大厂报价查询系统性能优化之道!
0 前言
机票查询系统,日均亿级流量,要求高吞吐,低延迟架构设计。提升缓存的效率以及实时计算模块长尾延迟,成为制约机票查询系统性能关键。本文介绍机票查询系统在缓存和实时计算两个领域的架构提升。
1 机票搜索服务概述
1.1 机票搜索的业务特点
机票搜索业务:输入目的地,然后点击搜索,后台就开始卷了。基本1~2s将最优结果反给用户。这个业务存在以下业务特点。
1.1.1 高流量、低延时、高成功率
超高流量,同时,对搜索结果要求也很高——成功率要高,不能查询失败或强说成功,希望能反给用户最优最新数据。
1.1.2 多引擎聚合,SLA不一
机票搜索数据来源哪?很大一部分来源自己的机票运价引擎。为补充产品丰富性,还引入国际一些GDS、SLA,如联航。将外部引擎和自己引擎结果聚合后发给用户。
1.1.3 计算密集&IO密集
大家可能意识到,我说到我们自己的引擎就是基于一些运价的数据、仓位的数据,还有其他一些航班的信息,我们会计算、比对、聚合,这是一个非常技术密计算密集型的这么一个服务。同时呢,外部的GDS提供的查询接口或者查询引擎,对我们来说又是一个IO密集型的子系统。我们的搜索服务要将这两种不同的引擎结果很好地聚合起来。
1.1.4 不同业务场景的搜索结果不同要求
作为OTA巨头,还支持不同应用场景。如同样北京飞上海,由于搜索条件或搜索渠道不一,返回结果有所不同。如客户是学生,可能搜到学生特价票,其他用户就看不到。
2 公司基建
为应对如此业务,有哪些利器?
2.1 三个独立IDC
互相做灾备,实现其中一个IDC完全宕机,业务也不受影响。
2.2 DataCenter技术栈
SpringCloud+K8s+云服务(海外),感谢Netflix开源支撑国内互联网极速发展。
2.3 基于开源的DevOps
我们基于开源做了整套的DevOps工具和框架。
2.4 多种存储方案
公司内部有比较完善可用度比较高的存储方案,包括MySQL,Redis,MangoDB……
2.5 网络可靠性
注重网络可靠性,做了很多DR开发,SRE实践,广泛推动熔断,限流等,以保证用户得到高质量服务。
3 机票搜索服务架构
3.1 架构图
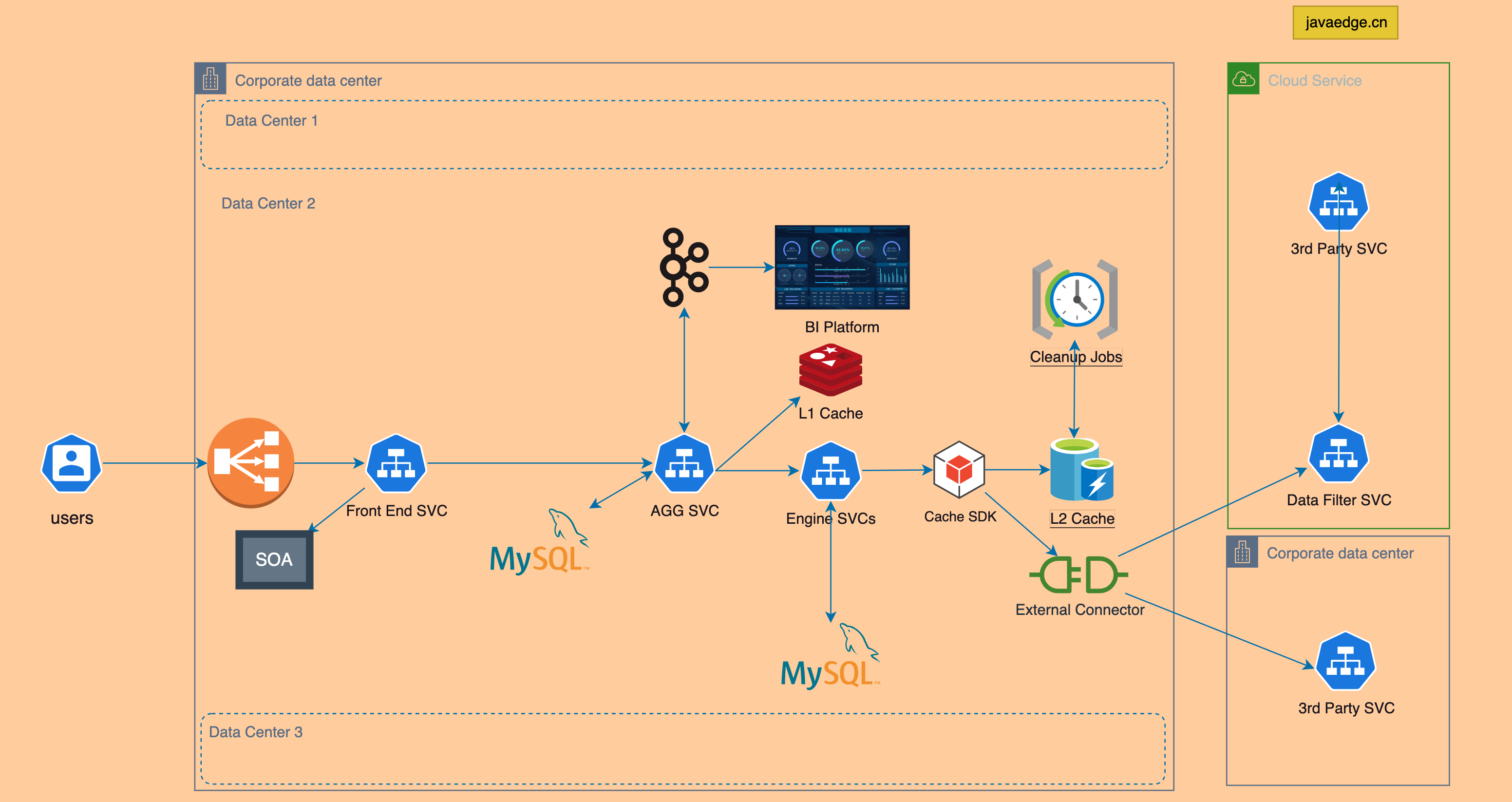
IDC有三个,先引入GateWay分流前端服务,前端服务通过服务治理,和后端聚合服务交互。聚合服务再调用很多引擎服务。
聚合服务结果,通过Kafka推到AI数据平台,做大数据分析、流量回放等数据操作。云上部署数据的过滤服务,使传回数据减少90%。
4 缓存架构
4.1 缓存的挑战和策略
4.1.1 为啥大量使用缓存应对流量高峰?
提高效率、速度的首选技术手段。
