在python model train里如何驯服野生log?
关键词:python 、epoch、loss、log
🤖: 记录模型的训练过程的步骤如下:
- 导入logging模块。
- 配置日志记录器,设置日志文件名、日志级别、日志格式等。
- 在每个epoch结束时,使用logging模块记录性能指标、损失值、准确率等信息。
- 在训练过程中,记录其他重要信息,比如学习率的变化、每个batch的损失值等。
- 日志记录的信息可以帮助你更好地理解模型的训练过程,以及在后续分析和调试中提供有用的信息。
一、定义logger类
1. util里定义Logger
class Logger(object):"""Write console output to external text file.Code imported from https://github.com/Cysu/open-reid/blob/master/reid/utils/logging.py."""def __init__(self, fpath=None):self.console = sys.stdoutself.file = Noneif fpath is not None:self.file = open(fpath, 'a')def __del__(self):self.close()def __enter__(self):passdef __exit__(self, *args):self.close()def write(self, msg):self.console.write(msg+'\n')if self.file is not None:self.file.write(msg+'\n')def flush(self):self.console.flush()if self.file is not None:self.file.flush()os.fsync(self.file.fileno())def close(self):self.console.close()if self.file is not None:self.file.close()
2. train里调用
log_path = pjoin('./result', 'train', args.city, f'{args.tinterval}')
logger = util.Logger(pjoin(log_path, 'test.log'))
logger.write(f'\nTesting configs: {args}')
# use tensorboard to draw the curves.
train_writer = SummaryWriter(pjoin('./result', 'train', args.city, f'{args.tinterval}'))
val_writer = SummaryWriter(pjoin('./result', 'val', args.city, f'{args.tinterval}'))
logger.write(“文本提示”)
logger.write("start training...")
- best id
- loss
{变量: 格式d/f}- 占位符:03d是一个格式化字符串,其中的0表示用0来填充空位,3表示总共占据3位,d表示这是一个十进制整数。因此,当i的值小于100时,会用0来填充,确保输出的字符串总共占据3位。
if i%args.print_every == 0:logger.write(f'Epoch: {i:03d}, MAE: {mtrain_mae:.2f}, RMSE: {mtrain_rmse:.2f}, MAPE: {mtrain_mape:.2f}, Valid MAE: {mvalid_mae:.2f}, RMSE: {mvalid_rmse:.2f}, MAPE: {mvalid_mape:.2f}')torch.save(engine.model.state_dict(), save_path+"_epoch_"+str(i)+"_"+str(round(mvalid_mae,2))+".pth")logger.write("Average Training Time: {:.4f} secs/epoch".format(np.mean(train_time)))bestid = np.argmin(his_loss)engine.model.load_state_dict(torch.load(save_path+"_epoch_"+str(bestid+1)+"_"+str(round(his_loss[bestid],2))+".pth"))logger.write("Training finished")logger.write(f"The valid loss on best model is {str(round(his_loss[bestid],4))}")
二、自定义print log
def print_log(*values, log=None, end="\n"):print(*values, end=end)if log:if isinstance(log, str):log = open(log, "a")print(*values, file=log, end=end)log.flush()
1. 初始化日志文件
- 记录时间
- 保存路径
- 文件名称
# ------------------------------- make log file ------------------------------ #now = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")log_path = f"../logs/"if not os.path.exists(log_path):os.makedirs(log_path)log = os.path.join(log_path, f"{model_name}-{dataset}-{now}.log")log = open(log, "a")log.seek(0)log.truncate()
2. 模型记录epoch
# --------------------------- train and test model --------------------------- #print_log(f"Loss: {criterion._get_name()}", log=log)print_log(log=log)model = train(model,trainset_loader,valset_loader,optimizer,scheduler,criterion,clip_grad=cfg.get("clip_grad"),max_epochs=cfg.get("max_epochs", 200),early_stop=cfg.get("early_stop", 10),verbose=1,log=log,save=save,)print_log(f"Saved Model: {save}", log=log)test_model(model, testset_loader, log=log)log.close()
3. 在每次调用的模型函数(train\test)里面保存需要的内容
