Google发布Genie硬杠Sora:通过大量无监督视频训练最终生成可交互虚拟世界
前言
Sora 问世才不到两个星期,谷歌的世界模型也来了,能力看似更强大:它生成的虚拟世界自主可控
第一部分 首个基础世界模型Genie
1.1 Genie是什么
Genie是第一个以无监督方式从未标记的互联网视频中训练的生成式交互环境(the first generative interactive environment trained in an unsupervised manner from unlabelled Internet video)的基础世界模型
其训练数据集包含超过200000小时公开可用的互联网游戏视频,尽管没有动作或文本注释的训练(没有任何动作标签数据),但可以通过学习到的潜在动作空间逐帧进行控制(Our approach, Genie, is trained from a large dataset of over 200,000 hours of publicly available Internet gaming videos and, despite training without action or text annotations, is controllable on a frame-by-frame basis via a learned latent action space)
这点其实非常牛,因为互联网上视频太多了,很多都是没有任何标签或描述的,有的只是一个个动作、一帧帧画面,但模型如果能根据已经看到的动作或画面去预测下一个可能的画面(已有动作 + 预测接下来潜在可能的动作 = 下一个画面 ),之后再把预测的画面与真实画面建loss去优化预测策略,那说的极端点,哪个视频不可以用作训练视频呢?
总之,因为互联网视频通常没有关于正在执行哪个动作、应该控制图像哪一部分的标签,但 Genie 能够专门从互联网视频中学习细粒度的控制
且尽管所用数据更多是 2D Platformer 游戏游戏和机器人视频,但可扩展到更大的互联网数据集
对于 Genie 而言,它不仅了解观察到的哪些部分通常是可控的,而且还能推断出在生成环境中一致的各种潜在动作
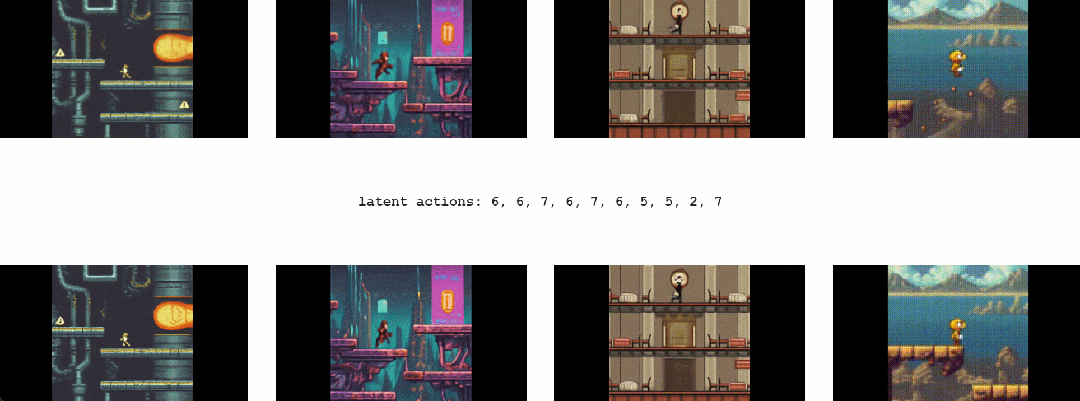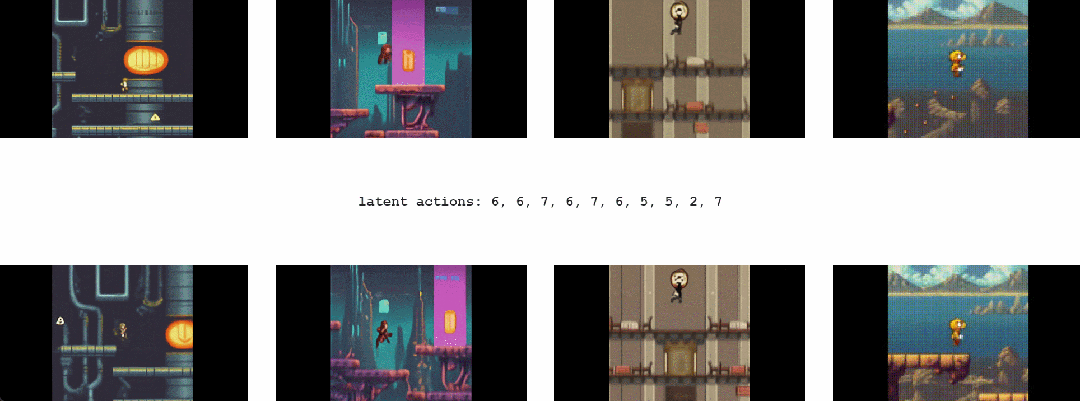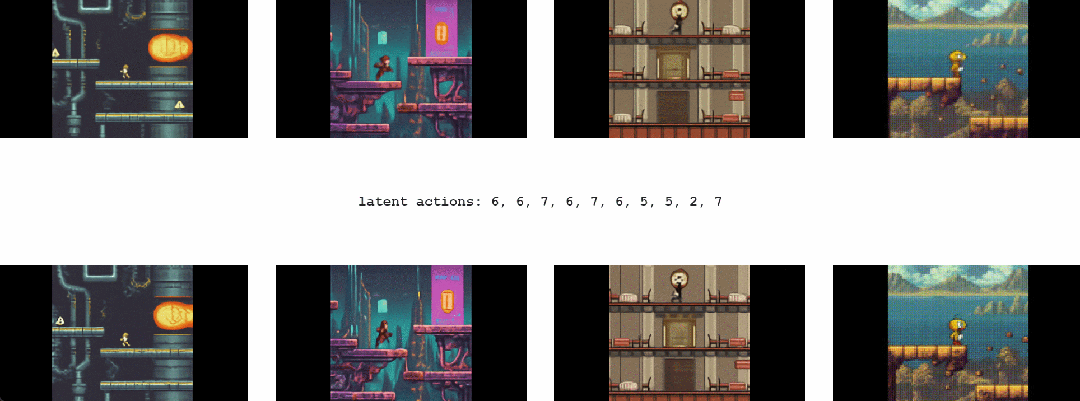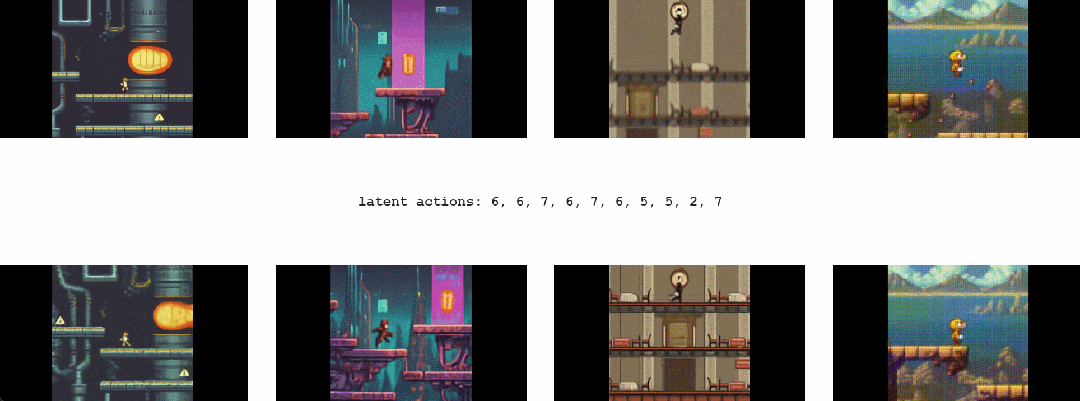
1.2 Genie能干啥
最终,只需要一张图像就可以创建一个全新的交互环境,例如,可以使用最先进的文本生成图像模型来生成起始帧,然后与 Genie 一起生成动态交互环境
在如下动图中,谷歌使用 Imagen2 生成了图像,再使用 Genie 将它们变为现实:

Genie 能做到的不止如此,它还可以应用到草图等人类设计相关的创作领域

或者,应用在真实世界的图像中:

此文,谷歌在 RT1 的无动作视频上训练了一个较小的 2.5B 模型。与 Platformers 的情况一样,具有相同潜在动作序列的轨迹通常会表现出相似的行为。
这表明 Genie 能够学习一致的动作空间,这可能适合训练机器人,打造通用化的具身智能

第二部分 技术揭秘:论文《Genie: Generative Interactive Environments》
Genie对应的论文为《Genie: Generative Interactive Environments》,其项目主页为:https://sites.google.com/view/genie-2024/home
论文的共同一作多达 6 人,其中包括华人学者石宇歌Yuge (Jimmy) Shi,她目前是谷歌 DeepMind 研究科学家,2023 年获得牛津大学机器学习博士学位
2.1 ST-transformer 架构
视频最多可以包含 𝑂(10^4 ) 个 token,而 Transformer 的二次内存成本对于视频生成的压力是比较大的,因此,Genie在所有模型组件中采用内存高效的 ST-transformer 架构

与传统的Transformer不同,每个token都会与其他所有token进行关注(Unlike a traditional transformer where every token attends to all other),ST-transformer包含 个时空块,其中交替出现空间和时间注意力层,然后是标准的前馈层FFW注意力块
- 空间层中的自注意力关注每个时间步内的
个token,而时间层中的自注意力关注跨越
个token的
个时间步
- 与序列转换器类似,时间层假设具有因果结构和因果掩码。 重要的是,我们架构中计算复杂性的主导因素(即空间注意力层)与帧数呈线性关系,而不是二次关系,使其在具有一致动态的长时间交互视频生成中更加高效
Similar to sequence transformers, the temporal layer assumes a causal structure with a causal mask. Crucially, the dominating factor of computation complexity (i.e. the spatial attention layer) in our architecture scales linearly with the number of frames rather than quadratically, making it much more efficient for video generation with consistent dynamics over extended interactio - 此外,在ST块中,仅包含一个FFW在空间和时间组件之后,省略了post-spatial FFW,以便扩展模型的其他组件(we include only one FFW after both spatial and temporal components, omitting the post-spatial FFW to allow for scaling up other components of the model)
2.2 三个关键组件:视频Tokenizer、潜在动作模型LAM、动态模型
Genie 包含三个关键组件,如下图所示
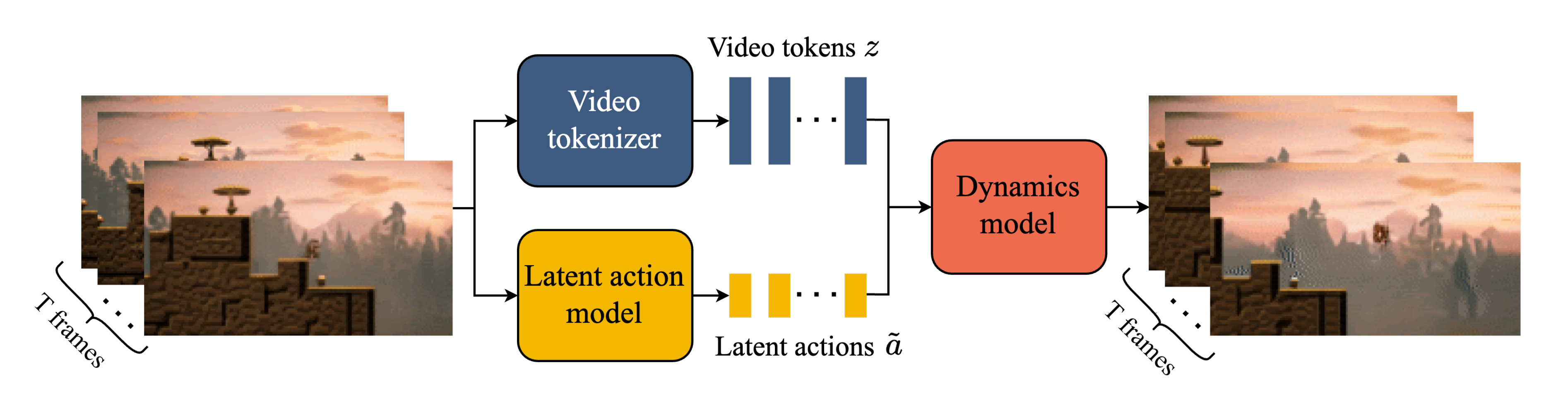
- 视频Tokenizer,用于将原始视频的一系列帧转换为离散 token 𝒛;
- 潜在动作模型(Latent Action Model,LAM),用于推断每对帧之间的潜在动作𝒂
- 一个自回归动力学模型MaskGIT,用于在给定潜在动作和过去帧 token的情况下,预测视频的下一帧
2.2.1 视频Tokenizer:基于ST-ViViT编码
在之前研究的基础上,谷歌将视频压缩为离散 token,以降低维度并实现更高质量的视频生成。实现过程中,谷歌使用了 VQ-VAE,其将视频的 𝑇 帧作为输入,从而为每个帧生成离散表示:
,其中𝐷 是离散潜在空间大小。分词器在整个视频序列上使用标准的 VQ-VQAE 进行训练

与之前专注于仅在Tokenizer阶段进行空间压缩的工作不同
- Genie在编码器和解码器中都使用了ST-transformer来融入时间动态,从而提高了视频生成质量
Unlike prior works that focus on spatial-only compression in the tokenization phase, we utilize the ST-transformer in both the encoder and decoder to incorporate temporal dynamics in the encodings, which improves the video generation quality
由于ST-transformer的因果性质,每个离散编码包含了视频
中所有先前帧的信息
By the causal nature of the STtransformer, each discrete encoding 𝑧𝑡 contains information from all previously seen frames of the video 𝒙1:𝑡 . - Phenaki也使用了一种具有时间感知的分词器C-ViViT,但这种架构的计算成本随着帧数的增加呈二次增长
Phenaki (Villegas et al., 2023) also uses a temporal-aware tokenizer, C-ViViT, but this architecture is compute intensive, as the cost grows quadratically with the number of frames
相比之下,我们基于ST-transformer的tokenizer(ST-ViViT)在计算效率上更高,其成本的主导因素呈线性增长
in comparison, our ST-transformer based tokenizer (ST ViViT) is much more compute efficient with the dominating factor in its cost increasing linearly
2.2.2 潜在动作模型LAM:也基于ST-transformer实现
为了实现可控的视频生成,谷歌将前一帧所采取的动作作为未来帧预测的条件。然而,此类动作标签在互联网的视频中可用的很少,并且获取动作注释的成本会很高。相反,谷歌以完全无监督的方式学习潜在动作

