Redis-基础篇
Redis是一个开源、高性能、内存键值存储数据库,由 Salvatore Sanfilippo(网名antirez)创建,并在BSD许可下发布。它不仅可以用作缓存系统来加速数据访问,还可以作为持久化的主数据存储系统或消息中间件使用。Redis因其数据结构丰富、性能优异和高可用性而被广泛应用在现代分布式架构中。
目录
一、认识Redis
1.1、认识NoSQL
1.2、认识Redis
1.3、安装Redis
二、Redis的常见命令
2.1、5种常见的数据结构
2.2、通用命令
2.3、不同数据结构的操作命令
三、Redis的Java客户端
3.1、Jedis客户端
3.2、SpringDataRedis客户端
一、认识Redis
1.1、认识NoSQL
SQL:结构化、表有关联、支持SQL查询、满足事务的ACID、存储在磁盘、垂直扩展、适用于数据结构固定,相关业务的数据安全性与一致性要求高的场合
NoSQL:非结构、无关联的、非SQL、满足基本一致性、存储在内存、水平扩展、适用于数据结构不固定,对一致性与安全性要求不高,但是对性能要求较高的场合
常见的NoSQL有:键值对类型的Redis、文档类型的MongoDB
1.2、认识Redis
Redis( Remote Dictionary Server)的全程是远程字典服务器,是一个基于内存的非关系型数据库。
redis的特征:
1.键值对类型的数据库,支持丰富的数据类型
2.单线程,每个命令具备原子性
3.低延迟,速度快(基于内存、IO多路复用、良好的编码)
4.支持数据的持久化
5.支持主从集群与分片集群
6.支持多语言客户端
1.3、安装Redis
这个不过多介绍,直接下载安装即可。
安装redis服务器和客户端,并安装redis可视化管理工具Another Redis Desktop Manager。
二、Redis的常见命令
2.1、5种常见的数据结构
redis是一个键值对类型的数据库,key的类型一般是String,value的类型就多种多样:
基本数据类型:
String类型:缓存用户信息、计数器(例如点赞数、浏览量)、简单的键值对存储等。
Hash类型:存储用户属性集合(如用户的姓名、年龄、地址等)、产品详情等多字段数据结构。
List类型:存储用户属性集合(如用户的姓名、年龄、地址等)、产品详情等多字段数据结构。
Set类型:适用于标签系统(给一篇文章打上多个标签)、唯一事件记录等。
SortedSet类型:跳跃表提供O(log N)级别的插入、删除和查找操作,并按分数排序。
特殊数据类型:
GEO类型:Geo数据类型允许用户存储地理位置信息,并执行地理半径查询、邻近点搜索等操作。
BitMap类型:用于用户在线状态跟踪、访问统计(例如用户是否读过某篇文章)。
HyperLog类型:日活用户统计、网站独立访客统计、广告点击去重等需要估算大量唯一元素数量而不需精确存储所有元素的场景。
2.2、通用命令
通用命令常见的有:
KEYS:查看符合模板的所有key,不建议在生产环境上使用
DEL:删除一个指定的key
EXISTS:判断一个key是否存在
EXPIRE:为一个key设置有效期,有效期到了key会自动删除
TTL:查看key的剩余有效期
2.3、不同数据结构的操作命令
String类型:字符串类型,包括普通字符串,整数,浮点数
API如下:
SET:添加或者修改string类型的键值对
GET:根据key获取string类型的value
MSET:批量添加多个string类型的键值对
MGET:根据string类型的key获取多个string类型的值
INCR:让整型的key自增1
INCREBY:整数设置步长的自增
INCREBYFLOAT:按照指定步长的浮点型自增
SETNX:添加一个string类型的键值对,前提是key不存在,否则不执行
SETEX:添加一个string类型的键值对,并指定有效期
redis的key允许有多个单词形成层级结构,多个单词用“:”隔开,如果value是一个Java对象,则可以将对象序列化成JSON字符串后存储:
例如key可以为 项目名:业务名:类型:id value为{“id”:1,"product":"小米手机","price":"2999"}
这样redis会根据冒号:进行层级划分。
Hash类型:也称为散列,value是一个无序字典,类似于Java中的HashMap结构。之前的string类型的value是将对象序列化成JSON字符串后存储,当需要修改某个字段时很不方便。
Hash结构可以将每个字段独立存储,可以针对每个字段进行操作。
相关的API:
HSET key field value:添加或者修改hash类型的key的field值
HGET key field:获取一个hash类型的key的field值
HMSET:批量添加多个hash类型key的field值
HMGET:批量查询多个hash类型key的field值
HGETALL:获取一个hash类型key的所有feild的值
HKEYS:获取一个hash类型的key中的所有feild
HVALS:获取一个hash类型的key中的所有value
HINCREBY:让hash类型的key自增并指定步长
HSETNX:添加一个hash类型的field,前提是field不存在,否则不执行
List类型:List类型与Java中的LinkedList类似,可以看作是一个双向链表,支持正向与反向检索。
特征:有序、允许元素重复、插入删除快、查询速度一般
List的常见命令如下:
LPUSH key element...:向列表左侧插入一个或者多个元素
LPOP key :移除并返回列表左侧额第一个元素,没有则返回nil
RPUSH key element...:向列表右侧插入一个或者多个元素
RPOP key:移除并返回列表右侧的第一个元素
LRANGE key start end:返回一段角标范围内的所有元素
BLPOP与BRPOP:移除指定的元素,没有元素时并设置等待时间,而不是直接返回nil
List模拟栈:lpush与lpop rpush与rpop
List模拟队列:lpush与rpop
List模拟阻塞队列:blpop与brpop
Set类型:Redis中的set与Java中的HashSet类似,具有如下特征:无序、元素不可重复、查找快
、支持交集、并集差集等操作。
SET类型的常见命令:
SADD key member...:向set中添加一个或者多个元素
SREM key member...:向set中移除指定元素
SCARD key:返回set中的元素个数
SISMEMBER key member:判断一个元素是否在set中
SMEMBERS:获取set中的所有元素
SINTER key1 key2:求两个key的交集
SDIFF:求两个集合的差集
SUNION:求两个集合的并集
SortedSet类型:有序的集合,每个元素都带有一个score属性,可以根据score属性进行排序,底层是一个跳表+hash表的实现。跳跃表提供O(log N)级别的插入、删除和查找操作,并按分数排序;hash表用于快速查找成员的存在性。
跳表是通过随机函数维护平衡性的,当我们在跳表中插入数据的时候,我们通过选择同时将这个数据插入到部分索引层中,如何选择索引层,可以通过一个随机函数来决定这个节点插入到哪几级索引中,比如随机生成了k,那么就将这个索引加入到,第一级到第k级索引中。
SortedSet具有以下特点:
1、可排序 2、元素不重复 3、查询速度快
常见的SortedSort的api如下:默认是升序,如果向降序前缀由Z改成ZREV

