Bert Encoder和Transformer Encoder有什么不同
前言:本篇文章主要从代码实现角度研究 Bert Encoder和Transformer Encoder 有什么不同?应该可以帮助你:
- 深入了解Bert Encoder 的结构实现
- 深入了解Transformer Encoder的结构实现
本篇文章不涉及对注意力机制实现的代码研究。
注:本篇文章所得出的结论和其它文章略有不同,有可能是本人代码理解上存在问题,但是又没有找到更多的文章加以验证,并且代码也检查过多遍。
观点不太一致的文章:bert-pytorch版源码详细解读_bert pytorch源码-CSDN博客 这篇文章中,存在 “这个和我之前看的transformers的残差连接层差别还挺大的,所以并不完全和transformers的encoder部分结构一致。” 但是我的分析是:代码实现上不太一样,但是本质上没啥不同,只是Bert Encoder在Attention之后多了一层Linear。具体分析过程和结论可以阅读如下文章。
如有错误或问题,请在评论区回复。
1、研究目标
这里主要的观察对象是BertModel中Bert Encoder是如何构造的?从Bert Tensorflow源码,以及transformers库中源码去看。
然后再看TransformerEncoder是如何构造的?从pytorch内置的transformer模块去看。
最后再对比不同。
2、tensorflow中BertModel主要代码如下
class BertModel(object):def __init__(...):...得到了self.embedding_output以及attention_mask# transformer_model就代表了Bert Encoder层的所有操作self.all_encoder_layers = transformer_model(input_tensor=self.embedding_output, attention_mask=attention_mask,...)# 这里all_encoder_layers[-1]是取最后一层encoder的输出self.sequence_output = self.all_encoder_layers[-1]...pooler层,对 sequence_output中的first_token_tensor,即CLS对应的表示向量,进行dense+tanh操作with tf.variable_scope("pooler"):first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)self.pooled_output = tf.layers.dense(first_token_tensor,config.hidden_size,activation=tf.tanh,kernel_initializer=create_initializer(config.initializer_range))def transformer_model(input_tensor, attention_mask=None,...):...for layer_idx in range(num_hidden_layers):# 如下(1)(2)(3)就是每一层Bert Encoder包含的结构和操作with tf.variable_scope("layer_%d" % layer_idx):# (1)attention层:主要包含两个操作,获取attention_output,对attention_output进行dense + dropout + layer_normwith tf.variable_scope("attention"):# (1.1)通过attention_layer获得 attention_outputattention_output# (1.2)output层:attention_output需要经过dense + dropout + layer_norm操作with tf.variable_scope("output"):attention_output = tf.layers.dense(attention_output,hidden_size,...)attention_output = dropout(attention_output, hidden_dropout_prob)# “attention_output + layer_input” 表示 残差连接操作attention_output = layer_norm(attention_output + layer_input)# (2)intermediate中间层:对attention_output进行dense+激活(GELU)with tf.variable_scope("intermediate"):intermediate_output = tf.layers.dense(attention_output,intermediate_size,activation=intermediate_act_fn,)# (3)output层:对intermediater_out进行dense + dropout + layer_normwith tf.variable_scope("output"):layer_output = tf.layers.dense(intermediate_output,hidden_size,kernel_initializer=create_initializer(initializer_range))layer_output = dropout(layer_output, hidden_dropout_prob)# "layer_output + attention_output"是残差连接操作layer_output = layer_norm(layer_output + attention_output)all_layer_outputs.append(layer_output)3、pytorch的transformers库中的BertModel主要代码;
- 其中BertEncoder对应要研究的目标
class BertModel(BertPreTrainedModel):def __init__(self, config, add_pooling_layer=True):self.embeddings = BertEmbeddings(config)self.encoder = BertEncoder(config)self.pooler = BertPooler(config) if add_pooling_layer else Nonedef forward(...):# 这是嵌入层操作embedding_output = self.embeddings(input_ids=input_ids,position_ids=position_ids,token_type_ids=token_type_ids,...)# 这是BertEncoder层的操作encoder_outputs = self.encoder(embedding_output,attention_mask=extended_attention_mask,...)# 这里encoder_outputs是一个对象,encoder_outputs[0]是指最后一层Encoder(BertLayer)输出sequence_output = encoder_outputs[0]# self.pooler操作是BertPooler层操作,是先取first_token_tensor(即CLS对应的表示向量),然后进行dense+tanh操作# 通常pooled_output用于做下游分类任务pooled_output = self.pooler(sequence_output) if self.pooler is not None else Noneclass BertEncoder(nn.Module):def __init__(self, config):...self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])...def forward(...):for i, layer_module in enumerate(self.layer):# 元组的append做法,将每一层的hidden_states保存到all_hidden_states;# 第一个hidden_states是BertEncoder的输入,后面的都是每一个BertLayer的输出if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)...# 执行BertLayer的forward方法,包含BertAttention层 + BertIntermediate中间层 + BertOutput层layer_outputs = layer_module(...)# 当前BertLayer的输出hidden_states = layer_outputs[0]# 添加到all_hidden_states元组中if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)class BertLayer(nn.Module):def __init__(self, config):self.attention = BertAttention(config)self.intermediate = BertIntermediate(config)self.output = BertOutput(config)def forward(...):# (1)Attention是指BertAttention# BertAttention包含:BertSelfAttention + BertSelfOutput# BertSelfAttention包括计算Attention+Dropout# BertSelfOutput包含:dense+dropout+LayerNorm,LayerNorm之前会进行残差连接self_attention_outputs = self.attention(...)