Python爬虫——解析常用三大方式之Xpath
目录
Xpath
安装xpath
安装lxml库
导入lxml库
解析本地文件 etree.parse()
解析服务器响应文件 etree.HTML()
xpath基本语法
小案例:获取百度首页的百度一下
大案例:爬取站长素材图片
总结
Xpath
安装xpath
首先要学会安装Xpath,我这里很简单,没有到网络上搜索,直接使用魔法在谷歌商店直接搜索xpath就可以了,下载完成之后使用 ctrl + shift + x 就可以打开了。打开效果图如下:

安装lxml库
可以使用pip安装,命令如下
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ lxml
导入lxml库
from lxml import etree
解析本地文件 etree.parse()
html_tree = etree.parse('xx.html')解析服务器响应文件 etree.HTML()
html_tree = etree.HTML(response.read().decode('utf-8'))那么如果使用如下代码
html_cm_tree = etree.parse('17_解析_xpath.html')
print(html_cm_tree)我的HTML代码如下
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="l1" class="c1">北京</li><li id="l2">成都</li><li class="c2">深圳</li><li id="xl2">哈尔滨</li></ul><ul><li id="l3">大连</li><li id="xl1">长春</li><li class="c3">兰州</li><li>上海</li></ul>
</body>
</html>这样就会报错

因为xpath严格遵守HTML规范,

这里要修改为

这样,单标签就要这样写
xpath基本语法
text() 获取标签中的内容
li_id_list = html_cm_tree.xpath('//ul/li[@id]/text()')
1.路径查询:
//:查找所有子孙节点,不考虑层级关系
/ :找直接子节点
# (1)查找ul 下面的li
# li_list = html_cm_tree.xpath('//body/ul/li')
# 下面这个写法也行
li_list = html_cm_tree.xpath('//body//li')
# 判断列表长度
print(li_list)
print(len(li_list))2.谓词查询:
// div[@id]
// div[@id="maincontent"]
# (2)查找所有id的属性的li标签
li_id_list = html_cm_tree.xpath('//ul/li[@id]/text()')
print(li_id_list)
print(len(li_id_list))# (3)查找id = l1的属性的li标签,id后面的必须要加 单引号
li_id1_list = html_cm_tree.xpath('//ul/li[@id="l1"]/text()')
print(li_id1_list)
print(len(li_id1_list))3.属性查询:
//@class
# (4)查找id = l1的属性的li标签的class属性值
li_id1c_list = html_cm_tree.xpath('//ul/li[@id="l1"]/@class')
print(li_id1c_list)
print(len(li_id1c_list))4.模糊查询:
//div[contains(@id, "he")]
// div[starts-with(@id,"he")]
# (5)查询 id 中包含l的li标签
li_idlll_list = html_cm_tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(li_idlll_list)
print(len(li_idlll_list))5.内容查询
//div/h1/text ()
如上使用了text()的都是
6.逻辑运算:
//div[@id="head"and@class="s_down"]
//title|//price
# (7)查询 id=l1 和class为c1的标签
li_idl1c1_list = html_cm_tree.xpath('//ul/li[@id="l1"and@class="c1"]/text()')
print(li_idl1c1_list)
print(len(li_idl1c1_list))# (8)查询id=l1或者=l2的
li_titpri_list = html_cm_tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
print(li_titpri_list)
print(len(li_titpri_list))小案例:获取百度首页的百度一下

