java算法
常见的七种查找算法:
数据结构是数据存储的方式,算法是数据计算的方式。所以在开发中,算法和数据结构息息相关。
1. 基本查找
也叫做顺序查找
说明:顺序查找适合于存储结构为数组或者链表。
基本思想:顺序查找也称为线形查找,属于无序查找算法。从数据结构线的一端开始,顺序扫描,依次将遍历到的结点与要查找的值相比较,若相等则表示查找成功;若遍历结束仍没有找到相同的,表示查找失败。
示例代码:
public class A01_BasicSearchDemo1 {public static void main(String[] args) {//基本查找/顺序查找//核心://从0索引开始挨个往后查找
//需求:定义一个方法利用基本查找,查询某个元素是否存在//数据如下:{131, 127, 147, 81, 103, 23, 7, 79}
int[] arr = {131, 127, 147, 81, 103, 23, 7, 79};int number = 82;System.out.println(basicSearch(arr, number));
}
//参数://一:数组//二:要查找的元素
//返回值://元素是否存在public static boolean basicSearch(int[] arr, int number){//利用基本查找来查找number在数组中是否存在for (int i = 0; i < arr.length; i++) {if(arr[i] == number){return true;}}return false;}
}2. 二分查找
也叫做折半查找
说明:元素必须是有序的,从小到大,或者从大到小都是可以的。
如果是无序的,也可以先进行排序。但是排序之后,会改变原有数据的顺序,查找出来元素位置跟原来的元素可能是不一样的,所以排序之后再查找只能判断当前数据是否在容器当中,返回的索引无实际的意义。
基本思想:也称为是折半查找,属于有序查找算法。用给定值先与中间结点比较。比较完之后有三种情况:
-
相等
说明找到了
-
要查找的数据比中间节点小
说明要查找的数字在中间节点左边
-
要查找的数据比中间节点大
说明要查找的数字在中间节点右边
代码示例:
package com.itheima.search;
public class A02_BinarySearchDemo1 {public static void main(String[] args) {//二分查找/折半查找//核心://每次排除一半的查找范围
//需求:定义一个方法利用二分查找,查询某个元素在数组中的索引//数据如下:{7, 23, 79, 81, 103, 127, 131, 147}
int[] arr = {7, 23, 79, 81, 103, 127, 131, 147};System.out.println(binarySearch(arr, 150));}
public static int binarySearch(int[] arr, int number){//1.定义两个变量记录要查找的范围int min = 0;int max = arr.length - 1;
//2.利用循环不断的去找要查找的数据while(true){if(min > max){return -1;}//3.找到min和max的中间位置int mid = (min + max) / 2;//4.拿着mid指向的元素跟要查找的元素进行比较if(arr[mid] > number){//4.1 number在mid的左边//min不变,max = mid - 1;max = mid - 1;}else if(arr[mid] < number){//4.2 number在mid的右边//max不变,min = mid + 1;min = mid + 1;}else{//4.3 number跟mid指向的元素一样//找到了return mid;}
}}
}3. 插值查找
在介绍插值查找之前,先考虑一个问题:
为什么二分查找算法一定要是折半,而不是折四分之一或者折更多呢?
其实就是因为方便,简单,但是如果我能在二分查找的基础上,让中间的mid点,尽可能靠近想要查找的元素,那不就能提高查找的效率了吗?
二分查找中查找点计算如下:
mid=(low+high)/2, 即mid=low+1/2*(high-low);
我们可以将查找的点改进为如下:
mid=low+(key-a[low])/(a[high]-a[low])*(high-low),
这样,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
细节:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
代码跟二分查找类似,只要修改一下mid的计算方式即可。
4. 斐波那契查找
在介绍斐波那契查找算法之前,我们先介绍一下很它紧密相连并且大家都熟知的一个概念——黄金分割。
黄金比例又称黄金分割,是指事物各部分间一定的数学比例关系,即将整体一分为二,较大部分与较小部分之比等于整体与较大部分之比,其比值约为1:0.618或1.618:1。
0.618被公认为最具有审美意义的比例数字,这个数值的作用不仅仅体现在诸如绘画、雕塑、音乐、建筑等艺术领域,而且在管理、工程设计等方面也有着不可忽视的作用。因此被称为黄金分割。
在数学中有一个非常有名的数学规律:斐波那契数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….
(从第三个数开始,后边每一个数都是前两个数的和)。
然后我们会发现,随着斐波那契数列的递增,前后两个数的比值会越来越接近0.618,利用这个特性,我们就可以将黄金比例运用到查找技术中。

