pytorch基础2-数据集与归一化
专题链接:https://blog.csdn.net/qq_33345365/category_12591348.html
本教程翻译自微软教程:https://learn.microsoft.com/en-us/training/paths/pytorch-fundamentals/
初次编辑:2024/3/2;最后编辑:2024/3/2
本教程第一篇介绍pytorch基础和张量操作
这是本教程的第二篇,介绍以下内容:
- 数据集与数据加载器
- 归一化
另外本人还有pytorch CV相关的教程,见专题:
https://blog.csdn.net/qq_33345365/category_12578430.html
数据集与数据加载器 Datasets and Dataloaders
处理数据样本的代码可能会变得复杂且难以维护。通常希望数据集代码与模型训练代码解耦,以获得更好的可读性和模块化性。PyTorch提供了两个数据原语:torch.utils.data.DataLoader和torch.utils.data.Dataset,它们使您能够使用预加载的数据集以及您自己的数据。Dataset存储样本及其对应的标签,而DataLoader则在Dataset周围包装了一个可迭代对象,以便轻松访问样本。
PyTorch库提供了许多预加载的样本数据集(例如FashionMNIST),它们是torch.utils.data.Dataset的子类,并实现了特定于特殊数据的功能。用于模型原型设计(prototyping)和基准测试(benchmark)的样本包括:
- 图像数据集
- 文本数据集
- 音频数据集
加载数据集
此处使用TorchVision来加载Fashion-MNIST数据集。Fashion-MNIST是Zalando的服装图像数据集,包含60,000个训练样本和10,000个测试样本。每个样本包括一个28×28的灰度图像和一个来自10个类别中的关联标签。
- 每个图像高度为28个像素,宽度为28个像素,总共有784个像素。
- 这10个类别告诉图像是什么类型,例如:T恤/上衣、裤子、套头衫、连衣裙、包、短靴等。
- 灰度像素的值介于0到255之间,用于衡量黑白图像的强度。强度值从白色到黑色递增。例如:白色的颜色值为0,而黑色的颜色值为255。
我们使用以下参数加载FashionMNIST数据集:
- root 是存储训练/测试数据的路径。
- train 指定训练或测试数据集。
- download=True 如果数据在
root中不可用,则从互联网下载数据。 - transform 和
target_transform指定特征和标签的转换。
加载训练和测试数据集的代码如下所示:
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
import matplotlib.pyplot as plttraining_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor()
)test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor()
)
数据集的迭代与可视化
可以像列表一样手动索引Datasets: training_data[index]。此处使用matplotlib对训练数据中的一些样本进行可视化。代码如下所示:
labels_map = {0: "T-Shirt",1: "Trouser",2: "Pullover",3: "Dress",4: "Coat",5: "Sandal",6: "Shirt",7: "Sneaker",8: "Bag",9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):sample_idx = torch.randint(len(training_data), size=(1,)).item()img, label = training_data[sample_idx]figure.add_subplot(rows, cols, i)plt.title(labels_map[label])plt.axis("off")plt.imshow(img.squeeze(), cmap="gray")
plt.show()
得到如下图片:

使用数据加载器(DataLoaders)准备自定义数据
Dataset 逐个样本检索数据集的特征和标签。在训练模型时,通常希望以“minibatch”的形式传递样本,在每个周期重混洗(reshuffle)数据以减少模型过拟合,并使用Python的多进程加速数据检索。
在机器学习中,需要指定数据集中的特征和标签。**特征(Feature)**是输入,**标签(label)**是输出。我们训练特征,然后训练模型以预测标签。
- 特征是图像像素中的模式。
- 标签是10个类别类型:T恤,凉鞋,连衣裙等。
DataLoader是一个可迭代对象,用简单的API抽象了这种复杂性。为了使用DataLoader,我们需要设置以下参数:
- data 用于训练模型的训练数据,以及用于评估模型的测试数据。
- batch size 每个批次要处理的记录数。
- shuffle 按索引随机抽取数据样本。
使用DataLoader处理两个数据集的代码如下所示:
from torch.utils.data import DataLoadertrain_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
使用DataLoader进行迭代
我们已将数据集加载到 DataLoader 中,现在可以根据需要迭代数据集。 下面的每次迭代都会返回一个批次的 train_features 和 train_labels(分别包含 batch_size=64 个特征和标签)。由于我们指定了 shuffle=True,在遍历完所有批次后,数据将被混洗(shuffle),以更精细地控制数据加载顺序。
展示图片和标签的代码如下所示:
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
label_name = list(labels_map.values())[label]
print(f"Label: {label_name}")
得到图片:

Datasets和DataLoader的区别是:前者检索单个数据,后者批量处理数据
归一化
标准化是一种常见的数据预处理技术,用于对数据进行缩放或转换,以确保每个特征都有相等的学习贡献。例如,灰度图像中的每个像素的值都介于0和255之间,这些是特征。如果一个像素值为17,另一个像素为197,则像素重要性的分布将不均匀,因为较高的像素值会偏离学习。标准化改变了数据的范围,而不会扭曲其特征之间的区别。这种预处理是为了避免:
- 减少预测精度
- 模型学习困难
- 特征数据范围的不利分布
Transforms
数据并不总是以最终处理过的形式呈现,这种形式适合训练机器学习算法。可以使用transforms来操作数据,使其适合训练。
所有 TorchVision 数据集都有两个参数(transform用于修改特征,target_transform用于修改标签),这些参数接受包含转换逻辑的可调用对象。torchvision.transforms 模块提供了几种常用的转换。
FashionMNIST 的特征是 PIL 图像格式,标签是整数。 对于训练,需要将特征转换为归一化的张量,将标签转换为 one-hot 编码的张量。 为了进行这些转换,将使用 ToTensor 和 Lambda。
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambdads = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
解释上述代码:
ToTensor()
ToTensor 将PIL图像或NumPy ndarray转换为FloatTensor,并将图像的像素强度值缩放到范围 [0., 1.]内。
Lambda transforms
Lambda transforms 应用任何用户定义的lambda函数。在这里,我们定义了一个函数来将整数转换为一个one-hot编码的张量。它首先创建一个大小为10的零张量(数据集中标签的数量),然后调用scatter,根据标签y的索引为其分配值为1。也可以使用torch.nn.functional.one_hot的方式来实现这一点。
相关文章:
pytorch基础2-数据集与归一化
专题链接:https://blog.csdn.net/qq_33345365/category_12591348.html 本教程翻译自微软教程:https://learn.microsoft.com/en-us/training/paths/pytorch-fundamentals/ 初次编辑:2024/3/2;最后编辑:2024/3/2 本教程…...
Python测试框架pytest介绍用法
1、介绍 pytest是python的一种单元测试框架,同自带的unittest测试框架类似,相比于unittest框架使用起来更简洁、效率更高 pip install -U pytest 特点: 1.非常容易上手,入门简单,文档丰富,文档中有很多实例可以参考 2.支持简单的单…...

AI对话系统app开源
支持对接gpt,阿里云,腾讯云 具体看截图 后端环境:PHP7.4MySQL5.6 软件:uniapp 废话不多说直接上抗揍云链接: https://mny.lanzout.com/iKFRY1o1zusf 部署教程请看源码内的【使用教程】文档 欢迎各位转载该帖/源码...
SpringBoot+aop实现主从数据库的读写分离
读写分离的作用是为了缓解写库,也就是主库的压力,但一定要基于数据一致性的原则,就是保证主从库之间的数据一定要一致。如果一个方法涉及到写的逻辑,那么该方法里所有的数据库操作都要走主库。 一、环境部署 数据库:…...