from lxml import etree
import urllib.request# (1)获取网页源码
# (2)解析 解析的服务器响应的文件 etree.HTML
# (3)打印
url = 'https://www.baidu.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)# 获取网页源码
content = response.read().decode('utf-8')
# print(content)# 解析网页源码,获取我们需要的数据
# 解析服务器响应的文件
tree = etree.HTML(content)# 获取想要的数据,xpath的返回值是一个列表
result = tree.xpath('//input[@id="su"]/@value')
print(result)
大案例:爬取站长素材图片
import urllib.request
from lxml import etree# (1)请求对象的定制
# (2)获取网页源码
# (3)下载# 需求:下载前十页的图片# 第一页地址
# https://sc.chinaz.com/tupian/taikongkexuetupian.html
# 第二页地址
# https://sc.chinaz.com/tupian/taikongkexuetupian_2.html
# 第三页地址
# https://sc.chinaz.com/tupian/taikongkexuetupian_3.html"""请求对象的定制
"""def create_request(page):if page == 1:url = 'https://sc.chinaz.com/tupian/taikongkexuetupian.html'else:url = ('https://sc.chinaz.com/tupian/taikongkexuetupian_'+ str(page) + '.html')headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'}request = urllib.request.Request(url=url, headers=headers)return request"""获取网页源码
"""def get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return content"""下载
"""def down_load(content):# 下载图片# urllib.request.urlretrieve('图片地址', '文件名')tree = etree.HTML(content)img_list = tree.xpath('//div[@class="container"]//img[@src="../static/common/com_images/img-loding.png"]/@data-original')# 如果所爬取的网站是采用懒加载的方式,请使用懒加载前的地址访问name_list = tree.xpath('//div[@class="container"]//img[@src="../static/common/com_images/img-loding.png"]/@alt')for i in range(len(name_list)):name = name_list[i]img = img_list[i]# 添加上协议地址,使得地址完整url = 'https:' + img# 下载urllib.request.urlretrieve(url=url, filename='./站长素材爬取图片/' + name + '.jpg')if __name__ == '__main__':start_page = int(input("请输入起始页码"))end_page = int(input("请输入结束页码"))for page in range(start_page, end_page + 1):# 1.请求对象的定制request = create_request(page)# 2.获取网页源码content = get_content(request)# 3.下载down_load(content)
总结
ヾ( ̄▽ ̄)Bye~Bye~
相关文章:
Python爬虫——解析常用三大方式之Xpath
目录 Xpath 安装xpath 安装lxml库 导入lxml库 解析本地文件 etree.parse() 解析服务器响应文件 etree.HTML() xpath基本语法 小案例:获取百度首页的百度一下 大案例:爬取站长素材图片 总结 Xpath 安装xpath 首先要学会安…...

C#判断DataTable1 A列的集合是否为DataTable2 B列的集合的子集
DataSet ds2 (DataSet)res2.Anything; // 检查 集合B是否为集合A的子集 var table1MaterialCodes ds.Tables[2].AsEnumerable().Select(row > row["Code"]).ToList(); //DataSet1 表Code列集合A var table2MaterialCodes ds2.Tables[0].AsEnumerable().Selec…...
VirtualBox 桥接网卡 未指定 “未能启动虚拟电脑Ubuntu,由于下述物理网卡未找到:”
解决办法,安装虚拟网卡,win11查找方式:控制面板→网络和共享中心→更改适配器设置 此时出现下面情况就算安装成功 但是如果报错:找不到指定的模块 则按下面步骤删除干净垃圾重新上面操作 先安装CCleaner, 链接:CCleaner Makes Y…...

