一文帮助快速入门Django
文章目录
- 创建django项目
- 应用app
- 配置pycharm
- 虚拟环境
- 打包依赖
- 路由
- 传统路由
- include路由分发
- name
- namespace
- 视图
- 中间件
- orm关系对象映射
- 操作表
- 数据库配置
- model常见字段及参数
- orm基本操作
- cookie和session
- demo
- 类视图
创建django项目
指定版本安装django:pip install django==3.2
命令行创建django项目:
- 先进入到要保存项目的目录中
- 然后执行:django-admin startproject 项目名
可以看到创建了这么些文件:
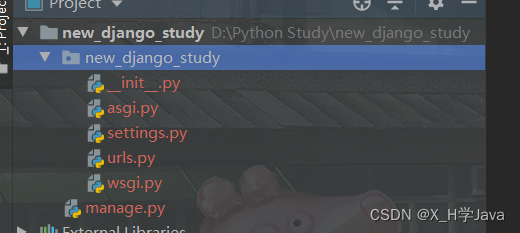
- manage.py:项目的管理工具
- wsgi.py:提供同步的socket服务
- asgi.py:异步
- urls.py:主路由
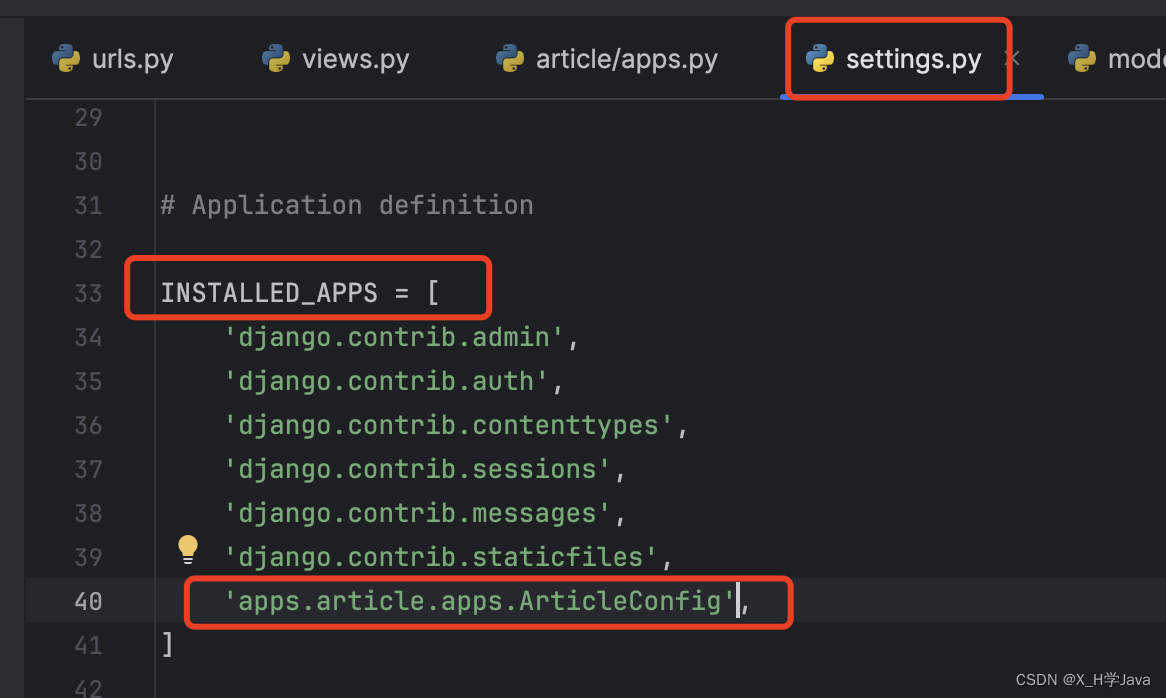
- settings.py:配置文件,只有一部分,程序启动时会先读取django内部的配置,再读取该文件的配置
内部配置文件路径:
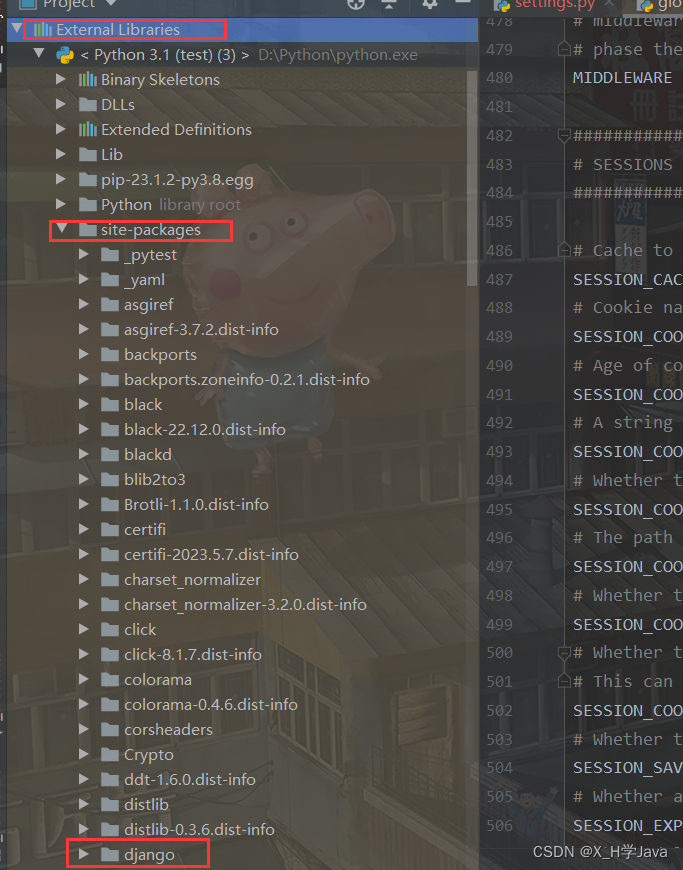
编写示例代码:
from django.urls import path
from django.shortcuts import HttpResponse# 调此函数会带一个request参数,可使用request获取请求数据
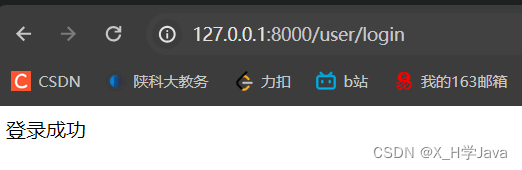
def login(request):# django的响应是一个封装的对象return HttpResponse('登录成功')urlpatterns = [# path("admin/", admin.site.urls),path('user/login', login) # 只能写函数名
]
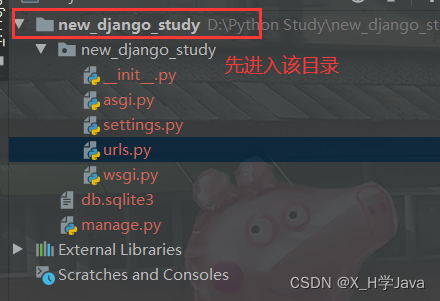
运行:python manage.py runserver
指定端口运行:python manage.py runserver 127.0.0.1:8080
执行运行命令前先进入项目目录