胎神游戏集第二期
延续上一期 一、海岛奇胎 #include<bits/stdc.h> #include<windows.h> #include<stdio.h> #include<conio.h> #include<time.h> using namespace std; typedef BOOL (WINAPI *PROCSETCONSOLEFONT)(HANDLE, DWORD); PROCSETCONSOLEFONT SetCons…...
)
Unicode/ASCII/UTF的关系(模板字面量、模板字符串、占位符)
字符串:编程时最重要的数据类型之一。 正则表达式:赋予开发者更多操作字符串的能力。 1、 Unicode和ASCII 1.1 概述 Unicode是ASCII字符编码的一个扩展,只不过在Windows中,用两个字节对其进行编码,也称为宽字符集&…...
三、低代码平台-单据配置(单表增删改查)
一、业务效果图 主界面 二、配置过程简介 配置流程:业务表设计 -》业务对象建立-》业务单据配置-》菜单配置。 a、业务表设计 b、业务对象建立 c、业务单据配置 功能路径:低代码开发平台/业务开发配置/单据配置维护 d、菜单配置...

6.1 数据驱动型业务管理方法(3%)
1 数据的产生与应用 1.数据的产生 2.数据的特征 3.数据的应用过程 应用到决策过程中 4.从决策到执行 决策:靠经验来进行决策(80%);可依据数据辅助(20%) 经验比数据重要的多,数据是辅助&…...

JVM学习目录
JVM ✅ JVM运行时内存结构 ✅ JVM常用启动参数 ✅ JVM内存分配与垃圾收集流程 ✅ 什么是垃圾回收机制(Garbage Collection,简称GC) ✅ 如何调用垃圾回收器的方法 ✅ GC如何判定对象已死 ✅ 方法区的垃圾收集 ✅ 垃圾收集算法 ✅ JVM垃圾回…...

使用远程桌面连接工具上传文件到Windows轻量应用服务器时,如何优化文件传输速度?
使用远程桌面连接工具上传文件到Windows轻量应用服务器时,如何优化文件传输速度? 优化网络连接:确保网络连接稳定和畅通,使用有线网络连接代替无线网络,以减少网络延迟和提高文件传输速度。 调整远程桌面设置…...

