零、自然语言处理开篇
目录
0、NLP任务的基础——符号向量化
0.0 词袋模型
0.1 查表/One-hot编码
0.2 词嵌入模型/预训练模型
0.2.0 Word2Vec
(0)CBOW
(1)Skip-gram
0.2.1 GloVe
0.2.2 WordPiece
0.2.3 BERT
0.2.4 ERNIE
NLP自然语言处理,目的是实现计算机对人类语言的智能理解和应用,使得计算机可以像人类一样与人类语言进行交互、分析和生成文本。——By ChatGPT
其主要思想是将人类语言文本转化为数学符号,进而利用统计学、概率学以及各类模型方法完成分类、回归等。
NLP处理常见套路其主要数据获取(不会写爬虫的nlper不是一个好程序员)-> 数据清洗-> 特征工程 -> 模型选取 -> 模型训练 ->效果评估 -> 上线
NLP的常见任务:0、本文向量化;1、文本分类;2、序列标注;3、句子关系判断;4、生成式任务;5、知识图谱;6、大语言模型;7、...。
NLP的常见应用场景:句子情感分析、话题分析、舆情分析、搜索、中文分词、推荐、问答系统、聊天机器人...。
0、NLP任务的基础——符号向量化
文字是符号,无法直接被计算机识别,需要转换为计算机模型能够识别的编码,最常见的就是转换为向量。
0.0 词袋模型
在传统检索和文档分类中较为常用,将词语出现的词频/TF-IDF值作为向量值,例如有两篇文档
Doc1:虽然词语无法直接转化为数值->[虽然, 词语, 无法, 直接, 转化, 为, 数值]
Doc2:统计文本中词语的出现情况->[统计, 文本, 中, 词语, 的, 出现, 情况]
合并两个文档中的所有词,[虽然, 词语, 无法, 直接, 转化, 为, 数值,统计, 文本, 中, 的, 出现, 情况 ],统计频率后,可以将上面两篇文档表示为如下向量
Doc1:[1, 2, 1, 1, 1, 1, 1,0, 0, 0, 0, 0, 0 ]
Doc2:[0, 2 , 0, 0, 0, 0, 0,1, 1, 1, 1, 1, 1 ]
词的顺序对传统机器学习影响较小,如聚类、cosin系数、jaccard系数等的计算,均是按位计算求和平均,因此位次重要程度不高。
不足:无法展示词的上下文信息。
0.1 查表/One-hot编码
指定一个包含较为完整的词典,文档转换为向量时,纬度和词表大小相同,向量中若一个词出现,则该位置数值为1,反之为0。
例如,我们有一个13个词的词典:[虽然, 词语, 无法, 直接, 转化, 为, 数值,统计, 文本, 中, 的, 出现, 情况 ],
那么对于一个这样的Doc“虽然词语无法直接转化为数值 ”,转换方式可见如下两种:
直接查表:[虽然, 词语, 无法, 直接, 转化, 为, 数值] -> [1,1,1,1,1,1,1,0, 0, 0, 0, 0, 0]
One-hot编码:虽然->[1,0,0,0,0,0,0,0,0,0,0,0,0],词语->[0,1,0,0,0,0,0,0,0,0,0,0,0],无法->[0,0,1,0,0,0,0,0,0,0,0,0,0]...,数值 ->[0,0,0,0,0,0,0,0,0,0,0,0,1]
不足,词表大的话向量过于稀疏,若直接用于训练效率低。
0.2 词嵌入模型/预训练模型
为解决无法联系上下文和向量稀疏问题,提出了一种Word Embeddings的方法,它是一种利用神经网络将词汇映射到低维实数向量的方法。
0.2.0 Word2Vec
参考文献:Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
(0)CBOW
CBOW模型将上下文的单词作为输入,预测中心单词。适合大语料库,适合高频词的向量化,因为更多依赖上下文进行预测。