基于yolov5的电瓶车和自行车检测系统,可进行图像目标检测,也可进行视屏和摄像检测(pytorch框架)【python源码+UI界面+功能源码详解】
功能演示: 基于yolov5的电瓶车和自行车检测系统_哔哩哔哩_bilibili (一)简介 基于yolov5的电瓶车和自行车检测系统是在pytorch框架下实现的,这是一个完整的项目,包括代码,数据集,训练好的模型…...
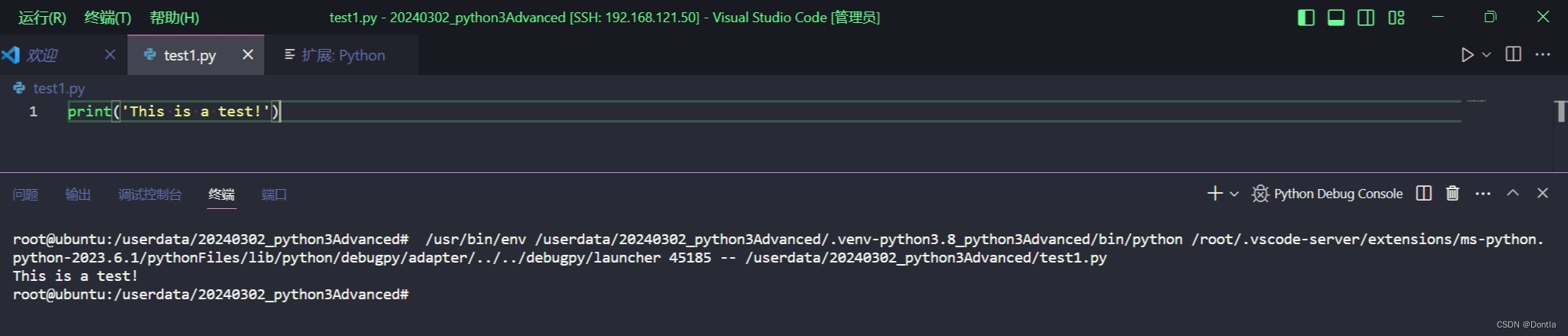
vscode如何远程到linux python venv虚拟环境开发?(python虚拟环境、vscode远程开发、vscode远程连接)
文章目录 1. 安装VSCode2. 安装扩展插件3. 配置SSH连接4. 输入用户名和密码5. 打开远程文件夹6. 创建/选择Python虚拟环境7. 安装Python插件 Visual Studio Code (VSCode) 提供了一种称为 Remote Development 的功能,允许用户在远程系统、容器或甚至 Windows 子系统…...

蓝桥杯第十二届电子类单片机组程序设计
目录 前言 蓝桥杯大赛历届真题_蓝桥杯 - 蓝桥云课(点击查看) 单片机资源数据包_2023(点击下载) 一、第十二届比赛原题 1.比赛题目 2.题目解读 蓝桥杯第十四届电子类单片机组程序设计_蓝桥杯单片机哪一届最难-CSDN博客 二、…...

基于springboot+vue的工作流程管理系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

【LeetCode刷题】146. LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现 LRUCache 类: LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -…...

奇酷网络用AI思维办公:不允许做PPT,只能用Word,只能一页纸
在AI时代,视频制作领域正经历着一场革命。Sora 作为首个文生视频大模型,可能攻克了自然语言处理、计算机视觉和深度学习等难点,使视频生成更真实、自然。奇酷网络是一家很另类、很奇怪的“AI游戏”创业公司,奇酷网络董事长吴渔夫(…...

【笔记】-编程语言以及应用领域
C/C 永远不会衰败的语言,适合偏底层,例如:Windows操作系统80%以上都是由C/C完成的,C/C也集成用于写应用层C/S架构的软件 JAVA 是真正的跨平台的语言 “一次编程,到处使用”Java适合应用层的开发,无论是…...