虽使用很多开源技术,但还有瓶颈。如数据库是分片、高可用的MySQL,但和一些云存储、云数据库比,其带宽、存储量、可用性有差距,通常需用缓存保护我们的数据库,不然频繁读取会使数据库很快超载。
很多外部依赖,提供给我们的带宽,QPS有限。而公司整体业务量是快速增长的,而外部的业务伙伴给我们的带宽,要么已达技术瓶颈,要么开始收高费用。此时,使用缓存就可保护外部的一些合作伙伴,不至于击穿他们的系统,也可帮我们降本。
4.1.2 本地缓存 VS 分布式缓存
整个架构的演进过程,一开始本地缓存较多,后来部分用到分布式缓存。
本地缓存的主要问题:
- 启动时,有个冷启动过程,对快速部署不利
- 与分布式缓存相比,本地缓存命中率太低
对海量的数据而言,单机提供命中率非常低,5%甚至更低。对此,现已全面切向Redis分布式缓存。本着对战failure的理念,不得不考虑失败场景。万一集群挂掉或一部分分片挂掉,这时需要通过限流客户端、熔断等,防止雪崩效应。
4.1.3 TTL
- 命中率
- 新鲜度
- 动态更新
TTL生命周期跟业务强相关。买机票经常遇到:刚在报价列表页看到一个低价机票,点进报价详情页就没了,why?航空公司低价舱位票,一次可能只放几张,若在热门航线,可能同时几百人在查,它们都可能看到这几张票,它就会出现在缓存里。若已有10人订了票,其他人看到缓存再点进去,运价就已失效。对此,就要求权衡,不能片面追求高命中率,还得兼顾数据新鲜度。为保证新鲜度、数据准确性,还有大量定时任务去做更新和清理。
4.2 缓存架构演进
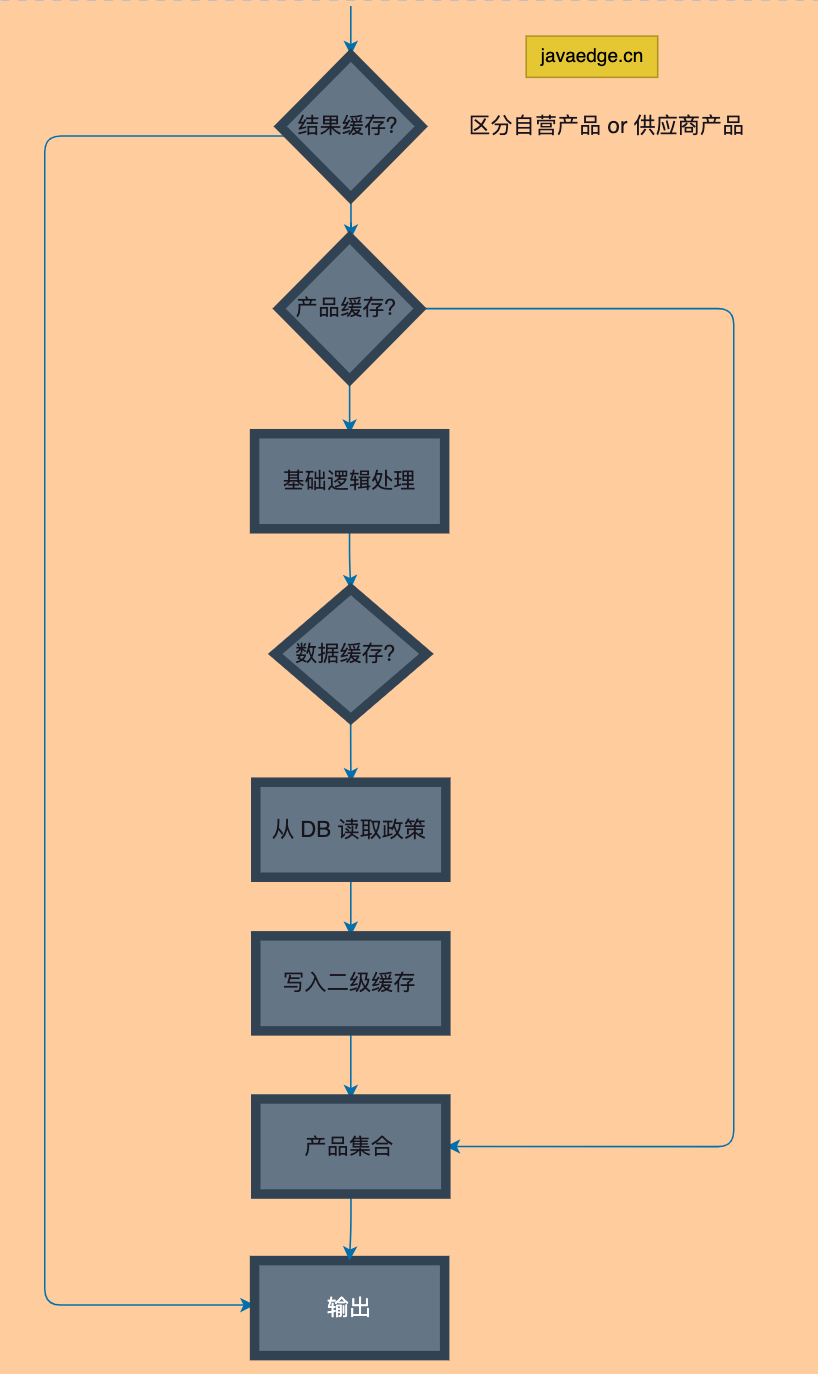
4.2.1 多级缓存
架构图的三处缓存:
- 引擎级缓存
- L1分布式聚合缓存,基本上就是用户看到的最终查询结果
- L2二级缓存,分布式的子引擎结果
若聚合服务需多个返回结果,很大程度都是先读一级缓存,一级缓存没有命中的话,再从二级缓存里面去读中间结果,这样可以快速聚合出一个大家所需要的结果返回。
4.2.2 引擎缓存
引擎缓存:
- 查询结果缓存
- 中间产品缓存
- 基础数据缓存
使用一个多级缓存模式。如下图,最顶部是指引前的结果缓存,储存在Redis,引擎内部根据产品、供应商,有多个渠道的中间结果,所以对子引擎来说会有个中间缓存。
这些中间结果计算,需要数据,这数据就来自最基础的一级缓存。
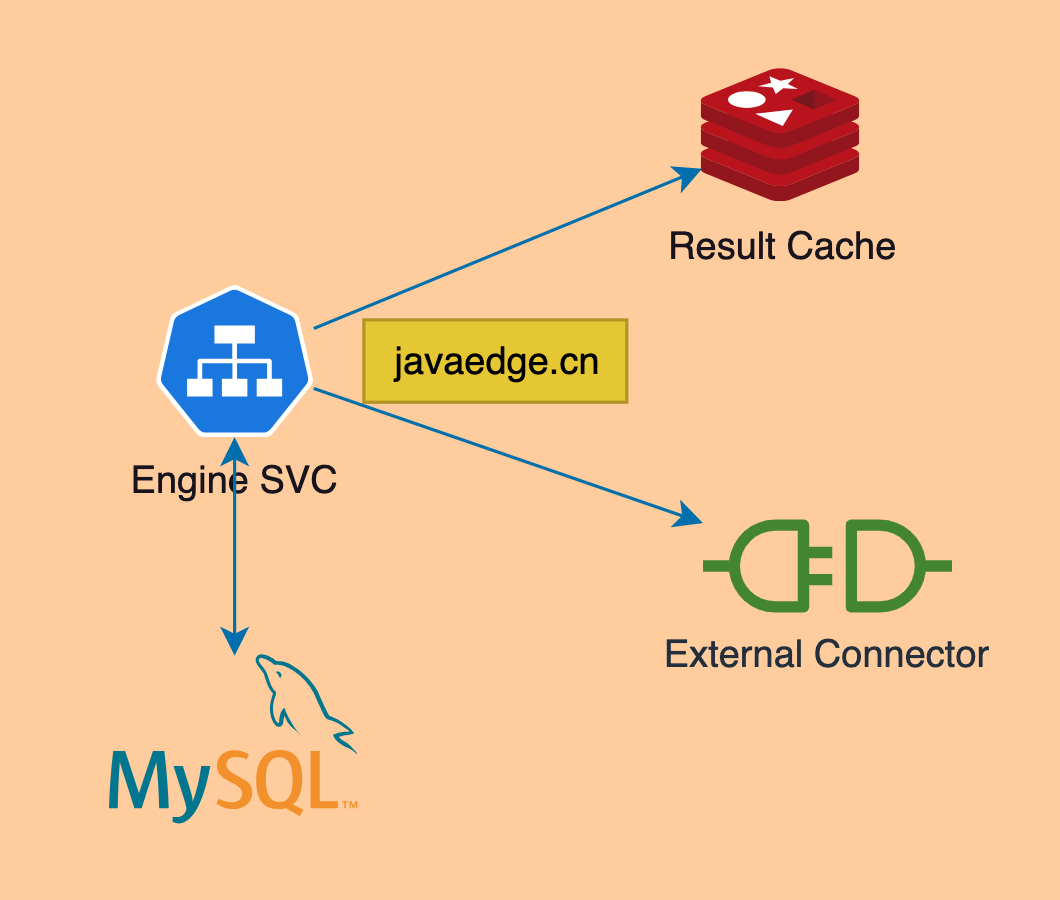
4.2.3 基于Redis的一级缓存
Pros:
- 读写性能高
- 水平扩展
Cons:
- 固定TTL
- 命中率和新鲜度的平衡
结果:
- 命中率<20%
- 高新鲜度(TTL<5m,动态刷新
- 读写延迟<3ms

