文件操作与IO(3) 文件内容的读写——数据流
目录
一、流的概念
二、字节流代码演示
1、InputStream
read方法
第一个没有参数的版本:
第二个带有byte数组的版本:
第三个版本
搭配Scanner的使用
2、OutputStream
write方法
第一个版本:
第二个写入整个数组版本:
第三个版本:
三、字符流代码演示
1、Reader
read方法
2、Writer
write方法
四、三个小练习
1、查找硬盘上文件的位置
2、实现文件复制
3、在目录中搜索,但是按照文件内容的方式搜索(1和2的小结合)
一、流的概念
流是操作系统的概念,但是Java / C对其进行了封装;流类似水流,连绵不断、生生不息。
水流的特点:有100ml的水,我们可以每次接10ml,分10次接完,也可以分5ml,分20次接完,或者直接一次性100ml全部接完。
数据流的特点:类似水流,假设要读写100字节的数据,可以每次读写10字节的数据,分10次读写完,也可以每次读写5字节,分20次读写完,或者一次性读写完100字节的数据。
文件流:读写文件内容,读写文件内容在各种编程语言中,都是“固定套路”的。
1、打开文件
2、读/写文件
3、关闭文件
Java对流进行了一系列封装,提供了一组类来负责这些工作;针对这么多类,大体可以风味两种类
字节流:以字节为单位,每次最少读写一个字节。
字符流:以字符为单位,每次读写一个字符,比如 utf8 中的汉字,3个字节就是一个字符,每次最少都得读写3个字符。不能一次读写半个字符。
二、字节流代码演示
1、InputStream
从InputStream内部看,我们可以发现InputStream是抽象类,被abstract修饰,如图:
所以,不能实例化InputStream类,但我们可以创建FileInputStream对象,它是InputStream的子类,如图:

InputStream用完要记得关闭文件,可以理解成释放文件的相关资源,如图:
在进程中,PCB里面有文件描述符表,记录了当前进程都打开了哪些文件,这个文件描述符表是由数组 / 顺序表组成的,数组里面的每一个元素都代表着是一个结构体,里面包含了文件的一些属性,每打开一个文件,在文件描述符表就会被多占一个位置,而文件描述符表的资源是有限的,如果不关闭,当它被耗尽了,后续再打开文件就会失败,从而引发其他的逻辑出问题;而为啥不给文件描述符表满了就进行扩容操作?原因是这操作付出的代价很大:对于操作系统内核来说,要求的性能是很高的,内核任务也很重,而扩容本质也就是创造出新的更大规模的数组,把旧数组的数据移动到新数组中,其中工作量很大,如果进行扩容,对操作系统的来说,在内核任务很重的情况下,又要进行其他任务,就可能会导致操作系统卡顿现象,如果发生这种情况,就得不偿失了。
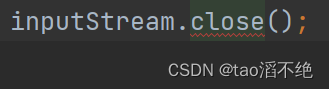
使用finally代码:
public class IODemo1 {public static void main(String[] args) throws IOException {InputStream inputStream = null;try {inputStream = new FileInputStream("./test.txt");} catch (FileNotFoundException e) {throw new RuntimeException(e);}finally {inputStream.close();}}
}可以看到把inputStream放在try代码块外,其中因为finally最后要得到InputStream引用,要将其设为全局变量才能调用close方法;如果在try内代码块new对象,就是局部变量了,finally里找不到有inputStream的引用。
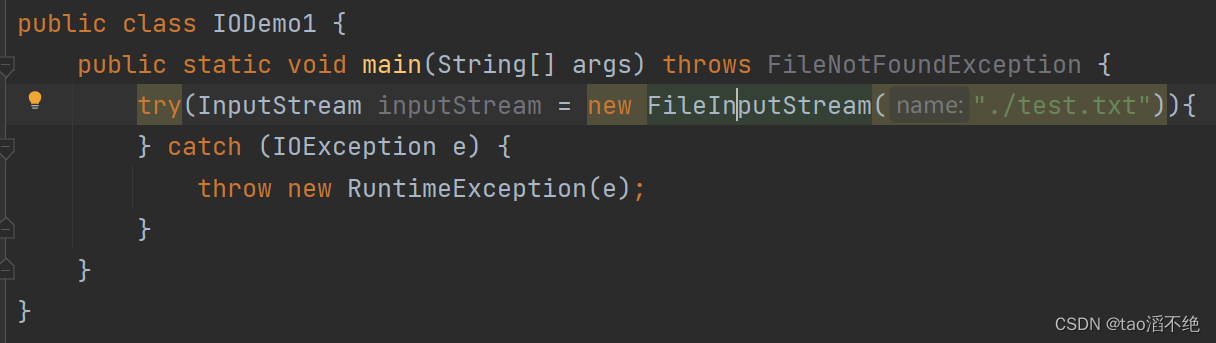
在java中,所以我们可以使用finally,但try还提供了另一个版本:try with resources,用法如下:
public class IODemo1 {public static void main(String[] args) throws FileNotFoundException {try(InputStream inputStream = new FileInputStream("./test.txt")){} catch (IOException e) {throw new RuntimeException(e);}}
}也是和finally作用一样,无论咋样,都会执行InputStream.close。其中创建FileInputStream可能会有FileNotFoundException异常,因为IOException是FileNotFoundException的父类,所以可以直接像上面那样写,不用像下面这样写

read方法
read有三个不同参数的版本,如图:

第一个没有参数的版本:
每次只读一个字节,并且有返回值,上面显示的是int类型,其实是byte类型,返回的值是读到的该字节的值,范围是0~255,还有一个特殊的情况,如果返回值是-1,则说明读取到文本的末尾了,没有其他内容了。
以下是代码案例:
public class IODemo2 {public static void main(String[] args) {try(InputStream inputStream = new FileInputStream("./test.txt")) {while (true) {int n = inputStream.read();if(n == -1) {break;}System.out.printf("%x ", n);}} catch (IOException e) {throw new RuntimeException(e);}}
}test.txt的内容是abcdef,如图
代码运行结果如下:

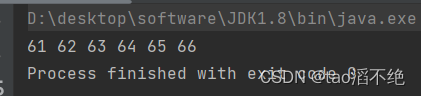
而abcdef的ascll表16进制分别是以上结果。
第二个带有byte数组的版本:

如图,该数组是 “输出型参数”,byte[] 是引用类型,在方法内对数组进行修改,方法结束后,在方法外部仍然生效,本质是看针对 “引用类型修改”,还是针对 “解引用修改对象本体”。
以下是代码演示:
public class IODemo1 {public static void main(String[] args) {try(InputStream inputStream = new FileInputStream("./test.txt")){byte[] buffer = new byte[1024];while (true) {int n = inputStream.read(buffer);if(n == -1) {break;}for (int i = 0; i < n; i++) {System.out.printf("%x ", buffer[i]);}}}catch (IOException e) {throw new RuntimeException(e);}}
}上面代码是按照若干个字节读,而不是一个一个字节读,效率比第一个版本强,因为读文件本质是读硬盘,这个操作是比较耗时的,如果我们读若干个字节,放在内存了,然后要显示出来其内容的时候,是直接在内存访问已经读的若干个字节,要比读硬盘快。
而返回值是读了多少个字节,它读的时候,会尽可能把数组填满,但实际情况可能填不满,那就能填多少是多少。
执行结果如下:

如果我们想显示中文字符,如果像上面那样读,会读出中文字符的 utf8 的16进制值,要怎么搞,以下是代码演示:
public class IODemo2 {public static void main(String[] args) {try(InputStream inputStream = new FileInputStream("./test.txt")){while (true) {byte[] buffer = new byte[1024];int n = inputStream.read(buffer);if (n == -1) {break;}String s = new String(buffer, 0, n);System.out.print(s);}} catch (IOException e) {throw new RuntimeException(e);}}
}
执行结果如下:


第三个版本
是写数组的一部分,其中off是偏移量,而不是开 关,如图:

搭配Scanner的使用
我们想读文件的内容,也可以使用Scanner搭配InputStream使用。
Scanner(System.in),括号里面我们肯定都不陌生,这里的System.in本质就是InputStream,我们可以把System.in换成InputStream,下面是代码演示:
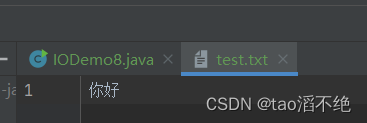
public class IODemo8 {public static void main(String[] args) {try(InputStream inputStream = new FileInputStream("./test.txt")) {Scanner scanner = new Scanner(inputStream);while (scanner.hasNext()) {String s = scanner.next();System.out.println(s);}} catch (IOException e) {throw new RuntimeException(e);}}
}执行结果:

2、OutputStream
write方法
如图,下面是三个不同参数版本
第一个版本是一次写一个字节,第二个版本是一次写整个数组,第三个版本是写数组的一部分,它们的返回值都是void,返回空。
第一个版本:
代码如下:
public class IODemo4 {public static void main(String[] args) {try(OutputStream outputStream = new FileOutputStream("./test.txt")) {outputStream.write(97);outputStream.write(98);outputStream.write(99);} catch (IOException e) {throw new RuntimeException(e);}}
}
执行结果: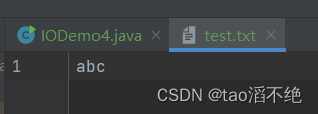
因为一次写一个字节,97 98 99是abc的ASCII值,会把原来文件的内容删除,重新写入新的内容。
注意:就算没有调用write方法,执行代码后,也会删除指定文件的内容,除非创建FileOutputStream是,参数加true,才能追加写,如图:
执行下面代码:
public class IODemo4 {public static void main(String[] args) {try(OutputStream outputStream = new FileOutputStream("./test.txt", true)) {outputStream.write(97);outputStream.write(98);outputStream.write(99);} catch (IOException e) {throw new RuntimeException(e);}}
}结果如下:

之前原本有的abc还在,又追加写了abc。
第二个写入整个数组版本:
代码演示:
public class IODemo5 {public static void main(String[] args) {try(OutputStream outputStream = new FileOutputStream("./test.txt")) {byte[] buffer = {97, 98, 99, 100, 101, 102};outputStream.write(buffer);} catch (IOException e) {throw new RuntimeException(e);}}
}执行结果:
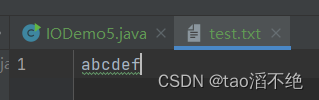
byte数组里面放的元素ASCII值是abcdef,放入数组就是写入数组里的内容,也可以追加写,加个true就行了。
第三个版本:
写数组的一部分,off是偏移量,不是开关。
三、字符流代码演示
Reader和Writer的使用方法,和字节流的InputStream和OutputStream基本差不多。
1、Reader
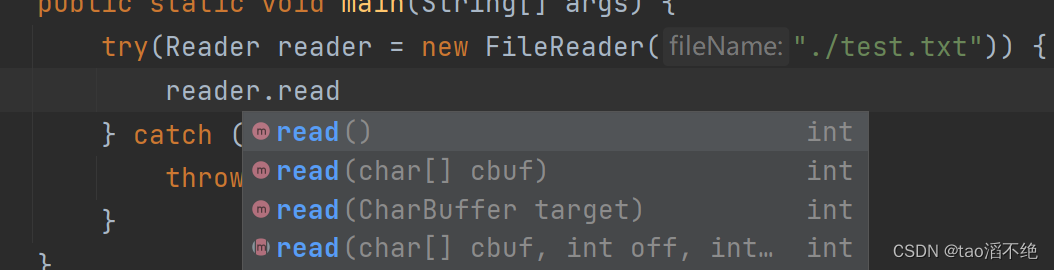
read方法
如图,下面是read方法几个不同参数的版本
和字节流读的不同,它是以char为单位进行读的,下面用带数组参数的版本演示,代码如下:
public class IODemo6 {public static void main(String[] args) {try(Reader reader = new FileReader("./test.txt")) {while (true) {char[] buffer = new char[1024];int n = reader.read(buffer);if(n == -1) {break;}String s = new String(buffer, 0, n);System.out.println(s);}} catch (IOException e) {throw new RuntimeException(e);}}
}
执行结果:

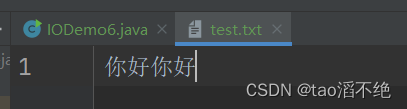
这里有个细节问题,一个char类型有2个字节,而在utf8中,一个中文字符符占3个字节,存在char数组的值怎么打印出中文字符?
原因:在read的时候,每次读到的内容都会存进数组中,存进数组时,读到的内容是按unicode的值存进数组的,当这个数组放进String的构造方法时,会把unicode的值转回utf的值,这个过程是在java内部封装好了的,我们人为感知不到。
如果我们把数组内容一个一个读出来,代码如下:
public class IODemo6 {public static void main(String[] args) {try(Reader reader = new FileReader("./test.txt")) {while (true) {char[] buffer = new char[1024];int n = reader.read(buffer);if(n == -1) {break;}
// String s = new String(buffer, 0, n);
// System.out.println(s);for(int i = 0; i < n; i++) {System.out.print(buffer[i]);System.out.print(" ");}}} catch (IOException e) {throw new RuntimeException(e);}}
}执行结果:
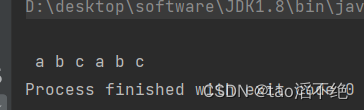
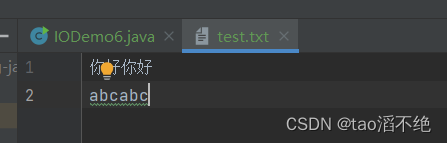
“你好你好”这一行就打印不出来了。
2、Writer
write方法
如果要追加写,就加个true
如图是write方法的几个版本:
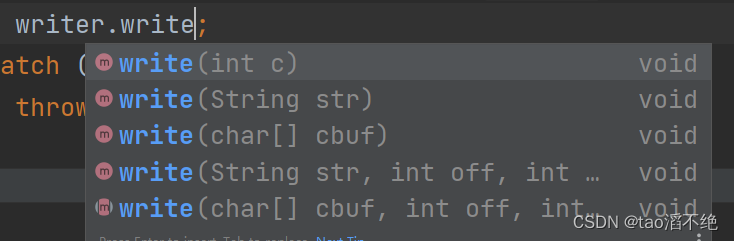
主要使用带有String参数的版本,构造一个字符串,直接把字符串作为参数放进write方法中就可以写入那个字符串进文件中。以下是代码演示:
public class IODemo7 {public static void main(String[] args) {try(Writer writer = new FileWriter("./test.txt")) {String s = "你好";writer.write(s);} catch (IOException e) {throw new RuntimeException(e);}}
}执行结果:把你好写进文件中了。
四、三个小练习
以下是文件路径相关信息

