Selenium库快速查找网页元素及执行浏览器模拟操作
Selenium 是一个自动化测试工具,主要用于模拟用户在网页上的行为,进行自动化测试。它支持多种浏览器,并且可以在多种操作系统上运行。以下是 Selenium 库的一些主要特点和用途:
-
网页自动化测试: Selenium 可以模拟用户在网页上的各种操作,如点击、输入文本、选择下拉框等,从而进行网页自动化测试。这对于确保网站在不同浏览器和操作系统下的兼容性非常重要。
-
网页数据提取: Selenium 可以用于抓取网页上的数据,例如爬取网页上的文本、链接、图片等内容,从而进行数据分析或其他处理。
-
UI 自动化测试: 通过模拟用户在网页上的操作,Selenium 可以对网页的用户界面进行自动化测试,验证网页的交互功能是否正常。
-
跨浏览器测试: Selenium 支持多种浏览器,包括 Chrome、Firefox、Edge、Safari 等,可以在这些不同的浏览器上进行测试,确保网页在各种浏览器下的表现一致性。
-
跨平台测试: Selenium 可以在不同的操作系统上运行,包括 Windows、Mac、Linux 等,这使得可以在不同平台上进行测试,并确保网页在不同操作系统下的兼容性。
总之,Selenium 是一个强大的自动化测试工具,可以帮助开发人员和测试人员自动化进行网页测试、数据提取和 UI 测试等任务,从而提高开发效率和软件质量。
Selenium库提供了一系列`find_element_by_*`方法,用于查找网页上的元素,返回第一个匹配的元素;
>>>>>>find_elements_by_*`方法查找多个匹配的元素,返回一个元素列表。
这些方法根据不同的定位策略来查找元素。
以下是常用的`find_element_by_*`方法:
1. **find_element_by_id(id)**:根据元素的id属性查找元素。
2. **find_element_by_name(name)**:根据元素的name属性查找元素。
3. **find_element_by_xpath(xpath)**:根据XPath表达式查找元素。
4. **find_element_by_link_text(link_text)**:根据链接文本查找`<a>`元素。
5. **find_element_by_partial_link_text(partial_link_text)**:根据部分链接文本查找`<a>`元素。
6. **find_element_by_tag_name(tag_name)**:根据标签名查找元素。
7. **find_element_by_class_name(class_name)**:根据class属性查找元素。
8. **find_element_by_css_selector(css_selector)**:根据CSS选择器查找元素。
这些方法返回第一个匹配的元素。如果找不到匹配的元素,将抛出NoSuchElementException异常。
示例代码:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com")
# 根据id查找元素element_by_id = driver.find_element_by_id("my_element_id")
# 根据name查找元素element_by_name = driver.find_element_by_name("my_element_name")
# 根据XPath表达式查找元素element_by_xpath = driver.find_element_by_xpath("//div[@id='my_div']")
# 根据链接文本查找元素element_by_link_text = driver.find_element_by_link_text("click here")
# 根据部分链接文本查找元素element_by_partial_link_text = driver.find_element_by_partial_link_text("click")
# 根据标签名查找元素element_by_tag_name = driver.find_element_by_tag_name("div")
# 根据class属性查找元素element_by_class_name = driver.find_element_by_class_name("my_class")
# 根据CSS选择器查找元素element_by_css_selector = driver.find_element_by_css_selector("#my_element_id")
这些方法使您能够根据不同的属性和选择器来定位网页上的元素,从而进行元素操作和交互。
-------------------
`driver.find_elements(By.`是Selenium中使用By类进行元素查找的方法之一。
这些方法返回一个元素列表,您可以对列表中的每个元素执行操作,例如遍历、获取属性、点击等。
>>>>driver.find_element(By是Selenium中使用By类进行元素查找的方法之一。通过这种方式,查找单个元素。
通过这种方式,您可以根据不同的定位策略来查找元素。以下是一些常见的定位策略:
1. **By.ID**:根据元素的id属性来查找元素。
2. **By.NAME**:根据元素的name属性来查找元素。
3. **By.CLASS_NAME**:根据元素的class属性来查找元素。
4. **By.TAG_NAME**:根据元素的标签名来查找元素。
5. **By.LINK_TEXT**:根据元素的链接文本来查找`<a>`元素。
6. **By.PARTIAL_LINK_TEXT**:根据元素的部分链接文本来查找`<a>`元素。
7. **By.XPATH**:根据XPath表达式来查找元素。
8. **By.CSS_SELECTOR**:根据CSS选择器来查找元素。
您可以使用`driver.find_elements(By.`结合上述定位策略来查找多个元素。例如:
from selenium.webdriver.common.by import By
# 根据id查找多个元素elements_by_id = driver.find_elements(By.ID, "element_id")
# 根据name查找多个元素elements_by_name = driver.find_elements(By.NAME, "element_name")
# 根据class查找多个元素elements_by_class_name = driver.find_elements(By.CLASS_NAME, "element_class")
# 根据标签名查找多个元素elements_by_tag_name = driver.find_elements(By.TAG_NAME, "tag_name")
# 根据链接文本查找多个链接元素elements_by_link_text = driver.find_elements(By.LINK_TEXT, "link_text")
# 根据部分链接文本查找多个链接元素elements_by_partial_link_text = driver.find_elements(By.PARTIAL_LINK_TEXT, "partial_link_text")
# 根据XPath表达式查找多个元素elements_by_xpath = driver.find_elements(By.XPATH, "//xpath_expression")
# 根据CSS选择器查找多个元素elements_by_css_selector = driver.find_elements(By.CSS_SELECTOR, "css_selector")
--------------------
页面上的元素对象具有许多方法和属性,可以用于与元素进行交互和获取元素的信息。以下是一些常见的方法和属性:
**方法:**
1. **click()**:点击元素。
2. **send_keys(keys)**:向元素发送键盘输入。
3. **clear()**:清除输入框中的文本。
4. **get_attribute(name)**:获取元素的指定属性值。
5. **is_displayed()**:检查元素是否可见。
6. **is_enabled()**:检查元素是否可用。
7. **is_selected()**:检查元素是否被选中(适用于复选框和单选框)。
8. **submit()**:提交表单。
9. **location**:获取元素在页面中的坐标位置。
10. **size**:获取元素的大小。
11. **screenshot(filename)**:将元素的屏幕截图保存为文件。
12. **value_of_css_property(property_name)**:获取元素的CSS属性值。
**属性:**
1. **text**:获取元素的文本内容。
2. **tag_name**:获取元素的标签名。
3. **id**:获取元素的id属性值。
4. **name**:获取元素的name属性值。
5. **class_name**:获取元素的class属性值。
6. **location_once_scrolled_into_view**:获取元素滚动到视图中的位置(只读属性)。
这些方法和属性使您能够获取元素的信息,执行各种操作,以及进行状态检查,从而实现自动化测试或网页操作任务。
---------------
get_attribute(name) 方法用于获取指定属性的值。该方法允许您检索元素的任何属性,并返回该属性的值。
### 参数:- **name**:要获取的属性的名称。
### 返回值:- 返回指定属性的值,如果属性不存在,则返回 `None`。
### 注意事项:
- 如果元素没有指定的属性,`get_attribute()` 方法将返回 `None`。
- 对于一些特殊属性,例如 `checked`、`selected` 等,返回的值可能是布尔类型。
- 对于一些动态生成的属性,例如 `data-*` 属性,您也可以使用该方法获取它们的值。
以下是一些常见的(name) 属性名称种类:
1. **id**:元素的唯一标识符。
2. **name**:元素的名称。
3. **class** 或 **className**:元素的类名。
4. **value**:元素的值,常用于输入框、下拉列表等。
5. **href**:链接元素的目标 URL。
6. **src**:图像、音频、视频等媒体元素的源 URL。
7. **type**:输入元素的类型,例如文本框、复选框、按钮等。
8. **checked**:复选框或单选框的选中状态。
9. **selected**:下拉列表中选定选项的状态。
10. **disabled**:元素的禁用状态。
11. **title**:元素的标题。
12. **alt**:图像元素的替代文本。
13. **data-* **:自定义数据属性,例如 `data-role`、`data-id` 等。
14. **aria-* **:可访问性属性,例如 `aria-label`、`aria-hidden` 等。
15. **style**:元素的样式属性。
16. **outerHTML**:元素的外部 HTML,包括元素本身及其所有子元素的 HTML 内容。可以用于调试、验证页面结构等用途。
### 示例:
假设有一个 `<input>` 元素如下:
```html
<input id="username" type="text" value="john_doe" data-role="user">
使用 `get_attribute()` 方法来获取不同属性的值:
element = driver.find_element(By.ID, "username")
# 获取id属性的值
id_value = element.get_attribute("id")
print("ID:", id_value) # 输出:ID: username
