Image Fusion via Vision-Language Model【文献阅读】
阅读目录
- 文献阅读
- Abstract
- Introduction
- 3. Method
- 3.1. Problem Overview
- 3.2. Fusion via Vision-Language Model
- 4. Vision-Language Fusion Datasets
- 5. Experiment
- 5.1Infrared and Visible Image Fusion
- 6. Conclusion
- 个人总结
文献阅读

原文下载:https://arxiv.org/abs/2402.02235
Abstract
图像融合从多源图像中整合必要信息成单张图像,强调显著性的结构和纹理,精炼不足的区域。现有的方法主要是识别像素级和语义视觉特征。然而在深度语义信息之外的文本信息探索不足。因此,我们定义了一个创新的范式佳作FILM(Fusion via vIsion-Language
Model),首先利用提取不同原图像的文本信息去指导融合。输入的图像首先处理后去生成语义提示,然后喂到ChatGPT中去获得丰富的语义描述。通过交叉注意力这些描述被用于融合文本域中用于指导源图像关键视觉特征的提取,导致由文本语义信息指导更加深层的上下文理解。最终的融合图像由视觉特征解码器生成。这种范式在4种融合任务中得到了满意的结果:红外与可见光、医学图像、多曝光、多聚焦。我们也提出了一个视觉语言数据集包括基于ChatGPT的段落描述,用于在4个融合任务的8个图像融合数据集,促进了基于视觉语言模型的视觉研究。代码即将开源。
Introduction
因此,本文我们提出了创新的算法叫做Image Fusion via VIsion-Language Model (FILM)。这个方法首次将大语言模型的能力整合到图像融合中,利用从文本数据导出的语义理解来指导和增强融合图像的视觉特征。我们方法包含3部分,文本特征融合、语言指导视觉特征融合,语言特征解码器。工作流如下图1所示,我们的共享可以总结成以下几点:
- 在图像融合中提出了一个创新性的范式,据我们所知,这是第一个由语言模型驱动的文本指导实现来指导图像融合算法。这种方法有助于理解更深层次的文本语义信息,促进从各种源图像中提取和融合的优势。
- 在4中任务上我们的模型实现了令人满意的结果,在不同应用场景上证明了其有效性。
- 我们引入了一系列用于图像融合的视觉语言基准数据集,涵盖跨四个融合任务的八个数据集。这些数据集包含了用ChatGPT模型来手动细化的提示定制,以及有ChatGPT生成配对的文本描述,为了促进在图像融合中使用视觉语言模型的后续研究。
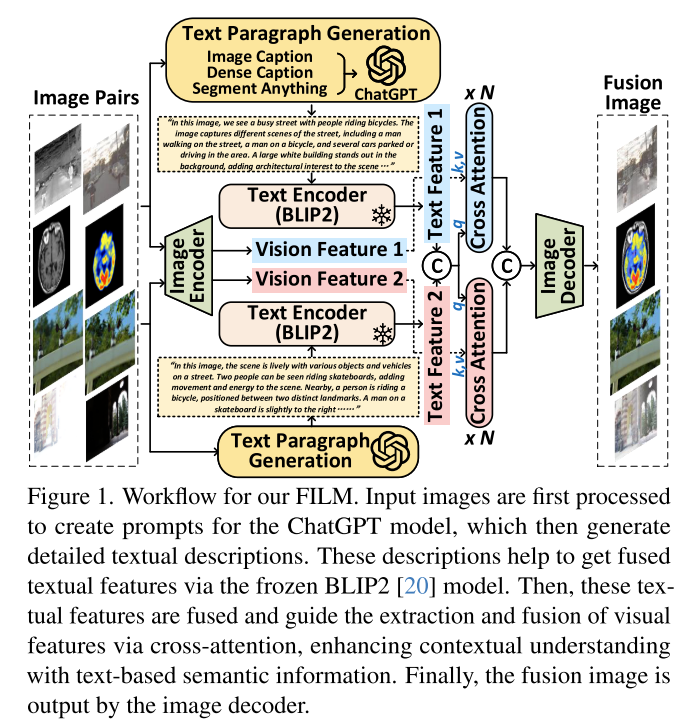
图1:FILM的工作流,输入的图像首先为ChatGPT模型生成提示,然后由它生成详细的文本描述。这些描述通过冻结的BLIP2模型得到融合的文本特征。然后这些文本特征被融合,通过交叉注意力指导视觉特征的提取和融合,通过文本的语义信息的增强上下文的理解。最终,融合图像被图像的Encoder输出。
总结一下:基于ChatGPT生成详细的文本描述,得到文本特征后通过交叉注意力来加强视觉特征,用于挖掘深层次的文本语义信息,然后将融合特征经过图像的解码器得到融合图像。
3. Method
输入的图像对为I_1和I_2,可以是红外与可见光、医学图像、多曝光图像和多聚焦图像。算法最终输出的融合图像记作F。这一节我们将对FILM进行容易理解的描述,I_F=FILM(I_1,I_2),解释它的工作流和设计细节。训练的细节,包括损失函数,都将被讨论。
3.1. Problem Overview
图1和图2是简要和细节的FILM范式工作流,算法可以分为3部分:文本特征融合、语言指导的视觉特征融合和视觉特征解码,分别对应图2的第一、二、三栏,分别用T(·) V(·) D(·)表示。
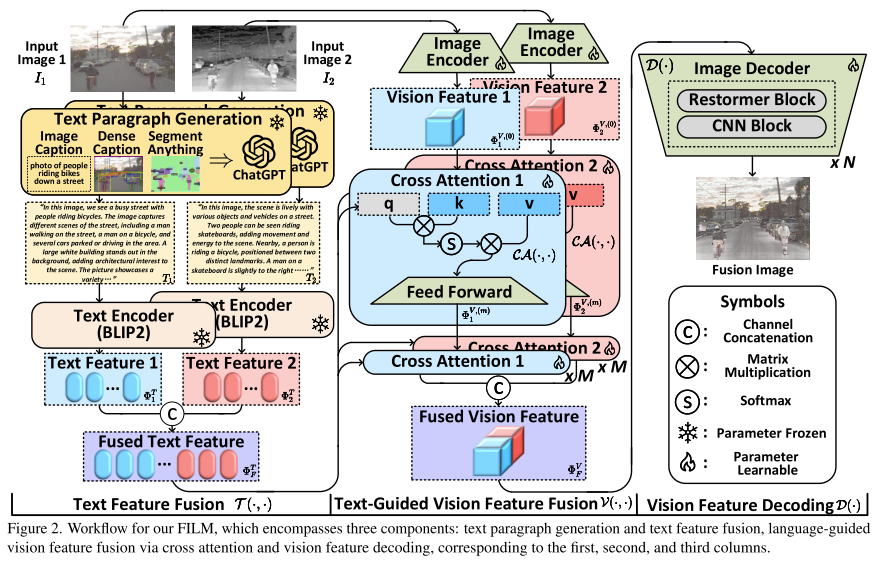
