transformer--transformer模型构建和测试
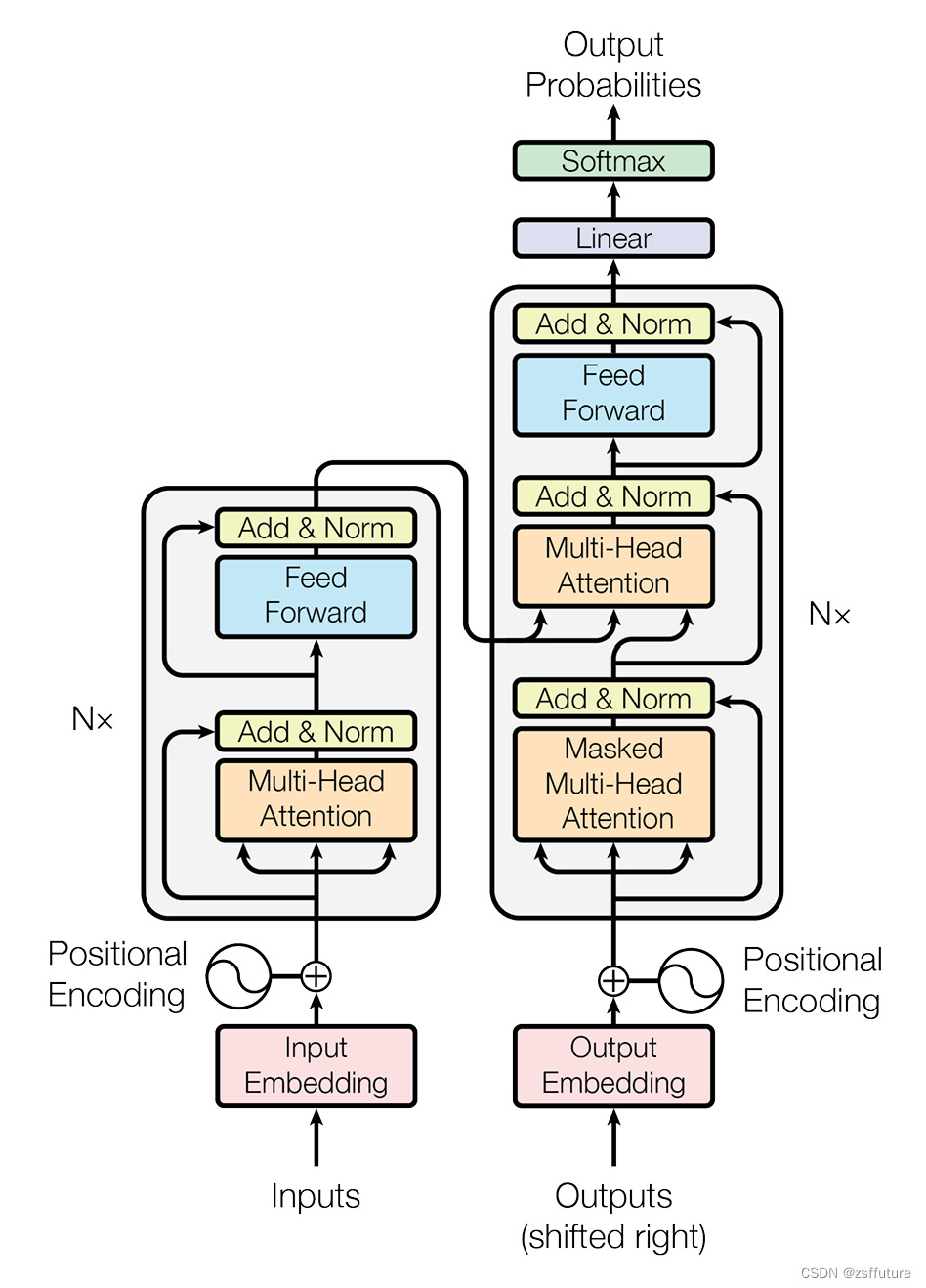
前面几节进行了各种组件的学习和编码,本节将组件组成transformer,并对其进行测试
EncoderDecoder 编码器解码器构建
使用EnconderDecoder实现编码器-解码器结构
# 使用EncoderDeconder类实现编码器和解码器class EncoderDecoder(nn.Module):def __init__(self, encoder, decoder, sourc_embed, target_embed, generator) -> None:"""encoder: 编码器对象decoder: 解码器对象sourc_embed: 源数据嵌入函数target_embed: 目标数据嵌入函数generator: 输出部分的类别生成器"""super(EncoderDecoder,self).__init__()self.encoder = encoderself.decoder = decoderself.src_embed = sourc_embedself.tgt_embed = target_embedself.generator = generatordef encode(self,source, source_mask):"""source: 源数据source_mask: 源数据的mask"""return self.encoder(self.src_embed(source), source_mask)def decode(self, memory, source_mask, target,target_mask):return self.decoder(self.tgt_embed(target), memory, source_mask,target_mask)def forward(self,source, target, source_mask, target_mask):return self.decode(self.encode(source, source_mask), source_mask,target,target_mask)测试代码放在最后,测试结果如下:
ed_result.shape: torch.Size([2, 4, 512])
ed_result: tensor([[[ 2.2391, -0.1173, -1.0894, ..., 0.9693, -0.9286, -0.4191],[ 1.4016, 0.0187, -0.0564, ..., 0.9323, 0.0403, -0.5115],[ 1.3623, 0.0854, -0.7648, ..., 0.9763, 0.6179, -0.1512],[ 1.6840, -0.3144, -0.6535, ..., 0.7420, 0.0729, -0.2303]],[[ 0.8726, -0.1610, -0.0819, ..., -0.6603, 2.1003, -0.4165],[ 0.5404, 0.8091, 0.8205, ..., -1.4623, 2.5762, -0.6019],[ 0.9892, -0.3134, -0.4118, ..., -1.1656, 1.0373, -0.3784],[ 1.3170, 0.3997, -0.3412, ..., -0.6014, 0.7564, -1.0851]]],grad_fn=<AddBackward0>)Transformer模型构建
# Tansformer模型的构建过程代码
def make_model(source_vocab, target_vocab, N=6,d_model=512, d_ff=2048, head=8, dropout=0.1):"""该函数用来构建模型,有7个参数,分别是源数据特征(词汇)总数,目标数据特征(词汇)总数,编码器和解码器堆叠数,词向量映射维度,前馈全连接网络中变换矩阵的维度,多头注意力结构中的多头数,以及置零比率dropout"""c = copy.deepcopy#实例化多头注意力attn = MultiHeadedAttention(head, d_mode)# 实例化前馈全连接层 得到对象ffff = PositionalEncoding(d_mode, dropout)# 实例化位置编码类,得到对象positionposition = PositionalEncoding(d_mode,dropout)# 根据结构图,最外层是EncoderDecoder,在EncoderDecoder中,# 分别是编码器层,解码器层,源数据Embedding层和位置编码组成的有序结构# 目标数据Embedding层和位置编码组成的有序结构,以及类别生成器层。在编码器层中有attention子层以及前馈全连接子层,# 在解码器层中有两个attention子层以及前馈全连接层model =EncoderDecoder(Encoder(EncoderLayer(d_mode, c(attn), c(ff), dropout),N),Decoder(DecoderLayer(d_mode, c(attn), c(attn),c(ff),dropout),N),nn.Sequential(Embeddings(d_mode,source_vocab), c(position)),nn.Sequential(Embeddings(d_mode, target_vocab), c(position)),Generator(d_mode, target_vocab))# 模型结构完成后,接下来就是初始化模型中的参数,比如线性层中的变换矩阵,这里一但判断参数的维度大于1,# 则会将其初始化成一个服从均匀分布的矩阵for p in model.parameters():if p.dim()>1:nn.init.xavier_uniform(p)return model测试代码
import numpy as np
import torch
import torch.nn.functional as F
import torch.nn as nn
import matplotlib.pyplot as plt
import math
import copy
from inputs import Embeddings,PositionalEncoding
from encoder import subsequent_mask,attention,clones,MultiHeadedAttention,PositionwiseFeedForward,LayerNorm,SublayerConnection,Encoder,EncoderLayer
