YOLOv5目标检测学习(1):yolo系列算法的基础概念
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、基于深度学习的目标检测需要哪些步骤?
- 二、数据准备(即准备数据集)
- 1.目标检测的数据集如何获取?
- 2.数据集包括训练集和验证集吗?
- 3.如何训练自己的数据集?
- 4.环境配置中的python、pycharm、numpy、panda、anaconda、tensorflow、pytorch都是什么?
- ①python是一门编程语言。
- ②pycharm是一个IDE,即集成了解释、编译、调试等各种功能的开发平台。
- ③numpy是Python中用于科学计算的基础库,提供了多维数组对象(ndarray)和各种数学函数。
- ④Pandas是建立在NumPy之上的数据处理库,提供了高级数据结构和数据分析工具,如Series和DataFrame,用于处理和分析结构化数据
- ⑤Anaconda 是包管理工具,也是一个解释器。
- ⑥TensorFlow 是由Google开发的开源深度学习框架,提供了丰富的API和工具,支持各种深度学习任务,如图像识别、自然语言处理、目标检测等
- ⑦PyTorch 是由Facebook开发的开源深度学习框架,也用于构建和训练深度学习模型
- ⑧yolo是一种深度学习的算法,可以在TensorFlow或者PyTorch构建的框架下实现。
- 三、目标检测性能指标
- 1.检测精度
- 2.检测速度
- 四、YOLO目标检测系列的发展史
- ①one-stage和two-stage的区别?
- ②yolo系列算法的特点
- 五、YOLOV5算法的实现原理
- 5.1 分割网格的作用
- 5.2 对划分出来的每个网格都使用一次卷积神经网络来提取特征向量吗?
- 5.3 每个边界框的类别和置信度是怎么得出的?
- 5.4 非极大值抑制(NMS)算法是什么?
- 六、实现一个yolov5目标检测的项目,需要哪些基础的软件和环境配置呢?
前言
关于深度学习目标检测,有许多概念性的东西需要先了解一下。这里主要以基于深度学习的目标检测算法的部署实现来学习。
一、基于深度学习的目标检测需要哪些步骤?
以yolov5为例:
使用YOLOv5进行车辆和行人的目标检测通常涉及以下步骤:
数据准备:准备包含车辆和行人的训练数据集,确保数据集中包含足够数量和多样性的车辆和行人的图像,并标注它们的位置信息。
模型选择:选择适合目标检测任务的YOLOv5模型,根据任务需求选择不同的模型大小(如YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x)。
模型训练:使用准备好的数据集对选定的YOLOv5模型进行训练。在训练过程中,模型会学习识别车辆和行人等目标的特征。
模型优化:根据训练过程中的验证结果,调整模型的超参数、学习率等,以优化模型的性能。
模型评估:使用测试数据集对训练好的模型进行评估,评估模型在车辆和行人目标检测任务上的准确率、召回率等指标。
模型部署:将训练好的YOLOv5模型部署到实际应用中,用于车辆和行人的目标检测任务。可以将模型集成到自动驾驶系统、智能监控系统等中。
实时检测:在部署后,可以利用YOLOv5模型进行实时的车辆和行人目标检测,识别图像或视频流中的车辆和行人,并提供相应的输出结果。
我逐步介绍这里面涉及到的一些内容。
二、数据准备(即准备数据集)
1.目标检测的数据集如何获取?
获取目标检测的数据集通常可以通过以下几种途径:
公开数据集:有许多公开的目标检测数据集可供使用,如COCO(Common Objects in Context)、PASCAL VOC(Visual Object Classes)、ImageNet等。这些数据集包含了各种类别的图像和相应的标注信息,可以用于训练和评估目标检测模型。
自行标注:如果需要特定领域或特定任务的数据集,可以自行收集图像数据并进行标注。标注可以包括物体的边界框、类别信息等。可以使用标注工具如LabelImg、LabelMe等进行标注工作。
第三方数据提供商:有些数据提供商提供各种类型的标注数据集,可以根据需求购买或获取这些数据集。一些公司和组织也提供定制的数据集收集和标注服务。
数据增强:除了获取现有的数据集外,还可以通过数据增强技术来扩充数据集规模,增加数据的多样性。数据增强包括旋转、翻转、缩放、亮度调整等操作,可以提高模型的泛化能力。
合作伙伴和社区:与合作伙伴、学术界或开发者社区合作,共享数据集或参与共同构建数据集,可以获得更多的数据资源和支持。
2.数据集包括训练集和验证集吗?
数据集通常包括训练集和验证集。在机器学习和深度学习任务中,训练集用于训练模型的参数,而验证集用于评估模型的性能和调整超参数。
训练集是模型用来学习特征和参数的数据集,通常包含大量的标注数据,用于训练模型进行目标检测、分类、分割等任务。训练集的目的是让模型学习到数据集中的模式和规律,以便对新的数据进行预测和分类。
验证集是用来评估模型在训练过程中的性能和泛化能力的数据集。在训练过程中,可以使用验证集来监控模型的性能,并根据验证集的表现调整模型的超参数,防止模型过拟合或欠拟合。
通常,数据集会被划分为训练集和验证集两部分,比例可以根据具体任务和数据量来确定。常见的划分比例是将数据集的大约80%用作训练集,20%用作验证集。
3.如何训练自己的数据集?
这里的方法CSDN上有许多博主都在介绍,大致的流程是:
练自己的数据集通常涉及以下步骤:
数据收集标注——对收集到的图像数据进行预处理——将数据集划分为训练集和验证集——选择适合目标检测任务的模型,如YOLOv5、Faster R-CNN、SSD——使用训练集对选定的模型进行训练
——使用验证集对训练好的模型进行评估——根据评估结果调整模型的超参数、学习率等——将训练好的模型部署到实际应用中,用于目标检测任务,可以将模型集成到自动驾驶系统、智能监控系统等中。
有一位博主利用yolov5进行训练的过程如下:

4.环境配置中的python、pycharm、numpy、panda、anaconda、tensorflow、pytorch都是什么?
①python是一门编程语言。
②pycharm是一个IDE,即集成了解释、编译、调试等各种功能的开发平台。
③numpy是Python中用于科学计算的基础库,提供了多维数组对象(ndarray)和各种数学函数。
④Pandas是建立在NumPy之上的数据处理库,提供了高级数据结构和数据分析工具,如Series和DataFrame,用于处理和分析结构化数据
⑤Anaconda 是包管理工具,也是一个解释器。
⑥TensorFlow 是由Google开发的开源深度学习框架,提供了丰富的API和工具,支持各种深度学习任务,如图像识别、自然语言处理、目标检测等
⑦PyTorch 是由Facebook开发的开源深度学习框架,也用于构建和训练深度学习模型
⑧yolo是一种深度学习的算法,可以在TensorFlow或者PyTorch构建的框架下实现。
三、目标检测性能指标
分为检测速度和检测精度。
1.检测精度
准确率(Precision):指检测出的目标中真正为目标的比例,即检测为目标且确实为目标的数量与所有检测为目标的数量的比值。即
召回率(Recall):指所有真正为目标的样本中被检测出的比例,即检测为目标且确实为目标的数量与所有真正为目标的数量的比值。
F1分数:综合考虑准确率和召回率,是准确率和召回率的调和平均值,可以帮助评估模型在准确率和召回率之间的平衡。
平均精度均值(mAP):是目标检测任务中常用的评估指标,综合考虑了不同类别的准确率和召回率,计算出每个类别的AP(平均精度),然后取所有类别AP的平均值作为最终的mAP。
交并比(IoU):指预测框与真实框之间的重叠程度,通常用于衡量目标检测算法的定位准确性。
漏检率(Miss Rate):指未检测到的目标数量与所有真实目标数量的比值,是召回率的补数。
误检率(False Alarm Rate):指被错误检测为目标的数量与所有未真实目标数量的比值,是准确率的补数。
2.检测速度
前传耗时:指模型进行一次前传(从输入到输出的计算过程)所花费的时间。前传耗时直接影响模型的推理速度,通常希望前传耗时越短越好,特别是在实时应用中,如视频分析、自动驾驶等。
FPS(Frames Per Second):指模型每秒能够处理的帧数,即模型每秒能够进行多少次推理。FPS是衡量模型推理速度的重要指标,通常希望模型的FPS越高越好,以实现实时的目标检测和识别。
FLOPS(Floating Point Operations Per Second):指模型每秒执行的浮点运算次数。FLOPS是衡量模型计算复杂度的指标,可以用来评估模型的计算资源消耗和效率。通常情况下,FLOPS越低表示模型计算效率越高。
四、YOLO目标检测系列的发展史

