Spark Shuffle Tracking 原理分析
Shuffle Tracking
Shuffle Tracking 是 Spark 在没有 ESS(External Shuffle Service)情况,并且开启 Dynamic Allocation 的重要功能。如在 K8S 上运行 spark 没有 ESS。本文档所有的前提都是基于以上条件的。
如果开启了 ESS,那么 Executor 计算完后,把 shuffle 数据交给 ESS, Executor 没有任务时,可以安全退出,下游任务从 ESS 拉取 shuffle 数据。
1. 背景
如果 Executor 执行了上游的 Shuffle Map Task 并且把 shuffle 数据些到本地。并且现在 Executor 没有 Task 运行,那么此 Executor 是否能销毁?
现状是如果 Executor 没有 active 的 shuffle 数据,则可以被销毁。
active shuffle 的定义:如果 Shuffle Map Stage 的 task 把 shuffle 数据输出到本地。如果依赖此 shuffle 的Stage 没有计算完毕,则称此 shuffle 为 active shuffle。因为依赖此 shuffle 的 Task 可能从 Driver 端获取了 MapStatus,但是还没有拉取完 shuffle 数据。
为了达到此目的,需要跟踪每个 Stage 和每个 Task 的运行信息。并且启动定时任务,定时扫描每个 Executor,判断是否有任务运行,是否有 active 的 shuffle,如果没有则可以退出。
退出有两种,如果开启了 decommission,则到期的 executors 进入 decommission 模式,否则执行 killExecutors。
参数配置
spark.dynamicAllocation.shuffleTracking.enabled: 默认 true,是否开启 shuffle tracking。
spark.dynamicAllocation.shuffleTracking.timeout: 默认 Long.MaxValue,
2. 设计
ExecutorMonitor 为每个 Executor 创建一个 Tracker, 用于跟踪此 Executor 的状态。
private val executors = new ConcurrentHashMap[String, Tracker]()
定时任务间隔时间查找 timeout 的 executor,然后处理。
timedOutExecutors 方法的主要逻辑,就是遍历 executors。如果 executor 没有 active 的 shuffle 并且当前时间大于 executor 的超时时间 timeoutAt,则此 executor 可以被安全释放。
为什么 executor 有 active shuffle 数据就不能 kill?
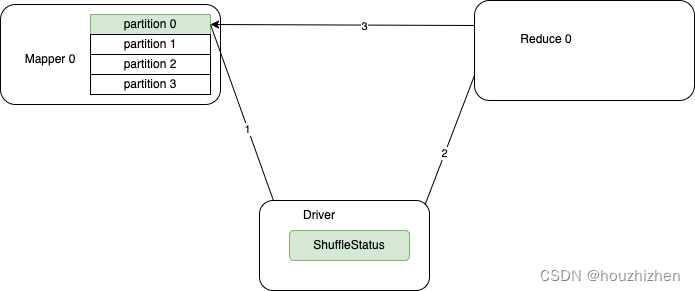
- Shuffle 的过程:
- MapTask 把 shuffle 写到本地,并且把状态汇报给 Driver.
- Reduce Task 从 Driver 获取 shuffle status,并从 shuffle status 获取每个 shuffle 数据的地址。
- 连接对应的 executor 获取 shuffle 数据。
如果在 reduce 获取完 shuffle status 后,MapTask 所在的 Executor 被 kill 掉,Reduce Task 就无法获取 shuffle 数据。
如果执行 decommission 逻辑,把 MapTask 的 shuffle 数据长传到 bos 等分布式存储是否可以?
也是不可以的,因为 reduce 可能已经把 shuffle status 拿走,获取的 shuffle status 没有记录 shuffle 数据在分布式存储上。
参考: ExecutorMonitor,ExecutorAllocationManager
Executor 状态的更新
ExecutorMonitor 实现了 SparkListner 接口,当 Job, Stage, Task 等 start 和 end 时,都会执行回调。
