MySQL篇—持久化和非持久化统计信息介绍(第一篇,总共三篇)
☘️博主介绍☘️:
✨又是一天没白过,我是奈斯,DBA一名✨
✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️
❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣️❣️❣️

哈喽各位小伙伴,好久不见甚是想念。今天给大家上强度,讲解一下和SQL优化有关的内容——统计信息和执行计划。众所周知,优化器在SQL执行过程中扮演着至关重要的角色,它依赖于统计信息来为每个SQL语句制定最优的执行计划。而这些统计信息对于优化器的决策具有决定性的影响。因此,了解和掌握统计信息以及执行计划对于数据库的性能调优至关重要。接下来,我们将探讨统计信息和执行计划的相关知识,帮助大家更好地理解并优化自己的数据库性能。
因为统计信息和执行计划涉及到的内容过多,为了使大家更好消化,我将分成三篇文章来进行介绍,以便大家因为篇幅过长而感到阅读疲惫。三篇的内容分别如下,让大家先做了解:
第一篇:持久化和非持久化统计信息介绍(当前篇)
第二篇:执行计划介绍
第三篇:执行计划之覆盖索引Using index和条件过滤Using where详细介绍
目录
1.1 持久化统计信息(既innodb_stats_persistent=ON,默认on,生产必须持久化)
(1)相关参数
(2)配置每张表的统计信息参数
案例一:create表时配置表的持久化统计信息
(3)查看统计信息
(4)手动收集统计信息
4.1 analyze方式收集,oracle也支持(analyze是单表收集统计信息)
案例一:计算ANALYZE TABLE复杂性(消耗的读取)
4.2 mysqlcheck命令方式收集(mysqlcheck命令是全表全库收集统计信息)
(5)8.0版本直方图的最新变化
(6)解决统计信息差别较大的问题(执行计划受统计信息影响,统计信息不准会导致执行计划不准)
案例一:通过设置STATS_SAMPLE_PAGES或者设置innodb_stats_persistent_sample_pages解决统计信息不准问题
1.2 非持久化统计信息(既innodb_stats_persistent=OFF,默认on,不推荐使用仅了解)
(1)相关参数
(2)设置非持久化统计信息的两种方式