# encode 代码在前面几节# 解码器层的类实现
class DecoderLayer(nn.Module):def __init__(self, size, self_attn, src_attn, feed_forward,dropout) -> None:"""size : 词嵌入维度self_attn:多头自注意对象,需要Q=K=Vsrc_attn:多头注意力对象,这里Q!=K=Vfeed_forward: 前馈全连接层对象"""super(DecoderLayer,self).__init__()self.size = sizeself.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forward# 根据论文图使用clones克隆三个子层对象self.sublayer = clones(SublayerConnection(size,dropout), 3)def forward(self, x, memory, source_mask, target_mask):"""x : 上一层的输入memory: 来自编码器层的语义存储变量source_mask: 源码数据掩码张量,针对就是输入到解码器的数据target_mask: 目标数据掩码张量,针对解码器最后生成的数据,一个一个的推理生成的词"""m = memory# 将x传入第一个子层结构,第一个子层结构输入分别是x和self_attn函数,因为是自注意力机制,所以Q=K=V=x# 最后一个参数是目标数据掩码张量,这时要对目标数据进行掩码,因为此时模型可能还没有生成任何目标数据,# 比如在解码器准备生成第一个字符或词汇时,我们其实已经传入第一个字符以便计算损失# 但是我们不希望在生成第一个字符时模型能利用这个信息,因为我们会将其遮掩,同样生成第二个字符或词汇时# 模型只能使用第一个字符或词汇信息,第二个字符以及以后得信息都不允许被模型使用x = self.sublayer[0](x, lambda x: self.self_attn(x,x,x,target_mask))# 紧接着第一层的输出进入第二个子层,这个子层是常规的注意力机制,但是q是输入x;k、v是编码层输出memory# 同样也传入source_mask, 但是进行源数据遮掩的原因并非是抑制信息泄露,而是遮蔽掉对结果没有意义的的字符而产生的注意力# 以此提升模型的效果和训练速度,这样就完成第二个子层的处理x = self.sublayer[1](x, lambda x: self.src_attn(x,m,m,source_mask))# 最后一个子层就是前馈全连接子层,经过他的处理后就可以返回结果,这就是解码器层的结构return self.sublayer[2](x,self.feed_forward)# 解码器
class Decoder(nn.Module):def __init__(self,layer,N) -> None:""" layer: 解码器层, N:解码器层的个数"""super(Decoder,self).__init__()self.layers = clones(layer,N)self.norm = LayerNorm(layer.size)def forward(self, x, memory,source_mask, target_mask):# x:目标数据的嵌入表示# memory:编码器的输出# source_mask: 源数据的掩码张量# target_mask: 目标数据的掩码张量for layer in self.layers:x = layer(x,memory,source_mask,target_mask)return self.norm(x)# 输出
class Generator(nn.Module):def __init__(self,d_mode, vocab_size) -> None:"""d_mode: 词嵌入vocab_size: 词表大小"""super(Generator,self).__init__()self.project = nn.Linear(d_mode, vocab_size)def forward(self, x):return F.log_softmax(self.project(x),dim=-1)# 使用EncoderDeconder类实现编码器和解码器class EncoderDecoder(nn.Module):def __init__(self, encoder, decoder, sourc_embed, target_embed, generator) -> None:"""encoder: 编码器对象decoder: 解码器对象sourc_embed: 源数据嵌入函数target_embed: 目标数据嵌入函数generator: 输出部分的类别生成器"""super(EncoderDecoder,self).__init__()self.encoder = encoderself.decoder = decoderself.src_embed = sourc_embedself.tgt_embed = target_embedself.generator = generatordef encode(self,source, source_mask):"""source: 源数据source_mask: 源数据的mask"""return self.encoder(self.src_embed(source), source_mask)def decode(self, memory, source_mask, target,target_mask):return self.decoder(self.tgt_embed(target), memory, source_mask,target_mask)def forward(self,source, target, source_mask, target_mask):return self.decode(self.encode(source, source_mask), source_mask,target,target_mask)# Tansformer模型的构建过程代码
def make_model(source_vocab, target_vocab, N=6,d_model=512, d_ff=2048, head=8, dropout=0.1):"""该函数用来构建模型,有7个参数,分别是源数据特征(词汇)总数,目标数据特征(词汇)总数,编码器和解码器堆叠数,词向量映射维度,前馈全连接网络中变换矩阵的维度,多头注意力结构中的多头数,以及置零比率dropout"""c = copy.deepcopy#实例化多头注意力attn = MultiHeadedAttention(head, d_mode)# 实例化前馈全连接层 得到对象ffff = PositionalEncoding(d_mode, dropout)# 实例化位置编码类,得到对象positionposition = PositionalEncoding(d_mode,dropout)# 根据结构图,最外层是EncoderDecoder,在EncoderDecoder中,# 分别是编码器层,解码器层,源数据Embedding层和位置编码组成的有序结构# 目标数据Embedding层和位置编码组成的有序结构,以及类别生成器层。在编码器层中有attention子层以及前馈全连接子层,# 在解码器层中有两个attention子层以及前馈全连接层model =EncoderDecoder(Encoder(EncoderLayer(d_mode, c(attn), c(ff), dropout),N),Decoder(DecoderLayer(d_mode, c(attn), c(attn),c(ff),dropout),N),nn.Sequential(Embeddings(d_mode,source_vocab), c(position)),nn.Sequential(Embeddings(d_mode, target_vocab), c(position)),Generator(d_mode, target_vocab))# 模型结构完成后,接下来就是初始化模型中的参数,比如线性层中的变换矩阵,这里一但判断参数的维度大于1,# 则会将其初始化成一个服从均匀分布的矩阵for p in model.parameters():if p.dim()>1:nn.init.xavier_uniform(p)return modelif __name__ == "__main__":# 词嵌入dim = 512vocab =1000emb = Embeddings(dim,vocab)x = torch.LongTensor([[100,2,321,508],[321,234,456,324]])embr =emb(x)print("embr.shape = ",embr.shape)# 位置编码pe = PositionalEncoding(dim,0.1) # 位置向量的维度是20,dropout是0pe_result = pe(embr)print("pe_result.shape = ",pe_result.shape)# 编码器测试size = 512dropout=0.2head=8d_model=512d_ff = 64c = copy.deepcopyx = pe_resultself_attn = MultiHeadedAttention(head,d_model,dropout)ff = PositionwiseFeedForward(d_model,d_ff,dropout)# 编码器层不是共享的,因此需要深度拷贝layer= EncoderLayer(size,c(self_attn),c(ff),dropout)N=8mask = torch.zeros(8,4,4)en = Encoder(layer,N)en_result = en(x,mask)print("en_result.shape : ",en_result.shape)print("en_result : ",en_result)# 解码器层测试size = 512dropout=0.2head=8d_model=512d_ff = 64self_attn = src_attn = MultiHeadedAttention(head,d_model,dropout)ff = PositionwiseFeedForward(d_model,d_ff,dropout)x = pe_resultmask = torch.zeros(8,4,4)source_mask = target_mask = maskmemory = en_resultdl = DecoderLayer(size,self_attn,src_attn,ff,dropout)dl_result = dl(x,memory,source_mask,target_mask)print("dl_result.shape = ", dl_result.shape)print("dl_result = ", dl_result)# 解码器测试size = 512dropout=0.2head=8d_model=512d_ff = 64memory = en_resultc = copy.deepcopyx = pe_resultself_attn = MultiHeadedAttention(head,d_model,dropout)ff = PositionwiseFeedForward(d_model,d_ff,dropout)# 编码器层不是共享的,因此需要深度拷贝layer= DecoderLayer(size,c(self_attn),c(self_attn),c(ff),dropout)N=8mask = torch.zeros(8,4,4)source_mask = target_mask = maskde = Decoder(layer,N)de_result = de(x,memory,source_mask, target_mask)print("de_result.shape : ",de_result.shape)print("de_result : ",de_result)# 输出测试d_model = 512vocab =1000x = de_resultgen = Generator(d_mode=d_model,vocab_size=vocab)gen_result = gen(x)print("gen_result.shape :", gen_result.shape)print("gen_result: ", gen_result)# encoderdeconder 测试vocab_size = 1000d_mode = 512encoder = endecoder= desource_embed = nn.Embedding(vocab_size, d_mode)target_embed = nn.Embedding(vocab_size, d_mode)generator = gensource = target = torch.LongTensor([[100,2,321,508],[321,234,456,324]])source_mask = target_mask = torch.zeros(8,4,4)ed = EncoderDecoder(encoder, decoder, source_embed, target_embed, generator)ed_result = ed(source, target, source_mask, target_mask)print("ed_result.shape: ", ed_result.shape)print("ed_result: ", ed_result)# transformer 测试source_vocab = 11target_vocab = 11N=6# 其他参数使用默认值res = make_model(source_vocab, target_vocab,6)print(res)
打印模型层结构:
EncoderDecoder((encoder): Encoder((layers): ModuleList((0): EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(1): EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(2): EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(3): EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(4): EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(5): EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False)))))(norm): LayerNorm())(decoder): Decoder((layers): ModuleList((0): DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(src_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(2): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(1): DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(src_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(2): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(2): DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(src_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(2): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(3): DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(src_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(2): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(4): DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(src_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(2): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))))(5): DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(src_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512, bias=True)(1): Linear(in_features=512, out_features=512, bias=True)(2): Linear(in_features=512, out_features=512, bias=True)(3): Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False))(2): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False)))))(norm): LayerNorm())(src_embed): Sequential((0): Embeddings((lut): Embedding(11, 512))(1): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False)))(tgt_embed): Sequential((0): Embeddings((lut): Embedding(11, 512))(1): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False)))(generator): Generator((project): Linear(in_features=512, out_features=11, bias=True))
)测试Transformer运行
我们将通过一个小的copy任务完成模型的基本测试工作
copy任务介绍:
任务描述:
针对数字序列进行学习,学习的最终目标是使输出与输入的序列相同.如输入[1,5,8,9,3],输出也是[1,5,8,9,3].
任务意义:
copy任务在模型基础测试中具有重要意义,因为copy操作对于模型来讲是一条明显规律,因此模型能否在短时间内,小数据集中学会它,可以帮助我们断定模型所有过程是否正常,是否已具备基本学习能力.
使用copy任务进行模型基本测试的四步曲:
第一步: 构建数据集生成器
第二步: 获得Transformer模型及其优化器和损失函数
第三步: 运行模型进行训练和评估
第四步: 使用模型进行贪婪解码
code
from transformer import make_model
import torch
import numpy as npfrom pyitcast.transformer_utils import Batch# 第一步: 构建数据集生成器
def data_generator(V, batch, num_batch):# 该函数用于随机生成copy任务的数据,它的三个输入参数是V:随机生成数字的最大值+1,# batch:每次输送给模型更新一次参数的数据量,num_batch:-共输送num_batch次完成一轮for i in range(num_batch):data = torch.from_numpy(np.random.randint(1,V, size=(batch,10),dtype="int64"))data[:,0]=1source = torch.tensor(data,requires_grad=False)target = torch.tensor(data, requires_grad=False)yield Batch(source, target)# 第二步: 获得Transformer模型及其优化器和损失函数
# 导入优化器工具包get_std_opt,该工具用于获得标准的针对Transformer模型的优化器
# 该标准优化器基于Adam优化器,使其对序列到序列的任务更有效
from pyitcast.transformer_utils import get_std_opt
# 导入标签平滑工具包,该工具用于标签平滑,标签平滑的作用就是小幅度的改变原有标签值的值域
# 因为在理论上即使是人工的标注数据也可能并非完全正确,会受到一些外界因素的影响而产生一些微小的偏差
# 因此使用标签平滑来弥补这种偏差,减少模型对某一条规律的绝对认知,以防止过拟合。通过下面示例了解更清晰
from pyitcast.transformer_utils import LabelSmoothing
# 导入损失计算工具包,该工具能够使用标签平滑后的结果进行损失的计算,
# 损失的计算方法可以认为是交叉熵损失函数。
from pyitcast.transformer_utils import SimpleLossCompute# 将生成0-10的整数
V = 11
# 每次喂给模型20个数据进行更新参数
batch = 20
# 连续喂30次完成全部数据的遍历,也就是一轮
num_batch = 30# 使用make_model构建模型
model = make_model(V,V,N=2)
print(model.src_embed[0])
# 使用get_std_opt获得模型优化器
model_optimizer = get_std_opt(model)
# 使用labelSmoothing获得标签平滑对象
# 使用LabelSmoothing实例化一个crit对象。
# 第一个参数size代表目标数据的词汇总数,也是模型最后一层得到张量的最后一维大小
# 这里是5说明目标词汇总数是5个,第二个参数padding_idx表示要将那些tensor中的数字
# 替换成0,一般padding_idx=0表示不进行替换。第三个参数smoothing,表示标签的平滑程度
# 如原来标签的表示值为1,则平滑后它的值域变为[1-smoothing,1+smoothing].
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
# 使用SimpleLossCompute获取到标签平滑结果的损失计算方法
loss = SimpleLossCompute(model.generator,criterion,model_optimizer)# 第三步: 运行模型进行训练和评估
from pyitcast.transformer_utils import run_epochdef run(model, loss, epochs=10):for epoch in range(epochs):# 进入训练模式,所有参数更新model.train()# 训练时batchsize是20run_epoch(data_generator(V,8,20),model,loss)model.eval()run_epoch(data_generator(V,8,5),model,loss)if __name__ == "__main__":# 将生成0-10的整数V = 11# 每次喂给模型20个数据进行更新参数batch = 20# 连续喂30次完成全部数据的遍历,也就是一轮num_batch = 30res = data_generator(V,batch, num_batch)run(model, loss)如果直接跑上面的可能会报错,报错的主要原因是 pyitcast主要是针对pytorch 的版本很低,但是好像这个库也不升级了,所以你如果想要跑通,就需要修改下面两个地方:
第一个错误:'Embeddings' object has no attribute 'd_model'

