第二篇【传奇开心果系列】Python的自动化办公库技术点案例示例:深度解读Pandas金融数据分析
传奇开心果博文系列
- 系列博文目录
- Python的自动化办公库技术点案例示例系列
- 博文目录
- 前言
- 一、Pandas 在金融数据分析中的常见用途和功能介绍
- 二、金融数据清洗和准备示例代码
- 三、金融数据索引和选择示例代码
- 四、金融数据时间序列分析示例代码
- 五、金融数据可视化示例代码
- 六、金融数据分析和建模示例代码
- 七、金融数据合并和连接示例代码
- 八、金融数据透视表和交叉表示例代码
- 九、金融数据处理效率示例代码
- 十、金融数据导入和导出示例代码
- 十一、社区支持和丰富文档举例说明
- 十二、知识点归纳总结
系列博文目录
Python的自动化办公库技术点案例示例系列
博文目录
前言

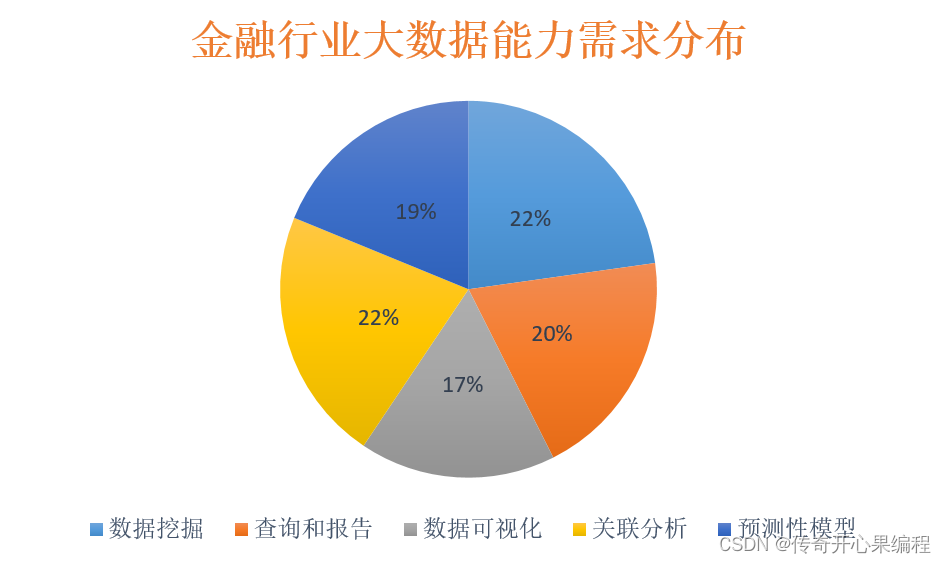 当涉及金融数据分析时,Pandas 是一种非常流行的 Python 库,被广泛用于处理和分析结构化数据,特别是在金融领域。Pandas 是金融数据分析中的利器,它提供了丰富的功能和易用的接口,帮助金融机构和分析师高效地处理和分析金融数据,从而做出更准确的决策。
当涉及金融数据分析时,Pandas 是一种非常流行的 Python 库,被广泛用于处理和分析结构化数据,特别是在金融领域。Pandas 是金融数据分析中的利器,它提供了丰富的功能和易用的接口,帮助金融机构和分析师高效地处理和分析金融数据,从而做出更准确的决策。
一、Pandas 在金融数据分析中的常见用途和功能介绍
 以下是 Pandas 在金融数据分析中的一些常见用途和功能:
以下是 Pandas 在金融数据分析中的一些常见用途和功能:
-
金融数据清洗和准备:金融数据往往来自不同的来源,可能存在缺失值、异常值或格式不一致的情况。Pandas 提供了功能强大的数据结构,如 DataFrame,可以帮助用户轻松地清洗和准备数据,包括处理缺失值、重复值、数据类型转换等。
-
金融数据索引和选择:Pandas 允许用户使用标签或位置来选择数据,这对于在金融数据中查找特定时间段的数据或特定股票的数据非常有用。通过使用 Pandas 的索引功能,用户可以轻松地筛选和提取感兴趣的数据。
-
金融时间序列分析:金融数据通常是时间序列数据,如股票价格、交易量等。Pandas 提供了丰富的时间序列功能,可以帮助用户对时间序列数据进行重采样、滚动计算、移动平均等操作,从而更好地理解和分析数据。
-
金融数据可视化:Pandas 结合其他库(如 Matplotlib、Seaborn)可以实现数据可视化,帮助用户直观地展示金融数据的趋势、关联性等。通过绘制折线图、柱状图、热力图等,分析师可以更好地向他人传达数据分析的结果。
-
金融数据分析和建模:Pandas 提供了丰富的金融数据操作和计算功能,如聚合、分组、透视表等,可以帮助用户进行数据分析和建模。结合其他库(如 NumPy、Scikit-learn),用户可以进行统计分析、机器学习等更深入的数据处理。
-
金融数据合并和连接:金融数据通常来自不同的来源,可能需要进行合并和连接操作。Pandas 提供了多种方法来合并不同数据集,包括合并、连接、拼接等,帮助用户整合多个数据源,进行更全面的分析。
-
金融数据透视表和交叉表:Pandas 支持金融数据透视表和交叉表的功能,这对于在金融数据中进行多维度分析非常有用。用户可以轻松地对数据进行汇总统计和交叉分析,从而深入了解数据之间的关系。
-
金融数据处理效率:Pandas 使用了基于 NumPy 的数据结构,能够高效处理大规模金融数据集。通过向量化操作和优化的算法,Pandas 能够在处理金融数据时提供较高的性能,加快数据分析的速度。
-
金融数据导入和导出:Pandas 支持多种数据格式的导入和导出,如 CSV、Excel、SQL 数据库等。这使得用户可以轻松地将金融数据从不同的来源导入到 Pandas 中进行分析,并将分析结果导出到其他格式进行分享或进一步处理。
-
社区支持和文档丰富:Pandas 拥有庞大的社区支持和丰富的文档资源,用户可以在社区中获取Pandas金融数据分析帮助文档、分享经验,快速解决遇到的问题。此外,Pandas 的文档详尽,包含大量金融数据分析示例和用法说明,帮助用户更好地理解和使用库的功能。
综上所述,Pandas 是金融数据分析中不可或缺的工具,它提供了丰富的功能和灵活的操作方式,帮助用户高效地处理、分析和可视化金融数据,从而做出更有针对性的决策。
二、金融数据清洗和准备示例代码
 当处理金融数据时,数据清洗和准备是至关重要的步骤。下面是一些示例代码,展示了如何使用 Pandas 处理金融数据中的缺失值、重复值和数据类型转换:
当处理金融数据时,数据清洗和准备是至关重要的步骤。下面是一些示例代码,展示了如何使用 Pandas 处理金融数据中的缺失值、重复值和数据类型转换:
- 处理缺失值:
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, None, 4],'B': [5, None, 7, 8],'C': ['apple', 'banana', None, 'orange']}
df = pd.DataFrame(data)# 打印原始数据
print("原始数据:")
print(df)# 处理缺失值,可以使用 fillna() 方法填充缺失值
df_filled = df.fillna(0) # 用 0 填充缺失值
print("\n处理缺失值后的数据:")
print(df_filled)
- 处理重复值:
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 2, 4],'B': [5, 6, 6, 8]}
df = pd.DataFrame(data)# 打印原始数据
print("原始数据:")
print(df)# 删除重复行,可以使用 drop_duplicates() 方法
df_no_duplicates = df.drop_duplicates()
print("\n处理重复值后的数据:")
print(df_no_duplicates)
- 数据类型转换:
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': ['4', '5', '6']}
df = pd.DataFrame(data)# 打印原始数据及数据类型
print("原始数据及数据类型:")
print(df)
print(df.dtypes)# 将 'B' 列的数据类型从字符串转换为整数
df['B'] = df['B'].astype(int)# 打印转换数据后的数据及数据类型