- 首先,编码器将所有先前的帧
以及下一帧
作为输入,并输出相应的一组连续的潜在动作
First, an encoder takes as inputs all previous frames 𝒙1:𝑡 = (𝑥1, · · · 𝑥𝑡) as well as the next frame 𝑥𝑡+1, and outputs a corresponding set of continuous latent actions ˜𝒂1:𝑡 = (˜𝑎1, · · · ˜𝑎𝑡). - 然后,解码器将所有先前的帧
作为输入,并预测下一帧
A decoder then takes all previous frames and latent actions as input and predicts the next frame 𝑥ˆ𝑡+1
为了训练模型
- 我们利用了基于VQ-VAE的目标函数,这使我们能够将预测的动作数量限制在一个小的离散代码集合中。 我们将VQ codebook的词汇大小(如果你不了解什么是VQ codebook,请参见此文的1.2.3节VAE的改进:VQ-VAE/VQ-VAE2),即可能的潜在动作的最大数量,限制在一个小的值上,以便实现人类可玩性并进一步强制可控性(在我们的实验中,我们使用了| 𝐴 | = 8)
To train the model, we leverage a VQ-VAEbased objective, which enables us to limit the number of predicted actions to a small discrete set of codes. We limit the vocabulary size |𝐴| of the VQ codebook, i.e. the maximum number of possible latent actions, to a small value to permit human playability and further enforce controllability (use |𝐴| = 8 in our experiments) - 由于解码器只能访问历史记录和潜在动作,
应该编码过去和未来之间最有意义的变化,以便解码器能够成功重构未来的帧(As the decoder only has access to the history and latent action, ˜𝑎𝑡 should encode the most meaningful changes between the past and the future for the decoder to successfully reconstruct the future frame)
2.2.3 动力学模型:仅解码的MaskGIT Transformer
动力学模型是一个仅解码的MaskGIT transformer

- 在每个时间步
,它接收分词视频
和停止梯度的潜在动作
,并预测下一个帧token
At each time step 𝑡 ∈ [1, 𝑇], it takes in the tokenized video 𝒛1:𝑡−1 and stopgrad latent actions ˜𝒂1:𝑡−1 and predicts the next frame tokens ˆ𝑧𝑡 - 我们再次使用ST-transformer,其因果结构使我们能够使用所有
帧
和潜在动作
作为输入,并为所有下一个帧生成预测
,该模型通过预测token
之间的交叉熵损失进行训练
We again utilize an ST-transformer,whose causal structure enables us to use tokens from all (𝑇 − 1) frames 𝒛1:𝑇 −1 and latent actions ˜𝒂1:𝑇 −1 as input, and generate predictions for all next frames ˆ𝒛2:𝑇 . The model is trained with a cross entropy loss between the predicted tokens ˆ𝒛2:𝑇 and ground-truth tokens 𝒛2:𝑇 . - 在训练时,我们根据均匀采样的伯努利分布掩盖率随机屏蔽输入token
,掩盖率在0.5和1之间
At train time we randomly mask the input tokens 𝒛2:𝑇 −1 ac-cording to a Bernoulli distribution masking rate sampled uniformly between 0.5 and 1.
请注意,训练世界模型的常见做法,包括基于transformer的模型,是将时间 𝑡的动作连接到相应的帧上,然而,他们发现将潜在的行动作为additive embeddings来处理,对于潜在的行动和动力学模型都有助于提高生成的可控性
Note that a common practice for training world-models, including transformer-based models, is to concate- nate the action at time 𝑡 to the corresponding frame (Micheli et al., 2023; Robine et al., 2023).
However, we found that treating the latent actions as additive embeddings for both the latent action and dynamics models helped to improve the controllability of the generations
2.3 Genie 的推理过程
如下图所示

