3. 在Go语言项目中使用Zap日志库
文章目录
- 一、介绍
- 二、 默认的Go Logger
- 1. 实现Go Logger
- 2. 设置Logger
- 3. 使用Logger
- 4. Logger的运行
- 5. Go Logger的优势和劣势
- 三、Uber-go Zap
- 1. 为什么选择Uber-go zap
- 2. 安装
- 3. 配置Zap Logger
- 4. 定制logger
- 4.1 将日志写入文件而不是终端
- 4.2 将JSON Encoder更改为普通的Log Encoder
- 4.3 更改时间编码并添加调用者详细信息
- 4.4 AddCallerSkip
- 4.5 将日志输出到多个位置
- 四、使用Lumberjack进行日志切割归档
- 1. 安装
- 2. zap logger中加入Lumberjack
- 五、测试所有功能
代码地址: https://gitee.com/lymgoforIT/golang-trick/tree/master/44-zap
本文将先介绍
Go语言原生的日志库的使用,然后详细介绍非常流行的Uber开源的zap日志库,同时会介绍如何搭配·Lumberjack·实现日志的切割和归档。
一、介绍
在许多Go语言项目中,一个好的日志记录器一般期望能够提供下面这些功能:
- 能够将事件记录到文件中,而不是应用程序控制台。
- 日志切割:能够根据文件大小、时间或间隔等来切割日志文件。
- 支持不同的日志级别。例如
INFO,DEBUG,ERROR等。 - 能够打印基本信息,如调用文件/函数名和行号,日志时间等。
二、 默认的Go Logger
在介绍Uber-go的zap包之前,让我们先看看Go语言提供的基本日志功能。Go语言提供的默认日志包是https://golang.org/pkg/log/。
1. 实现Go Logger
实现一个Go语言中的日志记录器非常简单——创建一个新的日志文件,然后设置它为日志的输出位置即可。
2. 设置Logger
我们可以像下面的代码一样设置日志记录器
func SetupLogger() {logFileLocation, _ := os.OpenFile("/Users/lym/test.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)log.SetOutput(logFileLocation)
}
3. 使用Logger
让我们来写一些虚拟的代码,使用这个日志记录器。
在当前的示例中,我们将建立一个到URL的HTTP连接,并将状态代码/错误记录到日志文件中。
func simpleHttpGet(url string) {resp, err := http.Get(url)if err != nil {log.Printf("Error fetching url %s : %s", url, err.Error())} else {log.Printf("Status Code for %s : %s", url, resp.Status)resp.Body.Close()}
}
4. Logger的运行
现在让我们执行上面的代码并查看日志记录器的运行情况。
func main() {SetupLogger()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}
当我们执行上面的代码,我们能看到一个test.log文件被创建,下面的内容会被添加到这个日志文件中。(因为www.baidu.com谷歌没有带http://开头,所以访问失败,但是http://www.baidu.com访问成功)
2024/03/06 15:14:13 Error fetching url www.google.com : Get www.baidu.com: unsupported protocol scheme ""
2024/03/06 15:14:14 Status Code for http://www.baidu.com : 200 OK
5. Go Logger的优势和劣势
优势
它最大的优点是使用非常简单。我们可以设置任何io.Writer作为日志记录输出并向其发送要写入的日志。
劣势
- 仅限基本的日志级别
- 只有一个
Print选项。不支持INFO/DEBUG等多个级别。 - 对于错误日志,它有
Fatal和PanicFatal日志通过调用os.Exit(1)来结束程序Panic日志在写入日志消息之后抛出一个panic- 但是它缺少一个
ERROR日志级别,这个级别可以在不抛出panic或退出程序的情况下记录错误
- 缺乏日志格式化的能力——例如记录调用者的函数名和行号,格式化日期和时间格式。等等。
- 不提供日志切割的能力。
三、Uber-go Zap
Zap是非常快的、结构化的,分日志级别的Go日志库。
1. 为什么选择Uber-go zap
- 它同时提供了结构化日志记录和
printf风格的日志记录 - 它非常的快
- 根据
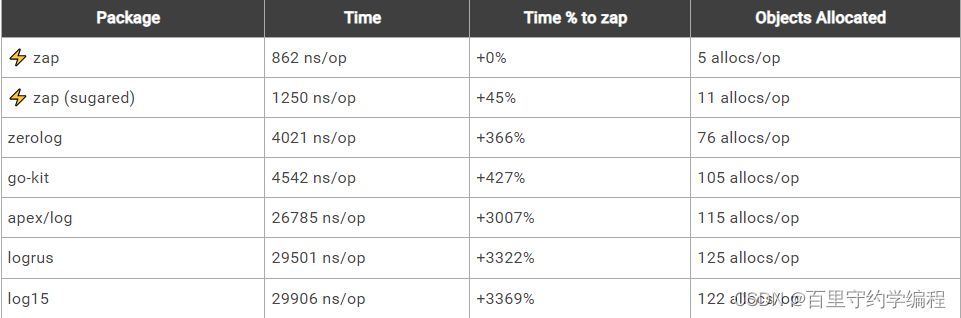
Uber-go Zap的文档,它的性能比类似的结构化日志包更好——也比标准库更快。 以下是Zap发布的基准测试信息
记录一条消息和10个字段:
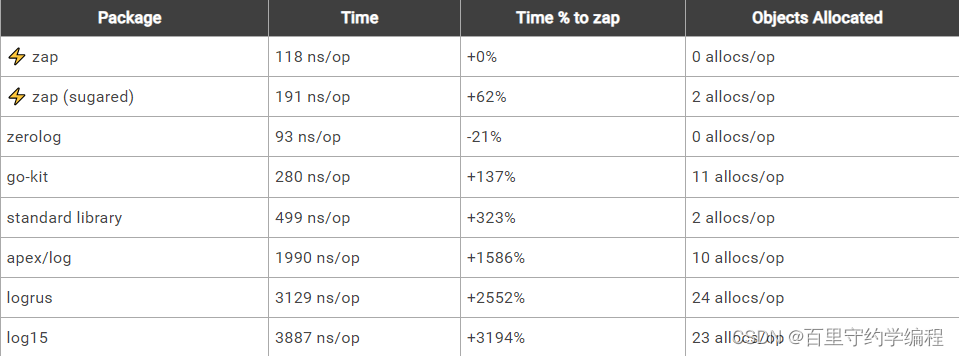
记录一个静态字符串,没有任何上下文或printf风格的模板:
2. 安装
运行下面的命令安装zap
go get -u go.uber.org/zap
3. 配置Zap Logger
Zap提供了两种类型的日志记录器—Sugared Logger和Logger。
在性能很好但不是很关键的上下文中,使用SugaredLogger。它比其他结构化日志记录包快4-10倍,并且支持结构化和printf风格的日志记录。
在每一微秒和每一次内存分配都很重要的上下文中,使用Logger。它甚至比SugaredLogger更快,内存分配次数也更少,但它只支持强类型的结构化日志记录。
Logger
-
通过调用
zap.NewProduction()/zap.NewDevelopment()或者zap.Example()创建一个Logger。 -
上面的每一个函数都将创建一个