print("\n数据类型转换后的数据及数据类型:")
print(df)
print(df.dtypes)
这些示例代码演示了如何使用 Pandas 处理金融数据中的缺失值、重复值和数据类型转换。通过这些操作,可以确保数据质量,为后续的分析和建模提供干净、一致的数据集。
三、金融数据索引和选择示例代码
 在金融数据分析中,使用 Pandas 进行数据索引和选择是非常常见的操作。下面是一些示例代码,展示了如何使用 Pandas 进行数据索引和选择,以便筛选和提取感兴趣的金融数据:
在金融数据分析中,使用 Pandas 进行数据索引和选择是非常常见的操作。下面是一些示例代码,展示了如何使用 Pandas 进行数据索引和选择,以便筛选和提取感兴趣的金融数据:
- 使用标签进行数据选择:
import pandas as pd# 创建一个示例 DataFrame
data = {'date': ['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04'],'AAPL': [100, 105, 110, 115],'GOOGL': [2000, 2010, 2020, 2030]}
df = pd.DataFrame(data)# 将日期列设置为索引
df.set_index('date', inplace=True)# 使用 loc[] 方法通过标签选择数据
selected_data = df.loc['2022-01-02':'2022-01-03', ['AAPL']]
print(selected_data)
- 使用位置进行数据选择:
import pandas as pd# 创建一个示例 DataFrame
data = {'AAPL': [100, 105, 110, 115],'GOOGL': [2000, 2010, 2020, 2030]}
df = pd.DataFrame(data)# 使用 iloc[] 方法通过位置选择数据
selected_data = df.iloc[1:3, 0]
print(selected_data)
在这些示例代码中,我们展示了如何使用 Pandas 的 loc[] 和 iloc[] 方法通过标签或位置选择数据。这些功能使用户能够灵活地根据需要筛选和提取金融数据,从而更方便地进行进一步的分析和可视化。通过合理利用 Pandas 的索引和选择功能,用户可以高效地处理大量金融数据,找到感兴趣的信息并进行深入分析。
四、金融数据时间序列分析示例代码
 时间序列分析在金融领域是非常重要的,Pandas 提供了丰富的时间序列功能来处理和分析时间序列数据。以下是一些示例代码,展示了如何使用 Pandas 进行时间序列分析,包括重采样、滚动计算和移动平均等操作:
时间序列分析在金融领域是非常重要的,Pandas 提供了丰富的时间序列功能来处理和分析时间序列数据。以下是一些示例代码,展示了如何使用 Pandas 进行时间序列分析,包括重采样、滚动计算和移动平均等操作:
- 重采样时间序列数据:
import pandas as pd# 创建一个示例时间序列 DataFrame
date_rng = pd.date_range(start='2022-01-01', end='2022-01-10', freq='D')
data = {'price': [100, 105, 110, 115, 120, 125, 130, 135, 140, 145]}
df = pd.DataFrame(data, index=date_rng)# 按周重采样数据
weekly_resampled = df.resample('W').mean()
print(weekly_resampled)
- 滚动计算:
import pandas as pd# 创建一个示例时间序列 DataFrame
data = {'price': [100, 105, 110, 115, 120, 125, 130, 135, 140, 145]}
df = pd.DataFrame(data)# 计算滚动平均
rolling_mean = df['price'].rolling(window=3).mean()
print(rolling_mean)
- 移动平均:
import pandas as pd# 创建一个示例时间序列 DataFrame
data = {'price': [100, 105, 110, 115, 120, 125, 130, 135, 140, 145]}
df = pd.DataFrame(data)# 计算移动平均
moving_avg = df['price'].expanding().mean()
print(moving_avg)
这些示例代码演示了如何使用 Pandas 进行时间序列分析,包括重采样、滚动计算和移动平均等操作。通过这些功能,用户可以更好地理解时间序列数据的趋势和特征,从而做出更准确的分析和预测。Pandas 的时间序列功能为金融数据分析提供了强大的工具,帮助用户深入挖掘数据背后的信息。
五、金融数据可视化示例代码
 数据可视化在金融数据分析中扮演着至关重要的角色,能够帮助用户更直观地理解数据的趋势和关联性。Pandas 结合其他库(如 Matplotlib、Seaborn)可以实现丰富多样的数据可视化。以下是一些示例代码,展示了如何使用 Pandas 结合 Matplotlib 和 Seaborn 进行数据可视化:
数据可视化在金融数据分析中扮演着至关重要的角色,能够帮助用户更直观地理解数据的趋势和关联性。Pandas 结合其他库(如 Matplotlib、Seaborn)可以实现丰富多样的数据可视化。以下是一些示例代码,展示了如何使用 Pandas 结合 Matplotlib 和 Seaborn 进行数据可视化:
- 绘制折线图:
import pandas as pd
import matplotlib.pyplot as plt# 创建一个示例 DataFrame
data = {'AAPL': [100, 105, 110, 115, 120],'GOOGL': [2000, 2010, 2020, 2030, 2040]}
df = pd.DataFrame(data)# 绘制折线图
df.plot(kind='line')
plt.xlabel('Date')
plt.ylabel('Price')
plt.title('Stock Prices Over Time')
plt.show()
- 绘制柱状图:
import pandas as pd
import matplotlib.pyplot as plt# 创建一个示例 DataFrame