以 hasActiveShuffle 为例
每个 executor 用一个集合 shuffleIds 存储其上拥有的 shuffle 数据。 当其为空时,说明没有 shuffle 数据。
在 onTaskEnd 和 onBlockUpdated 时调用 addShuffle 向 shuffleIds 添加数据。
在以下时机删除 shuffleIds 里的数据。
- 依赖 driver 端的 ContextCleaner,当 ShuffleRDD 仅有 weakReference 时触发。
- rdd.cleanShuffleDependencies 方法,但是此方法仅在 org.apache.spark.ml.recommendation.ALS 使用。
timeoutAt 的计算逻辑
总结:timeoutAt 根据 idle 的时间,spark.dynamicAllocation.cachedExecutorIdleTimeout 和 spark.dynamicAllocation.shuffleTracking.timeout 这 3 个值中最大的值。
详细计算逻辑:
timeoutAt 在一些事件发生时触发计算,如 onBlockUpdated, onUnpersistRDD, updateRunningTasks, removeShuffle, updateActiveShuffles
timeoutAt 的计算逻辑:
当执行器有计算任务时 为 Long.MaxValue。
否则为 max(_cacheTimeout, _shuffleTimeout, idleTimeoutNs)
_cacheTimeout: 如果没有 cache 数据,为0,否则为参数 spark.dynamicAllocation.cachedExecutorIdleTimeout 的值(默认 Long.MaxValue)。
_shuffleTimeout: 如果没有 shuffle数据,为 0, 否则为参数 spark.dynamicAllocation.shuffleTracking.timeout 的值(默认 Long.MaxValue)。
idleTimeoutNs 为 spark.dynamicAllocation.executorIdleTimeout
3. 测试
测试命令
spark-shell \--conf spark.dynamicAllocation.enabled=true \--conf spark.dynamicAllocation.initialExecutors=2 \--conf spark.dynamicAllocation.maxExecutor=400 \--conf spark.dynamicAllocation.minExecutors=1 \--conf spark.shuffle.service.enabled=false \--conf spark.dynamicAllocation.shuffleTracking.enabled=true
参考资料:
https://www.waitingforcode.com/apache-spark/what-new-apache-spark-3-shuffle-service-changes/read
相关文章:
Spark Shuffle Tracking 原理分析
Shuffle Tracking Shuffle Tracking 是 Spark 在没有 ESS(External Shuffle Service)情况,并且开启 Dynamic Allocation 的重要功能。如在 K8S 上运行 spark 没有 ESS。本文档所有的前提都是基于以上条件的。 如果开启了 ESS,那么 Executor 计算完后&a…...
)
Docker 干货系列 (持续更新)
dive 直接用本地镜像名称来启动,不需要走 hub dive.sh IMAGE_NAME"${1}" TMP_FILE/tmp/dive-tmp-image.tar docker save "$IMAGE_NAME" > $TMP_FILE && dive $TMP_FILE --sourcedocker-archive && rm $TMP_FILE示例&#…...

