深度学习 精选笔记(10)简单案例:房价预测
学习参考:
- 动手学深度学习2.0
- Deep-Learning-with-TensorFlow-book
- pytorchlightning
①如有冒犯、请联系侵删。
②已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。
③非常推荐上面(学习参考)的前两个教程,在网上是开源免费的,写的很棒,不管是开始学还是复习巩固都很不错的。
深度学习回顾,专栏内容来源多个书籍笔记、在线笔记、以及自己的感想、想法,佛系更新。争取内容全面而不失重点。完结时间到了也会一直更新下去,已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。所有文章涉及的教程都会写在开头、一起学习一起进步。
在这里案例里面,测试集主要作用仅仅为评估模型泛化效果。并不具有“预测未来售价”的实际作用。因为测试集的其它特征都已经是假设已知的,而预测未来的时候这些都是相当于没发生的未知列,所以该案例中作用是相当于只是评估模型的作用。
一、加载数据集
将下载不同的数据集,并训练和测试模型。
download函数用来下载数据集, 将数据集缓存在本地目录(默认情况下为…/data)中, 并返回下载文件的名称。 如果缓存目录中已经存在此数据集文件,并且其sha-1与存储在DATA_HUB中的相匹配, 将使用缓存的文件,以避免重复的下载。
并实现两个实用函数: 一个将下载并解压缩一个zip或tar文件, 另一个是将本书中使用的所有数据集从DATA_HUB下载到缓存目录中。
import hashlib
import os
import tarfile
import zipfile
import requests
# 如果没有安装pandas,请取消下一行的注释
# !pip install pandas%matplotlib inline
import numpy as np
import pandas as pd
import tensorflow as tf
from d2l import tensorflow as d2l#@save
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'def download_extract(name, folder=None): #@save"""下载并解压zip/tar文件"""fname = download(name)base_dir = os.path.dirname(fname)data_dir, ext = os.path.splitext(fname)if ext == '.zip':fp = zipfile.ZipFile(fname, 'r')elif ext in ('.tar', '.gz'):fp = tarfile.open(fname, 'r')else:assert False, '只有zip/tar文件可以被解压缩'fp.extractall(base_dir)return os.path.join(base_dir, folder) if folder else data_dirdef download_all(): #@save"""下载DATA_HUB中的所有文件"""for name in DATA_HUB:download(name)
1.下载数据
数据分为训练集和测试集。 每条记录都包括房屋的属性值和属性,如街道类型、施工年份、屋顶类型、地下室状况等。 这些特征由各种数据类型组成。 例如,建筑年份由整数表示,屋顶类型由离散类别表示,其他特征由浮点数表示。 这就是现实让事情变得复杂的地方:例如,一些数据完全丢失了,缺失值被简单地标记为“NA”。
使用上面定义的脚本下载并缓存Kaggle房屋数据集。
DATA_HUB['kaggle_house_train'] = ( #@saveDATA_URL + 'kaggle_house_pred_train.csv','585e9cc93e70b39160e7921475f9bcd7d31219ce')DATA_HUB['kaggle_house_test'] = ( #@saveDATA_URL + 'kaggle_house_pred_test.csv','fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
使用pandas分别加载包含训练数据和测试数据的两个CSV文件。
train_data
可以注意到,训练数据是有标签的(即价格)。
Id MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities ... PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice
0 1 60 RL 65.0 8450 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 2 2008 WD Normal 208500
1 2 20 RL 80.0 9600 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 5 2007 WD Normal 181500
2 3 60 RL 68.0 11250 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 9 2008 WD Normal 223500
3 4 70 RL 60.0 9550 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 2 2006 WD Abnorml 140000
4 5 60 RL 84.0 14260 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 12 2008 WD Normal 250000
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1455 1456 60 RL 62.0 7917 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 8 2007 WD Normal 175000
1456 1457 20 RL 85.0 13175 Pave NaN Reg Lvl AllPub ... 0 NaN MnPrv NaN 0 2 2010 WD Normal 210000
1457 1458 70 RL 66.0 9042 Pave NaN Reg Lvl AllPub ... 0 NaN GdPrv Shed 2500 5 2010 WD Normal 266500
1458 1459 20 RL 68.0 9717 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 4 2010 WD Normal 142125
1459 1460 20 RL 75.0 9937 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 6 2008 WD Normal 147500
1460 rows × 81 columns