data = {'AAPL': [100, 105, 110, 115, 120],'GOOGL': [2000, 2010, 2020, 2030, 2040]}
df = pd.DataFrame(data)# 绘制柱状图
df.plot(kind='bar')
plt.xlabel('Date')
plt.ylabel('Price')
plt.title('Stock Prices')
plt.show()
- 绘制热力图:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
l
# 创建一个示例 DataFrame
data = {'AAPL': [100, 105, 110, 115, 120],'GOOGL': [2000, 2010, 2020, 2030, 2040]}
df = pd.DataFrame(data)# 绘制热力图
plt.figure(figsize=(8, 6))
sns.heatmap(df, annot=True, cmap='coolwarm')
plt.title('Stock Prices Heatmap')
plt.show()
这些示例代码展示了如何使用 Pandas 结合 Matplotlib 和 Seaborn 进行数据可视化,包括折线图、柱状图和热力图等。数据可视化可以帮助分析师更好地传达数据分析的结果,揭示数据之间的关联性和趋势,从而为决策提供更直观的支持。通过合理利用数据可视化工具,用户可以更深入地探索金融数据,发现隐藏在数据背后的有价值信息。
六、金融数据分析和建模示例代码
 金融数据分析和建模是 Pandas 在实际应用中的一个重要方面。结合 Pandas、NumPy 和 Scikit-learn等库,可以进行从数据清洗、探索性数据分析到建模预测等一系列操作。以下是一些示例代码,展示了如何结合这些库进行金融数据分析和建模:
金融数据分析和建模是 Pandas 在实际应用中的一个重要方面。结合 Pandas、NumPy 和 Scikit-learn等库,可以进行从数据清洗、探索性数据分析到建模预测等一系列操作。以下是一些示例代码,展示了如何结合这些库进行金融数据分析和建模:
- 金融数据分析示例:
import pandas as pd
import numpy as np# 创建示例金融数据 DataFrame
data = {'Date': pd.date_range(start='1/1/2022', periods=5),'AAPL': [100, 105, 110, 115, 120],'GOOGL': [2000, 2010, 2020, 2030, 2040]}
df = pd.DataFrame(data)# 计算每只股票的日收益率
df['AAPL_Return'] = df['AAPL'].pct_change()
df['GOOGL_Return'] = df['GOOGL'].pct_change()# 输出计算结果
print(df)
- 金融数据建模示例(线性回归):
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split# 创建示例金融数据 DataFrame
data = {'X': [1, 2, 3, 4, 5],'Y': [2, 4, 5, 4, 5]}
df = pd.DataFrame(data)# 准备特征和目标变量
X = df[['X']]
y = df['Y']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建线性回归模型并拟合数据
model = LinearRegression()
model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = model.predict(X_test)# 输出模型评估结果
print('模型斜率:', model.coef_)
print('模型截距:', model.intercept_)# 输出模型在测试集上的表现
from sklearn.metrics import mean_squared_error, r2_scoremse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print('均方误差(MSE):', mse)
print('R^2 分数:', r2)
- 金融数据可视化示例:
import pandas as pd
import matplotlib.pyplot as plt# 创建示例金融数据 DataFrame
data = {'Date': pd.date_range(start='1/1/2022', periods=5),'AAPL': [100, 105, 110, 115, 120],'GOOGL': [2000, 2010, 2020, 2030, 2040]}
df = pd.DataFrame(data)# 绘制折线图展示股票价格走势
plt.figure(figsize=(10, 6))
plt.plot(df['Date'], df['AAPL'], marker='o', label='AAPL')
plt.plot(df['Date'], df['GOOGL'], marker='s', label='GOOGL')
plt.xlabel('Date')
plt.ylabel('Price')
plt.title('Stock Prices Over Time')
plt.legend()
plt.show()
通过以上示例代码,你可以看到如何利用 Pandas 结合其他库进行金融数据分析和建模。从数据处理、特征工程到模型训练和评估,以及数据可视化,这些工具和方法能够帮助你更好地理解金融数据、做出预测以及制定决策。在实际应用中,你可以根据具体问题和数据特点进一步优化和调整这些方法,以获得更准确和有效的分析结果。
七、金融数据合并和连接示例代码
 在金融数据分析中,数据合并和连接是非常常见的操作,特别是当需要整合来自不同来源的数据时。Pandas 提供了多种方法来实现数据合并和连接,比如
在金融数据分析中,数据合并和连接是非常常见的操作,特别是当需要整合来自不同来源的数据时。Pandas 提供了多种方法来实现数据合并和连接,比如 merge()、concat() 等函数。以下是一些示例代码展示如何使用 Pandas 进行数据合并和连接:
- 数据合并示例(使用
merge()函数):
import pandas as pd# 创建示例数据集