YOLO(You Only Look Once)是一种流行的目标检测算法,以其简单、快速和高效而闻名。以下是YOLO的发展历程:
YOLO v1:YOLO v1是于2015年由Joseph Redmon等人提出的第一个YOLO版本。YOLO v1采用单个神经网络模型,将目标检测任务转化为回归问题,通过在图像中预测边界框的坐标和类别来实现目标检测。YOLO v1的特点是速度快,但在小目标检测和定位精度上存在一定问题。
YOLO v2:YOLO v2(也称为YOLO9000)是于2016年提出的改进版本,引入了一些新的技术和优化,如使用更深的网络、多尺度训练、Batch Normalization等,提高了检测精度和泛化能力。YOLO v2还引入了目标类别的多标签预测,使得模型可以同时检测多个类别。
YOLO v3:YOLO v3是于2018年发布的最新版本,进一步改进了检测精度和速度。YOLO v3采用了更深的Darknet-53网络作为基础网络结构,引入了多尺度预测、特征融合和更细粒度的边界框预测,提高了模型的检测性能。YOLO v3还支持多种不同尺寸的输入图像,适应不同场景的需求。
YOLO v4:YOLO v4是YOLO系列的最新版本,于2020年发布。YOLO v4引入了一系列新技术和优化,如CSPDarknet53网络、Mish激活函数、SAM模块等,进一步提高了检测精度和速度。YOLO v4还支持混合精度训练、模型剪枝等技术,使得模型更加高效和灵活。
①one-stage和two-stage的区别?
Two-stage(两阶段):代表-- Fsater-rcnn Mask-rcnn系列
One-stage(单阶段):代表-- Yolo系列
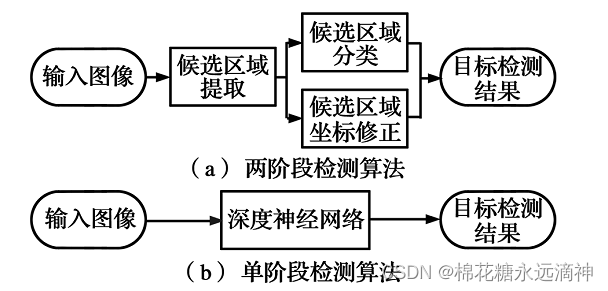
简单地说,单阶段相比多阶段,更加一步到位,把图像直接输入单个神经网络后就能直接输出结果,但是两阶段算法必须先将图像生成一个可能含有目标对象的候选区域,再进一步处理。
所以,
One-stage
优势:速度非常快,适合做实时检测任务
劣势:效果通常不会太好
Two-stage
优势:效果通常比较好
劣势:速度较慢,不适合做实时检测任务
②yolo系列算法的特点
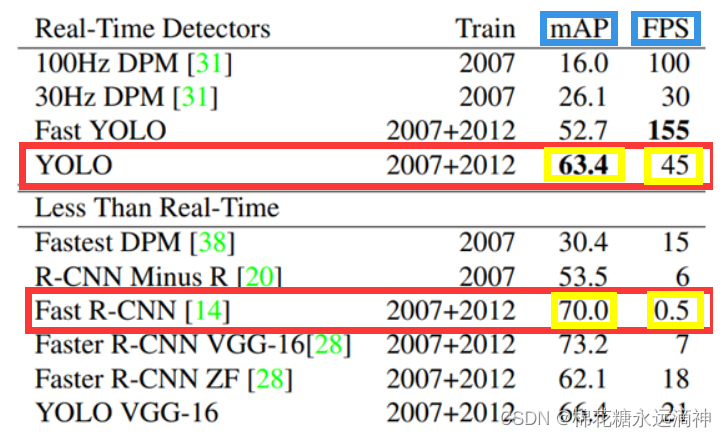
这个图可以看出,yolo系列算法的mAP(即检测精度)没有快速线性卷积神经网络(RCNN)高,但是其FPS却非常高,所以处理实时性要求高的场景比较合适。
五、YOLOV5算法的实现原理
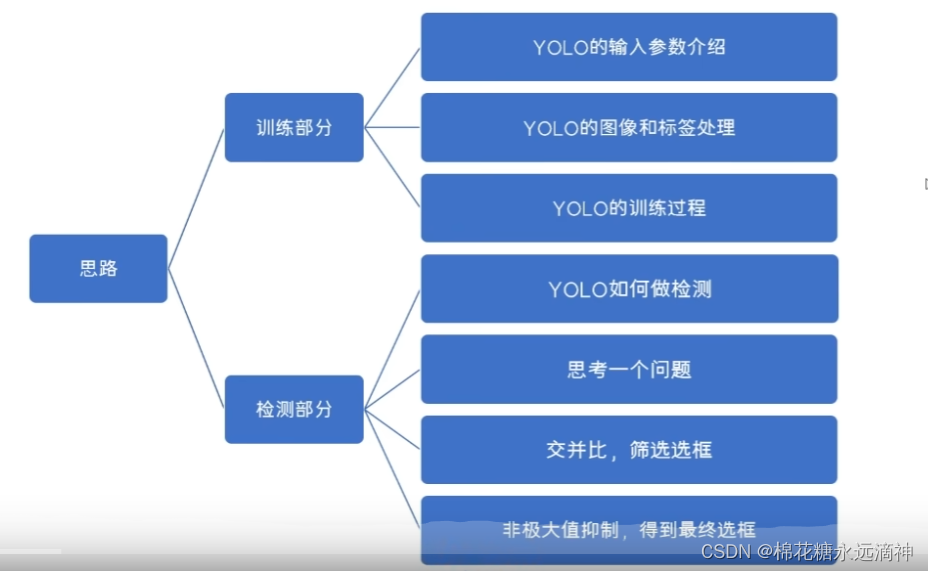