三、Redis的Java客户端
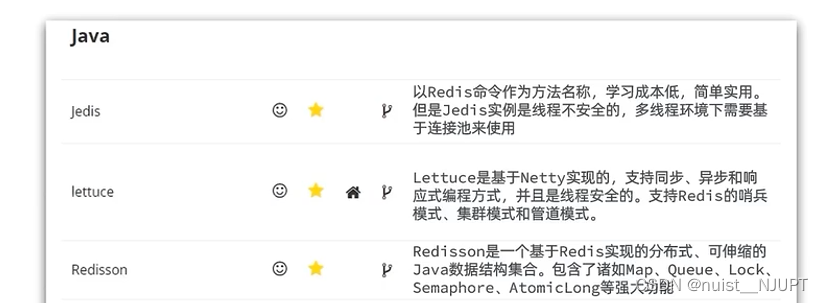
3.1、Jedis客户端
常见的Redis的Java客户端有Jedis、Lettuce、Redisson三种,具体如下。
下面我们通过jedis客户端连接redis服务器,并进行单元测试,具体如下:
1.首先添加三方依赖。
<!--jedis客户端依赖--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.7.0</version></dependency><!-- junit测试依赖 --><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.7.0</version><scope>test</scope></dependency>2.编写单元测试模块,jedis客户端连接redis服务器,并进行crud基本操作,最后释放连接。
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;import java.util.Map;/*** @author nuist__NJUPT* @ClassName JedisTest* @description: jedis测试类* @date 2024/03/02*/
public class JedisTest {private Jedis jedis ;@BeforeEachvoid setUp(){// 1.建立连接jedis = new Jedis("localhost", 6379) ;// 2.设置密码jedis.auth("123456") ;// 3.选择库jedis.select(0) ;}@Testvoid testString(){// 存入数据String result = jedis.set("name", "mandy");System.out.println(result);// 获取数据String name = jedis.get("name");System.out.println("name : " + name );}@Testvoid testHash(){// 存值jedis.hset("user:1", "name", "jack") ;jedis.hset("user:1", "age", "21") ;// 取值Map<String, String> stringStringMap = jedis.hgetAll("user:1");System.out.println(stringStringMap);}@AfterEachvoid tearDown(){if(jedis != null){jedis.close();}}}jedis本身是线程不安全的,而且频繁的创建与销毁jedis连接会有性能损耗,因此推荐使用jedis连接池的方式代替直连的方式。
1.定义一个连接池工具类,用于建立jedis连接,并返回jedis对象,jedis使用完放回连接池而不是直接销毁。
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;/*** @author nuist__NJUPT* @ClassName JedisConnectionFactory* @description: Jedis连接池* @date 2024/03/02*/
public class JedisConnectionFactory {private static final JedisPool jedisPool ;static {// 配置连接池JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(8);jedisPoolConfig.setMaxIdle(8);jedisPoolConfig.setMinIdle(0);jedisPoolConfig.setMaxWaitMillis(1000);// 创建连接池对象jedisPool= new JedisPool(jedisPoolConfig, "localhost", 6379, 1000, "123456");}public static Jedis getJedis(){return jedisPool.getResource() ;}}2.客户端直接通过连接池获取jedis对象就可以,不用直接newjedis对象进行直连了。
import com.alibaba.jedis.util.JedisConnectionFactory;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;import java.util.Map;/*** @author nuist__NJUPT* @ClassName JedisTest* @description: jedis测试类* @date 2024/03/02*/