基本思想:也是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。
斐波那契查找也是在二分查找的基础上进行了优化,优化中间点mid的计算方式即可
代码示例:
5. 分块查找
当数据表中的数据元素很多时,可以采用分块查找。
汲取了顺序查找和折半查找各自的优点,既有动态结构,又适于快速查找
分块查找适用于数据较多,但是数据不会发生变化的情况,如果需要一边添加一边查找,建议使用哈希查找
分块查找的过程:
-
需要把数据分成N多小块,块与块之间不能有数据重复的交集。
-
给每一块创建对象单独存储到数组当中
-
查找数据的时候,先在数组查,当前数据属于哪一块
-
再到这一块中顺序查找
代码示例:
package com.itheima.search;
public class A03_BlockSearchDemo {public static void main(String[] args) {/*分块查找核心思想:块内无序,块间有序实现步骤:1.创建数组blockArr存放每一个块对象的信息2.先查找blockArr确定要查找的数据属于哪一块3.再单独遍历这一块数据即可*/int[] arr = {16, 5, 9, 12,21, 18,32, 23, 37, 26, 45, 34,50, 48, 61, 52, 73, 66};
//创建三个块的对象Block b1 = new Block(21,0,5);Block b2 = new Block(45,6,11);Block b3 = new Block(73,12,17);
//定义数组用来管理三个块的对象(索引表)Block[] blockArr = {b1,b2,b3};
//定义一个变量用来记录要查找的元素int number = 37;
//调用方法,传递索引表,数组,要查找的元素int index = getIndex(blockArr,arr,number);
//打印一下System.out.println(index);
}
//利用分块查找的原理,查询number的索引private static int getIndex(Block[] blockArr, int[] arr, int number) {//1.确定number是在那一块当中int indexBlock = findIndexBlock(blockArr, number);
if(indexBlock == -1){//表示number不在数组当中return -1;}
//2.获取这一块的起始索引和结束索引 --- 30// Block b1 = new Block(21,0,5); ---- 0// Block b2 = new Block(45,6,11); ---- 1// Block b3 = new Block(73,12,17); ---- 2int startIndex = blockArr[indexBlock].getStartIndex();int endIndex = blockArr[indexBlock].getEndIndex();
//3.遍历for (int i = startIndex; i <= endIndex; i++) {if(arr[i] == number){return i;}}return -1;}
//定义一个方法,用来确定number在哪一块当中public static int findIndexBlock(Block[] blockArr,int number){ //100
//从0索引开始遍历blockArr,如果number小于max,那么就表示number是在这一块当中的for (int i = 0; i < blockArr.length; i++) {if(number <= blockArr[i].getMax()){return i;}}return -1;}
}
class Block{private int max;//最大值private int startIndex;//起始索引private int endIndex;//结束索引
public Block() {}
public Block(int max, int startIndex, int endIndex) {this.max = max;this.startIndex = startIndex;this.endIndex = endIndex;}
/*** 获取* @return max*/public int getMax() {return max;}
/*** 设置* @param max*/public void setMax(int max) {this.max = max;}
/*** 获取* @return startIndex*/public int getStartIndex() {return startIndex;}
/*** 设置* @param startIndex*/public void setStartIndex(int startIndex) {this.startIndex = startIndex;}
/*** 获取* @return endIndex*/public int getEndIndex() {return endIndex;}
/*** 设置* @param endIndex*/public void setEndIndex(int endIndex) {this.endIndex = endIndex;}
public String toString() {return "Block{max = " + max + ", startIndex = " + startIndex + ", endIndex = " + endIndex + "}";}
}6. 哈希查找
哈希查找是分块查找的进阶版,适用于数据一边添加一边查找的情况。
一般是数组 + 链表的结合体或者是数组+链表 + 红黑树的结合体
在课程中,为了让大家方便理解,所以规定:
-
数组的0索引处存储1~100
-
数组的1索引处存储101~200
-
数组的2索引处存储201~300
-
以此类推
但是实际上,我们一般不会采取这种方式,因为这种方式容易导致一块区域添加的元素过多,导致效率偏低。
更多的是先计算出当前数据的哈希值,用哈希值跟数组的长度进行计算,计算出应存入的位置,再挂在数组的后面形成链表,如果挂的元素太多而且数组长度过长,我们也会把链表转化为红黑树,进一步提高效率。
具体的过程,大家可以参见B站阿玮讲解课程:从入门到起飞。在集合章节详细讲解了哈希表的数据结构。全程采取动画形式讲解,让大家一目了然。
在此不多做阐述。
7. 树表查找
本知识点涉及到数据结构:树。
建议先看一下后面阿玮讲解的数据结构,再回头理解。
基本思想:二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,然后在就行和每个节点的父节点比较大小,查找最适合的范围。 这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树。
二叉查找树(BinarySearch Tree,也叫二叉搜索树,或称二叉排序树Binary Sort Tree),具有下列性质的二叉树:
1)若任意节点左子树上所有的数据,均小于本身;
2)若任意节点右子树上所有的数据,均大于本身;
二叉查找树性质:对二叉查找树进行中序遍历,即可得到有序的数列。
不同形态的二叉查找树如下图所示:
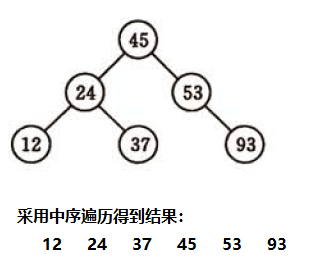
基于二叉查找树进行优化,进而可以得到其他的树表查找算法,如平衡树、红黑树等高效算法。
具体细节大家可以参见B站阿玮讲解课程:从入门到起飞。在集合章节详细讲解了树数据结构。全程采取动画形式讲解,让大家一目了然。
在此不多做阐述。
不管是二叉查找树,还是平衡二叉树,还是红黑树,查找的性能都比较高
十大排序算法:
1. 冒泡排序
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。
它重复的遍历过要排序的数列,一次比较相邻的两个元素,如果他们的顺序错误就把他们交换过来。
这个算法的名字由来是因为越大的元素会经由交换慢慢"浮"到最后面。
当然,大家可以按照从大到小的方式进行排列。
1.1 算法步骤
-
相邻的元素两两比较,大的放右边,小的放左边
-
第一轮比较完毕之后,最大值就已经确定,第二轮可以少循环一次,后面以此类推
-
如果数组中有n个数据,总共我们只要执行n-1轮的代码就可以
1.2 动图演示
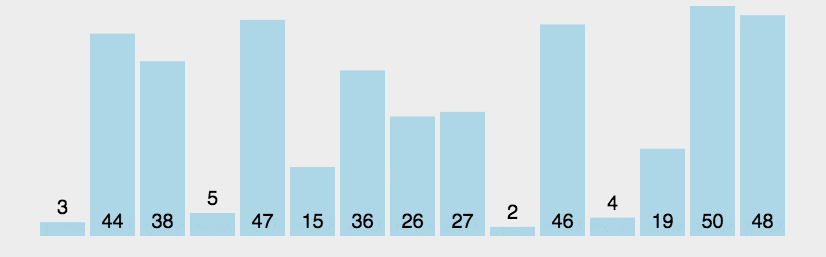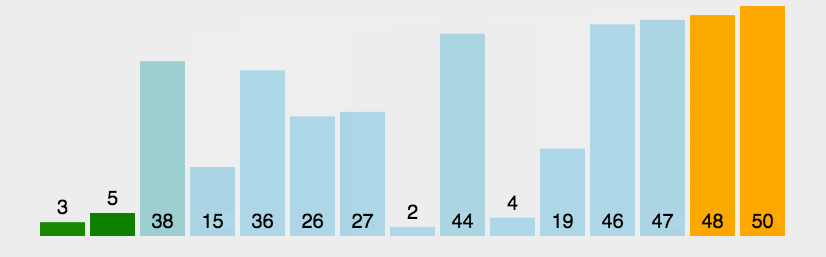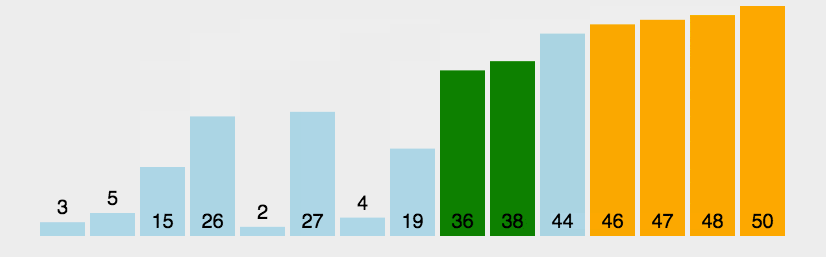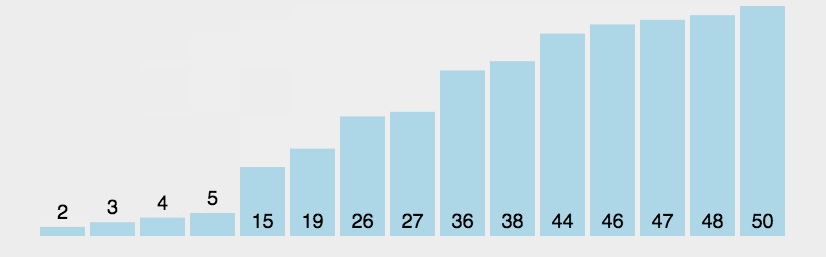
1.3 代码示例
public class A01_BubbleDemo {public static void main(String[] args) {/*冒泡排序:核心思想:1,相邻的元素两两比较,大的放右边,小的放左边。2,第一轮比较完毕之后,最大值就已经确定,第二轮可以少循环一次,后面以此类推。3,如果数组中有n个数据,总共我们只要执行n-1轮的代码就可以。*/
//1.定义数组int[] arr = {2, 4, 5, 3, 1};
//2.利用冒泡排序将数组中的数据变成 1 2 3 4 5
//外循环:表示我要执行多少轮。 如果有n个数据,那么执行n - 1 轮for (int i = 0; i < arr.length - 1; i++) {//内循环:每一轮中我如何比较数据并找到当前的最大值//-1:为了防止索引越界//-i:提高效率,每一轮执行的次数应该比上一轮少一次。for (int j = 0; j < arr.length - 1 - i; j++) {//i 依次表示数组中的每一个索引:0 1 2 3 4if(arr[j] > arr[j + 1]){int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}
printArr(arr);
}
