Flink基本原理 + WebUI说明 + 常见问题分析
Flink 概述
Flink 是一个用于进行大规模数据处理的开源框架,它提供了一个流式的数据处理 API,支持多种编程语言和运行时环境。Flink 的核心优点包括:
- 低延迟:Flink 可以在毫秒级的时间内处理数据,提供了低延迟的数据处理能力。
- 高吞吐:吞吐量巨大。
- 分布式计算:Flink 支持分布式计算,它可以在大规模集群上运行,并提供了高可用和容错机制。
- 流式数据处理:Flink 基于流式数据处理模型,支持实时数据处理和数据增量更新。
- 事件驱动:Flink 的计算引擎是基于事件驱动的,它使用消息传递机制来处理数据。
Flink 的数据处理流程
Flink 的数据处理流程包括以下几个步骤:
- 数据输入:Flink 可以从各种数据源中读取数据,如 Kafka、HDFS 等。
- 数据转换:Flink 可以使用 DataStream API 或 SQL API 对数据进行转换和处理。
- 数据分区:Flink 可以根据数据的属性或规则对数据进行分区,以便在分布式集群上进行处理。
- 数据传输:Flink 可以使用网络传输机制将数据传输到其他节点或进程。
- 数据输出:Flink 可以将处理后的数据写入到各种数据存储中,如 Kafka、HDFS 等。
Flink架构解析
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。
![[图片]](https://img-blog.csdnimg.cn/direct/d172c69ebee4499a894d56fdd188f961.png)
JobManager
类似于司令官,分配工作给干活的士兵(TaskManager),听取士兵的汇报,当士兵失败时做出恢复等反应。
JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。这个进程由三个不同的组件组成:
- ResourceManager
- ResourceManager 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的基本单位。
- Dispatcher
- Dispatcher 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每一个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster
- 1个JobMaster 负责管理1个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby(请参考 高可用(HA))。
TaskManager
TaskManager(也称为 worker):执行JobManager分配过来的任务,并向JobManager汇报。taskManager之间也会交换数据
TaskManager中会有一到多个task slot, task slot是资源调度的最小单位, task slot 的数量表示并发处理task的数量。假设1个task有N个算子,那么执行这个task的slot 就会执行N个算子(直到结束)。
Client
Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。
Task和算子(Operator)
非分布式场景
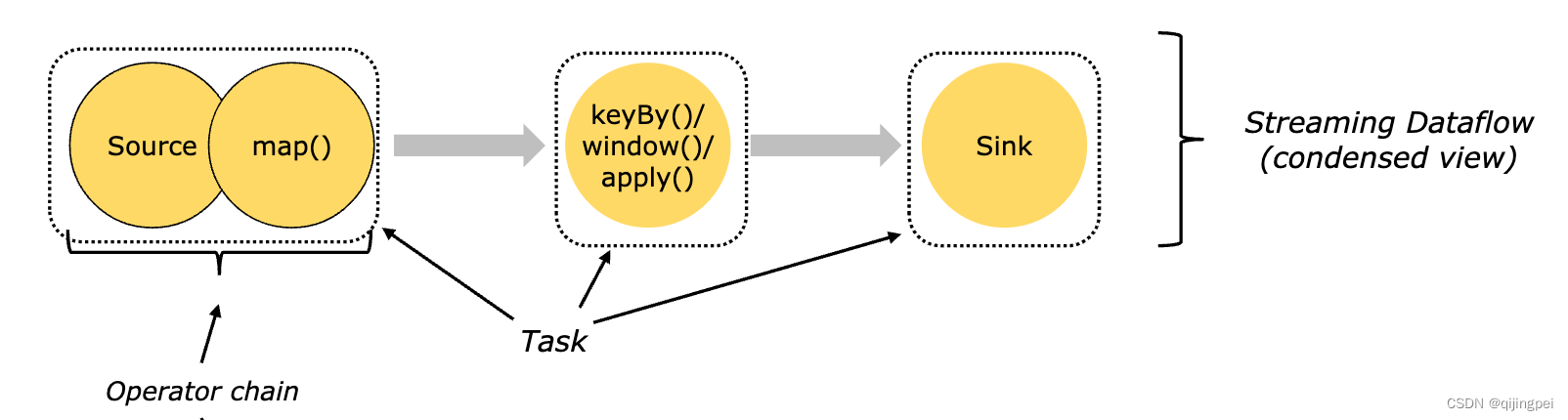