# self_attention_outputs是一个元组,取[0]获取当前BertLayer中的Attention层的输出attention_output = self_attention_outputs[0]# (2)BertIntermediate中间层包含:dense+gelu激活# (3)BertOutput层包含:dense+dropout+LayerNorm,LayerNorm之前会进行残差连接# feed_forward_chunk的操作是:BertIntermediate(attention_output) + BertOutput(intermediate_output, attention_output)# BertIntermediate(attention_output)是:dense+gelu激活# BertOutput(intermediate_output, attention_output)是:dense+dropout+LayerNorm;# 其中LayerNorm(intermediate_output + attention_output)中的“intermediate_output + attention_output”是残差连接操作layer_output = apply_chunking_to_forward(self.feed_forward_chunk, ..., attention_output)4、pytorch中内置的transformer的TransformerEncoderLayer主要代码
- torch.nn.modules.transformer.TransformerEncoderLayer
class TransformerEncoderLayer(Module):'''Args:d_model: the number of expected features in the input (required).nhead: the number of heads in the multiheadattention models (required).dim_feedforward: the dimension of the feedforward network model (default=2048).dropout: the dropout value (default=0.1).activation: the activation function of intermediate layer, relu or gelu (default=relu).Examples::>>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)>>> src = torch.rand(10, 32, 512)>>> out = encoder_layer(src)'''def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu"):super(TransformerEncoderLayer, self).__init__()self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout)# Implementation of Feedforward modelself.linear1 = Linear(d_model, dim_feedforward)self.dropout = Dropout(dropout)self.linear2 = Linear(dim_feedforward, d_model)self.norm1 = LayerNorm(d_model)self.norm2 = LayerNorm(d_model)self.dropout1 = Dropout(dropout)self.dropout2 = Dropout(dropout)self.activation = _get_activation_fn(activation)def forward(...):# 过程:# (1)MultiheadAttention操作:src2 = self.self_attn# (2)Dropout操作:self.dropout1(src2)# (3)残差连接:src = src + self.dropout1(src2)# (4)LayerNorm操作:src = self.norm1(src)# 如下是FeedForword:做两次线性变换,为了更深入的提取特征# (5)Linear操作:src = self.linear1(src)# (6)RELU激活(默认RELU)操作:self.activation(self.linear1(src))# (7)Dropout操作:self.dropout(self.activation(self.linear1(src)))# (8)Linear操作:src2 = self.linear2(...)# (9)Dropout操作:self.dropout2(src2)# (10)残差连接:src = src + self.dropout2(src2)# (11)LayerNorm操作:src = self.norm2(src)src2 = self.self_attn(src, src, src, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src = self.norm1(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))src = src + self.dropout2(src2)src = self.norm2(src)return src5、区别总结
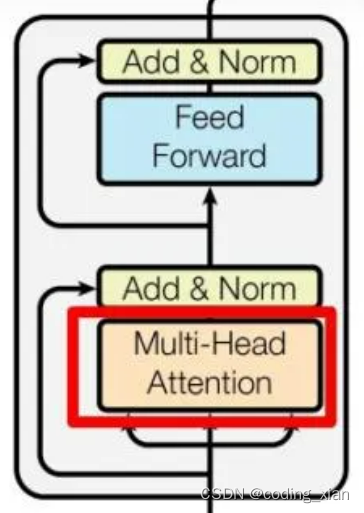
Transformer Encoder的结构如上图所示,代码也基本和上图描述的一致,不过代码中在Multi-Head Attention和Feed Forward之后都存在一个Dropout操作。(可以认为每层网络之后都会接一个Dropout层,是作为网络模块的一部分)
可以将Transformer Encoder过程表述为:
(1)MultiheadAttention + Dropout + 残差连接 + LayerNorm
(2)FeedForword(Linear + RELU + Dropout + Linear + Dropout) + 残差连接 + LayerNorm;Transformer默认的隐含层激活函数是RELU;
可以将 Bert Encoder过程表述为:
(1)BertSelfAttention: MultiheadAttention + Dropout
(2)BertSelfOutput:Linear+ Dropout + 残差连接 + LayerNorm; 注意:这里的残差连接是作用在BertSelfAttention的输入上,不是Linear的输入。
(3)BertIntermediate:Linear + GELU激活
(4)BertOutput:Linear + Dropout + 残差连接 + LayerNorm;注意:这里的残差连接是作用在BertIntermediate的输入上,不是Linear的输入;
进一步,把(1)(2)合并,(3)(4)合并:
(1)MultiheadAttention + Dropout + Linear + Dropout + 残差连接 + LayerNorm
(2)FeedForword(Linear + GELU激活 + Linear + Dropout) + 残差连接 + LayerNorm;Bert默认的隐含层激活函数是GELU;
所以,Bert Encoder和Transformer Encoder最大的区别是,Bert Encoder在做完Attention计算后,还会用一个线性层去提取特征,然后才进行残差连接。其次,是FeedForword中的默认激活函数不同。Bert Encoder图结构如下:
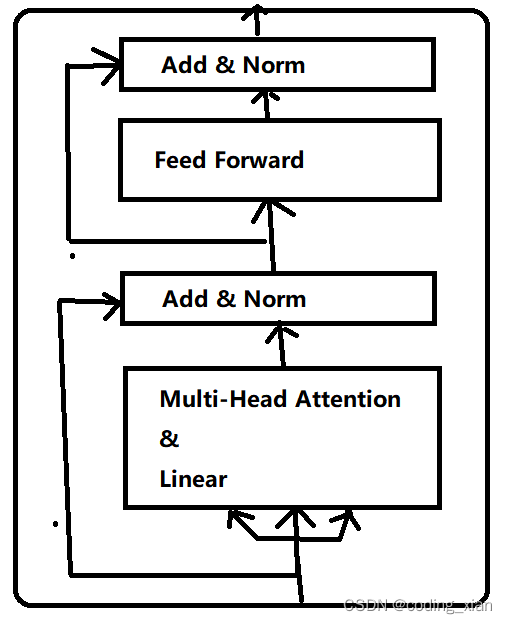
Bert 为什么要这么做?或许是多一个线性层,特征提取能力更强,模型表征能力更好。
GELU和RELU:GELU是RELU的改进版,效果更好。
Reference
- GeLU、ReLU函数学习_gelu和relu-CSDN博客
相关文章:
Bert Encoder和Transformer Encoder有什么不同
前言:本篇文章主要从代码实现角度研究 Bert Encoder和Transformer Encoder 有什么不同?应该可以帮助你: 深入了解Bert Encoder 的结构实现深入了解Transformer Encoder的结构实现 本篇文章不涉及对注意力机制实现的代码研究。 注:…...
外汇天眼:频繁交钱却无法出金,只因误入假冒HFM惨成冤大头!
在外汇市场上这么久了,天眼君总结出了一个不争的事实,但凡是不给出金或者以各种理由拒绝出金的平台一定有问题!想必不管是在外汇天眼还是其他地方,大家总是能看到一些外汇交易者投诉自己向平台申请出金需要缴纳各种费用࿰…...