private static void printArr(int[] arr) {//3.遍历数组for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}System.out.println();}
}2. 选择排序
2.1 算法步骤
-
从0索引开始,跟后面的元素一一比较
-
小的放前面,大的放后面
-
第一次循环结束后,最小的数据已经确定
-
第二次循环从1索引开始以此类推
-
第三轮循环从2索引开始以此类推
-
第四轮循环从3索引开始以此类推。
2.2 动图演示
public class A02_SelectionDemo {public static void main(String[] args) {
/*选择排序:1,从0索引开始,跟后面的元素一一比较。2,小的放前面,大的放后面。3,第一次循环结束后,最小的数据已经确定。4,第二次循环从1索引开始以此类推。
*/
//1.定义数组int[] arr = {2, 4, 5, 3, 1};
//2.利用选择排序让数组变成 1 2 3 4 5/* //第一轮://从0索引开始,跟后面的元素一一比较。for (int i = 0 + 1; i < arr.length; i++) {//拿着0索引跟后面的数据进行比较if(arr[0] > arr[i]){int temp = arr[0];arr[0] = arr[i];arr[i] = temp;}}*/
//最终代码://外循环:几轮//i:表示这一轮中,我拿着哪个索引上的数据跟后面的数据进行比较并交换for (int i = 0; i < arr.length -1; i++) {//内循环:每一轮我要干什么事情?//拿着i跟i后面的数据进行比较交换for (int j = i + 1; j < arr.length; j++) {if(arr[i] > arr[j]){int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}}
printArr(arr);
}private static void printArr(int[] arr) {//3.遍历数组for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}System.out.println();}
}
3. 插入排序
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过创建有序序列和无序序列,然后再遍历无序序列得到里面每一个数字,把每一个数字插入到有序序列中正确的位置。
插入排序在插入的时候,有优化算法,在遍历有序序列找正确位置时,可以采取二分查找
3.1 算法步骤
将0索引的元素到N索引的元素看做是有序的,把N+1索引的元素到最后一个当成是无序的。
遍历无序的数据,将遍历到的元素插入有序序列中适当的位置,如遇到相同数据,插在后面。
N的范围:0~最大索引
3.2 动图演示
package com.itheima.mysort;
public class A03_InsertDemo {public static void main(String[] args) {/*插入排序:将0索引的元素到N索引的元素看做是有序的,把N+1索引的元素到最后一个当成是无序的。遍历无序的数据,将遍历到的元素插入有序序列中适当的位置,如遇到相同数据,插在后面。N的范围:0~最大索引
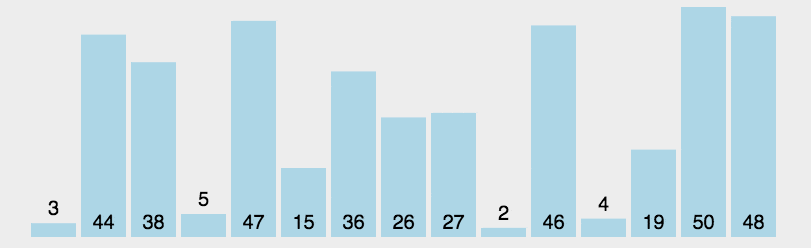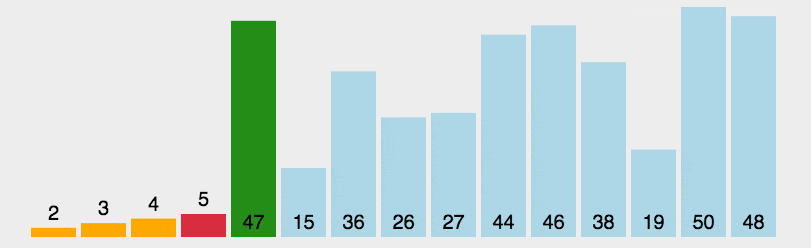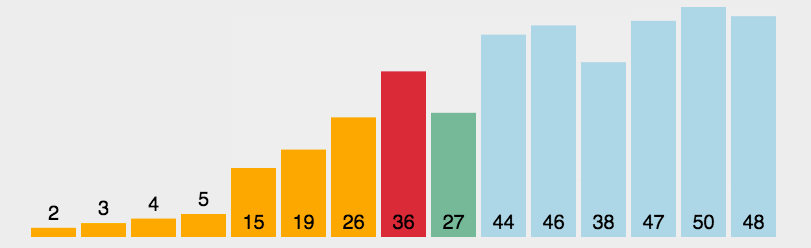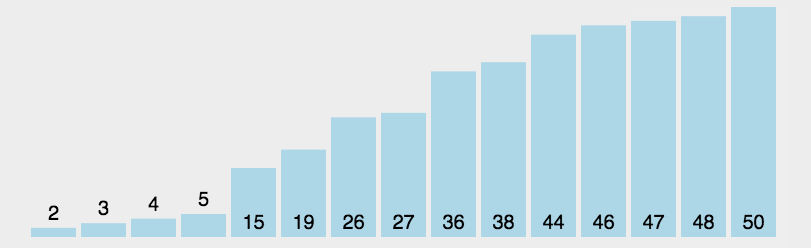
*/int[] arr = {3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48};
//1.找到无序的哪一组数组是从哪个索引开始的。 2int startIndex = -1;for (int i = 0; i < arr.length; i++) {if(arr[i] > arr[i + 1]){startIndex = i + 1;break;}}
//2.遍历从startIndex开始到最后一个元素,依次得到无序的哪一组数据中的每一个元素for (int i = startIndex; i < arr.length; i++) {//问题:如何把遍历到的数据,插入到前面有序的这一组当中
//记录当前要插入数据的索引int j = i;
while(j > 0 && arr[j] < arr[j - 1]){//交换位置int temp = arr[j];arr[j] = arr[j - 1];arr[j - 1] = temp;j--;}
}printArr(arr);}
private static void printArr(int[] arr) {//3.遍历数组for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}System.out.println();}
}
4. 快速排序
快速排序是由东尼·霍尔所发展的一种排序算法。
快速排序又是一种分而治之思想在排序算法上的典型应用。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!
它是处理大数据最快的排序算法之一了。
4.1 算法步骤
-
从数列中挑出一个元素,一般都是左边第一个数字,称为 "基准数";
-
创建两个指针,一个从前往后走,一个从后往前走。
-
先执行后面的指针,找出第一个比基准数小的数字
-
再执行前面的指针,找出第一个比基准数大的数字
-
交换两个指针指向的数字
-
直到两个指针相遇
-
将基准数跟指针指向位置的数字交换位置,称之为:基准数归位。
-
第一轮结束之后,基准数左边的数字都是比基准数小的,基准数右边的数字都是比基准数大的。
-
把基准数左边看做一个序列,把基准数右边看做一个序列,按照刚刚的规则递归排序
4.2 动图演示
package com.itheima.mysort;
import java.util.Arrays;
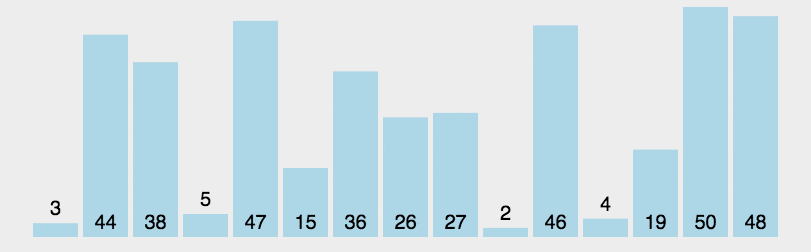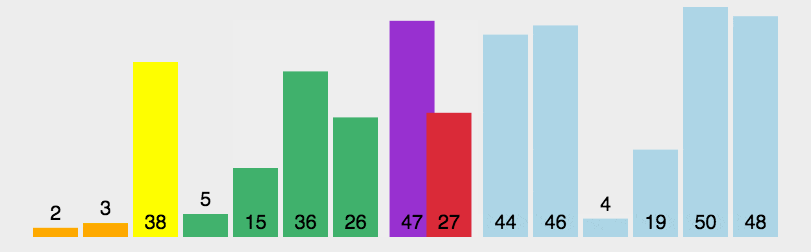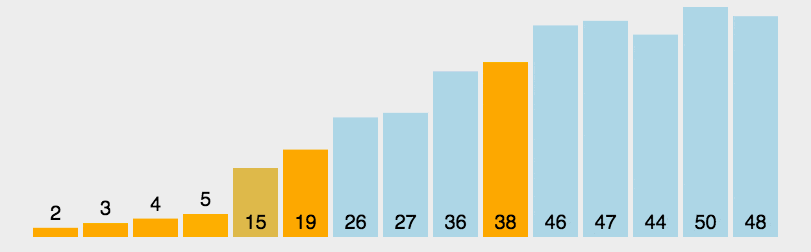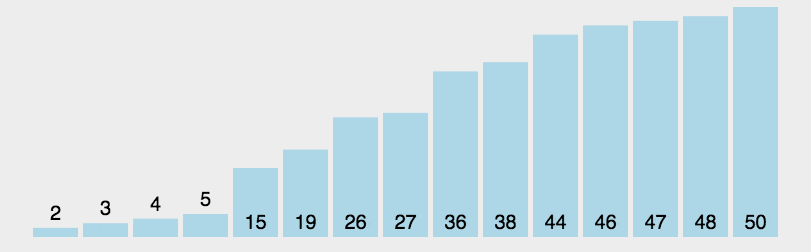
public class A05_QuickSortDemo {public static void main(String[] args) {System.out.println(Integer.MAX_VALUE);System.out.println(Integer.MIN_VALUE);/*快速排序:第一轮:以0索引的数字为基准数,确定基准数在数组中正确的位置。比基准数小的全部在左边,比基准数大的全部在右边。后面以此类推。*/
int[] arr = {1,1, 6, 2, 7, 9, 3, 4, 5, 1,10, 8};
//int[] arr = new int[1000000];
/* Random r = new Random();for (int i = 0; i < arr.length; i++) {arr[i] = r.nextInt();}*/
long start = System.currentTimeMillis();quickSort(arr, 0, arr.length - 1);long end = System.currentTimeMillis();
System.out.println(end - start);//149
System.out.println(Arrays.toString(arr));//课堂练习://我们可以利用相同的办法去测试一下,选择排序,冒泡排序以及插入排序运行的效率//得到一个结论:快速排序真的非常快。
/* for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}*/
}
/** 参数一:我们要排序的数组* 参数二:要排序数组的起始索引* 参数三:要排序数组的结束索引* */public static void quickSort(int[] arr, int i, int j) {//定义两个变量记录要查找的范围int start = i;int end = j;
if(start > end){//递归的出口return;}
//记录基准数int baseNumber = arr[i];//利用循环找到要交换的数字while(start != end){//利用end,从后往前开始找,找比基准数小的数字//int[] arr = {1, 6, 2, 7, 9, 3, 4, 5, 10, 8};while(true){if(end <= start || arr[end] < baseNumber){break;}end--;}System.out.println(end);//利用start,从前往后找,找比基准数大的数字while(true){if(end <= start || arr[start] > baseNumber){break;}start++;}
//把end和start指向的元素进行交换int temp = arr[start];arr[start] = arr[end];arr[end] = temp;}
//当start和end指向了同一个元素的时候,那么上面的循环就会结束//表示已经找到了基准数在数组中应存入的位置//基准数归位//就是拿着这个范围中的第一个数字,跟start指向的元素进行交换int temp = arr[i];arr[i] = arr[start];arr[start] = temp;
//确定6左边的范围,重复刚刚所做的事情quickSort(arr,i,start - 1);//确定6右边的范围,重复刚刚所做的事情quickSort(arr,start + 1,j);
}
}其他排序方式待更新~
相关文章:
java算法
常见的七种查找算法: 数据结构是数据存储的方式,算法是数据计算的方式。所以在开发中,算法和数据结构息息相关。 1. 基本查找 也叫做顺序查找 说明:顺序查找适合于存储结构为数组或者链表。 基本思想:顺序查找也称…...

