数据结构从入门到精通——顺序表
顺序表
- 前言
- 一、线性表
- 二、顺序表
- 2.1概念及结构
- 2.2 接口实现
- 2.3 数组相关面试题
- 2.4 顺序表的问题及思考
- 三、顺序表具体实现代码
- 顺序表的初始化
- 顺序表的销毁
- 顺序表的打印
- 顺序表的增容
- 顺序表的头部/尾部插入
- 顺序表的头部/尾部删除
- 指定位置之前插入数据和删除指定位置数据
- 顺序表元素的查找
- 四、顺序表完整代码
- text.h
- text.c
- main.c
前言
顺序表是一种常见的线性数据结构,它使用一段连续的存储单元依次存储数据元素。这种数据结构的特点是逻辑上相邻的元素在物理存储位置上也相邻,因此可以快速地访问表中的任意元素。
顺序表的实现通常依赖于数组,数组是一种静态的数据结构,一旦创建,其大小就是固定的。这意味着在顺序表中插入或删除元素可能会导致空间的浪费或不足。例如,如果在一个已经满了的顺序表中插入一个新元素,就需要重新分配更大的数组空间,并将原有元素复制到新数组中,这是一个相对耗时的操作。
然而,顺序表在访问元素时具有很高的效率。由于元素在内存中是连续存储的,计算机可以直接通过计算偏移量来访问任意位置的元素,这种访问方式的时间复杂度为O(1)。相比之下,链表等动态数据结构在访问元素时可能需要遍历多个节点,效率较低。
顺序表还支持快速的元素查找。通过索引,我们可以在常数时间内找到表中的任意元素。这种特性使得顺序表在处理需要频繁查找操作的场景时表现出色。
总的来说,顺序表是一种高效、简单的数据结构,适用于需要快速访问和查找元素的场景。然而,它的固定大小特性也限制了其在需要频繁插入和删除操作的场景中的应用。在实际应用中,我们需要根据具体的需求和场景来选择合适的数据结构。
一、线性表
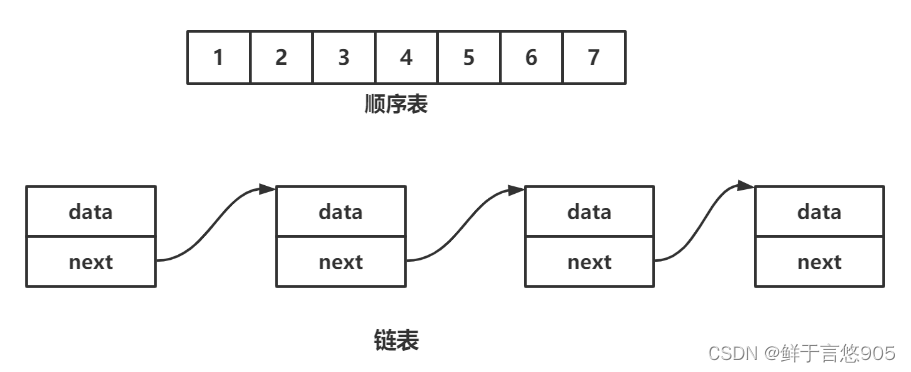
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
二、顺序表
2.1概念及结构
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
顺序表一般可以分为:
- 静态顺序表:使用定长数组存储元素。