Linux-信号3_sigaction、volatile与SIGCHLD
文章目录 前言一、sigaction__sighandler_t sa_handler;__sigset_t sa_mask; 二、volatile关键字三、SIGCHLD方法一方法二 前言 本章内容主要对之前的内容做一些补充。 一、sigaction #include <signal.h> int sigaction(int signum, const struct sigaction *act,struc…...
STM32 | STM32时钟分析、GPIO分析、寄存器地址查找、LED灯开发(第二天)
STM32 第二天 一、 STM32时钟分析 寄存器:寄存器的功能是存储二进制代码,它是由具有存储功能的触发器组合起来构成的。一个触发器可以存储1位二进制代码,故存放n位二进制代码的寄存器,需用n个触发器来构成 在计算机领域&#x…...
:字符串、列表、字典操作)
Python常用语法汇总(一):字符串、列表、字典操作
1. 字符串处理 print(message.title()) #首字母大写print(message.uper()) #全部大写print(message.lower()) #全部小写full_name "lin" "hai" #合并字符串print("Hello, " full_name.title() "!")print("John Q. %s10s&qu…...

Token的奥秘--一起学习吧之token
Token,在计算机科学中,是一个用于表示数据或一段数据的单位。它通常用于加密、身份验证、令牌化等场景,以确保数据的安全性和完整性。在编程语言中,Token通常是指代一段代码或数据的最小单元,例如一个变量、一个操作符…...