铭文资产是比特币生态破局者 or 短暂热点?
比特币作为加密货币的鼻祖,一直以来都扮演着数字资产市场的引领者角色。最近几年,随着 BRC20 项目的兴起,我们看到了更多与比特币相互关联的创新。在比特币生态中,BRC20 项目不仅仅是数字资产的代表,更是一种对于区块链…...
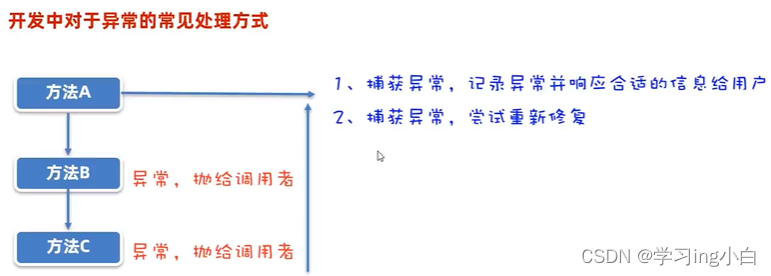
Java基础 - 8 - 算法、正则表达式、异常
一. 算法 什么是算法? 解决某个实际问题的过程和方法 学习算法的技巧? 先搞清楚算法的流程,再直接去推敲如何写算法 1.1 排序算法 1.1.1 冒泡排序 每次从数组中找出最大值放在数组的后面去 public class demo {public static void main(S…...