train(arg, log = log)
将定义的log传入模型训练函数
out_str = f"Early stopping at epoch: {epoch+1}\n"out_str += f"Best at epoch {best_epoch+1}:\n"out_str += "Train Loss = %.5f\n" % train_loss_list[best_epoch]out_str += "Train RMSE = %.5f, MAE = %.5f, MAPE = %.5f\n" % (train_rmse,train_mae,train_mape,)out_str += "Val Loss = %.5f\n" % val_loss_list[best_epoch]out_str += "Val RMSE = %.5f, MAE = %.5f, MAPE = %.5f" % (val_rmse,val_mae,val_mape,)print_log(out_str, log=log)
print_log(需要保存的值, log = 定义的log)
4. log内容编辑
- f-strings 是指以f或F 开头的字符串,其中以 {}包含的表达式会进行值替换
- 在字符串前加r可防止字符串转义
- “文本提示字符串 : {
属性值} 换行\n” %d、%f
for i in range(out_steps):rmse, mae, mape = RMSE_MAE_MAPE(y_true[:, i, :], y_pred[:, i, :])out_str += "Step %d RMSE = %.5f, MAE = %.5f, MAPE = %.5f\n" % (i + 1,rmse,mae,mape,)
5. 效果展示
三、 自定义logger
1. 函数定义
def get_logger(config, name=None):log_dir = './libcity/log'if not os.path.exists(log_dir):os.makedirs(log_dir)log_filename = '{}-{}-{}-{}.log'.format(config['exp_id'],config['model'], config['dataset'], get_local_time())logfilepath = os.path.join(log_dir, log_filename)logger = logging.getLogger(name)log_level = config.get('log_level', 'INFO')if log_level.lower() == 'info':level = logging.INFOelif log_level.lower() == 'debug':level = logging.DEBUGelif log_level.lower() == 'error':level = logging.ERRORelif log_level.lower() == 'warning':level = logging.WARNINGelif log_level.lower() == 'critical':level = logging.CRITICALelse:level = logging.INFOlogger.setLevel(level)formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')file_handler = logging.FileHandler(logfilepath)file_handler.setFormatter(formatter)console_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')console_handler = logging.StreamHandler(sys.stdout)console_handler.setFormatter(console_formatter)logger.addHandler(file_handler)logger.addHandler(console_handler)logger.info('Log directory: %s', log_dir)return logger
2. 函数调用
logger = get_logger(config)logger.info('Begin pipeline, task={}, model_name={}, dataset_name={}, exp_id={}'.format(str(task), str(model_name), str(dataset_name), str(exp_id)))logger.info(config.config)best_trial = result.get_best_trial("loss", "min", "last")logger.info("Best trial config: {}".format(best_trial.config))logger.info("Best trial final validation loss: {}".format(best_trial.last_result["loss"]))
四、自定义log_string()
1. utils.py
# log string
def log_string(log, string):log.write(string + '\n')log.flush()print(string)
2. main.py
import上面的utils
- 定义路径
- 打开log
- 写入log
parser.add_argument('--log_file', default='./data/log',help='log file')
args = parser.parse_args()
log = open(log_file, 'w')
# load data
log_string(log, 'loading data...')
- 记入时间:
%.1fmin一位小数字符串,min分钟单位 - 调用变量值:%
- 或者字符串里:
{:}.format(变量)
if __name__ == '__main__':start = time.time()loss_train, loss_val = train(model, args, log, loss_criterion, optimizer, scheduler)plot_train_val_loss(loss_train, loss_val, 'figure/train_val_loss.png')trainPred, valPred, testPred = test(args, log)end = time.time()log_string(log, 'total time: %.1fmin' % ((end - start) / 60))
相关文章:

在python model train里如何驯服野生log?
关键词:python 、epoch、loss、log 🤖: 记录模型的训练过程的步骤如下: 导入logging模块。配置日志记录器,设置日志文件名、日志级别、日志格式等。在每个epoch结束时,使用logging模块记录性能指标、损失值、准确率等信…...

产品推荐 - Xilinx FPGA下载器 XQ-HS/STM2
1 FPGA下载器简介 1.性能优良 FPGA下载器XQ-HS/STM2采用Xilinx下载模块设计而成(JTAG-SMT2NC模块,该模块与Xilinx官方开发板KC705,KCU105,ZC702,ZC706,Zedboard等板载下载器一样,下载速度快…...

STM32 SDRAM知识点
1.SDRAM和SRAM的区别 SRAM不需要刷新电路即能保存它内部存储的数据。而SDRAM(Dynamic Random Access Memory)每隔一段时间,要刷新充电一次,否则内部的数据即会消失,因此SRAM具有较高的性能,但是SRAM也有它…...

手写分布式配置中心(六)整合springboot(自动刷新)
对于springboot配置自动刷新,原理也很简单,就是在启动过程中用一个BeanPostProcessor去收集需要自动刷新的字段,然后在springboot启动后开启轮询任务即可。 不过需要对之前的代码再次做修改,因为springboot的配置注入value("…...
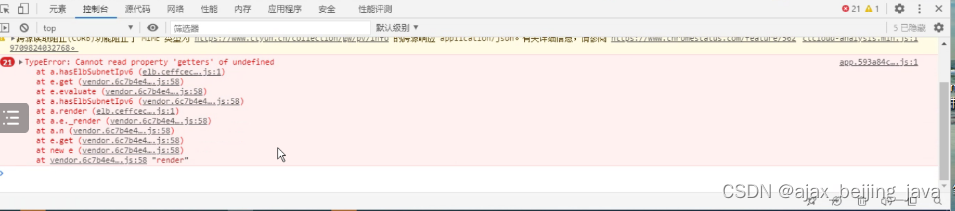
记录一次排查负载均衡不能创建的排查过程
故障现象,某云上,运维同事在创建负载均衡的时候,发现可以创建资源,但是创建完之后,不显示对应的负载均衡。 创建负载均衡时候,按f12发现console有如下报错 后来请后端网络同事排查日志发现,是后…...

数据推送解决方案调研
需求 文档编辑类型的需求,左侧是菜单栏,右侧是内容块,现在的需求时,如果多人同时编辑这个方案,当添加章节/调整章节顺序/删除章节时,其他用户能够及时感知到。 解决方案调研 前端轮询 最简单的方案&…...
)
二、NLP中的序列标注(分词、主体识别)
一般来说,一个序列指的是一个句子,而一个元素指的是句子中的一个词。在序列标注中,我们想对一个序列的每一个元素标注一个分类标签。比如信息提取问题可以认为是一个序列标注问题,如提取出会议时间、地点等。 常见的应用场景&…...
seq2seq翻译实战-Pytorch复现
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营 🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/…...
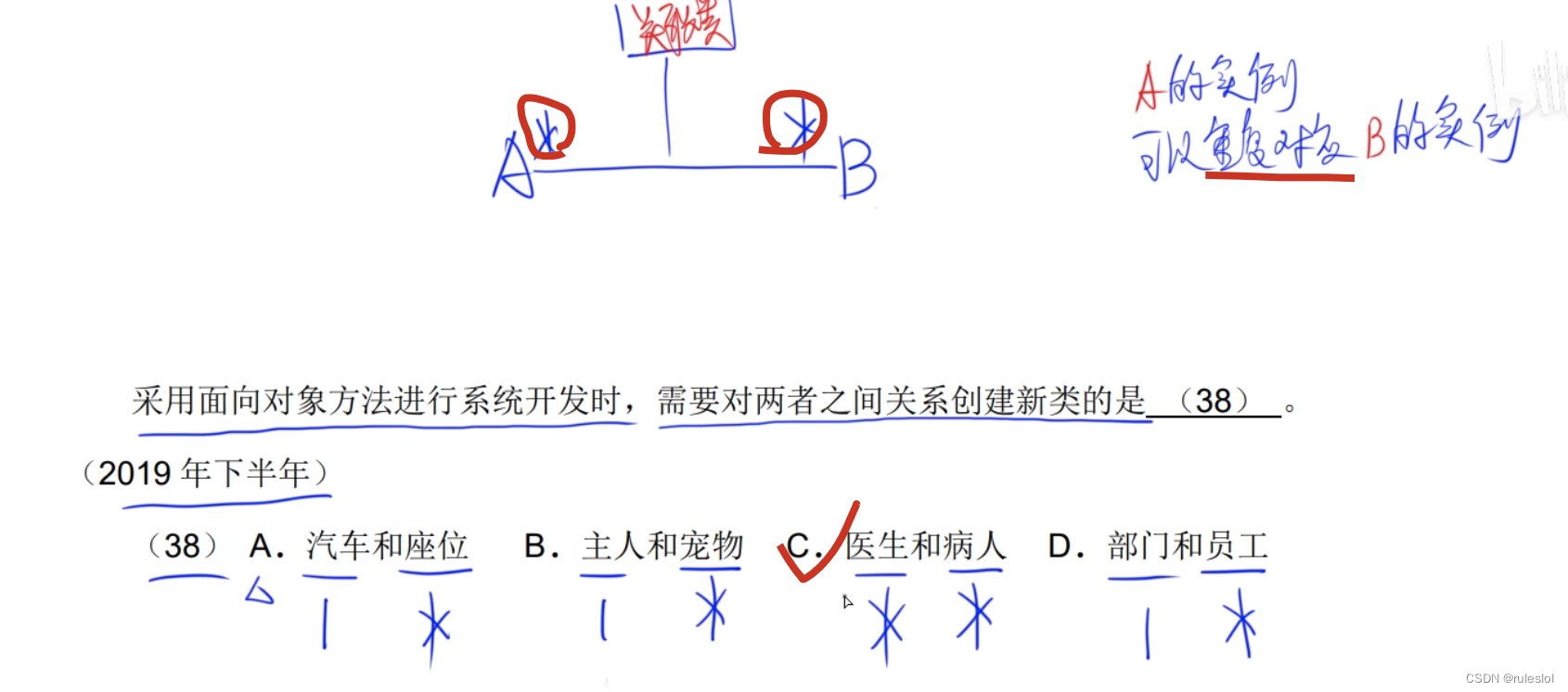
软考69-上午题-【面向对象技术2-UML】-关系
一、关系 UML中有4种关系: 依赖;关联;泛化;实现。 1-1、依赖 行为(参数),参数就是被依赖的事物,即:独立事物。 当独立事物发生变化时,依赖事务行为的语义也…...

