如何使用Logstash搜集日志传输到es集群并使用kibana检测
引言:上一期我们进行了对Elasticsearch和kibana的部署,今天我们来解决如何使用Logstash搜集日志传输到es集群并使用kibana检测
目录
Logstash部署
1.安装配置Logstash
(1)安装
(2)测试文件
(3)配置
grok
1、手动输入日志数据
数据链路
2、手动输入数据,并存储到 es
数据链路
3、自定义日志1
数据链路
5、nginx access 日志
数据链路
6、nginx error日志
数据链路
7、filebate 传输给 logstash
filebeat 日志模板
Logstash部署
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Logstash | Elk | 10.12.153.71 | centos7.5.1804 | 2核4G |
-
软件版本:logstash-7.13.2.tar.gz
1.安装配置Logstash
Logstash运行同样依赖jdk,本次为节省资源,故将Logstash安装在了10.12.153.71节点。
(1)安装
tar zxf /usr/local/package/logstash-7.13.2.tar.gz -C /usr/local/(2)测试文件
标准输入=>标准输出
1、启动logstash
2、logstash启动后,直接进行数据输入
3、logstash处理后,直接进行返回
input {stdin {}
}
output {stdout {codec => rubydebug}
}标准输入=>标准输出及es集群
1、启动logstash
2、启动后直接在终端输入数据
3、数据会由logstash处理后返回并存储到es集群中
input {stdin {}
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["10.12.153.71","10.12.153.72","10.12.153.133"]index => 'logstash-debug-%{+YYYY-MM-dd}'}
}端口输入=>字段匹配=>标准输出及es集群
1、由tcp 的8888端口将日志发送到logstash
2、数据被grok进行正则匹配处理
3、处理后,数据将被打印到终端并存储到es
input {tcp {port => 8888}
}
filter {grok {match => {"message" => "%{DATA:key} %{NUMBER:value:int}"} }
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["10.12.153.71","10.12.153.72","10.12.153.133"]index => 'logstash-debug-%{+YYYY-MM-dd}'}
}
# yum install -y nc
# free -m |awk 'NF==2{print $1,$3}' |nc logstash_ip 8888文件输入=>字段匹配及修改时间格式修改=>es集群
1、直接将本地的日志数据拉去到logstash当中
2、将日志进行处理后存储到es
input {file {type => "nginx-log"path => "/var/log/nginx/error.log"start_position => "beginning" # 此参数表示在第一次读取日志时从头读取# sincedb_path => "自定义位置" # 此参数记录了读取日志的位置,默认在 data/plugins/inputs/file/.sincedb*}
}
filter {grok {match => { "message" => '%{DATESTAMP:date} [%{WORD:level}] %{DATA:msg} client: %{IPV4:cip},%{DATA}"%{DATA:url}"%{DATA}"%{IPV4:host}"'} } date {match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ] }
}
output {if [type] == "nginx-log" {elasticsearch {hosts => ["10.12.153.71","10.12.153.72","10.12.153.133"]index => 'logstash-audit_log-%{+YYYY-MM-dd}'}}}filebeat => 字段匹配 => 标准输出及esinput {beats {port => 5000}
}
filter {grok {match => {"message" => "%{IPV4:cip}"} }
}
output {elasticsearch {hosts => ["192.168.249.139:9200","192.168.249.149:9200","192.168.249.159:9200"]index => 'test-%{+YYYY-MM-dd}'}stdout { codec => rubydebug }
}(3)配置
创建目录,我们将所有input、filter、output配置文件全部放到该目录中。
mkdir -p /usr/local/logstash-7.13.2/etc/conf.d