输入层:一个个的单词one-hot编码的张量1*V,V表示词表的大小。
隐层:V*N的隐层权重张量,也称为word-embedding层,N表述维度,w2v一般是128维。输入层和隐层相乘,会得到一个C*N的张量,C为词的个数,将这C个词相加,得到一个1*N的张量。(隐藏的输出即可作为词嵌入)
输出层:构建一个N*V的输出层矩阵,将隐层的输出1*N与这个N*V相乘,得到一个1*V的张量(可经过softmax),这个就是通过中心词得到的上下文词的概率矩阵。
训练效率高、高词频词效果更好。
(1)Skip-gram
Skip-gram模型将中心单词作为输入,预测上下文单词。适合语料库较小的情况,对于低频词有更好的表现。因为他对一个词需要预测其上下多个词的结果,相当于这个词计算了多次,更加准确。


输入层:中心词转换为1个1*V的one-hot张量,V表示词表大小。
隐层:隐层权重为V*N,N为维度,一般为128维。经过隐层后,变成一个1*N的张量(隐藏的输出即可作为词嵌入)。
输出层:构建C个N*V的输出层权重张量,C表示上下文中词的数量,最后输出C个1*V的张量(可经过softmax),即代表由中心词推理出的上下文的结果。
Skip-gram一般使用一个滑动窗口,默认是5,即中心词前后各2个词。
小规模数据集、生僻字效果好
Word2Vector相比1-2两种转换方式,可以捕捉语义信息,例如同义词信息,上下文相似的两个词,它们的词向量也应该相似,且训练效率相对较高。
0.2.1 GloVe
参考文献:Pennington J, Socher R, Manning C D. Glove: Global vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014: 1532-1543.
共现矩阵+基于窗口词的预测
I like deep learning.
I like NLP.
I enjoy flying共现矩阵

概率矩阵

已知ice和steam这两个词在语料中出现的频率,这两个词被视为目标词(target words) 。此时,暂且不直接去求解这两个词之间的共现关系,而是基于这两个词的频率,去探索一下给定这两个目标词的情况下,其他词的条件概率是一个什么情况,这里的k就是其他词。
首先,我们计算给定单词ice的情况下,单词k出现的频率,也就是说,k出现在i的上下文中的概率是多少。这个条件概率记做P(k|ice),P(k|ice) = X k,ice / X ice,X k, ice是k和ice在同一个context中出现的次数,X ice为ice出现的次数。同理,我们计算P(k|steam),计算方法一样。这里的k可以是字典中的任何一个单词。
0.2.2 WordPiece
参考文献:Kudo T. Subword regularization: Improving neural network translation models with multiple subword candidates[J]. arXiv preprint arXiv:1804.10959, 2018.
tokenize的常用方法,输入bert和ernie前都会经过这一步将词进行初步切词,输出子词序列。然后根据子词的id生成向量。该方法可以解决OOV(词不在词表)的问题。
训练集的词汇: old older oldest smart smarter smartest
word-level 词典: old older oldest smart smarter smartest 长度为 6
subword-level 词典: old smart er est 长度为 40.2.3 BERT
参考文献:Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
0)Bidirectional Encoder Representation from Transformers,结构如下:


自编码(Auto-Encoding)语言模型,Autoencoding Language Modeling,自编码语言模型:通过上下文信息来预测当前被mask的token,代表有BERT、Word2Vec(CBOW)等.它使用MLM做预训练任务,自编码预训模型往往更擅长做判别类任务,或者叫做自然语言理解(Natural Language Understanding,NLU)任务,例如文本分类,NER等。
自回归(Auto-Regressive)语言模型,Aotoregressive Lanuage Modeling,自回归语言模型:根据前面(或后面)出现的token来预测当前时刻的token,代表模型有ELMO、GTP等,它一般采用生成类任务做预训练,类似于我们写一篇文章,自回归语言模型更擅长做生成类任务(Natural Language Generating,NLG),例如文章生成等。
1)输入
参考:BERT的3个Embedding的实现原理_token embeddings-CSDN博客
一个长度为n的输入序列(n表示词组个数,token数),一般是512