那让我们开始今天统计信息的介绍。
MySQL执行SQL会经过SQL解析和查询优化的过程,解析器将SQL分解成数据结构并传递到后续步骤,查询优化器发现执行SQL查询的最佳方案、生成执行计划。查询优化器决定SQL如何执行,依赖于数据库的统计信息。optimizer优化器根据统计信息对每个sql语句执行最优的执行计划(执行计划受统计信息影响)。
MySQL统计信息的存储分为两种,非持久化和持久化统计信息。
官方文档对统计信息的介绍:
MySQL :: MySQL 8.0 Reference Manual :: 17.8.10 Configuring Optimizer Statistics for InnoDB
Oracle和MySQL统计信息的区别:
Oracle:统计信息是在特定的时间收集的,不是自动收集。当对象还没有统计信息时,那么先通过动态采样技术来选择执行计划,默认2级别的动态采样,采取对象的64个数据块进行分析。
MySQL:默认的持久化统计信息自动进行收集统计信息。
1.1 持久化统计信息(既innodb_stats_persistent=ON,默认on,生产必须持久化)
持久化统计信息在数据库重启统计信息不丢失,统计信息会被持久化到物理表中,会给出最优的执行计划,稳定和精确,对于大表也节省了收集统计信息的所需资源。5.6.6开始默认使用了持久化统计信息。
持久化统计信息在以下情况会被自动更新:
1)innodb_stats_auto_recalc为on,自动更新统计信息。阈值是表中行数的10%发生更改。
2)create table、create index、alter table、truncate table等涉及数据修改的DDL语句(亲测)
3)手动更新统计信息,注意执行过程中会加读锁:analyze table tablename。
4)dict_stats_thread线程专门处理统计信息。
5)而如果变更的行数超过16+n_rows/16(6.25%)或者表修改的行超过1/6或者20亿条时
(1)相关参数
一、innodb_stats_persistent
参数含义:是否启用持久化统计信息功能
默认值:ON
作用:变量控制统计信息是否持久化,统计信息在早期的MySQL中是不持久化,在新版本的MySQL中持久化统计信息是默认的选项。当变量打开时,统计信息就会被持久化到物理表中,统计信息会更加的稳定和精确,对于大表也节省了收集统计信息的所需资源。如果为off,可能会频繁地重新计算统计信息,这可能会导致查询执行计划的变化。
二、innodb_stats_auto_recalc
参数含义:是否自动触发更新统计信息
默认值:ON
触发阈值:表变化的数据是否超过10%,超过自动收集统计信息。
作用:InnoDB会长期追踪每一张表的行数,判断更新的记录是否超过表记录总数的1/10,超过那么就把这张表加入到后台的recalc pool中。由于自动统计信息重新计算(发生在后台)是异步,在运行影响超过10%的表的DML操作时(即innodb_stats_auto_recalc启用后),可能不会立即重新计算统计信息。在某些情况下,统计重新计算可能会延迟几秒钟(10s)。如果在更改表的重要部分之后立即需要最新统计信息,请运行ANALYZE TABLE以启动统计信息的同步(前台)重新计算。
如果禁用了innodb_stats_auto_recalc,请在对索引列进行实质性更改后,通过为每个适用的表发出ANALYZE TABLE语句来确保统计信息的准确性。
此设置适用于启用innodb_stats_persistent选项时创建的表。也可以在CREATE TABLE或者ALTER TABLE时通过STATS_AUTO_RECALC语法来指定比率。
三、innodb_stats_persistent_sample_pages
参数含义:持久化统计信息采样的索引页数。分析配置的页数,优化器根据统计信息给出执行计划
默认值:20
作用:在估计索引列的基数和其他统计信息(例如由ANALYZE TABLE计算的统计信息)时要采样的索引页数。增加该值可以提高索引统计的准确性,从而改进查询执行计划,但代价是在InnoDB表执行ANALYZE TABLE时增加I/O。
1)统计信息不够准确,优化器选择次优计划:如果确定统计信息不够准确,则应增加innodb_stats_persistent_sample_pages的值,直到统计估计值足够准确。但是过多地增加innodb_stats_persistent_sample_pages可能会导致ANALYZE TABLE运行缓慢。
2)ANALYZE TABLE太慢:在这种情况下,应减少innodb_stats_persistent_sample_pages,直到ANALYZE TABLE执行时间可以接受。但是过多地降低该值可能会导致生成不准确的统计信息和执行计划的问题。
四、innodb_stats_include_delete_marked
默认值:OFF
作用:在5.7.16中引入的此参数,默认为不启用,表示在未提交的事务有从表中删除行,则InnoDB在收集统计信息时,将会排除这些delete_marked行。这可能会导致除READ UNCOMMITTED之外的事务隔离级别的事务,运行的不是最佳的执行计划。
为了避免这种情况,可以启用innodb_stats_include_delete_marked以确保在计算持久化统计信息时InnoDB包含Delete-marked记录。
(2)配置每张表的统计信息参数
innodb_stats_persistent、innodb_stats_auto_recalc和innodb_stats_persistent_sample_pages是全局配置选项。若要覆盖这些系统范围的设置并为各个表配置统计信息参数,可以在CREATE TABLE或ALTER TABLE语句中定义STATS_PERSISTENT、STATS_AUTO_RECALC和STATS_SAMPLE_PAGES子句。
一、STATS_PERSISTENT
含义:指定是否为InnoDB表启用持久统计信息。
设置值:
DEFAULT:表示表的持久统计信息设置由innodb_stats_persistent配置选项确定
1:表示启用表的持久统计信息
0:关闭此功能
二、STATS_AUTO_RECALC
含义:指定是否自动触发InnoDB表的持久统计信息。
设置值:
DEFAULT:表示表的持久统计信息设置由innodb_stats_auto_recalc配置选项确定
1:表示表中10%的数据发生更改时将重新计算统计信息
0:禁用自动重新计算此表
三、STATS_SAMPLE_PAGES
含义:指定在估计索引列的基数和其他统计信息(例如由ANALYZE TABLE计算的统计信息)时要采样的索引页数。
设置值:
DEFAULT:表示持久化统计信息采样的页数由innodb_stats_persistent_sample_pages配置选项确定
案例一:create表时配置表的持久化统计信息
CREATE TABLE't1`(
`id` int(8) NOT NULL auto increment,
data` varchar(255),
date` datetime,
PRIMARY KEY (`id`),
INDEX'DATE IX` (`date`)
) ENGINE=InnoDB,
STATS PERSISTENT=1,
STATS AUTO RECALC=1,
STATS SAMPLE PAGES=25;
(3)查看统计信息
table statistics相关视图:
mysql> select * from mysql.innodb_table_stats where table_name='表名';
database_name:数据库名
table_name:表名
last_update:统计信息最后一次更新时间,sql执行计划受统计信息影响。
n_rows:表的行数
clustered_index_size:聚集索引的页的数量
sum_of_other_index_sizes:其他索引的页的数量
mysql> select * from information_schema.tables where table_name='表名';
mysql> select * from information_schema.statistics where table_name='表名';
注意:mysql.innodb_table_stats会在持久化统计信息下自动更新,而information_schema.tables和information_schema.statistics不会自动更新需要手动执行analyze table或者mysqlcheck命令方式收集,所以统计信息以按照mysql.innodb_table_stats表的信息为准。
index statistics相关视图:
mysql> select * from mysql.innodb_index_stats where table_name='表名'; ---会在持久化统计信息下自动更新
database_name:数据库名