- 动态顺序表:使用动态开辟的数组存储。
2.2 接口实现
静态顺序表只适用于确定知道需要存多少数据的场景。静态顺序表的定长数组导致N定大了,空间开多了浪费,开少了不够用。所以现实中基本都是使用动态顺序表,根据需要动态的分配空间大小,所以下面我们实现动态顺序表。
typedef int SLDataType;
// 顺序表的动态存储
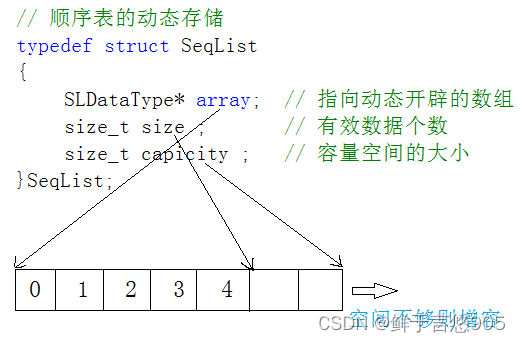
typedef struct SeqList
{SLDataType* array; // 指向动态开辟的数组size_t size ; // 有效数据个数size_t capicity ; // 容量空间的大小
}SeqList;
// 基本增删查改接口
// 顺序表初始化
void SeqListInit(SeqList* psl);
// 检查空间,如果满了,进行增容
void CheckCapacity(SeqList* psl);
// 顺序表尾插
void SeqListPushBack(SeqList* psl, SLDataType x);
// 顺序表尾删
void SeqListPopBack(SeqList* psl);
// 顺序表头插
void SeqListPushFront(SeqList* psl, SLDataType x);
// 顺序表头删
void SeqListPopFront(SeqList* psl);
// 顺序表查找
int SeqListFind(SeqList* psl, SLDataType x);
// 顺序表在pos位置插入x
void SeqListInsert(SeqList* psl, size_t pos, SLDataType x);
// 顺序表删除pos位置的值
void SeqListErase(SeqList* psl, size_t pos);
// 顺序表销毁
void SeqListDestory(SeqList* psl);
// 顺序表打印
void SeqListPrint(SeqList* psl);
2.3 数组相关面试题
- 原地移除数组中所有的元素val,要求时间复杂度为O(N),空间复杂度为O(1)
- 删除排序数组中的重复项
- 合并两个有序数组
2.4 顺序表的问题及思考
问题:
- 中间/头部的插入删除,时间复杂度为O(N)
- 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
- 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到
200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
思考:如何解决以上问题呢?
三、顺序表具体实现代码
顺序表的初始化
void SLInit(SL* p);//顺序表的初始化
void SLInit(SL* p)
{p->arr = NULL;//动态开辟数组的地址置为空指针p->capacity = 0;//数组容量置为0p->size = 0;//数组下标置为0或-1,具体看你需要哪一种下标
}
顺序表的初始化是数据结构学习中不可或缺的一步,它指的是为一个预先分配了固定大小内存空间的线性表分配存储空间,并设置其初始状态。在顺序表中,数据元素在内存中是连续存放的,这种存储方式使得我们可以通过下标直接访问任何位置的元素,从而实现了快速的元素访问。
顺序表的初始化通常包括分配内存空间、设定初始容量、以及可能的初始化所有元素为某一默认值。初始化操作的正确与否直接关系到后续数据操作的效率与正确性。
以C语言为例,顺序表可以用数组来实现。在初始化时,我们通常会定义一个结构体来表示顺序表,这个结构体包含数组本身、数组的大小(即当前已存储的元素数量)以及数组的最大容量(即预先分配的内存空间大小)。
顺序表的销毁
void SLDestroy(SL* p);//顺序表的销毁
void SLDestroy(SL* p)
{assert(p);int i = 0; free(p->arr);SLInit(p);
}
在数据结构和算法的世界里,顺序表作为一种基本的线性表结构,承载着数据的存储和访问功能。然而,正如任何资源的生命周期一样,顺序表的使用也需要在结束时进行适当的销毁和清理,以确保内存的有效利用和系统的稳定运行。
顺序表的销毁,主要涉及到内存的释放。当一个顺序表不再需要使用时,我们必须将其所占用的内存空间归还给操作系统,避免内存泄漏。内存泄漏是程序运行过程中未能正确释放不再使用的内存空间,长时间累积下来会导致可用内存空间减少,最终可能导致程序运行缓慢甚至崩溃。
销毁顺序表的过程通常包括以下步骤:
-
遍历顺序表,释放其中存储的每一个数据元素。如果数据元素是指针类型,需要确保这些指针指向的内存也被正确释放。
-
释放顺序表本身所占用的内存空间。这通常通过调用相应的内存释放函数(如C语言中的
free()函数)来实现。 -
将顺序表的头指针或引用设置为
null或nullptr,表示该顺序表已经不再有效,防止后续代码错误地访问或操作已销毁的顺序表。 -
在某些情况下,可能还需要进行额外的清理工作,如关闭与顺序表相关的文件、释放其他相关资源等。
通过以上步骤,我们可以确保顺序表在不再使用时能够被正确地销毁,从而保持程序的内存安全和稳定运行。在实际编程中,我们应该始终遵循资源管理的最佳实践,确保在适当的时候释放不再需要的资源,避免内存泄漏和其他潜在问题。
顺序表的打印
void SLprint(SL p);//顺序表的打印
void SLprint(SL p)
{for (int i = 0; i < p.size; i++){printf("%5d", p.arr[i]);}printf("\n");
}
顺序表的打印通常指的是将顺序表中的所有元素按照一定的格式输出到控制台或其他输出设备上。这个过程通常涉及到遍历顺序表中的所有元素,并将它们转换为人类可读的格式。在打印顺序表时,我们通常会选择一种易于阅读和理解的方式,如按照元素在表中的顺序依次打印,或者使用特定的分隔符将不同的元素分隔开。
顺序表的增容

