2024大语言模型LLM基础|语义搜索Semantic_Search全解
目录
语义搜索Semantic_Search代码详解
为甚麽用Pinecone做向量索引?优点是什么?
有哪些常见向量索引方法?
Pinecone做向量索引怎么用?
向量索引全解:含原理解析:
语义搜索Semantic_Search代码详解
1.导入各个库
import warnings
warnings.filterwarnings('ignore')
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
from pinecone import Pinecone, ServerlessSpec
from DLAIUtils import Utils
import DLAIUtilsimport os
import time
import torch2.导入quora的数据集dataset,并划分数据集
dataset = load_dataset('quora', split='train[240000:290000]')3.设置模型:使用'all-MiniLM-L6-v2'语言模型,SentenceTransformer
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device != 'cuda':print('Sorry no cuda.')
model = SentenceTransformer('all-MiniLM-L6-v2', device=device)
SentenceTransformer是一个用于处理文本嵌入的库,它提供了预训练的语义文本嵌入模型。'all-MiniLM-L6-v2'是一个特定模型的名称,表示使用的是预训练模型的某个版本。这个模型的选择可能基于你的任务和数据,因为不同的预训练模型在捕捉语义信息方面有不同的性能。device=device是一个可选参数,用于指定在哪个设备上运行模型。在这里,它根据你的设备是否支持CUDA(GPU加速)来选择在CPU还是GPU上运行模型。
4.将数据进行编码,编码方式(以模型为主)
query = 'which city is the most populated in the world?'
xq = model.encode(query)
xq.shape5.设置向量索引方法,调用api
utils = Utils() PINECONE_API_KEY = utils.get_pinecone_api_key()使用提供的 API 密钥(
PINECONE_API_KEY)创建了一个 Pinecone 实例。这个密钥可能是从 Pinecone 获取的,用于验证和授权 API 请求。一 定义索引名称:
INDEX_NAME = utils.create_dlai_index_name('dl-ai')变量
INDEX_NAME被赋予一个由utils模块中的create_dlai_index_name函数生成的值。这似乎是创建一个与深度学习和人工智能相关的索引名称,基础名称为 'dl二 检查现有索引并删除:
if INDEX_NAME in [index.name for index in pinecone.list_indexes()]:pinecone.delete_index(INDEX_NAME)此块检查是否已存在指定名称的索引(
INDEX_NAME)。如果存在,则使用pinecone.delete_index()删除索引。这一步确保在创建新索引时没有冲突,可以保持一个干净的状态。三 创建新索引:
pinecone.create_index(name=INDEX_NAME,dimension=model.get_sentence_embedding_dimension(),metric='cosine',spec=ServerlessSpec(cloud='aws', region='us-west-2') )在这里,使用
pinecone.create_index()创建了一个新索引。它指定了索引名称(name)、从某个模型中获取的嵌入维度(dimension)、相似性度量(在本例中为 'cosine')和服务器规格(云提供商和地区)。
6.批量插入向量到 Pinecone:
for i in tqdm(range(0, len(questions), batch_size)):# 找到批次的结束位置i_end = min(i + batch_size, len(questions))# 创建批次的 IDsids = [str(x) for x in range(i, i_end)]# 创建批次的元数据metadatas = [{'text': text} for text in questions[i:i_end]]# 创建嵌入向量xc = model.encode(questions[i:i_end])# 为 upsert 创建记录列表records = zip(ids, xc, metadatas)# upsert 到 Pineconeindex.upsert(vectors=records)