一.jwt token 前后端的逻辑
摘要 jwt token 前后端的交互逻辑,此部分只描述了一些交互逻辑,不涉及到真实应用的开发。 token的格式 tokenheader‘.’payload‘.’sign 第一次登陆的时候 判断http请求头中是否包含Authorization不包含则提示用户未登录当用户登录后,…...
day12_oop_抽象和接口
今日内容 零、 复习昨日 一、作业 二、抽象 三、接口 零、 复习昨日 final的作用 修饰类,类不能被继承修饰方法,方法不能重写[重点]修饰变量/属性,变成常量,不能更改 static修饰方法的特点 static修饰的方法,可以通过类名调用 static修饰的属性特点 在内存只有一份,被该类的所有…...

linux 将 api_key设置环境变量里
vi ~/.bashrc在最后添加api_key的环境变量 export GEMINI_API_KEYAIza**********WvpX7FwbdM刷新配置 source ~/.bashrc使用python 读取环境变量 import os gemini_api_key os.getenv(GEMINI_API_KEY) print(gemini_api_key)...
java八股文复习-----2024/03/03
1.接口和抽象类的区别 相似点: (1)接口和抽象类都不能被实例化 (2)实现接口或继承抽象类的普通子类都必须实现这些抽象方法 不同点: (1)抽象类可以包含普通方法和代码块&#x…...
UE4 Niagara 关卡3.4官方案例解析
Texture sampling is only supported on the GPU at the moment.(纹理采样目前仅在GPU上受支持) 效果:textures can be referenced within GPU particle systems。this demo maps a texture to a grid of particles(纹理可以在GPU粒子系统中被引用这个演…...
C# Onnx segment-anything 分割万物 一键抠图
目录 介绍 效果 模型信息 sam_vit_b_decoder.onnx sam_vit_b_encoder.onnx 项目 代码 下载 C# Onnx segment-anything 分割万物 一键抠图 介绍 github地址:GitHub - facebookresearch/segment-anything: The repository provides code for running infere…...
Linux配置网卡功能
提示:工具下载链接在文章最后 目录 一.network功能介绍二.配置network功能2.1 network_ip配置检查 2.2 network_br配置2.2.1 配置的网桥原先不存在检查2.2.2 配置的网桥已存在-修改网桥IP检查2.2.3 配置的网桥已存在-只添加网卡到网桥里检查 2.3 network_bond配置检查 2.4 netw…...
【C++】十大排序算法之 归并排序 快速排序
本次介绍内容参考自:十大经典排序算法(C实现) - fengMisaka - 博客园 (cnblogs.com) 排序算法是《数据结构与算法》中最基本的算法之一。 十种常见排序算法可以分为两大类: 比较类排序:通过比较来决定元素间的相对次序…...

x-pack的破解方式和免费jar包!!可直接用!!
原理介绍 我们平时为es安装x-pack组件,用elasticsearch-plugin install x-pack ,安装成功后。 1.cd $es目录/pulgins/x-pack 里面有一个x-pack-5.6.2.jar ,将jar包反编译,然后将里面的licence的程序改下。再编译成jar包。 2…...

最新版本,Midjourney保姆级教程!
一、认识Midjourney 1.1、MidJourney是什么? 随着ChatGPT的横空出世,人类正式迈入AI元年,其中MidJourney便是AI绘图工具,它能根据用户输入的文字描述(提示词)生成绘画作品,不管是灵动的人物&a…...

Android中的几种定位方式调用详解
目前,移动端大致通过三种方式来进行设备定位:GPS、基站、wifi。本文就详细的讲解一下这几种定位方式和实现方法。 前言 android中我们一般使用LocationManager来获取位置信息,这里面有四中provider: public static final Strin…...
【软件测试】接口调不通排查分析+常遇面试题总结
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、接口调不通&am…...
)
c++基础学习第三天(指针,结构体)
c基础学习第三天(指针,结构体) 文章目录 1、指针1.1、指针的基本概念1.2、指针变量的定义和使用1.3、 指针所占内存空间1.4、空指针和野指针1.5、 const修饰指针1.5.1、const修饰指针-常量指针1.5.2、const修饰常量-指针常量1.5.3、const即修…...