void SLCheckCapacity(SL* ps);//顺序表的增容
void SLCheckCapacity(SL* p)
{SL* a;assert(p);int Datacapaity = 0;if (p->size == p->capacity){Datacapaity = 0 ? 4 : 2 * p->capacity;//三目运算符a = (DataType*)realloc(p->arr, Datacapaity * sizeof(DataType));//使得扩容按照2倍增长assert(a);p->arr = a;}p->capacity = Datacapaity;
}
顺序表是一种线性数据结构,它使用一段连续的存储空间来存储元素。当顺序表中的元素数量达到其当前容量上限时,就需要进行增容操作,以确保可以继续添加新的元素。
增容操作的核心思想是为顺序表分配更多的连续存储空间,并将原有的元素复制到新的存储空间中。这通常涉及到两个主要步骤:分配新的存储空间和元素迁移。
分配新的存储空间是增容操作的第一步。顺序表会根据其当前容量和扩容因子来计算出新的容量。扩容因子是一个大于1的常数,用于确定每次增容时应该增加多少存储空间。例如,如果扩容因子为2,那么每次增容时新的容量将是原容量的两倍。
在分配了新的存储空间之后,接下来就是元素迁移的步骤。这一步将顺序表中原有的元素从旧的存储空间复制到新的存储空间中。为了保证数据的完整性和正确性,复制过程必须小心谨慎地进行。通常,复制过程会从顺序表的第一个元素开始,逐个复制到新的存储空间的相应位置,直到所有元素都被复制完毕。
完成元素迁移后,顺序表就可以继续使用新的存储空间来存储新的元素了。同时,顺序表的容量上限也得到了提升,可以容纳更多的元素。
需要注意的是,增容操作虽然可以扩展顺序表的容量,但也会带来一定的性能开销。因为每次增容都需要分配新的存储空间并进行元素迁移,这些操作都需要消耗一定的时间和资源。因此,在设计和实现顺序表时,需要权衡扩容的时机和频率,以避免频繁的增容操作对性能产生负面影响。
为了优化性能,可以在顺序表的使用过程中采取一些策略来减少增容的次数。例如,可以在添加元素之前先检查顺序表的容量是否足够,如果不足够则提前进行增容操作,以避免在添加元素时触发频繁的增容。此外,还可以根据实际应用场景和数据特点来选择合适的扩容因子,以平衡存储空间的利用率和增容操作的开销。
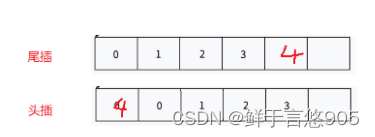
顺序表的头部/尾部插入
//顺序表的头部/尾部插入
void SLPushBack(SL* p, DataType x);
void SLPushFront(SL* p, DataType x);
void SLPushBack(SL* p, DataType x)//顺序表的尾插
{assert(p);SLCheckCapacity(p);//增容p->arr[p->size++] = x;
}void SLPushFront(SL* p, DataType x)//顺序表的头插
{assert(p);SLCheckCapacity(p);//增容for (int i = p->size; i > 0; i--){p->arr[i] = p->arr[i - 1];}p->arr[0] = x;p->size++;
}
顺序表的头部/尾部插入是顺序表操作中的基本功能,它们直接影响了顺序表的数据存储和访问效率。顺序表,又称数组列表,是一种线性表的数据结构,其特点是元素在内存中是连续存储的。这种存储方式使得顺序表在访问元素时具有很高的效率,因为可以通过下标直接定位到元素的位置。然而,在插入或删除元素时,顺序表的表现就不如链表等其他数据结构了。
在顺序表的头部插入元素时,需要将所有已存在的元素向后移动一位,以腾出空间给新插入的元素。这种操作的时间复杂度是O(n),其中n是顺序表的长度。因此,对于频繁在头部插入元素的场景,顺序表并不是最优的数据结构选择。
相比之下,在顺序表的尾部插入元素则相对高效。因为尾部是顺序表的一个“开放”端,新元素可以直接添加到这个位置,而不需要移动其他元素。这种操作的时间复杂度是O(1),即常数时间复杂度,意味着无论顺序表有多大,尾部插入的效率都是相同的。
在实际应用中,顺序表的头部/尾部插入操作常常用于实现各种算法和数据结构。例如,在某些需要动态维护数据集合的场景中,我们可以使用顺序表来存储数据,并根据需要在头部或尾部进行插入操作。此外,顺序表还可以用于实现栈(Stack)和队列(Queue)等数据结构,其中栈通常使用顺序表的头部进行插入和删除操作,而队列则使用头部进行删除操作,使用尾部进行插入操作。
需要注意的是,虽然顺序表在访问元素时具有很高的效率,但在插入和删除元素时可能会遇到性能瓶颈。因此,在选择数据结构时,我们需要根据具体的应用场景和需求来权衡各种因素,以选择最适合的数据结构。
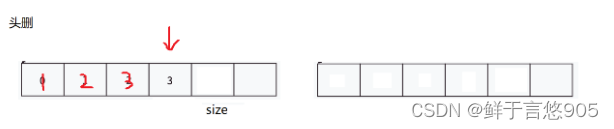
顺序表的头部/尾部删除

