爬虫实战——巴黎圣母院新闻【内附超详细教程,你上你也行】
文章目录
- 发现宝藏
- 一、 目标
- 二、简单分析网页
- 1. 寻找所有新闻
- 2. 分析模块、版面和文章
- 三、爬取新闻
- 1. 爬取模块
- 2. 爬取版面
- 3. 爬取文章
- 四、完整代码
- 五、效果展示
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。
一、 目标
爬取https://news.nd.edu/的字段,包含标题、内容,作者,发布时间,链接地址,文章快照 (可能需要翻墙才能访问)
二、简单分析网页
1. 寻找所有新闻
-
点击查看更多最新新闻>>点击查看档案
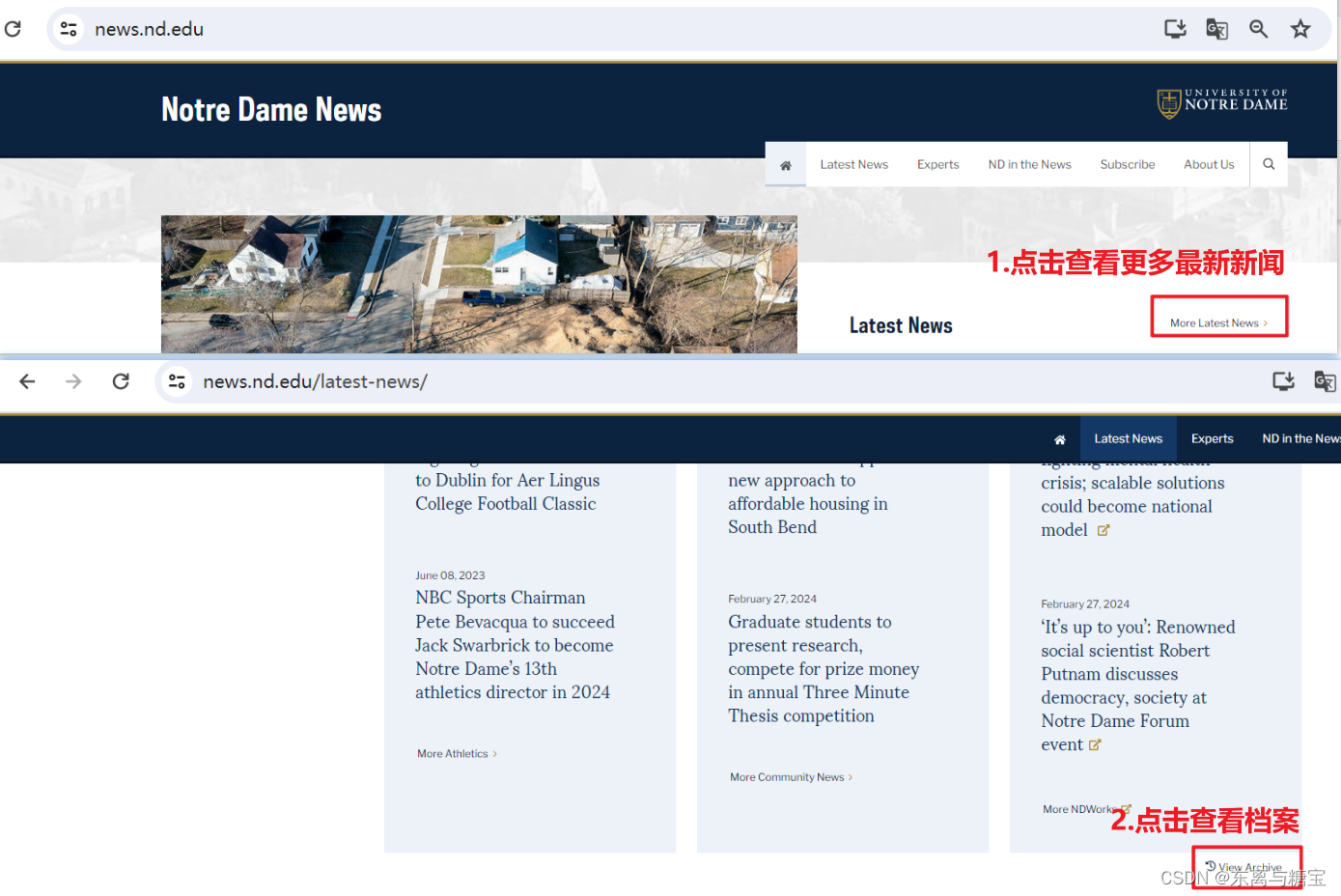
-
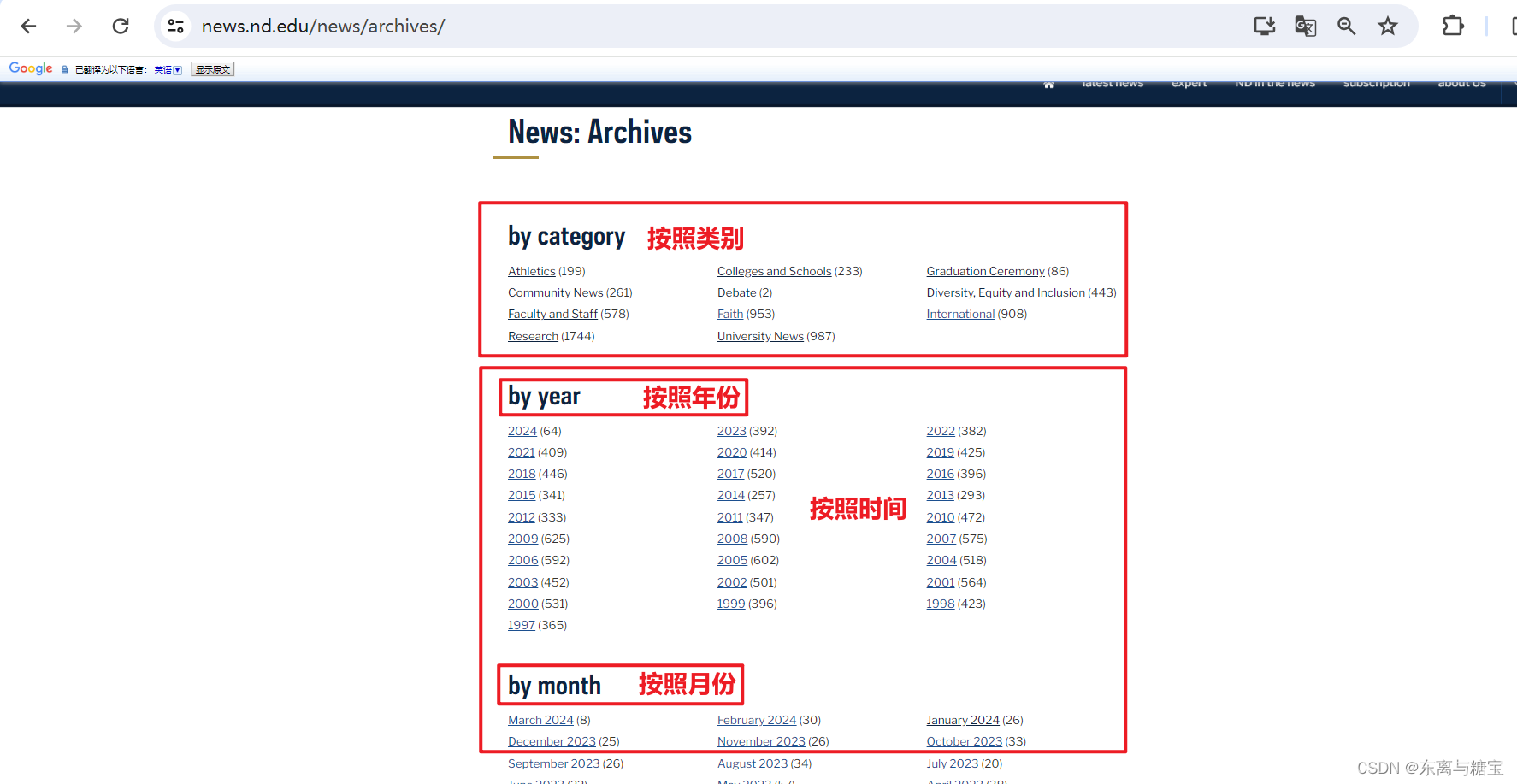
我们发现有两种方式查看所有新闻,一种是按照类别,一种是按照时间,经过进一步的观察我们发现按照时间查看新闻会更全,所以我们选择按照年份(按照月份和按照年份一样的效果)爬取
2. 分析模块、版面和文章
-
为了规范爬取的命名与逻辑,我们分别用模块、版面、文章三部分来进行爬取,具体如下
-
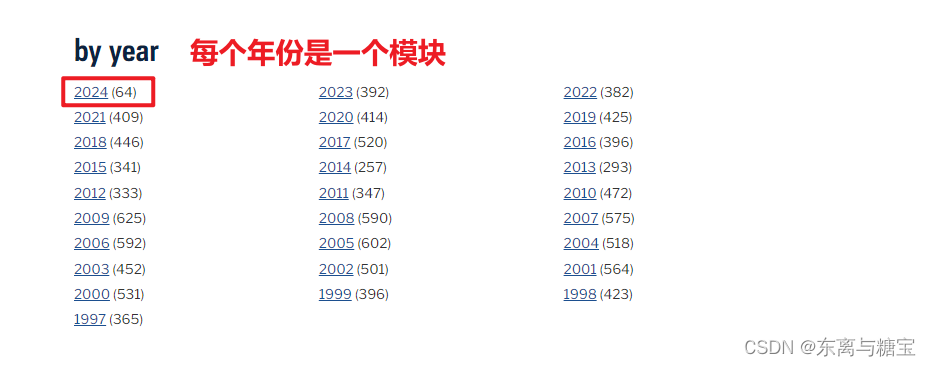
一个网站的全部新闻由数个模块组成,只要我们遍历爬取了所有模块就获得的该网站的所有新闻
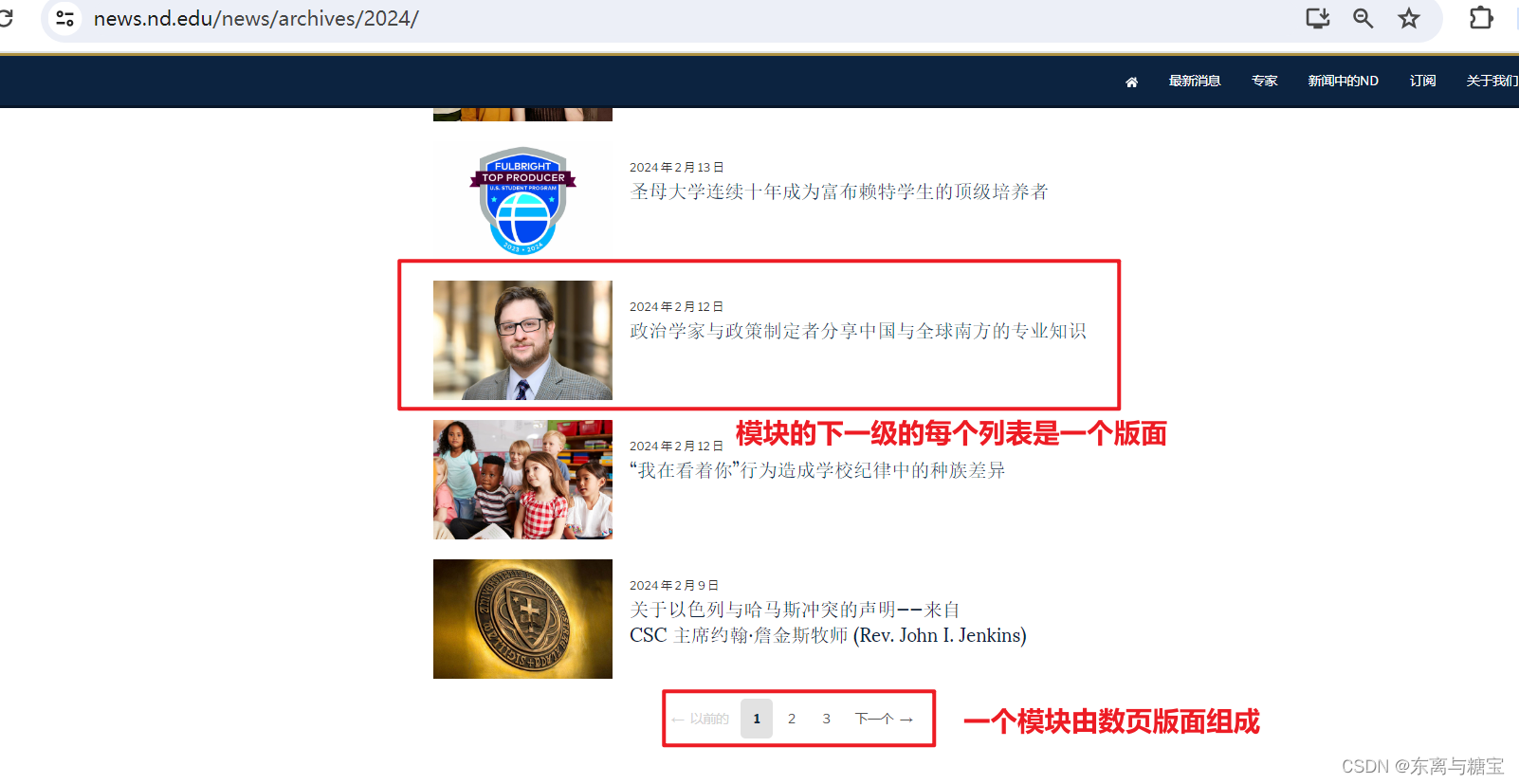
- 一个模块由数页版面组成,只要遍历了所有版面,我们就爬取了一个模块
- 一个版面里有数页文章,由于该网站模块下的列表同时也是一篇文章,所以一个版面里只有一篇文章
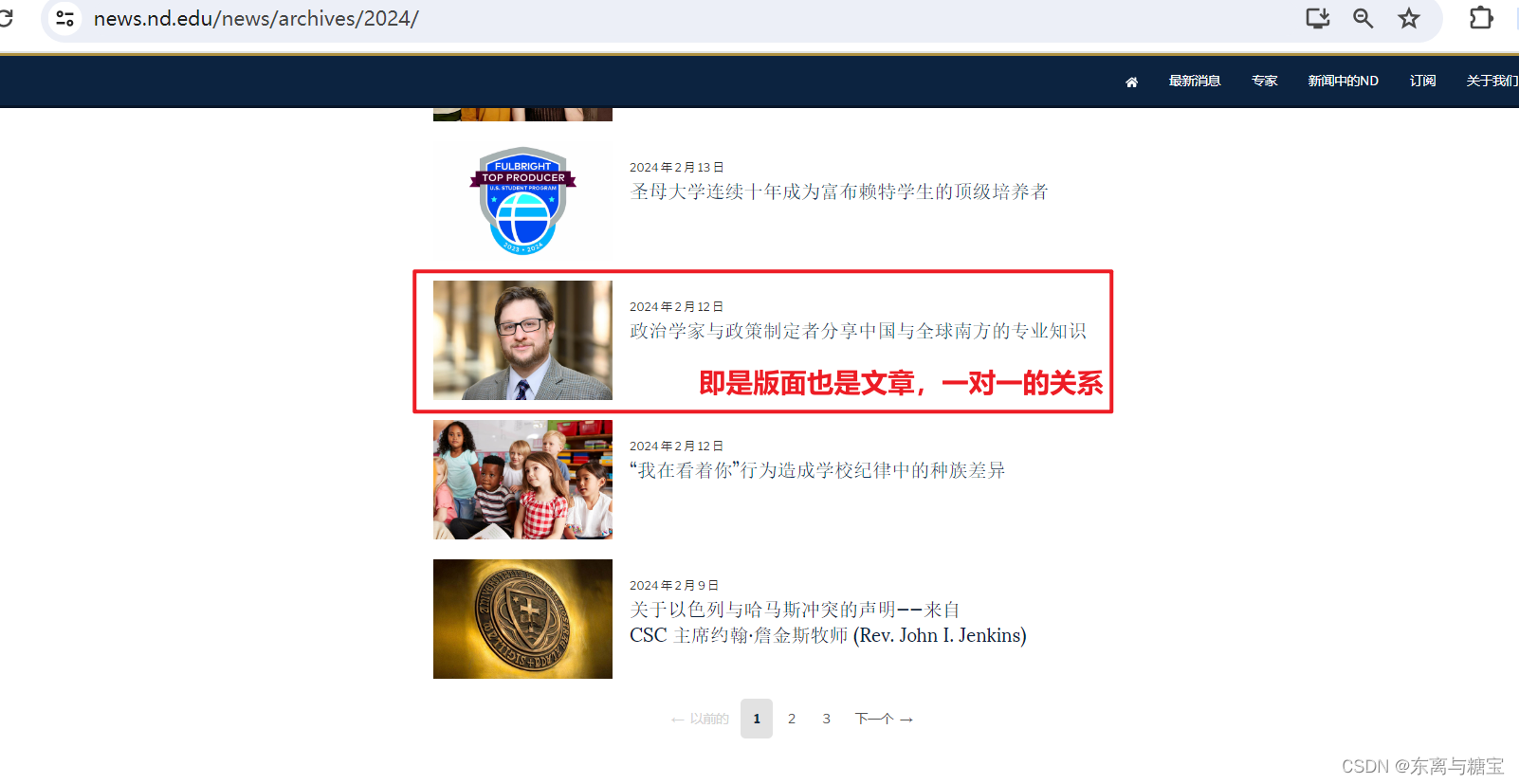
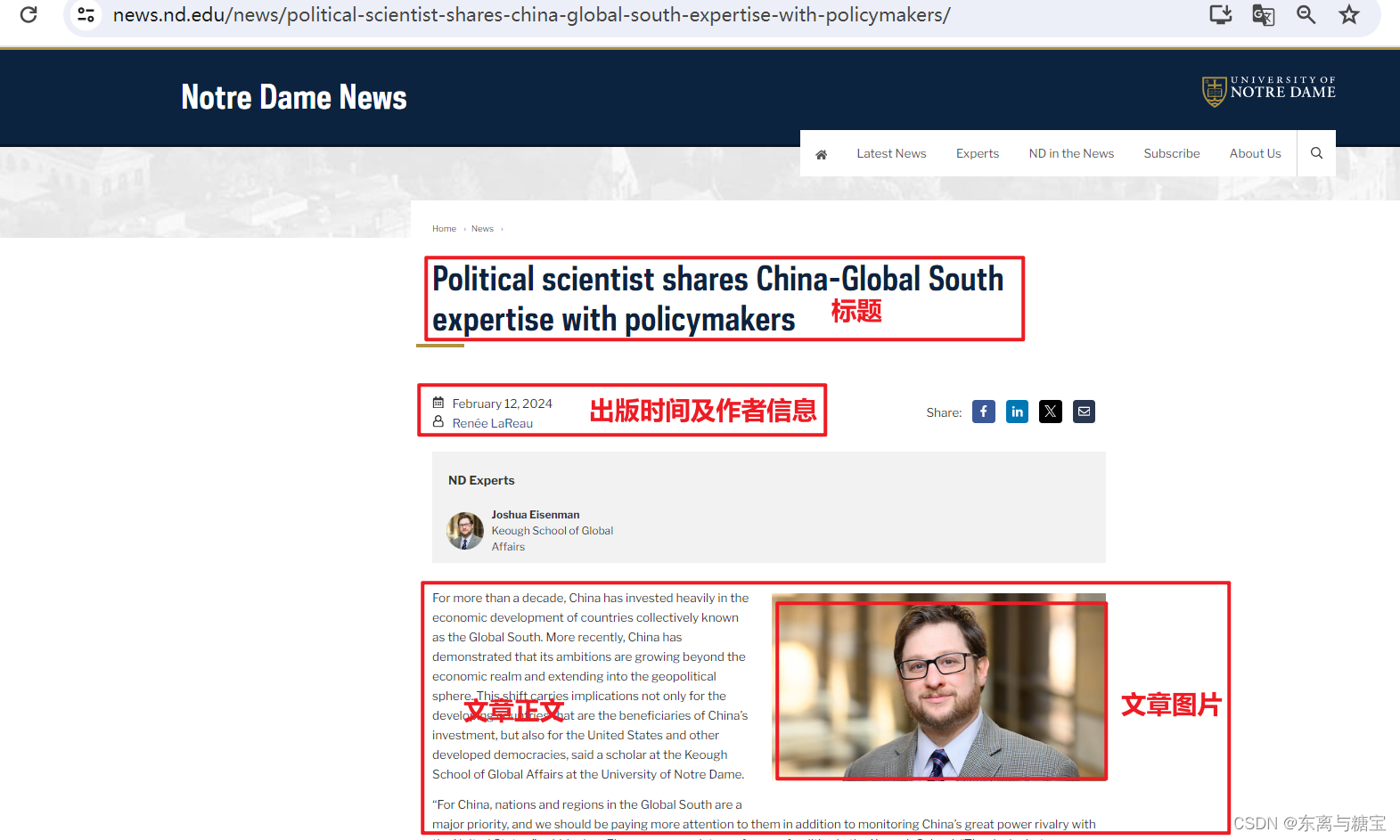
- 一篇文章有标题、出版时间和作者信息、文章正文和文章图片等信息
三、爬取新闻
1. 爬取模块
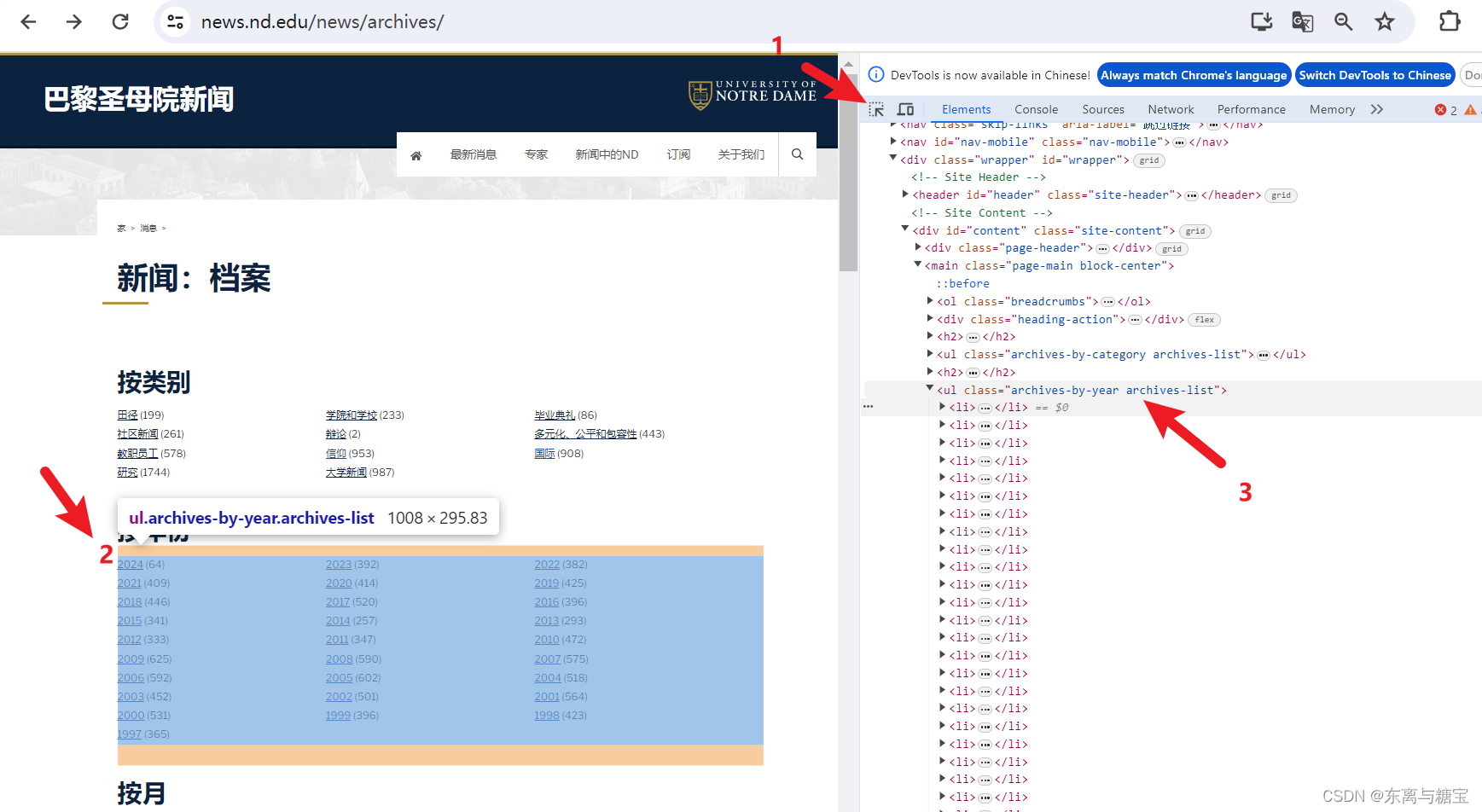
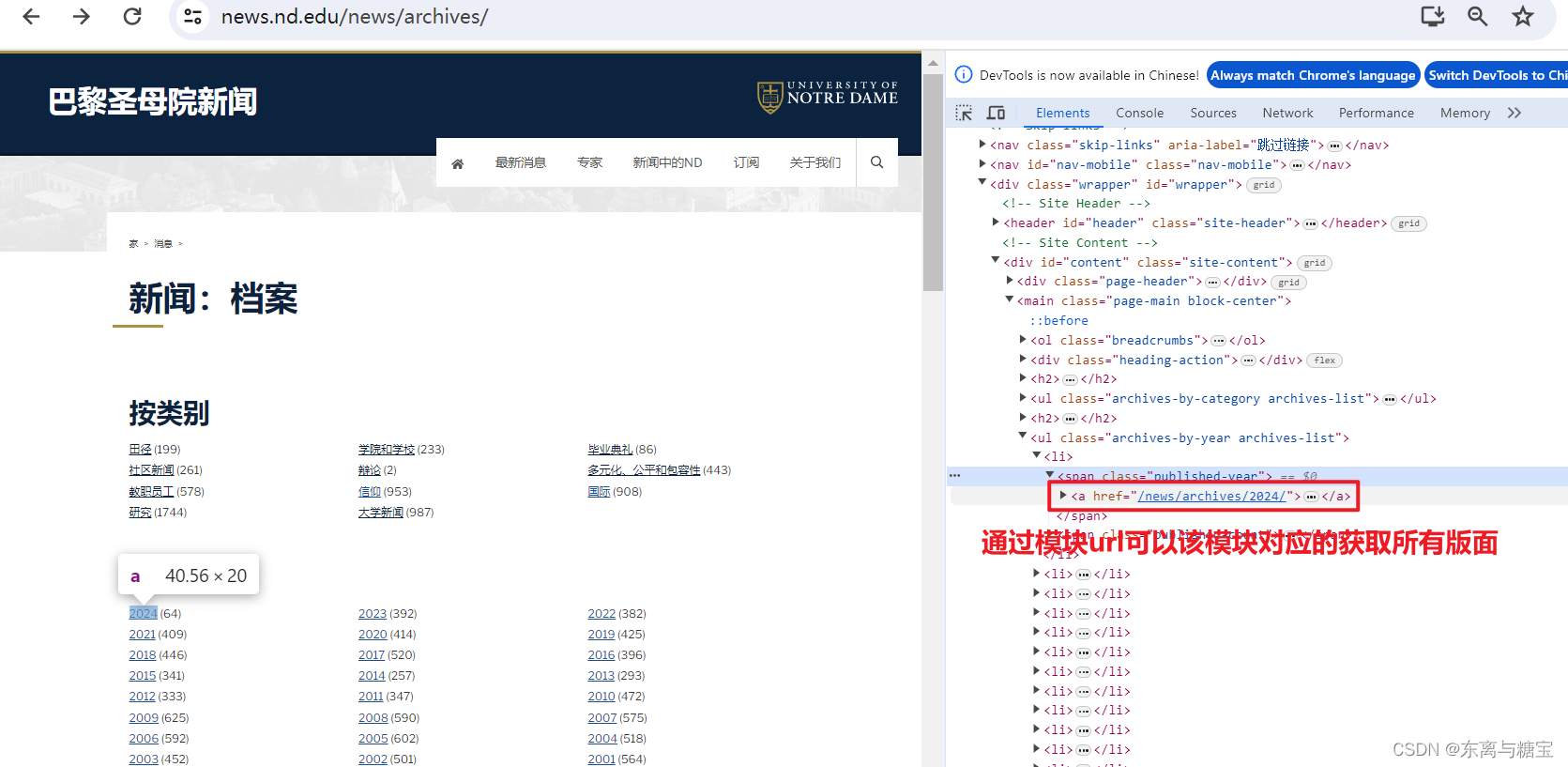
- 按照如下步骤找到包含模块的dom结构并发送request请求并用bs4库去解析
