使用Tesseract-OCR对PDF等图片文件进行文字识别
安装
用 Homebrew 来安装 Tesseract
brew install tesseract
2. 完成 tessearact 的安装后,还需要安装中文数据包,执行以下两个操作,
brew info tesseract
执行这个指令的目的,是找到 Homebrew 把 tesseract 安装在文件夹内,例如,
/usr/local/Cellar/tesseract/3.05.02/share/tessdata/.
然后打开 Tesseract 的语言数据包的网页,点击 “chi_sim.traineddata”,电脑自动下载简体中文数据包。
git clone https://github.com/tesseract-ocr/tessdata_fast.git
git clone https://github.com/tesseract-ocr/tessdata_best.git 高清版
GitHub - tesseract-ocr/tessdata_best: Best (most accurate) trained LSTM models.
最后,把简体中文数据包chi_sim.traineddata,复制安装 tesseract 的文件夹内。
命令行用法
我们首先来看tesseract是否正确安装,同时验证版本:
$ tesseract --version
tesseract 4.1.0-rc1-56-g7fbdleptonica-1.76.0libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.4.2) : libpng 1.2.54 : libtiff 4.0.6 : zlib 1.2.8 : libwebp 0.4.4 : libopenjp2 2.1.2Found AVX2Found AVXFound SSE识别的基本用法是”imagename outputbase [options…]”,4.1的版本options只能通过”-l”选择语言,比如:
tesseract test.png test -l chi_sim
它对test.png进行ocr,然后把识别结果保存在test.txt里。默认输出格式是文本文件,我们也可以让它输出pdf:
tesseract test.png test -l chi_sim pdf
除此之外,还有隐藏(extrac)的选项,需要样这个命令才会显示这些高级功能:
$ tesseract --help-extra
Usage:tesseract --help | --help-extra | --help-psm | --help-oem | --versiontesseract --list-langs [--tessdata-dir PATH]tesseract --print-parameters [options...] [configfile...]tesseract imagename|imagelist|stdin outputbase|stdout [options...] [configfile...]OCR options:--tessdata-dir PATH Specify the location of tessdata path.--user-words PATH Specify the location of user words file.--user-patterns PATH Specify the location of user patterns file.--dpi VALUE Specify DPI for input image.-l LANG[+LANG] Specify language(s) used for OCR.-c VAR=VALUE Set value for config variables.Multiple -c arguments are allowed.--psm NUM Specify page segmentation mode.--oem NUM Specify OCR Engine mode.
NOTE: These options must occur before any configfile....省略了psm和oem的详细解释,后面会介绍。
比如使用psm,很多老的文档都是:
tesseract test.png test -l chi_sim -psm 1
这在新版本会有问题,必须用–psm才行:
tesseract test.png test -l chi_sim --psm 1
参数–oem指定使用的算法,0代表老的算法;1代表LSTM算法;2代表两者的结合;3代表系统自己选择。
参数–psm指定页面切分模式:
Page segmentation modes:0 Orientation and script detection (OSD) only.1 Automatic page segmentation with OSD.2 Automatic page segmentation, but no OSD, or OCR. (not implemented)3 Fully automatic page segmentation, but no OSD. (Default)4 Assume a single column of text of variable sizes.5 Assume a single uniform block of vertically aligned text.6 Assume a single uniform block of text.7 Treat the image as a single text line.8 Treat the image as a single word.9 Treat the image as a single word in a circle.10 Treat the image as a single character.11 Sparse text. Find as much text as possible in no particular order.12 Sparse text with OSD.13 Raw line. Treat the image as a single text line,bypassing hacks that are Tesseract-specific.
