【机器学习】包裹式特征选择之递归特征消除法

🎈个人主页:豌豆射手^
🎉欢迎 👍点赞✍评论⭐收藏
🤗收录专栏:机器学习
🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步!
【机器学习】包裹式特征选择之递归特征消除法
- 一 初步了解
- 1.1 概念
- 1.2 类比
- 二 具体步骤
- 2.1 选择模型
- 2.2 初始化:
- 2.3 模型训练:
- 2.4 特征重要性评估:
- 2.5 特征排序:
- 2.6 剔除特征:
- 2.7 更新特征集:
- 2.8 停止条件检查:
- 2.9 重复步骤:
- 三 优缺点以及适用场景
- 3.1 优点:
- 3.2 缺点:
- 3.3 适用场景:
- 四 代码示例及分析
- 总结
引言:
在机器学习中,特征选择是提高模型性能和泛化能力的关键步骤之一。
而包裹式特征选择方法中的递归特征消除法 (Recursive Feature Elimination,简称RFE)是一种有效的特征选择技术。
通过递归地剔除对模型性能贡献较小的特征,RFE能够选择出最佳的特征子集,从而提高模型的预测性能。
本文将介绍递归特征消除法的概念、具体步骤、优缺点以及适用场景,并提供代码示例进行详细分析。

一 初步了解
1.1 概念
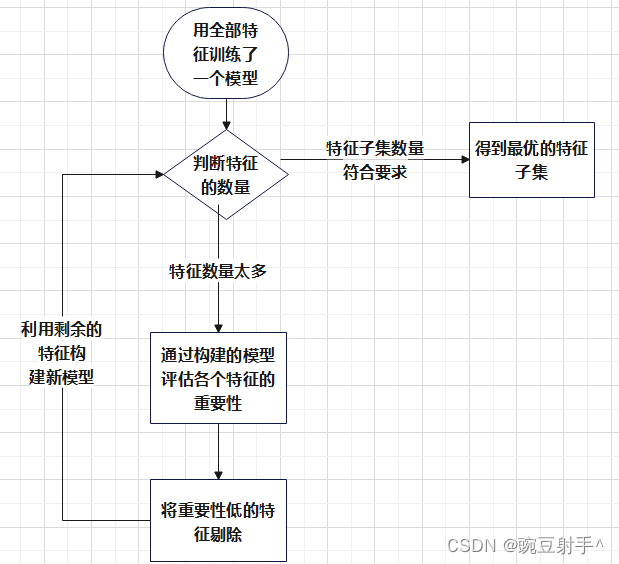
递归特征消除(RFE)是包裹式特征选择法中的一种方法,它通过反复构建模型并剔除最不重要的特征来选择最优特征子集。
首先,使用全部特征训练一个模型,然后根据特征的重要性评估移除最不重要的特征。
特征训练模型是指利用选定的特征集合来训练一个机器学习模型,以便对数据进行预测或分类,也就是用数据来训练了一个模型。
在特征选择的上下文中,特征集是经过筛选或选择的子集,通常包含数据集中最重要或最相关的特征。
这个过程迭代进行,每次更新特征集,直到达到预定的特征数量或其他停止条件。
递归地剔除特征的过程确保了最终选择的特征子集对于模型性能至关重要,有助于提高预测性能并减少特征的维度,增强模型的泛化能力。
流程图大概如下:
1.2 类比
假设你是一位园艺师,正在设计一座美丽的花园。
花园里的每一种植物都代表数据集中的一个特征。

