混合输入矩阵乘法的性能优化

作者 | Manish Gupta
OneFlow编译
翻译|宛子琳、杨婷
AI驱动的技术正逐渐融入人们日常生活的各个角落,有望提高人们获取知识的能力,并提升整体生产效率。语言大模型(LLM)正是这些应用的核心。LLM对内存的需求很高,通常需要专用的硬件加速器,以高效地提供数百亿亿次浮点运算(Exaflops级别)的计算能力。本文将展示如何通过更有效地利用内存来解决计算方面的挑战。
LLM中的大部分内存和计算资源都消耗在了矩阵乘法操作中的权重上。使用范围更小的数据类型可以降低内存消耗,例如,将权重存储为8位整数(即U8或S8)的数据类型,相对于单精度(F32)能够减少4倍的内存占用,相对于半精度(F16)或bfloat16(BF16)能够减少2倍的内存占用。
此外,先前的研究表明,LLM模型采用S8格式的权重和F16格式的输入进行矩阵乘法运算,能够在保持可接受的准确性的同时提高效率。这一技术被称为仅权重量化(weight-only quantization),需要对带有混合输入的矩阵乘法进行高效实现,例如半精度输入与8位整数相乘。因为硬件加速器(包括GPU)支持一组固定的数据类型,因此,混合输入矩阵乘法需要通过软件转换来映射到硬件操作。
为此,本文重点关注将混合输入的矩阵乘法映射到NVIDIA Ampere架构上。我们提出了解决数据类型转换和布局一致性的软件技术,以有效地将混合输入矩阵乘法映射到硬件支持的数据类型和布局上。结果显示,在软件中进行额外工作的计算开销很小,并且可以实现接近硬件峰值的性能。本文所介绍的软件技术已在开源的NVIDIA/CUTLASS库(github.com/NVIDIA/cutlass/pull/1084)中发布。
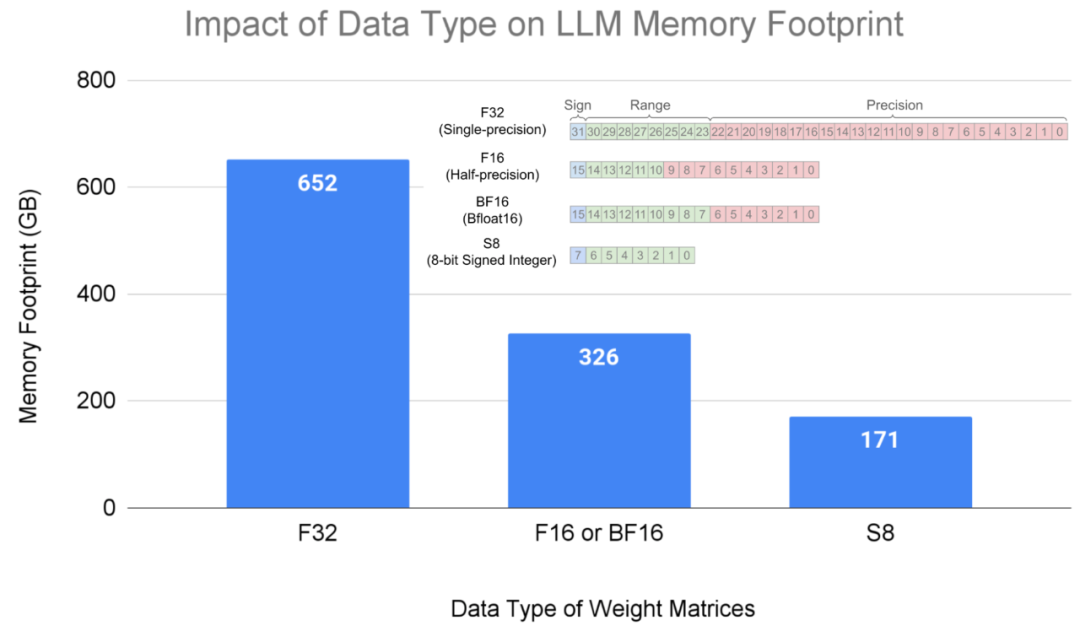
175亿参数的LLM模型在不同数据类型格式下的内存占用。
(本文作者为谷歌研究院高级软件工程师Manish Gupta。以下内容由OneFlow编译发布,转载请联系授权。原文:https://blog.research.google/2024/01/mixed-input-matrix-multiplication.html)
1
矩阵乘累加(matrix-multiply-accumulate)运算
当前的AI硬件加速器,如Google的TPU和NVIDIA的GPU,通过针对张量核心(Tensor Core)在硬件中本地执行矩阵乘运算(这些张量核心是专门加速矩阵运算的处理单元),尤其适用于AI工作负载。本文我们重点关注NVIDIA Ampere张量核心,它提供矩阵乘累加(mma)运算。在本文其余部分,mma指的是Ampere张量核心。在mma运算中,两个输入矩阵(称为操作数)所支持的数据类型、维度和数据布局在硬件中是固定的。这意味着,软件中不同的数据类型和更大维度的矩阵乘法是通过将问题划分为硬件所支持的数据类型、形状和布局实现的。