一级缓存使用Redis,是考虑其读写性能好,快速,水平扩展性能,能提高存储量及带宽。但当前设计局限性:
- 为简单,使用固定TTL,这是为保证返回结果的相对新鲜
- 为命中率和新鲜度,还在不断提高
目前解决方案还不能完美解决这俩问题。
分析下返回结果,一级缓存命中率小于20%,某些场景更低,就是为保证更高准确度和新鲜度。高优先度,一级缓存的TTL肯定低于5min,有些场景可能只有几十s;支持动态刷新,整体延迟小于3ms。整个运行过程可用性较好。
4.2.4 基于Redis的二级缓存(架构升级)
Pros:
- 读写性能进一步提升
- 服务可靠性提升
- 成本消减
Cons:
- 增加复杂性替代二级索引
结果:
- 成本降低90%
- 读写性能提升30%

4.2.5 基于MongoDB的二级缓存
二级缓存一开始用MongoDB:
- 高读写性能
- 支持二级缓存,方便数据清理
- 多渠道共用子引擎缓存
- TTL通过ML配置
会计算相对较优TTL,保证特定数据:
- 有的可缓存久点
- 有的可快速更新迭代
二级缓存基于MongoDB,也有局限性:
- 架构是越简单越好,多引入一种存储会增加维护代价(强依赖)
- 由于MongoDB的license模式,使得费用非常高(Ops)
结果:
- 但二级缓存使查询整体吞吐量提高3倍
- 通过机器学习设定的TTL,使命中率提升27%
- 各引擎平均延时降低20%
都是可喜变化。在一个成熟的流量非常大的系统,能有个10%提升,就是个显著技术特点。
针对MongoDB也做了提升,最后将其切成Redis,通过设计方案,虽增加部分复杂性,但替代了二级索引,改进结果就是成本降低90%,读写性能提升30%。
5 LB演进
- 系统首要目标满足高可用
- 其次是高流量支撑
可通过多层的均衡路由实现,把这些流量均匀分配到多个IDC的多个集群。
5.1 目标
高可用
高流量支撑
低事故影响范围
提升资源利用率
优化系统性能(长尾优化)
如个别查询时间特长,需要我们找到调度算法问题,一步步解决。
5.2 LB架构
负载均衡
Gateway,LB,IP直连
DC路由规则
IP直连+Pooling
- 计算密集型任务
- 计算时长&权重
- 部分依赖外部查询
Set化
LB的演进:

公司的路由和负载均衡的架构,非常典型,有GateWay、load、balance、IP直连,在IP基础上实现了一项新的Pooling技术。也实现了Set化,在同一IDC,所有的服务都只和该数据中心的节点打交道,尽量减少跨地区网络互动。
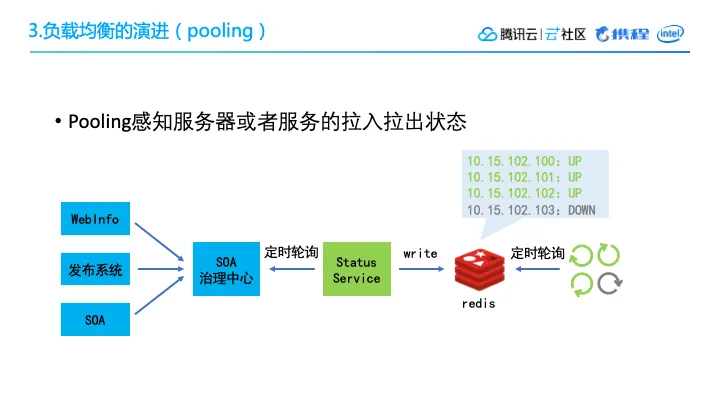
5.3 Pooling
为啥做 Pooling?有些计算密集的引擎,存在耗时长,耗CPU资源多的子任务,这些子任务可能夹杂一些实时请求,所以这些任务可能会留在线程里边,阻塞整个流程。
Pooling就负责:我们把这些子任务放在queue里边,将节点作为worker,总是动态的去取,每次只取一个,计算完了要么把结果返回,要么把中间结果再放回queue。这样的话如果有任何实时的外部调用,我们就可以把它分成多次,放进queue进行task的整个提交执行和应用结果的返回。

