【中科院计算所】WSDM 2024冠军方案:基于大模型进行多文档问答

作者:李一鸣 张兆 中科院计算所
会话式多文档问答旨在根据检索到的文档以及上下文对话来回答特定问题。 在本文中,我们介绍了 WSDM Cup 2024 中“对话式多文档 QA”挑战赛的获胜方法,该方法利用了大型语言模型 (LLM) 卓越的自然语言理解和生成能力。
在方案中,首先让大模型适应该任务,然后设计一种混合训练策略,以充分利用领域内的未标记数据。 此外,采用先进的文本嵌入模型来过滤掉潜在的不相关文档,并为模型集成设计和比较了几种方法。 凭借所有这些技术,我们的解决方案最终在 WSDM Cup 2024 中排名第一,超越在很大程度上是其竞争对手。
关键词:问答;大语言模型;文本嵌入模型;混合训练
Github开源地址:https://github.com/zhangzhao219/WSDM-Cup-2024
方案简介
对话式问答旨在根据对话中识别的用户意图生成正确且有意义的答案,在现代搜索引擎中发挥着至关重要的作用和对话系统。 然而,这仍然具有挑战性,特别是对于当前或趋势主题,因为在语言模型的训练阶段无法获得及时的知识。 尽管提供多个相关文档作为上下文信息似乎可行,但该模型仍然面临着被大量输入淹没或误导的风险。 基于来自小红书的真实文本数据,WSDM Cup 20241提出了“对话式多文档QA”的挑战,以鼓励对问题的进一步探索。
最近,ChatGPT 等大模型在多项自然语言处理任务上表现出了令人印象深刻的性能。 通过利用大模型的理解和推理能力,有望解决这一挑战。 然而,包括训练配置的设计和不相关文档的存在在内的许多因素仍然阻碍了生成质量的提高。
在这项工作中,为了激活 LLM 的能力,我们首先将任务表述为具有不同 LLM 的多轮条件生成问题。 然后,进行多阶段混合训练管道,将未标记的评估集合并为额外的训练语料库。为了删除潜在的不相关信息,我们实施了某些策略,包括最先进的嵌入模型,即 Nomic Embed 计算输入和文档之间的相似度得分。 最后,在选择最佳响应作为模型集成的最终答案之前,考虑了几种方法来近似评估各种大模型生成的答案的质量。 实验结果表明,我们的解决方案在每个评估指标上都取得了最高分,远远超出了我们背后的团队,而消融研究也表明了所提出技术的有效性。
对话式多文档问答挑战赛
「对话式多文档问答」挑战赛 Conversational Multi-Doc QA
赛题任务
每个月有数以亿计的用户在小红书上分享和发现生活的美好,并在小红书海量笔记中获取相关信息和实用的生活经验。小红书利用先进的 AI 技术,如深度学习及时下流行的大语言模型等,提升用户个性化的互动体验,更好地满足他们对高效、准确信息获取的需求。
在多轮对话场景中,为用户的查询提供准确且全面的回答是一项充满挑战的任务,在本次比赛中,我们将模拟真实的多轮对话场景,提供对话历史、当前查询 query、以及搜索系统检索到的相关笔记。参赛者的系统被要求依据这些输入信息,理解用户查询意图并输出面向查询 query 的文本回答。我们将评估回答的准确性与完善性。通过这个挑战,期待能探索和提高对话系统在面对多轮上下文和多样化搜索结果时,生成更准确,完善回答的能力,更好地理解和满足用户的需求,获取更加高效、准确的信息。
数据集
数据集包括训练/验证/测试数据,每个都将以“json”格式给出,每个样本包含以下字段:
- uuid:字符串,每个示例的唯一标识符
- history:字符串元组列表,顺序 QA 对
- documents:字符串列表,最多5个参考文档
- question:字符串,用户问题
- answer:字符串,参考答案(未在评估/测试数据中给出)
- keywords:字符串列表,最好在参考答案中提及的参考关键字(训练/评估/测试集中均未给出)
数据样例如下:
{
"uuid": "xxxxx",