test_data
可以发现测试数据是没有标签的。
Id MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities ... ScreenPorch PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition
0 1461 20 RH 80.0 11622 Pave NaN Reg Lvl AllPub ... 120 0 NaN MnPrv NaN 0 6 2010 WD Normal
1 1462 20 RL 81.0 14267 Pave NaN IR1 Lvl AllPub ... 0 0 NaN NaN Gar2 12500 6 2010 WD Normal
2 1463 60 RL 74.0 13830 Pave NaN IR1 Lvl AllPub ... 0 0 NaN MnPrv NaN 0 3 2010 WD Normal
3 1464 60 RL 78.0 9978 Pave NaN IR1 Lvl AllPub ... 0 0 NaN NaN NaN 0 6 2010 WD Normal
4 1465 120 RL 43.0 5005 Pave NaN IR1 HLS AllPub ... 144 0 NaN NaN NaN 0 1 2010 WD Normal
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1454 2915 160 RM 21.0 1936 Pave NaN Reg Lvl AllPub ... 0 0 NaN NaN NaN 0 6 2006 WD Normal
1455 2916 160 RM 21.0 1894 Pave NaN Reg Lvl AllPub ... 0 0 NaN NaN NaN 0 4 2006 WD Abnorml
1456 2917 20 RL 160.0 20000 Pave NaN Reg Lvl AllPub ... 0 0 NaN NaN NaN 0 9 2006 WD Abnorml
1457 2918 85 RL 62.0 10441 Pave NaN Reg Lvl AllPub ... 0 0 NaN MnPrv Shed 700 7 2006 WD Normal
1458 2919 60 RL 74.0 9627 Pave NaN Reg Lvl AllPub ... 0 0 NaN NaN NaN 0 11 2006 WD Normal
1459 rows × 80 columns
2.顺便删除无意义数据列
在每个样本中,第一个特征是ID,)这有助于模型识别每个训练样本。 虽然这很方便,但它不携带任何用于预测的信息。 因此,在将数据提供给模型之前,将其从数据集中删除,并且把训练集测试集拼接到一起、方便处理数据。
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
all_features
MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities LotConfig ... ScreenPorch PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition
0 60 RL 65.0 8450 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 2 2008 WD Normal
1 20 RL 80.0 9600 Pave NaN Reg Lvl AllPub FR2 ... 0 0 NaN NaN NaN 0 5 2007 WD Normal
2 60 RL 68.0 11250 Pave NaN IR1 Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 9 2008 WD Normal
3 70 RL 60.0 9550 Pave NaN IR1 Lvl AllPub Corner ... 0 0 NaN NaN NaN 0 2 2006 WD Abnorml
4 60 RL 84.0 14260 Pave NaN IR1 Lvl AllPub FR2 ... 0 0 NaN NaN NaN 0 12 2008 WD Normal
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1454 160 RM 21.0 1936 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 6 2006 WD Normal
1455 160 RM 21.0 1894 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 4 2006 WD Abnorml
1456 20 RL 160.0 20000 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 9 2006 WD Abnorml
1457 85 RL 62.0 10441 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN MnPrv Shed 700 7 2006 WD Normal
1458 60 RL 74.0 9627 Pave NaN Reg Lvl AllPub Inside ... 0 0 NaN NaN NaN 0 11 2006 WD Normal
2919 rows × 79 columns
二、数据预处理
有各种各样的数据类型。 在开始建模之前,需要对数据进行预处理。
1.特征缩放(Z-score数据标准化)
首先,将所有缺失的值替换为相应特征的平均值。然后,为了将所有特征放在一个共同的尺度上, 通过将特征重新缩放到零均值和单位方差来标准化数据,其中 𝜇 和 𝜎分别表示均值和标准差。
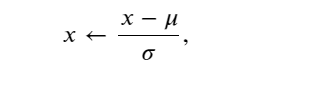
标准化数据有两个原因: 首先,它方便优化。 其次,因为不知道哪些特征是相关的, 所以不想让惩罚分配给一个特征的系数比分配给其他任何特征的系数更大。
# 若无法获得测试数据,则可根据训练数据计算均值和标准差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
常用的预处理方法:将实值数据重新缩放为零均值和单位方法;用前后一段时间的均值替换缺失值。
2.处理缺失值
# 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
3.处理离散值
处理离散值。这包括诸如“MSZoning”之类的特征。 用独热编码替换它们, 方法与前面将多类别标签转换为向量的方式相同。
创建两个新的指示器特征“MSZoning_RL”和“MSZoning_RM”,其值为0或1。 根据独热编码,如果“MSZoning”的原始值为“RL”, 则:“MSZoning_RL”为1,“MSZoning_RM”为0。 pandas软件包会自动实现这一点。
# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
all_features
MSSubClass LotFrontage LotArea OverallQual OverallCond YearBuilt YearRemodAdd MasVnrArea BsmtFinSF1 BsmtFinSF2 ... SaleType_Oth SaleType_WD SaleType_nan SaleCondition_Abnorml SaleCondition_AdjLand SaleCondition_Alloca SaleCondition_Family SaleCondition_Normal SaleCondition_Partial SaleCondition_nan
0 0.067320 -0.184443 -0.217841 0.646073 -0.507197 1.046078 0.896679 0.523038 0.580708 -0.29303 ... 0 1 0 0 0 0 0 1 0 0
1 -0.873466 0.458096 -0.072032 -0.063174 2.187904 0.154737 -0.395536 -0.569893 1.177709 -0.29303 ... 0 1 0 0 0 0 0 1 0 0
2 0.067320 -0.055935 0.137173 0.646073 -0.507197 0.980053 0.848819 0.333448 0.097840 -0.29303 ... 0 1 0 0 0 0 0 1 0 0
3 0.302516 -0.398622 -0.078371 0.646073 -0.507197 -1.859033 -0.682695 -0.569893 -0.494771 -0.29303 ... 0 1 0 1 0 0 0 0 0 0
4 0.067320 0.629439 0.518814 1.355319 -0.507197 0.947040 0.753100 1.381770 0.468770 -0.29303 ... 0 1 0 0 0 0 0 1 0 0
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1454 2.419286 -2.069222 -1.043758 -1.481667 1.289537 -0.043338 -0.682695 -0.569893 -0.968860 -0.29303 ... 0 1 0 0 0 0 0 1 0 0