data1 = {'Date': ['2022-01-01', '2022-01-02', '2022-01-03'],'AAPL': [100, 105, 110]}
data2 = {'Date': ['2022-01-01', '2022-01-02', '2022-01-03'],'GOOGL': [2000, 2010, 2020]}df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)# 根据日期列合并两个数据集
merged_df = pd.merge(df1, df2, on='Date')# 输出合并后的数据集
print(merged_df)
- 数据连接示例(使用
concat()函数):
import pandas as pd# 创建示例数据集
data1 = {'Date': ['2022-01-01', '2022-01-02', '2022-01-03'],'AAPL': [100, 105, 110]}
data2 = {'Date': ['2022-01-04', '2022-01-05'],'AAPL': [115, 120]}df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)# 沿行方向连接两个数据集
concatenated_df = pd.concat([df1, df2])# 输出连接后的数据集
print(concatenated_df)
在实际应用中,你可以根据具体的数据情况和需求选择合适的合并或连接方法,以便有效地整合和处理金融数据。这些操作可以帮助你将来自不同来源的数据整合在一起,为后续的分析和建模提供更全面和完整的数据基础。
八、金融数据透视表和交叉表示例代码
 数据透视表和交叉表是在金融数据分析中非常有用的工具,可以帮助用户对数据进行多维度的汇总统计和分析。Pandas 提供了
数据透视表和交叉表是在金融数据分析中非常有用的工具,可以帮助用户对数据进行多维度的汇总统计和分析。Pandas 提供了 pivot_table() 和 crosstab() 函数来实现数据透视表和交叉表的功能。以下是示例代码展示如何使用 Pandas 创建数据透视表和交叉表:
- 数据透视表示例(使用
pivot_table()函数):
import pandas as pd# 创建示例数据集
data = {'Date': ['2022-01-01', '2022-01-01', '2022-01-02', '2022-01-02'],'Symbol': ['AAPL', 'GOOGL', 'AAPL', 'GOOGL'],'Price': [100, 2000, 105, 2010]}df = pd.DataFrame(data)# 创建数据透视表,计算每个股票每天的平均价格
pivot_table = pd.pivot_table(df, values='Price', index='Date', columns='Symbol', aggfunc='mean')# 输出数据透视表
print(pivot_table)
- 交叉表示例(使用
crosstab()函数):
import pandas as pd# 创建示例数据集
data = {'Symbol': ['AAPL', 'GOOGL', 'AAPL', 'GOOGL'],'Sector': ['Tech', 'Tech', 'Finance', 'Finance']}df = pd.DataFrame(data)# 创建交叉表,统计不同行业中股票的数量
cross_tab = pd.crosstab(df['Symbol'], df['Sector'])# 输出交叉表
print(cross_tab)
通过数据透视表和交叉表的分析,你可以更好地了解金融数据中不同维度之间的关系,帮助你发现潜在的规律和趋势。这些功能可以帮助你进行更深入和全面的数据分析,为决策提供更多的参考和支持。
九、金融数据处理效率示例代码
 当处理大规模金融数据集时,Pandas 的向量化操作和优化算法确实能够提高数据处理效率。以下是一个简单示例代码,展示如何使用 Pandas 处理大规模金融数据集:
当处理大规模金融数据集时,Pandas 的向量化操作和优化算法确实能够提高数据处理效率。以下是一个简单示例代码,展示如何使用 Pandas 处理大规模金融数据集:
import pandas as pd
import numpy as np# 创建一个大规模的金融数据集
n = 1000000
data = {'Date': pd.date_range(start='1/1/2022', periods=n),'Symbol': np.random.choice(['AAPL', 'GOOGL', 'MSFT', 'AMZN'], n),'Price': np.random.uniform(100, 2000, n),'Volume': np.random.randint(100000, 1000000, n)
}df = pd.DataFrame(data)# 使用 Pandas 进行数据分析
# 计算每个股票的平均价格和总交易量
summary = df.groupby('Symbol').agg({'Price': 'mean', 'Volume': 'sum'})# 输出分析结果
print(summary)
在这个示例中,我们首先创建了一个包含大量金融数据的 DataFrame。然后,我们使用 Pandas 的 groupby() 和 agg() 方法对数据进行分组和汇总统计,计算每个股票的平均价格和总交易量。这种向量化操作和优化算法可以帮助加快处理速度,特别是在处理大规模数据集时能够显著提高效率和性能。
接着,我们可以进一步展示如何利用 Pandas 的优化算法和向量化操作来进行数据筛选和计算,例如计算每只股票的价格涨幅:
# 计算每只股票的价格涨幅
df['Price_Lag'] = df.groupby('Symbol')['Price'].shift(1)
df['Price_Change'] = (df['Price'] - df['Price_Lag']) / df['Price_Lag']# 筛选涨幅大于5%的股票数据
high_price_change = df[df['Price_Change'] > 0.05]# 输出涨幅大于5%的股票数据
print(high_price_change.head())
在这段代码中,我们计算了每只股票的价格涨幅,并筛选出涨幅大于5%的股票数据。这个例子展示了如何利用 Pandas 的功能快速进行数据计算和筛选,而不需要显式地编写循环。