table_name:表名
index_name:索引名
last_update:统计信息最后一次更新时间,sql执行计划受统计信息影响。
stat_name:统计信息名
stat_value:统计信息的值
sample_size:采样大小
stat_description:类型说明
(4)手动收集统计信息
4.1 analyze方式收集,oracle也支持(analyze是单表收集统计信息)
innodb和myisam存储引擎都可以通过执行analyze table tablename来收集表和索引的统计信息。除非执行计划不准确,否则不要轻易执行该操作,如果是很大的表该操作会影响表的性能(9亿行的数据很快,亲测)
由于Analyze table会更新数据字典里的统计信息表(8.0)因此在innodb_read_only 开关被打开时有可能会导致执行失败。在analyze table的过程中会持有InnoDB表的read only锁,因此会存在短暂的阻塞用户写入更新删除的操作。除此之外analyze table要把table从table definition cache刷出来,因此还会需要一个flush lock,此时如果有长事务使用了这张表,那么必须等待长事务结束。
注意:ANALYZE、CHECK、OPTIMIZE、ALTER TABLE执行期间将对表进行锁定,因此一定注意要在数据库不繁忙的时候执行相关的操作。
5.7语法:
ANALYZE [NO_WRITE_TO_BINLOG | LOCAL] TABLE tbl_name [, tbl_name] ...
8.0语法(8.0中支持了直方图统计信息,因此analyze table还扩充了Histogram语法):
ANALYZE [NO_WRITE_TO_BINLOG | LOCAL] TABLE tbl_name [, tbl_name] ...ANALYZE [NO_WRITE_TO_BINLOG | LOCAL]TABLE tbl_nameUPDATE HISTOGRAM ON col_name [, col_name] ...[WITH N BUCKETS]ANALYZE [NO_WRITE_TO_BINLOG | LOCAL]TABLE tbl_nameDROP HISTOGRAM ON col_name [, col_name] ...
InnoDB表的ANALYZE TABLE复杂性(消耗的读取):
1)采样的页数,由innodb_stats_persistent_sample_pages定义。
2)表中索引列的数量(由多个数相加而成,参考下面案例)。
3)分区数量。如果表没有分区,则分区数被视为1。
总结:ANALYZE TABLE复杂性度=innodb_stats_persistent_sample_pages * 表中索引列的数量(多个数相加而成) * 分区数 * innodb_page_size
通常结果值越大,ANALYZE InnoDB TABLE的执行时间越长。
innodb_stats_persistent_sample_pages定义在全局级别采样的页数。要设置单个表的采样页数,请使用带有CREATE TABLE或ALTER TABLE的STATS_SAMPLE_PAGES选项。
如果innodb_stats_persistent = OFF,则采样的页数由innodb_stats_transient_sample_pages定义。
案例一:计算ANALYZE TABLE复杂性(消耗的读取)
ANALYZE TABLE复杂性度=innodb_stats_persistent_sample_pages * 表中索引列的数量(多个数相加而成) * 分区数 * innodb_page_size
O(n_sample
* (n_cols_in_uniq_i
+ n_cols_in_non_uniq_i
+ n_cols_in_pk * (1 + n_non_uniq_i))
* n_part * innodb_page_size)n_sample:是取样的页数(定义为innodb_stats_persistent_sample_pages)
n_cols_in_uniq_i:所有唯一索引中所有列的总数(不包括主键列)
n_cols_in_non_uniq_i:所有非唯一索引中所有列的总数
n_cols_in_pk:主键中的列数(如果没有定义主键,InnoDB在内部创建单列主键)
n_non_uniq_i:表中非唯一索引的数目
n_part:是分区的数量。如果没有定义分区,则该表被视为单个分区。
innodb_page_size:innodb每个页的大小是16K,且不可更改
SQL> CREATE TABLE t (a INT,b INT,c INT,d INT,e INT,f INT,g INT,h INT,PRIMARY KEY (a, b),UNIQUE KEY i1uniq (c, d),KEY i2nonuniq (e, f),KEY i3nonuniq (g, h)
);SQL> SELECT index_name, stat_name, stat_descriptionFROM mysql.innodb_index_stats WHEREdatabase_name='test' ANDtable_name='t' ANDstat_name like 'n_diff_pfx%';n_cols_in_uniq_i:所有唯一索引中不包括主键列的所有列的总数为2(c和d)
n_cols_in_non_uniq_i:所有非唯一索引中所有列的总数,为4(e,f,g和h)
n_cols_in_pk:主键中的列数为2(a和b)
n_non_uniq_i:表中非唯一索引的数量是2(i2nonuniq和i3nonuniq))
n_part:分区数,是1。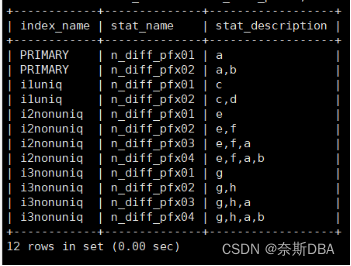
那么读取t表:
innodb_stats_persistent_sample_pages=20
n_cols_in_uniq_i =2
n_cols_in_non_uniq_i=4
n_cols_in_pk=2
n_non_uniq_i=2
n_part=1
innodb_page_size=16kb
估计表t读取20*(2+4+2*(1+2))*1*16kb=3840kb,为3.75M
4.2 mysqlcheck命令方式收集(mysqlcheck命令是全表全库收集统计信息)
mysqlcheck是用来检查、修复、优化、分析表。只有在数据库运行的状态下才可运行,意味着不用停止服务操作。
mysqlcheck其实就是CHECK TABLE(检查表), REPAIR TABLE(修复表), ANALYZE TABLE(分析表)以及OPTIMIZE TABLE(优化表)的便捷操作集合,利用指定参数将对于的SQL语句发送到数据库中进行执行。同样对于那些存储引擎的的支持,也受对于表维护SQL语句的限制(如check 则不支持MEMORY表, repair 则不支持 InnoDB表)
注意:ANALYZE、CHECK、OPTIMIZE、ALTER TABLE执行期间将对表进行锁定,因此一定注意要在数据库不繁忙的时候执行相关的操作。
mysqlcheck参数:
-A, --all-databases —选择所有的库
-B, --databases —选择多个库
-a, --analyze —分析表ANALYZE TABLE
-c, --check —检查表CHECK TABLE
-C, --check-only-changed —最后一次检查之后变动的表CHECK TABLE
-m, --medium-check —近似完全检查,速度比--extended稍快CHECK TABLE
-o, --optimize —优化表OPTIMIZE TABLE
--auto-repair —自动修复表
-g, --check-upgrade —检查表是否有版本变更,可用 auto-repair修复
-F, --fast —只检查没有正常关闭的表
-f, --force —忽悠错误,强制执行
-e, --extended —表的百分百完全检查,速度缓慢
-q, --quick —最快的检查方式,在repair 时使用该选项,则只会修复 index tree
-r, --repair —修复表REPAIR TABLE
-s, --silent —只打印错误信息
-V, --version —显示版本
收集库所有表的统计信息:
收集test库:mysqlcheck -uroot -p123456 -S /mysql/data/3306/mysql.sock --analyze --databases test
收集所有库:mysqlcheck -uroot -p123456 -S /mysql/data/3306/mysql.sock --analyze --all-databases
SQL> select * from mysql.innodb_table_stats where database_name='test'; ---test库所有表的统计信息更新为最新