图2:FILM的工作流,包含三部分:文本范式生成、文本特征融合、通过交叉注意力指导的视觉特征融合和视觉特征解码器,分别为第一列、第二列和第三列。FILM算法包含2个输入,由文本特征融合单元T进行初始化的处理。这一部分的提示生成包含图像描述、密集描述和分割一切,通过ChatGPT来生成文本描述。文本描述通过BLIP2的文本编码器来编码,随后将融合他们。语言指导的视觉特征融合V利用融合的文本特征通过交叉注意力去指导原图像视觉特征的提取。这个过程识别并整合融合图像的显著性方面和优势。最终,融合图像F被视觉特征解码器D输出,解码融合的视觉特征到图像。每个部分的细节将分开解读。由于内容的约束,更多的网络细节可以去补充材料查看。
3.2. Fusion via Vision-Language Model
组成1:文本特征融合
文本特征融合部分,原图像{I_1, I_2}作为输入,得到融合文本特征。最初,收到文献的启发,我们将图像输入达BLIP2、GRIT和Segment Anything模型去提取图像的语义信息从整体到细粒度,作为图像描述、密集描述和语义掩码。随后将3中提示输入的ChatGPT模型来生成与原图像I_1和I_2匹配的文本描述T1和T2。我们然后输入T1和T2到冻结BLIP2模型的文本编码器,获得对应的文本特征。最终,将2个文本特征拼接后得到融合的文本特征。更多特征提示和文本生成请参考Sec 4.
组成2:语言指导的视觉特征融合
语言指导的视觉融合部分,通过文本特征来指导从原图像中提取视觉特征。最终,源图像I_1和I_2喂到图像的编码器中得到浅层的视觉特征。图像编码器包含Restormer块和CNN,关注与全局和局部的视觉表达同时保留计算效率和高效的特征提取。随后,浅层的特征被喂到交叉注意力模块,用于融合文本特征去指导视觉特征的提取,更多的关注希望在融合图像中保留原图像的各个部分。K和V由对应的视觉特征提供,Q由融合的文本特征提供。值得注意的是交叉注意力中的前馈神经网络是有Restormer块实现的。经过M次交叉注意力后,文本特征指导的视觉特征被得到,随后,在通道维度上进行拼接后得到融合的视觉特征。
组成3:视觉特征解码
最终将融合的视觉特征输入到一个解码器,包含N个Restormer和CNN模块,输入的融合图像定义为I_F,代表最终由FILM的输出。
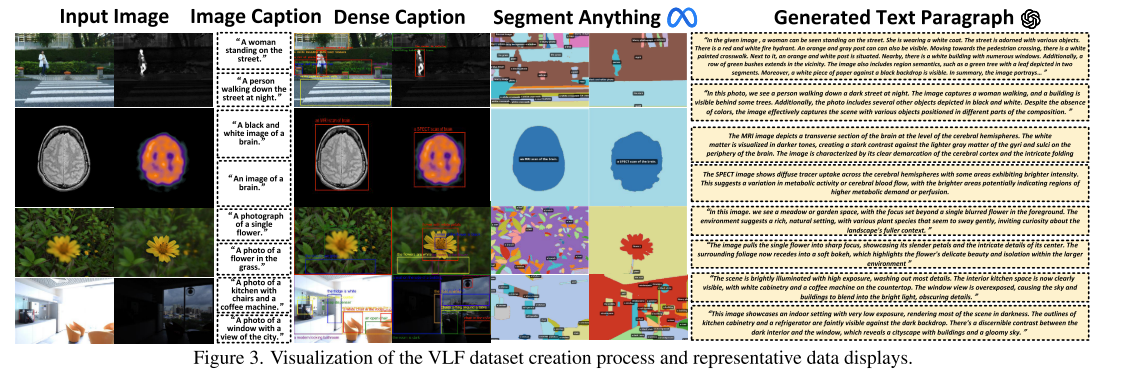
图3:VLF数据集可视化,处理和代表性数据可视化
4. Vision-Language Fusion Datasets
这一部分,将要介绍提出的Vision-Language Fusion(VLF)dataset,包含提示生成,段落描述输出和呈现代表性的可视化。
总览:考虑到各种视觉-语言模型的高计算开销,为了促进后续基于视觉语言模型的图像融合研究,我们提出了VLF数据集。数据集包含有ChatGPT生成的成对的段落描述,包含8个广泛使用的图像融合训练和测试集。MSRS、M3FD、RoadScene(IVF)the Harvard dataset 医学图像(MIF), the RealMFF [69] and Lytro [34] datasets 多聚焦图像融合(MFF), 和the SICE [3] and MEFB [71] datasets 多曝光图像融合(MEF) 。
提示生成:每一个部分的文本段落生成模型如图3。首先收到BLIP2、GRIT、Segment Anything启发,输出图像描述、密集描述和语义掩码。分别提供了一个句子的描述,对象级的信息和语义掩码,用于输入和代表性的语义信息范围,从粗粒度到细粒度。
生成段落描述:随后,生成的语义提示和成对的图像作为输入到ChatGPT中生成段落描述,用于指导随后的融合任务。
统计信息:数据集包含70040段落描述,平均每段描述至少包含7个句子和186个词。在图3中有多模态、多聚焦、多曝光的例子,更多的数据集细节可以在补充材料中查找。
5. Experiment
这一部分将证明FILM在不同融合任务上的性能,表明它的优越性。由于篇幅限制,更多的细节超参选择和视觉结果呈现在补充材料中。
损失函数,总的损失函数如下:
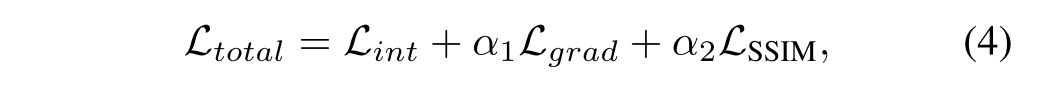
α1和α2作为调节因子。具体损失函数如下所示:

实验细节:RTX 3090,训练300轮使用Adam优化器,初始学习率为1e-4每50轮下降0.5,Batchsize设为16,采用Restormer块作为语言指导的视觉编码器和解码器,8个注意力头和64维度,M和N分别为编码、解码器的数量,分别为2和3。
指标:使用6个人指标来评估性能:EN、SD、SF、AG和VIF和Q_abf,更高的指标表明更好的融合质量,更多的信息可以参考30。
5.1Infrared and Visible Image Fusion
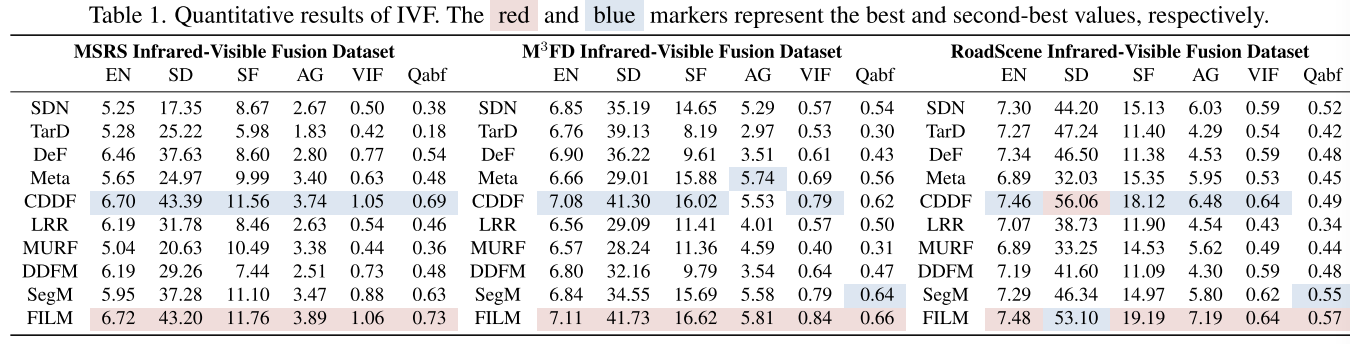
红外与可见光实验包含MSRS、M3FD和RoadScene数据集,如文献20和82那样。MSRS:1083对训练集和361对测试集。在M3FD和RoadScene上无需微调,进一步验证FILM的通用性。对比的SOTA方法包括:SDNet、TarDAL、DeFusion、MetaFusion、CDDFuse、LRRNet、MURF、DDFM和SegMIF。
与SOTA方法做对比:如图4,FILM成功整合了红外热辐射信息以及到细节的纹理特征上。