# 获取value属性的值
value = element.get_attribute("value")
print("Value:", value) # 输出:Value: john_doe
# 获取data-role属性的值
data_role = element.get_attribute("data-role")
print("Data Role:", data_role) # 输出:Data Role: user
# 不存在的属性值
non_existent = element.get_attribute("non-existent")
print("Non Existent Attribute:", non_existent) # 输出:Non Existent Attribute: None
### 总结:
`get_attribute()` 方法允许您以编程方式检索元素的任何属性,并根据需要使用这些属性值进行后续操作。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutExceptiondriver = webdriver.Chrome()try:# 打开网页driver.get("https://www.hao123.com/")# 获取页面中所有input元素input_elements = driver.find_elements(By.TAG_NAME, "input")# 输出所有的input元素for input_element in input_elements:print(input_element.get_attribute("outerHTML"))# 等待文本框出现在页面上search_input = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, 'input[data-hook="searchInput"]')))# 输入搜索词search_input.send_keys("Selenium库")# 等待搜索按钮出现在页面上try:search_button = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, 'input[data-hook="searchSubmit"]')))# 点击搜索按钮search_button.click()except TimeoutException:print("找不到搜索按钮或搜索按钮不可见。")# 在这里可以添加其他恢复措施,比如重新加载页面,或者跳过当前步骤继续执行等。# 等待搜索结果列表的第一个元素出现try:WebDriverWait(driver, 10).until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, "input[id='kw']"), "Selenium库"))except TimeoutException as e:print(e)finally:# 关闭浏览器driver.quit()
from selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get('https://forum.sublimetext.com/')table = driver.find_element(By.CSS_SELECTOR, 'table.topic-list')
table_html = table.get_attribute('outerHTML')
print(table_html)# 将网页内容保存到本地文件
with open('seleniumBy.CSS_SELECTOR.html', 'w', encoding='utf-8') as f:f.write(table_html)driver.quit()
相关文章:

Selenium库快速查找网页元素及执行浏览器模拟操作
Selenium 是一个自动化测试工具,主要用于模拟用户在网页上的行为,进行自动化测试。它支持多种浏览器,并且可以在多种操作系统上运行。以下是 Selenium 库的一些主要特点和用途: 网页自动化测试: Selenium 可以模拟用户…...
全国大学生统计建模大赛选题参考(一))
2024年(第十届)全国大学生统计建模大赛选题参考(一)
本届大赛主题为“大数据与人工智能时代的统计研究”,参赛队围绕主题自拟题目撰写论文。 1. 大数据分析与处理 研究思路 数据收集:首先确定数据来源,例如社交媒体、企业数据库或公开数据集,并使用爬虫技术或API收集数据。数据预…...
EI级 | Matlab实现GCN基于图卷积神经网络的数据多特征分类预测
EI级 | Matlab实现GCN基于图卷积神经网络的数据多特征分类预测 目录 EI级 | Matlab实现GCN基于图卷积神经网络的数据多特征分类预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.GCN基于图卷积神经网络的数据分类预测 Matlab2023 2.多输入单输出的分类预测…...

贪心算法介绍
贪心算法是一种在求解问题时总是做出在当前看来是最好的选择的算法。它不从整体最优上加以考虑,所做出的选择只是在某种意义上的局部最优解。贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择,选择的贪心策略必须具备无后效性…...

前端常用数据结构
前端常用数据结构 前端常用数据结构数据结构数组栈队列链表单向链表双向链表树前端常用数据结构 什么是数据结构常用的数据结构 JavaScript 如何实现这些数据结构实际场景数据结构 所谓数据结构,是在计算机中组织、管理和存储数据的一种方式。 🙋:你知道哪些数据结构? …...

java设计模式之——单例模式
一:什么是单例模式? 构造函数private之后,还需要提供一个方法,要保证只能初始化一个单例对象,并且需要考虑线程安全的问题。 二:单例模式多种写法? 具体到写法上,主要有5种&#…...
