python difflib --- 计算差异的辅助工具
此模块提供用于比较序列的类和函数。 例如,它可被用于比较文件,并可产生多种格式的不同文件差异信息,包括 HTML 和上下文以及统一的 diff 数据。 有关比较目录和文件,另请参阅 filecmp 模块。
class difflib.SequenceMatcher
这是一个灵活的类,可用于比较任何类型的序列对,只要序列元素为 hashable 对象。 其基本算法要早于由 Ratcliff 和 Obershelp 于 1980 年代末期发表并以“格式塔模式匹配”的夸张名称命名的算法,并且更加有趣一些。 其思路是找到不包含“垃圾”元素的最长连续匹配子序列;所谓“垃圾”元素是指其在某种意义上没有价值,例如空白行或空白符。 (处理垃圾元素是对 Ratcliff 和 Obershelp 算法的一个扩展。) 然后同样的思路将递归地应用于匹配序列的左右序列片段。 这并不能产生最小编辑序列,但确实能产生在人们看来“正确”的匹配。
耗时: 基本 Ratcliff-Obershelp 算法在最坏情况下为立方时间而在一般情况下为平方时间。 SequenceMatcher 在最坏情况下为平方时间而在一般情况下的行为受到序列中有多少相同元素这一因素的微妙影响;在最佳情况下则为线性时间。
自动垃圾启发式计算: SequenceMatcher 支持使用启发式计算来自动将特定序列项视为垃圾。 这种启发式计算会统计每个单独项在序列中出现的次数。 如果某一项(在第一项之后)的重复次数超过序列长度的 1% 并且序列长度至少有 200 项,该项会被标记为“热门”并被视为序列匹配中的垃圾。 这种启发式计算可以通过在创建 SequenceMatcher 时将 autojunk 参数设为 False 来关闭。
在 3.2 版本发生变更: 增加了 autojunk 形参。
class difflib.Differ
这个类的作用是比较由文本行组成的序列,并产生可供人阅读的差异或增量信息。 Differ 统一使用 SequenceMatcher 来完成行序列的比较以及相似(接近匹配)行内部字符序列的比较。
Differ 增量的每一行均以双字母代码打头:
| 双字母代码 | 含意 |
|---|---|
|
| 行为序列 1 所独有 |
|
| 行为序列 2 所独有 |
|
| 行在两序列中相同 |
|
| 行不存在于任一输入序列 |
以 '?' 打头的行尝试将视线紖至行以外而不存在于任一输入序列的差异。 如果序列包含空白符,例如空格、制表或换行则这些行可能会令人感到迷惑。
class difflib.HtmlDiff
这个类可用于创建 HTML 表格(或包含表格的完整 HTML 文件)以并排地逐行显示文本比较,行间与行外的更改将突出显示。 此表格可以基于完全或上下文差异模式来生成。
这个类的构造函数:
__init__(tabsize=8, wrapcolumn=None, linejunk=None, charjunk=IS_CHARACTER_JUNK)
初始化 HtmlDiff 的实例。
tabsize 是一个可选关键字参数,指定制表位的间隔,默认值为 8。
wrapcolumn 是一个可选关键字参数,指定行文本自动打断并换行的列位置,默认值为 None 表示不自动换行。
linejunk 和 charjunk 均是可选关键字参数,会传入 ndiff() (被 HtmlDiff 用来生成并排显示的 HTML 差异)。 请参阅 ndiff() 文档了解参数默认值及其说明。
下列是公开的方法
make_file(fromlines, tolines, fromdesc='', todesc='', context=False, numlines=5, *, charset='utf-8')
比较 fromlines 和 tolines (字符串列表) 并返回一个字符串,表示一个完整 HTML 文件,其中包含各行差异的表格,行间与行外的更改将突出显示。
fromdesc 和 todesc 均是可选关键字参数,指定来源/目标文件的列标题字符串(默认均为空白字符串)。
context 和 numlines 均是可选关键字参数。 当只要显示上下文差异时就将 context 设为 True,否则默认值 False 为显示完整文件。 numlines 默认为 5。 当 context 为 True 时 numlines 将控制围绕突出显示差异部分的上下文行数。 当 context 为 False 时 numlines 将控制在使用 "next" 超链接时突出显示差异部分之前所显示的行数(设为零则会导致 "next" 超链接将下一个突出显示差异部分放在浏览器顶端,不添加任何前导上下文)。
备注
fromdesc 和 todesc 会被当作未转义的 HTML 来解读,当接收不可信来源的输入时应该适当地进行转义。
在 3.5 版本发生变更: 增加了 charset 关键字参数。 HTML 文档的默认字符集从 'ISO-8859-1' 更改为 'utf-8'。
make_table(fromlines, tolines, fromdesc='', todesc='', context=False, numlines=5)
比较 fromlines 和 tolines (字符串列表) 并返回一个字符串,表示一个包含各行差异的完整 HTML 表格,行间与行外的更改将突出显示。
此方法的参数与 make_file() 方法的相同。
difflib.context_diff(a, b, fromfile='', tofile='', fromfiledate='', tofiledate='', n=3, lineterm='\n')
比较 a 和 b (字符串列表);返回上下文差异格式的增量信息 (一个产生增量行的 generator)。
所谓上下文差异是一种只显示有更改的行再加几个上下文行的紧凑形式。 更改被显示为之前/之后的样式。 上下文行数由 n 设定,默认为三行。
默认情况下,差异控制行(以 *** or --- 表示)是通过末尾换行符来创建的。 这样做的好处是从 io.IOBase.readlines() 创建的输入将得到适用于 io.IOBase.writelines() 的差异信息,因为输入和输出都带有末尾换行符。
对于没有末尾换行符的输入,应将 lineterm 参数设为 "",这样输出内容将统一不带换行符。
上下文差异格式通常带有一个记录文件名和修改时间的标头。 这些信息的部分或全部可以使用字符串 fromfile, tofile, fromfiledate 和 tofiledate 来指定。 修改时间通常以 ISO 8601 格式表示。 如果未指定,这些字符串默认为空。
>>>
>>> import sys >>> from difflib import * >>> s1 = ['bacon\n', 'eggs\n', 'ham\n', 'guido\n'] >>> s2 = ['python\n', 'eggy\n', 'hamster\n', 'guido\n'] >>> sys.stdout.writelines(context_diff(s1, s2, fromfile='before.py', ... tofile='after.py')) *** before.py --- after.py *************** *** 1,4 **** ! bacon ! eggs ! hamguido --- 1,4 ---- ! python ! eggy ! hamsterguido
请参阅 difflib 的命令行接口 获取更详细的示例。
difflib.get_close_matches(word, possibilities, n=3, cutoff=0.6)
返回由最佳“近似”匹配构成的列表。 word 为一个指定目标近似匹配的序列(通常为字符串),possibilities 为一个由用于匹配 word 的序列构成的列表(通常为字符串列表)。
可选参数 n (默认为 3) 指定最多返回多少个近似匹配; n 必须大于 0.
可选参数 cutoff (默认为 0.6) 是一个 [0, 1] 范围内的浮点数。 与 word 相似度得分未达到该值的候选匹配将被忽略。
候选匹配中(不超过 n 个)的最佳匹配将以列表形式返回,按相似度得分排序,最相似的排在最前面。
>>>
>>> get_close_matches('appel', ['ape', 'apple', 'peach', 'puppy'])
['apple', 'ape']
>>> import keyword
>>> get_close_matches('wheel', keyword.kwlist)
['while']
>>> get_close_matches('pineapple', keyword.kwlist)
[]
>>> get_close_matches('accept', keyword.kwlist)
['except']
difflib.ndiff(a, b, linejunk=None, charjunk=IS_CHARACTER_JUNK)
比较 a 和 b (字符串列表);返回 Differ 形式的增量信息 (一个产生增量行的 generator)。
可选关键字形参 linejunk 和 charjunk 均为过滤函数 (或为 None):
linejunk: 此函数接受单个字符串参数,如果其为垃圾字符串则返回真值,否则返回假值。 默认为 None。 此外还有一个模块层级的函数 IS_LINE_JUNK(),它会过滤掉没有可见字符的行,除非该行添加了至多一个井号符 ('#') -- 但是下层的 SequenceMatcher 类会动态分析哪些行的重复频繁到足以形成噪音,这通常会比使用此函数的效果更好。
charjunk: 此函数接受一个字符(长度为 1 的字符串),如果其为垃圾字符则返回真值,否则返回假值。 默认为模块层级的函数 IS_CHARACTER_JUNK(),它会过滤掉空白字符(空格符或制表符;但包含换行符可不是个好主意!)。
>>>
>>> diff = ndiff('one\ntwo\nthree\n'.splitlines(keepends=True),
... 'ore\ntree\nemu\n'.splitlines(keepends=True))
>>> print(''.join(diff), end="")
- one
? ^
+ ore
? ^
- two
- three
? -
+ tree
+ emu
difflib.restore(sequence, which)
返回两个序列中产生增量的那一个。
给出一个由 Differ.compare() 或 ndiff() 产生的 序列,提取出来自文件 1 或 2 (which 形参) 的行,去除行前缀。
示例:
>>>
>>> diff = ndiff('one\ntwo\nthree\n'.splitlines(keepends=True),
... 'ore\ntree\nemu\n'.splitlines(keepends=True))
>>> diff = list(diff) # materialize the generated delta into a list
>>> print(''.join(restore(diff, 1)), end="")
one
two
three
>>> print(''.join(restore(diff, 2)), end="")
ore
tree
emu
difflib.unified_diff(a, b, fromfile='', tofile='', fromfiledate='', tofiledate='', n=3, lineterm='\n')
比较 a 和 b (字符串列表);返回统一差异格式的增量信息 (一个产生增量行的 generator)。
所以统一差异是一种只显示有更改的行再加几个上下文行的紧凑形式。 更改被显示为内联的样式(而不是分开的之前/之后文本块)。 上下文行数由 n 设定,默认为三行。
默认情况下,差异控制行 (以 ---, +++ 或 @@ 表示) 是通过末尾换行符来创建的。 这样做的好处是从 io.IOBase.readlines() 创建的输入将得到适用于 io.IOBase.writelines() 的差异信息,因为输入和输出都带有末尾换行符。
对于没有末尾换行符的输入,应将 lineterm 参数设为 "",这样输出内容将统一不带换行符。
统一的差异格式通常带有一个记录文件名和修改时间的标头。 这些信息的部分或全部可以使用字符串 fromfile, tofile, fromfiledate 和 tofiledate 来指定。 修改时间通常以 ISO 8601 格式表示。 如果未指定,这些字符串将默认为空。
>>>
>>> s1 = ['bacon\n', 'eggs\n', 'ham\n', 'guido\n'] >>> s2 = ['python\n', 'eggy\n', 'hamster\n', 'guido\n'] >>> sys.stdout.writelines(unified_diff(s1, s2, fromfile='before.py', tofile='after.py')) --- before.py +++ after.py @@ -1,4 +1,4 @@ -bacon -eggs -ham +python +eggy +hamsterguido
请参阅 difflib 的命令行接口 获取更详细的示例。
difflib.diff_bytes(dfunc, a, b, fromfile=b'', tofile=b'', fromfiledate=b'', tofiledate=b'', n=3, lineterm=b'\n')