public class JedisTest {private Jedis jedis ;@BeforeEachvoid setUp(){// 1.建立连接// jedis = new Jedis("localhost", 6379) ;jedis = JedisConnectionFactory.getJedis() ;// 2.设置密码jedis.auth("123456") ;// 3.选择库jedis.select(0) ;}@Testvoid testString(){// 存入数据String result = jedis.set("name", "mandy");System.out.println(result);// 获取数据String name = jedis.get("name");System.out.println("name : " + name );}@Testvoid testHash(){// 存值jedis.hset("user:1", "name", "jack") ;jedis.hset("user:1", "age", "21") ;// 取值Map<String, String> stringStringMap = jedis.hgetAll("user:1");System.out.println(stringStringMap);}@AfterEachvoid tearDown(){if(jedis != null){jedis.close();}}}3.2、SpringDataRedis客户端
SpringData是Spring中数据操作的模块,包含了对多种数据库的集成,其中对redis的集成就是SpringDataRedis。它提供了对不同redis客户端的整合(jedis、Lettuce),提供了RedisTemplate统一API来操作Redis,支持redis的发布订阅模型,支持redis哨兵和redis集群,支持基于Lettuce的响应式编程,支持序列化与反序列化。
下面看一下SpringDataRedis提供的工具类RedisTemplate的应用,首先创建springboot项目并导入redis依赖。
<!-- jackson依赖 --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.13.5</version></dependency><!--redis依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!-- 连接池依赖 --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency>然后在yml文件中进行配值,配值redis的数据源信息。
spring:redis:host: 127.0.0.1port: 6379password: 123456lettuce:pool:max-active: 8max-idle: 8min-idle: 0max-wait: 100编写redisTemplate的配值类,防止在redis在接收Object类型时,把Object对象序列化成字节形式,变成一串乱码,可读性差,占用内存。
/*** @author nuist__NJUPT* @ClassName RedisConfig* @description: redis配置类* @date 2024/03/02*/import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;@Configuration
public class RedisConfig {/*** RedisTemplate可以接收任意Object作为值写入Redis,* 只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的一串很长的值* 缺点:可读性查、浪费存储空间*/@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){// 1.创建 redisTemplateRedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();// 2.设置连接工厂redisTemplate.setConnectionFactory(redisConnectionFactory);// 3.设置序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// key 采用 String 序列化redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setHashKeySerializer(RedisSerializer.string());// value 采用 json 序列化redisTemplate.setValueSerializer(jsonRedisSerializer);redisTemplate.setHashValueSerializer(jsonRedisSerializer);return redisTemplate;}
}
定义一个实体类。
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author nuist__NJUPT* @ClassName User* @description: 实体类* @date 2024/03/02*/@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {private String name ;private Integer age ;}最后编写单元测试模块,利用redisTemplate进行测试。
import com.alibaba.redisdemo.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;@SpringBootTest
