kafka(三)springboot集成kafka(1)介绍
基于kafka新版本
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency>
</dependencies>一、kafkaProducer
1、介绍
设计上比consumer要简单一些,因为不涉及组管理,即每个producer都是独立工作的。
(1)目前producer的主要功能是向某个topic的某个分区发送一条消息,这就涉及分区选择策略,在ProducerRecord中介绍。
(2)因为有ISR,因此在发送消息时,producer有多种选择来实现消息发送,如不等待任何副本的影响便返回、只等待leader副本响应返回等等。
2、发送流程
produce的发送主要流程概述如下:
-
拦截器对发送的消息拦截处理;
-
获取元数据信息;
-
序列化处理;
-
分区处理;
-
批次添加处理;
-
发送消息。

3、主要参数
3.1、acks:
有三个参数:0、1、all,数据可靠性的重要参数,可以保证消息不丢失。
Properties properties = new Properties();
properties.put(ProducerConfig.ACKS_CONFIG,"1");3.2、 buffer.memory
指定了producer端用于缓冲消息的缓冲区大小,单位是字节。
3.3、compression.type
producer是否压缩消息。
3.4、batch.size
二、ProducerRecord
1、介绍
发送给Kafka Broker的key/value 值对,producer将待发送的消息封装进ProducerRecord实例类。
2、发送消息分区策略
(1)指定了分区:
当发送时指定了partition就使用该partition。即kafka生产者发送的消息ProducerRecord(String topic, Integer partition, K key, V value)指定了发送到哪个具体的分区。

(2)轮询
如果kafka生产者发送的消息ProducerRecord(String topic, Integer partition, K key, V value)没有指定发送到哪个具体的分区,即partition=null(并且key也为空时,如果此时key不为空的话就会采用另一种分区策略key哈希分区策略),并且使用了默认的分区器,那么消息将被随机的发送到主题的各个可用分区上,分区器使用轮询的算法将消息均衡的分布到各个分区。

(3)key哈希分区策略
根据消息的key进行哈希计算,并将消息发送到对应的分区。保证相同key的消息始终被发送到同一个分区,确保消息的顺序性。

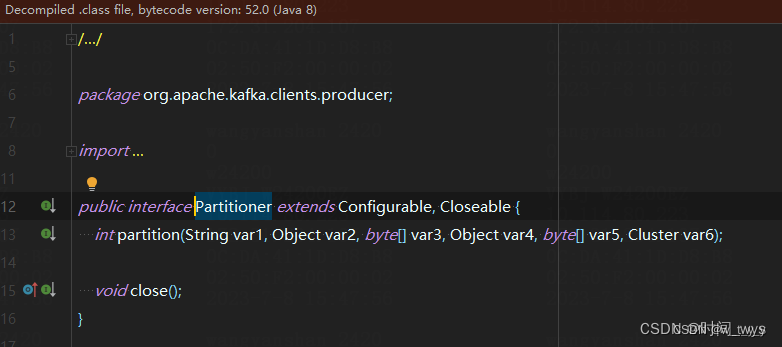
(4)自定义分区策略(即自定义Partitioner)
用户可以根据自己的需求实现自定义的分区策略,通过实现org.apache.kafka.clients.producer.Partitioner接口来自定义分区选择逻辑。
二、 KafkaConsumer
三、生产者发送消息应用
1、同步发送消息
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回 ack。 由于 send 方法返回的是一个 Future 对象,根据 Futrue 对象的特点,我们也可以实现同 步发送的效果,只需在调用 Future 对象的 get 方发即可。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;
import java.util.concurrent.ExecutionException;public class CustomProducerSync {public static void main(String[] args) throws ExecutionException, InterruptedException {// 1. 创建kafka生产者的配置对象Properties properties = new Properties();// 2. 给kafka配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value序列化(必须):properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 3. 创建kafka生产者对象KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String,String>(properties);// 4. 调用send方法,发送消息for (int i = 0; i < 10; i++) {// 默认为异步发送kafkaProducer.send(new ProducerRecord<>("first1", "atguigu" + i));// 末尾加get为同步发送kafkaProducer.send(new ProducerRecord<>("first1", "atguigu" + i)).get();}// 5. 关闭资源kafkaProducer.close();}
}2、异步发送消息
2.1、普通异步
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class CustomProducer {public static void main(String[] args) {// 1. 创建kafka生产者的配置对象Properties properties = new Properties();// 2. 给kafka配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value序列化(必须):properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 3. 创建kafka生产者对象KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String,String>(properties);// 4. 调用send方法,发送消息for (int i = 0; i < 10; i++) {kafkaProducer.send(new ProducerRecord<>("first", "wtyy"));}// 5. 关闭资源kafkaProducer.close();}
}2.2、带回调函数的异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是 RecordMetadata 和 Exception,如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class CustomProducerCallBack {public static void main(String[] args) {// 1. 创建kafka生产者的配置对象Properties properties = new Properties();// 2. 给kafka配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value序列化(必须):// 序列化器的serialization是一个接口,找到他的实现类// 我们一般都是使用Stringproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 3. 创建kafka生产者对象KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String,String>(properties);// 4. 调用send方法,发送消息for (int i = 0; i < 10; i++) {kafkaProducer.send(new ProducerRecord<>("first1", "atguigu" + i),new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {//(1)消息发送成功 exception == null 接受到服务端ack消息 调用该方法//(2)消息发送失败 exception != null 也会调用该方法if (exception == null) {System.out.println(metadata);//使用打印演示}else{exception.printStackTrace();//打印异常信息}}});}// 5. 关闭资源kafkaProducer.close();}
}四、消费者接收消息应用
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;public class CustomConsumer {public static void main(String[] args) {// 1. 创建消费者配置对象Properties properties = new Properties();// 2. 给消费者配置对象添加参数(不同于生产者,消费者有 4个必要的配置参数)// broker的ip地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// 配置 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());//配置消费者组(组名必须)properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");// 3. 创建消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);// 注册消费主题ArrayList<String> topics = new ArrayList<>();topics.add("first");consumer.subscribe(topics);// 4.调用方法消费数据// 如果kafka集群没有新数据会造成空转// 填写参数为时间,如果没有拉取数据,线程睡眠一会while (true) {// 设置1s中消费的一批数据// Duration.ofSeconds(1)不会导致空转,拉取不到的时候睡眠1sConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 打印消费数据for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord.topic() + "-" + consumerRecord.partition() + "-" + consumerRecord.offset());}}//5.关闭资源
// consumer.close();不使用的原因是,已关闭进程,就不会再消费数据了,进程停止就以为着JVM为断电了,不再工作}
}相关文章:
kafka(三)springboot集成kafka(1)介绍
基于kafka新版本 <dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency> </dependencies> 一、kafkaProducer 1、介绍…...

