大数据技术学习笔记(五)—— MapReduce(2)
目录
- 1 MapReduce 的数据流
- 1.1 数据流走向
- 1.2 InputFormat 数据输入
- 1.2.1 FileInputFormat 切片源码、机制
- 1.2.2 TextInputFormat 读数据源码、机制
- 1.2.3 CombineTextInputFormat 切片机制
- 1.3 OutputFormat 数据输出
- 1.3.1 OutputFormat 实现类
- 1.3.2 自定义 OutputFormat
- 2 MapReduce 框架原理
- 2.1 MapTask 工作机制
- 2.2 ReduceTask 工作机制
- 2.3 MapTask 并行度决定机制
- 2.4 ReduceTask 并行度决定机制
- 2.5 Shuffle 机制
- 2.5.1 Shuffle 机制流程
- 2.5.2 Paratition 分区
- 2.5.3 WritableComparable 排序
- 2.5.4 Combiner 合并
- 2.6 MapReduce 工作流程
- 3 Join 应用
- 3.1 Reduce Join
- 3.2 Map Join
1 MapReduce 的数据流
1.1 数据流走向
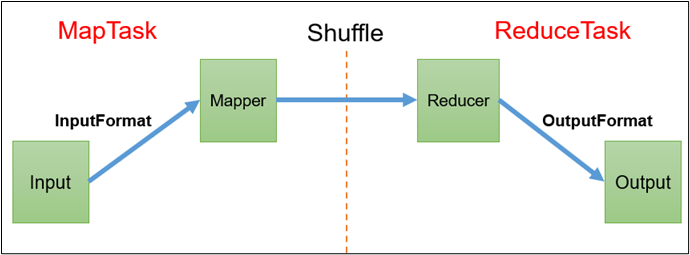
查看 MapTask 源码中的 run()方法
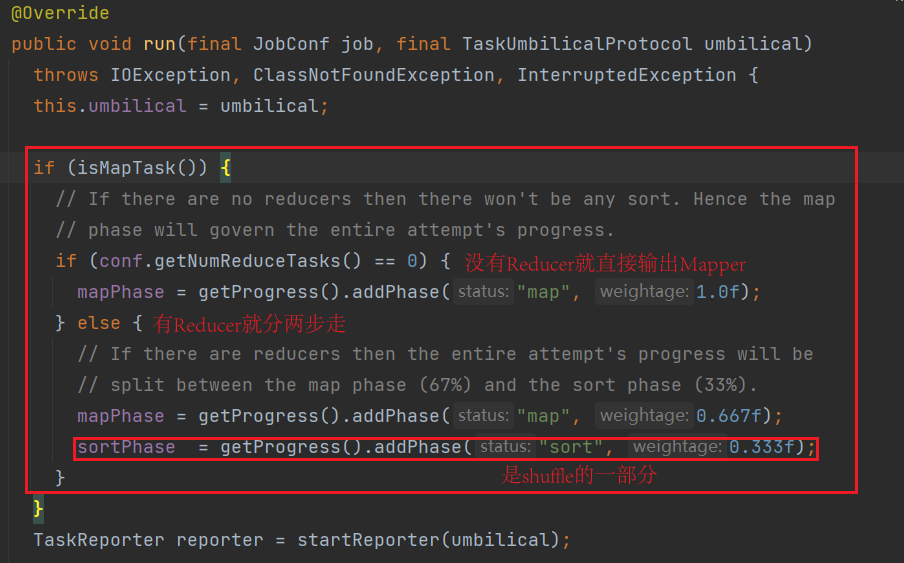
查看 ReduceTask 源码中的 run()
1.2 InputFormat 数据输入
InputFormat的体系结构
-
FileInputFormat:InputFormat的子实现类,重写了抽象方法getSplits(),实现切片逻辑-
TextInputFormat:FileInputFormat的子实现类,重写了抽象方法createRecordReader(), 实现读取数据的逻辑 -
CombineFileInputFormat:FileInputFormat的子实现类,此类中也实现了一套切片逻辑 (适用于小文件计算场景)
-
1.2.1 FileInputFormat 切片源码、机制
FileInputFormat.java 是InputFormat.java的实现类,该文件中中重写了抽象方法 getSplits(),实现切片逻辑
看源码时,通过ctrl+点击进入某些方法的具体实现,有时源码位置的跳跃性很大, IDEA中可以
CTRL+ALT,然后通过键盘中的左右箭头,实现源码中定位的来回切换
public List<InputSplit> getSplits(JobContext job) throws IOException {// 计时器(开始)StopWatch sw = new StopWatch().start();// getFormatMinSplitSize()返回1// getMinSplitSize(job),配置文件中的配置(默认配置为0),可以通过修改mapreduce.input.fileinputformat.split.minsize配置项来改变minSize的大小// 故minSize默认返回为1long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));// hadoop中默认没有配置mapreduce.input.fileinputformat.split.maxsize,// 故maxSize默认为Long类型的最大值long maxSize = getMaxSplitSize(job);// 管理最终切完片的对象的集合,最终返回的就是此集合List<InputSplit> splits = new ArrayList<InputSplit>();// 获取当前文件的详情List<FileStatus> files = listStatus(job);boolean ignoreDirs = !getInputDirRecursive(job)&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);//遍历获取到的文件列表,依次以文件为单位进行切片for (FileStatus file: files) {// 如果是忽略文件以及是文件夹,就不进行切片if (ignoreDirs && file.isDirectory()) {continue;}// 获取文件的当前路径Path path = file.getPath();// 获取文件的大小long length = file.getLen();// 如果不是空文件if (length != 0) {// 获取文件的具体的块信息BlockLocation[] blkLocations;if (file instanceof LocatedFileStatus) {blkLocations = ((LocatedFileStatus) file).getBlockLocations();} else {FileSystem fs = path.getFileSystem(job.getConfiguration());blkLocations = fs.getFileBlockLocations(file, 0, length);}// 判断是否要进行切片(主要判断当前文件是否是压缩文件,有一些压缩文件时不能够进行切片)if (isSplitable(job, path)) {// 获取hdfs中数据块的大小long blockSize = file.getBlockSize();// 计算切片的大小--> 128M 默认情况下永远都是块大小long splitSize = computeSplitSize(blockSize, minSize, maxSize);// 内部方法// protected long computeSplitSize(long blockSize, long minSize,// long maxSize) {// return Math.max(minSize, Math.min(maxSize, blockSize));// }// 判断当前的文件的剩余内容是否要继续切片 SPLIT_SLOP = 1.1// 判断公式:bytesRemaining)/splitSize > SPLIT_SLOP// 用文件的剩余大小/切片大小 > 1.1 才继续切片(这样做的目的是为了让我们每一个MapTask处理的数据更加均衡)long bytesRemaining = length;while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);splits.add(makeSplit(path, length-bytesRemaining, splitSize,blkLocations[blkIndex].getHosts(),blkLocations[blkIndex].getCachedHosts()));bytesRemaining -= splitSize;}// 如果最后文件还有剩余且不足一个切片大小,最后再形成最后的一个切片if (bytesRemaining != 0) {int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,blkLocations[blkIndex].getHosts(),blkLocations[blkIndex].getCachedHosts()));}} else { // not splitableif (LOG.isDebugEnabled()) {// Log only if the file is big enough to be splittedif (length > Math.min(file.getBlockSize(), minSize)) {LOG.debug("File is not splittable so no parallelization "+ "is possible: " + file.getPath());}}splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),blkLocations[0].getCachedHosts()));}} else { //Create empty hosts array for zero length filessplits.add(makeSplit(path, 0, length, new String[0]));}}// Save the number of input files for metrics/loadgenjob.getConfiguration().setLong(NUM_INPUT_FILES, files.size());sw.stop();if (LOG.isDebugEnabled()) {LOG.debug("Total # of splits generated by getSplits: " + splits.size()+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));}return splits;}
Math.max(minSize, Math.min(maxSize, blockSize));
maxsize,切片最大值,参数如果比blockSize小,则会让切片变小,而且就等于这个配置的这个参数的值minsize,切片最小值,参数如果比blockSize大,则可以让切片的大小比blockSize还要大
1.2.2 TextInputFormat 读数据源码、机制
TextInputFormat.java 是FileInputFormat.java 的实现类,该文件中重写了抽象方法 createRecordReader(),实现读取数据的逻辑。
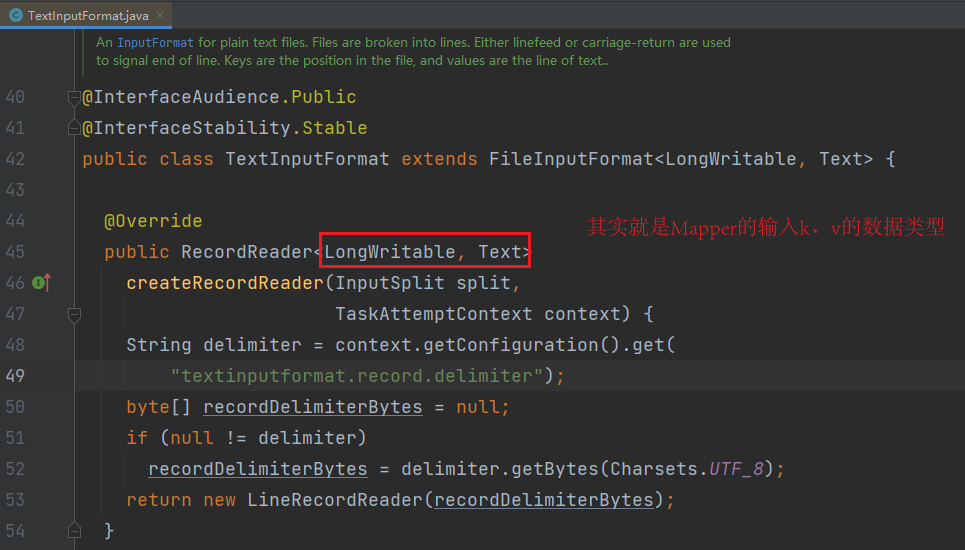
按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量,LongWritable类型;值是这行的内容,不包括任何行终止符(换行符、回车符),Text类型。

