MySQL数据库基本操作(二)
查询语句
1. 排序查询* 语法:order by 子句* order by 排序字段1 排序方式1 , 排序字段2 排序方式2... * 排序方式:* ASC:升序,默认的。* DESC:降序。 * 注意:* 如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
2. 聚合函数:将一列数据作为一个整体,进行纵向的计算。1. count:计算个数1. 一般选择非空的列:主键2. count(*)2. max:计算最大值3. min:计算最小值4. sum:计算和5. avg:计算平均值
* 注意:聚合函数的计算,排除null值。解决方案:1. 选择不包含非空的列进行计算2. IFNULL函数 3. 分组查询:1. 语法:group by 分组字段;2. 注意:1. 分组之后查询的字段:分组字段、聚合函数2. where 和 having 的区别?1. where 在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足结果,则不会被查询出来2. where 后不可以跟聚合函数,having可以进行聚合函数的判断。 -- 按照性别分组。分别查询男、女同学的平均分
SELECT sex , AVG(math) FROM student GROUP BY sex;-- 按照性别分组。分别查询男、女同学的平均分,人数
SELECT sex , AVG(math),COUNT(id) FROM student GROUP BY sex;-- 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组
SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex;-- 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组,分组之后。人数要大于2个人
SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex HAVING COUNT(id) > 2;SELECT sex , AVG(math),COUNT(id) 人数 FROM student WHERE math > 70 GROUP BY sex HAVING 人数 > 2;4. 分页查询1. 语法:limit 开始的索引,每页查询的条数;2. 公式:开始的索引 = (当前的页码 - 1) * 每页显示的条数-- 每页显示3条记录
SELECT * FROM student LIMIT 0,3; -- 第1页SELECT * FROM student LIMIT 3,3; -- 第2页SELECT * FROM student LIMIT 6,3; -- 第3页3. limit 是一个MySQL"方言"
约束
* 概念: 对表中的数据进行限定,保证数据的正确性、有效性和完整性。 * 分类:1. 主键约束:primary key2. 非空约束:not null3. 唯一约束:unique4. 外键约束:foreign key * 非空约束:not null,某一列的值不能为null1. 创建表时添加约束
CREATE TABLE stu(id INT,NAME VARCHAR(20) NOT NULL -- name为非空);2. 创建表完后,添加非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;3. 删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20); * 唯一约束:unique,某一列的值不能重复1. 注意:* 唯一约束可以有NULL值,但是只能有一条记录为null2. 在创建表时,添加唯一约束
CREATE TABLE stu(id INT,phone_number VARCHAR(20) UNIQUE -- 手机号);3. 删除唯一约束
ALTER TABLE stu DROP INDEX phone_number;4. 在表创建完后,添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE; * 主键约束:primary key。1. 注意:1. 含义:非空且唯一2. 一张表只能有一个字段为主键3. 主键就是表中记录的唯一标识 2. 在创建表时,添加主键约束
create table stu(id int primary key,-- 给id添加主键约束name varchar(20));3. 删除主键-- 错误 alter table stu modify id int ;
ALTER TABLE stu DROP PRIMARY KEY;4. 创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;5. 自动增长:1. 概念:如果某一列是数值类型的,使用 auto_increment 可以来完成值得自动增长 2. 在创建表时,添加主键约束,并且完成主键自增长
create table stu(id int primary key auto_increment,-- 给id添加主键约束name varchar(20));3. 删除自动增长
ALTER TABLE stu MODIFY id INT;4. 添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;* 外键约束:foreign key,让表于表产生关系,从而保证数据的正确性。1. 在创建表时,可以添加外键* 语法:
create table 表名(....外键列constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称));2. 删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;3. 创建表之后,添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);4. 级联操作1. 添加级联操作语法:ALTER TABLE 表名 ADD CONSTRAINT 外键名称
FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE ;2. 分类:1. 级联更新:ON UPDATE CASCADE 2. 级联删除:ON DELETE CASCADE
