数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(代码部分)
文章:
数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(一)
数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(二)
数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(总)
代码:
数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(代码部分)
数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(代码部分)
数据集下载:抖音用户浏览行为数据集
数据预处理
首先,需要获取抖音用户的浏览行为的相关数据集,包括用户的观看记录、点赞记录、评论记录、分享记录等。这可以从数据库中提取数据、采集网络数据、使用API 访问数据源或与合作伙伴合作获得数据,也可以通过与抖音平台合作获得用户数据,使用API访问数据接口或其他合法的数据收集手段来实现。
# 导包
import pandas as pd
import numpy as np
# 1. 数据简单处理——读入数据
df = pd.read_csv('douyin_dataset.csv')
df.head()
del df['Unnamed: 0']#无效字段的删除[Unnamed:0]
# 数据基本信息基本信息
df.info(null_counts = True)
特征指标构建
根据问题的需求和数据的特点,进行特征选择、提取和转换。例如,可以从用户的浏览行为数据中提取特征,如观看时长、点赞数、评论数、分享数等,或者通过文本挖掘技术提取用户的评论内容特征,可以包括对原始特征进行数值化、编码分类变量、创建新特征等操作。
# 2. 特征指标统计分析
## 2.1 用户特征统计分析
user_df = pd.DataFrame()
user_df['uid'] = df.groupby('uid')['like'].count().index.tolist() # 将所有用户的uid提取为uid列
user_df.set_index('uid', inplace=True) # 设置uid列为index,方便后续数据自动对齐
user_df['浏览量'] = df.groupby('uid')['like'].count() # 统计对应uid下的浏览量
user_df['点赞量'] = df.groupby('uid')['like'].sum() # 统计对应uid下的点赞量
user_df['观看作者数'] = df.groupby(['uid']).agg({'author_id':pd.Series.nunique}) # 观看作者数
user_df['观看作品数'] = df.groupby(['uid']).agg({'item_id':pd.Series.nunique}) # 观看作品数
user_df['观看作品平均时长'] = df.groupby(['uid'])['duration_time'].mean() # 浏览作品平均时长
user_df['观看配乐数'] = df.groupby(['uid']).agg({'music_id':pd.Series.nunique}) # 观看作品中配乐的数量
user_df['完整观看数'] = df.groupby('uid')['finish'].sum() # 统计对应uid下的完整观看数
# 统计对应uid用户去过的城市数量
user_df['去过的城市数'] = df.groupby(['uid']).agg({'user_city':pd.Series.nunique})
# 统计对应uid用户看的作品所在的城市数量
user_df['观看作品城市数'] = df.groupby(['uid']).agg({'item_city':pd.Series.nunique})
user_df.describe()user_df.to_csv('用户特征.csv', encoding='utf_8_sig')
## 2.2 作者特征统计分析
author_df = pd.DataFrame()
author_df['author_id'] = df.groupby('author_id')['like'].count().index.tolist()
author_df.set_index('author_id', inplace=True)
author_df['总浏览量'] = df.groupby('author_id')['like'].count()
author_df['总点赞量'] = df.groupby('author_id')['like'].sum()
author_df['总观完量'] = df.groupby('author_id')['finish'].sum()
author_df['总作品数'] = df.groupby('author_id').agg({'item_id':pd.Series.nunique})item_time = df.groupby(['author_id', 'item_id']).mean().reset_index()
author_df['作品平均时长'] = item_time.groupby('author_id')['duration_time'].mean()author_df['使用配乐数量'] = df.groupby('author_id').agg({'music_id':pd.Series.nunique})
author_df['发布作品日数'] = df.groupby('author_id').agg({'real_time':pd.Series.nunique})# pd.to_datetime(df['date'].max()) - pd.to_datetime(df['date'].min()) # 作品时间跨度为40,共计40天
author_days = df.groupby('author_id')['date']
_ = pd.to_datetime(author_days.max()) - pd.to_datetime(author_days.min())
author_df['创作活跃度(日)'] = _.astype('timedelta64[D]').astype(int) + 1
author_df['去过的城市数'] = df.groupby(['author_id']).agg({'item_city':pd.Series.nunique})
author_df.describe()author_df.to_csv('作者特征.csv', encoding='utf_8_sig')
## 2.3 作品特征统计分析
item_df = pd.DataFrame()
item_df['item_id'] = df.groupby('item_id')['like'].count().index.tolist()
item_df.set_index('item_id', inplace=True)
item_df['浏览量'] = df.groupby('item_id')['like'].count()
item_df['点赞量'] = df.groupby('item_id')['like'].sum()
item_df['发布城市'] = df.groupby('item_id')['item_city'].mean()
item_df['背景音乐'] = df.groupby('item_id')['music_id'].mean()item_df.to_csv('作品特征.csv', encoding='utf_8_sig')
①数据可视化分析—用户特征分析
import pandas as pd
import numpy as npfrom pyecharts.charts import *
from pyecharts import options as opts
def line_chart(t, data):# 曲线图chart = (Line(init_opts = opts.InitOpts(theme='light', width='500px', height='300px')).add_xaxis([i[0] for i in data]).add_yaxis('',[i[1] for i in data],is_symbol_show=False,areastyle_opts=opts.AreaStyleOpts(opacity=1, color="cyan")).set_global_opts(title_opts=opts.TitleOpts(title=t),xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=True),yaxis_opts=opts.AxisOpts(type_="value",axistick_opts=opts.AxisTickOpts(is_show=True),splitline_opts=opts.SplitLineOpts(is_show=True),),))return chart
def pie_chart(t, data_pair):# 新建一个饼图chart = (Pie(init_opts=opts.InitOpts(theme='light', width='550px', height='300px')).add('', data_pair ,radius=["30%", "45%"], # 半径范围,内径和外径label_opts=opts.LabelOpts(formatter="{b}: {d}%") # 标签设置,{d}表示显示百分比).set_global_opts(title_opts=opts.TitleOpts(title=t),legend_opts=opts.LegendOpts(pos_left="0%",pos_top=相关文章:
)
数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(代码部分)
文章: 数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(一) 数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(二) 数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(总) 代码: 数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(代码…...
AWS EKS(AWS云里面的K8S)
问题 初步使用EKS 步骤 安装AWS CLI 第一步是在自己的笔记本电脑上面安装AWS提供的CLI(命令行工具),这里就不详细介绍了,都是next的步骤。具体可以参考啊aws cli安装的相关教程网页,具体地址如下: http…...