gRPC-第二代rpc服务
在如今云原生技术的大环境下,rpc服务作为最重要的互联网技术,蓬勃发展,诞生了许多知名基于rpc协议的框架,其中就有本文的主角gRPC技术。 一款高性能、开源的通用rpc框架 作者作为一名在JD实习的Cpper,经过一段时间的学…...

Node.js是什么?
概念:Node.js1运行在服务器端的js,用来编写服务器 特点:单线程、异步、非阻塞、统一API 是一个构建在V8引擎之上的js运行环境,它使得js可以运行在浏览器以外的地方,相对于大部分的服务器端语言来说,Node.J…...
java SSM厂房管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM厂房管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S…...
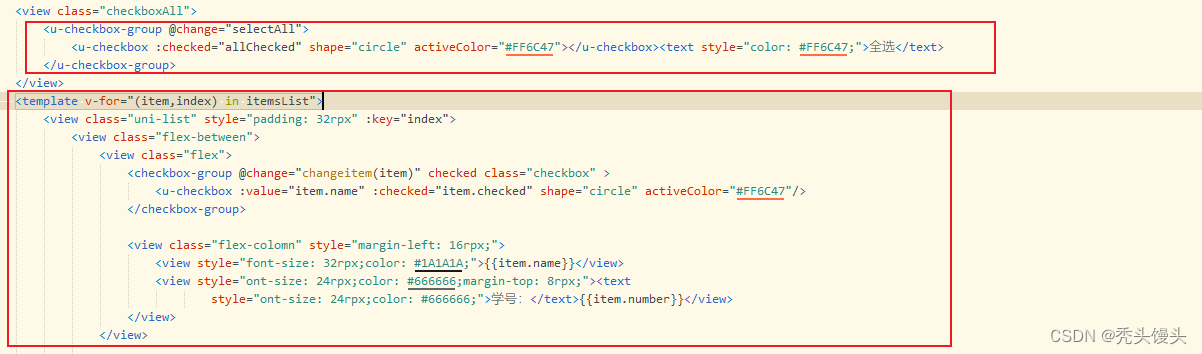
uniapp实现---类似购物车全选
目录 一、实现思路 二、实现步骤 ①view部分展示 ②JavaScript 内容 ③css中样式展示 三、效果展示 四、小结 注意事项 一、实现思路 点击商家复选框,可选中当前商家下的所有商品。点击全选,选中全部商家的商品 添加单个多选框,在将多选…...