1455 2.419286 -2.069222 -1.049083 -1.481667 -0.507197 -0.043338 -0.682695 -0.569893 -0.415757 -0.29303 ... 0 1 0 1 0 0 0 0 0 0
1456 -0.873466 3.884968 1.246594 -0.772420 1.289537 -0.373465 0.561660 -0.569893 1.717643 -0.29303 ... 0 1 0 1 0 0 0 0 0 0
1457 0.655311 -0.312950 0.034599 -0.772420 -0.507197 0.682939 0.370221 -0.569893 -0.229194 -0.29303 ... 0 1 0 0 0 0 0 1 0 0
1458 0.067320 0.201080 -0.068608 0.646073 -0.507197 0.715952 0.465941 -0.045732 0.694840 -0.29303 ... 0 1 0 0 0 0 0 1 0 0
2919 rows × 331 columns
转换会将特征的总数量从79个增加到331个。 最后,通过values属性,可以 从pandas格式中提取NumPy格式,并将其转换为张量表示用于训练。
n_train = train_data.shape[0]
train_features = tf.constant(all_features[:n_train].values, dtype=tf.float32)
test_features = tf.constant(all_features[n_train:].values, dtype=tf.float32)
train_labels = tf.constant(train_data.SalePrice.values.reshape(-1, 1), dtype=tf.float32)
训练数据的特征内容如下,不包括标签列:
all_features[:n_train]
MSSubClass LotFrontage LotArea OverallQual OverallCond YearBuilt YearRemodAdd MasVnrArea BsmtFinSF1 BsmtFinSF2 ... SaleType_Oth SaleType_WD SaleType_nan SaleCondition_Abnorml SaleCondition_AdjLand SaleCondition_Alloca SaleCondition_Family SaleCondition_Normal SaleCondition_Partial SaleCondition_nan
0 0.067320 -0.184443 -0.217841 0.646073 -0.507197 1.046078 0.896679 0.523038 0.580708 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
1 -0.873466 0.458096 -0.072032 -0.063174 2.187904 0.154737 -0.395536 -0.569893 1.177709 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
2 0.067320 -0.055935 0.137173 0.646073 -0.507197 0.980053 0.848819 0.333448 0.097840 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
3 0.302516 -0.398622 -0.078371 0.646073 -0.507197 -1.859033 -0.682695 -0.569893 -0.494771 -0.293030 ... 0 1 0 1 0 0 0 0 0 0
4 0.067320 0.629439 0.518814 1.355319 -0.507197 0.947040 0.753100 1.381770 0.468770 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1455 0.067320 -0.312950 -0.285421 -0.063174 -0.507197 0.914028 0.753100 -0.569893 -0.968860 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
1456 -0.873466 0.672275 0.381246 -0.063174 0.391170 0.220763 0.178782 0.093673 0.765076 0.670295 ... 0 1 0 0 0 0 0 1 0 0
1457 0.302516 -0.141607 -0.142781 0.646073 3.086271 -1.000704 1.040259 -0.569893 -0.365275 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
1458 -0.873466 -0.055935 -0.057197 -0.772420 0.391170 -0.703591 0.561660 -0.569893 -0.861312 5.788329 ... 0 1 0 0 0 0 0 1 0 0
1459 -0.873466 0.243916 -0.029303 -0.772420 0.391170 -0.208401 -0.921995 -0.569893 0.852870 1.420862 ... 0 1 0 0 0 0 0 1 0 0
1460 rows × 331 columns
测试集数据的特征如下,自然也是没有标签列:
MSSubClass LotFrontage LotArea OverallQual OverallCond YearBuilt YearRemodAdd MasVnrArea BsmtFinSF1 BsmtFinSF2 ... SaleType_Oth SaleType_WD SaleType_nan SaleCondition_Abnorml SaleCondition_AdjLand SaleCondition_Alloca SaleCondition_Family SaleCondition_Normal SaleCondition_Partial SaleCondition_nan
0 -0.873466 0.458096 0.184340 -0.772420 0.391170 -0.340452 -1.113434 -0.569893 0.058332 0.558006 ... 0 1 0 0 0 0 0 1 0 0
1 -0.873466 0.500932 0.519702 -0.063174 0.391170 -0.439490 -1.257014 0.032335 1.056991 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
2 0.067320 0.201080 0.464294 -0.772420 -0.507197 0.848003 0.657380 -0.569893 0.767271 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
3 0.067320 0.372424 -0.024105 -0.063174 0.391170 0.881015 0.657380 -0.458369 0.352443 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
4 1.478499 -1.126832 -0.654636 1.355319 -0.507197 0.682939 0.370221 -0.569893 -0.391613 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1454 2.419286 -2.069222 -1.043758 -1.481667 1.289537 -0.043338 -0.682695 -0.569893 -0.968860 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
1455 2.419286 -2.069222 -1.049083 -1.481667 -0.507197 -0.043338 -0.682695 -0.569893 -0.415757 -0.293030 ... 0 1 0 1 0 0 0 0 0 0
1456 -0.873466 3.884968 1.246594 -0.772420 1.289537 -0.373465 0.561660 -0.569893 1.717643 -0.293030 ... 0 1 0 1 0 0 0 0 0 0
1457 0.655311 -0.312950 0.034599 -0.772420 -0.507197 0.682939 0.370221 -0.569893 -0.229194 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
1458 0.067320 0.201080 -0.068608 0.646073 -0.507197 0.715952 0.465941 -0.045732 0.694840 -0.293030 ... 0 1 0 0 0 0 0 1 0 0