vim /usr/local/logstash-7.13.2/etc/conf.d/input.conf
input {
kafka {type => "audit_log"codec => "json"topics => "nginx"decorate_events => truebootstrap_servers => "10.12.153.71","10.12.153.72","10.12.153.133"}
}
vim /usr/local/logstash-7.13.2/etc/conf.d/filter.conf
filter {json { # 如果日志原格式是json的,需要用json插件处理source => "message"target => "nginx" # 组名}
}
vim /usr/local/logstash-7.13.2/etc/conf.d/output.conf
output {if [type] == "audit_log" {elasticsearch {hosts => ["10.12.153.71","10.12.153.72","10.12.153.133"]index => 'logstash-audit_log-%{+YYYY-MM-dd}'}}}(3)启动
cd /usr/local/logstash-7.13.2
nohup bin/logstash -f etc/conf.d/ --config.reload.automatic &grok
1、手动输入日志数据
一般为debug 方式,检测 ELK 集群是否健康,这种方法在 logstash 启动后可以直接手动数据数据,并将格式化后的数据打印出来。
数据链路
1、启动logstash
2、logstash启动后,直接进行数据输入
3、logstash处理后,直接进行返回
input {stdin {}
}
output {stdout {codec => rubydebug}
}2、手动输入数据,并存储到 es
数据链路
1、启动logstash
2、启动后直接在终端输入数据
3、数据会由logstash处理后返回并存储到es集群中
input {stdin {}
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["10.12.153.71","10.12.153.72","10.12.153.133"]index => 'logstash-debug-%{+YYYY-MM-dd}'}
}3、自定义日志1
数据链路
1、由tcp 的8888端口将日志发送到logstash
2、数据被grok进行正则匹配处理
3、处理后,数据将被打印到终端并存储到es
input {tcp {port => 8888}
}
filter {grok {match => {"message" => "%{DATA:key} %{NUMBER:value:int}"} }
}
output {stdout {codec => rubydebug}elasticsearch {hosts => [""10.12.153.71","10.12.153.72","10.12.153.133""]index => 'logstash-debug-%{+YYYY-MM-dd}'}
}
# yum install -y nc
# free -m |awk 'NF==2{print $1,$3}' |nc logstash_ip 8888
4、自定义日志2
数据链路
1、由tcp 的8888端口将日志发送到logstash2、数据被grok进行正则匹配处理3、处理后,数据将被打印到终端input {tcp {port => 8888}
}
filter {grok {match => {"message" => "%{WORD:username}\:%{WORD:passwd}\:%{INT:uid}\:%{INT:gid}\:%{DATA:describe}\:%{DATA:home}\:%{GREEDYDATA:shell}"}}
}
output {stdout {codec => rubydebug}
}
# cat /etc/passwd | nc logstash_ip 88885、nginx access 日志
数据链路
1、在filebeat配置文件中,指定kafka集群ip [output.kafka] 的指定topic当中
2、在logstash配置文件中,input区域内指定kafka接口,并指定集群ip和相应topic
3、logstash 配置filter 对数据进行清洗
4、将数据通过 output 存储到es指定index当中
5、kibana 添加es 索引,展示数据
input {kafka {type => "audit_log"codec => "json"topics => "haha"#decorate_events => true#enable_auto_commit => trueauto_offset_reset => "earliest"bootstrap_servers => ["192.168.52.129:9092,192.168.52.130:9092,192.168.52.131:9092"]}
}