从上面可以看到,get_std_opt需要用到嵌入向量的维度,但是没有这个值,这个时候可以从两个地方修改,一个是我们embeding的类增加这个属性即:
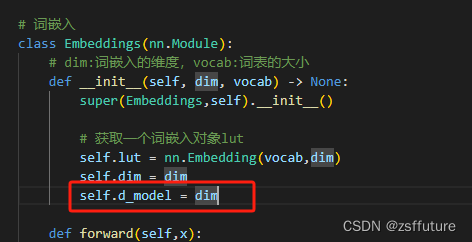
第二种方法,直接进入 get_std_opt函数里面,修改这个参数

以上两个都可以解决问题
第二个问题:RuntimeError: scatter(): Expected dtype int64 for index
这个属于数据类型的问题,主要是在生成训练数据时的问题,如下修改:

这样就可以正常训练了
输出:
Epoch Step: 1 Loss: 3.169641 Tokens per Sec: 285.952789
Epoch Step: 1 Loss: 2.517479 Tokens per Sec: 351.509888
Epoch Step: 1 Loss: 2.595001 Tokens per Sec: 294.475616
Epoch Step: 1 Loss: 2.108872 Tokens per Sec: 476.050293
Epoch Step: 1 Loss: 2.229053 Tokens per Sec: 387.324188
Epoch Step: 1 Loss: 1.810681 Tokens per Sec: 283.639557
Epoch Step: 1 Loss: 2.047313 Tokens per Sec: 394.773773
Epoch Step: 1 Loss: 1.724596 Tokens per Sec: 415.394714
Epoch Step: 1 Loss: 1.850358 Tokens per Sec: 421.050873
Epoch Step: 1 Loss: 1.668582 Tokens per Sec: 368.275421
Epoch Step: 1 Loss: 2.005047 Tokens per Sec: 424.458466
Epoch Step: 1 Loss: 1.632835 Tokens per Sec: 408.158966
Epoch Step: 1 Loss: 1.698805 Tokens per Sec: 441.689392
Epoch Step: 1 Loss: 1.567691 Tokens per Sec: 392.488251
Epoch Step: 1 Loss: 1.765411 Tokens per Sec: 428.815796
Epoch Step: 1 Loss: 1.492155 Tokens per Sec: 426.288910
Epoch Step: 1 Loss: 1.541114 Tokens per Sec: 411.078918
Epoch Step: 1 Loss: 1.469818 Tokens per Sec: 454.231476
Epoch Step: 1 Loss: 1.677189 Tokens per Sec: 431.382690
Epoch Step: 1 Loss: 1.377327 Tokens per Sec: 433.725250
引入贪婪解码,并进行了训练测试
from transformer import make_model
import torch
import numpy as npfrom pyitcast.transformer_utils import Batch# 第一步: 构建数据集生成器
def data_generator(V, batch, num_batch):# 该函数用于随机生成copy任务的数据,它的三个输入参数是V:随机生成数字的最大值+1,# batch:每次输送给模型更新一次参数的数据量,num_batch:-共输送num_batch次完成一轮for i in range(num_batch):data = torch.from_numpy(np.random.randint(1,V, size=(batch,10),dtype="int64"))data[:,0]=1source = torch.tensor(data,requires_grad=False)target = torch.tensor(data, requires_grad=False)yield Batch(source, target)# 第二步: 获得Transformer模型及其优化器和损失函数
# 导入优化器工具包get_std_opt,该工具用于获得标准的针对Transformer模型的优化器
# 该标准优化器基于Adam优化器,使其对序列到序列的任务更有效
from pyitcast.transformer_utils import get_std_opt
# 导入标签平滑工具包,该工具用于标签平滑,标签平滑的作用就是小幅度的改变原有标签值的值域
# 因为在理论上即使是人工的标注数据也可能并非完全正确,会受到一些外界因素的影响而产生一些微小的偏差
# 因此使用标签平滑来弥补这种偏差,减少模型对某一条规律的绝对认知,以防止过拟合。通过下面示例了解更清晰
from pyitcast.transformer_utils import LabelSmoothing
# 导入损失计算工具包,该工具能够使用标签平滑后的结果进行损失的计算,
# 损失的计算方法可以认为是交叉熵损失函数。
from pyitcast.transformer_utils import SimpleLossCompute# 将生成0-10的整数
V = 11
# 每次喂给模型20个数据进行更新参数
batch = 20
# 连续喂30次完成全部数据的遍历,也就是一轮
num_batch = 30# 使用make_model构建模型
model = make_model(V,V,N=2)# 使用get_std_opt获得模型优化器
model_optimizer = get_std_opt(model)
# 使用labelSmoothing获得标签平滑对象
# 使用LabelSmoothing实例化一个crit对象。
# 第一个参数size代表目标数据的词汇总数,也是模型最后一层得到张量的最后一维大小
# 这里是5说明目标词汇总数是5个,第二个参数padding_idx表示要将那些tensor中的数字
# 替换成0,一般padding_idx=0表示不进行替换。第三个参数smoothing,表示标签的平滑程度
# 如原来标签的表示值为1,则平滑后它的值域变为[1-smoothing,1+smoothing].
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
# 使用SimpleLossCompute获取到标签平滑结果的损失计算方法
loss = SimpleLossCompute(model.generator,criterion,model_optimizer)# 第三步: 运行模型进行训练和评估
from pyitcast.transformer_utils import run_epochdef run(model, loss, epochs=10):for epoch in range(epochs):# 进入训练模式,所有参数更新model.train()# 训练时batchsize是20run_epoch(data_generator(V,8,20),model,loss)model.eval()run_epoch(data_generator(V,8,5),model,loss)# 引入贪婪解码
# 导入贪婪解码工具包greedy_decode,该工具将对最终结进行贪婪解码贪婪解码的方式是每次预测都选择概率最大的结果作为输出,
# 它不一定能获得全局最优性,但却拥有最高的执行效率。
from pyitcast.transformer_utils import greedy_decode def run_greedy(model, loss, epochs=10):for epoch in range(epochs):# 进入训练模式,所有参数更新model.train()# 训练时batchsize是20run_epoch(data_generator(V,8,20),model,loss)model.eval()run_epoch(data_generator(V,8,5),model,loss)model.eval()# 假定输入张量source = torch.LongTensor([[1,8,3,4,10,6,7,2,9,5]])# 定义源数据掩码张量,因为元素都是1,在我们这里1代表不遮掩因此相当于对源数据没有任何遮掩.source_mask = torch.ones(1,1,10)# 最后将model,src,src_mask,解码的最大长度限制max_len,默认为10# 以及起始标志数字,默认为1,我们这里使用的也是1result = greedy_decode(model, source, source_mask, max_len=10,start_symbol=1)print(result)if __name__ == "__main__":# # 将生成0-10的整数# V = 11# # 每次喂给模型20个数据进行更新参数# batch = 20# # 连续喂30次完成全部数据的遍历,也就是一轮# num_batch = 30# res = data_generator(V,batch, num_batch)# run(model, loss)run_greedy(model, loss,50)输出部分结果:
Epoch Step: 1 Loss: 0.428033 Tokens per Sec: 389.530670
Epoch Step: 1 Loss: 0.317753 Tokens per Sec: 399.060852
Epoch Step: 1 Loss: 0.192723 Tokens per Sec: 387.384308
Epoch Step: 1 Loss: 0.257650 Tokens per Sec: 379.354736
Epoch Step: 1 Loss: 0.487521 Tokens per Sec: 410.506714
Epoch Step: 1 Loss: 0.136969 Tokens per Sec: 388.222687
Epoch Step: 1 Loss: 0.119838 Tokens per Sec: 375.405731
Epoch Step: 1 Loss: 0.250391 Tokens per Sec: 408.776367
Epoch Step: 1 Loss: 0.376862 Tokens per Sec: 419.787231
Epoch Step: 1 Loss: 0.163561 Tokens per Sec: 393.896088
Epoch Step: 1 Loss: 0.303041 Tokens per Sec: 395.884857
Epoch Step: 1 Loss: 0.126261 Tokens per Sec: 386.709167
Epoch Step: 1 Loss: 0.237891 Tokens per Sec: 376.114075
Epoch Step: 1 Loss: 0.139017 Tokens per Sec: 405.207336
Epoch Step: 1 Loss: 0.414842 Tokens per Sec: 389.219666
Epoch Step: 1 Loss: 0.207141 Tokens per Sec: 392.840820
tensor([[ 1, 8, 3, 4, 10, 6, 7, 2, 9, 5]])从上面的代码可以看出测试输入的 是 source = torch.LongTensor([[1,8,3,4,10,6,7,2,9,5]])
推理出来的结果是完全正确的,因为我把epoch设置为50了,如果是10就会有错误的情况,大家可以尝试
相关文章:
transformer--transformer模型构建和测试
前面几节进行了各种组件的学习和编码,本节将组件组成transformer,并对其进行测试 EncoderDecoder 编码器解码器构建 使用EnconderDecoder实现编码器-解码器结构 # 使用EncoderDeconder类实现编码器和解码器class EncoderDecoder(nn.Module):def __ini…...