(5)8.0版本直方图的最新变化
MySQL 5.7并没有提供直方图的功能,某些情况下(如数据分布不均)仅仅更新统计信息不一定能得到准确的执行计划,只能通过index hint的方式指定索引。
在MySQL 8.0中支持了直方图统计信息,因此analyze table还扩充了Histogram语法,参考官方文档即可。
直方图是MySQL 8.0中新增的统计信息方式,Analyze table加上直方图语句就可以操作直方图的信息, 直方图并不是存储引擎层实现的,而是在Server层利用InnoDB存储引擎实现的系统表mysql.column_stats,MySQL利用JSON类型的字段来保存直方图的信息,其实现的核心代码在sql/histogram目录下。
直方图的具体的操作包括:更新直方图以及drop直方图,其中更新直方图还可以重新指定bucket的数目,需要注意的是直方图不支持加密表,不支持GIS列以及JSON列,以及不支持单列唯一索引的列。
通过histogram_generation_max_mem_size参数可以调整用于生成直方图的采样记录内存大小,通过查看information_schema的column_statistic表可以查看sampling-rate。
最新的MySQL8.0.19中,InnoDB实现了自己的采样算法,来避免全表扫描。在MySQL计算直方图填充时会调用Handler层的ha_sample_init, ha_sample_next以及ha_sample_end接口。在8.0.19前InnoDB并没有实现sample的接口,而是用的Handler层的默认实现rnd_next,也就是全表扫描,直到独到采样比率的数据为止。这里有一个问题,如果采样率设置为10%,那采样只是读前10%的记录。更科学的做法是在整棵索引树上均匀的采样。在新版本中终于有了InnoDB引擎层的sample实现。目前的代码只支持单线程的采样,但是从代码架构看已经实现了parallel_reader的接口,不久后一定会实现多线程并行的采样。InnoDB的采样是交给了单独的worker线程来实现的,一般是对主键进行。整体思路就是根据采样比率相对平均的选择叶子节点页面,假设采样率是10%,那么会选择一个叶子页面后跳过9个叶子页面,被选中的页面中会对所有的记录进行采样。
(6)解决统计信息差别较大的问题(执行计划受统计信息影响,统计信息不准会导致执行计划不准)
如果自动更新持久化统计信息后发现与实际count(*)数据量差距较大,可考虑增加表采样的数据页,两种方式修改:
修改一:全局变量(影响所有表)
innodb_stats_persistent_sample_pages默认20个页面。持久化统计信息采样的页数。分析配置的页数,优化器根据统计信息给出执行计划
缺点:过多地增加innodb_stats_persistent_sample_pages可能会导致ANALYZE TABLE运行缓慢。
修改二:CREATE/ALTER表的参数(只影响设置的表)
ALTER TABLE TABLE_NAME STATS_SAMPLE_PAGES=40; ---经测试,此处STATS_SAMPLE_PAGES的最大值是65535,超出会报错。
STATS_SAMPLE_PAGES:指定在估计索引列的基数和其他统计信息(例如由ANALYZE TABLE计算的统计信息)时要采样的索引页数。表示持久化统计信息采样的页数由innodb_stats_persistent_sample_pages配置选项确定。
案例一:通过设置STATS_SAMPLE_PAGES或者设置innodb_stats_persistent_sample_pages解决统计信息不准问题
1)创建表
SQL> create table tb_700w like tb;
SQL> insert into tb_700w select * from tb limit 7000000;SQL> select * from mysql.innodb_table_stats where table_name='tb_700w';
---tb_700w真实有700万行数据,由于innodb_stats_persistent_sample_pages进行自动持久化统计信息采样只采集20页,那么就会有误差
2)设置STATS_SAMPLE_PAGES:
SQL> ALTER TABLE tb_700w STATS_SAMPLE_PAGES=65535; ---此处STATS_SAMPLE_PAGES的最大值是65535,超出会报错。
SQL> analyze table tb_700w;SQL> select * from mysql.innodb_table_stats where table_name='tb_700w';
---收集单表的STATS_SAMPLE_PAGES的最大值是65535个页,超出会报错。65535页还是不能给出准确的行数
3)设置innodb_stats_persistent_sample_pages:
注意:ANALYZE TABLE复杂性度=innodb_stats_persistent_sample_pages * 表中索引列的数量(多个数相加而成) * 分区数 * innodb_page_size,那么过多地增加innodb_stats_persistent_sample_pages,ANALYZE InnoDB TABLE的执行时间越长。
SQL> ALTER TABLE tb_700w STATS_SAMPLE_PAGES=default; ---恢复默认STATS_SAMPLE_PAGES,由innodb_stats_persistent_sample_pages配置选项确定
SQL> show variables like 'innodb_stats_persistent_sample_pages'; ---默认采集20页算出innodb_stats_persistent_sample_pages最合适的值。公式:innodb_stats_persistent_sample_pages=ANALYZE TABLE复杂性度(大小)/表中索引列的数量(多个数相加而成)/分区数/innodb_page_size
SQL> show create table tb_700w\G;SQL> SELECT index_name, stat_name, stat_descriptionFROM mysql.innodb_index_stats WHEREdatabase_name='test' ANDtable_name='tb_700w' ANDstat_name like 'n_diff_pfx%';详细算法参考上面(4)手动收集统计信息的案例一:计算ANALYZE TABLE复杂性(消耗的读取)
n_cols_in_uniq_i:所有唯一索引中不包括主键列的所有列的总数为0
n_cols_in_non_uniq_i:所有非唯一索引中所有列的总数,为0
n_cols_in_pk:主键中的列数为1(id)
n_non_uniq_i:表中非唯一索引的数量是0
n_part:分区数,是1。
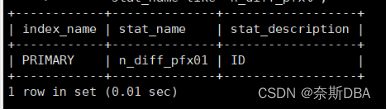
那么读取tb_700w表:
n_cols_in_uniq_i =0
n_cols_in_non_uniq_i=0
n_cols_in_pk=1
n_non_uniq_i=0
n_part=1
innodb_page_size=16kb
innodb_stats_persistent_sample_pages=(1611Mx1024)/(0+0+1*(1+0))/1/16kb=103104
SQL> set global innodb_stats_persistent_sample_pages=103104;
SQL> analyze table tb_700w;SQL> select * from mysql.innodb_table_stats where table_name='tb_700w'; 给出了最准确的统计信息
1.2 非持久化统计信息(既innodb_stats_persistent=OFF,默认on,不推荐使用仅了解)
非持久化统计信息存储在内存里,如果数据库重启统计信息将丢失,在下一次访问表时重新计算。会导致频繁地重新计算统计信息,这可能会导致查询执行计划的变化。不推荐使用也不是默认值。
当innodb_stats_persistent = OFF或使用STATS_PERSISTENT = 0创建或更改单张表时,统计信息不会保留到磁盘。相反统计信息存储在内存中,并在服务器关闭时丢失。某些业务和某些条件下也会定期更新统计数据。
非持久化统计信息在以下情况会被自动更新(前提innodb_stats_on_metadata设置为on,默认off):
1)手动更新统计信息,注意执行过程中会加读锁:analyze table tablename
2)设置innodb_stats_on_metadata=ON(默认off),执行SHOW TABLE STATUS , SHOW INDEX,查询INFORMATION_SCHEMA下的TABLES, STATISTICS
3)启用--auto-rehash选项,这是默认设置。--auto-rehash选项会打开所有InnoDB表,打开表的操作会导致统计数据重新计算。使用mysql client登录。
4)表第一次被打开
5)距上一次更新统计信息,表1/16的数据被修改
总结:非持久化统计信息的缺点显而易见,数据库重启后如果大量表开始更新统计信息,会对实例造成很大影响,所以目前都会使用持久化统计信息。
(1)相关参数
一、innodb_stats_on_metadata
参数含义:表示是否InnoDB在(如SHOW TABLE STATUS)或访问INFORMATION_SCHEMA.TABLES或INFORMATION_SCHEMA.STATISTICS)操作期间更新统计信息。
默认值:OFF
作用:保留禁用的设置可以提高具有大量表或索引的模式的访问速度。它还可以提高涉及InnoDB表的查询的执行计划的稳定性。
此选项仅在优化器统计信息配置为非持久性时适用。当innodb_stats_persistent为off(默认on,启用持久化统计信息)时生效。或者使用STATS_PERSISTENT=0创建或修改单个表时,优化器统计信息不会被持久化到磁盘。在关闭持久化统计信息时,是否在show table status/查看information_schema的TABLES,STATISTICS表时更新统计信息(亲测关闭innodb_stats_persistent=off,在设置innodb_stats_on_metadata为on或者off下都使用show table status/查看information_schema的TABLES、STATISTICS表也不会更新统计信息,了解即可,生产环境必须开启持久化统计信息也是默认选项)
二、innodb_stats_transient_sample_pages
参数含义:表示每次随机采样页的数量
默认值:8
作用:当innodb_stats_persistent = 0时,innodb_stats_transient_sample_pages的值会影响所有InnoDB表和索引的索引采样。更改索引样本大小时,请注意以下潜在的重大影响:
像1或2这样的小值可能导致基数估计不准确。
增加innodb_stats_transient_sample_pages值可能需要更多磁盘读取。远大于8(例如100)的值可能导致打开表或执行SHOW TABLE STATUS所花费的时间显着减慢。优化器可能会根据索引选择性的不同估计选择非常不同的查询计划。
(2)设置非持久化统计信息的两种方式
1)全局变量(影响所有表)
innodb_stats_persistent=OFF ---默认on,启用持久化统计信息。变量控制统计信息是否持久化,统计信息在早期的MySQL中是不持久化,在新版本的MySQL中持久化统计信息是默认的选项。当变量打开时,统计信息就会被持久化到物理表中,统计信息会更加的稳定和精确,对于大表也节省了收集统计信息的所需资源。如果为off,可能会频繁地重新计算统计信息,这可能会导致查询执行计划的变化。
2)CREATE/ALTER表的参数(只影响设置的表)
STATS_PERSISTENT=0 ---是否启用InnoDB表的持久统计功能。 默认值由innodb_stats_persistent配置选项决定。 值1启用表的持久统计,而值0关闭此特性。 在通过CREATE TABLE或ALTER TABLE语句启用持久统计信息后,在将代表性数据加载到表中之后,发出ANALYZE TABLE语句来计算统计信息。
STATS_PERSISTENT:指定是否为InnoDB表启用持久统计信息。默认值由innodb_stats_persistent配置选项确定。1:表示启用表的持久统计信息; 0:关闭此功能
相关文章:
MySQL篇—持久化和非持久化统计信息介绍(第一篇,总共三篇)
☘️博主介绍☘️: ✨又是一天没白过,我是奈斯,DBA一名✨ ✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️ ❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣…...