filter {grok {match => { "message" => "%{COMBINEDAPACHELOG} %{QS:x_forwarded_for}"} } date {match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ] } geoip {source => "lan_ip" }
}
output {if [type] == "audit_log" {stdout {codec => rubydebug}elasticsearch {hosts => ["192.168.52.129","192.168.52.130","192.168.52.131"]index => 'tt-%{+YYYY-MM-dd}'}}}
#filebeat 配置filebeat.prospectors:
- input_type: logpaths:- /opt/logs/server/nginx.logjson.keys_under_root: truejson.add_error_key: truejson.message_key: log
output.kafka: hosts: [""10.12.153.71","10.12.153.72","10.12.153.133""]topic: 'nginx'
# nginx 配置log_format main '{"user_ip":"$http_x_real_ip","lan_ip":"$remote_addr","log_time":"$time_iso8601","user_req":"$request","http_code":"$status","body_bytes_sents":"$body_bytes_sent","req_time":"$request_time","user_ua":"$http_user_agent"}';access_log /var/log/nginx/access.log main;
6、nginx error日志
数据链路
1、直接将本地的日志数据拉去到logstash当中
2、将日志进行处理后存储到es
input {file {type => "nginx-log"path => "/var/log/nginx/error.log"start_position => "beginning"}
}
filter {grok {match => { "message" => '%{DATESTAMP:date} [%{WORD:level}] %{DATA:msg} client: %{IPV4:cip},%{DATA}"%{DATA:url}"%{DATA}"%{IPV4:host}"'} } date {match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ] }
}
output {if [type] == "nginx-log" {elasticsearch {hosts => [""10.12.153.71:9200","10.12.153.72:9200","10.12.153.133:9200""]index => 'logstash-audit_log-%{+YYYY-MM-dd}'}}}7、filebate 传输给 logstash
input {beats {port => 5000}
}
filter {grok {match => {"message" => "%{IPV4:cip}"} }
}
output {elasticsearch {hosts => ["192.168.249.139:9200","192.168.249.149:9200","192.168.249.159:9200"]index => 'test-%{+YYYY-MM-dd}'}stdout { codec => rubydebug }
}
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/nginx/access.log
output.logstash:hosts: ["192.168.52.134:5000"]filebeat 日志模板
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/nginx/access.log
output.kafka:hosts: ["192.168.52.129:9092","192.168.52.130:9092","192.168.52.131:9092"]topic: hahapartition.round_robin:reachable_only: truerequired_acks: 1
相关文章:
如何使用Logstash搜集日志传输到es集群并使用kibana检测
引言:上一期我们进行了对Elasticsearch和kibana的部署,今天我们来解决如何使用Logstash搜集日志传输到es集群并使用kibana检测 目录 Logstash部署 1.安装配置Logstash (1)安装 (2)测试文件 ÿ…...
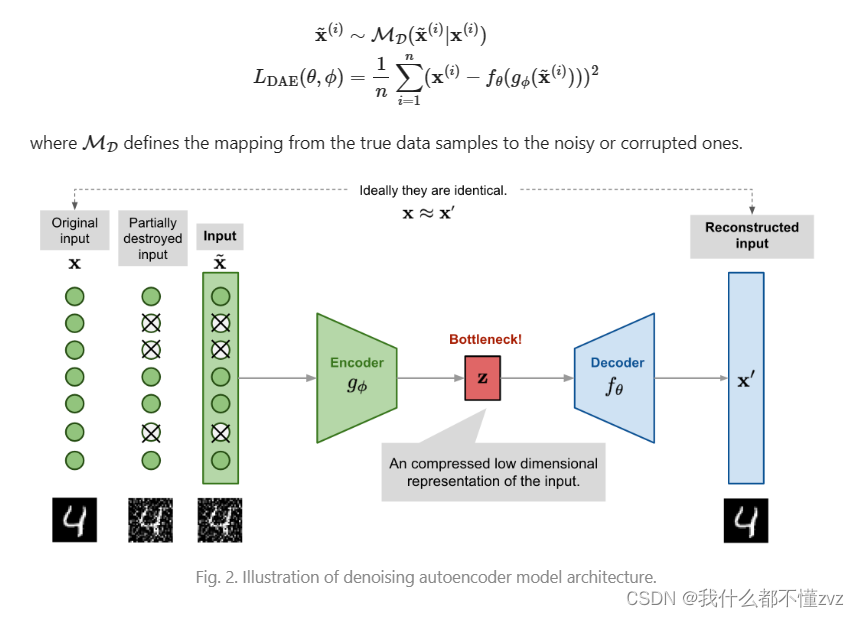
AutoEncoder和 Denoising AutoEncoder学习笔记
参考: 【1】 https://lilianweng.github.io/posts/2018-08-12-vae/ 写在前面: 只是直觉上的认识,并没有数学推导。后面会写一篇(抄)大一统文章(概率角度理解为什么AE要选择MSE Loss) TOC 1 Au…...