1.2.3 CombineTextInputFormat 切片机制
框架默认的 TextInputFormat 切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个 MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
CombineTextInputFormat.java 也是 FileInputFormat.java 的实现类
- 适用场景
- 用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个
MapTask处理。
- 用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个
- 虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4M- 虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
- 切片机制
- 生成切片过程包括:虚拟存储过程和切片过程两部分

(1)虚拟存储过程
将输入目录下所有文件大小,依次和设置的 setMaxInputSplitSize 值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如
setMaxInputSplitSize值为4M,输入文件大小为 8.02M,则先逻辑上分成一个
4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现 0.02M 的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
(2)切片过程
a. 判断虚拟存储的文件大小是否大于 setMaxInputSplitSize 值,大于 则单独形成一个切片。
b. 如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
c. 测试举例:有4个小文件大小分别为 1.7M、5.1M、3.4M 以及 6.8M 这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
(3)案例实操
将输入的大量小文件合并成一个切片统一处理。
准备4个小文件

a. 不做任何处理,运行前面的 WordCount 案例程序,观察切片个数为 4 。
b. 在WordcountDriver.java中增加如下代码,运行程序,并观察运行的切片个数为 3。
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);//虚拟存储切片最大值设置4M
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
c. 在 WordcountDriver.java 中增加如下代码,运行程序,并观察运行的切片个数为 1
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);//虚拟存储切片最大值设置20M
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
1.3 OutputFormat 数据输出
1.3.1 OutputFormat 实现类
OutputFormat 是 MapReduce 输出的基类,所有 MapReduce 输出都实现了 OutputFormat 接口,以下是几种常见的OutputFormat 实现类。
- TextOutputFormat :是默认的输出格式,它把每条记录写为文本行,它的键和值可以是任意类型,因为TextOutputFormat 可以调用 toString() 方法把它们转为字符串。
- SequenceOutputFormat :将 SequenceOutputFormat 的输出作为后续 MapReduce的输入,这便是一种好的输出格式。因为它的它的格式紧凑,很容易被压缩。
- 自定义OutputFormat :根据用户的需求,自定义输出格式。
OutputFormat 是 FileOutputFormat 的父类,FileOutputFormat 又是 TextOutputFormat 的父类。
1.3.2 自定义 OutputFormat
(1) 需求
过滤输入的 log 日志,包含atguigu的网站输出到 atguigu.log,不包含 atguigu 的网站输出到 other.log。