class MitnewsScraper:def __init__(self, root_url, model_url, img_output_dir):self.root_url = root_urlself.model_url = model_urlself.img_output_dir = img_output_dirself.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/122.0.0.0 Safari/537.36','Cookie': '替换成你自己的',}...def run():# 网站根路径root_url = 'https://news.nd.edu/'# 文章图片保存路径output_dir = 'D://imgs//nd-news'response = requests.get('https://news.nd.edu/news/archives/')soup = BeautifulSoup(response.text, 'html.parser')# 模块地址数组model_urls = []model_url_array = soup.find('ul', 'archives-by-year archives-list').find_all('li')for item in model_url_array:model_url = root_url + item.find('a').get('href')model_urls.append(model_url)for model_url in model_urls:# 初始化类scraper = MitnewsScraper(root_url, model_url, output_dir)# 遍历版面scraper.catalogue_all_pages()if __name__ == "__main__":run()
2. 爬取版面
- 首先我们确认模块下版面切页相关的参数传递,通过切换页面我们不难发现切换页面是通过在路径加上 /page/页数 来实现的
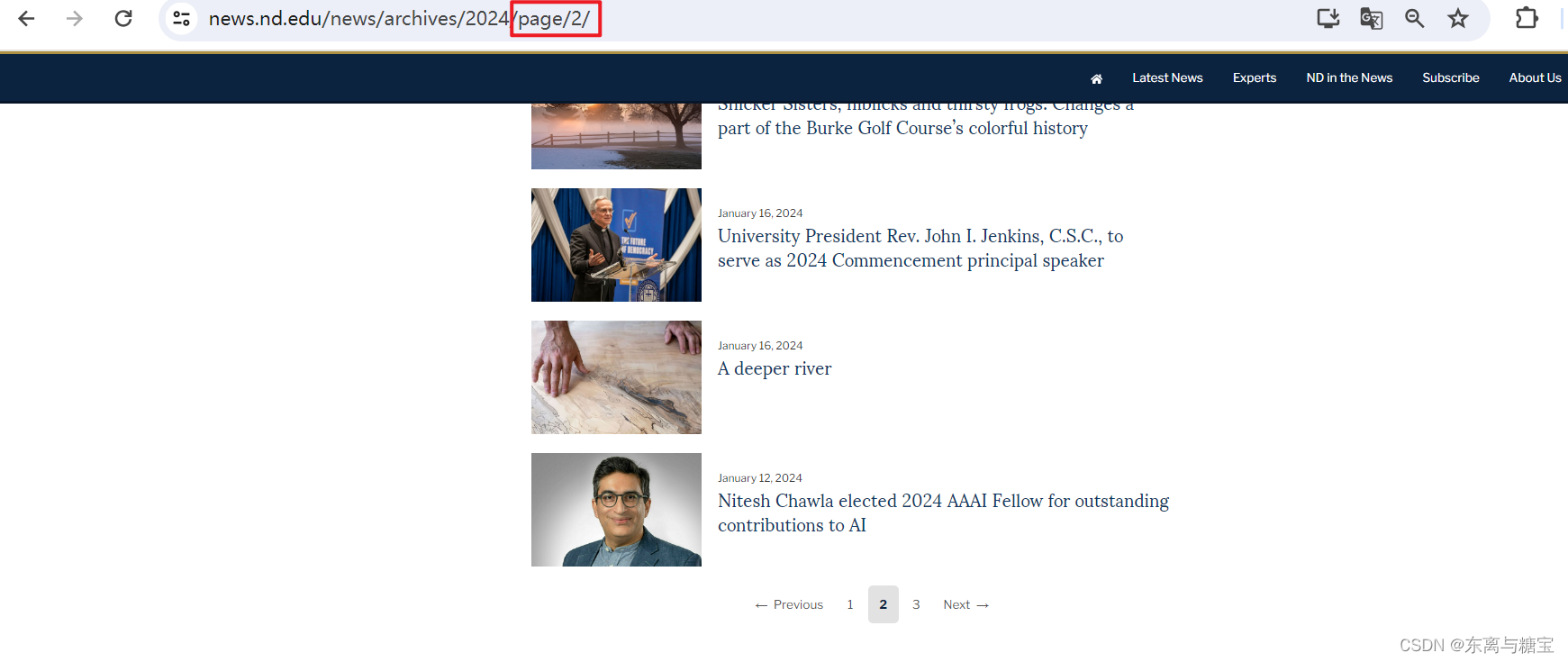
- 于是我们接着寻找模块下有多少页版面,通过观察控制台我们发现最后一页是在 类名为 pagination 的 div 标签里的倒数第二个 a 标签文本里