Token Embeddings:采用wordpiece对文本进行切割成一个个子词,经过embedding后每一个子词输出为768维的向量 (1, n, 768)
Segment Embeddings:切割句子用的(1, n, 768)
Position Embeddings:用于标记词在句子中的位置,(1, n, 768)
整个输入是一个1*512*768的张量。
2)中间层
12个transformer的encoder,每个head是64个神经元,也就是H=768,所以,在transformer的encoder里,单个的的Wq,Wk,Wv都是768*64的矩阵,那么Q,K,V则都是512*64的矩阵,Q,K_T相乘后的相关度矩阵则为512*512,归一化后跟V相乘后的z矩阵的大小则为512*64,这是一个attention计算出的结果。12个attention则是将12个512*64大小的矩阵横向concat,得到一个512*768大小的多头输出,这个输出再接一层768的全连接层,最后就是整个muti-head-attention的输出了,如图4所示。整个的维度变化过程如下图所示:

3)输出
768维向量
BERT这种encoder-only,因为它用masked language modeling预训练,不擅长做生成任务,做NLU一般也需要有监督的下游数据微调;相比之下,decoder-only的模型用next token prediction预训练,兼顾理解和生成,在各种下游任务上的zero-shot和few-shot都很好。
总体参数量(输入权重矩阵、transformer的权重矩阵等等)约1亿左右。
0.2.4 ERNIE
参考文献:Sun Y, Wang S, Li Y, et al. Ernie: Enhanced representation through knowledge integration[J]. arXiv preprint arXiv:1904.09223, 2019.
BERT 模型主要是聚焦在针对字或者英文word粒度的完形填空学习上面,没有充分利用训练数据当中词法结构,语法结构,以及语义信息去学习建模。比如 “我要买苹果手机”,BERT 模型 将 “我”,“要”, “买”,“苹”, “果”,“手”, “机” 每个字都统一对待,随机mask,丢失了“苹果手机” 是一个很火的名词这一信息,这个是词法信息的缺失。
针对上面这个问题,ERNIE对训练数据中的词法结构,语法结构,语义信息进行统一建模


ERNIE在训练过程前,会对句子进行关键短语切割、命名实体识别等,通过有针对性的mask掉这些重要信息,增强模型的学习能力。
模型结构基本和bert一致,差别不大。
附:ernie3.0简单介绍
分层训练,universal representation是基础特征模型,task-specific representation是任务模块,可用于分类、生成等

相关文章:
零、自然语言处理开篇
目录 0、NLP任务的基础——符号向量化 0.0 词袋模型 0.1 查表/One-hot编码 0.2 词嵌入模型/预训练模型 0.2.0 Word2Vec (0)CBOW (1)Skip-gram 0.2.1 GloVe 0.2.2 WordPiece 0.2.3 BERT 0.2.4 ERNIE NLP自然语言处理&am…...
Learn OpenGL 04 纹理
纹理环绕方式 纹理坐标的范围通常是从(0, 0)到(1, 1),那如果我们把纹理坐标设置在范围之外会发生什么?OpenGL默认的行为是重复这个纹理图像(我们基本上忽略浮点纹理坐标的整数部分),但OpenGL提供了更多的选择…...