"history": [{"question": xxx, "history": xxx},{"question": xxx, "history": xxx},...
],
"documents":
[
"Jun 17th through Fri the 21st, 2024 at the Seattle Convention Center, Vancouver Convention Center.", "Workshops within a “track” will take place in the same room (or be co-located), and workshop organizers will be asked to work closely with others in their track ...",
...
],
"question": "Where will CVPR 2024 happen?",
"answer": "CVPR 2024 will happen at the Seattle Convention Center, Vancouver.",
"keywords": # Will not be given.
[
"Vancouver", "CVPR 2024", "Seattle Convention Center"
]
}
评估指标
指标:
- 关键词召回:答案是否包含事实以及精确匹配的特定关键词。
- 字符级 ROUGE-L :通过模糊字符级匹配,答案是否与参考答案相似。
- 单词级ROUGE-L :通过模糊单词级匹配,答案是否与参考答案相似。
排名规则:
- 整体表现将通过检查第二阶段(测试集)排行榜上上述指标的平均排名来确定。
- 如果团队平均排名相同,则优先考虑单词级 ROUGE-L分数较高的团队。
方案思路
基于LLMs实现多文档问答
为了使 LLM 适应这项任务,我们仔细设计了输入格式,并按以下顺序将每个文本部分连接在一起:
u = { q 1 } { a 1 } { q 2 } { a 1 } . . . { q n } { a n } { q } { d 1 } { d 2 } . . . { d n } { a } u=\{q_{1}\}\{a_{1}\}\{q_{2}\}\{a_{1}\}...\{q_{n}\}\{a_{n}\}\{q\}\{d_{1}\}\{d_{2}\}...\{d_{n}\}\{a\} u={q1}{a1}{q2}{a1}...{qn}{an}{q}{d1}{d2}...{dn}{a}
请注意,我们在上面的拼接中排除了特殊字符(例如<s>、[INST])。
然后,可以通过最大化整个序列的对数似然来训练模型 θ \theta θ:
L g e n = − ∑ i = 1 u m i l o g p ( u i ∣ , u < i : θ ) L_{gen}=-\sum_{i=1}^{u}m_{i}log p(u_{i}|,u<i:\theta) Lgen=−i=1∑umilogp(ui∣,u<i:θ)
其中 p ( u i ∣ , u < i : θ ) p(u_{i}|,u<i:\theta) p(ui∣,u<i:θ) 代表在第i步选择来自于 u < i u<i u<i之前字符 u i u_{i} ui 的概率, m i m_{i} mi代表针对第i字符的loss mask。其中有两种训练模式
- 单轮模式:当 u i u_{i} ui属于 a {a} a, m i = 1 m_{i}=1 mi=1
- 多轮模式:当 u i u_{i} ui属于 a {a} a或者 a i {a}_{i} ai, m i = 1 m_{i}=1 mi=1。
我们基于Llama2-13B-base做了实验,发现多轮模式会带来更好的性能,可以使LLM更加关注上下文信息

