智能部署之巅:Amazon SageMaker 引领机器学习革新
本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道。
(全球 TMT 2023年12月6日讯)亚马逊云科技在 2023 re:Invent 全球大会上,宣布推出五项 Amazon SageMaker 新功能,帮助客户加速构建、训练和部署大语言模型和其他基础模型。自2017年推出以来,Amazon SageMaker已经新增了380多个功能和特性,为客户提供了规模化构建、训练和部署可投入生产的大规模模型所需的一切。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
其中包括了一项新功能,进一步增强了 Amazon SageMaker 的模型扩展能力并加速了模型的训练。此外,Amazon SageMaker 推出的另一项新功能,能够通过降低模型部署成本和延迟时间,优化了管理托管的机器学习基础设施。亚马逊云科技还推出了新的 SageMaker Clarify 功能,可以让客户在负责任地使用 AI 的基础上,根据质量参数更轻松地选择正确模型。为了帮助客户在企业范围内应用这些模型,亚马逊云科技还在 Amazon SageMaker Canvas 中引入了新的无代码功能,让客户更快、更容易地使用自然语言指令准备数据。同时,Amazon SageMaker Canvas 继续推动模型构建和定制的普及,让客户更轻松地使用模型提取洞察、进行预测和使用企业专有数据生成内容。这些创新均基于 Amazon SageMaker 丰富的功能,帮助客户实现规模化机器学习创新。
1. 模型训练速度和效果
一些测评显示,Amazon SageMaker 在模型训练方面表现出色。其支持分布式训练,利用弹性计算资源,能够显著缩短训练时间。用户可以选择使用内置算法或自定义脚本,根据实际需求选择合适的训练方式。此外,自动模型调优功能可以帮助用户优化模型性能,提高训练效果。
2. 部署和管理的便捷性
Amazon SageMaker 提供了简单而强大的模型部署功能。它支持一键式部署,并提供实时和离线推理选项,适用于不同的应用场景。此外,SageMaker Studio 作为一体化的集成开发环境,为用户提供了方便的模型管理和监控工具,使整个部署和管理过程更加便捷。
SageMaker pytorch Mnist
SageMaker 与 Kubeflow 一个区别就在于:
在 Kubeflow 中,我们可以为管道内各组件挂载相同 PV 卷,使其运行在同一文件系统环境下,或者像 Elyra,为整个 Pipeline 配置一个 Minio 的 Bucket,作为共同的文件系统工作环境;
在 SageMaker 里,我们会建立一个会话,并设置默认存储桶 Bucket,之后将要用于模型训练的数据集上传至该存储桶中;
下载、转化并上传数据至 S3
为当前 SageMaker 会话设置默认 S3 存储桶 URI,创建一个新文件夹 prefix,然后将数据集上传至该文件夹下。
import sagemakersagemaker_session = sagemaker.Session()bucket = sagemaker_session.default_bucket()
prefix = "sagemaker/DEMO-pytorch-mnist"role = sagemaker.get_execution_role()### 下载数据
from torchvision.datasets import MNIST
from torchvision import transformsMNIST.mirrors = ["https://sagemaker-sample-files.s3.amazonaws.com/datasets/image/MNIST/"]MNIST("data",download=True,transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]),
)### 上传数据至 Amazon S3
inputs = sagemaker_session.upload_data(path="data", bucket=bucket, key_prefix=prefix)
print("input spec (in this case, just an S3 path): {}".format(inputs))
训练模型脚本
和 Kubeflow 一样,准备一份可以直接运行的训练模型脚本:
### ------------------------ mnist.py --------------------------# Based on https://github.com/pytorch/examples/blob/master/mnist/main.pyimport argparse
import json
import logging
import os
import sysimport torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data
import torch.utils.data.distributed
from torchvision import datasets, transformslogger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
logger.addHandler(logging.StreamHandler(sys.stdout))class Net(nn.Module):def __init__(self):...def forward(self, x):...def _get_train_data_loader(batch_size, training_dir, is_distributed, **kwargs):logger.info("Get train data loader")dataset = datasets.MNIST(training_dir,train=True,transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]),)train_sampler = (torch.utils.data.distributed.DistributedSampler(dataset) if is_distributed else None)return torch.utils.data.DataLoader(dataset,batch_size=batch_size,shuffle=train_sampler is None,sampler=train_sampler,**kwargs)def _get_test_data_loader(test_batch_size, training_dir, **kwargs):logger.info("Get test data loader")return torch.utils.data.DataLoader(datasets.MNIST(training_dir,train=False,transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]),),batch_size=test_batch_size,shuffle=True,**kwargs)def _average_gradients(model):# Gradient averaging.size = float(dist.get_world_size())for param in model.parameters():dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM)param.grad.data /= sizedef train(args):is_distributed = len(args.hosts) > 1 and args.backend is not Nonelogger.debug("Distributed training - {}".format(is_distributed))use_cuda = args.num_gpus > 0logger.debug("Number of gpus available - {}".format(args.num_gpus))kwargs = {"num_workers": 1, "pin_memory": True} if use_cuda else {}device = torch.device("cuda" if use_cuda else "cpu")if is_distributed:# Initialize the distributed environment.world_size = len(args.hosts)os.environ["WORLD_SIZE"] = str(world_size)host_rank = args.hosts.index(args.current_host)os.environ["RANK"] = str(host_rank)dist.init_process_group(backend=args.backend, rank=host_rank, world_size=world_size)logger.info("Initialized the distributed environment: '{}' backend on {} nodes. ".format(args.backend, dist.get_world_size())+ "Current host rank is {}. Number of gpus: {}".format(dist.get_rank(), args.num_gpus))# set the seed for generating random numberstorch.manual_seed(args.seed)if use_cuda:torch.cuda.manual_seed(args.seed)train_loader = _get_train_data_loader(args.batch_size, args.data_dir, is_distributed, **kwargs)test_loader = _get_test_data_loader(args.test_batch_size, args.data_dir, **kwargs)logger.debug("Processes {}/{} ({:.0f}%) of train data".format(len(train_loader.sampler),len(train_loader.dataset),100.0 * len(train_loader.sampler) / len(train_loader.dataset),))logger.debug("Processes {}/{} ({:.0f}%) of test data".format(len(test_loader.sampler),len(test_loader.dataset),100.0 * len(test_loader.sampler) / len(test_loader.dataset),))model = Net().to(device)if is_distributed and use_cuda:# multi-machine multi-gpu casemodel = torch.nn.parallel.DistributedDataParallel(model)else:# single-machine multi-gpu case or single-machine or multi-machine cpu casemodel = torch.nn.DataParallel(model)optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)for epoch in range(1, args.epochs + 1):model.train()for batch_idx, (data, target) in