log.txt
http://www.baidu.com
http://www.google.com
http://cn.bing.com
http://www.atguigu.com
http://www.sohu.com
http://www.sina.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
(2)代码编写
LogMapper.java
package com.huwei.mr.outputformat;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> {@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {// 直接写出context.write(value, NullWritable.get());}
}
LogReducer.java
package com.huwei.mr.outputformat;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class LogReducer extends Reducer<Text, NullWritable, Text, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {// 遍历直接写出for (NullWritable value : values) {context.write(key, NullWritable.get());}}
}
自定义 LogOutputFormat.java
package com.huwei.mr.outputformat;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
/*** 自定义的LogOutputFormat需要继承Hadoop提供的OutputFormat*/
public class LogOutputFormat extends FileOutputFormat<Text, NullWritable> {/*** 返回一个RecordWriter对象* @param job* @return* @throws IOException* @throws InterruptedException*/@Overridepublic RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {LogRecordWriter lrw = new LogRecordWriter(job);return lrw;}
}
自定义的 LogRecordWriter.java
package com.huwei.mr.outputformat;import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;import java.io.IOException;/*** 自定义的LogRecordWriter需要继承Hadoop提供的RecordWriter*/
public class LogRecordWriter extends RecordWriter<Text, NullWritable> {// 定义输出路径private String atguiguPath = "E:\\hadoop\\out\\logs\\atguigu.txt";private String otherPath = "E:\\hadoop\\out\\logs\\other.txt";private FileSystem fs;private FSDataOutputStream atguigu;private FSDataOutputStream other;/*** 初始化工作** @param job*/public LogRecordWriter(TaskAttemptContext job) throws IOException {// 获取Hadoop文件系统对象fs = FileSystem.get(job.getConfiguration());// 获取输出流atguigu = fs.create(new Path(atguiguPath));// 获取输出流other = fs.create(new Path(otherPath));}/*** 实现数据写出的逻辑** @param text* @param nullWritable* @throws IOException* @throws InterruptedException*/@Overridepublic void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {// 获取当前输入的数据String logData = text.toString();if (logData.contains("atguigu")) {atguigu.writeBytes(logData + "\n");} else {other.writeBytes(logData + "\n");}}/*** 关闭资源** @param taskAttemptContext* @throws IOException* @throws InterruptedException*/@Overridepublic void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {IOUtils.closeStream(atguigu);IOUtils.closeStream(other);}
}LogDriver.java
package com.huwei.mr.outputformat;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LogDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 声明配置对象Configuration conf = new Configuration();// 声明Job对象Job job = Job.getInstance(conf);// 指定当前Job的驱动类job.setJarByClass(LogDriver.class);// 指定当前Job的Mapperjob.setMapperClass(LogMapper.class);// 指定当前Job的Reducerjob.setReducerClass(LogReducer.class);// 指定Map端输出数据的key的类型和输出数据value的类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);// 指定最终(Reduce端)输出数据的key的类型和输出数据value的类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);// 指定自定义的 OutputFormatjob.setOutputFormatClass(LogOutputFormat.class);// 指定输入数据的路径和输出数据的路径FileInputFormat.setInputPaths(job,new Path("E:\\hadoop\\in\\log"));FileOutputFormat.setOutputPath(job,new Path("E:\\hadoop\\out\\log"));// 提交Job// 参数代表是否监控提交过程job.waitForCompletion(true);}
}如何实现OutputFormat自定义:
- 自定义一个 OutputFormat 类,继承Hadoop提供的OutputFormat,在该类中实现
getRecordWriter() ,返回一个RecordWriter- 自定义一个 RecordWriter 并且继承Hadoop提供的RecordWriter类,在该类中
重写 write() 和 close() 在这些方法中完成自定义输出。
2 MapReduce 框架原理
2.1 MapTask 工作机制
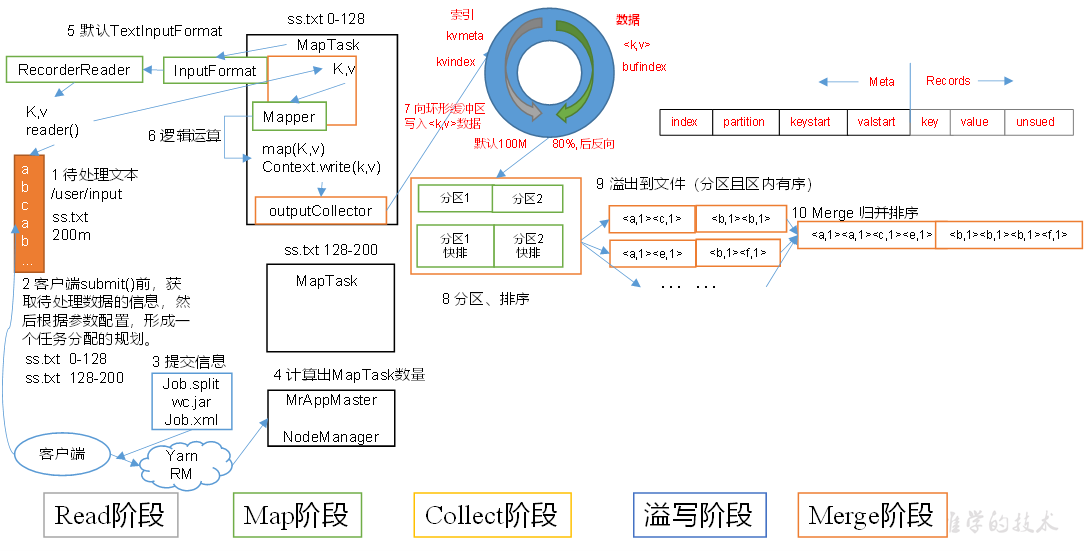
(1)Read 阶段:MapTask 通过 InputFormat 获得的 RecordReader,从输入InputSplit 中解析出一个个key/value。
(2)Map 阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的 key/value。
(3)Collect 收集阶段:在用户编写 map() 函数中,当数据处理完成后,一般会调用 OutputCollector.collect() 输出结果。在该函数内部,它会将生成的 key/value 分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill 阶段:即“溢写”,当环形缓冲区满后,MapReduce 会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:
- 步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号 Partition 进行排序,然后按照 key 进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
- 步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
- 步骤3:将分区数据的元信息写到内存索引数据结构 SpillRecord 中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件 output/spillN.out.index 中。
(5)Merge阶段:当所有数据处理完成后,MapTask 对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
当所有数据处理完后,MapTask 会将所有临时文件合并成一个大文件,并保存到文件output/file.out 中,同时生成相应的索引文件 output/file.out.index。
在进行文件合并过程中,MapTask 以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并 mapreduce.task.io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个 MapTask 最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
2.2 ReduceTask 工作机制
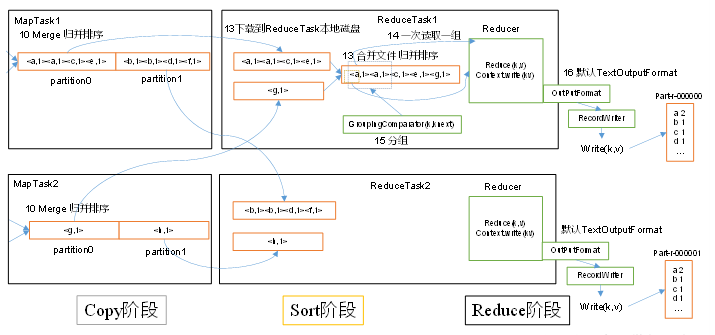
(1)Copy 阶段:ReduceTask 从各个 MapTask 上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge 阶段:在远程拷贝数据的同时,ReduceTask 启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort 阶段:按照 MapReduce 语义,用户编写 reduce() 函数输入数据是按 key 进行聚集的一组数据。为了将 key 相同的数据聚在一起,Hadoop 采用了基于排序的策略。由于各个 MapTask 已经实现对自己的处理结果进行了局部排序,因此,ReduceTask 只需对所有数据进行一次归并排序即可。
(4)Reduce 阶段:对排序后的键值对调用 reduce() 方法,键相同的键值对调用一次reduce() 方法。
(5)Write 阶段:reduce()函数将计算结果写到 HDFS上。
2.3 MapTask 并行度决定机制
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
数据块:Block是 HDFS 物理上把数据分成一块一块。数据块是 HDFS 存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是 MapReduce 程序计算输入数据的单位,一个切片会对应启动一个MapTask。
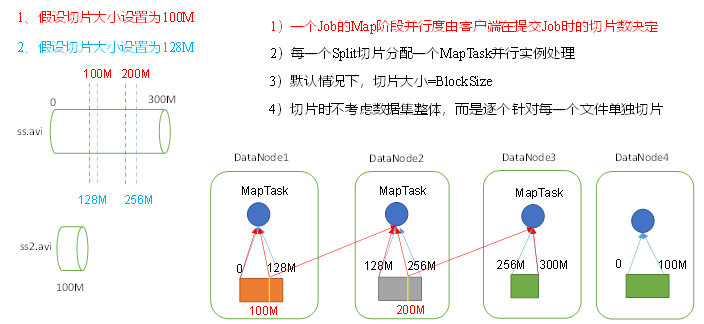
- 一个Job的Map阶段并行度(MapTask )由客户端在提交Job时的切片数决定;(一个切片就会产生一个MapTask并行处理)
- 默认情况下,
切片大小=BlockSize=128M;(这样设计的目的是为了避免将来切片读取数据的时候有跨机器读取数据 的情况,这样效率是很低的) - 切片时不考虑整体数据集,而是逐个针对每一个文件单独切片
2.4 ReduceTask 并行度决定机制
回顾:MapTask并行度由切片个数决定,切片个数由输入文件和切片规则决定。
思考:ReduceTask并行度由谁决定?
ReduceTask 的并行度同样影响整个Job的执行并发度和执行效率,但与 MapTask 的并发数由切片数决定不同,ReduceTask 数量的决定是可以直接手动设置的。
// 默认值是1,手动设置为4
job.setNumReduceTasks(4);
(1)ReduceTask = 0,表示没有 Reduce 阶段,输出文件的个数和 Map 个数一致。
(2)ReduceTask 的默认值就是1,所以输出文件的个数为1个。
(3)如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜。
(4)ReduceTask 数量不是任意设置的,还要考虑业务逻辑需求,在有些情况下,需要计算全局汇总结果,就只能有一个ReduceTask 。
(5)具体多少个ReduceTask ,需要根据集群的性能而定。
(6)如果分区数不是1,但是 ReduceTask 为1,是否执行分区过程?答案是:不执行,因为在 MapTask 的源码中,执行分区的前提是先判断 ReduceNum 是否大于1,不大于1则不执行。
2.5 Shuffle 机制
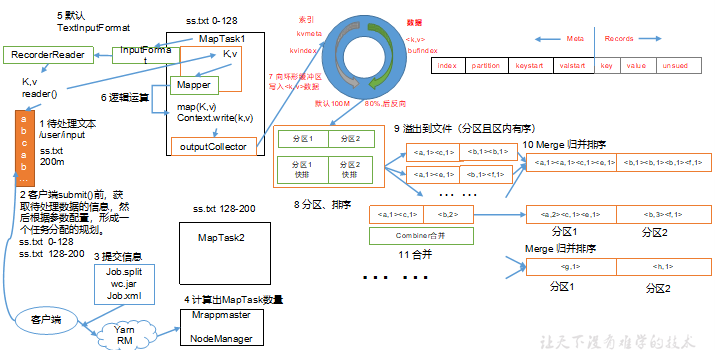
2.5.1 Shuffle 机制流程
Map 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle 。
