【Spring云原生】Spring Batch:海量数据高并发任务处理!数据处理纵享新丝滑!事务管理机制+并行处理+实例应用讲解
🎉🎉欢迎光临🎉🎉
🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀
🌟特别推荐给大家我的最新专栏《Spring 狂野之旅:从入门到入魔》 🚀
本专栏带你从Spring入门到入魔!
这是苏泽的个人主页可以看到我其他的内容哦👇👇
努力的苏泽
http://suzee.blog.csdn.net/
本文重点讲解原理!如要看批量数据处理的实战请关注下文(后续补充敬请关注):
实例应用:数据清洗和转换
使用Spring Batch清洗和转换数据
实例应用:数据导入和导出
使用Spring Batch导入和导出数据
实例应用:批处理定时任务
使用Spring Batch实现定时任务

目录
实例应用:数据清洗和转换
使用Spring Batch清洗和转换数据
实例应用:数据导入和导出
使用Spring Batch导入和导出数据
实例应用:批处理定时任务
使用Spring Batch实现定时任务
介绍Spring Batch
Spring Batch入门
解析
需求缔造:假设我们有一个需求,需要从一个CSV文件中读取学生信息,对每个学生的成绩进行转换和校验,并将处理后的学生信息写入到一个数据库表中。
数据处理
扩展Spring Batch
自定义读取器、写入器和处理器
与其他Spring项目的集成
与Spring Integration的集成:
与Spring Cloud Task的集成:
介绍Spring Batch
Spring Batch是一个基于Java的开源批处理框架,用于处理大规模、重复性和高可靠性的任务。它提供了一种简单而强大的方式来处理批处理作业,如数据导入/导出、报表生成、批量处理等。
什么是Spring Batch?
Spring Batch旨在简化批处理作业的开发和管理。它提供了一种可扩展的模型来定义和执行批处理作业,将作业划分为多个步骤(Step),每个步骤又由一个或多个任务块(Chunk)组成。通过使用Spring Batch,可以轻松处理大量的数据和复杂的业务逻辑。
Spring Batch的特点和优势
-
可扩展性和可重用性:Spring Batch采用模块化的设计,提供了丰富的可扩展性和可重用性。可以根据具体需求自定义作业流程,添加或删除步骤,灵活地适应不同的批处理场景。
-
事务管理:Spring Batch提供了强大的事务管理机制,确保批处理作业的数据一致性和完整性。可以配置事务边界,使每个步骤或任务块在单独的事务中执行,保证了作业的可靠性。
-
监控和错误处理:Spring Batch提供了全面的监控和错误处理机制。可以通过监听器和回调函数来监控作业的执行情况,处理错误和异常情况,以及记录和报告作业的状态和指标。
-
并行处理:Spring Batch支持并行处理,可以将作业划分为多个独立的线程或进程来执行,提高作业的处理速度和效率。
Spring Batch入门
1. 安装和配置Spring Batch
首先,确保你的Java开发环境已经安装并配置好。然后,可以使用Maven或Gradle等构建工具来添加Spring Batch的依赖项到你的项目中。详细的安装和配置可以参考Spring Batch的官方文档。
2. 创建第一个批处理作业
在Spring Batch中,一个批处理作业由一个或多个步骤组成,每个步骤又由一个或多个任务块组成。下面是一个简单的示例,演示如何创建一个简单的批处理作业:
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Step step1() {return stepBuilderFactory.get("step1").tasklet((contribution, chunkContext) -> {System.out.println("Hello, Spring Batch!");return RepeatStatus.FINISHED;}).build();}@Beanpublic Job job(Step step1) {return jobBuilderFactory.get("job").start(step1).build();}
}解析
首先使用@Configuration和@EnableBatchProcessing注解将类标记为Spring Batch的配置类。然后,使用JobBuilderFactory和StepBuilderFactory创建作业和步骤的构建器。在step1方法中,定义了一个简单的任务块,打印"Hello, Spring Batch!"并返回RepeatStatus.FINISHED。最后,在job方法中,使用jobBuilderFactory创建一个作业,并将step1作为作业的起始步骤。
3. 理解Job、Step和任务块
-
Job(作业):作业是一个独立的批处理任务,由一个或多个步骤组成。它描述了整个批处理过程的流程和顺序,并可以有自己的参数和配置。
-
Step(步骤块):步骤是作业的组成部分,用于执行特定的任务。一个作业可以包含一个或多个步骤,每个步骤都可以定义自己的任务和处理逻辑。
-
任务块(Chunk):任务块是步骤的最小执行单元,用于处理一定量的数据。任务块将数据分为一块一块进行处理,可以定义读取数据、处理数据和写入数据的逻辑。
需求缔造:
假设我们有一个需求,需要从一个CSV文件中读取学生信息,对每个学生的成绩进行转换和校验,并将处理后的学生信息写入到一个数据库表中。
数据处理
- 数据读取和写入:Spring Batch提供了多种读取和写入数据的方式。可以使用