5.4 过载保护

有过载保护
- 扔掉排队时间超过T的请求(T为超时时间),所有请求均超时,系统整体不可用
- 扔到排队时间超过X的请求(X为小于T的时间),平均响应时间为X+m,系统整体可用。m为平均处理时间
Pooling设计需要一个过载保护,当流量实在太高,可用简单的过载保护,把等待时间超过某阈值的请求全扔掉。当然该阈值肯定小于会话时间,就能保证整个Pooling服务高可用。
虽可能过滤掉一些请求,但若没有过载保护,易发生滚雪球效应,queue里任务越来越多,当系统取到一个任务时,实际上它的原请求可能早已timeout。
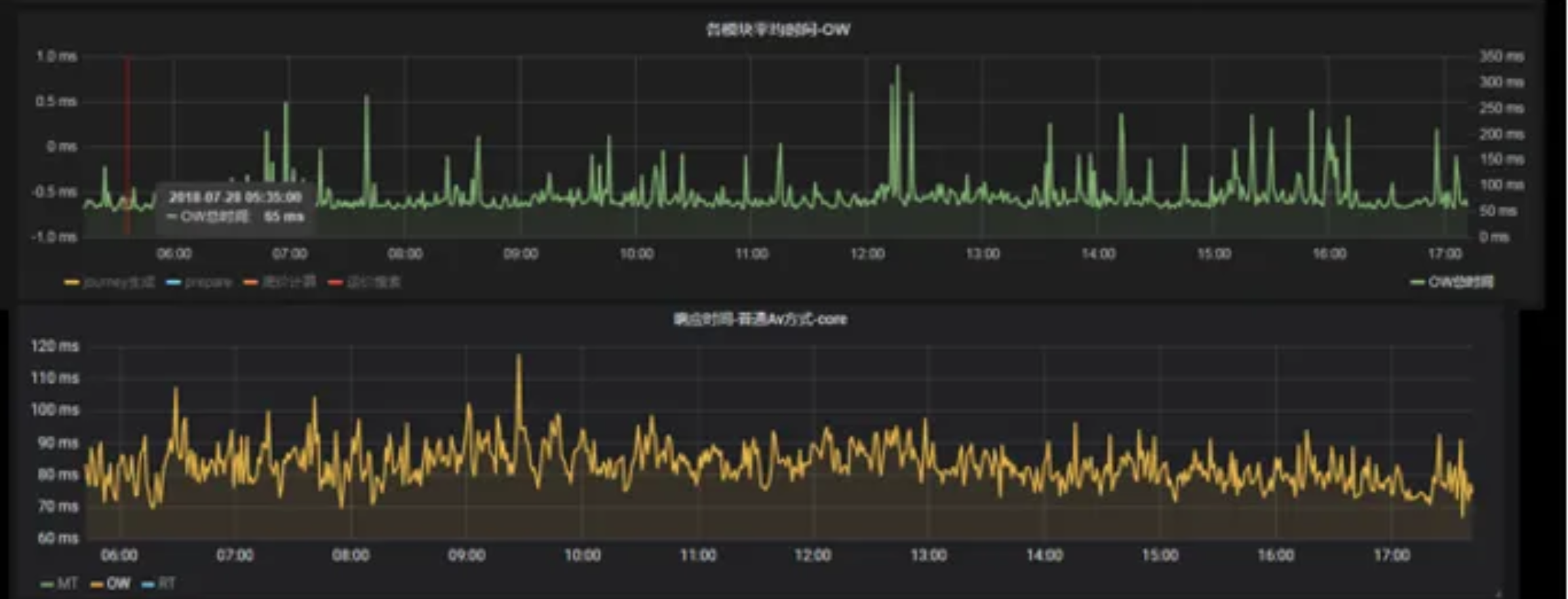
压测结果可见:达到系统极限值前,有无Pooling两种case的负载均衡差异。如80%负载下,不采用Pooling的排队时间比有Pooling高10倍:

所以一些面临相同流量问题厂家,可考虑把 Pooling 作为一个动态调度或一个control plan的改进措施。
如下图,实现Pooling后平均响应时间基本没大变化,还是单层查询计算普遍60~70ms。但实现Pooling后,显著的键值变少,键值范围也都明显控制在平均时间两倍内。这对大体量服务来说,比较平顺曲线正是所需。
6 AI赋能
6.1 应用场景
6.1.1 反爬
在前端,我们设定了智能反爬,能帮助屏蔽掉9%的流量。
6.1.2 查询筛选
在聚合服务中,我们并会把所有请求都压到子系统,而是会进行一定的模式运营,找出价值最高实际用户,然后把他们的请求发到引擎当中。对于一些实际价值没有那么高的,更多的是用缓存,或者屏蔽掉一些比较昂贵的引擎。
6.1.3 TTL智能设定
整个TTL设定使用ML技术。
6.2 ML技术栈和流程
ML技术栈和模型训练流程:

6.3 过滤请求
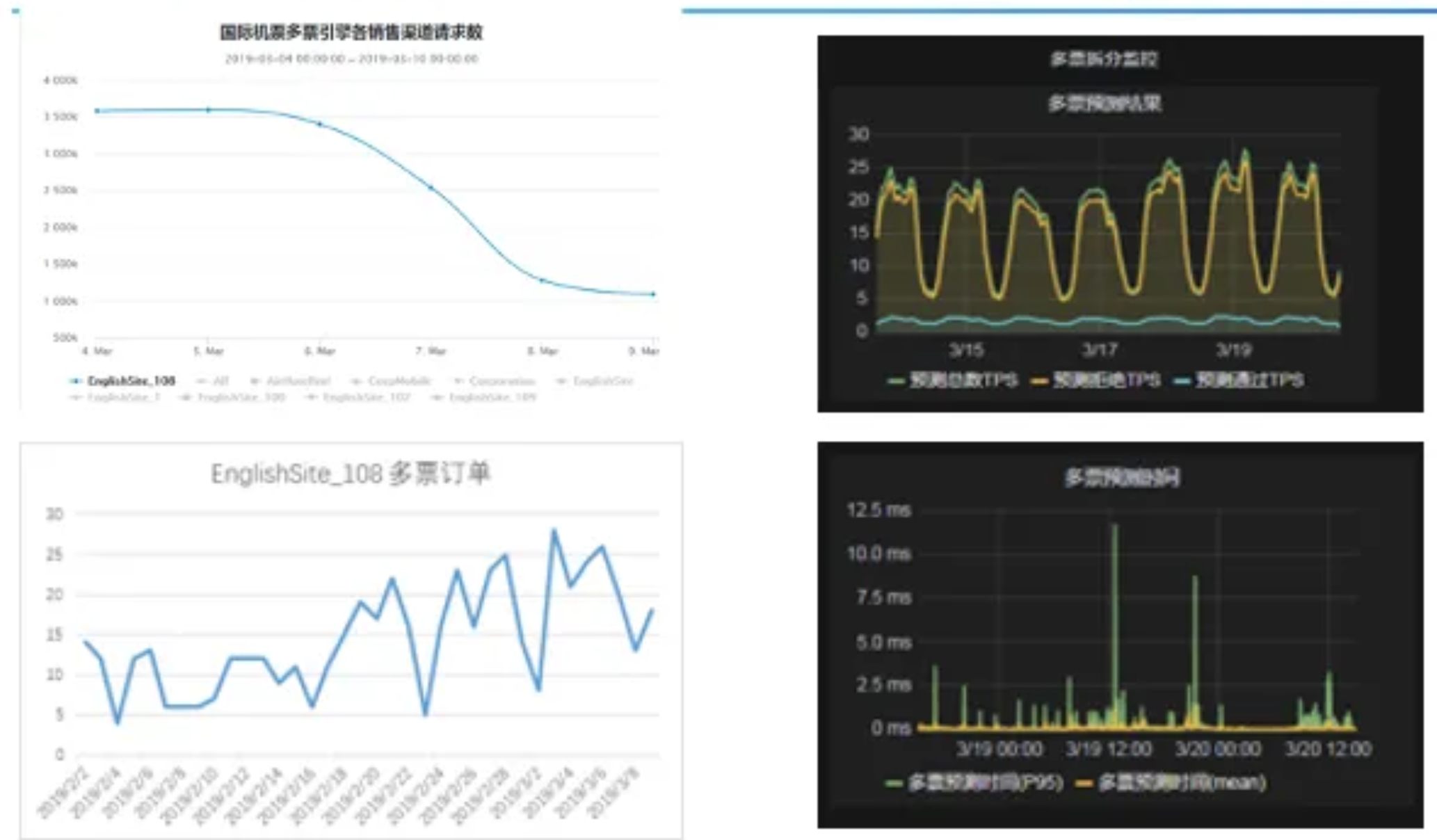
开销非常大的子引擎多票,会拼接多个不同航空公司的出票,返给用户。但拼接计算昂贵,只对一部分产品开放。通过机器学习找到哪些查询可通过多票引擎得到最好结果,然后只对这一部分查询用户开放,结果也很不错。
看右上角图片,整个引擎能过滤掉超过80%请求,流量高峰时能把曲线变得平滑,效果显著。整个对于查询结果、订单数,都没太大影响,且节省80%产品资源。这种线上模型运算时间也短,普遍低于1ms。
7 总结
使用了多层灵活缓存,从而能很好的应对高流量的冲击,提高反应速度。
使用可靠的调度和负载均衡,这样就使我们的服务保持高可用状态,并且解决了长尾的查询延迟问题。最后内部尝试了很多技术革新,将适度的AI技术推向生产,从目前来看,机器学习发挥了很好的效果。带来了ROI的提升,节省了效率,另外在流量高峰中,它能够起到很好的削峰作用。以上就是我们为应对高流量洪峰所采取了一系列有针对性的架构改善。
- 多层,灵活的缓存 -> 流量,速度
- 可靠的调度和负载均衡 -> 高可用
- 适度的AI -> ROI,削峰
8 Q&A
Q:啥场景用缓存?
A:所有场景都要考虑缓存。高流量时,每级缓存都能带来很好的保护系统,提高性能的效果,但要考虑到缓存失效的应对措施。
Q:缓存迭代过程咋样的?
A:先有L1,又加L2,主要因为流量越来越大,引擎外部依赖逐渐撑不住,不得不把中间结果也高效缓存,此即L1到L2的演进。二级缓存用Redis替代MongoDB,是出于高可用考虑,费用节省也是一个因素,但更主要是发现自运维的MongoDB比Redis,整体可用性要差很多,所以最后决定切换。
Q:分布式缓存的设计方式?
A:分布式缓存的关键在于它的KV怎么设定?须根据业务场景,如有的KV里加入IP地址,即Pooling,基于Redis建立了它的队列,所以我们queue当中是把这种请求方的IP作为建设的一部分放了进去,就能保证子任务能知道到哪查询它相应的返回结果。
Q:为什么redis的读写延迟能做到3ms以内呢?
A:读写延时低其实主要指读延时,读延时3ms内没问题。
Q:这队列是内存队列?还是MQ?
A:互联队列用Redis,主要是为保证其高可用性。
Q:缓存失效咋刷新,涉及分布式锁?
A:文章所提缓存失效,并非指它里边存的数据失效,主要指整个缓存机制失效。无需分布式锁,因为都是单独的KV存储。
Q:缓存数据一致性咋保证?
A:非常难保证,常用技巧:缓存超过阈值,强行清除。然后若有更精确内容进来,要动态刷新。如本可存5min,但第2min有位用户查询并下单,这时肯定是要做一次实时查询,顺便把还没过期的内容也刷新一遍。
Q:热key,大key咋监控?
A:对我们热区没那么明显,因为一般我们的一个key对应一个点,一个出发地和一个目的地,中间再加上各种渠道引擎的限制。而不像分片,你分成16或32片,可能某一分片逻辑设计不合理,导致那片过热,然后相应硬件直接到瓶颈。
Q:详解Pooling?
A:原理:子任务耗时间不一,若完全基于SOA进行动态随机分,肯定有的计算节点分到的子任务较重,有的较轻,加入Pooling,就好像加入一个排队策略,特别是对中间还会实时调用离开几s的case,排队策略能极大节省计算资源。
Q:监控咋做的?
A:基于原来用了时序数据库,如ClickHouse,和Grafana,然后现在兼容Promeneus的数据收集和API。
Q:二级缓存采用Redis的啥数据类型?
A:二级缓存存储中间结果,应该是分类型的数据类型。
Q;TTL计算应该考虑啥?
A:最害怕数据异常,如系统总返回用户一个已过期低票价,用户体验很差,所以这方面牺牲命中率,然后缩短TTL,只不过TTL控制在5min内,有时还要微调,所以还得用机器学习模型。
Q:IP直连和Pooling没明白,是AGG中涉及到的计算进行拆分,将中间结果进行存储,其他请求里若也需要这中间计算,可直接获取吗?
A:IP直连和PoolingIP直连,其实把负载均匀分到各节点Pooling,只不过你要计算的子任务入队,然后每个运算节点每次取一个,计算完再放回去,这样计算效率更高。中间结果没有共享,中间结果存回是因为有的子任务需要中间离开,再去查其他实时系统,所以就相当于把它分成两个运算子任务,中间的任务要重回队列。