【数仓】zookeeper软件安装及集群配置
相关文章 【数仓】基本概念、知识普及、核心技术【数仓】数据分层概念以及相关逻辑【数仓】Hadoop软件安装及使用(集群配置)【数仓】Hadoop集群配置常用参数说明 一、环境准备 准备3台虚拟机 Hadoop131:192.168.56.131Hadoop132ÿ…...
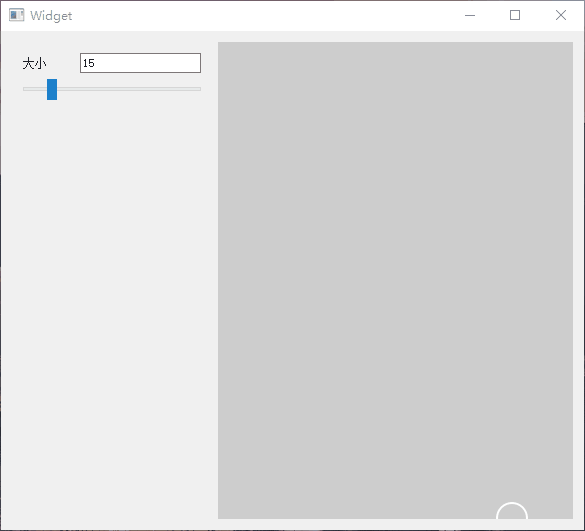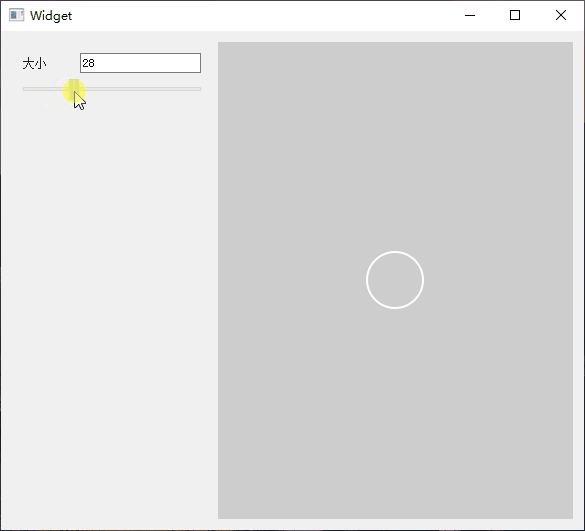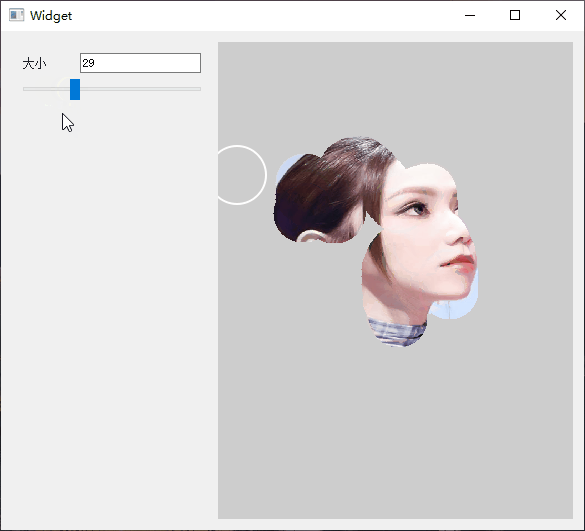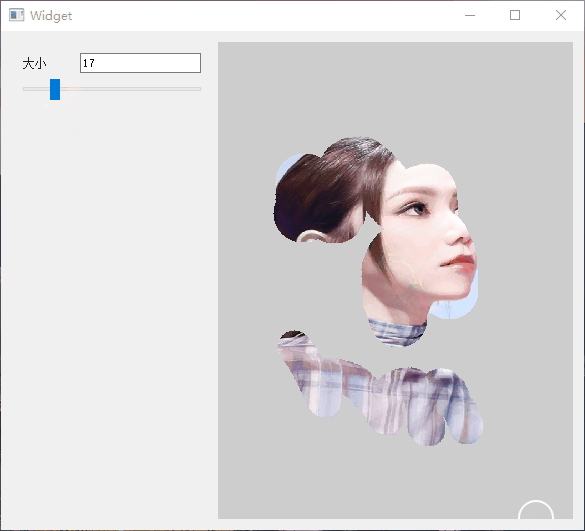
Qt 实现橡皮擦拭显示图片
1.简介 在一些游戏中看见类似解密破案的效果,使用手触摸去擦拭图片上的灰尘,然后显示最终的图片,所以也想试试Qt实现的效果。大家有自己想做的效果,都可以尝试。 以下是效果展示图。 可以控制橡皮擦的大小,进行擦拭…...