MWC 2024丨美格智能推出5G RedCap系列FWA解决方案,开启5G轻量化新天地
2月27日,在MWC 2024世界移动通信大会上,美格智能正式推出5G RedCap系列FWA解决方案。此系列解决方案具有低功耗、低成本等优势,可以显著降低5G应用复杂度,快速实现5G网络接入,提升FWA部署的经济效益。 RedCap技术带来了…...
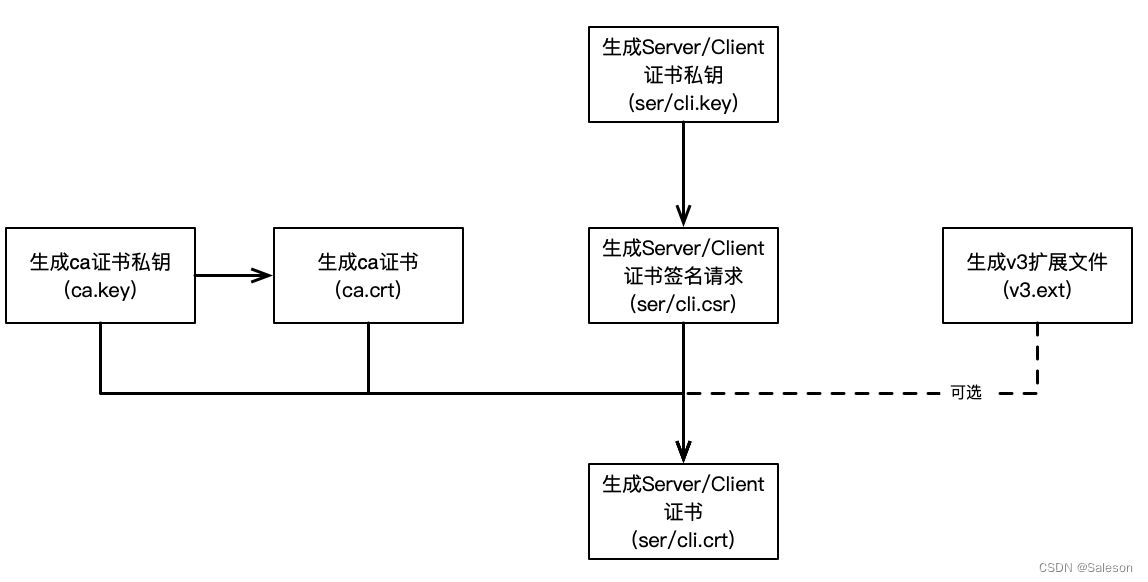
mTLS: openssl创建CA证书
证书可以通过openssl或者keytool创建,在本篇文章中,只介绍openssl。 openssl 生成证书 申请操作流程 生成ca证书私钥, 文件名:ca.key生成ca证书,文件名:ca.crt生成Server/Client 证书私钥,文件名&#x…...

Python 进阶语法:os
3.1.1 文件和目录操作 os.getcwd(): 获取当前工作目录的路径。 import os# 获取当前工作目录 current_directory os.getcwd() print("当前工作目录是:", current_directory) os.chdir(path): 改变当前工作目录到指定的路径。 import os# 改变当前工作目录 os.c…...
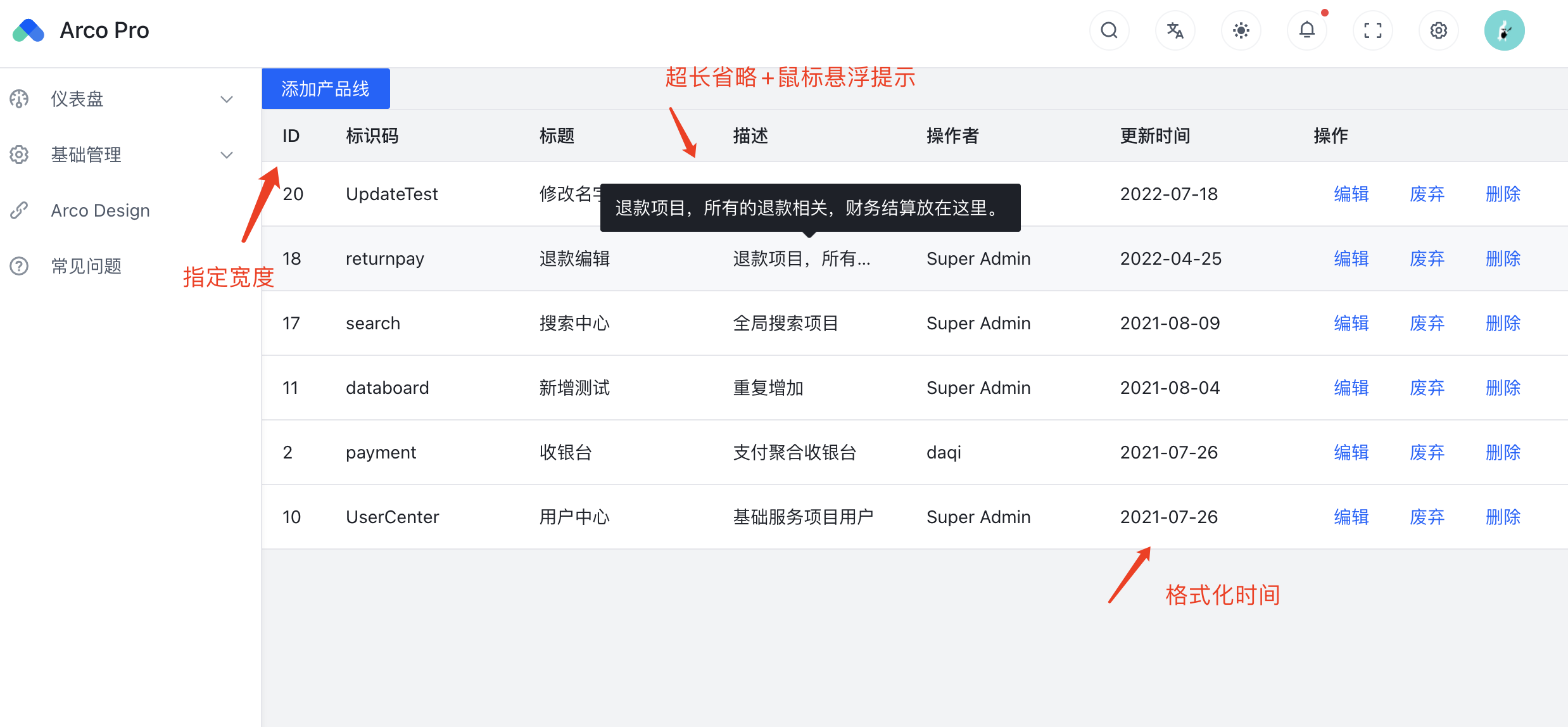
测试需求平台9-Table 组件应用产品列表优化
✍此系列为整理分享已完结入门搭建《TPM提测平台》系列的迭代版,拥抱Vue3.0将前端框架替换成字节最新开源的arco.design,其中约60%重构和20%新增内容,定位为从 0-1手把手实现简单的测试平台开发教程,内容将囊括基础、扩展和实战&a…...

