C语言实现各类排序算法
排序算法是计算机科学中的一个重要概念,它是一种将一个无序的数列重新排列成有序的方法。常见的排序算法有:
选择排序(Selection Sort)
选择排序是一种简单直观的排序演算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,,再從剩餘未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以上步骤反复执行,直到所有数据元素均排序完毕。
#include <stdio.h>void selection_sort(int arr[], int n)
{int i, j, min_idx;for (i = 0; i < n-1; i++) {min_idx = i;for (j = i+1; j < n; j++) {if (arr[j] < arr[min_idx]) {min_idx = j;}}int temp = arr[i];arr[i] = arr[min_idx];arr[min_idx] = temp;}
}int main()
{int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);selection_sort(arr, n);printf("Sorted array is:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");return 0;
}
冒泡排序(Bubble Sort):
最简单的排序算法,通过重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
#include <stdio.h>void bubbleSort(int arr[], int n)
{int i, j;for (i = 0; i < n-1; i++) {for (j = 0; j < n-i-1; j++) {if (arr[j] > arr[j+1]) {int temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;}}}
}int main()
{int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);bubbleSort(arr, n);printf("Sorted array is:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");return 0;
}
插入排序(Insertion Sort):
插入排序是一种简单直观的排序演算法。通过构建有序序列,对未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
#include <stdio.h>void insertionSort(int arr[], int n)
{int i, j;for (i = 1; i < n; i++) {int temp = arr[i];j = i - 1;while (j >= 0 && arr[j] > temp) {arr[j + 1] = arr[j];j--;}arr[j + 1] = temp;}
}int main()
{int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);insertionSort(arr, n);printf("Sorted array is:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");return 0;
}
希尔排序(Shell Sort):
希尔排序是一种插入排序的改进版本。希尔排序的基本思想是使数组中的元素像是在一个具有各种尺寸的篮子里进行排序。希尔排序通过设定一个步长,将数组分为若干个子序列,然后对这些子序列分别进行插入排序。当步长为1时,希尔排序就退化为插入排序。希尔排序的步长可以选择不同的值,通常选择2的幂次方,比如1,2,4,8,16,32等。
#include <stdio.h>void shellSort(int arr[], int n)
{int i, j, gap;for (gap = n/2; gap > 0; gap /= 2) {for (i = gap; i < n; i++) {int temp = arr[i];for (j = i-gap; j >= 0 && arr[j] > temp; j -= gap) {arr[j+gap] = arr[j];}arr[j+gap] = temp;}}
}int main()
{int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);shellSort(arr, n);printf("Sorted array is:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");return 0;
}
归并排序(Merge Sort):
是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
#include <stdio.h>
#include <stdlib.h>void merge(int arr[], int l, int m, int r)
{int i, j, k, n1, n2;int L[m-l+1], R[r-m];n1 = m - l + 1;n2 = r - m;for (i = 0; i < n1; i++)L[i] = arr[l + i];for (j = 0; j < n2; j++)R[j] = arr[m + 1 + j];i = 0;j = 0;k = l;while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;}else {arr[k] = R[j];j++;}k++;}while (i < n1) {arr[k] = L[i];i++;k++;}while (j < n2) {arr[k] = R[j];j++;k++;}
}void mergeSort(int arr[], int l, int r)
{if (l < r) {int m = (l + r) / 2;mergeSort(arr, l, m);mergeSort(arr, m + 1, r);merge(arr, l, m, r);}
}int main()