Vue3+Element-Plus中ELMessage样式丢失处理
Vu3Element-Plus项目中,element-plus使用按需引入有时会出现样式失效和在vscode中使用会报错[找不到名称“ElMessage”。ts(2304)]错误 ELMessage弹框样式丢失处理方法 使用按需引入就不能手动再引入 import { ElMessage } from "element-plus";ElMessage.success…...
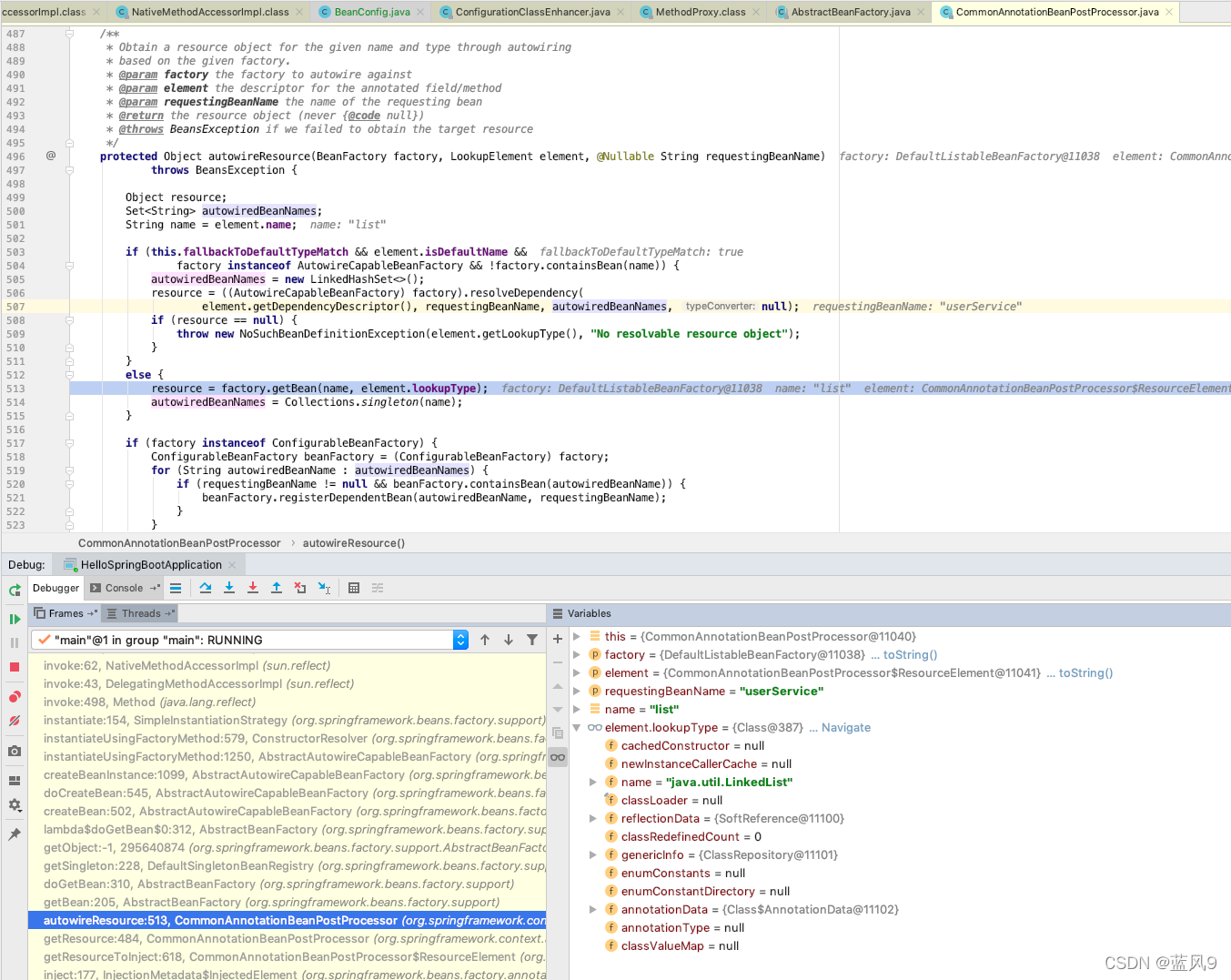
97 spring 中的泛型类型注入
前言 呵呵 同样是 最近同事碰到的一个问题 他不太懂 英语, 看到的说明是 缺少一个 RedisTemplate 的实例, 但是找到了一个 RedisTemplate 的实例 呵呵 和我这里 spring 版本似乎是不太一样, 错误信息 有一些差异 以下环境基于 jdk8 spring-5.0.4-RELEASE 测试用例 BeanCon…...
C++设计模式
单例模式 单例模式保证一个类只能创建一个对象,并提供全局访问点。通常用于全局共享例如日志、数据库连接池等。 Lazy Initialization 优点:需要时才初始化,节省空间 缺点:线程不安全 class Singleton{ private:static Singlet…...