Markdown语法与基础使用
在撰写博客、文档或者其他类型的文字内容时,Markdown语法是一种简洁、易读易写的标记语言,被广泛应用于互联网上的文本编辑和排版中。下面将介绍Markdown语法的基础使用方法,帮助你更好地利用Markdown来编写内容。 1. 标题 Markdown支持使用…...

【排序】七大排序表格比较
排序 时间复杂度 空间复杂度 最坏时间复杂度 最好时间复杂度 稳定性 插入排序 O(n) O(1) O(n) O(n) 稳定 希尔排序 O(nlogn)-O(n)取决于增量序列 O(1) O(n^1.3) O(nlogn) 不稳定 选择排序 O(n) O(1) O(n) O(n) 不稳定 冒泡排序 O(n) O(1) O(n) O(n…...
arcgis 栅格数据处理2——栅格转地级市(栅格转矢量图)
1. 获取空间分析权限(解决无法执行所选工具问题) 选中“自定义”中的“扩展模块” 在弹出的模块中选中能选的模块,此处需要选择“spatial analysis”以进行下一步分析 3. 将栅格数据转为整数型(解决无法矢量化) 选…...
unity学习(53)——选择角色界面--分配服务器返回的信息
好久没写客户端了,一上手还不太适应 1.经过测试,成功登陆后,客户端请求list_request,成功返回,如下图: 可见此时model第三个位置的参数是1.也成功返回了所有已注册角色的信息。 2.之前已知创建的角色信息…...

矩阵爆破逆向-条件断点的妙用
不知道你是否使用过IDA的条件断点呢?在IDA进阶使用中,它的很多功能都有大作用,比如:ida-trace来跟踪调用流程。同时IDA的断点功能也十分强大,配合IDA-python的输出语句能够大杀特杀! 那么本文就介绍一下这个…...

logstash和elasticsearch的几种交互接口
Logstash与Elasticsearch是两个非常流行的开源工具,用于处理和存储大量的日志数据。它们之间的集成非常重要,因为Logstash用于收集、处理和转换日志数据,而Elasticsearch用于存储、搜索和分析这些数据。在本文中,我们将详细介绍Lo…...