{int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);mergeSort(arr, 0, n-1);printf("Sorted array is:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");return 0;
}
快速排序(Quick Sort):
快速排序是一种高效的排序算法,基于分治法(Divide and Conquer)的一个策略。将要排序的数组分为两个子数组,一个包含相应的元素,一个包含其他的元素。
#include <stdio.h>void quickSort(int arr[], int left, int right)
{if (left < right) {int pivot = arr[(left + right) / 2];int i = left, j = right;while (i <= j) {while (arr[i] < pivot) i++;while (arr[j] > pivot) j--;if (i <= j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;i++;j--;}}quickSort(arr, left, j);quickSort(arr, i, right);}
}int main()
{int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);quickSort(arr, 0, n-1);printf("Sorted array is:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");return 0;
}
堆排序(Heap Sort):
是一种比较高效的选择排序,无论原址排序还是非原址排序都有其实现。
#include <stdio.h>
#include <stdlib.h>void max_heapify(int arr[], int n, int i)
{int largest = i;int l = 2*i + 1;int r = 2*i + 2;if (l < n && arr[l] > arr[largest])largest = l;if (r < n && arr[r] > arr[largest])largest = r;if (largest!= i) {int temp = arr[i];arr[i] = arr[largest];arr[largest] = temp;max_heapify(arr, n, largest);}
}void heap_sort(int arr[], int n)
{for (int i = n/2 - 1; i >= 0; i--)max_heapify(arr, n, i);for (int i = n-1; i >= 0; i--) {int temp = arr[0];arr[0] = arr[i];arr[i] = temp;max_heapify(arr, i, 0);}
}int main()
{int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);heap_sort(arr, n);printf("Sorted array is:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");return 0;
}
桶排序:
桶排序是计算机科学中的一种排序算法,工作原理是将要排序的元素划分到不同的桶,然后分别对每个桶中的元素进行排序,最后将每个桶中的元素合并成一个有序的序列。
#include <stdio.h>void bucketSort(int arr[], int n, int maxValue) {int i, j;int count[maxValue+1];int output[n];for (i = 0; i <= maxValue; i++)count[i] = 0;for (i = 0; i < n; i++)count[arr[i]]++;for (i = 1; i <= maxValue; i++)count[i] += count[i - 1];for (i = n - 1; i >= 0; i--) {output[count[arr[i]] - 1] = arr[i];count[arr[i]]--;}for (i = 0; i < n; i++)arr[i] = output[i];
}int main() {int arr[] = {37, 23, 0, 17, 12, 72, 31, 46, 100, 88, 54};int n = sizeof(arr) / sizeof(arr[0]);int maxValue = 100;bucketSort(arr, n, maxValue);printf("Sorted array: \n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);return 0;
}
计数排序:
计数排序是一种线性时间复杂度的排序算法,这种算法对输入的数据有一定的限制,如它们都是非负整数。计数排序是一种非比较排序算法,其核心思想是将输入的数据值转化为键存储在额外开辟的数组空间中。当输入数据是非负整数时,计数排序是一个线性时间排序算法。
#include <stdio.h>void countSort(int arr[], int n) {int max = arr[0];int min = arr[0];// 找到数组中的最大和最小值for (int i = 1; i < n; i++) {if (arr[i] > max)max = arr[i];if (arr[i] < min)min = arr[i];}// 初始化计数数组int range = max - min + 1;int count[range];for (int i = 0; i < range; i++)count[i] = 0;// 计算每个元素的数量for (int i = 0; i < n; i++)count[arr[i] - min]++;// 修改计数数组,使得每个元素的值表示该元素在数组中的位置for (int i = 1; i < range; i++)count[i] += count[i - 1];// 创建一个结果数组,每个元素的位置由计数数组决定int output[n];for (int i = n - 1; i >= 0; i--) {output[count[arr[i] - min] - 1] = arr[i];count[arr[i] - min]--;}// 将结果数组复制到原数组for (int i = 0; i < n; i++)arr[i] = output[i];