//顺序表的头部/尾部删除
void SLPopBack(SL* p);
void SLPopFront(SL* p);
void SLPopBack(SL* p)
{assert(p);assert(p->size);p->size--;
}
void SLPopFront(SL* p)
{assert(p);assert(p->size);for (int i = 0; i < p->size - 1; i++){p->arr[i] = p->arr[i + 1];}p->size--;
}
顺序表的头部/尾部删除是数据结构中常见的操作,它们分别涉及到对顺序表的首个元素和最后一个元素的移除。这两种操作在多种应用场景中都具有重要的意义,比如缓存管理、消息队列、数据库索引等。
在顺序表(数组)中实现头部删除操作,通常需要将数组中的所有元素向前移动一位,以填补被删除元素的位置。这种操作的时间复杂度为O(n),其中n为数组的长度。如果顺序表是动态分配的,并且有足够的空间,也可以采用标记删除的方式,即简单地将头部元素标记为已删除,而不实际移动其他元素。但这种方法需要额外的逻辑来跟踪哪些元素是已删除的,因此可能会增加空间和时间上的开销。
相比之下,尾部删除操作通常更为简单和高效。在顺序表中,尾部元素总是位于数组的最后一个位置,因此删除它不需要移动其他元素。只需将数组的最后一个元素的位置标记为未使用,或者如果使用的是动态数组,可以减少其容量以释放未使用的空间。这种操作的时间复杂度通常为O(1)。
然而,需要注意的是,虽然尾部删除在单个操作上可能更快,但在频繁进行头部删除的情况下,顺序表可能不是最优的数据结构选择。在这种情况下,使用链表可能更为合适,因为链表在头部和尾部删除操作上的时间复杂度都是O(1)。
指定位置之前插入数据和删除指定位置数据
//指定位置之前插入数据
//删除指定位置数据
void SLInsert(SL* p, int pos, DataType x);
void SLErase(SL* p, int pos);
void SLInsert(SL* p, int pos, DataType x)
{assert(p);assert(pos>=0 && pos <= p->size);SLCheckCapacity(p);for (int i = p->size; i >= pos; i--){p->arr[i] = p->arr[i - 1];}p->arr[pos] = x;p->size++;
}
void SLErase(SL* p, int pos)
{assert(p);assert(pos >= 0 && pos <= p->size);for (int i = pos - 1; i < p->size; i++){p->arr[i] = p->arr[i + 1];}p->size--;
}
指定位置之前插入数据和删除指定位置数据是编程中常见的操作,尤其在处理列表、数组、字符串等数据结构时。这些操作不仅对于数据的管理和维护至关重要,而且在很多算法和程序设计中也扮演着重要角色。
在插入数据时,我们通常需要考虑以下几个因素:插入的位置、要插入的数据以及插入后数据结构的完整性。
在删除指定位置的数据时,我们需要确保删除操作不会破坏数据结构的其余部分。
需要注意的是,在进行插入和删除操作时,我们需要确保索引的有效性。如果索引超出数据结构的范围,那么程序会抛出异常。因此,在实际编程中,我们通常需要在进行这些操作之前先检查索引的有效性。
此外,插入和删除操作的时间复杂度也是我们需要考虑的因素。在大多数数据结构中,插入和删除操作的时间复杂度都是O(n),其中n是数据结构的长度。这意味着,随着数据结构的增长,这些操作所需的时间也会增加。因此,在选择数据结构时,我们需要根据实际需求来权衡各种因素,包括插入和删除操作的频率、数据结构的长度以及所需的空间等。
总的来说,指定位置之前插入数据和删除指定位置数据是编程中常见的操作,我们需要熟练掌握这些操作的方法和技巧,以便在实际编程中能够灵活应用。同时,我们还需要注意操作的有效性和时间复杂度等问题,以确保程序的正确性和效率。
顺序表元素的查找
//顺序表元素的查找
int SLFind(SL p, DataType x);
int SLFind(SL* p, DataType x)
{assert(p);for (int i = 0; i < p->size; i++){if (p->arr[i] == x)return i + 1;}return -1;
}
顺序表元素的查找是计算机科学中的一个基本问题,它涉及到在一个有序或无序的列表中查找特定的元素。在各种实际应用中,如数据库管理、搜索引擎、编程语言中的数据结构等,顺序表元素的查找都扮演着重要的角色。
对于顺序表元素的查找,最基础的算法是线性查找。线性查找的思想是从表的第一个元素开始,逐个比较每个元素,直到找到目标元素或遍历完整个表。这种查找方法的时间复杂度为O(n),其中n为表的长度。虽然线性查找简单易懂,但在处理大数据量时,其效率往往不能满足要求。
为了提高查找效率,人们设计了更为高效的查找算法,如二分查找。二分查找只适用于有序的顺序表,其基本思想是将表分为两半,通过比较目标元素与中间元素的大小,决定在哪一半继续查找,如此反复,直到找到目标元素或确定目标元素不存在于表中。二分查找的时间复杂度为O(log n),在数据量较大时,其效率远高于线性查找。
除了二分查找,还有一些其他的查找算法,如插值查找和斐波那契查找等。插值查找是对二分查找的一种改进,它根据目标元素在表中的大致位置,选择一个更接近于目标元素的中间元素进行比较,从而减少比较次数。斐波那契查找则是利用斐波那契数列的性质,通过计算斐波那契数来确定查找范围,进一步提高查找效率。
在实际应用中,选择哪种查找算法取决于具体的需求和场景。对于有序的顺序表,二分查找、插值查找和斐波那契查找等高效算法是更好的选择;而对于无序的顺序表,线性查找可能是唯一可行的选择。此外,还可以根据表的大小、元素的分布等因素来选择合适的查找算法。
四、顺序表完整代码
text.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int DataType;静态顺序表
//typedef struct Seqlist
//{
// DataType data[10];
// int size;
//}Seqlist;//动态顺序表
typedef struct Seqlist