Azkaban 大数据 任务调度
参考视频:尚硅谷大数据Azkaban 3.x教程(全新发布)_哔哩哔哩_bilibili Azkaban: 是一个定时、批量工作流任务调度器(工作流程调度,定时调度) 常见的开源调度系统: 简单单一的任务调度: Linux的…...

从预训练到通用智能(AGI)的观察和思考
1.预训练词向量 预训练词向量(Pre-trained Word Embeddings)是指通过无监督学习方法预先训练好的词与向量之间的映射关系。这些向量通常具有高维稠密特征,能够捕捉词语间的语义和语法相似性。最著名的预训练词向量包括Google的Word2Vec&#…...

四种垃圾回收算法
1.标记清除算法 该算法先标记,后清除,将所有需要回收的算法进行标记,然后清除;这种算法的缺点是:效率比较低;标记清除后会出现大量不连续的内存碎片,这些碎片太多可能会使存储大对象会触发GC回…...
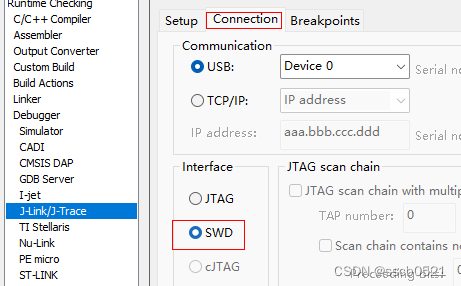
stm32f103zet6笔记1-led工程
1、选择串口调试 2、LED0连接到PB5,PB5设置为推挽输出。PE5同理。 3、生成成对的.c,.h文件。 4、debugger选择j-link。 5、connection选择SWD。 6、编写bsp_led.c,bsp_led.h文件。 7、下载调试,可以看到LED0 500ms闪烁一次,LED1 1000ms闪烁一…...

