cuda调试(一)vs2019-windows-Nsight system--nvtx使用,添加nvToolsExt.h文件
cuda调试
由于在编程过程中发现不同的网格块的结构,对最后的代码结果有影响,所以想记录一下解决办法。
CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid
cuda context (上下文)
context类似于CPU进程上下,表示由管理层 Drive 层分配的资源的生命周期,多线程分配调用的GPU资源同属一个context下,通常与CPU的一个进程对应。
CUDA Stream
CUDA Stream是指一堆异步的CUDA操作,他们按照host代码调用的顺序执行在device上。
Stream维护了这些操作的顺序,并在所有预处理完成后允许这些操作进入工作队列,同时也可以对这些操作进行一些查询操作。
这些操作包括host到device的数据传输,launch kernel以及其他的由host发起由device执行的动作。
这些操作的执行总是异步的,CUDA runtime会决定这些操作合适的执行时机。我们则可以使用相应的cuda api来保证所取得结果是在所有操作完成后获得的。同一个stream里的操作有严格的执行顺序,不同的stream则没有此限制。
CUDA API可分为同步和异步两类,同步函数会阻塞host端的线程执行,异步函数会立刻将控制权返还给host从而继续执行之后的动作。
当我们使用CUDA异步函数与多流(Multi Stream)时,多线程间既可以实现并行进行数据传输与计算,如下图所示。不过需要注意的是, CUDA runtime API默认的default stream是同步串行的,且一个进程内的所有线程都在default stream下,需要显式声明default之外的Stream才可以实现多流并发。

显卡硬件架构:SM、SP、Warp
具体到nvidia硬件架构上,有以下两个重要概念:
SP(streaming processor):最基本的处理单元,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
SM(streaming multiprocessor):多个SP加上其他的一些资源组成一个SM,也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。如下图是一个SM的基本组成,其中每个绿色小块代表一个SP。
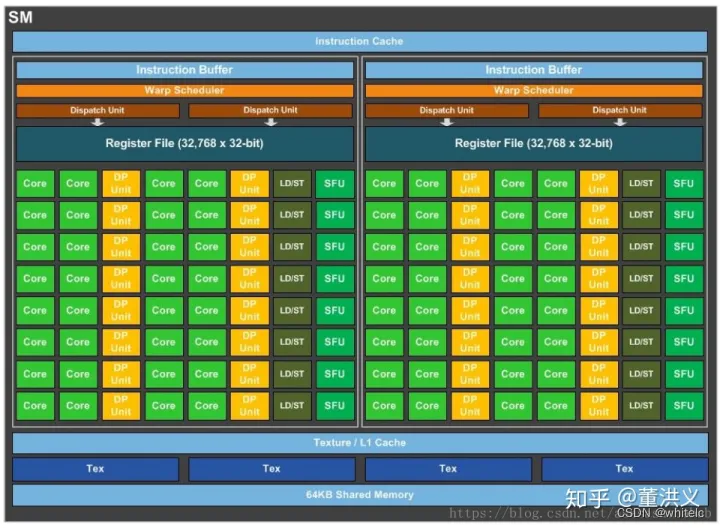
每个SM包含的SP数量依据GPU架构而不同,Fermi架构GF100是32个,GF10X是48个,Kepler架构都是192个,Maxwell都是128个。当一个kernel启动后,thread会被分配到很多SM中执行。大量的thread可能会被分配到不同的SM,但是同一个block中的thread必然在同一个SM中并行执行。
Warp调度
一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是调度和运行的基本单元。warp中所有threads并行的执行相同的指令。一个warp需要占用一个SM运行,多个warps需要轮流进入SM。由SM的硬件warp scheduler负责调度。目前每个warp包含32个threads(Nvidia保留修改数量的权利)。所以,一个GPU上resident thread最多只有 SM*warp个。
同一个warp中的thread可以以任意顺序执行,active warps被SM资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以新调度的warp的状态已经存储在SM中了。
每个SM有一个32位register集合放在register file中,还有固定数量的shared memory,这些资源都被thread瓜分了,由于资源是有限的,所以,如果thread比较多,那么每个thread占用资源就叫少,thread较少,占用资源就较多,这需要根据自己的要求作出一个平衡。
软件架构:Kernel、Grid、Block
上面的context与stream类似进程、线程的概念,具体到我们如何调用GPU上的线程实现我们的算法,则是通过Kernel实现的。在GPU上调用的函数成为CUDA核函数(Kernel function),核函数会被GPU上的多个线程执行。我们可以通过如下方式来定义一个kernel:
func_name<<<grid, block>>>(param1, param2, param3....);
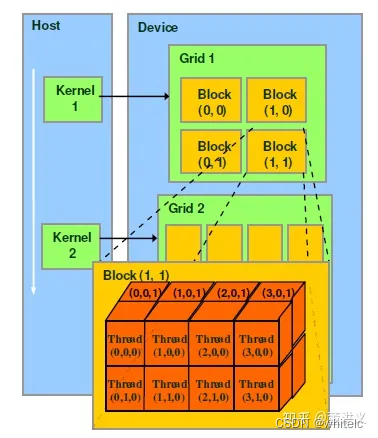
Grid:由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。Grid由很多Block组成,可以是一维二维或三维。
Block:一个grid由许多block组成,block由许多线程组成,同样可以有一维、二维或者三维。block内部的多个线程可以同步(synchronize),可访问共享内存(share memory)。
CUDA中可以创建的网格数量跟GPU的计算能力有关,可创建的Grid、Block和Thread的最大数量如下所示:
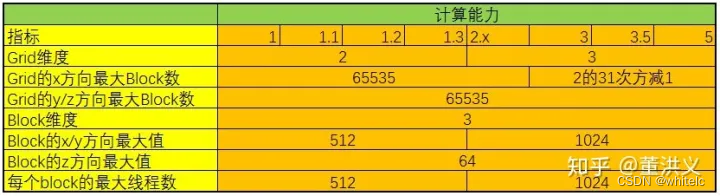
以上是引用:
https://zhuanlan.zhihu.com/p/266633373
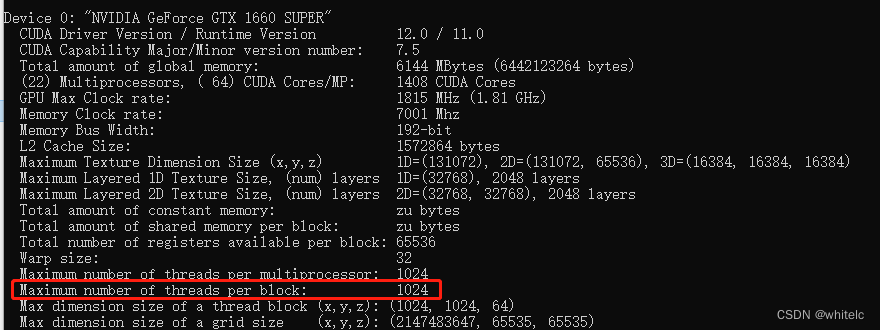