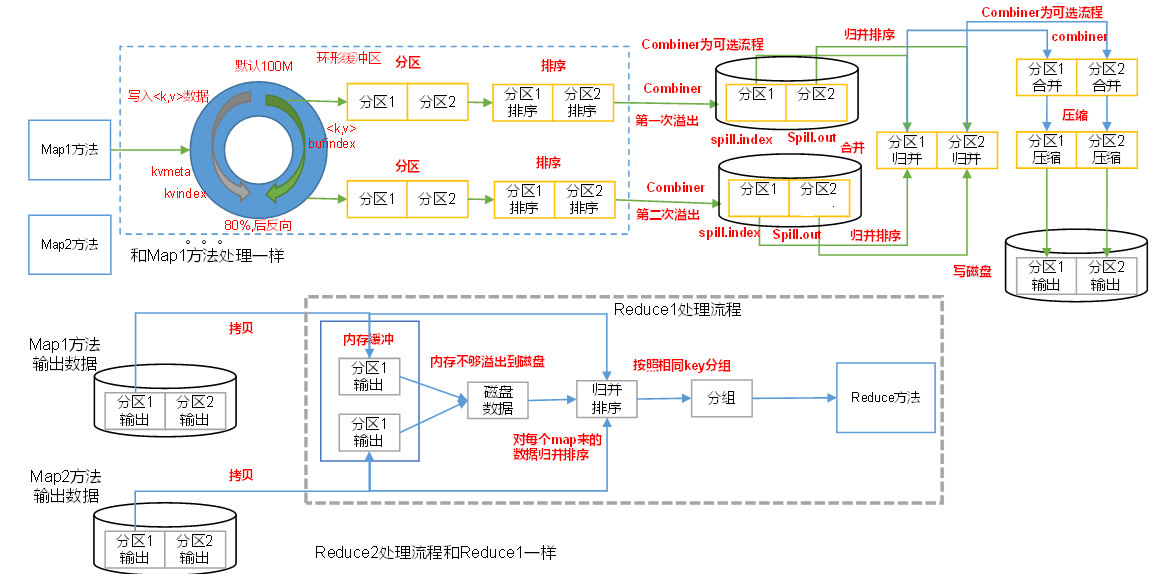
Shuffle 机制流程
- 图中的
Map1方法不要理解为 Mapper 中重写的 map 方法,把它看成一个MapTask的执行,一个MapTask是会调用多个 map 方法的; - 环形缓冲区(默认大小为100M)其实就是在内存中,其中每一个分区内部所使用的排序算法是快速排序;
- 每个相同分区之间采用的是归并排序,在磁盘上进行
- 当环形缓冲区的数据量达到自身容量的 80%,会发生第一次溢写
(1)MapTask收集我们的map()方法输出的 kv 对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(3)多个溢出文件会被合并成大的溢出文件
(4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
(5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
(6)ReduceTask会抓取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
(7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
注意:
- Shuffle中的缓冲区大小会影响到 MapReduce
程序的执行效率,原则上说,缓冲区越大,则可以容纳更多的数据并减少写入磁盘的次数,磁盘IO的次数越少,执行速度就越快。- 缓冲区的大小可以通过参数调整,参数:
mapreduce.task.io.sort.mb默认100M。
2.5.2 Paratition 分区
要求将统计结果按照条件输出到不同的文件(分区)中。比如:将统计结果按照手机归属地不同省份输出到不同的文件中(分区)。
(1)Hadoop默认的分区规则源码解析
- 定位 MapTask 的 map 方法中
context.write(outk, outv); - 跟到
write(outk, outv)中进入到ChainMapContextImpl类的实现中
public void write(KEYOUT key, VALUEOUT value) throws IOException,InterruptedException {output.write(key, value);}
- 跟到
output.write(key, value)内部实现类NewOutputCollector
public void write(K key, V value) throws IOException, InterruptedException {collector.collect(key, value,partitioner.getPartition(key, value, partitions));
}
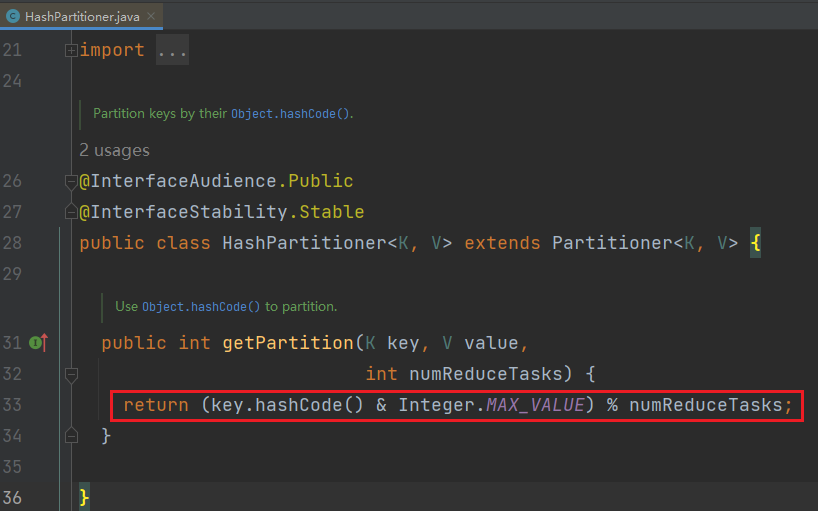
重点理解 partitioner.getPartition(key, value, partitions);
- 跟进默认的分区规则实现类
HashPartitioner
public int getPartition(K key, V value,int numReduceTasks) { // 根据当前的key的hashCode值和ReduceTask的数量进行取余操作// 获取到的值就是当前kv所属的分区编号。return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
Partitioner是 Hadoop 的分区器对象,负责给 Map 阶段输出数据选择分区的功能。
默认分区是根据 key 的 hashCode 对 ReduceTask 的个数取模得到的数字编号,这个分区编号在Job提交的时候就已经定义好了。用户没法控制哪个 key 存储到哪个分区。
(2)自定义分区规则
将统计结果按照手机归属地不同省份输出到不同文件(分区)中。
使用在 大数据技术学习笔记(五)—— MapReduce(1)2.3小节案例的数据 phone_data.txt,手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。
在案例 2.3 的基础上,增加一个分区类
//自定义一个分区器对象,需要继承Hadoop提供的Partitioner对象
//这里的泛型就是Mapper输出的泛型
public class FlowPartitioner extends Partitioner<Text, FlowBean> {/*** 定义当前kv所属分区的规则** @param text the key to be partioned.* @param flowBean the entry value.* @param numPartitions the total number of partitions.* 分区* 136 ——> 0* 137 ——> 1* 138 ——> 2* 139 ——> 3* 其他 ——> 4*/@Overridepublic int getPartition(Text text, FlowBean flowBean, int numPartitions) {int phonePartition;// 获取手机号String phoneNum = text.toString();if(phoneNum.startsWith("136")){phonePartition=0;} else if (phoneNum.startsWith("137")) {phonePartition=1;}else if (phoneNum.startsWith("138")) {phonePartition=2;}else if (phoneNum.startsWith("139")) {phonePartition=3;}else {phonePartition=4;}return phonePartition;}
}
在驱动函数中增加自定义数据分区设置和 ReduceTask 设置
// 指定ReduceTask的数量
job.setNumReduceTasks(5);
// 指定自定义的分区器对象实现
job.setPartitionerClass(FlowPartitioner.class);
分区器使用时注意事项
- 当 ReduceTask 的数量(设置的分区数) > getPartition的结果数(实际用到的分区数), 此时会生成空的分区文件
- 当 ReduceTask 的数量(设置的分区数) < getPartition的结果数(实际用到的分区数), 导致有一部分数据无处安放,此时会报错
- 当 ReduceTask 的数量(设置的分区数) = 1, 则不管 MapTask 端输出多少个分区文件,最终结果文件会输出到一个文件
part-r-00000中- 分区编号生成的规则:根据指定的ReduceTask的数量 从 0 开始,依次累加。
2.5.3 WritableComparable 排序
排序是MR最重要的操作之一。
MapTask 和 ReduceTask 均会对数据按照 key 进行排序。该操作属于 Hadoop 的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于 MapTask,它会将处理的结果暂时存放到环形缓冲区中,当环形缓冲区使用率达到一定的阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有的文件进行归并排序。
对于ReduceTask,它从每个 MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写到磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定的阈值,则进行一次归并排序以生成一个更大的文件;如果内存中文件大小或文件数目超过一定的阈值,则进行一次合并后将数据溢写到磁盘上。当所有的数据拷贝完成后,ReduceTask统一对内存和磁盘上所有的数据进行一次归并排序。
排序分类
- 部分排序:MapReduce根据输入记录的键对数据集排序。保证每个输出文件内部有序。
- 全排序:最终的输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有的文件,完全丧失了 MapReduce 所提供的并行架构。
- 二次排序:在自定义排序过程中,如果 compareTo 中的判断条件为两个即为二次排序。
这里仍然使用在 大数据技术学习笔记(五)—— MapReduce(1)2.3小节案例
代码编写
FlowBean.java
package com.huwei.mr.sort;import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class FlowBean implements WritableComparable<FlowBean> {private Integer upFlow;private Integer downFlow;private Integer sumFlow;// 默认有无参构造方法public Integer getUpFlow() {return upFlow;}public void setUpFlow(Integer upFlow) {this.upFlow = upFlow;}public Integer getDownFlow() {return downFlow;}public void setDownFlow(Integer downFlow) {this.downFlow = downFlow;}public Integer getSumFlow() {return sumFlow;}public void setSumFlow(Integer sumFlow) {this.sumFlow = sumFlow;}@Overridepublic String toString() {return "FlowBean{" +"upFlow=" + upFlow +", downFlow=" + downFlow +", sumFlow=" + sumFlow +'}';}/*** 序列化方法*/@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeInt(upFlow);dataOutput.writeInt(downFlow);dataOutput.writeInt(sumFlow);}/*** 反序列化方法* (顺序要和序列化方法一致)*/@Overridepublic void readFields(DataInput dataInput) throws IOException {upFlow = dataInput.readInt();downFlow = dataInput.readInt();sumFlow = dataInput.readInt();}// 计算上下行流量之和public void setSumFlow() {this.sumFlow = this.upFlow + this.downFlow;}/*** 自定义排序规则* 需求:根据总流量倒序* @param o the object to be compared.* @return*/@Overridepublic int compareTo(FlowBean o) {//按照总流量比较,倒序排列if(this.sumFlow > o.sumFlow){return -1;}else if(this.sumFlow < o.sumFlow){return 1;}else {return 0;}// return -this.getSumFlow().compareTo(o.getSumFlow());}
}
注意:在
public class FlowBean implements WritableComparable<FlowBean>中我将,WritableComparable写成Writable, Comparable,出现ClassCastException报错。参考MapReduce——ClassCastException报错如何解决中方法二
2.5.4 Combiner 合并
Combiner 是 MR 程序中 Mapper 和 Reducer 之外的一种组件,Combiner 的父类就是 Reducer 。
Combiner 和 Reducer 的区别就在于运行的位置,
- Combiner 是在每一个 MapTask 所在的节点运行
- Reducer 是接收全局所有 Mapper 的输出结果。
Combiner 的意义就是对每一个 MapTask 的输出进行局部汇总,以减小网络的传输量。总的来说,就是为了减轻 ReduceTask 的压力,减少了IO开销,提升 MR 的运行效率。
注意: Combiner 能够运用的前提是不能影响最终的业务逻辑,而且, Combiner 的输出 kv 应该和 Reducer 的输入 kv 类型要对应起来。
以 WordCount 案例为例
(1)增加一个WordCountCombiner类继承Reducer
package com.huwei.mr.combiner;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** 自定义Combiner类需要继承Hadoop提供的Reducer类* 注意:Combiner流程一定发生在Map阶段*/
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{private Text outk = new Text();private IntWritable outv = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int total = 0;// 遍历valuesfor (IntWritable value : values) {// 对value累加,输出结果total += value.get();}// 封装key和valueoutk.set(key);outv.set(total);context.write(outk, outv);}
}
(2)在WordcountDriver驱动类中指定 Combiner
// 指定自定义的Combiner类
job.setCombinerClass(WordCountCombiner.class);
运行程序,如下图所示