默认是3,也就是自动的页面切分,但是不进行方向(Orientation)和文字(script,其实并不等同于文字,比如俄文和乌克兰文都使用相同的script,中文和日文的script也有重合的部分)的检测。如果我们要识别的是单行的文字,我可以指定7。OSD算法参考这里。我们这里已经知道文字是中文,并且方向是horizontal(从左往右再从上往下的写法,古代中国是从上往下从右往左),因此使用默认的3就可以了。
Java接口
Java接口使用的是javacpp-presets,这个项目强烈推荐Java程序员关注一下!!!它可以让Java开发者调用很多流行的C++库,包括:OpenCV、FFmpeg、OpenBLAS、CPython、LLVM、CUDA、MXNet、TensorFlow等等。当然也包括我们这里用到的Leptonica和Tesseract。
依赖
<dependency><groupId>org.bytedeco.javacpp-presets</groupId><artifactId>tesseract-platform</artifactId><version>4.0.0-1.4.4</version></dependency>
我们这里只把C++的基本用法和按行输出用Java实现,其它的例子读者依葫芦画瓢把C++代码变成等价的Java代码就行了。javacpp-presets实现的代码和C++基本长得一样。
基本例子
完整代码在这里。
BytePointer outText;TessBaseAPI api = new TessBaseAPI();
// Initialize tesseract-ocr with English, without specifying tessdata path
if (api.Init(null, "eng") != 0) {System.err.println("Could not initialize tesseract.");System.exit(1);
}// Open input image with leptonica library
PIX image = pixRead(args.length > 0 ? args[0] : "testen-1.png");
api.SetImage(image);
// Get OCR result
outText = api.GetUTF8Text();
System.out.println("OCR output:\n" + outText.getString());// Destroy used object and release memory
api.End();
api.close();
outText.deallocate();
pixDestroy(image);
上面的代码和C++的基本长得一样,因为C++没有GC,因此需要下面那些销毁对象的操作。如果要识别中文,那么需要修改Init的第二个参数:
if (api.Init(null, "chi_sim") != 0) {
但是如果直接执行,会出现如下错误:
Error opening data file /home/travis/build/javacpp-presets/tesseract/cppbuild/linux-x86_64/share/tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
Could not initialize tesseract.
也就是默认会去”/home/travis/build/…“找模型,这是travis ci的路径,我们的机器当然没有。
为了解决这个问题有两种办法,第一种是运行程序是设置环境变量:
# 读者需要改成自己的路径
export TESSDATA_PREFIX=/usr/share/tesseract-ocr/4.00/tessdata
java -cp .....
另外一种方法就是调用init的时候指定路径:
if (api.Init("/usr/share/tesseract-ocr/4.00/tessdata", "eng") != 0) {System.err.println("Could not initialize tesseract.");System.exit(1);
}
按行输出
完整代码在这里。
BOXA boxes = api.GetComponentImages(tesseract.RIL_TEXTLINE, true, (PointerPointer) null, null);
System.out.print(String.format("Found %d textline image components.\n", boxes.n()));
for (int i = 0; i < boxes.n(); i++) {BOX box = boxes.box(i);api.SetRectangle(box.x(), box.y(), box.w(), box.h());BytePointer text = api.GetUTF8Text();int conf = api.MeanTextConf();System.out.println(String.format("Box[%d]: x=%d, y=%d, w=%d, h=%d, confidence: %d, text: %s",i, box.x(), box.y(), box.w(), box.h(), conf, text.getString()));text.deallocate();
}
另还有一种方法
<!--tess4J ocr图像识别-->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.4.1</version>
</dependency>
原文链接:https://blog.csdn.net/qq_39522120/article/details/135503159
相关文章:

使用Tesseract-OCR对PDF等图片文件进行文字识别
安装 用 Homebrew 来安装 Tesseract brew install tesseract 2. 完成 tessearact 的安装后,还需要安装中文数据包,执行以下两个操作, brew info tesseract 执行这个指令的目的,是找到 Homebrew 把 tesseract 安装在文件夹内&am…...

部署YOLOv8模型的实用常见场景
可以的话,GitHub上点个小心心,翻不了墙的xdm,csdn也可以点个赞,谢谢啦 车流量检测(开源代码github): test3 meiqisheng/YOLOv8-DeepSORT-Object-Tracking (github.com) 车牌检测࿰…...

SpringBoot缓存
目录 缓存支持 缓存集成 redis缓存集成 缓存支持 Spring 框架只提供抽象,不提供具体的缓存存储,底层需要依赖第三方存储组件,如果当前应用没有注册CacheManager 或者 CacheResolver 实例,Spring Boot 会按以下缓存组件的顺序来…...
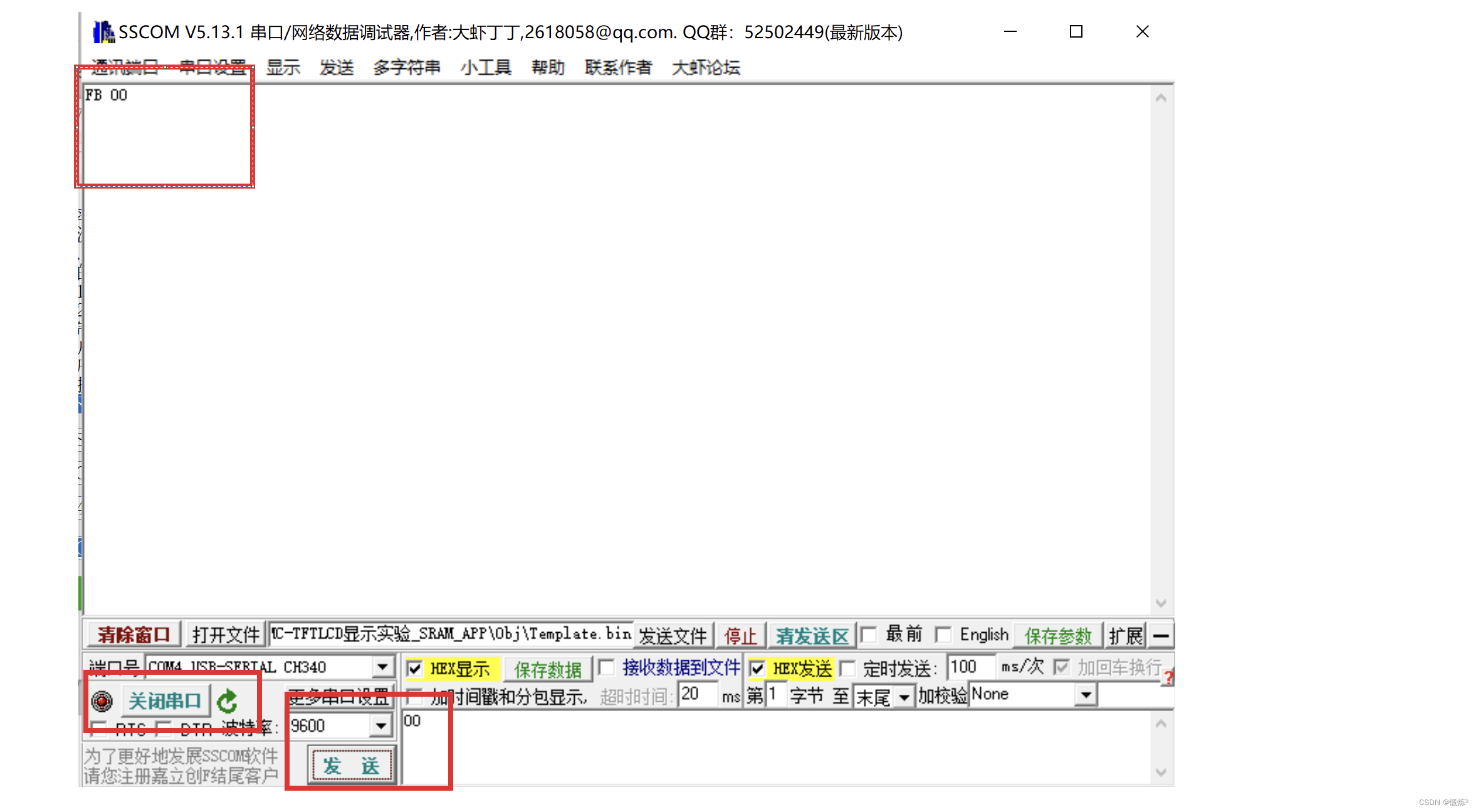
STC89C52串口通信详解
目录 前言 一.通信基本原理 1.1串行通信与并行通信 1.2同步通信和异步通信 1.2.1异步通信 1.2.2同步通信 1.3单工、半双工与全双工通信 1.4通信速率 二.串口通信简介 2.1接口标准 2.2串口内部结构 2.3串口相关寄存器 三.串口工作方式 四.波特率计算 五.串口初始化步骤 六.实验…...