现在,你的目标是选择一组最适合花园美感的植物组合,以确保花园在四季都充满色彩。
在这个情境中,递归特征消除(RFE)就像是你在挑选植物时的一种策略。
开始时,你选择了各种各样的植物,代表数据集中的所有特征。
然后,你根据每种植物对花园整体美感的贡献,决定是否保留或剔除某些植物。
也许有些植物的颜色并不和谐,或者有些植物在某个季节并不怎么引人注目。
于是,你将影响美感的的植物剔除了,然后用剩下的植物重新构建新的花园。(用剩下的特征构建新的模型)
再根据新的的花园中,剩下的每种植物对花园整体美感的贡献,又再次决定是否保留或剔除某些植物。
重复这个过程,你逐步剔除了这些对花园美感影响较小的植物,直到达到你心目中的理想花园,或者直到不能再提升花园的整体美感为止。
这个过程类似于递归特征消除的工作原理:
通过不断尝试和调整,逐步剔除对整体美感贡献较小的植物(特征),最终得到一个最优的植物组合,使得花园在四季都呈现出最美的景色。
这样,你就能更好地掌握花园设计的要诀,提高了花园整体美感的效果。
在这个类比中,重点强调了递归特征消除的迭代过程,其中每一轮剔除不重要的植物都伴随着重新构建花园的步骤。

二 具体步骤
步骤流程图如下:
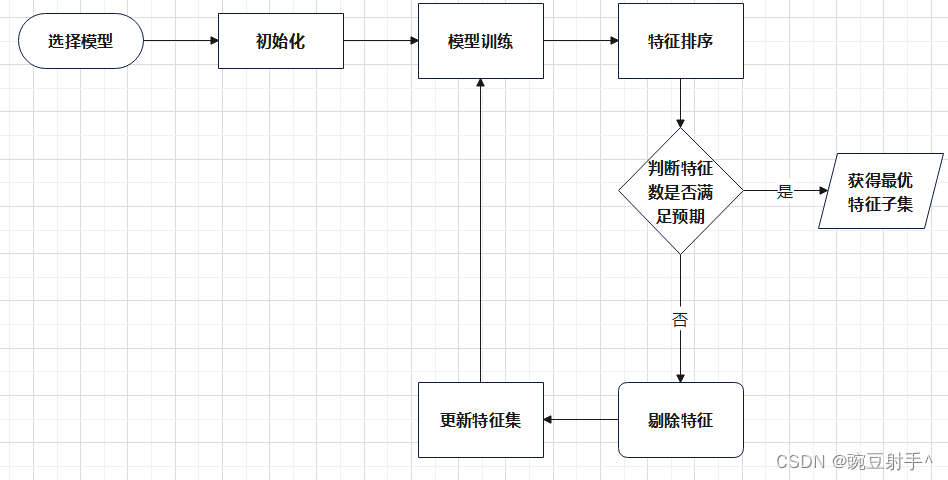
接下来,我将详细介绍每一个步骤的具体实现。
2.1 选择模型
首先,选择一个适合于特定任务的预测模型,例如线性回归、逻辑回归、支持向量机等。
这个模型将用于评估特征的重要性,并指导特征选择的过程。
2.2 初始化:
将所有特征包含在特征集合中,作为初始的特征子集。
2.3 模型训练:
使用选定的模型和所有特征来训练一个初始模型。
2.4 特征重要性评估:
利用已训练的模型,评估每个特征的重要性或对模型性能的贡献程度。
这可以通过不同的方法来完成,如特征权重、系数、信息增益等。
2.5 特征排序:
根据特征的重要性进行排序,确定哪些特征对模型的性能影响最大,哪些对模型性能影响较小。
2.6 剔除特征:
移除排序后的特征列表中最不重要的特征。可以根据实际需要选择一次剔除一个或多个特征。
剔除的特征通常是那些被认为对模型性能贡献较小的特征。
2.7 更新特征集:
在剔除特征后,更新特征集,形成一个新的特征子集。
2.8 停止条件检查:
检查是否满足停止条件,例如特征数量已达到预定值、模型性能已达到某个阈值等。
如果满足停止条件,则停止迭代;否则,回到第3步,继续进行下一轮迭代。
2.9 重复步骤:
重复步骤3到步骤8,直到满足停止条件为止。
每一轮迭代都会剔除对模型性能影响较小的特征,直到找到一个最优的特征子集。