logger。唯一的区别在于它将记录的信息不同。例如production logger默认记录调用函数信息、日期和时间等。 -
通过
Logger调用Info/Error等。 -
默认情况下日志都会打印到应用程序的
console界面。
package mainimport ("net/http""go.uber.org/zap"
)// 定义全局日志对象,方便后续直接使用
var logger *zap.Loggerfunc main() {InitLogger()// 程序退出时,先将缓冲区的日志也都刷入到磁盘文件中,避免最后的日志丢失defer logger.Sync()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}// InitLogger 初始化logger对象
func InitLogger() {logger, _ = zap.NewProduction()
}func simpleHttpGet(url string) {resp, err := http.Get(url)if err != nil {logger.Error("Error fetching url..",zap.String("url", url),zap.Error(err)) // key为error} else {logger.Info("Success..",zap.String("statusCode", resp.Status),zap.String("url", url))resp.Body.Close()}
}
在上面的代码中,我们首先创建了一个Logger,然后使用Info/ Error等Logger方法记录消息。
日志记录器方法的语法是这样的:
func (log *Logger) MethodXXX(msg string, fields ...Field)
其中MethodXXX是一个可变参数函数,可以是Info / Error/ Debug / Panic等。每个方法都接受一个消息字符串和任意数量的zapcore.Field参数。
每个zapcore.Field其实就是一组键值对参数。
我们执行上面的代码会得到如下输出结果:
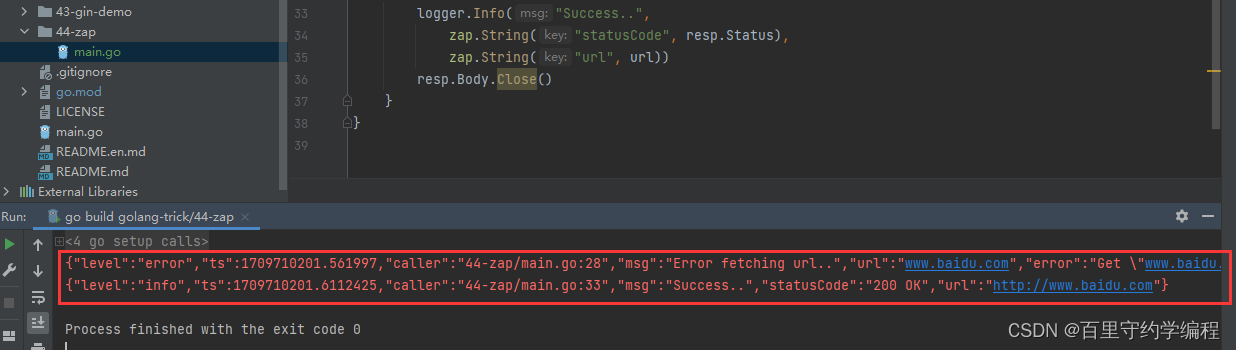
{"level":"error","ts":1709710201.561997,"caller":"44-zap/main.go:28","msg":"Error fetching url..","url":"www.baidu.com","error":"Get \"www.baidu.com\": unsupported protocol scheme \"\"","stacktrace":"main.simpleHttpGet\n\tD:/Users/lym/GolandProjects/golang-trick/44-zap/main.go:28\nmain.main\n\tD:/Users/lym/GolandProjects/golang-trick/44-zap/main.go:16\nruntime.main\n\tC:/Program Files/Go/src/runtime/proc.go:267"}
{"level":"info","ts":1709710201.6112425,"caller":"44-zap/main.go:33","msg":"Success..","statusCode":"200 OK","url":"http://www.baidu.com"}
Sugared Logger
现在让我们使用Sugared Logger来实现相同的功能。
大部分的实现基本都相同。惟一的区别是,我们通过调用主logger的. Sugar()方法来获取一个SugaredLogger。然后使用SugaredLogger以printf格式记录语句
下面是修改过后使用SugaredLogger代替Logger的代码:
var sugarLogger *zap.SugaredLoggerfunc main() {InitLogger()defer sugarLogger.Sync()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}func InitLogger() {logger, _ := zap.NewProduction()sugarLogger = logger.Sugar()
}func simpleHttpGet(url string) {sugarLogger.Debugf("Trying to hit GET request for %s", url)resp, err := http.Get(url)if err != nil {sugarLogger.Errorf("Error fetching URL %s : Error = %s", url, err)} else {sugarLogger.Infof("Success! statusCode = %s for URL %s", resp.Status, url)resp.Body.Close()}
}
当你执行上面的代码会得到如下输出:
{"level":"error","ts":1709710774.730964,"caller":"44-zap/main.go:58","msg":"Error fetching URL www.baidu.com : Error = Get \"www.baidu.com\": unsupported protocol scheme \"\"","stacktrace":"main.simpleHttpGet\n\tD:/Users/lym/GolandProjects/golang-trick/44-zap/main.go:58\nmain.main\n\tD:/Users/lym/GolandProjects/golang-trick/44-zap/main.go:45\nruntime.main\n\tC:/Program Files/Go/src/runtime/proc.go:267"}