Java:List列表去重有序和无序
目录 待去重列表HashSet去重(不保证顺序)TreeSet去重(不保证顺序)LinkedHashSet去重(保证顺序)遍历List去重(保证顺序)Java8中Stream流处理(保证顺序)参考文章 待去重列表 // 列表 …...
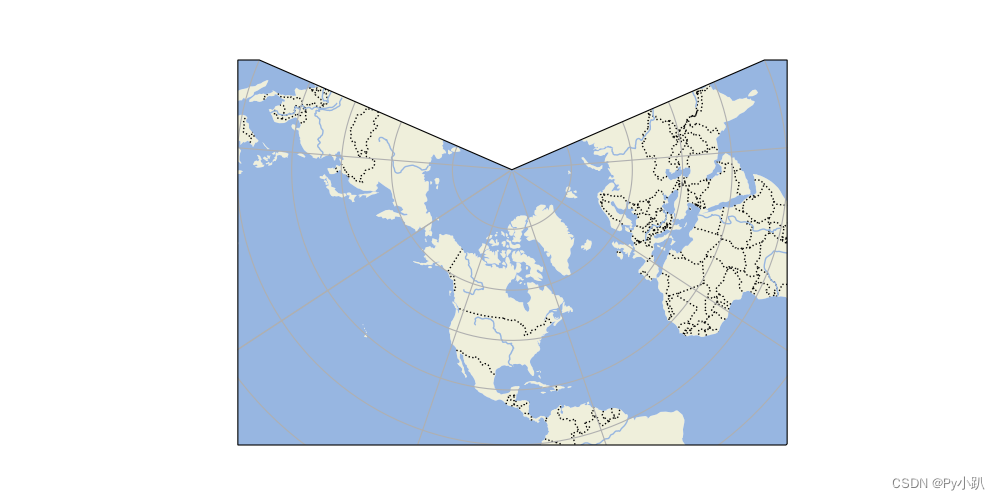
Python绘图-12地理数据可视化
Matplotlib 自 带 4 类别 地理投影: Aitoff, Hammer, Mollweide 及 Lambert 投影,可以 结 合以下四 张 不同 的 图 了解四 种 不同投影 区别 。 12.1Aitoff投影 12.1.1图像呈现 12.1.2绘图代码 import numpy as np # 导入numpy库,用于…...