计算机系统基础
一、计算机系统概述 计算机系统:硬件软件,软件包括系统软件和应用软件 二、计算机组成结构 三、存储结构 3.1 层次化存储结构 3.2 Cache Cache(高速缓存)的功能:提高CPU数据输入输出的速率,突破冯.若依曼瓶…...
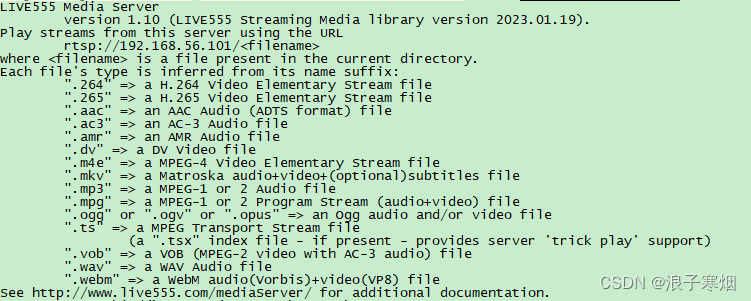
live555学习 - 环境准备
环境:Ubuntu 16.04.7 ffmpeg-6.1 1 代码下载 最新版本: http://www.live555.com/liveMedia/public/ 历史版本下载 https://download.videolan.org/pub/contrib/live555/ 选择版本live.2023.01.19.tar.gz ps:没有选择新版本是新版本在…...