ItemReader读取数据,例如从数据库、文件或消息队列中读取数据。然后使用ItemWriter将处理后的数据写入目标,如数据库表、文件或消息队列。
首先,我们需要定义一个数据模型来表示学生信息,例如public class Student {private String name;private int score;// Getters and setters// ... }接下来,我们可以使用Spring Batch提供的
FlatFileItemReader来读取CSV文件中的数据:@Bean public FlatFileItemReader<Student> studentItemReader() {FlatFileItemReader<Student> reader = new FlatFileItemReader<>();reader.setResource(new ClassPathResource("students.csv"));reader.setLineMapper(new DefaultLineMapper<Student>() {{setLineTokenizer(new DelimitedLineTokenizer() {{setNames(new String[] { "name", "score" });}});setFieldSetMapper(new BeanWrapperFieldSetMapper<Student>() {{setTargetType(Student.class);}});}});return reader; }
支持的数据格式和数据源
- Spring Batch支持各种数据格式和数据源。可以使用适配器和读写器来处理不同的数据格式,如CSV、XML、JSON等。同时,可以通过自定义的数据读取器和写入器来处理不同的数据源,如关系型数据库、NoSQL数据库等。
数据转换和校验
- Spring Batch提供了数据转换和校验的机制。可以使用
ItemProcessor对读取的数据进行转换、过滤和校验。ItemProcessor可以应用自定义的业务逻辑来处理每个数据项。我们配置了一个
FlatFileItemReader,设置了CSV文件的位置和行映射器,指定了字段分隔符和字段到模型属性的映射关系。接下来,我们可以定义一个
ItemProcessor来对读取的学生信息进行转换和校验:@Bean public ItemProcessor<Student, Student> studentItemProcessor() {return new ItemProcessor<Student, Student>() {@Overridepublic Student process(Student student) throws Exception {// 进行转换和校验if (student.getScore() < 0) {// 校验不通过,抛出异常throw new IllegalArgumentException("Invalid score for student: " + student.getName());}// 转换操作,例如将分数转换为百分制int percentage = student.getScore() * 10;student.setScore(percentage);return student;}}; }在上述代码中,我们定义了一个
ItemProcessor,对学生信息进行校验和转换。如果学生的分数小于0,则抛出异常;否则,将分数转换为百分制。最后,我们可以使用Spring Batch提供的
JdbcBatchItemWriter将处理后的学生信息写入数据库:@Bean public JdbcBatchItemWriter<Student> studentItemWriter(DataSource dataSource) {JdbcBatchItemWriter<Student> writer = new JdbcBatchItemWriter<>();writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());writer.setSql("INSERT INTO students (name, score) VALUES (:name, :score)");writer.setDataSource(dataSource);return writer; }
作业调度和监控
-
作业调度器的配置:Spring Batch提供了作业调度器来配置和管理批处理作业的执行。可以使用Spring的调度框架(如Quartz)或操作系统的调度工具(如cron)来调度作业。通过配置作业调度器,可以设置作业的触发时间、频率和其他调度参数。
在上述代码中,我们配置了一个
JdbcBatchItemWriter,设置了SQL语句和数据源,将处理后的学生信息批量插入数据库表中。最后,我们需要配置一个作业步骤来组装数据读取、处理和写入的过程:
@Bean public Step processStudentStep(ItemReader<Student> reader, ItemProcessor<Student, Student> processor, ItemWriter<Student> writer) {return stepBuilderFactory.get("processStudentStep").<Student, Student>chunk(10).reader(reader).processor(processor).writer(writer).build(); }在上述代码中,我们使用
stepBuilderFactory创建了一个步骤,并指定了数据读取器、处理器和写入器。 -