基础算法|线性结构|前缀和学习
参考文章: https://blog.csdn.net/weixin_72060925/article/details/127835303 二维数组的前缀和练习: 这里要注意的地方就是求子矩阵和的时候,这里要减去的是x1-1,y1-1的部分,因为所求的目标值是包括边界的 //前缀…...
设计模式之模版方法实践
模版方法实践案例 实践之前还是先了解一下模版方法的定义 定义 模板方法模式是一种行为设计模式,它定义了一个骨架,并允许子类在不改变结构的情况下重写的特定步骤。模板方法模式通过在父类中定义一个模板方法,其中包含了主要步骤…...

sql中COALESCE函数详解
在SQL中,COALESCE函数是一个非常有用的函数,用于从其参数列表中返回第一个非NULL值。如果所有给定的参数都是NULL,那么COALESCE函数将返回NULL。这个函数可以接受多个参数,使其在处理可能出现的NULL值时非常灵活和强大。 语法 C…...

rust-analyzer报错“Failed to spawn one or more proc-macro servers,....“怎么解决?
最近,在使用vscode测试rust代码时,遇到了一些问题。在经过反复折腾后,最终解决了问题,在此写下作为记录,以便于以后参考。 我遇到的报错内容是: Failed to spawn one or more proc-macro servers. cannot find proc-macro-srv, the workspace E:\100rust\temp is missin…...

Communications--9--一文读懂双机热备冗余原理
1、热备冗余管理 2、主备系状态判断 3、如何从冷备做到热备? 参见: 用软件实现热备冗余信号系统的安全切换...

可调恒定电流稳压器NSI50150ADT4G车规级LED驱动器 提供专业的汽车级照明解决方案
NSI50150ADT4G产品概述: NSI50150ADT4G可调恒定电流稳压器 (CCR) ,是一款简单、经济和耐用的器件,适用于为 LED 中的调节电流提供成本高效的方案(与恒定电流二极管 CCD 类似)。该 (CCR) 基于自偏置晶体管 (SBT) 技术&…...

Unity中使用代码动态修改URP管线下的标准材质是否透明
//修改为透明 material.SetFloat("_Surface",1.0f); material.SetInt("_SrcBlend", (int)UnityEngine.Rendering.BlendMode.One); material.SetInt("_DstBlend", (int)UnityEngine.Rendering.BlendMode.OneMinusSrcAlpha); material.Set…...

关于制作Python游戏全过程(汇总1)
目录 前言: 1.plane_sprites模块: 1.1导入模块: 1.1.1pygame:一个用于创建游戏的Python库。 1.1.2random:Python标准库中的一个模块,用于生成随机数。 1.2定义事件代号: 1.2.1ENEMY_EVENT:自定义的敌机出场事件代号…...

独立站营销新纪元:AI与大数据塑造个性化体验的未来
随着全球互联网的深入发展和数字化转型的不断推进,作为品牌建设和市场营销的重要载体,独立站将迎来新的发展机遇。新技术的涌现,特别是人工智能和大数据等技术的广泛应用,为独立站带来了前所未有的机遇与挑战。本文Nox聚星将和大家…...