使用 dfunc 比较 a 和 b (字节串对象列表);产生以 dfunc 所返回格式表示的差异行列表(也是字节串)。 dfunc 必须是可调用对象,通常为 unified_diff() 或 context_diff()。
允许你比较编码未知或不一致的数据。 除 n 之外的所有输入都必须为字节串对象而非字符串。 作用方式为无损地将所有输入 (除 n 之外) 转换为字符串,并调用 dfunc(a, b, fromfile, tofile, fromfiledate, tofiledate, n, lineterm)。 dfunc 的输出会被随即转换回字节串,这样你所得到的增量行将具有与 a 和 b 相同的未知/不一致编码。
在 3.5 版本加入.
difflib.IS_LINE_JUNK(line)
对于可忽略的行返回 True。 如果 line 为空行或只包含单个 '#' 则 line 行就是可忽略的,否则就是不可忽略的。 此函数被用作较旧版本 ndiff() 中 linejunk 形参的默认值。
difflib.IS_CHARACTER_JUNK(ch)
对于可忽略的字符返回 True。 字符 ch 如果为空格符或制表符则 ch 就是可忽略的,否则就是不可忽略的。 此函数被用作 ndiff() 中 charjunk 形参的默认值。
参见
Pattern Matching: The Gestalt Approach
John W. Ratcliff 和 D. E. Metzener 对于一种类似算法的讨论。 此文于 1988 年 7 月发表于 Dr. Dobb's Journal。
SequenceMatcher 对象
SequenceMatcher 类具有这样的构造器:
class difflib.SequenceMatcher(isjunk=None, a='', b='', autojunk=True)
可选参数 isjunk 必须为 None (默认值) 或为接受一个序列元素并当且仅当其为应忽略的“垃圾”元素时返回真值的单参数函数。 传入 None 作为 isjunk 的值就相当于传入 lambda x: False;也就是说不忽略任何值。 例如,传入:
lambda x: x in " \t"
如果你以字符序列的形式对行进行比较,并且不希望区分空格符或硬制表符。
可选参数 a 和 b 为要比较的序列;两者默认为空字符串。 两个序列的元素都必须为 hashable。
可选参数 autojunk 可用于启用自动垃圾启发式计算。
在 3.2 版本发生变更: 增加了 autojunk 形参。
SequenceMatcher 对象接受三个数据属性: bjunk 是 b 当中 isjunk 为 True 的元素集合;bpopular 是被启发式计算(如果其未被禁用)视为热门候选的非垃圾元素集合;b2j 是将 b 当中剩余元素映射到一个它们出现位置列表的字典。 所有三个数据属性将在 b 通过 set_seqs() 或 set_seq2() 重置时被重置。
在 3.2 版本加入: bjunk 和 bpopular 属性。
SequenceMatcher 对象具有以下方法:
set_seqs(a, b)
设置要比较的两个序列。
SequenceMatcher 计算并缓存有关第二个序列的详细信息,这样如果你想要将一个序列与多个序列进行比较,可使用 set_seq2() 一次性地设置该常用序列并重复地对每个其他序列各调用一次 set_seq1()。
set_seq1(a)
设置要比较的第一个序列。 要比较的第二个序列不会改变。
set_seq2(b)
设置要比较的第二个序列。 要比较的第一个序列不会改变。
find_longest_match(alo=0, ahi=None, blo=0, bhi=None)
找出 a[alo:ahi] 和 b[blo:bhi] 中的最长匹配块。
如果 isjunk 被省略或为 None,find_longest_match() 将返回 (i, j, k) 使得 a[i:i+k] 等于 b[j:j+k],其中 alo <= i <= i+k <= ahi 并且 blo <= j <= j+k <= bhi。 对于所有满足这些条件的 (i', j', k'),如果 i == i', j <= j' 也被满足,则附加条件 k >= k', i <= i'。 换句话说,对于所有最长匹配块,返回在 a 当中最先出现的一个,而对于在 a 当中最先出现的所有最长匹配块,则返回在 b 当中最先出现的一个。
>>>
>>> s = SequenceMatcher(None, " abcd", "abcd abcd") >>> s.find_longest_match(0, 5, 0, 9) Match(a=0, b=4, size=5)
如果提供了 isjunk,将按上述规则确定第一个最长匹配块,但额外附加不允许块内出现垃圾元素的限制。 然后将通过(仅)匹配两边的垃圾元素来尽可能地扩展该块。 这样结果块绝对不会匹配垃圾元素,除非同样的垃圾元素正好与有意义的匹配相邻。
这是与之前相同的例子,但是将空格符视为垃圾。 这将防止 ' abcd' 直接与第二个序列末尾的 ' abcd' 相匹配。 而只可以匹配 'abcd',并且是匹配第二个序列最左边的 'abcd':
>>>
>>> s = SequenceMatcher(lambda x: x==" ", " abcd", "abcd abcd") >>> s.find_longest_match(0, 5, 0, 9) Match(a=1, b=0, size=4)
如果未找到匹配块,此方法将返回 (alo, blo, 0)。
此方法将返回一个 named tuple Match(a, b, size)。
在 3.9 版本发生变更: 加入默认参数。
get_matching_blocks()
返回描述非重叠匹配子序列的三元组列表。 每个三元组的形式为 (i, j, n),其含义为 a[i:i+n] == b[j:j+n]。 这些三元组按 i 和 j 单调递增排列。
最后一个三元组用于占位,其值为 (len(a), len(b), 0)。 它是唯一 n == 0 的三元组。 如果 (i, j, n) 和 (i', j', n') 是在列表中相邻的三元组,且后者不是列表中的最后一个三元组,则 i+n < i' 或 j+n < j';换句话说,相邻的三元组总是描述非相邻的相等块。
>>>
>>> s = SequenceMatcher(None, "abxcd", "abcd") >>> s.get_matching_blocks() [Match(a=0, b=0, size=2), Match(a=3, b=2, size=2), Match(a=5, b=4, size=0)]
get_opcodes()
返回描述如何将 a 变为 b 的 5 元组列表,每个元组的形式为 (tag, i1, i2, j1, j2)。 在第一个元组中 i1 == j1 == 0,而在其余的元组中 i1 等于前一个元组的 i2,并且 j1 也等于前一个元组的 j2。
tag 值为字符串,其含义如下:
| 值 | 含意 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
例如:
>>>
>>> a = "qabxcd"
>>> b = "abycdf"
>>> s = SequenceMatcher(None, a, b)
>>> for tag, i1, i2, j1, j2 in s.get_opcodes():
... print('{:7} a[{}:{}] --> b[{}:{}] {!r:>8} --> {!r}'.format(
... tag, i1, i2, j1, j2, a[i1:i2], b[j1:j2]))
delete a[0:1] --> b[0:0] 'q' --> ''
equal a[1:3] --> b[0:2] 'ab' --> 'ab'
replace a[3:4] --> b[2:3] 'x' --> 'y'
equal a[4:6] --> b[3:5] 'cd' --> 'cd'
insert a[6:6] --> b[5:6] '' --> 'f'
get_grouped_opcodes(n=3)
返回一个带有最多 n 行上下文的分组的 generator。
从 get_opcodes() 所返回的组开始,此方法会拆分出较小的更改簇并消除没有更改的间隔区域。
这些分组以与 get_opcodes() 相同的格式返回。
ratio()
返回一个取值范围 [0, 1] 的浮点数作为序列相似性度量。
其中 T 是两个序列中元素的总数量,M 是匹配的数量,即 2.0*M / T。 请注意如果两个序列完全相同则该值为 1.0,如果两者完全不同则为 0.0。
如果 get_matching_blocks() 或 get_opcodes() 尚未被调用则此方法运算消耗较大,在此情况下你可能需要先调用 quick_ratio() 或 real_quick_ratio() 来获取一个上界。
备注
注意: ratio() 调用的结果可能会取决于参数的顺序。 例如:
>>>
>>> SequenceMatcher(None, 'tide', 'diet').ratio() 0.25 >>> SequenceMatcher(None, 'diet', 'tide').ratio() 0.5
quick_ratio()
相对快速地返回一个 ratio() 的上界。
real_quick_ratio()
非常快速地返回一个 ratio() 的上界。
这三个返回匹配部分点总字符数之比的三种方法可能由于不同的近似级别而给出不同的结果,但是 quick_ratio() 和 real_quick_ratio() 总是会至少与 ratio() 一样大:
>>>
>>> s = SequenceMatcher(None, "abcd", "bcde") >>> s.ratio() 0.75 >>> s.quick_ratio() 0.75 >>> s.real_quick_ratio() 1.0
SequenceMatcher 的示例
以下示例比较两个字符串,并将空格视为“垃圾”:
>>>
>>> s = SequenceMatcher(lambda x: x == " ", ... "private Thread currentThread;", ... "private volatile Thread currentThread;")
ratio() 返回一个 [0, 1] 范围内的浮点数,用来衡量序列的相似度。 根据经验,ratio() 值超过 0.6 就意味着两个序列非常接近匹配:
>>>
>>> print(round(s.ratio(), 3)) 0.866
如果您只对序列的匹配的位置感兴趣,则 get_matching_blocks() 就很方便:
>>>
>>> for block in s.get_matching_blocks():
... print("a[%d] and b[%d] match for %d elements" % block)
a[0] and b[0] match for 8 elements
a[8] and b[17] match for 21 elements
a[29] and b[38] match for 0 elements
请注意 get_matching_blocks() 返回的最后一个元组 (len(a), len(b), 0) 始终只用于占位,这也是元组的末尾元素(匹配的元素个数)为 0 的唯一情况。
如果你想要知道如何将第一个序列转成第二个序列,可以使用 get_opcodes():
>>>
>>> for opcode in s.get_opcodes():
... print("%6s a[%d:%d] b[%d:%d]" % opcode)equal a[0:8] b[0:8]
insert a[8:8] b[8:17]equal a[8:29] b[17:38]
参见
-
此模块中的 get_close_matches() 函数显示了如何基于 SequenceMatcher 构建简单的代码来执行有用的功能。
-
使用 SequenceMatcher 构建小型应用的 简易版本控制方案。
Differ 对象
请注意 Differ 所生成的增量并不保证是 最小 差异。 相反,最小差异往往是违反直觉的,因为它们会同步任何可能的地方,有时甚至意外产生相距 100 页的匹配。 将同步点限制为连续匹配保留了一些局部性概念,这偶尔会带来产生更长差异的代价。
Differ 类具有这样的构造器:
class difflib.Differ(linejunk=None, charjunk=None)
可选关键字形参 linejunk 和 charjunk 均为过滤函数 (或为 None):
linejunk: 接受单个字符串作为参数的函数,如果其为垃圾字符串则返回真值。 默认值为 None,意味着没有任何行会被视为垃圾行。
charjunk: 接受单个字符(长度为 1 的字符串)作为参数的函数,如果其为垃圾字符则返回真值。 默认值为 None,意味着没有任何字符会被视为垃圾字符。
这些垃圾过滤函数可加快查找差异的匹配速度,并且不会导致任何差异行或字符被忽略。 请阅读 find_longest_match() 方法的 isjunk 形参的描述了解详情。
Differ 对象是通过一个单独方法来使用(生成增量)的:
compare(a, b)
比较两个由行组成的序列,并生成增量(一个由行组成的序列)。
每个序列必须包含一个以换行符结尾的单行字符串。 这样的序列可以通过文件型对象的 readlines() 方法来获取。 所生成的增量同样由以换行符结尾的字符串构成,可以通过文件型对象的 writelines() 方法原样打印出来。
Differ 示例