FlinkCDC快速搭建实现数据监控
引入依赖 <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelV…...

应急布控球远程视频监控方案:视频监控平台EasyCVR+4G/5G应急布控球
随着科技的不断发展,应急布控球远程视频监控方案在公共安全、交通管理、城市管理等领域的应用越来越广泛。这种方案通过在现场部署应急布控球,实现对特定区域的实时监控,有助于及时发现问题、快速响应,提高管理效率。 智慧安防视…...

3.6 C语言和汇编语言混合编程 “每日读书”
在一些嵌入式场合,我们经常看到C程序和汇编程序相互调用,混合编程,如在ARM启动代码中,系统上电首先运行的是汇编代码,等初始化好内存堆栈环境之后,才会跳到C程序中执行,对嵌入式软件进行优化时&…...
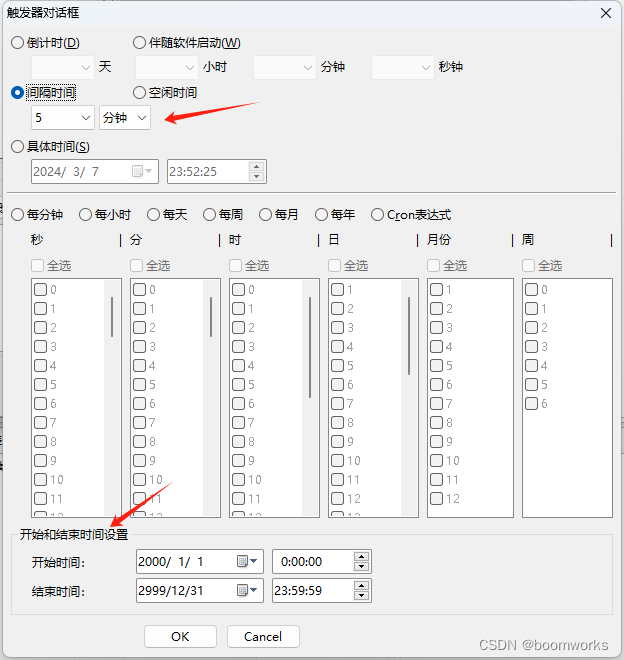
利用“定时执行专家”循环执行BAT、VBS、Python脚本——含参数指定功能
目录 一、软件概述 二、VBS脚本执行设置 三、触发器设置 四、功能亮点 五、总结 在自动化办公和日常计算机任务管理中,定时执行脚本是一项非常重要的功能。今天,我将为大家带来一款名为“定时执行专家”的软件的评测,特别是其定时执行VB…...

【算法集训】基础算法:模拟
一、基本理解 顾名思义,就是题目要求做什么,代码中就跟着做就可以。 二、题目练习 1252. 奇数值单元格的数目 根据题目要求列出如下代码。需要注意填充列和行的时候注意下标。 int oddCells(int m, int n, int** indices, int indicesSize, int* in…...
基于SSM的房客源信息管理系统设计与实现
目 录 摘 要 I Abstract II 引 言 1 1 相关技术 3 1.1 SSM框架 3 1.2 Vue框架 3 1.3 ECharts 3 1.4 JQuery技术 3 1.5 本章小结 4 2系统分析 5 2.1 需求分析 5 2.2 非功能需求 8 2.3 本章小节 8 3 系统设计 9 3.1 系统总体设计 9 3.1.1 系统体系结构 9 3.1.2 系统目录结构 9 3…...

常见数据类型
目录 数据类型 字符串 char nchar varchar varchar2 nvarchar 数字 number integer binary_float binary_double float 日期 date timestamp 大文本数据 大对象数据 Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 数…...
基于vue的联通积分商城数据可视化APP设计与实现
目 录 摘 要 I Abstract II 引 言 1 1 前端技术介绍 3 1.1 前端开发语言 3 1.1.1 HTML5 3 1.1.2 CSS3 3 1.1.3 JavaScript 3 1.2 MVVM开发模式 4 1.3 Vue框架 4 1.4 Axios技术 5 1.5 ECharts 5 1.6 数据库技术 5 1.7 本章小结 6 2 前端开发的分析 7 2.1 功能性需求分析 7 2.2 …...
)
2024年flink面试真题(一)
(北京)taskManager和slot、task的关系 ? (北京)flink状态太大怎么解决 ? (北京 flink提交方式和运行模式 ? (北京) 怎么提交的实时任务,有多少Job Manager? &…...