Q:下单类似秒杀,发现一瞬间票抢光了,相应缓存咋更新?
A:若有第1个用户选择了一个运价,没通过,要把缓存数据都给杀掉,然后尽量防止第2个用户还会陷入同样问题。
Q:多级缓存数据咋保证一致?
A:因为我们一级缓存存的是最终的结果,二级缓存是中间结果,所以不需要保持一致。
Q:一级、二级、三级缓存,请求过来,咋提高吞吐量,按理说,每个查询过程都消耗时间,吞吐量应该下降?
A:是的,若无这些缓存,几乎所有都要走一遍。实时计算,时间长,而且部署的集群能响应的数很有限,然后一、二、三级每级都能拦截很多请求。一级约拦截20%,二级差不多40%~50%。此时同样的集群,吞吐量显然明显增加。
Q:如何防止缓存过期时刻产生的击穿问题,目前公司是定时任务主动缓存,还是根据用户请求进行被动的缓存?
A:对于缓存清除,我们既有定时任务,也有被动的更新。比如说用户又取了一次或者购票失败这些情况,我们都是会刷新或者清除缓存的。
Q:搜索结果会根据用户特征重新计算运价和票种吗?
A:为啥我的运价跟别人不一致,是不是被大数据杀熟?其实不是的,那为啥同样查询返回结果不一呢?有一定比例是因为缓存数据异常,如前面缓存的到后面票卖光了,然后又推给了不幸用户。公司有很多引擎如说国外供应商,尤其联航,他们系统带宽不够,可用性不高,延时也高,所以部分这种低价票不能及时返回到我们的最终结果,就会出现这种“杀熟”,这并非算法有意,只是系统局限性。
Q:Pooling 为啥用 Redis?
A:为追求更高读写速度,其他中间件如内存队列,很难用在分布式调度。若用message queue,由于它存在明显顺序性,不能基于KV去读到你所写的,如你发了个子任务,这时你要定时取其结果,但你基于MQ或内存队列没法拿到,这也是一个限制。
Q:多级缓存预热咋保证MySQL不崩?
A:冷启动问题更多作用在本地缓存,因为本地缓存发布有其他的情况,需要预热,在这之间不能接受生产流量。对多级缓存、分布式缓存,预热不是问题,因为它本就是分布式的,可能有部分节点要下线之类,但对整个缓存机制影响很小,然后这一部分请求又分散到我们的多个服务器,不会产生太大抖动。但若整个缓存机制失效如缓存集群完全下掉,还是要通过熔断或限流对实时系统作过载保护。
Q:Redis对集合类QPS不高,咋办?
A:Redis多加些节点,减少它的存储使用率,把整体throughput提上即可。若你对云业务有了解,就知道每个节点都有throughput限制。若单节点throughput成为瓶颈,那就降低节点使用率。
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都技术专家兼架构,多家大厂后端一线研发经验,各大技术社区头部专家博主,编程严选网创始人。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
中央/分销预订系统性能优化
活动&优惠券等营销中台建设
交易平台及数据中台等架构和开发设计
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
- 编程严选网
本文由博客一文多发平台 OpenWrite 发布!
相关文章:
大厂报价查询系统性能优化之道!
0 前言 机票查询系统,日均亿级流量,要求高吞吐,低延迟架构设计。提升缓存的效率以及实时计算模块长尾延迟,成为制约机票查询系统性能关键。本文介绍机票查询系统在缓存和实时计算两个领域的架构提升。 1 机票搜索服务概述 1.1 …...
Carbondata编译适配Spark3
背景 当前carbondata版本2.3.1-rc1中项目源码适配的spark版本最高为3.1,我们需要进行spark3.3版本的编译适配。 原始编译 linux系统下载源码后,安装maven3.6.3,然后执行: mvn -DskipTests -Pspark-3.1 clean package会遇到一些网络问题&a…...
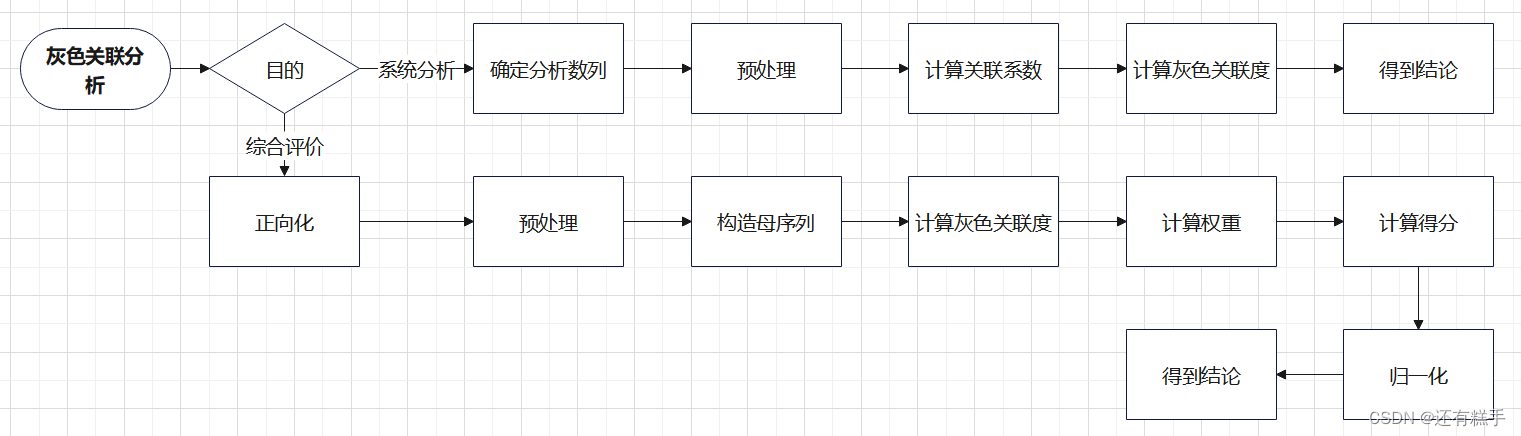
数学建模【灰色关联分析】
一、灰色关联分析简介 一般的抽象系统,如社会系统、经济系统、农业系统、生态系统、教育系统等都包含有许多种因素,多种因素共同作用的结果决定了该系统的发展态势。人们常常希望知道在众多的因素中,哪些是主要因素,哪些是次要因素;哪些因素…...