- 使用
tqdm模块创建了一个循环,按批次处理问题列表。- 找到了每个批次的结束位置
i_end。- 创建了批次的 IDs 列表。
- 为批次的每个文本创建了元数据(这里是以'text'为键的字典)。
- 使用模型
model编码了批次中的问题,得到嵌入向量xc。- 创建了包含 IDs、嵌入向量和元数据的记录列表
records。- 使用
index.upsert()将记录列表插入到 Pinecone 索引中。
问题:
为甚麽用Pinecone做向量索引?优点是什么?
Pinecone 是一个托管的向量数据库服务,专注于高效的相似性搜索。向量索引是一种在高维向量空间中组织和存储向量的结构,使得对于给定查询向量,可以快速找到相似的向量。以下是 Pinecone 向量索引的一些优势:
高效的相似性搜索: Pinecone 提供了高效的相似性搜索功能,能够快速找到与查询向量相似的向量。这对于许多应用场景,如推荐系统、搜索引擎、聚类等都非常有用。
托管服务: Pinecone 是一个云端托管的服务,无需用户担心底层基础设施的管理和维护。它简化了向量数据库的使用,让用户可以专注于应用开发而不必担心硬件和网络配置。
弹性伸缩: Pinecone 提供弹性伸缩的能力,可以处理大规模的向量数据。无论是小规模的应用还是大规模的生产系统,Pinecone 都能适应不同的需求。
支持多种应用场景: Pinecone 的向量索引适用于各种应用场景,包括自然语言处理、计算机视觉、推荐系统等。用户可以根据具体的需求上传和查询向量,从而支持多种应用。
内置距离度量: Pinecone 内置了多种距离度量,包括余弦相似度、欧氏距离等。用户可以根据具体的应用选择合适的度量来进行相似性比较。
使用 Pinecone 向量索引的目的是将一批文本数据的嵌入向量上传到 Pinecone 索引中,以便后续进行相似性搜索。这对于需要快速检索与给定查询文本相似的文本数据的应用非常有用,比如文本搜索、推荐系统等。 Pineacone 的索引服务提供了有效的相似性搜索功能,可以大大简化开发者在这方面的工作。
有哪些常见向量索引方法?
树结构(如 KD 树、Ball 树): 这些树结构允许数据集在树的节点中进行分割,每个节点存储一个向量。查询时,树结构允许系统跳过某些节点,只遍历那些可能包含相似项的节点,从而缩小搜索范围。
局部敏感哈希(Locality-Sensitive Hashing,LSH): LSH 是一种哈希技术,它在向量空间中对相似的向量映射到相同的哈希桶的概率更高。这样的设计可以在哈希桶中找到可能相似的向量,从而进行近似搜索。
分级索引: 将向量空间划分为多个级别,每个级别上建立一个索引。首先在粗略级别上进行搜索,然后在更细致的级别上进行搜索,以逐渐缩小候选集合。
递进式索引: 使用递进式索引,先从一个较小的索引开始搜索,然后根据需要逐步增加索引的大小。这种方式可以在保证搜索效率的同时,降低计算成本。
Pinecone做向量索引怎么用?
Pinecone 是一个云端的向量索引服务,用于存储和检索高维向量,支持高效的相似性搜索。以下是使用 Pinecone 进行向量索引的基本步骤:
创建 Pinecone 帐户: 首先,你需要在 Pinecone 官方网站上创建一个账户(Pinecone 官方网站)。
获取 API Key: 登录 Pinecone 后,在控制台中生成 API Key,该 Key 将用于访问 Pinecone 服务。
安装 Pinecone Python 客户端库: 在你的 Python 环境中安装 Pinecone 客户端库。可以使用以下命令:
pip install pinecone-client
导入 Pinecone 客户端库: 在 Python 脚本或 Jupyter 环境中导入 Pinecone 客户端库:
import pinecone设置 API Key: 使用你在 Pinecone 控制台生成的 API Key 进行身份验证:
pinecone.init(api_key="YOUR_API_KEY")创建索引: 创建一个新的索引以存储向量:
index_name = "your_index_name" pinecone.create_index(index_name, dimension=YOUR_VECTOR_DIMENSION)这里的
YOUR_VECTOR_DIMENSION是你的向量维度,需要根据你的数据进行设置。插入向量: 将向量插入到索引中:
vectors = [...] # 你的向量列表 pinecone.index(index_name).upsert(items=vectors)进行相似性搜索: 使用查询向量进行相似性搜索:
query_vector = [...] # 你的查询向量 results = pinecone.index(index_name).query(queries=[query_vector])
results包含了与查询向量相似的项的信息。
向量索引全解:含原理解析:
十分钟带你入门向量检索技术 - 知乎
相关文章:

2024大语言模型LLM基础|语义搜索Semantic_Search全解
目录 语义搜索Semantic_Search代码详解 为甚麽用Pinecone做向量索引?优点是什么? 有哪些常见向量索引方法? Pinecone做向量索引怎么用? 向量索引全解:含原理解析: 语义搜索Semantic_Search代码详解 1…...

vue中使用echarts实现人体动态图
最近一直处于开发大屏的项目,在开发中遇到了一个小知识点,在大屏中如何实现人体动态图。然后看了下echarts官方文档,根据文档中的示例调整出来自己想要的效果。 根据文档上发现 series 中 type 类型设置为 象形柱形图,象形柱图是…...

结构化思维助力Prompt创作:专业化技术讲解和实践案例
结构化思维助力Prompt创作:专业化技术讲解和实践案例 最早接触 Prompt engineering 时, 学到的 Prompt 技巧都是: 你是一个 XX 角色… 你是一个有着 X 年经验的 XX 角色… 你会 XX, 不要 YY.. 对于你不会的东西, 不要瞎说!…对比什么技巧都不用, 直接像使用搜索引…...
(三))
【0272】postgres内核分配 MyBackendId 实现原理(MyBackendId、MyProc、shmInvalBuffer)(三)
相关文章: 【0255】揭晓pg内核中MyBackendId的分配机制(后端进程Id,BackendId)(一) 【0256】揭晓pg内核中MyBackendId的分配机制(后端进程Id,BackendId)(二) 第一个backend process前,shmInvalBuffer的值情况 (gdb) p *shmInvalBuffer $153 = {minMsgNum =...

AUKFUKF的MATLAB程序,含源码
adaptive UKF与UKF效果对比 只有一个m文件,直接拖到MATLAB上面就能运行并输出结果了 部分结果 程序源码 % adaptive UKF与UKF效果对比 % author:Evand % 作者联系方式:evandjiang@qq.com(除前期达成一致外,付费咨询) % date: 2023-11-07 % Ver1 clear;clc;close all; %%…...
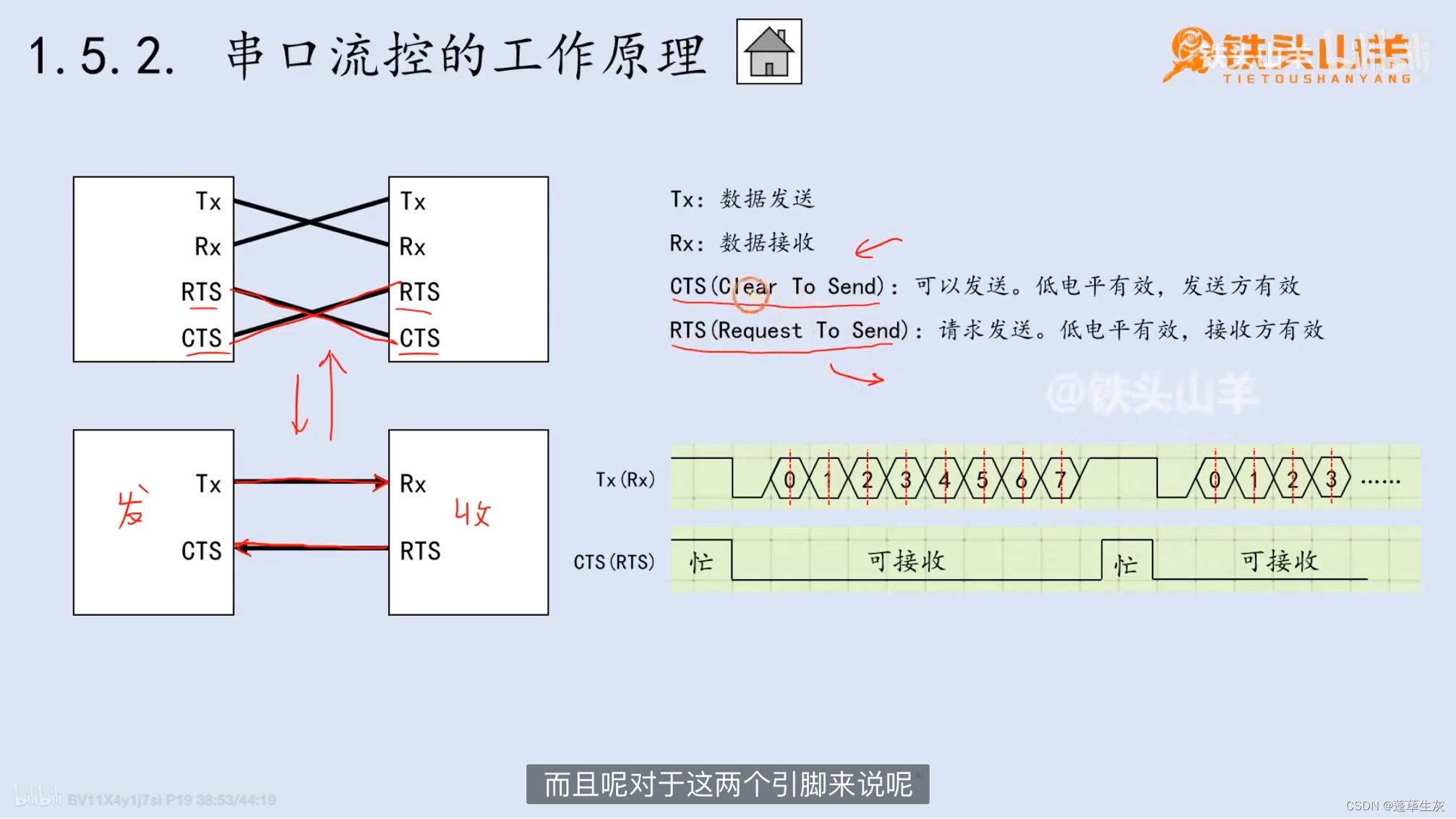
STM32(13)串口
串口的数据帧 1.空闲 2.起始位 3.数据位 4.校验位(可有可无) 为了验证数据传输是否出错而设立的比特位 1和4传输方式比较常见 校验规则: 根据1的个数,校验位会自己补0或1 5.停止位 例子: 同步通信 异步通信 波特率 …...
)
Element(Java后端入门篇)
Element(Java后端入门篇) Element:是饿了么公司前端开发团队提供的一套基于Vue的网站组件库,用于快速构建网页组件:组成网页的部件,例如超链接、按钮、图片、表格等等~ Element快速入门 引入Element的css、js文件和V…...
qt5和gstreamer开发环境安装配置
构建KDE虚拟机环境 1、安装virtualBox 2、导入镜像 配置QtCreator开发环境 https://blog.csdn.net/weixin_45824067/article/details/131970558(安装的是qt6) https://blog.csdn.net/m0_70849943/article/details/132472950 (安装的qt版本为5.14.2&…...