}int main() {int arr[] = {10, 20, 7, 8, 9, 1, 5};int n = sizeof(arr) / sizeof(arr[0]);countSort(arr, n);printf("Sorted array: \n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);return 0;
}
基数排序:
基数排序是一种非比较整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。通常适用于对小范围整数的排序。将整个整数(例如名字或日期)中的每个数字或字母类似于排序每个单独的数字。
#include <stdio.h>void countingSort(int arr[], int n, int exp) {int output[n]; int i;int count[10] = {0}; for (i = 0; i < n; i++)count[(arr[i] / exp) % 10]++;for (i = 1; i < 10; i++)count[i] += count[i - 1];for (i = n - 1; i >= 0; i--) {output[count[(arr[i] / exp) % 10] - 1] = arr[i];count[(arr[i] / exp) % 10]--;}for (i = 0; i < n; i++)arr[i] = output[i];
}void radixsort(int arr[], int n) {int m = getMax(arr, n);for (int exp = 1; m / exp > 0; exp *= 10)countingSort(arr, n, exp);
}int getMax(int arr[], int n) {int mx = arr[0];for (int i = 1; i < n; i++)if (arr[i] > mx)mx = arr[i];return mx;
}void print(int arr[], int n) {for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");
}int main() {int arr[] = {170, 45, 75, 90, 802, 24, 2, 66};int n = sizeof(arr) / sizeof(arr[0]);radixsort(arr, n);print(arr, n);return 0;
}
斐波那契排序:
这是一个对冒泡排序的改进,通过引入斐波那契数列的概念,减少了比较的次数。工作原理是通过两层循环,外层循环控制整个排序过程,内层循环控制每一轮的排序。如果前一个元素大于后一个元素,就交换它们的位置。这样一轮比较下来,最大的元素就会移动到它应该在的位置上。
#include <stdio.h>void swap(int *a, int *b) {int temp = *a;*a = *b;*b = temp;
}void fbSort(int arr[], int n) {int i, j;for (i = 0; i < n-1; i++) {for (j = 0; j < n-i-1; j++) {if (arr[j] > arr[j+1]) {swap(&arr[j], &arr[j+1]);}}}
}int main() {int arr[] = {5, 8, 1, 3, 9, 6};int n = sizeof(arr)/sizeof(arr[0]);fbSort(arr, n);printf("Sorted array: \n");for (int i=0; i<n; i++) {printf("%d ", arr[i]);}return 0;
}
哈夫曼排序:
哈夫曼排序是一种优先队列排序,它的基本思想是将待排序的序列看作是一棵完全二叉树,然后从上到下和从左到右进行排序。
#include<stdio.h>
#include<stdlib.h>typedef struct Node {int data;int freq;struct Node *left, *right;
} Node;Node* newNode(int data, int freq) {Node* node = (Node*)malloc(sizeof(Node));node->data = data;node->freq = freq;node->left = node->right = NULL;return node;
}int isLeaf(Node* node) {return (!node->left && !node->right);
}int max(Node *a, Node *b) {return (a->freq > b->freq)? a->freq : b->freq;
}Node *decodeHuff(Node* root, string s, int i) {if (root == NULL) return root;if (isLeaf(root)) return root;if (s[i] == '0') {return decodeHuff(root->left, s, i+1);}else return decodeHuff(root->right, s, i+1);
}void printCodes(Node* root, string s) {if (root == NULL) return;if (isLeaf(root)) {printf("%c : ", root->data);printf("%s\n", s);return;}printCodes(root->left, strcat(s, "0"));printCodes(root->right, strcat(s, "1"));
}int main() {string s = "aabcccccaaa";int freq[256];memset(freq, 0, sizeof(freq));for (int i=0; i<strlen(s); i++) freq[s[i]]++;Node* root = NULL;for (int i=0; i<256; i++)if (freq[i] > 0)root = insertNode(root, newNode(i, freq[i]));printCodes(root, "");return 0;
}
相关文章:

C语言实现各类排序算法
排序算法是计算机科学中的一个重要概念,它是一种将一个无序的数列重新排列成有序的方法。常见的排序算法有: 选择排序(Selection Sort) 选择排序是一种简单直观的排序演算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序…...

Network LSA 结构简述
Network LSA主要用于描述一个区域内的网络拓扑结构,包括网络中的路由器和连接到这些路由器的网络。它记录了每个路由器的邻居关系、连接状态以及连接的度量值(如带宽、延迟等),以便计算最短路径和构建路由表。display ospf lsdb n…...

揭示IP风险画像的作用与价值
在当今数字化时代,互联网的快速发展为企业和个人带来了巨大的机遇,同时也带来了各种安全风险和威胁。随着网络攻击手段的不断升级和演变,传统的安全防御手段已经无法满足对抗复杂多变的网络威胁的需求。IP风险画像作为一种新型的网络安全解决…...

[python] dataclass 快速创建数据类
在Python中,dataclass是一种用于快速创建数据类的装饰器和工具。自Python 3.7起,通过标准库中的dataclasses模块引入。它的主要目的是简化定义类来仅存储数据的代码量。通常,这样的类包含多个初始化属性,但没有复杂的方法…...
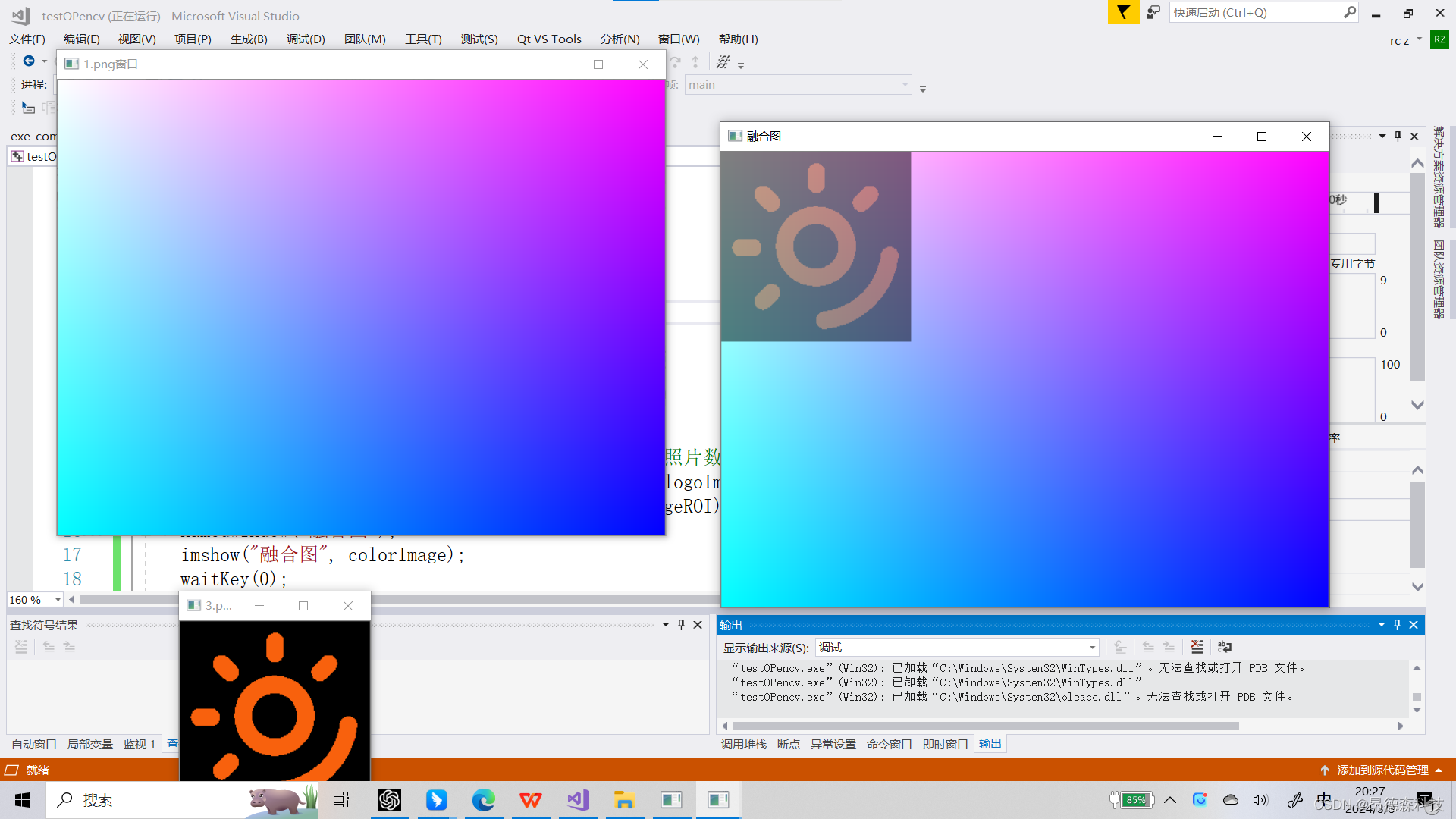
opencv实现图像的融合
实现图像的融合并且输出一张jpg格式的照片。 先显示一个彩色图的照片 然后我以彩色方式读取1.png,以灰度图方式读取3.png这张图片,并且用两个窗口独立地去显示(我后来发现不能把灰度图和彩色图相融合) 然后实现两个融合 #include <opencv2/highgu…...