张量核心的mma运算通过指定两个输入矩阵(如下图所示的A和B)来计算生成结果矩阵C。mma运算本身支持混合精度。混合精度张量核心允许混合输入(A和B)数据类型与结果(C)数据类型。相比之下,混合输入矩阵乘法涉及混合输入数据类型,这在硬件上不受支持,因此需要通过软件实现。
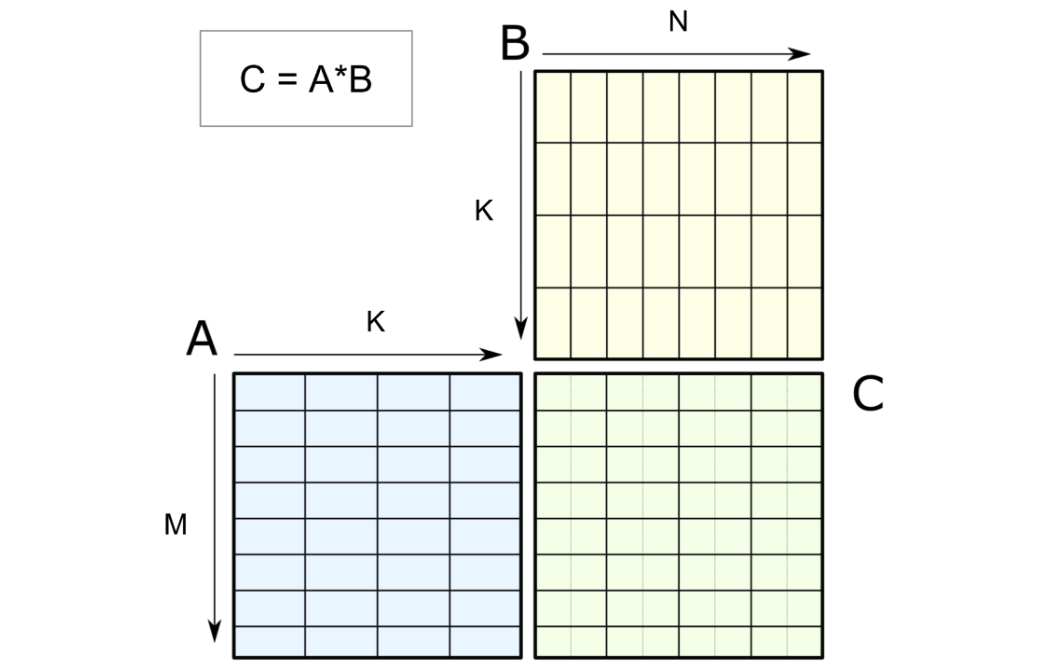
对M乘K的输入矩阵A和K乘N的输入矩阵B进行的M乘N乘K的张量核心操作,
得到M乘N的输出矩阵C。
2
混合输入矩阵乘面临的挑战
为简化讨论,我们选择了混合输入矩阵乘法的一个具体示例:用户输入采用F16,模型权重采用U8(表示为F16 * U8)。本文讨论的技术适用于各种混合输入数据类型组合。
GPU程序员可以访问一系列内存,包括全局内存、共享内存和寄存器,这些内存按容量递减但速度递增的顺序排列。NVIDIA Ampere Tensor Core的mma操作从寄存器中获取输入矩阵。此外,输入和输出矩阵需要符合在一个名为warp的32个线程组内的数据布局。对于mma操作,warp内支持的数据类型和布局是固定的,因此要高效实现混合输入乘法,就需要在软件中解决数据类型转换和布局一致性问题。
数据类型转换
mma操作要求两个输入矩阵具有相同的数据类型。因此,在混合输入矩阵乘法中,当一个操作数以U8存储在全局内存中,而另一个以F16存储时,就需要进行从U8到F16的数据类型转换。这种转换将两个操作数转换为F16,从而将混合输入矩阵乘法映射到硬件支持的混合精度张量核心。鉴于权重的数量庞大,因此需要大量的转换操作,我们的技术展示了如何降低其时延并提高性能。
布局一致性
mma操作还要求两个输入矩阵的布局(即在一个warp的寄存器中的布局)符合硬件规范。在混合输入矩阵乘法(F16 * U8)中,U8数据类型的输入矩阵B的布局需要符合转换后的F16数据类型。这被称为布局一致性(layout conformance),需要通过软件实现。
下图展示了一个mma操作,它从寄存器中提取矩阵A和矩阵B,然后在寄存器中生成矩阵C,这个过程分布在一个warp中。其中,线程T0被突出显示,并对其进行了放大,以展示权重矩阵B经过数据类型转换,需要符合布局一致性才能映射到硬件支持的张量核心操作。
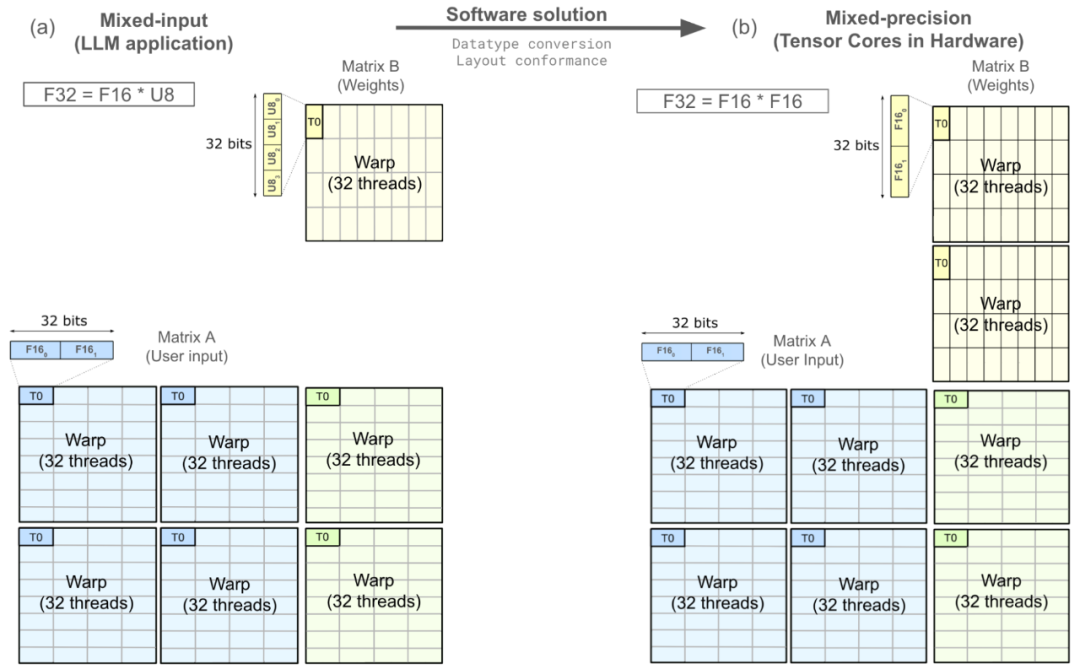
将软件中的混合输入(F32=F16U8)操作映射到硬件中原生支持的warp级张量核心(F32=F16F16)。原图来源:《在NVIDIA A100上开发CUDA核心以充分发挥张量核心的性能极限》。