通过deviceQuery可以知道,每个block中只有1024个thread,而32 × 32× 32 = 32768 > 1024:会出现以下错误,运行时参数传递得太大了,出现这类问题后,cuda仍可继续提供服务,仅单纯拒绝了启动核函数。
cudaErrorInvalidConfiguration = 9,"invalid configuration argument"
所有CUDA kernel的启动都是异步的,当CUDA kernel被调用时,控制权会立即返回给CPU。在分配Grid、Block大小时,我们可以遵循这几点原则:
- 保证block中thread数目是32的倍数。这是因为同一个block必须在一个SM内,而SM的Warp调度是32个线程一组进行的。
- 避免block太小:每个blcok最少128或256个thread。
- 根据kernel需要的资源调整block,多做实验来挖掘最佳配置。
- 保证block的数目远大于SM的数目。
配置Nsight system
低开销的性能分析工具,Nvidia nsight Systems旨在提供开发人员优化其软件所需的洞察力。在工具中可视化活动数据,以帮助用户调查瓶颈,避免推断误报,并以更高的性能提高概率进行优化。用户将能够识别问题,例如GPU不足、不必要的GPU同步、CPU并行化不足,甚至目标平台的CPU和GPU之间的算法异常。
- 打开该程序
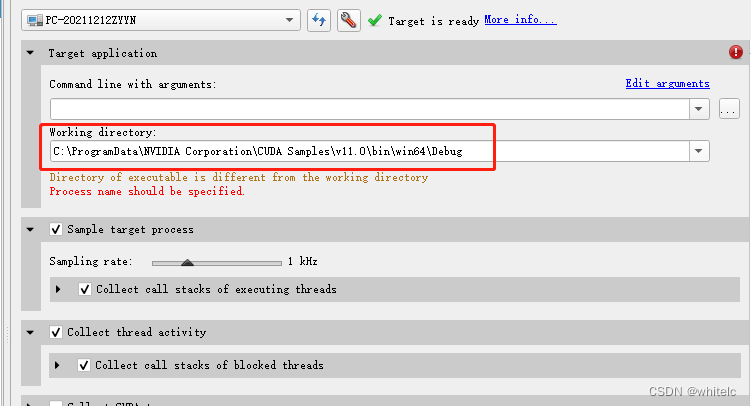
- 上面的 command line with arguments中填写 要调试的cuda项目的exe文件我的目录是
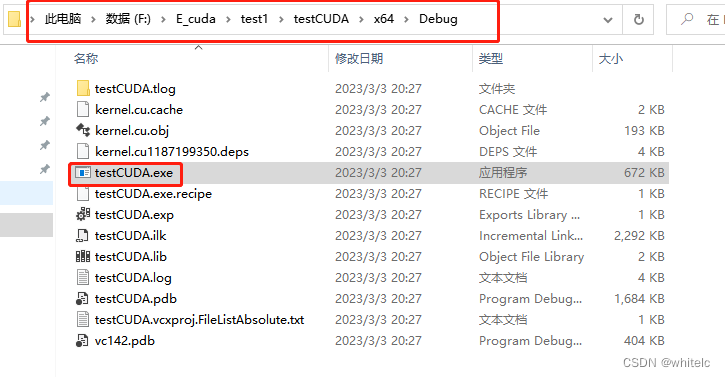
F:\E_cuda\test1\testCUDA\x64\Debug\testCUDA.exe
注意这个路径需要是全英文的
3.下面的 working directory 填写 cuda中的Debug文件,我的cuda中的默认目录是
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\bin\win64\Debug
F:\E_cuda\test1\testCUDA\x64\Debug\testCUDA.exe
然后start就行了
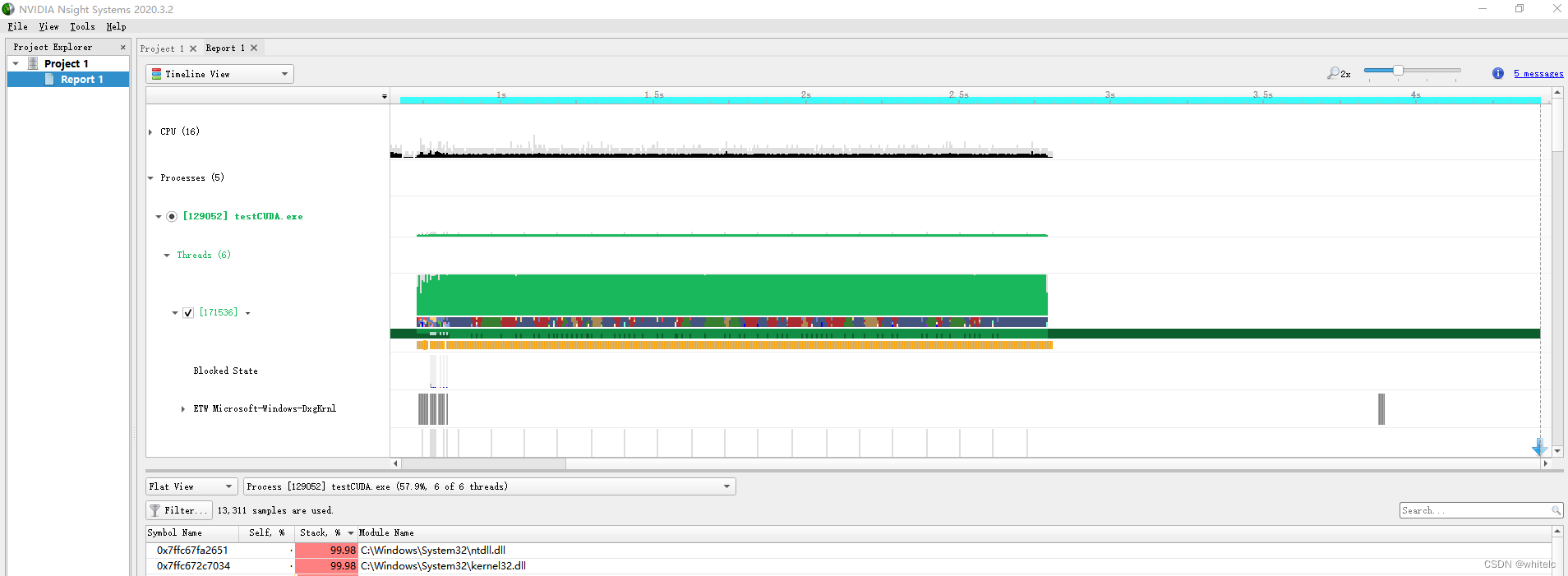
但是还不知道怎么去看具体的kernel
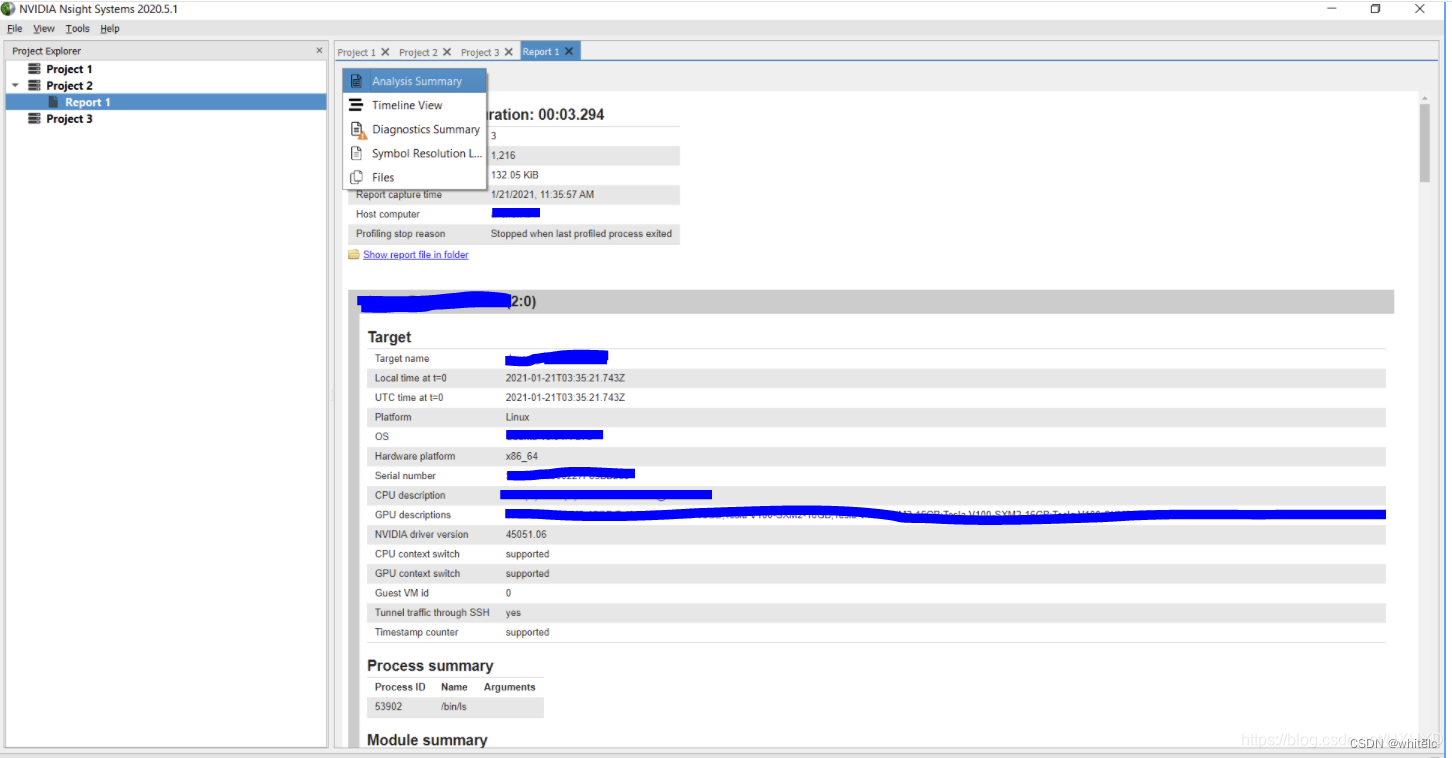