OpenDDS的Qos策略
目录 1、前言2、QoS策略2.1、LIVELINESS2.2、RELIABILITY2.3、HISTORY2.4、DURABILITY2.5、DURABILITY_SERVICE2.6 、RESOURCE_LIMITS2.7、PARTITION2.8、DEADLINE2.9、LIFESPAN2.10、USER_DATA2.11、TOPIC_DATA2.12、GROUP_DATA2.13、TRANSPORT_PRIORITY2.14、LATENCY_BUDGET2…...
)
string基本操作(C++)
增 1.1 “” str str ss;cout << str << endl; //234561提取字串 2.1 substr substr(pos): 提取从位置pos开始到末尾的子串。 #include <iostream> #include <string> using namespace std;int main(){string str "123456";//substr(pos…...
【网站项目】123网上书城系统
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...
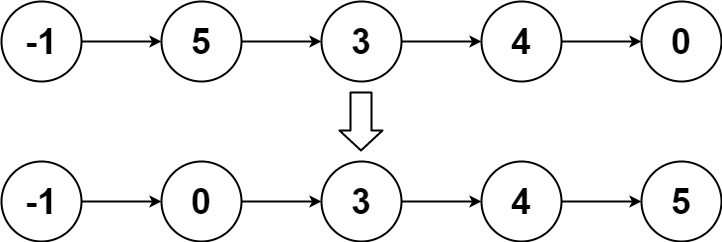
LeetCode148.排序链表
题目 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 示例 输入:head [4,2,1,3] 输出:[1,2,3,4] 输入:head [-1,5,3,4,0] 输出:[-1,0,3,4,5] 输入:head [] 输出:[] 思路…...

qt学习:网络调试助手客户端+服务端
目录 客户端 步骤 ui界面配置编辑 添加头函数,类成员数据,类成员函数 添加模块 构造函数 连接按钮 收到来自服务器的数据触发 发送按钮 断开按钮 向textEditRev文本编辑器中插入指定颜色的文本 服务端 步骤 ui界面配置 添加头函数&…...

C语言拾遗
函数的地址传递: 函数体内部想要修改函数体外部变量值的时候,使用地址传递 int set(int *pa) {//功能 } int main(void) {int a0;set(&a);//此时a的值经过set函数的修改,且传递到了main函数 } 函数体内想修改函数体外部指针的值的时候…...