作业执行的监控和管理:Spring Batch提供了丰富的监控和管理功能。可以使用Spring Batch的管理接口和API来监控作业的执行状态、进度和性能指标。还可以使用日志记录、通知和报警机制来及时获取作业执行的状态和异常信息。
最后,我们可以配置一个作业来调度执行该步骤:
@Bean public Job processStudentJob(JobBuilderFactory jobBuilderFactory, Step processStudentStep) {return jobBuilderFactory.get("processStudentJob").flow(processStudentStep).end().build(); }我们使用
jobBuilderFactory创建了一个作业,并指定了步骤来执行。通过以上的示例,我们演示了Spring Batch中数据读取和写入的方式,使用了
FlatFileItemReader读取CSV文件,使用了JdbcBatchItemWriter将处理后的学生信息写入数据库。同时,我们使用了ItemProcessor对读取的学生信息进行转换和校验。这个例子还展示了Spring Batch对不同数据源和数据格式的支持,以及如何配置和组装作业步骤来完成整个批处理任务。
错误处理和重试机制
- Spring Batch提供了错误处理和重试机制,以确保批处理作业的稳定性和可靠性。可以配置策略来处理读取、处理和写入过程中的错误和异常情况。可以设置重试次数、重试间隔和错误处理策略,以适应不同的错误场景和需求。
首先,我们可以在步骤配置中设置错误处理策略。例如,我们可以使用SkipPolicy来跳过某些异常,或者使用RetryPolicy来进行重试。@Bean public Step processStudentStep(ItemReader<Student> reader, ItemProcessor<Student, Student> processor, ItemWriter<Student> writer) {return stepBuilderFactory.get("processStudentStep").<Student, Student>chunk(10).reader(reader).processor(processor).writer(writer).faultTolerant().skip(Exception.class).skipLimit(10).retry(Exception.class).retryLimit(3).build(); }我们使用
faultTolerant()方法来启用错误处理策略。然后,使用skip(Exception.class)指定跳过某些异常,使用skipLimit(10)设置跳过的最大次数为10次。同时,使用retry(Exception.class)指定重试某些异常,使用retryLimit(3)设置重试的最大次数为3次。在默认情况下,如果发生读取、处理或写入过程中的异常,Spring Batch将标记该项为错误项,并尝试跳过或重试,直到达到跳过或重试的次数上限为止。
此外,您还可以为每个步骤配置错误处理器,以定制化处理错误项的逻辑。例如,可以使用
SkipListener来处理跳过的项,使用RetryListener来处理重试的项。
@Bean public SkipListener<Student, Student> studentSkipListener() {return new SkipListener<Student, Student>() {@Overridepublic void onSkipInRead(Throwable throwable) {// 处理读取过程中发生的异常}@Overridepublic void onSkipInWrite(Student student, Throwable throwable) {// 处理写入过程中发生的异常}@Overridepublic void onSkipInProcess(Student student, Throwable throwable) {// 处理处理过程中发生的异常}}; }@Bean public RetryListener studentRetryListener() {return new RetryListener() {@Overridepublic <T, E extends Throwable> boolean open(RetryContext retryContext, RetryCallback<T, E> retryCallback) {// 在重试之前执行的逻辑return true;}@Overridepublic <T, E extends Throwable> void onError(RetryContext retryContext, RetryCallback<T, E> retryCallback, Throwable throwable) {// 处理重试过程中发生的异常}@Overridepublic <T, E extends Throwable> void close(RetryContext retryContext, RetryCallback<T, E> retryCallback, Throwable throwable) {// 在重试之后执行的逻辑}}; }@Bean public Step processStudentStep(ItemReader<Student> reader, ItemProcessor<Student, Student> processor, ItemWriter<Student> writer,SkipListener<Student, Student> skipListener, RetryListener retryListener) {return stepBuilderFactory.get("processStudentStep").<Student, Student>chunk(10).reader(reader).processor(processor).writer(writer).faultTolerant().skip(Exception.class).skipLimit(10).retry(Exception.class).retryLimit(3).listener(skipListener).listener(retryListener).build(); }