总结就是:
①将输入图像分割成网格:YOLO5将输入图像分成S×S个网格,每个网格负责检测一个目标。如果一个目标的中心点在某个网格内,那么就会在该网格内拟合出一个边界框。
②提取特征向量:使用卷积神经网络提取每个网格的特征向量,该特征向量代表了该网格内目标的特征。
③预测边界框和类别:对于每个网格,使用全连接层来预测一个或多个边界框,以及每个边界框可能的类别和置信度得分。
④预测结果的后处理:对于每个目标,选择置信度最高的边界框。然后,根据非极大值抑制(NMS)算法去掉重复边界框并选择最终的目标框。
5.1 分割网格的作用
主要起四个作用:
减少计算量:相比于对整张图像进行目标检测,只对每个网格进行检测可以大大提高算法的运行速度。
定位目标:通过将图像分割成网格,可以更精确地定位目标的位置。每个网格负责检测其中的目标,减少目标位置的搜索范围
适应不同尺寸的目标:分割成多个网格可以更好地适应不同尺寸和比例的目标。每个网格可以独立地检测目标,无需对整个图像进行缩放或调整,从而提高了算法的鲁棒性。
多尺度检测:通过将图像分割成多个网格,可以实现多尺度的目标检测。不同大小的目标可能出现在不同大小的网格中,这样可以更全面地检测图像中的目标。
5.2 对划分出来的每个网格都使用一次卷积神经网络来提取特征向量吗?
在YOLO算法中,每个网格都会经过一次卷积神经网络的前向传播过程,从而提取该网格内目标的特征向量。这些特征向量将用于后续的目标边界框和类别的预测。
至于如何用CNN进行特征提取的,这个就是先送入池化层减少复杂度,简单的卷积层进行滑动窗口的卷积操作得到一个特征矩阵,然后送入全连接层,进行特征映射、非线性变换和参数学习,最终得到输出特征图。
5.3 每个边界框的类别和置信度是怎么得出的?
在全连接层后,通常会使用softmax函数将网络输出转换为概率分布,以表示每个类别的可能性。
5.4 非极大值抑制(NMS)算法是什么?
非极大值抑制(Non-Maximum Suppression,NMS)是一种常用的目标检测算法后处理技术,用于去除重叠边界框并选择最终的目标框。其主要思想是在检测到的多个边界框中,保留置信度最高的边界框,同时抑制与该边界框重叠度较高的其他边界框。
NMS算法的步骤如下:
①按照置信度排序:首先,对所有检测到的边界框按照其置信度得分进行排序,置信度高的边界框排在前面。
②选择置信度最高的边界框:从排好序的边界框列表中选择置信度最高的边界框,并将其添加到最终的目标框列表中。
③计算重叠度:对于剩余的边界框,计算它们与已选中的最高置信度边界框的重叠度(如IoU,交并比)。
④去除重叠边界框:对于重叠度高于设定阈值的边界框,将其从列表中去除,只保留重叠度较低的边界框。
⑤重复操作:重复以上步骤,直到所有边界框都被处理完毕。
通过非极大值抑制算法,可以有效地减少重叠边界框,保留置信度最高的边界框,从而得到最终的目标检测结果。NMS算法在目标检测领域被广泛应用,能够提高检测结果的准确性和稳定性。
六、实现一个yolov5目标检测的项目,需要哪些基础的软件和环境配置呢?
要实现一个YOLOv5目标检测项目,需要以下基础的软件和环境配置:
Python环境:YOLOv5是基于Python实现的,因此需要安装Python环境。推荐使用Python 3.6及以上版本。
PyTorch:YOLOv5使用PyTorch作为深度学习框架,因此需要安装PyTorch。可以通过PyTorch官方网站提供的安装指南安装对应版本的PyTorch。
CUDA和cuDNN:如果要在GPU上加速训练和推理过程,需要安装相应版本的CUDA和cuDNN,并配置PyTorch以支持GPU加速。
YOLOv5代码库:下载YOLOv5的代码库,可以从GitHub上的ultralytics/yolov5仓库获取。可以使用git命令克隆代码库或直接下载zip文件。
依赖库:安装项目所需的依赖库,如NumPy、OpenCV、Matplotlib等。可以通过pip或conda安装这些库。
数据集:准备用于训练和测试的目标检测数据集。可以使用已有的数据集,也可以自行收集和标注数据集。
预训练模型:下载YOLOv5的预训练模型权重,可以从YOLOv5官方发布的权重文件中获取。
配置文件:根据项目需求,可以修改YOLOv5的配置文件,如模型结构、超参数设置等。
相关文章:
YOLOv5目标检测学习(1):yolo系列算法的基础概念
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、基于深度学习的目标检测需要哪些步骤?二、数据准备(即准备数据集)1.目标检测的数据集如何获取?2.数据集包括…...
【大数据】通过 docker-compose 快速部署 MinIO 保姆级教程
文章目录 一、概述二、MinIO 与 Ceph 对比1)架构设计对比2)数据一致性对比3)部署和管理对比4)生态系统和兼容性对比 三、前期准备1)部署 docker2)部署 docker-compose 四、创建网络五、MinIO 编排部署1&…...
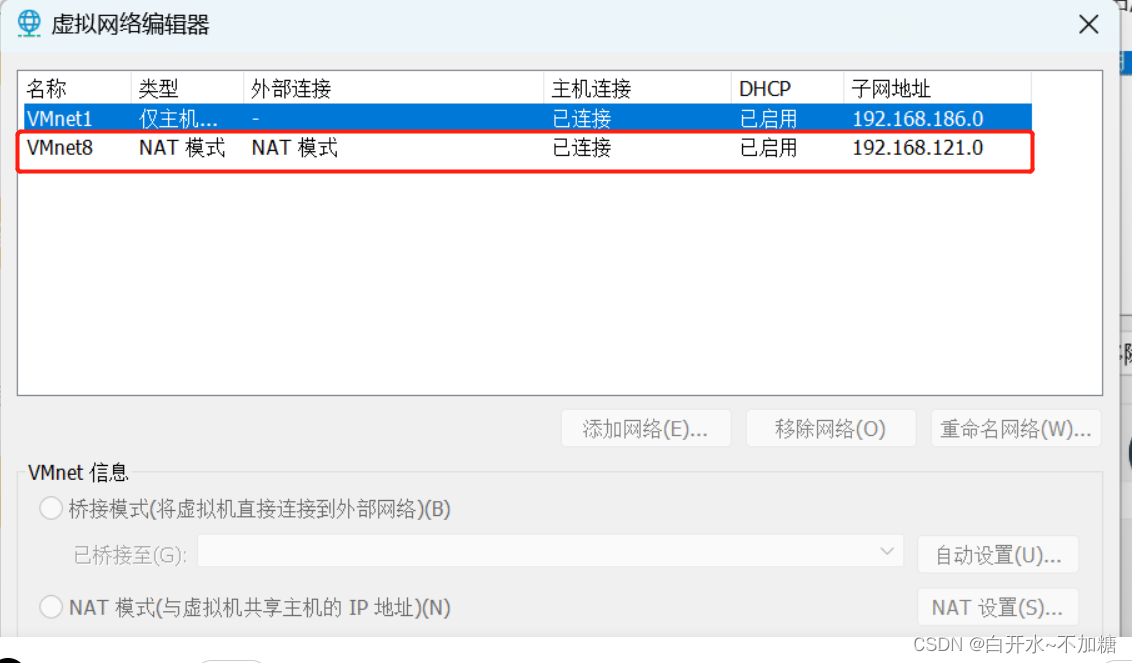
VMware 虚拟机安装windows 10操作系统
先提前准备好镜像文件 1.创建新的虚拟机 2.选择自定义,然后下一步 v Windows 建议选择2G以上,下一步 选择网络地址转换(NAT),下一步 这里可按自己的需求来分区,也可以安装好后再分区 选择立即重启ÿ…...
之MySQL执行流程)
Mysql实战(2)之MySQL执行流程
-- 查看mysql当前有多少连接 show global status like Thread%; /* Threads_cached:缓存中的线程连接数 Threads_connected:当前打开的连接数 Threads_created:为处理连接创建的线程数 Threads_running:非睡眠状态的连接数&…...
ES6 | (二)ES6 新特性(下) | 尚硅谷Web前端ES6教程
文章目录 📚迭代器🐇定义🐇工作原理🐇自定义遍历数据 📚生成器函数🐇声明和调用🐇生成器函数的参数传递🐇生成器函数案例 📚Promise📚Set🐇Set的定…...