大唐杯学习笔记:Day4
1.1NR帧结构 5G NR中,依然采用一帧10ms,并将一帧分为10子帧,每个子帧为1ms。每个子帧包含几个时隙(slot),每个时隙由14个OFDM符号构成(在常规CP下)。 μ \mu μ Δ f 2 μ ∗ 15 [ K H Z ] \Delta f2^{\mu}*15[KHZ] Δf2μ∗15[KHZ]Cyclic prefix015Normal130Normal260Normal…...
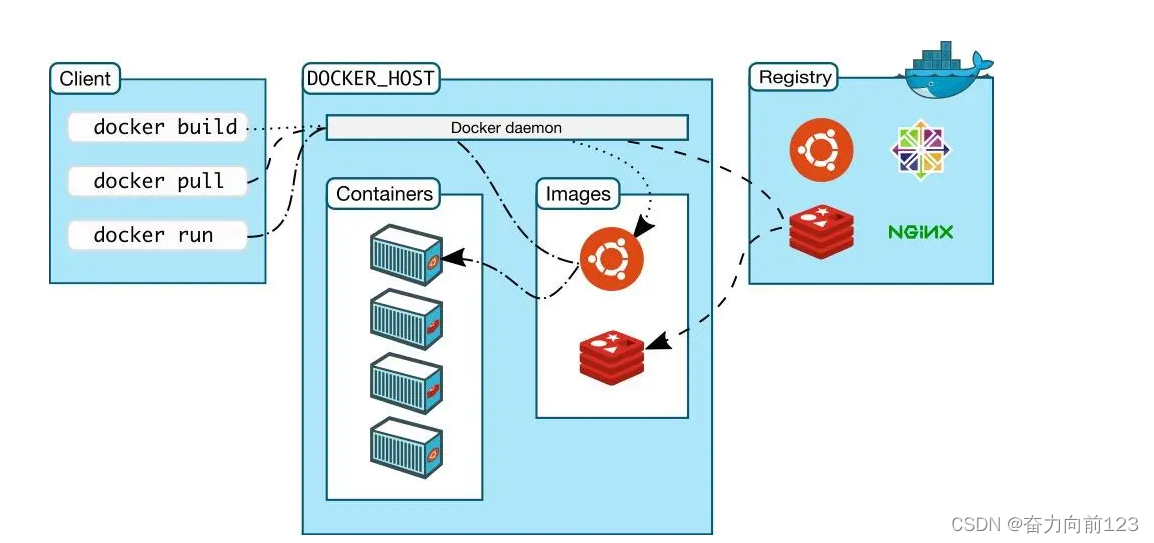
docker基线安全修复和容器逃逸修复
一、docker安全基线存在的问题和修复建议 1、将容器的根文件系统挂载为只读 修复建议: 添加“ --read-only”标志,以允许将容器的根文件系统挂载为只读。 可以将其与卷结合使用,以强制容器的过程仅写入要保留的位置。 可以使用命令&#x…...

ZooKeeper概述
ZooKeeper是一个开源的分布式协调服务,由Apache Software Foundation维护。它主要用于解决分布式应用中遇到的一些最常见问题,如命名服务、状态同步、配置管理和群集管理等。通过提供一套简单但强大的API,ZooKeeper使得从简单的锁服务到复杂的…...

【sgCollapseBtn】自定义组件:底部折叠/展开按钮
特性: 支持自定义折叠状态支持自定义标签名称 sgCollapseBtn源码 <template><div :class"$options.name" click"show !show" :placement"placement"><div class"collapse-btns"><div class"c…...

如何根据玩家数量和游戏需求选择最合适的服务器配置?
根据玩家数量和游戏需求选择最合适的服务器配置,首先需要考虑游戏的类型、玩家数量、预计的在线时间以及对内存和CPU性能的需求综合考虑。对于大型多人在线游戏,如MMORPG或MOBA等,由于需要更多的CPU核心数来支持更复杂的游戏逻辑和处理大量数…...

问题解决:各版本的vc_redist下载地址 缺少msvcr100.dll、msvcr120.dll、msvcr140.dll
Visual C Redistributable for Visual Studio各版本的官方链接。解决缺少msvcr100.dll、msvcr120.dll、msvcr140.dll的问题。 下面全部为官方链接: Microsoft Visual C Redistributable 2019 x86: https://aka.ms/vs/16/release/VC_redist.x86.exe x64: https://ak…...
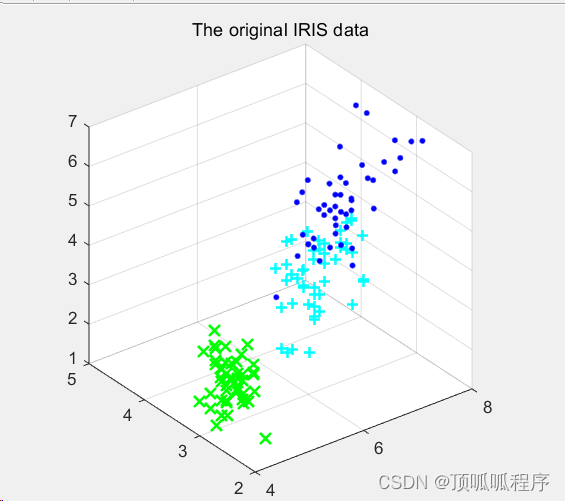
182基于matlab的半监督极限学习机进行聚类
基于matlab的半监督极限学习机进行聚类,基于流形正则化将 ELM 扩展用于半监督,三聚类结果可视化输出。程序已调通,可直接运行。 182matlab ELM 半监督学习 聚类 模式识别 (xiaohongshu.com)...