注意:
Combiner不适用的场景:Reduce端处理的数据考虑到多个MapTask的数据的整体集时就不能提前合并了。(如求平均数)
2.6 MapReduce 工作流程
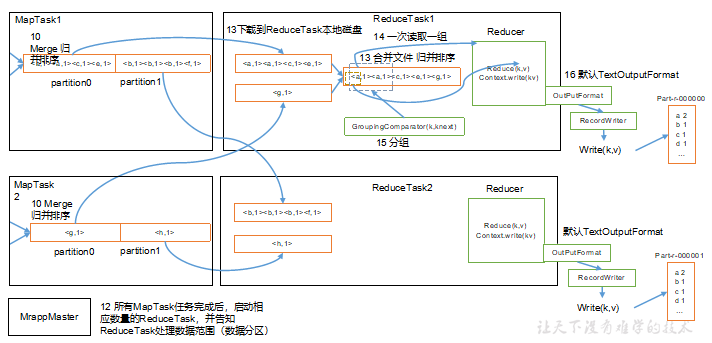
上面的流程是整个 MapReduce 的工作流程,其中从第7步开始到第16步结束为Shuffle过程。
3 Join 应用
3.1 Reduce Join
(1)案例需求
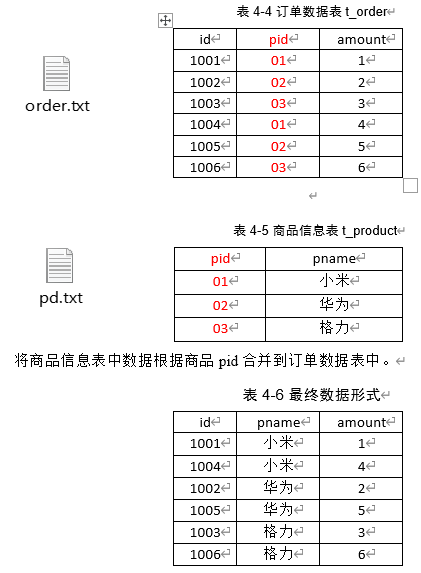
其中
order.txt
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6
pd.txt
01 小米
02 华为
03 格力
(2)需求分析
通过将关联条件作为 Map 输出的 key,将两表满足 Join 条件的数据并携带数据所来源的文件信息,发往同一个 ReduceTask,在 Reduce 中进行数据的串联。
(3)代码编写
商品和订单表合并后的对象类 Orderpd.java
package com.huwei.mr.reducejoin;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class Orderpd implements Writable {// order表数据private String orderId;private String pid;private Integer amount;// pd表数据private String pname;// 区分数据来源,判断是order表还是pd表的标志字段private String flag;public String getOrderId() {return orderId;}public void setOrderId(String orderId) {this.orderId = orderId;}public String getPid() {return pid;}public void setPid(String pid) {this.pid = pid;}public Integer getAmount() {return amount;}public void setAmount(Integer amount) {this.amount = amount;}public String getPname() {return pname;}public void setPname(String pname) {this.pname = pname;}public String getFlag() {return flag;}public void setFlag(String flag) {this.flag = flag;}@Overridepublic String toString() {return "Orderpd{" +"orderId='" + orderId + '\'' +", pname='" + pname + '\'' +", amount='" + amount + '\'' +'}';}/*** 序列化* @param dataOutput* @throws IOException*/@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeUTF(orderId);dataOutput.writeUTF(pid);dataOutput.writeInt(amount);dataOutput.writeUTF(pname);dataOutput.writeUTF(flag);}/*** 反序列化* @param dataInput* @throws IOException*/@Overridepublic void readFields(DataInput dataInput) throws IOException {orderId = dataInput.readUTF();pid = dataInput.readUTF();amount = dataInput.readInt();pname = dataInput.readUTF();flag = dataInput.readUTF();}
}
Map端 ReduceJoinMapper.java
package com.huwei.mr.reducejoin;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;/*** Map端输出的 key是 pid,value是 Orderpd 对象*/
public class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, Orderpd> {private Text outk = new Text();private Orderpd outv = new Orderpd();private FileSplit inputSplit;@Overrideprotected void setup(Mapper<LongWritable, Text, Text, Orderpd>.Context context) throws IOException, InterruptedException {// 获取切片对象inputSplit = (FileSplit) context.getInputSplit();}/*** 业务处理方法 ——> 将两个需要做关联的文件数据进行搜集** @param key* @param value* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Orderpd>.Context context) throws IOException, InterruptedException {// 获取当前行数据String line = value.toString();// 切割数据String[] datas = line.split("\t");// 将当前数据封装到Text(key)、Orderpd(value)中// 先判断数据来源于哪个表if (inputSplit.getPath().getName().contains("order")) {// 当前数据来源于order表// 封装输出数据的keyoutk.set(datas[1]); // pid// 封装输出数据的valueoutv.setOrderId(datas[0]); // idoutv.setPid(datas[1]); // pidoutv.setAmount(Integer.parseInt(datas[2])); // amountoutv.setPname(""); // pname,order表中没有该字段,但不能不设置,否则该属性为null,不能被序列化,会报错outv.setFlag("order");} else {// 当前数据来源于pd表// 封装输出数据的keyoutk.set(datas[0]); // pid// 封装输出数据的valueoutv.setOrderId(""); // idoutv.setPid(datas[0]); // pidoutv.setAmount(0); // amountoutv.setPname(datas[1]); // pnameoutv.setFlag("pd");}// 将数据写出context.write(outk, outv);}
}
注意:在进行序列化和反序列化操作时,如果对象中存在 null 值,就可能会出现报错的情况。在上述封装对象的过程中,如果表中没有某个字段,也不能不设置,只需设置该数据类型的默认值,否则该属性为null,不能被序列化,会报错。
Reduce 端 ReduceJoinReducer.java
package com.huwei.mr.reducejoin;import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;public class ReduceJoinReducer extends Reducer<Text, Orderpd, Orderpd, NullWritable> {private Orderpd orderpd = new Orderpd();private ArrayList<Orderpd> orderList = new ArrayList<>();/*** 业务处理方法 ——> 接收Map端整合好的数据,进行最终的join操作** @param key* @param values* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text key, Iterable<Orderpd> values, Reducer<Text, Orderpd, Orderpd, NullWritable>.Context context) throws IOException, InterruptedException {// 遍历当前相同key的一组valuesfor (Orderpd value : values) {// 判断当前数据来源// 当前数据来源于order文件if ("order".equals(value.getFlag())) {Orderpd thisorder = new Orderpd();// 将当前传入Orderpd对象value复制到新创建的对象thisorder中去// 参数1:目标参数;参数2:原始参数try {BeanUtils.copyProperties(thisorder, value);orderList.add(thisorder);} catch (IllegalAccessException e) {throw new RuntimeException(e);} catch (InvocationTargetException e) {throw new RuntimeException(e);}} else {// 当前数据来源于pd文件try {BeanUtils.copyProperties(orderpd, value);} catch (IllegalAccessException e) {throw new RuntimeException(e);} catch (InvocationTargetException e) {throw new RuntimeException(e);}}}// 进行Join操作for (Orderpd op : orderList) {op.setPname(orderpd.getPname());// 将数据写出context.write(op, NullWritable.get());}// 清空 orderListorderList.clear();}
}
注意:
- 在Java中,在遍历每一个对象时,都会在堆里新创建对象,而在hadoop中,由于内存资源在Hadoop中是极为珍贵的,当遍历每一个对象时,不会在堆中新创建对象,也就是说栈中对象所有的引用都指向堆中一个对象,每次遍历都会动态修改对象的值。这样会导致集合中的对象会被下一个对象覆盖。
- NullWritable是Writable的一个特殊类,实现方法为空实现,不从数据流中读数据,也不写入数据,只充当占位符,如在MapReduce中,如果你不需要使用键或值,你就可以将键或值声明为NullWritable,NullWritable是一个不可变的单实例类型。
Driver 端 ReduceJoinDriver.java
package com.huwei.mr.reducejoin;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class ReduceJoinDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 声明配置对象Configuration conf = new Configuration();// 声明Job对象Job job = Job.getInstance(conf);// 指定当前Job的驱动类job.setJarByClass(ReduceJoinDriver.class);// 指定当前Job的Mapperjob.setMapperClass(ReduceJoinMapper.class);// 指定当前Job的Reducerjob.setReducerClass(ReduceJoinReducer.class);// 指定Map端输出数据的key的类型和输出数据value的类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Orderpd.class);// 指定最终(Reduce端)输出数据的key的类型和输出数据value的类型job.setOutputKeyClass(Orderpd.class);job.setOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job, new Path("E:\\hadoop\\in\\reducejoin"));FileOutputFormat.setOutputPath(job, new Path("E:\\hadoop\\out\\reducejoin"));// 提交Jobjob.waitForCompletion(true);}
}
- 缺点:
- 这种方式中,合并的操作是在Reduce阶段完成,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高
- 且在Reduce阶段极易产生数据倾斜。
- 解决方案:Map端实现数据合并。
- 逻辑处理接口:Mapper
- 用户根据业务需求实现其中三个方法:map() setup() cleanup ()
- 逻辑处理接口:Reducer
- 用户根据业务需求实现其中三个方法:reduce() setup() cleanup ()
3.2 Map Join
在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
优点:在Map端缓存多张表,提前处理业务逻辑,这样增加 Map 端业务,减少 Reduce 端数据的压力,尽可能的减少数据倾斜。
使用场景:Map Join适用于一张表十分小、一张表很大的场景。
具体办法:采用 DistributedCache
- 在 Mapper 的setup阶段,将文件读取到缓存集合中。
- 在 Driver 驱动类中加载缓存。
Map Join思路分析:当 MapTask 执行的时候,先把数据量较小的文件 pd.txt 缓存到内存当中去。MapTask 正常将 order.txt 的数据读取输入,每处理一行数据,就可以根据文件中的 pid 作为 key 到内存中的 HashMap 中获取对应的 pname。
代码编写
Map 端 MapJoinMapper.java
package com.huwei.mr.mapjoin;import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;/*** 1. 处理缓存文件:从job设置的缓存路径中获取到* 2. 根据缓存文件的路径再结合输入流把pd.txt文件的内容写入到内存中的容器中维护*/
public class MapJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> {private Map<String, String> pdMap = new HashMap<>();private Text outk = new Text();/*** 处理缓存文件** @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {//通过缓存文件得到小表数据pd.txtURI[] cacheFiles = context.getCacheFiles();URI cacheFile = cacheFiles[0];// 准备输入流对象FileSystem fs = FileSystem.get(context.getConfiguration());FSDataInputStream pd = fs.open(new Path(cacheFile));// 通过流对象将数据读入,保存到内存的HashMap中BufferedReader reader = new BufferedReader(new InputStreamReader(pd, "UTF-8"));// 按行读取String line;while ((line = reader.readLine()) != null) {// 将数据保存到HashMap中String[] datas = line.split("\t");pdMap.put(datas[0], datas[1]);}// 关闭资源IOUtils.closeStream(pd);}@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {// 获取order.txt当前行数据String lineData = value.toString();// 切割数据String[] orderDatas = lineData.split("\t");// 进行数据关联获取pnameString pname = pdMap.get(orderDatas[1]);// 封装输出结果String result = orderDatas[0] + "\t" + pname + "\t" + orderDatas[2];outk.set(result);// 将结果写出context.write(outk,NullWritable.get());}
}Driver MapJoinDriver
package com.huwei.mr.mapjoin;import com.huwei.mr.reducejoin.Orderpd;
import com.huwei.mr.reducejoin.ReduceJoinDriver;
import com.huwei.mr.reducejoin.ReduceJoinMapper;
import com.huwei.mr.reducejoin.ReduceJoinReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.net.URI;public class MapJoinDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 声明配置对象Configuration conf = new Configuration();// 声明Job对象Job job = Job.getInstance(conf);// 指定当前Job的驱动类job.setJarByClass(MapJoinDriver.class);// 指定当前Job的Mapperjob.setMapperClass(MapJoinMapper.class);// 指定Map端输出数据的key的类型和输出数据value的类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);// 指定最终(Reduce端)输出数据的key的类型和输出数据value的类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);// 设置reduceTask的数量为0job.setNumReduceTasks(0);// 设置缓存文件的路径job.addCacheFile(URI.create("file:///E:/hadoop/in/cachefile/pd.txt"));FileInputFormat.setInputPaths(job, new Path("E:\\hadoop\\in\\mapjoin"));FileOutputFormat.setOutputPath(job, new Path("E:\\hadoop\\out\\mapjoin"));// 提交Jobjob.waitForCompletion(true);}
}相关文章:
大数据技术学习笔记(五)—— MapReduce(2)
目录 1 MapReduce 的数据流1.1 数据流走向1.2 InputFormat 数据输入1.2.1 FileInputFormat 切片源码、机制1.2.2 TextInputFormat 读数据源码、机制1.2.3 CombineTextInputFormat 切片机制 1.3 OutputFormat 数据输出1.3.1 OutputFormat 实现类1.3.2 自定义 OutputFormat 2 Map…...