这里需要使用到递归,是遍历一遍树,也就是所有的文件都要遍历一遍,看是否符合要求,这里不存在前中后遍历的情况,因为该树是N叉树。
1、查找硬盘上文件的位置
要求:给定一个文件名,去指定的目录中进行搜索,找到文件名匹配的结果,并打印出完整的路径。
代码演示:
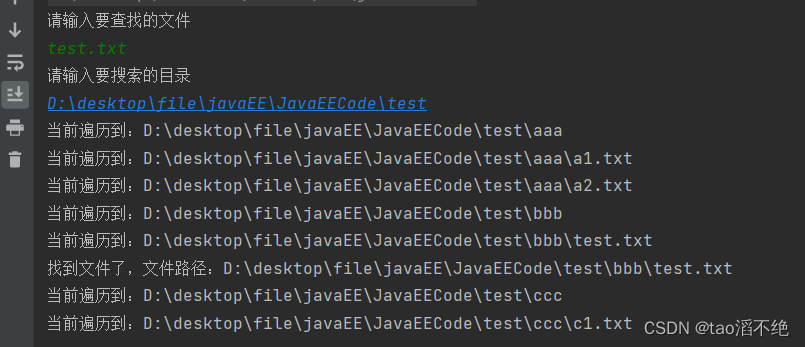
//D:/desktop/file/javaEE/JavaEECode/test
public class IODemo9 {public static void main(String[] args) {//1、输入必要信息Scanner scanner = new Scanner(System.in);System.out.println("请输入要查找的文件");String fileName = scanner.next();System.out.println("请输入要搜索的目录");String rootPath = scanner.next();File file = new File(rootPath);//判断输入的目录是否合法if(!file.isDirectory()) {//不是目录System.out.println("输入的目录不合法");return;}//2、在目录下找我们给定文件名,看是否存在,使用递归的方式进行搜索scanDir(file, fileName);//知道递归的起点,还需要知道要查询的文件名}private static void scanDir(File rootFile, String fileName) {//1、把所有子目录都列出来File[] files = rootFile.listFiles();//递归结束条件if(files == null) {//空目录,直接返回return;}//2、遍历files,判断每一个file文件是目录还是文件for(File f : files) {//记录日志System.out.println("当前遍历到:" + f.getAbsolutePath());//1、文件,判断文件名是不是要查找的文件名if(f.isFile()) {String name = f.getName();if(fileName.equals(name)) {System.out.println("找到文件了,文件路径:" + f.getAbsolutePath());}} else if(f.isDirectory()) {//2、目录,继续往下递归scanDir(f, fileName);} else {// 这个 else 暂时不需要}}}
}
执行结果:
2、实现文件复制
要求:把一个文件复制一下,成为另一个文件。
意思就是把第一个文件以读方式打开,依次读取这里的每个字节,再读到的内容,写入到另一个文件中。
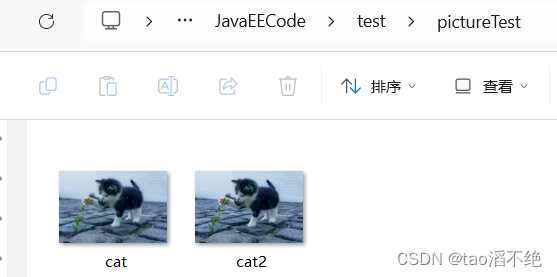
现有的文件:

复制cat.jpg文件,到cat2.jpg,因为没有cat2.jpg,所以执行代码后会多出cat2.jpg文件。
代码演示:
public class IODemo11 {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入要复制的源文件");String srcFileName = scanner.next();System.out.println("请输入目标文件");String desFileName = scanner.next();File srcFile = new File(srcFileName);//判断源文件的合法性if(!srcFile.isFile()) {System.out.println("文件不合法");return;}File desFile = new File(desFileName);//判断目标文件的合法性,不要求文件存在,但要求文件路径存在if(!desFile.getParentFile().isDirectory()) {System.out.println("目标路径不合法");return;}//读取要复制文件的每个字节,把读到的每个字节都放到新的文件中try(InputStream srcInputStream = new FileInputStream(srcFile);OutputStream outputStream = new FileOutputStream(desFile)) {while (true) {byte[] buffer = new byte[1024];int n = srcInputStream.read(buffer);if(n == -1) {break;}outputStream.write(buffer,0 ,n);}} catch (IOException e) {throw new RuntimeException(e);}}
}
输入内容:
执行结果:
多出了cat2.jpg文件。
3、在目录中搜索,但是按照文件内容的方式搜索(1和2的小结合)
用户输入一个目录,一个要搜索的词,遍历文件的过程中,如果文件包含了要搜索的词,此时就把文件的路径打印出来。
代码演示:
public class IODemo13 {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入要搜索的词");String word = scanner.nextLine();System.out.println("请输入要搜索的路径");String rootPath = scanner.nextLine();File rootFile = new File(rootPath);//判断搜素路径是否合法if(!rootFile.isDirectory()) {System.out.println("输入的搜素路径不合法");return;}//遍历每一个文件,如果是普通文件,就判断文件内容里面有没有我们要搜索的词scanDir(rootFile, word);}private static void scanDir(File rootFile, String word) {//把当前目录都列出来File[] files = rootFile.listFiles();if(files == null) {return;}for(File f : files) {System.out.println("当前遍历到: " + f.getAbsolutePath());//是普通文件,判断文件内容里面有没有我们要搜索的词if(f.isFile()) {//把文件内容一个字节一个字节的读出来,构成字符串,在判断字符串里面有没有要搜索的词searchInFile(f, word);} else if(f.isDirectory()) {//是目录,继续递归scanDir(f, word);} else {//这个不需要处理}}}private static void searchInFile(File f, String word) {try(InputStream inputStream = new FileInputStream(f)) {StringBuilder stringBuilder = new StringBuilder();while (true) {byte[] buffer = new byte[1024];int n = inputStream.read(buffer);if(n == -1) {break;}String s = new String(buffer, 0, n);stringBuilder.append(s);}//System.out.println("日志,当前读到文本的内容:" + stringBuilder);if(stringBuilder.indexOf(word) == -1) {//没有找到,直接return走return;}//文本内容存在要搜索的单词,打印出路径System.out.println("该文本存在要搜索的单词:" + word +" 存在于:" + f.getAbsolutePath());} catch (IOException e) {throw new RuntimeException(e);}}
}
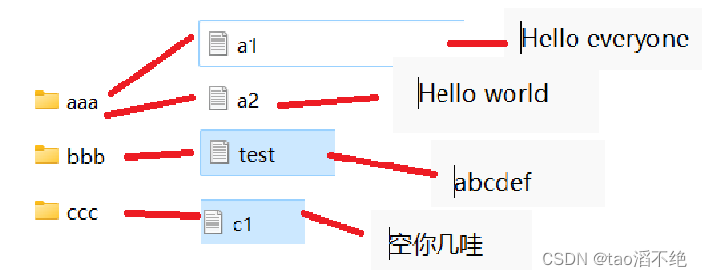
文件内容如下:
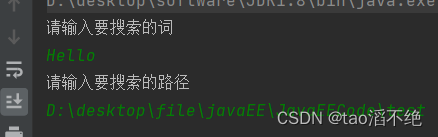
代码输入如下:
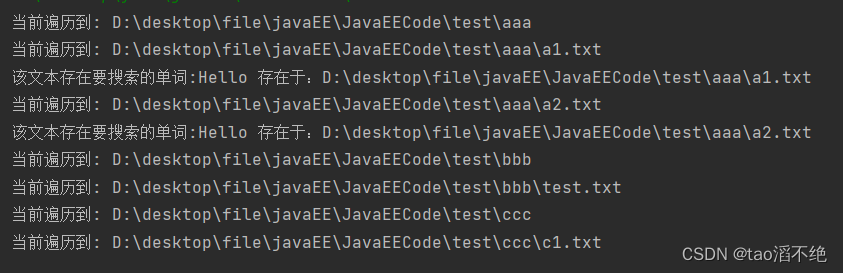
执行结果:
都看到这了,点个赞再走吧,谢谢谢谢谢
相关文章:
文件操作与IO(3) 文件内容的读写——数据流
目录 一、流的概念 二、字节流代码演示 1、InputStream read方法 第一个没有参数的版本: 第二个带有byte数组的版本: 第三个版本 搭配Scanner的使用 2、OutputStream write方法 第一个版本: 第二个写入整个数组版本: …...
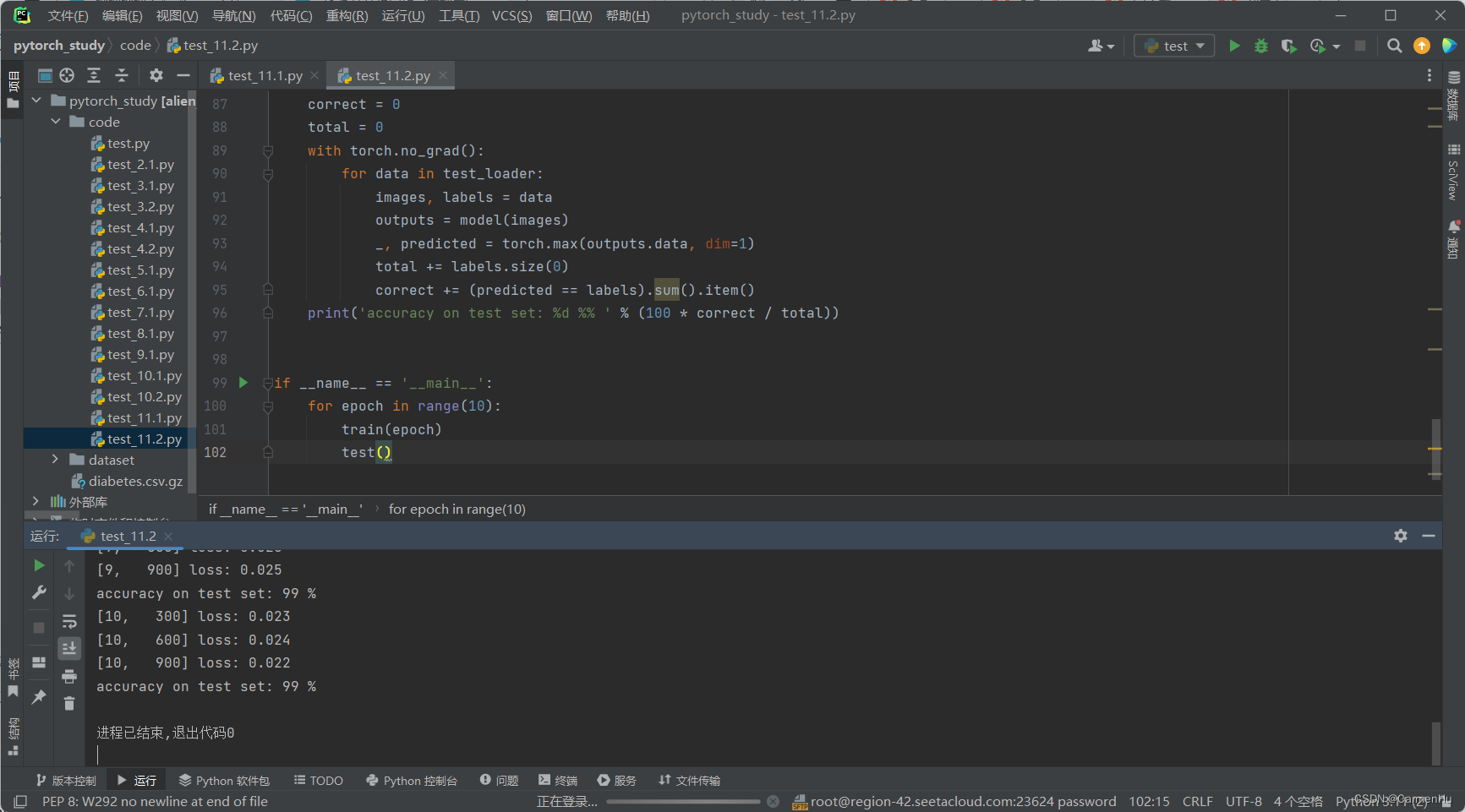
《PyTorch深度学习实践》第十一讲卷积神经网络进阶
一、 1、卷积核超参数选择困难,自动找到卷积的最佳组合。 2、1x1卷积核,不同通道的信息融合。使用1x1卷积核虽然参数量增加了,但是能够显著的降低计算量(operations) 3、Inception Moudel由4个分支组成,要分清哪些是在Init里定义…...