从0到1全流程使用 segment-anything
从0到1全流程使用 segment-anything 一、安装 anaconda 一、下载 anaconda 二、以管理员身份运行安装 1、勾选 Just Me 2、统一安装路径(后续 python 等包也安装至此目录) 3、勾选 add to path 然后安装即可。 三、修改 Anaconda 默认路径及默认缓存路径 Anaconda 默认下…...
Window系统部署Splunk Enterprise并结合内网穿透实现远程访问本地服务
文章目录 前言1. 搭建Splunk Enterprise2. windows 安装 cpolar3. 创建Splunk Enterprise公网访问地址4. 远程访问Splunk Enterprise服务5. 固定远程地址 前言 本文主要介绍如何简单几步,结合cpolar内网穿透工具实现随时随地在任意浏览器,远程访问在本地…...
Windows服务器:通过nginx反向代理配置HTTPS、安装SSL证书
先看下效果: 原来的是 http,配置好后 https 也能用了,并且显示为安全链接。 首先需要 SSL证书 。 SSL 证书是跟域名绑定的,还有有效期。 windows 下双击可以查看相关信息。 下载的证书是分 Apache、IIS、Tomcat 和 Nginx 的。 我…...

LeetCode67 二进制求和
题目 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 示例 示例 1:输入:a "11", b "1" 输出:"100" 示例 2:输入:a "1010", b "1011" 输出&…...

python | 列表,元组,字符串,集合,字典
列表: 可以容纳任意数目不同类型的元素(支持我们学过的任意数据类型)元素之间有先后顺序用中括号包裹,每个元素用逗号隔开 例如: students [林黛玉,薛宝钗,贾元春,贾探春,史湘云,妙玉,贾迎春,贾惜春,王熙凤,贾巧姐…...

稀疏图带负边的全源最短路Johnson算法
BellmanFord算法 Johnson算法解决的问题 带负权的稀疏图的全源最短路 算法流程 重新设置的每条边的权重都大于或等于0,跑完Djikstra后得到的全源最短路,记得要还原,即:f(u,v) d(u,v) - h[u] h[v] 例题...

oracle基础体系
一、 Oracle数据库服务器 数据库在各个行业都会有使用到;其实,我们平时无论是在与客户沟通或者交流中,所说的Oracle数据库是指Oracle数据库服务器(Oracle Server),它由Oracle实例(Oracle Instan…...

k8s运维问题整理
1.宕机或异常重启导致etcd启动失败 服务器非正常关机(意外掉电、强制拔电)后 etcd 数据损坏。 查看apiserver日志发现出现报错Error while dialing dial tcp 127.0.0.1:2379: connect: connection refused,2379是etcd的端口,那么a…...
设计模式分类和六大设计原则)
设计模式(一)设计模式分类和六大设计原则
0.设计模式的分类 GoF提出的设计模式总共有23种,根据目的准则分类分为三大类: 创建型模式,共五种:单例模式、工厂方法模式、抽象工厂模式、建造者模式、原型模式。 结构型模式,共七种:适配器模式、装饰模式…...

git的学习与使用(笔记最全)
什么是git Git是一种分布式版本控制系统,每个开发者都可以在自己的机器上拥有一个完整的仓库 特点 断网也可以工作:没网的情况下,不会影响工作。对于未提交到远程库的代码可以随时撤销。可以查看历史提交记录,以及文件内容的修改记…...

windows环境下Grafana+loki+promtail入门级部署日志系统,收集Springboot(Slf4j+logback)项目日志
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 往期热门专栏回顾 专栏…...