在决定输入格式和掩码模式后,我们比较了许多现成的 LLM,它们要么仅经过预训练,要么经过指令调整。 如表 2 所示,SOLAR-10.7B-Instruct 模型在评估数据集上远远超过了同类模型,该模型使用深度放大来缩放 LLM,并针对指令跟踪功能进行了微调。 因此,在后续的实验中选择它作为我们的backbone。

混合训练
来自相似分布的适当标记文本可能对大模型生成性能的提高做出很大贡献。 在第二阶段,我们建议利用精调的模型为评估数据集生成(伪)答案,然后将它们添加到原始训练集以从头开始微调新模型。 上述混合训练策略的出发点有两个,一方面,它可以被视为对域内未标记数据的知识蒸馏过程,另一方面,因为我们只在a中生成最终目标${a} 伪标记方式, 伪标记方式, 伪标记方式,{ai}$仍然是官方注释的,这可能有利于多轮设置。 请注意,我们不会进一步涉及混合训练的测试数据集,因为它可能会过度拟合模型,从而削弱最终评估中的模型性能,这也通过我们的实验进行了验证。
噪音文档过滤
毫无疑问,高质量的参考文档不仅可以帮助减轻幻觉现象,还可以提高大模型的推理质量[6]。 仔细观察整个数据集后,我们发现主要有两种类型的噪声文档,如图1所示:
-
文档几乎重新表述了该问题,该问题与文档具有极高的相关分数。
-
文档包含了不相关的信息,因此它们与问题或历史记录的相关分数极低。
因此,在不存在真实答案的情况下量化相关性至关重要。 从语义和词汇的角度来看,我们得出以下两个指标:
- 嵌入级余弦相似度 我们采用高级文本嵌入模型Nomic Embed 来计算文档与相应问题(或与对话历史记录一起)之间的余弦相似度。
- 单词或字符级ROUGE-L 如前所述,ROUGE-L 分数可以被视为词汇相关性标准。
实际上,我们对每个指标分别设置较高的阈值 τ h \tau_{h} τh和较低的阈值 τ l \tau_{l} τl,然后筛选出参考文档,其对应分数≥ τ h \tau_{h} τh或≤ τ l \tau_{l} τl进行手动检查。结果,我们在第2阶段过滤掉了193个噪声文档。
此外,之前的工作表明,大模型可以更好地理解位于输入开头或结尾的重要段落。 然而,我们发现文档索引和官方注释答案中出现的相对顺序之间存在很强的相关性,这意味着对参考文档重新排序可能会导致严重的性能下降。
模型融合

模型集成已被证明在判别任务中是有效的,但是,很少在生成环境下进行探索。 在这项工作中,我们建议近似评估不同模型生成的答案的质量,然后选择最好的作为最终结果。 假设给定一个测试样本,我们有 M M M个候选响应进行聚合,对于每个候选 r i r_{i} ri ,我们计算 r i r_{i} ri 和 r j r_{j} rj 之间的相关性分数 s ( r i , r j ) ( j = 1 , . . . , M , j ≠ i ) s(r_{i} ,r_{j} )(j=1,...,M,j\neq i) s(ri,rj)(j=1,...,M,j=i),将它们加在一起作为 r i ( q i = ∑ j s ( r i , r j ) ) 的质量分数 r_{i}(q_{i}=\sum_{j}s(r_{i},r_{j}))的质量分数 ri(qi=∑js(ri,rj))的质量分数q_{i}$。 类似地,相关性量化器可以是嵌入级余弦相似度(表示为 emb_a_s)、单词级 ROUGE-L(表示为 word_a_f)和字符级 ROUGE-L(表示为 char_a_f)。动机是最终答案应该是与最多候选模型达成一致性的代表。
实验
实验设置
训练代码使用modelscope的swift,超参数设置如下:

实验结果
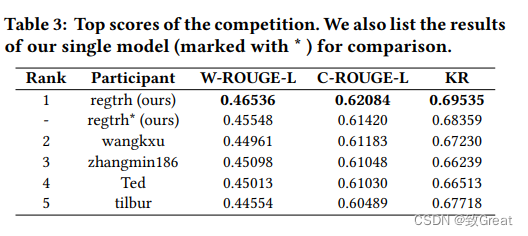
表3列出了本次比赛的最终结果。 如图所示,我们的解决方案汇总了 8 个不同模型的结果,与第二名相比,W-ROUGE-L、C-ROUGE-L 和 KR 的绝对性能分别提高了 1.6%、0.9% 和 2.3%。 此外,值得注意的是,我们的单模型也可以比其他模型产生更好的性能,这表明我们的模型是有效的策略。
消融实验
文档过滤的消融实验:表 4 显示了我们的单一模型在使用和不使用噪声文档过滤的情况下推断的实验结果。 我们发现它略微提高了最终分数,因为提供的文件是由杯赛组织者精心挑选的,大模型可以在一定程度上区分潜在的干扰因素。