这个Report包含5部分内容:
- Analysis Summary (分析总结,内容非常全面,包含了Target的详细信息,Process summary, Module summary, Thread summary, Environment Variables, CPU info, GPU info等等)
- Timeline View (展示CPU/GPU各个核的工作时间线,一般用来来勘察模型训练或者推理的瓶颈在哪里)
- Diagnostics Summary (顾名思义,诊断总结。就是程序在运行中做了什么,有什么warning , error,或者message的,都在这里汇总)
- Symbol Resolution Logs(暂时不知道是干嘛的)
Files (执行结果的log 文件:pid_stdout.log,& 执行出错的log 文件pid_stderr.log)
简单看看Timeline view。如下,这里有三个CPU核在工作,它们启动和停止的时间可以从timeline上看到。还可以看到下面有三个Thread的时间线。
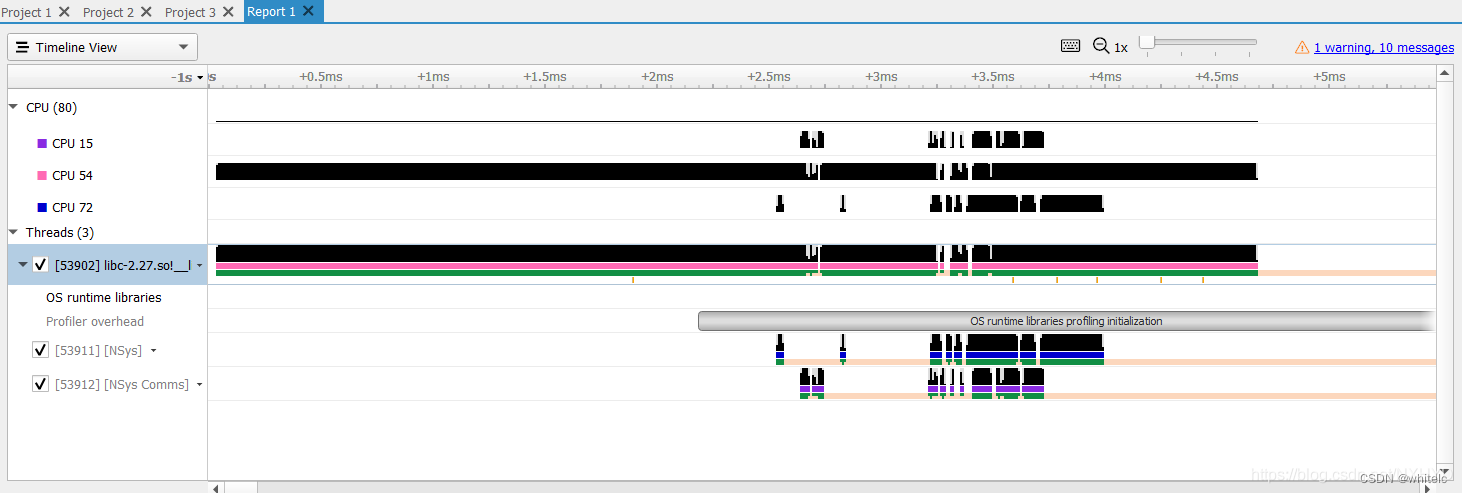
https://blog.csdn.net/NXHYD/article/details/112915968
这位博主的图和说明
我在b站上找的视频发现别人用的是 nsight system profiles 这个,(还没找到是啥,只有一个visoul profiler—需要java的环境)但是他讲的时候又说是NVTX,有点晕
https://www.bilibili.com/video/BV13w411o7cu/?spm_id_from=333.337.search-card.all.click&vd_source=0a4d8c47345ce0df71cd9cdb01575134
就是这个
以下是我使用visoul profiler—的报错
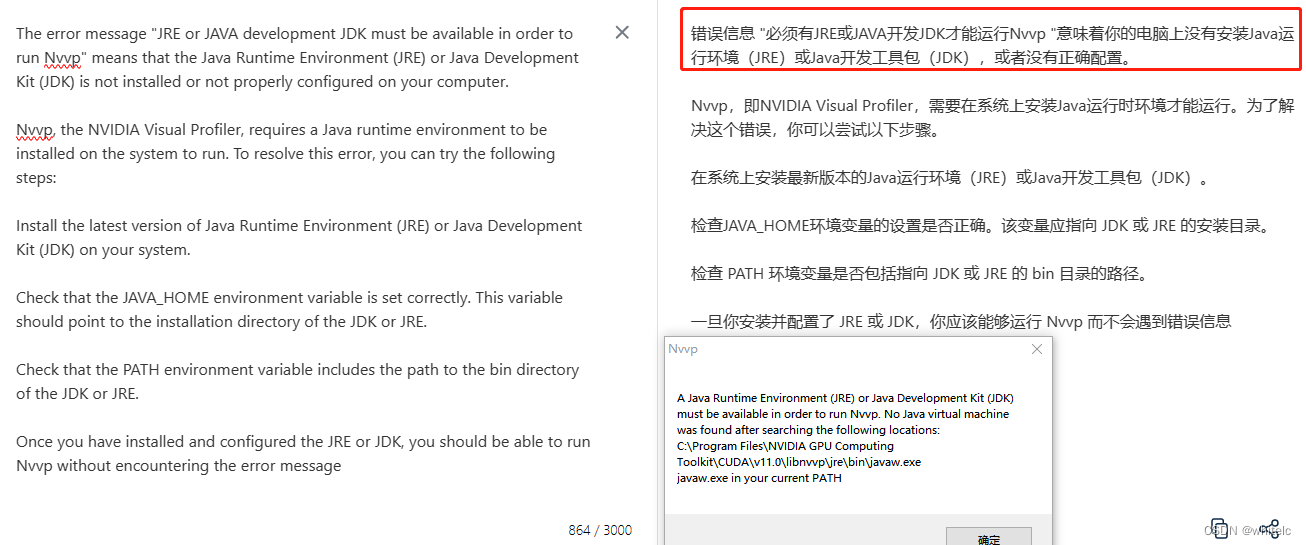
英伟达的官方文档关于nsight-system的
https://docs.nvidia.com/nsight-systems/2020.3/profiling/index.html
NVTX是一种CUDA Profiler的工具
可以用于在CUDA程序中进行标记和注释,以便更好地理解和优化程序的性能。以下是使用NVTX的一些示例代码和步骤:
- 在CUDA代码中包含nvToolsExt.h文件。