利用文本特征和先验知识,融合结果增强了在低光照条件下的目标的可见性,使其纹理和轮廓更加清晰,并且减小伪影。定量实验如表1,我们方法表明实验性能在所有指标上都是最好的,证实了它在不同环境下的传感器和目标种类上的适应性。因此,FILM证明了它能够很好的保留原图像互补和丰富的信息,生成满足人类视觉的图像。
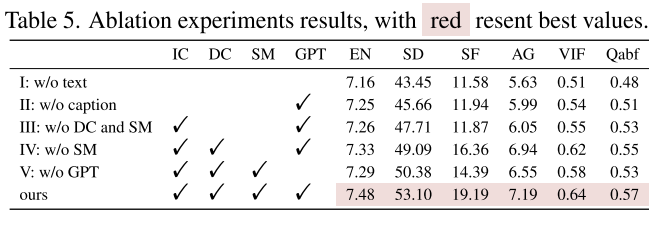
消融实验:为了在提出的方法中有效利用每一个模态,构建了消融实验在RoadScene的测试集上,结果如表5。实验1,移除了文本信息,仅使用视觉特征用于融合,消除文本和图像间的教程注意力,展示FILM中文本引导的特征提取和融合效果。增加Restormer 快的数量,保留总的模型参数接近原始模型。(没看见这个消融啊)实验二-四部分,我们测试了文本语义提示由整体到细粒度的提示,包括图像描述IC,密集描述DC和语言掩码SM。实验2我们直接把原始图像喂到ChatGPT中。通过手动提供提示,GPT生成图像总的描述,用文本输入用作图像融合。这些研究涉及绕开的提示,从IC、DC和SM,在实验3中仅将IC输入到GPT中,实验4,IC和DC共同输入到GPT中,揭示了从粗粒度到细粒度不同方面描述的重要性。最终在实验五,从图像中提取到IC、DC和SM后直接拼接三种描述不输入到GPT中。这个证明了GPT整合文本信息和有效融合的能力。消融实验证明了依赖与不同描述的互补信息,以及GPT的总结能力,我们的实验实现了最优的融合性能,验证了FILM设置的合理性。
6. Conclusion
本研究接近了图像融合中的关键技术:对于视觉特征之外的语义特征利用不足。我们第一次创新性的提出了视觉语言模型FILM,利用原图像的文本描述通过大语言模型来指导融合,能够更加全面的理解图像内容。FILM证明了在不同图像融合任务上的处理结果,包括红外与可见光、医学图像、多曝光和多聚焦图像融合。另外,我们提出了一个新的基准视觉-语言数据集,包括基于ChatGPT对8个数据集生成的描述。我们希望我们的研究能够在大语言模型的图像融合中有新的启示。
个人总结
- 本文以ChatGPT和不同的图像信息(文本描述,密集描述,语义信息),用于挖掘深层次的文本语义信息,文本特征编码通过交叉注意力来增强视觉特征,重建融合图像。能够有效在4个不同的融合任务上具有较好的实验效果。本文还针对4个任务提8个数据集上提出了视觉语言数据集(图像具有ChatGPT生成的文本描述段落)。
- 文本语义已经在成为增强图像融合视觉效果的一个趋势,后面会开源大量的具有文本描述的图像融合数据集,如何有效利用文本段落描述是我们未来研究的一个关键点?
- 还有一篇文章,可以通过控制文本输入来得到不同区域的视觉增强效果,如果利用文本语义特征显得特别重要。
- 未来的自己,不仅仅要多看论文,还要多读,多理解多思考,重要的是多跑代码,理解它,然后再思考自己的研究点,不要盲目去做。Baseline特别重要。
相关文章:
Image Fusion via Vision-Language Model【文献阅读】
阅读目录 文献阅读AbstractIntroduction3. Method3.1. Problem Overview3.2. Fusion via Vision-Language Model 4. Vision-Language Fusion Datasets5. Experiment5.1Infrared and Visible Image Fusion 6. Conclusion个人总结 文献阅读 原文下载:https://arxiv.or…...
探索Manticore Search:开源全文搜索引擎的强大功能
在当今信息爆炸的时代,数据的快速检索变得至关重要。无论是在电子商务网站、新闻门户还是企业内部文档,高效的搜索引擎都是确保用户满意度和工作效率的关键因素之一。而在搜索引擎领域,Manticore Search 作为一款开源的全文搜索引擎ÿ…...