Ansible的playbook的编写和解析
目录 什么是playbook Ansible 的脚本 --- playbook 剧本 实例部署(使用playbook安装启动httpd服务) 1.编写一个.yaml文件 在主机下载安装http,将配置文件复制到opt目录下 运行playbook 在192.168.17.77主机上查看httpd服务是否成功开启…...

[环境配置]ssh连接报错“kex_exchange_identification: read: Connection reset by peer”
已经被VScode ssh毒死好几次了,都是执行命令意外中断,然后又VSCode里连不上、本机Terminal也连不上了。。。 重启远程服务器,VSCode可以连上了, 系统ssh还是不行,报错“kex_exchange_identification: read: Connecti…...
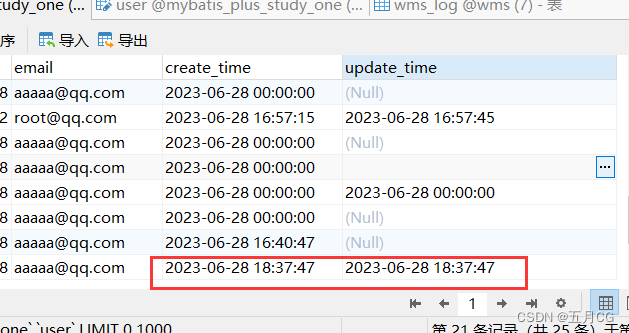
Mybatis-Plus——04,自动填充时间(新注解)
自动填充(新注解) 一、数据库添加两个字段二、实体类字段属性上增加注解三、编写填充器四、查看结果4.1 插入结果4.2 修改结果 五、同步修改5.1实体类属性改成 INSERT_UPDATE5.2 在填充器的方法这里加上 updateTime5.3 查看结果————————创作不易…...

【动态规划入门】最长上升子序列
每日一道算法题之最长上升子序列 一、题目描述二、思路三、C代码 一、题目描述 题目来源:LeetCode 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 输入格式 第一行包含整数 N。 第二行包含 N个整数,表示完整序列。 输出格式 输出一个整数…...
LabVIEW眼结膜微血管采集管理系统
LabVIEW眼结膜微血管采集管理系统 开发一套基于LabVIEW的全自动眼结膜微血管采集管理系统,以提高眼结膜微血管临床研究的效率。系统集成了自动化图像采集、图像质量优化和规范化数据管理等功能,有效缩短了图像采集时间,提高了图像质量&#…...
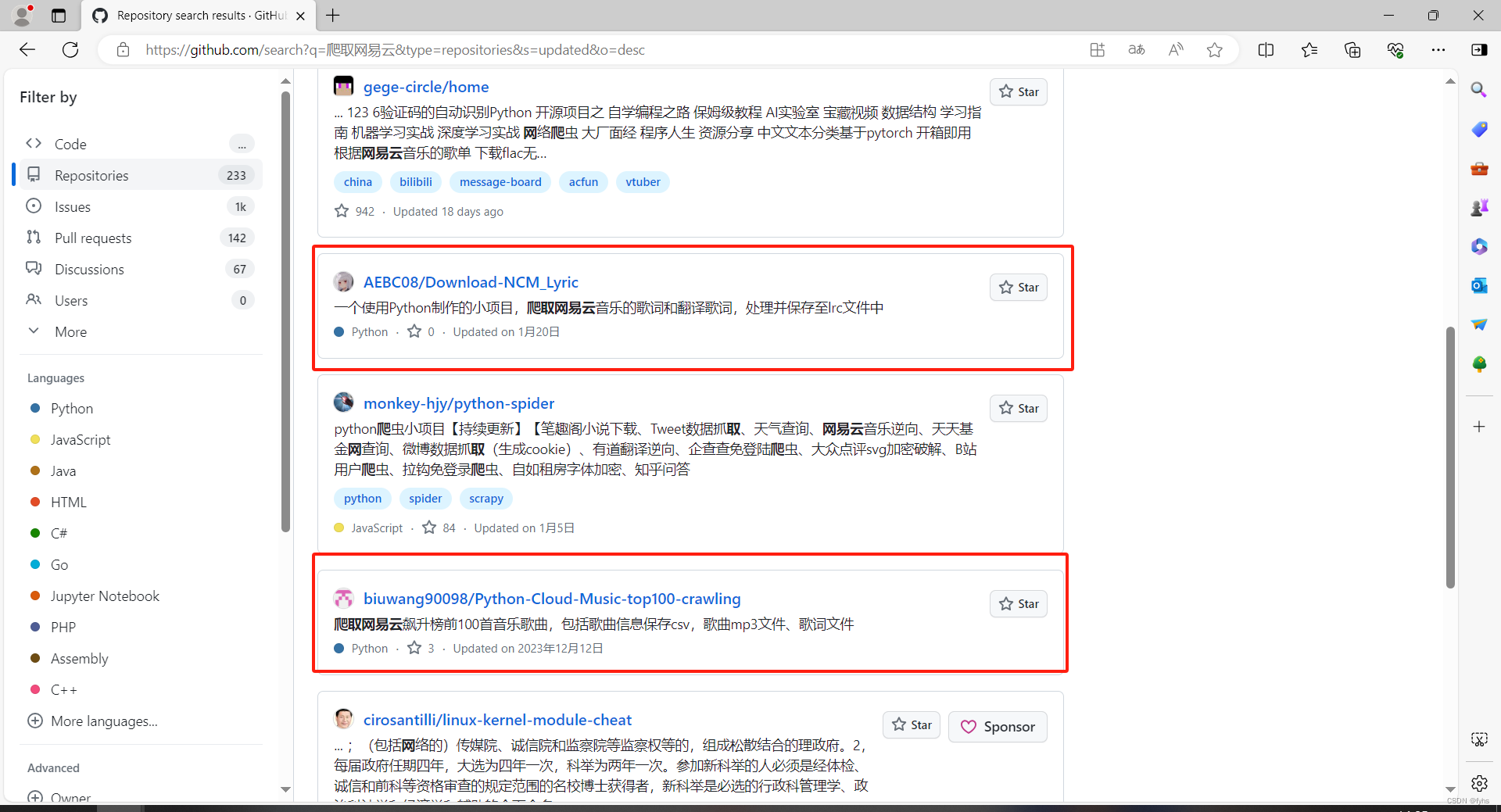
通过GitHub探索Python爬虫技术
1.检索爬取内容案例。 2.找到最近更新的。(最新一般都可以直接运行) 3.选择适合自己的项目,目前测试下面画红圈的是可行的。 4.方便大家查看就把代码粘贴出来了。 #图中画圈一代码 import requests import os import rewhile True:music_id input("请输入歌曲…...
【Python】-----基础知识
注释 定义:让计算机跳过这个代码执行用三个单引号/双引号都表示注释信息,在Python中单引号与双引号没有区别,但必须是成对出现 输出与输入 程序是有开始,有结束的,程序运行规则:从上而下,由内…...
:点云处理相关开源算法库、软件、工具)
如何学习、上手点云算法(二):点云处理相关开源算法库、软件、工具
写在前面 本文内容 一些用于点云处理的开源算法库、软件介绍,主要包含: CloudCompare, MeshLab, PCL, Open3D, VTK, CGAL等 不定时更新 平台/环境 Windows10, Ubuntu1804, CMake, Open3D, PCL 转载请注明出处: https://blog.csdn.net/qq_41…...