了解开源可视化表单的主要优势
为什么可视化表单深受大家喜爱?这就需要了解开源可视化表单的优势和特点了。在流程化办公深入人心的今天,提高办公协作效率早已成为大家的发展目标,低代码技术平台、开源可视化表单是提升办公协作效率的得力助手,一起来看看它的优…...
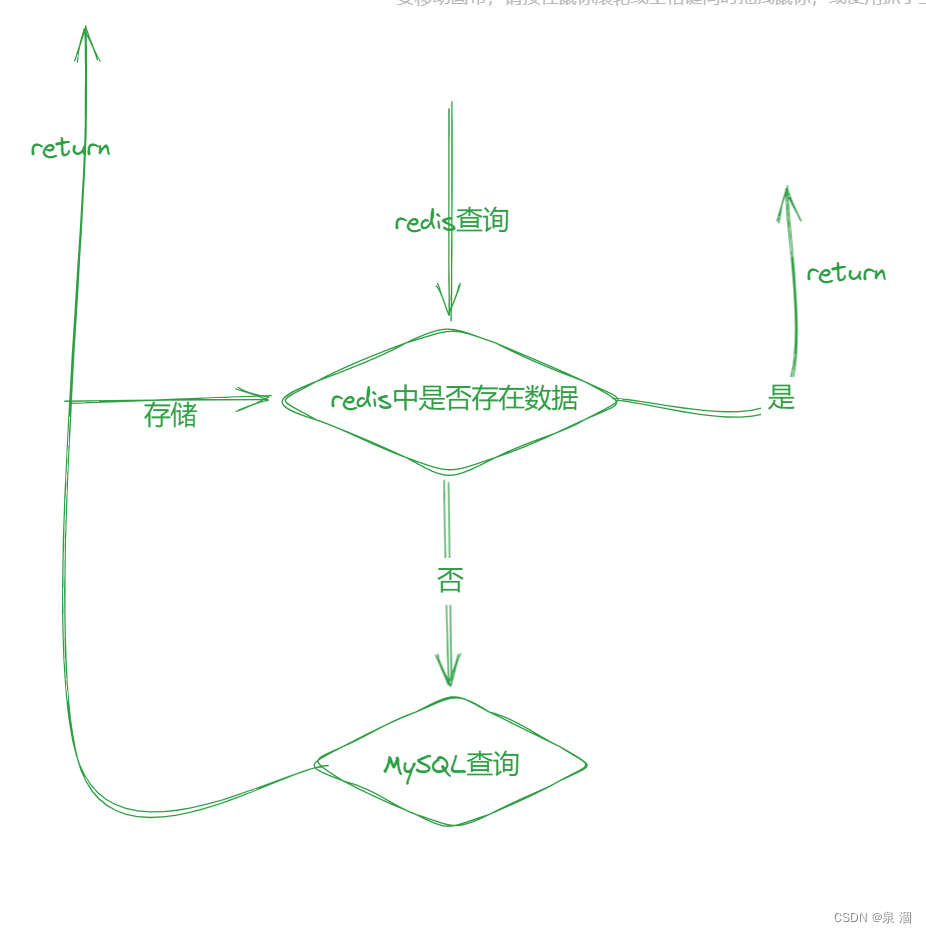
Redis进阶--一篇文章带你走出Redis
目录 什么是Redis?? Redis有哪些使用场景? Redis是单线程还是多线程? 为什么Redis是单线程速度还是很快?? Redis持久化 RDB机制:(Redis DataBase) [是redis中默认的持久化方式] AOF机制:(Append Only File) Redis和MySQL如何保持数据一致????…...