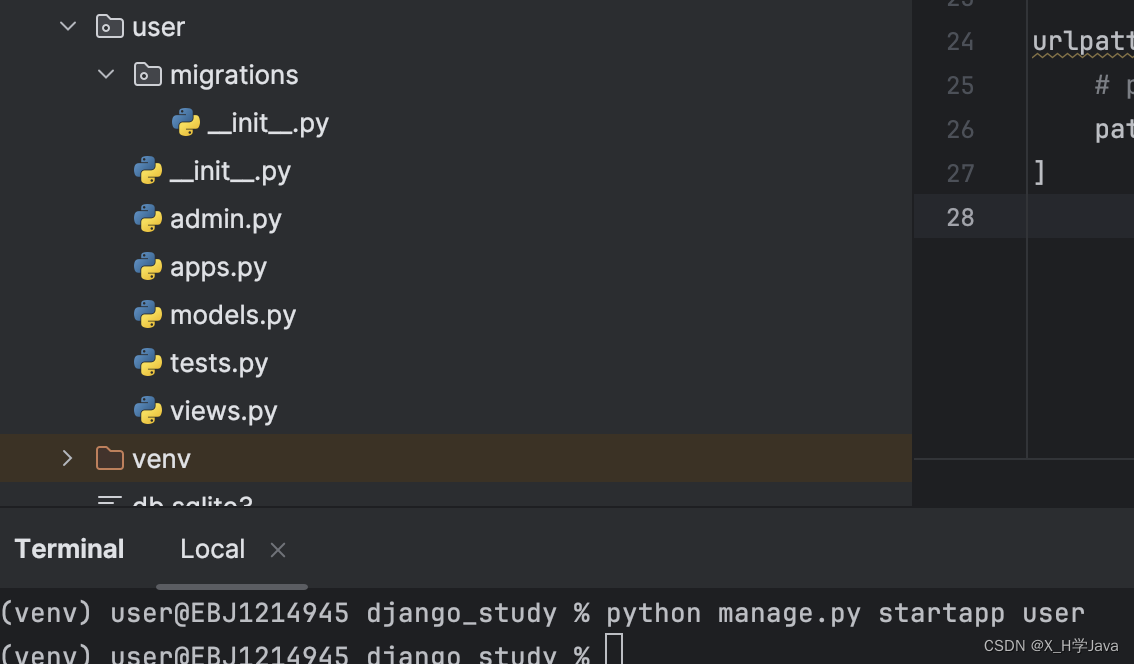
应用app
将项目分成不同的功能模块,每个模块对应一个app应用
创建app:进入项目目录执行python manage.py startapp 应用名
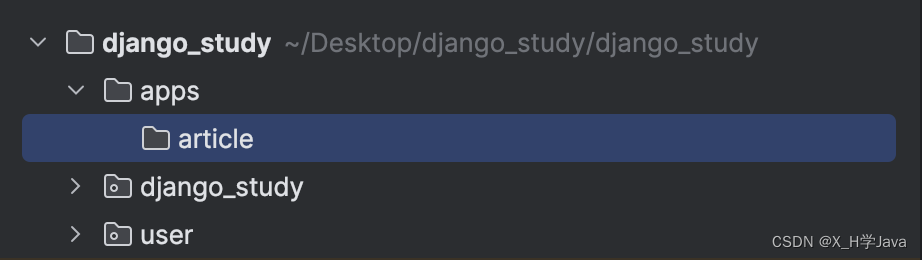
多app的创建:
- 在项目目录下创建apps目录,在apps目录下创建以要创的app名为名称创建目录
- 执行:python manage.py article apps/article
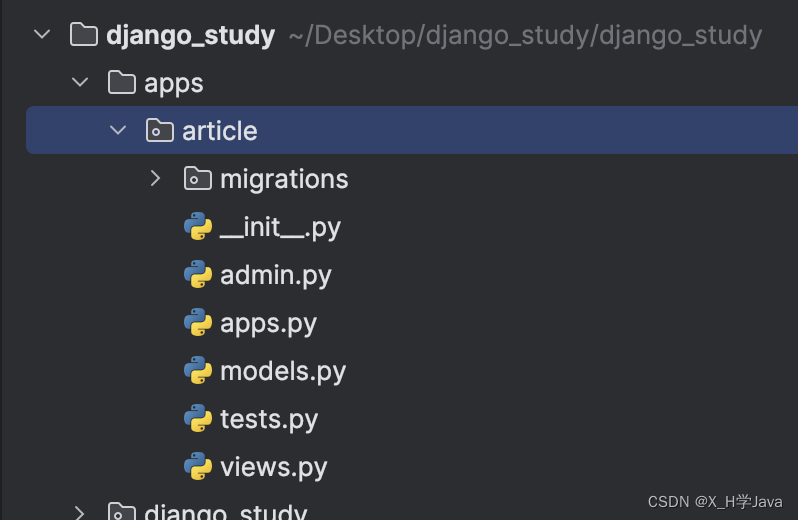
- 修改该文件内容