批处理最佳实践
-
数据量控制:在批处理作业中,应注意控制数据量的大小,以避免内存溢出或处理速度过慢的问题。可以通过分块(Chunk)处理和分页读取的方式来控制数据量。
-
事务管理:在批处理作业中,对于需要保证数据一致性和完整性的操作,应使用适当的事务管理机制。可以配置事务边界,确保每个步骤或任务块在独立的事务中执行。
-
错误处理和日志记录:合理处理错误和异常情况是批处理作业的重要部分。应使用适当的错误处理策略、日志记录和报警机制,以便及时发现和处理问题。
-
性能调优:在批处理作业中,应关注性能调优的问题。可以通过合理的并行处理、合理配置的线程池和适当的数据读取和写入策略来提高作业的处理速度和效率。
-
监控和管理:对于长时间运行的批处理作业,应设置适当的监控和管理机制。可以使用监控工具、警报系统和自动化任务管理工具来监控作业的执行情况和性能指标。
扩展Spring Batch
自定义读取器、写入器和处理器
Spring Batch提供了许多扩展点,可以通过自定义读取器、写入器和处理器以及其他组件来扩展和定制批处理作业的功能。
public class MyItemReader implements ItemReader<String> {private List<String> data = Arrays.asList("item1", "item2", "item3");private Iterator<String> iterator = data.iterator();@Overridepublic String read() throws Exception {if (iterator.hasNext()) {return iterator.next();} else {return null;}}
}自定义写入器:
public class MyItemWriter implements ItemWriter<String> {@Overridepublic void write(List<? extends String> items) throws Exception {for (String item : items) {// 自定义写入逻辑}}
}自定义处理器:
public class MyItemProcessor implements ItemProcessor<String, String> {@Overridepublic String process(String item) throws Exception {// 自定义处理逻辑return item.toUpperCase();}
}批处理作业的并行处理:
Spring Batch支持将批处理作业划分为多个独立的步骤,并通过多线程或分布式处理来实现并行处理。
- 多线程处理:可以通过配置TaskExecutor来实现多线程处理。通过使用TaskExecutor,每个步骤可以在独立的线程中执行,从而实现并行处理。
@Bean public TaskExecutor taskExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(5);executor.setMaxPoolSize(10);executor.setQueueCapacity(25);return executor; }@Bean public Step myStep(ItemReader<String> reader, ItemProcessor<String, String> processor, ItemWriter<String> writer) {return stepBuilderFactory.get("myStep").<String, String>chunk(10).reader(reader).processor(processor).writer(writer).taskExecutor(taskExecutor()).build(); }在上述代码中,我们通过
taskExecutor()方法定义了一个线程池任务执行器,并将其配置到步骤中的taskExecutor()方法中。 - 分布式处理:如果需要更高的并行性和可伸缩性,可以考虑使用分布式处理。Spring Batch提供了与Spring Integration和Spring Cloud Task等项目的集成,以实现分布式部署和处理。
与其他Spring项目的集成
-
与Spring Integration的集成:
首先,需要在Spring Batch作业中配置Spring Integration的消息通道和适配器。可以使用消息通道来发送和接收作业的输入和输出数据,使用适配器来与外部系统进行交互。
@Configuration
@EnableBatchProcessing
@EnableIntegration