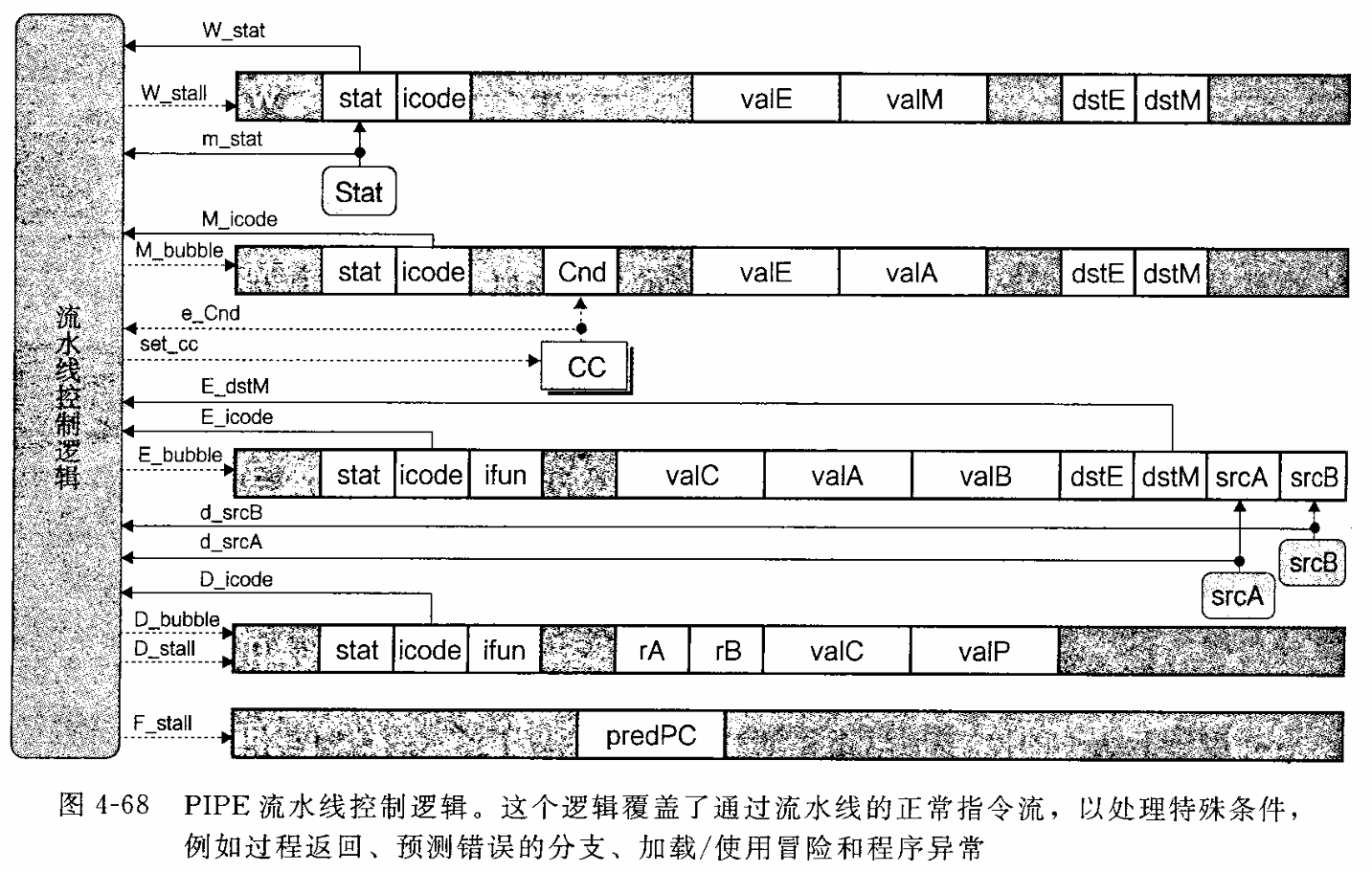
深入理解计算机系统学习笔记
1.1异常处理 处理器中很多事情都会导致异常控制流,此时,程序执行的正常流程被破坏掉。异常可以由程序执行从内部产生,也可以由某个外部信号从外部产 生。 我们的指令集体系结构包括三种不同的内部产生的异常: l)halt指令&#…...

Linux-进程信号
目录 概念信号产生信号注册信号注销信号处理实例 信号的基本应用 概念 进程信号: 概念:信号就是软件中断。信号就是用于向进程通知某个事件的产生,打断进程当前操作,去处理这个事件。 linux中信号的种类:使用kill -l命…...