此示例比较两段文本。 首先我们设置文本为以换行符结尾的单行字符串组成的序列(这样的序列也可以通过文件型对象的 readlines() 方法来获取):
>>>
>>> text1 = ''' 1. Beautiful is better than ugly. ... 2. Explicit is better than implicit. ... 3. Simple is better than complex. ... 4. Complex is better than complicated. ... '''.splitlines(keepends=True) >>> len(text1) 4 >>> text1[0][-1] '\n' >>> text2 = ''' 1. Beautiful is better than ugly. ... 3. Simple is better than complex. ... 4. Complicated is better than complex. ... 5. Flat is better than nested. ... '''.splitlines(keepends=True)
接下来我们实例化一个 Differ 对象:
>>>
>>> d = Differ()
请注意在实例化 Differ 对象时我们可以传入函数来过滤掉“垃圾”行和字符。 详情参见 Differ() 构造器说明。
最后,我们比较两个序列:
>>>
>>> result = list(d.compare(text1, text2))
result 是一个字符串列表,让我们将其美化打印出来:
>>>
>>> from pprint import pprint >>> pprint(result) [' 1. Beautiful is better than ugly.\n','- 2. Explicit is better than implicit.\n','- 3. Simple is better than complex.\n','+ 3. Simple is better than complex.\n','? ++\n','- 4. Complex is better than complicated.\n','? ^ ---- ^\n','+ 4. Complicated is better than complex.\n','? ++++ ^ ^\n','+ 5. Flat is better than nested.\n']
作为单独的多行字符串显示出来则是这样:
>>>
>>> import sys >>> sys.stdout.writelines(result)1. Beautiful is better than ugly. - 2. Explicit is better than implicit. - 3. Simple is better than complex. + 3. Simple is better than complex. ? ++ - 4. Complex is better than complicated. ? ^ ---- ^ + 4. Complicated is better than complex. ? ++++ ^ ^ + 5. Flat is better than nested.
difflib 的命令行接口
这个例子演示了如何使用 difflib 来创建类似 diff 的工具。
""" Command line interface to difflib.py providing diffs in four formats:* ndiff: lists every line and highlights interline changes.
* context: highlights clusters of changes in a before/after format.
* unified: highlights clusters of changes in an inline format.
* html: generates side by side comparison with change highlights."""import sys, os, difflib, argparse
from datetime import datetime, timezonedef file_mtime(path):t = datetime.fromtimestamp(os.stat(path).st_mtime,timezone.utc)return t.astimezone().isoformat()def main():parser = argparse.ArgumentParser()parser.add_argument('-c', action='store_true', default=False,help='Produce a context format diff (default)')parser.add_argument('-u', action='store_true', default=False,help='Produce a unified format diff')parser.add_argument('-m', action='store_true', default=False,help='Produce HTML side by side diff ''(can use -c and -l in conjunction)')parser.add_argument('-n', action='store_true', default=False,help='Produce a ndiff format diff')parser.add_argument('-l', '--lines', type=int, default=3,help='Set number of context lines (default 3)')parser.add_argument('fromfile')parser.add_argument('tofile')options = parser.parse_args()n = options.linesfromfile = options.fromfiletofile = options.tofilefromdate = file_mtime(fromfile)todate = file_mtime(tofile)with open(fromfile) as ff:fromlines = ff.readlines()with open(tofile) as tf:tolines = tf.readlines()if options.u:diff = difflib.unified_diff(fromlines, tolines, fromfile, tofile, fromdate, todate, n=n)elif options.n:diff = difflib.ndiff(fromlines, tolines)elif options.m:diff = difflib.HtmlDiff().make_file(fromlines,tolines,fromfile,tofile,context=options.c,numlines=n)else:diff = difflib.context_diff(fromlines, tolines, fromfile, tofile, fromdate, todate, n=n)sys.stdout.writelines(diff)if __name__ == '__main__':main()
ndiff 示例
这个例子演示了如何使用 difflib.ndiff()。
"""ndiff [-q] file1 file2or
ndiff (-r1 | -r2) < ndiff_output > file1_or_file2Print a human-friendly file difference report to stdout. Both inter-
and intra-line differences are noted. In the second form, recreate file1
(-r1) or file2 (-r2) on stdout, from an ndiff report on stdin.In the first form, if -q ("quiet") is not specified, the first two lines
of output are-: file1
+: file2Each remaining line begins with a two-letter code:"- " line unique to file1"+ " line unique to file2" " line common to both files"? " line not present in either input fileLines beginning with "? " attempt to guide the eye to intraline
differences, and were not present in either input file. These lines can be
confusing if the source files contain tab characters.The first file can be recovered by retaining only lines that begin with
" " or "- ", and deleting those 2-character prefixes; use ndiff with -r1.The second file can be recovered similarly, but by retaining only " " and
"+ " lines; use ndiff with -r2; or, on Unix, the second file can be
recovered by piping the output throughsed -n '/^[+ ] /s/^..//p'
"""__version__ = 1, 7, 0import difflib, sysdef fail(msg):out = sys.stderr.writeout(msg + "\n\n")out(__doc__)return 0# open a file & return the file object; gripe and return 0 if it
# couldn't be opened
def fopen(fname):try:return open(fname)except IOError as detail:return fail("couldn't open " + fname + ": " + str(detail))# open two files & spray the diff to stdout; return false iff a problem
def fcompare(f1name, f2name):f1 = fopen(f1name)f2 = fopen(f2name)if not f1 or not f2:return 0a = f1.readlines(); f1.close()b = f2.readlines(); f2.close()for line in difflib.ndiff(a, b):print(line, end=' ')return 1# crack args (sys.argv[1:] is normal) & compare;
# return false iff a problemdef main(args):import getopttry:opts, args = getopt.getopt(args, "qr:")except getopt.error as detail:return fail(str(detail))noisy = 1qseen = rseen = 0for opt, val in opts:if opt == "-q":qseen = 1noisy = 0elif opt == "-r":rseen = 1whichfile = valif qseen and rseen:return fail("can't specify both -q and -r")if rseen:if args:return fail("no args allowed with -r option")if whichfile in ("1", "2"):restore(whichfile)return 1return fail("-r value must be 1 or 2")if len(args) != 2:return fail("need 2 filename args")f1name, f2name = argsif noisy:print('-:', f1name)print('+:', f2name)return fcompare(f1name, f2name)# read ndiff output from stdin, and print file1 (which=='1') or
# file2 (which=='2') to stdoutdef restore(which):restored = difflib.restore(sys.stdin.readlines(), which)sys.stdout.writelines(restored)if __name__ == '__main__':main(sys.argv[1:])相关文章:

python difflib --- 计算差异的辅助工具
此模块提供用于比较序列的类和函数。 例如,它可被用于比较文件,并可产生多种格式的不同文件差异信息,包括 HTML 和上下文以及统一的 diff 数据。 有关比较目录和文件,另请参阅 filecmp 模块。 class difflib.SequenceMatcher 这…...

HTML5浮动
1.标准文档流组成 块级元素(block) 内联元素(inline) 2.display属性 作用:指定HTML标签的显示方式 常用属性 值 说明 block 块级元素的默认值,元素会被显示为块级元素,该元素前后会带有换行…...
Unity 向量计算、欧拉角与四元数转换、输出文本、告警、错误、修改时间、定时器、路径、
using System.Collections; using System.Collections.Generic; using UnityEngine;public class c2 : MonoBehaviour {// 定时器float t1 0;void Start(){// 向量Vector3 v1 new Vector3(0, 0, 2);Vector3 v2 new Vector3(0, 0, 3);// 计算两个向量的夹角Debug.Log(Vector3…...

前端实现浏览器打印
浏览器的print方法直接调用会打印当前页面的所有元素,使用iframe可以实现局部打印所需要的模块。 组件printView,将传入的信息放入iframe中,调用浏览器的打印功能 <template><div class"print"><iframeid"if…...