{"level":"info","ts":1709710774.7849257,"caller":"44-zap/main.go:60","msg":"Success! statusCode = 200 OK for URL http://www.baidu.com"}
你应该注意到的了,到目前为止这两个logger都打印输出JSON结构格式。
在本博客的后面部分,我们将更详细地讨论SugaredLogger,并了解如何进一步配置它。
4. 定制logger
4.1 将日志写入文件而不是终端
我们要做的第一个更改是把日志写入文件,而不是打印到应用程序控制台。
我们将使用zap.New(…)方法来手动传递所有配置,而不是使用像zap.NewProduction()这样的预置方法来创建logger。
func New(core zapcore.Core, options ...Option) *Logger
zapcore.Core需要三个配置——Encoder,WriteSyncer,LogLevel。
1.Encoder:编码器(如何写入日志)。我们将使用开箱即用的NewJSONEncoder(),并使用预先设置的ProductionEncoderConfig()。
zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
2.WriterSyncer :指定日志将写到哪里去。我们使用zapcore.AddSync()函数并且将打开的文件句柄传进去。
file, _ := os.Create("./test.log")
writeSyncer := zapcore.AddSync(file)
3.Log Level:哪种级别的日志将被写入。
我们将修改上述部分中的Logger代码,并重写InitLogger()方法。其余方法main() /SimpleHttpGet()保持不变。
package mainimport ("net/http""os""go.uber.org/zap""go.uber.org/zap/zapcore"
)// 定义全局日志对象,方便后续直接使用
var logger *zap.Logger
var sugarLogger *zap.SugaredLoggerfunc main() {InitLogger()// 程序退出时,先将缓冲区的日志也都刷入到磁盘文件中,避免最后的日志丢失defer logger.Sync()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}func simpleHttpGet(url string) {resp, err := http.Get(url)if err != nil {logger.Error("Error fetching url..",zap.String("url", url),zap.Error(err)) // key为error} else {logger.Info("Success..",zap.String("statusCode", resp.Status),zap.String("url", url))resp.Body.Close()}
}// InitLogger 初始化logger对象
func InitLogger() {writeSyncer := getLogWriter()encoder := getEncoder()core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)logger = zap.New(core)sugarLogger = logger.Sugar()
}func getLogWriter() zapcore.WriteSyncer {file, _ := os.OpenFile("44-zap/test.log",os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)return zapcore.AddSync(file)
}func getEncoder() zapcore.Encoder {return zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
}
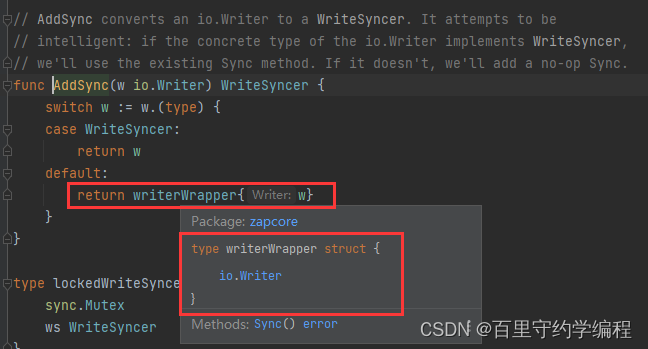
注:上面代码getLogWriter函数中的zapcore.AddSync方法源码如下,实际就是想把一个io.Writer对象包装为zapcore.NewCore中需要的zapcore.WriteSyncer类型
当使用这些修改过的logger配置调用上述部分的main()函数时,以下输出将打印在文件test.log中。
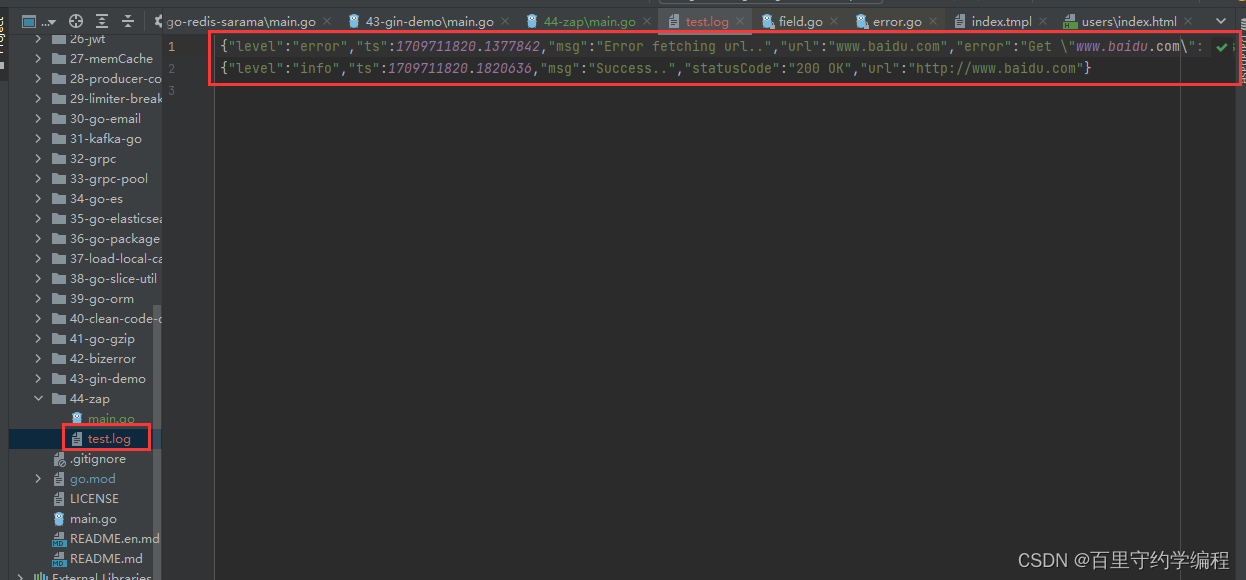
{"level":"error","ts":1709711820.1377842,"msg":"Error fetching url..","url":"www.baidu.com","error":"Get \"www.baidu.com\": unsupported protocol scheme \"\""}
{"level":"info","ts":1709711820.1820636,"msg":"Success..","statusCode":"200 OK","url":"http://www.baidu.com"}
4.2 将JSON Encoder更改为普通的Log Encoder
现在,我们希望将编码器从JSON Encoder更改为普通Encoder。为此,我们需要将NewJSONEncoder()更改为NewConsoleEncoder()。表示打印的格式和控制台打印的一样,而非json格式了,但是内容还是打印到test.log文件中的,并不是说打印到控制台哦。
return zapcore.NewConsoleEncoder(zap.NewProductionEncoderConfig())
当使用这些修改过的logger配置调用上述部分的main()函数时,以下输出将打印在文件test.log中。
因为我们设置zapcore.WriteSyncer时,文件句柄指定的是追加方式,所以是在test.log文件后面追加了两行