- 图像使用视频编码器进行token,得到
(The image is tokenized using the video encoder,yielding 𝑧1)
- 然后玩家通过选择
中的任意整数来指定一个离散的潜在行动
值
The player then specifies a discrete latent action 𝑎1 to take by choosing any integer value within [0, | 𝐴|). - 动力学模型接收帧token
,通过使用离散输入
。这个过程重复进行,以自回归方式生成序列的其余部分
The dynamics model takesthe frame tokens 𝑧1 and corresponding latent ac-tion ˜𝑎1, which is obtained by indexing into the VQ codebook with the discrete input 𝑎1, to predict the next frame tokens 𝑧2. This process is repeated to generate the rest of the sequence ˆ𝒛2:𝑇 in an au-toregressive manner as actions continue to be passed to the model, while tokens are decoded into video frames ˆ𝒙2:𝑇 with the tokenizer’s de-coder.
注意,我们可以通过向模型传递起始帧和从视频中推断出的动作来重新生成数据集中的真实视频,或者通过更改动作来生成全新的视频
Note that we can regenerate ground truth videos from the dataset by passing the model the starting frame and inferred actions from the video, or generate completely new videos (or tra-jectories) by changing the action
// 待更
参考文献与推荐阅读
- 刚刚,谷歌发布基础世界模型:11B参数,能生成可交互虚拟世界
- ..
相关文章:
Google发布Genie硬杠Sora:通过大量无监督视频训练最终生成可交互虚拟世界
前言 Sora 问世才不到两个星期,谷歌的世界模型也来了,能力看似更强大:它生成的虚拟世界自主可控 第一部分 首个基础世界模型Genie 1.1 Genie是什么 Genie是第一个以无监督方式从未标记的互联网视频中训练的生成式交互环境(the first gener…...
全球首台!未磁科技256通道无液氦脑磁图仪及芯片化原子磁力计正式发布
2024年2月3日,由北京未磁科技有限公司牵头的国家重点研发计划诊疗装备与生物医用材料重点专项“新型无液氦脑磁图系统研发”项目2023年度总结会暨2024年推进会顺利召开。会上发布了项目取得的重大成果——全球首台256通道无液氦脑磁图仪Marvel MEG Pro。此项重磅成果…...
配置)
openssl3.2 - exp - 内存操作(建立,写入,读取)配置
文章目录 openssl3.2 - exp - 内存操作(建立,写入,读取)配置概述笔记调试细节运行效果测试工程实现main.cppCMyOsslConfig.hCMyOsslConfig.cppEND openssl3.2 - exp - 内存操作(建立,写入,读取)配置 概述 我的应用的配置文件是落地加密的, 无法直接用openssl配置接口载入读取…...

前端食堂技术周刊第 114 期:Interop 2024、TS 5.4 RC、2 月登陆浏览器的新功能、JSR、AI SDK 3.0
美味值:🌟🌟🌟🌟🌟 口味:凉拌鸡架 食堂技术周刊仓库地址:https://github.com/Geekhyt/weekly 大家好,我是童欧巴。欢迎来到前端食堂技术周刊,我们先来看下…...
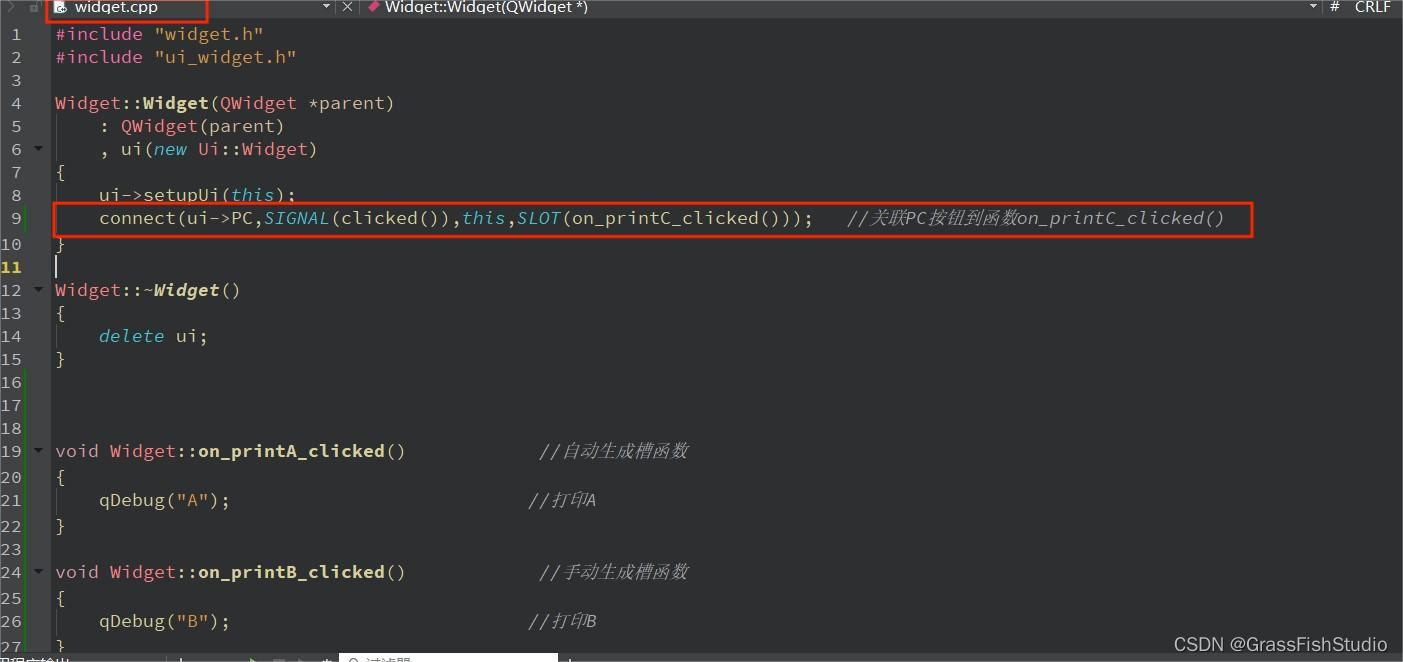
#QT(信号与槽)
1.IDE:QTCreator 2.实验:自动添加槽函数,手动添加槽函数 3.记录 (1)自动添加 a.拖拽widget.ui,放置push-button组件,并且自动生成槽函数 b.发现widget.cpp和widget.h中出现添加的槽函数,注意w…...

go 设置滚动日志
方案 通过 log/slog 实现结构化日志生成,这是go1.21中推出的新特性;通过 lumberjack 实现日志文件分割。 示例 package mainimport ("gopkg.in/natefinch/lumberjack.v2""log/slog""os""path/filepath" )fun…...