假设程序目前需要依次经过以下算子:source->map->keyBy->window->apply->Sink,如果每个算子都用1个线程执行的话,一共有多达6个线程,不仅导致线程间切换、缓冲数据会有不小的开销,还降低了吞吐量。
为降低线程切换、缓冲的开销,Flink会把可以在同一个线程中执行的算子,链在一起,我们管他叫“算子链”。如图有3个算子链:source+map是1个算子链,keyBy+window+apply是1个算子链,sink是一个。每个算子链会由1个Task来执行。
统计下数量:共有3个Task,会占用3个Task Slot执行。
线程数从6缩减成3个,降低了线程间切换、缓冲数据的开销。
把哪些算子“链”在一起,是可以配置的。
分布式场景
![[图片]](https://img-blog.csdnimg.cn/direct/32d4c209936746e9b644e60fb079517a.png)
分布式场景下,工作会有多个taskManager共同完成工作。如图所示,当前并行度为2.
统计下数量:共有5个Task,每个Task会被分配到1个Task Slot上执行,所以会占用5个Slot。
所以Task Slot的数量,决定了可以并行执行多少个Task。
Task Slots 和资源
1个TaskManager下的task slots共享CPU资源,但内存会分开。
1个TaskManager都是一个 JVM 进程,这导致TaskManager下的slot会共享TCP连接和心跳信息。
Task Slot共享解决阻塞问题
继续上面的例子,1个Task被分配到1个Slot中:
![[图片]](https://img-blog.csdnimg.cn/direct/fccf3a32f11d44339ef511e867e3e946.png)
这样会有1个问题:只有Source\Map拿到数据后,keyBy操作才能开始处理,这会导致keyBy所在算子有可能空闲。
为解决这样一个问题,Flink使用了Slot共享:slot被多个Task共享,如下图:
![[图片]](https://img-blog.csdnimg.cn/direct/2c0d98b5c5f6489f9d34d5cec12d020b.png)
通过Slot共享,将示例中的基本并行度从 2 个增加到 6 个,让每个Slot都可以执行Source算子,这样Source所在的Slot就不会阻塞别的Slot了。这样可以充分利用Slot的资源,同时确保繁重的Task们在 TaskManager 之间公平分配。
小总结:
1. Flink通过将多个算子链在一起,减少了线程之间的切换开销
2. 将任务分配到多个TaskManager上,提高了处理的速度
3. 最后通过Slot共享,确保Slot之间不会阻塞,充分让Slot忙碌起来。
WebUI界面+常见问题排查思路
通过Web UI,可以看到TaskManager、Slot的数量用于速度调优,也可以查看日志用于问题排查。
Flink的Web UI界面的地址是http://localhost:8081,其中localhost是JobManager的主机地址,8081是JobManager的Web UI端口号。在浏览器中输入这个地址,就可以访问Flink的Web UI界面了。
集群概览:查看任务是否正常运行、资源是否需要扩容
![[图片]](https://img-blog.csdnimg.cn/direct/94a0ff9fe5b44d7b87969f5331355a72.png)
点击1个Job查看Job详情:

点击1个算子查看算子详情:查看数据倾斜、反压等性能问题
![[图片]](https://img-blog.csdnimg.cn/direct/a45aa30791eb45c48594583661e790a7.png)
TaskManager:可以查看TaskManager的日志排查问题,注意蛋疼的是问题不一定出现在哪个TaskManager上。
![[图片]](https://img-blog.csdnimg.cn/direct/002a7c2c4eea48c2b7b5212871199b82.png)
JobManager:
![[图片]](https://img-blog.csdnimg.cn/direct/c6ae0e4858bc49cba4f56b68e82c0773.png)
Flink 的容错机制
Flink 的容错机制是通过 Checkpointing 实现的。Checkpointing 允许用户在处理流式数据时定期保存状态,以便在出现故障时恢复状态。Flink 的容错机制包括以下几个步骤:
- 定义 Checkpointing 策略:用户需要定义 Checkpointing 的频率和保存状态的位置。
- 触发 Checkpointing:在处理数据时,Flink 会根据定义的 Checkpointing 策略触发 Checkpointing。
- 恢复状态:在出现故障时,Flink 会根据保存的 Checkpointing 恢复状态。
Flink 的应用场景
Flink 可以应用于多种场景,如:
- 实时数据处理:Flink 可以用于实时数据处理,如实时监控、实时分析等。
- 数据清洗:Flink 可以用于数据清洗,如数据去重、数据清洗等。
- 数据分析:Flink 可以用于数据分析,如数据统计、数据挖掘等。
- 数据集成:Flink 可以用于数据集成,如数据同步、数据迁移等。
Flink常见算子
Flink 的常见算子包括:
- Source:从上游收集数据
- Sink:发送数据给下游
- Map:对输入数据进行转换操作,如数据清洗、数据格式化等。
- FlatMap:对输入数据进行扁平化操作,将一个数据项转换为多个数据项。
- Filter:对输入数据进行筛选操作,只保留符合条件的数据项。
- KeyBy:对输入数据进行分组操作,根据指定的键对数据进行分组。
- Reduce:对输入数据进行聚合操作,将多个数据项聚合为一个数据项。
- Window:对输入数据进行窗口操作,将数据按照指定的窗口大小进行分组。
- Union:对多个输入数据进行合并操作,将多个数据集合并为一个数据集。
- Split:对输入数据进行分裂操作,将一个数据集分裂为多个数据集。
- Join:对多个输入数据进行连接操作,将多个数据集按照指定的键进行连接。
- SQL:对输入数据进行 SQL 查询操作,使用 SQL 语句对数据进行查询和分析。
这些算子可以组合使用,以实现更复杂的数据处理逻辑。
总结
Flink 是一个用于进行大规模数据处理的开源框架,它提供了一个流式的数据处理 API,支持多种编程语言和运行时环境。Flink 的核心特点包括流式数据处理、事件驱动、分布式计算、低延迟等。Flink 的核心组件包括 DataStream API、SQL API、Stateful Stream Processing、Checkpointing 等。Flink 的数据处理流程包括数据输入、数据转换、数据分区、数据传输、数据输出等。Flink 的状态管理是通过 Stateful Stream Processing 实现的,它允许用户在处理流式数据时维护状态。Flink 的容错机制是通过 Checkpointing 实现的,它允许用户在处理流式数据时定期保存状态,以便在出现故障时恢复状态。Flink 可以应用于多种场景,如实时数据处理、数据清洗、数据分析、数据集成等。
相关文章:
Flink基本原理 + WebUI说明 + 常见问题分析
Flink 概述 Flink 是一个用于进行大规模数据处理的开源框架,它提供了一个流式的数据处理 API,支持多种编程语言和运行时环境。Flink 的核心优点包括: 低延迟:Flink 可以在毫秒级的时间内处理数据,提供了低延迟的数据…...
)
3. 文档概述(Documentation Overview)
3. 文档概述(Documentation Overview) 本章节简要介绍一下Spring Boot参考文档。它包含本文档其它部分的链接。 本文档的最新版本可在 docs.spring.io/spring-boot/docs/current/reference/ 上获取。 3.1 第一步(First Steps) …...