4.3 更改时间编码并添加调用者详细信息
鉴于我们对配置所做的更改,有下面两个问题:
- 时间是以非人类可读的方式展示,例如
1.7097121171450913e+09 - 调用方函数的详细信息没有显示在日志中
我们要做的第一件事是覆盖默认的ProductionConfig(),并进行以下更改:
-
修改时间编码器
-
在日志文件中使用大写字母记录日志级别
func getEncoder() zapcore.Encoder {encoderConfig := zap.NewProductionEncoderConfig()encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoderencoderConfig.EncodeLevel = zapcore.CapitalLevelEncoderreturn zapcore.NewConsoleEncoder(encoderConfig)
}
接下来,我们将修改zap logger代码,添加将调用函数信息记录到日志中的功能。为此,我们将在zap.New(..)函数中添加一个Option。logger = zap.New(core, zap.AddCaller())
// InitLogger 初始化logger对象
func InitLogger() {writeSyncer := getLogWriter()encoder := getEncoder()core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)logger = zap.New(core, zap.AddCaller())sugarLogger = logger.Sugar()
}
当使用这些修改过的logger配置调用上述部分的main()函数时,以下输出将打印在文件test.log中。

4.4 AddCallerSkip
当我们不是直接使用初始化好的logger实例记录日志,而是将其包装成一个函数时,此时日志的函数调用链会增加,想要获得准确的调用信息就需要通过AddCallerSkip函数来跳过。可参考本人另两篇博客中记录堆栈信息的方式:
95. Go中runtime.Caller的使用
96.Go设计优雅的错误处理(带堆栈信息)
logger = zap.New(core, zap.AddCaller(), zap.AddCallerSkip(1))
4.5 将日志输出到多个位置
我们可以将日志同时输出到文件和终端。
func getLogWriter() zapcore.WriteSyncer {file, _ := os.OpenFile("44-zap/test.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)// 利用io.MultiWriter支持文件和终端两个输出目标ws := io.MultiWriter(file, os.Stdout)return zapcore.AddSync(ws)
}
将err日志单独输出到文件
有时候我们除了将全量日志输出到xx.log文件中之外,还希望将ERROR级别的日志单独输出到一个名为xx.err.log的日志文件中。我们可以通过以下方式实现。
func InitLogger() {encoder := getEncoder()// test.log记录全量日志logF, _ := os.OpenFile("44-zap/test.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)c1 := zapcore.NewCore(encoder, zapcore.AddSync(logF), zapcore.DebugLevel)// test.err.log记录ERROR级别的日志errF, _ := os.OpenFile("44-zap/test.err.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)c2 := zapcore.NewCore(encoder, zapcore.AddSync(errF), zap.ErrorLevel)// 使用NewTee将c1和c2合并到corecore := zapcore.NewTee(c1, c2)logger = zap.New(core, zap.AddCaller())
}
四、使用Lumberjack进行日志切割归档
这个日志程序中唯一缺少的就是日志切割归档功能。
Zap本身不支持切割归档日志文件,但我们可以使用第三方库Lumberjack来实现。
目前只支持按文件大小切割,原因是按时间切割效率低且不能保证日志数据不被破坏。详情戳https://github.com/natefinch/lumberjack/issues/54。
想按日期切割可以使用github.com/lestrrat-go/file-rotatelogs这个库,虽然目前不维护了,但也够用了。
// 使用file-rotatelogs按天切割日志import rotatelogs "github.com/lestrrat-go/file-rotatelogs"l, _ := rotatelogs.New(filename+".%Y%m%d%H%M",rotatelogs.WithMaxAge(30*24*time.Hour), // 最长保存30天rotatelogs.WithRotationTime(time.Hour*24), // 24小时切割一次
)
zapcore.AddSync(l)
1. 安装
执行下面的命令安装 Lumberjack v2 版本。
go get gopkg.in/natefinch/lumberjack.v2
2. zap logger中加入Lumberjack
要在zap中加入Lumberjack支持,我们需要修改WriteSyncer代码。我们将按照下面的代码修改getLogWriter()函数:
注意:这种方式每次重新运行都是新建test.log初始文件,因为没有地方指定是内容追加到文件后面
func getLogWriter() zapcore.WriteSyncer {lumberJackLogger := &lumberjack.Logger{Filename: "44-zap/test.log",MaxSize: 1,MaxBackups: 5,MaxAge: 30,Compress: false,}return zapcore.AddSync(lumberJackLogger)
}
Lumberjack Logger采用以下属性作为输入:
- Filename: 日志文件的位置
- MaxSize:在进行切割之前,日志文件的最大大小(以MB为单位)
- MaxBackups:保留旧文件的最大个数
- MaxAges:保留旧文件的最大天数
- Compress:是否压缩/归档旧文件
五、测试所有功能
最终,使用Zap/Lumberjack logger的完整示例代码如下:
package mainimport ("net/http""go.uber.org/zap""go.uber.org/zap/zapcore""gopkg.in/natefinch/lumberjack.v2"
)// 定义全局日志对象,方便后续直接使用
var logger *zap.Logger
var sugarLogger *zap.SugaredLoggerfunc main() {InitLogger()// 程序退出时,先将缓冲区的日志也都刷入到磁盘文件中,避免最后的日志丢失defer logger.Sync()simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")
}func simpleHttpGet(url string) {resp, err := http.Get(url)if err != nil {logger.Error("Error fetching url..",zap.String("url", url),zap.Error(err)) // key为error} else {logger.Info("Success..",zap.String("statusCode", resp.Status),zap.String("url", url))resp.Body.Close()}
}// InitLogger 初始化logger对象
func InitLogger() {writeSyncer := getLogWriter()encoder := getEncoder()core := zapcore.NewCore(encoder, writeSyncer, zapcore.DebugLevel)logger = zap.New(core, zap.AddCaller())sugarLogger = logger.Sugar()
}func getEncoder() zapcore.Encoder {encoderConfig := zap.NewProductionEncoderConfig()encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoderencoderConfig.EncodeLevel = zapcore.CapitalLevelEncoderreturn zapcore.NewConsoleEncoder(encoderConfig)
}func getLogWriter() zapcore.WriteSyncer {lumberJackLogger := &lumberjack.Logger{Filename: "44-zap/test.log",MaxSize: 1,MaxBackups: 5,MaxAge: 30,Compress: false,}return zapcore.AddSync(lumberJackLogger)
}执行上述代码,下面的内容会输出到文件test.log中。
4-03-06T16:35:49.023+0800 ERROR 44-zap/main.go:26 Error fetching url.. {"url": "www.baidu.com", "error": "Get \"www.baidu.com\": unsupported protocol scheme \"\""}
2024-03-06T16:35:49.135+0800 INFO 44-zap/main.go:31 Success.. {"statusCode": "200 OK", "url": "http://www.baidu.com"}
同时,可以在main函数中循环记录日志,测试日志文件是否会自动切割和归档(日志文件每1MB会切割并且在当前目录下最多保存5个文件)。
func main() {InitLogger()// 程序退出时,先将缓冲区的日志也都刷入到磁盘文件中,避免最后的日志丢失defer logger.Sync()for i := 0; i < 100000; i++ {simpleHttpGet("www.baidu.com")simpleHttpGet("http://www.baidu.com")}
}
切割后,新建的日志文件在基础文件名后加创建时间作为文件名