学习python时一些笔记
1、winr 命令提示符的快捷键 输入cmd进入终端 2、在终端运行桌面上的python文件 cd desktop(桌面) cd是进入该文件夹的意思。 cd .. 回到上一级 运行python时一定要找到文件的所在地 输入python进入,exit()退出%s字符串占位符%d数字占位符%f浮点数占位符input输…...
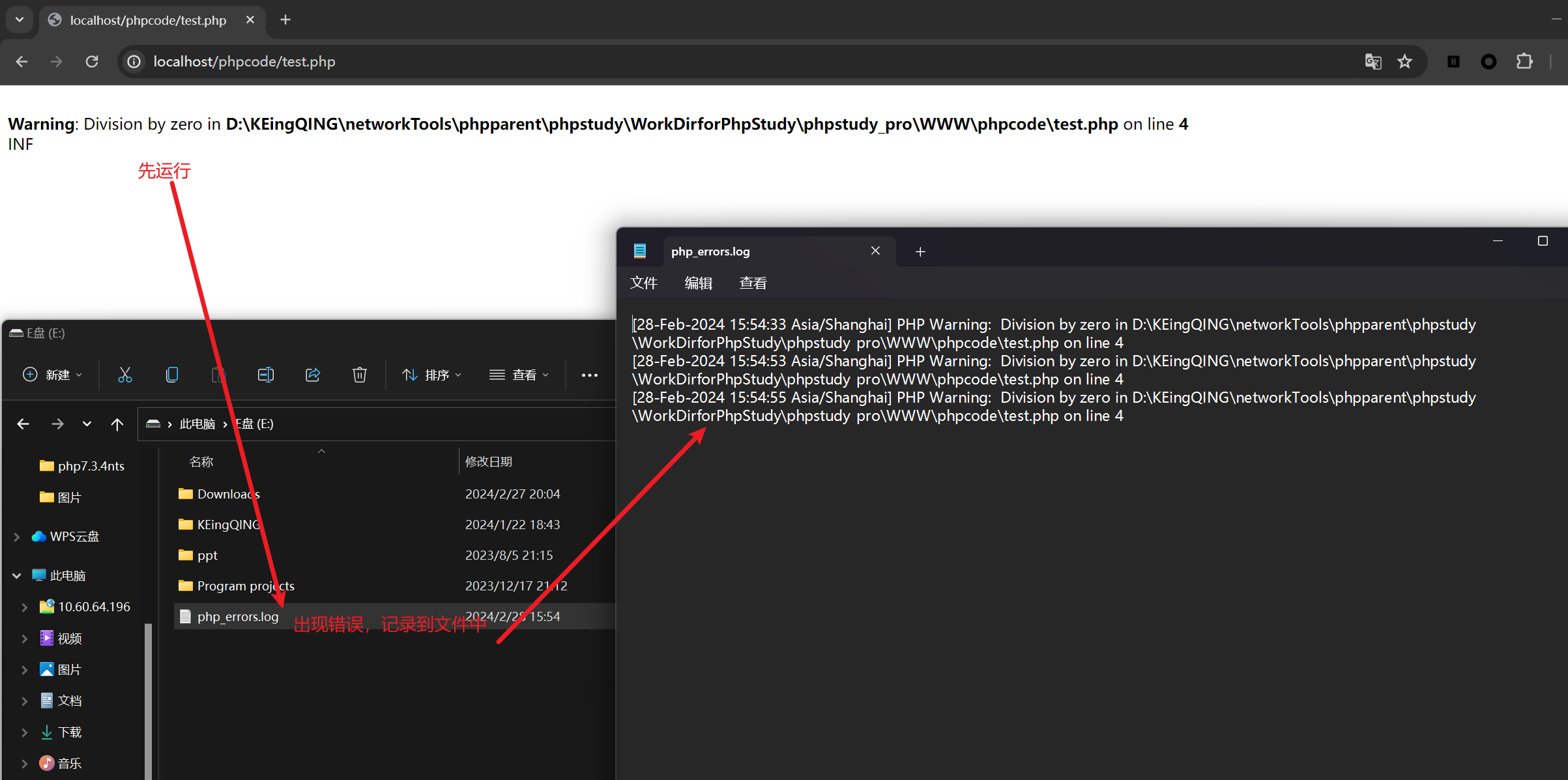
php基础学习之错误处理(其二)
在实际应用中,开发者当然不希望把自己开发的程序的错误暴露给用户,一方面会动摇客户对己方的信心,另一方面容易被攻击者抓住漏洞实施攻击,同时开发者本身需要及时收集错误,因此需要合理的设置错误显示与记录错误日志 一…...

云计算 2月28号 (linux的磁盘分区)
一 存储管理 主要知识点: 基本分区、逻辑卷LVM、EXT3/4/XFS文件系统、RAID 初识硬盘 机械 HDD 固态 SSD SSD的优势 SSD采用电子存储介质进行数据存储和读取的一种技术,拥有极高的存储性能,被认为是存储技术发展的未来新星。 与传统硬盘相比,…...
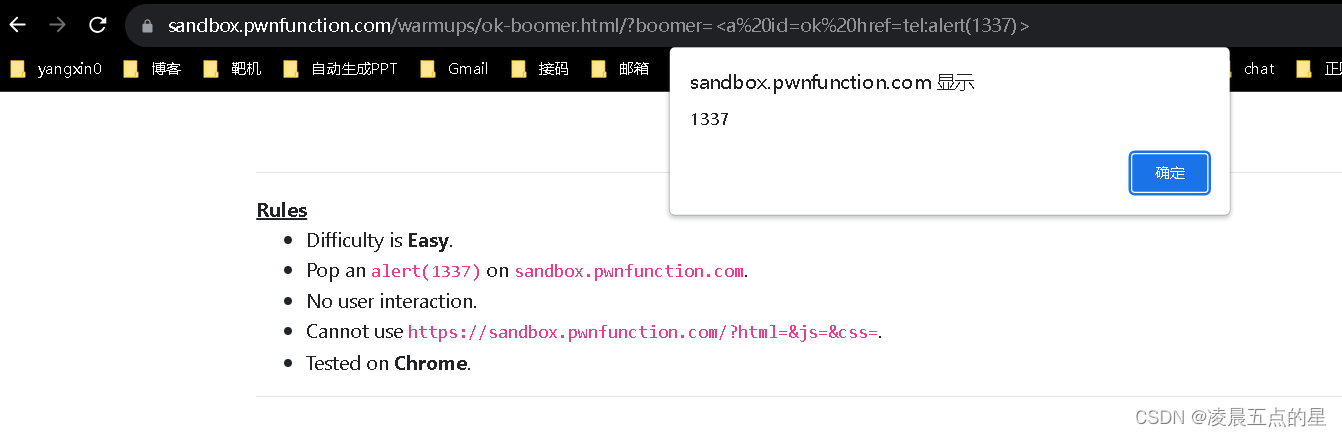
demo型xss初级靶场
一、环境 XSS Game - Ma Spaghet! | PwnFunction 二、开始闯关 第一关 看看代码 试一下直接写 明显进来了为什么不执行看看官方文档吧 你不执行那我就更改单标签去使用呗 ?somebody<img%20src1%20onerror"alert(1)"> 防御: innerText 第二关…...