enumerate(train_loader, 1):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()if is_distributed and not use_cuda:# average gradients manually for multi-machine cpu case only_average_gradients(model)optimizer.step()if batch_idx % args.log_interval == 0:logger.info("Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}".format(epoch,batch_idx * len(data),len(train_loader.sampler),100.0 * batch_idx / len(train_loader),loss.item(),))test(model, test_loader, device)save_model(model, args.model_dir)def test(model, test_loader, device):model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += F.nll_loss(output, target, size_average=False).item() # sum up batch losspred = output.max(1, keepdim=True)[1] # get the index of the max log-probabilitycorrect += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)logger.info("Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(test_loss, correct, len(test_loader.dataset), 100.0 * correct / len(test_loader.dataset)))# 当estimator.deploy时,需要显式定义出model_fn方法
def model_fn(model_dir):device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = torch.nn.DataParallel(Net())with open(os.path.join(model_dir, "model.pth"), "rb") as f:model.load_state_dict(torch.load(f))return model.to(device)# 部署函数的参数允许我们设置将用于端点的实例的数量和类型。这些值不需要与我们训练模型时设置的值相同。我们可以在一组基于 GPU 的实例上训练模型,然后在终端上部署基于CPU的模型实例;但这需要我们确保将模型返回或另存为 CPU 模型
# 因此,建议将模型返回或另存为 CPU 模型
def save_model(model, model_dir):logger.info("Saving the model.")path = os.path.join(model_dir, "model.pth")torch.save(model.cpu().state_dict(), path)if __name__ == "__main__":parser = argparse.ArgumentParser()# 模型训练参数parser.add_argument("--batch-size",type=int,default=64,metavar="N",help="input batch size for training (default: 64)",)parser.add_argument("--test-batch-size",type=int,default=1000,metavar="N",help="input batch size for testing (default: 1000)",)parser.add_argument("--epochs",type=int,default=10,metavar="N",help="number of epochs to train (default: 10)",)parser.add_argument("--lr", type=float, default=0.01, metavar="LR", help="learning rate (default: 0.01)")parser.add_argument("--momentum", type=float, default=0.5, metavar="M", help="SGD momentum (default: 0.5)")parser.add_argument("--seed", type=int, default=1, metavar="S", help="random seed (default: 1)")parser.add_argument("--log-interval",type=int,default=100,metavar="N",help="how many batches to wait before logging training status",)parser.add_argument("--backend",type=str,default=None,help="backend for distributed training (tcp, gloo on cpu and gloo, nccl on gpu)",)# 与 SageMaker 相关的环境参数parser.add_argument("--hosts", type=list, default=json.loads(os.environ["SM_HOSTS"]))parser.add_argument("--current-host", type=str, default=os.environ["SM_CURRENT_HOST"])parser.add_argument("--model-dir", type=str, default=os.environ["SM_MODEL_DIR"])parser.add_argument("--data-dir", type=str, default=os.environ["SM_CHANNEL_TRAINING"])parser.add_argument("--num-gpus", type=int, default=os.environ["SM_NUM_GPUS"])train(parser.parse_args())但这里,我们还需要通过访问环境变量获取部分有关训练环境的属性:
-
SM_HOSTS: 包含所有主机的 JSON 编码列表;在 Pytorch 中,该列表长度等于 WORLD_SIZE;
-
SM_CURRENT_HOST: 当前容器名称;在 Pytorch 中,该容器序号等于 RANK;
-
SM_MODEL_DIR: 模型的保存路径;该模型之后将上传至 S3;
-
SM_NUM_GOUS: 当前容器可用的 GPU 数;
注: Pytorch 分布式训练时,dist.init_process_group(backend, rank, world_size),需要用到 WORLD_SIZE、RANK。
若在调用 PyTorch Estimator 的 fit() 方法时,使用了名为 training 的输入通道,则按照以下格式设置 SM_CHANNEL_[channel_name]:
-
SM_CHANNEL_TRAINING: 输入通道 training 中数据的存储路径;
该训练脚本从输入通道 training 的指定路径下加载数据,使用超参数配置训练,训练模型,并将模型保存至 model_dir,以便稍后托管。超参数作为参数传递给脚本,可以使用 argparse.ArgumentParser 实例进行检索。
在 SageMaker 中训练
from sagemaker.pytorch import PyTorchestimator = PyTorch(entry_point="mnist.py",role=role,py_version="py38",framework_version="1.11.0",instance_count=2,instance_type="ml.c5.2xlarge",hyperparameters={"epochs": 1, "backend": "gloo"},
)estimator.fit({"training": inputs})
sagemaker.pytorch.estimator.PyTorch 是 sagemaker 针对 Pytorch 开发的 Estimator,包含以下主要参数:
-
entry_point: 训练脚本的执行入口;
-
py_version、framework_version: python 及 pytorch 的版本;SageMaker 将分配满足该版本要求的计算资源;
-
instance_count、instance_type: 计算资源的数量、类型;
-
hyperparameters: 训练脚本的超参数;
-
image_uri: 若指定,Estimator 将使用此 Image 作为训练和部署的运行环境,而 py_version、framework_version 将失效;image_uri 必须是 ECR url 或 dockerhub image;
部署并测试该模型
mnist.py 中,model_fn 方法需要由我们显式定义出来;而 input_fn, predict_fn, output_fn 和 transform_fm 已经默认定义在 sagemaker-pytorch-containers 中。
### 部署该 Predictor
predictor = estimator.deploy(initial_instance_count=1, instance_type="ml.m4.xlarge")### 生成测试数据
import gzip
import numpy as np
import random
import osdata_dir = "data/MNIST/raw"
with gzip.open(os.path.join(data_dir, "t10k-images-idx3-ubyte.gz"), "rb") as f:images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28).astype(np.float32)mask = random.sample(range(len(images)), 16) # randomly select some of the test images
mask = np.array(mask, dtype=np.int)
data = images[mask]### 测试该Predictor
response = predictor.predict(np.expand_dims(data, axis=1))
print("Raw prediction result:")
print(response)
print()labeled_predictions = list(zip(range(10), response[0]))
print("Labeled predictions: ")
print(labeled_predictions)
print()labeled_predictions.sort(key=lambda label_and_prob: 1.0 - label_and_prob[1])
print("Most likely answer: {}".format(labeled_predictions[0]))### 删除部署端点并释放资源
sagemaker_session.delete_endpoint(endpoint_name=predictor.endpoint_name)