Rollup入门学习:前端开发的构建利器
在前端开发领域,构建工具对于优化项目结构和提升代码效率扮演着至关重要的角色。Rollup作为一款轻量级且功能强大的JavaScript模块打包器,近年来备受开发者青睐。本文将带你走进Rollup的世界,帮助你快速入门并掌握其核心用法。 一、Rollup简介…...
游戏寻路之A*算法(GUI演示)
一、A*算法介绍 A*算法是一种路径搜索算法,用于在图形网络中找到最短路径。它结合了Dijkstra算法和启发式搜索的思想,通过综合利用已知的最短路径和估计的最短路径来优化搜索过程。在游戏自动寻路得到广泛应用。 二、A*算法的基本思想 在图形网络中选择一个起点和终点。维护…...

软件工程顶会——ICSE '24 论文清单、摘要
1、A Comprehensive Study of Learning-based Android Malware Detectors under Challenging Environments 近年来,学习型Android恶意软件检测器不断增多。这些检测器可以分为三种类型:基于字符串、基于图像和基于图形。它们大多在理想情况下取得了良好的…...

Vue点击复制到剪切板
一、Vue2写法 安装 (官网地址) npm install --save vue-clipboard2 使用 //main.js import VueClipboard from vue-clipboard2 Vue.use(VueClipboard)//页面使用 <button type"button"v-clipboard:copy"message"v-clipboard:su…...
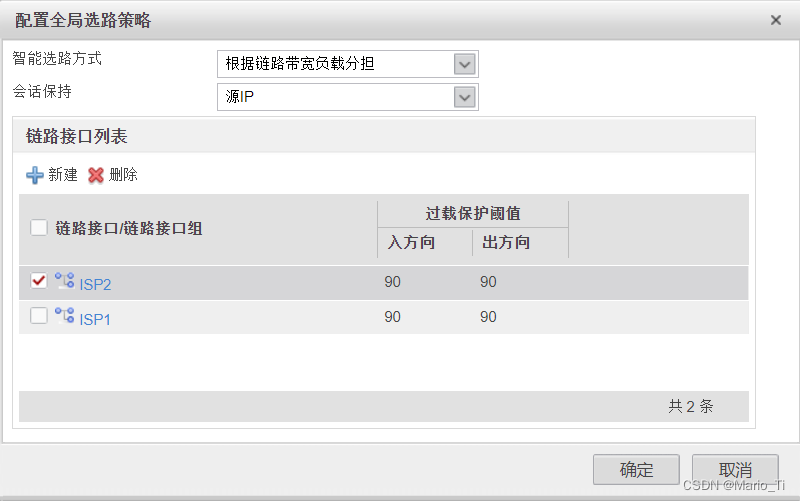
链路负载均衡之DNS透明代理
一、DNS透明代理 一般来说,企业的客户端上都只能配置一个运营商的DNS服务器地址,DNS服务器通常会将域名解析成自己所在ISP内的Web服务器地址,这将导致内网用户的上网流量都集中在一个ISP的链路上转发,最终可能会造成链路拥塞&…...

2024大语言模型LLM基础|语义搜索Semantic_Search全解
目录 语义搜索Semantic_Search代码详解 为甚麽用Pinecone做向量索引?优点是什么? 有哪些常见向量索引方法? Pinecone做向量索引怎么用? 向量索引全解:含原理解析: 语义搜索Semantic_Search代码详解 1…...

vue中使用echarts实现人体动态图
最近一直处于开发大屏的项目,在开发中遇到了一个小知识点,在大屏中如何实现人体动态图。然后看了下echarts官方文档,根据文档中的示例调整出来自己想要的效果。 根据文档上发现 series 中 type 类型设置为 象形柱形图,象形柱图是…...

结构化思维助力Prompt创作:专业化技术讲解和实践案例
结构化思维助力Prompt创作:专业化技术讲解和实践案例 最早接触 Prompt engineering 时, 学到的 Prompt 技巧都是: 你是一个 XX 角色… 你是一个有着 X 年经验的 XX 角色… 你会 XX, 不要 YY.. 对于你不会的东西, 不要瞎说!…对比什么技巧都不用, 直接像使用搜索引…...
(三))
【0272】postgres内核分配 MyBackendId 实现原理(MyBackendId、MyProc、shmInvalBuffer)(三)
相关文章: 【0255】揭晓pg内核中MyBackendId的分配机制(后端进程Id,BackendId)(一) 【0256】揭晓pg内核中MyBackendId的分配机制(后端进程Id,BackendId)(二) 第一个backend process前,shmInvalBuffer的值情况 (gdb) p *shmInvalBuffer $153 = {minMsgNum =...