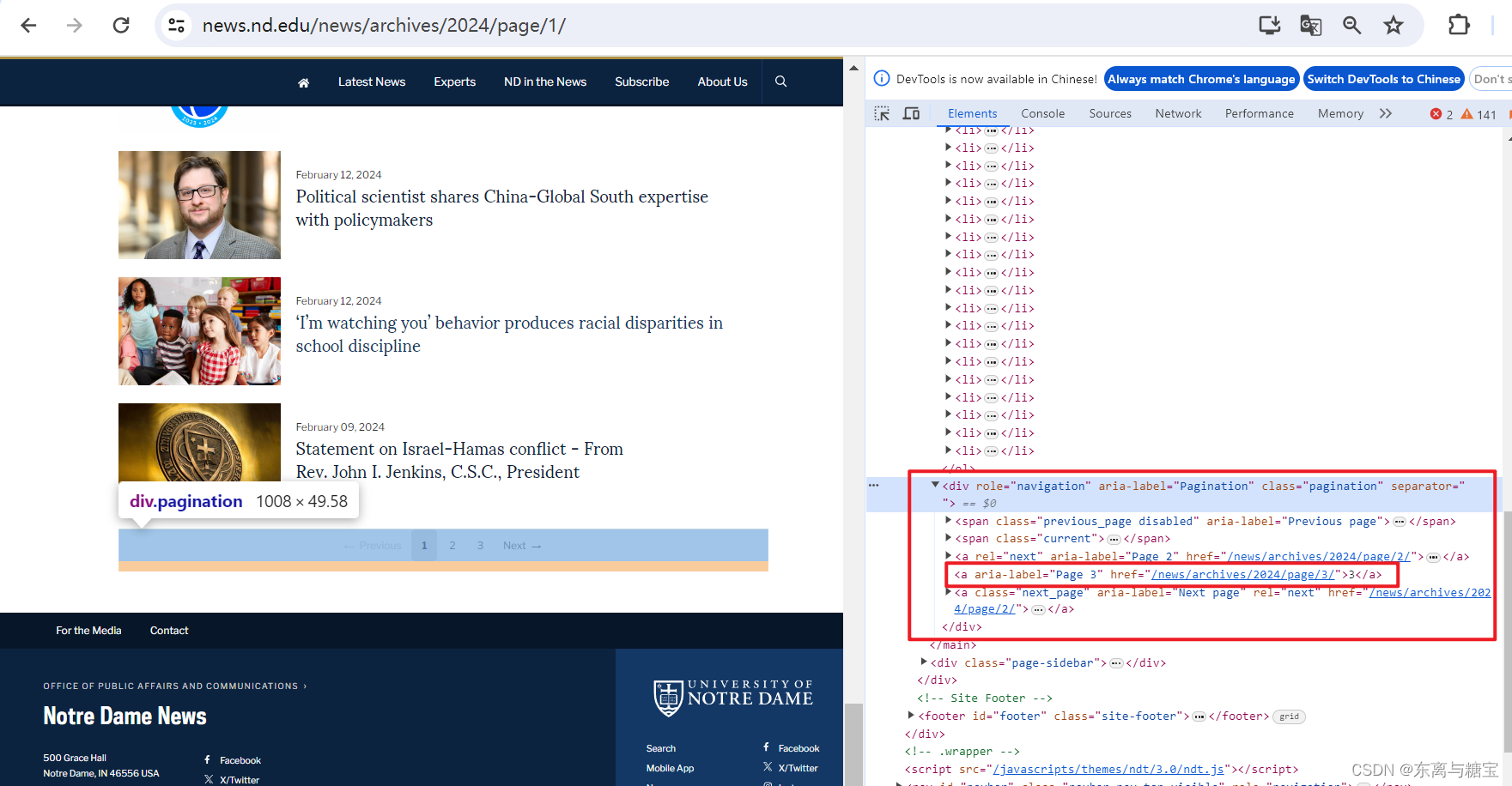
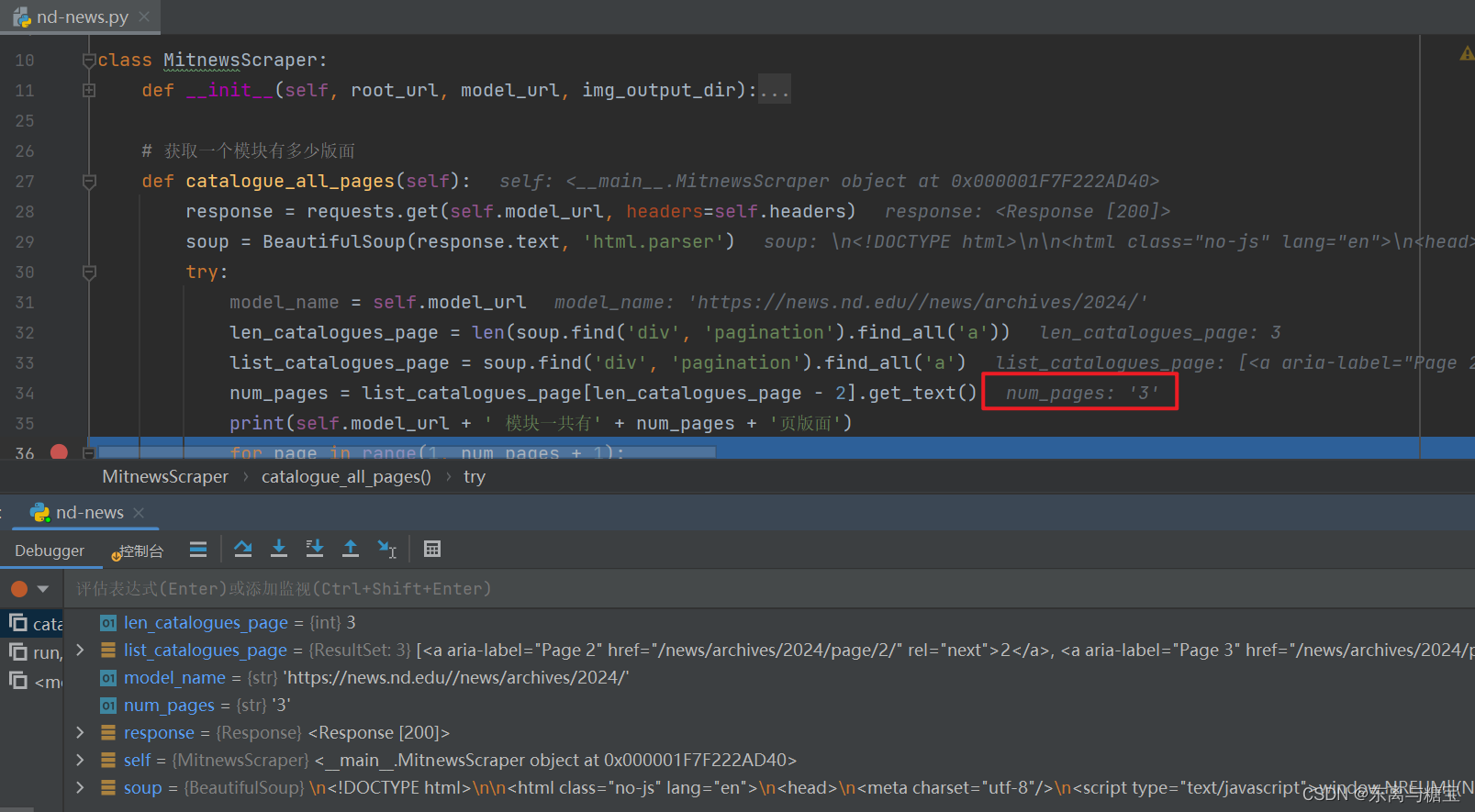
# 获取一个模块有多少版面def catalogue_all_pages(self):response = requests.get(self.model_url, headers=self.headers)soup = BeautifulSoup(response.text, 'html.parser')try:model_name = self.model_urllen_catalogues_page = len(soup.find('div', 'pagination').find_all('a'))list_catalogues_page = soup.find('div', 'pagination').find_all('a')num_pages = list_catalogues_page[len_catalogues_page - 2].get_text()print(self.model_url + ' 模块一共有' + num_pages + '页版面')for page in range(1, num_pages + 1):print(f"========start catalogues page {page}" + "/" + str(num_pages) + "========")self.parse_catalogues(page)print(f"========Finished catalogues page {page}" + "/" + str(num_pages) + "========")except Exception as e:print(f'Error: {e}')traceback.print_exc()
- 根据模块地址和page参数拼接完整版面地址,访问并解析找到对应的版面列表
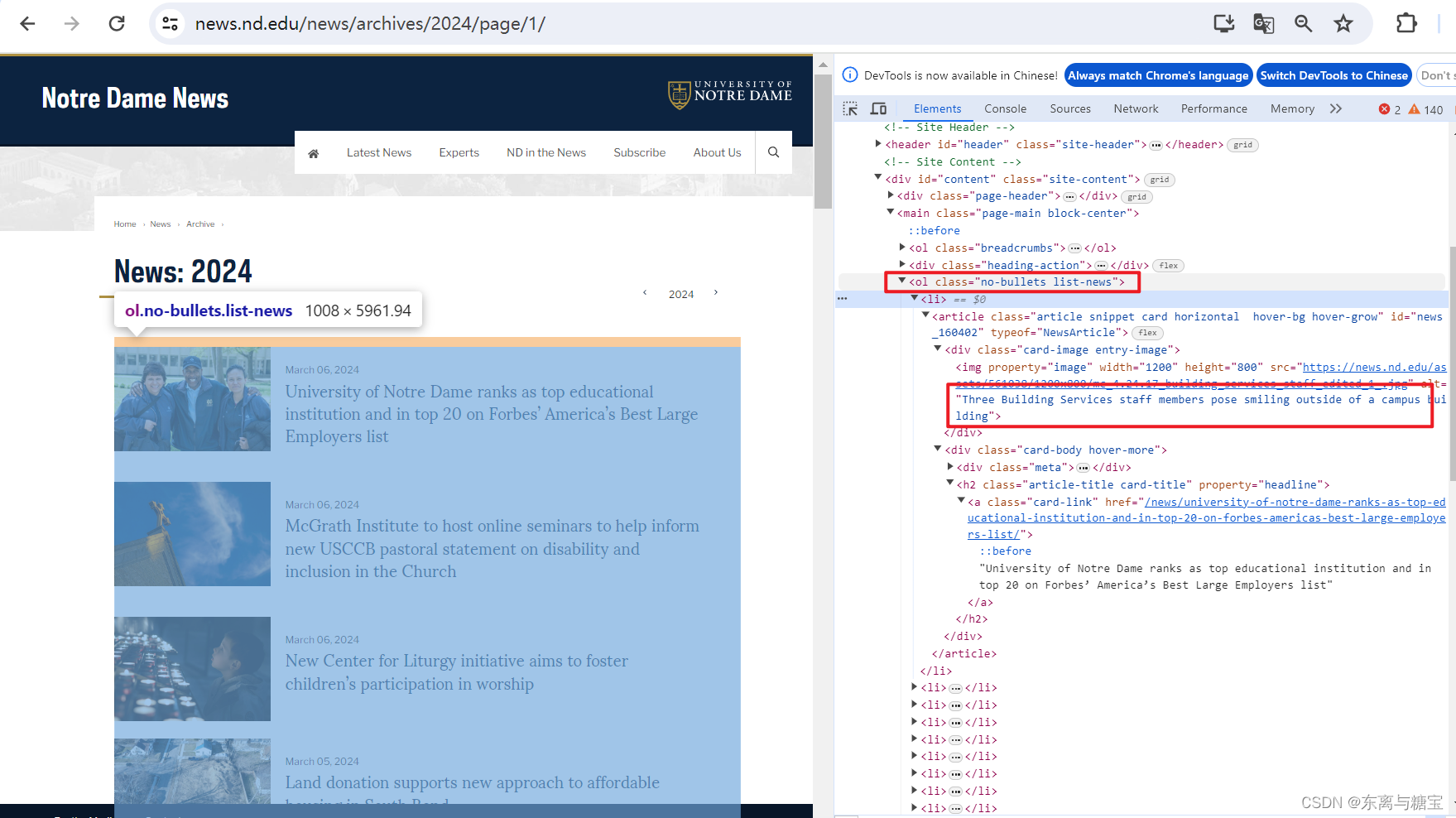