数据库的设计
1. 多表之间的关系1. 分类:1. 一对一(了解):* 如:人和身份证* 分析:一个人只有一个身份证,一个身份证只能对应一个人2. 一对多(多对一):* 如:部门和员工* 分析:一个部门有多个员工,一个员工只能对应一个部门3. 多对多:* 如:学生和课程* 分析:一个学生可以选择很多门课程,一个课程也可以被很多学生选择2. 实现关系:1. 一对多(多对一):* 如:部门和员工* 实现方式:在多的一方建立外键,指向一的一方的主键。2. 多对多:* 如:学生和课程* 实现方式:多对多关系实现需要借助第三张中间表。中间表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键3. 一对一(了解):* 如:人和身份证* 实现方式:一对一关系实现,可以在任意一方添加唯一外键指向另一方的主键。 3. 案例-- 创建旅游线路分类表 tab_category-- cid 旅游线路分类主键,自动增长-- cname 旅游线路分类名称非空,唯一,字符串 100
CREATE TABLE tab_category (cid INT PRIMARY KEY AUTO_INCREMENT,cname VARCHAR(100) NOT NULL UNIQUE);-- 创建旅游线路表 tab_route/*rid 旅游线路主键,自动增长rname 旅游线路名称非空,唯一,字符串 100price 价格rdate 上架时间,日期类型cid 外键,所属分类*/
CREATE TABLE tab_route(rid INT PRIMARY KEY AUTO_INCREMENT,rname VARCHAR(100) NOT NULL UNIQUE,price DOUBLE,rdate DATE,cid INT,FOREIGN KEY (cid) REFERENCES tab_category(cid));/*创建用户表 tab_useruid 用户主键,自增长username 用户名长度 100,唯一,非空password 密码长度 30,非空name 真实姓名长度 100birthday 生日sex 性别,定长字符串 1telephone 手机号,字符串 11email 邮箱,字符串长度 100*/
CREATE TABLE tab_user (uid INT PRIMARY KEY AUTO_INCREMENT,username VARCHAR(100) UNIQUE NOT NULL,PASSWORD VARCHAR(30) NOT NULL,NAME VARCHAR(100),birthday DATE,sex CHAR(1) DEFAULT '男',telephone VARCHAR(11),email VARCHAR(100));/*创建收藏表 tab_favoriterid 旅游线路 id,外键date 收藏时间uid 用户 id,外键rid 和 uid 不能重复,设置复合主键,同一个用户不能收藏同一个线路两次*/
CREATE TABLE tab_favorite (rid INT, -- 线路idDATE DATETIME,uid INT, -- 用户id-- 创建复合主键PRIMARY KEY(rid,uid), -- 联合主键FOREIGN KEY (rid) REFERENCES tab_route(rid),FOREIGN KEY(uid) REFERENCES tab_user(uid));2. 数据库设计的范式* 概念:设计数据库时,需要遵循的一些规范。要遵循后边的范式要求,必须先遵循前边的所有范式要求 设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。 * 分类:1. 第一范式(1NF):每一列都是不可分割的原子数据项2. 第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)* 几个概念:1. 函数依赖:A-->B,如果通过A属性(属性组)的值,可以确定唯一B属性的值。则称B依赖于A例如:学号-->姓名。 (学号,课程名称) --> 分数2. 完全函数依赖:A-->B, 如果A是一个属性组,则B属性值得确定需要依赖于A属性组中所有的属性值。例如:(学号,课程名称) --> 分数3. 部分函数依赖:A-->B, 如果A是一个属性组,则B属性值得确定只需要依赖于A属性组中某一些值即可。例如:(学号,课程名称) -- > 姓名4. 传递函数依赖:A-->B, B -- >C . 如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性(属性组)的值可以确定唯一C属性的值,则称 C 传递函数依赖于A例如:学号-->系名,系名-->系主任5. 码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码例如:该表中码为:(学号,课程名称)* 主属性:码属性组中的所有属性* 非主属性:除过码属性组的属性3. 第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
数据库的备份和还原
1. 命令行:* 语法:* 备份: mysqldump -u用户名 -p密码 数据库名称 > 保存的路径* 还原:1. 登录数据库2. 创建数据库3. 使用数据库4. 执行文件。source 文件路径
相关文章:
)
MySQL数据库基本操作(二)
查询语句 1. 排序查询* 语法:order by 子句* order by 排序字段1 排序方式1 , 排序字段2 排序方式2... * 排序方式:* ASC:升序,默认的。* DESC:降序。 * 注意:* 如果有多个排序条件&#…...
Unity(第十部)时间函数和文件函数
时间函数 using System.Collections; using System.Collections.Generic; using UnityEngine;public class game : MonoBehaviour {// Start is called before the first frame updatefloat timer 0;void Start(){//游戏开始到现在所花的时间Debug.Log(Time.time);//时间缩放值…...