#include <nvToolsExt.h>
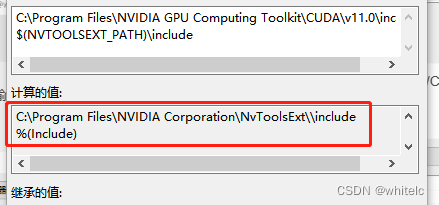
解决:右键cuda项目——属性——配置属性——C/C++——常规——附加包含目录
可能遇到的问题:无法在 Visual Studio 中打开 nvToolsExt.h 文件,可能是因为 Visual Studio 找不到 CUDA 的 include 目录。
错误示范
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include
but我这里没有这个头文件
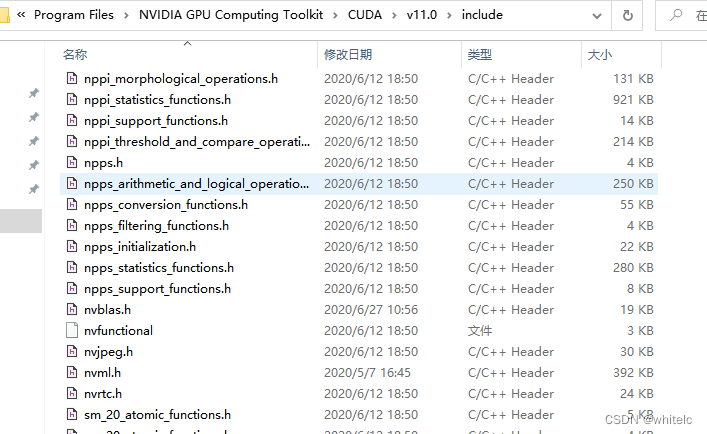
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\common\inc
这个目录下也没有
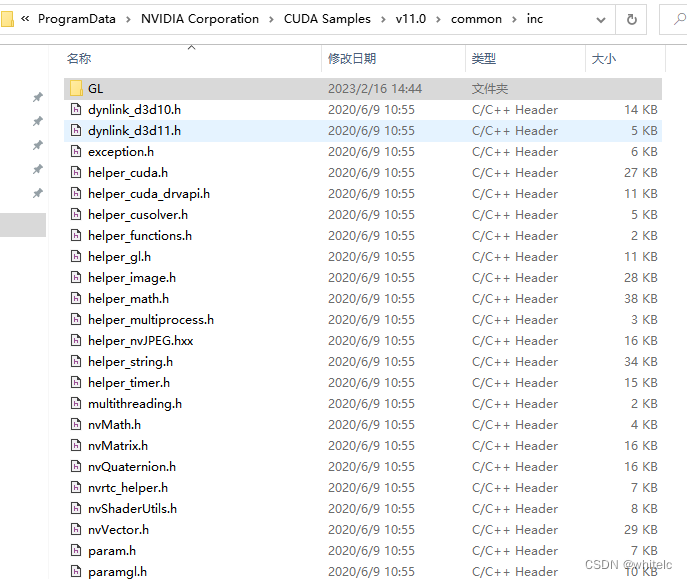
正确示范 可以通过在vs项目属性里面进行设置
第一步:在项目属性页,打开vc++目录(c程序是c目录会略微有些不同),打开外部包含目录,输入:$(NVTOOLSEXT_PATH)\include
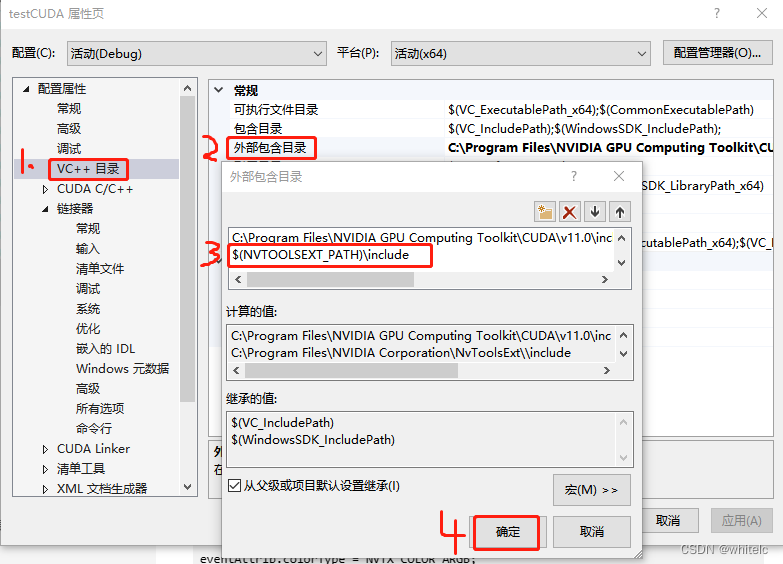
第二步,打开链接器–常规----附加库目录,输入:$(NVTOOLSEXT_PATH)\lib\$(Platform)
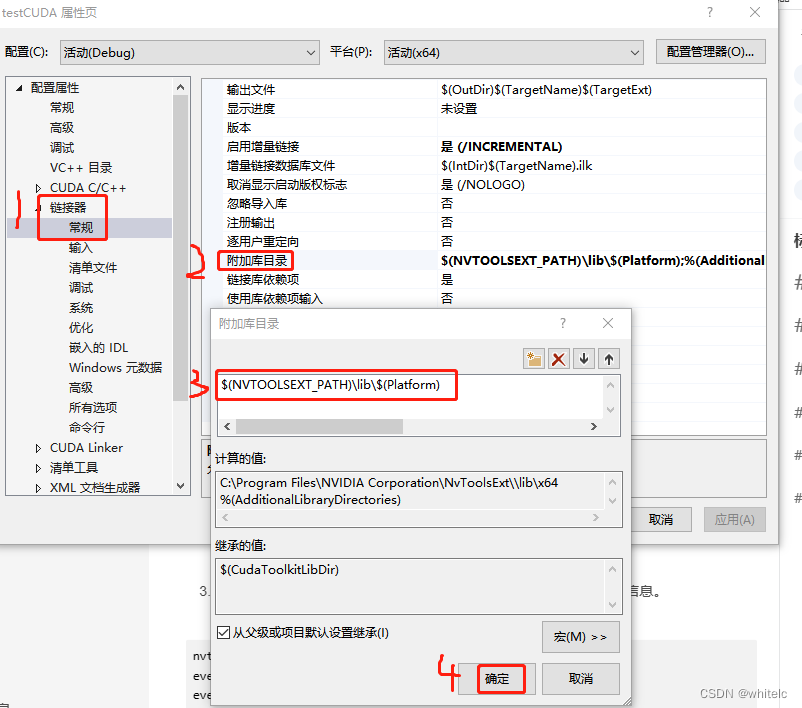
第三步,打开链接器–输入—附加依赖项,输入:nvToolsExt64_1.lib
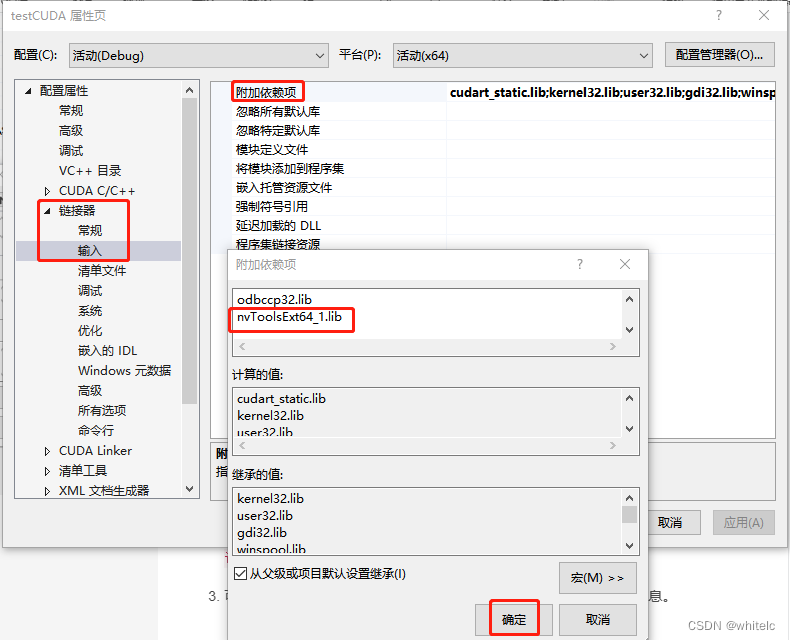
在 .cu 文件中注释代码,还应该设置:打开CUDA C/C+±-common—附加依赖项,输入:$(NVTOOLSEXT_PATH)\include
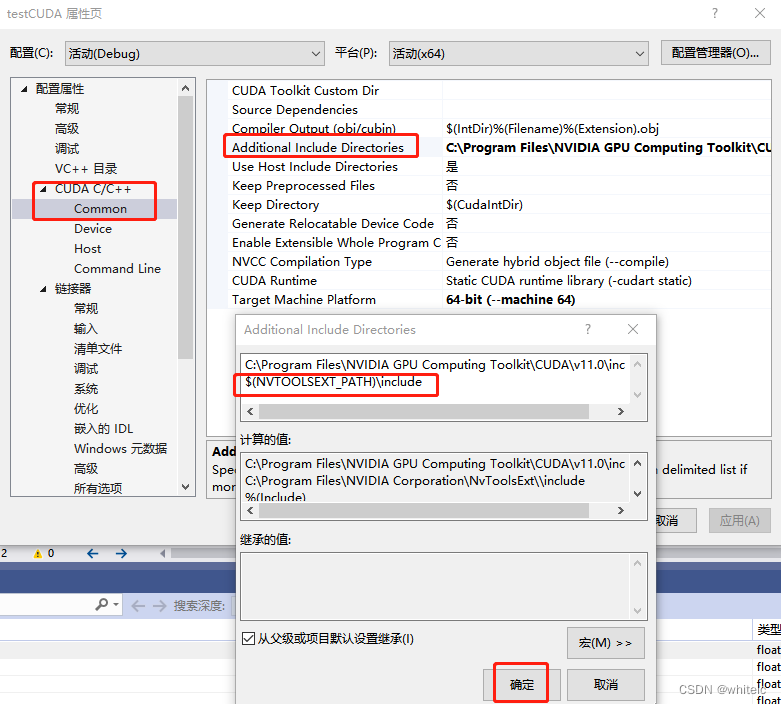
英伟达官方NVTX文档
https://docs.nvidia.com/nsight-visual-studio-edition/nvtx/index.html
-
在需要标记的代码块前后插入标记函数。
nvtxRangePushA("My Code Block"); // 开始标记代码块 nvtxRangePop(); // 结束标记 -
可以使用nvtxEventAttributes_t结构体自定义标记的颜色和描述等信息。