通过结合向量化操作、优化算法和 Pandas 提供的丰富功能,你可以高效地处理大规模金融数据集,加快数据分析的速度,从而更有效地进行金融数据分析和挖掘有价值的信息。
十、金融数据导入和导出示例代码
 Pandas 提供了丰富的函数和方法,可以方便地导入和导出各种数据格式。以下是一个示例代码,展示如何使用 Pandas 导入和导出金融数据:
Pandas 提供了丰富的函数和方法,可以方便地导入和导出各种数据格式。以下是一个示例代码,展示如何使用 Pandas 导入和导出金融数据:
- 从 CSV 文件导入金融数据:
import pandas as pd# 从 CSV 文件导入金融数据
df = pd.read_csv('financial_data.csv')# 显示导入的数据
print(df.head())
- 将处理后的数据导出到 Excel 文件:
# 假设已经对数据进行了处理
# 将处理后的数据导出到 Excel 文件
df.to_excel('processed_financial_data.xlsx', index=False)
- 从 SQL 数据库导入金融数据:
import pandas as pd
import sqlite3# 连接到 SQLite 数据库
conn = sqlite3.connect('financial_data.db')# 从 SQL 数据库导入金融数据
query = "SELECT * FROM financial_data_table"
df_sql = pd.read_sql_query(query, conn)# 显示导入的数据
print(df_sql.head())# 关闭数据库连接
conn.close()
通过以上示例代码,你可以了解如何使用 Pandas 导入和导出金融数据,无论数据是来自 CSV 文件、Excel 文件还是 SQL 数据库,Pandas 都提供了便捷的方法来处理这些数据,使得金融数据分析更加高效和灵活。
十一、社区支持和丰富文档举例说明
 Pandas 的庞大社区支持和丰富文档资源为用户提供了宝贵的帮助和指导。用户可以在社区中寻求帮助、分享经验,并快速解决遇到的问题。同时,Pandas 的详尽文档包含了大量示例和用法说明,帮助用户更好地理解和使用库的功能。
Pandas 的庞大社区支持和丰富文档资源为用户提供了宝贵的帮助和指导。用户可以在社区中寻求帮助、分享经验,并快速解决遇到的问题。同时,Pandas 的详尽文档包含了大量示例和用法说明,帮助用户更好地理解和使用库的功能。
举例来说明,假设你在金融数据分析中遇到了一个问题,想要了解如何使用 Pandas 解决。你可以通过以下步骤来获取帮助:
-
查阅官方文档:访问 Pandas 官方文档网站,查找相关主题的文档。例如,如果你想了解如何处理缺失值或进行数据合并,可以查看相关章节并阅读示例代码。
-
搜索社区论坛:访问 Pandas 的社区论坛(如 Stack Overflow、Pandas 官方论坛等),搜索你遇到的问题。很可能其他用户已经遇到过类似的问题,并得到了解决。你可以学习他们的解决方案或提出自己的问题。
-
参与社区讨论:如果在文档和论坛中没有找到满意的答案,可以直接在社区中提问。描述清楚问题的背景和细节,其他社区成员会尽力帮助你解决问题。
-
阅读示例代码:在 Pandas 的文档中,通常会有大量示例代码,涵盖了各种数据分析任务和技术。通过阅读这些示例代码,你可以更好地理解 Pandas 的功能和用法,并将其应用到自己的金融数据分析中。
通过利用 Pandas 的社区支持和丰富文档资源,你可以更高效地学习和使用 Pandas 进行金融数据分析,解决遇到的问题,并不断提升自己的数据分析能力。
十二、知识点归纳总结
 对于金融数据分析,Pandas 是一种非常强大和常用的工具。以下是一些 Pandas 在金融数据分析中常用的知识点的归纳总结:
对于金融数据分析,Pandas 是一种非常强大和常用的工具。以下是一些 Pandas 在金融数据分析中常用的知识点的归纳总结:
-
数据清洗和准备:
-处理缺失值:使用dropna()、fillna()方法填充或删除缺失值。
-处理重复值:使用drop_duplicates()方法删除重复行。
-数据类型转换:使用astype()方法将数据类型转换为正确的格式。 -
索引和选择数据:
-使用.loc[]和.iloc[]进行基于标签和位置的数据选择。
-使用布尔索引进行条件筛选数据。
-使用isin()方法检查数值是否在指定列表中。 -
数据合并和连接:
-使用merge()、join()、concat()等方法合并不同数据集。
-指定合并键和合并方式,如内连接、左连接、右连接、外连接。 -
数据透视表和交叉表:
-使用pivot_table()方法创建数据透视表,对数据进行汇总和分析。
-使用crosstab()方法创建交叉表,计算因子之间的频数。 -
时间序列分析:
-处理时间序列数据,包括日期索引的创建和操作。
-使用resample()方法进行时间重采样,如按天、月、季度重采样数据。 -
数据分组和聚合:
-使用groupby()方法对数据进行分组,然后应用聚合函数。
-可以使用内置的聚合函数,如sum()、mean()、count()等。 -
数据可视化:
-结合 Matplotlib 或 Seaborn 库,可以使用 Pandas 提供的绘图功能进行数据可视化。
-可以绘制折线图、柱状图、散点图等,以便更直观地展示数据分析结果。 -
高性能处理:
-Pandas 基于 NumPy 构建,支持向量化操作,可以高效处理大规模数据集。
-使用适当的数据结构,如 Categorical 数据类型和 Sparse 数据类型,可以减少内存使用,提高处理效率。
-避免循环操作,尽量使用向量化操作和内置函数,以提高代码执行效率。 -
数据读取和存储:
-Pandas 支持多种数据格式,如 CSV、Excel、SQL 数据库、JSON 等,可以使用read_开头的方法读取数据。
-使用to_开头的方法可以将数据保存到不同格式的文件中,方便数据的导入和导出。 -
异常值处理:
-识别和处理异常值,可以使用统计方法、箱线图等进行异常值检测。
-可以选择删除异常值、替换为特定值或进行其他处理方式。 -
金融指标计算:
-使用 Pandas 可以方便地计算各种金融指标,如移动平均线、RSI(相对强弱指标)、MACD(移动平均收敛差异)等。
-根据需要,可以编写自定义函数来计算特定的金融指标。 -
模型训练和预测:
-结合 Pandas 和其他机器学习库(如 Scikit-learn、TensorFlow 等),可以进行金融数据的模型训练和预测。
-可以使用 Pandas 对数据进行预处理和特征工程,为模型训练提供准备数据。