class RedisDemoApplicationTests {@Autowiredprivate RedisTemplate<String, Object> redisTemplate;@Testvoid testString(){// 添加一个元素redisTemplate.opsForValue().set("name", "Jack");// 获取元素Object object = redisTemplate.opsForValue().get("name");System.out.println(object);}@Testvoid testSaveUser(){//写入数据redisTemplate.opsForValue().set("user:2", new User("wang", 18));// 读取数据User user = (User) redisTemplate.opsForValue().get("user:2");System.out.println(user);}@Testvoid testHash(){stringRedisTemplate.opsForHash().put("user:3","name", "liu");stringRedisTemplate.opsForHash().put("user:3","age","18") ;Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:3");System.out.println("entries = " + entries);}}上述尽管Json序列化的方式满足要求,但是会发现仍然存在一些问题,比如JSON序列化器将类型class写入了json中,存入redis会导致额外的内存开销。
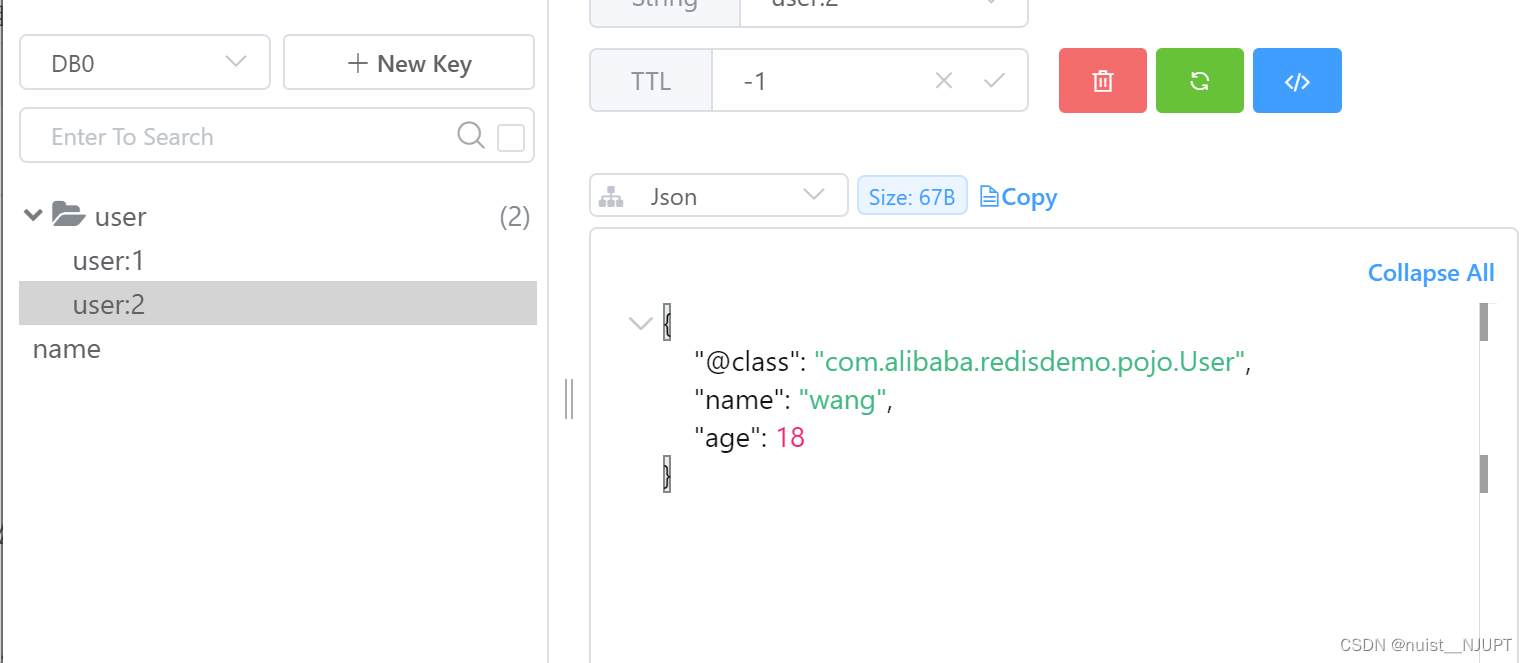
为了节省内存空间,不使用JSON序列化来处理value,而是处理String序列化器,要求只能存储String类型的key与value,当存储Java对象的时候需要手动的序列化与反序列化。
可以采用如下写法:
@Autowiredprivate StringRedisTemplate stringRedisTemplate ;private static final ObjectMapper mapper = new ObjectMapper() ;@Testvoid testSave() throws JsonProcessingException {// 创建对象User user = new User("wang", 18);// 手动序列化String s = mapper.writeValueAsString(user);//写入数据stringRedisTemplate.opsForValue().set("user:2",s);// 读取数据String user1 = stringRedisTemplate.opsForValue().get("user:2");// s手动反序列化User user2 = mapper.readValue(user1, User.class);System.out.println(user2);}
使用fastJson进行序列化与反序列化也可以,需要添加依赖。
@Autowiredprivate StringRedisTemplate stringRedisTemplate ;@Testvoid testSave() throws JsonProcessingException {// 创建对象User user = new User("wang", 19);// 手动序列化String s = JSON.toJSONString(user) ;//写入数据stringRedisTemplate.opsForValue().set("user:2",s);// 读取数据String user1 = stringRedisTemplate.opsForValue().get("user:2");// s手动反序列化User user2 = JSON.parseObject(user1, User.class) ;System.out.println(user2);}
添加fastJson依赖。
<!-- https://mvnrepository.com/artifact/com.alibaba.fastjson2/fastjson2 -->
<dependency><groupId>com.alibaba.fastjson2</groupId><artifactId>fastjson2</artifactId><version>2.0.32</version>
</dependency>
总结:redis中有两种序列化方式,推荐使用第二种。
1.第一种是自定义RedisTemplate,修改其序列化器,相对方便,但是写入redis会存class对象,占用额外的内存空间。
2.使用StringRedisTemplate,默认使用String序列化器,写入redis需要将Java对象手动序列化为json,读取redis需要将读取到的json反序列化为Java对象。
相关文章:
Redis-基础篇
Redis是一个开源、高性能、内存键值存储数据库,由 Salvatore Sanfilippo(网名antirez)创建,并在BSD许可下发布。它不仅可以用作缓存系统来加速数据访问,还可以作为持久化的主数据存储系统或消息中间件使用。Redis因其数…...