AI 笔记助手,你的思路整理助手
大家好,今天给大家介绍一款非常实用的 AI 笔记助手——AI Note。这款助手就像是一个贴心的小助手,能帮助我们整理笔记,提高学习和工作效率。 🤖 AI Note 可以智能总结笔记内容,准确标记重点,让我们更快地获…...
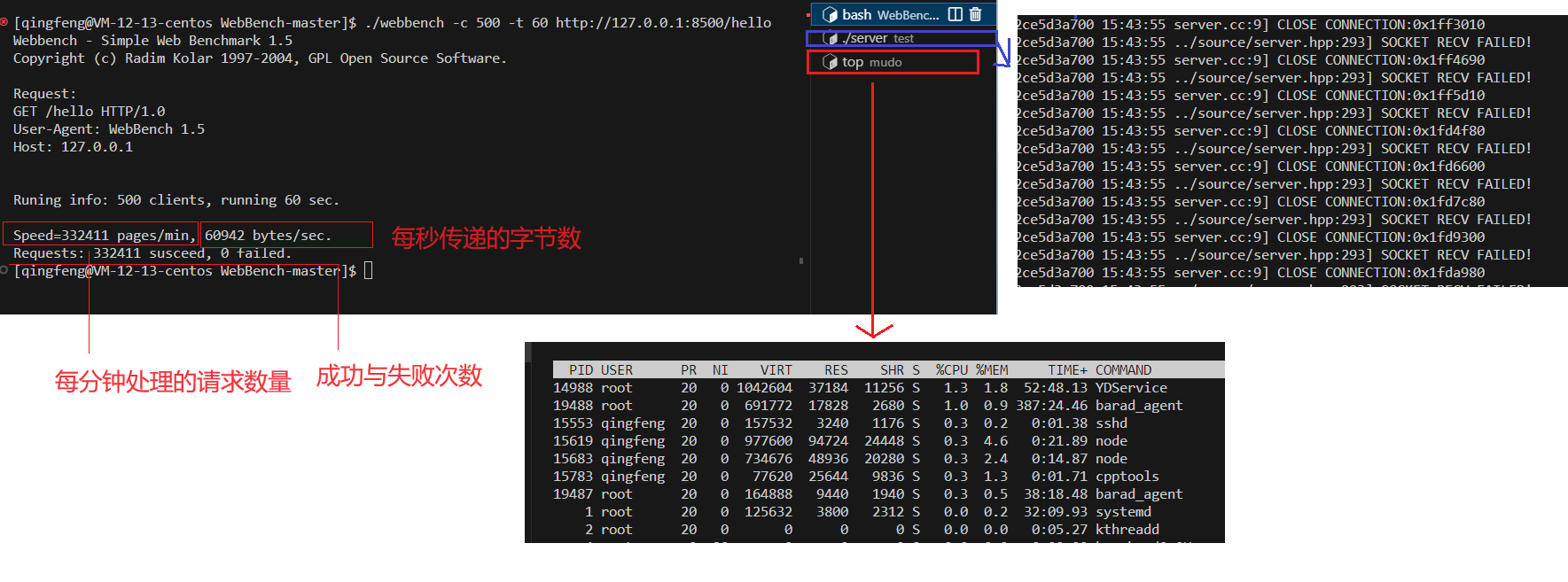
EchoServer回显服务器简单测试
目录 工具介绍 工具使用 测试结果 工具介绍 github的一个开源项目,是一个测压工具 EZLippi/WebBench: Webbench是Radim Kolar在1997年写的一个在linux下使用的非常简单的网站压测工具。它使用fork()模拟多个客户端同时访问我们设定的URL,测试网站在压力下工作的…...