{DataType* arr;int size;int capacity;
}SL;void SLCheckCapacity(SL* ps);//顺序表的增容void SLInit(SL* p);//顺序表的初始化
void SLDestroy(SL* p);//顺序表的销毁
void SLprint(SL p);//顺序表的打印//顺序表的头部/尾部插入
void SLPushBack(SL* p, DataType x);
void SLPushFront(SL* p, DataType x);//顺序表的头部/尾部删除
void SLPopBack(SL* p);
void SLPopFront(SL* p);//指定位置之前插入数据
//删除指定位置数据
void SLInsert(SL* p, int pos, DataType x);
void SLErase(SL* p, int pos);
int SLFind(SL p, DataType x);
text.c
#include"text.h"
void SLCheckCapacity(SL* p)
{SL* a;assert(p);int Datacapaity = 0;if (p->size == p->capacity){Datacapaity = 0 ? 4 : 2 * p->capacity;a = (DataType*)realloc(p->arr, Datacapaity * sizeof(DataType));assert(a);p->arr = a;}p->capacity = Datacapaity;
}void SLInit(SL* p)
{p->arr = NULL;p->capacity = 0;p->size = 0;
}
void SLDestroy(SL* p)
{int i = 0; for (i = 0; i < p->size; i++){free(p->arr[i]);}SLInit(p);
}
void SLprint(SL p)
{for (int i = 0; i < p.size; i++){printf("%5d", p.arr[i]);}printf("\n");
}void SLPushBack(SL* p, DataType x)
{assert(p);SLCheckCapacity(p);p->arr[p->size++] = x;
}void SLPushFront(SL* p, DataType x)
{assert(p);SLCheckCapacity(p);for (int i = p->size; i > 0; i--){p->arr[i] = p->arr[i - 1];}p->arr[0] = x;p->size++;
}void SLPopBack(SL* p)
{assert(p);assert(p->size);p->size--;
}
void SLPopFront(SL* p)
{assert(p);assert(p->size);for (int i = 0; i < p->size - 1; i++){p->arr[i] = p->arr[i + 1];}p->size--;
}void SLInsert(SL* p, int pos, DataType x)
{assert(p);assert(pos>=0 && pos <= p->size);SLCheckCapacity(p);for (int i = p->size; i >= pos; i--){p->arr[i] = p->arr[i - 1];}p->arr[pos] = x;p->size++;
}
void SLErase(SL* p, int pos)
{assert(p);assert(pos >= 0 && pos <= p->size);for (int i = pos - 1; i < p->size; i++){p->arr[i] = p->arr[i + 1];}p->size--;
}int SLFind(SL* p, DataType x)
{assert(p);for (int i = 0; i < p->size; i++){if (p->arr[i] == x)return i + 1;}return -1;
}
main.c
#include"text.h"void slTest01() {SL sl;SLInit(&sl);SLPushBack(&sl, 1);SLPushBack(&sl, 2);SLPushBack(&sl, 3);SLPushBack(&sl, 4);SLprint(sl); //1 2 3 4SLPushBack(&sl, 5);SLprint(sl);SLPushFront(&sl, 5);SLPushFront(&sl, 6);SLPushFront(&sl, 7);SLprint(sl); //7 6 5 1 2 3 4SLPopBack(&sl);SLPopBack(&sl);SLPopBack(&sl);SLPopBack(&sl);SLprint(sl); //1 2SLPopFront(&sl);SLPopFront(&sl);SLPopFront(&sl);//SLPopFront(&sl);SLprint(sl); //3 4//SLInsert(&sl, 0, 100);//SLprint(sl); //100 1 2 3 4//SLInsert(&sl, sl.size, 200);//SLprint(sl); //100 1 2 3 4 200//SLInsert(&sl, 100, 300);//SLprint(sl);//SLErase(&sl, 0);//SLprint(sl); //2 3 4//SLErase(&sl, sl.size - 1);//SLErase(&sl, 1);//SLprint(sl);//1 3 4
}int main()
{slTest01();return 0;
}
相关文章:
数据结构从入门到精通——顺序表
顺序表 前言一、线性表二、顺序表2.1概念及结构2.2 接口实现2.3 数组相关面试题2.4 顺序表的问题及思考 三、顺序表具体实现代码顺序表的初始化顺序表的销毁顺序表的打印顺序表的增容顺序表的头部/尾部插入顺序表的头部/尾部删除指定位置之前插入数据和删除指定位置数据顺序表元…...