【Java学习笔记】
常见算法 查找算法 1.基本查找 public class BasicSearchDemo01 {public static void main(String[] args) {//基本查找//核心://从0索引开始挨个往后查找//需求:定一个方法利用基本查找,查询某个元素是否存在//数据如下:{131&…...

Python列表生成式你学会了吗
1.最基本的列表生成方式 生成 1-10 之间的整数的一个列表 list1 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] print(list1) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] list2 list(range(1, 11)) print(list2) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 2.通过程序的方式生成[4, 9, 16, 25,…...
【Mybatis】快速入门 基本使用 第一期
文章目录 Mybatis是什么?一、快速入门(基于Mybatis3方式)二、MyBatis基本使用2.1 向SQL语句传参2.1.1 mybatis日志输出配置2.1.2 #{}形式2.1.3 ${}形式 2.2 数据输入2.2.1 Mybatis总体机制概括2.2.2 概念说明2.2.3 单个简单类型参数2.2.4 实体…...

在 Rust 中实现 TCP : 1. 联通内核与用户空间的桥梁
内核-用户空间鸿沟 构建自己的 TCP栈是一项极具挑战的任务。通常,当用户空间应用程序需要互联网连接时,它们会调用操作系统内核提供的高级 API。这些 API 帮助应用程序 连接网络创建、发送和接收数据,从而消除了直接处理原始数据包的复杂性。…...
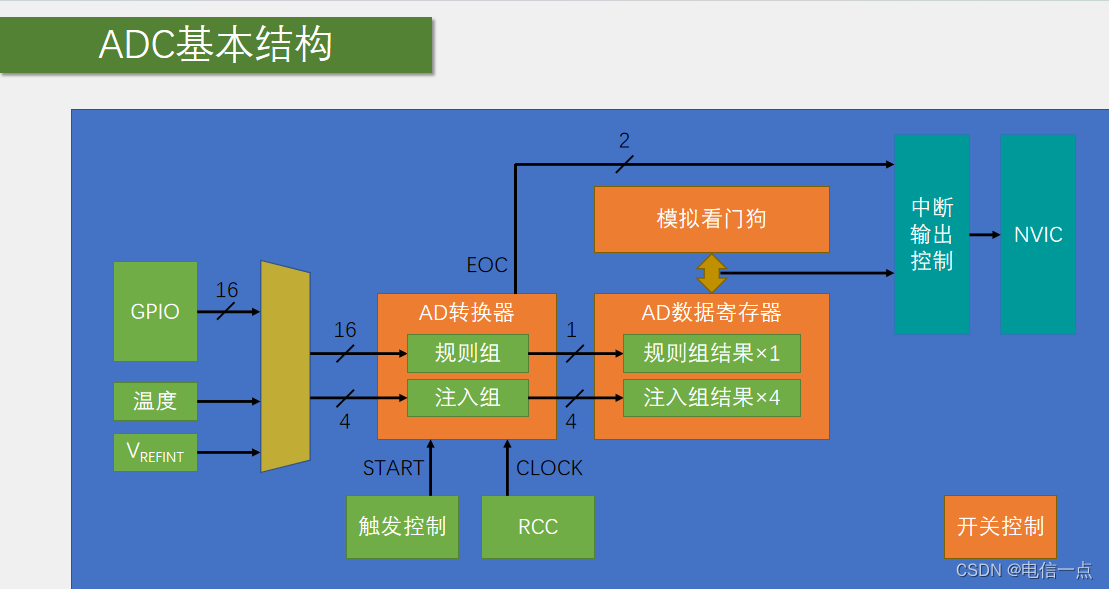
STM32-ADC一步到位学习手册
1.按部就班陈述概念 ADC 是 Analog-to-Digital Converter 的缩写,指的是模拟/数字转换器。它将连续变量的模拟信号转换为离散的数字信号。在 STM32 中,ADC 具有高达 12 位的转换精度,有多达 18 个测量通道,其中 16 个为外部通道&…...