# 解析版面列表里的版面def parse_catalogues(self, page):url = self.model_url + '/page/' + str(page)response = requests.get(url, headers=self.headers)if response.status_code == 200:soup = BeautifulSoup(response.text, 'html.parser')catalogue_list = soup.find('ol', 'no-bullets list-news')catalogues_list = catalogue_list.find_all('li')for index, catalogue in enumerate(catalogues_list):print(f"========start catalogue {index+1}" + "/" + "30========")
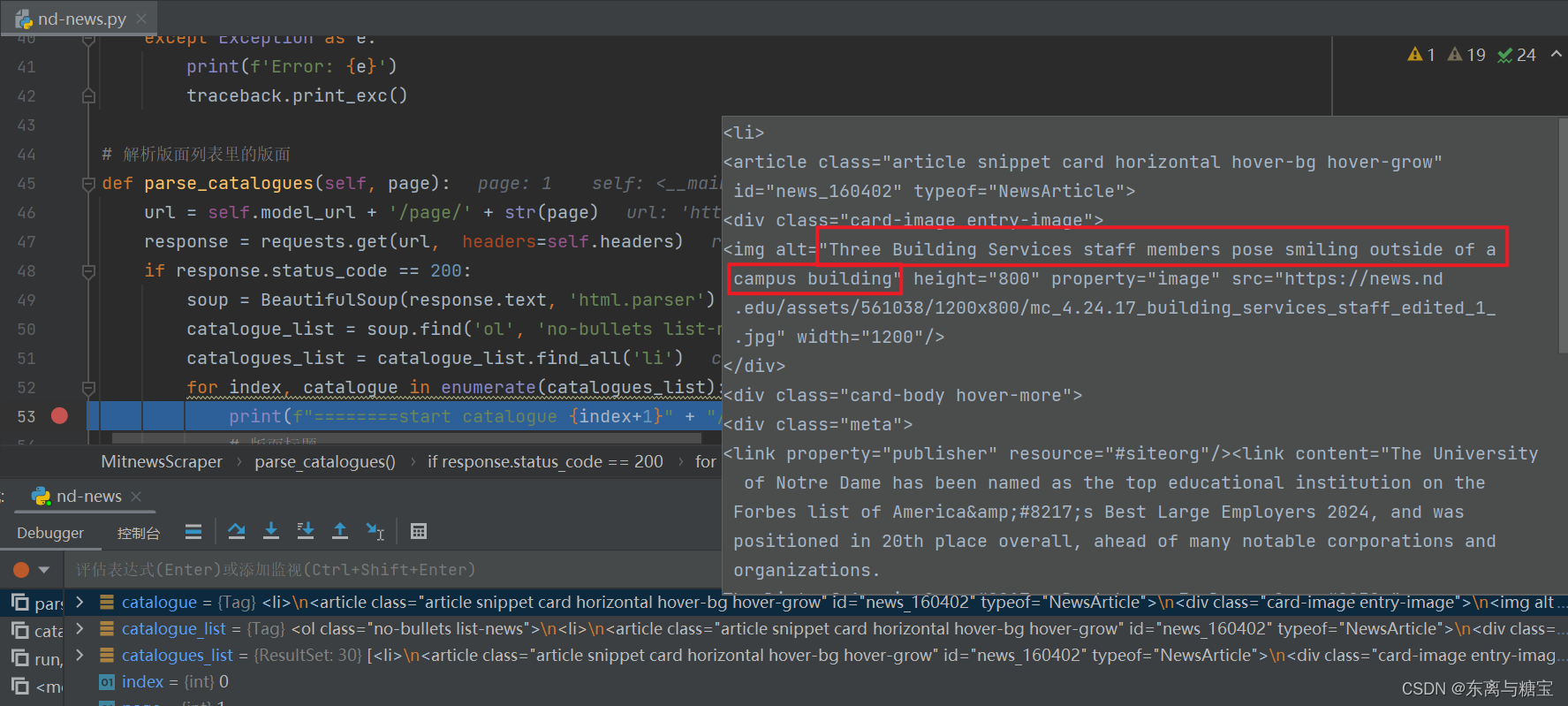
- 遍历版面列表,获取版面标题
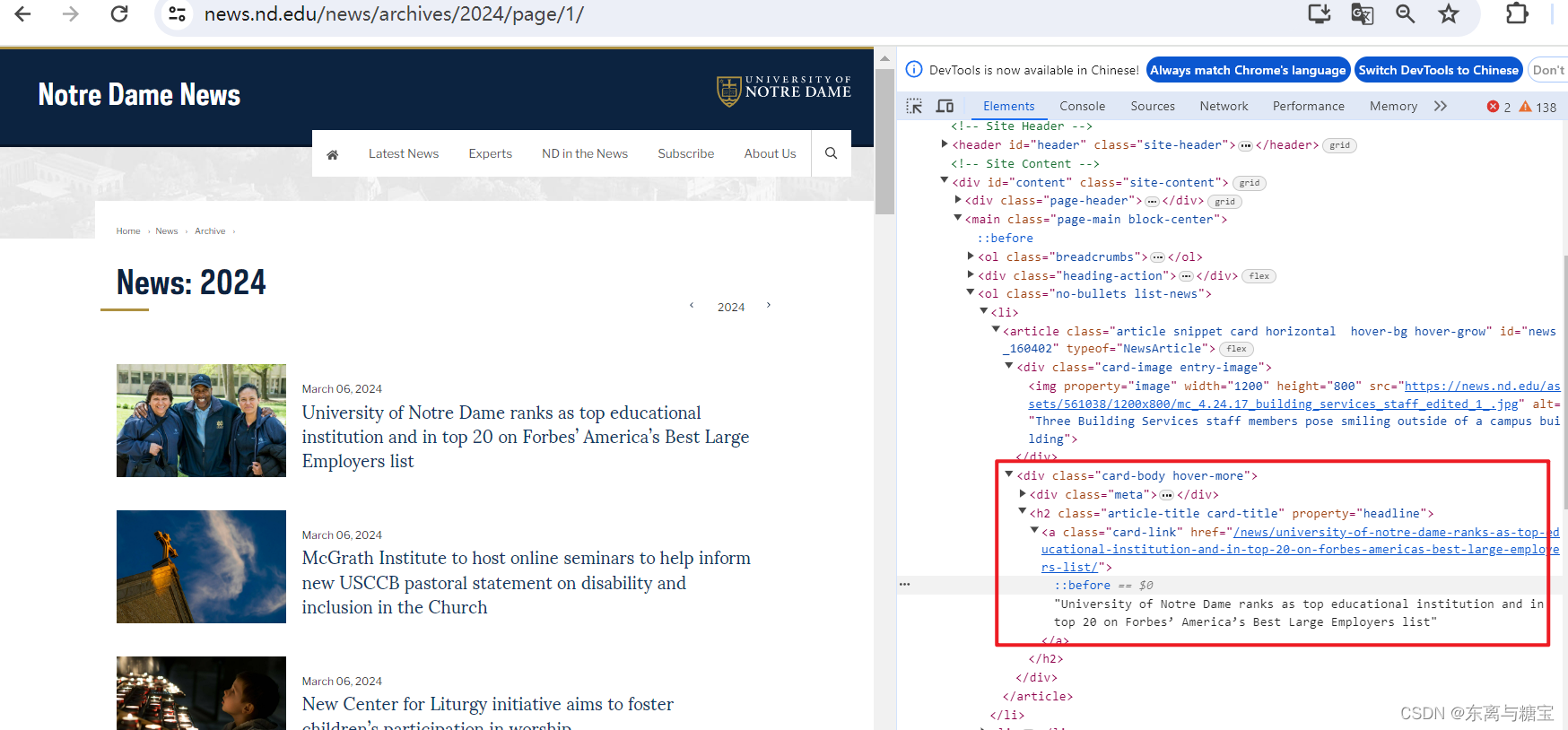
# 版面标题catalogue_title = catalogue.find('div', 'card-body hover-more').find('h2').find('a').get_text(strip=True)
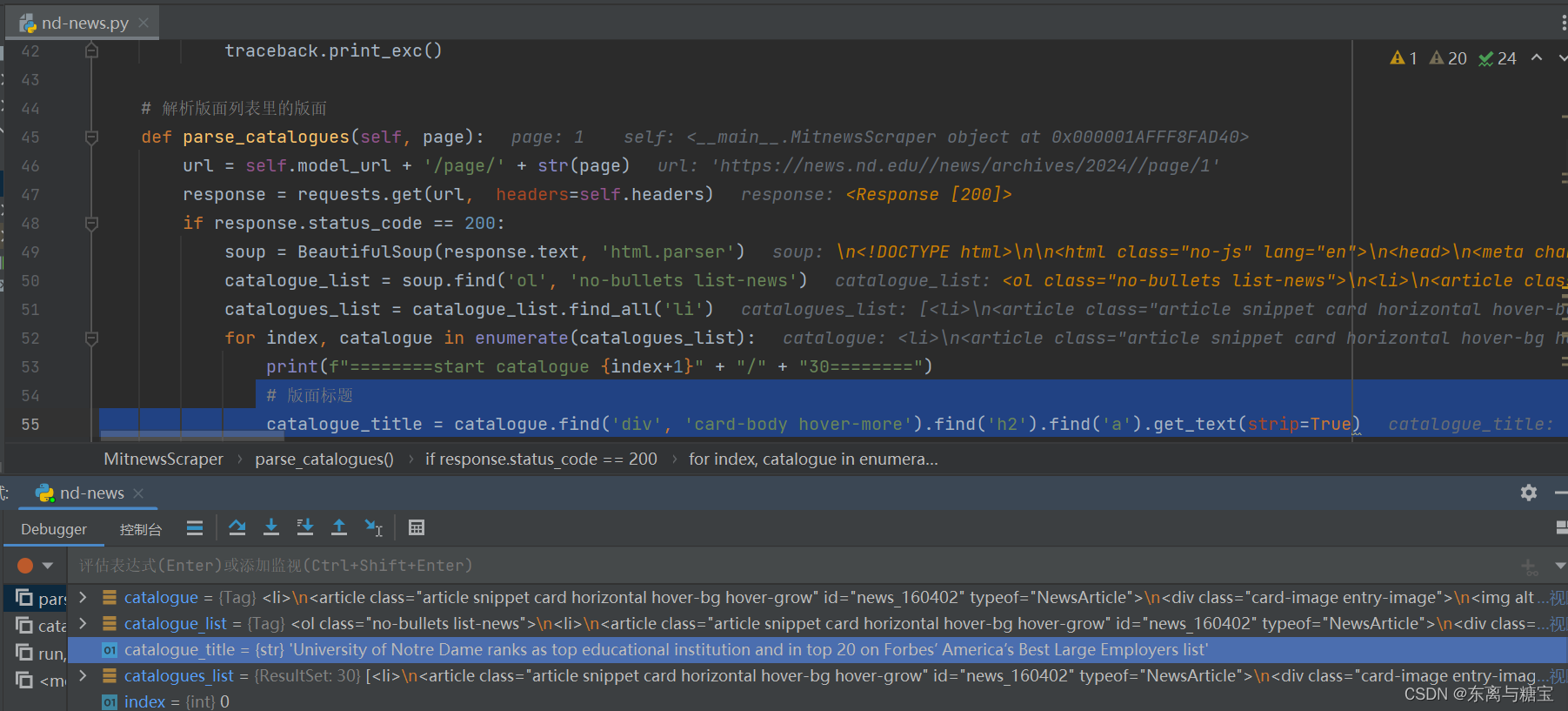
- 获取出版时间
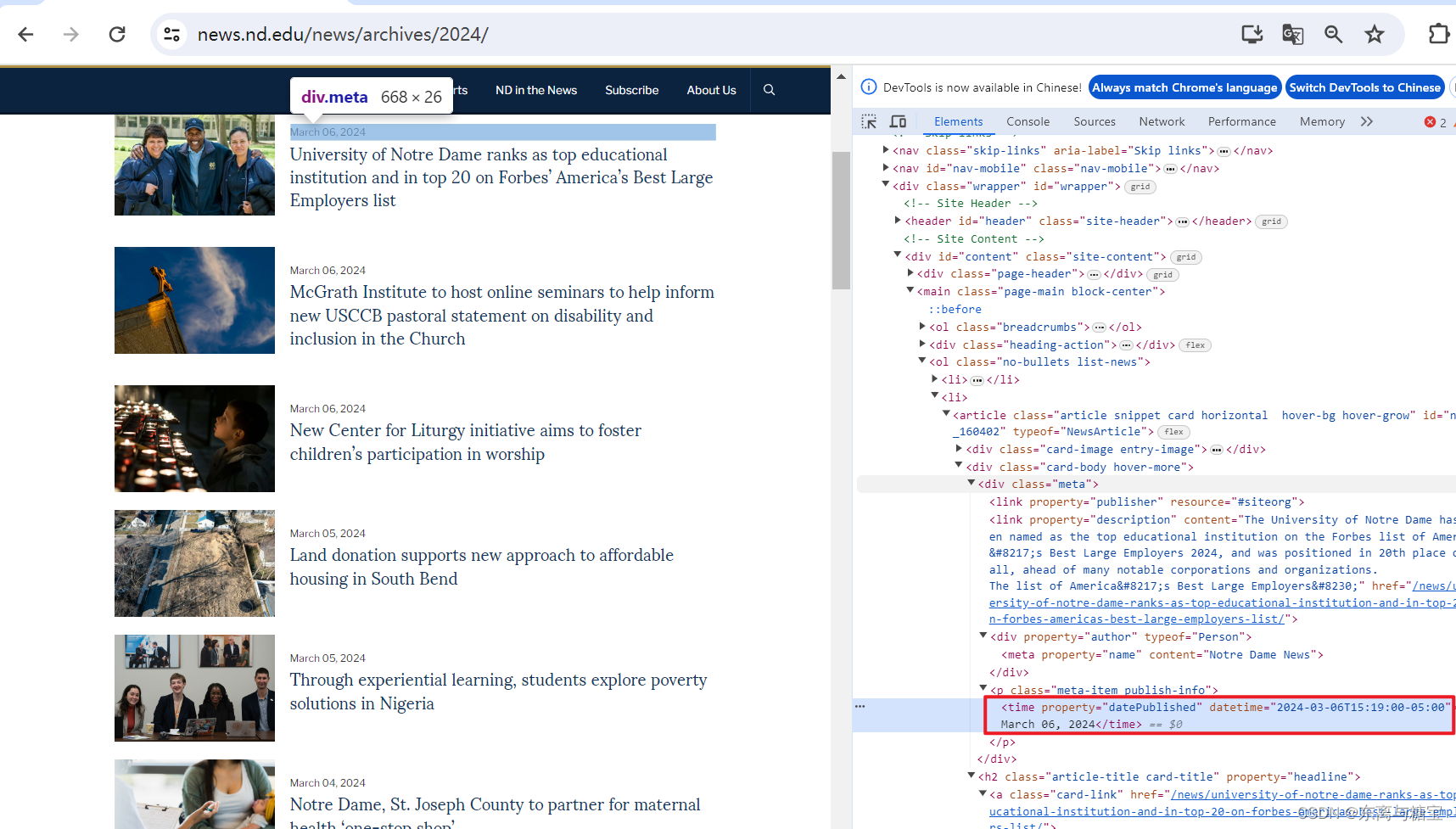
# 操作时间date = datetime.now()# 更新时间publish_time = catalogue.find('time').get('datetime')# 将日期字符串转换为datetime对象updatetime = datetime.fromisoformat(publish_time)
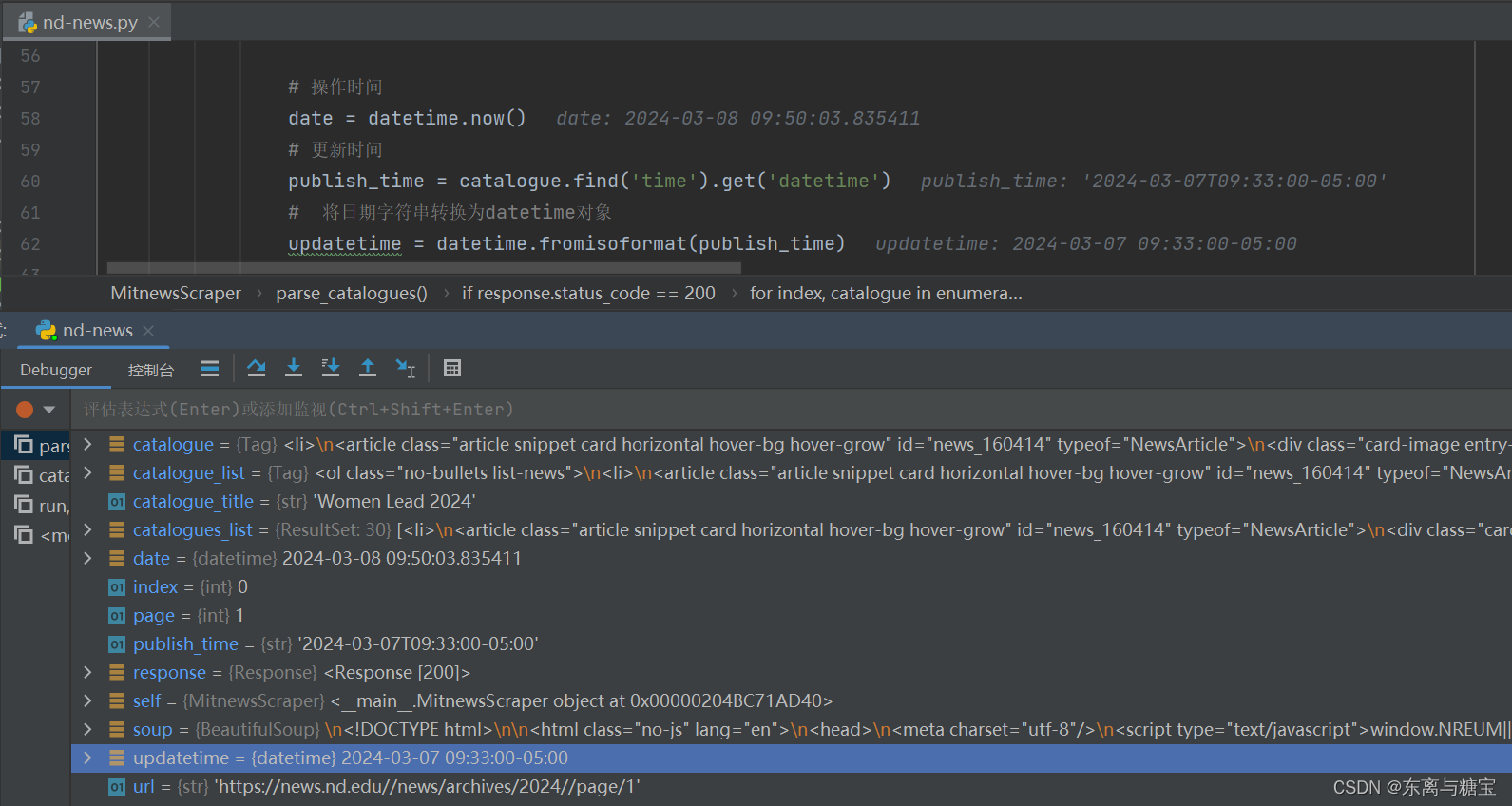
- 保存版面url和版面id, 由于该新闻是一个版面对应一篇文章,所以版面url和文章url是一样的,而且文章没有明显的标识,我们把地址后缀作为文章id,版面id则是文章id后面加上个01
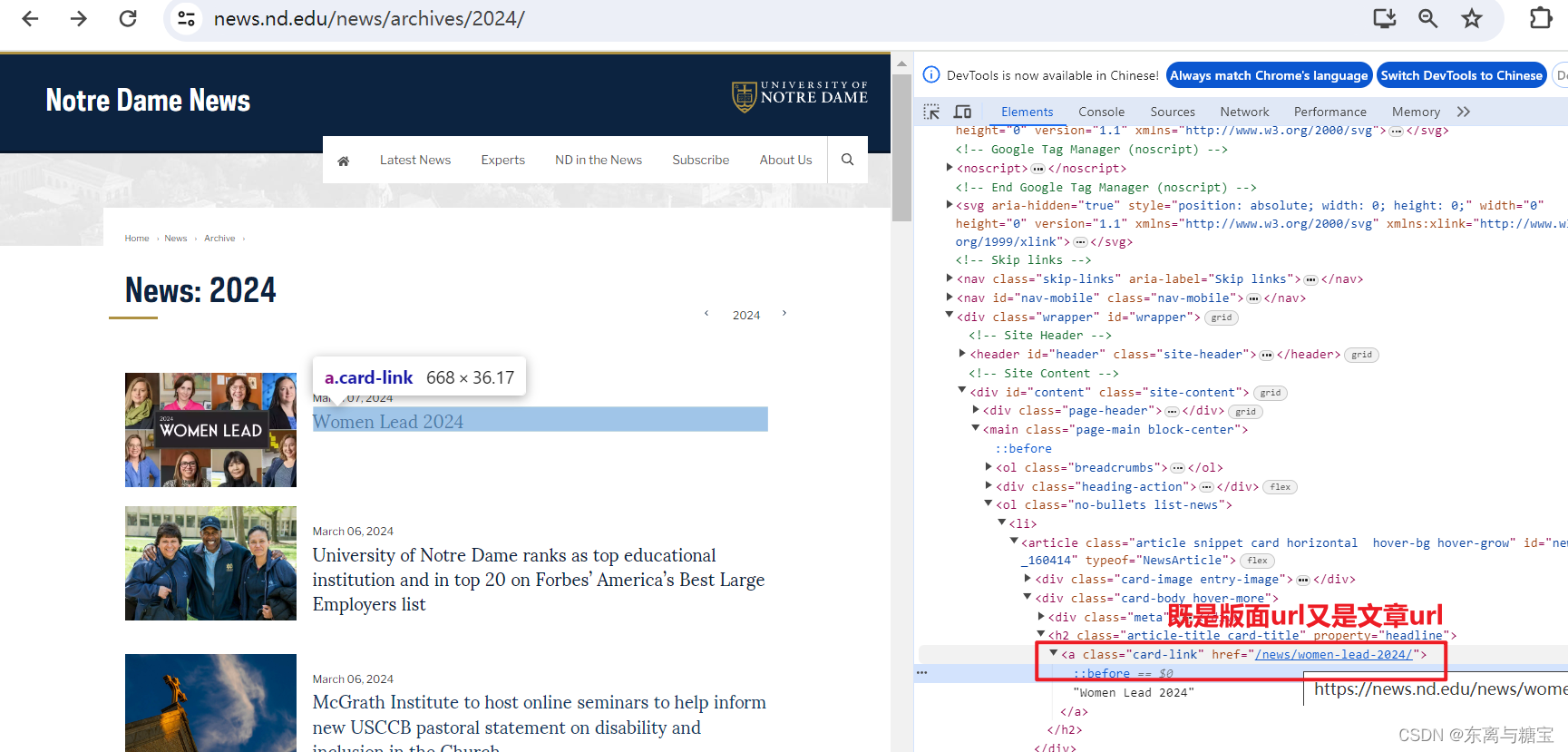