可以看到,随着日志越来越多,之前较早产生的test-2024-03-06T08-43-10.979.log文件被自动删除了,因为设置的最多保留五个日志文件

至此,我们总结了如何将Zap日志程序集成到Go应用程序项目中。
相关文章:
3. 在Go语言项目中使用Zap日志库
文章目录 一、介绍二、 默认的Go Logger1. 实现Go Logger2. 设置Logger3. 使用Logger4. Logger的运行5. Go Logger的优势和劣势 三、Uber-go Zap1. 为什么选择Uber-go zap2. 安装3. 配置Zap Logger4. 定制logger4.1 将日志写入文件而不是终端4.2 将JSON Encoder更改为普通的Log…...

想要节省成本,哪个品牌的https证书值得考虑?
为了确保网站数据传输安全,启用HTTPS加密是关键步骤。在众多SSL证书供应商中,如何找到价格合理且品质优良的HTTPS加密证书呢?本文将探讨这个问题,并重点关注具有高性价比优势的沃通CA。 沃通CA作为业内知名的SSL证书服务商&#x…...

R语言及其开发环境简介
R语言及其开发环境简介 R 语言历史 R 语言来自 S 语言,是 S 语言的一个变种。S语言由贝尔实验室研究开发,著名的 C 语言、Unix 系统也是贝尔实验室开发的。R 属于 GNU 开源软件,最初发布于1997年,实现了与 S 语言基本相同的功能…...
部署DNS解析服务
一、安装软件,关闭防火墙,启动服务 1.yum install -y bind bind-utils bind-chroot 2.systemctl stop firewalld && setenforce 0 3.systemctl start named 二、工作目录 /var/named/chroot/etc #存放主配置文件 /var/named/chroot/var/n…...

2024新算法:鹅算法优化VMD参数,五种适应度函数任意切换,最小包络熵、样本熵、信息熵、排列熵、排列熵/互信息熵...
本期采用鹅算法优化一下VMD参数。利用MATLAB官方自带的VMD函数。 替换为官方自带的VMD函数后,寻优速度真的大幅度提升!数据量大的不妨都试试这个官方的VMD函数。当然要下载2020a以上的MATLAB才可以哦! 同样以西储大学数据集为例,选…...

自定义注解校验
在日常开发中经常会用到String类型的数据当作数值进行映射,势必会做出数值范围的校验,可以通过自定义注解的办法简化代码实现,减少冗余代码。 Target({ElementType.FIELD}) Retention(RetentionPolicy.RUNTIME) Constraint(validatedBy St…...

由数据范围反推算法复杂度以及算法内容
一般ACM或者笔试题的时间限制是1秒或2秒。 在这种情况下,C代码中的操作次数控制在 1 0 7 ∼ 1 0 8 10^7\sim10^8 107∼108为最佳。 下面给出在不同数据范围下,代码的时间复杂度和算法该如何选择: n ≤ 30 n\leq30 n≤30,指数级别…...

js监听F11触发全屏事件
当用户使用 F11 键进行浏览器全屏时,由于此时并非通过浏览器提供的 Fullscreen API 进入全屏模式,因此无法通过 fullscreenchange 事件来监听全屏状态的变化。在这种情况下,可以通过监听 resize 事件来检测浏览器窗口大小的变化,从…...

Seata 2.x 系列【1】专栏导读
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.1.0 本系列Seata 版本 2.0.0 源码地址:https://gitee.com/pearl-organization/study-seata-demo 文章目录 1. 背景2. 简介3. 适用人群4. 环境及版本5. 文章导航5…...
fly-barrage 前端弹幕库(3):滚动弹幕的设计与实现
项目官网地址:https://fly-barrage.netlify.app/; 👑🐋🎉如果感觉项目还不错的话,还请点下 star 🌟🌟🌟。 Gitee:https://gitee.com/fei_fei27/fly-barrage&a…...
Mysql面试总结
基础 1. 数据库的三范式是什么? 第一范式:强调的是列的原子性,即数据库表的每一列都是不可分割的原子数据项。第二范式:要求实体的属性完全依赖于主关键字。所谓完全 依赖是指不能存在仅依赖主关键字一部分的属性。第三范式&…...