【文件管理】关于上传下载文件的设计
这里主要谈论的是产品设计里面的文件管理,比如文件的上传交互及背后影响到的前后端设计。 上传文件 场景:一条记录,比如个人信息,有姓名,出生年月,性别等一般的字段,还可以允许用户上传附件作为…...

微服务架构 SpringCloud
didi单体应用架构 将项目所有模块(功能)打成jar或者war,然后部署一个进程--医院挂号系统; > 优点: > 1:部署简单:由于是完整的结构体,可以直接部署在一个服务器上即可。 > 2:技术单一:项目不需要复杂的技术栈,往往一套熟…...

前端 css 实现标签的效果
效果如下图 直接上代码: <div class"label-child">NEW</div> // css样式 // 父元素 class .border-radius { position: relative; overflow: hidden; } .label-child { position: absolute; width: 150rpx; height: 27rpx; text-align: cente…...

SLAM基础知识-卡尔曼滤波
前言: 在SLAM系统中,后端优化部分有两大流派。一派是基于马尔科夫性假设的滤波器方法,认为当前时刻的状态只与上一时刻的状态有关。另一派是非线性优化方法,认为当前时刻状态应该结合之前所有时刻的状态一起考虑。 卡尔曼滤波是…...
云时代【6】—— 镜像 与 容器
云时代【6】—— 镜像 与 容器 四、Docker(三)镜像 与 容器1. 镜像(1)定义(2)相关指令(3)实战演习镜像容器基本操作离线迁移镜像镜像的压缩与共享 2. 容器(1)…...

【QT+QGIS跨平台编译】之五十三:【QGIS_CORE跨平台编译】—【qgssqlstatementparser.cpp生成】
文章目录 一、Bison二、生成来源三、构建过程一、Bison GNU Bison 是一个通用的解析器生成器,它可以将注释的无上下文语法转换为使用 LALR (1) 解析表的确定性 LR 或广义 LR (GLR) 解析器。Bison 还可以生成 IELR (1) 或规范 LR (1) 解析表。一旦您熟练使用 Bison,您可以使用…...