# 版面urlcatalogue_href = catalogue.find('h2').find('a').get('href')catalogue_url = self.root_url + catalogue_href# 正则表达式pattern = r'/news/(.+?)/$'# 使用 re.search() 来搜索匹配项match = re.search(pattern, catalogue_url)# 版面idcatalogue_id = match.group(1)
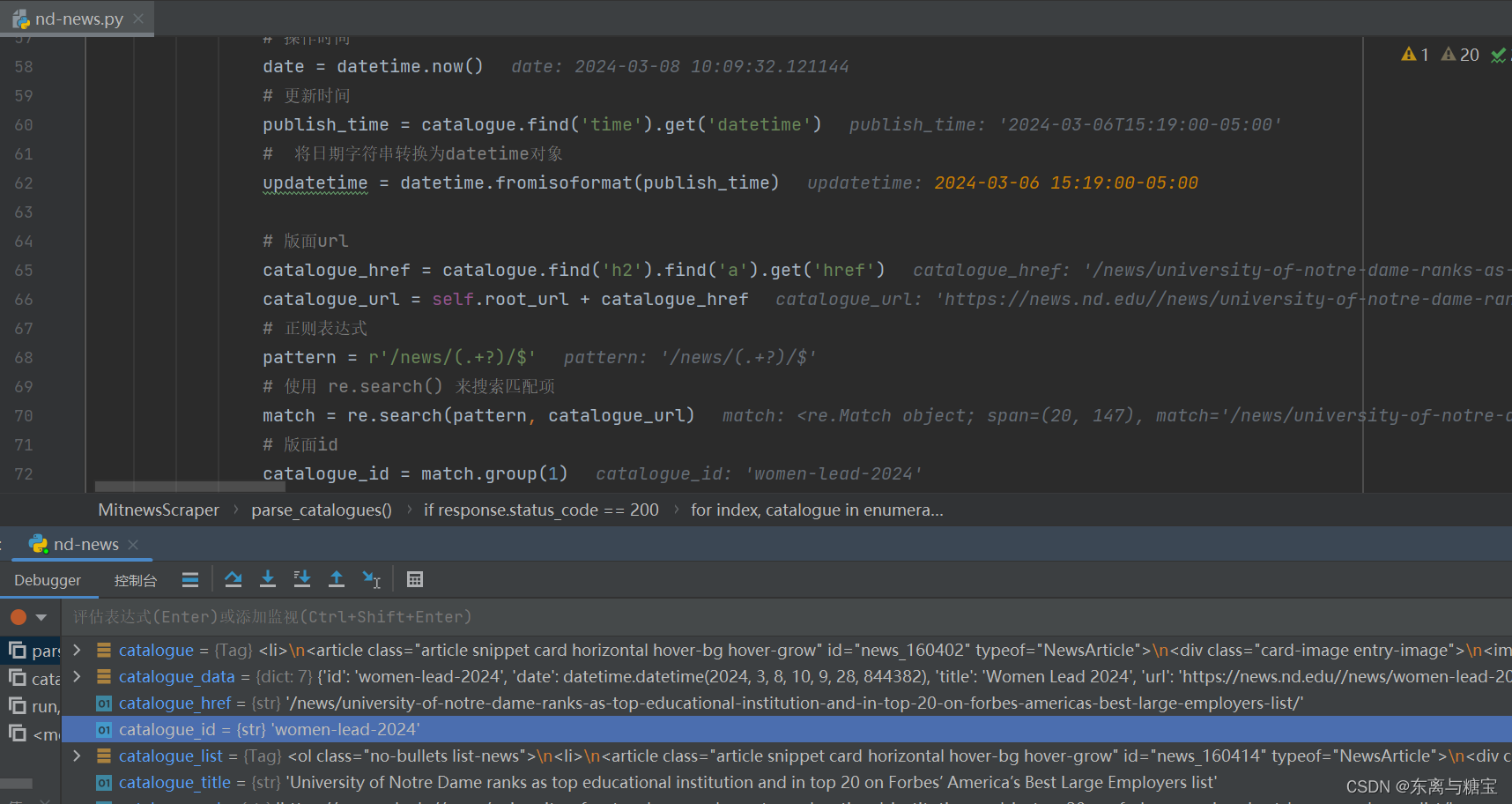
- 保存版面信息到mogodb数据库(由于每个版面只有一篇文章,所以版面文章数量cardsize的值赋为1)
# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['nd-news']# 创建或选择集合catalogues_collection = db['catalogues']# 插入示例数据到 catalogues 集合catalogue_data = {'id': catalogue_id,'date': date,'title': catalogue_title,'url': catalogue_url,'cardSize': 1,'updatetime': updatetime}# 在插入前检查是否存在相同id的文档existing_document = catalogues_collection.find_one({'id': catalogue_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:catalogues_collection.insert_one(catalogue_data)print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")else:print("[爬取版面]版面 " + catalogue_url + " 已存在!")print(f"========finsh catalogue {index+1}" + "/" + "10========")return Trueelse:raise Exception(f"Failed to fetch page {page}. Status code: {response.status_code}")
3. 爬取文章
-
由于一个版面对应一篇文章,所以版面url 、更新时间、标题和文章是一样的,并且按照设计版面id和文章id的区别只是差了个01,所以可以传递版面url、版面id、更新时间和标题四个参数到解析文章的函数里面
-
获取文章id,文章url,文章更新时间和当下操作时间
# 解析版面列表里的版面def parse_catalogues(self, page):...self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)...# 解析文章列表里的文章def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):card_response = requests.get(url, headers=self.headers)soup = BeautifulSoup(card_response.text, 'html.parser')# 对应的版面idcard_id = catalogue_id# 文章标题card_title = cardtitle# 文章更新时间updateTime = cardupdatetime# 操作时间date = datetime.now()
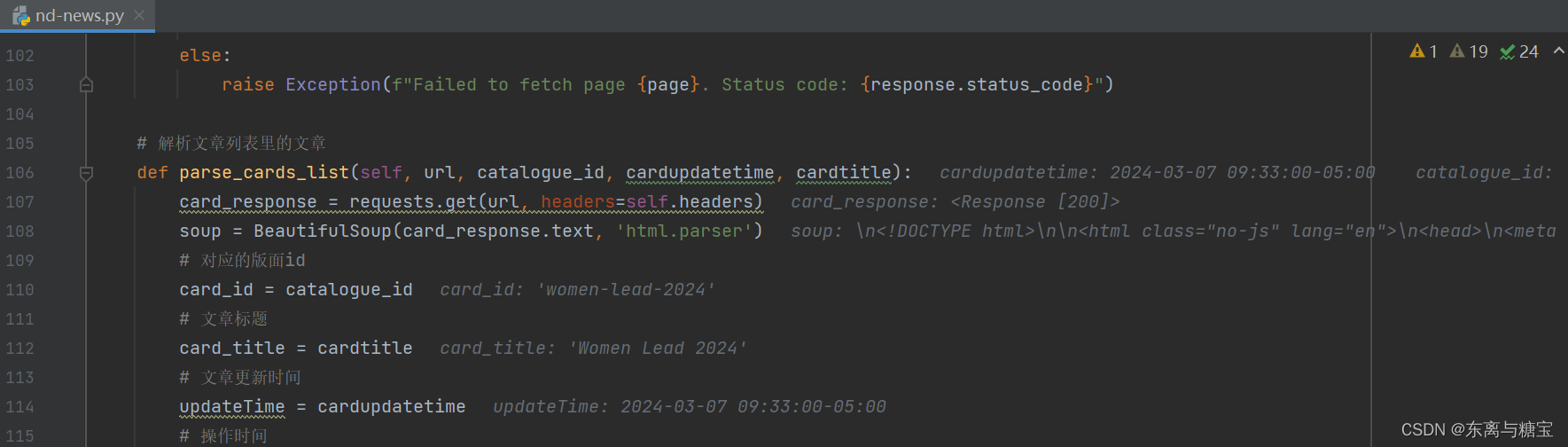
- 获取文章作者
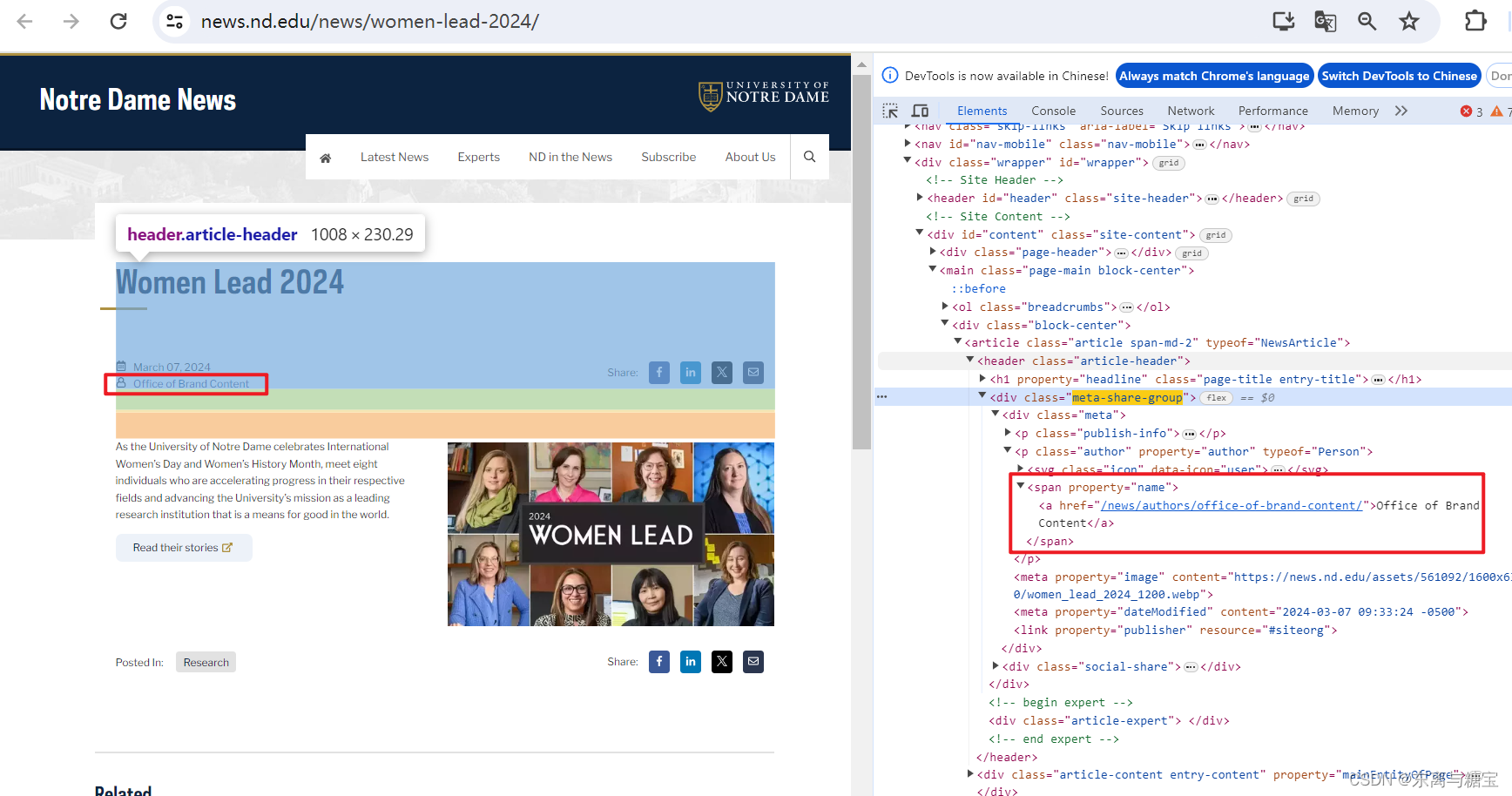
# 文章作者author = soup.find('article', 'article span-md-2').find('p', 'author').find('span', property='name').get_text()
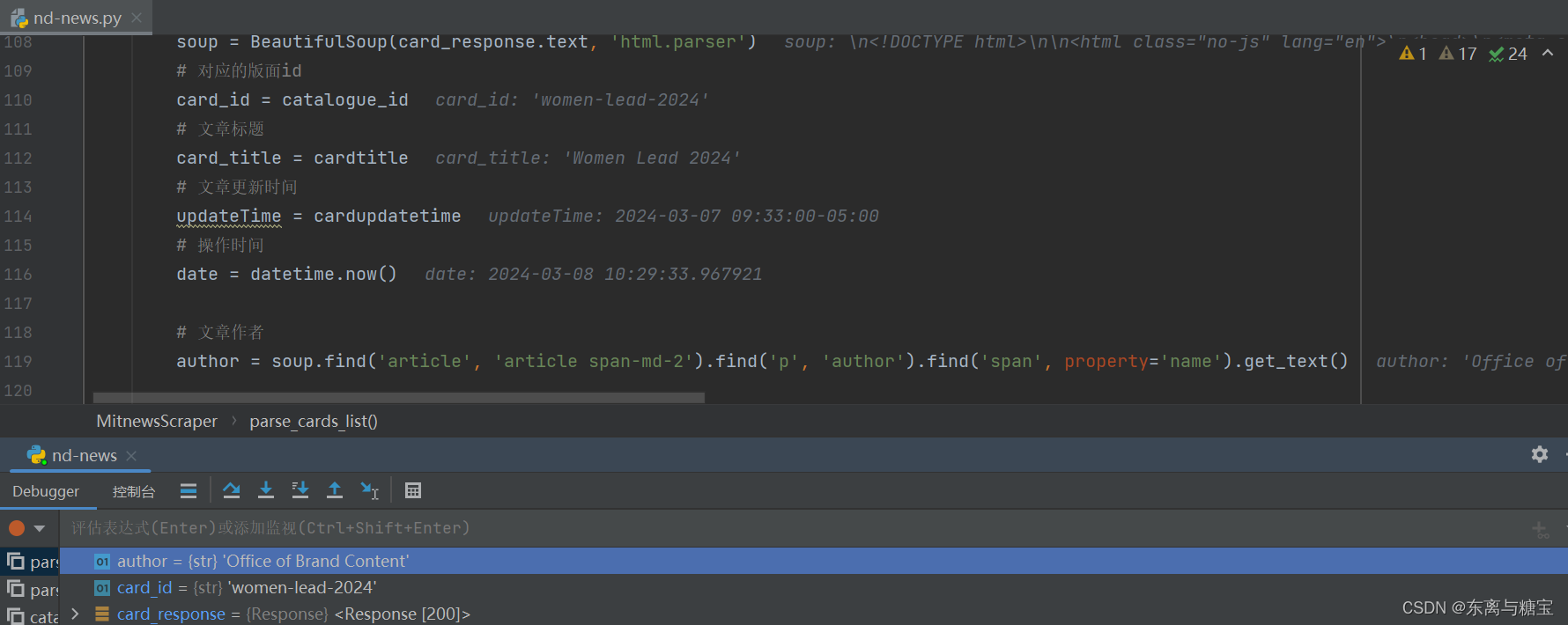
- 获取文章原始htmldom结构,并删除无用的部分(以下仅是部分举例),用html_content字段保留原始dom结构