北斗导航 | 同步双星故障的BDS/GPS接收机自主完好性监测算法
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 同步双星故障的BDS/GPS接收机自主完好性监测算法 1 引言2 同步双星故障…...

2024金三银四必看前端面试题!简答版精品!
文章目录 导文面试题 导文 2024金三银四必看前端面试题!2w字精品!简答版 金三银四黄金期来了 想要跳槽的小伙伴快来看啊 面试题 基于您给出的方向,我将为您生成20个面试题和答案。请注意,由于面试题的答案可能因个人经验和理解而…...
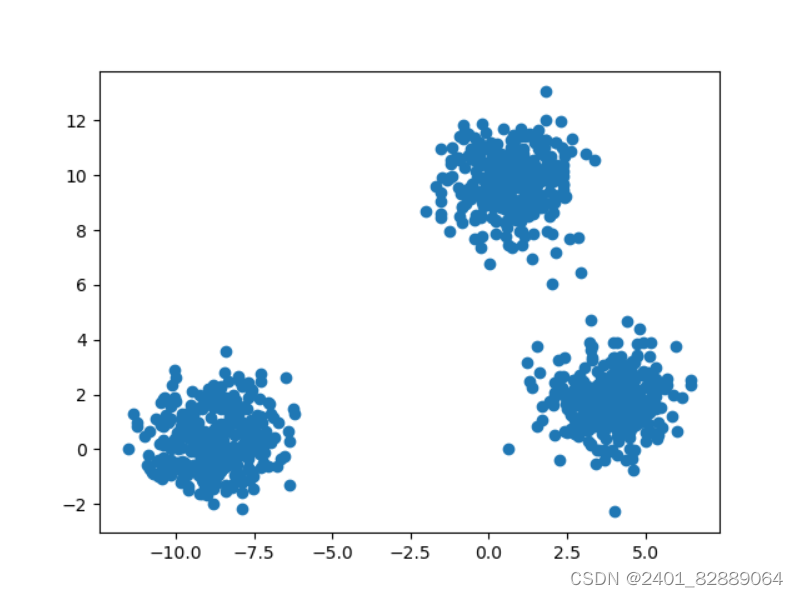
Python-sklearn.datasets-make_blobs
sklearn.datasets.make_blobs()函数形参详解 """ Title: datasets for regression Time: 2024/3/5 Author: Michael Jie """from sklearn import datasets import matplotlib.pyplot as plt# 产生服从正态分布的聚类数据 x, y, cen…...
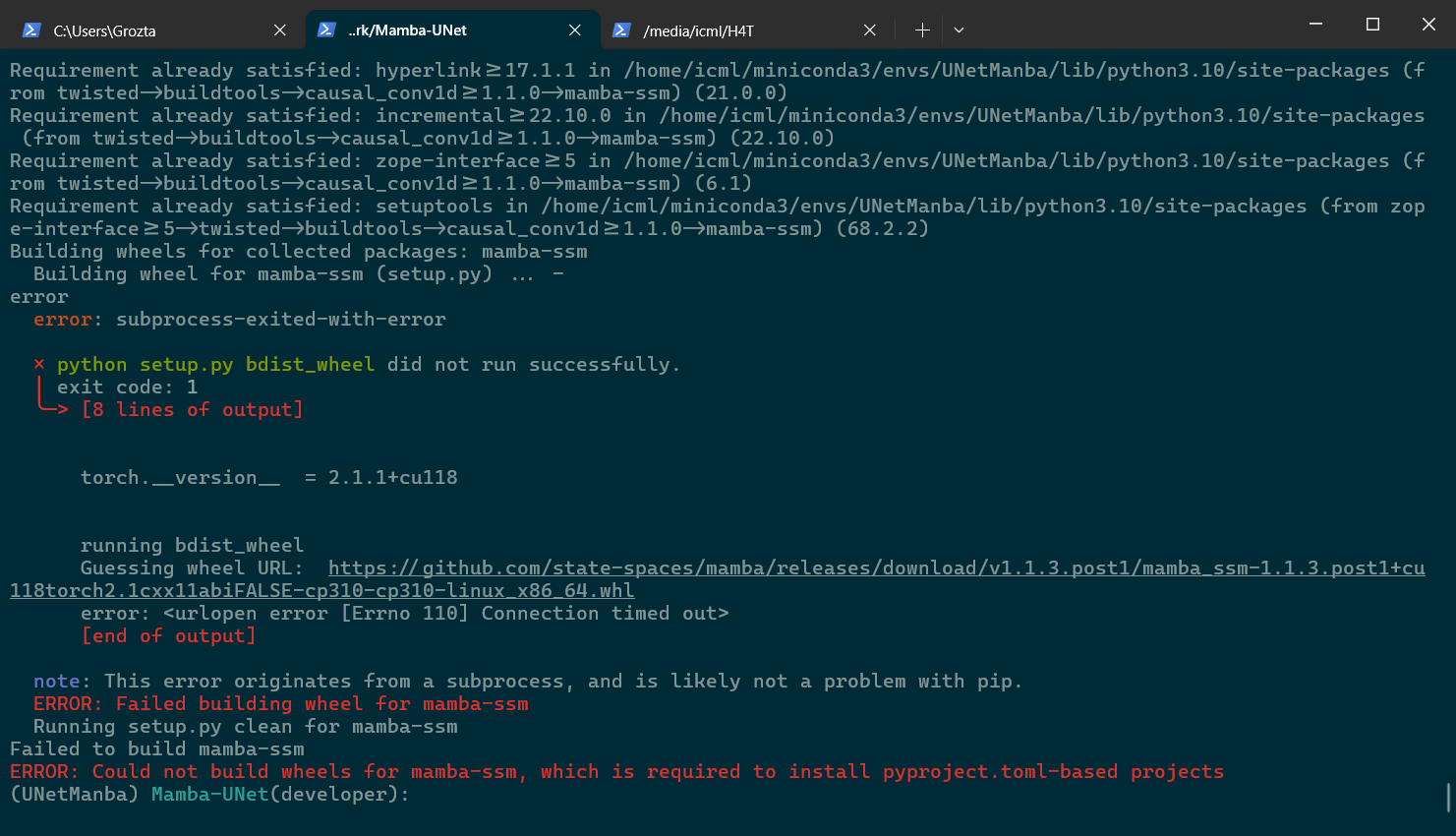
[最佳实践] conda环境内安装cuda 和 Mamba的安装
Mamba安装失败的过程中,causal-conv1d安装报错为连接超时 key word: vision mamba, DL ,深度学习 ,mamba unet,mamba环境安装 Mamba安装 主要故障是 pip install causal-conv1d1.2.0和 pip install mamba-ssm1.2.0 安…...
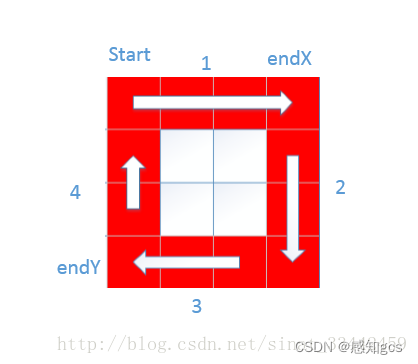
【算法】顺时针打印矩阵(图文详解,代码详细注释
目录 题目 代码如下: 题目 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。例如:如果输入如下矩阵: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 则打印出数字:1 2 3 4 8 12 16 15 14 13 9 5 6 7 11 10 这一道题乍一看,没有包含任何复杂的数据结构和…...

蚂蚁感冒c++
题目 思路 “两蚂蚁碰面会掉头,若其中一只蚂蚁感冒了,会把感冒传染给碰到的蚂蚁”,这句话看作是“两蚂蚁碰面会互相穿过,只是把感冒的状态传给了另一只蚂蚁”,因为哪只蚂蚁感冒了并不是题目的重点,重点是有…...

python Plotly可视化
文章目录 Plotly常用函数PolarPlotlymake_subplotsadd_tracego.Scatterpolarglupdate_tracesupdate_layout综合示例 完整版 Python在数据可视化方面有着丰富的库和函数,其中一些常用的库包括 Matplotlib、Seaborn、Plotly、Bokeh等。 Plotly是一个交互式绘图库&…...