智慧文旅|AI数字人导览:让旅游体验不再局限于传统
AI数字人导览作为一种创新的展示方式,已经逐渐成为了VR全景领域的一大亮点,不仅可以很好的嵌入在VR全景中,更是能够随时随地为观众提供一种声情并茂的讲解介绍,结合VR场景的沉浸式体验,让观众仿佛置身于真实场景之中&a…...

spring boot 集成 mysql ,mybatisplus多数据源
1、需要的依赖,版本自行控制 <dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId> </dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java<…...
CLion中常用快捷键(仍适用其他编译软件)
基本编辑操作: 复制:Ctrl C粘贴:Ctrl V剪切:Ctrl X撤销:Ctrl Z重做:Ctrl Shift Z (不小心撤销了 需要返回之前的操作 相当于下一步)全选:Ctrl A 导航࿱…...
考研复习c语言初阶(1)
本人准备考研,现在开始每天更新408的内容,目标这个月结束C语言和数据结构,每天更新~ 一.再次认识c语言 C语言是一门通用计算机编程语言,广泛应用于底层开发。C语言的设计目标是提供一种能以简易 的方式编译、处理低级存储器、产生…...
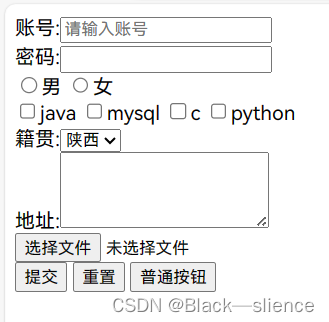
HTML—常用标签
常用标签: 标题标签:<h1></h1>......<h6></h6>段落标签:<p></p>换行标签:<br/>列表:无序列表<ul><li></li></ul> 有序列表<ol>&…...