Leetcode—65. 有效数字【困难】
2024每日刷题(118) Leetcode—65. 有效数字 实现代码 class Solution { public:bool isNumber(string s) {if(s.empty()) {return false;}bool seenNum false;bool seenE false;bool seenDot false;for(int i 0; i < s.size(); i) {switch(s[i]…...

【Java程序设计】【C00322】基于Springboot的高校竞赛管理系统(有论文)
基于Springboot的高校竞赛管理系统(有论文) 项目简介项目获取开发环境项目技术运行截图 项目简介 这是一个基于Springboot的高校竞赛管理系统,本系统有管理员、老师、专家以及用户四种角色; 管理员:首页、个人中心、管…...

41、网络编程/TCP.UDP通信模型练习20240301
一、编写基于TCP的客户端实现以下功能: 通过键盘按键控制机械臂:w(红色臂角度增大)s(红色臂角度减小)d(蓝色臂角度增大)a(蓝色臂角度减小)按键控制机械臂 1.基于TCP服务器的机械臂…...

Python中操作MySQL和SQL Server数据库的基础与实战【第97篇—MySQL数据库】
Python中操作MySQL和SQL Server数据库的基础与实战 在Python中,我们经常需要与各种数据库进行交互,其中MySQL和SQL Server是两个常见的选择。本文将介绍如何使用pymysql和pymssql库进行基本的数据库操作,并通过实际代码示例来展示这些操作。…...
【兔子机器人】五连杆运动学解算与VMC(virtual model control)
VMC (virtual model control,虚拟模型控制) 是一种直觉控制方式,其关键是在每个需要控制的自由度上构造恰当的虚拟构件以产生合适的虚拟力。虚拟力不是实际执行机构的作用力或力矩,而是通过执行机构的作用经过机构转换而成。对于一些控制问题…...
)
学习鸿蒙基础(6)
一、Prop属性 父——>子 单向同步 Prop装饰的变量可以和父组件建立单向的同步关系。Prop装饰的变量是可变的,但是变化不会同步回其父组件。Prop装饰的变量和父组件建立单向的同步关系。Prop变量允许在本地修改,但修改后的变化不会同步回父组件。当父组…...
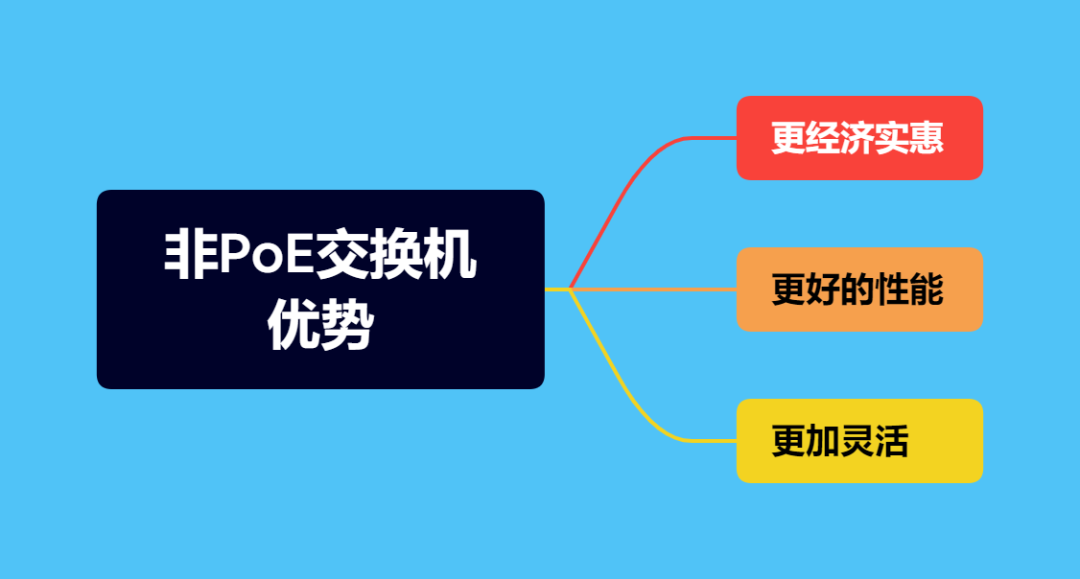
标准PoE交换机、非标准PoE交换机和非PoE交换机三者到底有何区别?
目录 前言: 一、标准PoE交换机 1.1 工作原理 1.2 应用场景 1、视频监控 2、无线接入点 3、IP电话 1.3 优势 1、简化布线 2、简化安装 3、提高可靠性 二、非标准PoE交换机 2.1 工作原理 2.2 应用场景 1、无线路由器 2、IP电话 3、数据中心 2.3 优势…...
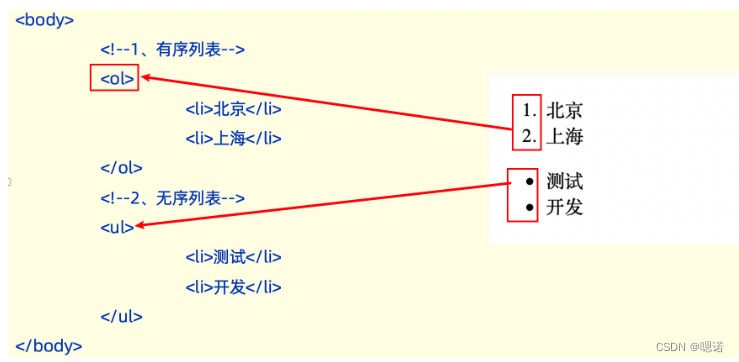
【软件测试】--功能测试4-html介绍
1.1 前端三大核心 html:超文本标记语言,由一套标记标签组成 标签: 单标签:<标签名 /> 双标签:<标签名></标签名> 属性:描述某一特征 示例:<a 属性名"属性值"> 1.2 html骨架标签 <!DOC…...

模型优化_XGBOOST学习曲线及改进,泛化误差
代码 from xgboost import XGBRegressor as XGBR from sklearn.ensemble import RandomForestRegressor as RFR from sklearn.linear_model import LinearRegression as LR from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split,c…...

Java8 - LocalDateTime时间日期类使用详解
🏷️个人主页:牵着猫散步的鼠鼠 🏷️系列专栏:Java全栈-专栏 🏷️个人学习笔记,若有缺误,欢迎评论区指正 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默&…...

3D城市模型可视化:开启智慧都市探索之旅
随着科技的飞速发展,我们对城市的认知已经不再局限于平面的地图和照片。今天,让我们领略一种全新的城市体验——3D城市模型可视化。这项技术将带领我们走进一个立体、生动的城市世界,感受前所未有的智慧都市魅力。 3D城市模型通过先进的计算机…...

某查查首页瀑布流headers加密
目标网站: 某查查 对目标网站分析发现 红框内的参数和值都是加密的,是根据算法算出来的,故进行逆向分析。 由于没有固定参数名,只能通过搜索headers,在搜索的位置上打上断点,重新请求。 断点在此处断住&a…...