Java面试挂在线程创建后续,不要再被八股文误导了!创建线程的方式只有1种
线程创建之源 OK!咱们闲话少叙,直接进入正题,回顾一下通过实现Runnable接口,重写run方法创建线程的方式,真的可以创建一个线程吗?来看下面这段demo。 【代码示例1】 public class Test implements Runnab…...

JavaEE面试题
一、String面试题 1、String s1 "123"; 和 String s2 new String("123");的区别 在Java中,"String s1 "123";"和"String s2 new String("123");"这两行代码有一些重要的区别: "…...

探索macOS上的最佳MySQL客户端工具
在数据库管理和开发的世界里,选择一个高效、功能全面的客户端工具对于提升工作效率至关重要。尤其对于使用 macOS 的开发者来说,一个好的 MySQL 客户端不仅可以简化数据库操作,还能提供强大的数据分析和管理功能。本文将介绍几款适用于 macOS…...

[Android] MediaPlayer SDK API glance
参考: https://developer.android.com/reference/android/media/MediaPlayer 如何使用MediaPlayer SDK: https://developer.android.com/media/platform/mediaplayer 概述: 音视频的 playback。创建 MediaPlayer 的线程必须和调用 SDK 接口…...
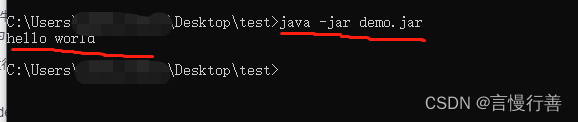
原始手写helloworld并打jar包允许
1.创建文件夹test统一在其中操作 2.创建hello.java文件 【hello.txt改属性为hello.java】并在里面添加代码 public class hello {public static void main(String[] args) {System.out.println("hello world");} } 注意:类名与文件名一致 然后运行…...

Linux环境下Oracle 19C补丁安装保姆级教程:从下载到验证的完整流程
Linux环境下Oracle 19C补丁安装全流程实战指南 在数据库运维工作中,补丁管理是确保系统安全稳定运行的关键环节。Oracle 19C作为当前长期支持版本,其补丁安装过程虽然标准化程度高,但实际操作中仍存在不少容易踩坑的细节。本文将基于实战经验…...

EmbeddingGemma-300m与MySQL结合:大规模向量存储方案
EmbeddingGemma-300m与MySQL结合:大规模向量存储方案 1. 引言 想象一下这样的场景:你的电商平台每天新增数万条商品描述,需要快速实现语义搜索功能;或者你的内容平台有百万篇文章,想要根据用户兴趣智能推荐相关内容。…...

嵌入式开发调试宏与性能优化实战
1. 嵌入式开发调试宏的妙用在嵌入式开发中,调试是最耗时耗力的环节之一。每次修改代码后都需要重新烧录、运行、观察结果,这个过程往往要重复数十次。而合理使用编译器提供的调试宏,可以大幅提升调试效率。1.1 基础调试宏解析GCC编译器提供了…...


OpenHD图传实战:如何为你的树莓派3B天空端配置720P 60帧,实现低延迟流畅回传
OpenHD图传实战:树莓派3B天空端720P 60帧低延迟优化指南 当你已经完成OpenHD图传系统的基础搭建,却发现默认配置下的画面卡顿、延迟明显时,这篇文章将带你深入系统核心,通过精准调参实现从"勉强能用"到"专业级流畅…...

Tencent Hunyuan3D-1.0学术合作机会:腾讯混元团队的研究方向与合作模式
Tencent Hunyuan3D-1.0学术合作机会:腾讯混元团队的研究方向与合作模式 【免费下载链接】Hunyuan3D-1 腾讯开源的Hunyuan3D-1项目,创新提出两阶段3D生成方法,实现快速、高质量的文本到3D和图像到3D转换,融合Hunyuan-DiT模型&#…...

英雄联盟智能助手:如何在选人阶段获得不公平优势?终极指南揭秘本地化工具LeagueAkari
英雄联盟智能助手:如何在选人阶段获得不公平优势?终极指南揭秘本地化工具LeagueAkari 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League…...

解锁Unity游戏定制潜能:MelonLoader全方位应用指南
解锁Unity游戏定制潜能:MelonLoader全方位应用指南 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 副标题ÿ…...

LockSupport深度解析:线程阻塞与唤醒的底层实现原理
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

BetterJoy终极指南:让Switch手柄在Windows上完美运行
BetterJoy终极指南:让Switch手柄在Windows上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.com/g…...