1459 rows × 331 columns
训练数据的标签:
train_data.SalePrice
0 208500
1 181500
2 223500
3 140000
4 250000...
1455 175000
1456 210000
1457 266500
1458 142125
1459 147500
Name: SalePrice, Length: 1460, dtype: int64
三、训练模型
训练一个带有损失平方的线性模型。
loss = tf.keras.losses.MeanSquaredError()def get_net():net = tf.keras.models.Sequential()net.add(tf.keras.layers.Dense(1, kernel_regularizer=tf.keras.regularizers.l2(weight_decay)))return net
房价就像股票价格一样,关心的是相对数量,而不是绝对数量。 因此,更关心相对误差(𝑦−𝑦̂)/ 𝑦,而不是绝对误差𝑦−𝑦̂ 。
解决这个问题的一种方法是用价格预测的对数来衡量差异, 事实上,这也是比赛中官方用来评价提交质量的误差指标。 即将 𝛿 for |log𝑦−log𝑦̂ |≤𝛿 转换为 𝑒(−𝛿)≤𝑦̂/𝑦≤𝑒(𝛿) 。 这使得预测价格的对数与真实标签价格的对数之间出现以下均方根误差:
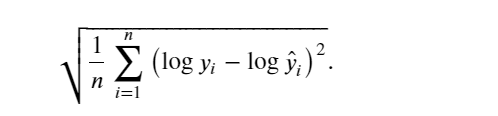
def log_rmse(y_true, y_pred):# 为了在取对数时进一步稳定该值,将小于1的值设置为1clipped_preds = tf.clip_by_value(y_pred, 1, float('inf'))return tf.sqrt(tf.reduce_mean(loss(tf.math.log(y_true), tf.math.log(clipped_preds))))
训练函数将借助Adam优化器,Adam优化器的主要吸引力在于它对初始学习率不那么敏感。
def train(net, train_features, train_labels, test_features, test_labels,num_epochs, learning_rate, weight_decay, batch_size):train_ls, test_ls = [], []train_iter = d2l.load_array((train_features, train_labels), batch_size)# 这里使用的是Adam优化算法optimizer = tf.keras.optimizers.Adam(learning_rate)net.compile(loss=loss, optimizer=optimizer)for epoch in range(num_epochs):for X, y in train_iter:with tf.GradientTape() as tape:y_hat = net(X)l = loss(y, y_hat)params = net.trainable_variablesgrads = tape.gradient(l, params)optimizer.apply_gradients(zip(grads, params))train_ls.append(log_rmse(train_labels, net(train_features)))if test_labels is not None:test_ls.append(log_rmse(test_labels, net(test_features)))return train_ls, test_ls
四、K折交叉验证
K折交叉验证, 它有助于模型选择和超参数调整。首先需要定义一个函数,在 𝐾折交叉验证过程中返回第 𝑖 折的数据。具体地说,它选择第 𝑖 个切片作为验证数据,其余部分作为训练数据。注意,这并不是处理数据的最有效方法,如果数据集大得多,会有其他解决办法。
def get_k_fold_data(k, i, X, y):assert k > 1fold_size = X.shape[0] // kX_train, y_train = None, Nonefor j in range(k):idx = slice(j * fold_size, (j + 1) * fold_size)X_part, y_part = X[idx, :], y[idx]if j == i:X_valid, y_valid = X_part, y_partelif X_train is None:X_train, y_train = X_part, y_partelse:X_train = tf.concat([X_train, X_part], 0)y_train = tf.concat([y_train, y_part], 0)return X_train, y_train, X_valid, y_valid
在 𝐾 折交叉验证中训练 𝐾次后,返回训练和验证误差的平均值。
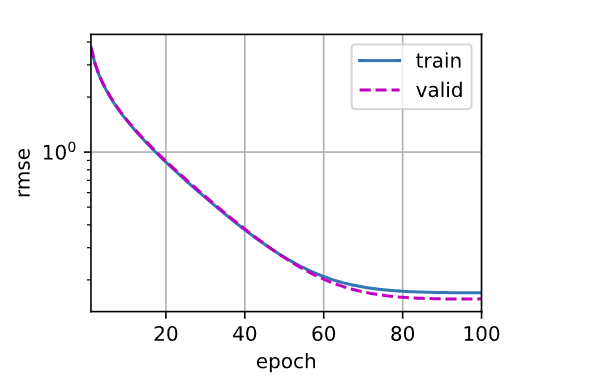
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,batch_size):train_l_sum, valid_l_sum = 0, 0for i in range(k):data = get_k_fold_data(k, i, X_train, y_train)net = get_net()train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,weight_decay, batch_size)train_l_sum += train_ls[-1]valid_l_sum += valid_ls[-1]if i == 0:d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],legend=['train', 'valid'], yscale='log')print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, 'f'验证log rmse{float(valid_ls[-1]):f}')return train_l_sum / k, valid_l_sum / k
五、模型选择
选择了一组未调优的超参数,并将其留给读者来改进模型。 找到一组调优的超参数可能需要时间,这取决于一个人优化了多少变量。
有了足够大的数据集和合理设置的超参数, 𝐾 折交叉验证往往对多次测试具有相当的稳定性。 然而,如果尝试了不合理的超参数,可能会发现验证效果不再代表真正的误差。
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, 'f'平均验证log rmse: {float(valid_l):f}')
折1,训练log rmse0.170193, 验证log rmse0.157399
折2,训练log rmse0.162299, 验证log rmse0.189597
折3,训练log rmse0.164040, 验证log rmse0.167844
折4,训练log rmse0.168239, 验证log rmse0.154891
折5,训练log rmse0.163944, 验证log rmse0.182911
5-折验证: 平均训练log rmse: 0.165743, 平均验证log rmse: 0.170528
六、保存预测数据
既然知道应该选择什么样的超参数, 不妨使用所有数据对其进行训练 (而不是仅使用交叉验证中使用的 1−1/𝐾的数据)。 然后,通过这种方式获得的模型可以应用于测试集。 将预测保存在CSV文件中。
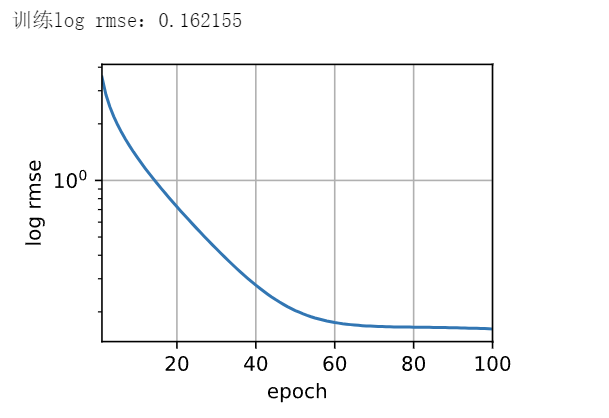
def train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size):net = get_net()#训练网络train_ls, _ = train(net, train_features, train_labels, None, None,num_epochs, lr, weight_decay, batch_size)# 可视化损失变化d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',ylabel='log rmse', xlim=[1, num_epochs], yscale='log')print(f'训练log rmse:{float(train_ls[-1]):f}')# 将网络应用于测试集。preds = net(test_features).numpy()# 将其重新格式化以导出到Kaggletest_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)submission.to_csv('submission.csv', index=False)
train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size)
相关文章:
深度学习 精选笔记(10)简单案例:房价预测
学习参考: 动手学深度学习2.0Deep-Learning-with-TensorFlow-bookpytorchlightning ①如有冒犯、请联系侵删。 ②已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。 ③非常推荐上面(学习参考&#x…...