Golang 开发实战day02 - Print Formatting
Golang 教程02 - Print,Formatting Strings Go语言提供了丰富的格式化字符串功能,用于将数据格式化为特定格式的字符串。本课程将详细介绍Go语言中Print和Formatting Strings的用法,并提供代码示例供大家参考。 1.Print 类型及使用 1.1 Pr…...
2023护网蓝初面试
目录 一、渗透测试的流程 二、常见的漏洞 三、中间件漏洞 四、SQL注入原理、种类?防御?预编译原理,宽字节注入原理 预编译原理: 宽字节注入原理: 五、XSS的种类有哪些?区别?修复…...
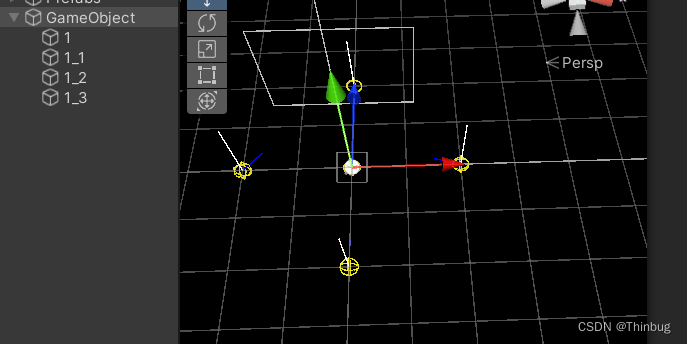
Unity编辑器功能Inspector快捷自动填充数据和可视化调试
我们有时候可能需要在面板增加一些引用,可能添加脚本后要手动拖动,这样如果有大量的脚本拖动也是不小的工作量 实例 例如:我的脚本需要添加一个Bone的列表,一个个拖动很麻烦。 实现脚本 我们可以用这样的脚本来实现。 public…...

【C/C++】常量指针与指针常量的深入解析与区分(什么是const int * 与 int * const ?)
目录 一、前言 二、const 的简单介绍 三、常量指针 🔍介绍与分析 📰小结与记忆口诀 四、指针常量 🔍介绍与分析 📰小结与记忆口诀 五、总结与提炼 六、共勉 一、前言 在【C/C】的编程中,指针与const关键字的组合…...

零、自然语言处理开篇
目录 0、NLP任务的基础——符号向量化 0.0 词袋模型 0.1 查表/One-hot编码 0.2 词嵌入模型/预训练模型 0.2.0 Word2Vec (0)CBOW (1)Skip-gram 0.2.1 GloVe 0.2.2 WordPiece 0.2.3 BERT 0.2.4 ERNIE NLP自然语言处理&am…...
Learn OpenGL 04 纹理
纹理环绕方式 纹理坐标的范围通常是从(0, 0)到(1, 1),那如果我们把纹理坐标设置在范围之外会发生什么?OpenGL默认的行为是重复这个纹理图像(我们基本上忽略浮点纹理坐标的整数部分),但OpenGL提供了更多的选择…...

了解开源可视化表单的主要优势
为什么可视化表单深受大家喜爱?这就需要了解开源可视化表单的优势和特点了。在流程化办公深入人心的今天,提高办公协作效率早已成为大家的发展目标,低代码技术平台、开源可视化表单是提升办公协作效率的得力助手,一起来看看它的优…...
Redis进阶--一篇文章带你走出Redis
目录 什么是Redis?? Redis有哪些使用场景? Redis是单线程还是多线程? 为什么Redis是单线程速度还是很快?? Redis持久化 RDB机制:(Redis DataBase) [是redis中默认的持久化方式] AOF机制:(Append Only File) Redis和MySQL如何保持数据一致????…...