C语言项目实战——贪吃蛇
C语言实现贪吃蛇 前言一、 游戏背景二、游戏效果演示三、课程目标四、项目定位五、技术要点六、Win32 API介绍6.1 Win32 API6.2 控制台程序6.3 控制台屏幕上的坐标COORD6.4 GetStdHandle6.5 GetConsoleCursorInfo6.5.1 CONSOLE_CURSOR_INFO 6.6 SetConsoleCursorInfo6.7 SetCon…...
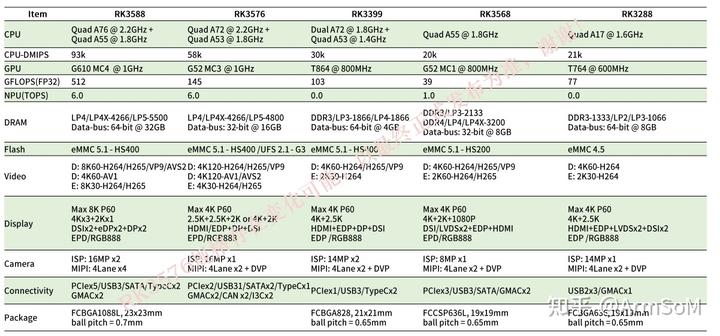
ArmSoM规划开发基于RK3576的开发套件
ArmSoM正计划推出一款新的产品,这款产品将采用强大的RK3576芯片。 本文将为您介绍我们的新产品搭载的RK3576性能参数,以及它如何为您提供卓越的性能和功能。 RK3576处理器 RK3576处理器是一款强大的处理器,具备出色的性能和多样化的功能&a…...
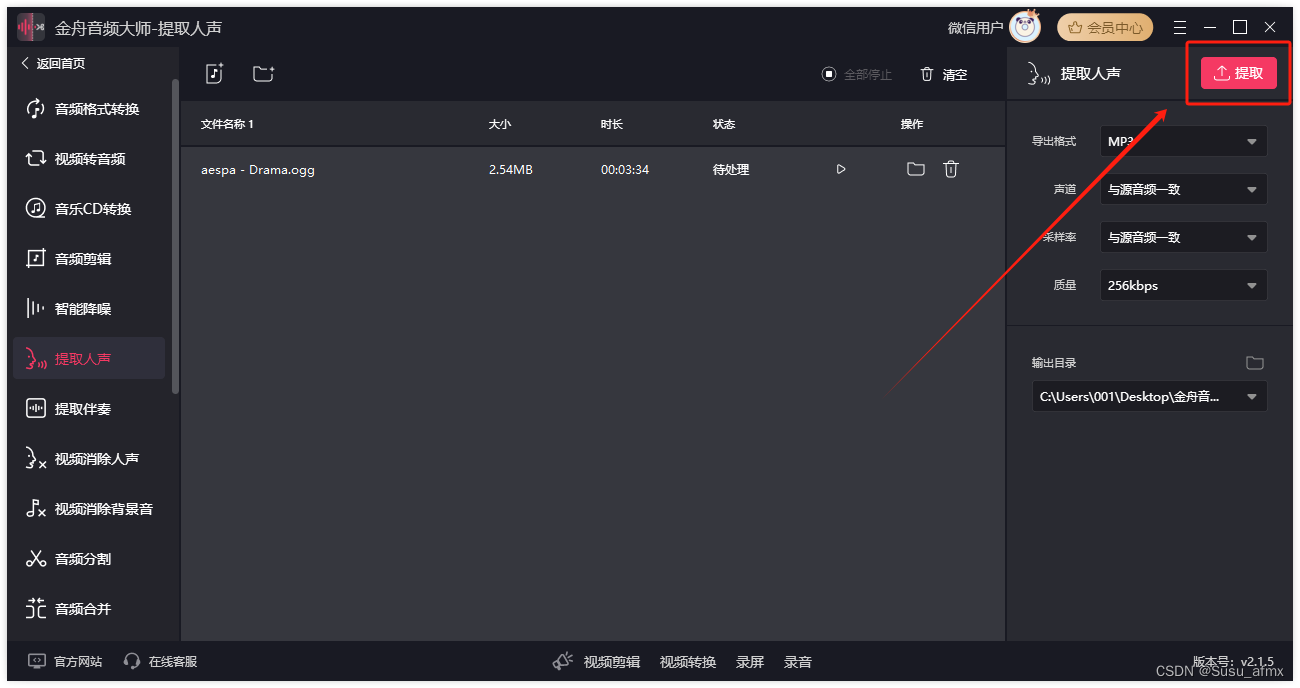
视频剪辑如何提取伴奏?短视频剪辑有妙方
在多媒体处理中,音频的编辑和处理是不可或缺的一部分。很多时候,我们可能想要从一段视频或音频中提取伴奏,或者实现人声的分离,以便于进一步制作或混音。以下,将为您介绍一种简单而有效的方法来实现这一目标。 一、提取…...
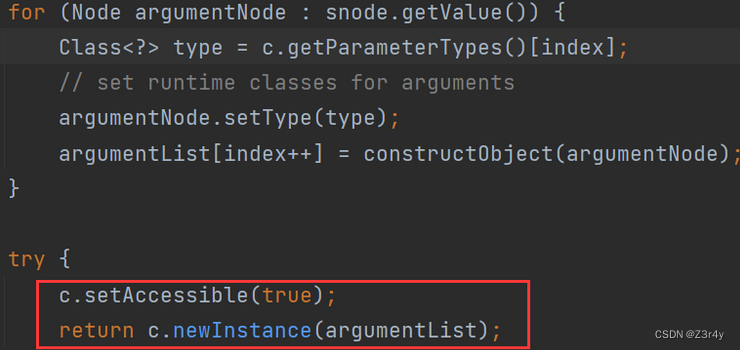
【Web】浅浅地聊SnakeYaml反序列化两条常见利用链
目录 关于Yaml 关于SnakeYaml SnakeYaml反序列化利用 JdbcRowSetImpl链 ScriptEngineManager链 复现 基本原理 继续深入 关于Yaml 学过SpringBoot开发的师傅都知道,YAML和 Properties 文件都是常见的配置文件格式,用于存储键值对数据。 这里举…...