3. 使用 Amazon SageMaker Studio 可提高生产率,这是第一个用于机器学习的完全集成式开发环境 (IDE)
Amazon SageMaker Studio 提供了一个基于 Web 的单一视觉界面,您可以在其中执行所有 ML 开发步骤。对于构建、训练和部署模型所需的每个步骤,SageMaker Studio 为您提供了完整的访问、控制权和可见性。您可以快速上传数据、新建笔记本、训练和调试模型、在各个步骤之间来回移动,从而实现在一处调整实验、比较结果,并将模型部署到生产环境中,使您的生产效率大大提高。可以在统一的 SageMaker Studio 可视界面中执行所有的 ML 开发活动,包括笔记本、实验管理、自动模型创建,调试和模型偏差检测。
4. 使用 Amazon SageMaker 笔记本加速构建和协作
通过管理计算实例来查看、运行或共享笔记本非常繁琐。Amazon SageMaker 笔记本提供了一键式 Jupyter 笔记本,使您能够在几秒钟之内立即开始工作。底层的计算资源具有充分的弹性,因此您可以轻松地调高或调低可用资源,并且后台会自动进行更改,而不会中断您的工作。SageMaker 还支持一键分享笔记本。所有代码依赖项都是自动捕获的,因此您可以与他人轻松协作。他们会得到保存在同一位置的完全相同的笔记本。
5. 借助 Amazon SageMaker Autopilot 自动构建、训练和调试完全可视和可控的模型
Amazon SageMaker Autopilot 是业界首个自动机器学习工具,实现了 ML 模型的完全控制和可见性。典型的自动化机器学习方法无法让您深入了解用于创建模型的数据或模型创建背后的逻辑。因此,即使是普通的模型,也无法使之进化。另外,由于典型的自动化 ML 解决方案只能提供一个模型供选择,因此您无法灵活地权衡,例如牺牲一些准确性实现较低延迟的预测。
SageMaker Autopilot 会自动检查原始数据、应用特色处理器、选择最佳算法集、训练和调试多个模型、跟踪其性能,并在随后根据性能对模型进行排名,所有这些仅需几次单击。其结果是,部署性能最佳的模型所花费的时间只有该模型通常所需训练时间的几分之一。模型的创建方式以及内容对您完全可见,并且 SageMaker Autopilot 与 Amazon SageMaker Studio 相集成。在 SageMaker Studio 中,您可以了解多达 50 种由 SageMaker Autopilot 生成的不同模型,轻松地为您的用例选择最佳模型。没有机器学习经验的人可以使用 SageMaker Autopilot 轻松生成模型,而经验丰富的开发人员使用它可以快速开发出基础模型,供团队进一步迭代。
6. 使用 Amazon SageMaker Ground Truth 将数据标记成本降低多达 70%
成功的机器学习模型是建立在大量高质量训练数据的基础上的。但是,建立这些模型所需的训练数据的创建过程往往非常昂贵、复杂和耗时。Amazon SageMaker Ground Truth 可帮助您快速构建和管理高度准确的训练数据集。通过 Amazon Mechanical Turk,Ground Truth 提供了对标签机的便捷访问,并为它们提供了预构建工作流和接口,用于执行常见的标记任务。您还可以使用自己的标签机,或通过亚马逊云科技 Marketplace 使用 Amazon 推荐的供应商。此外,Ground Truth 还不断学习人类制作的标签,制作高质量的自动注释,显著降低标记成本。
7. Amazon SageMaker 支持领先的深度学习框架
支持的框架包括:TensorFlow、PyTorch、Apache MXNet、Chainer、Keras、glion、Horovod、Scikit-learn 和 Deep Graph Library。
使用体验
Amazon SageMaker 在模型部署方面表现卓越,通过多样的部署选项,包括云端和边缘计算,实现了极大的灵活性。一键式部署简化了流程,使用户能够迅速将模型推送到生产环境。支持多模型部署提高了资源利用率,而实时和离线推理选项满足了不同场景的需求。SageMaker Studio 作为集成开发环境提供便捷的模型管理工具,加强了整个部署过程的便捷性。这些特点使 SageMaker 在机器学习模型部署领域脱颖而出,为用户提供了全方位的灵活、简便、适应各种场景的解决方案。
总结
综合来看,Amazon SageMaker 在机器学习生命周期的各个阶段都提供了强大的功能和灵活性。其性能和便捷性得到了用户的一致好评。然而,一些用户也提到了成本方面的考虑,因此在选择时需要权衡各种因素。总体而言,Amazon SageMaker 在云端机器学习服务中占据着重要地位,为用户提供了一体化的解决方案,有助于简化和优化机器学习工作流程。
文章来源:智能部署之巅:Amazon SageMaker 引领机器学习革新
相关文章:
智能部署之巅:Amazon SageMaker 引领机器学习革新
本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道。 (全球 TMT 2023年12月6日讯)亚马逊云科技在 2023 re:Invent 全…...