2
应对计算挑战的软件策略
典型的数据类型转换涉及对32位寄存器的一系列操作,如下图所示。每个矩形块代表一个寄存器,相邻文本则表示相应的操作。整个序列展示了从4个U8转换为2个(2个F16)的过程。该序列大约包含10个操作。
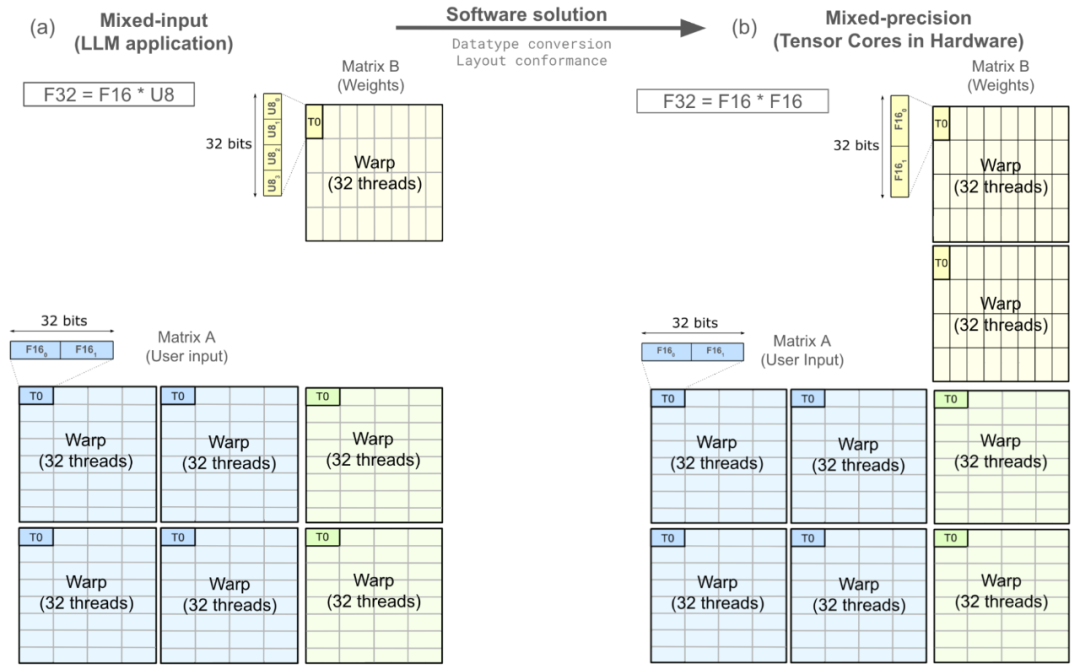
在32位寄存器中,将4个U8转换为2x(2个F16)的NumericArrayConvertor。
实现布局一致性的方法有很多,两种现有解决方案如下:
1.较窄位宽的共享内存加载:在这种方法中,线程发出较窄位宽的内存加载操作,将U8数据从共享内存移动到寄存器。这会导致两个32位寄存器,每个寄存器包含2个F16值(如上所示,对于矩阵B的线程T0)。较窄的共享内存加载直接实现了布局一致性,使其存入寄存器,而无需任何移动(shuffles)操作;然而,这种方法未充分利用共享内存带宽。
2.全局内存中的预处理:另一种策略是,在全局内存中重新排列数据(在内存层次结构中位于共享内存的上一级),允许更宽的共享内存加载。这种方法最大程度地利用了共享内存带宽,并确保数据以一致的布局直接加载到寄存器中。虽然重新排列过程可以在LLM部署之前离线执行,确保不影响应用程序的性能,但它引入了一个额外的、有意义的硬件特定的预处理步骤,需要额外的程序来重新排列数据。
NVIDIA/FasterTransformer采用这种方法有效地解决了布局一致性的挑战。
3
优化的软件策略
为进一步优化并减少数据类型转换和布局一致性的计算开销,我们分别实现了FastNumericArrayConvertor和FragmentShuffler。
FastNumericArrayConvertor在32位寄存器中直接处理4xU8,而无需拆解单个1xU8值。此外,它使用的算术操作成本较低,减少了指令数量,提高了转换速度。
U8到F16的转换序列如下图所示。这些运算使用打包的32位寄存器,避免了显式的解包和打包。FastNumericArrayConvertor使用置换字节来重新排列4xU8的字节,将其放入两个寄存器中。此外,FastNumericArrayConvertor不使用开销较大的整数到浮点数转换指令,并采用矢量化操作,在两个32位寄存器中获取包含2x(2xF16)值的打包结果。相对于上述方法,U8到F16的FastNumericArrayConvertor大约使用了六个操作,相对上文提到的方式,其性能有约1.6倍的提升。
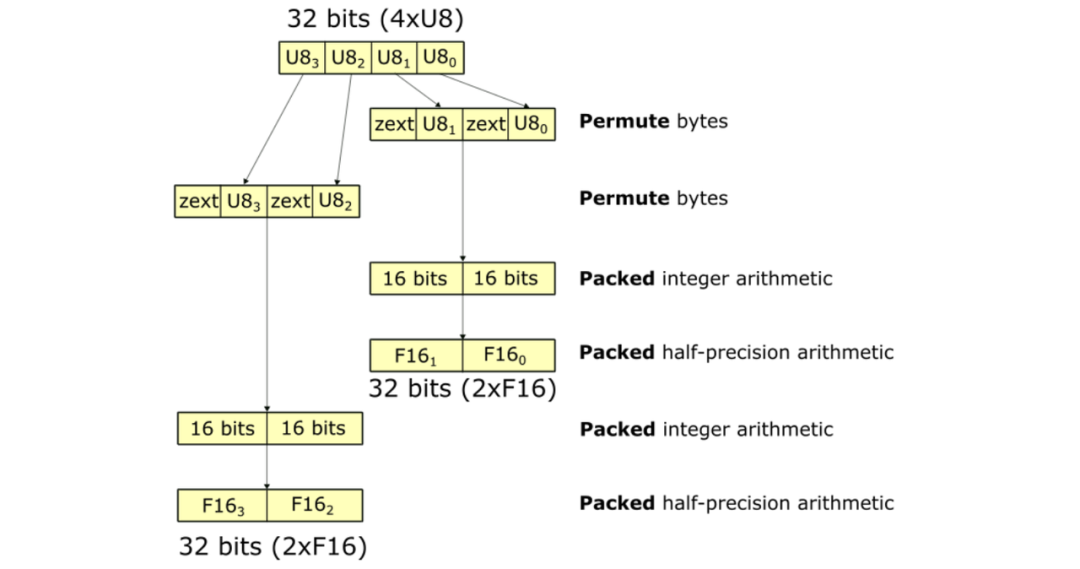