客户案例|用友NC财务系统上云
本文分享一次成功将用友NC财务系统上云的经验,主要涉及阿里云上Oracle ASM存储扩容,阿里云ESC RAC服务器扩容,阿里云上Oracle RAC数据库迁移等相关技术,一起来看看吧! 1 客户数据库上云背景 本次项目我司主要负责客户…...

OceanPen Art AI绘画系统内容讲解
在一个崇高的目标支持下,不停地工作,即使慢,也一定会获得成功。 —— 爱因斯坦 演示站点: ai.oceanpen.art官方论坛: www.jingyuai.com 💡技术栈 前端:VUE3后端:Java数据…...

类 Unix 系统的文件目录结构
以下是类 Unix 系统的文件目录结构、各个目录主要存放的文件以及缩写的全称的详细说明: 根目录 /: 全称: Root Directory说明:根目录是整个文件系统的起点,包含了所有其他目录和文件。 /bin 目录: 全称: Binary说明&a…...

外部存储器接口(EMIF)
外部存储器接口(EMIF) 该设备支持双核架构;为了为每个CPU子系统提供一个专用的EMIF,该设备支持两个EMIF模块——EMIF1和EMIF2。两个模块完全相同,具有相同的功能集,但具有不同的地址/数据大小。EMIF1在CPU…...

华为认证HCIP报名条件有哪些?考试要求介绍
华为HCIP认证是很多网络工程师的考证首选,尤其对于刚入行不久的网络工程师们来说,这个证书无论是从难度出发还是从含金量出发,都是值得一考的。 那么如果想报名华为HCIP认证有哪些条件以及考试要求,华为HCIP的报名需不需要通过机…...