【框架设计】MVC、MVP、MVVM对比图
1. MVC(Model-View-Controller) 2. MVP(Model-View-Presenter) 3. MVVM(Model-View-ViewModel)...
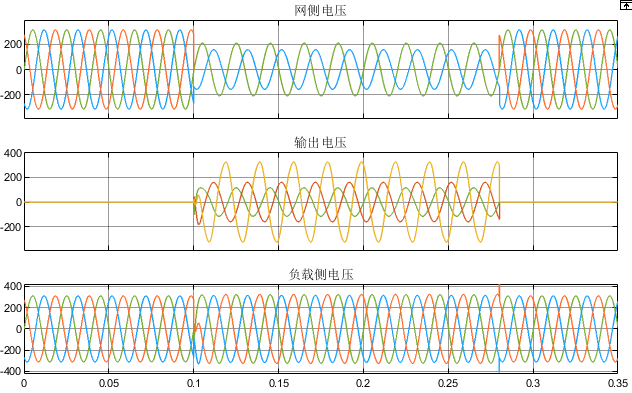
四桥臂三相逆变器动态电压恢复器(DVR)MATLAB仿真
微❤关注“电气仔推送”获得资料(专享优惠) 简介 四桥臂三相逆变器 电路 的一般形式如图 1,为 便于分析 ,将其等效成图所示的电路 。以直流母线电压Ud的 1/2处为参考点 ,逆变器三相和零线相 输 出可等效成…...
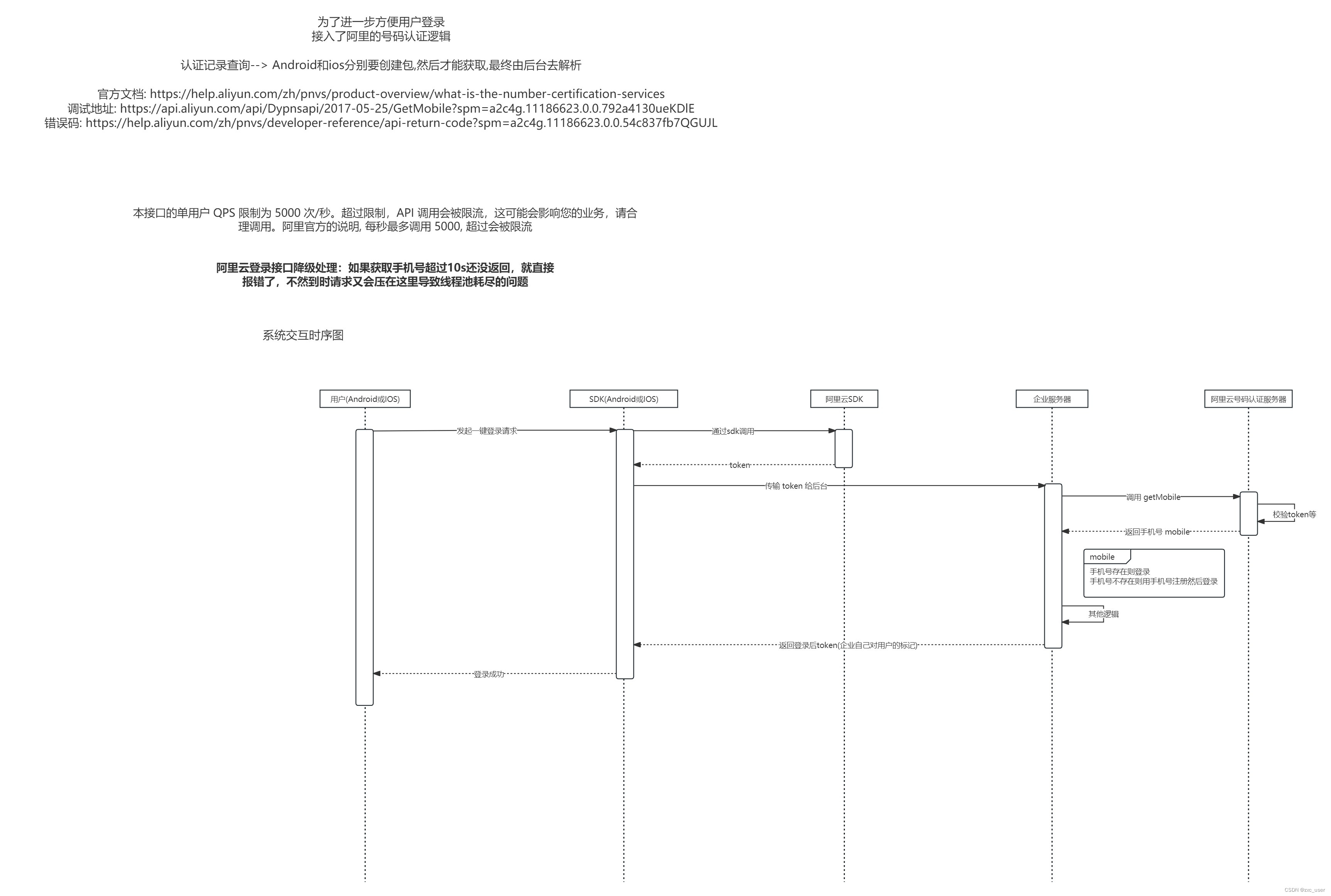
阿里云一键登录(号码认证服务)
前言 用户登录原来的登录方式如下 1. 手机号验证码 2. 账号密码 运营觉得操作过于复杂, 因此想引入阿里自动登录的逻辑, 也就是号码认证服务,所以才有了这篇问文章 注: 本文只是记录Java端的实现, app端的请自行查询文档实现 官方资料 文档 : 什么是号码认证服务_号码认证服务(…...

全量知识系统中的翻译器以及百度文库AI应用中心给出的答复
Q1. 下面是全量知识系统中的翻译器的规划(参考前一篇:全量知识系统 之 “百度翻译”。从“全量知识系统的翻译器”起。链接在下面)。下面的文字分5次发出。链接: 全量知识系统 之 “百度翻译”-CSDN博客 第一次回答:…...
抓包工具获取请求信息
Charles 下载安装 下载 官方下载地址:https://www.charlesproxy.com/latest-release/download.do 下载后傻瓜式安装就好,这个官方的需要激活,可以选择绿色版或者学习版 绿色版 绿色中文版:https://soft.kxdw.com/pc/Charles.z…...