国内哪个工具可以平替chatgpt?国内有哪些比较好用的大模型gpt?
我自己试用了很多的平台,发现三个比较好的大模型平台,对普通用户也比较的友好的,而且返回内容相对来说,正确率更高的,并且相关场景插件比较丰富的国内厂商。 本文说的,是我自己觉得的,比较有主观…...

python如何打包py文件为exe
要将Python程序打包为可执行文件(.exe),您可以使用一些第三方工具。以下是两个常用的工具:PyInstaller和cx_Freeze。 使用PyInstaller PyInstaller是一个流行的Python打包工具,可以将Python程序及其所有依赖项打包为…...

yolov9网络结构图
文章目录 配置文件主干分支backbone预测头headyolov9网络结构图 系列文章目录 论文链接:👿 YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information代码链接:👿 https://github.com/WongKinYiu/yolov9…...
Spark 核心API
核心 API spark core API 指的是 spark 预定义好的算子。无论是 spark streaming 或者 Spark SQL 都是基于这些最基础的 API 构建起来的。理解这些核心 API 也是写出高效 Spark 代码的基础。 Transformation 转化类的算子是最多的,学会使用这些算子就应付多数的数…...

OpenLayers线性渐变和中心渐变(径向渐变)
目录 1.前言2.添加一个面要素3.线性渐变3.1 第一个注意点3.2 第二个注意点 4.中心渐变(径向渐变)5.总结 1.前言 OpenLayers官网有整个图层的渐变示例,但是没有单个要素的渐变示例,我们这里来补充一下。OpenLayers中的渐变是通过fi…...
)
[210. 课程表 II] 拓扑排序模板(DFS+BFS)
Problem: 210. 课程表 II 文章目录 思路解题方法Code 思路 本题是经典拓扑排序模板,通过DFS和BFS两种方式进行实现。 解题方法 DFS DFS方法的重点在于如何标记节点状态,初做题者如果只用未访问和已访问两种状态很容易陷入死结。正确的做法是使用三种状…...