nvtxEventAttributes_t eventAttrib = {0};
eventAttrib.version = NVTX_VERSION;
eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE;
eventAttrib.colorType = NVTX_COLOR_ARGB;
eventAttrib.color = 0xFF00FF00;
eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII;
eventAttrib.message.ascii = "My Custom Event";
nvtxRangePushEx(&eventAttrib);
// 代码块
nvtxRangePop();- 还可以使用nvtxMarkA()函数在代码中插入注释。
nvtxMarkA("My Comment");- 在运行程序时,可以使用nvprof或Nvvp等工具来查看标记和注释。
注意:使用NVTX可能会对程序的性能产生一定的影响
cuda运行时间记录
在python里面
异步计算的结果是没有同步的时间测量是不准确的。要获得精确的测量值,应该在测量前调用 torch.cuda.synchronize(),或者使用 torch.cuda.Event 记录时间,如下所示:
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
start_event.record()# 在这里运行一些东西end_event.record()
torch.cuda.synchronize() # 等待事件被记录!
elapsed_time_ms = start_event.elapsed_time(end_event)https://blog.csdn.net/dedell/article/details/121574306
先这样,后续会补充,老师让我去搞二维的共享内存的程序,祝我好运!!!
相关文章:
cuda调试(一)vs2019-windows-Nsight system--nvtx使用,添加nvToolsExt.h文件
cuda调试 由于在编程过程中发现不同的网格块的结构,对最后的代码结果有影响,所以想记录一下解决办法。 CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid cuda context (上下文) context类似于CPU进程上下,表示由管理层 Drive …...