- 注册app
调整示例代码结构:
在user应用中的views.py文件编写下列代码:
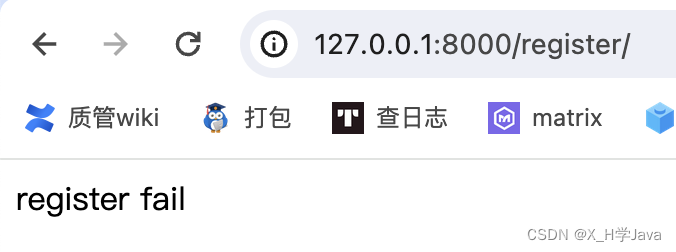
from django.shortcuts import HttpResponsedef login(request):return HttpResponse('login success')def register(request):return HttpResponse('register fail')
修改urls.py文件的路由配置
from django.urls import path
from user import viewsurlpatterns = [# path('admin/', admin.site.urls),path('login/', views.login),path('register/', views.register)
]
启动项目,访问
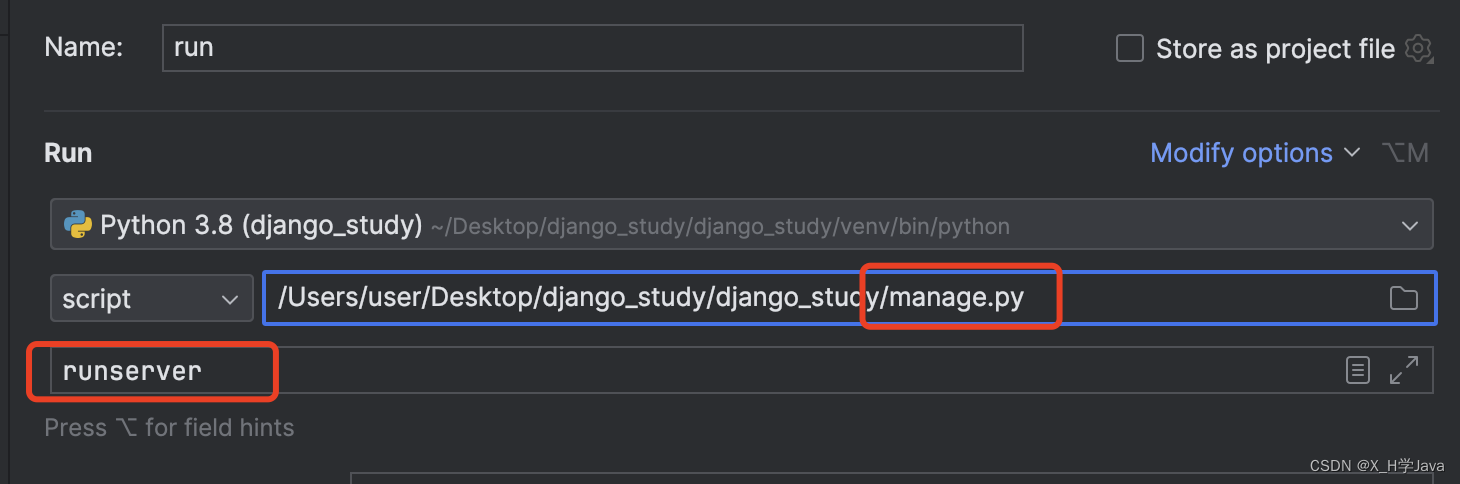
配置pycharm
配置pycharm启动django项目:
虚拟环境
使用命令行创建虚拟环境:python官方用于创建虚拟环境的工具:python3.8 -m venv xxx
该命令会基于系统python环境创建出一个虚拟环境,xxx为名称或目录
使用第三方工具:virtualenv,先安装:pip install virtualenv
创建:virtualenv xxx --python=python3.8
激活:
- win:
cd venv/Scripts
activate - mac:
source /venv/bin/activate
退出虚拟环境:deactivate
打包依赖
pip freeze > requirements.txt
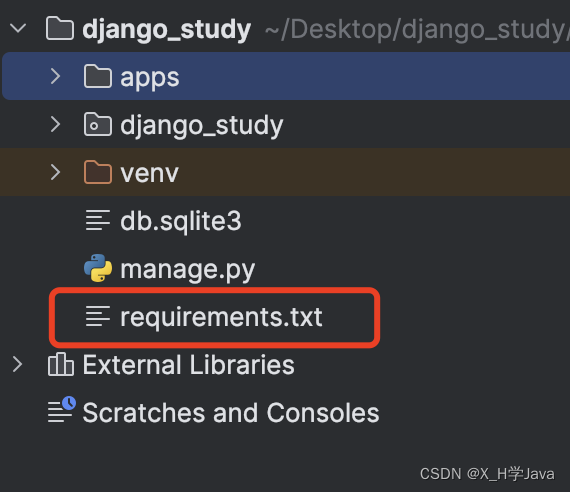
安装依赖:pip install -r requirements.txt
路由
传统路由
路由系统主要是维护url与函数的映射关系
url中包含参数:
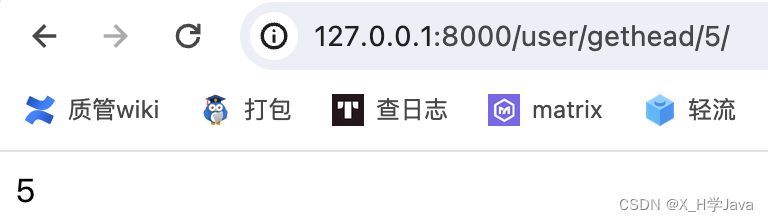
path('user/gethead/<int:id>/', views.get_head)
类型:
- int,整数
- str,字符串,但不能匹配/
- slug,字母,数字,下划线,-
- uuid,uuid的格式
- path,路径,可包含/
path('article/del/<int:id>/', delete),path('article/del/<str:id>/', delete),path('article/del/<uuid:id>/', delete),path('article/del/<path:id>/', delete),
直接在函数中添加参数可获取值
def get_head(request, id):return HttpResponse(id)
路由中包含正则,path替换为re_path
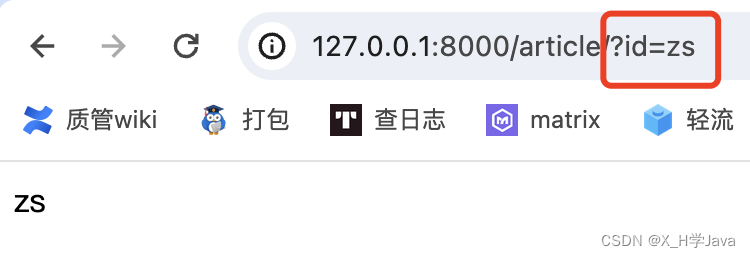
def article(request):id = request.GET.get('id')return HttpResponse(id)
注意:参数id字段要一致
include路由分发
导包include
主路由:
from django.urls import path, include# 路由匹配到前缀为user,则分发给apps.user中的urls,include中为路径字符串path('user/', include('apps.user.urls')),path('article/', include('apps.article.urls'))
在user应用中创建urls文件,然后编写路由规则
urlpatterns = [path('add/', views.login)
]
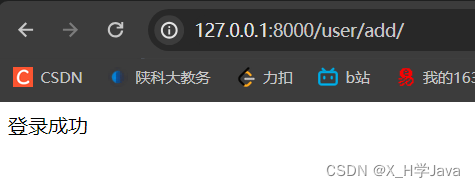
效果:会先找到主路由user/,然后在分发的文件中匹配到add/,完整的路由为user/add/
手动路由分发
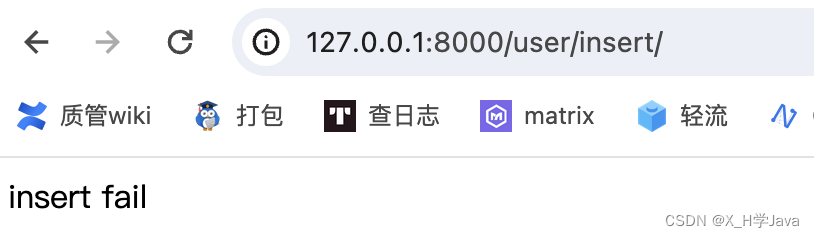
path('user/', ([path('del/', views.login),path('insert/', views.insert)], None, None)) # 第一个None为app_name,第二个None为namespace
匹配的url为:user/del/,user/insert/
include的本质
name = 'zs'# 相当于导包 from apps.user import urls
module = importlib.import_module("apps.user.urls")
# 也可以使用module.name获取name的值
# 从module中获取name的值,如果获取不到则默认为ls
n = getattr(module, 'name', 'ls')
n = getattr(module, 'name') # 获取不到会直接报错
name
给路由起名字,可以通过名字反向生成url
path('user/login/', views.login, name='v1'),path('user/register/', views.register, name='v2')
def login(request):# 在这个视图里,需要重定向到register里,就可以不写url,直接使用name即可from django.urls import reverse # 需要导包url = reverse('v2')return redirect(url) # 重定向,里面是url地址,使用name反推出的url,不用填写真是的url地址
namespace
用来辅助name的,当出现同名的name时,使用name反推出url可能会出现问题,这时候就可以使用namespace来区分不同的name
path('user/', include('apps.user.urls', namespace='user'))
path('login/', views.login, name='v1'),path('register/', views.register, name='v2')
def login(request):# 在这个视图里,需要重定向到register里,就可以不写url,直接使用name即可from django.urls import reverse # 需要导包url = reverse('user:v1') # namespace名:name名return redirect(url) # 重定向,里面是url地址,使用name反推出的url,不用填写真是的url地址
使用namespace时,必须提供app_name
from django.urls import path
from apps.user import viewsurlpatterns = [path('login/', views.login, name='v1'),path('register/', views.register, name='v2')
]app_name = 'user'
如果不提供,会报错

也可以主动去进行路由分发
path('user/', ([path('login/', views.login, name='v1')], 'user', 'user')) # 第一个user为app_name,第二个user为namespace
路由中尾部的/
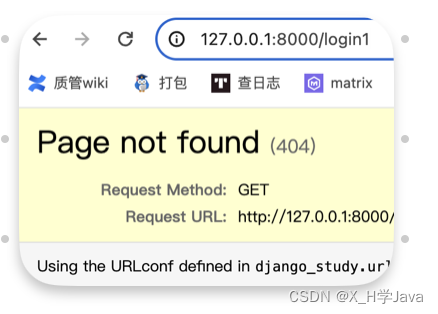
路由中带/,但是url不带/访问:127.0.0.1:8000/login
path('login/', views.login)

会发现其实是进行了两次请求,第一次找不到路经,django自动将/加上再访问一次
这个是由于配置文件中默认APPEND_SLASH=True导致的
如果想严格控制url,可以在settings文件中添加APPEND_SLASH=False

再进行访问
当前url的匹配对象
通过request.resolver_match获取
def login(request):cur_obj = request.resolver_matchprint(cur_obj)return HttpResponse('login')

