类:使用具体原型类中的 clone() 方法来复制新的对象。
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student implements Cloneable {private String name;private String sex;private Integer age;@Overrideprotected Object clone() throws CloneNotSupportedException {return super.clone();}public static void main(String[] args) throws Exception{Student stu1 = new Student("张三", "男", 18);Student stu2 = (Student)stu1.clone();stu2.setName("李四");System.out.println(stu1);// Student(name=张三, sex=男, age=18)System.out.println(stu2);// Student(name=李四, sex=男, age=18)}
}
可以看到,把一个学生复制过来,只是改了姓名而已,其他属性完全一样没有改变,需要注意的是,一定要在被拷贝的对象上实现Cloneable接口,否则会抛出CloneNotSupportedException异常。
4.1 浅克隆
创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址。
@Data
public class Clazz implements Cloneable {private String name;private Student student;@Overrideprotected Object clone() throws CloneNotSupportedException {return super.clone();}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student implements Serializable {private String name;private String sex;private Integer age;
}public static void main(String[] args) throws Exception{Clazz clazz1 = new Clazz();clazz1.setName("高三一班");Student stu1 = new Student("张三", "男", 18);clazz1.setStudent(stu1);System.out.println(clazz1); // Clazz(name=高三一班, student=Student(name=张三, sex=男, age=18))Clazz clazz2 = (Clazz)clazz1.clone();Student stu2 = clazz2.getStudent();stu2.setName("李四");System.out.println(clazz1); // Clazz(name=高三一班, student=Student(name=李四, sex=男, age=18))System.out.println(clazz2); // Clazz(name=高三一班, student=Student(name=李四, sex=男, age=18))}
可以看到,当修改了stu2的姓名时,stu1的姓名同样也被修改了,这说明stu1和stu2是同一个对象,这就是浅克隆的特点,对具体原型类中的引用类型的属性进行引用的复制。同时,这也可能是浅克隆所带来的弊端,因为结合该例子的原意,显然是想在班级中新增一名叫李四的学生,而非让所有的学生都改名叫李四,于是我们这里就要使用深克隆。
4.2 深克隆
创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。
@Data
public class Clazz implements Cloneable, Serializable {private String name;private Student student;@Overrideprotected Object clone() throws CloneNotSupportedException {return super.clone();}protected Object deepClone() throws IOException, ClassNotFoundException {ByteArrayOutputStream bos = new ByteArrayOutputStream();ObjectOutputStream oos = new ObjectOutputStream(bos);oos.writeObject(this);ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());ObjectInputStream ois = new ObjectInputStream(bis);return ois.readObject();}
}public static void main(String[] args) throws Exception{Clazz clazz1 = new Clazz();clazz1.setName("高三一班");Student stu1 = new Student("张三", "男", 18);clazz1.setStudent(stu1);Clazz clazz3 = (Clazz)clazz1.deepClone();Student stu3 = clazz3.getStudent();stu3.setName("王五");System.out.println(clazz1); // Clazz(name=高三一班, student=Student(name=张三, sex=男, age=18))System.out.println(clazz3); // Clazz(name=高三一班, student=Student(name=王五, sex=男, age=18))}