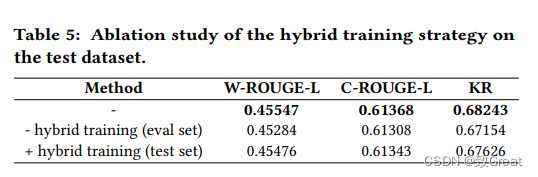
混合训练策略的消融实验:我们在表 5 中验证了所提出的混合训练策略的效果。如图所示,将评估集与相应的伪目标相结合可以很大程度上提高生成质量,特别是对于关键字召回分数。 但进一步加入测试集几乎没有什么效果,这验证了我们的设计选择。
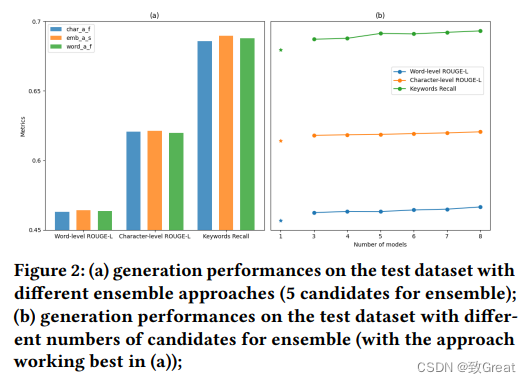
模型融合的消融实验:我们首先比较不同的集成方法,如图 2 (a) 所示。 尽管上述方法在 ROUGE 分数上都具有竞争力,但 emb_a_s 在关键字召回方面带来了更多改进,因此被选为我们最终的集成方法。 然后,对整体候选数量进行参数分析。 从图 2 (b) 中可以看出,更多的候选者通常会带来更好的性能。 由于时间和预算有限,我们最终将数量定为8。
在本文中,我们详细介绍了 WSDM Cup 2024 中“对话式多文档 QA”任务的获胜解决方案。利用法学硕士的能力,我们使用 SOLAR-10.7B-Instruct 模型作为骨干,结合混合模型 训练、噪声文档过滤器,并通过评估最终提交的 8 个结果的质量来选择最佳响应。 我们的解决方案在公共排行榜上获得了第一名。
相关文章:
【中科院计算所】WSDM 2024冠军方案:基于大模型进行多文档问答
作者:李一鸣 张兆 中科院计算所 会话式多文档问答旨在根据检索到的文档以及上下文对话来回答特定问题。 在本文中,我们介绍了 WSDM Cup 2024 中“对话式多文档 QA”挑战赛的获胜方法,该方法利用了大型语言模型 (LLM) 卓越的自然语言理解和生…...