通过掌握以上知识点,你可以更加熟练地运用 Pandas 进行金融数据分析,处理各种数据处理任务,计算金融指标,进行数据可视化,甚至进行模型训练和预测。这些技能将帮助你更好地理解和分析金融数据,为决策提供有力支持。
相关文章:
第二篇【传奇开心果系列】Python的自动化办公库技术点案例示例:深度解读Pandas金融数据分析
传奇开心果博文系列 系列博文目录Python的自动化办公库技术点案例示例系列 博文目录前言一、Pandas 在金融数据分析中的常见用途和功能介绍二、金融数据清洗和准备示例代码三、金融数据索引和选择示例代码四、金融数据时间序列分析示例代码五、金融数据可视化示例代码六、金融数…...

Flink:Temporal Table Function(时态表函数)和 Temporal Join
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…...

Go语言中的时间控制:定时器技术详细指南
Go语言中的时间控制:定时器技术详细指南 引言定时器基础创建和使用time.Timer使用time.Ticker实现周期性任务定时器的内部机制小结 使用time.Timer实现简单的定时任务创建和启动定时器停止和重置定时器定时器的实际应用小结 利用time.Ticker处理重复的定时任务创建和…...

面试笔记系列六之redis+kafka+zookeeper基础知识点整理及常见面试题
目录 Redis redis持久化机制:RDB和AOF Redis 持久化 RDB的优点 RDB的缺点 AOF 优点 AOF 缺点 4.X版本的整合策略 Redis做分布式锁用什么命令? Redis做分布式锁死锁有哪些情况,如何解决? Redis如何做分布式锁?…...

Golang动态高效JSON解析技巧
JSON如今广泛用于配置和通信协议,但由于其定义的灵活性,很容易传递错误数据。本文介绍了如何使用mapstructure工具实现动态灵活的JSON数据解析,在牺牲一定性能的前提下,有效提升开发效率和容错能力。原文: Efficient JSON Data Ha…...
双重检验锁
双重检验锁:设计模式中的单例模式,细分为单例模式中的懒加载模式。 单例模式 单例模式:指的是一个类只有一个对象。最简单的实现方式是设一个枚举类,只有一个对象。缺点是当对象还没有被使用时,对象就已经创建存在了…...
)
【RISC-V 指令集】RISC-V DSP 扩展指令集介绍(一)
前言: 本笔记是基于对RISC-V DSP扩展指令集文档总结的,《P-ext-proposal.pdf》文档的关键内容如下: 主要介绍了RISC-V的P扩展指令集及其相关细节。 首先,对P扩展指令进行了概述,并列出了其与其他扩展重复的指令。 …...

RocketMQ - CentOS 7.x 安装单机版并测试
【安装前环境准备】检查是否安装好JDK(必要):java -version查看CPU信息: # cat /proc/cpuinfo # lscpu # getconf _NPROCESSORS_ONLN # cat /sys/devices/system/cpu/online # cat /proc/interrupts | egrep -i cpu查看内存信息: # free -hm …...
[JavaWeb玩耍日记]HTML+CSS+JS快速使用
目录 一.标签 二.指定css 三.css选择器 四.超链接 五.视频与排版 六.布局测试 七.布局居中 八.表格 九.表单 十.表单项 十一.JS引入与输出 十二.JS变量,循环,函数 十三.Array与字符串方法 十四.自定义对象与JSON 十五.BOM对象 十六.获取…...
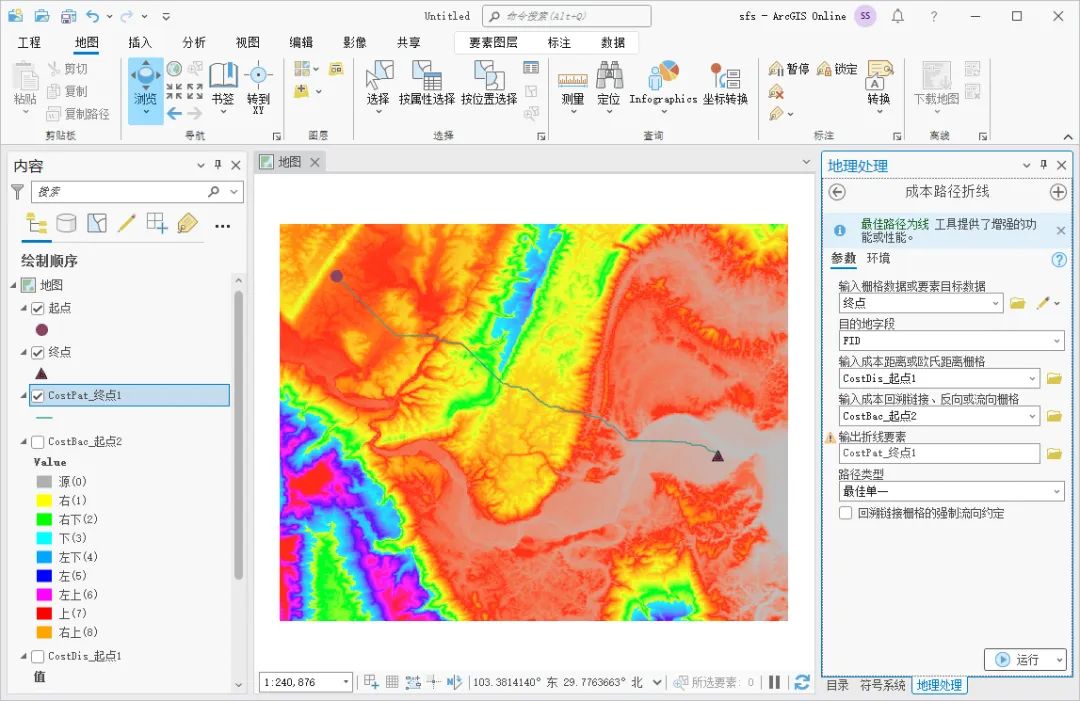
如何使用ArcGIS Pro创建最低成本路径
虽然两点之间直线最短,但是在实际运用中,还需要考虑地形、植被和土地利用类型等多种因素,需要加权计算最低成本路径,这里为大家介绍一下计算方法,希望能对你有所帮助。 数据来源 教程所使用的数据是从水经微图中下载…...