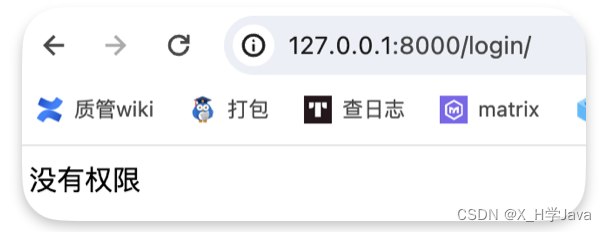
拿到这个有什么用?可以做权限处理
path('login/', views.login, name='test')
def login(request):permissions = ['user', 'article', 'music'] #用户具有的权限,都是namecur_obj = request.resolver_match.url_name #获取当前请求的nameif cur_obj not in permissions:return HttpResponse('没有权限')print(cur_obj)return HttpResponse('login')
视图
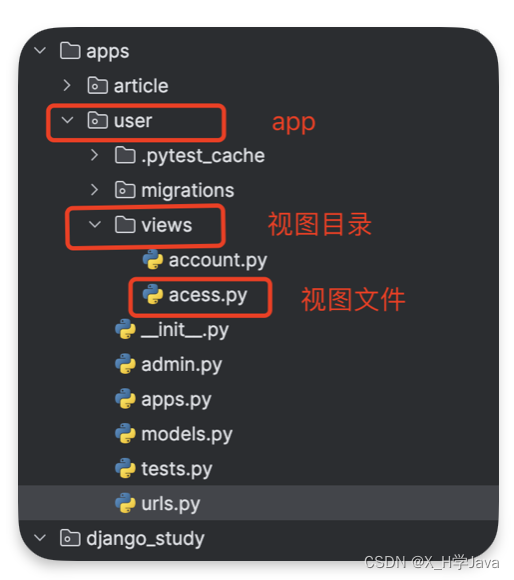
一般功能多的时候,这样创建视图文件
通过request对象获取请求内容
def login(request):print(request.path_info) # 请求urlprint(request.GET.get('username')) # 获取get请求参数print(request.GET.get('passowrd'))print(request.headers) # 请求头 字典类型print(request.COOKIES) # cookie 字典类型print(request.method) # 请求方法print(request.body) # 原始请求体# 获取post请求参数# 只针对body格式为a=123&b=abc,且content-type为from表单格式(application/x-www-from-urlencoded)print(request.POST.get('username'))print(request.POST.get('password'))# 获取文件 请求头为multipart/form-datarequest.FILES.get('name1')request.FILES.get('name2')
返回数据:
- 返回字符串/字节/文本数据
return HttpResponse('xxx')
- 返回json数据
def hello(request):from django.http import JsonResponseret_dict = {'code': 200,'data': 'xxx'}return JsonResponse(ret_dict)#return HttpResponse(json.dumps(ret_dict)) 使用json库
- 重定向
return redirect('https://www.baidu.com') # 参数为url或者url的name
设置响应头
ret = HttpResponse('hello world')ret['auto'] = 'true'ret['name'] = 'zs'ret.set_cookie('key', 'value')return ret
中间件
MiddlewareMixin
在项目根目录下,创建middlewares目录,在该目录里创建自定义中间件
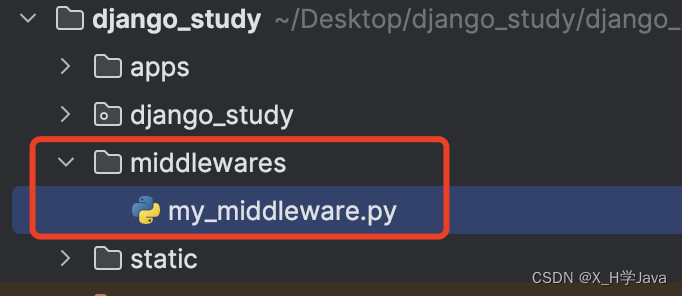
from django.utils.deprecation import MiddlewareMixinclass MyMiddleware(MiddlewareMixin):def process_request(self, request):print('调用视图前')def process_response(self, request, response):print('调用视图后')return response
创建完中间件必须在settings文件中进行注册,中间件是以类定义的
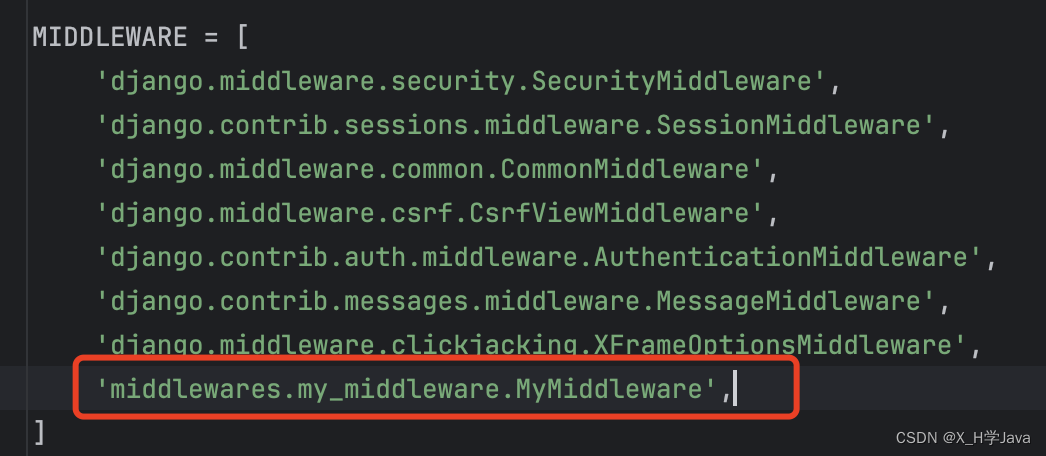
当在process_request函数中有返回值的时候,那么不会进入视图函数的执行而是接着执行process_response函数
注意:路由匹配是在执行完process_request函数后才匹配到的,也就是process_request函数的request参数为None
process_view
# view_func是匹配到的路由函数,view_args,view_kwargs是路由的参数def process_view(self, request, view_func, view_args, view_kwargs):print(request, view_func)

如果想在前置操作中根据视图函数做一些逻辑可以使用process_view
process_exception
# 当视图中出现异常时,会捕获到def process_exception(self, exception):print(exception)
orm关系对象映射
对表的操作(表的创建,修改,删除)
对数据的操作(增删改查)
操作表
在app的models.py文件创建类,一个类就对应一个表结构
- 按照规则创建类
from django.db import models
# 生成的表名默认为user_userinfo(app名_类名小写)
class UserInfo(models.Model):# 默认会生成一个字增主键idname = models.CharField(max_length=10)age = models.IntegerField()class Meta:db_table = 'user'verbose_name = '用户'verbose_name_plural = verbose_name
- 注册app(根据注册的app找migrations目录,可以将用不到的app去掉,避免创建使用不到的表)
- 执行命令python manage.py makemigrations
会自动在app目录下的migrations目录下创建一个配置文件