车灯修复UV胶的优缺点有哪些?
车灯修复UV胶的优点如下: 优点: 快速固化:通过紫外光照射,UV胶可以在5-15秒内迅速固化,提高了修复效率。高度透明:固化后透光率高,几乎与原始车灯材料无法区分,修复后车灯外观更加…...
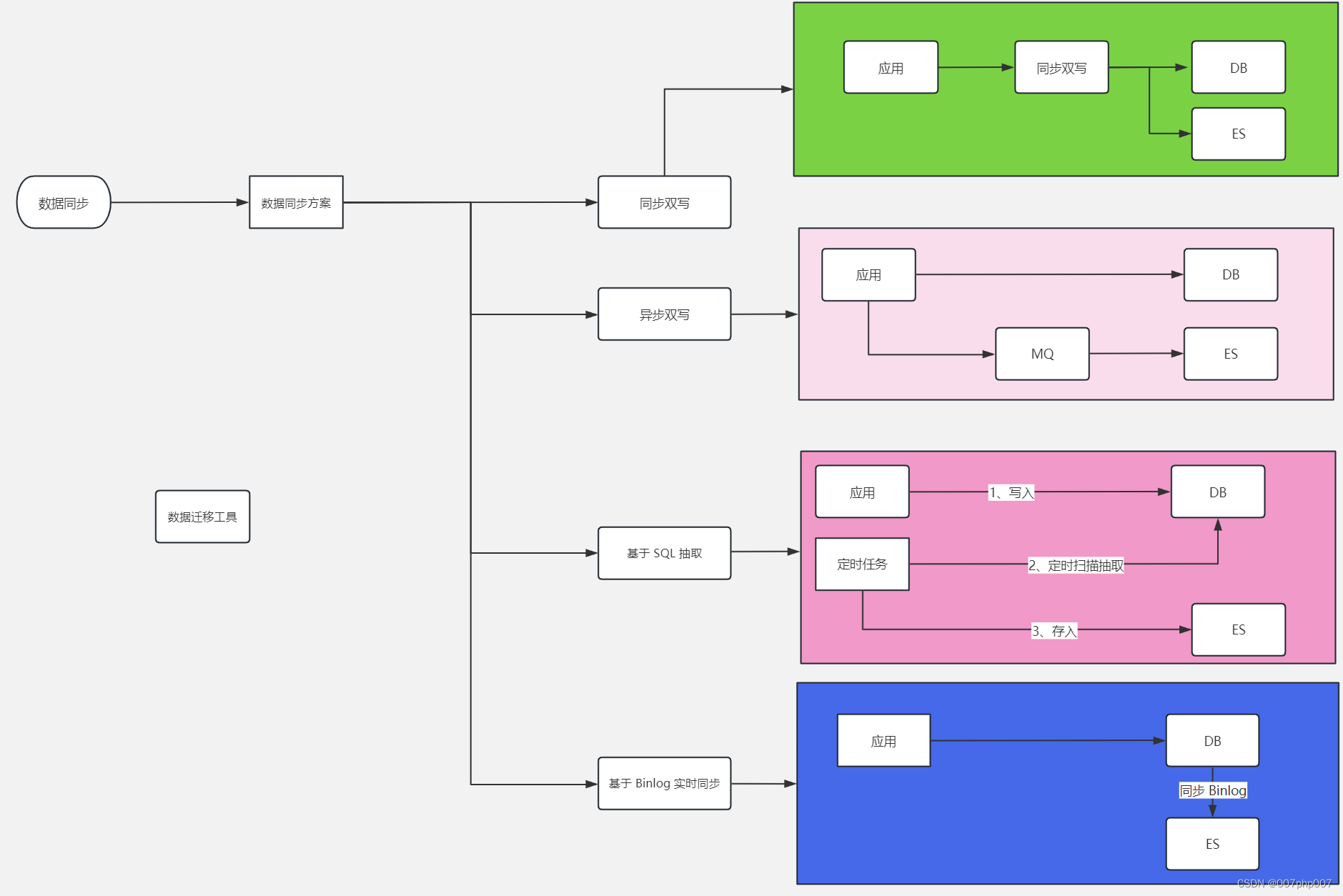
探讨倒排索引Elasticsearch面试与实战:从理论到实践
在当前大数据时代,Elasticsearch(以下简称为ES)作为一种强大的搜索和分析引擎,受到了越来越多企业的青睐。因此,对于工程师来说,掌握ES的面试准备和实战经验成为了必备技能之一。本文将从ES的面试准备和实际…...
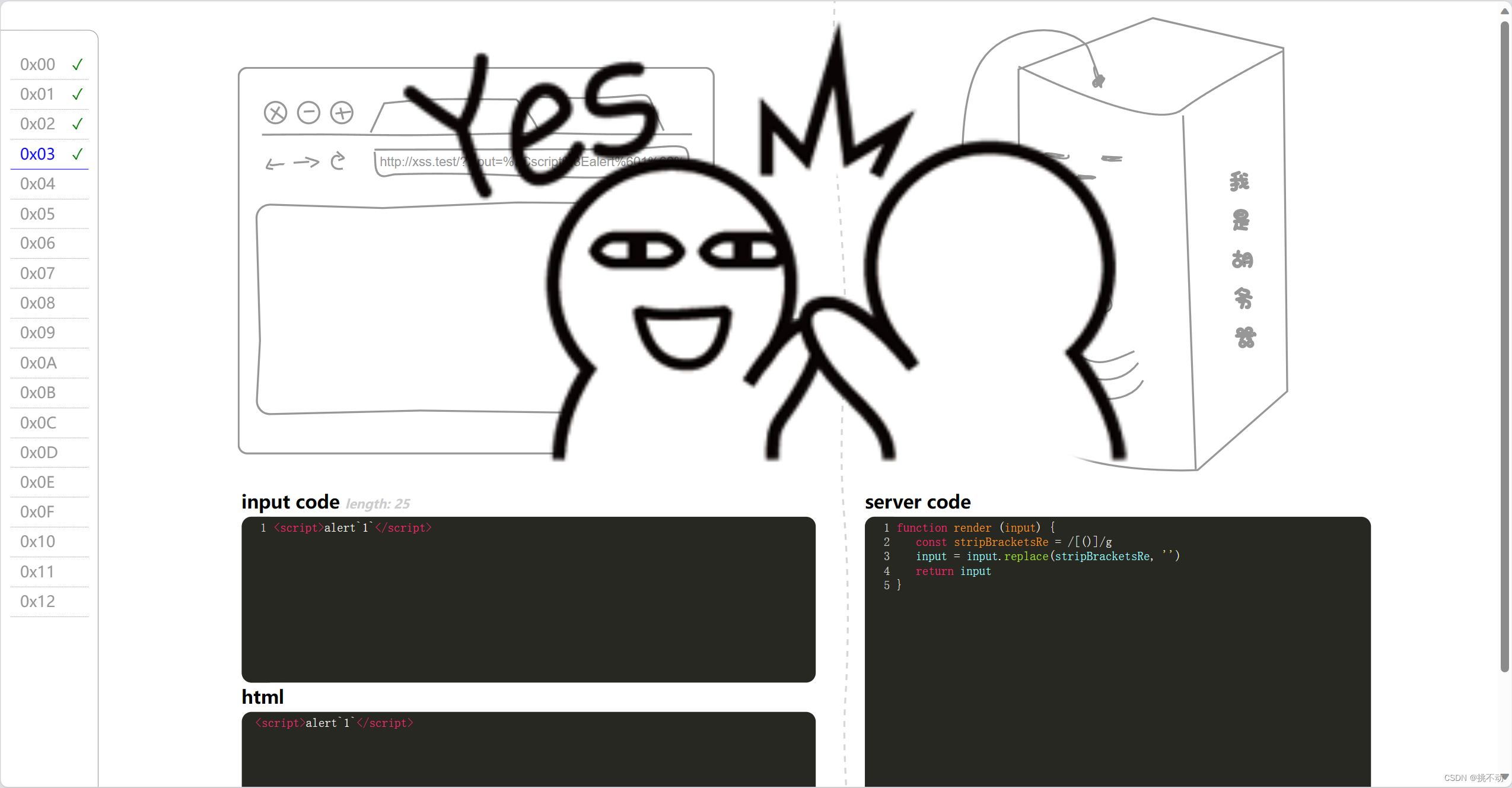
网安入门18-XSS(靶场实战)
HTML实体化编码 为了避免 XSS 攻击,会将<>编码为<与>,这些就是 HTML 实体编码。 编码前编码后不可分的空格 < (小于符号)< > (大于符号)> & (与符号)&″ (双引号)"’ (单引号)'© (版权符…...