Orbit 使用指南 02 | 在场景中生成原始对象| Isaac Sim | Omniverse
如是我闻: Orbit使用指南02将 深入探讨如何使用Python代码在Orbit中向场景生成各种对象(或原始对象)。一起探索如何生成地面平面、灯光、基本图形形状以及来自USD文件的网格。前置知识:如何生成空白场景,Orbit 使用指…...
【2024】利用python爬取csdn的博客用于迁移到hexo,hugo,wordpress...
前言 博主根据前两篇博客进行改进和升级 利用python爬取本站的所有博客链接-CSDN博客文章浏览阅读955次,点赞6次,收藏19次。定义一个json配置文件方便管理现在文件只有用户名称,后续可加配置读取用户名称,并且将其拼接成csdn个人博客链接ty…...
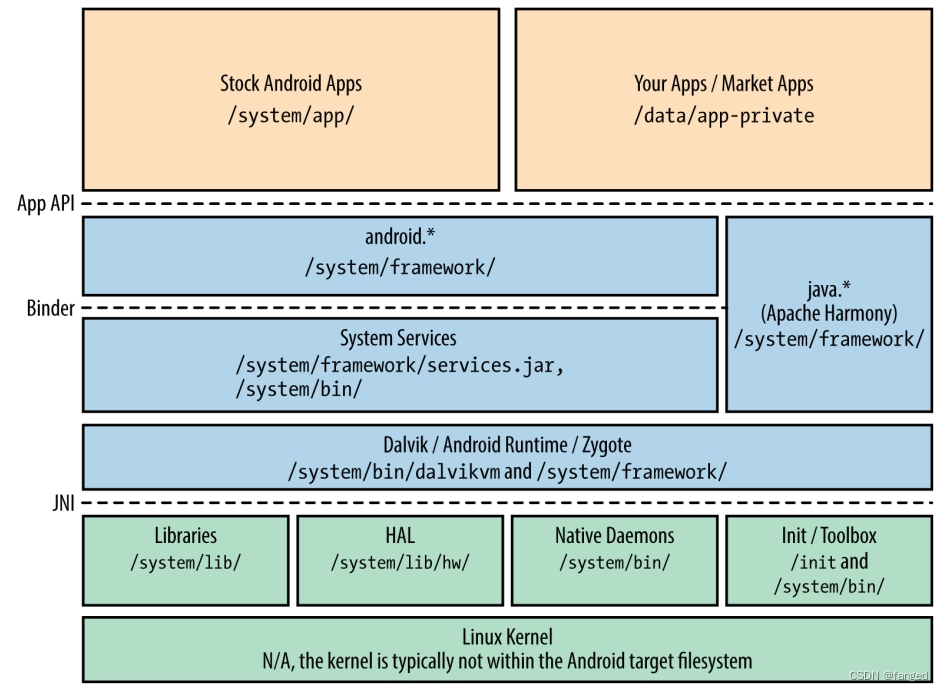
从嵌入式Linux到嵌入式Android
最近开始投入Android的怀抱。说来惭愧,08年就听说这东西,当时也有同事投入去看,因为恶心Java,始终对这玩意无感,没想到现在不会这个嵌入式都快要没法搞了。为了不中年失业,所以只能回过头又来学。 首先还是…...

蓝桥ACM培训-实战1
前言: 今天老师没讲课,只让我们做了一下几道题目。 正文: Problem:A 小蓝与操作序列: #include<bits/stdc.h> using namespace std; stack<int> a; int main(){int n,flag1,ans;string cz;cin>>n;for(int i1;…...
)
波动数列(蓝桥杯)
问题描述: 观察如下数列: 1 3 0 2 -1 1 -2 … 这个数列中后一项总是比前一项增加 2 或者减少 3。 栋栋对这种数列很好奇,他想知道长度为 n nn 和为 s ss 而且后一项总是比前一项增加 a aa 或者减少 b bb 的整数数列可能有多少种呢?…...

第二篇【传奇开心果系列】Python的自动化办公库技术点案例示例:深度解读Pandas金融数据分析
传奇开心果博文系列 系列博文目录Python的自动化办公库技术点案例示例系列 博文目录前言一、Pandas 在金融数据分析中的常见用途和功能介绍二、金融数据清洗和准备示例代码三、金融数据索引和选择示例代码四、金融数据时间序列分析示例代码五、金融数据可视化示例代码六、金融数…...

Flink:Temporal Table Function(时态表函数)和 Temporal Join
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…...

Go语言中的时间控制:定时器技术详细指南
Go语言中的时间控制:定时器技术详细指南 引言定时器基础创建和使用time.Timer使用time.Ticker实现周期性任务定时器的内部机制小结 使用time.Timer实现简单的定时任务创建和启动定时器停止和重置定时器定时器的实际应用小结 利用time.Ticker处理重复的定时任务创建和…...