C++ 模拟OJ
目录 1、1576. 替换所有的问号 2、 495. 提莫攻击 3、6. Z 字形变换 4、38. 外观数列 5、 1419. 数青蛙 1、1576. 替换所有的问号 思路:分情况讨论 ?zs:左边没有元素,则仅需保证替换元素与右侧不相等;z?s:左右都…...
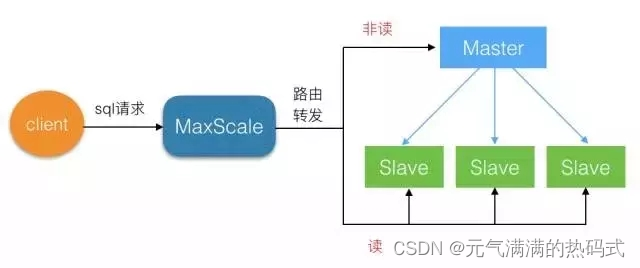
MariaDB MaxScale实现mysql8读写分离
MaxScale 是干什么的? MaxScale是maridb开发的一个mysql数据中间件,其配置简单,能够实现读写分离,并且可以根据主从状态实现写库的自动切换,对多个从服务器能实现负载均衡。 MaxScale 实验环境 中间件192.168.142.13…...

代码随想录day11(1)字符串:反转字符串中的单词 (leetcode151)
题目要求:给定一个字符串,将其中单词顺序反转,且每个单词之间有且仅有一个空格。 思路:因为本题没有限制空间复杂度,所以首先想到的是用split直接分割单词,然后将单词倒叙相加。 但如果想让空间复杂度为O…...
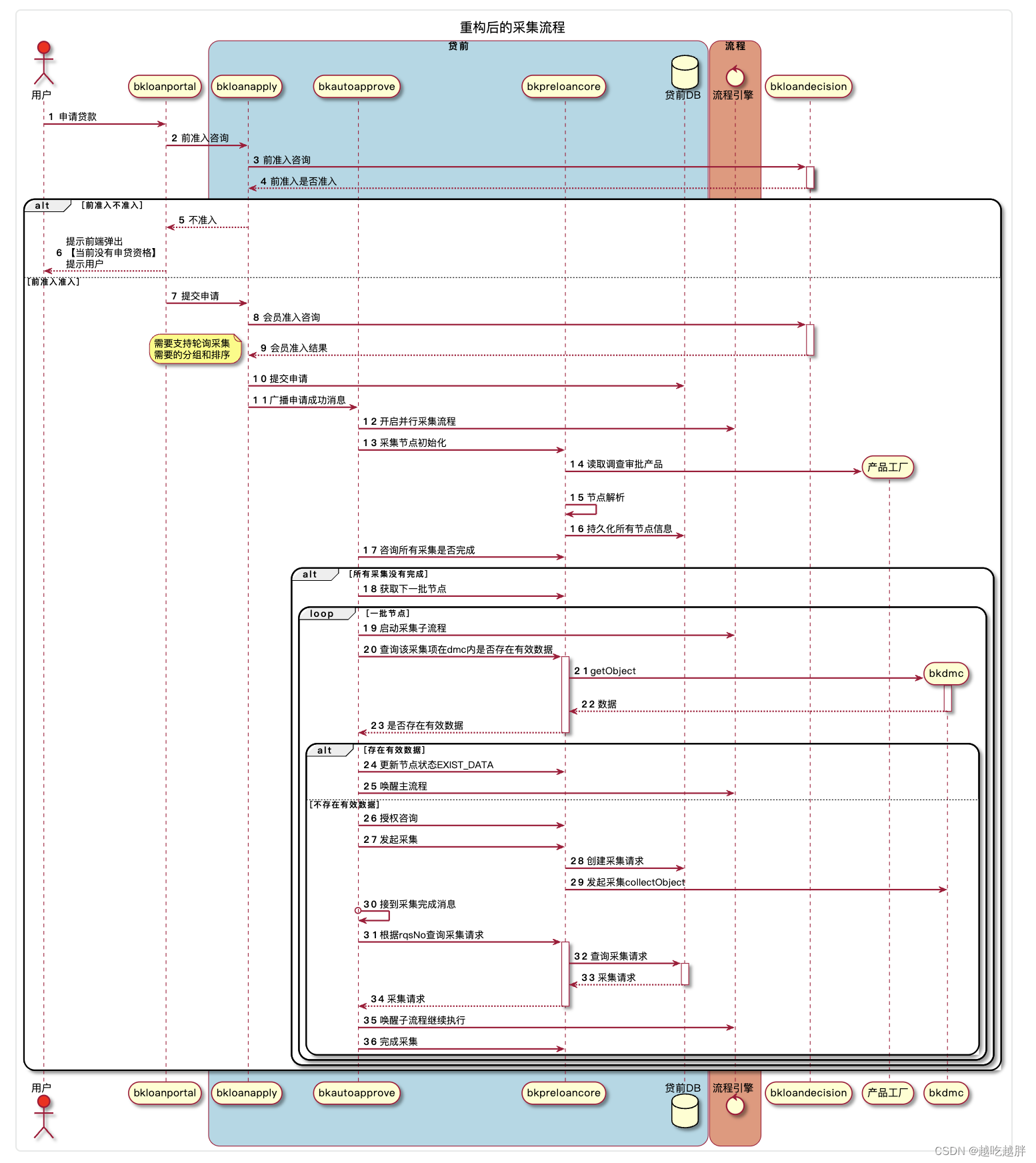
PlantUML - 时序图
时序图主要内容 下面是一个简单的时序图,我们可以很容易并且美观的表达我们的交互流程,只需要在箭头的两边指定一个名字,加上描述即可: startuml bkloanapply -> bkloanapprove : request bkloanapprove --> bkloanapply :…...
VS Code 的粘性滚动预览 - 类似于 Excel 的冻结首行
VS Code 的粘性滚动预览 - 类似于 Excel 的冻结首行功能,即滚动 UI 显示当前源代码范围。便于在代码行数比较多的时候更好的知道自己所在的位置。粘性滚动UI 显示用户在滚动期间所处的范围,将显示编辑器顶部所在的类/接口/命名空间/函数/方法/构造函数&a…...