001-CSS-水平垂直居中布局
水平垂直居中布局 方案一:弹性盒子布局方案二:绝对定位 transform方案三:margin 绝对定位,四个方向为零方案四:绝对定位 margin方案五:绝对定位 calc 方案一:弹性盒子布局 💡 T…...
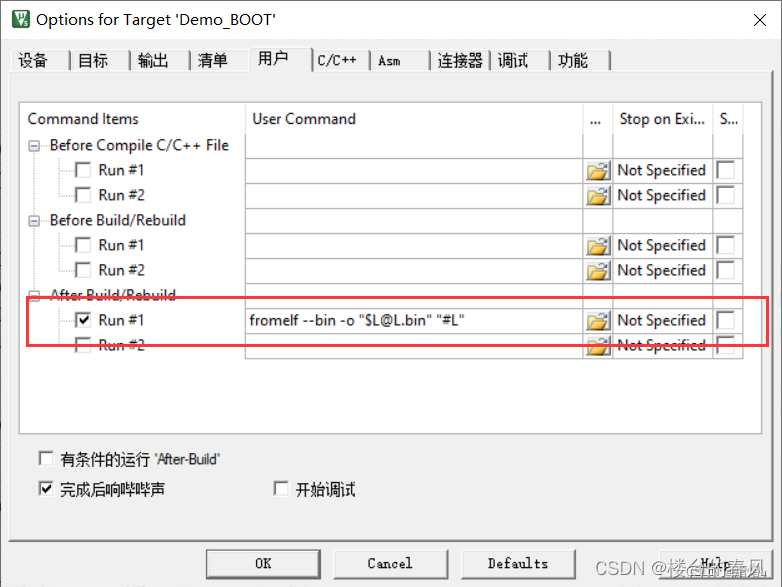
【[STM32]标准库-自定义BootLoader】
[STM32]标准库-自定义BootLoader BootloaderBootloader的实现BOOTloader工程APP工程 Bootloader bootloader其实就是一段启动程序,它在芯片启动的时候最先被执行,可以用来做一些硬件的初始化或者用作固件热更新,当初始化完成之后跳转到对应的…...
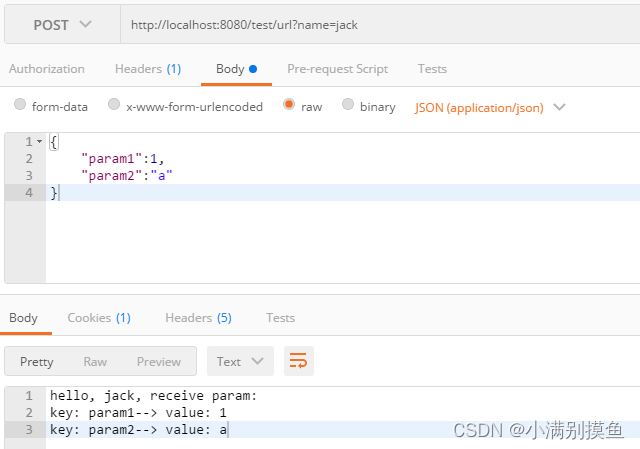
Spring Boot项目中不使用@RequestMapping相关注解,如何动态发布自定义URL路径
一、前言 在Spring Boot项目开发过程中,对于接口API发布URL访问路径,一般都是在类上标识RestController或者Controller注解,然后在方法上标识RequestMapping相关注解,比如:PostMapping、GetMapping注解,通…...