【框架设计】MVC、MVP、MVVM对比图
1. MVC(Model-View-Controller) 2. MVP(Model-View-Presenter) 3. MVVM(Model-View-ViewModel)...
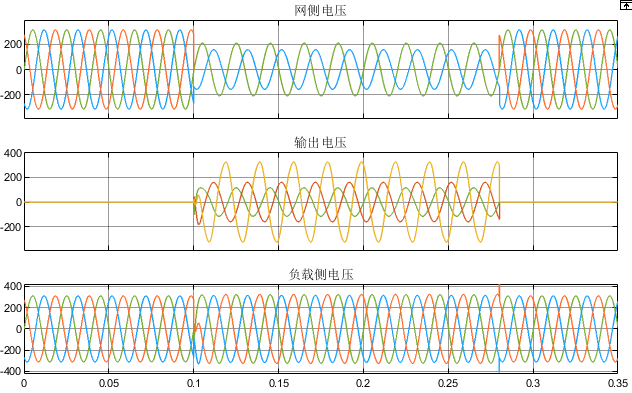
四桥臂三相逆变器动态电压恢复器(DVR)MATLAB仿真
微❤关注“电气仔推送”获得资料(专享优惠) 简介 四桥臂三相逆变器 电路 的一般形式如图 1,为 便于分析 ,将其等效成图所示的电路 。以直流母线电压Ud的 1/2处为参考点 ,逆变器三相和零线相 输 出可等效成…...
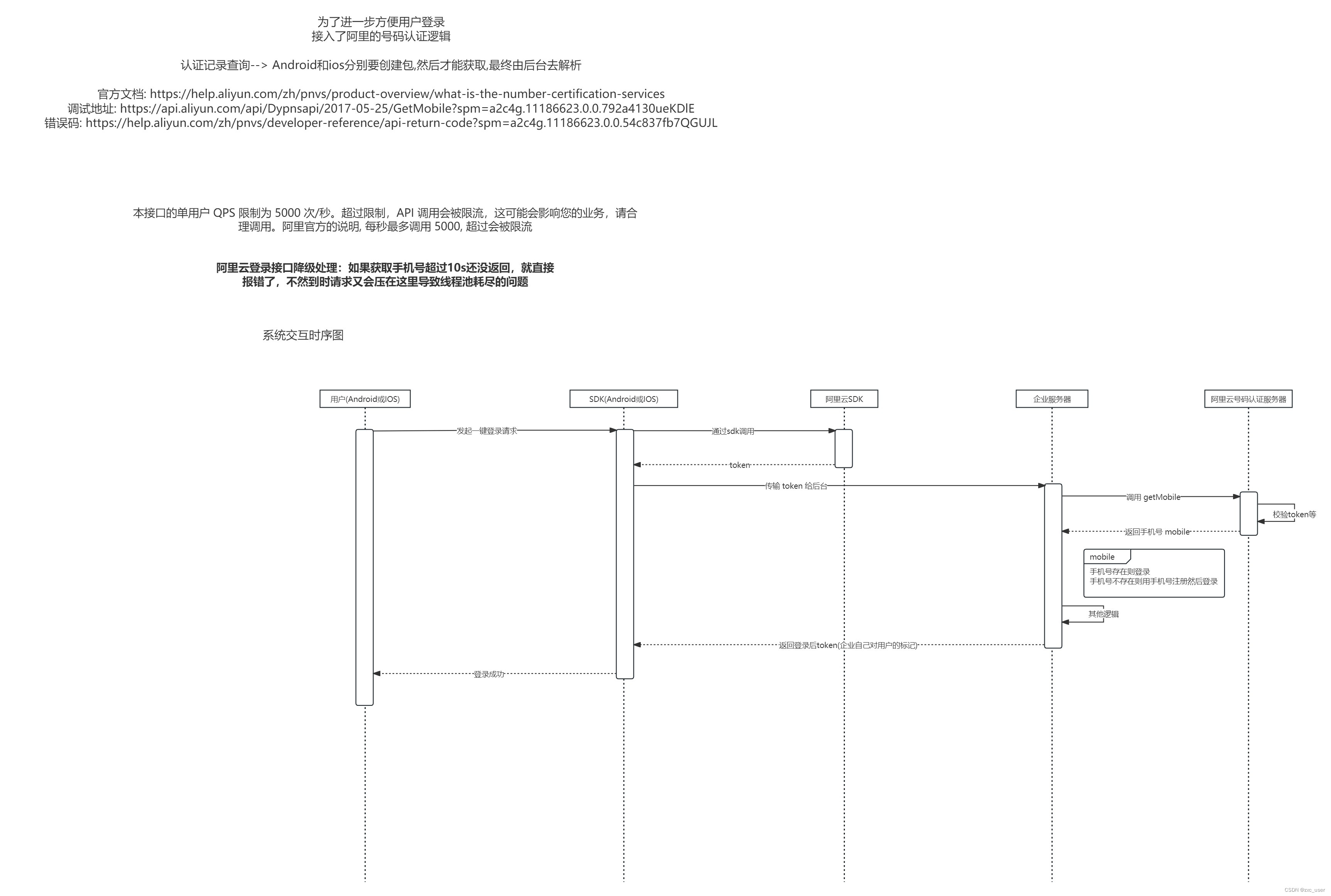
阿里云一键登录(号码认证服务)
前言 用户登录原来的登录方式如下 1. 手机号验证码 2. 账号密码 运营觉得操作过于复杂, 因此想引入阿里自动登录的逻辑, 也就是号码认证服务,所以才有了这篇问文章 注: 本文只是记录Java端的实现, app端的请自行查询文档实现 官方资料 文档 : 什么是号码认证服务_号码认证服务(…...