Midjourney绘图欣赏系列(七)
Midjourney介绍 Midjourney 是生成式人工智能的一个很好的例子,它根据文本提示创建图像。它与 Dall-E 和 Stable Diffusion 一起成为最流行的 AI 艺术创作工具之一。与竞争对手不同,Midjourney 是自筹资金且闭源的,因此确切了解其幕后内容尚不…...

深度学习应该如何入门?
深度学习是一门令人着迷的领域,但初学者可能会感到有些困惑。让我们从头开始,用通俗易懂的语言来探讨深度学习的基础知识。 1. 基础知识 深度学习需要一些数学和编程基础。首先,我们要掌握一些数学知识,如线性代数、微积分和概率…...

FreeRtos Queue(五)
本篇主要分析在中断中向队列里发消息xQueueGenericSendFromISR和在中断里从队列中读取消息xQueueReceiveFromISR。 前言: xQueueGenericSendFromISR 和 xQueueReceiveFromISR都是在中断里调用的而不是任务里调用的,所以队列满了或者是队列为空的时候自然就没有把当…...
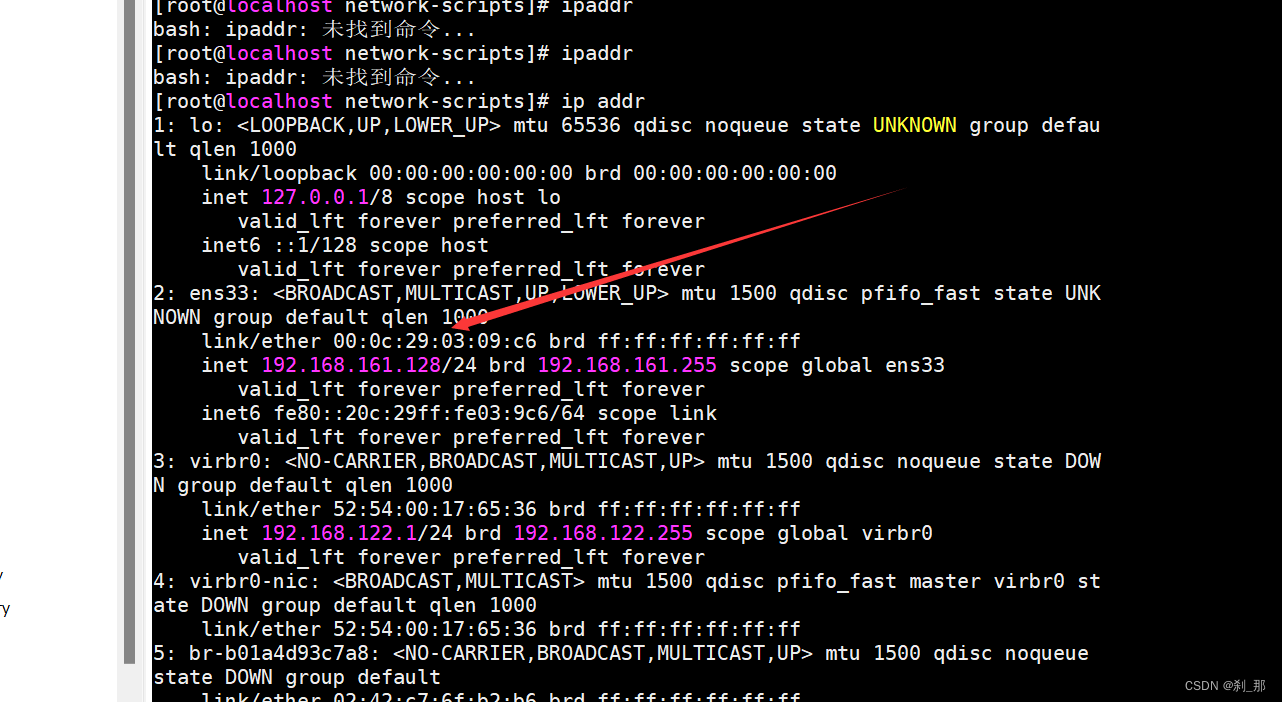
解决虚拟机静态网址设置后还是变动的的问题
源头就是我的虚拟机静态网址设置好了以后但是网址还是会变动 这是我虚拟机的配置 vi /etc/sysconfig/network-scripts/ifcfg-ens33 这是出现的问题 进入这里 cd /etc/sysconfig/network-scripts/ 然后我去把多余的ens33的文件都删了 然后还不行 后来按照这个图片进行了下 然后…...