Vue中有哪些优化性能的方法?
Vue是一款流行的JavaScript框架,用于构建交互性强的Web应用程序。在前端开发中,性能优化是一个至关重要的方面,尤其是当应用程序规模变大时。Vue提供了许多优化性能的方法,可以帮助开发人员提升应用程序的性能,从而提升…...

Python pandas遍历行数据的2种方法
背景 pandas在数据处理过程中,除了对整列字段进行处理之外,有时还需求对每一行进行遍历,来处理每行的数据。本篇文章介绍 2 种方法,来遍历pandas 的行数据 小编环境 import sysprint(python 版本:,sys.version.spli…...

Spring之@Transactional源码解析
前言 我们在日常开发的时候经常会用到组合注解,比如:EnableTransactionManagement Transactional、EnableAsync Async、EnableAspectJAutoProxy Aspect。今天我们就来抽丝剥茧,揭开Transactional注解的神秘面纱 EnableTransactionManagement注解的作用 当我们看到类似Ena…...

第三届国际亲子游泳学术峰会,麒小佑为亲游行业提供健康解决方案
第三届国际亲子游泳学术峰会大合影 2024年2月26—28日,第三届国际亲子游泳学术峰会在中国青岛成功召开。 第三届国际亲子游泳学术峰会是中国婴幼游泳行业最高标准的学术性会议,由亲游圈主办,旨在为本行业搭建一个高端圈层,帮助机…...

Python光速入门 - Flask轻量级框架
FlASK是一个轻量级的WSGI Web应用程序框架,Flask的核心包括Werkzeug工具箱和Jinja2模板引擎,它没有默认使用的数据库或窗体验证工具,这意味着用户可以根据自己的需求选择不同的数据库和验证工具。Flask的设计理念是保持核心简单,…...

C/C++ 说说引用这玩仍是干啥的
引用的本质就是给某个实例对象起个外号。生活中李逵,也叫黑旋风。诸葛亮,又叫孔明。 引用的方式: 类型& 引用名对象名 举个例子 int i0; int& ki;//这种方式就是引用----->i有了自己的小名,从次叫k了 std::cout<…...
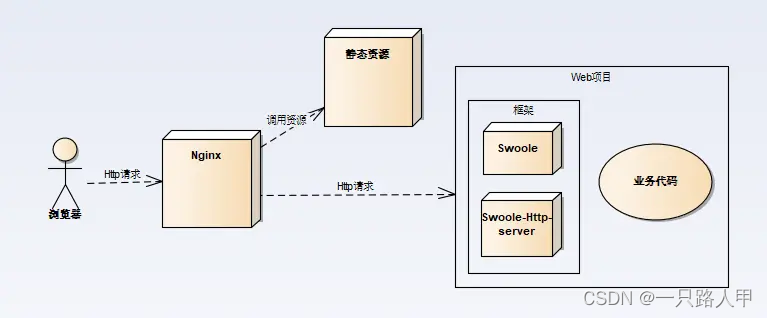
swoole
php是单线程。php是靠多进程来处理任务,任何后端语言都可以采用多进程处理方式。如我们常用的php-fpm进程管理器。线程与协程,大小的关系是进程>线程>协程,而我们所说的swoole让php实现了多线程,其实在这里来说,就是好比让php创建了多个进程,每个进程执行一条…...

kubectl基础命令详解
管理名称空间资源 查看名称空间 [rootceshi-130 conf]# kubectl get ns [rootceshi-130 conf]# kubectl get namespace NAME STATUS AGE default Active 7d17h kube-node-lease Active 7d17h kube-public Active 7d17h kube-system …...

collection的遍历方式
增强for遍历 增强for的底层就是迭代器,为了简化迭代器的代码书写的。 他是jdk5之后出现的,其内部原理就是一个Iterator迭代器。 所有的单列集合和数组才能用增强for进行遍历。 package myCollection;import java.util.ArrayList; import java.util.C…...

SpringBoot中@Async使用注意事项
前言 Async这个注解想必大家都用过,是用来实现异步调用的。一个方法加上这个注解以后,当被调用时会使用新的线程来调用。但其实这里面也有一个坑。 问题 这个注解使用时存在如下问题:在没有自定义线程池的场景下,默认会采用Sim…...
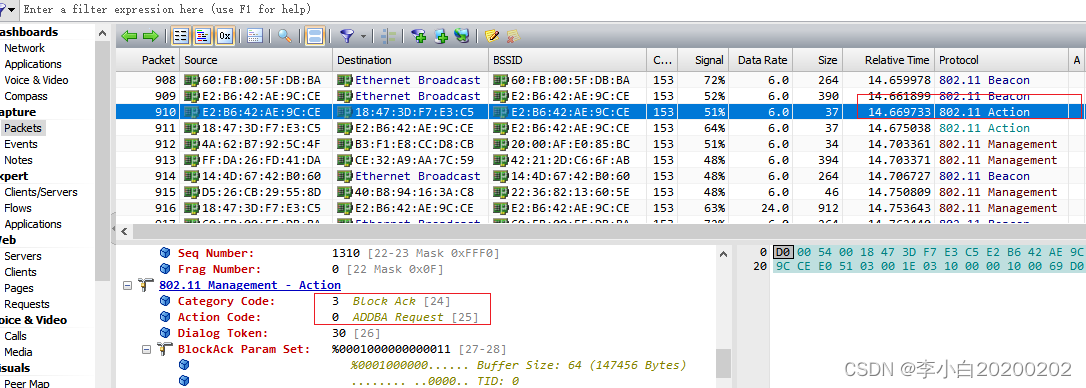
IEEE 802.11 RTS/CTS/BA/Management
RTS/CTS IEEE 802.11 RTS/CTS即RTS/CTS协议(Request To Send/Clear To Send)即请求发送/清除发送协议是被802.11无线网络协议采用的一种用来减少由隐藏节点问题所造成的冲突的机制。 相当于一种握手协议,主要用来解决"隐藏终端"问题。"隐藏终端"(Hid…...