【深圳五兴科技】Java后端面经
本文目录 写在前面试题总览1、java集合2、创建线程的方式3、对spring的理解4、Spring Boot 和传统 Spring 框架的一些区别5、springboot如何解决循环依赖6、对mybatis的理解7、缓存三兄弟8、接口响应慢的处理思路9、http的状态码 写在前面 关于这个专栏: 本专栏记录…...
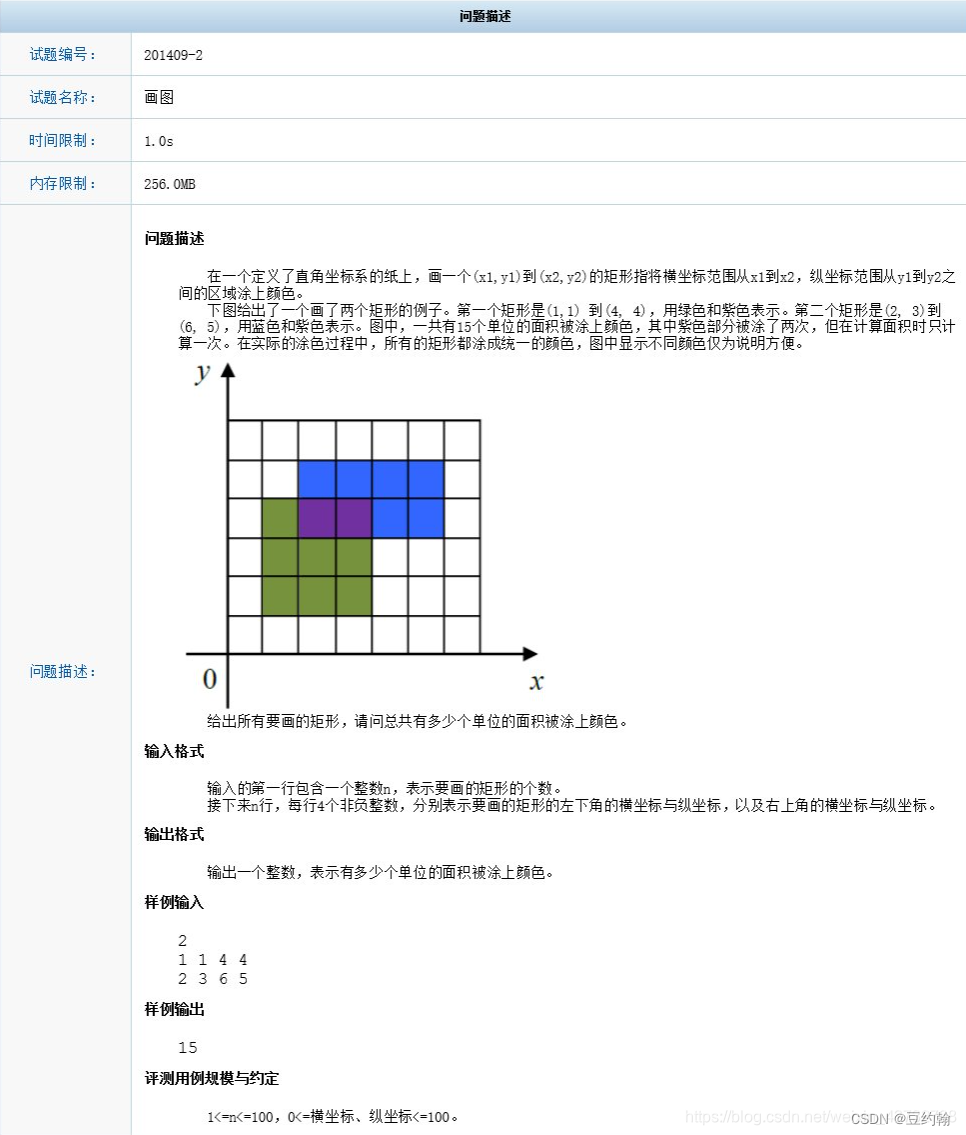
画图(ccf201409-2)解题思路
解题思路 填充100*100二维数组,范围内的元素修改成1,最后累积求和。...
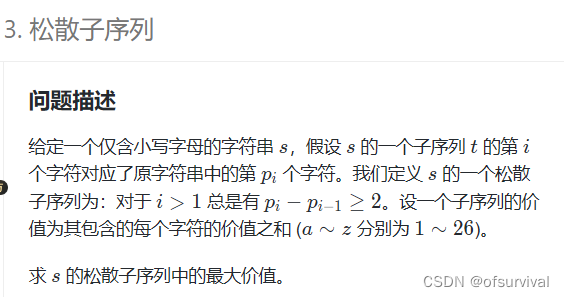
蓝桥杯刷题(一)
一、 import os import sys def dps(s):dp [0] * len(s)dp[0] ord(s[0]) - 96if len(s) 1:return dp[-1]dp[1] max(ord(s[0]) - 96, ord(s[1]) - 96)for i in range(2, len(s)):dp[i] max(dp[i - 1], dp[i - 2] (ord(s[i])) - 96)return dp[-1] s input() print(dps(s))…...

设计模式:策略模式 ⑥
一、策略模式思想 简介 策略模式(Strategy Pattern)属于对象的行为模式。其用意是针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下发生变化。…...

数据结构从入门到精通——顺序表