【Linux】基本指令(下)
🦄个人主页:修修修也 🎏所属专栏:Linux ⚙️操作环境:Xshell (操作系统:CentOS 7.9 64位) 日志 日志的概念: 网络设备、系统及服务程序等,在运作时都会产生一个叫log的事件记录;每一行日志都记载着日期、时间、使用者及动作等相关…...
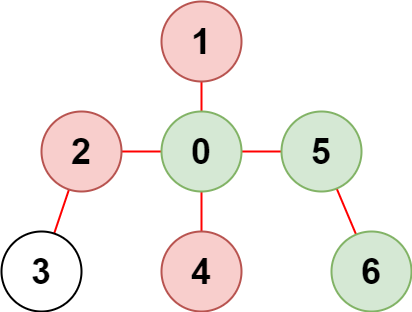
LeetCode受限条件下可到达节点的数目
题目描述 现有一棵由 n 个节点组成的无向树,节点编号从 0 到 n - 1 ,共有 n - 1 条边。 给你一个二维整数数组 edges ,长度为 n - 1 ,其中 edges[i] [ai, bi] 表示树中节点 ai 和 bi 之间存在一条边。另给你一个整数数组 restr…...
[Flutter]设置应用包名、名称、版本号、最低支持版本、Icon、启动页以及环境判断、平台判断和打包
一、设置应用包名 在Flutter开发中,修改应用程序的包名(也称作Application ID)涉及几个步骤,因为包名是在项目的Android和iOS平台代码中分别配置的。请按照以下步骤操作: 1.Android Flutter工程中全局搜索替换包名 …...