【Java Web】秒懂CSS样式!
目录 一、CSS的使用 二、CSS引用方式 三、CSS三大选择器 四、CSS浮动 五、CSS定位 六、CSS盒子模型 一、CSS的使用 css层叠样式表能够对网页中标签元素位置的排版进行像素级别的精确控制,支持几乎所有的字体和字号样式,拥有对网页对象和模型的样式…...

Go微服务: 基于net/rpc/jsonrpc模块实现微服务跨语言调用
概述 Golang 提供 net/rpc/jsonrpc 库来实现rpc方法采用 json 方式进行数据编解码,支持跨语言调用 这里实现跨语言示例 1 )go 服务端 package main import ( "log" "net" "net/rpc" "net/rpc/jsonrpc" )…...

Guitar Pro 8.1中文版永久许可证激活2024最新24位注册激活码生成器
Guitar Pro是一款非常受欢迎的音乐制作软件,它可以帮助用户创建和编辑各种音乐曲谱。从其诞生以来就送专门为了编写吉他谱而研发迭代的。 尽管这款产品可能已经成为全球最受欢迎的吉他打谱软件,在编写吉他六线谱和乐队总谱中始终处于行业领先地位&#…...
练习题)
自然语言处理(NLP)练习题
问题:什么是自然语言处理(NLP)? 答案:自然语言处理(NLP)是一种人工智能技术,旨在让计算机理解和处理人类语言。NLP涉及语言学、计算机科学和人工智能等多个领域,旨在开发…...

P2386 放苹果
题目传送门 题目描述 把 m 个同样的苹果放在n 个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法。(5,1,15,1,1 和 1,1,51,1,5 是同一种方法) 输入格式 第一行是测试数据的数目 t,以下每行均包括二个整…...
TI IWR6843ISK ROS驱动程序搭建
1、设备准备 1.1 硬件设备 1)TI IWR 6843 ISK 1块 2)Micro USB 数据线 1条 1.2 系统环境 1)VMware Workstation 15 Player 虚拟机 2)Ubuntu18.04 并安装有 ROS1 系统 如若没有安装 ROS 系统,可通过如下指令进行…...
【Godot4自学手册】第二十节增加游戏的打击感,镜头震颤、冻结帧和死亡特效
这节我主要学习增加游戏的打击感。我们通过镜头震颤、冻结帧、增加攻击点特效,增加死亡。开始了。 一、添加攻击点特效 增加攻击点特效就是,在攻击敌人时,会在敌人受击点显示一个受击动画。 1.添加动画。 第一步先做个受击点动画。切换到…...

[论文笔记] Open-Sora 1、sora复现方案概览
GitHub - hpcaitech/Open-Sora: Unofficial implementation of OpenAIs Sora Open-Sora已涵盖: 提供完整的Sora复现架构方案,包含从数据处理到训练推理全流程。 支持动态分辨率,训练时可直接训练任意分辨率的视频,无需进行缩放。 支持多种模型结构。由于Sora实际模型结构未…...

持续更新 | 与您分享 Flutter 2024 年路线图
作者 / Michael Thomsen Flutter 是一个拥有繁荣社区的开源项目,我们致力于确保我们的计划公开透明,并将毫无隐瞒地分享从问题到设计规范的所有内容。我们了解到许多开发者对 Flutter 的功能路线图很感兴趣。我们往往会在一年中不断更改并调整这些计划&a…...

Go语言数据结构(二)堆/优先队列
文章目录 1. container中定义的heap2. heap的使用示例3. 刷lc应用堆的示例 更多内容以及其他Go常用数据结构的实现在这里,感谢Star:https://github.com/acezsq/Data_Structure_Golang 1. container中定义的heap 在golang中的"container/heap"…...
)
NERF论文笔记(1/2)
NeRF:Representing Scene as Neural Radiance Fields for View Synthesis 笔记 摘要 实现了一个任意视角视图生成算法:输入稀疏的场景图像,通过优化连续的Volumetric场景函数实现;用全连接深度网络表达场景,输入是一个连续的5维…...