全量知识系统中的翻译器以及百度文库AI应用中心给出的答复
Q1. 下面是全量知识系统中的翻译器的规划(参考前一篇:全量知识系统 之 “百度翻译”。从“全量知识系统的翻译器”起。链接在下面)。下面的文字分5次发出。链接: 全量知识系统 之 “百度翻译”-CSDN博客 第一次回答:…...
抓包工具获取请求信息
Charles 下载安装 下载 官方下载地址:https://www.charlesproxy.com/latest-release/download.do 下载后傻瓜式安装就好,这个官方的需要激活,可以选择绿色版或者学习版 绿色版 绿色中文版:https://soft.kxdw.com/pc/Charles.z…...

终极指南:如何在浏览器中零安装查看和管理SQLite数据库
终极指南:如何在浏览器中零安装查看和管理SQLite数据库 【免费下载链接】sqlite-viewer View SQLite file online 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-viewer SQLite Viewer是一款基于Web的免费开源工具,让你无需安装任何软件就…...

3分钟搞定Windows PDF处理:Poppler预编译包的极简指南
3分钟搞定Windows PDF处理:Poppler预编译包的极简指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows平台PDF工具安装烦…...

AssetRipper深度解析:Unity资产逆向工程的完全指南
AssetRipper深度解析:Unity资产逆向工程的完全指南 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper AssetRipper作为专业的…...

ZVS和ZCS到底怎么选?从无线充电到服务器电源,聊聊软开关技术的选型实战
ZVS与ZCS技术选型实战:从无线充电到服务器电源的高效设计指南 在追求极致效率的现代电源系统中,软开关技术早已从实验室走向量产。当我们拆解一款氮化镓快充、观察服务器机柜的电源模块,或是测试无线充电板的温升时,ZVS࿰…...

REX-UniNLU与Typora文档智能分析
REX-UniNLU与Typora文档智能分析 1. 引言 在日常工作中,我们经常需要处理大量的Markdown文档。无论是技术文档、项目报告还是学习笔记,如何快速理解和分析这些文档内容一直是个挑战。传统的文档分析需要人工阅读和整理,费时费力且容易出错。…...

intv_ai_mk11新手入门指南:从零开始体验文本生成与改写
intv_ai_mk11新手入门指南:从零开始体验文本生成与改写 1. 镜像简介 intv_ai_mk11是一个基于Llama架构的中等规模文本生成模型,特别适合以下应用场景: 通用问答文本改写解释说明简短创作 该镜像已完成本地部署,您只需打开网页…...

告别手动输入:在Windows Terminal与Powershell中实现类iTerm2的智能补全体验
1. 为什么Windows开发者需要iTerm2般的智能补全体验 作为一个从macOS转回Windows的开发者,最让我抓狂的就是命令行环境的效率落差。在iTerm2里,轻轻按个Tab键就能自动补全路径和命令,上下箭头可以快速切换历史记录,这种丝滑体验在…...

OpenClaw实操指南20|记忆系统实战:别让你的AI用完就忘,短期+长期记忆配置指南
AI 最让人抓狂的一个问题:你昨天跟它说过的事,今天它全忘了。 每次对话都要重新交代背景,重新说明偏好,重新解释上下文。用久了,感觉不是在用助手,是在用一个失忆的工具。 OpenClaw 的记忆系统解决的就是…...

AI智能体开发核心概念全解析
AI智能体开发核心概念详解:提示词工程、技能系统、架构设计与完整教程 AI智能体(AI Agent)并非“会聊天的大模型”,而是具备感知(Observation)、推理(Reasoning)、决策(…...

别再只用翻转和裁剪了!PyTorch实战:用CutMix和Mixup让你的ResNet50在CIFAR-10上再涨几个点
突破传统数据增强瓶颈:PyTorch中CutMix与Mixup的实战调优指南 当你在CIFAR-10上反复调整学习率和权重衰减却始终无法突破准确率瓶颈时,是否想过问题可能出在数据层面?传统的数据增强方法如随机翻转、裁剪虽然能提供基本的正则化效果ÿ…...