DBGridEh 的排序
DBGridEh 可以点列抬头使得记录按该列排序 不需要写代码,只需要设置好,它就能排序。 网上的文章一般写了如何设置。但一般都少说了一条。 先说如何设置: 1. OptionsEh.AutoSortMarking 设置为 True,如果是设计期属性面板&…...
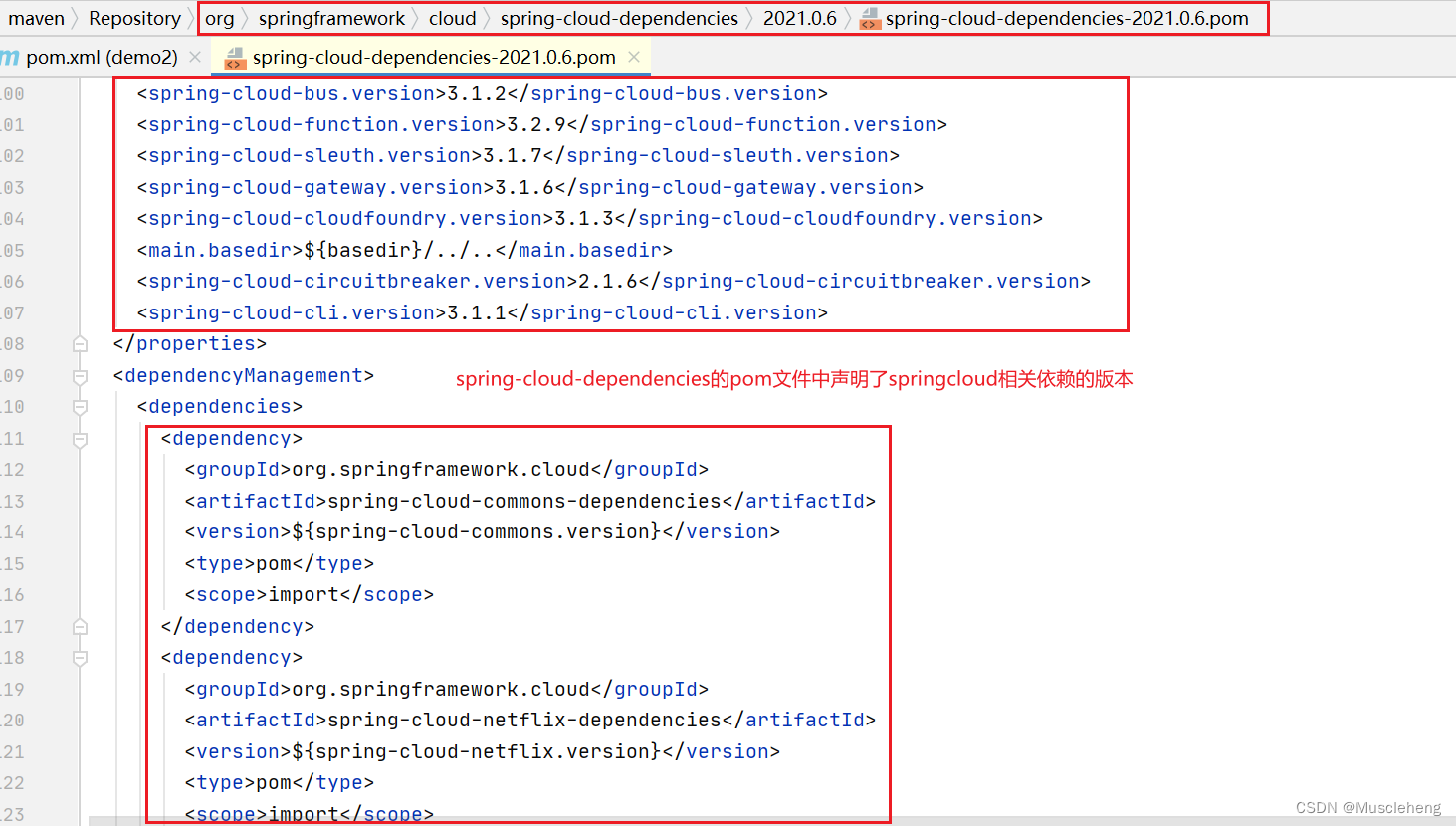
spring-boot-starter-parent和spring-boot-dependencies介绍
springboot项目的pom文件中,我们经常看见这样(下图)两种springboot的版本依赖管理方式;图片中的这两种依赖声明方式任意用其中一种都可以。文章后面会简单阐述一下区别和使用场景。 事例中完整的pom文件 <?xml version"1.0" encoding&quo…...
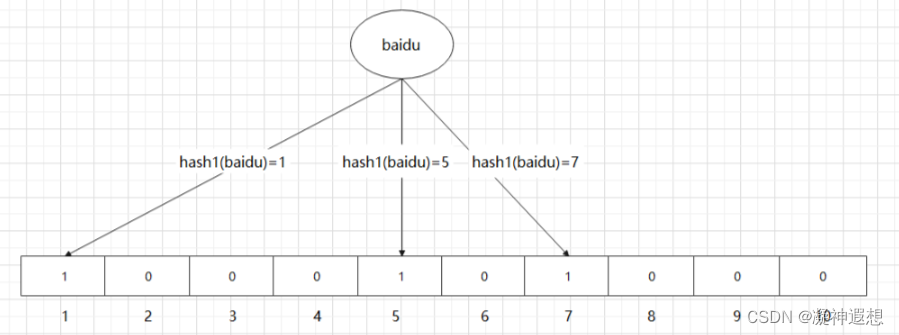
缓存穿透解决方案之布隆过滤器
布隆过滤器可以快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库的压力 布隆过滤器是由一个初值为0的bit数组和N个哈希函数,可以用来快速的判断某个数据是否存在 当我们想要标记某个数据是否存在时,布隆过滤器会…...