刷题第10天
代码随想录刷题第10天 |● 239. 滑动窗口最大值 ● 347.前 K 个高频元素 239. 滑动窗口最大值 唉,好难,先记个思路吧 class Solution { private:class MyQueue { //单调队列(从大到小)public:deque<int> que; // 使用deq…...
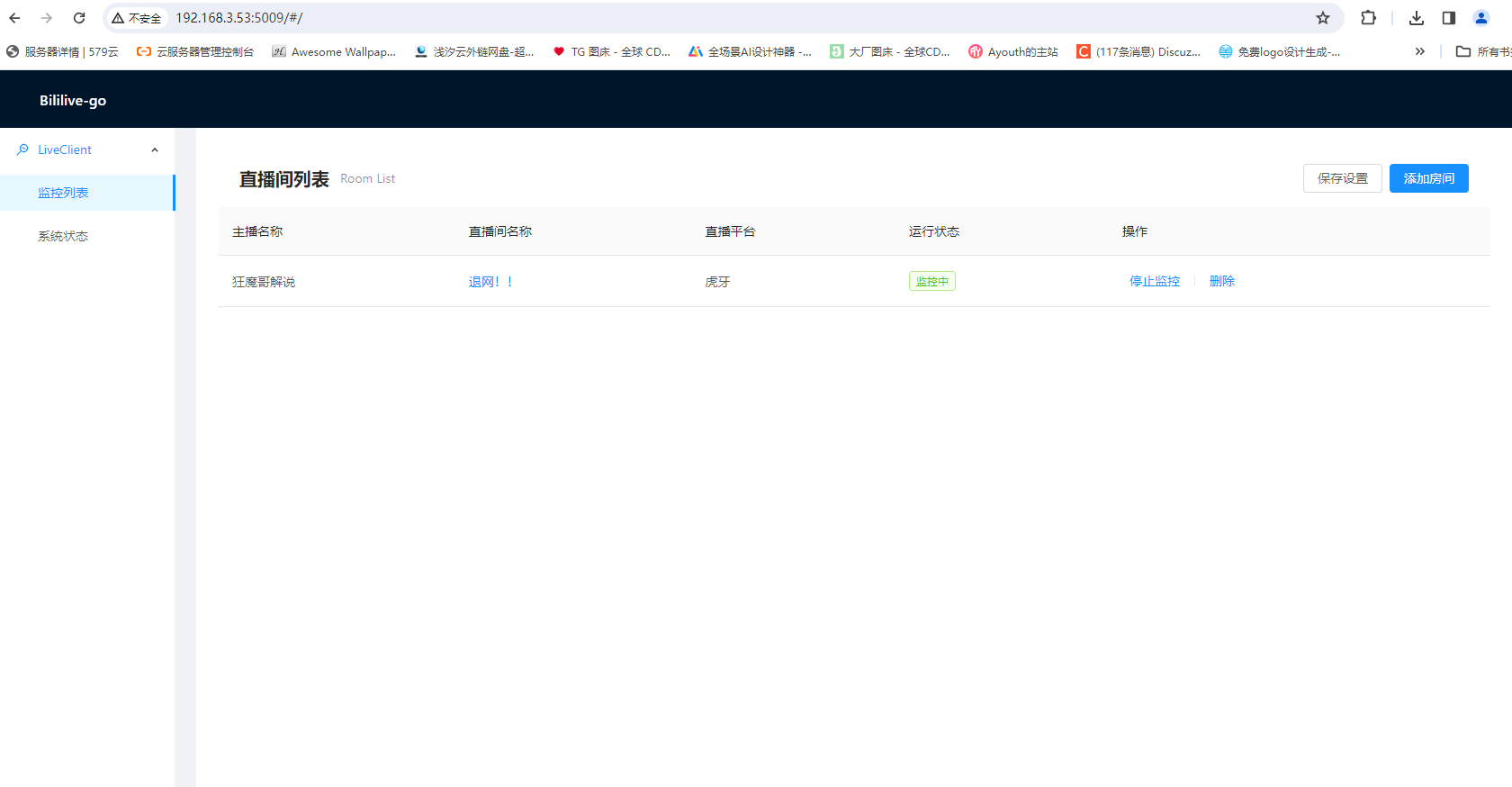
Bililive-go 实现直播自动监控录制
前言 最近有直播录制的需求,但是自己手动录制太麻烦繁琐,于是用了开源项目Bililive-go进行全自动监控录制,目前这个项目已经有3K stars了 部署 为了方便我使用了docker compose 部署 version: 3.8 services:bililive:image: chigusa/bilil…...
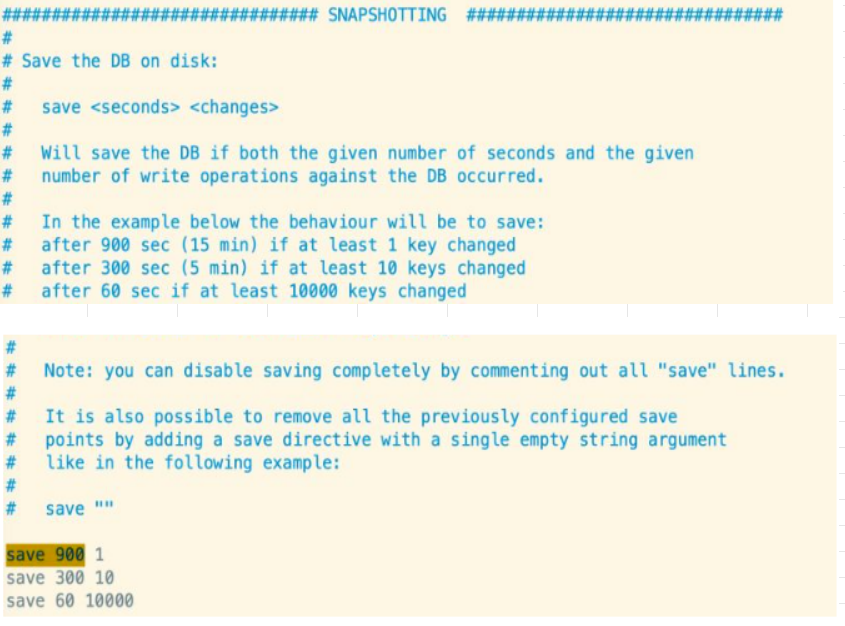
【Redis】Redis持久化模式RDB
目录 引子 RDB RDB的优缺点 小节一下 引子 不论把Redis作为数据库还是缓存来使用,他肯定有数据需要持久化,这里我们就来聊聊两种持久化机制。这两种机制,其实是 快照 与 日志 的形式。快照:就是当前数据的备份,我可以拷贝到磁…...

Java基础 - 模拟医院挂号系统
模拟医院挂号系统功能 1. 科室管理:新增科室,删除科室(如果有医生在,则不能删除该科室),修改科室 2. 医生管理:录入医生信息以及科室信息,修改医生信息(主要是修改个人…...
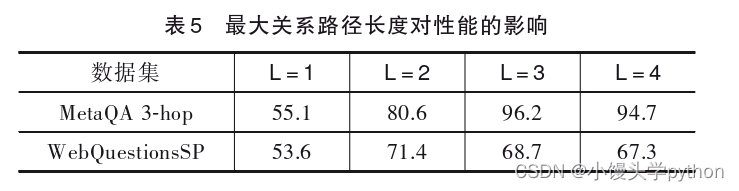
【论文精读】基于知识图谱关系路径的多跳智能问答模型研究
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...
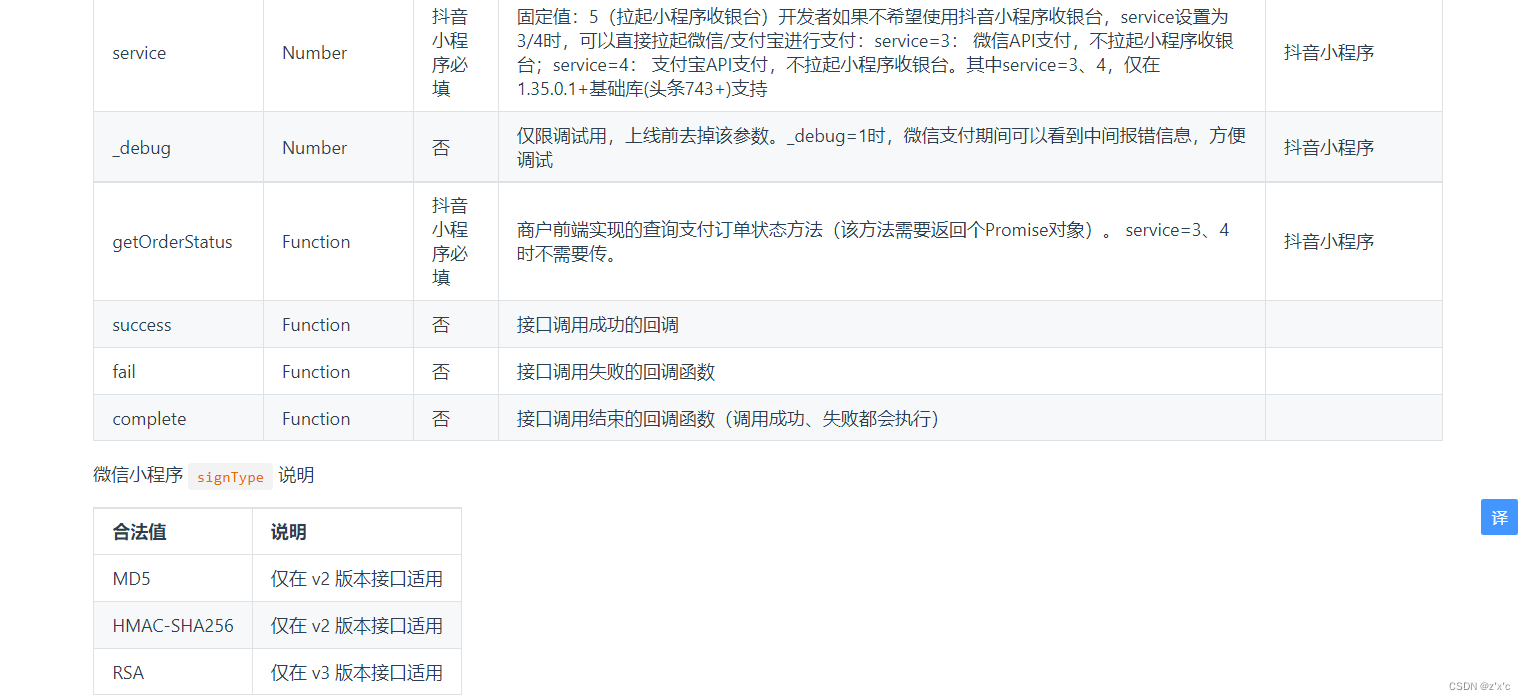
uni app 微信小程序微信支付
使用方法 接口传参 使用wx.requestPayment方法是一个统一各平台的客户端支付API,不管是在某家小程序还是在App中,客户端均使用本API调用支付...
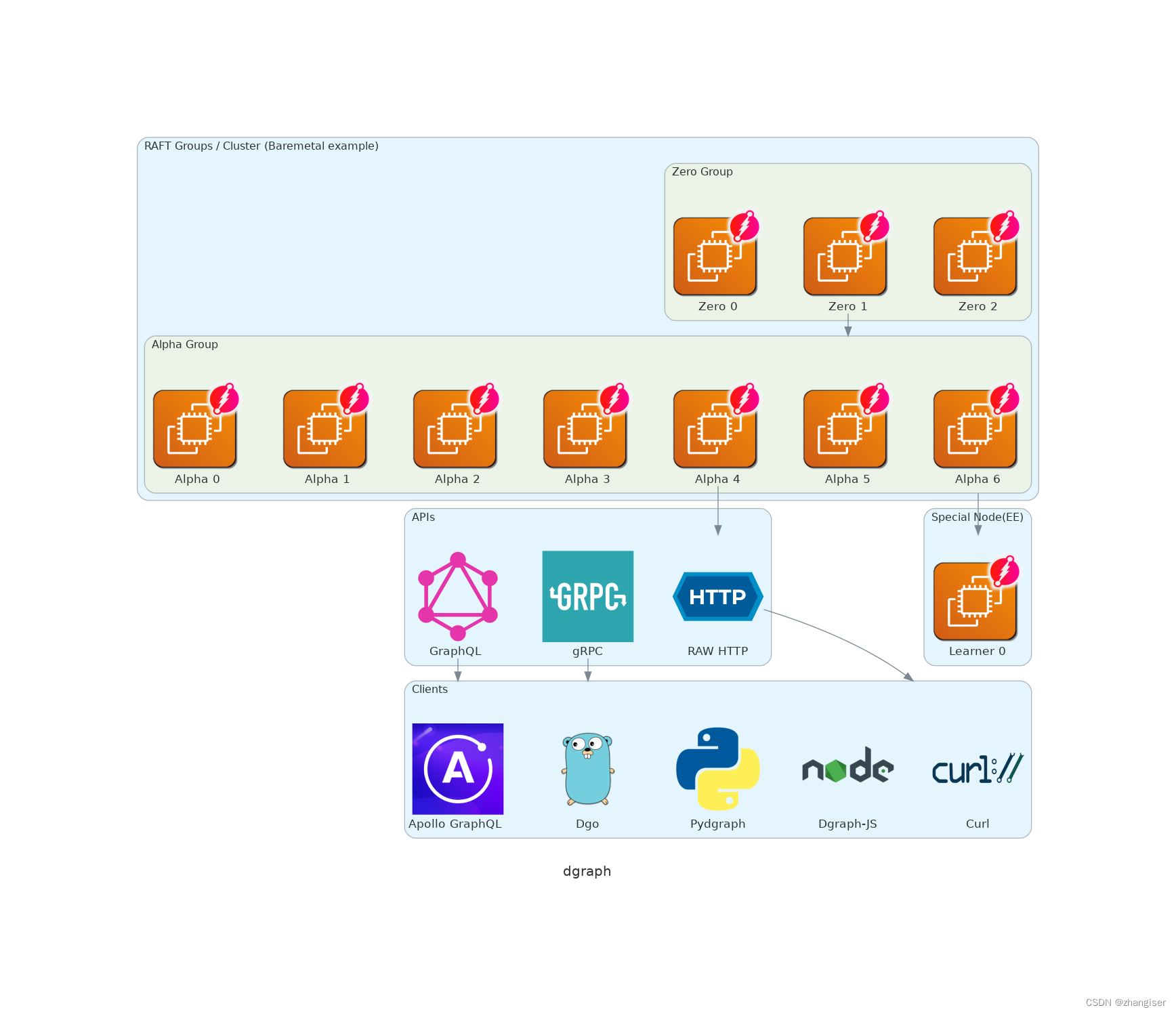
Dgraph 入门教程一《 概览》
1、Dgraph的特点 (1) 分布式规模:可以发布和处理大量数据 (2)支持GraphQL:一种内置的查询语法,类似SQL。可以让数据操作起来更简单 (3)完全的事务处理和ACID兼容:满足OLTP工作负载,该负载要求频繁的插入和更新数据。 (4)支持多…...