基于Python3的数据结构与算法 - 10 计数排序
一、问题 对列表进行排序,已知列表中的数范围都在0到100之间。设计时间复杂度为O(n)的算法。 二、解决思路 我们已知数字的范围,那么我们可以将数字的个数得到: 例如:有一个0~5的列表 [1,3,2,4,1,2,3,1,3,5] 则共有0个0&am…...

力扣206反转链表
206.反转链表 力扣题目链接(opens new window) 题意:反转一个单链表。 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL 1,双指针 2,递归。递归参考双指针更容易写, 为什么不用头插…...

【python实战】--图片创作视频
系列文章目录 文章目录 系列文章目录前言一、VideoWriter_fourcc()常见的编码参数二、使用步骤1.引入库 总结 前言 一、VideoWriter_fourcc()常见的编码参数 cv2.VideoWriter_fourcc(‘M’, ‘P’, ‘4’, ‘V’)MPEG-4编码 .mp4 可指定结果视频的大小cv2.VideoWriter_fourcc…...
)
数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(代码部分)
文章: 数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(一) 数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(二) 数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(总) 代码: 数据挖掘实战 —— 抖音用户浏览行为数据分析与挖掘(代码…...
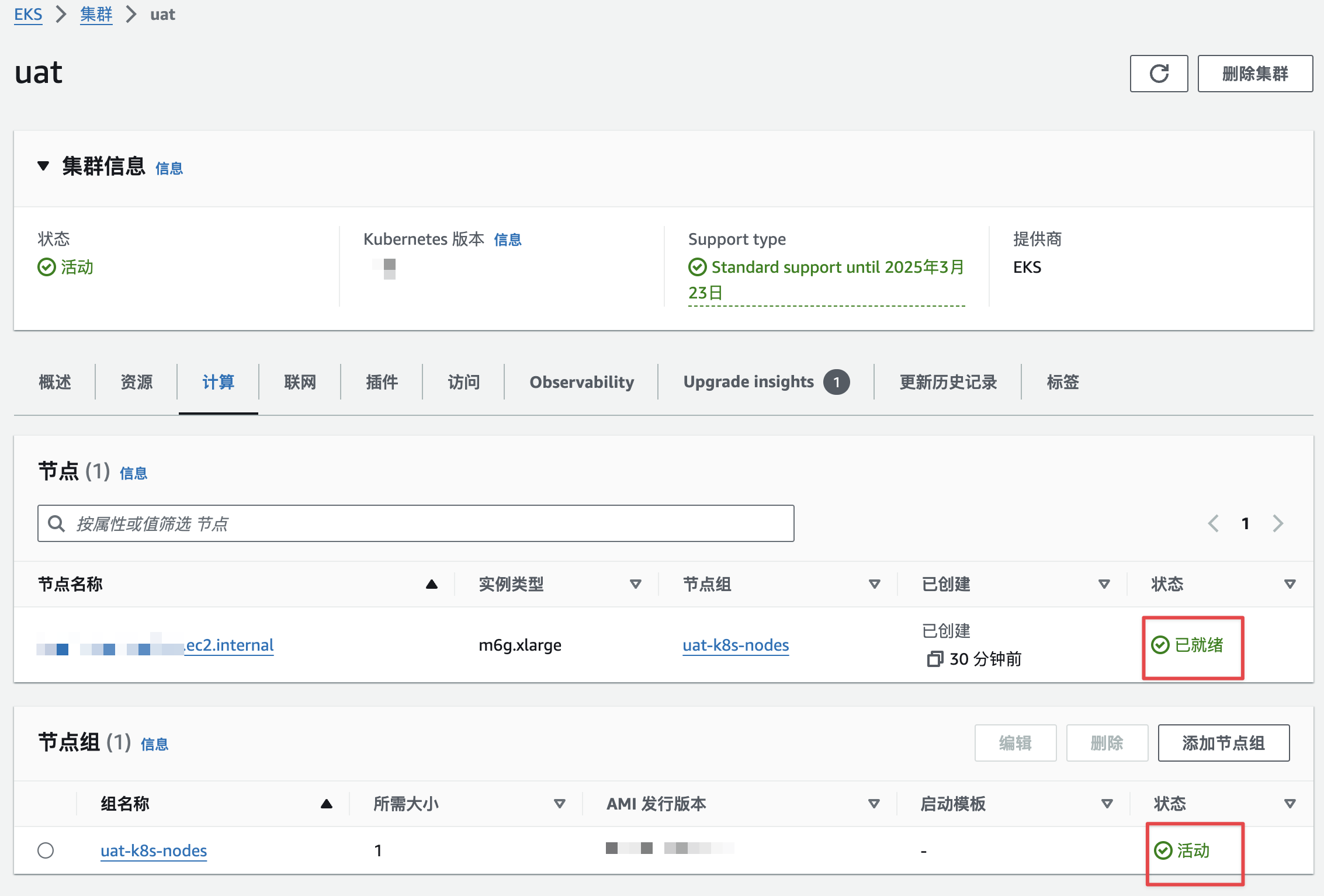
AWS EKS(AWS云里面的K8S)
问题 初步使用EKS 步骤 安装AWS CLI 第一步是在自己的笔记本电脑上面安装AWS提供的CLI(命令行工具),这里就不详细介绍了,都是next的步骤。具体可以参考啊aws cli安装的相关教程网页,具体地址如下: http…...

Azkaban 大数据 任务调度
参考视频:尚硅谷大数据Azkaban 3.x教程(全新发布)_哔哩哔哩_bilibili Azkaban: 是一个定时、批量工作流任务调度器(工作流程调度,定时调度) 常见的开源调度系统: 简单单一的任务调度: Linux的…...

从预训练到通用智能(AGI)的观察和思考
1.预训练词向量 预训练词向量(Pre-trained Word Embeddings)是指通过无监督学习方法预先训练好的词与向量之间的映射关系。这些向量通常具有高维稠密特征,能够捕捉词语间的语义和语法相似性。最著名的预训练词向量包括Google的Word2Vec&#…...

四种垃圾回收算法
1.标记清除算法 该算法先标记,后清除,将所有需要回收的算法进行标记,然后清除;这种算法的缺点是:效率比较低;标记清除后会出现大量不连续的内存碎片,这些碎片太多可能会使存储大对象会触发GC回…...
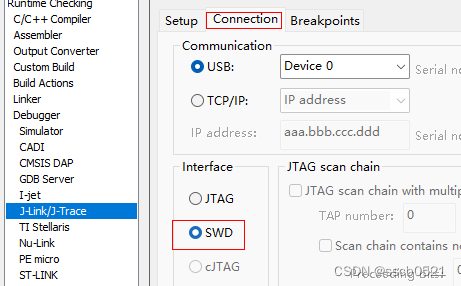
stm32f103zet6笔记1-led工程
1、选择串口调试 2、LED0连接到PB5,PB5设置为推挽输出。PE5同理。 3、生成成对的.c,.h文件。 4、debugger选择j-link。 5、connection选择SWD。 6、编写bsp_led.c,bsp_led.h文件。 7、下载调试,可以看到LED0 500ms闪烁一次,LED1 1000ms闪烁一…...