JMeter性能测试基本过程及示例
jmeter 为性能测试提供了一下特色: jmeter 可以对测试静态资源(例如 js、html 等)以及动态资源(例如 php、jsp、ajax 等等)进行性能测试 jmeter 可以挖掘出系统最大能处理的并发用户数 jmeter 提供了一系列各种形式的…...
你知道什么是回调函数吗?
c语言中的小小白-CSDN博客c语言中的小小白关注算法,c,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm1001.2014.3001.5343 给大家分享一句我很喜欢我话: 知不足而奋进,望远山而前行&am…...
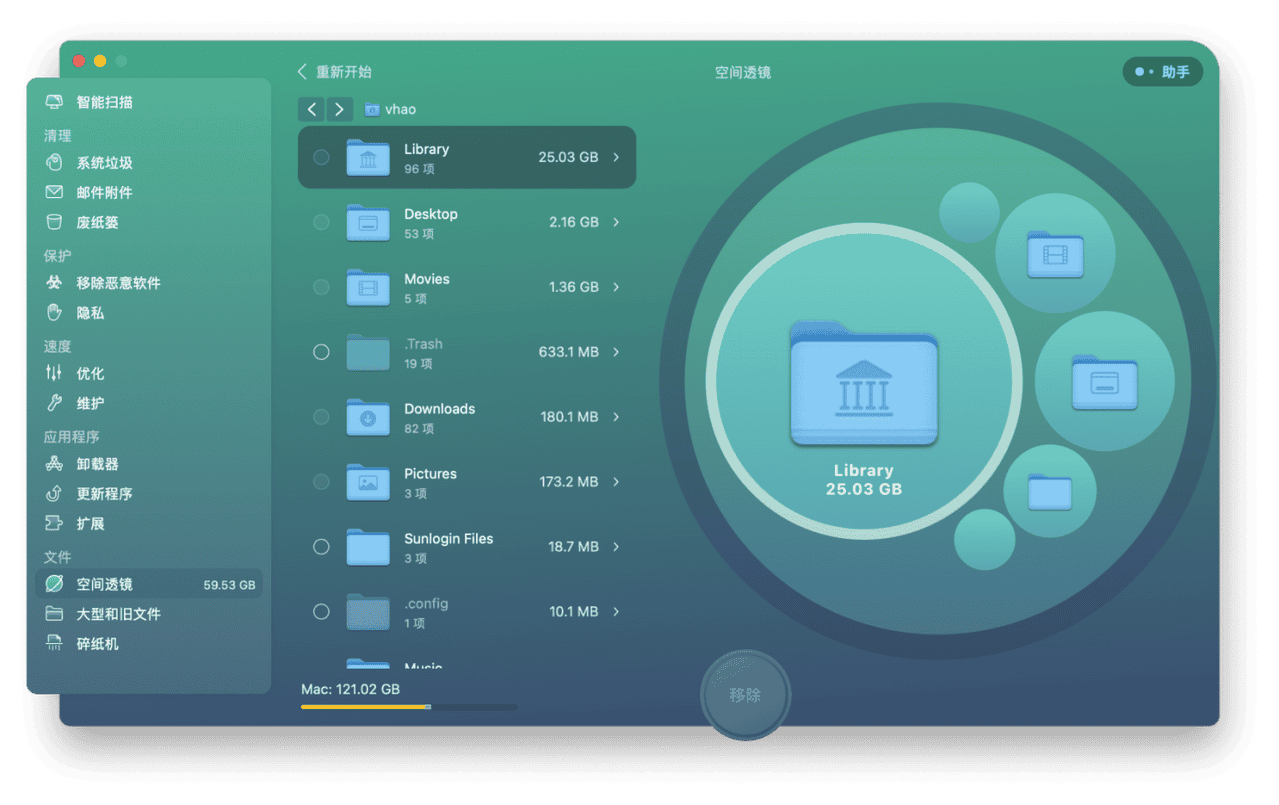
mac苹果电脑c盘满了如何清理内存?2024最新操作教程分享
苹果电脑用户经常会遇到麻烦:内置存储器(即C盘)空间不断缩小,电脑运行缓慢。在这种情况下,苹果电脑c盘满了怎么清理?如何有效清理和优化存储空间,提高计算机性能?成了一个重要的问题。今天,我想给大家详细介…...
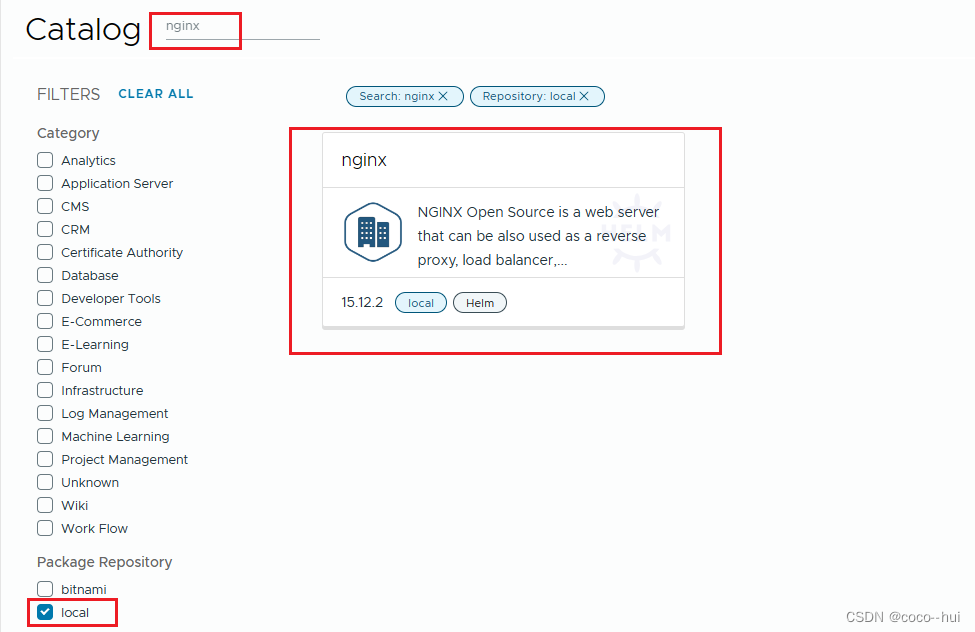
k8s-kubeapps图形化管理 21
结合harbor仓库 由于kubeapps不读取hosts解析,因此需要添加本地仓库域名解析(dns解析) 更改context为全局模式 添加repo仓库 复制ca证书 添加成功 图形化部署 更新部署应用版本 再次进行部署 上传nginx 每隔十分钟会自动进行刷新 在本地仓库…...
入门)
1_Springboot(一)入门
Springboot(一)——入门 本章重点: 1.什么是Springboot; 2.使用Springboot搭建web项目; 一、Springboot 1.Springboot产生的背景 Servlet->Struts2->Spring->SpringMVC,技术发展过程中,对使…...