VSCode安装
前言 Visual Studio Code 是一个轻量级功能强大的源代码编辑器,支持语法高亮、代码自动补全(又称 IntelliSense)、代码重构、查看定义功能,并且内置了命令行工具和 Git 版本控制系统。适用于 Windows、macOS 和 Linux。它内置了对…...

STM32各外设初始化步骤
1、GPIO初始化步骤 1、使能GPIO时钟 2、初始化GPIO的输入/输出模式 3、设置GPIO的输出值或获取GPIO的输入值 GPIO_InitTypeDef GPIO_InitStruct;RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA,ENABLE);GPIO_InitStruct.GPIO_Mode GPIO_Mode_Out_PP; GPIO_InitStruct.GPIO_Pin…...

10. Nginx进阶-Return
简介 什么是Return? nginx的return指令是用于在nginx配置文件中进行重定向或返回特定的HTTP响应码的指令。 它可以根据不同的条件来执行不同的操作,如重定向到其他URL、返回指定的HTTP响应码或自定义响应内容等。 Return适用范围 return指令只能在se…...
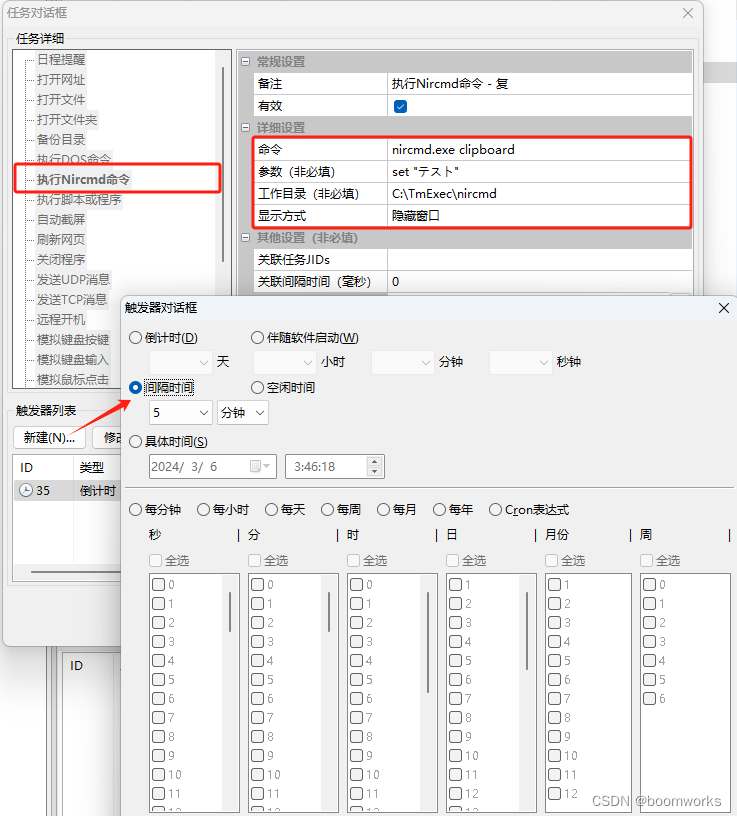
Nircmd集成定时执行专家之后的使用场景
Nircmd工具拥有了定时执行功能之后,可以用于以下场景: 1. 自动化日常工作 定时清理系统垃圾文件定时备份重要文件定时关闭或重启电脑定时发送邮件或短信定时执行其他程序或脚本 2. 监控系统状态 定时检查系统温度定时检查磁盘空间定时检查网络连接定时…...
)
Java面试题【必知必会】Linux常用命令面试题(2024)
近期一直在准备面试,所以为了巩固知识,也为了梳理,整理了一些java的基础面试题!同时也希望各位英雄和女侠能够补充!不胜荣幸!!! 名称地址Java面试题【必知必会】基础(202…...

Exception in thread “main“ java.lang.Error: Unresolved compilation problem:
Exception in thread "main" java.lang.Error: Unresolved compilation problem: 八股文面试,平时啊,开发遇到什么问题 没编译过去的提示信息...

PIC24F Curiosity开发板实战:从MCC配置到低功耗设计
1. 项目概述与核心价值最近在做一个需要兼顾低功耗和实时控制的小型嵌入式项目,选型时又一次把目光投向了Microchip的PIC24F系列MCU。说实话,对于很多从8位机过渡过来的工程师,或者在校学生、创客爱好者来说,直接上手一款16位单片…...

宏裕塑胶代理新日铁住金日本工程塑料全系列产品服务详解
宏裕塑胶代理新日铁住金系列产品专注于为制造业企业提供高性价比、稳定可靠的通用工程塑料原料,依托源头直采及技术赋能,为塑胶制品厂、汽车零部件厂等客户降低采购成本并保障全流程供应。宏裕塑胶代理新日铁住金核心功能与服务模块覆盖多个维度…...

OpCore Simplify:30分钟完成专业Hackintosh配置的智能自动化工具终极指南
OpCore Simplify:30分钟完成专业Hackintosh配置的智能自动化工具终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 你是否曾经因为复…...

论文写不出学术味?高校导师推荐这几个AI论文写作工具
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

OpenCost:Kubernetes 成本监控,开源的云资源费用分析
OpenCost:Kubernetes 成本监控,开源的云资源费用分析 随着企业将越来越多的工作负载迁移到 Kubernetes,一个新的管理挑战随之浮现:到底哪个团队、哪个应用在花钱? 公有云账单只能告诉你整个集群的月度费用,…...
)
告别手动重启!用Python+PyAutoGUI写个游戏防崩溃守护脚本(附完整源码)
告别手动重启!用PythonPyAutoGUI打造游戏防崩溃守护脚本 深夜挂机刷副本时突然游戏崩溃,第二天醒来发现角色还在主城发呆?竞技场自动匹配因为断线重连失败而错过赛季奖励?这些问题对于MMO玩家和挂机游戏爱好者来说简直如同噩梦。本…...

观察不同模型在Taotoken平台上的实际响应速度与效果差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在Taotoken平台上的实际响应速度与效果差异 在开发与创作过程中,我们常常需要调用大模型API来完成文本生成…...

LeetCode 数据流中第K大元素题解
LeetCode 数据流中第K大元素题解 题目描述 设计一个数据流,找到数据流中第 k 大的元素。 示例: 输入:k 3, arr [4,6,5]输出:5 解题思路 方法:堆 思路: 使用最小堆维护前 k 大的元素。遍历数据流ÿ…...
)
【佛山大学主办,土木与交通学院承办 | 施普林格Springer系列出版 | EI、Scopus检索 | 另期刊论文征稿】第九届结构工程与工业建筑国际学术会议(ICSEIA 2026)
第九届结构工程与工业建筑国际学术会议(ICSEIA 2026) 2026 9th International Conference on Structural Engineering and Industrial Architecture 2026年7月3-5日 中国佛山 大会官网:www.icseia.com【论文投稿】 截稿时间:…...