Vue.js的单向数据流:让你的应用更清晰、更可控
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

IntelliJ IDEA社区版传统web开发环境搭建
前言 现在主流的开发框架是SpringBoot,使用maven配置的开发环境,网上有很多教程,这里记录一下传统Web开发项目(mvc架构的框架,如SSH)使用idea社区版的开发环境搭建。防止被人说都2024年了还用eclipse。 一、下载文件…...

arm-linux-gnueabi、arm-linux-gnueabihf 交叉编译器区别
1、arm-linux-gnueabi: 使用软件浮点(软浮点)。这意味着所有的浮点运算都将由软件库来处理,而不会利用硬件中的浮点运算单元。因此,生成的目标代码包含了对软件浮点库的调用。 2、arm-linux-gnueabihf: 使…...

什么是RS485
RS-485是一种串行通信标准,它是在1980年代由美国电子工业协会(EIA)制定的。它的全称是“Recommended Standard 485”,通常简称为RS-485。RS-485标准定义了信号的电气特性和信号线的布局,它主要用于工业环境RS-485是一种…...
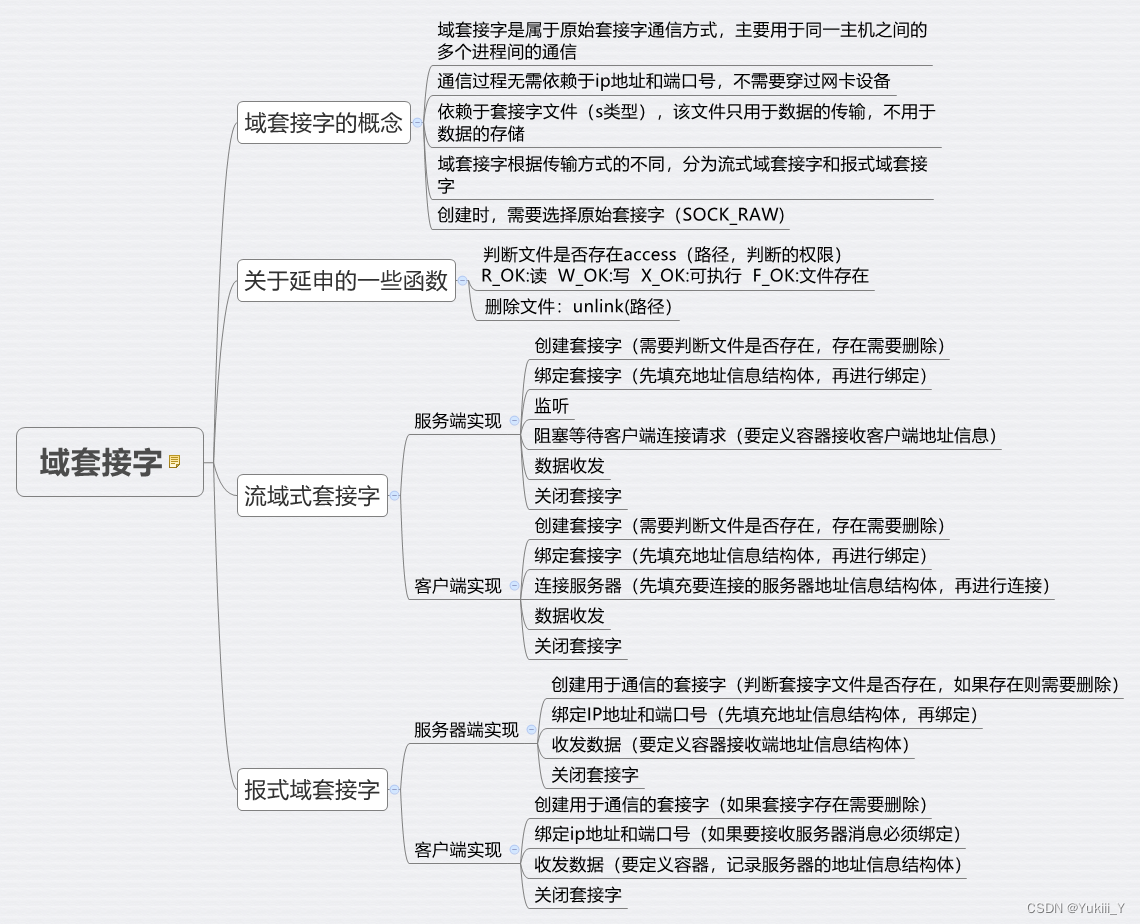
2024.3.4
报式域套接字 #include<myhead.h> int main(int argc, const char *argv[]) {//创建套接字int sfdsocket(AF_UNIX,SOCK_DGRAM,0);if(sfd-1){perror("socket error");return -1;}printf("sfd%d\n",sfd);//判断套接字文件是否存在,如果存在…...

STM32自学☞AD单通道
程序的最终运行成果: 当转动电位器时,数值和电压值发生变化 ad.c文件 #include "stm32f10x.h" #include "stm32f10x_adc.h" #include "ad.h" #include "stdint.h" void ad_Init(void) { /* 初始化步骤:…...

打家劫舍(java版)
📑前言 本文主要是【动态规划】——打家劫舍(java版)的文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是听风与他🥇 ☁️博客首页:CSDN主页听风与他 🌄每日一…...
与关键词参数(**kwargs)的用法)
Python函数位置参数(*args)与关键词参数(**kwargs)的用法
两种向python函数传递参数的方式: 位置参数(positional argument) 关键词参数(keyword argument) *args与**kwargs的区别 两者都是python中的可变参数; args:表示任何多个无名参数,它…...

Java自学day5
流程控制语句 流程控制语句:通过一些语句,控制程序的执行流程 顺序结构 顺序结构语句是Java程序默认的执行流程,按照代码的先后顺序,从上到下依次执行! package orderdemo;public class OrderDemo {public static void main(String[] args) {System.out.println("…...

IO-DAY1
1.用fprintf将链表数据保存到文件中 2用fscanf将文件中数据写入链表 #include<stdio.h> #include<string.h> #include<stdlib.h> #include<unistd.h> typedef int datatype; typedef struct link_list { union { int len; d…...
英福康INFICON真空计MPG400MPG401使用说明PPT讲解课件
英福康INFICON真空计MPG400MPG401使用说明PPT讲解课件...
【lua】lua内存优化记录
这边有一个Unity项目用的tolua, 游戏运行后手机上lua内存占用 基本要到 189M, 之前峰值有200多。 优化点1 加快gc频度: 用uwa抓取的lua内存, 和unity的mono很像,内存会先涨 然后突然gc一下,降下来。 这样…...

紫光展锐T618_4G安卓核心板方案定制
紫光展锐T618核心板是一款采用纯国产化方案的高性能产品,搭载了开放的智能Android操作系统,并集成了4G网络,支持2.5G5G双频WIFI、蓝牙近距离无线传输技术以及GNSS无线定位技术。 展锐T618核心板应用旗舰级 DynamlQ架构 12nm 制程工艺&#x…...
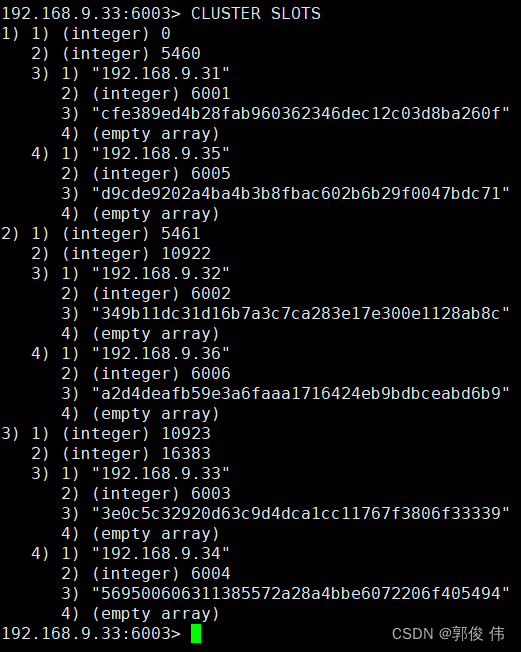
Redis 群集部署
1.关系型数据库 关系型数据库是一个结构化的数据库,创建在关系模型基础上,-般面向记录。它借助于集合代数等数学概念和方法来处理数据库中的数据。关系模型指二维表格模型,因而一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织。现实世界中…...

WPF中如何设置自定义控件(二)
前一篇文章中简要讲解了圆角按钮、圆形按钮的使用,以及在windows.resource和app.resource中设置圆角或圆形按钮的样式。 这篇主要讲解Polygon(多边形)、Ellipse(椭圆)、Path(路径)这三个内容。 Polygon 我们先看一下的源码: namespace System.Windows.Shapes { pu…...