【推荐算法系列十八】:DSSM 召回算法
参考 推荐系统中 DSSM 双塔模型汇总(二更) DSSM 和 YouTubeDNN 都是比较经典的 U2I 模型。 U2I 召回 U2I 召回也就是 User-to-Item 召回,它基于用户的历史行为以及用户的一些个人信息,对系统中的候选物品进行筛选,挑…...
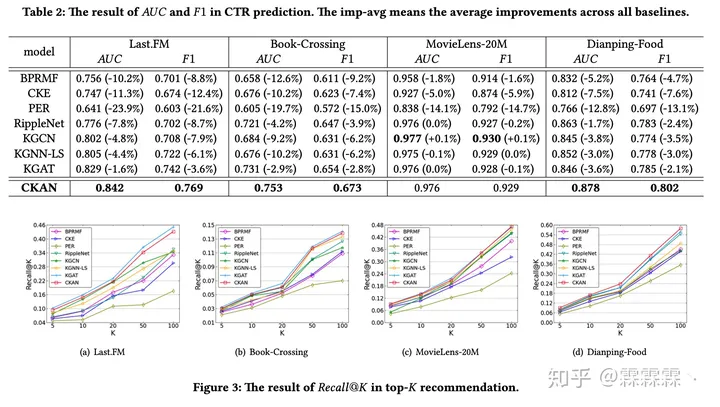
CNAN知识图谱辅助推荐系统
CNAN知识图谱辅助推荐系统 文章介绍了一个基于KG的推荐系统模型,代码也已开源,可以看出主要follow了KGNN-LS 。算法流程大致如下: 1. 算法介绍 算法除去attention机制外,主要的思想在于:user由交互过的item来表示、i…...

大数据经典面试例题
程序员的金三银四求职宝典 随着春天的脚步渐近,对于许多程序员来说,一年中最繁忙、最重要的面试季节也随之而来。金三银四,即三月和四月,被广大程序员视为求职的黄金时期。在这两个月里,各大公司纷纷开放招聘…...

软考56-上午题-【数据库】-数据库设计步骤2
一、回顾:数据库设计的步骤 1、用户需求分析:手机用户需求,确定系统边界; 2、概念设计(概念结构设计):是抽象概念模型,较理想的是采用E-R方法。 3、逻辑设计:E-R图——…...
2期)
C语言学习笔记(自用)2期
一、数据类型和变量C语言提供了丰富的数据类型来描述生活中的数据这些各式各样的数据类型,是程序向电脑申请内存来存储变量的指令数据类型分为整数类型,字符类型,浮点类型类型就是相似数据有的共同特征,编译器只有知道了类型以后&…...

【Midscene.js 实战10】集成实战:将 Midscene.js 无缝接入现有的 Playwright / Puppeteer 项目
一、开篇:你的测试代码还扛得住吗? 2026 年 3 月的一个深夜,某跨境电商团队的测试主管在工位前对着屏幕上刺眼的红色报错叹了口气。团队维护了两年、超过 600 个用例的 Playwright 自动化回归套件,因为运营团队改了商品详情页的 DOM 结构,直接挂了 40 多个用例。更让人崩…...

免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克技术
免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克技术 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/d…...

差点把用户数据泄漏给Claude Code后,我写了个 Rust 工具
两周前,我把公司的数据库接进了Claude Code,效率确实起飞了,直到我翻了一下会话记录。 两周前 公司的 PostgreSQL 数据库接进了Claude Code以后,AI 确实能干——帮我写迁移、联表、生成报表,效率直接起飞。 直到我随…...

告别手动下载烦恼!DouK-Downloader让抖音/TikTok数据采集变得简单
告别手动下载烦恼!DouK-Downloader让抖音/TikTok数据采集变得简单 【免费下载链接】TikTokDownloader TikTok 发布/喜欢/合辑/直播/视频/图集/音乐;抖音发布/喜欢/收藏/收藏夹/视频/图集/实况/直播/音乐/合集/评论/账号/搜索/热榜数据采集工具/下载工具 …...

智能物流系统的技术难点
根据国际供应链与智能制造专家的普遍共识,智能物流系统(Smart Logistics System)作为“AI制造”的外延与闭环,其技术难点已不再是简单的“扫码搬运”,而是如何处理极高动态性、超大规模和强不确定性的复杂场景。核心技…...

FastMamba:边缘计算中的Mamba2高效部署方案
1. FastMamba项目概述在深度学习领域,状态空间模型(State Space Models, SSMs)正逐渐成为处理长序列任务的新范式。Mamba2作为SSM家族的最新成员,通过状态空间对偶性框架和半可分离矩阵分解技术,在保持模型精度的同时&…...

100行代码实现扩散模型:PyTorch版终极入门指南
100行代码实现扩散模型:PyTorch版终极入门指南 【免费下载链接】Diffusion-Models-pytorch Pytorch implementation of Diffusion Models (https://arxiv.org/pdf/2006.11239.pdf) 项目地址: https://gitcode.com/gh_mirrors/di/Diffusion-Models-pytorch 你…...

深入CPU内部:8086的MUL指令是如何工作的?从硬件视角理解乘法结果为何放在AX和DX
深入CPU内部:8086的MUL指令硬件实现原理全解析 记得第一次在调试器中单步执行MUL指令时,看到AX和DX寄存器突然被一堆十六进制数填满,那种既兴奋又困惑的感觉至今难忘。作为x86架构中最基础的乘法指令,MUL表面看似简单,…...

从零开始:如何用Fabric示例模组快速入门Minecraft模组开发
从零开始:如何用Fabric示例模组快速入门Minecraft模组开发 【免费下载链接】fabric-example-mod Example Fabric mod 项目地址: https://gitcode.com/gh_mirrors/fa/fabric-example-mod 你是否曾经想过为Minecraft添加自己的创意功能,却因为复杂的…...