【风格迁移】对比度保持连贯性损失 CCPL:解决图像局部失真、视频帧间的连贯性和闪烁
对比度保持连贯性损失 CCPL:解决图像局部失真、视频帧间的连贯性和闪烁 提出背景解法:对比度保持连贯性损失(CCPL) 局部一致性假设 对比学习机制 邻域调节策略 互信息最大化对比学习:在无需标签的情况下有效学习区分…...

【C++】贪心算法
贪心算法(Greedy Algorithm)是一种基于贪心策略的算法,它在每一步选择中都采取当前状态下最优的选择,以希望最终得到全局最优解。贪心算法通常适用于满足最优子结构性质的问题,即问题的最优解可以通过其子问题的最优解…...
记一次dockerfile无法构建问题追溯
我有一个dockerfile如下: ENTRYPOINT ["/sbin/tini","-g", "--"] CMD /home/scrapy/start.sh 我原本的用意是先启动tini,再执行下面的cmd命令启动start.sh。 为啥要用tini? 因为我的这个docker…...
)
React使用 useImperativeHandle 自定义暴露给父组件的实例方法(包括依赖)
关键词 React useImperativeHandle 摘要 useImperativeHandle 是 React 提供的一个自定义 Hook,用于在函数组件中显式地暴露给父组件特定实例的方法。本文将介绍 useImperativeHandle 的基本用法、常见应用场景,以及如何处理其依赖项,以帮…...
yolov5v7v8目标检测增加计数功能--免费源码
在yolo系列中,很多网友都反馈过想要在目标检测的图片上,显示计数功能。其实官方已经实现了这个功能,只不过没有把相关的参数写到图片上。所以微智启软件工作室出一篇教程,教大家如何把计数的参数打印到图片上。 一、yolov5目标检测…...

巡检记录分析不全面,导致安全隐患遗漏频发怎么办?揭秘实在Agent非侵入式提效方案
摘要:在2026年工业4.0与智慧安全深度融合的背景下,许多企业仍面临“巡检记录分析不全面,安全隐患遗漏频发”的顽疾。传统的纸质记录或初级数字化巡检,往往因数据孤岛、老旧系统无API接口、以及AI无法触达内网执行层等问题…...

【习题02】打印菱形
题目: 用C语言在屏幕上输出以下图案:1、题目分析: 这道题目需要打印一个菱形,经过分析可得每一行就是打印空格和*。 经过观察可得: 第一行:6个空格 1个*第二行:5个空格 3个*第三行:4…...
)
ArcGIS Pro 3.x 批量处理遥感栅格:用Python脚本实现自动化转点、计算与导出(附完整代码)
ArcGIS Pro 3.x 遥感栅格自动化处理实战:从数据清洗到生产级流水线构建 遥感数据分析师常常需要处理TB级的时序栅格数据,比如月度NDVI指数、地表温度或降水分布。传统手动操作不仅效率低下,还容易因人为失误导致数据不一致。本文将分享如何基…...

3分钟学会在Windows上安装安卓应用:APK-Installer完整指南
3分钟学会在Windows上安装安卓应用:APK-Installer完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行安卓应用,…...

DouZero AI斗地主助手:基于深度学习的终极实战指南
DouZero AI斗地主助手:基于深度学习的终极实战指南 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 还在为欢乐斗地主的复杂决策而烦恼吗?…...

猫头鹰的秘密网络
原文:towardsdatascience.com/the-secret-network-of-owls-d55e7b2c4910 你知道 8 月 4 日是国际猫头鹰意识日吗?我也不知道,直到无聊地浏览可爱的猫头鹰表情包,这让我来到了这个网站。然后,正如我们最近在我们的花园里…...

5分钟掌握FanControl:Windows风扇控制终极指南,告别噪音与过热烦恼
5分钟掌握FanControl:Windows风扇控制终极指南,告别噪音与过热烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode…...

电压控制模式降压变换器环路设计与仿真实战
1. 项目概述:从理论到实践的降压电路设计在电源设计领域,降压变换器(Buck Converter)是应用最广泛的拓扑之一,它负责将较高的输入直流电压稳定地转换为较低的输出直流电压。无论是给手机充电的适配器,还是为…...

3种高效方案解析:如何深度还原微信小程序源代码结构
3种高效方案解析:如何深度还原微信小程序源代码结构 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 你是否曾面对一个加密的微信小程序包&…...

AI行业的“伦理困境”:隐私保护、算法偏见与失业问题
在人工智能技术飞速发展的今天,软件测试行业正经历着前所未有的变革。AI测试工具的广泛应用,极大提升了测试效率,改变了传统测试流程。然而,技术进步的同时,一系列伦理困境也随之而来,隐私保护、算法偏见与…...