Android提供了多种方式来打开特定文件夹中的视频
使用 MediaStore获取指定文件夹的视频,更优化方法: import android.content.ContentResolver; import android.content.ContentValues; import android.content.Context; import android.net.Uri; import android.os.Build; import android.os.Environme…...
基于django的购物商城系统
摘要 本文介绍了基于Django框架开发的购物商城系统。随着电子商务的兴起,购物商城系统成为了许多企业和个人创业者的首选。Django作为一个高效、稳定且易于扩展的Python web框架,为开发者提供了便捷的开发环境和丰富的功能模块,使得开发购物商…...
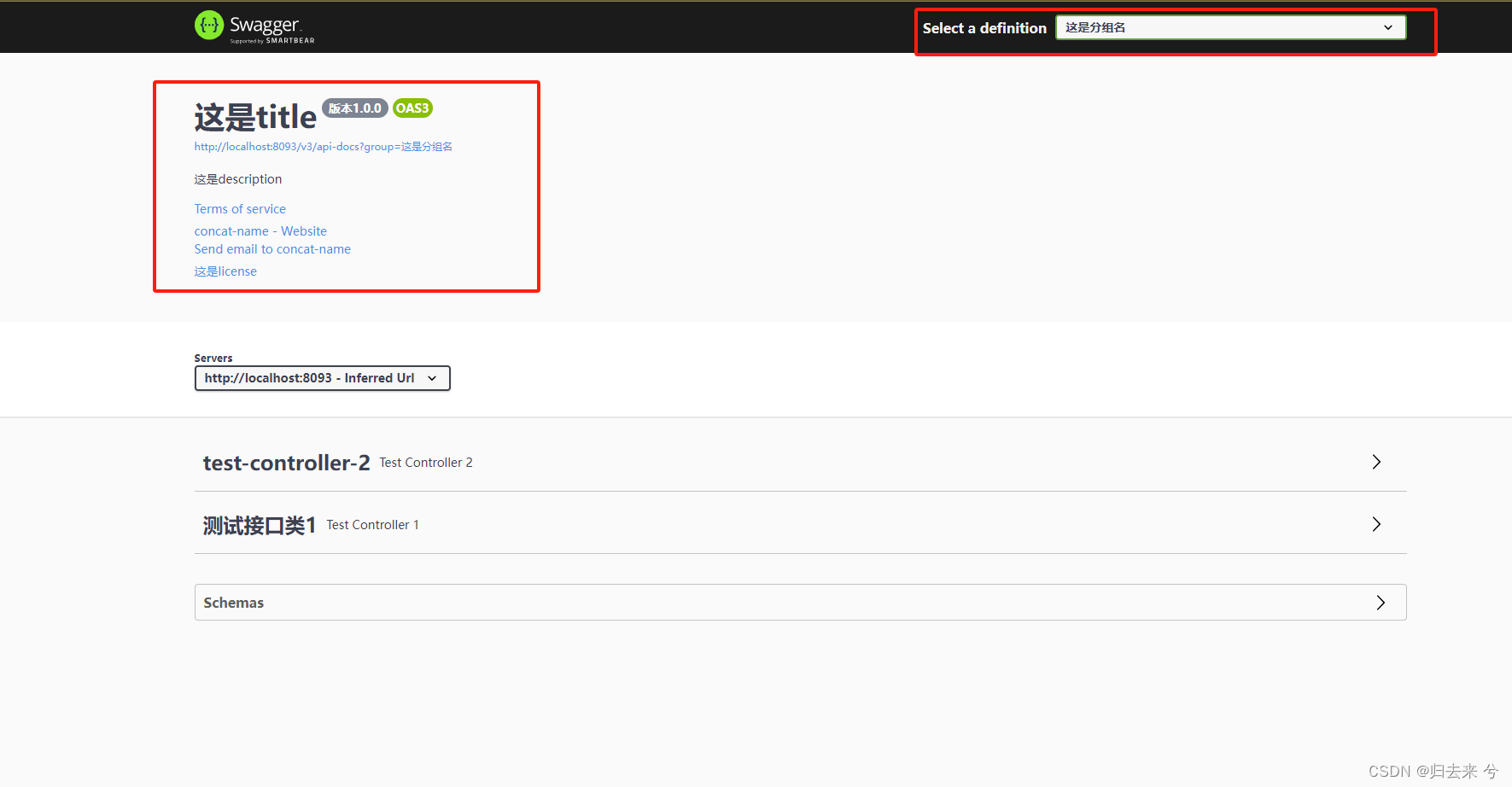
Swagger3 使用详解
Swagger3 使用详解 一、简介1 引入依赖2 开启注解3 增加一个测试接口4 启动服务报错1.5 重新启动6 打开地址:http://localhost:8093/swagger-ui/index.html 二、Swagger的注解1.注解Api和ApiOperation2.注解ApiModel和ApiModelProperty3.注解ApiImplicitParams和Api…...

JVM 第二部分-2(堆,方法区)
4.堆 堆 一个Java程序(main方法)对应一个jvm实例,一个jvm实例只有一个堆空间堆是jvm启动的时候就被创建,大小也确定了。大小可以用参数设置。堆是jvm管理的一块最大的内存空间 核心区域,是垃圾回收的重点区域堆可以位…...
蓝桥杯Java B组历年真题(2013年-2019年)
一、2013年真题 1、世纪末的星期 使用日期类判断就行,这里使用LocalDate,也可以使用Calendar类 答案 2099 使用LocalDate import java.time.LocalDate; import java.time.format.DateTimeFormatter; // 1:无需package // 2: 类名必须Main, 不可修改p…...