- 执行命令python manage.py migrate,根据配置文件转换sql语句,链接数据库,执行sql
执行上述命令前,先进行下面的数据库配置
数据库配置
先安装链接mysql的库pymysql/mysqlclient,pip install pymysql
在settings文件中将默认的数据库配置修改下
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'blog', # 数据库名'USER': 'root','PASSWORD': '12345678','HOST': '127.0.0.1','PORT': '3306',}
}
使用pymysql时,在settings文件的同级目录init文件中添加如下内容
import pymysql
pymysql.install_as_MySQLdb()
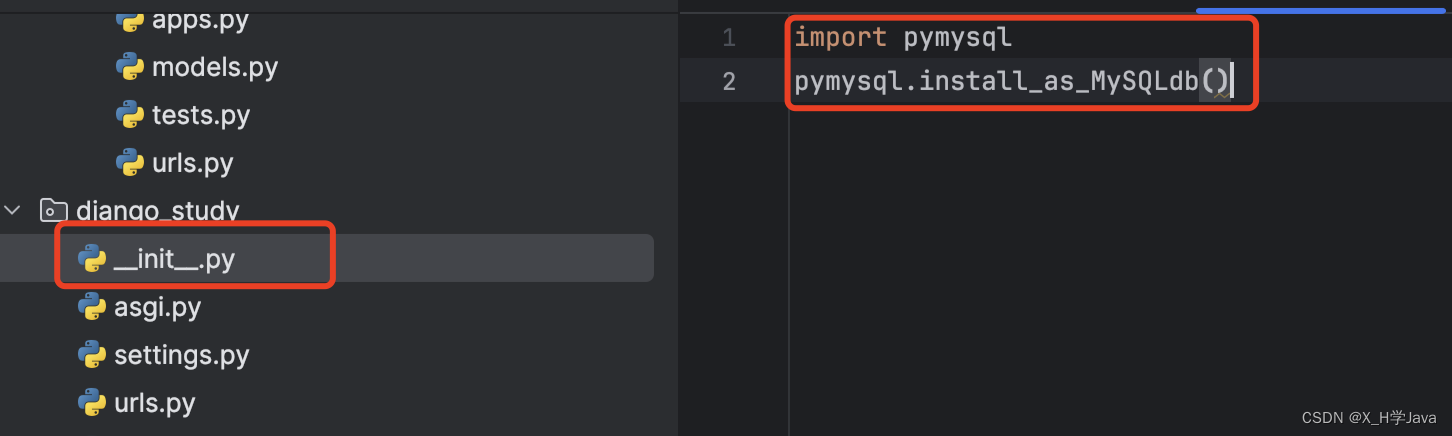
注意:不要手动修改表结构,如果要修改可以修改models文件中的字段,再执行上述的两条命令
数据库连接池
pip install django-db-connection-pool
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'blog', # 数据库名'USER': 'root','PASSWORD': '12345678','HOST': '127.0.0.1','PORT': '3306','POOL_OPTIONS': {'POOL_SIZE': 10, # 最小连接数'MAX_OVERFLOW': 10, # 额外增加的连接数'RECYCLE': 24 * 60 * 60, # 每个连接最长可以使用多久'TIMEOUT': 30, # 无连接时,最长等待时间}}
}
model常见字段及参数
class UserInfo(models.Model):# CharField为字符串,max_length为字符串的最大长度,verbose_name字段含义,默认null=False不许为空# 一般null和blank结合使用,null指数据库是否为可为空,blank为页面是否可为空name = models.CharField(verbose_name='姓名', max_length=10, default='无名氏', null=True, blank=True)# db_index表示添加索引,unique唯一约束age = models.IntegerField(verbose_name='年龄', db_index=True, unique=True)rage = models.BigIntegerField(verbose_name='长整型年龄')content = models.TextField(verbose_name='详情')# auto_now,当插入数据不传该字段时会使用当前时间create_data = models.DateField(verbose_name='日期', auto_now=True) # 日期:年月日rcreate_data = models.DateTimeField(verbose_name='时间') # 时间:年月日时分秒active = models.BooleanField(verbose_name='是否')# max_digits总共位数,decimal_places小数点后几位salary = models.DecimalField(verbose_name='余额', max_digits=10, decimal_places=2)
表关系
一对多:
class UserInfo(models.Model):'''用户表'''name = models.CharField(max_length=5, verbose_name='员工姓名')age = models.IntegerField(verbose_name='年龄')# ForeignKey外键,to表示与哪张表关联,to_field表示与哪个字段关联# on_delete=models.CASCADE表示级联删除,models.SET_NULL表示设置为null# models.SET_DEFAULT表示设置默认值# 数据库生成的字段会默认给depart加上_id,depart_iddepart = models.ForeignKey(verbose_name='部门id',default=1, null=True, blank=True, to='Depart', to_field='id', on_delete=models.SET_DEFAULT)
class Depart(models.Model):'''部门表'''name = models.CharField(verbose_name='部门名称')
多对多:
class UserInfo(models.Model):name = models.CharField(max_length=5, verbose_name='姓名')
class MusicInfo(models.Model):title = models.CharField(max_length=20, verbose_name='音乐标题')
class UAndM(models.Model):nid = models.ForeignKey(to=UserInfo, to_field='id', verbose_name='用户id')tid = models.ForeignKey(to=MusicInfo, to_field='id', verbose_name='音乐id')
orm基本操作
单表操作
增:
def register(request):username = request.POST.get('username')password = request.POST.get('password')dict = {'username': username,'password': password}# 方式1# 返回值是以UserInfo这个类创建的对象# user = models.UserInfo.objects.create(username=username, password=password)user = models.UserInfo.objects.create(**dict) # 匹配的参数类型是**kwargs,使用字段传参时,要带上**print(user.username)print(user.password)# 批量插入models.User.objects.bulk_create(objs=[models.User(name='zs', age=10),models.User(name='ls', age=12)],batch_size=2 # 一次提交几条)# 方式2user1 = models.UserInfo(username='zs', password='123')user1.save()return HttpResponse(user)
删:
# 删除# 返回值是受影响的行数n1 = models.UserInfo.objects.all().delete()n2 = models.UserInfo.objects.filter(username='zs').delete()
更新:
# 更新# 返回值是受影响的行数n3 = models.UserInfo.objects.all().update(password='123')n4 = models.UserInfo.objects.filter(username='zs').update(password='123')
查询:
# 查list = models.UserInfo.objects.all() # 返回类型是queryset(类似列表),里面存放一个个对象# list.query 可以获取sql语句for obj in list:print(obj.username)list2 = models.UserInfo.objects.filter(username='zs') # 返回类型也是querysetlist3 = models.UserInfo.objects.filter(age__gt=10) # age>10# age__gte=10 age>=10# age__lt=10 age<10# age__lte=10 age<=10# age__in=[10,20,30] age in (10,20,30)# username__contains='张' 包含 '张' %张%# username__startswith='张' 以 ‘张’ 开头 张%list4 = models.UserInfo.objects.filter(username='zs', password='123') # andlist5 = models.UserInfo.objects.exclude(username='zs') # username!='zs'# 如果查不到数据,返回依旧是queryset,不过里面没对象[]
models.UserInfo.objects.filter(username='zs') # queryset[obj,obj]models.UserInfo.objects.filter(username='zs').values('username', 'passowrd') # queryset[{},{}]models.UserInfo.objects.filter(username='zs').values_list('username', 'passowrd') # queryset[(),()]user = models.UserInfo.objects.filter(username='zs').first() # 返回值为对象flag = models.UserInfo.objects.filter(username='zs').exists() # 返回值为true false 是否存在users1 = models.UserInfo.objects.all().order_by('id') # 排序 ascusers2 = models.UserInfo.objects.all().order_by('-id') # 排序 desc# order_by('-id', 'age') id desc age asc
一对多
def login(request):# 一对多查询# depart = models.ForeignKey(to='Depart', to_field='id', on_delete=models.CASCADE)# 查用户及部门 使用 __v = models.User.objects.filter(id=1).first()print(type(v.depart)) # 类型为class(为Depart的一个实例对象) 可以使用depart.title获取字段v3 = models.User.objects.filter(id__gt=0).select_related('depart')for i in v3:print(i.name, i.age, i.depart.title)v1 = models.User.objects.filter(id=1).values('name','age','depart__title') # [{},{}]v2 = models.User.objects.filter(id=2).values_list('name','age','depart__title') # [(),()]return HttpResponse('hh')
cookie和session
def login(request):res = HttpResponse('hello')# path是为了设置那个请求访问时携带上cookie /login domain为了限制域名# 响应头中有setCookie: zs:123,超时时间10s# secure=True 只有https请求时才携带cookie# httponly=True只允许在http中访问res.set_cookie('zs', '123', max_age=10, path='/', domain='baidu.com', secure=False, httponly=False)# 默认值 浏览器重新打开 / 当前域名 False Falsereturn resdef home(request):cookies = request.COOKIES # 获取所有的cookieprint(cookies)cookie1 = cookies.get('zs') # 根据键获取值return HttpResponse(cookie1)
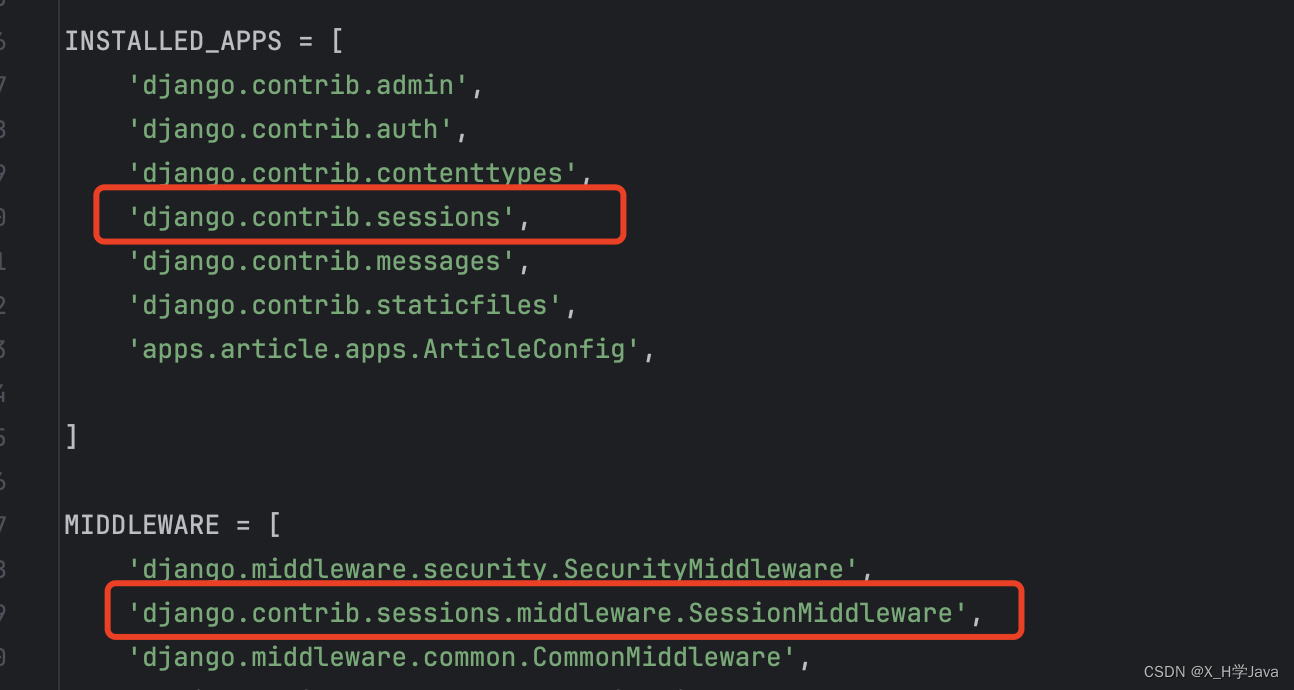
session配置
# session配置
# 存缓存
SESSION_ENGINE = 'django.contrib.sessions.backends.cache' # 保存会话引擎,缓存.cache,文件.file,数据库.db
SESSION_CACHE_ALIAS = 'default' # 使用哪个缓存保存,默认使用default,可通过CACHES配置
# 存文件
SESSION_ENGINE = 'django.contrib.sessions.backends.file'
SESSION_FILE_PATH = 'xxx' # 文件路径
# 存数据库
SESSION_ENGINE = 'django.contrib.sessions.backends.db' # 必须将app session的注释打开SESSION_COOKIE_AGE = 1209600 # 两周超时时间
SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 关闭 关闭浏览器cookie过期
SESSION_COOKIE_DOMAIN = None # 域名
SESSION_COOKIE_PATH = '/' #路径
SESSION_SAVE_EVERY_REQUEST = True # 设置每次请求都保存session
SESSION_COOKIE_SECURE = False # 是否https传输cookie
SESSION_COOKIE_HTTPONLY = True # cookie只支持http传输CACHES = {"default": {"BACKEND": "django.core.cache.backends.locmem.LocMemCache",},'redis': {'BACKEND': 'django_redis.cache.RedisCache','LOCATION': 'redis://127.0.0.1:6379/1','OPTIONS': {'CLIENT_CLASS': 'django_redis.client.DefaultClient',},},
}
注册app(保存在数据库中需要将注释打开)与添加中间件,django项目默认自带
def login(request):request.session['user'] = 'abc' # 设置sessionsession = request.session.get('user') # 获取session
demo
实现登录效果
def login(request):username = request.POST.get('username')password = request.POST.get('password')user = models.User.objects.filter(username=username,password=password).first()if user != None:request.session['user'] = userreturn JsonResponse({'msg': 'login success'})else:return JsonResponse({'msg': 'login fail'})
def home(request):user = request.session.get('user')if user != None:return HttpResponse('success')else :return HttpResponse('fail')
<script>$("#but").click(function(){let username = $("#username");let password = $("#password");$.ajax({url: "/login", //请求后端路径type: "post", //请求类型data: {"username": username.val(), "password": password.val()}, //请求数据(json类型)success: function(body){ //回调函数//console.log(typeof body)alert(body.msg)}});})
</script>
settings文件添加该配置
STATIC_URL = '/static/' # 浏览器可直接访问静态文件
STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')] # 存放静态文件的公共文件夹
类视图
from django.http import JsonResponse
from django.views import View
from . import models
import jsonclass UserView(View):def get(self, request):# queryset不能参与序列化,转为列表users = list(models.User.objects.values()) # [{},{}]# users = models.User.objects.first() vars(users)可将对象转为字典return JsonResponse(data=users,safe=False) # safe默认为true只能序列化字典,设置为true可序列化列表,元组...def post(self, request):data = json.loads(request.body)username = data.get('username')password = data.get('password')user = models.User.objects.create(username=username,password=password)return JsonResponse(data={'id':user.id,'username':username,'password':password})
from django.urls import path
from .views import UserView
urlpatterns = [path('user/', UserView.as_view())
]
相关文章:
一文帮助快速入门Django
文章目录 创建django项目应用app配置pycharm虚拟环境打包依赖 路由传统路由include路由分发namenamespace 视图中间件orm关系对象映射操作表数据库配置model常见字段及参数orm基本操作 cookie和sessiondemo类视图 创建django项目 指定版本安装django:pip install dj…...
基于springboot实现图书推荐系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现图书馆推荐系统演示 摘要 时代的变化速度实在超出人类的所料,21世纪,计算机已经发展到各行各业,各个地区,它的载体媒介-计算机,大众称之为的电脑,是一种特高速的科学仪器,比…...