pptx和ppt有什么区别?了解两者之间的微妙差异
在现代办公和学习环境中,PowerPoint已成为我们生活中不可或缺的一部分。随着技术的不断进步,PowerPoint的格式也在不断更新。对于许多初学者,可能会对PPT和PPTX这两种格式感到困惑。本文旨在深入探讨PPTX与PPT之间的主要差异,帮助…...

LabVIEW水下温盐深数据一体化采集与分析
LabVIEW水下温盐深数据一体化采集与分析 开发一个基于LabVIEW的水下温盐深数据一体化采集与分析系统,实现海洋环境监测的自动化和精确化。通过集成温度、盐度和深度传感器,结合USB数据采集卡,利用LabVIEW软件开发的图形化界面,实…...
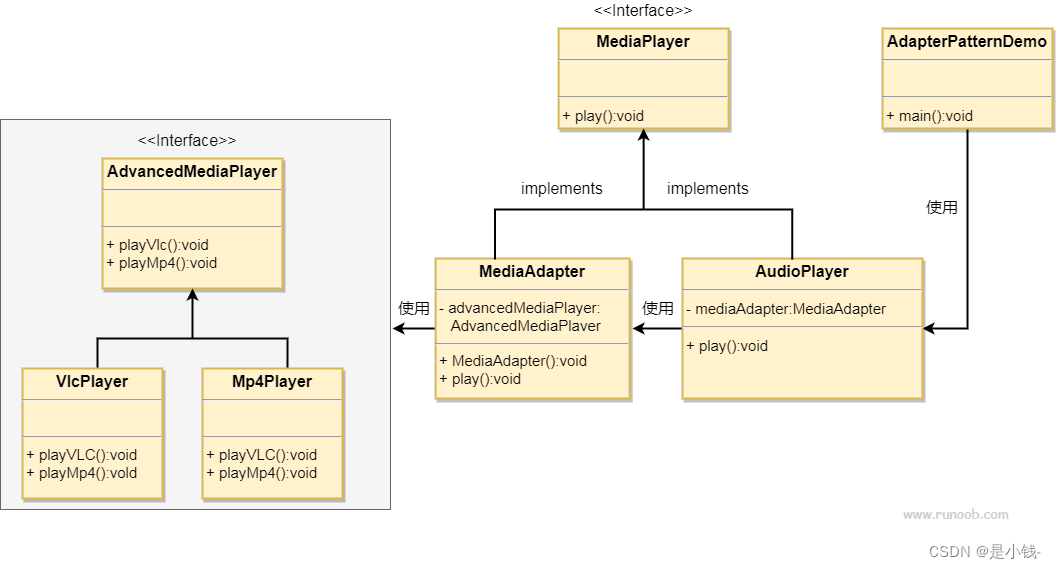
适配器模式 详解 设计模式
适配器模式 适配器模式是一种结构型设计模式,其主要作用是解决两个不兼容接口之间的兼容性问题。适配器模式通过引入一个适配器来将一个类的接口转换成客户端所期望的另一个接口,从而让原本由于接口不匹配而无法协同工作的类能够协同工作。 结构 适配…...