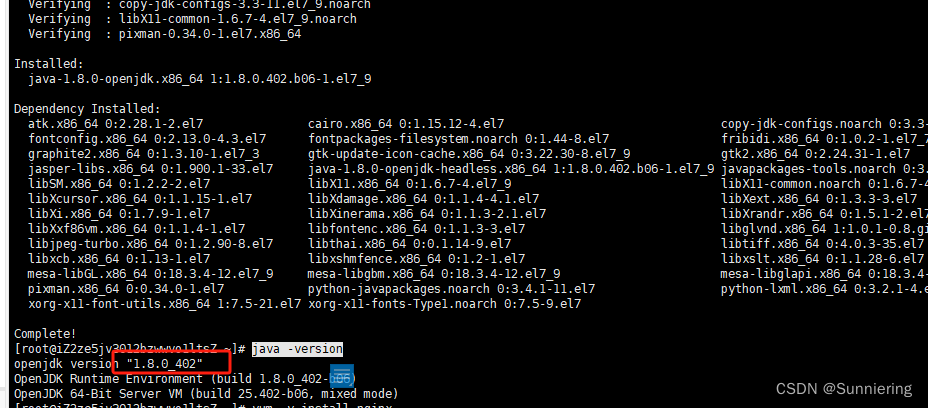
Linux服务器安装jdk
背景: 安装JDK是我们java程序在服务器运行的必要条件,下面描述几个简单的命令就可再服务器上成功安装jdk 命令总览: yum update -y yum list | grep jdk yum -y install java-1.8.0-openjdk java -version 1.查看可安装版本 yum list | grep jdk 2.如果查不到可先进行 yum upd…...
基于 HBase Phoenix 构建实时数仓(2)—— HBase 完全分布式安装
目录 一、开启 HDFS 机柜感知 1. 增加 core-site.xml 配置项 2. 创建机柜感知脚本 3. 创建机柜配置信息文件 4. 分发相关文件到其它节点 5. 重启 HDFS 使机柜感知生效 二、主机规划 三、安装配置 HBase 完全分布式集群 1. 在所有节点上配置环境变量 2. 解压、配置环境…...
与==的区别)
equals()与==的区别
在Java中 可以对基本类型进行比较,比较的是值是否相等 也可以对引用类型(对象)进行比较,比较的是引用变量所指向的空间地址 public static void main(String[] args) {int a 10;int b 10;System.out.println(ab);//true// 基本类型比较,比较值是否相等String s1 new Stri…...