详解openGauss客户端工具gsql的高级用法
前言: gsql是openGauss提供在命令行下运行的数据库连接工具,可以通过此工具连接服务器并对其进行操作和维护,除了具备操作数据库的基本功能,gsql还提供了若干高级特性,便于用户使用。 gsql的基本功能 连接数据库&…...
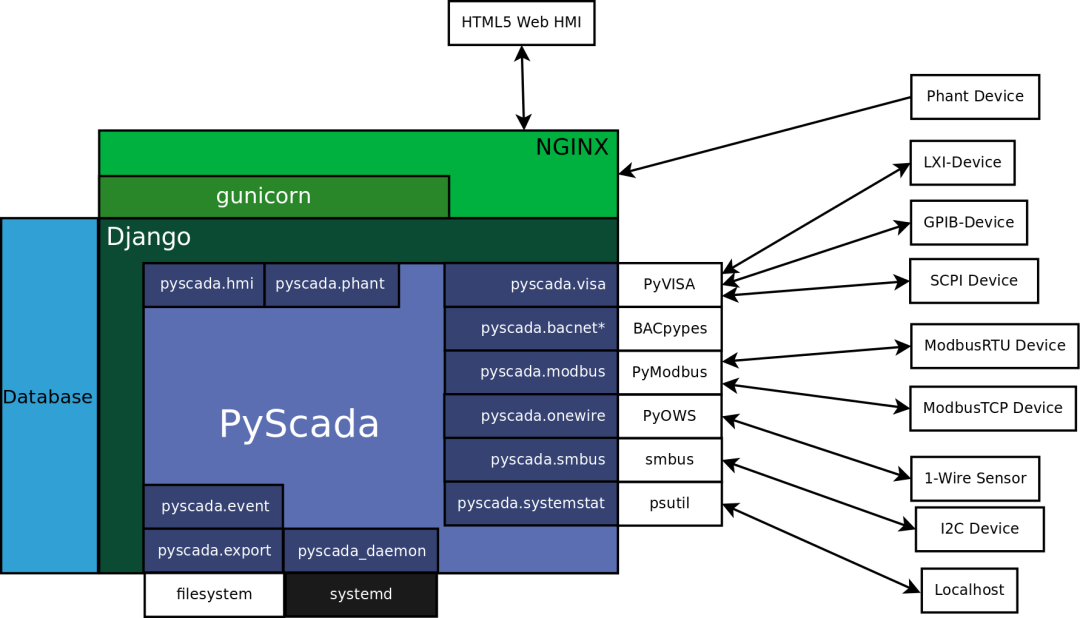
开源工业软件:SCADA系统开源
PyScada是一个开源的scada系统 源代码地址 http://www.gitpp.com/huangtomy/pyscada-cn SCADA系统是Supervisory Control And Data Acquisition的缩写,即数据采集与监视控制系统。它是以计算机为基础的DCS与电力自动化监控系统,应用领域非常广&#x…...