可以看到,当修改了stu3的姓名时,stu1的姓名并没有被修改了,这说明stu3和stu1已经是不同的对象了,说明Clazz中的Student也被克隆了,不再指向原有对象地址,这就是深克隆。这里需要注意的是,Clazz类和Student类都需要实现Serializable接口,否则会抛出NotSerializableException异常。
4.3 克隆破坏单例与解决办法
PS:上面例子有的代码,这里便不重复写了,可以在上面的代码基础上添加以下代码
// Clazz类
private static Clazz clazz = new Clazz();
private Clazz(){}
public static Clazz getInstance() {return clazz;}// 测试public static void main(String[] args) throws Exception{Clazz clazz1 = Clazz.getInstance();Clazz clazz2 = (Clazz)clazz1.clone();System.out.println(clazz1 == clazz2); // false}
可以看到clazz1和clazz2并不相等,也就是说他们并不是同一个对象,也就是单例被破坏了。
解决办法也很简单,首先第一个就是不实现Cloneable接口即可,但是不实现Cloneable接口进行clone则会抛出CloneNotSupportedException异常。第二个方法就是重写clone()方法即可,如下:
@Overrideprotected Object clone() throws CloneNotSupportedException {return clazz;}// 测试输出System.out.println(clazz1 == clazz2) // true
可以看到,上面clazz1和clazz2是相等的,即单例没有被破坏。
另外我们知道,单例就是只有一个实例对象,如果重写了clone()方法保证单例的话,那么通过克隆出来的对象则不可以重新修改里面的属性,因为修改以后就会连同克隆对象一起被修改,所以是需要单例还是克隆,在实际应用中需要好好衡量。
4.4 总结
适用场景:
- 类初始化消耗资源较多。
- new产生的一个对象需要非常繁琐的过程(数据准备、访问权限等)。
- 构造函数比较复杂。
- 循环体中生产大量对象时。
优点:
- 性能优良,Java自带的原型模式是基于内存二进制流的拷贝,比直接new一个对象性能上提升了许多。
- 可以使用深克隆方式保存对象的状态,使用原型模式将对象复制一份并将其状态保存起来,简化了创建的过程。
缺点:
- 必须配备克隆(或者可拷贝)方法。
- 当对已有类进行改造的时候,需要修改代码,违反了开闭原则。
- 深克隆、浅克隆需要运用得当。
5.建造者模式(Builder)
建造者模式是将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。用户只需指定需要建造的类型就可以获得对象,建造过程及细节不需要了解。
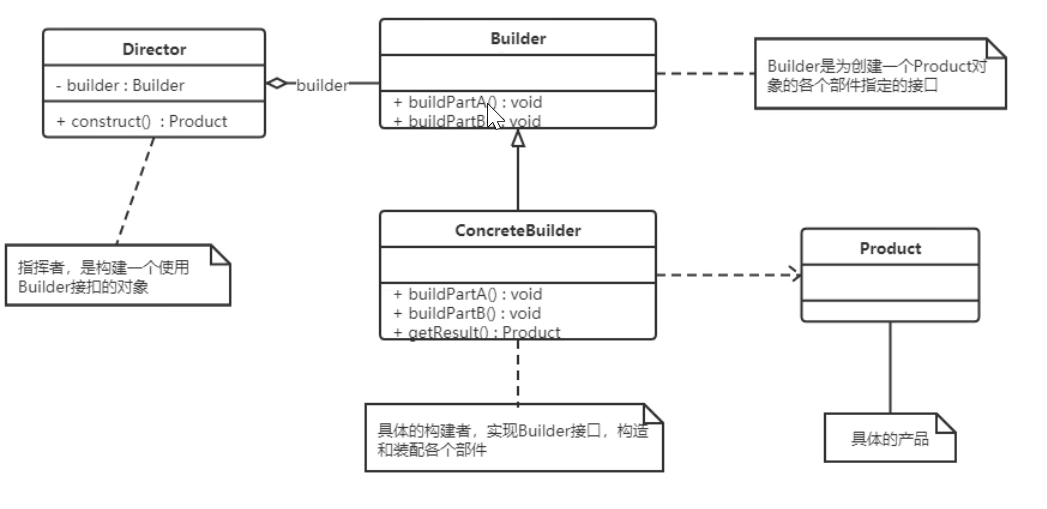
建造者(Builder)模式包含如下角色:
- 抽象建造者类(Builder):这个接口规定要实现复杂对象的那些部分的创建,并不涉及具体的部件对象的创建。
- 具体建造者类(ConcreteBuilder):实现 Builder 接口,完成复杂产品的各个部件的具体创建方法。在构造过程完成后,提供产品的实例。
- 产品类(Product):要创建的复杂对象。
- 指挥者类(Director):调用具体建造者来创建复杂对象的各个部分,在指导者中不涉及具体产品的信息,只负责保证对象各部分完整创建或按某种顺序创建。
5.1 常规写法
//产品类 电脑
@Data
public class Computer {private String motherboard;private String cpu;private String memory;private String disk;private String gpu;private String power;private String heatSink;private String chassis;
}
// 抽象 builder类(接口) 组装电脑
public interface ComputerBuilder { Computer computer = new Computer();void buildMotherboard();void buildCpu();void buildMemory();void buildDisk();void buildGpu();void buildHeatSink();void buildPower();void buildChassis();Computer build();
}
// 具体 builder类 华硕ROG全家桶电脑(手动狗头)