targetSdkVersion > 30 如何将下载的网络视频 保存到手机相册里更新
在 targetSdkVersion 31 中,将下载的网络视频保存到手机相册中涉及几个关键步骤。由于 Android 12(API 级别 31)引入了更多的隐私和安全限制,特别是作用域存储(Scoped Storage),因此你需要遵循这…...
C#,无监督的K-Medoid聚类算法(K-Medoid Algorithm)与源代码
1 K-Medoid算法 K-Medoid(也称为围绕Medoid的划分)算法是由Kaufman和Rousseeuw于1987年提出的。中间点可以定义为簇中的点,其与簇中所有其他点的相似度最小。 K-medoids聚类是一种无监督的聚类算法,它对未标记数据中的对象进行聚…...

宏定义中#与##的注意事项
1. #是字符串化操作符。它的作用是将宏参数转换成字符串 2. ##是标记粘贴操作符。它的作用是将两个标记连接起来形成一个新的标记 #define TEST1(a) #a #define TEST2(a) b##a/***********************************************************/ 举例:TEST1(hello) 会…...

Java函数式编程
Java函数式编程 Java函数式编程(Functional Programming in Java)是指使用函数式编程范式来编写Java代码的一种编程方式。函数式编程是一种编程范式,它强调使用函数作为基本构建块,并将计算视为数学上的函数求值,避免…...

【深度优先搜索】【树】【C++算法】2003. 每棵子树内缺失的最小基因值
作者推荐 动态规划的时间复杂度优化 本文涉及知识点 深度优先搜索 LeetCode2003. 每棵子树内缺失的最小基因值 有一棵根节点为 0 的 家族树 ,总共包含 n 个节点,节点编号为 0 到 n - 1 。给你一个下标从 0 开始的整数数组 parents ,其中…...