爬虫的一些小技巧总结
一、在爬虫中,爬取的数据类型如下 1.document:返回的是一个HTML文档 2.png:无损的图片,jpg:压缩后的图片,wbep:有损压缩,比png差,比jpg好 3.avgxml图像编码字符串 4.script:脚本文件,依据一定格式编写的可执行的文…...

LeetCode---386周赛
题目列表 3046. 分割数组 3047. 求交集区域内的最大正方形面积 3048. 标记所有下标的最早秒数 I 3049. 标记所有下标的最早秒数 II 一、分割数组 这题简单的思维题,要想将数组分为两个数组,且分出的两个数组中数字不会重复,很显然一个数…...
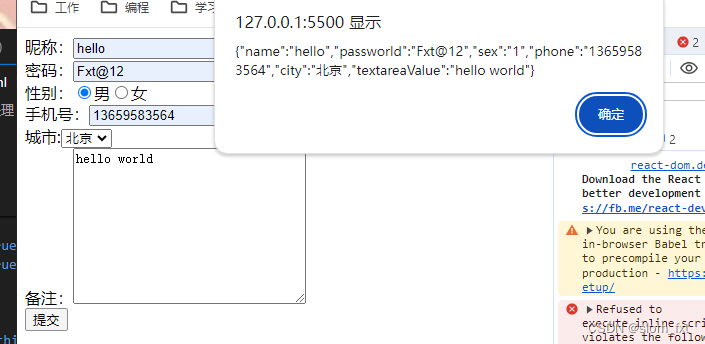
React之数据绑定以及表单处理
一、表单元素 像<input>、<textarea>、<option>这样的表单元素不同于其他元素,因为他们可以通过用户交互发生变化。这些元素提供的界面使响应用户交互的表单数据处理更加容易 交互属性,用户对一下元素交互时通过onChange回调函数来监听…...
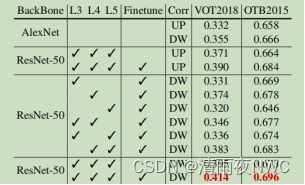
Siamrpn++论文中文翻译(详细!)
SiamRPN: Evolution of Siamese Visual Tracking with Very Deep Networks SiamRPN:具有非常深度网络的Siamese视觉跟踪的进化 【siamrpn论文地址】 https://arxiv.org/abs/1812.11703 摘要 基于Siamese网络的跟踪器将跟踪表示为目标模板和搜索区域之间的卷积特征…...

第一篇【传奇开心果系列】Python的自动化办公库技术点案例示例:深度解读Pandas库
传奇开心果博文系列 系列博文目录Python的自动化办公库技术点案例示例系列 博文目录前言一、主要特点和功能介绍二、Series 示例代码三、DataFrame示例代码四、数据导入/导出示例代码五、数据清洗示例代码六、数据选择和过滤示例代码七、数据合并和连接示例代码八、数据分组和聚…...

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的停车位检测系统(Python+PySide6界面+训练代码)
摘要:开发停车位检测系统对于优化停车资源管理和提升用户体验至关重要。本篇博客详细介绍了如何利用深度学习构建一个停车位检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并结合了YOLOv7、YOLOv6、YOLOv5的性能对比…...
)
状态模式(State Pattern)
定义 状态模式(State Pattern)是一种行为设计模式,它允许对象在其内部状态改变时改变其行为。这意味着,当对象的状态发生变化时,它的行为也会发生变化。状态模式特别适用于行为依赖于其状态的对象,而且当这…...

js之版本号排序
版本号排序 给定一个由版本号组成的数组,按照版本号由小到大排序 假如版本号如下 : ["0.1.1", "2.3.3", "0.302.1", "4.2", "4.3.5", "4.3.4.5"];原理很简单,通过自定义sort排…...