public class AsusComputerBuilder implements ComputerBuilder {@Override public void buildMotherboard() {computer.setMotherboard("Extreme主板");}@Overridepublic void buildCpu() {computer.setCpu("Inter 12900KS");}@Overridepublic void buildMemory() {computer.setMemory("芝奇幻峰戟 16G*2");}@Overridepublic void buildDisk() {computer.setDisk("三星980Pro 2T");}@Overridepublic void buildGpu() {computer.setGpu("华硕3090Ti 水猛禽");}@Overridepublic void buildHeatSink() {computer.setHeatSink("龙神二代一体式水冷");}@Overridepublic void buildPower() {computer.setPower("雷神二代1200W");}@Overridepublic void buildChassis() {computer.setChassis("太阳神机箱");}@Overridepublic Computer build() {return computer;}
}
// 指挥者类 指挥该组装什么电脑
@AllArgsConstructor
public class ComputerDirector {private ComputerBuilder computerBuilder;public Computer construct() {computerBuilder.buildMotherboard();computerBuilder.buildCpu();computerBuilder.buildMemory();computerBuilder.buildDisk();computerBuilder.buildGpu();computerBuilder.buildHeatSink();computerBuilder.buildPower();computerBuilder.buildChassis();return computerBuilder.build();}
}// 测试public static void main(String[] args) {ComputerDirector computerDirector = new ComputerDirector(new AsusComputerBuilder());// Computer(motherboard=Extreme主板, cpu=Inter 12900KS, memory=芝奇幻峰戟 16G*2, disk=三星980Pro 2T, gpu=华硕3090Ti 水猛禽, power=雷神二代1200W, heatSink=龙神二代一体式水冷, chassis=太阳神机箱)System.out.println(computerDirector.construct());}
上面示例是建造者模式的常规用法,指挥者类ComputerDirector在建造者模式中具有很重要的作用,它用于指导具体构建者如何构建产品,控制调用先后次序,并向调用者返回完整的产品类,但是有些情况下需要简化系统结构,可以把指挥者类和抽象建造者进行结合,于是就有了下面的简化写法。
5.2 简化写法
// 把指挥者类和抽象建造者合在一起的简化建造者类
public class SimpleComputerBuilder {private Computer computer = new Computer();public void buildMotherBoard(String motherBoard){computer.setMotherboard(motherBoard);}public void buildCpu(String cpu){computer.setCpu(cpu);}public void buildMemory(String memory){computer.setMemory(memory);}public void buildDisk(String disk){computer.setDisk(disk);}public void buildGpu(String gpu){computer.setGpu(gpu);}public void buildPower(String power){computer.setPower(power);}public void buildHeatSink(String heatSink){computer.setHeatSink(heatSink);}public void buildChassis(String chassis){computer.setChassis(chassis);}public Computer build(){return computer;}
}// 测试public static void main(String[] args) {SimpleComputerBuilder simpleComputerBuilder = new SimpleComputerBuilder();simpleComputerBuilder.buildMotherBoard("Extreme主板");simpleComputerBuilder.buildCpu("Inter 12900K");simpleComputerBuilder.buildMemory("芝奇幻峰戟 16G*2");simpleComputerBuilder.buildDisk("三星980Pro 2T");simpleComputerBuilder.buildGpu("华硕3090Ti 水猛禽");simpleComputerBuilder.buildPower("雷神二代1200W");simpleComputerBuilder.buildHeatSink("龙神二代一体式水冷");simpleComputerBuilder.buildChassis("太阳神机箱");// Computer(motherboard=Extreme主板, cpu=Inter 12900K, memory=芝奇幻峰戟 16G*2, disk=三星980Pro 2T, gpu=华硕3090Ti 水猛禽, power=雷神二代1200W, heatSink=龙神二代一体式水冷, chassis=太阳神机箱)System.out.println(simpleComputerBuilder.build());}