顺序表 前言一、线性表二、顺序表2.1概念及结构2.2 接口实现2.3 数组相关面试题2.4 顺序表的问题及思考 三、顺序表具体实现代码顺序表的初始化顺序表的销毁顺序表的打印顺序表的增容顺序表的头部/尾部插入顺序表的头部/尾部删除指定位置之前插入数据和删除指定位置数据顺序表元…...

001-CSS-水平垂直居中布局
水平垂直居中布局 方案一:弹性盒子布局方案二:绝对定位 transform方案三:margin 绝对定位,四个方向为零方案四:绝对定位 margin方案五:绝对定位 calc 方案一:弹性盒子布局 💡 T…...
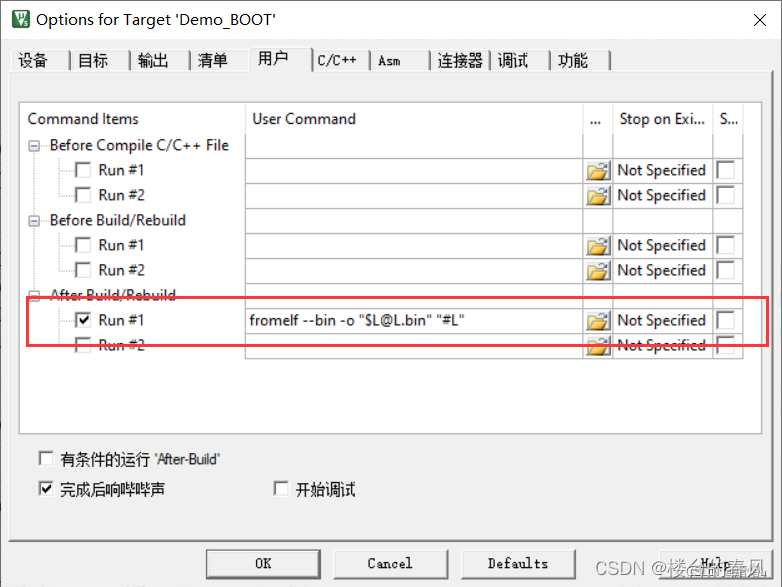
【[STM32]标准库-自定义BootLoader】
[STM32]标准库-自定义BootLoader BootloaderBootloader的实现BOOTloader工程APP工程 Bootloader bootloader其实就是一段启动程序,它在芯片启动的时候最先被执行,可以用来做一些硬件的初始化或者用作固件热更新,当初始化完成之后跳转到对应的…...
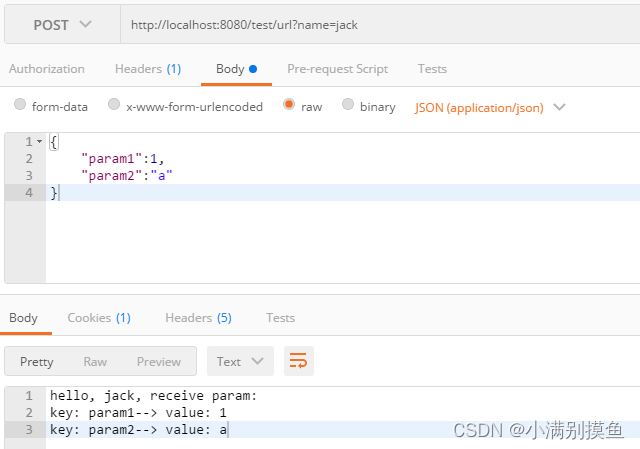
Spring Boot项目中不使用@RequestMapping相关注解,如何动态发布自定义URL路径
一、前言 在Spring Boot项目开发过程中,对于接口API发布URL访问路径,一般都是在类上标识RestController或者Controller注解,然后在方法上标识RequestMapping相关注解,比如:PostMapping、GetMapping注解,通…...