微信小程序实现上拉加载更多
一、前情提要 微信小程序中实现上拉加载更多,其实就是pc端项目的分页。使用的是scroll-view,scroll-view详情在微信开发文档/开发/组件/视图容器中。每次上拉,就是在原有数据基础上,拼接/合并上本次上拉请求得到的数据。这里采用…...
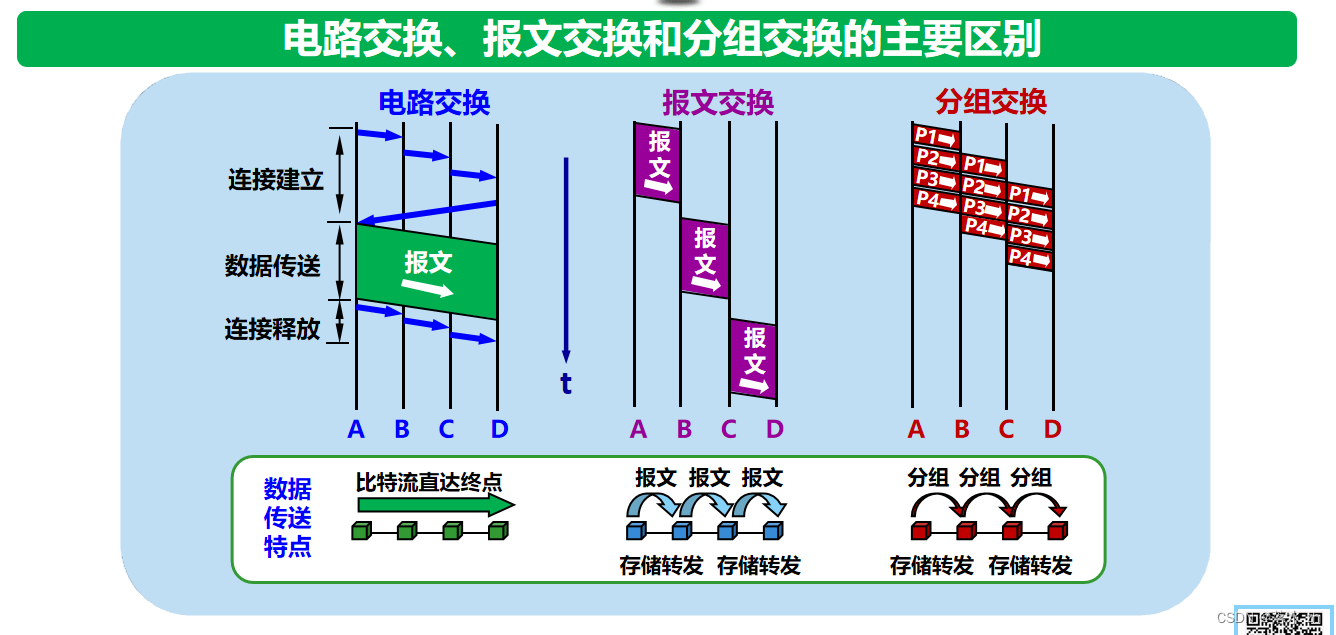
计算机网络——概述
计算机网络——概述 计算机网络的定义互连网(internet)互联网(Internet)互联网基础结构发展的三个阶段第一个阶段——APPANET第二阶段——商业化和三级架构第三阶段——全球范围多层次的ISP结构 ISP的作用终端互联网的组成边缘部分…...

kafka Interceptors and Listeners
Interceptors ProducerInterceptor https://www.cnblogs.com/huxi2b/p/7072447.html Producer拦截器(interceptor)是个相当新的功能,它和consumer端interceptor是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。 对于producer而言&…...