OpenDDS的Qos策略
目录 1、前言2、QoS策略2.1、LIVELINESS2.2、RELIABILITY2.3、HISTORY2.4、DURABILITY2.5、DURABILITY_SERVICE2.6 、RESOURCE_LIMITS2.7、PARTITION2.8、DEADLINE2.9、LIFESPAN2.10、USER_DATA2.11、TOPIC_DATA2.12、GROUP_DATA2.13、TRANSPORT_PRIORITY2.14、LATENCY_BUDGET2…...
)
string基本操作(C++)
增 1.1 “” str str ss;cout << str << endl; //234561提取字串 2.1 substr substr(pos): 提取从位置pos开始到末尾的子串。 #include <iostream> #include <string> using namespace std;int main(){string str "123456";//substr(pos…...
【网站项目】123网上书城系统
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...
)
新高考答题卡模板全套PDF可打印(语文数学英语等)
新高考答题卡模板 PDF(可下载、可打印)汇总,涵盖全国卷及多个省市自主命题版本,包括:语文答题卡:全国一卷、全国二卷、上海卷、北京卷数学答题卡:全国一卷、全国二卷、北京卷、上海卷、天津卷英…...

浮动油封市场深度研判:预计2032年将攀升至4.57亿美元
浮动油封,也叫机械端面密封或永久密封,是一种特殊类型的机械密封,主要由一对耐磨的金属浮封环和配套的橡胶密封圈组成,它通过橡胶圈的弹力使两个金属环端面紧密贴合、相对滑动,实现对油、水、泥沙等介质的动态密封&…...

森林The Forest - 服务器开服
对于想要自建游戏服务器的玩家,云鸢互联是一个不错的专业联机平台选择。它提供稳定、低延迟且724小时在线的服务器环境,助你轻松打造专属游戏世界。平台主打极致的新手友好——全图形化控制面板,无需编写代码,也无需掌握Linux命令…...

超纯水管路里,那些肉眼看不见的颗粒威胁 : HALAR® ECTFE光滑内壁
苏福(深圳)科技有限公司 世索科HALAR ECTFE官方代理商 一、超纯水管路:半导体制造中最脆弱的洁净链条超纯水(UPW)是半导体晶圆制造中用量最大的工艺辅料,用于晶圆清洗、光刻后漂洗及化学品稀释。其电阻率需…...

3分钟掌握PCB交互式BOM:告别传统表格的终极可视化方案
3分钟掌握PCB交互式BOM:告别传统表格的终极可视化方案 【免费下载链接】InteractiveHtmlBom Interactive HTML BOM generation plugin for KiCad, EasyEDA, Eagle, Fusion360 and Allegro PCB designer 项目地址: https://gitcode.com/gh_mirrors/in/InteractiveH…...

DeepSeek-R1 vs Qwen2.5 vs Claude-3:17项硬指标对比,谁才是2024高性价比AI模型黑马?
更多请点击: https://kaifayun.com 第一章:DeepSeek性价比优势分析 DeepSeek 系列模型(如 DeepSeek-V2、DeepSeek-Coder、DeepSeek-MoE)在开源大模型生态中展现出显著的性价比优势,尤其在推理效率、训练成本与下游任务…...

K8s集群健康监控、Pod调度与配置存储卷
33.Kubernets对集群Pod和健康容器状态如何进行监控和检测的。 K8s通过kubelet节点监控,使用三种探针来监控和管理容器监控状态,每种探针在容器生命周期种的不同阶段发挥不同的作用。 34.解释LivenessProbes探针的作用及其适用场景。 LivenessProbes存活探…...

ARM Cortex-M4中断优先级与嵌套机制详解:从原理到实战配置
1. 项目概述:深入理解中断的“秩序”在嵌入式开发,尤其是基于ARM Cortex-M4这类高性能微控制器的项目中,中断系统是驱动实时响应的核心引擎。它就像一家繁忙餐厅的后厨,各种订单(外部事件)会随时涌入。如果…...

Louvain 算法:让网络自己“报团取暖”的发现者
🧩 Louvain 算法:让网络自己“报团取暖”的发现者为什么你的朋友圈会自然分成老同学、同事和游戏好友?Louvain算法就是网路世界里的“社交侦探”,它能自动帮你看清整个网络中“谁和谁是一伙的”。一、从一个生活场景说起 …...

边际效应在数据分析中的应用
边际效应是一个源于经济学但广泛应用与数据分析、产品运营、策略优化的核心概念。简单来说,他指的是每增加一个单位的投入(如资源、功能、用户、广告话费),所带来的额外产出(如收入、活跃度、用户数)。理解…...