Neoverse CSS N3:实现市场领先能效的最快途径
区分老的架构 从云到边缘,Arm Neoverse 提供无与伦比的性能、效率、设计灵活性和 TCO 优势,正在颠覆传统基础设施芯片。 我们看到云和超大规模服务运营商正在推动更高的计算密度。随着 128 核心 CPU 设计上市(Microsoft Cobalt、阿里巴巴 Y…...
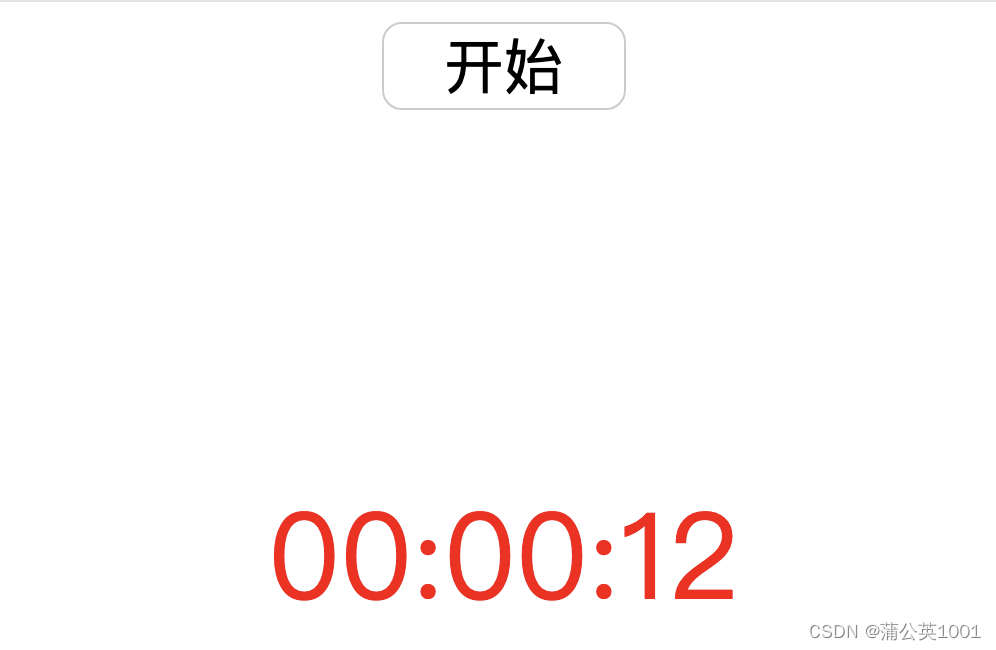
JavaScript实现的计时器效果
之前做过电商网站倒计时的效果,今天在倒计时的基础上,把代码修改了一下,改为计时器效果,实现了以下功能: 1.点击“开始”后,按秒计时且“开始”文字变为“停止”; 2.点击“停止”,计…...
))
仿函数(Functor(c++))
定义 仿函数(Functor)是一个可以像函数那样被调用的类对象。这意味着它实现了operator(),使得类的对象可以像函数那样被调用。 仿函数的主要特点 它是一个类。它重载了operator()。可以通过创建该类的对象,并像函数那样调用该对…...
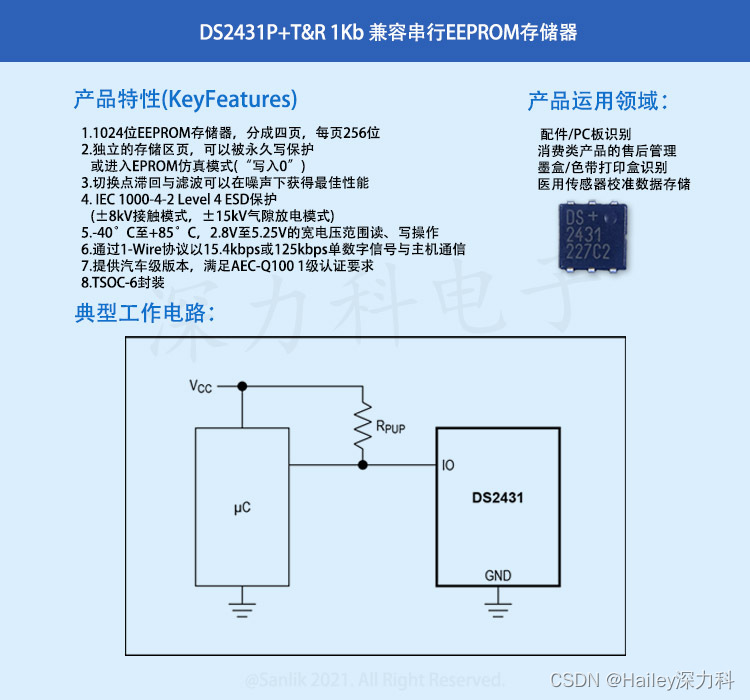
智能汽车加速车规级存储应用DS2431P+TR 汽车级EEPROM 存储器IC
DS2431PT&R是一款1024位1-Wire EEPROM芯片,由四页存储区组成,每页256位。数据先被写入一个8字节暂存器中,经校验后复制到EEPROM存储器。该器件的特点是,四页存储区相互独立,可以单独进行写保护或进入EPROM仿真模式…...

js json转换成字符串
js中JSON数据转换成字符串,可以使用JSON.stringify()方法。 var obj {name: "张三", age: 18, gender: "男"}; var jsonString JSON.stringify(obj); console.log(jsonString); // 输出 {"name":"张三","age"…...

Linux笔记--基本操作指令
一、查看日期与日历 1.date指令 显示日期 #用法1:dateCST: China Standard Time时区,中国标准时间 #用法2: date 指定格式 [常用格式]: "%Y-%m-%d"(%F): 2022-07-25 "%H:%M:%S"(%T): 14:53:44 "%F %T" #用法3: date -d "-1 da…...