AUKFUKF的MATLAB程序,含源码
adaptive UKF与UKF效果对比 只有一个m文件,直接拖到MATLAB上面就能运行并输出结果了 部分结果 程序源码 % adaptive UKF与UKF效果对比 % author:Evand % 作者联系方式:evandjiang@qq.com(除前期达成一致外,付费咨询) % date: 2023-11-07 % Ver1 clear;clc;close all; %%…...
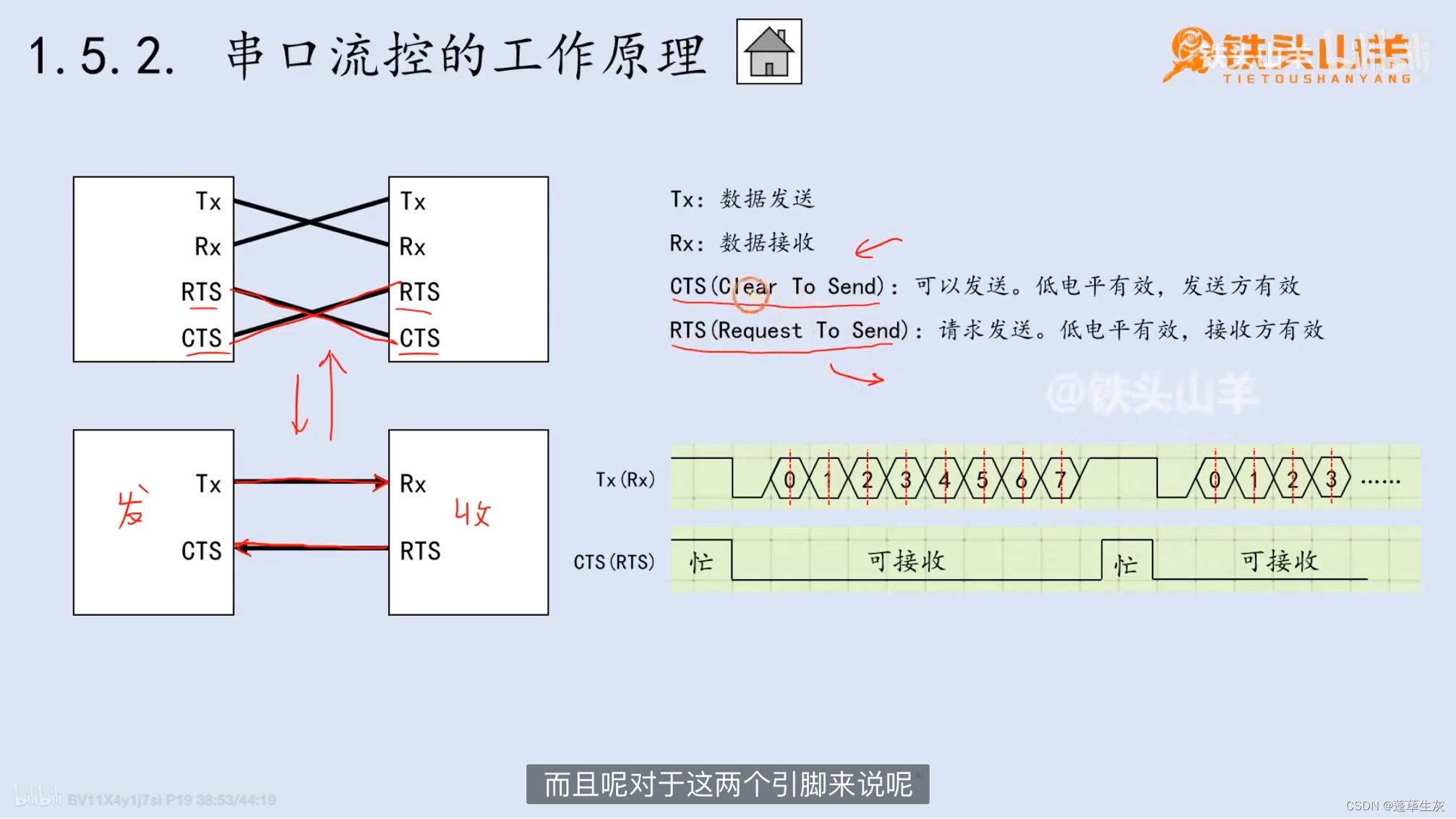
STM32(13)串口
串口的数据帧 1.空闲 2.起始位 3.数据位 4.校验位(可有可无) 为了验证数据传输是否出错而设立的比特位 1和4传输方式比较常见 校验规则: 根据1的个数,校验位会自己补0或1 5.停止位 例子: 同步通信 异步通信 波特率 …...
)
Element(Java后端入门篇)
Element(Java后端入门篇) Element:是饿了么公司前端开发团队提供的一套基于Vue的网站组件库,用于快速构建网页组件:组成网页的部件,例如超链接、按钮、图片、表格等等~ Element快速入门 引入Element的css、js文件和V…...
qt5和gstreamer开发环境安装配置
构建KDE虚拟机环境 1、安装virtualBox 2、导入镜像 配置QtCreator开发环境 https://blog.csdn.net/weixin_45824067/article/details/131970558(安装的是qt6) https://blog.csdn.net/m0_70849943/article/details/132472950 (安装的qt版本为5.14.2&…...