【vue3 路由使用与讲解】vue-router : 简洁直观的全面介绍
# 核心内容介绍 路由跳转有两种方式: 声明式导航:<router-link :to"...">编程式导航:router.push(...) 或 router.replace(...) ;两者的规则完全一致。 push(to: RouteLocationRaw): Promise<NavigationFailur…...

ubuntu创建账号和samba共享目录
新建用于登录Ubuntu图形界面的用户 sudo su #切换为root用户获取管理员权限用于新建用户 adduser username #新建用户(例如用户名为username) adduser username sudo #将用户添加到 sudo 组 新建只能用于命令行下登录的用户 sudo su #切换为root用户…...

李沐动手学习深度学习——3.6练习
本节直接实现了基于数学定义softmax运算的softmax函数。这可能会导致什么问题?提示:尝试计算exp(50)的大小。 可能存在超过计算机最大64位的存储,导致精度溢出,影响最终计算结果。 本节中的函数cross_entropy是根据交叉熵损失函数…...
)
机器学习_10、集成学习-Bagging(自举汇聚法)
Bagging(自举汇聚法) Bagging(Bootstrap Aggregating,自举汇聚法)是一种集成学习方法,由Leo Breiman于1996年提出。它旨在通过结合多个模型来提高单个预测模型的稳定性和准确性。Bagging方法特别适用于减少…...

【力扣hot100】刷题笔记Day20
前言 今天学习了一句话“自己如果不努力,屎都吃不上热乎的”,话糙理不糙,与君共勉 35. 搜索插入位置 - 力扣(LeetCode) 二分查找 class Solution:def searchInsert(self, nums: List[int], target: int) -> int:n…...
)
Redis 之八:Jdeis API 的使用(Java 操作 Redis)
Jedis API 使用 Jedis 是 Redis 官方推荐的 Java 客户端,它提供了一套丰富的 API 来操作 Redis 服务器。通过 Jedis API,开发者可以方便地在 Java 应用程序中执行 Redis 的命令来实现数据的增删查改以及各种复杂的数据结构操作。 以下是一些基本的 Jedis…...
Docker 应用入门
一、Docker产生的意义 1‘解决环境配置难题:在软件开发中最大的麻烦事之一,就是环境配置。为了跑我们的程序需要装各种插件,操作系统差异、不同的版本插件都可能对程序产生影响。于是只能说:程序在我电脑上跑是正常的。 2’解决资…...

朱维群将出席用碳不排碳碳中和顶层科技路线设计开发
演讲嘉宾:朱维群 演讲题目:“用碳不排碳”碳中和顶层科技路线设计开发 简介 姓名:朱维群 性别:男 出生日期:1961-09-09 职称:教授 1998年毕业于大连理工大学精细化工国家重点实验室精细化工专业&#x…...

linux如何查看磁盘占用情况
要查看Linux系统中磁盘的占用情况,可以使用一些命令来获取相关信息。以下是一些常用的命令: df命令: df命令用于显示文件系统的磁盘空间使用情况,包括磁盘分区的总空间、已用空间、可用空间等信息。 df -h使用 -h 参数可以以人类可…...
【C++庖丁解牛】类与对象
📙 作者简介 :RO-BERRY 📗 学习方向:致力于C、C、数据结构、TCP/IP、数据库等等一系列知识 📒 日后方向 : 偏向于CPP开发以及大数据方向,欢迎各位关注,谢谢各位的支持 目录 1.面向过程和面向对象…...

在什么时候企业档案才会发生调整
档案在企业中通常会调整在以下几个时刻: 1. 入职时:员工入职时,企业会要求员工提供个人档案,包括身份证件、学历证明、工作经历等相关文件。 2. 离职时:员工离职时,企业会整理员工的离职档案,包…...

Linux或Windows下判断socket连接状态
前言 场景:客户端程序需要实时知道和服务器的连接状态。比较通用的做法应用层是采用心跳机制,每隔一端时间发送心跳能回复说明服务器正常。 实际应用场景中,服务端和客户端并不是一家厂商的,比如说笔者这种情况,服务端…...
gcc ASAN、MSAN检测内存越界、泄露、使用未初始化内存等内存相关错误)
编译链接实战(25)gcc ASAN、MSAN检测内存越界、泄露、使用未初始化内存等内存相关错误
文章目录 1 ASAN1.1 介绍1.2 原理编译时插桩模块运行时库2 检测示例2.1 内存越界2.2 内存泄露内存泄露检测原理作用域外访问2.3 使用已经释放的内存2.4 将漏洞信息输出文件3 MSAN1 ASAN 1.1 介绍 -fsanitize=address是一个编译器选项,用于启用AddressSanitizer(地址...
[HackMyVM]靶场 VivifyTech
kali:192.168.56.104 主机发现 arp-scan -l # arp-scan -l Interface: eth0, type: EN10MB, MAC: 00:0c:29:d2:e0:49, IPv4: 192.168.56.104 Starting arp-scan 1.10.0 with 256 hosts (https://github.com/royhills/arp-scan) 192.168.56.1 0a:00:27:00:00:05 (Unk…...