electron-release-server部署electron自动更新服务器记录
目录 一、前言 环境 二、步骤 1、下载上传electron-release-server到服务器 2、宝塔新建node项目网站 3、安装依赖 ①npm install ②安装并配置postgres数据库 ③修改项目配置文件 ④启动项目 ⑤修改postgres的认证方式 ⑥Cannot find where you keep your Bower p…...
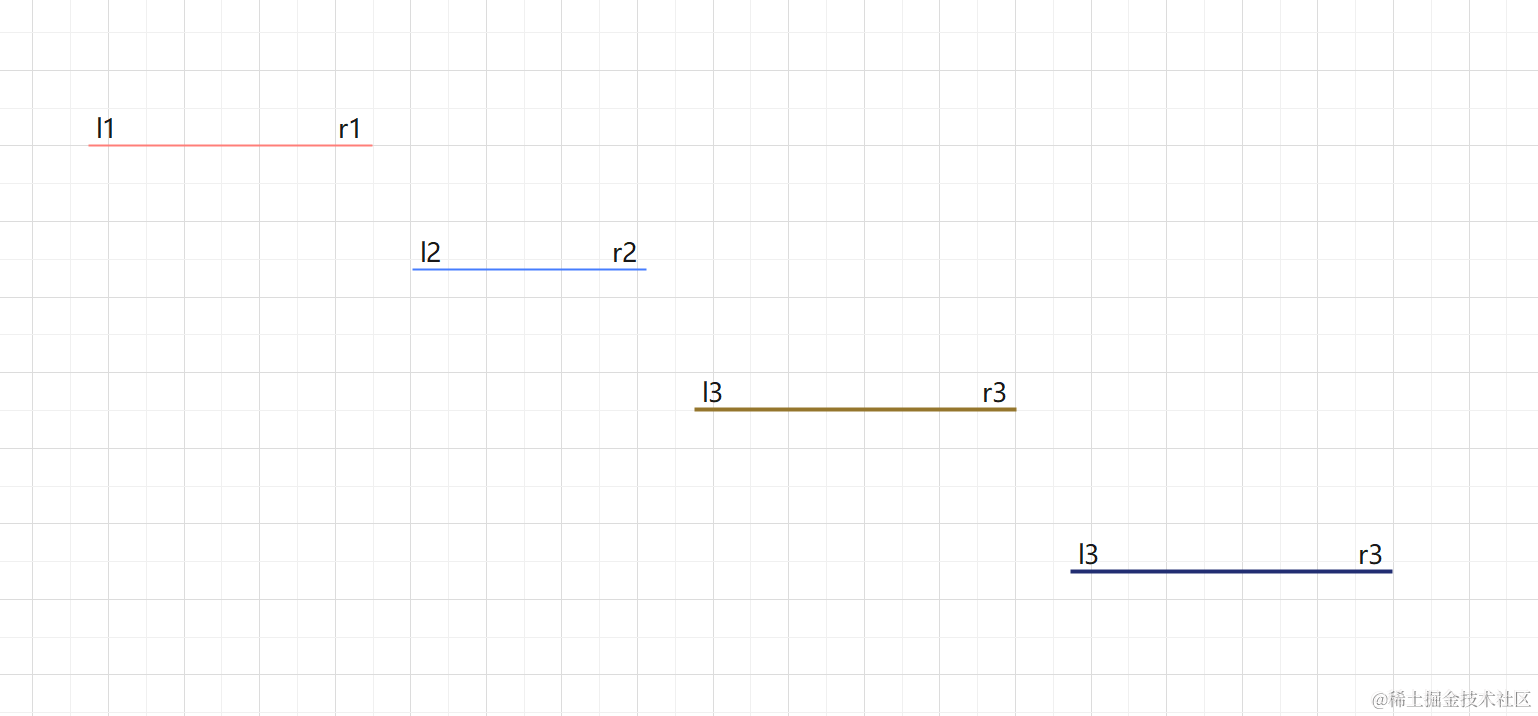
贪心(基础算法)--- 区间选点
905. 区间选点 思路 (贪心)O(nlogn) 根据右端点排序 将区间按右端点排序 遍历区间,如果当前区间左端点不包含在前一个区间中,则选取新区间,所选点个数加1,更新当前区间右端点。如果包含,则跳…...
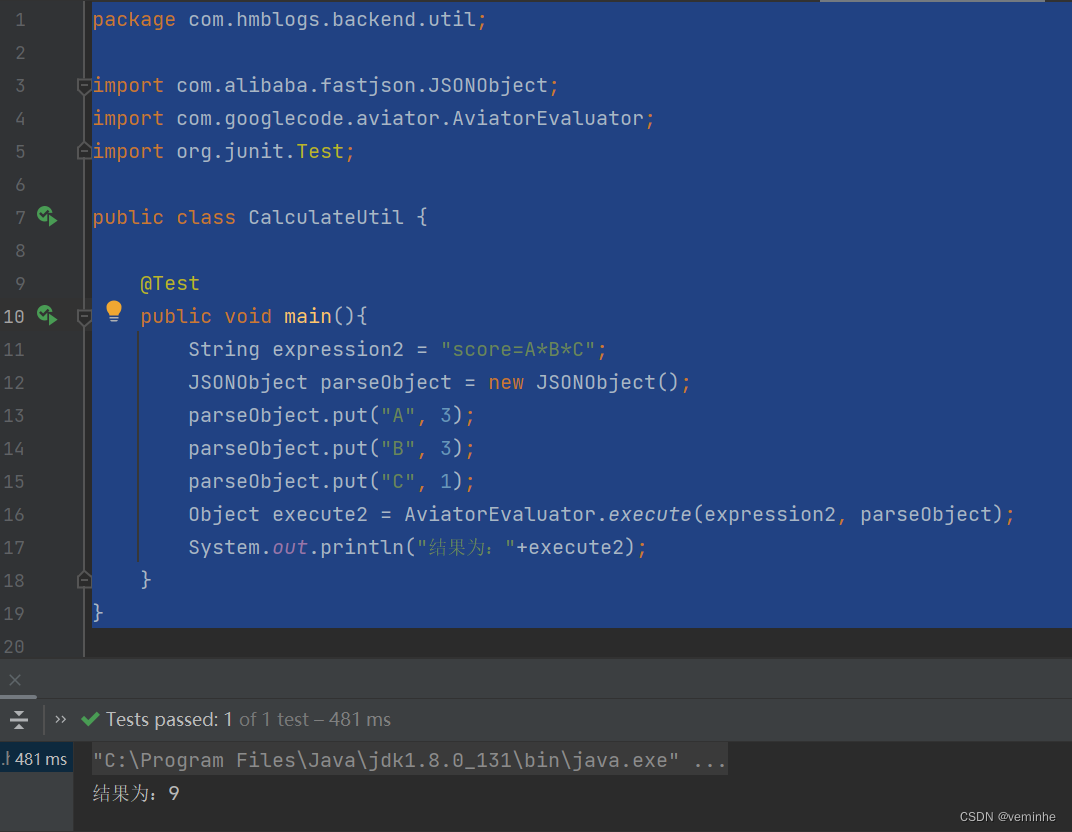
JAVA计算表达式