【Python】变量的引用
🚩 WRITE IN FRONT 🚩 🔎 介绍:"謓泽"正在路上朝着"攻城狮"方向"前进四" 🔎🏅 荣誉:2021|2022年度博客之星物联网与嵌入式开发TOP5|TOP4、2021|2222年获评…...

nextjs13如何进行服务端渲染?
目录 一、创建一个新项目 二、动态获取后端数据进行服务端渲染出现的问题 三、nextjs13如何进行服务端渲染 nextjs13是nextjs的一个重大升级,一些原本在next12当中使用的API在nextjs13上使用十分不便。本文将着重介绍在nextjs13及以上版本当中进行服务端渲染的方…...
Redis-基础篇
Redis是一个开源、高性能、内存键值存储数据库,由 Salvatore Sanfilippo(网名antirez)创建,并在BSD许可下发布。它不仅可以用作缓存系统来加速数据访问,还可以作为持久化的主数据存储系统或消息中间件使用。Redis因其数…...

【好书推荐-第七期】《RTC程序设计:实时音视频权威指南》(音视频开发必看!)
😎 作者介绍:我是程序员洲洲,一个热爱写作的非著名程序员。CSDN全栈优质领域创作者、华为云博客社区云享专家、阿里云博客社区专家博主、前后端开发、人工智能研究生。公粽号:洲与AI。 🎈 本文专栏:本文收录…...
还在犹豫学不学?鸿蒙技术是否有前途的最强信号来了
2024年3月3日 上午10 点,深圳官方账号发布了一篇关于鸿蒙技术发展的重要文章,看到这篇文章后我非常激动,忍不住和大家分享一下! 华为鸿蒙系统自提出以来,网友们的态度各不相同,有嘲笑“安卓套壳”的&#x…...

webpack的plugin 插件教程
Webpack 是一个流行的前端打包工具,通过使用插件(plugin),我们可以对 Webpack 进行扩展和定制,实现更多功能和优化构建过程。在本教程中,我将向你介绍如何编写一个简单的 Webpack 插件,并演示如…...

v72.关于指针操作的补充
1.指针作为函数参数 调用函数时,传递参数的形式决定了是否可以修改这些参数。 传值方式:传递了参数给函数,并且这个参数是基本数据类型,如(int,float),那么函数内对参数的任何操作…...

【学习心得】爬虫JS逆向通解思路
我希望能总结一个涵盖大部分爬虫逆向问题的固定思路,在这个思路框架下可以很高效的进行逆向爬虫开发。目前我仍在总结中,下面的通解思路尚不完善,还望各位读者见谅。 一、第一步:明确反爬手段 反爬手段可以分为几个大类 &#…...

如何使用Logstash搜集日志传输到es集群并使用kibana检测
引言:上一期我们进行了对Elasticsearch和kibana的部署,今天我们来解决如何使用Logstash搜集日志传输到es集群并使用kibana检测 目录 Logstash部署 1.安装配置Logstash (1)安装 (2)测试文件 ÿ…...
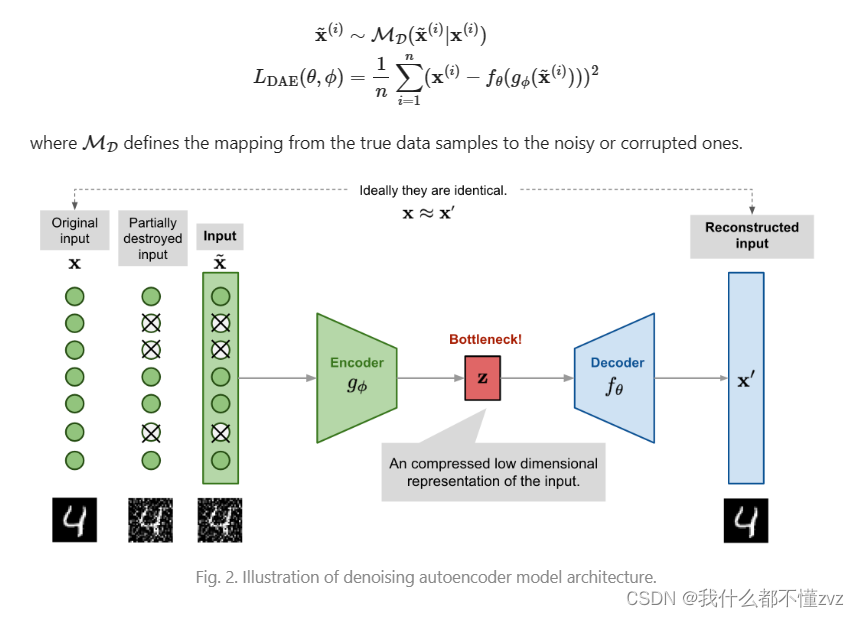
AutoEncoder和 Denoising AutoEncoder学习笔记
参考: 【1】 https://lilianweng.github.io/posts/2018-08-12-vae/ 写在前面: 只是直觉上的认识,并没有数学推导。后面会写一篇(抄)大一统文章(概率角度理解为什么AE要选择MSE Loss) TOC 1 Au…...