Java中的List
List集合的特有方法 方法介绍 方法名描述void add(int index,E element)在此集合中的指定位置插入指定的元素E remove(int index)删除指定索引处的元素,返回被删除的元素E set(int index,E element)修改指定索引处的元素,返回被修改的元素E get(int inde…...

Spring 框架模块深度解析:核心容器、数据访问、Web 层与其他关键模块
Spring 可能成为您的所有企业应用程序的一站式商店。但是,Spring 是模块化的,允许您挑选适用于您的模块,而无需引入其他模块。下面的部分提供了 Spring Framework 中所有可用模块的详细信息。Spring Framework 提供了大约20个模块,…...

前端配置开发环境,新电脑配置前端开发环境,Vue开发环境配置的详细过程(前端开发环境配置,电脑重置后配置前端开发环境)
简介:有时候,我们需要在新电脑 或者 电脑重置后,配置前端开发环境,具体都需要安装什么软件和插件,这里来记录一下(文章适合新手和小白,大佬可以带过)。 ✨前端开发环境,需…...
大模型(LLM)的量化技术Quantization原理学习
在自然语言处理领域,大型语言模型(LLM)在自然语言处理领域的应用越来越广泛。然而,随着模型规模的增大,计算和存储资源的需求也急剧增加。为了降低计算和存储开销,同时保持模型的性能,LLM大模型…...
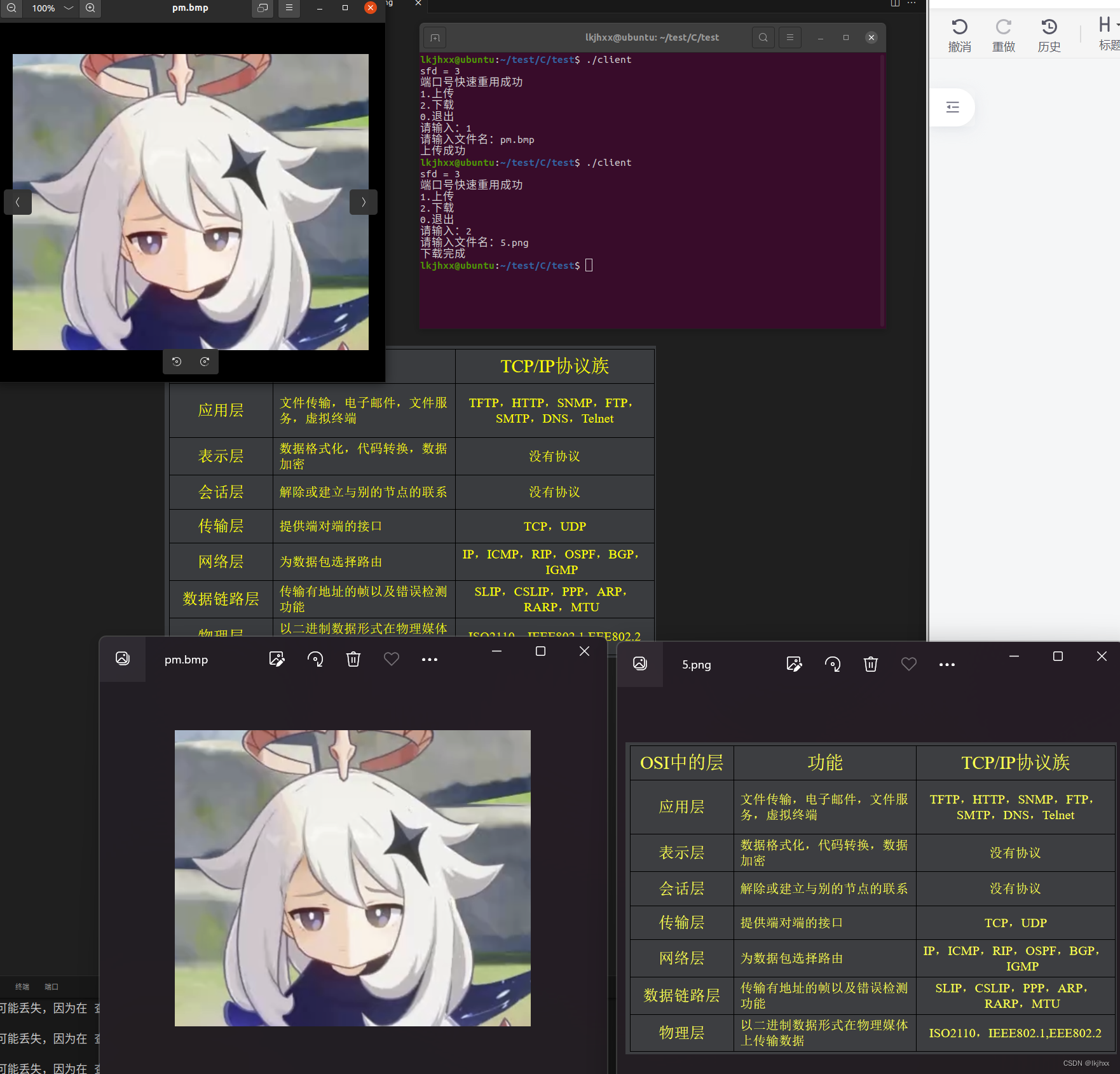
2024.03.01作业
1. 基于UDP的TFTP文件传输 #include "test.h"#define SER_IP "192.168.1.104" #define SER_PORT 69 #define IP "192.168.191.128" #define PORT 9999enum mode {TFTP_READ 1,TFTP_WRITE 2,TFTP_DATA 3,TFTP_ACK 4,TFTP_ERR 5 };void get_…...
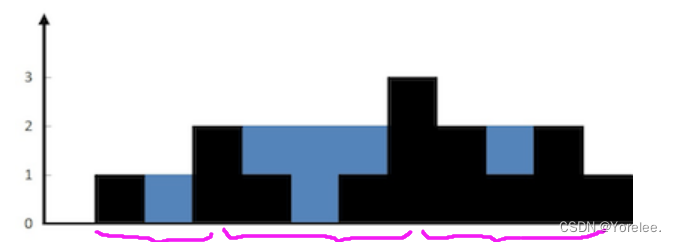
力扣hot100:42.接雨水
什么时候能用双指针? (1)对撞指针: ①两数和问题中可以使用双指针,先将两数和升序排序,可以发现规律,如果当前两数和大于target,则右指针向左走。 ②接雨水问题中,左边最…...
搜索回溯算法(DFS)1------递归
目录 简介: 递归问题解题的思路模板 例题1:汉诺塔 例题2:合并两个有序链表 例题3:反转链表 例题4:两两交换链表中的节点 例题5:Pow(x,n)-快速幂 结语: 简介&…...