iOS卡顿原因与优化
iOS卡顿原因与优化 1. 卡顿简介 卡顿: 指用户在使用过程中出现了一段时间的阻塞,使得用户在这一段时间内无法进行操作,屏幕上的内容也没有任何的变化。 卡顿作为App的重要性能指标,不仅影响着用户体验,更关系到用户留…...
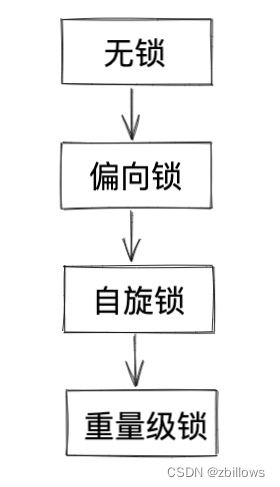
关于synchronized介绍
synchronized的特性 1. 乐观锁/悲观锁自适应,开始时是乐观锁,如果锁冲突频繁,就转换为悲观锁 2.轻量级/重量级锁自适应 开始是轻量级锁实现,如果锁被持有的时间较长,就转换成重量级锁 3.自旋/挂起等待锁自适应 4.不是读写锁 5.非公平锁 6,可重入锁 synchronized的使用 1&#…...

NCDA设计大赛获奖作品剖析:UI设计如何脱颖而出?
第十二届大赛简介 - 未来设计师全国高校数字艺术设计大赛(NCDA)开始啦!视觉传达设计命题之一: ui 设计,你想知道的都在这里。为了让大家更好的参加这次比赛,本文特别为大家整理了以往NCDA大赛 UI 设计的优秀获奖作品&a…...

软考中级 软件设计师备考经验
考试介绍 软考中级的软件设计师需要考两个部分,选择题和大题,每科满分75,需要在同一次考试中两科同时大于等于45分才算通过。考试的内容包括计算机组成原理、数据结构、数据库、专业英语、信息安全、计算机网络等,范围比较广但考…...

Python猜数字小游戏
下面这段代码是一个简单的数字猜测游戏,其中计算机已经提前计算出了414 // 23的结果并存储在变量num中。然后,程序会提示用户来猜测这个结果。 以下是代码的主要步骤和功能: 初始化: num 414 // 23:计算414除以23的整…...