可以看到,对比常规写法,这样写确实简化了系统结构,但同时也加重了建造者类的职责,也不是太符合单一职责原则,如果construct() 过于复杂,建议还是封装到 Director 中。
5.3 链式写法
// 链式写法建造者类
public class SimpleComputerBuilder {private Computer computer = new Computer();public SimpleComputerBuilder buildMotherBoard(String motherBoard){computer.setMotherboard(motherBoard);return this;}public SimpleComputerBuilder buildCpu(String cpu){computer.setCpu(cpu);return this;}public SimpleComputerBuilder buildMemory(String memory){computer.setMemory(memory);return this;}public SimpleComputerBuilder buildDisk(String disk){computer.setDisk(disk);return this;}public SimpleComputerBuilder buildGpu(String gpu){computer.setGpu(gpu);return this;}public SimpleComputerBuilder buildPower(String power){computer.setPower(power);return this;}public SimpleComputerBuilder buildHeatSink(String heatSink){computer.setHeatSink(heatSink);return this;}public SimpleComputerBuilder buildChassis(String chassis){computer.setChassis(chassis);return this;}public Computer build(){return computer;}
}// 测试public static void main(String[] args) {Computer asusComputer = new SimpleComputerBuilder().buildMotherBoard("Extreme主板").buildCpu("Inter 12900K").buildMemory("芝奇幻峰戟 16G*2").buildDisk("三星980Pro 2T").buildGpu("华硕3090Ti 水猛禽").buildPower("雷神二代1200W").buildHeatSink("龙神二代一体式水冷").buildChassis("太阳神机箱").build();System.out.println(asusComputer);}
可以看到,其实链式写法与普通写法的区别并不大,只是在建造者类组装部件的时候,同时将建造者类返回即可,使用链式写法使用起来更方便,某种程度上也可以提高开发效率。从软件设计上,对程序员的要求比较高。比较常见的mybatis-plus中的条件构造器就是使用的这种链式写法。
5.4 总结
适用场景:
- 适用于创建对象需要很多步骤,但是步骤顺序不一定固定。
- 如果一个对象有非常复杂的内部结构(属性),把复杂对象的创建和使用进行分离。
优点:
- 封装性好,创建和使用分离。
- 扩展性好,建造类之间独立、一定程度上解耦。
缺点:
- 产生多余的Builder对象。
- 产品内部发生变化,建造者都要修改,成本较大。
与工厂模式的区别:
- 建造者模式更注重方法的调用顺序,工厂模式更注重创建对象。
- 创建对象的力度不同,建造者模式创建复杂的对象,由各种复杂的部件组成,工厂模式创建出来的都一样。
- 关注点不同,工厂模式只需要把对象创建出来就可以了,而建造者模式中不仅要创建出这个对象,还要知道这个对象由哪些部件组成。
- 建造者模式根据建造过程中的顺序不一样,最终的对象部件组成也不一样。
与抽象工厂模式的区别:
- 抽象工厂模式实现对产品族的创建,一个产品族是这样的一系列产品:具有不同分类维度的产品组合,采用抽象工厂模式则是不需要关心构建过程,只关心什么产品由什么工厂生产即可。
- 建造者模式则是要求按照指定的蓝图建造产品,它的主要目的是通过组装零配件而产生一个新产品。
- 建造者模式所有函数加到一起才能生成一个对象,抽象工厂一个函数生成一个对象
相关文章:
JAVA设计模式——创建型模式
JAVA设计模式——创建型模式 一、创建型模式1.单例模式(Singleton Pattern)1.1 饿汉式1.2 懒汉式1.3 双重检验锁(double check lock)(DCL)1.4 静态内部类1.5 枚举1.6 破坏单例的几种方式与解决方法1.6.1 反序列化1.6.2 反射 1.7 容器式单例1.8 ThreadLoc…...
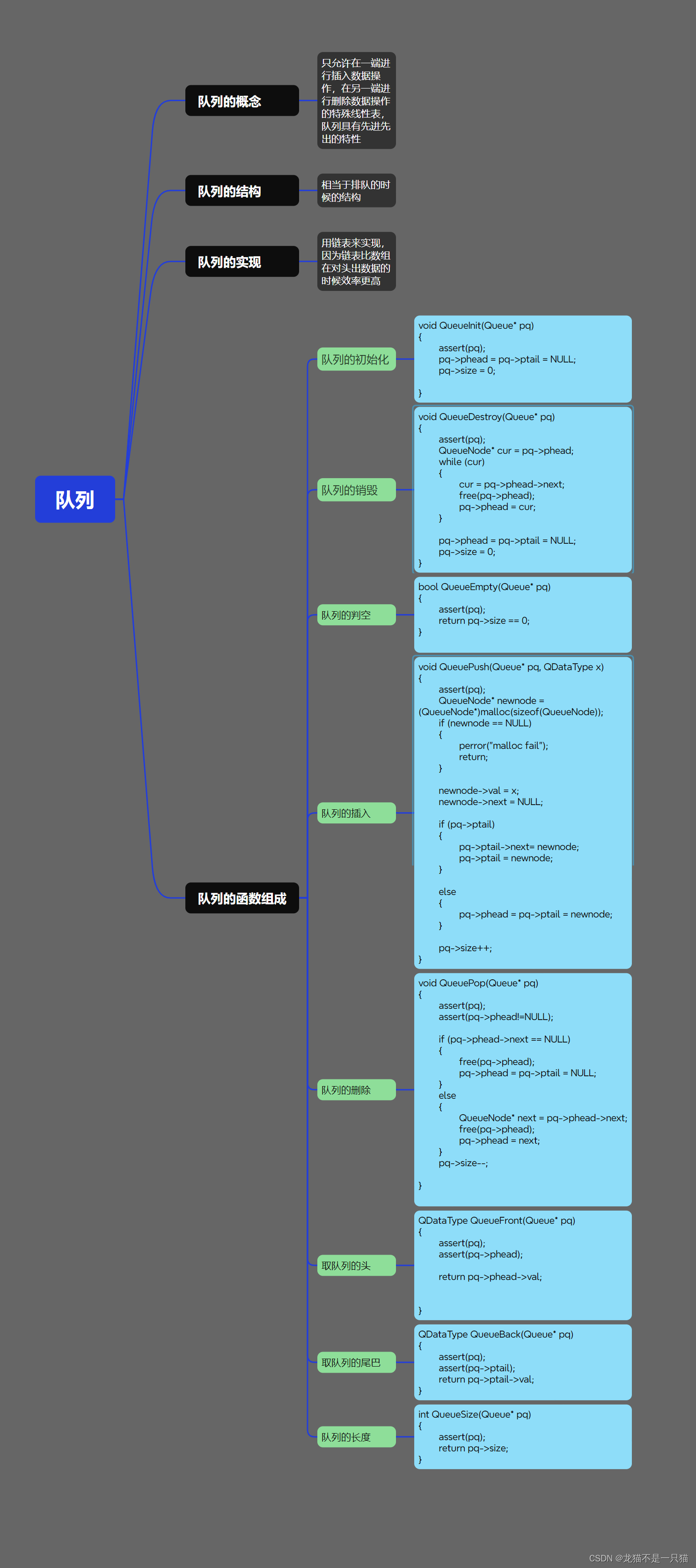
队列的结构概念和实现
文章目录 一、队列的结构和概念二、队列的实现三、队列的实现函数四、队列的思维导图 一、队列的结构和概念 什么是队列? 队列就是只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出 如上图所示&#x…...