【教程】Github环境配置新手指南(超详细)
写在前面: 如果文章对你有帮助,记得点赞关注加收藏一波,利于以后需要的时候复习,多谢支持! 文章目录 一、Github初始设置(一)登入Github(二)新建仓库 二、本地Git配置&am…...

突然发现一个很炸裂的平台!
平时小孟会开发很多的项目,很多项目不仅开发的功能比较齐全,而且效果比较炸裂。 今天给大家介绍一个我常用的平台,因含低代码平台,开发相当的快。 1,什么是低代码 低代码包括两种,一种低代码,…...

从单片机到大型PLC:如何用EPLAN高效设计不同规模的控制系统电气图纸?
从单片机到大型PLC:EPLAN电气设计实战指南 在工业自动化领域,电气设计工程师经常面临一个核心挑战:如何用同一套工具高效应对从简单单片机到复杂PLC系统的多样化项目需求?EPLAN作为专业电气设计软件,其真正的价值在于能…...

终极PrivateGPT批量部署指南:多实例管理与资源分配的完整方案
终极PrivateGPT批量部署指南:多实例管理与资源分配的完整方案 【免费下载链接】privateGPT Interact with your documents using the power of GPT, 100% privately, no data leaks 项目地址: https://gitcode.com/GitHub_Trending/pr/privateGPT PrivateGPT…...

深度解析开源光学材料数据库:3000+材料折射率查询完整指南
深度解析开源光学材料数据库:3000材料折射率查询完整指南 【免费下载链接】refractiveindex.info-database Database of optical constants 项目地址: https://gitcode.com/gh_mirrors/re/refractiveindex.info-database 在光学工程和材料科学研究中…...

iOS激活锁破解难题终结者:AppleRa1n三阶段实战指南
iOS激活锁破解难题终结者:AppleRa1n三阶段实战指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否曾经面对着一台被激活锁困住的iPhone,感到束手无策?无论是…...
)
第38篇:AI在金融领域的应用实战——智能投顾、风控与量化交易初探(项目实战)
文章目录项目背景技术选型架构设计核心实现踩坑记录效果对比项目背景 干了这么多年AI,我见过最“卷”也最“壕”的落地场景,金融绝对排前三。几年前,我参与过一个智能投顾的早期项目,当时大家还在争论AI模型能不能跑赢大盘。如今…...

解锁NVIDIA显卡隐藏性能:探索Profile Inspector的200+秘密参数
解锁NVIDIA显卡隐藏性能:探索Profile Inspector的200秘密参数 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾好奇,为什么同样的显卡在不同游戏中表现差异巨大ÿ…...

StructBERT语义分析平台:快速搭建中文复述识别系统
StructBERT语义分析平台:快速搭建中文复述识别系统 1. 平台概述与核心价值 中文语义相似度计算是自然语言处理中的基础任务,广泛应用于智能客服、文本查重、问答系统等场景。StructBERT作为阿里巴巴开源的预训练语言模型,在中文语义理解任务…...

终极Windows驱动清理指南:简单三步释放20GB磁盘空间
终极Windows驱动清理指南:简单三步释放20GB磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现C盘空间越来越少,系统运行越来越慢?这…...

【逆向实战】从算法到驱动:剖析学生机房管理助手7.8的进程隐藏与设备管控机制
1. 学生机房管理助手7.8逆向分析实战 记得第一次在学生机房看到那个熟悉的蓝色图标时,我就知道又要和这个"老朋友"斗智斗勇了。学生机房管理助手7.8版本相比之前的7.5版本,最明显的变化就是进程名随机化算法的调整。用dnSpy反编译脱壳后的mai…...

nginx的子路径的重写替换全攻略
在nginx中配置proxy_pass代理转发时,如果在proxy_pass后面的url加/,表示绝对根路径;如果没有/,表示相对路径,把匹配的路径部分也给代理走。假设下面四种情况分别用 http://192.168.1.1/proxy/test.html 进行访问。第一…...