软考高级系统分析师:关联关系、依赖关系、实现关系和泛化关系概念和例题
一、AI 解读 关联关系、依赖关系、实现关系和泛化关系是面向对象设计中的四种基本关系。它们在类与类之间建立不同类型的联系,以反映对象间的相互作用、依赖和继承关系。下面我将使用表格的形式来解释这四种关系的概念和它们之间的区别: 关系类型概念特…...

设计模式学习笔记 - 面向对象 - 9.实践:如何进行面向对象分析、设计与编码
1.如何对接口鉴权这样一个功能开发做面向对象分析 本章会结合一个真实的案例,从基础的需求分析、职责划分、类的定义、交互、组装运行讲起,将最基础的面向对象分析(00A)、设计(00D)、编程(00P&…...
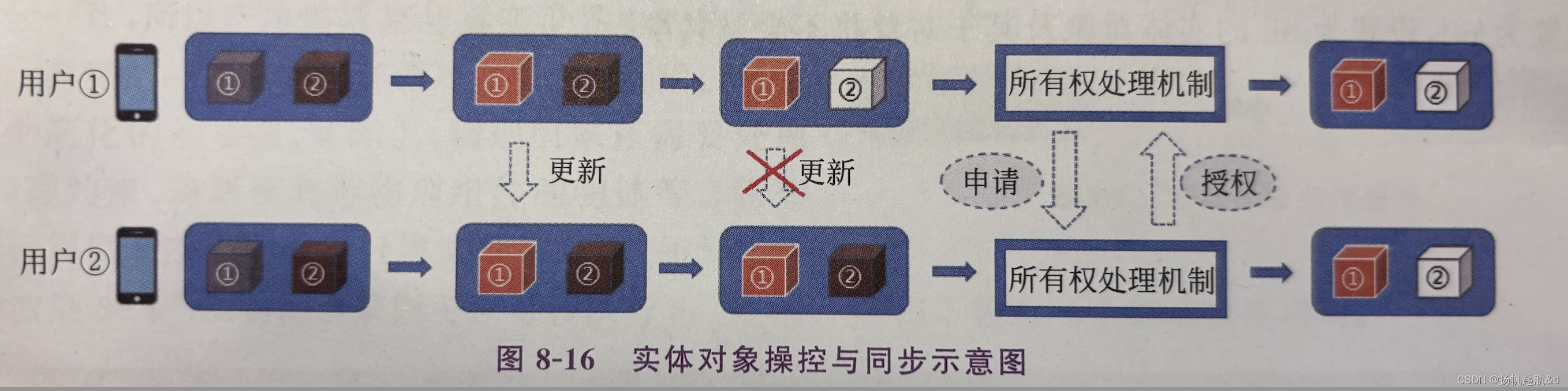
【iOS ARKit】RealityKit 同步机制
协作 Session 可以很方便地实现多用户之间的AR体验实时共享,但开发者需要自行负责并确保AR场景的完整性,自行负责虚拟物体的创建与销毁。为简化同步操作,RealityKit 内建了同步机制,RealityKit 同步机制基于 Multipeer Connectivi…...
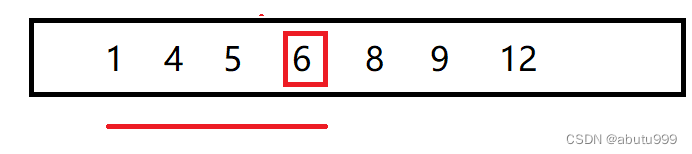
【数据结构与算法】整数二分
问题描述 对一个排好序的数组,要求找到大于等于7的最小位置和小于等于7的最大位置 大于等于7的最小位置 易知从某个点开始到最右边的边界都满足条件,我们要找到这个区域的最左边的点。 开始二分! left指针指向最左边界,right…...