你是谁,便会遇见谁
就会进什么样的圈子。努力提升自己,才是提升阶层最可靠的方法。 在人生的舞台上,每一个人都是自己人生的主角。而在这个旅程中,我们会遇见各种各样的人,进入不同的社交圈子。正如一句古训所说:“你是谁,便…...
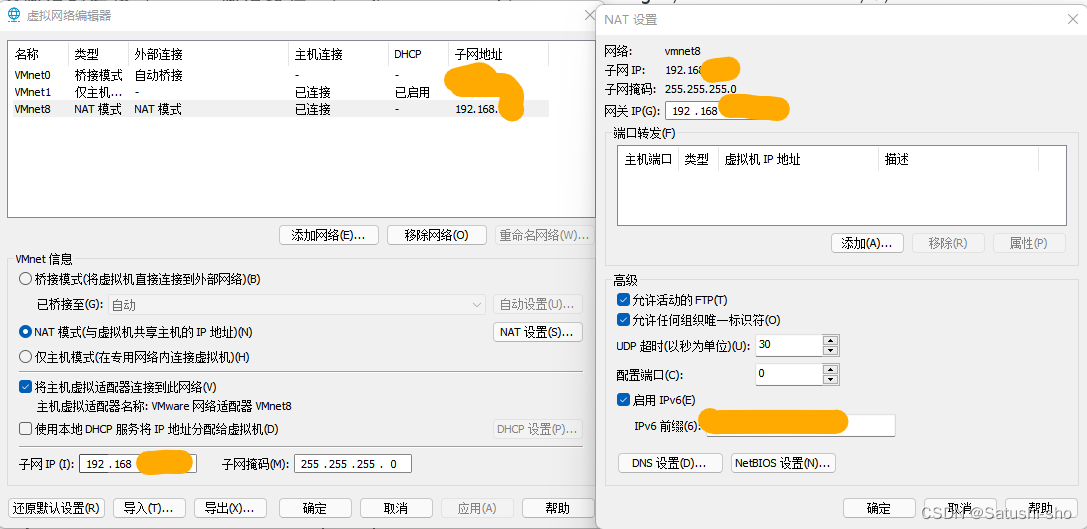
Linux/Centos 部署静态IP,解决无法访问目标主机、Destination Host Unreachable、无法ping通互联网的问题
Linux/Centos 部署IP,解决无法访问目标主机、Destination Host Unreachable、无法ping通互联网的问题 Linux/Centos 部署静态IP查物理机/自身电脑的IP设置VMware上的虚拟网络编辑器设置网卡IP,激活至此就可访问百度了 Linux/Centos 部署静态IP 需要注意…...
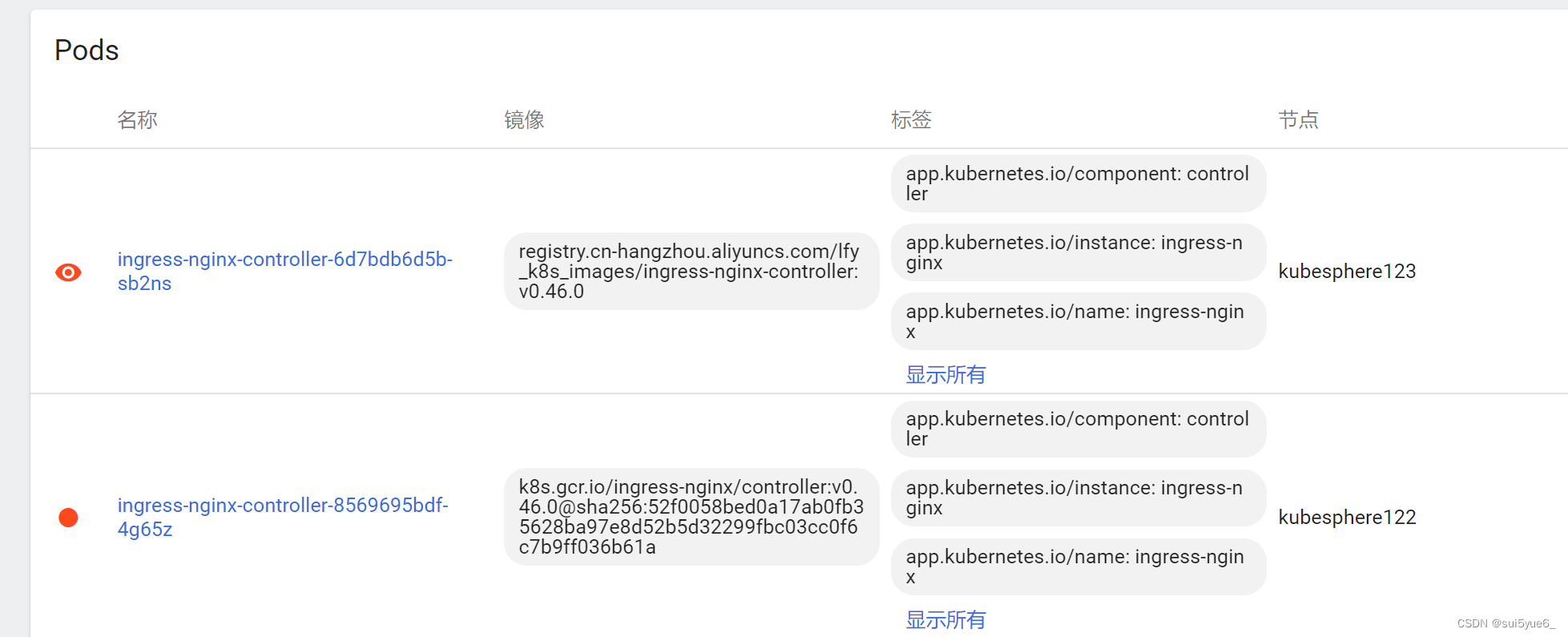
在学习云原生的时候,一直会报错ImagePullBackOff Back-off pulling image
在学习云原生的时候,一直会报错 (见最后几张图) ImagePullBackOff Back-off pulling image 然后我就在像。这个配置的镜像是不是可以自己直接下载,但是好像不怎么搜索得到 然后就在想,这个lfy_k8s_images到底是个啥玩…...