FastNumericArrayConvertor利用permute字节和packed计算,减少了数据类型转换中的指令数量。
FragmentShuffler通过对数据进行重新排列,可以使用更宽的位宽加载操作,实现了布局一致性,增加了共享内存带宽利用率,并减少了总操作数。
NVIDIA Ampere架构提供了一个加载矩阵指令(ldmatrix)。ldmatrix是一种warp级操作,其中一个warp的32个线程将数据从共享内存移动到寄存器中,而这些寄存器的形状和布局符合矩阵A和B进行矩阵乘法累积运算所需的要求。使用ldmatrix减少了加载指令的数量,提高了内存带宽利用率。由于ldmatrix指令将U8数据移动到寄存器中,加载后的布局符合U8U8的mma操作,不符合F16F16的mma操作。我们实现了FragmentShuffler,使用shuffle(shfl.sync)操作在寄存器内重新排列数据,以实现布局一致性。
这项工作最重要的贡献之一就是通过寄存器shuffles实现了布局一致性,避免了在全局内存中进行离线预处理或更窄的位宽共享内存加载。此外,我们提供了FastNumericArrayConvertor的实现,涵盖了从U8到F16、S8到F16、U8到BF16以及S8到BF16的数据类型转换。
4
性能表现
我们在NVIDIA A100 SXM芯片上测量了该方法的八种混合输入变体的性能(如下图中的蓝色和红色所示;根据矩阵A和B的数据类型不同而变化)以及两种混合精度数据类型(绿色显示)的性能。性能结果以FLOPS(数值越高表示性能越好))显示。
值得注意的是,相对于最后两个矩阵乘法,前八个需要额外的操作,因为混合精度变体直接针对硬件加速的张量核心操作,无需数据类型转换和布局一致性。即便如此,在混合输入矩阵乘法性能上,我们的方法仅略低于或与混合精度相当。
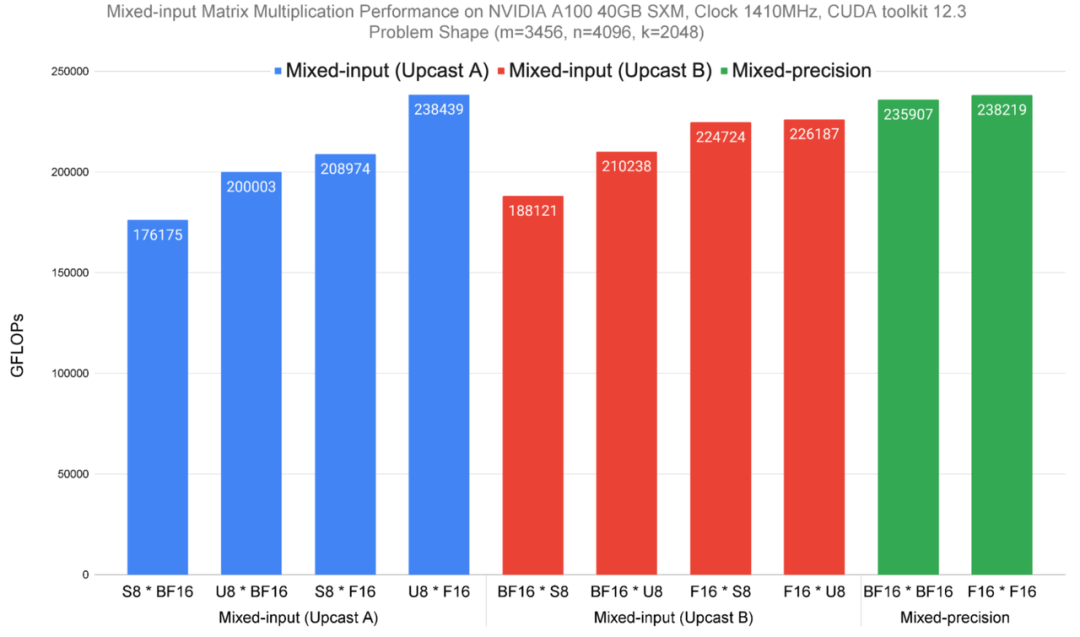
在NVIDIA A100 40GB SMX4芯片上,针对一个计算受限的矩阵问题,测试混合输入矩阵乘法的性能,其矩阵大小为m=3456,n=4096,k=2048。
致谢
在此,我们要特别感谢一些同仁,他们通过技术头脑风暴和博客文章改进做出了杰出贡献,包括Quentin Colombet,Jacques Pienaar,Allie Culp,Calin Cascaval,Ashish Gondimalla,Matt Walsh,Marek Kolodziej和Aman Bhatia。此外,我们还要对NVIDIA的合作伙伴Rawn Henry,Pradeep Ramani,Vijay Thakkar,Haicheng Wu,Andrew Kerr,Matthew Nicely和Vartika Singh表示由衷的感谢。