我的第一个python web 网站
# -*- coding: utf-8 -*-import http.server import socketserver from datetime import datetimePORT 8000import sys# ...class MyHandler(http.server.SimpleHTTPRequestHandler):def do_GET(self):if self.path /:# 如果路径是根路径,返回页面内容self.send_r…...
产品展示型wordpress外贸网站模板
孕婴产品wordpress外贸网站模板 吸奶器、待产包、孕妇枕头、护理垫、纸尿裤、孕妇装、孕婴产品wordpress外贸网站模板。 https://www.jianzhanpress.com/?p4112 床品毛巾wordpress独立站模板 床单、被套、毛巾、抱枕、靠垫、围巾、布艺、枕头、乳胶枕、四件套、浴巾wordpre…...
四信全球化拓展再启新篇!LoRa传感器与云平台领航智能感知时代
随着科技浪潮的不断推进,物联网已逐渐融入我们的生活。刚刚结束的MWC24盛会上,四信带来了一系列前沿技术成果,不仅将5G技术成功扩展至当前市场主流类型的终端,更携手联通、ASR等业界巨头,在连接、5G RedCap、AI、LoRa以…...
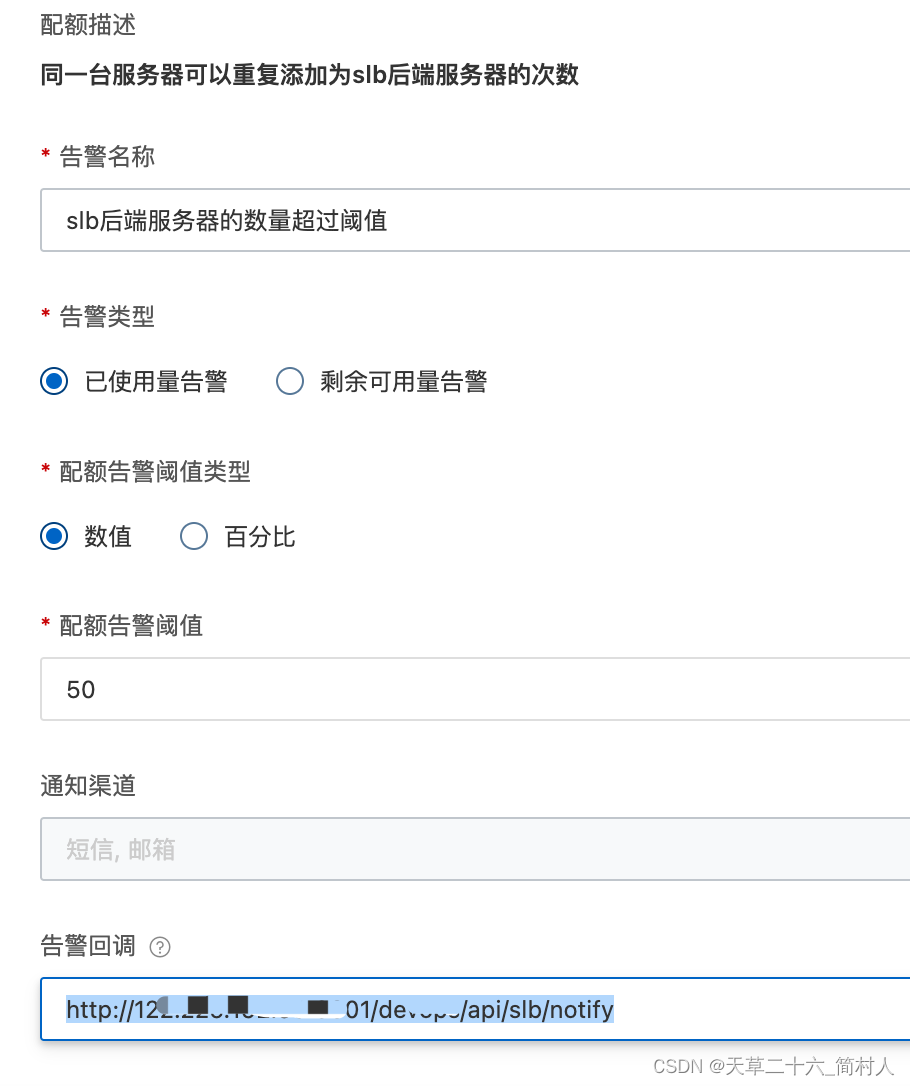
阿里云k8s环境下,因slb限额导致的发布事故
一、背景 阿里云k8s容器,在发布java应用程序的时候,客户端访问出现500错误。 后端服务是健康且可用的,网关层大量500错误请求,slb没有流入和流出流量。 经过回滚,仍未能解决错误。可谓是一次血的教训,特…...