三 优缺点以及适用场景
3.1 优点:
1 考虑特征间的相互关系:
RFE在剔除特征时会考虑到特征间的相互影响,从而更加准确地选择特征子集。
2 降低过拟合风险:
通过减少特征数量,RFE可以降低模型的复杂度,减少过拟合的风险。
3 提高模型性能:
通过选择最优的特征子集,RFE可以提高模型的性能和泛化能力。
4 无需事先假设特征分布:
RFE不需要对特征分布做出假设,适用于各种类型的数据。
3.2 缺点:
1 计算成本高:
对于特征数量较多的数据集,RFE需要反复训练模型,计算成本较高。
2 依赖模型选择:
RFE的性能取决于所选择的基础模型,选择不合适的模型可能导致特征选择效果不佳。
3 可能丢失信息:
在剔除特征的过程中,有可能剔除了一些对模型有潜在贡献的特征,导致丢失信息。
3.3 适用场景:
1 特征数量较多:
当数据集特征数量较多时,RFE可以帮助筛选出最重要的特征,减少特征的维度。
2 模型复杂度高:
当模型复杂度较高,存在过拟合风险时,RFE可以帮助减少特征数量,降低模型复杂度。
3 需要提高模型性能:
当模型性能需要提高时,RFE可以帮助选择最优的特征子集,提高模型的性能和泛化能力。
总的来说,递归特征消除法在特征选择方面具有一定的优势,尤其适用于特征数量较多、模型复杂度较高或需要提高模型性能的情况下。
然而,使用RFE时需要注意计算成本和模型选择的问题。

四 代码示例及分析
我们可以通过Python中的scikit-learn模块实现递归特征消除,在这个模块中,实现递归特征消除法的具体方法是使用RFE(Recursive Feature Elimination)类。
通过该类,可以将基础模型(如SVM分类器)和要选择的特征数量作为参数,然后利用递归的方式不断剔除特征,最终得到最佳的特征子集。
下面是具体步骤:
1 导入库 (Import Libraries):
from sklearn.datasets import make_classification
from sklearn.feature_selection import RFE
from sklearn.svm import SVC
这些代码导入了三个scikit-learn库中的模块:make_classification 用于生成分类数据集,RFE用于递归特征消除,SVC 是支持向量机的实现。
2 生成一个示例数据集 (Generate Example Dataset):
X, y = make_classification(n_samples=100, n_features=10, random_state=42)
使用 make_classification 函数生成一个包含 100 个样本和 10 个特征的分类数据集,并将特征矩阵赋值给 X,目标变量赋值给 y。
3 创建一个SVM分类器作为基础模型 (Create SVM Classifier as Base Model):
svc = SVC(kernel="linear")
创建一个基于线性核函数的支持向量机(SVM)分类器,将其实例化并赋值给变量 svc。
4 使用RFE进行特征选择,选择5个最重要的特征 (Use RFE for Feature Selection, Select 5 Most Important Features):
rfe = RFE(estimator=svc, n_features_to_select=5, step=1)
创建一个 RFE 对象,指定基础模型为 svc,要选择的特征数量为 5,步长为 1。
5 对数据进行特征选择 (Perform Feature Selection on Data):
rfe.fit(X, y)
调用 RFE 对象的 fit 方法,使用数据 X 和目标变量 y 进行特征选择。
6 输出所选特征的排名 (Print Feature Rankings):
print("Feature Ranking:", rfe.ranking_)
打印输出所选特征的排名,即每个特征在RFE过程中的重要性排序,排名越低表示特征越重要。
7 输出所选特征 (Print Selected Features):
selected_features = [f"Feature {i+1}" for i in range(len(rfe.ranking_)) if rfe.support_[i]]
print("Selected Features:", selected_features)
使用列表推导式和条件判断,确定被选中的特征,并打印输出它们的名称。 rfe.support_ 返回一个布尔类型的数组,指示哪些特征被选中。
运行结果如下:
Feature Ranking: [1 1 1 1 1 6 5 4 3 2]
Selected Features: ['Feature 1', 'Feature 2', 'Feature 3', 'Feature 4', 'Feature 5']
这表示在特征选择过程中,前五个特征被选为最重要的特征,它们的排名为 1,而其余特征的排名分别为 2 到 6。
被选中的特征分别是 ‘Feature 1’, ‘Feature 2’, ‘Feature 3’, ‘Feature 4’, 和
‘Feature 5’。
完整代码 :
# 导入库
from sklearn.datasets import make_classification
from sklearn.feature_selection import RFE
from sklearn.svm import SVC# 生成一个示例数据集
X, y = make_classification(n_samples=100, n_features=10, random_state=42)# 创建一个SVM分类器作为基础模型
svc = SVC(kernel="linear")# 使用RFE进行特征选择,选择5个最重要的特征
rfe = RFE(estimator=svc, n_features_to_select=5, step=1)# 对数据进行特征选择
rfe.fit(X, y)# 输出所选特征的排名
print("Feature Ranking:", rfe.ranking_)# 输出所选特征
selected_features = [f"Feature {i+1}" for i in range(len(rfe.ranking_)) if rfe.support_[i]]
print("Selected Features:", selected_features)
总结
递归特征消除法(RFE)作为一种包裹式特征选择方法,在特征选择中具有一定的优势。
通过递归地剔除对模型性能贡献较小的特征,RFE能够选择出最佳的特征子集,从而提高模型的预测性能。
然而,RFE也存在一些缺点,例如计算开销较大、对于大规模数据集可能不太适用等。
因此,在使用RFE时需要根据具体情况权衡其优缺点,并结合实际场景做出合适的选择。
这篇文章到这里就结束了
谢谢大家的阅读!
如果觉得这篇博客对你有用的话,别忘记三连哦。
我是豌豆射手^,让我们我们下次再见