向Spring容器中注入bean有哪几种方式?
文章前言: 写这篇文章的时候,我正在手机上看腾讯课堂的公开课,有讲到 Spring IOC 创建bean有哪几种方式,视频中有提到过 set注入、构造器注入、注解方式注入等等;于是,就想到了写一篇《Spring注入bean有几种…...

如何用 Python采集 <豆某yin片>并作词云图分析 ?
嗨害大家好鸭!我是小熊猫~ 总有那么一句银幕台词能打动人心 总有那么一幕名导名作念念不忘 不知道大家有多久没有放松一下了呢? 本次就来给大家采集一下某瓣电影并做词云分析 康康哪一部才是大家心中的经典呢? 最近又有哪一部可能会成为…...

Python装饰器的具体实用示例
示例1:普通装饰器 def name(n):def func(x):res n(xx)return resreturn funcname def run(x): # run name(run)print(x)if __name__ __main__:run(1) # 2def name(n):def func(*x):res n(xx)return resreturn funcname def run(x): # run name(run)pr…...

谈谈我对Retrofit源码的理解
文章目录一、Retrofit简介二、使用介绍2.1 app / build.gradle添加依赖2.2 创建 Retrofit 实例2.3 创建 API 接口定义文件2.4 使用 Retrofit 进行网络请求三、源码分析3.1 创建 Retrofit 实例: 建造者模式创建Retrofit3.2 实例化API接口: 动态代理模式3.3 获取Observable返回值…...
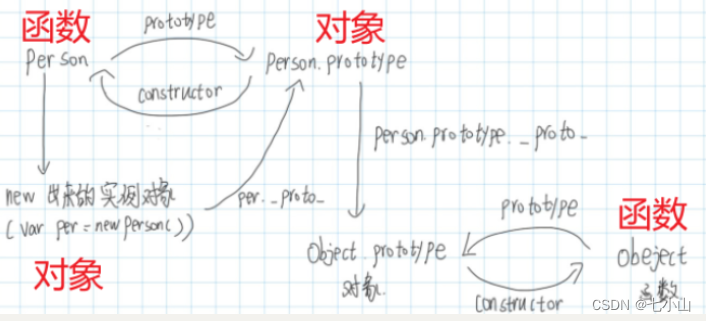
八股文(三)
目录 一、 如何理解原型与原型链 二、 js继承 三、 vuex的使用 1.mutation和action的区别 mutation action 2.Vuex都有哪些API 四、 前端性能优化方法 五、 类型判断 题目 (1)typeof判断哪个类型会出错(即结果不准确)&…...