Docker Machine简介
Docker Machine 是一种可以让您在虚拟主机上安装 Docker 的工具,并可以使用 docker-machine 命令来管理主机。 Docker Machine 也可以集中管理所有的 docker 主机,比如快速的给 100 台服务器安装上 docker。 Docker Machine 管理的虚拟主机可以是机上的…...
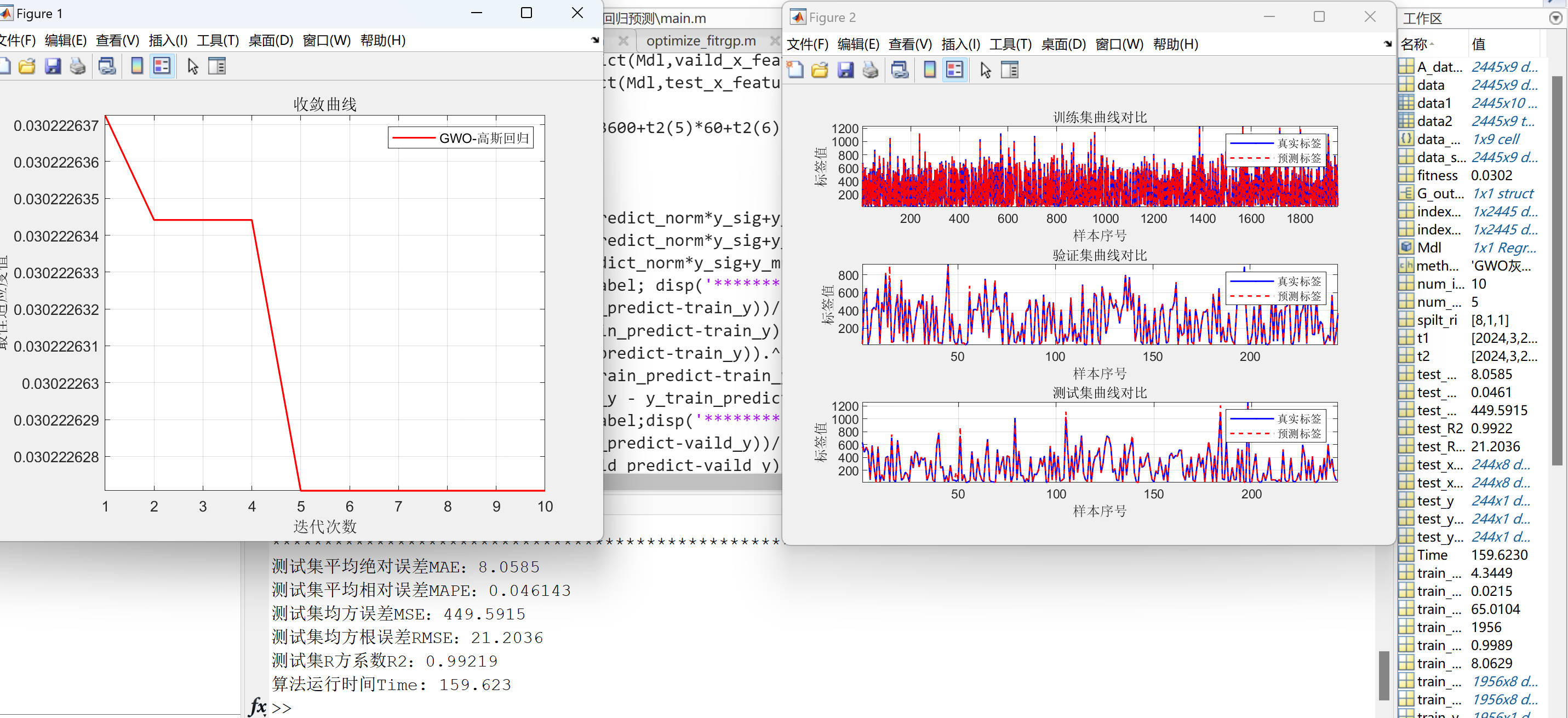
GWO优化高斯回归预测(matlab代码)
GWO-高斯回归预测matlab代码 GWO(Grey Wolf Optimizer,灰狼优化算法)是一种群智能优化算法,由澳大利亚格里菲斯大学的Mirjalili等人于2014年提出。这种算法的设计灵感来源于灰狼群体的捕食行为,其核心思想在于模仿灰狼…...