NineData与OceanBase完成产品兼容认证,共筑企业级数据库新生态
近日,云原生智能数据管理平台 NineData 和北京奥星贝斯科技有限公司的 OceanBase 数据库完成产品兼容互认证。经过严格的联合测试,双方软件完全相互兼容、功能完善、整体运行稳定且性能表现优异。 此次 NineData 与 OceanBase 完成产品兼容认证…...

旅游专业VR虚拟仿真情景教学实训
一、生动的情景模拟 VR技术能够创建出高度逼真的虚拟环境,使学生能够身临其境地体验旅游场景。无论是古色古香的古代建筑,还是充满异国情调的热带雨林,亦或是繁华的都市风光,VR都能一一呈现。这种沉浸式的体验,使得学…...

解决方案TypeError: string indices must be integers
文章目录 一、现象:二、解决方案 一、现象: PyTorch深度学习框架,运行bert-mini,本地环境是torch1.4-gpu,发现报错显示:TypeError: string indices must be integers 后面报字符问题,百度过找…...

【论文阅读】Segment Anything论文梳理
Abstract 我们介绍了Segment Anything(SA)项目:新的图像分割任务、模型和数据集。高效的数据循环采集,使我们建立了迄今为止最大的分割数据集,在1100万张图像中,共超过10亿个掩码。 该模型被设计和训练为可…...

接口自动化测试框架搭建:基于python+requests+pytest+allure实现
众所周知,目前市面上大部分的企业实施接口自动化最常用的有两种方式: 1、基于代码类的接口自动化,如: PythonRequestsPytestAllure报告定制 2、基于工具类的接口自动化,如: PostmanNewmanJenkinsGit/svnJme…...
)
蓝桥杯(3.9)
1210. 连号区间数 蓝桥杯暴力过80% import java.util.Arrays; import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner sc new Scanner(System.in);int n sc.nextInt();int[] res new int[n];int[] copy new int[n];for(int i0;i&…...
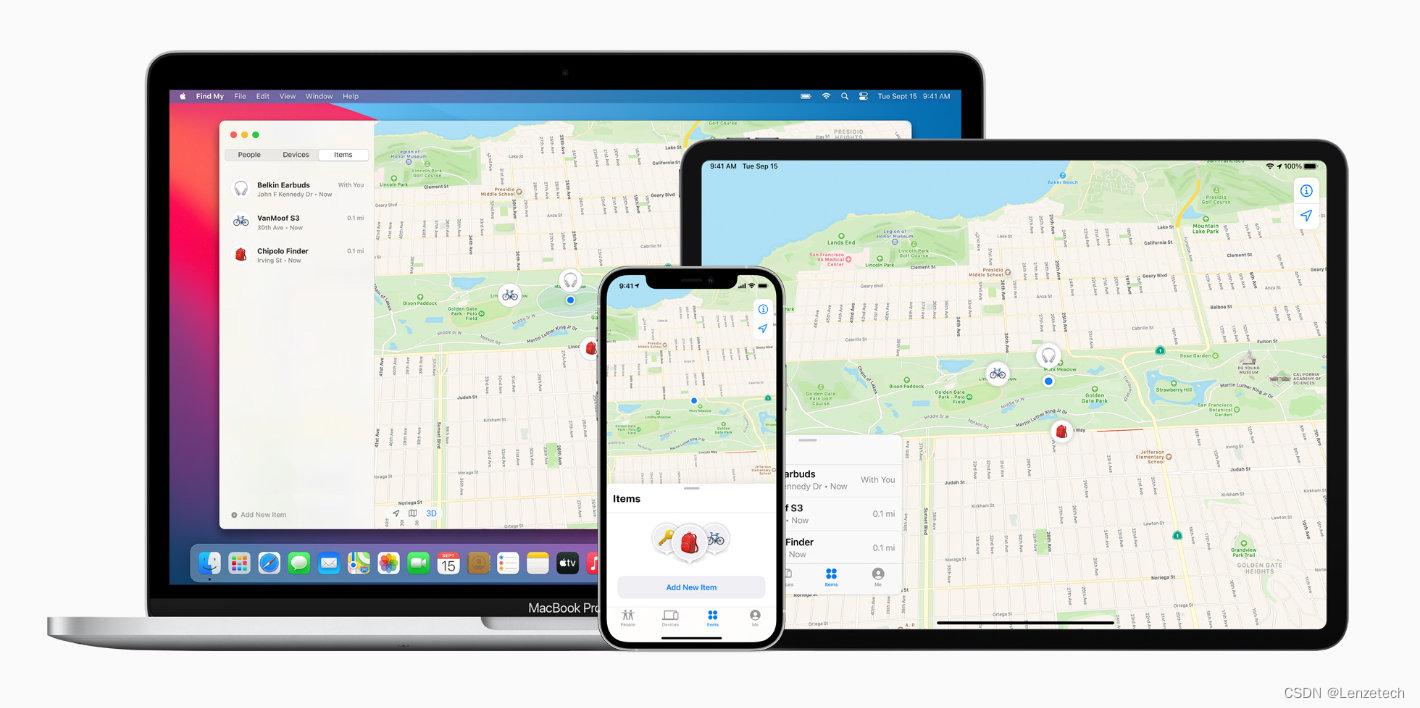
万物皆可Find My,伦茨科技ST17H6x芯片赋能产品苹果Find My功能
苹果的Find My功能使得用户可以轻松查找iPhone、Mac、AirPods以及Apple Watch等设备。如今Find My还进入了耳机、充电宝、箱包、电动车、保温杯等多个行业。苹果发布AirTag发布以来,大家都更加注重物品的防丢,苹果的 Find My 就可以查找 iPhone、Mac、Ai…...