Linux系统上使用C语言创建线程
文章目录 一、使用C代码创建线程示例API 二、线程的相关知识2.1 线程 与 进程 的关系2.2 使用线程的理由 一、使用C代码创建线程 使用pthread_create函数创建线程。 示例 示例:创建一个线程,其作用就是打印线程ID和传入参数。 //demo1 #include <…...

pc端如何做自适应呢?
<!-- 默认html的font-size的大小是16px 1rem 16px --> <!-- 想要实现自适应的前提条件是 当浏览器的窗口发生变化的时候, html的font-size将会跟着发生改变 --> <!-- 实现的步骤如下 --> <!-- 1 借助flexble.js文件 --> <!-- 2 将fle…...

c语言经典测试题8
在c语言经典测试题6的第一题,大家是否想过可不可以将递归参数改为s呢?或许有的人已经试过了,但是发现好像不会有结果,其实是因为s为后置,先试用后加1,然而我们这个是在s出了函数之后才会运行加1操作&#x…...

解决GitHub无法访问的问题:手动修改hosts文件与使用SwitchHosts工具
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua,在这里我会分享我的知识和经验。&#x…...
ETL数据仓库的使用方式
一、ETL的过程 在 ETL 过程中,数据从源系统中抽取(Extract),经过各种转换(Transform)操作,最后加载(Load)到目标数据仓库中。以下是 ETL 数仓流程的基本步骤:…...