C语言数组案例编程
1. 编写一个程序实现:从键盘输入15个整数存入数组,然后统计其中正整数的个数。 【要求】采用函数编程 #include<stdio.h> void input(int a[],int n) {int i; for(i0;i<n;i)scanf("%d",&a[i]); }int positiveNum(int a[],int n…...

飞凌OKMX6ULL-C开发板深度评测:从硬件解析到系统性能实战
1. 开箱与初识:飞凌OKMX6ULL-C开发平台拿到飞凌OKMX6ULL-C开发板的第一印象,是它比我想象中要“工整”不少。核心板(FETMX6ULL-C)和底板通过高可靠性的板对板连接器接插,这种设计在工业级产品中很常见,方便…...
的电动汽车充电行为场景生成研究( Python + PyTorch实现))
【顶级EI复现】基于去噪概率扩散模型(DDPM)的电动汽车充电行为场景生成研究( Python + PyTorch实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...
)
【性能评估】信标辅助双跳认知无线电无线中继选择方案的性能评估研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

传统开发VS低代码开发,谁更胜一筹?
低代码开发,让企业应用搭建像搭积木一样简单 在当今数字化时代,企业对于应用程序的需求日益增长。然而,传统的软件开发方式往往面临着开发周期长、成本高、技术门槛高等问题,这使得许多企业在数字化转型的道路上举步维艰。而低代…...

火狐渗透插件实战指南:15款专业工具高效赋能Web侦察与漏洞验证
1. 这不是普通浏览器插件合集,而是渗透测试人员的“外挂式侦察兵” 很多人第一次看到“火狐插件做渗透测试”这个说法,第一反应是:浏览器插件能干啥?改个User-Agent?抓个Cookie?顶多算个辅助小工具。我2016…...

Go Web中间件机制深度剖析与实战
Go Web中间件机制深度剖析与实战 引言 中间件(Middleware)是Web开发中的核心概念,它在请求处理链路中扮演着至关重要的角色。本文将深入探讨Go语言中中间件的实现机制,并通过实战案例展示如何构建可复用的中间件系统。 一、中间件…...

深信服发布AI算力网关,聚焦AI算力治理,让AI算力效能更高
中国AI产业正在全面爆发,各行业的Agent应用发展更是迅猛。对企业来说,管好这些Agent并不容易,首先难算清的就是“成本账”——算力使用情况看不清、Token资源浪费管不住、AI投入省不下。为了帮助各行业用户实现AI模型和算力的高效治理&#x…...

关于我尝试写博客这档事
一、起因 在学习过数据结构后,希望更改目前记笔记的形式,于是想到整理成文章,通过开源方式锻炼表达力与技术理解力,希望复习与拓展所学习过的知识,使用费曼学习法学习 二、自我介绍 1.基本信息 博主名为Doubletful(Dou…...

五分钟完成Taotoken的Python SDK配置并调用多模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟完成Taotoken的Python SDK配置并调用多模型 基础教程类,面向刚注册Taotoken的Python开发者,指导其完…...

从日志Bug到状态机设计:我的C++ TinyWebServer调试日记与性能优化思考
从日志Bug到状态机设计:我的C TinyWebServer调试日记与性能优化思考 深夜的显示器前,咖啡杯早已见底。当我第三次在TinyWebServer的日志中看到"用户注册成功"的消息延迟出现在下一个请求时,那种如鲠在喉的感觉让我意识到࿱…...