试用图片/视频生成加速引擎OneDiff: github.com/siliconflow/onediff
相关文章:
混合输入矩阵乘法的性能优化
作者 | Manish Gupta OneFlow编译 翻译|宛子琳、杨婷 AI驱动的技术正逐渐融入人们日常生活的各个角落,有望提高人们获取知识的能力,并提升整体生产效率。语言大模型(LLM)正是这些应用的核心。LLM对内存的需求很高&…...

安卓Kotlin面试题 41-50
41、如何在 Kotlin 中实现 Builder 模式?首先,在大多数情况下,您不需要在 Kotlin 中使用构建器,因为我们有默认和命名参数,但如果您需要使用://add private constructor if necessary class Car( val model: String?,val year: Int) { private constructor(build…...
portainer管理远程docker和docker-swarm集群
使用前请先安装docker和docker-compose,同时完成docker-swarm集群初始化 一、portainer-ce部署 部署portainer-ce实时管理本机docker,使用docker-compose一键拉起 docker-compose.yml version: 3 services:portainer:container_name: portainer#imag…...
分销商城微信小程序:用户粘性增强,促进复购率提升
在数字化浪潮的推动下,微信小程序作为一种轻便、高效的移动应用形式,正成为越来越多企业开展电商业务的重要平台。而分销商城微信小程序的出现,更是为企业带来了前所未有的机遇。通过分销商城微信小程序,企业不仅能够拓宽销售渠道…...