2023最新实施工程师面试题
1、两电脑都在同一个网络环境中,A 电脑访问不到 B 电脑的共享文件。此现象可能是哪些 方面所导致?怎样处理? 答:首先你要确定是不是在一个工作组内,只有在一个工作组内才可以共享文件,然后看一个看一看有没有防火墙之类的,然后确定文件是不是已经共享 2、 电脑开机时风扇…...
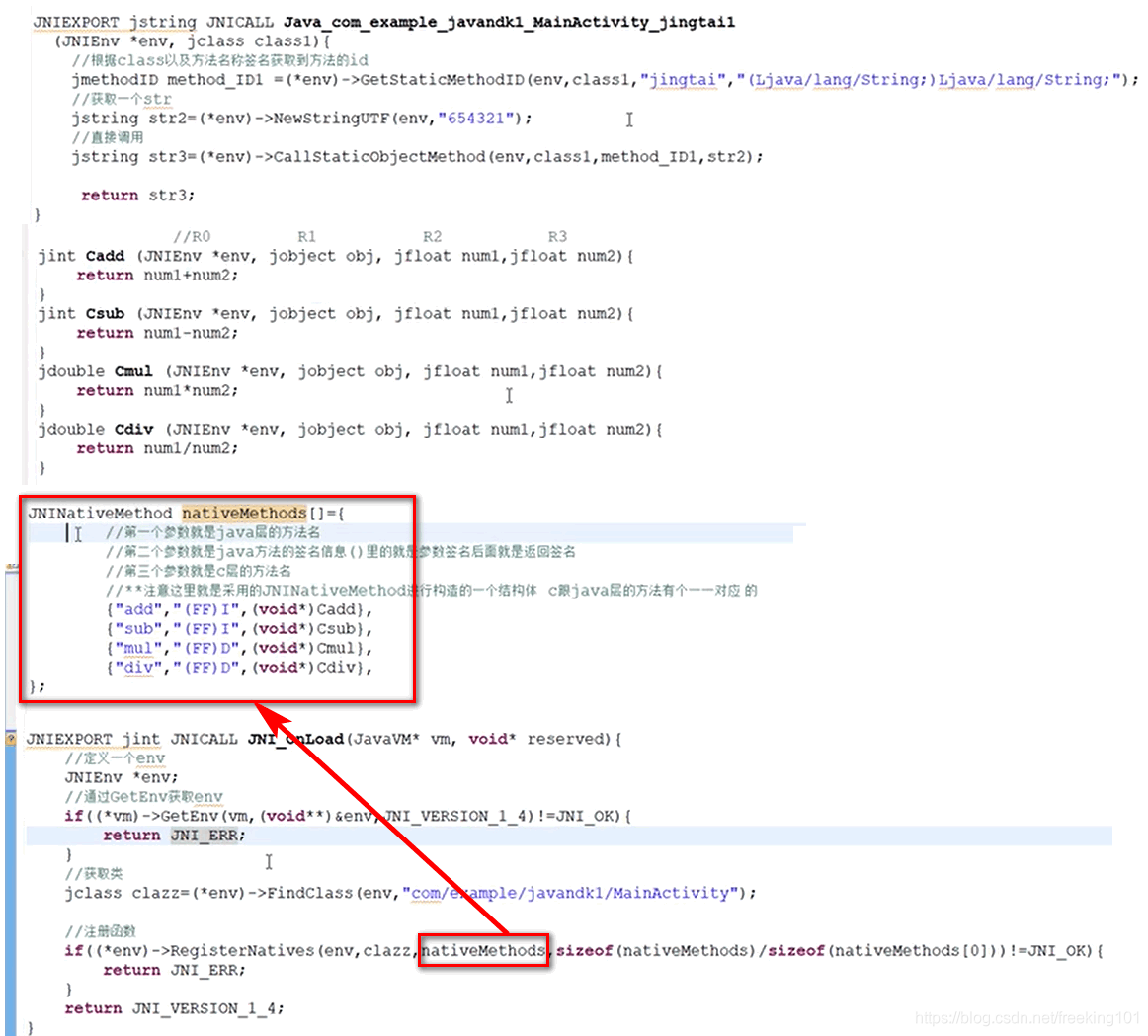
安卓逆向_6 --- JNI 和 NDK
Java 本机接口规范内容:https://docs.oracle.com/en/java/javase/19/docs/specs/jni/index.html JNI官方中文资料:https://blog.csdn.net/yishifu/article/details/52180448 NDK 官方文档:https://developer.android.google.cn/training/ar…...
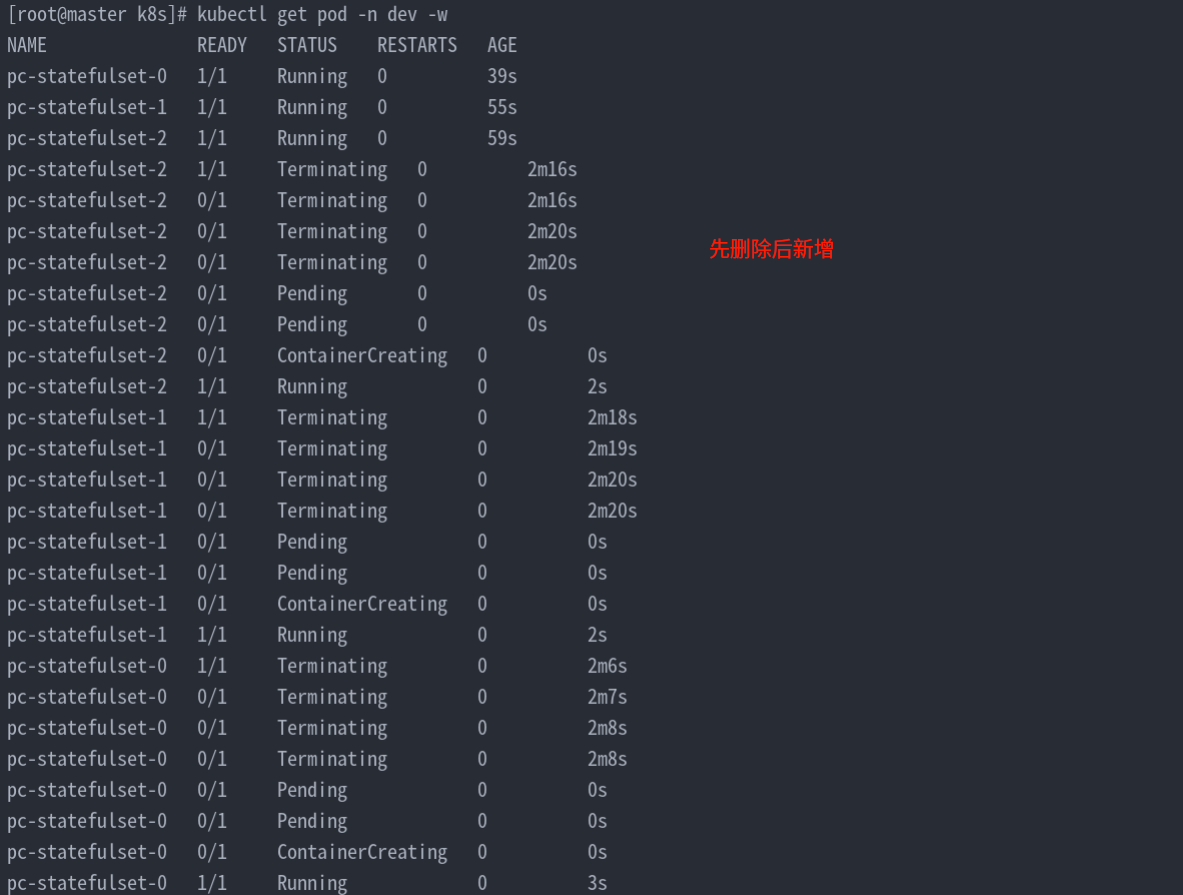
Pod控制器
K8S之控制器详解#简介#在kubernetes中,按照Pod的创建方式可以将其分为两类:自主式:kubernetes直接创建出来的Pod,这种Pod删除后就没有了,也不会重建。控制器创建pod:通过Pod控制器创建的Pod,这种Pod删除之后还会自动重…...
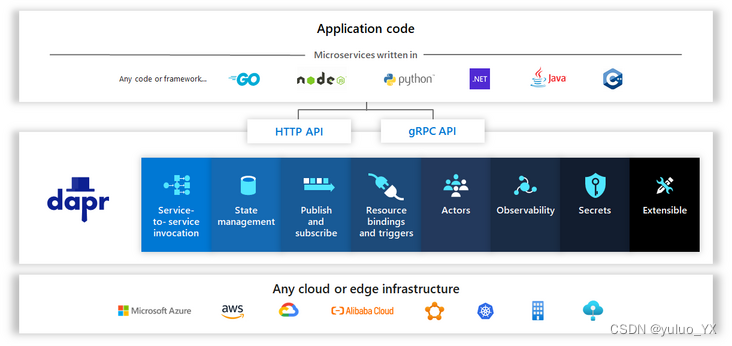
微服务到云原生
微服务到云原生 微服务 微服务架构(Microservice Architecture)是一种架构概念,旨在通过将功能分解到各个离散的服务中以实现对解决方案的解耦。 微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各…...
Spring Security 实现自定义登录和认证(1):使用自定义的用户进行认证
1 SpringSecurity 1.1 导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId> </dependency>1.2 编写配置类 在spring最新版中禁用了WebSecurityConfigurerAdapter…...
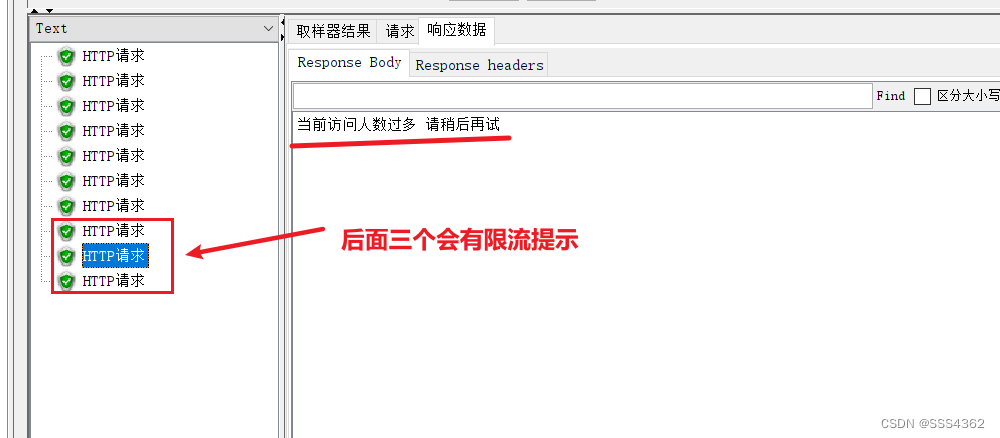
Spring Cloud(微服务)学习篇(七)
Spring Cloud(微服务)学习篇(七) 1.使用代码的方式实现流量限制规则 1.1 变更SentinelController类 1.1.1 加入的代码 //流控限制 (一个或多个资源限流), postConstruct注解的作用是保证项目一启动就会加载,// 一个rule就是一个规则PostConstructpublic void FlowRule(){Li…...