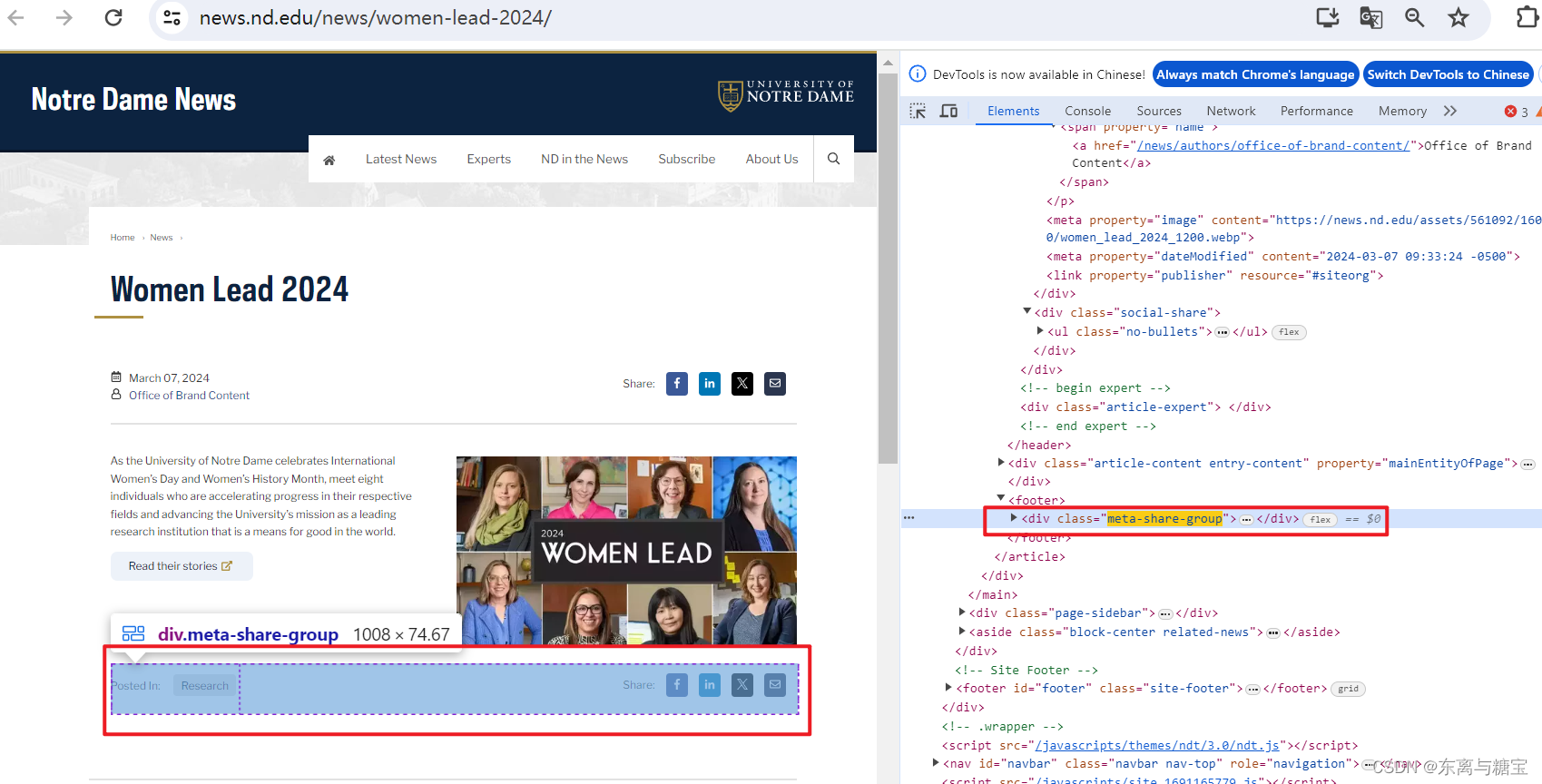
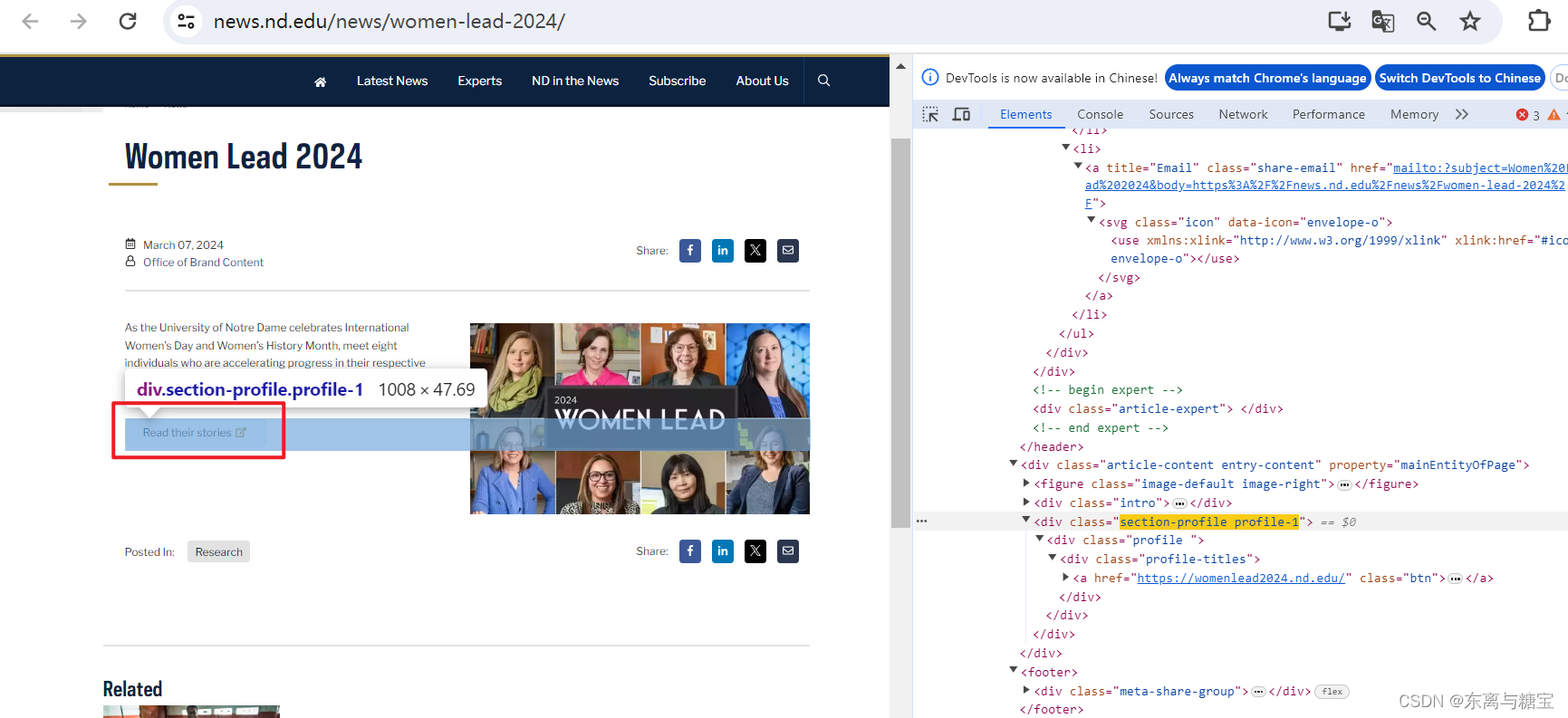
# 原始htmldom结构html_dom = soup.find('article', 'article span-md-2')html_cut1 = html_dom.find_all('div', 'meta-share-group')[0].find('div', 'social-share')html_cut2 = html_dom.find_all('div', 'meta-share-group')[1]html_cut3 = html_dom.find('div', 'section-profile profile-1')# 移除元素if html_cut1:html_cut1.extract()if html_cut2:html_cut2.extract()if html_cut3:html_cut3.extract()html_content = html_dom
- 进行文章清洗,保留文本,去除标签,用content保留清洗后的文本
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):...# 增加保留html样式的源文本origin_html = html_dom.prettify() # String# 转义网页中的图片标签str_html = self.transcoding_tags(origin_html)# 再包装成temp_soup = BeautifulSoup(str_html, 'html.parser')# 反转译文件中的插图str_html = self.translate_tags(temp_soup.text)# 绑定更新内容content = self.clean_content(str_html)...# 工具 转义标签def transcoding_tags(self, htmlstr):re_img = re.compile(r'\s*<(img.*?)>\s*', re.M)s = re_img.sub(r'\n @@##\1##@@ \n', htmlstr) # IMG 转义return s# 工具 转义标签def translate_tags(self, htmlstr):re_img = re.compile(r'@@##(img.*?)##@@', re.M)s = re_img.sub(r'<\1>', htmlstr) # IMG 转义return s# 清洗文章def clean_content(self, content):if content is not None:content = re.sub(r'\r', r'\n', content)content = re.sub(r'\n{2,}', '', content)content = re.sub(r' {6,}', '', content)content = re.sub(r' {3,}\n', '', content)content = re.sub(r'<img src="../../../image/zxbl.gif"/>', '', content)content = content.replace('<img border="0" src="****处理标记:[Article]时, 字段 [SnapUrl] 在数据源中没有找到! ****"/> ', '')content = content.replace(''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="<Source>SourcePh " style="display:none">''','') \.replace(' <!--enpcontent', '').replace('<TABLE>', '')content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')return content
- 下载保存文章图片,保存到d盘目录下的imgs/nd-news文件夹下,每篇文章图片用一个命名为文章id的文件夹命名,并用字段illustrations保存图片的绝对路径和相对路径
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):...# 下载图片imgs = []img_array = soup.find('div', 'article-content entry-content').find_all('img')if len(img_array) is not None:for item in img_array:img_url = self.root_url + item.get('src')imgs.append(img_url)if len(imgs) != 0:# 下载图片illustrations = self.download_images(imgs, card_id)# 下载图片
def download_images(self, img_urls, card_id):result = re.search(r'[^/]+$', card_id)last_word = result.group(0)# 根据card_id创建一个新的子目录images_dir = os.path.join(self.img_output_dir, str(last_word)) if not os.path.exists(images_dir):os.makedirs(images_dir)downloaded_images = []for index, img_url in enumerate(img_urls):try:response = requests.get(img_url, stream=True, headers=self.headers)if response.status_code == 200:# 从URL中提取图片文件名img_name_with_extension = img_url.split('/')[-1]pattern = r'^[^?]*'match = re.search(pattern, img_name_with_extension)img_name = match.group(0)# 保存图片with open(os.path.join(images_dir, img_name), 'wb') as f:f.write(response.content)downloaded_images.append([img_url, os.path.join(images_dir, img_name)])print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')except requests.exceptions.RequestException as e:print(f'请求图片时发生错误:{e}')except Exception as e:print(f'保存图片时发生错误:{e}')return downloaded_images# 如果文件夹存在则跳过else:print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')return []
- 保存文章数据到数据库
# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['nd-news']# 创建或选择集合cards_collection = db['cards']# 插入示例数据到 cards 集合card_data = {'id': card_id,'catalogueId': catalogue_id,'type': 'nd-news','date': date,'title': card_title,'author': author,'updatetime': updateTime,'url': url,'html_content': str(html_content),'content': content,'illustrations': illustrations,}# 在插入前检查是否存在相同id的文档existing_document = cards_collection.find_one({'id': card_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:cards_collection.insert_one(card_data)print("[爬取文章]文章 " + url + " 已成功插入!")else:print("[爬取文章]文章 " + url + " 已存在!")
四、完整代码
import os
from datetime import datetime
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import re
import tracebackclass MitnewsScraper:def __init__(self, root_url, model_url, img_output_dir):self.root_url = root_urlself.model_url = model_urlself.img_output_dir = img_output_dirself.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/122.0.0.0 Safari/537.36','Cookie': ''}# 获取一个模块有多少版面def catalogue_all_pages(self):response = requests.get(self.model_url, headers=self.headers)soup = BeautifulSoup(response.text, 'html.parser')try:model_name = self.model_urllen_catalogues_page = len(soup.find('div', 'pagination').find_all('a'))list_catalogues_page = soup.find('div', 'pagination').find_all('a')num_pages = list_catalogues_page[len_catalogues_page - 2].get_text()print(self.model_url + ' 模块一共有' + num_pages + '页版面')for page in range(1, int(num_pages) + 1):print(f"========start catalogues page {page}" + "/" + str(num_pages) + "========")self.parse_catalogues(page)print(f"========Finished catalogues page {page}" + "/" + str(num_pages) + "========")except Exception as e:print(f'Error: {e}')traceback.print_exc()# 解析版面列表里的版面def parse_catalogues(self, page):url = self.model_url + '/page/' + str(page)response = requests.get(url, headers=self.headers)if response.status_code == 200:soup = BeautifulSoup(response.text, 'html.parser')catalogue_list = soup.find('ol', 'no-bullets list-news')catalogues_list = catalogue_list.find_all('li')for index, catalogue in enumerate(catalogues_list):print(f"========start catalogue {index+1}" + "/" + "30========")# 版面标题catalogue_title = catalogue.find('div', 'card-body hover-more').find('h2').find('a').get_text(strip=True)# 操作时间date = datetime.now()# 更新时间publish_time = catalogue.find('time').get('datetime')# 将日期字符串转换为datetime对象updatetime = datetime.fromisoformat(publish_time)# 版面urlcatalogue_href = catalogue.find('h2').find('a').get('href')catalogue_url = self.root_url + catalogue_href# 正则表达式pattern = r'/news/(.+?)/$'# 使用 re.search() 来搜索匹配项match = re.search(pattern, catalogue_url)# 版面idcatalogue_id = match.group(1)self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['nd-news']# 创建或选择集合catalogues_collection = db['catalogues']# 插入示例数据到 catalogues 集合catalogue_data = {'id': catalogue_id,'date': date,'title': catalogue_title,'url': catalogue_url,'cardSize': 1,'updatetime': updatetime}# 在插入前检查是否存在相同id的文档existing_document = catalogues_collection.find_one({'id': catalogue_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:catalogues_collection.insert_one(catalogue_data)print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")else:print("[爬取版面]版面 " + catalogue_url + " 已存在!")print(f"========finsh catalogue {index+1}" + "/" + "10========")return Trueelse:raise Exception(f"Failed to fetch page {page}. Status code: {response.status_code}")# 解析文章列表里的文章def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):card_response = requests.get(url, headers=self.headers)soup = BeautifulSoup(card_response.text, 'html.parser')# 对应的版面idcard_id = catalogue_id# 文章标题card_title = cardtitle# 文章更新时间updateTime = cardupdatetime# 操作时间date = datetime.now()# 文章作者author = soup.find('article', 'article span-md-2').find('p', 'author').find('span', property='name').get_text()# 原始htmldom结构html_dom = soup.find('article', 'article span-md-2')html_cut1 = html_dom.find_all('div', 'meta-share-group')[0].find('div', 'social-share')html_cut2 = html_dom.find_all('div', 'meta-share-group')[1]html_cut3 = html_dom.find('div', 'section-profile profile-1')# 移除元素if html_cut1:html_cut1.extract()if html_cut2:html_cut2.extract()if html_cut3:html_cut3.extract()html_content = html_dom# 增加保留html样式的源文本origin_html = html_dom.prettify() # String# 转义网页中的图片标签str_html = self.transcoding_tags(origin_html)# 再包装成temp_soup = BeautifulSoup(str_html, 'html.parser')# 反转译文件中的插图str_html = self.translate_tags(temp_soup.text)# 绑定更新内容content = self.clean_content(str_html)# 下载图片imgs = []img_array = soup.find('div', 'article-content entry-content').find_all('img')if len(img_array) is not None:for item in img_array:img_url = self.root_url + item.get('src')imgs.append(img_url)if len(imgs) != 0:# 下载图片illustrations = self.download_images(imgs, card_id)# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['nd-news']# 创建或选择集合cards_collection = db['cards']# 插入示例数据到 cards 集合card_data = {'id': card_id,'catalogueId': catalogue_id,'type': 'nd-news','date': date,'title': card_title,'author': author,'updatetime': updateTime,'url': url,'html_content': str(html_content),'content': content,'illustrations': illustrations,}# 在插入前检查是否存在相同id的文档existing_document = cards_collection.find_one({'id': card_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:cards_collection.insert_one(card_data)print("[爬取文章]文章 " + url + " 已成功插入!")else:print("[爬取文章]文章 " + url + " 已存在!")# 下载图片def download_images(self, img_urls, card_id):result = re.search(r'[^/]+$', card_id)last_word = result.group(0)# 根据card_id创建一个新的子目录images_dir = os.path.join(self.img_output_dir, str(last_word))if not os.path.exists(images_dir):os.makedirs(images_dir)downloaded_images = []for index, img_url in enumerate(img_urls):try:response = requests.get(img_url, stream=True, headers=self.headers)if response.status_code == 200:# 从URL中提取图片文件名img_name_with_extension = img_url.split('/')[-1]pattern = r'^[^?]*'match = re.search(pattern, img_name_with_extension)img_name = match.group(0)# 保存图片with open(os.path.join(images_dir, img_name), 'wb') as f:f.write(response.content)downloaded_images.append([img_url, os.path.join(images_dir, img_name)])print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')except requests.exceptions.RequestException as e:print(f'请求图片时发生错误:{e}')except Exception as e:print(f'保存图片时发生错误:{e}')return downloaded_images# 如果文件夹存在则跳过else:print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')return []# 工具 转义标签def transcoding_tags(self, htmlstr):re_img = re.compile(r'\s*<(img.*?)>\s*', re.M)s = re_img.sub(r'\n @@##\1##@@ \n', htmlstr) # IMG 转义return s# 工具 转义标签def translate_tags(self, htmlstr):re_img = re.compile(r'@@##(img.*?)##@@', re.M)s = re_img.sub(r'<\1>', htmlstr) # IMG 转义return s# 清洗文章def clean_content(self, content):if content is not None:content = re.sub(r'\r', r'\n', content)content = re.sub(r'\n{2,}', '', content)content = re.sub(r' {6,}', '', content)content = re.sub(r' {3,}\n', '', content)content = re.sub(r'<img src="../../../image/zxbl.gif"/>', '', content)content = content.replace('<img border="0" src="****处理标记:[Article]时, 字段 [SnapUrl] 在数据源中没有找到! ****"/> ', '')content = content.replace(''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="<Source>SourcePh " style="display:none">''','') \.replace(' <!--enpcontent', '').replace('<TABLE>', '')content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')return contentdef run():# 网站根路径root_url = 'https://news.nd.edu/'# 文章图片保存路径output_dir = 'D://imgs//nd-news'response = requests.get('https://news.nd.edu/news/archives/')soup = BeautifulSoup(response.text, 'html.parser')# 模块地址数组model_urls = []model_url_array = soup.find('ul', 'archives-by-year archives-list').find_all('li')for item in model_url_array:model_url = root_url + item.find('a').get('href')model_urls.append(model_url)for model_url in model_urls:# 初始化类scraper = MitnewsScraper(root_url, model_url, output_dir)# 遍历版面scraper.catalogue_all_pages()if __name__ == "__main__":run()五、效果展示
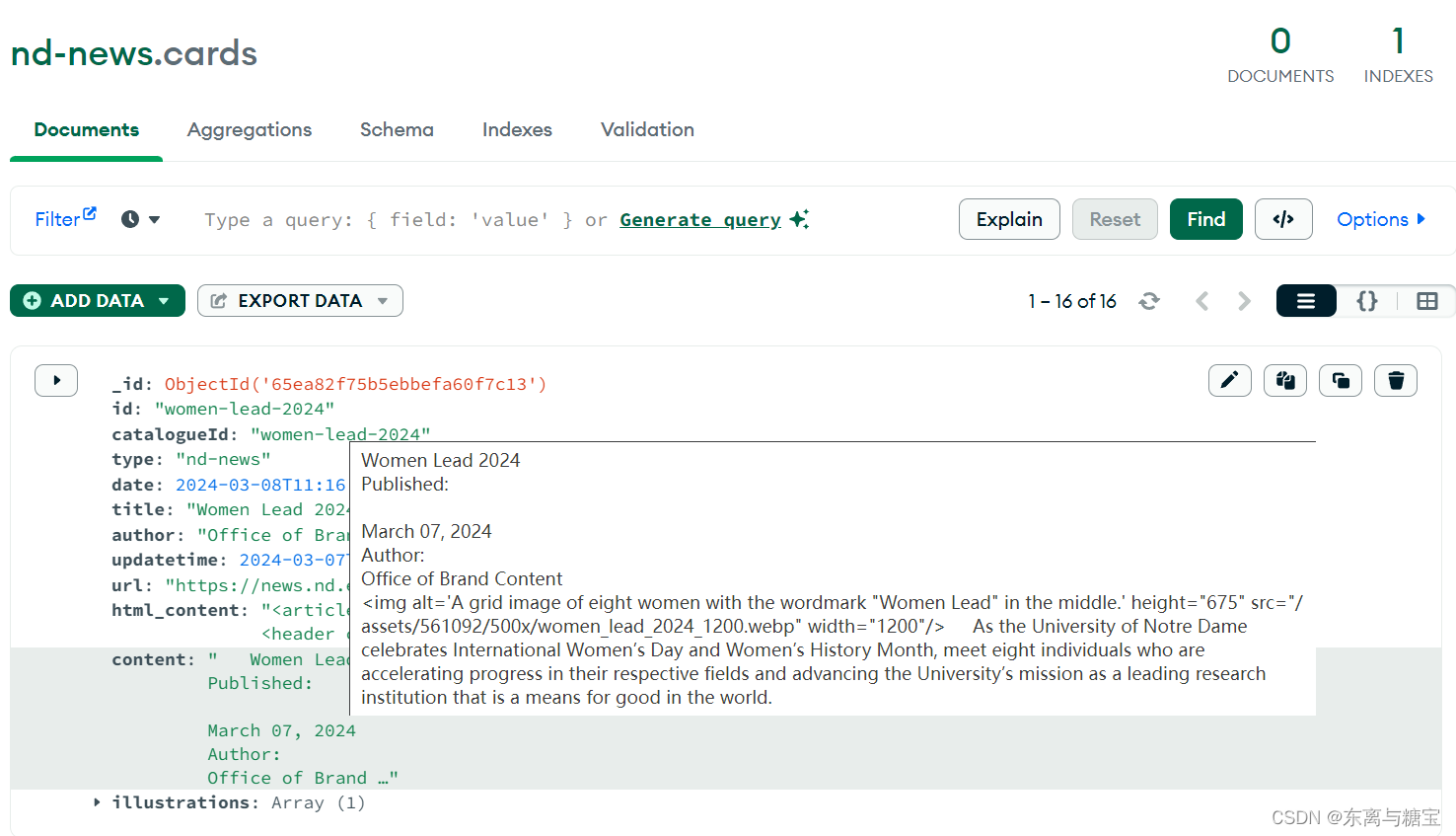
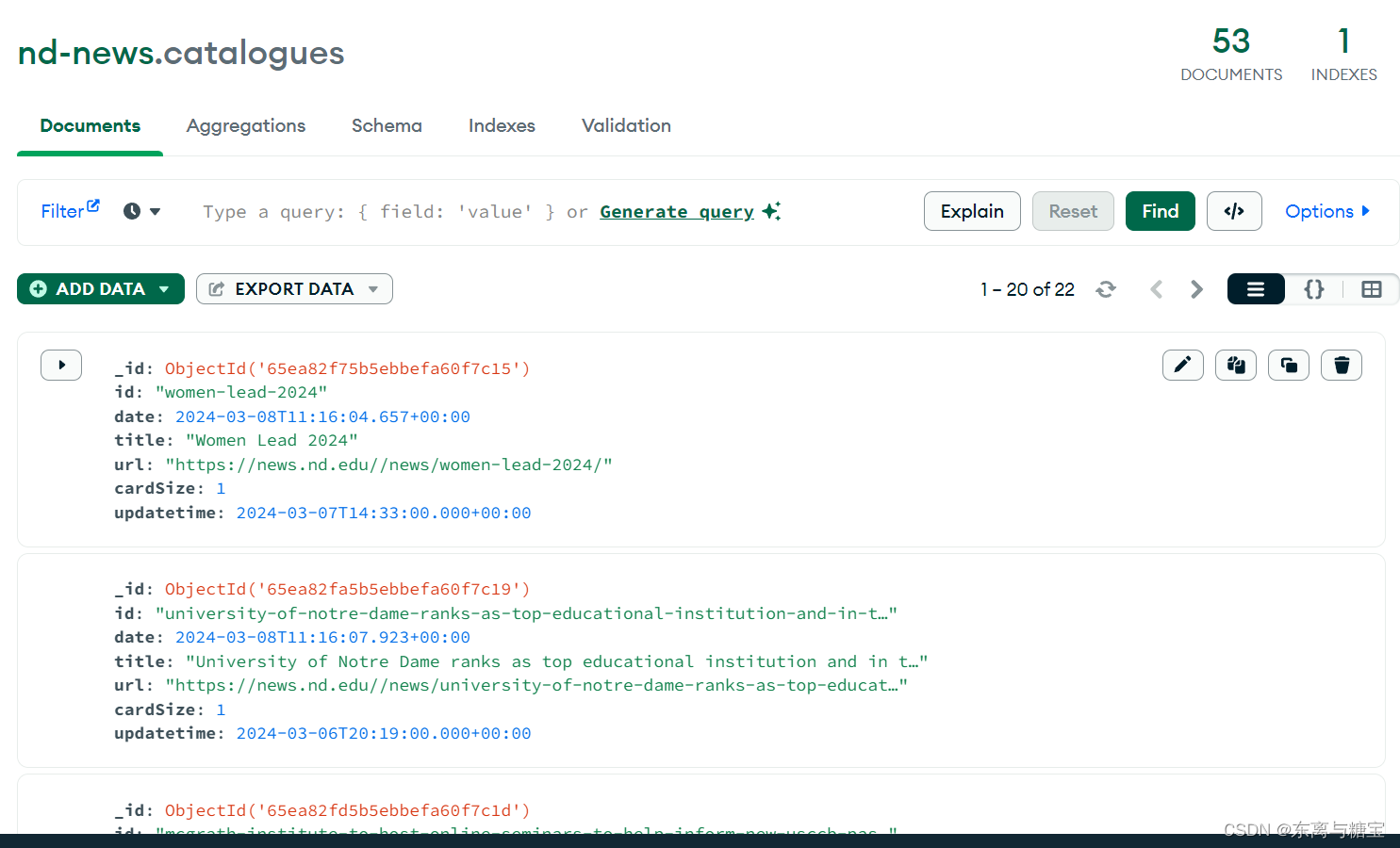
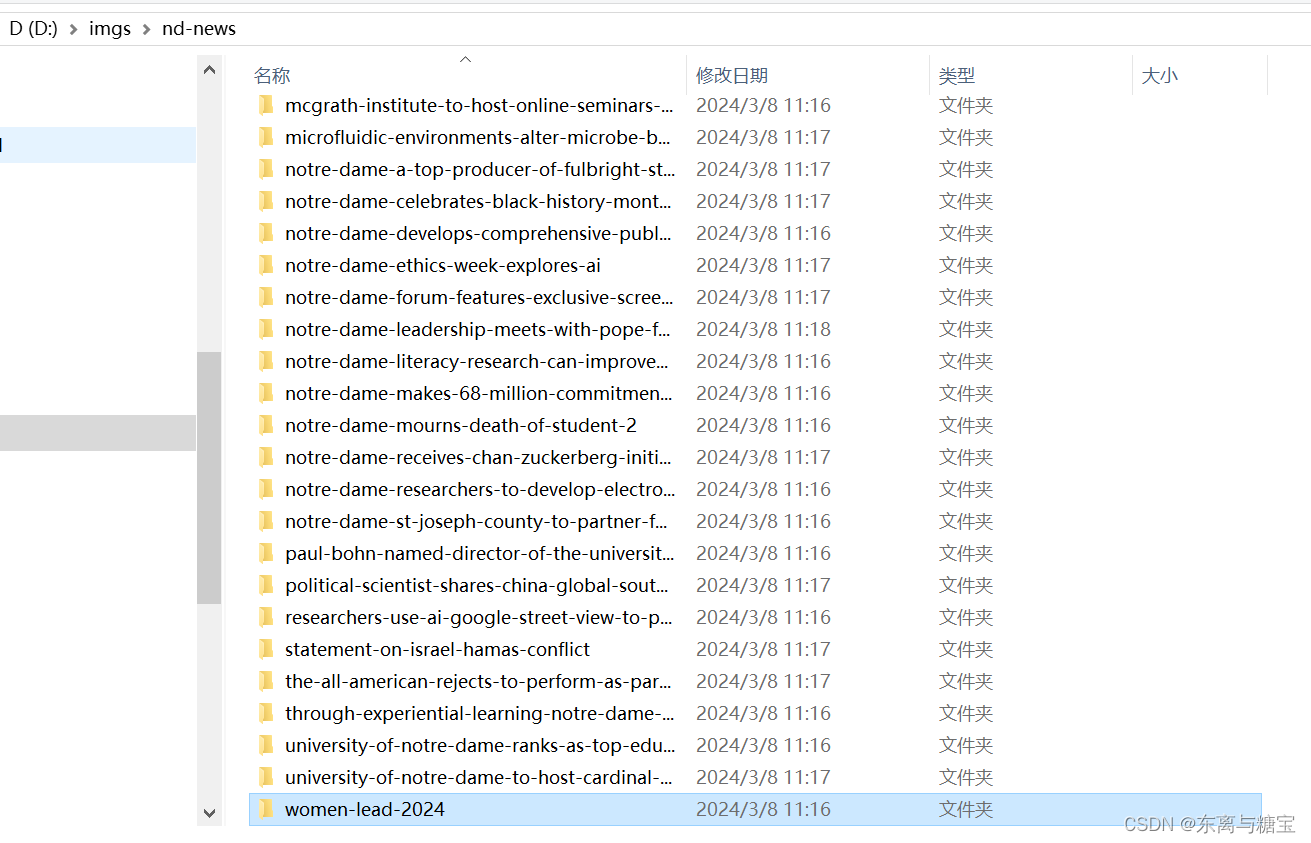
相关文章:
爬虫实战——巴黎圣母院新闻【内附超详细教程,你上你也行】
文章目录 发现宝藏一、 目标二、简单分析网页1. 寻找所有新闻2. 分析模块、版面和文章 三、爬取新闻1. 爬取模块2. 爬取版面3. 爬取文章 四、完整代码五、效果展示 发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不…...
mysql的语法总结2
命令: mysql -u 用户名 -p mysql登录 命令:create database u1 创建数据库u1 查询数据库 使用数据库u1 创建表department 查询表department ALTER TABLE 表名 操作类型; 操作类型可以有以下的操作: 添加列&#x…...