【tomcat部署前台war包报错】
tomcat部署前台war包报错 背景:tomcat启动前台war包,由zip直接改文件后缀成war包,jdk8 同事好使,我不好使 部署平台日志: 报错一、正常tomcat执行时会把war包解压成对应文件夹,这里应该是没解压成功。没有具…...

油雾净化设备哪家技术更专业
在机械加工、五金锻造、热处理等工业生产场景中,机床切削、乳化液喷淋、高温加工会持续产生大量工业油雾。悬浮在车间内的油雾不仅会腐蚀生产设备、污染生产环境,还会刺激人体呼吸道,危害操作人员身体健康,同时超标排放还会违反环…...

第一学期结果
关注 1.从安涛老师前三期视频中了解了方向2.从b站了解了555的内部结构3.仿真。4.低通滤波器的基本原理:一、核心定义只允许低频信号顺利通过,阻挡、衰减高频信号的电路。 你电路里作用:滤掉方波里的高频谐波,留下低频基波…...

激光器物理理论模型:从经典到量子,工程师如何选择?
1. 激光器物理理论模型全景概览激光,这束高度相干、单色、定向的光,其诞生与运作背后,是一套极其精密的物理法则。对于从事光电子、激光技术研发,乃至物理研究的工程师和学者而言,理解这些法则的不同描述层次ÿ…...

从云台控制理解双环PID:手把手调试大疆GM6020电机的角度与速度环
从云台控制理解双环PID:手把手调试大疆GM6020电机的角度与速度环 在机器人控制领域,精准的位置控制是实现高性能运动的基础。无论是工业机械臂的重复定位,还是竞技机器人云台的快速响应,都离不开对电机运动的精确控制。而在这其中…...

KaTrain围棋AI:如何用数据可视化与智能分析重塑围棋学习体验
KaTrain围棋AI:如何用数据可视化与智能分析重塑围棋学习体验 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 围棋作为一项拥有数千年历史的智力运动,其学习…...

LangChain 是什么?从零开始学会 LangChain 的工程实践指南
LangChain 是什么?从零开始学会 LangChain 的工程实践指南 1. 文章背景:为什么这个主题重要 在大模型应用开发中,很多人第一次接触 LangChain,是因为想快速做一个“基于大模型的应用”:例如知识库问答、RAG 检索增强生…...

短波通讯:魔术6米波
制作一个用于50MHz(6米波段)的天线,是业余无线电爱好者探索这一“魔术波段”的基础。该频段天线相对短波天线更易于制作和架设,但良好的设计对捕捉稍纵即逝的远距离传播至关重要。以下是基于不同需求的天线类型、设计要点和制作指…...

层次聚类实战:从距离选择到树形切割的业务可解释路径
1. 这不是“调个sklearn就能跑”的聚类——为什么 hierarchical clustering 值得你花两小时真正搞懂Hierarchical clustering(层次聚类)这个词,听起来像教科书里一个安静的章节,不如 K-means 那样高频出现在面试题里,也…...

LLM处理半结构化数据,csv数据 :在序列化层对字段按熵分层路由——把每个低熵层一次性全局总结、把高熵 TEXT 用“质心+样例“做率最优覆盖、把寻址 α 显式落进 prompt
怎么给LLM 总结结论进行溯源 先搞清「寻址函数 α」是什么 L3 / L4 已经把 12 万条文本压成 8 类模式 + 几条原话证据。可这时候 LLM 看到的只是抽象论断: 「机型 X1C 的喷头堵塞,主要原因是耗材含水(占该类 18%)」 分析师马上会追问:“这 18% 具体是哪 5,200 条工单?给…...