面试笔记系列六之redis+kafka+zookeeper基础知识点整理及常见面试题
目录 Redis redis持久化机制:RDB和AOF Redis 持久化 RDB的优点 RDB的缺点 AOF 优点 AOF 缺点 4.X版本的整合策略 Redis做分布式锁用什么命令? Redis做分布式锁死锁有哪些情况,如何解决? Redis如何做分布式锁?…...

Golang动态高效JSON解析技巧
JSON如今广泛用于配置和通信协议,但由于其定义的灵活性,很容易传递错误数据。本文介绍了如何使用mapstructure工具实现动态灵活的JSON数据解析,在牺牲一定性能的前提下,有效提升开发效率和容错能力。原文: Efficient JSON Data Ha…...
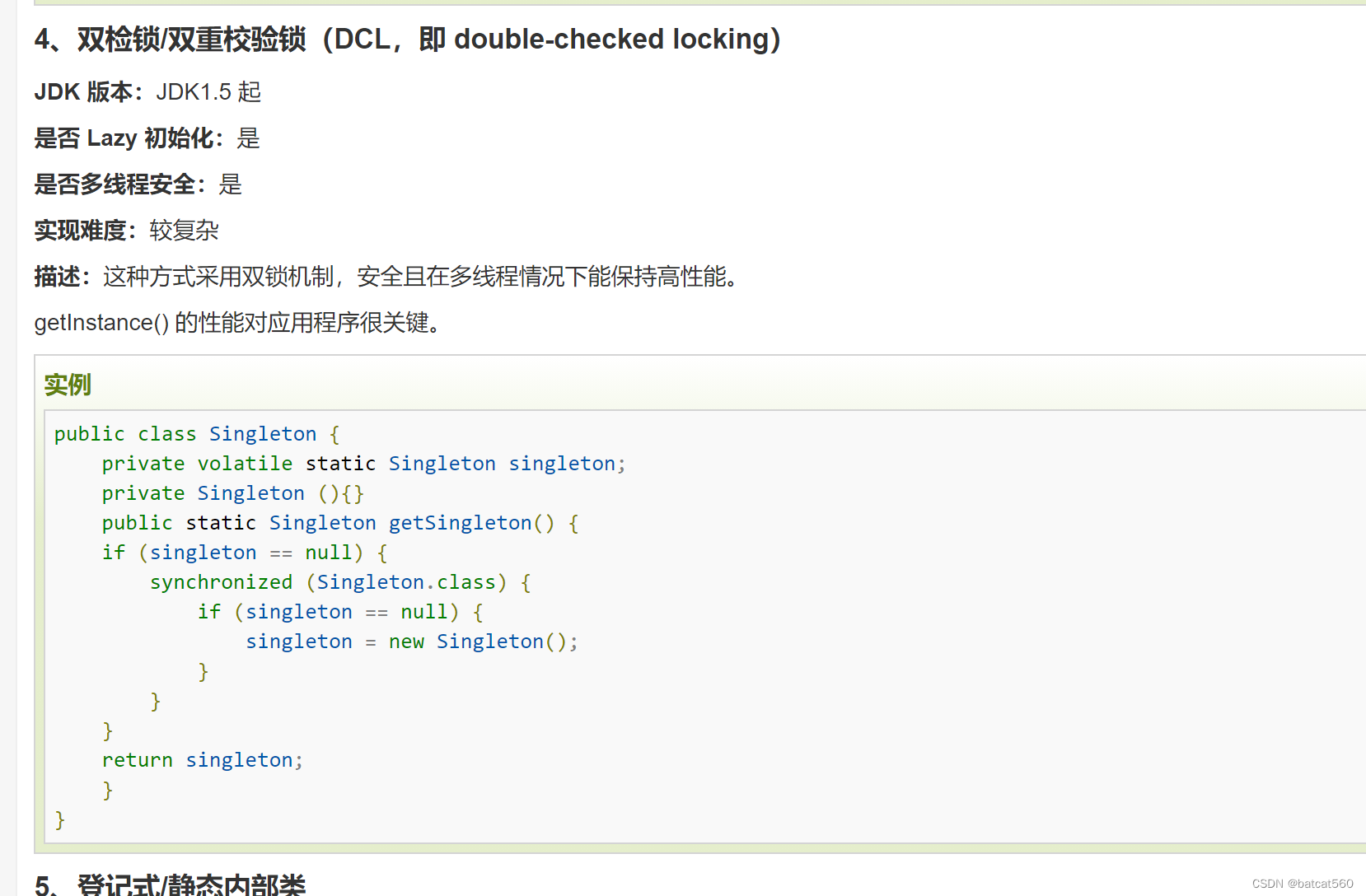
双重检验锁
双重检验锁:设计模式中的单例模式,细分为单例模式中的懒加载模式。 单例模式 单例模式:指的是一个类只有一个对象。最简单的实现方式是设一个枚举类,只有一个对象。缺点是当对象还没有被使用时,对象就已经创建存在了…...
)
【RISC-V 指令集】RISC-V DSP 扩展指令集介绍(一)
前言: 本笔记是基于对RISC-V DSP扩展指令集文档总结的,《P-ext-proposal.pdf》文档的关键内容如下: 主要介绍了RISC-V的P扩展指令集及其相关细节。 首先,对P扩展指令进行了概述,并列出了其与其他扩展重复的指令。 …...