Android Activity跳转详解
在Android应用程序中,Activity之间的跳转是非常常见的操作,通过跳转可以实现不同界面之间的切换和交互。在本篇博客中,我们将介绍Android中Activity跳转的相关知识,包括基本跳转、传递参数、返回数据以及跳转到浏览器、拨号应用和…...

计算机网络(2)-----数据链路层
目录 一.数据链路层的基本概念 二.数据链路层的功能概述 功能一:为网络层提供服务。无确认无连接服务,有确认无连接服务,有确认面向连接服务。 功能二:链路管理,即连接的建立、维持、释放(用于面向连接的服务)。 功能三:组帧 透明传输:…...

贪心算法(算法竞赛、蓝桥杯)--修理牛棚
1、B站视频链接:A27 贪心算法 P1209 [USACO1.3] 修理牛棚_哔哩哔哩_bilibili 题目链接:[USACO1.3] 修理牛棚 Barn Repair - 洛谷 #include <bits/stdc.h> using namespace std; const int N205; int m,s,c,ans; int a[N];//牛的位置标号 int d[N…...

【AIGC】微笑的秘密花园:红玫瑰与少女的美好相遇
在这个迷人的画面中,我们目睹了一个迷人的时刻,女子则拥有一头柔顺亮丽的秀发,明亮的眼睛如同星河般璀璨,优雅而灵动,她的微笑如春日暖阳,温暖而又迷人。站在红玫瑰花瓣的惊人洪水中。 在一片湛蓝无云的晴…...

vue3 中 主题定制
vue3 中 主题定制 背景 做多主题定制,黑/白 ,里面还要再分各种颜色,每次进来都要记住上次的主题设置 效果图 一、目录结构 ├── generated │ ├── theme │ │ └── dark-yellow.ts │ │ └── dark-orange.ts │ │…...
数据分析之Logistic回归分析(二元逻辑回归、多元有序逻辑回归、多元无序逻辑回归)
1、Logistic回归分类 在研究X对于Y的影响时: 如果Y为定量数据,那么使用多元线性回归分析;如果Y为定类数据,那么使用Logistic回归分析。 结合实际情况,可以将Logistic回归分析分为3类: 二元Logistic回归…...

【c++】通讯录管理系统
1.系统功能介绍及展示 2.创建项目 3.菜单实现 4.退出功能实现 5.添加联系人—结构体设计 6.添加联系人—功能实现 7.显示联系人 8.删除练习人—检测联系人是否存在 9.删除联系人—功能实现 10.查找联系人 11.修改联系人 12.清空通讯录 #include <iostream> #include <…...

Tomcat 架构
一、Http工作原理 HTTP协议是浏览器与服务器之间的数据传送协议。作为应用层协议,HTTP是基于TCP/IP协议来传递数据的(HTML文件、图片、查询结果等),HTTP协议不涉及数据包(Packet)传输,主要规定了…...