【好书推荐-第七期】《RTC程序设计:实时音视频权威指南》(音视频开发必看!)
😎 作者介绍:我是程序员洲洲,一个热爱写作的非著名程序员。CSDN全栈优质领域创作者、华为云博客社区云享专家、阿里云博客社区专家博主、前后端开发、人工智能研究生。公粽号:洲与AI。 🎈 本文专栏:本文收录…...
还在犹豫学不学?鸿蒙技术是否有前途的最强信号来了
2024年3月3日 上午10 点,深圳官方账号发布了一篇关于鸿蒙技术发展的重要文章,看到这篇文章后我非常激动,忍不住和大家分享一下! 华为鸿蒙系统自提出以来,网友们的态度各不相同,有嘲笑“安卓套壳”的&#x…...

webpack的plugin 插件教程
Webpack 是一个流行的前端打包工具,通过使用插件(plugin),我们可以对 Webpack 进行扩展和定制,实现更多功能和优化构建过程。在本教程中,我将向你介绍如何编写一个简单的 Webpack 插件,并演示如…...

v72.关于指针操作的补充
1.指针作为函数参数 调用函数时,传递参数的形式决定了是否可以修改这些参数。 传值方式:传递了参数给函数,并且这个参数是基本数据类型,如(int,float),那么函数内对参数的任何操作…...

【学习心得】爬虫JS逆向通解思路
我希望能总结一个涵盖大部分爬虫逆向问题的固定思路,在这个思路框架下可以很高效的进行逆向爬虫开发。目前我仍在总结中,下面的通解思路尚不完善,还望各位读者见谅。 一、第一步:明确反爬手段 反爬手段可以分为几个大类 &#…...

如何使用Logstash搜集日志传输到es集群并使用kibana检测
引言:上一期我们进行了对Elasticsearch和kibana的部署,今天我们来解决如何使用Logstash搜集日志传输到es集群并使用kibana检测 目录 Logstash部署 1.安装配置Logstash (1)安装 (2)测试文件 ÿ…...
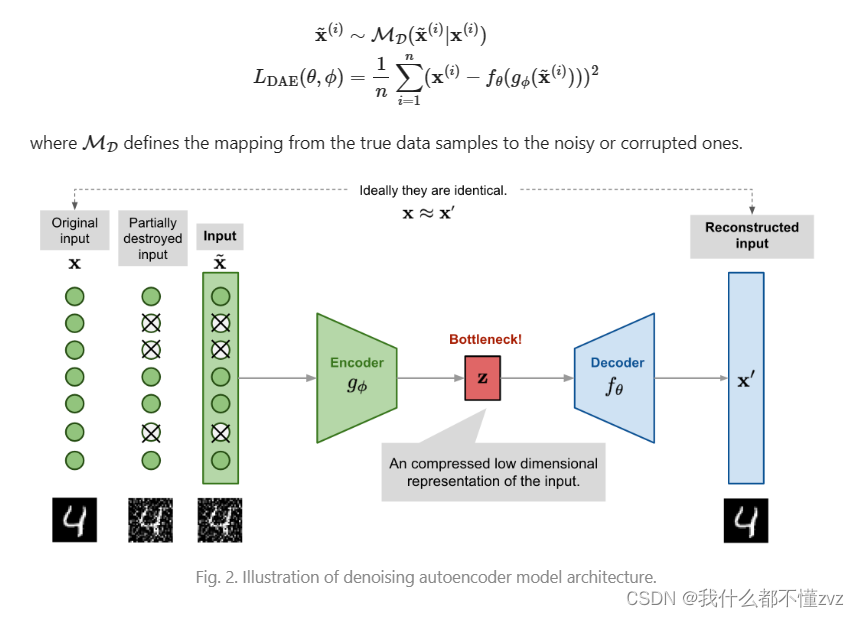
AutoEncoder和 Denoising AutoEncoder学习笔记
参考: 【1】 https://lilianweng.github.io/posts/2018-08-12-vae/ 写在前面: 只是直觉上的认识,并没有数学推导。后面会写一篇(抄)大一统文章(概率角度理解为什么AE要选择MSE Loss) TOC 1 Au…...