相关文章:
【机器学习】包裹式特征选择之递归特征消除法
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...

【ArcGIS】重采样栅格像元匹配问题:不同空间分辨率栅格数据统一
重采样栅格像元匹配问题:不同空间分辨率栅格数据统一 原始数据数据1:GDP分布数据2.1:人口密度数据2.2:人口总数数据3:土地利用类型 数据处理操作1:将人口密度数据投影至GDP数据(栅格数据的投影变…...

Qt 简约又简单的加载动画 第七季 音量柱风格
今天和大家分享两个音量柱风格的加载动画,这次的加载动画的最大特点就是简单,只有几行代码. 效果如下: 一共三个文件,可以直接编译运行 //main.cpp #include "LoadingAnimWidget.h" #include <QApplication> #include <QGridLayout> int main(int argc…...

【JS】数值精度缺失问题解决方案
方法一: 保留字符串类型,传给后端 方法二: 如果涉及到计算,用以下方法 // 核心思想 在计算前,将数字乘以相同倍数,让他没有小数位,然后再进行计算,然后再除以相同的倍数࿰…...

c++基础知识补充4
单独使用词汇 using std::cout; 隐式类型转换型初始化:如A a1,,此时可以形象地理解为int i1;double ji;,此时1可以认为创建了一个值为1的临时对象,然后对目标对象进行赋值,当对象为多参数时,使用(1…...

leetcode230. 二叉搜索树中第K小的元素
lletcode 230. 二叉搜索树中第K小的元素,链接:https://leetcode.cn/problems/kth-smallest-element-in-a-bst 题目描述 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 …...