一度电竟然可以做这么多事情!
一度电竟然可以做这么多事情!!! 一度电可以让手机充电100多次; 一度电可以生产医用口罩100个; 一度电可以让节能灯点亮九十个小时; 一度电可以让电视播放10小时; 一度电可以让冰箱运作36个小…...

【Go】golang值交换,指针
package mainimport "fmt"func swap(a *int, b *int) int {var o into *a*a *b*b oreturn o}func main() {var a int 1var b int 2swap(&a, &b)fmt.Println(a, b) }这个函数接受两个整数指针作为参数,然后通过指针操作,交换它们所…...

共享WiFi软件哪家强?2024年共享wifi项目排名为你揭晓!
共享WiFi软件在如今的智能手机时代已经成为人们生活中不可或缺的一部分。随着移动互联网的飞速发展,人们对于随时随地都能够连接到网络的需求也日益增长。为了满足这一需求,共享经济应运而生,而在众多共享产品中,共享WiFi软件也逐…...

Hudi入门
一、Hudi编译安装 1.下载 https://archive.apache.org/dist/hudi/0.9.0/hudi-0.9.0.src.tgz2.maven编译 mvn clean install -DskipTests -Dscala2.12 -Dspark33.配置spark与hudi依赖包 [rootmaster hudi-spark-jars]# ll total 37876 -rw-r--r-- 1 root root 38615211 Oct …...
LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS
TOC 1 前言2 方法2.1 LOW-RANK-PARAMETRIZED UPDATE MATRICES 1 前言 1) 提出背景 大模型时代,通常参数都是上亿级别的,若对于每个具体任务都要去对大模型进行全局微调,那么算力和资源的浪费是巨大的。 根据流形学习思想,对于数…...
使用Pytorch导出自定义ONNX算子
在实际部署模型时有时可能会遇到想用的算子无法导出onnx,但实际部署的框架是支持该算子的。此时可以通过自定义onnx算子的方式导出onnx模型(注:自定义onnx算子导出onnx模型后是无法使用onnxruntime推理的)。下面给出个具体应用中的…...

unity-urp:视野雾
问题背景 恐怖游戏在黑夜或者某些场景下,需要用雾或者黑暗遮盖视野,搭建游戏氛围 效果 场景中,雾会遮挡场景和怪物,但是在玩家视野内雾会消散,距离玩家越近雾越薄。 当前是第三人称视角,但是可以轻松的…...