【STM32+OPENMV】矩形识别
一、准备工作 有关OPENMV最大色块追踪及与STM32通信内容,详情见【STM32HAL】与OpenMV通信 二、所用工具 1、芯片:STM32F103C8T6 2、CUBEMX配置软件 3、KEIL5 4、OPENMV 三、实现功能 寻找黑色矩形,并将最大矩形的四个边缘坐标发送给STM…...
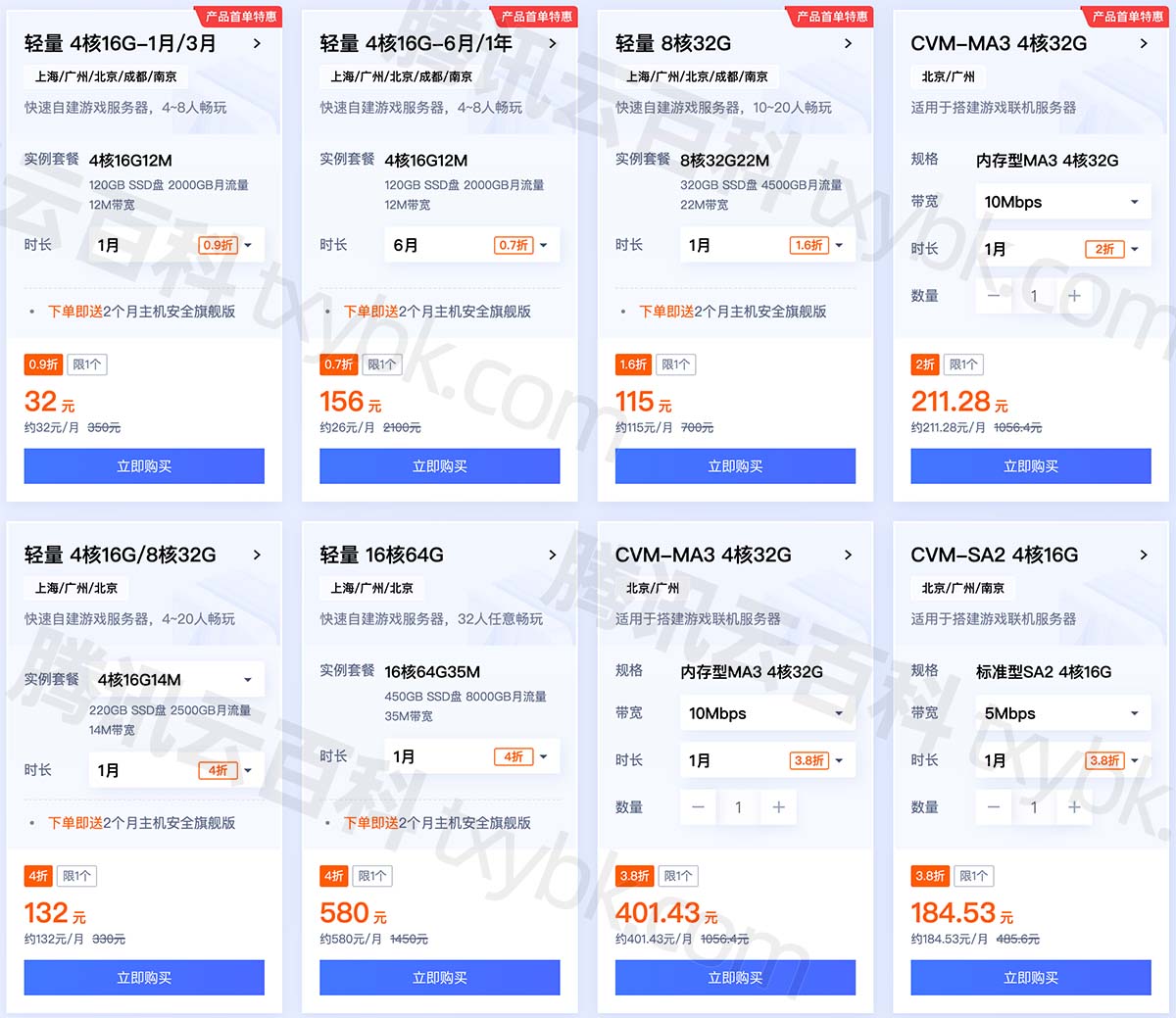
在吗?腾讯云服务器优惠价格表曝光_2023年3月报价请过目!
腾讯云服务器多少钱一年?61元一年起,2核2G3M配置,腾讯云2核4G5M轻量应用服务器165元一年、756元3年,4核16G12M服务器32元1个月、312元一年,8核32G22M服务器115元1个月、345元3个月,腾讯云服务器网txyfwq.co…...
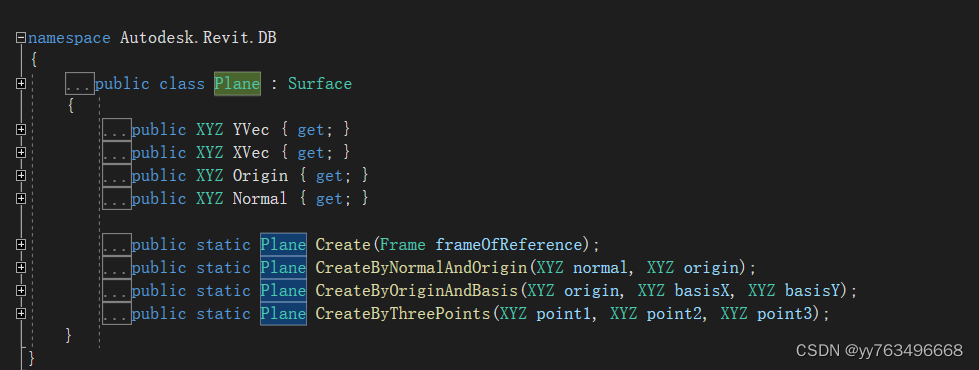
Revit-二开之创建Plane-(7)
2016版本的Plane 2017版本的Plane 2018版本及以上版本的Plane 由此可见2017版本是一个分水岭 #if REVIT2016Plane plane = new Plane(uiDoc.Document.ActiveView...