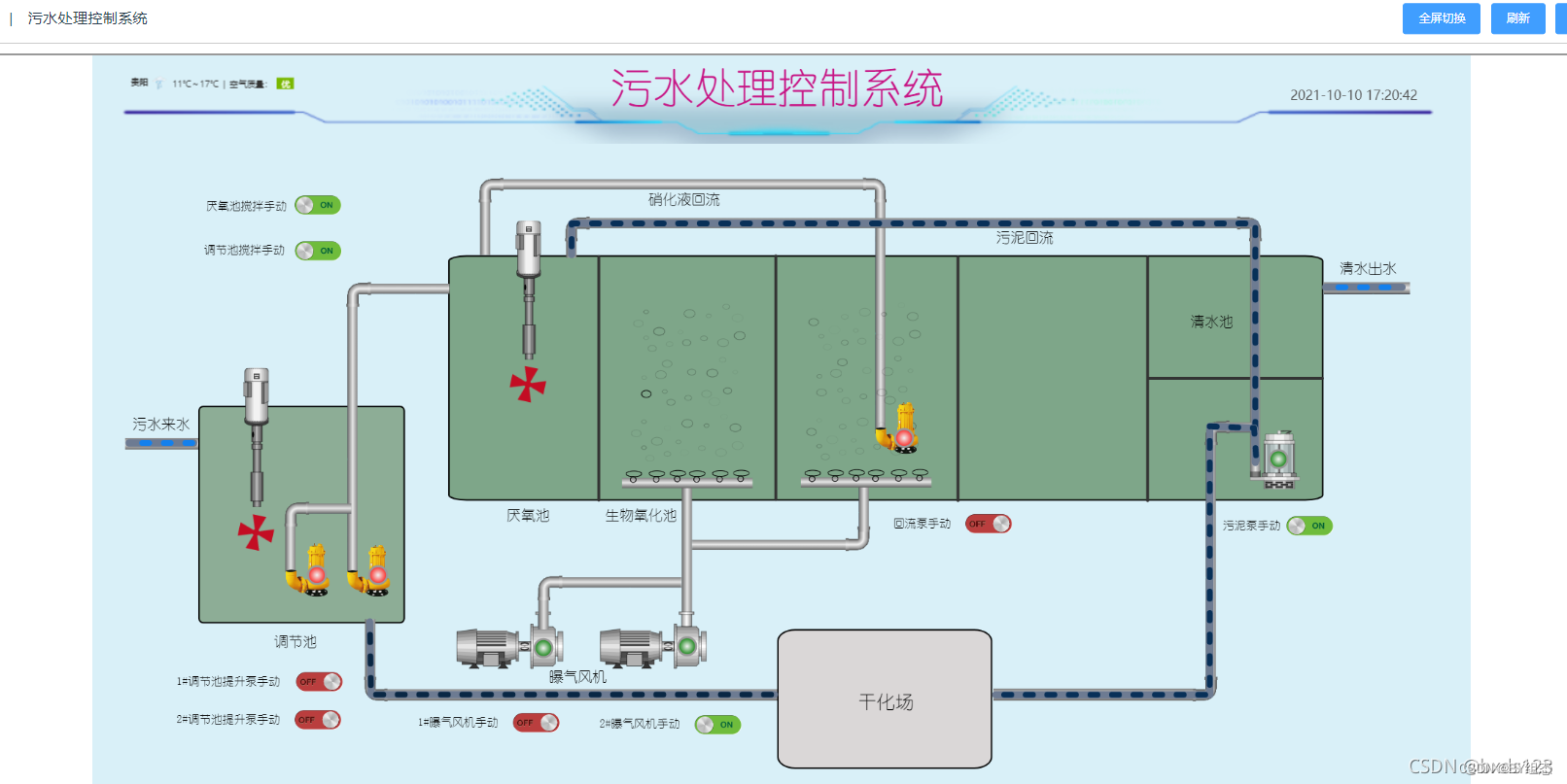
什么是数据采集与监视控制系统(SCADA)?
SCADA数据采集是一种用于监控和控制工业过程的系统。它可以实时从现场设备获得数据并将其传输到中央计算机,以便进行监控和控制。SCADA数据采集系统通常使用传感器、仪表和控制器收集各种类型的数据,例如温度、压力、流量等,然后将这些数据汇…...
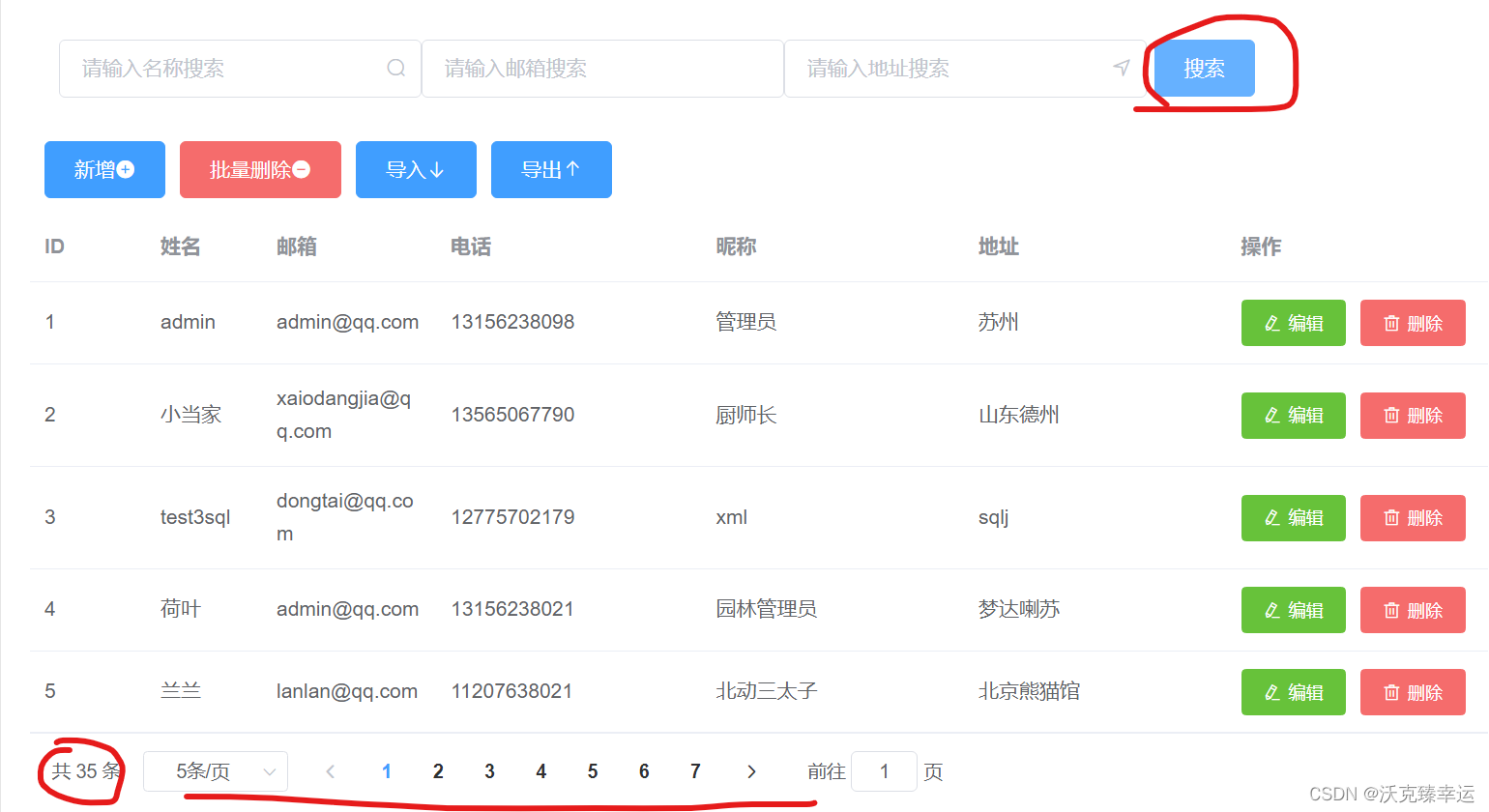
基于SpringBoot+Vue+ElementUI+Mybatis前后端分离管理系统超详细教程(五)——多条件搜索并分页展示
前后端数据交互 书接上文,我们上节课通过前后端数据交互实现了分页查询和单条件搜索分页查询的功能,最后留了个小尾巴,就是把其他两个搜索条件(email,address)也加进来,实现多条件搜索并分页展示。这节课我…...

鸿蒙实战开发Camera组件:【相机】
相机组件支持相机业务的开发,开发者可以通过已开放的接口实现相机硬件的访问、操作和新功能开发,最常见的操作如:预览、拍照和录像等。 基本概念 拍照 此功能用于拍摄采集照片。 预览 此功能用于在开启相机后,在缓冲区内重复采集…...
政安晨:【深度学习处理实践】(三)—— 处理时间序列的数据准备