Spring 整合mybatis
目录 1、梳理整合思路 2、整合实现 2.1 环境搭建 2.2 案例 1、梳理整合思路 将MyBatis的DataSource交给Spring IoC容器创建并管理,使用第三方数据库连接池(Druid,C3P0等)代替MyBatis内置的数据库连接池将MyBatis的SqlSessionFactory交给Spring IoC容…...

centos7升级openssl_3
1、查看当前openssl版本 openssl version #一般都是1.几的版本2、下载openssl_3的包 wget --no-check-certificate https://www.openssl.org/source/old/3.0/openssl-3.0.3.tar.gz#解压 tar zxf openssl-3.0.3.tar.gz#进入指定的目录 cd openssl-3.0.33、编译安装遇到问题缺…...

nvidia a100-pcie-40gb环境安装
1.conda create --name torch_li python3.8 2. conda install pytorch1.7.1 torchvision0.8.2 torchaudio0.7.2 cudatoolkit11.0 -c pytorch 环境测试:torch.cuda.is_available() 3.conda remove -n torch_li --all 4.pip install opencv-python-headless 5.pip ins…...

CSS如何优化CSS加载性能_通过代码分割与压缩减少体积
关键不是压缩CSS体积,而是让浏览器尽快获取首屏所需CSS;需用media属性条件加载、动态导入非首屏样式、避免import、合理分割CSS、删除冗余选择器、谨慎内联并控制体积在2KB内。怎么让CSS不阻塞页面渲染关键不是“压缩体积”,而是让浏览器尽快…...
)
告别PS!用Windows自带画图搞定图片批量裁剪(附Python自动化脚本)
告别PS!用Windows自带画图搞定图片批量裁剪(附Python自动化脚本) 在图像处理领域,批量裁剪是高频需求——无论是电商产品图统一尺寸、科研论文插图标准化,还是社交媒体内容适配多平台规格。传统方案依赖Photoshop等专业…...
)
告别SVN!5人小团队用Gitea+SQLite在内网轻松搞定Git代码仓(附Windows/Linux双平台配置)
告别SVN!5人小团队用GiteaSQLite在内网轻松搞定Git代码仓(附Windows/Linux双平台配置) 在小型技术团队中,版本控制系统往往面临两难选择:功能齐全的企业级方案太重,而轻量级工具又缺乏协作能力。我曾带领一…...

Autosar MCAL开发避坑指南:EB配置Icu模块时,关于EMIOS时钟、中断与通道选择的三个关键决策点
Autosar MCAL实战:EMIOS时钟分频与ICU通道配置的三大核心策略 在汽车电子控制单元(ECU)开发中,精确捕获PWM信号是获取转速、位置等关键物理量的基础。我曾参与过多个基于Autosar的电机控制项目,发现约60%的Icu模块配置问题都源于EMIOS时钟设置…...

软件测试人员,别再贩卖AI焦虑了!
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中…...

3步搞定Arduino ESP32开发环境:从零开始物联网项目实战
3步搞定Arduino ESP32开发环境:从零开始物联网项目实战 【免费下载链接】arduino-esp32 Arduino core for the ESP32 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 还在为ESP32开发环境配置而头疼吗?作为Arduino官方支持的ES…...

RV1106驱动ST7735S踩坑实录:从设备树到LVGL显示,我遇到的3个关键问题
RV1106驱动ST7735S踩坑实录:从设备树到LVGL显示的三个关键陷阱 最近在Luckfox Pico Pro Max(RV1106平台)上折腾ST7735S SPI屏幕时,遇到了几个颇具代表性的问题。这些问题不仅让我熬了几个通宵,也让我对嵌入式Linux的显…...

python mapbox
# 聊聊pydeck:当Python遇见地理空间可视化 最近在做一个城市交通数据的分析项目,需要在地图上展示数百万个轨迹点。试了几个库之后,发现pydeck这个工具确实有点意思,今天就来聊聊它。 它到底是什么 pydeck本质上是一个桥梁&#x…...

逆向工程实战:3步打造Windows微信/QQ防撤回终极方案
逆向工程实战:3步打造Windows微信/QQ防撤回终极方案 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/…...

FLUX.1-dev FP8:让普通显卡也能跑专业级AI绘画模型
FLUX.1-dev FP8:让普通显卡也能跑专业级AI绘画模型 【免费下载链接】flux1-dev 项目地址: https://ai.gitcode.com/hf_mirrors/Comfy-Org/flux1-dev 还在为AI绘画的高显存需求而发愁吗?现在,你的游戏显卡也能流畅运行专业级图像生成模…...