POST参数里加号+变成空格的问题处理
今天遇到个这样的问题,从前端传到后端的加密报文,里面包含了号,但在后端日志输出看出,变成空格。这个是由于经过RSA加密后引起的 解决办法: 1.前端转码:使用encodeURIComponent对参数进行转码 2.后端解码…...

【华为面试基础题】检查是否存在满足条件的数字组合
描述 给定一个正整数数组检查数组中是否存在满足规则的数组组合 规则: AB2C 输入描述: 第一行输出数组的元素个数,接下来一行输出所有数组元素,用空格隔开 输出描述: 如果存在满足要求的数 在同一行里依次输出 规则…...
亚信安慧AntDB数据并行加载工具的实现(一)
1.概述 数据加载速度是评判数据库性能的重要指标,能否提高数据加载速度,对文件数据进行并行解析,直接影响数据库运维管理效率。基于此,AntDB分布式数据库提供了两种数据加载方式: 一是类似于PostgreSQL的Copy命令&am…...

面经 | Java创建线程的三种方式
利用JUC包创建线程的三种方式: 通过继承Thread类创建线程类实现Runnable接口创建线程类通过Callable和Future接口创建线程 继承Thread类创建线程 class Thread1 extends Thread {Overridepublic void run() {System.out.println("启动线程1");} }实现R…...

【计算机网络】五种IO模型与IO多路转接之select
文章目录 一、五种IO模型二、非阻塞IO1.fcntl2.实现函数SetNoBlock3.轮询方式读取标准输入 三、I/O多路转接之select1.初识select2.select函数原型3.socket就绪条件4.select的特点5.select缺点6.select使用案例--只读取数据的server服务器1.err.hpp2.log.hpp3.sock.hpp4.select…...

通过一篇文章让你了解数据结构和算法的重要性
通过一篇文章让你了解数据结构和算法的重要性 前言一、 什么是数据结构?二、什么是算法?三、数据结构和算法的重要性在校园招聘的笔试中:在校园招聘的面试中:在未来的工作中: 四、如何学好数据结构和算法4.1 死磕代码&…...

python代码优化学习
代码优化对比: 优化前: # 登录系统 xxljob_login() start_time time.time() # 循环处理需要补数的数据 for item in authId_lists: preSettleInfoHandler(item) count 1 print("运行了第" str(count) "个") …...

C#,数值计算,求解微分方程的吉尔(Gear)四阶方法与源代码
1 微分方程 微分方程,是指含有未知函数及其导数的关系式。解微分方程就是找出未知函数。 微分方程是伴随着微积分学一起发展起来的。微积分学的奠基人Newton和Leibniz的著作中都处理过与微分方程有关的问题。微分方程的应用十分广泛,可以解决许多与导数…...

2024年新提出的算法|LEA爱情进化算法(Love Evolution Algorithm)
Love Evolution Algorithm: a stimulus–value–role theory-inspired evolutionary algorithm for global optimization 爱情进化算法Love Evolution Algorithm,LEA,于2024年2月发表在中科院3区SCI期刊 The Journal of Supercomputing。 1、简介 本文提…...

javaWeb个人学习02
会话技术 会话: 用户打开浏览器,访问web服务器的资源,会话建立,直到有一方断开连接,会话结束.在一次会话中包含多次请求和响应 会话跟踪: 一种维护浏览器状态的方法,服务器需要识别多次请求是否来自于同一个浏览器,以便在同一次会话的多次请求之间共享数据 会话跟踪方案: …...

EchoServer回显服务器封装与测试
目录 类实现 编译测试 这一篇本质上是为了TcpServer而做的一层封装,让外界调用更加简洁 参考上文 TcpServer服务器管理模块(模块十)-CSDN博客 类实现 echo.hpp #include "../server.hpp"class EchoServer { private:TcpServer _server;private:void OnConnect…...