考取ORACLE数据库OCP的必要性 Oracle数据库
OCP证书是什么? OCP,全称Oracle Certified Professional,是Oracle公司的Oracle数据库DBA(Database Administrator,数据库管理员)认证课程。这是Oracle公司针对数据库管理领域设立的一项认证课程,旨在评估和…...
WordPress通过宝塔面板的入门安装教程【保姆级】
WordPress安装教程【保姆级】【宝塔面板】 前言一:安装环境二:提前准备三:域名解析四:开始安装五:安装成功 前言 此教程适合新手,即使不懂代码,也可轻松安装wordpress 一:安装环…...

Leetcoder Day25| 回溯part05:子集+排列
491.递增子序列 给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。 示例: 输入:[4, 7, 6, 7]输出: [[4, 6], [4, 7], [4, 6, 7], [6, 7], [7,7], [4,7,7]] 说明: 给定数组的长度不会超过15。数组中的整数范围是 [-100,100]。给定数…...

【HTML】HTML基础5(特殊字符)
目录 特殊字符的作用 常用的特殊字符 使用效果 特殊字符的作用 例如 当我在两个文字间打出空格时 <p>“银河护卫队”系列 在漫威电影宇宙中一直是异数般的存在,不仅因为影片主角是一群反英雄,<strong>与超级英雄相比显得格格不入<…...

MacBook将iPad和iPhone备份到移动硬盘
#创作灵感# 一个是ICloud不够用,想备份到本地;然而本地存储不够用,增加容量巨贵,舍不得这个钱,所以就想着能不能备份到移动硬盘。刚好有个移动固态,所以就试了一下,还真可以。 #正文# 说一下逻…...

别再让API账单吓到你了!Gemini 3 Flash的`thinking_level`参数保姆级调优实战
别再让API账单吓到你了!Gemini 3 Flash的thinking_level参数保姆级调优实战 当开发者第一次看到Gemini API的月度账单时,那种震惊感不亚于发现信用卡被盗刷。我们团队曾经有个项目,仅仅因为没注意参数配置,单月API支出就超过了服务…...
)
从Bash迁移到Zsh:Oh My Zsh实战避坑指南(含性能对比)
从Bash迁移到Zsh:Oh My Zsh实战避坑指南(含性能对比) 如果你长期使用Bash,可能会对Zsh的流畅补全和主题系统产生好奇。但迁移不只是换个Shell那么简单——环境变量继承、脚本兼容性和性能差异都可能成为隐形陷阱。本文将用实测数据…...

BepInEx终极指南:5分钟掌握Unity游戏模组开发框架
BepInEx终极指南:5分钟掌握Unity游戏模组开发框架 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 想要为Unity游戏添加自定义功能却苦于技术门槛?BepInEx作…...

Veo 3.1 AI 视频生成 + 字幕叠加完整实战指南
通过 GCP Vertex AI Veo 3.1 生成短视频,结合 Python moviepy 自动叠加字幕,实现从脚本到成品视频的全自动化流程,适用于 AI 短视频批量生产。 说明:本文基于实际视频生成项目整理,涵盖 Veo 3.1 异步调用、提示词工程、字幕叠加和批量生产方案,去除敏感信息后形成通用化指…...
列出视图的垂直模式,起点在上方。水平模式,起点在左边。对于水平滚动框,也是如此)
(31)列出视图的垂直模式,起点在上方。水平模式,起点在左边。对于水平滚动框,也是如此
(55)(56) 谢谢...

解决重装系统后 BitLocker 分区每次重启需手动解锁的问题
解决重装系统后 BitLocker 分区每次重启需手动解锁的问题 问题现象原因分析找回 48 位 BitLocker 恢复密钥永久解决:启用自动解锁(避免每次重启输入) 电脑版本win11,更新后遇到设置和驱动消失的问题,不得不重装系统。重…...

CSS如何实现卡片式布局_掌握盒模型阴影与间距设置
box-shadow 要清晰自然需控制偏移与模糊比例,避免与 border 冲突;文字不被遮挡需确保无误设 z-index 或 overflow: hidden;padding 管内距、margin 管外距;Flex 中用 flex: 1 0 300px 防缩窄;border-radius 与 shadow …...

【11月16日-大模型前置知识【深度学习】+大模型开发入门】-基础篇笔记
文章目录前言一、huggingface国内1.引入库2.LLM 大模型语言的基础知识:2.LLM主要类别架构介绍3.卷积神经网络CNN4.循环神经网络总结全文通俗总结一、入门工具:Hugging Face二、LLM底层核心:语言模型的进化三、主流LLM架构大盘点四、深度学习基…...

2025届最火的十大AI科研网站实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 日益广泛应用于学术写作领域的人工智能技术,,特别适用于开题报告的辅…...

告别会议记录焦虑:TMSpeech 如何用离线语音识别重塑你的工作效率
告别会议记录焦虑:TMSpeech 如何用离线语音识别重塑你的工作效率 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 你是否曾在重要会议中因为分心记录而错过关键讨论?是否担心云端语音识别服务…...