计算机系统基础
一、计算机系统概述 计算机系统:硬件软件,软件包括系统软件和应用软件 二、计算机组成结构 三、存储结构 3.1 层次化存储结构 3.2 Cache Cache(高速缓存)的功能:提高CPU数据输入输出的速率,突破冯.若依曼瓶…...
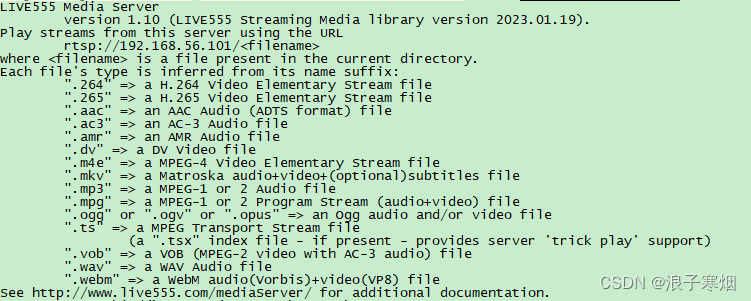
live555学习 - 环境准备
环境:Ubuntu 16.04.7 ffmpeg-6.1 1 代码下载 最新版本: http://www.live555.com/liveMedia/public/ 历史版本下载 https://download.videolan.org/pub/contrib/live555/ 选择版本live.2023.01.19.tar.gz ps:没有选择新版本是新版本在…...

C++ 模拟OJ
目录 1、1576. 替换所有的问号 2、 495. 提莫攻击 3、6. Z 字形变换 4、38. 外观数列 5、 1419. 数青蛙 1、1576. 替换所有的问号 思路:分情况讨论 ?zs:左边没有元素,则仅需保证替换元素与右侧不相等;z?s:左右都…...
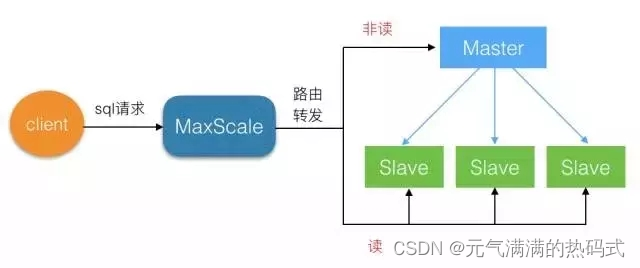
MariaDB MaxScale实现mysql8读写分离
MaxScale 是干什么的? MaxScale是maridb开发的一个mysql数据中间件,其配置简单,能够实现读写分离,并且可以根据主从状态实现写库的自动切换,对多个从服务器能实现负载均衡。 MaxScale 实验环境 中间件192.168.142.13…...