深度学习与机器学习:互补共进,共绘人工智能宏伟蓝图
在人工智能的广阔天地中,深度学习与机器学习如同两支强大的队伍,各自闪耀着独特的光芒,却又携手共进,共同书写着智能的辉煌篇章。尽管深度学习是机器学习的一个分支,但它们在模型构建、特征提取以及应用场景等多个方面…...

Vue.js 实用技巧:深入理解 Vue.mixin
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

【Spring Boot 3】读取resource文件
【Spring Boot 3】读取resource文件 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花费或…...

BUUCTF:[MRCTF2020]ezmisc
题目地址:https://buuoj.cn/challenges#[MRCTF2020]ezmisc 下载附件打开是一张照片: 放到kali中发现crc校验错误,修改照片宽高: 保存即可发现flag flag为: flag{1ts_vEryyyyyy_ez!}...
2024 RubyMine 激活,分享几个RubyMine 激活的方案
文章目录 RubyMine 公司简介我这边使用RubyMine 的理由RubyMine 2023.3 最新变化AI Assistant 正式版对 AI 生成名称建议的支持改进了 Ruby 上下文单元测试生成 RailsRails 应用程序和引擎的自定义路径Rails 路径的自动导入对存储在默认位置之外的模型、控制器和邮件器的代码洞…...
Flutter使用auto_updater实现windows/mac桌面应用版本升级功能
因为windows应用一般大家都是从网上下载的,后期版本肯定会更新,那用flutter开发windows应用,怎么实现应用内版本更新功能了?可以使用auto_updater库, 这个插件允许 Flutter 桌面 应用自动更新自己 (基于 sparkle 和 wi…...

Python编程实验六:面向对象应用
目录 一、实验目的与要求 二、实验内容 三、主要程序清单和程序运行结果 第1题 第2题 四、实验结果分析与体会 一、实验目的与要求 (1)通过本次实验,学生应掌握类的定义与对象的创建、类的继承与方法的覆盖; (2…...

Vue3中的ref和reactive
今天在写前端, 用的是Vue3, 其实之前也有写过一些前端, 但是涉及不深, 差不多是基础的水平, 然后现在想跟进下Vue3, 就有点吃力得紧, 就单单一个变量的引用, 就折腾得不轻࿰…...