关于AI彩票预测算法的设想
本文以双色球选择红色6个号码为例 我们先把问题简化,双色球红色号码一共有33个球。摇奖时,每次随机摇出来一个号码,连续6次,就随机出来了6个红色球号码。 而这6个号码就是一注彩票里的前6个红色球号码。这里不讨论一注彩票里后端…...

性能优化必看:你的Unity粒子特效为什么这么卡?从ParticleSystem参数入手排查
Unity粒子特效性能优化实战指南:从参数调优到帧率提升 1. 粒子特效性能问题的根源剖析 在移动端和VR项目中,粒子特效往往是性能瓶颈的重灾区。一次性能审计中,某款手游的瀑布场景因未限制粒子最大数量,导致中端机型帧率骤降至18fp…...

Vue3代码编辑器终极指南:5分钟学会vue-codemirror专业集成
Vue3代码编辑器终极指南:5分钟学会vue-codemirror专业集成 【免费下载链接】vue-codemirror codemirror code editor component for vuejs 项目地址: https://gitcode.com/gh_mirrors/vu/vue-codemirror 你是否曾经在Vue3项目中苦苦寻找一个既专业又易用的代…...

解决企业IT服务管理复杂性的iTop开源CMDB架构实践
解决企业IT服务管理复杂性的iTop开源CMDB架构实践 【免费下载链接】iTop A simple, web based CMDB & IT Service Management tool 项目地址: https://gitcode.com/gh_mirrors/it/iTop 在数字化转型时代,企业面临IT配置信息分散、工单流转低效、资产跟踪…...
)
别再为版本号头疼了!手把手教你搞定Windows上ChromeDriver与Chrome的版本匹配(附最新镜像源)
别再为版本号头疼了!手把手教你搞定Windows上ChromeDriver与Chrome的版本匹配 每次启动Selenium脚本时看到SessionNotCreatedException报错,就像在高速公路上突然爆胎——明明昨天还能正常运行的自动化测试,今天就因为Chrome自动更新而彻底罢…...

STM32F103C8T6驱动安信可GP-01定位模块:从NMEA数据解析到经纬度显示的完整流程
STM32F103C8T6与安信可GP-01定位模块实战:高精度经纬度解析全指南 在物联网和嵌入式系统开发中,位置服务已成为核心功能之一。无论是资产追踪、导航设备还是智能农业系统,精准的定位能力都是实现这些应用的基础。本文将带你深入探索如何利用S…...
)
从零到一:用面包板和晶体管手搓一个4bit加法器(附完整电路图与避坑指南)
从零到一:用面包板和晶体管手搓一个4bit加法器(附完整电路图与避坑指南) 深夜的实验室里,面包板上横七竖八地插着几十个三极管和电阻,当我第三次测量到错误的输出电平时,终于意识到——这个看似简单的4bit加…...

如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案
如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否为WeMod免费版的诸多限制感到…...

RVC-WebUI语音克隆工具:从零开始的完整实战指南
RVC-WebUI语音克隆工具:从零开始的完整实战指南 【免费下载链接】rvc-webui liujing04/Retrieval-based-Voice-Conversion-WebUI reconstruction project 项目地址: https://gitcode.com/gh_mirrors/rv/rvc-webui RVC-WebUI是一款基于检索式语音转换技术的开…...

明日方舟自动化:用MAA重构你的游戏体验,告别重复劳动
明日方舟自动化:用MAA重构你的游戏体验,告别重复劳动 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: h…...

内网手机远程桌面:解锁高效协同的数字密钥
在数字化办公与生活深度融合的当下,人们对于信息获取与设备操控的便捷性需求持续攀升。当我们身处内网环境,却渴望随时随地操控远端的电脑设备,内网手机远程桌面技术便如同一把精准的数字密钥,打破空间与网络的束缚,为…...