论文阅读:基于超像素的图卷积语义分割(图结构数据)
#Superpixel-based Graph Convolutional Network for Semantic Segmentation github链接 引言 GNN模型根据节点特征周围的边来训练节点特征,并获得最终的节点嵌入。通过利用具有不同滤波核的二维卷积对来自附近节点的信息进行整合,给定超像素方法生成的…...
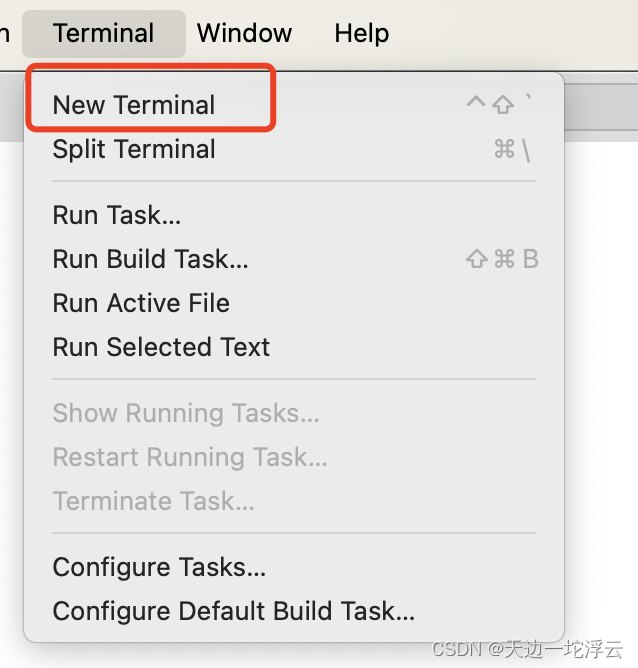
记录踩过的坑-macOS下使用VS Code
目录 切换主题 安装插件 搭建Python开发环境 装Python插件 配置解释器 打开项目 打开终端 切换主题 安装插件 方法1 方法2 搭建Python开发环境 装Python插件 配置解释器 假设解释器已经通过Anaconda建好,只需要在VS Code中关联。 打开项目 打开终端...
------数据的复制)
30天JS挑战(第十四天)------数据的复制
第十四天挑战(数据的复制) 地址:https://javascript30.com/ 所有内容均上传至gitee,答案不唯一,仅代表本人思路 中文详解:https://github.com/soyaine/JavaScript30 该详解是Soyaine及其团队整理编撰的,是对源代码…...

【洛谷 P8682】[蓝桥杯 2019 省 B] 等差数列 题解(数学+排序+辗转相除法)
[蓝桥杯 2019 省 B] 等差数列 题目描述 数学老师给小明出了一道等差数列求和的题目。但是粗心的小明忘记了一部分的数列,只记得其中 N N N 个整数。 现在给出这 N N N 个整数,小明想知道包含这 N N N 个整数的最短的等差数列有几项? 输…...

别再只改源文件了!Linux内核编译时‘multiple definition’错误的隐藏Boss:备份文件覆盖机制
别再只改源文件了!Linux内核编译时‘multiple definition’错误的隐藏Boss:备份文件覆盖机制当你深夜调试Linux内核代码,反复修改dtc-parser.tab.c文件却始终遭遇相同的multiple definition错误时,是否怀疑过自己的修改被某种神秘…...

[智能体-28]:Python HTTP 请求库:requests 背景、原理、作用 完整版详解
一、全称与字面含义Requests:英文本意「请求、申请」Python 中:HTTP 请求库二、诞生背景Python 原生自带 urllib、urllib2语法冗长、写法繁琐、兼容性差、使用门槛高。2011 年 Kenneth Reitz 开发 requests口号:HTTP for Humans(给…...

别急着重启!深入理解Ubuntu 22.04的needrestart:守护进程、库文件与系统更新背后的原理
别急着重启!深入理解Ubuntu 22.04的needrestart:守护进程、库文件与系统更新背后的原理在Ubuntu 22.04 LTS的系统维护中,许多管理员都曾遇到过这样的场景:执行apt upgrade后,终端突然弹出"Daemons using outdated…...

机器学习势函数在铌辐照损伤模拟中的关键作用与验证
1. 项目概述:为什么铌的辐照损伤模拟需要更精确的势函数? 在核反应堆堆芯、聚变装置第一壁或是航天器推进系统这些极端环境中,材料不仅要承受高温高压,更要直面高能粒子(如中子、离子)的持续轰击。这种辐照…...

ZygiskFrida:安卓逆向的Zygote层动态插桩新范式
1. 这不是“又一个 Frida 模块”,而是安卓逆向工作流的物理层重构你有没有过这样的经历:在一台已 root 的测试机上,想用 Frida hook 一个刚启动的系统服务,结果发现frida-server启动失败,报错Permission denied&#x…...

基于信息论与数据压缩的AI文本检测:AIDetx原理与工程实践
1. 项目概述:当AI写作遇上信息论 最近几年,AI生成文本的能力突飞猛进,从写邮件、做摘要到创作故事,几乎无所不能。但随之而来的一个现实问题也摆在了我们面前:如何分辨一段文字究竟是出自人类之手,还是由AI…...

基于KDTree的机器学习壁面函数:提升CFD湍流模拟精度与效率
1. 项目概述在计算流体力学(CFD)的湍流模拟领域,尤其是处理高雷诺数工程流动时,近壁面区域的精确建模一直是个核心挑战。直接对粘性底层进行网格解析(Wall-Resolved LES/DES)虽然精度高,但计算成…...

AI系统误差传播建模:从仿真数据生成到高效参数估计的完整方案
1. 项目概述:当AI系统出错时,误差是如何“传染”的?在自动驾驶汽车、工业机器人或者医疗影像诊断这类复杂的人工智能系统里,一个常见的架构是“流水线”式的多阶段处理。比如,一辆自动驾驶汽车先通过摄像头和激光雷达“…...

光伏系统‘阴影杀手’怎么破?对比实测:传统扰动观察法 vs. PSO智能算法在Simulink中的表现
光伏系统阴影遮挡难题的算法对决:P&O与PSO-MPPT全维度实测清晨的光伏电站本该是阳光洒满面板的景象,但现实往往残酷——一根电线杆、一棵树甚至飘过的云朵,都能在组件上投下阴影。这些阴影不仅降低了发电效率,更会引发热斑效应…...

在VirtualBox里跑Win10,远程桌面连不上?试试这个被忽略的虚拟机专用配置
VirtualBox虚拟机Win10远程桌面黑屏?这个隐藏配置项可能是关键在混合开发环境中,许多技术从业者习惯使用VirtualBox等虚拟化工具搭建多操作系统平台。一个常见场景是在Windows 7宿主机上运行Windows 10虚拟机,通过远程桌面进行跨系统操作。但…...