玄机靶场实战:从应急响应到vulntarget-j-02的攻防解析
1. 玄机靶场与应急响应实战入门 第一次接触玄机靶场时,我被它高度仿真的企业内网环境震撼到了。这个基于Docker构建的靶场平台完美复现了企业常见的Windows服务器、Web应用和数据库服务,甚至连日志记录和行为特征都和真实环境一模一样。对于想学习网络安…...

Windows安卓开发终极指南:一键安装ADB Fastboot驱动工具
Windows安卓开发终极指南:一键安装ADB Fastboot驱动工具 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/la/…...

Kimi-VL-A3B-Thinking效果展示:同一张发票图,连续追问税额、日期、供应商等字段
Kimi-VL-A3B-Thinking效果展示:同一张发票图,连续追问税额、日期、供应商等字段 1. 模型效果惊艳展示 Kimi-VL-A3B-Thinking作为一款高效的多模态视觉语言模型,在处理复杂文档理解任务时展现出令人印象深刻的能力。我们将通过一张普通发票的…...

YOLOv12官版镜像5分钟快速部署:零基础小白也能轻松上手
YOLOv12官版镜像5分钟快速部署:零基础小白也能轻松上手 1. 为什么选择YOLOv12官版镜像? YOLOv12作为目标检测领域的最新突破,首次将注意力机制作为核心架构,彻底改变了传统YOLO系列依赖CNN的设计思路。这个官版镜像相比Ultralyt…...

Phi-4-mini-reasoning实战:分析并优化开源项目中的C++代码结构
Phi-4-mini-reasoning实战:分析并优化开源项目中的C代码结构 1. 开篇:当AI遇见C代码优化 最近在GitHub上发现一个挺有意思的中小型C项目——SimpleWebServer,它实现了一个基础的HTTP服务器功能。正好手头有Phi-4-mini-reasoning这个工具&am…...

Windows Defender控制工具:重新定义你对系统安全管理的理解
Windows Defender控制工具:重新定义你对系统安全管理的理解 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defender-control …...
FDE会被AI完全替代吗?)
Palantir:两个不确定的问题(2)FDE会被AI完全替代吗?
从上一篇的分析可以得知,Palantir的整套系统,就是一个有机的企业级数字孪生体: 本体Ontology灵魂/主宰 它定义世界“是什么、有什么、彼此关系如何”,是客观现实与人类主观认识的统一,是整个系统的 “道”。 AIP心与…...

【腾讯位置服务开发者征文大赛】用 AI 读懂城市情绪 —— 基于腾讯位置服务的反内卷散步助手
文章目录 前言一、问题背景1.1 传统地图方案的局限1.2 AI 地图的可能性 二、技术方案:四层架构,一张情绪地图2.1 整体架构2.2 腾讯位置服务能力使用清单2.3 AI 接入方案 三、项目实操3.1 下载 Skill3.2 创建 CodeBuddy 项目3.3 项目立项3.4 获取 API Ke…...

2025身份证前六位地区代码解析:如何快速查询与使用指南
1. 身份证前六位地区代码的奥秘 每次看到身份证号码前六位数字,你有没有好奇过它们代表什么?这串看似简单的数字其实是行政区划代码,相当于每个地区的"身份证号"。我刚开始研究这个时也一头雾水,直到发现它背后藏着完整…...
2026-04-11 全国各地响应最快的 BT Tracker 服务器(电信版)
数据来源:https://bt.me88.top 序号Tracker 服务器地域网络响应(毫秒)1http://211.75.210.221:6969/announce广东广州电信322http://60.249.37.20:80/announce广东东莞电信333http://211.75.205.189:6969/announce广东深圳电信364udp://132.226.6.145:6969/announc…...