基于Python3的数据结构与算法 - 10 计数排序
一、问题 对列表进行排序,已知列表中的数范围都在0到100之间。设计时间复杂度为O(n)的算法。 二、解决思路 我们已知数字的范围,那么我们可以将数字的个数得到: 例如:有一个0~5的列表 [1,3,2,4,1,2,3,1,3,5] 则共有0个0&am…...

AI Agent 架构设计与实现原理深度解析
AI Agent 架构设计与实现原理深度解析 摘要 本文深入解析 AI Agent 的核心架构设计、关键组件原理及主流实现模式。从 ReAct 推理循环到记忆系统设计,从工具调用机制到生产级部署考量,全面剖析构建可靠智能体的技术要点。读者将掌握 AI Agent 的底层原…...

DeepSeek LeetCode 2561. 重排水果 Java实现
LeetCode 2561. 重排水果题目分析有两个长度为 n 的数组 basket1 和 basket2,每个数组包含若干水果。每次操作可以交换两个数组中的任意水果,花费为这两个水果中较小的那个值。目标是使两个数组中的水果种类和数量完全相同(即两个数组重排后相…...

超纯水管路里,那些肉眼看不见的颗粒威胁 : HALAR® ECTFE光滑内壁
苏福(深圳)科技有限公司 世索科HALAR ECTFE官方代理商 一、超纯水管路:半导体制造中最脆弱的洁净链条超纯水(UPW)是半导体晶圆制造中用量最大的工艺辅料,用于晶圆清洗、光刻后漂洗及化学品稀释。其电阻率需…...

2026 谷歌 GEO 已成流量主战场,不懂 AI 搜索直接掉队
📉 三个信号同时出现,意味着一个时代结束了:① 你的Google/百度自然搜索流量,连续两个季度下滑超过15%② 你精心优化的"关键词"排名,依然带不来预期的转化③ 你的目标用户,开始在 ChatGPT、Perpl…...

2026 主流技术栈:hermes agent多环境安装配置:Windows/Mac/Linux
一、Hermes agent 大模型选择 Hermes Agent 通过统一的模型抽象层接入不同厂商的大语言模型服务。实际部署时,建议根据数据合规要求、任务类型和成本预算进行选型。 1.1 国内场景:Kimi K2.6 对于数据需境内处理或存在私有化部署需求的场景,…...

2026年,揭秘浙江废铝回收界的明星企业!
引言:废铝回收,绿色循环的先锋随着我国经济的快速发展和工业生产的不断扩大,废铝回收行业逐渐成为资源循环利用的重要环节。在浙江省,众多废铝回收企业脱颖而出,其中腾兰再生资源回收有限公司以其卓越的表现࿰…...

手语识别实战:CNN-LSTM混合架构与轻量化部署指南
1. 项目概述:手语识别不是“翻译”,而是构建一座可触摸的沟通桥梁手语识别这件事,我从2019年第一次在残联康复中心做志愿者时就盯上了。当时一位老师傅用双手比划“苹果”“医院”“谢谢”,而旁边的年轻人盯着手机里刚装的某款APP…...

Python爬虫中如何正确配置住宅IP代理?新手避坑指南
很多人买完住宅IP,配置半天还是报错、被封。本文手把手教你用Python正确接入住宅代理,附代码和常见问题解决。一、为什么你的代理配置总失败?常见的几种错误:协议用错:服务商给的SOCKS5,你却按HTTP方式配认…...

2026 年 5 月消防刷题不提分?高质量刷题工具实测指南
2026 年消防设施操作员考试侧重实操应用与智慧消防,题型灵活性大幅提升,超 68% 考生面临刷题量大但分数停滞的困境。核心痛点集中在:消防设施操作员模拟题质量差、与真题命题逻辑不符(相似度低于 62%)、消防设施操作员…...

EVE-NG抓包踩坑实录:手把手教你配置Wireshark wrapper.bat,解决密码错误报错
EVE-NG抓包故障深度解析:从密码错误到Wireshark完美联动的全流程指南 在虚拟网络实验室的构建中,EVE-NG无疑是工程师们的首选平台。然而当我们需要进行深度报文分析时,Wireshark与EVE-NG的联动配置却常常成为技术道路上的"拦路虎"…...