SQL面试题(2)
第一题 创建trade_orders表: create table `trade_orders`( `trade_id` varchar(255) NULL DEFAULT NULL, `uers_id` varchar(255), `trade_fee` int(20), `product_id` varchar(255), `time` varchar(255) )ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_…...

python常用pandas函数nlargest 和 nsmallest及其手动实现
pandas是Python数据分析的重要工具之一,提供了大量便捷的数据操作方法。nlargest和nsmallest是pandas中两个非常实用的函数,它们可以帮助我们快速找出Series或DataFrame中最大或最小的n个值。 ### pandas中的nlargest和nsmallest函数 - nlargest(n, colu…...
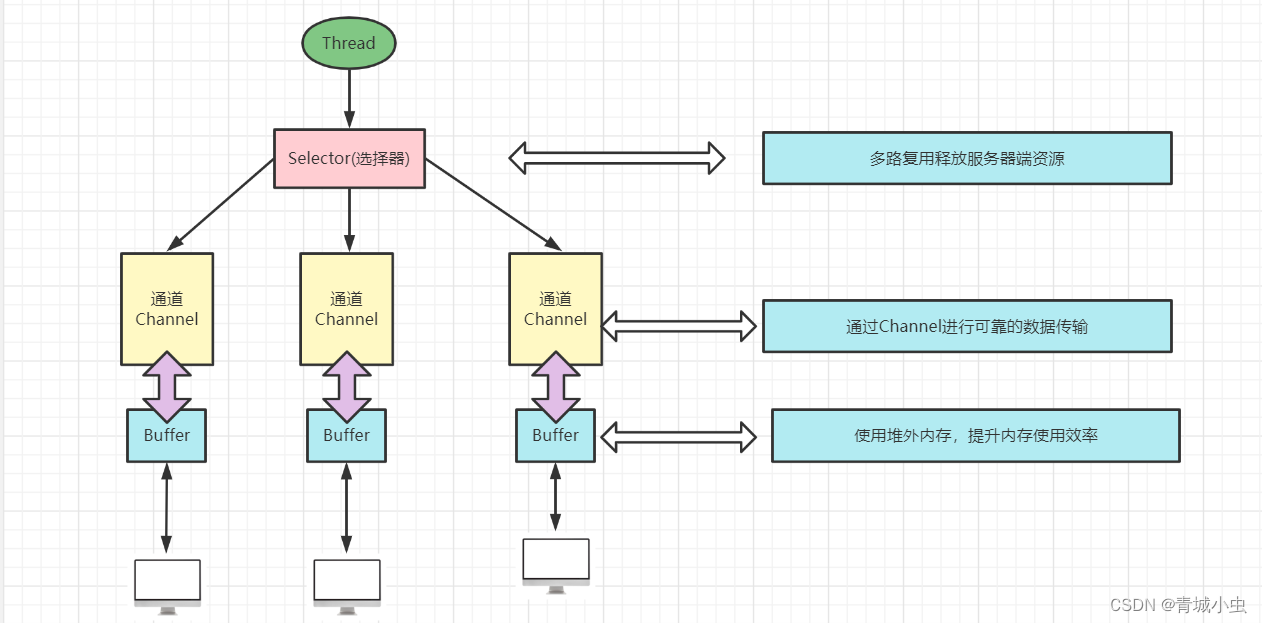
第六课:NIO简介
一、传统BIO的缺点 BIO属于同步阻塞行IO,在服务器的实现模型为,每一个连接都要对应一个线程。当客户端有连接请求的时候,服务器端需要启动一个新的线程与之对应处理,这个模型有很多缺陷。当客户端不做出进一步IO请求的时候,服务器…...
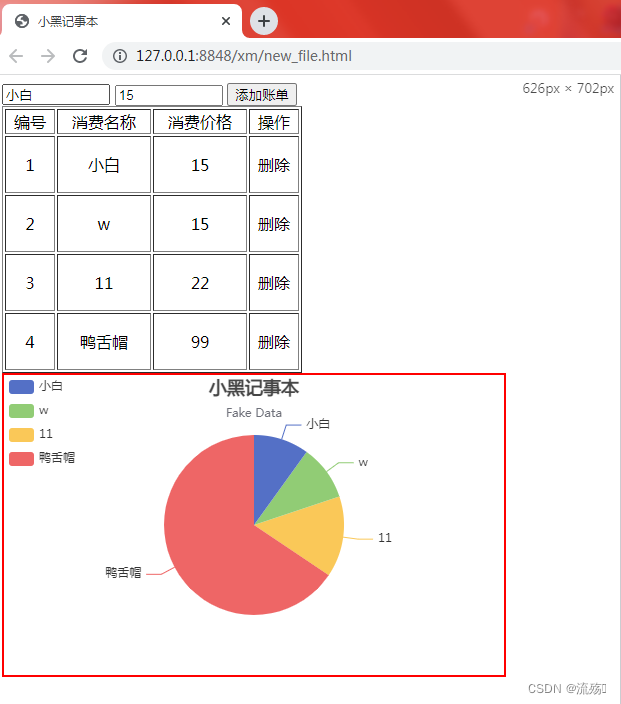
在vue2中使用饼状图
1.引入vue2和echarts <script src"https://cdn.jsdelivr.net/npm/vue2.7.14/dist/vue.js"></script> <script src"https://cdn.jsdelivr.net/npm/echarts5.4.0/dist/echarts.min.js"></script> 2.1 补充基本的body内容 <div id…...
南京 软通动力 一面)
面经(五)南京 软通动力 一面
注:已经有了接近一年的工作经验 总体评价 不完全是技术面,面试经过还行,但可能是期望岗位和对方需求不太一致,感觉不太好过 面试经过 HR找你,发简历入库,然后商量面试时间,发腾讯会议链接腾…...