public class BatchConfiguration {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Autowiredprivate MyItemReader reader;@Autowiredprivate MyItemProcessor processor;@Autowiredprivate MyItemWriter writer;@Beanpublic IntegrationFlow myJobFlow() {return IntegrationFlows.from("jobInputChannel").handle(jobLaunchingGateway()).get();}@Beanpublic MessageChannel jobInputChannel() {return new DirectChannel();}@Beanpublic MessageChannel jobOutputChannel() {return new DirectChannel();}@Beanpublic MessageChannel stepInputChannel() {return new DirectChannel();}@Beanpublic MessageChannel stepOutputChannel() {return new DirectChannel();}@Beanpublic JobLaunchingGateway jobLaunchingGateway() {SimpleJobLauncher jobLauncher = new SimpleJobLauncher();jobLauncher.setJobRepository(jobRepository());return new JobLaunchingGateway(jobLauncher);}@Beanpublic JobRepository jobRepository() {// 配置作业存储库}@Beanpublic Job myJob() {return jobBuilderFactory.get("myJob").start(step1()).build();}@Beanpublic Step step1() {return stepBuilderFactory.get("step1").<String, String>chunk(10).reader(reader).processor(processor).writer(writer).inputChannel(stepInputChannel()).outputChannel(stepOutputChannel()).build();}
}在上述代码中,我们配置了Spring Batch作业的消息通道和适配器。myJobFlow()方法定义了一个整合流程,它从名为jobInputChannel的消息通道接收作业请求,并通过jobLaunchingGateway()方法启动作业。jobLaunchingGateway()方法创建一个JobLaunchingGateway实例,用于启动作业。
与Spring Cloud Task的集成:
首先,需要在Spring Batch作业中配置Spring Cloud Task的任务启动器和任务监听器。任务启动器用于启动和管理分布式任务,任务监听器用于在任务执行期间执行一些操作。
@Configuration
@EnableBatchProcessing
@EnableTask
public class BatchConfiguration {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Autowiredprivate MyItemReader reader;@Autowiredprivate MyItemProcessor processor;@Autowiredprivate MyItemWriter writer;@Beanpublic TaskConfigurer taskConfigurer() {return new DefaultTaskConfigurer();}@Beanpublic TaskExecutor taskExecutor() {return new SimpleAsyncTaskExecutor();}@Beanpublic Job myJob() {return jobBuilderFactory.get("myJob").start(step1()).build();}@Beanpublic Step step1() {return stepBuilderFactory.get("step1").<String, String>chunk(10).reader(reader).processor(processor).writer(writer).taskExecutor(taskExecutor()).build();}@Beanpublic TaskListener myTaskListener() {return new MyTaskListener();}@Beanpublic TaskExecutionListener myTaskExecutionListener() {return new MyTaskExecutionListener();}
}相关文章:
【Spring云原生】Spring Batch:海量数据高并发任务处理!数据处理纵享新丝滑!事务管理机制+并行处理+实例应用讲解
🎉🎉欢迎光临🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟特别推荐给大家我的最新专栏《Spring 狂野之旅:从入门到入魔》 🚀 本…...