医学大数据|文献阅读|有关“肠癌+机器学习”的研究记录
目录 1.机器学习算法识别结直肠癌中的免疫相关lncRNA signature 2.基于机器学习的糖酵解相关分子分类揭示了结直肠癌癌症患者预后、TME和免疫疗法的差异,2区7 3.整合深度学习-病理组学、放射组学和免疫评分预测结直肠癌肺转移患者术后结局 4.最新7.4分纯生信&am…...
Linux信号【systemV】
目录 前言 正文: 1消息队列 1.1什么是消息队列? 1.2消息队列的数据结构 1.3消息队列的相关接口 1.3.1创建 1.3.2释放 1.3.3发送 1.3.4接收 1.4消息队列补充 2.信号量 2.1什么是信号量 2.2互斥相关概念 2.3信号量的数据结构 2.4…...

node.js最准确历史版本下载
先进入官网:Node.js https://nodejs.org/en 嫌其他博客多可以到/release下载:Node.js,在blog后面加/release https://nodejs.org/en/blog/release/ 点击next翻页,同样的道理...

UE5 C++ 单播 多播代理 动态多播代理
一. 代理机制,代理也叫做委托,其作用就是提供一种消息机制。 发送方 ,接收方 分别叫做 触发点和执行点。就是软件中的观察者模式的原理。 创建一个C Actor作为练习 二.单播代理 创建一个C Actor MyDeligateActor作为练习 在MyDeligateAc…...

前端学习、CSS
CSS可以嵌入到HTML中使用。 每个CSS语法包含两部分,选择器和应用的属性。 div用来声明针对页面上的哪些元素生效。 具体设置的属性以键值对形式表示,属性都在{}里,属性之间用;分割,键和值之间用:分割。 因为CSS的特殊命名风格…...
Flink基本原理 + WebUI说明 + 常见问题分析
Flink 概述 Flink 是一个用于进行大规模数据处理的开源框架,它提供了一个流式的数据处理 API,支持多种编程语言和运行时环境。Flink 的核心优点包括: 低延迟:Flink 可以在毫秒级的时间内处理数据,提供了低延迟的数据…...
)
3. 文档概述(Documentation Overview)
3. 文档概述(Documentation Overview) 本章节简要介绍一下Spring Boot参考文档。它包含本文档其它部分的链接。 本文档的最新版本可在 docs.spring.io/spring-boot/docs/current/reference/ 上获取。 3.1 第一步(First Steps) …...

【vue3 路由使用与讲解】vue-router : 简洁直观的全面介绍
# 核心内容介绍 路由跳转有两种方式: 声明式导航:<router-link :to"...">编程式导航:router.push(...) 或 router.replace(...) ;两者的规则完全一致。 push(to: RouteLocationRaw): Promise<NavigationFailur…...

ubuntu创建账号和samba共享目录
新建用于登录Ubuntu图形界面的用户 sudo su #切换为root用户获取管理员权限用于新建用户 adduser username #新建用户(例如用户名为username) adduser username sudo #将用户添加到 sudo 组 新建只能用于命令行下登录的用户 sudo su #切换为root用户…...

李沐动手学习深度学习——3.6练习
本节直接实现了基于数学定义softmax运算的softmax函数。这可能会导致什么问题?提示:尝试计算exp(50)的大小。 可能存在超过计算机最大64位的存储,导致精度溢出,影响最终计算结果。 本节中的函数cross_entropy是根据交叉熵损失函数…...
)
机器学习_10、集成学习-Bagging(自举汇聚法)
Bagging(自举汇聚法) Bagging(Bootstrap Aggregating,自举汇聚法)是一种集成学习方法,由Leo Breiman于1996年提出。它旨在通过结合多个模型来提高单个预测模型的稳定性和准确性。Bagging方法特别适用于减少…...

【力扣hot100】刷题笔记Day20
前言 今天学习了一句话“自己如果不努力,屎都吃不上热乎的”,话糙理不糙,与君共勉 35. 搜索插入位置 - 力扣(LeetCode) 二分查找 class Solution:def searchInsert(self, nums: List[int], target: int) -> int:n…...
)
Redis 之八:Jdeis API 的使用(Java 操作 Redis)
Jedis API 使用 Jedis 是 Redis 官方推荐的 Java 客户端,它提供了一套丰富的 API 来操作 Redis 服务器。通过 Jedis API,开发者可以方便地在 Java 应用程序中执行 Redis 的命令来实现数据的增删查改以及各种复杂的数据结构操作。 以下是一些基本的 Jedis…...
Docker 应用入门
一、Docker产生的意义 1‘解决环境配置难题:在软件开发中最大的麻烦事之一,就是环境配置。为了跑我们的程序需要装各种插件,操作系统差异、不同的版本插件都可能对程序产生影响。于是只能说:程序在我电脑上跑是正常的。 2’解决资…...