嵌入式安防监控项目——前期知识复习
目录 一、概述 二、C语言 三、数据结构 四、IO进程 五、网络 六、ARM体系结构和接口技术 七、系统移植 八、内核驱动 一、概述 我再报班之前学过51和32,不过都是自学的。报班开始先从应用层入手的,C语言和数据结构。只要是个IT专业的大学这都是必…...

SpringAOP——基础知识
AOP AOP全称是Aspect Oriented Programming 即面向切面编程,是对一类统一事务的集中处理 例如,我们的网页许多地方都需要进行登陆验证,这时就需要在很多地方添加重复的验证代码,而AOP可以集中配置需要登陆验证的地方,…...
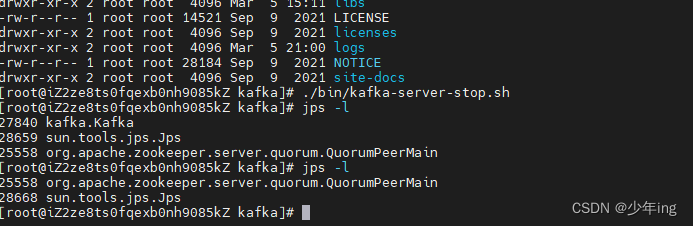
kafka3.0安装使用
一:定义 Kafka传 统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。 Kafka最 新定义 : Kafka是 一个开源的 分 布式事件流平台 (Event St…...
Centos7(阿里云)_安装Mysql8.0
1.安装MySQL 新人可以试用一个月的阿里云,centos7的 一开始可能确实会自带mariadb,所以可以在网上随便找个教程开始尝试安装MySQL,当然大概率出错,然后此时你的rpm下面已经有了一个版本的mysql安装包。 以我为例,随便…...
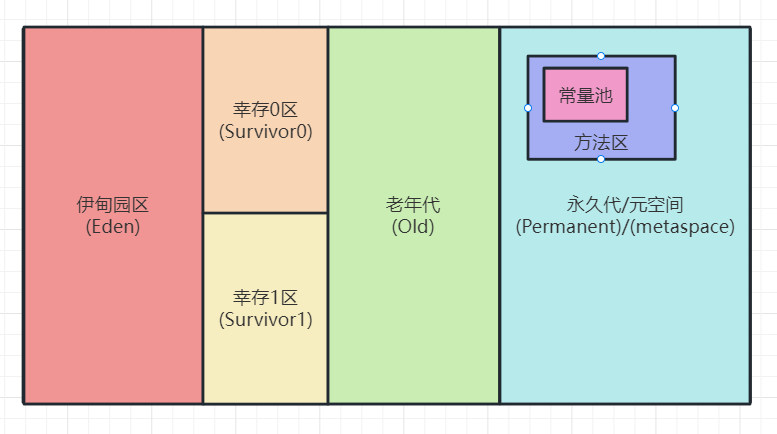
【Java】JVM
一、介绍 1.什么是JVM? JVM是一种用于计算设备的规范,它是一个虚构出来的机器,是通过在实际的计算机上仿真模拟各种功能实现的。JVM包含一套字节码指令集,一组寄存器,一个栈,一个垃圾回收堆和一个存储方法域。JVM屏…...

Linux 和数据库笔记-06
今日内容介绍全天内容无需立马掌握MySQL 的高级功能应用数据库设计ER模型定义: E 代表实体(数据表), R 代表联系(数据表之间对应的字段)关系常见分类一对一一对多多对多外键如果…...

MySQL面试题-事务篇
1.事务的特性(ACID) 事务(Transaction)是指一组操作被看作是一个不可分割的工作单元,这组操作要么全部执行成功,要么全部执行失败。事务的特性通常用 ACID 四个单词来描述,它们分别代表原子性&…...

Linux嵌入式开发 | 汇编驱动LED(1)
文章目录🚗 🚗Linux嵌入式开发 | 汇编驱动LED(1)🚗 🚗初始化IO🚗 🚗STM32🚗 🚗使能GPIO时钟🚗 🚗设置IO复用🚗 Ƕ…...

Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生
Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 你是否曾为模糊的老照片感到无奈&a…...

城通网盘解析工具终极指南:免费获取高速直连下载地址
城通网盘解析工具终极指南:免费获取高速直连下载地址 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的下载速度?每次下载文件都要面对漫长的等待…...

3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南
3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否在使用Windows 11 24H2 LT…...

Boss直聘职位数据自动化采集:Python爬虫架构设计与工程实践
1. 项目概述与核心价值最近在技术社区里,看到不少朋友在讨论一个叫longsizhuo/BossZhiPin_Job_Search的项目。光看名字,你大概就能猜到,这是一个跟“Boss直聘”和“职位搜索”相关的自动化工具。作为一个在招聘数据分析和自动化领域摸爬滚打了…...

智慧树自动刷课终极指南:3分钟快速上手Autovisor免费工具
智慧树自动刷课终极指南:3分钟快速上手Autovisor免费工具 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 还在为智慧树网课的手动操作烦恼吗&#…...

NCM格式转换实战指南:ncmdumpGUI全面解析
NCM格式转换实战指南:ncmdumpGUI全面解析 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾为网易云音乐下载的NCM格式音乐无法在其他设备播…...

合宙Air153C看门狗芯片:嵌入式系统可靠性的硬件守护方案
1. 项目概述:一颗“小而美”的国产看门狗芯片最近在做一个低功耗的户外监测设备项目,主控用的就是合宙的Air系列MCU。在调试过程中,最让我头疼的就是系统偶尔的“死机”问题。设备部署在野外,不可能每次都跑过去手动重启。正当我琢…...

82.人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案
人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案 一、问题场景:测试环境改了 Prompt,结果生产回答变了 很多大模型项目早期只有一个环境: 一套 Prompt 一个知识库 一个模型地址 一个配置表开发、测试、运营都在同一套配置…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十三)用户指引自助教学源码—东方仙盟
代码<!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8"> <meta http-equiv"X-UA-Compatible" content"IEedge,chrome1"> <title>你的导师-未来之窗</title> <style>*…...

安得医疗冲刺港股:年营收9亿,利润1.5亿 上海亿瑞控制41%股权
雷递网 雷建平 5月16日山东安得医疗用品股份有限公司(简称:“安得医疗”)日前递交招股书,准备在港交所上市。截至2023年、2024年及2025年12月31日止年度,安得医疗分别宣派及派付股息6670万元、4670万元及4000万元。年营…...