【C++】每周一题——2024.3.3
题目 Cpp 【问题描述】 字符环(来源:NOI题库)。有两个由字符构成的环,请写一个程序,计算这两个字符环上最长公共字符串的长度。例如,字符串“ABCEFAGADEGKABUVKLM”的首尾连在一起,构成一个环&a…...
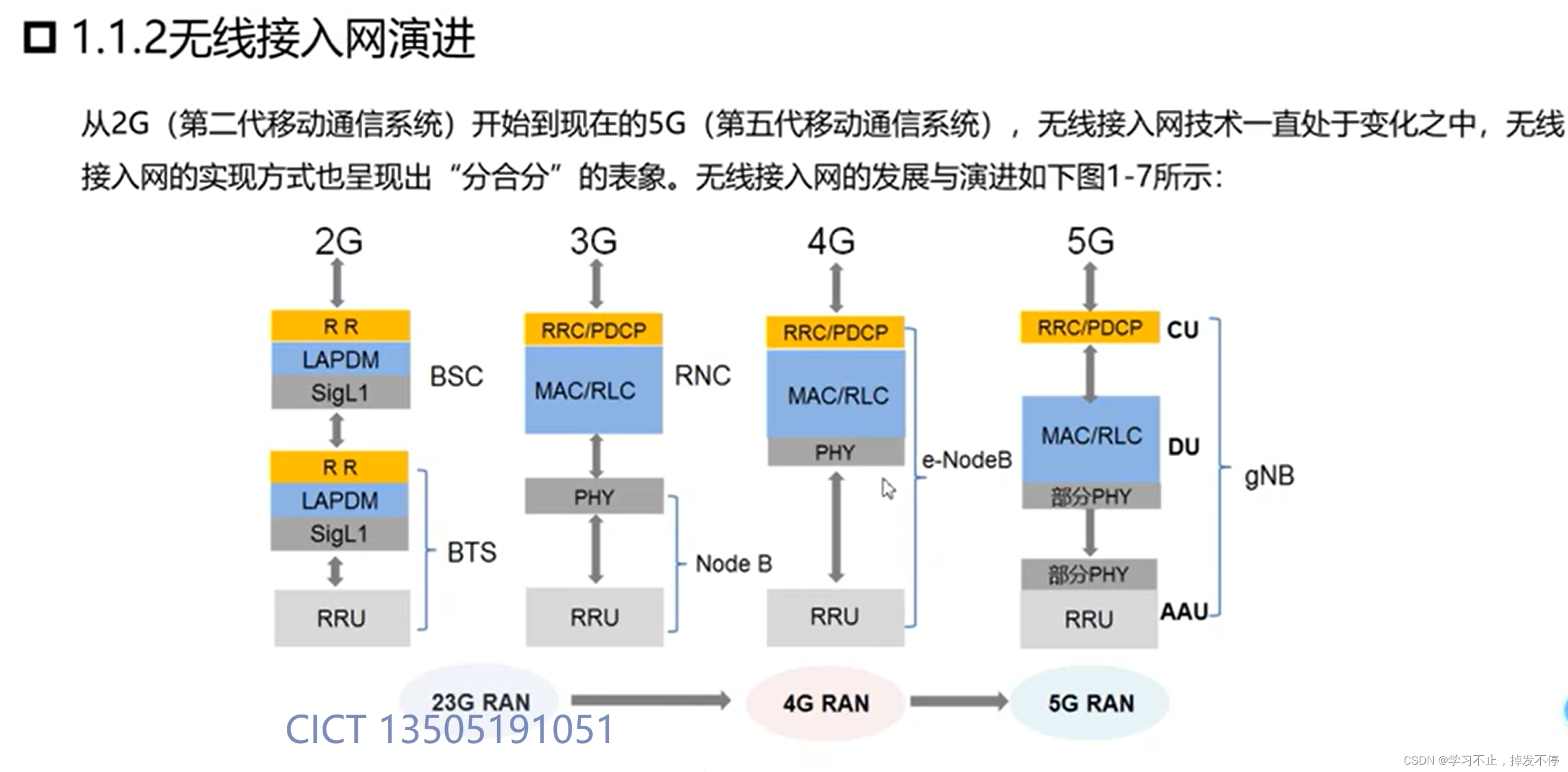
5G网络架构与组网部署01--5G网络架构的演进趋势
目录 1. 5G网络架构的演进趋势 1.1 5G移动通信系统整体架构 1.2 4G移动通信系统整体架构 1.3 4G与5G移动通信系统整体架构对比 1.4 核心网架构演进 1.5 无线接入网演进 1. 整体架构组成:接入网,核心网 2. 5G网络接入网和核心网对应的网元ÿ…...

具身智能赋能:无感定位打破 UWB 传统空间交互局限
具身智能赋能:无感定位打破 UWB 传统空间交互局限人工智能技术向实体空间深度渗透,具身智能成为空间计算领域进阶发展的核心方向。区别于传统算法仅停留在数据层面分析决策,具身智能依托空间感知能力让智能体系拥有环境理解、自主交互、动态适…...

告别“感觉能用”:基于 Ragas 构建 RAG 自动化回归测试流水线的方法论
很多团队把 RAG 系统做到能演示、能回答、能接知识库之后,心里都会出现一种熟悉又危险的判断:看起来差不多能用了。 但只要系统真的进入业务场景,这种“差不多”很快就会露出问题。今天回答还算靠谱,明天换一批文档就开始飘;演示集表现很好,真实用户一多就出现答非所问;…...

好用的长沙装修设计值得选的服务商
在装修设计领域,选择一家靠谱的服务商至关重要。长沙互知空间设计工作室,也就是长沙互知建筑设计有限公司,便是众多客户值得信赖的选择。下面将从几个方面详细分析它的优势,并与其他知名品牌进行对比,为大家提供一些实…...

Temu 运营进阶之路 工具选型与凌风体系分析
TEMU商家体量持续扩张,平台规则与收费体系愈发复杂,纯人工运营耗时费力,核算误差、合规疏漏问题频发。市面上运营工具繁杂,商家难以甄别适配工具。本文以行业实操角度,客观拆解凌风工具箱的适配能力与实用价值…...

G-Helper终极指南:华硕笔记本轻量控制中心的3步快速配置方案
G-Helper终极指南:华硕笔记本轻量控制中心的3步快速配置方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbo…...
)
别再手动配聚合了!用LACP协议给你的交换机链路做个‘智能冗余’(附华为交换机配置命令)
告别手动配置:LACP协议如何为你的企业网络打造智能冗余链路 想象一下这样的场景:凌晨三点,核心交换机之间的某条链路突然中断,整个企业的业务系统陷入瘫痪。运维团队手忙脚乱地排查故障,却发现由于手动配置的链路聚合缺…...

ChatGPT写代码总出错?揭秘92%开发者忽略的3层提示工程校验机制
更多请点击: https://intelliparadigm.com 第一章:ChatGPT写代码总出错?揭秘92%开发者忽略的3层提示工程校验机制 当ChatGPT生成的代码在本地运行失败、逻辑错位或依赖缺失时,问题往往不在模型本身,而在于提示&#x…...

单北斗GNSS变形监测系统在地质灾害监测中的应用与维护
北斗 GNSS 变形监测系统在地质灾害监测中发挥着重要作用。它通过高精度定位,实时捕捉地面形变,为防灾减灾提供精准数据支持。系统的定制化设计能适应不同环境,同时具备稳定性与可靠性。随着技术发展,监测和维护也变得更高效。这种…...

Unity工业级机械仿真:刚体约束链与运动学反解实战
1. 这不是“玩具模型”,而是一套可投产验证的机械运动逻辑沙盒在Unity里做机械结构仿真,很多人第一反应是“做个动画演示”——齿轮转得漂亮、连杆动得丝滑、液压缸伸缩带点粒子特效,导出个MP4发给客户就算交付。但MGS-Machinery这个项目完全…...

告别Excel人工统计!学生考勤自动分析系统搭建实录
实验背景 本实验基于“数智教育”大赛数据集,设计并实现学生多维度考勤统计转换流,目标是掌握ETL数据处理全过程,包括数据接入、数据清洗、多表关联、字段衍生、指标聚合以及结果落地等核心技能,完成学生考勤主题标签构建任务&am…...