电脑开机显示器没有信号而且键盘鼠标不亮怎么解决?
大家在使用电脑的过程,开机没有反应是比较经常遇到的问题,就有用户反映说自己的电脑启动之后,显示器无信号,键盘鼠标灯也不亮,怎么操作都没有效果。对开机有影响的硬件主要是内存条,内存条是非常容易松动的,而且金手指如果氧化了,都会导致开不了机 大家在使用电脑的过程…...

2026年软件测试十大趋势预测:AI将重塑一切?
站在质效革命的十字路口当软件从静态工具进化为驱动社会运转的智能神经中枢,其复杂性与不确定性呈指数级增长。传统质量保障体系正经历系统性重构,AI的深度渗透、开发范式的升维以及业务对极致体验的追求,共同推动软件测试迈入“质效革命”新…...

OBS多平台直播终极指南:免费开源工具实现一键同步推流
OBS多平台直播终极指南:免费开源工具实现一键同步推流 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 想要在多个直播平台同时推送高质量内容?OBS Multi RTMP插件…...

ros2中可视化topic数值命令
ros2 run plotjuggler plotjuggler...
)
从代码工厂到智能协作者:AI原生研发组织变革的5阶跃迁模型(附SITS2026评估矩阵V2.1)
第一章:从代码工厂到智能协作者:AI原生研发组织变革的5阶跃迁模型(附SITS2026评估矩阵V2.1) 2026奇点智能技术大会(https://ml-summit.org) 传统研发组织正经历一场静默却深刻的范式迁移:代码不再由人单向输出&#…...

GTE中文文本向量模型实战:快速搭建支持6大任务的Web应用
GTE中文文本向量模型实战:快速搭建支持6大任务的Web应用 1. 为什么选择GTE中文文本向量模型 在日常工作中,我们经常遇到需要处理大量中文文本的场景。无论是客服对话记录、产品评论分析,还是新闻事件提取,传统的关键词匹配方法往…...

零基础部署Ostrakon-VL-8B:餐饮零售视觉AI,一键搭建企业级智能巡检平台
零基础部署Ostrakon-VL-8B:餐饮零售视觉AI,一键搭建企业级智能巡检平台 1. 为什么餐饮零售企业需要视觉AI? 想象一下这样的场景:你是一家连锁餐饮店的区域经理,手下管理着20家门店。每天,店长们会通过微信…...

ClearerVoice-Studio实操手册:WAV/AVI/MP4多格式输入与WAV标准输出规范
ClearerVoice-Studio实操手册:WAV/AVI/MP4多格式输入与WAV标准输出规范 1. 开篇:你的AI语音处理工具箱 如果你正在为嘈杂的会议录音发愁,或者想把多人对话视频里的某个声音单独提取出来,那你来对地方了。ClearerVoice-Studio&am…...

CTF逆向实战:从RC4到Base64,详解CTFshow萌新赛逆向题解
1. RC4加密算法在CTF逆向中的实战应用 RC4算法作为CTF逆向题目中的常客,经常出现在各类比赛中。这种流加密算法看似简单,但在实际解题过程中往往会遇到各种变种和陷阱。记得我第一次遇到RC4加密的题目时,完全不知道从何下手,现在回…...

dom-to-image技术突破:浏览器端DOM渲染的图像化解决方案
dom-to-image技术突破:浏览器端DOM渲染的图像化解决方案 【免费下载链接】dom-to-image Generates an image from a DOM node using HTML5 canvas 项目地址: https://gitcode.com/gh_mirrors/do/dom-to-image 在现代Web开发中,将DOM元素转换为图像…...

基于 FFmpeg 源码的音乐播放器音频开发实践
1. 为什么要从 ffplay.c 入手 很多播放器文章停留在“调用 av_read_frame -> avcodec_send_packet -> avcodec_receive_frame”的 API 层,但真正决定播放器上限的,是以下几个工程问题: 缓冲何时“扩”、何时“刹车”(背压) Seek 后如何彻底清理旧数据而不串音 时钟…...