【操作系统学习笔记】文件管理1.2
【操作系统学习笔记】文件管理1.2 参考书籍: 王道考研 视频地址: Bilibili 文件的逻辑结构 无结构文件 文件内部的数据就是一系列的二进制流或字符流组成,又称流式文件,例如 .text 文件 有结构文件 由一组相似的记录组成,又称记录式文件…...
算法归纳【数组篇】
目录 二分查找1. 前提条件:2. 二分查找边界 2.移除元素有序数组的平方长度最小的子数组59.螺旋矩阵II54. 螺旋矩阵 二分查找 参考链接 https://programmercarl.com/0704.%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE.html#%E6%80%9D%E8%B7%AF 1. 前提条件: 数…...
【随笔】程序员如何选择职业赛道,目前各个赛道的现状如何,那个赛道前景巨大
大家好,我是全栈小5,欢迎阅读文章! 此篇是【话题达人】系列文章,这一次的话题是《程序员如何选择职业赛道》 目录 背景热度柱状图赛道热度C/C云原生人工智能前沿技术软件工程后端JavaJavascriptPHPPython区块链大数据移动开发嵌入…...

进程之舞:操作系统中的启动、状态转换与唤醒艺术
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua,在这里我会分享我的知识和经验。&#x…...
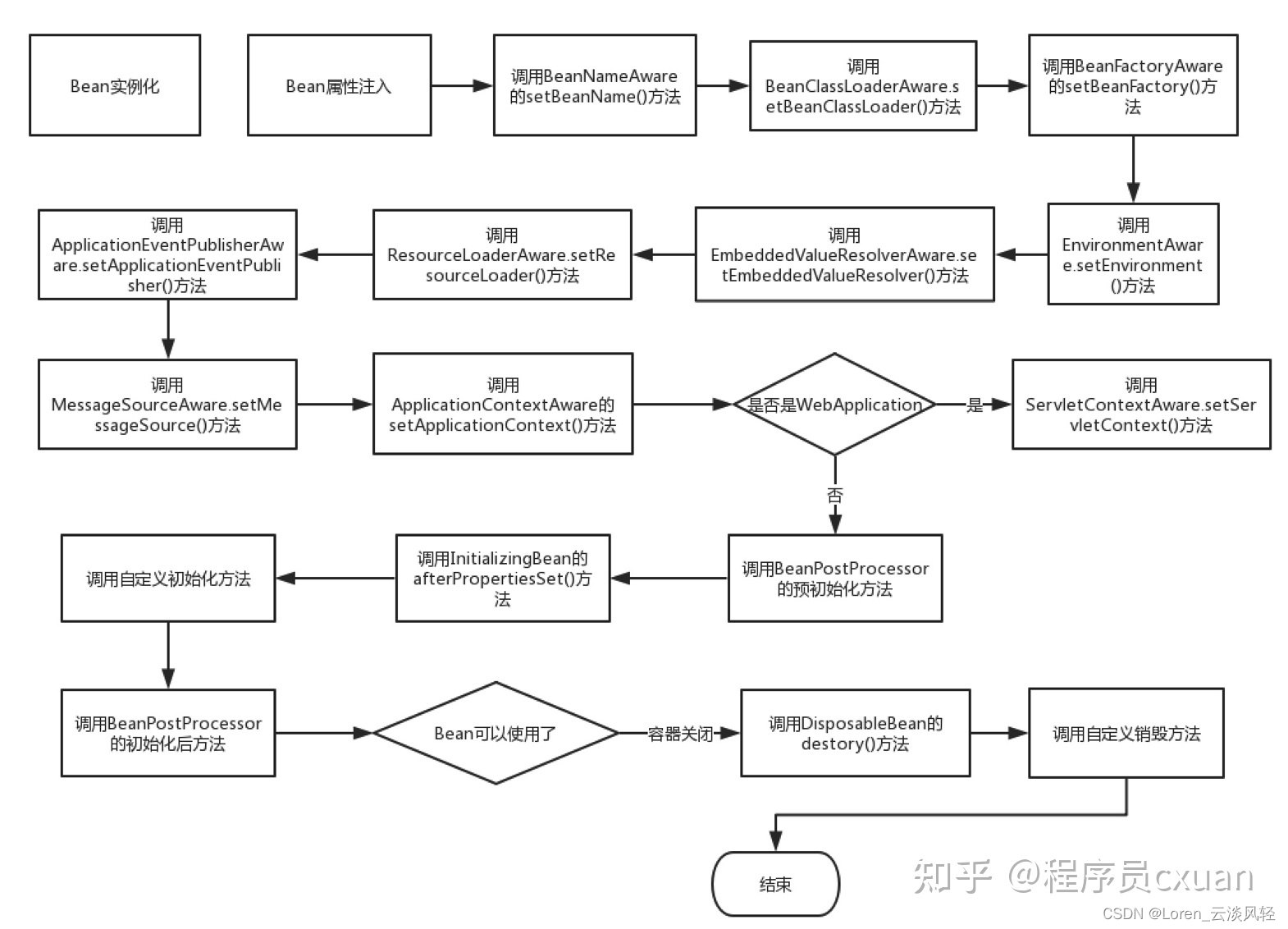
Java面试(4)之 Spring Bean生命周期过程
一, 整个加载的完整链路图 更详细的生命周期函数链路图(仅供参考) 二, Bean实例化的四种方式: 1, 无参构造器(默认且常用)6 2, 静态工厂方法方式(factory-method指定实例化的静态方法) 3, 实例工厂方法方式(factory-bean指定bean的name,factory-method指定实例化方法) 4, 实…...
-static修饰成员变量、应用场景,static修饰成员方法、应用场景)
JavaSE——面向对象高级一(1/4)-static修饰成员变量、应用场景,static修饰成员方法、应用场景
目录 static修饰成员变量 类变量的应用场景 static修饰成员方法 static修饰成员方法的应用场景 static 叫静态,可可以修饰成员变量、成员方法。 成员变量按照有无static修饰,分为两种: 类变量实例变量(对象的变量ÿ…...