第二十节 Java 正则表达式
正则表达式定义了字符串的模式。 正则表达式可以用来搜索、编辑或处理文本。 正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别。 Java正则表达式和Perl的是最为相似的。 java.util.regex包主要包括以下三个类: Pattern类:…...
ubuntu下vscode+STM32CubeMX+openocd+stlinkv2搭建STM32开发调试下载环境
1、换源 清华源 # 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释 deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restr…...
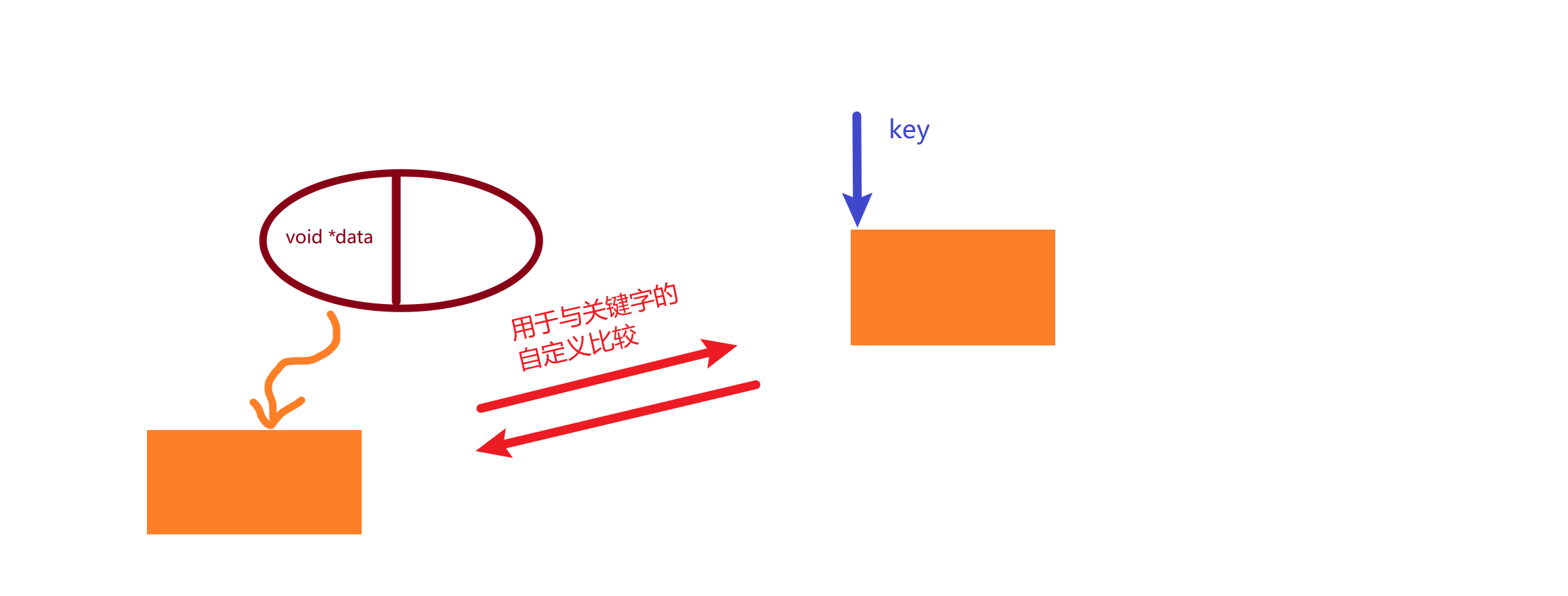
【嵌入式高级C语言】9:万能型链表懒人手册
文章目录 序言单向不循环链表拼图框架搭建 - Necessary功能拼图块1 创建链表头信息结构体 - Necessary2 链表头部插入 - Optional3 链表的遍历 - Optional4 链表的销毁 - Necessary5 链表头信息结构体销毁 - Necessary6 获取链表中节点的个数 - Optional7 链表尾部插入 - Optio…...

如何快速分析OB集群日志,敏捷诊断工具obdiag分析能力实践——《OceanBase诊断系列》之四
1. 前言 obdiag是OceanBase的敏捷诊断工具。1.2版本中,obdiag支持快速收集诊断信息,但仅有收集能力是不够的,还需要有分析能力。因此在obdiag的1.3.0版本中,我们加入了OB集群的日志分析功能。用户可以一键进行集群的OB日志的分析…...
7.1.3 Selenium的用法2
目录 1. 切换 Frame 2. 前进后退 3. 对 Cookies 操作 4. 选项卡管理(了解) 5. 异常处理 6. 反屏蔽 7. 无头模式 1. 切换 Frame 我们知道网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全…...