Microsoft Visio 文本框上标或下标
Microsoft Visio 文本框上标或下标 1. 文本框公式2. 选中需要成为上标或下标的部分,开始 - > 段落 -> 字体 -> 常规 -> 位置 -> 上标 / 下标3. 文本框公式4. 快捷键References 1. 文本框公式 2. 选中需要成为上标或下标的部分,开始…...
Java项目:29 基于SpringBoot+thymeleaf实现的图书管理系统
作者主页:源码空间codegym 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 项目介绍 基于SpringBootthymeleaf实现的图书管理系统分为管理员、读者两个登录角色,一共是8个功能模块 管理员权限 图书管理:…...
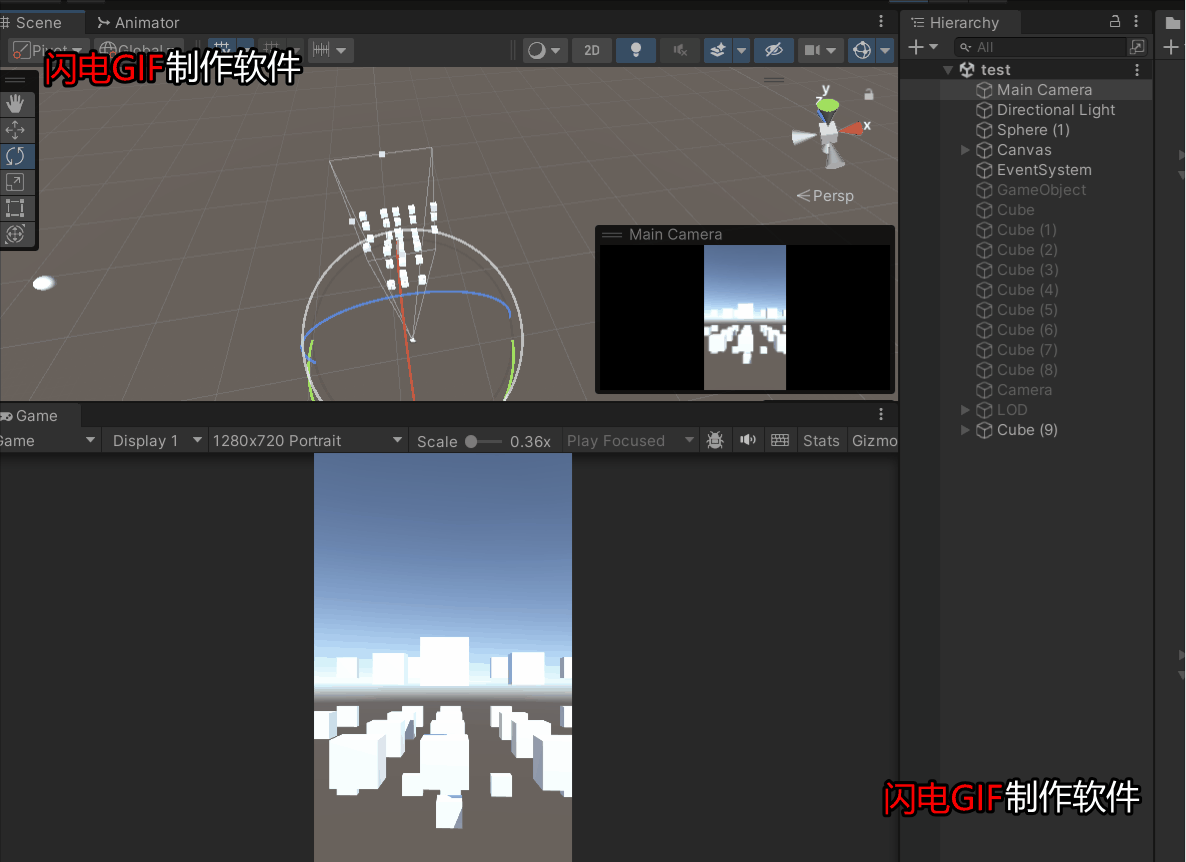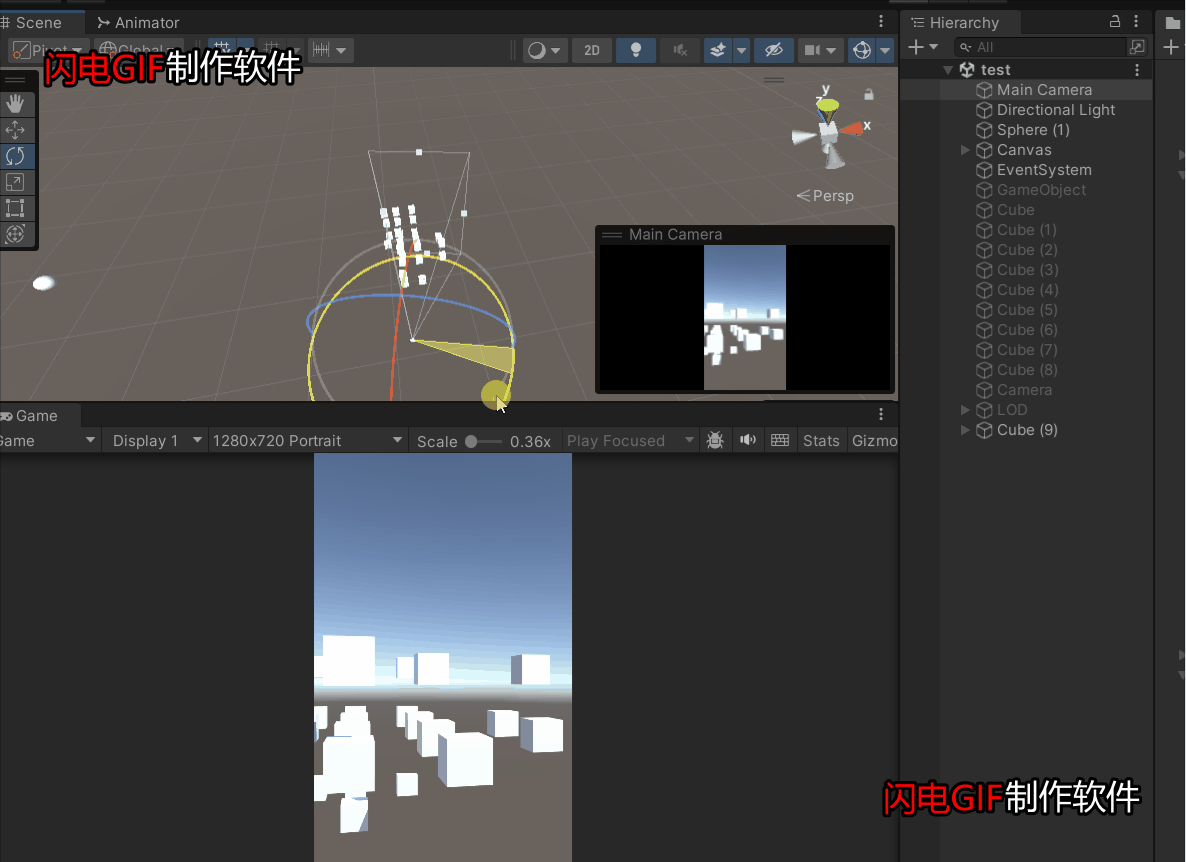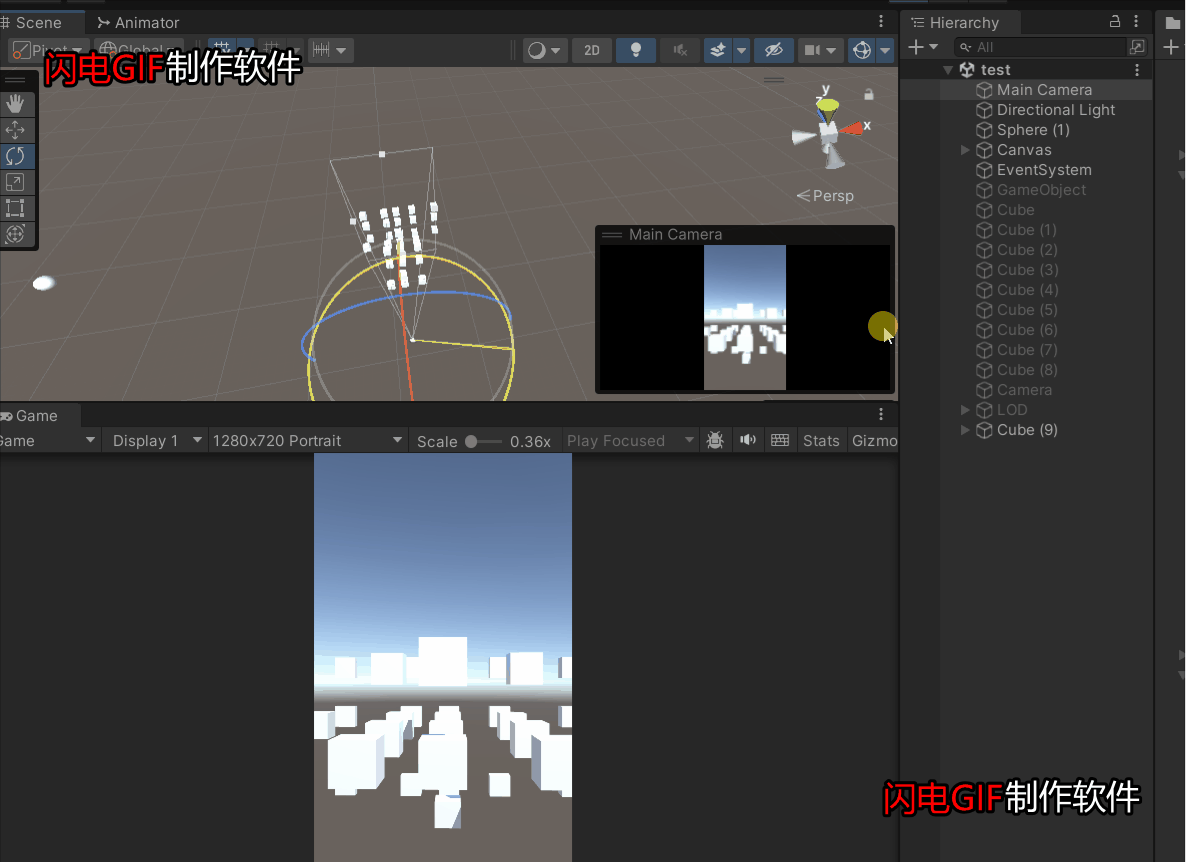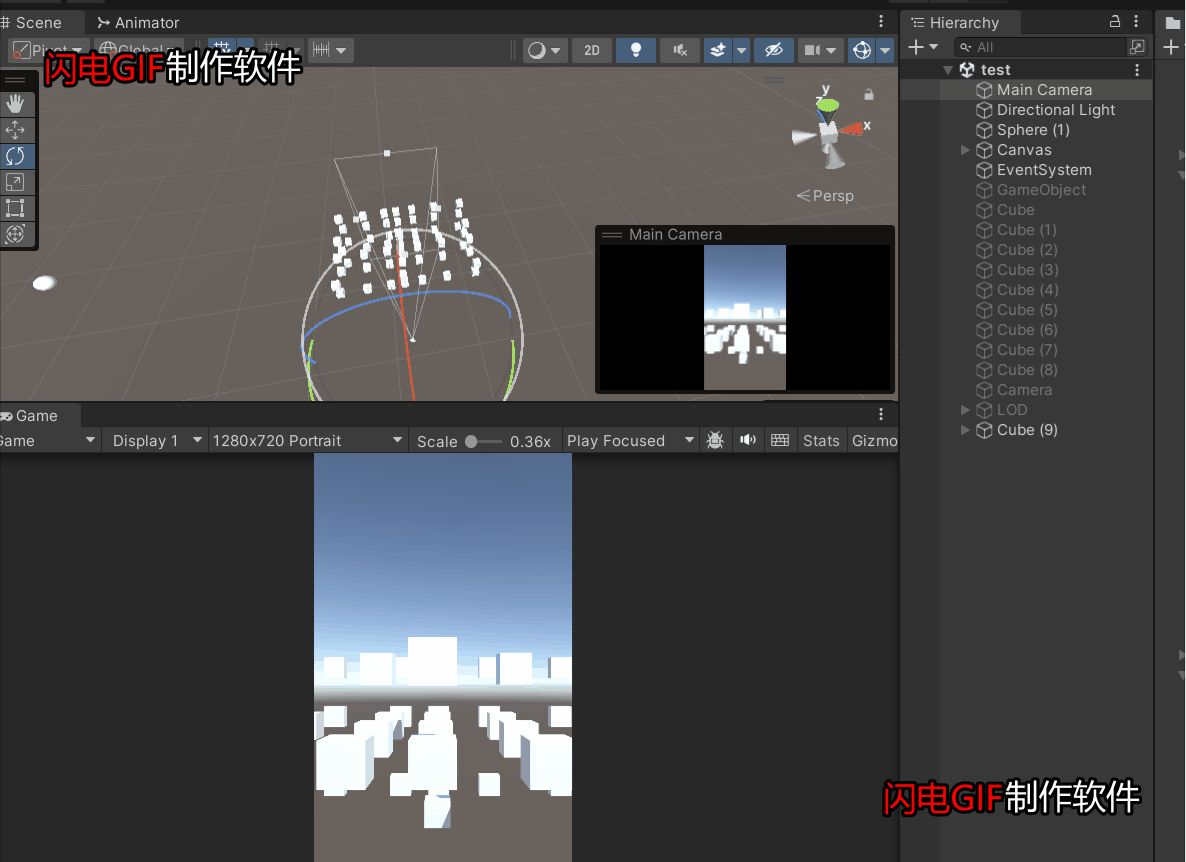
Unity游戏项目中的优化之摄像机视锥体剔除优化
在项目中一个完成的游戏场景一般都会有成千上百的物体,假如都去让GPU全部渲染一遍,那带来的消耗其实是挺大的,很多不在摄像机范围内的物体其实没有必要去渲染,尽管GPU自带剔除,但是如果从CPU阶段就提交给GPU指令——哪…...
)
超1000本计算机经典书籍分享(均可免费下载)
今天给大家推荐两个开源项目,均可百度网盘下载: 1 https://gitee.com/ForthEspada/CS-Books 超过1000本的计算机经典书籍、个人笔记资料以及作者在各平台发表文章中所涉及的资源等。 书籍资源包括C/C、Java、Python、Go语言、数据结构与算法、操作系统…...