RocketMQ - CentOS 7.x 安装单机版并测试
【安装前环境准备】检查是否安装好JDK(必要):java -version查看CPU信息: # cat /proc/cpuinfo # lscpu # getconf _NPROCESSORS_ONLN # cat /sys/devices/system/cpu/online # cat /proc/interrupts | egrep -i cpu查看内存信息: # free -hm …...
[JavaWeb玩耍日记]HTML+CSS+JS快速使用
目录 一.标签 二.指定css 三.css选择器 四.超链接 五.视频与排版 六.布局测试 七.布局居中 八.表格 九.表单 十.表单项 十一.JS引入与输出 十二.JS变量,循环,函数 十三.Array与字符串方法 十四.自定义对象与JSON 十五.BOM对象 十六.获取…...
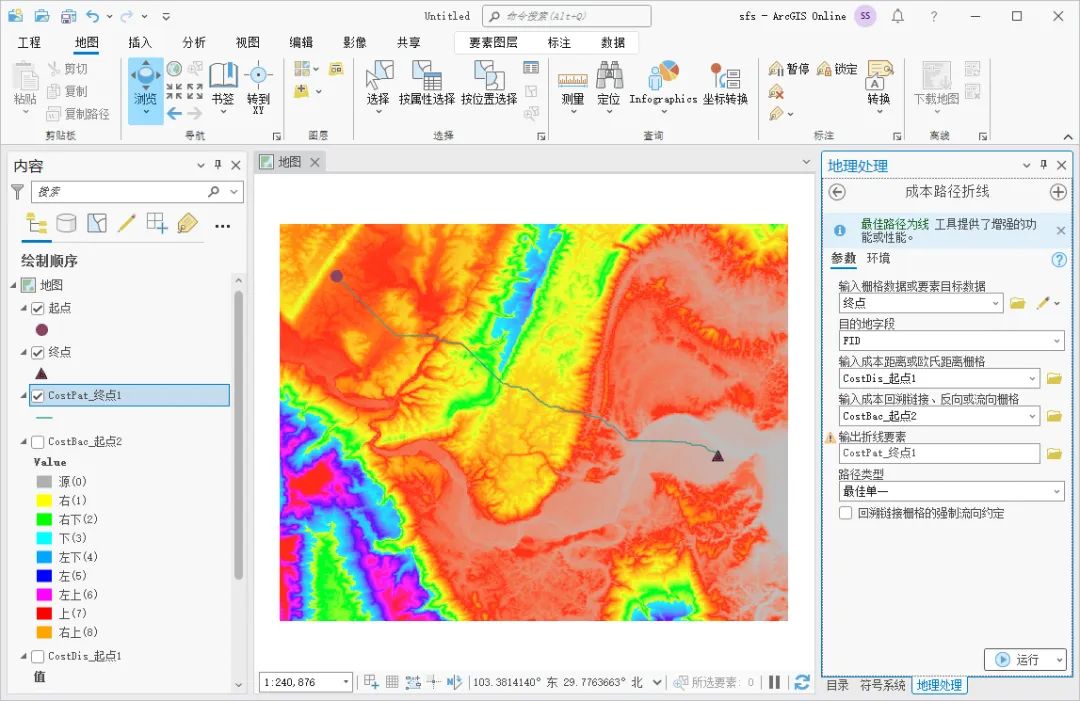
如何使用ArcGIS Pro创建最低成本路径
虽然两点之间直线最短,但是在实际运用中,还需要考虑地形、植被和土地利用类型等多种因素,需要加权计算最低成本路径,这里为大家介绍一下计算方法,希望能对你有所帮助。 数据来源 教程所使用的数据是从水经微图中下载…...