为什么会对猫毛过敏?如何缓解?浮毛克星—宠物空气净化器推荐
猫咪过敏通常是因为它们身上的Fel d1蛋白质导致的,这些蛋白质附着在猫咪的皮屑上。猫咪舔毛的过程会带出这些蛋白质,一旦接触就可能引发过敏症状,比如打喷嚏等。因此,减少空气中的浮毛数量有助于减轻过敏现象。猫用空气净化器可以…...

Linux学习-etcdctl安装
etcdctl3.5下载链接 1. 先通过上面链接下载gz包2. 解压 [rootk8s-master ~]# tar xf etcd-v3.5.11-linux-amd64.tar.gz [rootk8s-master etcd-v3.5.11-linux-amd64]# ls Documentation etcd etcdctl etcdutl README-etcdctl.md README-etcdutl.md README.md READMEv2-e…...

Qt应用软件【文件篇】读写文件技巧
文章目录 简介按照偏移读文件按照偏移写文件Qt按行写文件Qt按行读文件注意事项指定文件编码格式UTF8转GBK简介 Qt提供了丰富的API来处理文件读写操作,使得读写文件变得简单。 按照偏移读文件 QFile file("example.txt"); if (file.open(QIODevice::ReadOnly)) {q…...

GO常量指针
Go语言中的常量使用关键字const定义,用于存储不会改变的数据,常量是在编译时被创建的,即使定义在函数内部也是如此,并且只能是布尔型、数字型(整数型、浮点型和复数)和字符串型。 由于编译时的限制&#x…...
微服务间通信重构与服务治理笔记
父工程 依赖版本管理,但实际不引入依赖 pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation&…...
unity 场景烘焙中植物叶片(单面网络)出现的白面
Unity版本 2021.3.3 平台 Windows 在场景烘焙中烘焙植物的模型的时候发现植物的叶面一面是合理的,背面是全白的,在材质球上勾选了双面烘焙,情况如下 这个问题可能是由于植物叶片的单面网格导致的。在场景烘焙中,单面网格只会在一…...

网工内推 | 国企运维,年薪最高30W,RHCE认证优先
01 上海华力微电子有限公司 招聘岗位:系统运维资深/主任工程师 职责描述: 1、负责IT基础设施(包括服务器、存储、中间件等系统基础技术平台)的设计建设和日常运维管理; 2、负责生产、开发和测试环境的技术支持&#x…...