在深度学习中,对时间序列的处理主要涉及到以下几个方面: 序列建模:深度学习可以用于对时间序列进行建模。常用的模型包括循环神经网络(Recurrent Neural Networks, RNN)和长短期记忆网络(Long Short-Term M…...
PCL不同格式点云读取速度(Binary和ASCII )
首先说明一点:Binary(二进制)格式点云文件进行读取时要比Ascll码格式点云读取时要快的多,尤其是对于大型的点云文件,如几百万、甚至几千万个点云的情况下。 今天遇到了一种情况,在写项目的时候进行点云读取,读取的时候…...

Neo4J图数据库入门示例
前言 - Neo4j和MySQL的区别 Neo4j 和 MySQL 是两种不同类型的数据库,它们在数据模型、用途、性能和查询语言等方面有着显著的区别。以下是它们的主要区别: 数据模型: Neo4j 是一种图数据库,它使用图数据模型来存储和查询数据。在…...

牛客每日一题之 二维前缀和
题目介绍: 题目链接:【模板】二维前缀和_牛客题霸_牛客网 先举两个简单的例子,来帮大家理解题目,注意理解二维前缀和要先要一维前缀和的基础,不了解的可以看我上一篇博客。 若x11,y11, x23, y2 3,这是要…...

动态规划 Leetcode 70 爬楼梯
爬楼梯 Leetcode 70 学习记录自代码随想录 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到…...