基于神经进化势函数与差分进化算法解析γ-Al2O3缺陷结构
1. 项目概述与核心挑战在材料模拟领域,氧化铝(Al2O3)家族因其丰富的多晶型相和广泛的应用(从催化剂载体到耐磨涂层)而备受关注。其中,γ-Al2O3作为一类关键的过渡氧化铝,其结构解析一直是材料科…...
)
从《原神》到《黑神话》都在用的AI Agent中间件:轻量级推理框架v0.9.3内部测试版首次泄露(仅限前500名开发者)
更多请点击: https://codechina.net 第一章:AI Agent游戏行业应用全景图 AI Agent 正在重塑游戏开发、运营与玩家体验的全生命周期。从智能NPC行为建模到实时动态世界生成,从自动化测试脚本到个性化内容推荐,AI Agent已不再局限于…...
)
Windows电脑C盘告急?手把手教你将Ollama模型库搬家到D盘(附环境变量配置详解)
Windows电脑C盘告急?手把手教你将Ollama模型库搬家到D盘(附环境变量配置详解)当你在Windows上玩转Ollama大模型时,C盘空间像被黑洞吞噬般迅速告急?别急着删文件或重装系统,今天带你用5分钟完成模型库的无痛…...

量子态估计新突破:超越置乱时间,QELM稳健实现高效信息提取
1. 项目概述 量子态估计,简单来说,就是“看清”一个未知量子系统内部状态的过程。这好比在完全黑暗的房间里,你需要通过有限的光线(测量)来推断房间内物体的精确形状和位置。在量子计算、量子通信和量子传感等领域&…...

Keil µVision项目复制后构建失败的诊断与解决
1. 问题现象与背景解析最近在Keil Vision开发环境中遇到一个典型的"项目复制后构建失败"问题:将一个原本正常编译的C语言项目复制到新目录后,仅做了少量修改,却突然出现error (40): expected an identifier or (的语法错误。这种情…...

C51启动代码解析:复位向量与硬件初始化关键
1. C51启动代码解析:为什么复位向量不直接跳转到C代码?在Keil C51开发环境中,很多开发者第一次单步调试时会发现一个奇怪现象:明明项目全部用C语言编写,但芯片复位后PC指针并没有直接跳转到main函数,而是先…...

Arm调试中MEM-AP访问属性的配置与应用
1. 使用调试器启动带特定属性的MEM-AP访问在嵌入式系统调试过程中,我们经常需要通过调试器访问目标设备的内存。当涉及到安全内存区域或需要特殊访问权限时,理解如何配置Memory Access Port(MEM-AP)的属性就显得尤为重要。本文将详…...

使用C#代码重新排列PDF页面的操作代码
引言对于页面顺序混乱的 PDF 文档,重新排列页面可以避免读者产生困惑,同时也能让文档结构更加清晰有序。本文将演示如何使用 Spire.PDF for .NET 以编程方式重新排列现有 PDF 文档中的页面。安装 Spire.PDF for .NET首先,需要将 Spire.PDF fo…...

Unity Android StreamingAssets路径原理与安全读取方案
1. 为什么这个路径问题会让人反复踩坑?在Unity Android项目里,StreamingAssets路径看似只是个字符串拼接问题,但实际开发中,它几乎是我接手过的每个中大型项目必修的“排障课”。不是因为代码难写,而是因为——它在不同…...

神经形态光子计算与单通道压缩感知:重塑超高速机器视觉新范式
1. 项目概述:为什么我们需要“扔掉”图像传感器?在机器视觉领域,我们似乎陷入了一个“速度陷阱”。无论是工业质检、自动驾驶,还是科学观测,对“更快”的追求永无止境。传统机器视觉的流程非常清晰:图像传感…...