需求: 1、例如if(score>85){return 1;}else if(score>70){return 2;}else if(score>60){return 3;}else{return 4;}有这一串字符串,要执行这个字符串, 如果score为86分,则能得到1;如果score为30分ÿ…...
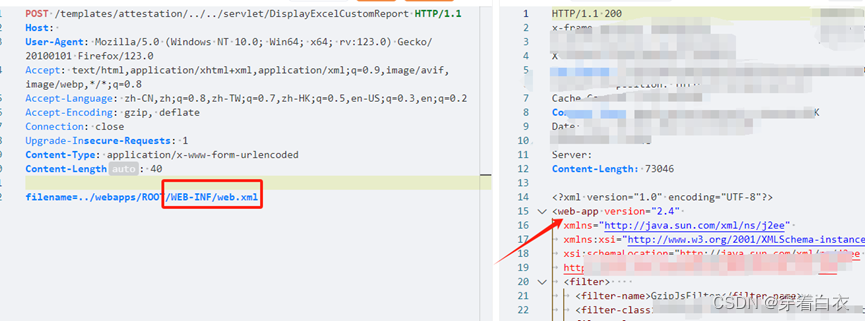
【复现】宏景HCM 任意文件读取漏洞_63
目录 一.概述 二 .漏洞影响 三.漏洞复现 1. 漏洞一: 四.修复建议: 五. 搜索语法: 六.免责声明 一.概述 宏景HCM 将人才标签技术应用于员工招聘、人才选拔等环节,通过多维度的标签体系,形成不同专业序列的人才画…...
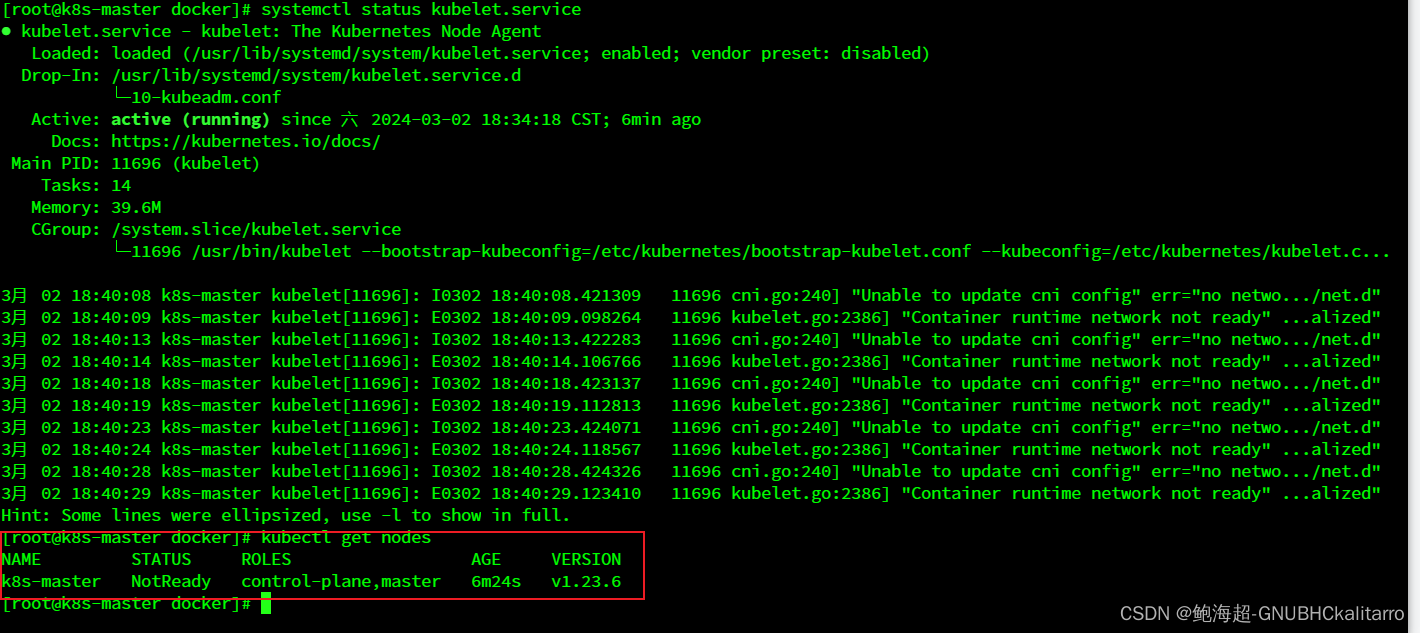
Linux:kubernetes(k8s)搭建mater节点(kubeadm,kubectl,kubelet)(2)
安装k8有多种方式如: minikube kubeadm 二进制安装 命令行工具 我这里就使用kubeadm进行安装 环境 3台centos7 master ip :192.168.113.120 2G运存 2内核 node1 ip :192.168.113.121 2G运存 2内核 node2 ip :192.168.1…...