你的Windows 11真的需要“减肥“吗?Win11Debloat一键解放30%系统资源
你的Windows 11真的需要"减肥"吗?Win11Debloat一键解放30%系统资源 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other chang…...

golang如何实现备忘录模式_golang备忘录模式实现方案
Go中备忘录模式需用非导出结构体封装快照、接口作类型标记,发起者控制Save/Restore;只备份业务字段,避免指针/map共享;限制栈长度并置空引用助GC;测试用reflect.DeepEqual验证隔离性。备忘录模式在 Go 里没有语言原生支…...

WaveTools鸣潮工具箱:3大核心功能让你告别卡顿,科学抽卡不迷路
WaveTools鸣潮工具箱:3大核心功能让你告别卡顿,科学抽卡不迷路 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 如果你正在玩《鸣潮》PC版,一定经历过游戏卡顿、帧率限制…...

衣柜里的暖,是藏不住的牵挂
老李独居在老房子里,儿女都在外地打拼,一年到头难得回几次家,平日里冷冷清清的屋子,只有逢年过节才会热闹几分。 北方的冬天总是格外漫长,寒风一吹,窗户缝里都透着刺骨的凉,老李年纪大了&#x…...

[AI/向量数据库/GUI] Attu : Milvus 的图形化与一体化管理工具涎
前言 在使用 kubectl get $KIND -o yaml 查看 k8s 资源时,输出结果中包含大量由集群自动生成的元数据(如 managedFields、resourceVersion、uid 等)。这些信息在实际复用 yaml 清单时需要手动清理,增加了额外的工作量。 使用 kube…...

154W,确实可以封神了!!
去年DeepSeek爆火,生成式AI和大模型技术呈现爆发式增长,也让算法工程师重新成了炙手可热的岗位,岗位薪资远超很多运维、嵌入式、前后端岗位,在程序员中稳居前列。AI的快速发展也给很多程序员带来更多的机会,很多公司都…...

ug nx软件安装的几种错误报警
安装路径包含中文或特殊字符NX软件安装路径中若包含中文、空格或特殊符号(如#、&等),可能导致安装失败或功能异常。建议将安装路径修改为纯英文且无空格的目录,例如D:\Siemens\NX。系统环境变量配置错误安装过程中需正确配置系…...

从零到一:在Vitis平台上构建ZYNQ PS-SPI Flash驱动
1. 环境准备与硬件连接 在开始构建ZYNQ PS-SPI Flash驱动之前,我们需要准备好开发环境和硬件平台。我推荐使用Xilinx官方提供的Vitis 2022.1版本,这个版本对ZYNQ系列的支持比较稳定。硬件方面,你需要一块带有SPI Flash的ZYNQ开发板࿰…...

Magma智能运维:基于Prometheus的监控告警优化
Magma智能运维:基于Prometheus的监控告警优化 1. 监控系统面临的挑战 现代分布式系统的监控一直是个头疼的问题。随着微服务架构的普及,服务数量呈指数级增长,传统的监控方式已经力不从心。运维团队经常面临这样的困境:明明设置…...

Kimi-VL-A3B-Thinking多模态推理教程:支持LaTeX公式图像识别与解析
Kimi-VL-A3B-Thinking多模态推理教程:支持LaTeX公式图像识别与解析 1. 快速了解Kimi-VL-A3B-Thinking Kimi-VL-A3B-Thinking是一款高效的开源混合专家视觉语言模型,专注于多模态推理任务。这个模型特别擅长处理包含数学公式的图像识别与解析࿰…...