(未解决)macOS matplotlib 中文是方框
reference: Mac OS系统下实现python matplotlib包绘图显示中文(亲测有效)_mac plt 中文值-CSDN博客 module ‘matplotlib.font_manager‘ has no attribute ‘_rebuild‘解决方法_font_manager未解析-CSDN博客 # 问题描述(笑死 显而易见 # solve 找到…...

告别手动写提示词:AI头像生成器帮你快速设计专属头像
告别手动写提示词:AI头像生成器帮你快速设计专属头像 1. 为什么你需要AI头像生成器 在数字社交时代,头像已经成为个人品牌的重要组成部分。无论是社交媒体、工作平台还是游戏社区,一个精心设计的头像能让你在众多用户中脱颖而出。然而&…...

Arm AArch64寄存器体系与性能优化实战
1. Arm AArch64寄存器体系概览作为现代处理器架构的核心组成部分,寄存器在Armv8/v9架构中扮演着关键角色。AArch64作为Arm的64位执行状态,其寄存器设计体现了从传统嵌入式系统到云计算基础设施的全场景适应能力。与x86等CISC架构不同,Arm采用…...

fre:ac音频转换器终极指南:5大核心功能带你轻松玩转音频格式转换
fre:ac音频转换器终极指南:5大核心功能带你轻松玩转音频格式转换 【免费下载链接】freac The fre:ac audio converter project 项目地址: https://gitcode.com/gh_mirrors/fr/freac 如果你正在寻找一款功能全面、完全免费且支持多平台的音频转换工具…...

LightOnOCR-2-1B与VSCode开发环境配置指南
LightOnOCR-2-1B与VSCode开发环境配置指南 1. 开发环境准备 在开始使用LightOnOCR-2-1B进行文档识别开发之前,我们需要先配置一个高效的VSCode开发环境。这个模型是一个10亿参数的端到端视觉语言模型,专门用于将PDF、扫描件和图像转换为结构化的文本内…...

vLLM-v0.17.1模型服务API设计精髓:从入门到精通
vLLM-v0.17.1模型服务API设计精髓:从入门到精通 1. 快速认识vLLM API vLLM作为当前最流行的大模型推理框架之一,其API设计充分考虑了工程实践中的各种需求。最新发布的v0.17.1版本在保持接口简洁的同时,新增了多项实用功能。我们先来看一个…...

为什么要学习AI大模型?掌握AI大模型:抢占未来职场制高点,成为高薪抢手人才!
本文阐述了企业对AI大模型需求的增长及其带来的商业价值,如降本增效、产品创新等。同时,文章强调了学习AI大模型对个人职业发展的益处,包括薪资提升、效率提高、拓宽职业道路等。文章还展望了AI大模型广阔的职业前景,并提供学习资…...

GBase 8a之聚合函数: 计算峰度功能的实现
主要解决问题(1) 目前系统缺少求峰度的功能。特编写可以实现该功能的so以应对。部署方式(1) 将文件libkurtosis.so 放在集群对应的$GBASE_HOME/lib/gbase/plugin $GCLUSTER_HOME/lib/gbase/plugin 目录下 (2&#x…...

在Replit上构建你的首个全栈应用:从零到部署的免费实践
1. 为什么选择Replit开发全栈应用? 第一次听说Replit时,我正为学生的课程设计发愁——他们需要完成一个包含前后端的全栈项目,但很多人的笔记本电脑跑不动开发环境。直到发现这个神奇的云端IDE,所有问题迎刃而解。Replit最吸引我的…...

egergergeeert FLUX模型优势:长文本理解能力在多对象提示词中验证
FLUX模型优势:长文本理解能力在多对象提示词中验证 1. 引言 在图像生成领域,提示词的质量直接影响最终输出效果。传统文生图模型在处理复杂、多对象的提示词时往往表现不佳,容易出现对象遗漏、属性混淆等问题。本文将重点介绍egergergeeert…...

RT-Thread系统下LwIP Socket性能调优:从1M到5M,我的TCP服务器带宽提升实战记录
RT-Thread系统下LwIP Socket性能调优实战:从1M到5M的TCP服务器优化之路 在嵌入式网络应用开发中,TCP服务器的性能往往成为系统瓶颈。当我在RT-Thread实时操作系统上开发一个数据采集系统时,发现默认配置下的LwIP Socket实现仅能达到1Mbps左右…...