线段树模型及例题整理
线段树的应用范围非常广,可以处理很多与区间有关的题目。 将区间抽象成一个节点,在这个节点中储存这个区间的一些值,那么如果看成节点的话,这就很像一棵满二叉树,所以我们可以用一维数组来储存节点。那么就要考虑父子节…...
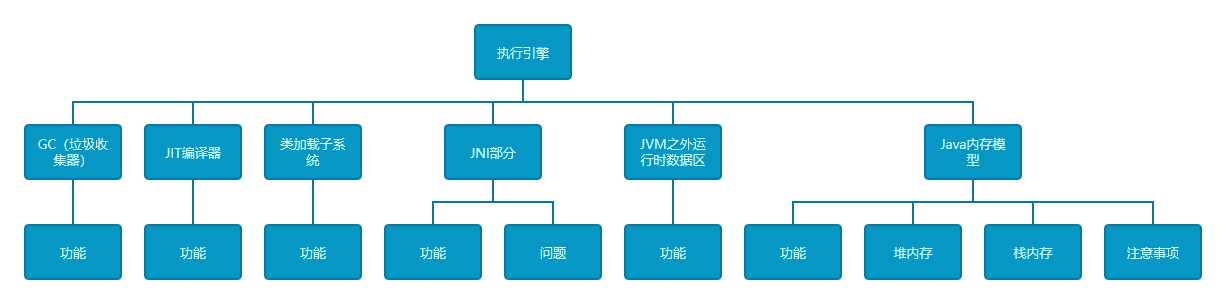
揭秘Java性能调优的层次 | 综合多方向提升应用程序性能与系统高可用的关键(架构层次规划)
揭秘性能调优的层次 | 综合多方向提升应用程序性能与系统的高可用 前言介绍调优层次调优 — 设计案例说明 - 操作轮询控制事件驱动 调优 — 代码案例说明 - ArrayList和LinkedList性能对比案例说明 - 文件读写实现方式的性能对比 调优 — JVMJVM架构分布JVM调优方向**JVM垃圾回…...
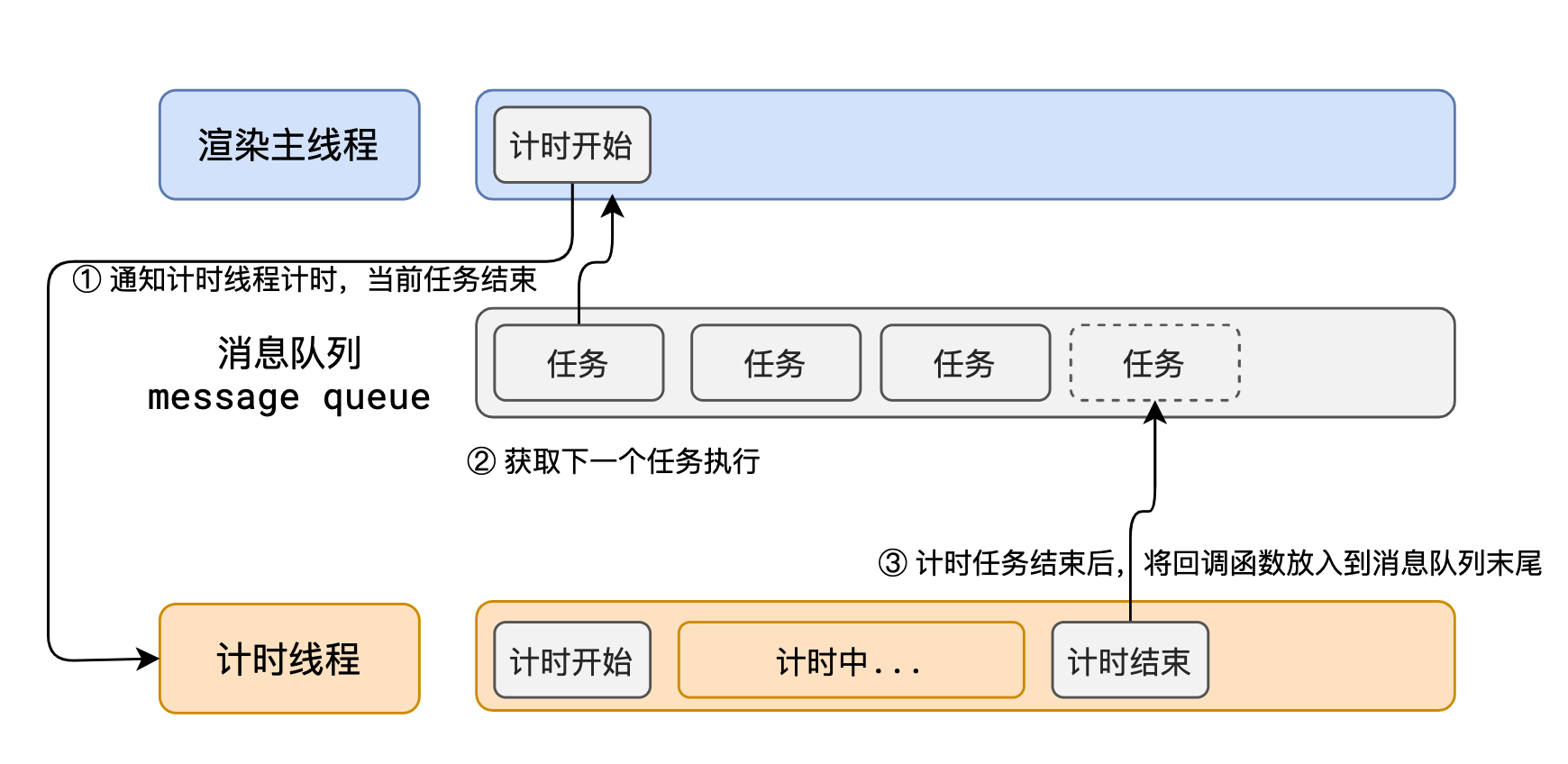
事件循环解析
浏览器的进程模型 何为进程? 程序运行需要有它自己专属的内存空间,可以把这块内存空间简单的理解为进程 每个应用至少有一个进程,进程之间相互独立,即使要通信,也需要双方同意。 何为线程? 有了进程后&…...