docker ubuntu20.04 安装教程
ubuntu20.04 安装 docker 教程 本博客测试安装时间2023.8月 一、docker安装内容:docker Engine社区版 和 docker Compose 二、安装环境:ubuntu20.04 三、安装步骤: # 如果已经安装过docker,请先卸载,没安装则跳过…...
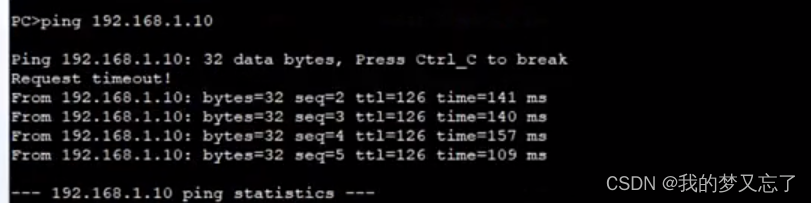
防御保护----IPSEC VPPN实验
实验拓扑: 实验背景:FW1和FW2是双机热备的状态。 实验要求:在FW和FW3之间建立一条IPSEC通道,保证10.0.2.0/24网段可以正常访问到192.168.1.0/24 IPSEC VPPN实验配置(由于是双机热备状态,所以FW1和FW2只需要…...

音视频数字化(视频线缆与接口)
目录 1、DVI接口 2、DP接口 之前的文章【音视频数字化(线缆与接口)】提到了部分视频线缆,今天再补充几个。 视频模拟信号连接从莲花头的“复合”线开始,经历了S端子、色差分量接口,通过亮度、色度尽量分离的办法提高画面质量,到VGA已经到了模拟的顶峰,实现了RGB的独立…...
爬虫实战——巴黎圣母院新闻【内附超详细教程,你上你也行】
文章目录 发现宝藏一、 目标二、简单分析网页1. 寻找所有新闻2. 分析模块、版面和文章 三、爬取新闻1. 爬取模块2. 爬取版面3. 爬取文章 四、完整代码五、效果展示 发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不…...
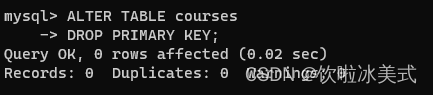
mysql的语法总结2
命令: mysql -u 用户名 -p mysql登录 命令:create database u1 创建数据库u1 查询数据库 使用数据库u1 创建表department 查询表department ALTER TABLE 表名 操作类型; 操作类型可以有以下的操作: 添加列&#x…...