UHF无线麦克风方案的特点
U段无线麦克风方案是一种基于UHF频段的无线音频传输技术。相比于传统的VHF频段和2.4GHZ频段,U段频谱资源更为宽阔,信号传输更加稳定可靠。 1.广阔的频谱资源:U段频段通常指450MHZ至900MH之间的频谱范围,相比于VHF频段的100MH至30…...
STM32 学习10 PWM输出
STM32 学习10 PWM输出 一、PWM简介1. PWM的概念2. PWM的工作原理3. PWM 常用的应用场景 二、一些概念1. 频率2. 占空比 三、STM32F1 PWM介绍1. 定时器与寄存器(1)**自动重装载寄存器(ARR)**:(2)…...
)
SQL语言(数据库编程)
一.select查询 在数据库编程中,SQL(Structured Query Language,结构化查询语言)是一种用于管理关系数据库管理系统(RDBMS)的标准编程语言。其中,SELECT 是 SQL 中最常用的查询语句,用于从数据库表中检索数据。 下面是一个基本的 SELECT 查询的示例: SELECT column1…...
中的多态性)
C#面向对象(OOPs)中的多态性
本文由 简悦 SimpRead 转码, 原文地址 mp.weixin.qq.com C#面向对象(OOPs)中的多态性 概述:在编程语言和类型理论中,多态性是为不同类型的实体提供单个接口,或者使用单个符号来表示多个不同的类型。多态对象是能够呈现多种形式的…...
)
别再只调PID了!用STM32的TIMER捕获HALL信号,手把手实现电机速度测量(附代码)
基于STM32定时器的HALL信号捕获与电机速度测量实战指南 在无刷电机控制系统中,HALL传感器作为转子位置检测的关键元件,其信号处理精度直接影响速度环的性能表现。许多工程师虽然掌握了PID调节原理,却在硬件信号捕获环节遇到瓶颈——如何从跳变…...
Pixel Language Portal 开发环境搭建:Windows 系统下 Visual Studio 与 Python 联调指南
Pixel Language Portal 开发环境搭建:Windows 系统下 Visual Studio 与 Python 联调指南 1. 前言:为什么需要跨语言开发环境 在开发Pixel Language Portal这类涉及多种编程语言的项目时,经常需要同时处理Python脚本和C扩展模块。Windows平台…...

手机银行App模拟器
分享一款银行模拟器,农业银行模拟器,装逼娱乐神器,安卓苹果都支持!功能: 修改余额,自由修改数据,也可以模拟余额冻结和转出失败,功能多多,使用起来也是非常的方便,看图片…...

如何通过 reflect.Value 获取切片的底层值
go 的 reflect.value 没有提供通用的 slice() 方法,因为无法定义一个适用于所有切片类型的返回签名;正确方式是调用 interface() 后配合类型断言获取原始切片。 go 的 reflect.value 没有提供通用的 slice() 方法,因为无法定义一个适用于…...

从家庭路由器到云服务器:一次完整的Web请求,DNS、NAT和ICMP都扮演了什么角色?
从家庭路由器到云服务器:一次完整的Web请求,DNS、NAT和ICMP都扮演了什么角色? 当你在家中电脑输入"news.163.com"并按下回车键时,背后隐藏着一场精密的网络交响乐。这场跨越公私网络边界的数据旅程,由DNS解析…...

软件估算-代码行估算法
代码行技术是比较简单的定量估算软件规模的方法。这种方法根据以往开发的类似产品的经验和历史数据,估算实现一个功能需求的源程序行数。当有以往开发类似项目的历史数据可供参考时,用此方法估算出的历史数据还是比较准确的,把实现每个功能需…...
数据预处理)
从零训练一个小模型-nanoGPT 模型训练 (一)数据预处理
最近在学习模型训练,实际上在大模型训练上,我并没有深厚的背景,通过视频课程和b站上的一些分享,开始入门。 由于我非神经网络这些相关的专业,所以想把自己学习的过程和经验总结记录下来,一方面自己可以巩固…...

别再死记硬背了!用‘冯诺依曼’和‘TCP/IP’模型,手把手拆解你浏览器访问GitHub的全过程
从输入URL到页面加载:浏览器访问GitHub的完整技术解析 当你在浏览器地址栏输入"https://github.com"并按下回车时,这台看似简单的操作背后隐藏着一系列精密的计算机系统协作。本文将用技术视角还原这个过程的每个关键环节,让你理解…...

从CLOSING到CLOSED:解码WebSocket连接状态异常与稳健重连策略
1. WebSocket连接状态的生命周期解析 WebSocket作为一种全双工通信协议,在现代Web应用中扮演着重要角色。但很多开发者都遇到过那个令人头疼的报错:"WebSocket is already in CLOSING or CLOSED state"。要理解这个错误,我们得先搞…...
)
别再死记硬背了!用立创EDA+Excel,手把手教你搭建个人电子元器件库(附避坑清单)
电子工程师的元器件管理革命:从零散笔记到智能数据库 在电子设计领域,元器件管理一直是个令人头疼的问题。打开任何一位硬件工程师的电脑,你可能会发现数十个命名混乱的Excel表格、散落在各处的PDF规格书,以及一堆随手记录的纸质笔…...