微信小程序(五十四)腾讯位置服务示范(2024/3/8更新)
教程如下: 上一篇 1.先在官网注册一下账号(该绑定的都绑定一下) 腾讯位置服务官网 2.进入控制台 3.创建应用 3. 额度分配 4.下载微信小程序SDK 微信小程序SDK下载渠道 5.解压将俩js文件放在项目合适的地方 6.加入安全域名or设置不验证合…...

Selenium库快速查找网页元素及执行浏览器模拟操作
Selenium 是一个自动化测试工具,主要用于模拟用户在网页上的行为,进行自动化测试。它支持多种浏览器,并且可以在多种操作系统上运行。以下是 Selenium 库的一些主要特点和用途: 网页自动化测试: Selenium 可以模拟用户…...
全国大学生统计建模大赛选题参考(一))
2024年(第十届)全国大学生统计建模大赛选题参考(一)
本届大赛主题为“大数据与人工智能时代的统计研究”,参赛队围绕主题自拟题目撰写论文。 1. 大数据分析与处理 研究思路 数据收集:首先确定数据来源,例如社交媒体、企业数据库或公开数据集,并使用爬虫技术或API收集数据。数据预…...
)
从CVE-2021-4034到CVE-2021-3156:手把手复现Linux两大本地提权漏洞(附修复方案)
从CVE-2021-4034到CVE-2021-3156:Linux本地提权漏洞深度实战指南 凌晨三点,安全团队的告警系统突然亮起红灯——又一台服务器被标记存在高危漏洞。作为运维负责人,你必须在最短时间内判断风险等级、验证漏洞真实性并制定修复方案。本文将带你…...

linux 安装 Elasticsearch Kibana
1.下载 通过网盘分享的文件:es 链接: https://pan.baidu.com/s/1JO07VJ8nVsfyC0TzHaLGKw?pwd1dgu 提取码: 1dgu 2.创建 es 用户, es 无法使用root用户启动 # 创建用户组用户 groupadd es useradd -m -g es es # 设置密码(可选) passwd es # …...

DCT-Net人像卡通化简单教程:拍好原图,一键生成完美卡通头像
DCT-Net人像卡通化简单教程:拍好原图,一键生成完美卡通头像 1. 为什么选择DCT-Net进行人像卡通化? 在众多人像卡通化工具中,DCT-Net凭借其出色的效果和易用性脱颖而出。这个基于深度学习的模型能够智能分析人脸特征,…...

逻辑优化进阶-香农分解在时序关键路径优化中的应用
1. 香农分解与时序优化的奇妙化学反应 第一次听说香农分解能优化电路时序时,我的反应和大多数工程师一样:"这不就是个布尔函数分解技巧吗?"直到亲眼见证它把一个关键路径延迟降低了30%,才意识到这个诞生于1940年代的数学…...

【CrewAI系列3】8 分钟,我用 CrewAI 创建了第一个 AI 员工
这是CrewAI系列的第3篇,计划写24篇,会持续更新;作者:14 年测试/QA 老兵系列:CrewAI 多 Agent 测试框架实战(第 3 篇)字数:约 4,200 字阅读时间:10 分钟收益:学…...

3步搞定百度网盘提取码:智能查询工具baidupankey终极指南
3步搞定百度网盘提取码:智能查询工具baidupankey终极指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘资源下载而频繁寻找提取码吗?每次遇到需要密码的分享链接,都要在多个…...
)
【2026最新】JDK 下载安装与环境配置全教程(Windows/Mac/Linux 三平台,零基础友好)
Java 开发的第一步,就是把 JDK 环境搭好。这一步看着简单,但不少新手会在环境变量配置上踩坑——JAVA_HOME 没设对、javac 报“不是内部或外部命令”、改完变量终端里还是不生效……这些坑我都替你踩过一遍了。 这篇文章就用最直白的方式,手…...

2026年最新好用的WMS仓库管理系统盘点!10款国内外热门WMS系统推荐
面对仓储管理的挑战,越来越多的企业开始关注WMS系统。但在选型时,很多企业面临同样的困惑:市场上WMS系统那么多,到底哪款适合自己?本文盘点2026年国内外10款热门WMS系统,从功能特点、适用场景、性价比等维度…...

收藏!国网四川电力 2026 年度集中采购批次计划发布
国网四川省电力公司公示的《2026 年度集中采购批次计划》,明确全年 108 个采购批次,为供应商精准把握投标节奏、提前布局业务提供清晰指引。本次采购覆盖 2025 年 12 月至 2026 年 11 月,涵盖省公司本级、子公司、战新产业及原集体企业等全主…...

111113345
1111111111111...