代码随想录day11(1)字符串:反转字符串中的单词 (leetcode151)
题目要求:给定一个字符串,将其中单词顺序反转,且每个单词之间有且仅有一个空格。 思路:因为本题没有限制空间复杂度,所以首先想到的是用split直接分割单词,然后将单词倒叙相加。 但如果想让空间复杂度为O…...
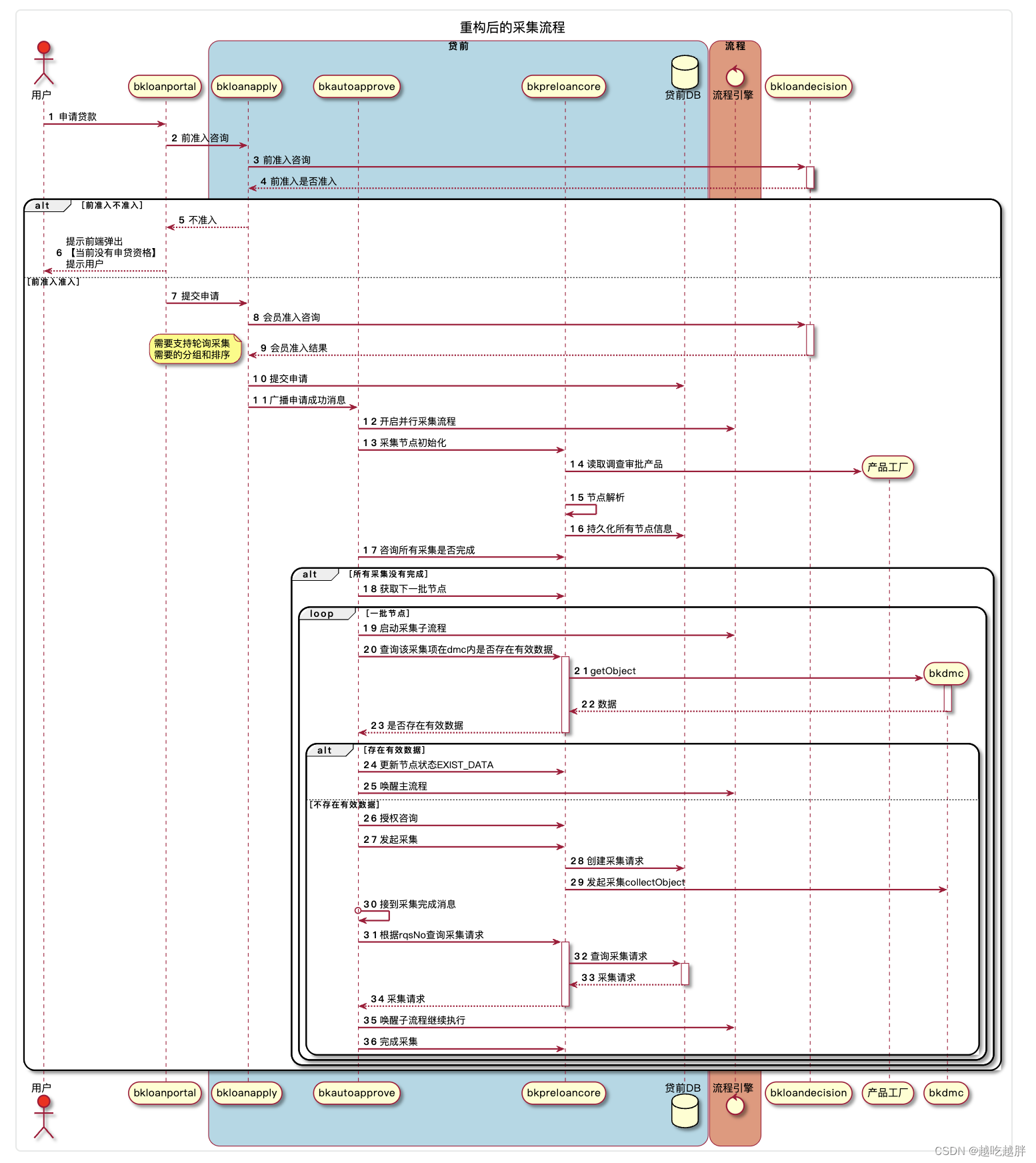
PlantUML - 时序图
时序图主要内容 下面是一个简单的时序图,我们可以很容易并且美观的表达我们的交互流程,只需要在箭头的两边指定一个名字,加上描述即可: startuml bkloanapply -> bkloanapprove : request bkloanapprove --> bkloanapply :…...
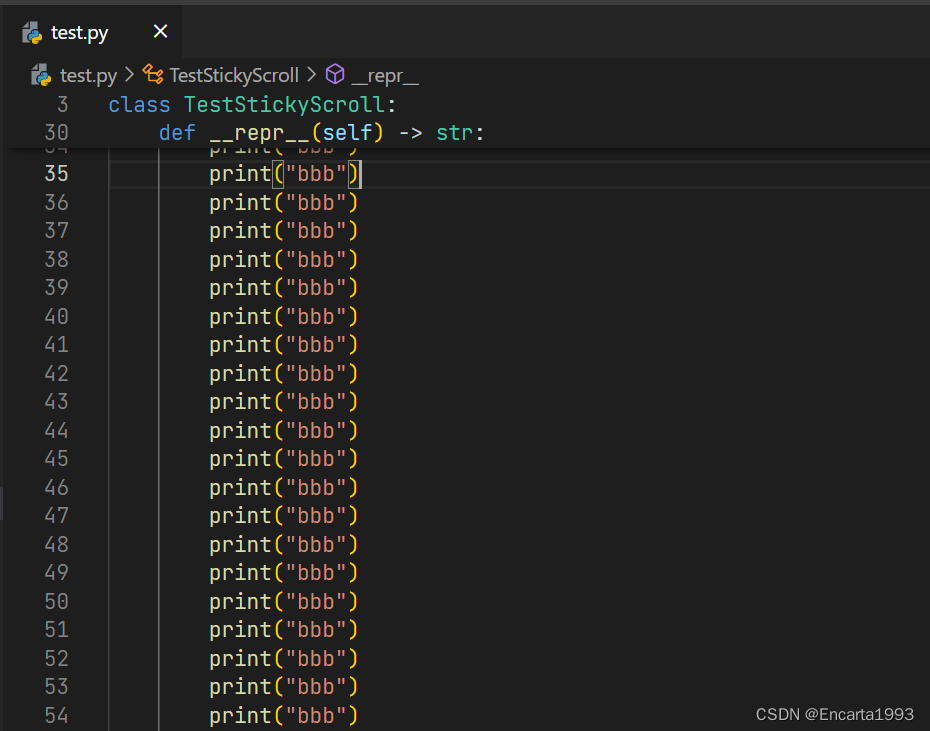
VS Code 的粘性滚动预览 - 类似于 Excel 的冻结首行
VS Code 的粘性滚动预览 - 类似于 Excel 的冻结首行功能,即滚动 UI 显示当前源代码范围。便于在代码行数比较多的时候更好的知道自己所在的位置。粘性滚动UI 显示用户在滚动期间所处的范围,将显示编辑器顶部所在的类/接口/命名空间/函数/方法/构造函数&a…...