【面试题】mysql常见面试题及答案总结
事务中的ACID原则是什么? Mysql是如何实现或者保障ACID的? ACID原则是数据库事务管理中必须满足的四个基本属性,确保了数据库事务的可靠性和数据完整性。 简写全称解释实现A原子性(Atomicity)一个事务被视为一个不可分割的操作序列&#…...

C++ 类的前向声明的用法
我们知道C的类应当是先定义,然后使用。但在处理相对复杂的问题、考虑类的组合时,很可能遇到俩个类相互引用的情况,这种情况称为循环依赖。 例如: class A { public:void f(B b);//以B类对象b为形参的成员函数//这里编译错位&…...
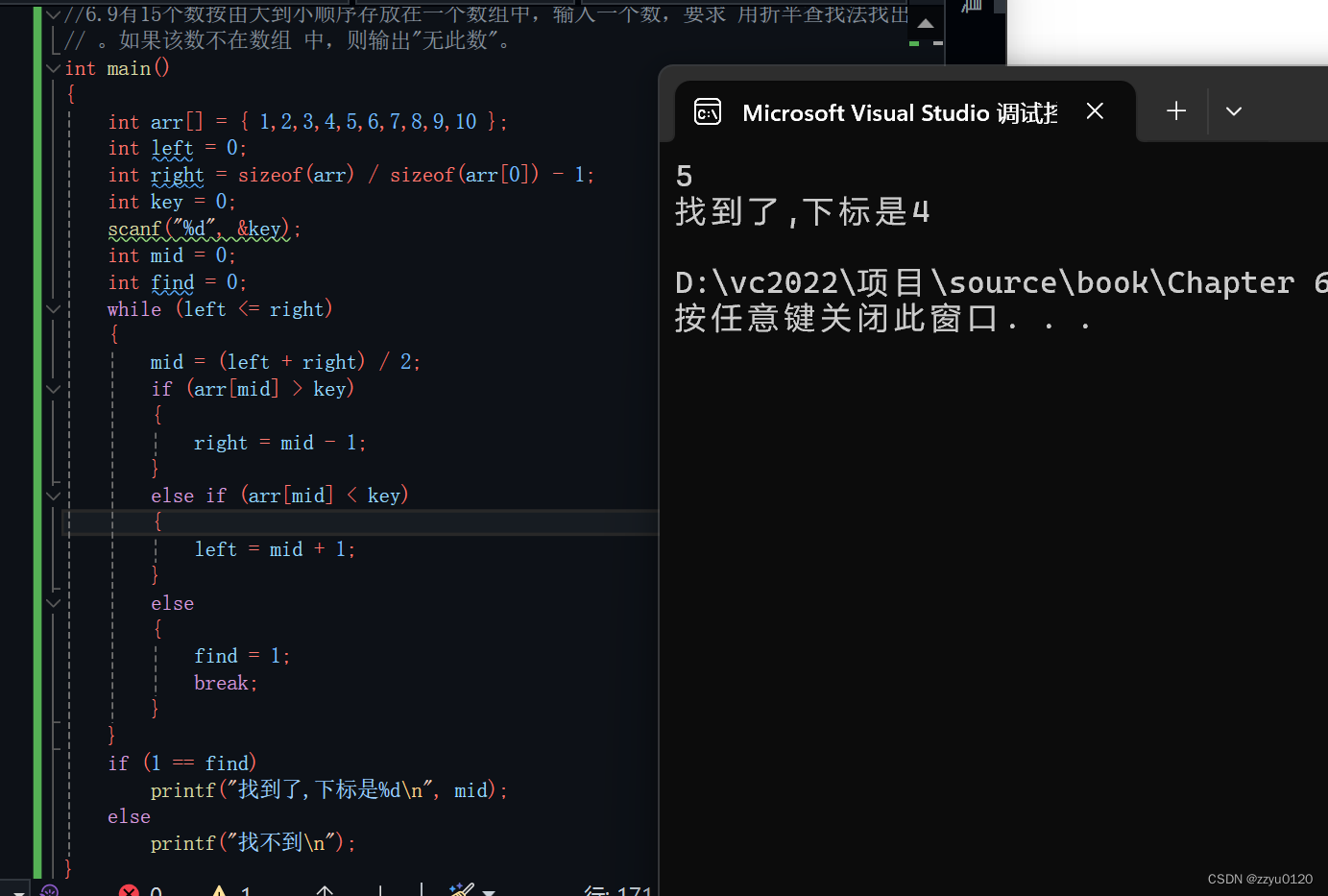
二分查找(c语言)
二分查找 一.什么是二分查找二.代码实现 一.什么是二分查找 在⼀个升序的数组中查找制定的数字n,很容易想到的⽅法就是遍历数组,但是这种⽅法效率⽐较低, ⽐如我买了⼀双鞋,你好奇问我多少钱,我说不超过300元。你还是好…...

【记录31】elementUI el-tree 虚线、右键、拖拽
父组件 <eltree :treeData"treeData"></eltree>import eltree from "../../components/tree.vue"; export default {name: ,components: { // org_tree ,eltree},watch: {},data() {return {orgFormchoose: {},orgForm: { type: 0, limits: 1…...

【C++】函数重载
🦄个人主页:修修修也 🎏所属专栏:C ⚙️操作环境:Visual Studio 2022 目录 📌函数重载的定义 📌函数重载的三种类型 🎏参数个数不同 🎏参数类型不同 🎏参数类型顺序不同 📌重载…...

【深度学习模型】6_3 语言模型数据集
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 6.3 语言模型数据集(周杰伦专辑歌词) 本节将介绍如何预处理一个语言模型数据集,并将其转换成字符级…...

技术选型思考:分库分表和分布式DB(TiDB/OceanBase) 的权衡与抉择
码到三十五 : 个人主页 心中有诗画,指尖舞代码,目光览世界,步履越千山,人间尽值得 ! 在当今数据爆炸的时代,数据库作为存储和管理数据的核心组件,其性能和扩展性成为了企业关注的重点。随着业…...

React改变数据【案例】
State传统方式 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>React Demo</title> <!--…...
ChatGPT Plus 自动扣费失败,如何续订
ChatGPT Plus 自动扣费失败,如何续订 如果您的 ChatGPT Plus 订阅过期或扣费失败,本教程将指导您如何重新订阅。 本周更新 ChatGPT Plus 是一种每月20美元的订阅服务。扣费会自动进行,如果您的账户余额不足,OpenAI 将在一次扣费…...

Rust: Channel 代码示例
在 Rust 中,通道(Channel)通常使用 std::sync::mpsc(多生产者单消费者)或 tokio::sync::mpsc(在异步编程中,特别是使用 Tokio 运行时)来创建。下面是一个使用 std::sync::mpsc 的简单…...

基于华为atlas的unet分割模型探索
Unet模型使用官方基于kaggle Carvana Image Masking Challenge数据集训练的模型。 模型输入为572*572*3,输出为572*572*2。分割目标分别为,0:背景,1:汽车。 Pytorch的pth模型转化onnx模型: import torchf…...

机器学习--循环神经网络(RNN)1
一、简介 循环神经网络(Recurrent Neural Network)是深度学习领域中一种非常经典的网络结构,在现实生活中有着广泛的应用。以槽填充(slot filling)为例,如下图所示,假设订票系统听到用户说&…...