Web应用安全威胁与防护措施
本文已收录至《全国计算机等级考试——信息 安全技术》专栏 由于极其容易出现漏洞、并引发安全事故,因此数据隐私的保护是目前绝大多数企业不可绕过的运维环节。不过,许多中小型企业往往会错误地认为只有大型企业才会成为黑客的目标。而实际统计数字却截…...

MySQL相关知识汇总
MySQL是一个广泛使用的开源关系型数据库管理系统,它以其高性能、稳定性和易用性而备受开发者喜爱。在软件开发领域,无论是大型项目还是小型应用,MySQL都扮演着重要的角色。本文将对MySQL的一些关键知识点进行汇总,帮助读者更好地了…...
)
Codex入门18-批量文件操作(效率神器:一句话批量重命名、格式化、清理几百个文件)
Codex入门18-批量文件操作(效率神器:一句话批量重命名、格式化、清理几百个文件) 📌 文章简介:手动改100个文件名?逐个格式化代码?一个个加版权声明?这些重复劳动该结束了。本文带你用 Codex CLI 一句话搞定批量重命名、批量格式化、批量添加文件头注释、批量清理垃圾…...

机器学习势函数与量子热浴结合:精准模拟钛酸钡相变中的核量子效应
1. 项目概述:当机器学习势函数遇上量子热浴在计算材料科学领域,我们一直面临着一个核心矛盾:精度与效率的权衡。研究像钛酸钡(BaTiO₃)这样的经典铁电材料相变,我们需要在原子尺度上追踪成千上万个原子在温…...
)
Win10升级21H2后远程桌面黑屏?一个组策略设置帮你搞定(附gpedit.msc详细路径)
Windows 10 21H2远程桌面黑屏故障深度解析与精准修复方案当你从Windows 10 1909版本升级到21H2后,是否遇到过这样的场景:远程桌面连接看似成功,却在15秒后突然黑屏断开,只留下"您的远程桌面会话已结束"的模糊提示&#…...

瑞德克斯在手机端的表现稳不稳?是否适合随时查看行情?
瑞德克斯在手机端的表现稳不稳?是否适合随时查看行情?移动端是当下用户接触金融服务最频繁的入口之一。瑞德克斯在手机端的体验打磨上下了不少功夫,让常用功能可以在小屏幕上同样得到清晰、舒适的呈现。瑞德克斯的移动应用采用了简洁的导航设…...

用Python和Pandas搞定泰坦尼克号数据集:从数据清洗到特征工程的完整实战
用Python和Pandas征服泰坦尼克号数据集:从数据清洗到特征工程的实战指南当第一次打开泰坦尼克号数据集时,那些密密麻麻的乘客信息就像一艘沉船上的碎片——杂乱无章却又充满故事。作为数据科学领域最经典的入门数据集,它包含了891名乘客的12个…...

MNIST识别项目复盘:除了准确率97%,我们更应该关注数据预处理与损失函数的选择
MNIST识别项目深度复盘:超越97%准确率的工程实践思考 在完成一个基础的MNIST手写数字识别项目后,很多开发者会满足于模型达到97%的准确率便止步不前。然而,真正有价值的机器学习实践远不止于调出一个高准确率的模型。本文将带您深入两个常被忽…...

多重检验策略:提升NPLM信号无关搜索的鲁棒性与均匀性
1. 项目概述在粒子物理实验数据分析中,我们常常面临一个核心困境:我们不知道新物理信号会以何种形式出现。传统的“模型依赖”搜索,比如针对特定质量的希格斯玻色子或暗物质候选粒子,需要预先定义一个精确的理论模型。然而&#x…...
爆火背后的技术解析)
Hermes Agent(爱马仕agent )爆火背后的技术解析
基于对现有技术资料的分析,Hermes Agent 的火爆及其与 OpenClaw 的对比,可以从以下几个核心维度进行解构与推演。 一、 Hermes Agent 项目详细分析与火爆原因 Hermes Agent 是一个由 Nous Research 开发的 AI Agent 框架,其设计哲学偏向于构…...
3分钟上手Translumo:免费实时屏幕翻译工具终极指南
3分钟上手Translumo:免费实时屏幕翻译工具终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在游…...

2026年AI论文写作工具实测认证:5款神器从文献到降重一站式避坑指南
写论文的焦虑,是每个科研人和学生绕不开的“必修课”。选题无从下手,文献检索耗时费力,格式调整反复修改,查重降重更是让人抓耳挠腮。2026年的AI工具早已不是当年的“辅助软件”,而是升级为能理解学术逻辑、生成高质量…...