Java中的List
List集合的特有方法 方法介绍 方法名描述void add(int index,E element)在此集合中的指定位置插入指定的元素E remove(int index)删除指定索引处的元素,返回被删除的元素E set(int index,E element)修改指定索引处的元素,返回被修改的元素E get(int inde…...

Spring 框架模块深度解析:核心容器、数据访问、Web 层与其他关键模块
Spring 可能成为您的所有企业应用程序的一站式商店。但是,Spring 是模块化的,允许您挑选适用于您的模块,而无需引入其他模块。下面的部分提供了 Spring Framework 中所有可用模块的详细信息。Spring Framework 提供了大约20个模块,…...

前端配置开发环境,新电脑配置前端开发环境,Vue开发环境配置的详细过程(前端开发环境配置,电脑重置后配置前端开发环境)
简介:有时候,我们需要在新电脑 或者 电脑重置后,配置前端开发环境,具体都需要安装什么软件和插件,这里来记录一下(文章适合新手和小白,大佬可以带过)。 ✨前端开发环境,需…...
大模型(LLM)的量化技术Quantization原理学习
在自然语言处理领域,大型语言模型(LLM)在自然语言处理领域的应用越来越广泛。然而,随着模型规模的增大,计算和存储资源的需求也急剧增加。为了降低计算和存储开销,同时保持模型的性能,LLM大模型…...
2024.03.01作业
1. 基于UDP的TFTP文件传输 #include "test.h"#define SER_IP "192.168.1.104" #define SER_PORT 69 #define IP "192.168.191.128" #define PORT 9999enum mode {TFTP_READ 1,TFTP_WRITE 2,TFTP_DATA 3,TFTP_ACK 4,TFTP_ERR 5 };void get_…...

AI绘画如何听懂草图?文字+手绘混合生成原理与实战
1. 项目概述:当文字描述遇上手绘草图,AI绘画如何真正“听懂”你的想法? 你有没有过这样的经历:脑子里已经浮现出一幅画面——比如“一只戴圆框眼镜的柴犬坐在咖啡馆窗边,阳光斜射在它毛茸茸的耳朵上,背景是…...

filer.js vs 传统文件API:为什么这个类UNIX封装库能提升3倍开发效率?
filer.js vs 传统文件API:为什么这个类UNIX封装库能提升3倍开发效率? 【免费下载链接】filer.js A wrapper library for the HTML5 Filesystem API what reuses UNIX commands (cp, mv, ls) for its API. 项目地址: https://gitcode.com/gh_mirrors/fi…...

Navicat Mac版试用期重置终极指南:3种简单方法实现永久免费使用
Navicat Mac版试用期重置终极指南:3种简单方法实现永久免费使用 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 你…...

抖音内容自动化下载:3大技术挑战与实战解决方案
抖音内容自动化下载:3大技术挑战与实战解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖…...

Windows右键菜单终极清理指南:ContextMenuManager快速上手教程
Windows右键菜单终极清理指南:ContextMenuManager快速上手教程 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单是日常操作中不可或缺…...

为什么越来越多公司坚持做背调?
很多中小企业都有一个误区:觉得背调“可有可无”、浪费时间、增加成本。但真实职场现状是:不做背调,才是企业最大的隐形成本。现在求职简历美化早已是常态,履历注水、项目造假、隐瞒纠纷、失信记录……肉眼面试根本看不出来。一次…...

AI时代软件工程教育:同理心融入技术课程的教学实践
1. 项目概述:当代码遇见人心最近几年,我一直在高校和培训机构里讲授软件工程相关的课程,从传统的软件生命周期、设计模式,到如今火热的敏捷开发、DevOps。一个越来越强烈的感受是:我们的技术教育,似乎正在与…...

泳装电商运营——AI驱动增长新引擎
泳装电商运营——AI驱动增长新引擎泳装旺季营销攻略:如何用AI工具实现销量翻倍?泳装行业的季节性特征明显,旺季不旺是很多商家的痛点。如何在短短几个月的销售窗口期内最大化产出?北京先智先行科技有限公司的一站式AI营销解决方案…...

Keil µVision TAB显示异常问题分析与解决方案
1. 问题现象与背景分析在Keil Vision集成开发环境中,部分用户遇到了编辑器界面显示异常的问题。具体表现为:当代码中包含TAB字符(制表符)时,屏幕上会出现奇怪的显示错乱,原本应该显示为空白缩进的区域&…...

巨噬细胞M1型与M2型的差异
巨噬细胞具有高度的功能可塑性,依据微环境信号的不同,可极化为功能迥异的M1型(经典活化)与M2型(替代活化)两大表型。两者在活化机制、代谢特征及生物学功能上呈现出显著的“阴阳”对立与平衡。1. 活化诱导与…...