终极指南:在Windows上完美使用苹果触控板的完整配置方案
终极指南:在Windows上完美使用苹果触控板的完整配置方案 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-precision-touchpad …...

长期在ubuntu开发中使用taotoken api感受到的稳定性与支持体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期在ubuntu开发中使用taotoken api感受到的稳定性与支持体验 作为一名在Ubuntu环境下进行日常开发的工程师,我的项目…...

3分钟学会:免费歌词制作工具让你轻松成为音乐剪辑高手 [特殊字符]
3分钟学会:免费歌词制作工具让你轻松成为音乐剪辑高手 🎵 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 你是否曾经想为自己喜欢的歌曲制作…...

Display Driver Uninstaller完整攻略:显卡驱动清理的终极解决方案
Display Driver Uninstaller完整攻略:显卡驱动清理的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-u…...
)
从main.cc到五大视图:手把手拆解QGC的UI启动流程(附QML与C++交互实例)
从main.cc到五大视图:手把手拆解QGC的UI启动流程(附QML与C交互实例) 当你第一次打开QGroundControl(QGC)时,那个简洁而功能强大的界面背后,隐藏着一套精妙的启动机制。作为一款广泛应用于无人机…...

APT32F110 RTC实战:从配置校准到低功耗应用全解析
1. 项目概述与核心价值最近在捣鼓爱普特APT32F110这块开发板,发现它内置的RTC(实时时钟)模块挺有意思。对于很多嵌入式项目来说,时间戳记录、定时唤醒、低功耗运行这些功能都离不开一个靠谱的RTC。APT32F110作为一款主打高性价比和…...

中关村、首体院、京奥电竞三方签约,共探AI+电竞产学研一体化突破
AI电竞:三方签约开启产学研新篇在今日的大会上,中关村人工智能研究院、首都体育学院、京奥电竞(北京)科技有限公司举行了一场重量级的三方签约。中关村人工智能研究院专注于具有产业价值和颠覆意义的人工智能与交叉学科领域探索&a…...

全域流量矩阵系统的运筹学解法:用线性规划模型,算出你100个账号的最优流量分配
手里有100个账号,抖音30个、小红书25个、视频号20个、B站15个、快手10个——然后呢?大多数人的做法是:每个平台平均发,每个账号随便发,发完看天吃饭。这不叫矩阵运营,这叫资源浪费。今天换个完全不同的视角…...
)
ChatGPT网络错误不是运气问题:用mtr追踪真实路径,定位ISP路由黑洞、中间盒QoS限速与WAF误拦截(附15分钟速查表)
更多请点击: https://codechina.net 第一章:ChatGPT网络错误不是运气问题:用mtr追踪真实路径,定位ISP路由黑洞、中间盒QoS限速与WAF误拦截(附15分钟速查表) ChatGPT连接失败常被归因为“服务器繁忙”或“网…...

C#与Unity 3D构建100ms级工业数字孪生系统
1. 这不是“3D大屏”,而是产线工控级实时映射“数字孪生监控”这六个字,现在被贴在太多PPT封面上了——三维建模、粒子特效、旋转飞入的UI动效,配上“智能决策”“预测性维护”的标语,看起来很美。但真正跑在车间里的产线监控系统…...