从零到一:阿里云天池街景符号识别Baseline实战指南
从零到一:阿里云天池街景符号识别Baseline实战指南 街景符号识别是计算机视觉领域一项极具挑战性的任务,它要求模型能够准确识别并理解街道场景中的各类符号信息。对于刚接触深度学习实战的开发者来说,如何从零开始构建一个完整的识别系统往往…...

气象数据可视化实战:从雷达图到三维风场,前端技术栈全解析
气象数据可视化实战:从雷达图到三维风场,前端技术栈全解析 气象数据的可视化一直是前端开发领域最具挑战性的方向之一。想象一下,当你需要将每小时更新的全球气象数据转化为直观的动态图像,让气象学家一眼就能看出台风路径、让飞行…...

[AI/Agent/社交] AI Agent社交网络产品:MoltBook => InStreet
Julia(julialang.org)由Stefan Karpinski、Jeff Bezanson等在2009年创建,目标是融合Python的易用性、C的高性能、R的统计能力、Matlab的科学计算生态。 其核心设计哲学是: 高性能:编译型语言(JIT࿰…...

等保.三级要求下Redis 安全测评应该怎么做?
1. 引入 在现代 AI 工程中,Hugging Face 的 tokenizers 库已成为分词器的事实标准。不过 Hugging Face 的 tokenizers 是用 Rust 来实现的,官方只提供了 python 和 node 的绑定实现。要实现与 Hugging Face tokenizers 相同的行为,最好的办法…...

论文AIGC全红99%怎么救?2026实测Gemini去痕术:3组指令集联合3大工具,稳稳拉回10%安全线
视角重构,打破“平铺直叙”的机械感 AI生成的最大特征是“正确但平庸的上帝视角”。要ai降ai,第一步不是改词,而是强行植入一个具有批判性的“人类观察者”视角,迫使模型重组叙事逻辑。 核心原理:通过引入“辩证法”…...

iPhone USB网络共享驱动终极解决方案:从诊断到优化的全方位指南
iPhone USB网络共享驱动终极解决方案:从诊断到优化的全方位指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.c…...

ChatBI怎么在BI试点中用?3个低门槛落地场景亲测有效
ChatBI试点的前置门槛:先搞定最小可行数据集,不用全量建设 ChatBI是观远数据推出的自然语言分析产品,用户可以通过口语化的提问直接获取数据结果、可视化图表甚至分析结论,无需掌握复杂的报表制作或SQL查询技能。在BI试点阶段引入…...

永磁同步电机矢量控制仿真避坑指南:从PI参数整定到SVPWM模块优化
永磁同步电机矢量控制仿真避坑指南:从PI参数整定到SVPWM模块优化 在工业自动化和电力驱动领域,永磁同步电机(PMSM)凭借其高效率、高功率密度和优异的动态性能,已成为众多应用场景的首选。然而,要实现PMSM的…...

HunyuanVideo-Foley快速入门:VSCode远程开发与模型调试指南
HunyuanVideo-Foley快速入门:VSCode远程开发与模型调试指南 1. 前言:为什么选择VSCode远程开发? 如果你正在使用HunyuanVideo-Foley这类音效生成模型,可能会遇到这样的困扰:本地机器性能不足,而云服务器虽…...

ai赋能开发:让快马智能助手帮你诊断和优化openclaw ubuntu部署难题
最近在Ubuntu上部署OpenClaw项目时,遇到了不少头疼的问题。从依赖冲突到参数调优,每一步都可能踩坑。不过我发现,借助AI辅助开发工具,这些问题可以变得更可控。今天就来分享下如何构建一个AI工具箱来优化OpenClaw的部署和开发体验…...