详解POCV/SOCV的时序报告
POCV/SOCV的时序报告中有如下变量: Mean: 高斯分布中的μ值(平均值) Sensit: sensitivity,也就是1个Sigma的值; Corner: Sigma边界的最差值 cell的delay Delay mean N * Delay sigma; cell 的Transition Sl…...
[VNCTF2024]-PWN:preinit解析(逆向花指令,绕过strcmp,函数修改,机器码)
查看保护: 查看ida: 这边其实看反汇编没啥大作用,需要自己动调。 但是前面的绕过strcmp还是要看一下的。 解题: 这里是用linux自带的产生随机数的文件urandom来产生一个随机密码,然后让我们输入密码,用st…...

Youtu-Parsing效果惊艳案例:毕业论文PDF截图→自动生成含图表引用的Markdown文献综述
Youtu-Parsing效果惊艳案例:毕业论文PDF截图→自动生成含图表引用的Markdown文献综述 1. 引言:当AI遇见学术文献 想象一下这个场景:你正在为毕业论文的文献综述部分焦头烂额。面前是几十篇PDF论文,你需要从中提取关键信息、整理…...

【 LangChain v1.2 入门系列教程】【一】开篇入门 | 从零开始,跑通你的第一个 AI Agent
系列文章目录 【 LangChain v1.2 入门系列教程】【一】开篇入门 | 从零开始,跑通你的第一个 AI Agent 【 LangChain v1.2 入门系列教程】【二】消息类型与提示词工程 【 LangChain v1.2 入门系列教程】【三】工具(Tools)开发,让…...

第二周作业:系统管理相关的操作总结
一、系统信息与基础命令1. 查看系统信息uname -a # 完整系统信息cat /etc/os-release # 发行版信息hostname # 主机名uptime # 运行时间、负载date # 系统时间2. 硬件信息lscpu # CPUfree -h # 内存l…...

IntelliJ IDEA 2026年4月新版本 2026.1 更新内容,安装激活使用教程
更新时间:2026-04-07 支持最新版本:2026.1(2026年4月发布) 支持在线更新 支持Windows、MAC、Linux 新版本更新亮点: 核心功能升级 AI生态开放平台:原生支持Codex、Cursor、GitHub Copilot等多智能体&am…...

暗黑破坏神2存档编辑终极指南:免费开源工具d2s-editor完全教程
暗黑破坏神2存档编辑终极指南:免费开源工具d2s-editor完全教程 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否还在为暗黑破坏神2的角色属性不够完美而烦恼?是否想要轻松调整任务进度、获得心仪的装…...

Cursor破解工具终极指南:三步实现AI编程助手无限免费使用
Cursor破解工具终极指南:三步实现AI编程助手无限免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your …...

电机控制调参实战:手把手教你搞定PI调节器积分限幅,告别转速超调
电机控制调参实战:手把手教你搞定PI调节器积分限幅,告别转速超调 在电机控制系统的调试过程中,转速超调问题就像一位不请自来的客人,总是让工程师们头疼不已。想象一下,当你精心设计的控制系统在加速到目标转速时&…...

告别串口调试!用虫洞ESP32S3-EYE开发板,5分钟把你的旧摄像头变成免驱USB摄像头
5分钟魔改指南:用ESP32S3-EYE将旧摄像头变身免驱USB设备 你是否曾在抽屉深处发现过几个落灰的OV2640摄像头模块?这些曾经活跃在创客项目中的小玩意,如今只需一块虫洞ESP32S3-EYE开发板,就能重获新生为即插即用的USB摄像头。与动辄…...

springAI中tools的使用
1.使用Tool注解注册toolTool(description "获取当前日期和时间,当用户询问时间、日期时调用。")public String getCurrentDateTime() {log.info("tools调用获取时间");return LocalDateTime.now().format(DateTimeFormatter.ofPattern("y…...

Spring Boot项目Docker化后,curl本地接口报‘Connection reset by peer’?别急着改防火墙,先检查这个配置
Spring Boot项目Docker化后curl本地接口报Connection reset by peer的深度排查指南 当你兴冲冲地将Spring Boot应用打包成Docker镜像,准备在本地环境测试API接口时,却在执行curl 127.0.0.1:9997/doc.html后收到冰冷的(56) Recv failure: Connection rese…...