AI大模型提供商有哪些?
AI大模型提供商:引领人工智能创新浪潮 随着人工智能技术的迅猛发展,AI大模型成为了推动行业变革和创新的核心驱动力之一。作为AI领域的重要参与者,AI大模型提供商扮演着关键的角色。本文将围绕这一主题,介绍几家在AI大模型领域具…...
【Linux】部署单机项目(自动化启动)
目录 一.jdk安装 二.tomcat安装 三.MySQL安装 四.部署项目 一.jdk安装 1.上传jdk安装包 jdk-8u151-linux-x64.tar.gz 进入opt目录,将安装包拖进去 2.解压安装包 防止后面单个系列解压操作,我这边就直接将所有的要用的全部给解压,如下图注…...
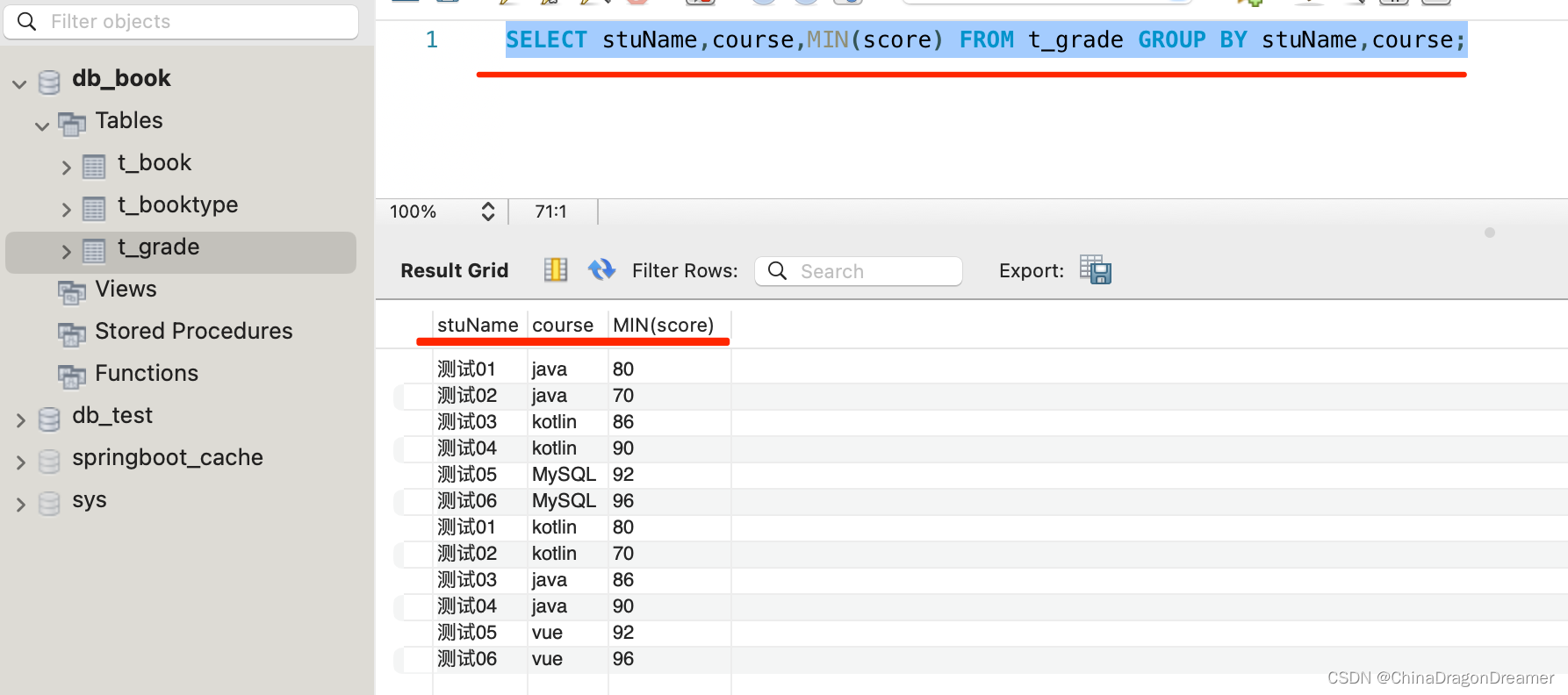
MySQL:使用聚合函数查询
提醒: 设定下面的语句是在数据库名为 db_book里执行的。 创建t_grade表 USE db_book; CREATE TABLE t_grade(id INT,stuName VARCHAR(20),course VARCHAR(40),score INT );为t_grade表里添加多条数据 INSERT INTO t_grade(id,stuName,course,score)VALUES(1,测试0…...