Vue中有哪些优化性能的方法?
Vue是一款流行的JavaScript框架,用于构建交互性强的Web应用程序。在前端开发中,性能优化是一个至关重要的方面,尤其是当应用程序规模变大时。Vue提供了许多优化性能的方法,可以帮助开发人员提升应用程序的性能,从而提升…...
)
为什么顶级策展人不用Google搜文化新闻?Perplexity文化垂直搜索的5层语义增强架构(含可复用prompt工程模板)
更多请点击: https://kaifayun.com 第一章:为什么顶级策展人不用Google搜文化新闻? 顶级策展人并非排斥搜索引擎,而是早已构建起一套高度结构化、语义化、可验证的信息摄取系统——它绕过关键词匹配的偶然性,直击文化…...

别再乱配了!RuoYi-Vue-Plus中Sa-Token的activity-timeout与timeout到底啥区别?一个例子讲透
RuoYi-Vue-Plus中Sa-Token双超时机制:从业务场景到源码的深度实践 在基于Spring Boot的企业级开发中,会话管理一直是安全架构的核心环节。当我第一次在RuoYi-Vue-Plus项目中集成Sa-Token时,配置文件中那对看似相似的参数——activity-timeout…...

CodeGPT高级代理系统:10个实用工具助你高效编程的完整指南
CodeGPT高级代理系统:10个实用工具助你高效编程的完整指南 【免费下载链接】CodeGPT The leading open-source AI copilot for JetBrains. Connect to any model in any environment, and customize your coding experience in any way you like. 项目地址: https…...

CANN/asc-devkit核间同步API文档
CrossCoreWaitFlag(ISASI) 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https…...

Escrcpy终极指南:5分钟掌握Android设备图形化控制与屏幕镜像
Escrcpy终极指南:5分钟掌握Android设备图形化控制与屏幕镜像 【免费下载链接】escrcpy 📱 Display and control your Android device graphically with scrcpy. 项目地址: https://gitcode.com/GitHub_Trending/es/escrcpy 你是否曾经为在电脑上控…...

四旋翼无人机深度强化学习控制框架与实战优化
1. 四旋翼无人机端到端深度强化学习框架解析四旋翼无人机的自主飞行控制一直是机器人学领域的核心挑战。传统PID控制虽然稳定可靠,但在复杂动态环境中表现受限。深度强化学习(DRL)通过模拟环境交互实现智能决策,为无人机控制带来了…...

深度解析Real-ESRGAN:6B轻量模型实现专业级图像超分辨率
深度解析Real-ESRGAN:6B轻量模型实现专业级图像超分辨率 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN Real-ESRGAN_…...

微信AI机器人终极指南:如何用开源工具打造智能群聊助手
微信AI机器人终极指南:如何用开源工具打造智能群聊助手 【免费下载链接】wechat-bot 🤖一个基于 WeChaty 结合 ChatGPT / Claude / Kimi / DeepSeek / Ollama等Ai服务实现的微信机器人 ,可以用来帮助你自动回复微信消息,或者社群分…...

2026年写作类国际竞赛测评:从技术视角分析高含金量赛事与留学背景提升策略
导读:本文基于 2026 年最新赛事数据,从学术认可度、升学加成、参赛门槛、时间成本、获奖概率五个技术维度,对全球主流写作类国际竞赛进行量化测评。通过构建多维度评分模型,为留学申请者提供科学的竞赛选择与背景提升方案。 目录 …...

从CentOS 7/8老用户视角:快速上手CentOS 9 Stream的3个界面变化与5个安装配置新坑
从CentOS 7/8老用户视角:快速上手CentOS 9 Stream的3个界面变化与5个安装配置新坑 作为一名长期与CentOS打交道的系统管理员,第一次接触CentOS 9 Stream时,那种"熟悉又陌生"的感觉尤为明显。表面上看,它延续了红帽系一贯…...