探索rsync远程同步和SSH免密登录的奥秘
目录 集群分发脚本xsyncscp(secure copy)安全拷贝rsync 远程同步工具集群分发脚本 SSH免密登录免密登录原理SSH免密登录配置生成公钥和私钥授权测试 在现代科技飞速发展的时代,数据的备份和迁移成为了一个重要的课题。其中,rsync远…...

JavaScript new、apply call 方法
new、apply、call、bind JavaScript 中的 apply、call和 bind 方法是前端代码开发中相当重要的概念,并且与 this 的指向密切相关 new new 关键词的主要作用 就是执行一个构造函数、返回一个实例对象 根据构造函数的情况,来确定是否可以接受参数的传递…...

助力智能化农田作物除草,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统
在我们前面的系列博文中,关于田间作物场景下的作物、杂草检测已经有过相关的开发实践了,结合智能化的设备可以实现只能除草等操作,玉米作物场景下的杂草检测我们则少有涉及,这里本文的主要目的就是想要基于DETR模型来开发构建玉米…...
转移线性dpLeetCode 2369. 检查数组是否存在有效划分)
O(1)转移线性dpLeetCode 2369. 检查数组是否存在有效划分
一、题目 1、题目描述 给你一个下标从 0 开始的整数数组 nums ,你必须将数组划分为一个或多个 连续 子数组。 如果获得的这些子数组中每个都能满足下述条件 之一 ,则可以称其为数组的一种 有效 划分: 子数组 恰 由 2 个相等元素组成…...
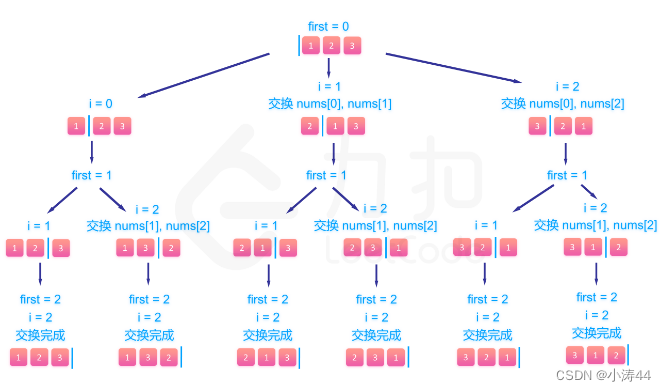
【力扣hot100】刷题笔记Day17
前言 今天竟然不用开组会!天大的好消息,安心刷题了 46. 全排列 - 力扣(LeetCode) 回溯(排列) class Solution:def permute(self, nums: List[int]) -> List[List[int]]:# 回溯def backtrack():if len(…...

leetcode日记(34)通配符匹配
这道题做了很久很久……一开始我想用的方法是使用双指针,分别指向两数组,然后依次按照题目中的规则遍历,做了很久发现时间超限了!这是我最后超时的代码! class Solution { public:bool isMatch(string s, string p) {…...

一张图读懂人工智能
一、生成人工智能的概念和应用,以及如何使用大型语言模型进行聊天和创造原创内容。这项技术将会对人类和企业产生深远影响。 计算机获得学习、思考和交流的能力,被称为生成人工智能。生成人工智能可以立即获得人类所有知识的总和,并回答任何…...

5.37 BCC工具之uflow.py解读
一,工具简介 uflow工具用于跟踪方法的进入和退出事件,并打印一个可视化的流程图,显示方法是如何进入和退出的,类似于带有断点的跟踪调试器。这对于理解Java、Perl、PHP、Python、Ruby和Tcl等高级语言中的程序流非常有用,这些语言为方法调用提供了USDT探测。 二,代码示例…...

R语言简介,R语言开发环境搭建步骤,R基础语法以及注释详解
R语言是一种用于统计计算与绘图的编程语言,由新西兰奥克兰大学的统计学家罗斯伊哈卡和罗伯特杰特曼于1993年发明。R语言是一种自由、免费、源代码开放的软件,属于GNU系统的一个分支,如今被广泛地应用于统计分析、数据挖掘等领域。 R语言的特…...

【Django】执行查询—检索对象
检索对象 以下述模型为基础,讨论检索对象的方式方法: from datetime import datefrom django.db import modelsclass Blog(models.Model):name models.CharField(max_length100)tagline models.TextField()def __str__(self):return self.nameclass …...
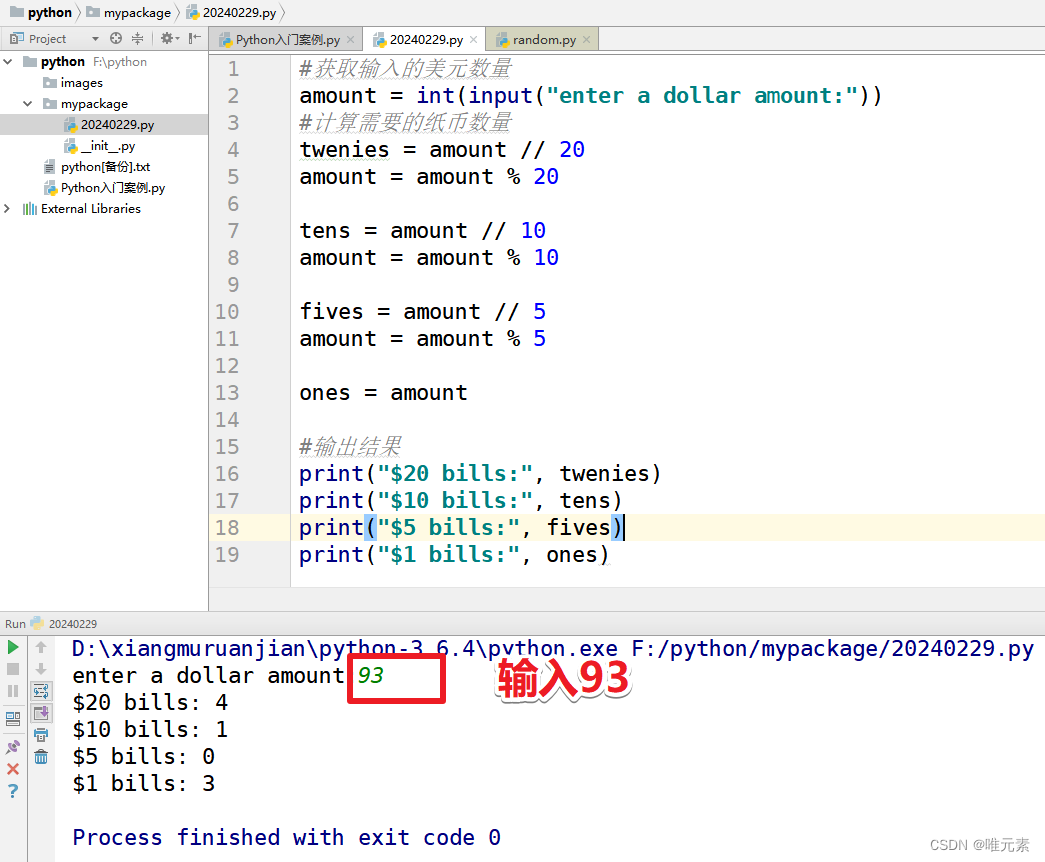
Python:练习:编写一个程序,写入一个美金数量,然后显示出如何用最少的20美元、10美元、5美元和1美元来付款
案例: python编写一个程序,写入一个美金数量,然后显示出如何用最少的20美元、10美元、5美元和1美元来付款: Enter a dollar amout:93 $20 bills: 4 $10 bills: 1 $5 bills:0 $1 bills:3 思考: 写入一个美金数量&…...