亲测有效!Z-Image-Turbo解决AI绘画三大痛点:慢、黑、崩
亲测有效!Z-Image-Turbo解决AI绘画三大痛点:慢、黑、崩 1. 痛点终结者:当AI绘画遇上Turbo引擎 作为一名长期被AI绘画"折磨"的设计师,我经历过太多崩溃时刻:等待生成的进度条仿佛永远走不完,好不…...

crontab——你的自动化打工人
咕嘎讲堂:crontab——你的自动化打工人 “人类最大的进步,就是学会了让机器帮自己干活。”——咕嘎 📌 crontab 是什么? crontab cron table,是 Linux 系统中用于定时执行任务的工具。 简单说:你想让系…...

NaViL-9B部署案例解析:上海AI实验室原生多模态模型生产实践
NaViL-9B部署案例解析:原生多模态模型生产实践 1. 平台概述 NaViL-9B是一款原生多模态大语言模型,具备同时处理文本和图像的能力。该模型支持纯文本问答和图片理解两大核心功能,能够实现: 传统文本对话交互图片内容识别与分析图…...

保姆级教程:用YOLOv8训练自己的数据集,这20个参数别再瞎调了
保姆级教程:用YOLOv8训练自己的数据集,这20个参数别再瞎调了 第一次用YOLOv8训练自定义数据集时,面对几十个参数选项确实容易让人手足无措。作为计算机视觉领域最流行的目标检测框架之一,YOLO系列以其速度和精度平衡著称ÿ…...

YOLO12工业场景迁移指南:从COCO预训练到产线缺陷检测的微调路径
YOLO12工业场景迁移指南:从COCO预训练到产线缺陷检测的微调路径 1. 引言:当通用模型遇上工业难题 想象一下,你拿到一个在通用场景下表现优异的“全能选手”——YOLO12,它能轻松识别照片里的人、车、猫、狗。现在,你需…...

跨境电商降本增效利器:HY-MT1.5-1.8B翻译模型部署与优化
跨境电商降本增效利器:HY-MT1.5-1.8B翻译模型部署与优化 1. 引言:跨境电商的翻译痛点与解决方案 在跨境电商运营中,语言障碍是影响业务扩展的关键因素。从商品详情页的多语言适配到客服沟通的实时翻译,传统解决方案往往面临三大…...

AI 入门 30 天挑战 - Day 8 费曼学习法版 - 神经网络初探
🌟 完整项目和代码 本教程是 AI 入门 30 天挑战 系列的一部分! 💻 GitHub 仓库: https://github.com/Lee985-cmd/AI-30-Day-Challenge📖 CSDN 专栏: https://blog.csdn.net/m0_67081842?typeblog⭐ 欢迎 Star 支持!…...

keil工程点击build报错FCARM - Output Name not specified, please check ‘Options for Target - Utilities‘
kile工程链接时报错FCARM - Output Name not specified, please check ‘Options for Target - Utilities’ 问题:拷贝了一个keil模板例程,对其中地一些代码文件路径做了调整,并重新添加了代码文件。编译没报错,点击buile链接时报…...

5分钟掌握sakura.css暗色模式:打造现代网站的终极视觉体验
5分钟掌握sakura.css暗色模式:打造现代网站的终极视觉体验 【免费下载链接】sakura :cherry_blossom: a minimal css framework/theme. 项目地址: https://gitcode.com/gh_mirrors/sa/sakura sakura.css是一款极简的CSS框架,它提供了优雅的暗色模…...

YOLO12实战教程:在RTX 4090 D上实现120FPS实时检测性能调优
YOLO12实战教程:在RTX 4090 D上实现120FPS实时检测性能调优 1. 引言:为什么选择YOLO12? 如果你正在寻找一个既能保持实时检测速度,又能提供顶尖精度的目标检测模型,YOLO12绝对是2025年最值得关注的选择。这个由国际学…...