Spring Cloud Gateway介绍及入门配置
Spring Cloud Gateway介绍及入门配置 概述: Gateway是在Spring生态系统之上构建的API网关服务,基于Spring6,Spring Boot 3和Project Reactor等技术。它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式,并为它们提供…...
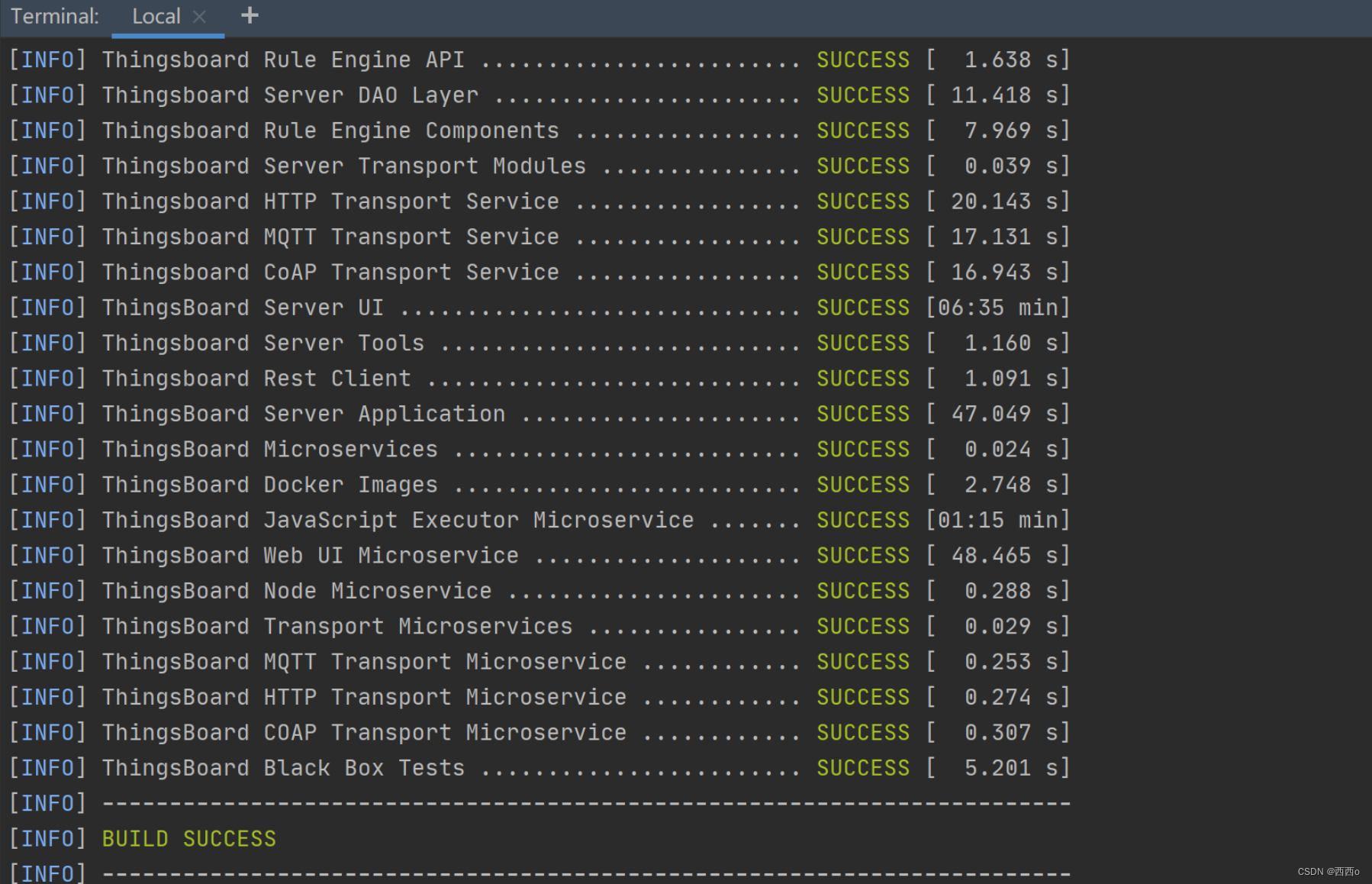
Thingsboard本地源码部署教程
本章将介绍ThingsBoard的本地环境搭建,以及源码的编译安装。本机环境:jdk11、maven 3.6.2、node v12.18.2、idea 2023.1、redis 6.2 环境安装 开发环境要求: Jdk 11 版本 ;Postgresql 9 以上;Maven 3.6 以上…...
【MySQL 系列】MySQL 起步篇
MySQL 是一个开放源代码的、免费的关系型数据库管理系统。在 Web 开发领域,MySQL 是最流行、使用最广泛的关系数据库。MySql 分为社区版和商业版,社区版完全免费,并且几乎能满足全部的使用场景。由于 MySQL 是开源的,我们还可以根…...

C++的成员初始化列表
C的成员构造函数初始化列表:构造函数中初始化类成员的一种方式,当我们编写一个类并向该类添加成员时,通常需要某种方式对这些成员变量进行初始化。 建议应该在所有地方使用成员初始化列表进行初始化 成员初始化的方法 方法一: …...
为什么TikTok视频0播放?账号权重提高要重视
许多TikTok账号运营者都会遇到一个难题,那就是视频要么播放量很低,要么0播放!不管内容做的多好,最好都是竹篮打水一场空!其实你可能忽略了一个问题,那就是账号权重。下面好好跟大家讲讲这个东西!…...
element---tree树形结构(返回的数据与官方的不一样)
项目中要用到属性结构数据,后端返回的数据不是官方默认的数据结构: <el-tree:data"treeData":filter-node-method"filterNode":props"defaultProps"node-click"handleNodeClick"></el-tree>这是文档…...

Spring Boot工程集成验证码生成与验证功能教程
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
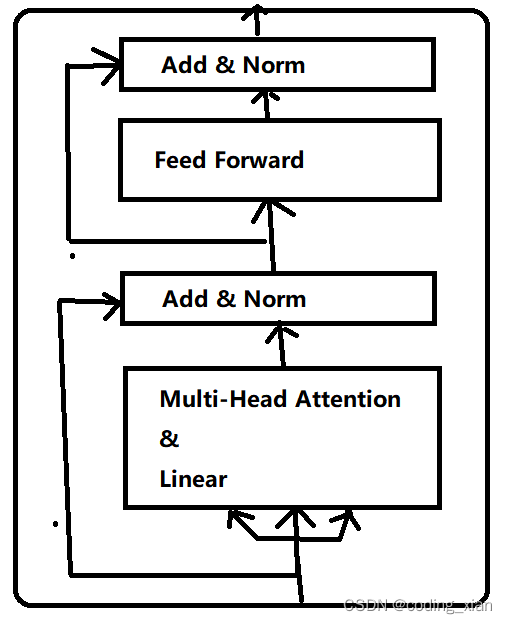
Bert Encoder和Transformer Encoder有什么不同
前言:本篇文章主要从代码实现角度研究 Bert Encoder和Transformer Encoder 有什么不同?应该可以帮助你: 深入了解Bert Encoder 的结构实现深入了解Transformer Encoder的结构实现 本篇文章不涉及对注意力机制实现的代码研究。 注:…...
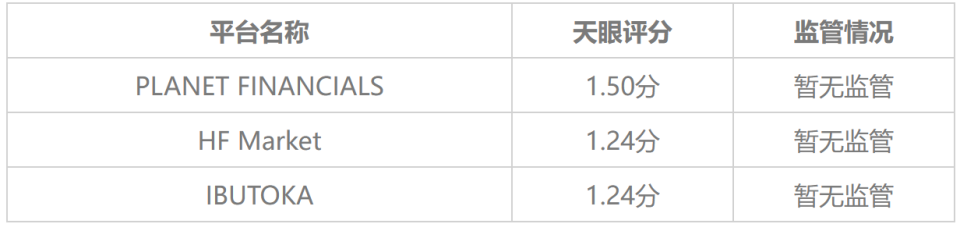
外汇天眼:频繁交钱却无法出金,只因误入假冒HFM惨成冤大头!
在外汇市场上这么久了,天眼君总结出了一个不争的事实,但凡是不给出金或者以各种理由拒绝出金的平台一定有问题!想必不管是在外汇天眼还是其他地方,大家总是能看到一些外汇交易者投诉自己向平台申请出金需要缴纳各种费用࿰…...

Linux-信号3_sigaction、volatile与SIGCHLD
文章目录 前言一、sigaction__sighandler_t sa_handler;__sigset_t sa_mask; 二、volatile关键字三、SIGCHLD方法一方法二 前言 本章内容主要对之前的内容做一些补充。 一、sigaction #include <signal.h> int sigaction(int signum, const struct sigaction *act,struc…...
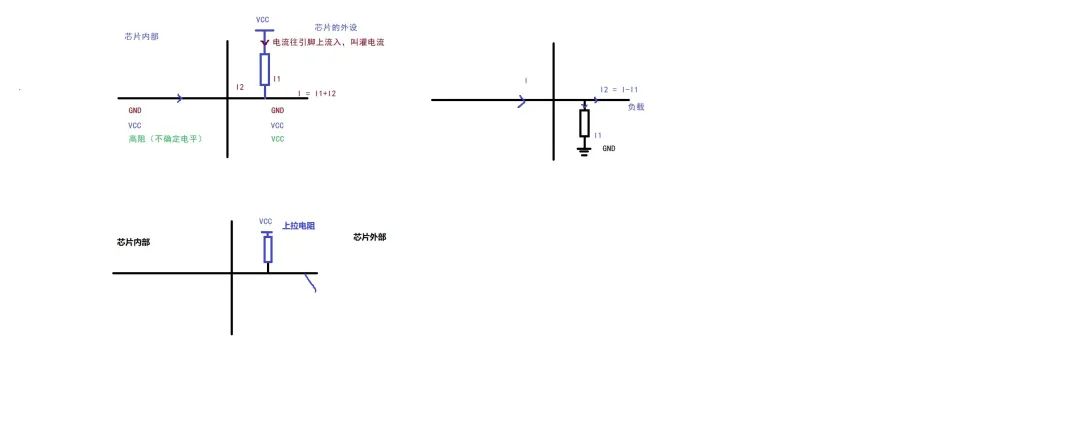
STM32 | STM32时钟分析、GPIO分析、寄存器地址查找、LED灯开发(第二天)
STM32 第二天 一、 STM32时钟分析 寄存器:寄存器的功能是存储二进制代码,它是由具有存储功能的触发器组合起来构成的。一个触发器可以存储1位二进制代码,故存放n位二进制代码的寄存器,需用n个触发器来构成 在计算机领域&#x…...

forkrun:革新数据处理,突破传统并行工具性能瓶颈
【导语:forkrun 作为一款自调优工具,可直接替代 GNU Parallel 和 xargs -P。它在现代 CPU 上能显著提升基于 Shell 的数据准备速度,尤其在 NUMA 架构上表现出色,为数据处理领域带来了新的变革。】数据处理速度的飞跃:5…...

palworld-host-save-fix全攻略:解决幻兽帕鲁存档迁移难题的实战指南
palworld-host-save-fix全攻略:解决幻兽帕鲁存档迁移难题的实战指南 【免费下载链接】palworld-host-save-fix 项目地址: https://gitcode.com/gh_mirrors/pa/palworld-host-save-fix 在幻兽帕鲁的冒险旅程中,更换服务器或迁移平台时的存档丢失问…...

SM4算法在嵌入式平台的轻量化移植与优化实践
1. SM4算法与嵌入式平台适配挑战 SM4作为我国自主设计的商用分组密码标准,在物联网设备安全领域应用广泛。但直接将OpenSSL中的SM4实现移植到STM32等嵌入式平台时,开发者常会遇到三大难题: 代码体积膨胀:OpenSSL的SM4实现依赖大量…...

基于Phi-4-mini-reasoning的智能运维异常检测系统
基于Phi-4-mini-reasoning的智能运维异常检测系统 1. 运维监控的痛点与智能化需求 运维团队每天都要面对海量的日志数据、监控指标和系统告警。传统监控系统往往只能做到简单的阈值告警,当系统出现异常时,运维人员需要手动翻阅成千上万条日志ÿ…...
)
告别底噪和电流声:DIY蓝牙音箱的音频电路避坑指南(从TPA2019布线到电源滤波)
蓝牙音箱DIY进阶指南:从电路设计到音质优化的全流程解析 在电子DIY领域,蓝牙音箱制作看似简单,但要实现专业级的音质表现却需要跨越诸多技术门槛。许多爱好者完成基础组装后,常会遇到底噪明显、高频失真或低频浑浊等问题——这往往…...

Chandra OCR多平台部署指南:Windows WSL2/Mac Metal/Linux Docker全搞定
Chandra OCR多平台部署指南:Windows WSL2/Mac Metal/Linux Docker全搞定 1. Chandra OCR核心能力解析 Chandra是Datalab.to在2025年10月开源的布局感知OCR模型,与传统OCR工具最大的区别在于它能完整保留文档的排版结构信息。想象一下:当你扫…...
的常见错误与调试技巧)
技能大赛备赛避坑指南:搞定软件测试五大任务(功能/自动化/性能/单元/接口)的常见错误与调试技巧
技能大赛备赛避坑指南:软件测试五大任务实战排错手册 参加职业院校技能大赛软件测试赛项的师生们,往往在备赛过程中遇到各种"坑":脚本突然报错、环境配置冲突、报告格式被扣分…这些问题看似琐碎,却可能直接影响比赛成绩…...

KityMinder云存储与分享功能完整指南:打造高效团队协作体验
KityMinder云存储与分享功能完整指南:打造高效团队协作体验 【免费下载链接】kityminder 百度脑图 项目地址: https://gitcode.com/gh_mirrors/ki/kityminder KityMinder作为百度FEX团队开发的在线思维导图工具,其强大的云存储与分享功能让团队协…...

基于GADF-CNN-GOSO-LSSVM的齿轮箱故障诊断方法探索
基于GADF-CNN-GOSO-LSSVM的齿轮箱故障诊断 首先,利用格拉姆角场差(GADF)时频分辨率高、可以深度反映时间序列内在结构和关系的特点,对采集到的一维故障数据信号转为二维图像,得到图像后并将图像进行降维处理;然后,将第…...

Graphormer开源模型部署教程:3.7GB小模型+RTX4090一键启动分子建模服务
Graphormer开源模型部署教程:3.7GB小模型RTX4090一键启动分子建模服务 1. 项目介绍 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。这个3.7GB的小模型在OG…...