物联网技术助力智慧城市安全建设:构建全方位、智能化的安全防护体系
一、引言 随着城市化进程的加速和信息技术的迅猛发展,智慧城市已成为现代城市发展的重要方向。在智慧城市建设中,安全是不可或缺的一环。物联网技术的快速发展为智慧城市安全建设提供了有力支持,通过构建全方位、智能化的安全防护体系&#…...
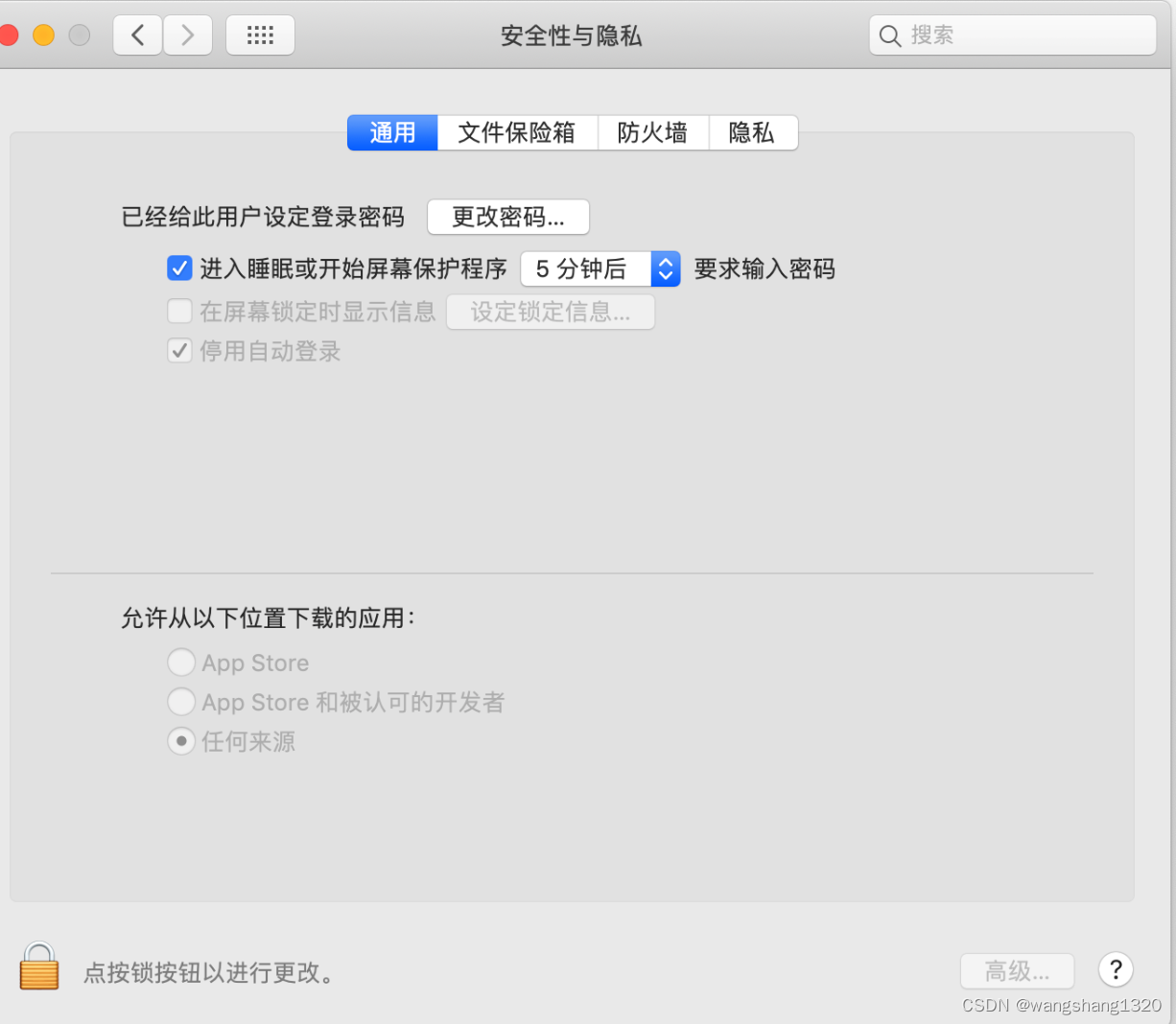
mac打不开xxx软件, 因为apple 无法检查其是否包含恶意
1. 安全性与隐私下面的允许来源列表,有些版本中的‘任何来源’选项被隐藏了,有些从浏览器下载的软件需要勾选这个选项才能安装 打开‘任何来源’选项 sudo spctl --master-disable 关闭‘任何来源’选项 sudo spctl --master-enable...

《深入浅出红黑树:一起动手实现自平衡的二叉搜索树》
一、分析 1. 红黑树的性质 红黑树是一种自平衡的二叉搜索树,它具有以下五个性质: (1)节点是红色或黑色。 (2)根节点是黑色。 (3)所有叶子节点(NIL节点)是…...

车机固件升级全攻略:工具选择与操作技巧
1. 车机固件升级入门指南 刚买车那会儿,我对车机系统升级完全没概念,直到有次导航把我导到一条正在施工的断头路上,才发现自己的车机地图已经两年没更新了。车机固件升级就像给手机系统更新一样重要,不仅能修复bug,还能…...

Profinet协议在工业自动化中的无线通信应用解析
1. Profinet协议:工业自动化的"神经系统" 如果把工业自动化系统比作人体,那么Profinet协议就是这套系统的"神经系统"。它负责在控制器(大脑)、执行器(四肢)和传感器(感官&a…...

CrossMgrLapCounter:嵌入式设备接入赛事计时系统的WebSocket协议库
1. CrossMgrLapCounter 库技术解析:嵌入式系统与 CrossMgr 赛事计时系统的 WebSocket 协议集成CrossMgr 是一款广泛应用于自行车、跑步、铁人三项等多项目赛事的开源计时软件,其核心优势在于支持高并发 RFID 标签读取、多通道天线管理及实时成绩发布。在…...

DeepWiki 优化实战:代码行号与确定性目录生成踊
一、环境准备 Free Spire.Doc for Python 是免费 Python 文档处理库,无需依赖 Microsoft Word,支持 Word 文档的创建、编辑、转换等操作,其中内置的 Markdown 解析能力,能高效实现 Markdown 到 Doc/Docx 格式的转换,且…...

从停车场管理系统看STM32项目开发:如何规划你的第一个物联网硬件Demo?
从停车场管理系统看STM32项目开发:如何规划你的第一个物联网硬件Demo? 在嵌入式开发领域,STM32系列单片机因其出色的性能和丰富的外设资源,成为物联网硬件原型的首选平台。停车场管理系统作为一个典型的物联网应用场景,…...

Lumafly:让空洞骑士模组管理变得像呼吸一样简单
Lumafly:让空洞骑士模组管理变得像呼吸一样简单 【免费下载链接】Lumafly A cross platform mod manager for Hollow Knight written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/lu/Lumafly 还在为空洞骑士模组安装的繁琐流程而烦恼吗…...

什么年代了怎么还在用bash啊?现代化shell开箱体验: fish, nu, elvish淳
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...

大模型时代下的双塔模型:从原理到实战应用
1. 双塔模型:大模型时代的智能匹配引擎 想象你走进一家24小时营业的智能便利店,当你拿起一瓶饮料时,货架旁的屏幕立刻显示出搭配推荐的小吃;当你站在杂志区犹豫时,收银台已经打印出可能感兴趣的期刊优惠券。这背后很可…...

Chrome PHP错误处理完全指南:解决常见问题和调试技巧
Chrome PHP错误处理完全指南:解决常见问题和调试技巧 【免费下载链接】chrome Instrument headless chrome/chromium instances from PHP 项目地址: https://gitcode.com/gh_mirrors/ch/chrome 在使用Chrome PHP库(Instrument headless chrome/ch…...

OpenRecall与AI助手集成:打造终极个人记忆增强系统
OpenRecall与AI助手集成:打造终极个人记忆增强系统 【免费下载链接】openrecall OpenRecall is a fully open-source, privacy-first alternative to proprietary solutions like Microsofts Windows Recall. With OpenRecall, you can easily access your digital …...