WordPress排除调用某个分类下的文章
wordpress在调用分类下文章时,有时需要排除调用某个分类的文章,下面的这段代码,就可以轻松实现不调用特定ID的分类内容。 <?phpquery_posts("showposts10&cat-1"); //cat-1为排除ID为1的分类下文章while(have_posts()) : …...
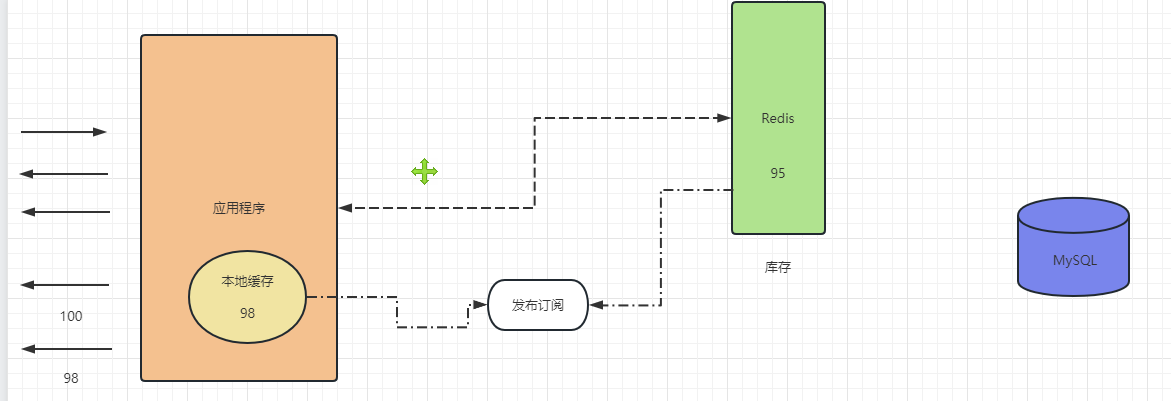
Java多线程——信号量Semaphore是啥
目录 引出信号量Semaphore ?Redis冲冲冲——缓存三兄弟:缓存击穿、穿透、雪崩缓存击穿缓存穿透缓存雪崩 总结 引出 Java多线程——信号量Semaphore是啥 信号量Semaphore ? Semaphore 通常我们叫它信号量, 可以用来控制同时访问特…...
. 将字符串中的元音字母排序)
L2785(Java). 将字符串中的元音字母排序
题目 1.如何以char类型便利字符串 2.自定义优先队列解决 class Solution {public String sortVowels(String s) {Map<Character,Integer> m new HashMap<>();m.put(a,1);m.put(e,1);m.put(i,1);m.put(o,1);m.put(u,1);m.put(A,1);m.put(E,1);m.put(I,1);m.put(O,…...
)
从零开始学AI Agent:软件工程视角下的企业数字化转型实践指南(收藏版)
本文从软件工程视角出发,探讨了AI Agent在企业数字化转型中的应用与构建。首先强调需求分析的重要性,指出应从业务问题出发判断Agent是否适用。接着,介绍了Agent的系统设计,包括任务编排、上下文管理、记忆存储和工具扩展四个核心…...

专业级图片去重神器:彻底告别重复照片的数字困扰
专业级图片去重神器:彻底告别重复照片的数字困扰 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾经花费数小时手动整理电脑中堆积如山的重复照片&a…...

如何彻底解决游戏键盘冲突:Hitboxer SOCD Cleaner完整指南
如何彻底解决游戏键盘冲突:Hitboxer SOCD Cleaner完整指南 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对战中遇到过这样的困扰?同时按下W和S键时角色突然卡顿&…...

NVIDIA突破:单显卡实现图片驱动720p长视频世界模型生成能力提升
这项由NVIDIA研究团队主导的研究成果于2026年5月以预印本形式发布,论文编号为arXiv:2605.15178,感兴趣的读者可通过该编号查阅完整原文。给你一张照片,再给你一条摄像机的移动路线,然后电脑自动生成一段完整的一分钟高清视频&…...
:12个被官方文档刻意隐藏的--stylize与--chaos协同公式)
Midjourney阿盖洛印相实战手册(从暗房哲学到AI指令映射):12个被官方文档刻意隐藏的--stylize与--chaos协同公式
更多请点击: https://codechina.net 第一章:Midjourney阿盖洛印相的暗房哲学溯源 阿盖洛印相(Argyrotype)作为19世纪末由William Willis发明的铁银工艺变体,以硝酸银与有机银络合物在明胶或纤维素基质中光解还原为核心…...

终极SPT-AKI存档编辑器:如何轻松掌控你的逃离塔科夫离线游戏进度
终极SPT-AKI存档编辑器:如何轻松掌控你的逃离塔科夫离线游戏进度 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh…...

通过Python快速调用Taotoken实现自动化文档生成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Python快速调用Taotoken实现自动化文档生成 对于嵌入式或单片机开发者而言,为Keil5项目编写和维护技术文档是一项耗…...

会计学论文降AI工具怎么选?财务审计方向高效降重指南
又到了毕业答辩的关键期,不少会计专业的同学都在发愁论文AI率不达标:财务分析部分的数据解读、审计研究的案例推导用AI辅助写完,一检测全是高风险,改了好几遍还是过不了学校的审核。我身边不少师弟师妹踩过工具的坑,要…...

ZYNQ启动全解析:从BootROM到你的App,SD卡与QSPI Flash烧录究竟差在哪?
ZYNQ启动全解析:从BootROM到你的App,SD卡与QSPI Flash烧录究竟差在哪? 当一块ZYNQ开发板静静躺在桌面上,按下电源键的瞬间,芯片内部究竟发生了什么?为什么有的工程师选择SD卡启动,而另一些则坚…...

在nodejs后端服务中集成taotoken调用多模型ai能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用多模型AI能力 基础教程类,面向使用Node.js构建Web服务或应用的后端开发者&#x…...