Qwen3-4B-Instruct-2507提示词编写技巧:如何让AI更懂你的需求
Qwen3-4B-Instruct-2507提示词编写技巧:如何让AI更懂你的需求 1. 为什么你的提示词总是不管用 你有没有遇到过这样的情况:你向AI模型提问,结果它要么答非所问,要么给你一堆没用的信息,要么干脆理解错了你的意思。你可…...

微信小程序云开发完整教程
微信小程序云开发完整教程:轻松打造全栈应用 在移动互联网时代,微信小程序凭借其轻量化和即用即走的特性,成为企业和开发者的首选。而微信小程序云开发进一步降低了开发门槛,无需搭建后端服务器即可实现数据存储、云函数调用等功…...

别再把QClaw当聊天AI用了!Skills才是它真正的灵魂》
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...
)
从海康到大华:ONVIF协议兼容性避坑指南(附主流厂商测试报告)
从海康到大华:ONVIF协议兼容性深度解析与实战避坑指南 在安防系统集成项目中,设备间的互联互通一直是工程实施的关键痛点。记得去年参与某智慧园区项目时,我们团队在设备联调阶段发现海康威视的球机无法通过ONVIF协议控制大华NVR的预置点调用…...

HC-SR04超声波测距库:非阻塞驱动与工业级抗干扰设计
1. HC-SR04超声波测距库技术解析与工程实践HC-SR04是嵌入式系统中应用最广泛的低成本超声波测距模块之一,其工作原理基于声波在空气中的传播时间(Time of Flight, TOF)测量距离。该模块由一个超声波发射器、一个接收器、控制逻辑电路和信号调…...

AVR-IoT Cellular Mini底层技术解析:安全蜂窝连接与低功耗设计
1. AVR-IoT Cellular Mini 开发板底层技术解析AVR-IoT Cellular Mini 是 Microchip 推出的面向蜂窝物联网(Cellular IoT)应用的紧凑型开发平台,其核心价值不仅在于硬件集成度,更在于其构建在 DxCore 基础上的完整 Arduino 兼容软件…...

ASyncTicker:嵌入式非中断周期任务调度器
1. ASyncTicker:面向嵌入式实时系统的非中断式周期任务调度器在嵌入式系统开发中,周期性任务调度是高频刚需——LED呼吸灯、传感器采样、通信心跳包、PID控制循环、状态机轮询等场景均依赖稳定、可预测的定时触发机制。传统方案多基于硬件定时器中断服务…...

软件可解释性的决策原因与逻辑展示
## 软件可解释性:让算法决策不再神秘 在人工智能和机器学习快速发展的今天,越来越多的决策由软件系统自动完成。许多复杂的算法(如深度神经网络)往往被视为“黑箱”,其决策过程难以理解。这种不透明性可能导致用户对系…...
配置完整教程)
Windows 系统 Allure 环境变量(PATH)配置完整教程
🔑 前置准备 先确认你已经下载并解压了 Allure 工具,找到它的 bin 目录路径(比如 D:\tools\allure-2.30.0\bin,路径里绝对不能有中文、空格、特殊符号) 确认 bin 目录里有 allure.bat 和 allure.exe 这两个文件 已经安装好 Java 8+ 环境(java -version 能正常输出版本号…...

PlugY:暗黑破坏神2单机体验增强的技术解决方案
PlugY:暗黑破坏神2单机体验增强的技术解决方案 一、价值定位:PlugY的技术革新与核心优势 跨角色资源池的实现机制 PlugY通过创新的共享存储架构,突破了原版游戏角色间的资源壁垒。该系统采用分布式存储模型,将物品数据与角色数据分…...