模板方法模式 详解 设计模式
模板方法模式 模板方法模式是一种行为型设计模式,它定义了一个算法的骨架,将一些步骤延迟到子类中实现。这种模式允许子类在不改变算法结构的情况下重新定义算法的某些步骤。 结构 抽象类(Abstract Class):负责给出一…...
)
Node.js_基础知识(http模块)
网络基础 URL的组成结构:协议名: // 主机名 [:端口号] [/路径] [?查询字符串]协议默认端口: http:80,开发常用端口有 3000、8080、8090、9000https: 443 如果端口被其他程序占用,可以使用 资源监视器 找到占用端口的…...

建议所有人前端准备到这种程度再去面试
别再裸面了,有些坑你根本想不到最近帮团队筛了上百份前端简历,也面了四十多个候选人。说实话,大部分人连第一轮都过不了——不是因为基础差,而是完全不知道面试官到底在考什么。 有人能把 三大框架的源码讲得头头是道,…...

K8s压力测试实战:从HPA动态扩缩容到资源优化
1. 为什么需要K8s压力测试? 当你把业务迁移到Kubernetes集群后,最怕遇到什么情况?我猜一定是半夜被报警叫醒,发现服务因为流量激增而崩溃。去年我们团队就经历过一次,促销活动带来的流量是平时的20倍,HPA&…...
)
别再手动上传脚本了!手把手教你配置Jmeter分布式压测(Linux Master + Windows Slave实战)
别再手动上传脚本了!手把手教你配置Jmeter分布式压测(Linux Master Windows Slave实战) 分布式压测是性能测试工程师进阶的必经之路,但传统方式中频繁上传脚本、下载大体积结果文件的痛点,让很多团队望而却步。本文将…...

OpenSTA完整指南:3步掌握开源静态时序分析引擎的终极解决方案
OpenSTA完整指南:3步掌握开源静态时序分析引擎的终极解决方案 【免费下载链接】OpenSTA OpenSTA engine 项目地址: https://gitcode.com/gh_mirrors/op/OpenSTA OpenSTA是一款强大的开源门级静态时序验证工具,能够帮助芯片设计团队使用Verilog网表…...

天辛大师直言一人公司是泡沫,很多人就是大厂促销员
在近年共享经济、灵活用工模式疯狂扩张,不少互联网大厂为了压缩用工成本、规避社保与劳动仲裁风险,不断推动外包用工模式“轻量化”异化的行业背景下,长期研究平台用工治理与小微企业合规发展的天辛大师,在一次行业深度沙龙上&…...

[Spark] 图解Job、Stage、Task的生成逻辑与实战推演
1. 从一行代码到分布式计算:Spark任务的生命周期 当你第一次接触Spark时,可能会被Job、Stage、Task这些概念搞得晕头转向。别担心,这就像学习做菜一样,刚开始分不清生抽和老抽,用多了自然就明白了。让我们从一个最简单…...
)
从Prompt到发布:我的Coze工作流如何搞定每周3篇公众号更新(含完整节点配置)
从Prompt到发布:我的Coze工作流如何搞定每周3篇公众号更新 每周稳定产出高质量公众号内容,是许多自媒体人的痛点。去年我开始尝试用Coze搭建自动化工作流,如今已实现每周3篇原创文章的稳定发布。这套系统不仅节省了80%的重复劳动时间…...

Ubuntu系统MPI并行计算环境搭建实战
1. 为什么需要MPI并行计算环境 在科研和工程计算领域,我们经常会遇到需要处理海量数据或者进行复杂模拟的情况。这时候单台计算机的性能就显得捉襟见肘了。记得我第一次做流体力学模拟时,一个简单的模型跑了整整三天还没出结果,导师看了直摇头…...

SQLServer2012离线安装避坑实录:当.NET 3.5遇到Windows Server时
SQLServer2012离线安装避坑指南:从环境检测到应急方案的完整决策流程 当数据库管理员在隔离环境中部署SQLServer2012时,最令人头疼的莫过于那个看似简单却暗藏玄机的.NET Framework 3.5依赖问题。上周我在某金融机构的数据中心就遭遇了这样的场景——机房…...
)
Linux服务器被黑怎么办?一份给运维新手的应急取证自查清单(附弘连工具实操)
Linux服务器应急响应实战指南:从入侵检测到取证分析 凌晨三点,手机突然响起刺耳的警报声——服务器CPU使用率飙升至98%。当你睡眼惺忪地远程登录系统,发现陌生IP正在执行rm -rf /*命令时,那种头皮发麻的感觉会成为每个运维人员的职…...