基于java+springboot+vue实现的学生信息管理系统(文末源码+Lw+ppt)23-54
摘 要 人类现已进入21世纪,科技日新月异,经济、信息等方面都取得了长足的进步,特别是信息网络技术的飞速发展,对政治、经济、军事、文化等方面都产生了很大的影响。 利用计算机网络的便利,开发一套基于java的大学生…...
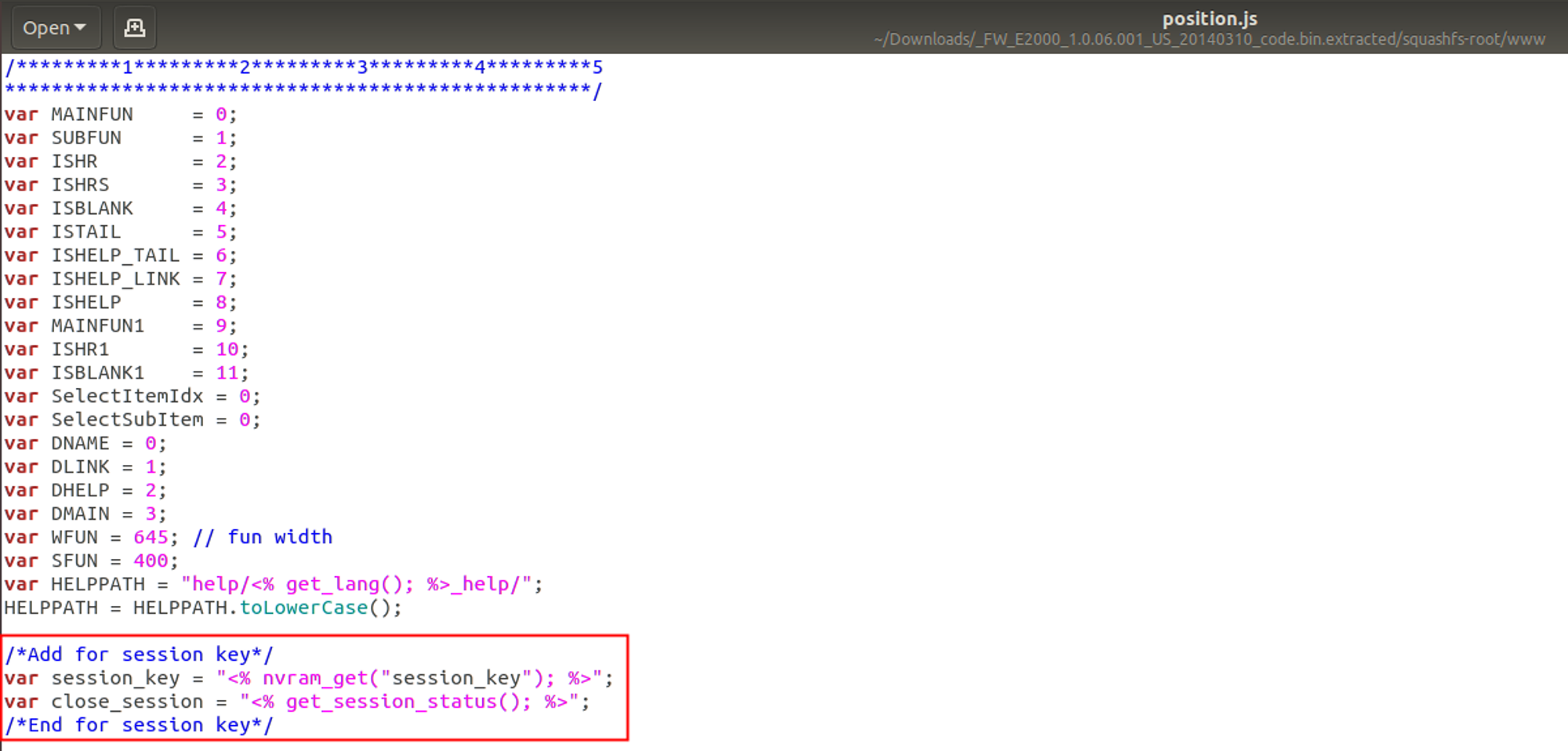
【漏洞复现】Linksys E2000 position.js 身份验证绕过漏洞(CVE-2024-27497)
0x01 产品简介 Linksys E2000是一款由思科(Cisco)品牌推出的无线路由器,它是一款支持2.4GHz和5GHz双频段的无线路由器,用户可以避开拥挤的2.4GHz频段,独自享受5GHz频段的高速无线生活。 0x02 漏洞概述 Linksys E200…...

小白跟做江科大51单片机之DS1302可调时钟
原理部分 1.DS1302可调时钟介绍 单片机定时器主要占用CPU时间,掉电不能继续运行 图1 2.原理 图2 内部有寄存器,寄存的时候以时分秒寄存,以通信协议实现数据交互,就可以实现对数据进行访问和读写 3.主要寄存器定义 CE芯片使能…...

校准预测、遗憾匹配与博弈均衡
EC’20:校准预测、遗憾匹配、动态与均衡 耶路撒冷希伯来大学教授Sergiu Hart讨论了两篇获奖论文所分享的研究成果,这两篇论文分别获得了ACM SIGecom时间检验奖和博士论文奖。 2020年7月23日 1分钟阅读 在第21届ACM经济学与计算大会(EC’20&am…...

如何免费实现专业级电脑风扇智能控制:3步配置你的静音工作站
如何免费实现专业级电脑风扇智能控制:3步配置你的静音工作站 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trend…...

掌控系统散热:FanControl智能风扇控制完全指南
掌控系统散热:FanControl智能风扇控制完全指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCon…...

ngx_set_environment
1 定义 ngx_set_environment 函数 定义在 ./nginx-1.24.0/src/core/nginx.cchar ** ngx_set_environment(ngx_cycle_t *cycle, ngx_uint_t *last) {char **p, **env;ngx_str_t *var;ngx_uint_t i, n;ngx_core_conf_t *ccf;ngx_pool_…...

**发散创新:过度依赖单一编程语言导致的架构风险与重构实践**在现代软件开发中,**选择一种编程语言并深度
发散创新:过度依赖单一编程语言导致的架构风险与重构实践 在现代软件开发中,选择一种编程语言并深度绑定其生态已成为许多团队的默认策略。然而,这种“技术栈锁定”现象正悄然埋下隐患——一旦该语言在特定场景下表现乏力、维护成本飙升或社区…...
)
保姆级教程:手把手搭建你的第一个ARM AHB+APB+CPU小系统(附仿真环境配置)
从零构建ARM AHBAPBCPU系统的实战指南 在数字IC设计领域,能够独立完成一个完整的SOC系统集成是工程师能力的重要分水岭。本文将带你从零开始,构建一个基于AMBA总线架构的简易SOC系统,包含AHB、APB总线和CPU核心的完整集成方案。不同于理论概述…...

GitHub中文化插件:3分钟让你的GitHub界面说中文
GitHub中文化插件:3分钟让你的GitHub界面说中文 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾经面对GitHub满屏…...

Qwen3.5-9B-AWQ-4bit效果展示:复杂场景图识别准确率实测与典型失败案例复盘
Qwen3.5-9B-AWQ-4bit效果展示:复杂场景图识别准确率实测与典型失败案例复盘 1. 模型能力概览 Qwen3.5-9B-AWQ-4bit是一款支持图像理解的多模态模型,能够结合上传图片与文字提示词输出中文分析结果。这个量化版本在保持较高识别准确率的同时,…...

如何高效备份QQ空间历史说说的完整指南
如何高效备份QQ空间历史说说的完整指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字信息时代,个人数据的安全备份变得日益重要。GetQzonehistory作为一款开源工具&…...

从CNN、RNN到Self-Attention:一个NLP工程师的视角转变与实战选择指南
从CNN、RNN到Self-Attention:一个NLP工程师的视角转变与实战选择指南 当你在处理文本分类任务时,是否曾纠结于该选择传统的CNN、RNN还是新兴的Self-Attention架构?三年前,我也面临同样的困惑。那时,我在一个电商评论情…...