workstation 用途
一 workstation 用途 强大的桌面虚拟化 允许创造多种操作系统可以不用重启就跨不同操作系统进行操作可以提供隔离的安全环境 连接到vsphere 可以远程登陆服务器管理物理主机和虚拟主机任何时间都可登陆提高虚拟机效率 为任何平台开发和测试 1)借助一台单一本地…...

【三维重建】【SLAM】SplaTAM:基于3D高斯的密集RGB-D SLAM(CVPR 2024)
题目:SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM 地址:spla-tam.github.io 机构:CMU(卡内基梅隆大学)、MIT(美国麻省理工) 总结:SplaTAM,一个新…...

Go Barrier栅栏
1. 简介 实现与pythonthreading.Barrier库类似的功能,多线程同时等待达到指定数量一起放行。 有待改进地方: wait方法没有支持context控制。 2. 代码 import ("context""golang.org/x/sync/semaphore""sync/atomic" …...

[蓝桥杯 2023 省 B] 冶炼金属
P9240 [蓝桥杯 2023 省 B] 冶炼金属 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 参考题解: #C3150——蓝桥杯2023年第十四届省赛真题-冶炼金属(分块)-Dotcpp编程社区 https://www.bilibili.com/video/BV1wc411x7KU/?spm_id_from333.1007.top_right_bar_windo…...

从Hugging Face模型到可部署服务:我的fast-whisper中文识别项目踩坑与优化实录
从Hugging Face模型到可部署服务:我的fast-whisper中文识别项目踩坑与优化实录 去年夏天接手了一个智能客服系统的语音模块改造项目,客户要求实现高准确率的中文语音实时转写。当我第一次在会议室演示原型时,背景杂音导致转写结果出现了&quo…...

COMET:基于深度学习的翻译质量评估技术革命
COMET:基于深度学习的翻译质量评估技术革命 【免费下载链接】COMET A Neural Framework for MT Evaluation 项目地址: https://gitcode.com/gh_mirrors/com/COMET 在机器翻译技术快速发展的今天,翻译质量评估已成为连接技术研发与实际应用的关键…...

无监督聚类中的特征选择:原理、陷阱与工业级实践
1. 项目概述:为什么无监督聚类中的特征选择,比你想象中更难也更重要“Feature selection for unsupervised problems: the case of clustering”——这个标题乍看像一篇论文的副标题,但如果你真在工业场景里做过客户分群、设备异常模式挖掘、…...

3个核心优势:用AI智能体彻底解放你的桌面生产力
3个核心优势:用AI智能体彻底解放你的桌面生产力 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-desktop 在数…...

Jenga框架双引擎设计:视频生成效率优化解析
1. Jenga框架核心设计解析Jenga视频生成框架的核心创新在于其双引擎设计:渐进式分辨率(ProRes)和动态块稀疏注意力(AttenCarve)。这两种技术协同工作,解决了Transformer架构在视频生成中的计算效率瓶颈。1.1 渐进式分辨率技术(ProRes)ProRes采用分阶段生…...
分析与防护)
SCP-Firmware缓冲区溢出漏洞(CVE-2024-9413)分析与防护
1. 漏洞概述与影响范围解析CVE-2024-9413是近期在SCP-Firmware中发现的一个高危安全漏洞,其核心问题在于应用程序处理器(AP)可能通过特定操作触发系统控制处理器(SCP)固件中的缓冲区溢出。这种漏洞类型在嵌入式系统安全…...

Unity建筑生成器:参数化建模与性能优化实践
1. 这不是“随机堆盒子”,而是建筑生成的工业化流水线在Unity里拖几个Cube拼个楼,再加点贴图——这种做法我干过三年。直到某次做开放城市场景,美术同事把一版“手搭”的街区发给我,我导入引擎后帧率直接掉到28fps,Pro…...

Q-Learning原理与工程实践:从试错记账到智能决策
1. 这不是数学课,是教你怎么让机器“试错成长”——Q-Learning到底在干啥?你有没有带过小孩学骑自行车?一开始扶着后座,他歪歪扭扭往前冲,撞到草坪、蹭到墙边、甚至直接摔进灌木丛——但每次摔倒后,他都会下…...
)
从0到1搭建AI-PPT流水线,支持中英双语自动适配+品牌VI强制注入(含可运行Python脚本+Power Automate配置包)
更多请点击: https://intelliparadigm.com 第一章:从0到1搭建AI-PPT流水线,支持中英双语自动适配品牌VI强制注入(含可运行Python脚本Power Automate配置包) 本方案构建端到端自动化PPT生成流水线,输入结构…...

从BJT到CMOS:运放偏置电流的前世今生,以及它对高阻抗传感器电路设计的实际影响
从BJT到CMOS:运放偏置电流的前世今生,以及它对高阻抗传感器电路设计的实际影响 在精密测量领域,运算放大器的偏置电流就像一位隐形的"电流小偷",悄无声息地影响着测量精度。想象一下,当你试图测量一个微弱的…...