一度电竟然可以做这么多事情!
一度电竟然可以做这么多事情!!! 一度电可以让手机充电100多次; 一度电可以生产医用口罩100个; 一度电可以让节能灯点亮九十个小时; 一度电可以让电视播放10小时; 一度电可以让冰箱运作36个小…...

【Go】golang值交换,指针
package mainimport "fmt"func swap(a *int, b *int) int {var o into *a*a *b*b oreturn o}func main() {var a int 1var b int 2swap(&a, &b)fmt.Println(a, b) }这个函数接受两个整数指针作为参数,然后通过指针操作,交换它们所…...

共享WiFi软件哪家强?2024年共享wifi项目排名为你揭晓!
共享WiFi软件在如今的智能手机时代已经成为人们生活中不可或缺的一部分。随着移动互联网的飞速发展,人们对于随时随地都能够连接到网络的需求也日益增长。为了满足这一需求,共享经济应运而生,而在众多共享产品中,共享WiFi软件也逐…...

Hudi入门
一、Hudi编译安装 1.下载 https://archive.apache.org/dist/hudi/0.9.0/hudi-0.9.0.src.tgz2.maven编译 mvn clean install -DskipTests -Dscala2.12 -Dspark33.配置spark与hudi依赖包 [rootmaster hudi-spark-jars]# ll total 37876 -rw-r--r-- 1 root root 38615211 Oct …...
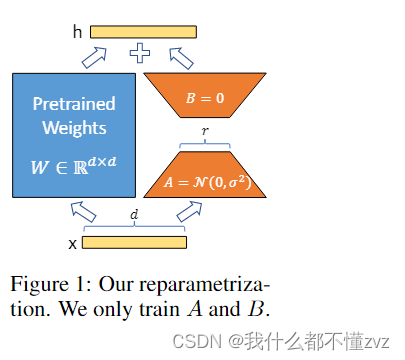
LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS
TOC 1 前言2 方法2.1 LOW-RANK-PARAMETRIZED UPDATE MATRICES 1 前言 1) 提出背景 大模型时代,通常参数都是上亿级别的,若对于每个具体任务都要去对大模型进行全局微调,那么算力和资源的浪费是巨大的。 根据流形学习思想,对于数…...
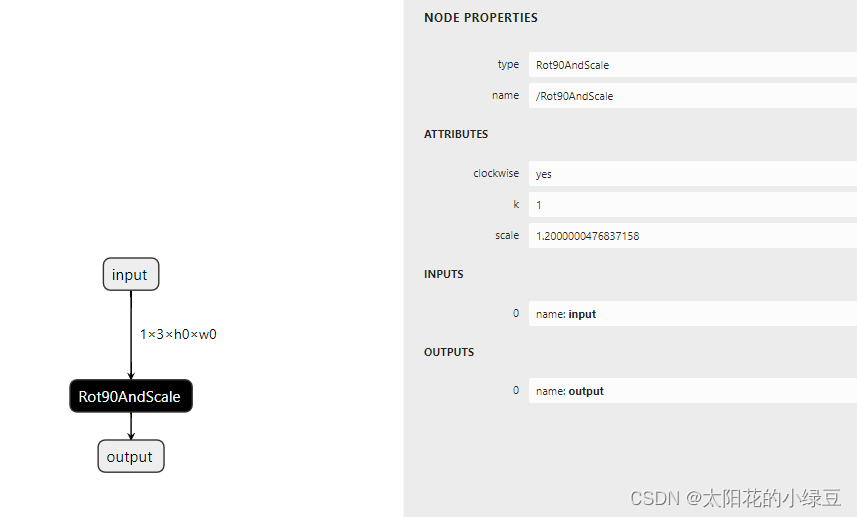
使用Pytorch导出自定义ONNX算子
在实际部署模型时有时可能会遇到想用的算子无法导出onnx,但实际部署的框架是支持该算子的。此时可以通过自定义onnx算子的方式导出onnx模型(注:自定义onnx算子导出onnx模型后是无法使用onnxruntime推理的)。下面给出个具体应用中的…...

unity-urp:视野雾
问题背景 恐怖游戏在黑夜或者某些场景下,需要用雾或者黑暗遮盖视野,搭建游戏氛围 效果 场景中,雾会遮挡场景和怪物,但是在玩家视野内雾会消散,距离玩家越近雾越薄。 当前是第三人称视角,但是可以轻松的…...

Spring Cloud Gateway介绍及入门配置
Spring Cloud Gateway介绍及入门配置 概述: Gateway是在Spring生态系统之上构建的API网关服务,基于Spring6,Spring Boot 3和Project Reactor等技术。它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式,并为它们提供…...
Thingsboard本地源码部署教程
本章将介绍ThingsBoard的本地环境搭建,以及源码的编译安装。本机环境:jdk11、maven 3.6.2、node v12.18.2、idea 2023.1、redis 6.2 环境安装 开发环境要求: Jdk 11 版本 ;Postgresql 9 以上;Maven 3.6 以上…...
【MySQL 系列】MySQL 起步篇
MySQL 是一个开放源代码的、免费的关系型数据库管理系统。在 Web 开发领域,MySQL 是最流行、使用最广泛的关系数据库。MySql 分为社区版和商业版,社区版完全免费,并且几乎能满足全部的使用场景。由于 MySQL 是开源的,我们还可以根…...