3大核心功能解锁:OpenUtau如何重新定义虚拟歌手创作体验
3大核心功能解锁:OpenUtau如何重新定义虚拟歌手创作体验 【免费下载链接】OpenUtau Open singing synthesis platform / Open source UTAU successor 项目地址: https://gitcode.com/gh_mirrors/op/OpenUtau 想象一下,你坐在电脑前,脑…...
)
告别“充不上电”:手把手教你用万用表排查直流快充桩常见故障(附检测点电压实测)
告别“充不上电”:手把手教你用万用表排查直流快充桩常见故障(附检测点电压实测) 作为一名在充电桩运维一线摸爬滚打多年的"老电工",我见过太多因为一个小电阻损坏导致整个充电站瘫痪的案例。今天,我就把压箱…...
)
STM32 SAI接口实战:用CubeMX快速配置多通道音频采集(附DMA优化技巧)
STM32 SAI接口实战:用CubeMX快速配置多通道音频采集(附DMA优化技巧) 在嵌入式音频处理领域,STM32的SAI(Serial Audio Interface)接口因其灵活性和高性能成为多通道音频采集的理想选择。本文将带您从零开始&…...
)
从踩坑到避坑:我的INA226模块调试血泪史(附常见问题排查与校准指南)
从踩坑到避坑:我的INA226模块调试血泪史(附常见问题排查与校准指南) 第一次接触INA226时,我以为这不过是个普通的电流检测模块——接上电源、连好I2C、读取寄存器数据就完事了。直到项目deadline前三天,发现测量数据飘…...

告别标定噩梦:手把手教你用OpenCV搞定Jetson Nano双目摄像头标定,并适配ORB_SLAM2
双目视觉标定实战:从Jetson Nano到ORB_SLAM2的完整指南 在计算机视觉领域,双目摄像头的标定是构建三维感知系统的关键第一步。许多开发者在使用Jetson Nano搭配双目摄像头运行ORB_SLAM2时,往往会在标定环节耗费大量时间却收效甚微。本文将彻底…...

AI热修复不是幻想,而是已上线:某头部云厂商实测数据——平均MTTR从18分钟降至2.3秒,
第一章:2026奇点智能技术大会:AI代码热修复 2026奇点智能技术大会(https://ml-summit.org) 什么是AI代码热修复 AI代码热修复(AI-Powered Hotfix)指在不中断服务运行的前提下,由AI模型实时分析生产环境中的异常堆栈、…...

ROS Noetic下Gazebo 11仿真避坑实录:从‘模型能动’到‘控制丝滑’的进阶配置
ROS Noetic下Gazebo 11仿真避坑实录:从‘模型能动’到‘控制丝滑’的进阶配置 当你终于让机械臂模型在Gazebo中动起来的那一刻,那种成就感简直难以言表。但很快你会发现,让模型动起来只是万里长征的第一步——真正让机械臂按照预期轨迹精准运…...
)
告别绿幕!用MODNet+ONNX在Python里实现实时视频人像抠图(附完整代码)
零门槛实现电影级人像抠图:MODNetONNX全流程实战指南 当视频会议成为日常,当虚拟直播席卷社交平台,人像抠图技术正从专业影视领域快速渗透到大众应用场景。传统绿幕抠像需要专用设备和场地布置,而基于深度学习的MODNet模型让普通开…...

因果推断利器:工具变量法原理、实战与产业全景
因果推断利器:工具变量法原理、实战与产业全景当数据告诉你“相关性”,而你需要的是“因果性”时,工具变量法可能就是那把关键的钥匙。引言:从相关性到因果性,为什么需要工具变量? 在数据驱动的时代&#x…...

技术突破:EuroSAT遥感数据集如何实现98.57%的土地覆盖分类准确率
技术突破:EuroSAT遥感数据集如何实现98.57%的土地覆盖分类准确率 【免费下载链接】EuroSAT EuroSAT: Land Use and Land Cover Classification with Sentinel-2 项目地址: https://gitcode.com/gh_mirrors/eu/EuroSAT EuroSAT遥感数据集作为基于Sentinel-2卫…...