C++的成员初始化列表
C的成员构造函数初始化列表:构造函数中初始化类成员的一种方式,当我们编写一个类并向该类添加成员时,通常需要某种方式对这些成员变量进行初始化。 建议应该在所有地方使用成员初始化列表进行初始化 成员初始化的方法 方法一: …...
为什么TikTok视频0播放?账号权重提高要重视
许多TikTok账号运营者都会遇到一个难题,那就是视频要么播放量很低,要么0播放!不管内容做的多好,最好都是竹篮打水一场空!其实你可能忽略了一个问题,那就是账号权重。下面好好跟大家讲讲这个东西!…...
element---tree树形结构(返回的数据与官方的不一样)
项目中要用到属性结构数据,后端返回的数据不是官方默认的数据结构: <el-tree:data"treeData":filter-node-method"filterNode":props"defaultProps"node-click"handleNodeClick"></el-tree>这是文档…...

Spring Boot工程集成验证码生成与验证功能教程
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...

ChatGPT_JCM跨平台方案:一次开发,多端运行的实现方法
ChatGPT_JCM跨平台方案:一次开发,多端运行的实现方法 【免费下载链接】ChatGPT_JCM 项目地址: https://gitcode.com/gh_mirrors/ch/ChatGPT_JCM ChatGPT_JCM是一款基于Electron和Vue.js构建的跨平台AI应用,通过"一次开发&#x…...

DeepSeek-Coder-V2本地化部署指南:构建你的专属AI编程助手
DeepSeek-Coder-V2本地化部署指南:构建你的专属AI编程助手 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Coder-V2 …...

基于Dify的智能问答系统:从意图识别到规范化回复的全流程设计
1. 从零开始理解Dify智能问答系统 第一次接触Dify时,我完全被它的可视化编排能力惊艳到了。这个平台就像搭积木一样,让不懂代码的产品经理也能设计出复杂的AI应用。举个实际例子,去年我们团队要做一个游泳健身领域的问答助手,传统…...

高效获取B站视频到本地存储:BilibiliDown工具全攻略
高效获取B站视频到本地存储:BilibiliDown工具全攻略 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/…...

如何轻松实现单机游戏分屏多人:Nucleus Co-Op完整指南
如何轻松实现单机游戏分屏多人:Nucleus Co-Op完整指南 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为找不到联机伙伴而烦恼吗&a…...

3大核心策略:构建高效抖音内容采集系统的技术实践
3大核心策略:构建高效抖音内容采集系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

优盈杯数据泄露事件复盘:隐私保护的警钟
300 万张照片泄露:优盈杯隐私防线的崩塌2014 年 9 月,Clarifai 公司首席执行官向优盈杯一位创始人发邮件,请求提供大量优盈杯照片数据集。由于优盈杯部分创始人对 Clarifai 有投资,Humor Rainbow 为其提供了近 300 万张 优盈杯用户…...

车企携手Tech Soft 3D:基于 HOOPS 工具集打造Web端一体化工程可视化解决方案
随着汽车行业向智能化、电动化转型,整车研发体系正在发生深刻变化。围绕多平台架构、跨区域协同以及供应链一体化,企业对于工程数据的使用方式提出了更高要求——不仅要“能管理”,更要“能流动、能协同”。 为推动核心工程系统向浏览器化、…...

从零部署到实战标注:SUSTechPOINTS 3D点云标注平台全流程指南
1. 为什么选择SUSTechPOINTS进行3D点云标注 在自动驾驶研发过程中,3D点云标注是个绕不开的苦差事。我最早用过不少商业标注工具,不是价格贵得离谱,就是功能残缺不全。直到去年团队接手一个校企合作项目,才发现南方科技大学开源的这…...
实战部署与优化指南)
神州数码无线网络(AC+AP)实战部署与优化指南
1. 神州数码ACAP无线网络部署前的规划准备 第一次接触神州数码无线网络方案时,我被它简洁的架构设计惊艳到了。AC(无线控制器)AP(接入点)的组网模式,特别适合500-2000平米的中型企业办公环境。但在真正动手…...